
Abstract
Despite the widespread application of finite mixture models in marketing research, the decision of how many segments to retain in the models is an important unresolved issue. Almost all applications of the models in marketing rely on segment retention criteria such as Akaike's information criterion, Bayesian information criterion, consistent Akaike's information criterion, and information complexity to determine the number of latent segments to retain. Because these applications employ real-world data in which the true number of segments is unknown, it is not clear whether these criteria are effective. Retaining the true number of segments is crucial because many product design and marketing decisions depend on it. The purpose of this extensive simulation study is to determine how well commonly used segment retention criteria perform in the context of simulated multinomial choice data, as obtained from supermarket scanner panels, in which the true number of segments is known. The authors find that an Akaike's information criterion with a penalty factor of three rather than the traditional value of two has the highest segment retention success rate across nearly all experimental conditions. Currently, this criterion is rarely, if ever, applied in the marketing literature. Experimental factors of particular interest in marketing contexts, such as the number of choices per household, the number of choice alternatives, the error variance of the choices, and the minimum segment size, have not been considered in the statistics literature. The authors show that they, among other factors, affect the performance of segment retention criteria.
Since their introduction to the marketing literature on consumer choice models more than a decade ago, finite mixture logit models (Kamakura and Russell 1989) have been employed regularly with supermarket scanner panel data to identify segments of customers whose preferences for brands and marketing-mix sensitivities vary (e.g., Abramson, Buchmueller, and Currim 1998; Abramson et al. 2000; Andrews, Ainslie, and Currim 2002; Andrews and Currim 2002; Andrews and Manrai 1999; Chintagunta 1994; Chintagunta, Jain, and Vilcassim 1991; Fader and Hardie 1996; Gupta and Chintagunta 1994; Jain, Vilcassim, and Chintagunta 1994; Kamakura, Kim, and Lee 1996; Kamakura and Russell 1993; Roy, Chintagunta, and Haldar 1996; Wedel and Kamakura 2000). Despite the widespread application of finite mixture models, the decision of how many segments to retain in the models remains an important issue that is not resolved (Bozdogan 1992, 1994; de Borrero 1993; DeSarbo et al. 1997; Dillon et al. 1994; McLachlan and Basford 1988; Wedel and DeSarbo 1994; Wedel and Kamakura 2000). Indeed, Dillon and Kumar (1994, p. 345) argue that “The challenges that lie ahead are, in our opinion, clear, falling squarely on the development of procedures for identifying the number of support points needed to characterize the components of the mixture distribution under investigation.” More recently, Wedel and Kamakura (2000, p. 91) state that “the problem of identifying the number of segments is still without a satisfactory solution.” Retaining the true number of segments is crucial because many managerial decisions on segmentation, targeting, positioning, and the marketing mix are based on it.
The purpose of this study is to determine how well commonly used segment retention criteria perform in a context that has not been studied previously in the marketing or statistics literatures—multinomial choice data as obtained from supermarket scanner panels. Although mixtures of multivariate normal and other distributions have been studied in the statistics literature, no previous study has examined the effects of multinomial data characteristics of particular interest in marketing contexts (e.g., number of choice alternatives, number of choices per household, variance of the error term, segment sizes) on the success rates of segment retention criteria. Given recent studies showing that finite mixture models are at least as effective as more recent methods for recovering consumer heterogeneity (Andrews, Ainslie, and Currim 2002; Andrews, Ansari, and Currim 2002), and given that choice models remain an important managerial tool for marketing-mix planning and new product development, this study makes an important contribution to the practice of consumer choice modeling.
The plan of the study is as follows: After a discussion of previous research on this topic, we describe the experimental design used to generate data for the large-scale simulation study. We then develop a priori expectations of the results and present the findings of the study.
Background
Although it is tempting to use likelihood ratio tests to determine the correct number of segments to retain in finite mixture models, the likelihood ratio statistic does not have its usual chi-square distribution because standard regularity conditions break down when a parameter is on the boundary of the parameter space (McLachlan and Basford 1988). It is possible to use bootstrapping methods (e.g., Aitkin, Anderson and Hinde 1981; Hope 1968; McLachlan 1987) to assess the empirical distribution of the likelihood ratio statistic, but this method can be extremely costly in terms of computing resources (Wedel and Kamakura 2000, p. 91), depending on the number of observations and parameters.
In light of such problems, researchers frequently use criteria such as Akaike's information criterion (AIC), Bayesian information criterion (BIC), consistent Akaike's information criterion (CAIC), and information complexity (ICOMP) to determine how many segments to retain and increase the number of segments until the criterion is minimized (Wedel and Kamakura 2000). The AIC, which is based on the use of generalized entropy as a goodness-of-fit measure, is calculated as

where L is the value of the maximized log-likelihood function and k is the number of parameters required to estimate the model. The AIC is obtained by estimating twice the negentropy (the Kullback–Leibler information quantity, a measure of the distance between the fitted model and the true distribution), which is asymptotically equivalent to estimating minus twice the expected log-likelihood of the true distribution with parameters estimated by maximum likelihood (Bozdogan 1987). Akaike (1973) provides a derivation; see also Bozdogan (1987).
Various modifications of AIC have been proposed. Bozdogan (1981, 1992, 1994) argues that the marginal cost per parameter, the so-called magic number 2 in Equation 1, is not correct for finite mixture models. He conjectures that the likelihood ratio for comparing mixture model. 1 with K and k parameters is asymptotically distributed as a noncentral chi-square,
Bozdogan (1994) makes this conjecture in the context of mixtures of multivariate normal distributions and does not address whether it applies to mixtures of other distributions. He notes that proof of the conjecture in general is difficult within the context of the mixture model but that we can justify it on the basis of Feder's (1968) results and established asymptotic results in information theory.

with noncentrality parameter δ and v* = 2(K – k) degrees of freedom instead of the usual (K – k) degrees of freedom (as assumed in the derivation of AIC). If this is the case, we obtain 3 as the magic number in AIC in Equation 1 (for a proof, see Bozdogan 1994). We refer to this criterion as AIC3.
Another modification of AIC, the CAIC, makes AIC consistent without violating Akaike's principle of minimizing the Kullback-Leibler information quantity (Bozdogan 1987). By making the degrees of freedom of the likelihood ratio an increasing function of the sample size n (Kendall and Stuart 1967), such as v* = (K – k) log n, instead of the usual (K – k) used in deriving AIC, we obtain

The CAIC therefore imposes a larger penalty per parameter than AIC, and the penalty grows with the sample size. (For a derivation of CAIC, see Bozdogan 1987, pp. 358–59.)
The key factor determining the relative quality of AIC, AIC3, and CAIC as segment retention criteria is the assumption made about the distribution of the likelihood ratio for finite mixtures. Because we cannot prove mathematically the exact form of the distribution, the simulation methods used in this study provide important insight on the matter.
As an alternative to AIC and CAIC, Bozdogan (1988a, 1990) developed a new entropic statistical complexity criterion called ICOMP. Although in the spirit of AIC, ICOMP removes any need to consider explicitly the parameter dimension of a model and adjusts automatically for the sample size. Rather than penalizing the log-likelihood for the number of parameters, ICOMP penalizes according to the interdependencies or correlations among the parameter estimates of the model. It is based on the properties of the estimated information matrix F, as follows:
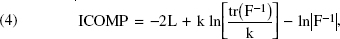

and θ includes the segment-specific parameters and the parameters used to form the mixing weights (S – 1 parameters for an S-segment model). The first component of ICOMP measures the lack of fit of the model, and the second and third components measure the complexity of the estimated inverse-Fisher information matrix, which gives a scalar measure of the Cramer–Rao lower bound matrix of the model (Bozdogan 1992, 1994). In addition, ICOMP penalizes models that produce high variances in the parameter estimates through the second term and models in which the Hessian becomes nearly singular because of an increasing number of parameters through the third term (Wedel and Kamakura 2000).
The development of AIC, AIC3, CAIC, and ICOMP does not rely on a Bayesian approach. Schwarz (1978) develops a Bayes solution that consists of selecting the model that is a posteriori most probable. Known as BIC, the procedure differs from AIC only in that the dimension of the model is multiplied by log n rather than 2, which leads to lower dimensional models when there are eight or more observations. For large numbers of observations, the procedures differ markedly. Schwarz argues that under the assumptions set out in his analysis, AIC cannot be asymptotically optimal. The minimum description length criterion Rissanen (1987) developed using coding theory is identical in form to BIC.
No previous research has examined the performance of the log-likelihood value from the validation sample (LOGLV) as a segment retention criterion. The same logic that motivates an analyst to use a validation sample to indicate a model's suitability (e.g., the Bayesian cross-validated likelihood method by Rust and Schmittlein [1985]) also suggests that LOGLV could be used to determine the number of segments to retain in a finite mixture model. Indeed, AIC, BIC, CAIC, and ICOMP were first developed to select the proper subset of predictor variables to retain in regression models before they were used to select the number of components in a finite mixture model. Unlike the estimation sample log-likelihood, LOGLV may decrease when the number of segments increases, which may indicate misspecification. When consumers not used in the estimation process compose the validation sample, LOGLV is computed with the maximum likelihood estimates of parameters from the estimation sample, in exactly the same manner that the estimation sample log-likelihood is computed. 2 If the validation sample consists of additional purchases made by the same consumers used in model estimation, LOGLV may be calculated in a variety of ways. For example, consumers could be assigned to segments on the basis of the posterior probabilities using the estimation sample posterior probabilities, and each consumer's validation log-likelihood would be computed using the parameters from the segment with the highest posterior probability. Or an individual-level parameter vector could be computed as a convex combination of segment-level parameter estimates, for which the weights are posterior probabilities. Regardless of the exact form of LOGLV, the number of segments to retain in a finite mixture model is determined by increasing the number of segments until LOGLV is maximized.
Specifically, in this study we compute the likelihoods for each household–segment combination using the maximum likelihood estimates for each segment. We then create a weighted likelihood for each household using the estimated weights, take the logs, and sum across households.
We could also choose the number of segments on the basis of the separation between group centroids (Wedel and DeSarbo 1994). Celeux and Soromenho (1996) propose a normed entropy criterion (NEC) for the selection of the number of segments in finite mixture models, though it is unable to compare between S = 1 segments and S > 1 segments (except in certain circumstances). The NEC for some number of segments S is defined as

where L(S) and L(l) are the log-likelihoods for the S-segment and 1-segment solutions, and E(S) is the entropy for the S-segment model and indicates the separation between segments, defined as

where πis is the posterior probability that consumer i belongs to segment s. The number of segments to retain in a finite mixture model is determined by increasing the number of segments until NEC is minimized. 3
Another criterion unique to the segment retention problem is the minimum information ratio (MIR) proposed by Windham and Cutler (1992). Despite its initial appeal, proponents and others later reported substantial empirical drawbacks (for details, see Celeux and Soromenho 1996; Cutler and Windham 1994). Consequently, we do not consider MIR in our study.
There is no empirical evidence of whether these criteria perform satisfactorily in the context of finite mixture logit models applied to scanner panel data. Bozdogan (1988b) applies AIC to the task of selecting the proper order and subset of predictors in a loglinear model for a smoking risk data set but does not address the problem of segment retention. Given the widespread use of such criteria for segment retention in scanner data–based applications, the problem is important and in need of research.
Results of studies performed in contexts other than multinomial choice data vary widely, as we review subsequently, and thus are inconclusive. These studies consider a limited number of segment retention criteria and data characteristics (mostly multivariate normal data with no predictors). More important, because previous studies have appeared mostly in the statistics literature, there has been no investigation of factors of particular interest to marketing analysts using multinomial choice data, such as the number of choice alternatives, the number of choices per household, the error variance in the choice data, and the segment sizes.
The study by de Borrero (1993) examines the performance of selected fit criteria (AIC, CAIC, ICOMP, and MIR) for a univariate Poisson mixture model by varying the separation of the segments and the sample size. In that context, CAIC appears to be the best overall criterion. Rust and colleagues (1995) perform a simulation with regression models and find that BIC is the best overall model selection criterion in terms of selection accuracy, accuracy of posterior probabilities, and ease of use. However, their study was not conducted in the context of finite mixture models.
Bozdogan (1992, 1994) studies the problem of choosing the number of components in mixtures of multivariate normal distributions without predictor variables. The 1992 study compares AIC3, BIC, and ICOMP on two structures of simulated data. In both applications, all three criteria generally selected the same numbers of components, but in one application, none of the three selected the correct number of components. The 1994 study demonstrates the utility of ICOMP, AIC3, and CAIC in identifying the number of true segments using real medical data and two structures of simulated data.
Cutler and Windham (1994) study the performance of ten criteria in the context of mixtures of bivariate normal distributions with no predictors, varying the sample size (100, 200, 400), the number of components (2, 3, 4), the separation of components (0, 1, 2), and the specification of the covariance matrices (full, equal, and unequal, as is discussed in the next section). The performance of ICOMP is shown to be impressive, though they note that more research is needed on the criterion before generalizable conclusions can be drawn.
To summarize, the performance of segment retention criteria in the context of finite mixture logit models is unknown. In addition, no previous study has considered as many experimental factors of importance to marketing analysts with as many segment retention criteria. Our study manipulates seven experimental factors, whereas the largest previous study manipulates only four. Factors such as the number of choices per household, the number of choice alternatives, the error variance of the choices, and the minimum segment size are relevant in marketing settings but have not been considered in previous studies. Our study examines the performance of seven segment retention criteria, including two whose behaviors are largely untested and unknown. Given the gaps in the literature and the large variability in the findings of existing studies, there is no accepted solution to the segment retention problem. Answering the call of previous studies (e.g., DeSarbo et al. 1997), we examine the performance of segment retention criteria in an important analysis context in marketing.
Experimental Design
We test seven of the major segment retention criteria previously described (AIC, AIC3, BIC, CAIC, ICOMP, LOGLV, and NEC) in the context of multinomial choice data, described in detail subsequently.
We manipulate seven data characteristics. The factors and their levels, chosen from previous simulation studies by Vriens, Wedel, and Wilms (1996) and Andrews, Ainslie, and Currim (2002), are as follows:
Factor 1. The number of segments: 2 or 3;
Factor 2. The mean separation between segment coefficients: small (1.0), medium (1.5), or large (2.0). 4
We first randomly generate the vector of parameters β1 for Segment 1, as detailed subsequently. A vector of separations δ with mean 1.0, 1.5, or 2.0 (and standard deviations equal to 10% of the mean) is then randomly generated, as is a vector of signs S for δ. We do not want one segment to have all coefficients larger (or smaller) than another because this would indicate that one segment is more sensitive than another in every way. We then compute β2 = β1 + Sδ (element-by-element) and β3 = β1 – Sδ.
Factor 3. The number of households: 100 or 300;
Factor 4. The mean number of purchases per household: 5 or 10;
Factor 5. The number of choice alternatives: 3 or 6;
Factor 6. Error variance: standard (1.645) or high (50% higher than standard);
Factor 7. Minimum segment size: 5%–10%, 10%–20%, or 20%–30%.
The design is factorial, so with 3 replications (data sets) for each cell, we have a total of 3325 = 864 data sets. The number of replications (purchases) per individual in each data set is generated from a gamma distribution with a mean (and variance) of 5 or 10 (Factor 4). 5 In addition, we generate purchases of 100 additional individuals not used in the estimation sample for the purposes of model validation (with the number of replications per individual again having a mean of 5 or 10).
The number of purchases per household in actual scanner panel data is often skewed in this manner, with some households having many purchases.
For each data set, we generate two binary variables (possibly but not necessarily representing promotional activities) and one variable with a standard normal distribution (possibly representing price) to represent the attributes consumers use to make choices. To improve generalizability, the parameter values are generated randomly for each segment and data set. Brand-specific constants (2 or 5 of them, depending on Factor 5) are generated uniformly to be in the range of −1 to 1 (they must be small enough that each brand has enough choices to allow accurate estimation of its constant). The coefficient for the normally distributed variable is generated in the range of −1 to −2.5. Coefficients for the two binary variables are between 1 and 2.5. These values are consistent with those observed in scanner panel applications. Consumers are assigned to segments on the basis of randomly determined segment sizes for each data set. The smallest segment will consist of 5%–10%, 10%–20%, or 20%–30% of the sample, depending on the level of Factor 7. Given a consumer's segment assignment, we use segment-specific parameters to compute deterministic utilities, to which double exponential errors (with variances determined by Factor 6) are added. The consumer is assumed to choose the brand with the highest logit choice probability.
Expected Results
The most comprehensive simulation study to date (Cutler and Windham 1994) suggests that the type of model affects the performance of segment retention criteria. That study examined three mixtures of bivariate normal distributions: (1) the full model, in which the true covariance matrices and segment sizes were generated randomly; (2) the unequal model, in which the true covariance matrices were set to identity matrices, but the segment sizes were generated randomly; and (3) the equal model, in which the true covariance matrices were set to identity matrices and the segments sizes were set to 1/k, where k is the number of segments. The AIC showed a consistent tendency to overfit across experimental conditions with the full model but not with the equal and unequal models. The AIC3 tended to underfit with the full model but performed well with the equal and unequal models. The BIC almost never overfitted the number of segments but had alarmingly high rates of underfitting with the full model. Although the CAIC was not tested, it would have underfitted the number of segments as least as badly as BIC because it has a larger penalty per parameter. The ICOMP criterion did not have a systematic tendency to underfit or overfit, in that it underfit the full model but overfit the equal model somewhat more than the other criteria.
Of the three mixture models Cutler and Windham (1994) test, our multinomial logit model most closely resembles the unequal model because (1) the parameter vectors for each segment must be estimated, (2) covariances are not applicable in multinomial logit choice models and therefore do not require estimation, and (3) the segment sizes must be estimated. If this is the case, on the basis of Cutler and Wind-ham's results, we expect ICOMP to have the highest success rates in general, with AIC, AIC3, BIC, and CAIC (in that order) resulting in more severe underfitting compared with ICOMP. On the basis of these results, we do not expect any of the criteria to have a tendency to overfit. There is no basis for speculating about the relative performance of LOGLV and NEC, though given that NEC cannot be calculated for one-segment models, there is an increased chance that it will overfit the number of segments (or at least a decreased chance that it will underfit).
In general, we expect the segment retention criteria to underfit more when the number of true segments is three rather than two, the separation between segments is smaller, the number of households is smaller, the number of choices per household is smaller, the number of choice alternatives is larger, the error variance is larger, and the minimum segment size is smaller. Bozdogan (1992) and Cutler and Windham (1994) both find that criteria tend to underfit more when the true number of segments is larger. Cutler and Windham find more underfitting with three segments than with two. They also provide support for the assertion that segments that are closer together are more difficult to detect. With smaller sample sizes, additional segments capture fewer households, and consequently the incremental contribution to the likelihood is smaller, making justification of additional segments more difficult. Bozdogan (1987) argues that as the number of observations becomes large, the probability of underfitting a model will diminish, especially for consistent criteria (BIC and CAIC). More parameters are required when there are more choice alternatives, which should lead to increased underfitting. Larger error variance, in our experience, makes the identification of segments more difficult, which results in a tendency to underfit. Finally, smaller segments should be more difficult to detect than larger segments, which leads to increased underfitting.
Summary of Results
We measure the performance of the various segment retention criteria by their success rates, or the percentages of data sets in which the criteria identify the true number of segments. Given two criteria with similar success rates, we then prefer underfitting to overfitting. Our research for this study shows that overfitting produces larger parameter bias at the individual level than underfitting does. Although we might not expect a priori that overfitting would produce larger parameter bias than underfitting, the explanation seems to be that overfitting sometimes produces very small segments with large or unstable parameter values, which can result in severe bias. Cutler and Windham (1994, p. 154) also prefer underfitting to overfitting, especially for small sample sizes and components that are not well separated.
Tables 1 and 2 present the results of the simulation experiment. Table 1 shows the success rates (S) of each criterion by experimental condition, along with the rates of underfitting (U) and overfitting (O). For example, AIC correctly identified the number of segments in 66% of data sets with two components (Factor 1), underfitted the number of components in 14% of these data sets, and overfitted the number of components in 20% of these data sets. At the bottom of Table 1, we use z-tests to test for statistically significant differences among the overall success rates of the criteria, based on the least significant difference rule. For example, AIC and AIC3 have the best overall success rates, followed by LOGLV, ICOMP, BIC and NEC, and CAIC. In Table 2, we meta-analyze the results by fitting logit models to the success data from Table 2 (where 1 = success); the predictors are dummy variables that represent the simulation design factors. For example, because F1 = 1 when the number of segments is two, AIC has a significantly higher success rate when there are two segments (66%, Table 1) than when there are three segments (55%). Separate logit models are fit to the data for each criterion, which is conceptually equivalent to fitting a common model to all data and including criteria by factor interactions, as other recent studies have done (Andrews, Ainslie, and Currim 2002; Andrews, Ansari, and Currim 2002; Vriens, Wedel, and Wilms 1996).
Surprisingly, AIC3 has the best overall performance in the simulation. Although AIC has an equally good success rate (61%, Table 1), AIC3 has low rates of overfitting (2%), and the rate of overfitting is much higher for AIC (19%). As we mentioned previously, we prefer to avoid criteria that overfit the true number of segments because parameter bias is much more likely with overfitted models. The AIC3 typically has success rates at or near the best in all experimental conditions, though AIC has higher success rates for some experimental conditions (at the expense of significant overfitting).
The LOGLV criterion has the second best success rate, though overfitting is higher than we prefer (17%). The ICOMP criterion has lower success rates than AIC3, AIC, and LOGLV, which is not consistent with the performance of the criterion in the context of mixtures of bivariate normal distributions (Cutler and Windham 1994). We discuss this finding in the next section.
The BIC is better than only CAIC for the multinomial data. As expected, BIC underfits significantly (62%) but never overfits. The CAIC underfits even more severely (67%) and is the least effective criterion overall.
The logit meta-analysis (Table 2) confirms that, as expected, the criteria generally have significantly higher success rates when there are two segments rather than three, there is larger separation between segments, sample sizes are larger, there are more choices per household, error variance is smaller, and the segments are larger. There was one unexpected finding: Success rates are generally higher when there are six choice alternatives rather than three. We expected more underfitting when there were six alternatives, but the opposite is true. Perhaps this is because the fit of the model is better when there are three alternatives rather than six (the consumer has fewer choice options, which makes prediction easier), which leaves less opportunity for improvement in fit by increasing the number of segments. Overall, the logit results are remarkably consistent with our expectations.
To investigate how well the simulation results generalize to data sets with more latent segments, we generated 100 additional data sets with six true segments instead of two or three. 6 The success rates were as follows: AIC 52%, AIC3 59%, BIC 54%, CAIC 53%, ICOMP 44%, LOGLV 54%, and NEC 2%. The rates of underfitting were as follows: AIC 17%, AIC3 22%, BIC 36%, CAIC 38%, ICOMP 28%, LOGLV 16%, and NEC 98%. Thus, even with six segments, AIC3 still appears to be a good segment retention criterion. With an average of 4000 purchases per data set, however, there is less variation among the success rates of the segment retention criteria (with the exception of NEC). The consistent criteria (BIC and CAIC), in particular, perform better than would be expected from the larger simulation study.
The mean separation between segments was 2.0 (level three of Factor 2) because it may be unrealistic to recover six segments that are close together. The sample size was set at 400 because it is not realistic to attempt to identify six segments with 100 (or maybe even 300) households. Likewise, the mean number of purchases per household was set at 10 (level two of Factor 4) by the same reasoning. We assumed six alternatives (level two of Factor 5), standard error variance (level one of Factor 6), and a minimum segment size of 10%.
Rates of Underfitting (U), Success (S), and Overfitting (O) by Criterion and Experimental Condition
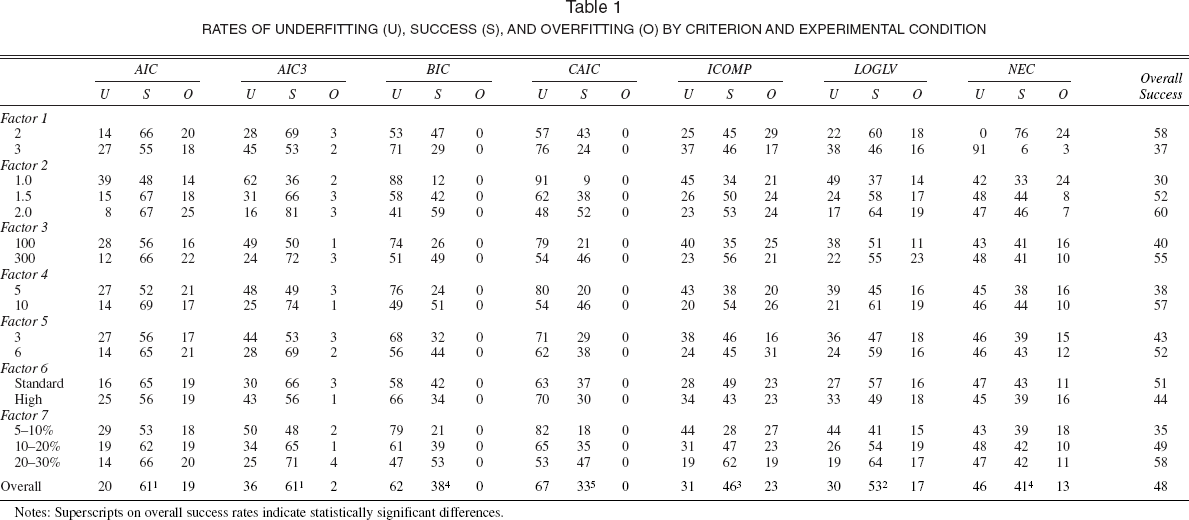
Notes: Superscripts on overall success rates indicate statistically significant differences.
Meta-Analysis Of Results: Logit Results by Criterion and Experimental Condition

Factor 1: Number of components: 2 (1 for F1) or 3 (0 for F1).
Factor 2: Mean separation between component coefficients: 1.0 (1 for F2(1)), 1.5 (1 for F2(2)), or 2.0 (0).
Factor 3: Sample size: 100 (1 for F3) or 300 (0 for F3).
Factor 4: Number of choices per household: mean of 5 (1 for F4) or 10 (0 for F4).
Factor 5: Number of choice alternatives: 3 (1 for F5) or 6 (0 for F5).
Factor 6: Error variance: standard (1 for F6) or high (0 for F6).
Factor 7: Minimum segment size: 5%–10% (1 for F7(1)), 10%–20% (1 for F7(2)), or 20%-30% (0).
Notes: Dependent variable is 0–1 indicator of success in identifying the correct number of segments, with success = 1.
Conclusion
Despite the emergence of Bayesian error components models and other random coefficient procedures in recent years, applications of finite mixture models still accumulate (Wedel and Kamakura 2000) and should continue to do so given new evidence of their effectiveness (Andrews, Ansari, and Currim 2002). As the range of application of finite mixture models continues to extend to the domains of cluster analysis (McLachlan and Basford 1988; Wedel and Kamakura 2000), multidimensional scaling (Andrews and Manrai 1999; Chintagunta 1994; Wedel and DeSarbo 1996), and conjoint analysis (Andrews and Manrai 1999; DeSarbo et al. 1992; Fader and Hardie 1996; Kamakura, Wedel, and Agrawal 1994), the models will likely become more important to applied and theoretical research in marketing.
This study shows that AIC with a per parameter penalty factor of three rather than the traditional value of two is the best segment retention criterion to use with a large variety of data configurations. Because AIC3 differs from AIC and CAIC only in the assumption made about the distribution of the likelihood ratio in finite mixtures (in which parameters are often on the boundaries of parameter spaces), we conclude that the actual distribution of the likelihood ratio is better approximated as a noncentral chi-square with 2(K – k) degrees of freedom. Currently, AIC3 is rarely, if ever, applied in the marketing literature. With very large sample sizes, the consistent criteria (BIC and CAIC) also perform well, as suggested by Bozdogan (1987).
Because the results of this study conducted in the context of multinomial choice data are not completely consistent with results of prior studies conducted with mixtures of other distributions, it may be that no one segment retention criterion is best for all types of mixtures in all situations. Perhaps it is not realistic to assume that there is one best criterion to use for all scenarios; even different specifications of a bivariate normal mixture produced varying results in Cutler and Windham's (1994) study. We are currently running simulations with mixtures of other types of distributions to test the generality of the findings on AIC3. Also, because no criterion has been perfectly capable of identifying the correct number of segments, additional research should continue to search for better criteria for segment retention. For analysts, another potentially important factor that was not studied directly in these simulations was distributional misspecification, that is, when the distribution of the data does not match that of the model. A manager, in contrast, must consider the costs and benefits (in dollars and cents) of under- or overestimating the true number of segments. By beginning to address the last major statistical deficiency with finite mixture models, the segment retention problem, researchers can significantly increase the utility of logit models for managers who make segmentation, new product development, and marketing-mix decisions.