
Abstract
One of the nagging issues in using discrete choice models is how softer attributes, such as attitudes and perceptions, that are not explicitly manipulated within the context of the choice experiment can be accommodated. In many cases, it is reasonable to expect that the choice of a particular alternative may be influenced by non–product-related attributes. For example, latent attitudes and perceptions may play as much of a role in shaping choice as the attributes that have been manipulated and used to define the alternative offerings. In this article, the authors present several full information models that can accommodate latent variables such as attitudes and satisfaction within the context of binary and multinomial choice models. The models proposed are particularly useful when the focus is on understanding how softer attributes can influence choice decisions. The authors accomplish this by integrating structural equation models within the basic framework of binary and multinomial choice models. Two empirical applications are provided. In addition to illustrating the proposed models, these applications provide insights into the circumstances under which the simultaneous factor–choice modeling approach makes a difference.
Choice models have proved to be of enormous value in a wide variety of theoretical and applied settings. Many of the advances in understanding purchase dynamics through the analysis of scanner and panel data, for example, can be traced to the creative use of various binary and multinomial choice models (Erdem and Winer 1999). Similarly, binary and multinomial choice models have been used widely in the experimental analysis of choice (Carson et al. 1994). Experimental choice models have grown in popularity and today are also used in customer satisfaction studies, along with the traditional areas of price and product experimentation. The appeal of this genre of models can be traced to at least two primary features: (1) realism: In real markets, consumers are faced with competing offerings and must choose among them, and (2) experimental control: By varying the levels of an attribute, researchers can estimate how the frequency with which a particular option is chosen varies with changes in the levels of a given attribute, even for attributes that lack sufficient variation in the marketplace.
This article focuses on one of the nagging issues in using discrete choice models in practice; namely, How can softer attributes, such as attitudes and perceptions, that are not explicitly manipulated within the context of the choice experiment be accommodated? In many cases, it is reasonable to expect that the choice of a particular alternative may be influenced by non–product-related attributes. 1 That is, latent attitudes and perceptions may play as much of a role in shaping choice as the attributes that have been manipulated and used to define the alternative offerings. For example, consider the following problem setting, which is, in spirit, similar to one of the empirical applications discussed in a subsequent section:
Although we motivate our work in response to the need to include non-product-related attributes, the large number of product-related attributes that might need to be considered could necessitate that a subset be evaluated (e.g., rated) outside of the experiment. The models to be presented would also prove useful in such cases. We return to this potential application area in a subsequent section.
A cable television provider was interested in assessing the price sensitivity of its current customers to a competitive offer. A sample of customers agreed to participate in an experiment that varied the basic service and the price levels offered by a potential competitor. Respondents were exposed to four different price levels; one price level was equal to their current price structure, whereas the other three offered price savings. After exposure to each price structure, the respondents were asked to indicate on a scale of 0–10 the likelihood of switching to the competitive provider. Among other things, respondents were also asked a series of questions that attempted to assess attitudes toward and satisfaction with their current provider. Satisfaction with the current provider was thought to be particularly important, because the cable industry historically has suffered from low levels of customer satisfaction.
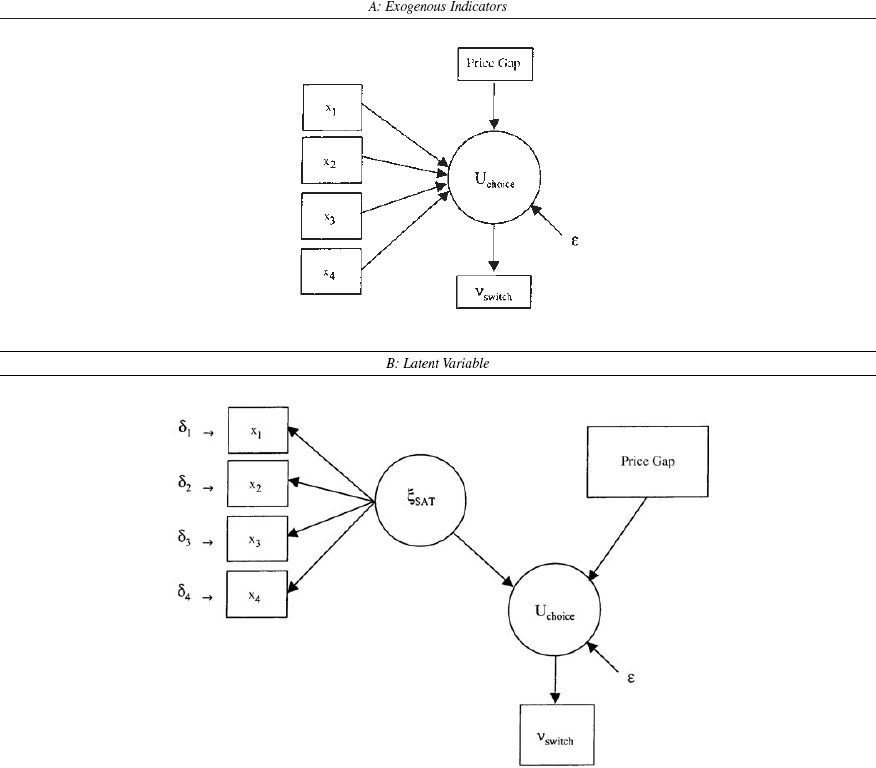
Figure 1 provides a diagrammatic representation of two analysis approaches. The elements in the figure represent the following: There are four reflective indicators of overall satisfaction with the current provider, x1, x2, x3, and x4; one price variable, price gap, which reflects the savings offered by the competing provider; and one response measure, vswitch, which captures the respondents' likelihood of switching to a competitive provider. The utility of switching is denoted by Uchoice, which determines the individual's switching decision as evidenced by vswitch. In Figure 1, Panel A, the utility of switching, Uchoice, is directly influenced by the four exogenous manifest variables, x1, x2, x3, and x4, and the price variable, price gap. In such a case, the four manifest variables would be treated as elements of the deterministic component of utility. The situation in Figure 1, Panel B, is very different. Here, the utility of switching from the current provider, Uchoice, is conceptualized as being influenced by a latent satisfaction variable (ξSAT) and by the price gap offered, price gap. Although it is straightforward to include individual-specific covariates in the systematic component of utility, incorporating latent constructs such as attitudes and satisfaction is not so easy because the distribution of the latent variable is needed; in other words, the model shown in Figure 1, Panel B, requires use of full information estimation methods. 2
Apparently, McFadden (1986) was the first to argue for the need to incorporate latent variables in discrete choice models. And following McFadden's suggestion, Ben-Akiva and colleagues (1998) present various restricted versions of the general models described in this article.
Alternative Representations
More often than not, latent variables have been incorporated into discrete choice models in one of two ways. One way is consistent with the model form shown in Figure 1, Panel A. The reflective indicators (i.e., manifest items) are treated as explanatory predictors of choice (Koppelman and Hauser 1979). The other way is to adopt a two-stage limited information approach in which factor scores on the latent variables are first computed and then entered as error-free explanatory predictors when the multinomial choice model is estimated (Madanat, Yang, and Yen 1995). Unfortunately, both approaches lead to inconsistent and biased estimators. Incorporating the manifest items as (error-free) explanatory predictors of choice ignores the fact that the items contain measurement error, whereas the two-stage approach does not take explicit account of the covariation between the manifest items and choice. Under either approach, the choice model parameter estimates associated with the latent variable or its reflective indicators can be badly misleading.
In light of the difficulty of incorporating latent variables within the discrete choice modeling framework, it is not surprising that constructs such as attitudes and satisfaction have not been used widely in binary and multinomial choice models, and it is doubtful that the potential influence of such constructs on choice could be accurately measured through the simplified methods described previously. Therefore, it is important to develop and investigate the performance of full information estimation techniques that can extend choice models to incorporate latent variables. In the remainder of this article, we present several full information models that can accommodate latent variables such as attitudes and satisfaction within the context of binary and multinomial choice models. The models proposed are particularly useful when the focus is on understanding how softer attributes can influence choice decisions. We accomplish this by integrating confirmatory factor measurement models within the basic framework of binary and multinomial choice models.
We begin by presenting a general form of the basic model. We next present two model extensions that may also prove useful to marketing practitioners and analysts who are investigating unobserved individual differences in the context of the experimental analysis of choice. We provide two empirical applications. In addition to illustrating the proposed models, these applications provide insights into the circumstances under which the simultaneous factor-choice modeling approach makes a difference.
The General Model
Again, let ξ denote the vector of latent exogenous variables with manifest indicators denoted by
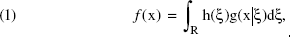

There are two important features of Equation 2 that warrant mention. The first is that the ξs affect only the mean of the conditional distribution of the xs; that is,

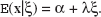
As is customary, we assume that ξ ˜ Np(0,I), which we use in computing the unconditional density of
Consider now, for any particular individual, a discrete choice model of the following form: 3
It suffices to denote that particular respondents have been omitted for notational simplicity.
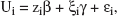
where Ui denotes the utility of alternative i, zi is a (1 × k) vector of attributes (i.e., explanatory variables) describing alternative i, β is a (k × 1) vector of fixed coefficients reflecting the importance of an attribute on the utility of an alternative, ξi is a (1 × h) vector of latent variables scores for alternative i, γ is a (h × 1) vector of fixed coefficients reflecting the importance of each latent factor on the utility of an alternative, and εi is an i.i.d. random error component. This formulation implies that the utility of an alternative is a function of unknown latent variables; however, the latent variables are, by definition, not directly observable, and all of the available information is contained in the manifest items. A solution to this problem is first to condition on the latent variables and then to integrate over their joint distribution in evaluations of the utility of an alternative. Denoting the latent variables by ξ as previously and assuming that the error components δ and ε are independent, we can express the joint probability of observing the choice indicator, yi, and the manifest items as
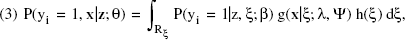
Notice that we have assumed here that, conditional on the latent variables ξ, the choice probability P(yi = 1|
Model parameters θ can be estimated by means of maximum likelihood procedures. The component of the likelihood function for any particular individual can be written as

In developing the basic model, we have, for ease of exposition, described the discrete choice utility function as being influenced only by exogenous latent variables ξs. This type of model, as well as several multiple-indicator, multiple-cause variants, has been discussed by others; for a summary, see Ben-Akiva and colleagues (1998). It is reasonable, however, to consider the case in which the choice utility function is also influenced by one or more endogenous latent variables, denoted by η, where the ηs are themselves related to the ξs through structural equations. With both endogenous and exogenous latent variables, the likelihood function for any particular individual shown in Equation 4 would be rewritten as
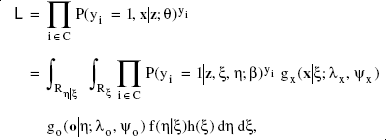
Estimation
In general, estimation of this class of models requires multidimensional integrals with dimensionality given by the number of latent variables. For problems with three or fewer latent variables (as in the two case studies that follow), numerical integration using quadrature methods is a viable option. With more than three latent variables, estimation can be accomplished by Monte Carlo integration. We provide an overview of both methods here; further details can be found in the references cited.
Numerical Integration
A popular method of computing numerical integrals is to use some form of Gaussian quadrature. The general approach is to use an approximation of the form
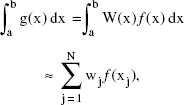
When the dimension of integration exceeds three, numerical integration methods become impractical. First, the number of function evaluations necessary to evaluate the integral increases exponentially with the increase in the number of dimensions. Second, whereas for a single dimension, the region of integration is defined simply by two numbers (an upper and a lower limit), the shape of a high-dimensional boundary can become extremely complicated.
Monte Carlo Integration
In the case of three or more latent variables, Monte Carlo integration can be used. For example, a simple application of this technique to Equation 4 would involve the following three steps for each observation:
Generate P draws ξ1, ξ2, …, ξp from h(ξ).
Evaluate the conditional likelihoods L1, L2, …, Lp at each of these realizations, where Lj (1 ≤ j ≤ P) = Πi ∊ CP(yi = 1|
Compute the sample average of these conditional likelihoods to get an unbiased estimate
4
of L; that is,
Note that even though the likelihood is unbiased, the log of the likelihood is biased because of the nonlinearity of the transformation.
Various acceleration techniques can be used to reduce the minimum number of draws of ξ required to attain any given accuracy level. For example, antithetic draws involve pairs of draws that are negatively correlated (Davidson and MacKinnon 1993). Draws based on Halton sequences (Train 1999) attempt to achieve uniform coverage over the domain of the mixing distribution h(ξ). Details on estimation methods using simulation can be found in McFadden (1989) and McFadden and Ruud (1994).
We now present two empirical applications, which enable us to illustrate the proposed methodology as well as provide two extensions that would be useful to analysts who suspect either (1) correlated errors or (2) unobserved individual differences. We present each of the two case studies and then provide a general discussion of the likely factors that have contributed to the relative performance of the various models.
Study 1
The data for the first empirical application come from a survey commissioned by a major cable television provider. 5 Operating in an industry that is about to be deregulated, this company wanted to gain a better understanding of its existing customers as well as investigate the potential for acquiring new customers from competing providers. Among other things, the survey had a section in which a stated preference experiment was conducted. Respondents were asked to assume that in addition to their current provider, they could buy the service from a new entrant. The characteristics of the offer made by the competing company were described—in particular, the new entrant's price structure was varied from the incumbent's price to a situation with a 15% discount, in steps of 5%. For each of the four price points, respondents were asked to indicate their likelihood of switching to the competing offer; responses were collected on a 0–10 likelihood scale.
The identities of the company and industry have been disguised to preserve confidentiality.
To understand the switching decision better, the following additional information was collected: (1) overall satisfaction (sat), (2) overall impression (feeling), and (3) positive word of mouth (wofm). For sat and feeling, the scale ranged from 0 (“highly dissatisfied”) to 10 (“highly satisfied”); for wofm, the scale ranged from 0 (“completely disagree”) to 10 (“completely agree”). Because there are real costs to switching to another provider, the survey also asked respondents a series of questions that focused on possible barriers to switching: (1) the presence of local crews and offices of the other provider (presence), (2) the general level of difficulty in changing providers (hassle), (3) the nature and depth of the relationship with the current provider (relation), (4) the structure of decision making in the household (structure), and (5) the risk associated with a new provider (risk). Responses to each of these items were collected on a 0 (“not at all likely to be a barrier”) to 10 (“highly likely to be a barrier”) scale.
These two sets of items were viewed as having a possible influence on the respondents' likelihood of switching providers. Exploratory and confirmatory factor analysis provided evidence consistent with the view that the first three items represent a latent satisfaction variable (Sat), whereas the next five items reflect a latent cost-of-switching variable (Barriers). With respect to the components of

Study 1
Study 1 Summary Statistics

Models
Limited Information Baseline Models
The first three models rely on limited information estimation and in this sense stand as baseline models. Model ML1 is a simple ordered probit with no latent variables. The ordered probit model for a 0–10 scale under the assumption of symmetry requires the estimation of five threshold constants. In addition to these five parameters, the model ML1 estimates four additional parameters: an alternative specific constant βASC and βdiscount, βcable, and βmodem, corresponding to the choice covariates (i.e., the elements of
Model ML2 investigates the influence of the satisfaction and barrier variables in addition to the covariates included under model ML1. Under model ML2, the eight attitudinal items described previously are used directly in the utility function, without regard for the likely presence of measurement error; therefore, eight additional β-parameters need to be estimated. The final baseline model, ML3, is consistent with the two-stage limited information approach in which factor scores for the two exogenous latent variables ξSat and ξBarriers are included in the utility function as error-free variables. Factor scores were computed by the regression method from a two-factor confirmatory factor model in which the first three attitudinal items loaded on ξSat and the remaining five items loaded on ξBarriers.
Full Information Models
Two full information estimation models were also fit. The first model, MF1, adopts a parameterization consistent with Equation 4. This model estimates four choice parameters, βASC, βdiscount, βcable, and βmodem, and two parameters, βSat and βBarriers, that are associated with the two exogenous latent variables. Model MF1 assumes that the choice data can be adequately characterized by these four choice covariates and the two exogenous latent variables; however, in this study there may be another source of unobserved variation in that respondents were asked to make repeated choices. With repeated choices there can be (within-respondent) choice dependency, which results in correlated errors. This provides the basis for model MF2, a correlated response model.
The correlated response model is appropriate for situations in which each respondent makes repeated choices (Ben-Akiva et al. 1998; Heckman 1981). Under model MF2, we hypothesize that the error term εinr, which represents the value taken by εi for individual n and response r, can be further decomposed as follows:


Because the μs, are latent, we first compute the conditional probability of observing a particular sequence of choices from a respondent—in addition to conditioning on the latent variable ξ, we now also must condition on μ. We then derive the marginal probability, as previously, by computing the mathematical expectation of this expression, that is, by integrating over the distribution of ξ and μ. Thus, the likelihood for respondent n can be expressed as
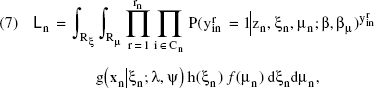
Estimation
Estimation of the limited information baseline models using maximum likelihood is fairly straightforward. The likelihood of observing a rating measured on a 0–10 scale, where 0 implies choice of the incumbent and 1 implies choice of a competing offer for any respondent, can be represented by a symmetric ordered probit of the following form:

Estimation of the full information models MF1 and MF2 is significantly more complicated. Model MF1 consists of two exogenous latent variables, ξSat and LBarriers, and MF2 also contains the individual-specific latent term μn. As we mentioned previously, if there are up to three dimensions of integration, quadrature-based numerical methods can be used to evaluate the unconditional likelihood function; accordingly, we used the intquad2 and intquad3 GAUSS procedures to perform the two- and three-dimensional integrations, respectively. Both of these procedures use Gauss-Legendre quadrature (Aptech Systems 1995) and were embedded within the GAUSS maximum likelihood programming environment. We carried out numerical optimization using the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm. In both models MF1 and MF2, we specified the conditional choice probability P(yi = 1|
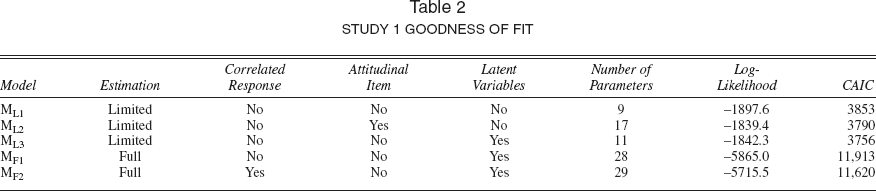
Results
Table 2 provides goodness-of-fit information, and Table 3 provides structural parameter estimates along with asymptotic t-statistics for the baseline and full information models. Model ML2 provides improved fit over model ML1 This model estimates eight additional β-parameters associated with the attitudinal indicators, with a log-likelihood of −1839.4, which yields a likelihood-ratio (LR) statistic of 116.3, which with 8 degrees of freedom (d.f.) is highly significant (p < .001). The consistent Akaike information criterion (CAIC) statistic is lower as well. 6 Model ML3 also provides a better fit than model ML1, with respect to both the CAIC and the log-likelihood: LR = 110.6 with 2 d.f. (p < .001). And on the basis of the CAIC, we further conclude that model ML3 provides a better fit than model ML2. 7 With respect to the full information model forms, although the likelihoods obtained under models MF1 and MF2 are strictly not comparable, we choose model MF2 on the basis of the CAIC statistics.
The CAIC (Bozdogan 1987) is defined as −2LM + QM(lnn + 1), where LM denotes the log-likelihood associated with model M, QM is the number of parameters estimated under model M, and n gives the number of observations.
Because models ML2 and ML3 are not nested, they cannot be directly compared by means of the LR statistic.
Study 1 Goodness of Fit
Study 1 Structural Parameter Estimates a

Asymptotic t-values are shown in parentheses.
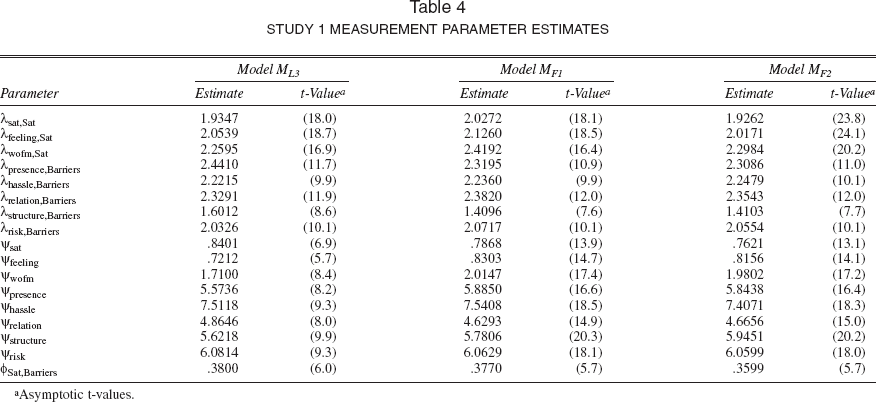
In general, there is considerable similarity in the structural parameter estimates obtained under the various model forms. The same is true for the measurement parameter estimates. Table 4 provides measurement parameter estimates for the best fitting baseline model, model ML3, and the two full information models. All the model forms yield parameter estimates that have the expected algebraic signs, with the exception of model ML2. Under this model, βhassle and βstructure have algebraic signs that are contrary to expectations. 8 In addition, it appears that the attitudinal variables have a relatively minor impact on the decision to stay with the current provider—only two effects, βsat and βrelation, are statistically significant (one-sided test). Under all model forms, the alternative specific constant parameter βASC is negative and indicates that, all else being equal, consumers prefer to stay with their current provider—a measure of the incumbent advantage. The price discount effect βdiscount is positive and significant, indicating that price discounts indeed influence the probability of switching providers. The cable usage parameter βcable is also positive, which suggests that households with high cable bills have a higher propensity to switch, though under model MF2 this effect is not statistically significant (p > .05). The modem ownership parameter estimate βmodem is negative, in support of the hypothesis that owning a modem makes a household less likely to switch providers (perhaps because of the greater hassle and higher stakes involved), though again, under model MF2 this effect is not statistically significant.
This will likely be a common problem whenever perceptual and attitudinal indicators are directly included in the utility function, which is another serious limitation of this approach.
Study 1 Measurement Parameter Estimates
Asymptotic t-values.
Given the similarity of parameter estimates in this problem setting, the primary advantage of using either of the full information model forms is increased precision. (We discuss the reasons for this further after the second application.) Notice that the parameter estimates associated with the exogenous latent satisfaction and cost of switching constructs, βSat and βBarriers, under both of these models are higher in absolute value and more robust than those obtained under model ML3, reflecting the disattenuation from measurement error. This is especially true for βBarriers. Notice finally that βμ is robust and statistically significant. 9 This indicates that the choice data cannot be adequately represented unless the dependency resulting from collecting repeated choices from the same respondent is captured.
The uniformly larger structural parameter estimates obtained under model MF2 compared with MF1 reflects a scale difference between the two models. The scaling of utility is defined by the normalization of the error term in the utility function, in this case, as a probit. This error variance is smaller for model MF2 than model MF1 because the heterogeneity term absorbs some of the variance. Because the scale is inversely related to the error variance, the same normalization in both models results in larger parameter values under model MF2 than under model MF1.
Study 2
The data for the second study come from an ongoing customer satisfaction study conducted for a health care provider. This health care provider was facing several challenges. First, satisfaction scores had been falling for the last six quarters, putatively because of several rate increases. Second, the firm, through competitive intelligence and regulatory disclosure, had reliable information that a national underwriter was going to enter two of its larger served markets aggressively, offering plans that might be attractive to the first provider's core policyholders. Given this competitor's historical behavior, management believed that the competitor's plans would likely appeal to the largest segment of policyholders, those with a basic configuration of benefits, who paid approximately $200–$250 per month, by offering a similar benefits package but with more attractive deductibles, copayments, or reimbursement options. Therefore, in the third quarter of 1999, the customer satisfaction survey was augmented with a view toward assessing the resistance of the first provider's core customer base to such a competitive offer. Specifically, a subset of current policyholders was exposed to a possible competitive offering and asked whether the policyholders would stay or leave.
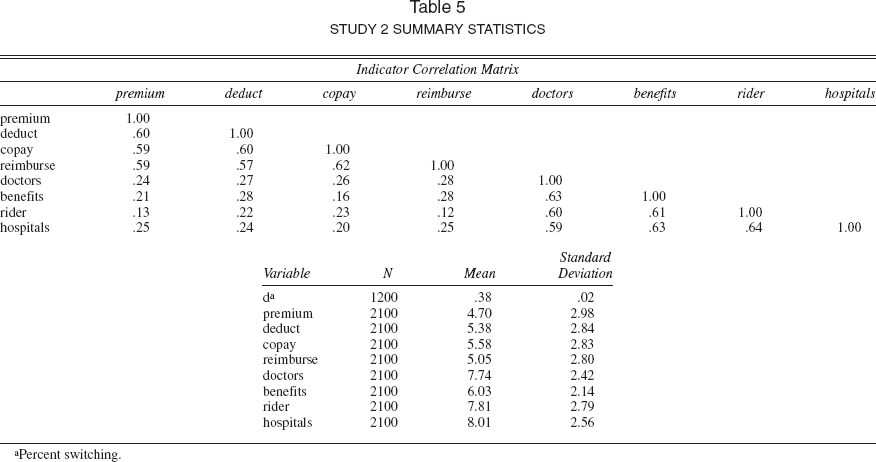
Figure 3 depicts the basic model forms. There are two antecedent exogenous latent satisfaction constructs. The observable indicators for satisfaction with cost (ξCost) are satisfaction with monthly premium (premium), annual deductibles (deduct), amount of copayment (copay), and amount of reimbursement (reimburse). The indicators of satisfaction with coverage ξCoverage are quality of doctors in plan (doctors), basic medical care benefits (benefits), extended policy rider coverage (rider), and the quality of the hospitals in the plan (hospitals). Summary statistics are shown in Table 5. The choice manipulation involved offering more attractive offers with regard to mandatory deductibles, copayments, and reimbursement schedules. In response to a favorable change in the amount of deductible (deductamt), the amount of copayment (copayamt), or the percentage reimbursed (reimburse%), policyholders indicated that they would either stay with their current policy provider or switch policies. Manipulations were randomly assigned to selected policyholders so as to produce a balanced design; that is, over the data collection period, approximately 1/3 of these policyholders were exposed to an offer promising more attractive deductibles, 1/3 were exposed to an offer promising lower copayments, and 1/3 were exposed to an offer promising higher reimbursement levels.

Study 2
Study 2 Summary Statistics
Models
Limited Information Baseline Models
As in Study 1, the first three models rely on limited information estimation and stand as baseline models. Model ML4 is a binary logit (“stay” = 1, “leave” = 0) with no latent variables. In addition to the alternative specific constant, the three covariates, deductamt, copayamt, and reimburse%, described previously, were included in specifying a policyholder's utility function. Model ML5 investigated the influence of the eight cost and coverage satisfaction variables in addition to the covariates included under model ML4. Under model ML5, the eight attitudinal items described previously are used directly in the utility function, without regard for the likely presence of measurement error. The final baseline model, ML6, is consistent with the two-stage limited information approach in which factor scores for the two latent variables ξCost and ξCoverage are included in the utility function as error-free variables. Factor scores were again computed by the regression method from a two-factor confirmatory factor model in which the first four attitudinal items loaded on ξCost and the remaining four items were restricted to load on ξCoverage.
Full Information Models
The first full information model, MF3, adopts a parameterization consistent with Equation 4. This model estimates all latent exogenous and endogenous parameters simultaneously and assumes that all the choice variation can be adequately captured without the introduction of additional terms. The issue is whether this specification can indeed capture individual choice variation. In Study 1, we introduced the correlated response model for this purpose. However, in Study 2 we do not have replications; each policyholder made only one choice. Therefore, another specification is needed to answer this question, a finite mixture model.
So far, we have assumed that all the choice variation can be entirely explained by the latent variables ξs along with any individual or choice covariates specified in
Finite mixture models assume that people belong to different segments that are exhaustive and mutually exclusive. Each of the segments s (s = 1, …, S) is characterized by its set of unique measurement model parameters and choice probabilities. The relative size of segment s is denoted by πs, (0 < πs ≤ 1 and Σsπs = 1). With mixing proportion πs, the probability of observing choice i and indicators 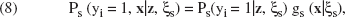

Thus, the likelihood for any one person can be written as

With respect to the latent variable measurement model, there potentially is a large number of model forms that can be considered. These models come about from relaxing or imposing restrictions on which parameters are free to vary across segments. And, as Blåfield (1980) and Yung (1995) discuss, such restrictions are important from both a substantive and an estimation perspective. From a substantive perspective, for example, if the number of latent variables (i.e., factors) is allowed to vary across segments, then it will always be impossible to compare factor loadings; similarly, if factor loading matrices are allowed to vary across segments, then we must set κs =
Unfortunately, the likelihood function in this class of models may be unbounded, and multiple local maxima are possible. However, Titterington, Smith, and Makov (1985) point to many empirical studies and to asymptotic theory, which suggest the existence of satisfactory local maximum.
Yung (1995) provides an informative discussion of other cases of underidentified model specifications in the context of finite mixture confirmatory factor models.
Estimation
Estimation of the limited information baseline models using maximum likelihood is straightforward. With a binary choice indicator, the models considered here treat the conditional probability of choice as an extreme value, thus resulting in a logit, as opposed to an ordered probit as was used in Study 1.
Estimation of the full information models proceeded in much the same manner as in Study 1, with the exception of the logit specification; we used intquad2 and intquad3 to perform the numerical integration within a GAUSS maximum likelihood estimation environment that relied on the BFGS algorithm. For model MF3, we assumed the attitudinal indicators to be independent and normally distributed, conditional on ξCost and ξCoverage. We assumed ξCost and ξCoverage to be bivariate normal with zero means, unit variances, and correlation ϕCost,Coverage. Models MF3a, MF3b, and MF3c represent mixtures with two, three, and four latent segments. For these models, we used a similar estimation method as for model MF3, except that to ensure identification for each model, we set for the first segment, κ1 = 0 and diag(Φ1) = Ip, where Ip is a p × p identity matrix. In addition, we imposed the constraint of invariant error variances, which also aids in identification, and set the measurement intercepts and factor loadings invariant across segments, so that we estimate segment-specific latent variable means, variances, and structural parameters. To further minimize problems of local minima, we used 50 random start values and retained the best fitting model.
Results
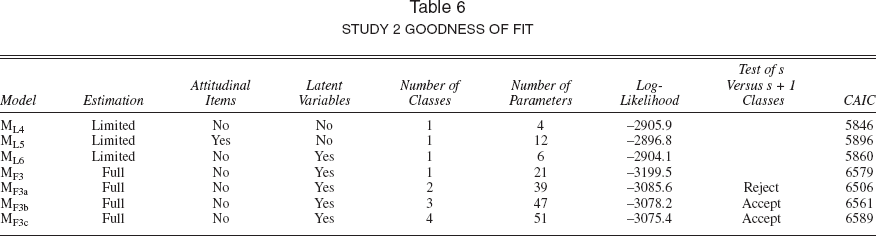
Table 6 provides goodness-of-fit information. Models MF3a, MF3b, and MF3c represent the two–, three–, and four–latent class solutions, respectively. With respect to the “best” baseline model, the results are somewhat inconclusive, though favoring model ML4. On the basis of the LR statistic, we would conclude that model ML5 provides an improvement in fit over model ML4. This model estimates eight additional β-parameters associated with the attitudinal indicators with a log-likelihood of −2896.8, which yields an LR statistic of 18.2, which with 8 d.f. is statistically significant (p < .05). However, the CAIC statistic favors model ML4. Model ML6 does not provide improved fit over model ML4 (LR = 3.6 with 2 d.f.). Therefore, model ML4 is the preferred model. With respect to the full information models, the finite mixture models MF3a–MF3c provide statistically significant improvements in fit over model MF3, which suggests that substantial choice variation cannot be adequately captured by an aggregate model with only common effects. Furthermore, the goodness-of-fit measures point to the adequacy of the two-segment (S = 2) solution.
Study 2 Goodness of Fit
Structural parameter estimates for the baseline models along with asymptotic t-statistics are provided in Table 7. Again, we find that the baseline model forms yield fairly similar parameter estimates. Notice that the alternative specific constant parameter βASC is positive and statistically significant, indicating that, all else being the same, consumers prefer to stay with their current policy provider. The negative parameter estimates for
Study 2 Structural Parameter Estimates: Baseline Models a

Asymptotic t-values are shown in parentheses.
Structural parameter estimates for models MF3 and MF3a are shown in Table 8. Figure 4 shows both measurement and structural parameters for model MF3a. Notice first that model MF3 provides a different take on the importance of the latent satisfaction constructs than that suggested by the limited information model forms. Notice also that the parameters associated with both latent satisfaction constructs βCost and βCoverage are statistically significant (p < .01). And finally, the incumbent effect as evidenced in βASC is smaller than under any of the limited information model forms.
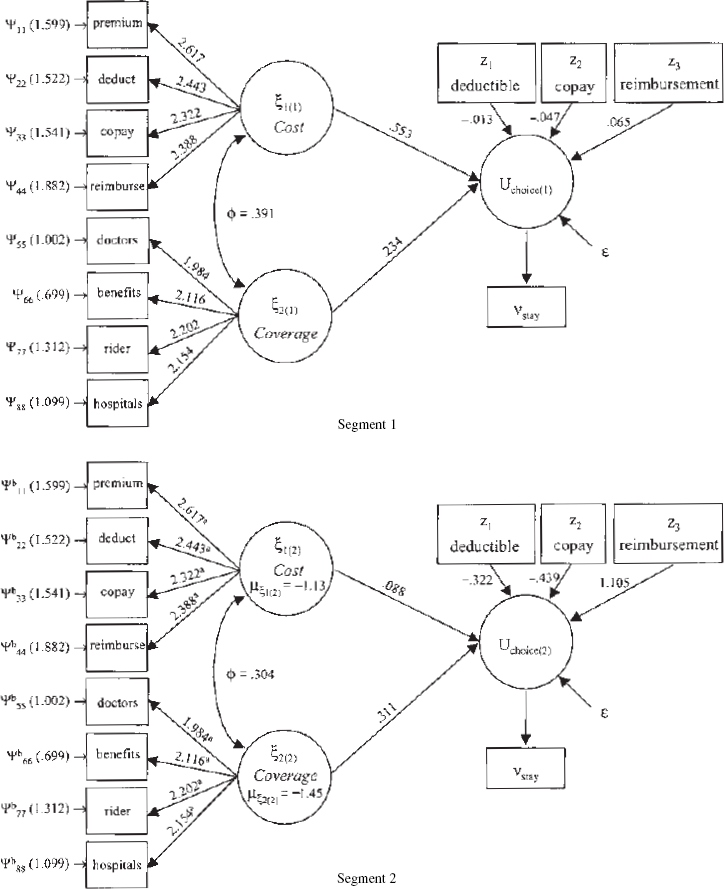
Study 2: Model MF3a
Study 2 Structural Parameter Estimates: Models MF3 and MF3a a

Asymptotic t-values are shown in parentheses.
Model MF3a provides a more complete story regarding the role of satisfaction in a policyholder's decision to stay in the sense that the two latent segments can be viewed as two discrete latent moderators of the relationships among the latent exogenous satisfaction constructs, the choice covariates, and choice. From the mean levels for the satisfaction latent exogenous constructs provided in Table 8 and shown in Figure 4, we find that the latent segments are very different. The mean levels for the latent satisfaction constructs across the segments show that Segment 2 (41.1% of the sample) is a relatively dissatisfied group and has the lowest satisfaction levels. And the mean differences for both latent satisfaction constructs are highly significant across both groups. Low levels of satisfaction produce a group of policyholders that is very likely to leave and that does not endow the incumbent with much equity—notice that βASC is negative and statistically significant. Compared with model MF3, which suggests that both latent satisfaction constructs are significant determinants of the decision to stay with the current policy, model MF3a points to the presence of both common and segment-specific effects. In Segment 1, representing 58.9% of the policyholders, ξCost and ξCoverage satisfaction are the only significant drivers of choice. Segment 1 is, in general, a satisfied group, and satisfaction is the major reason for members staying. Policyholders in Segment 2 have a much higher probability of leaving in response to more advantageous deductible, copayment, and reimbursement offers—notice that
Discussion
The case studies presented in this article raise three important questions: (1) What are the potential implications of the different estimation approaches on marketing decisions? (2) What accounts for the different conclusions regarding the relative performance of full information estimation models? and (3) In what problem settings can this class of models prove useful?
Implications of Different Approaches
The two empirical applications produced very different conclusions regarding the efficacy of using full information estimation techniques when incorporating latent variables into discrete choice models. From a managerial perspective, the substantive differences between the baseline models and the full information model forms in Study 1 were minor, though the full information models yielded more precise estimates. In contrast, in Study 2 the differences were substantial, and the use of any of the baseline models would provide managers with misleading results regarding the role of satisfaction in determining whether to stay with the current policy.
Specifically, managers using the two-stage limited information method would conclude (erroneously) that satisfaction plays a limited role in determining choice of policy, and therefore they might discontinue or underinvest in their customer satisfaction programs. The full information methods, in contrast, clearly illustrate the importance of satisfaction—the finite mixture solution would aver that satisfaction levels with cost and coverage are the primary determinants of choice in almost 60% of the population. Note also that the coefficient of ξCoverage is higher than ξCost in the limited information model, which suggests that managers should focus greater attention on improving their subscribers' perceptions of the coverage aspects of their policy as opposed to cost perceptions, that is, by improving the quality of enrolled doctors and hospitals, ensuring basic medical benefits, and improving extended policy rider coverage. The full information models, however, strongly dispute that suggestion. The finite mixture model asserts that ξCoverage is more important than ξCost only in one segment of policyholders, which accounts for 40% of the population, and that for 60%, ξCost is more important. Therefore, all else being equal, more marketing resources should be allocated to improving satisfaction with cost aspects to counter the threat from the national underwriter. The limited information models would thus lead managers to two actions that are potentially deleterious: first, an overall underinvestment in their customer satisfaction programs, and second, an inefficient allocation of marketing resources between these two facets of satisfaction.
Relative Performance Issues
To further investigate the relative performance of these models, we conducted a Monte Carlo simulation experiment. Aside from the method of estimation (limited versus full), the simulation experiments focused attention on four factors thought to influence relative model performance: (1) the number of respondents, (2) the number of items per construct, (3) item reliability, and (4) the strength of the structural parameter linking the latent variable to choice. The results of the simulations suggest that full information models will be superior to limited information models, regardless of sample size, when item reliabilities are poor to moderate and when the latent variables explain a substantial amount of the variation in choice. More specifically, the simulation results clearly show that the two estimation approaches differ the most with respect to their ability to capture the structural parameter that links the latent variable and utility. In the presence of a strong relationship between the latent variable and utility, the two-stage limited information approach yielded structural parameters that had biases averaging more than 18%. 12 The root mean square errors associated with the limited information methods were three times larger than with full information estimation. And larger sample sizes did not result in substantially improved parameter recovery for the two-stage limited information approach. As a general rule, full information estimation yielded estimates of the structural parameter that were in most cases at least twice as precise as those obtained with the two-stage limited information approach. 13
Note again that the biases in the limited information methods arise because the latent constructs are treated as error free instead of as random variables. This is analogous to the bias or attenuation in slope parameters in regression equations in which an independent variable is measured with error (Greene 2000). The full information methods are unbiased.
Specific details on how the sampling experiments were conducted and results can be obtained by contacting the authors.
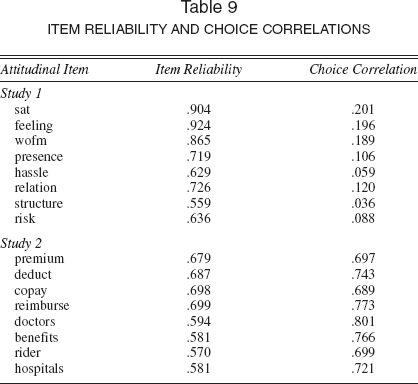
Table 9 provides additional support for the simulation findings in the context of the two empirical studies. For each manifest item, Table 9 gives the item reliabilities and the bivariate correlations with the choice variable. In Study 1, the latent variable indicators were relatively reliable but had weak association with the choice variables. Notice that the reliabilities are fairly robust, especially for the first three attitudinal items that load on ξSat, and the highest choice correlation is approximately .20 (in absolute value). In contrast, in Study 2 the items were for the most part less reliable but had much stronger association with choice. Notice that the weakest choice correlation is .69, which means that the satisfaction items explain a larger percentage of the variation in choice. Therefore, our practical finding from the two case studies would be that the full information methods offer significant improvements over their limited information counterparts when the latent constructs are strong drivers of choice; in the absence of such a relationship, there does not appear to be a substantive difference between the two.
Item Reliability and Choice Correlations
Application Areas
We perceive at least three general application areas in which the models developed in this article may provide large benefit. The first is in modeling customer satisfaction and its relationship to observed behaviors such as provider choice. The importance of customer retention has been well documented, and many firms have allocated significant dollars to developing or enhancing existing customer satisfaction programs. The full information methods described and illustrated in two empirical applications enable a marketing manager to assess, much more accurately than do existing limited information methods, the efficacy of investments in a customer satisfaction program by accurately predicting its impact on metrics such as attrition, revenues, and profitability.
The second application area is in the modeling of scanner-panel data. It is reasonable to suspect that brand perceptions and consumer attitudes play a major contributing role in what, how much, and when consumers buy. With the models described and illustrated herein, it is possible to augment conventional scanner-panel data with information on potentially important latent constructs that represent the softer brand attributes or consumer attitudes. Consider, for example, the salted snacks category and, in particular, potato chips. A pure scanner-panel attribute–based approach (Fader and Hardie 1996) might consider only independent variables such as brand name (e.g., Frito-Lays, Ruffles), fat content (e.g., regular, reduced fat, fat free), size (e.g., 8 oz., 16 oz.), package type (e.g., bag, canister), flavor (e.g., regular, barbecue, sour cream and onion), and price. However, there are other potentially important softer attributes that could influence a customer's choice of a particular stockkeeping unit. For example, attitudes toward “healthiness” or “natural” ingredients could influence choice. Some consumers could be influenced by the texture and appearance of the chip; others could be influenced by their desire for a chip that is hot or spicy; and still others could be influenced by the communicated positioning of the brand, that is, brand imagery—a “contemporary brand,” a “fun brand,” and so forth. These attributes are not, in a strict sense, directly measurable in terms of a brand's physical attributes but rather, in most cases, must be indirectly measured through psychometric methods. The models presented in this article provide a direct and efficient means of incorporating these perceptual and attitudinal attributes as latent variables in conjunction with harder attributes in predicting stockkeeping unit choice, thus resulting in a richer and more veridical description of consumer behavior.
The third application area is also related to the design and analysis of choice experiments. The primary motivation for the models developed in this article was the need to accommodate non–product-related attributes. However, even with the availability of highly efficient D-optimal designs, there may be cases in which not all of the many product-related attributes can be reasonably considered within the context of the experimental design. The lack of large sample sizes or fears of respondent fatigue or excessive cognitive effort are factors that may lead to the decision to evaluate a subset of product-related attributes outside of the choice experiment. With the use of limited information models, assessing the importance of these attributes would be problematic, especially if they are strong determinants of choice, because structural parameters associated with these covariates would be attenuated. In contrast, estimation with the class of full information models described previously would not suffer in this regard and, in addition to yielding more accurate parameter estimates, would provide a holistic framework for better managing both product-related and non–product-related attribute information.