
Abstract
Companies are eager to leverage social interactions among consumers by embedding social networking tools on their websites and actively integrating marketing actions with consumers' social activities. In this article, the authors investigate the impact of online social interactions on repeat usage behavior and the effectiveness of monetary incentives by formulating a model that parses out the effects of these individual factors. Using a unique data set from a wellness program, they find that online social interactions play a key role in driving repeat behavior, and after controlling for contemporaneous correlations from same-office friends, the social influence emanates even from distant friends working in different offices. The authors also find that monetary incentives have a significant impact on repeat usage and that ignoring this may overstate the impact of social influence. Furthermore, what-if scenario analyses show that social interactions are more effective than monetary incentives when both are present. The authors then explore social influence theories to understand the underlying process mechanisms that may operate in the repeat usage context. Using these findings, they offer strategic implications for marketing practice.
Social interactions have now become a substantial part of consumers' online activities, with more than 500 million users sharing opinions, experiences, reviews, and pictures with their friends on Facebook, and more than one billion tweets being shared on Twitter each week. As consumers' comfort level with online sharing increases, companies are keen on leveraging social interactions among consumers by embedding social networking tools on their websites and actively integrating their marketing actions with consumers' social activities (Aral, Dellarocas, and Godes 2013). For instance, Lay's crowdsourcing of its Facebook followers in designing its latest potato chip is becoming a standard practice in the industry (Sharma 2012). Moreover, Nike has emphasized the social aspect of its brand experience and encouraged customers to share their NIKEiD designs with friends. More recently, Fitbit, the wearable health tracker, is helping people reach their fitness goals by turning exercise into a game that people can play with their friends. By teaming up with a few companies such as BP, Fitbit is helping its employees be physically active while saving them significant costs in terms of health insurance premiums (Satariano 2014). Companies are embracing such customer-to-customer interactions to retain and engage consumers and to improve their marketing strategies.
The academic literature reflects the importance of this area of research, and a significant amount of work has studied the effects of social interactions; however, some gaps remain. First, the impact of social interactions currently focuses on consumers' adoption behavior, and there is little that extends these analyses to other outcomes such as repeat usage. Given that repeat usage is one of the most common behavioral outcomes of interest in marketing, this topic may well warrant further attention. Indeed, literature has suggested that such behavior might differ in nature in terms of how social influence operates (Haenlein 2013; Iyengar, Van den Bulte, and Lee 2015; Nitzan and Libai 2011), making it misleading to generalize the results of adoption studies in the repeat usage context without further investigation.
Second, although there are studies incorporating the effects of marketing actions such as detailing and advertising (e.g., Nair, Manchanda, and Bhatia 2010; Van den Bulte and Lilien 2001), few studies have investigated other widely used marketing tools such as monetary incentives. Indeed, little is known about the effectiveness of traditional marketing actions in today's connected world, in which companies increasingly integrate traditional marketing with consumers' social connections. The current role of traditional marketing actions consequently needs further investigation. Finally, much of the literature in social influence has used aggregate-level marketing data that provides broader insights; the few studies using individual-level marketing data incorporate the impact of direct marketing or detailing on adoption behavior alone. The complex relationship between marketing actions and social interactions makes it challenging—and critical—to distinguish the role of these factors and understand their joint impact on consumer behavior.
Our objective, then, is to study the impact of online social interactions on consumers' repeat usage behavior and compare its effect with a commonly used but understudied marketing action—monetary incentives. More specifically, we aim to understand (1) what happens when consumers interact with friends using online social networking tools, (2) how the effect of monetary incentives on repeat usage behavior changes in the presence of social interactions, and (3) to what extent social interactions are more effective than monetary incentives in driving repeat usage. Furthermore, if social influence is indeed present, we want to explore the possible drivers from social influence theories that may be operating in the repeat usage behavior context.
To study these issues, we obtain data from a company that offers employees an online wellness program to encourage an active and healthy lifestyle. Participants use a pedometer to log their steps and receive cash rewards contingent on the level of participation. Furthermore, the company deploys a social networking interface that enables participants to track the activities of friends working in the same office or in other branches. This institutional setting provides a unique opportunity to investigate the effects of social interactions and monetary incentives on repeat usage. Our research context is also attractive for the following two reasons. First, the health care industry and its technology advancements are increasingly important: the increasing penetration of wearable health devices provides each user with a personal system to track physical activities as well as a social platform to share real-time records. Second, the success of the wellness program is determined by the participants' continued usage rather than by initial signups. In this context, companies may want to focus on providing interesting and engaging content continuously to drive repeat usage.
Using individual-level participation data, we develop a modeling framework that parses out the unique contributions from online social interactions as well as monetary incentives. After controlling for contemporaneous correlation among program participants in the same office, we also parse out the effects of online social interactions with both same-office and out-of-office friends. Furthermore, we examine whether the presence of social interactions magnifies or diminishes the impact of monetary incentives offered by such rewards program. Our main empirical findings are as follows.
Consistent with the previous literature, social interactions indeed influence consumers' repeat usage behavior positively. Specifically, online interactions with distant out-of-office friends turn out to be a critical driver of participation after we control for contemporaneous correlations among coparticipants working in the same office.
Monetary incentives have a significant and positive impact on encouraging repeat usage behavior even in the presence of social interactions—ignoring the latter may overstate the impact of incentives.
Social interactions are significantly more effective than monetary rewards when both are present. This finding opens the door to a new set of strategies that companies may implement to increase program participation in the presence of online social interactions while actually decreasing the cost of running such reward programs.
Among various drivers suggested in the classical social influence theories, we posit that informational influence is most likely to be at work in our research setting. That is, people may still seek informational guidance even in the repeat usage service context.
We organize the rest of the article as follows: First, we discuss the related literature and our contribution to the field. Then, we describe the data, present our modeling framework, and discuss the identification issues that typically arise in such a setting. Next, we present the results from the estimation and the scenario analyses and explore the nature of social influence. Finally, we offer conclusions and discuss directions for further research.
Related Literature
Our study is related to the growing literature focusing on understanding social interactions and their consequences. We focus on the three aspects that are relevant to our research: (1) social interactions and repeat usage behavior, (2) the underlying mechanisms of social influence, and (3) the comparison of monetary incentives with social interactions. We differentiate our study relative to the existing research and discuss the contribution we offer in the following subsections.
Social Interactions and Repeat Usage Behavior
A significant amount of research has been dedicated to understanding the effects of social interactions on diffusion or adoption behavior (see, e.g., Aral and Walker 2012; Goldenberg et al. 2009; Goldenberg, Libai, and Muller 2001; Iyengar, Van den Bulte, and Valente 2011; Katona, Zubcsek, and Sarvary 2011; Kratzer and Lettl 2009; Tucker 2008; Van den Bulte and Lilien 2001). However, the impact of social interactions on repeat purchasing or continued usage may in fact be significantly different in nature from a one-time adoption scenario (Iyengar, Van den Bulte, and Lee 2015). While the market success of some product categories (e.g., high-tech innovations) is primarily driven by adoptions, that of many others is determined by the extent to which they are purchased and consumed repeatedly.
Despite the overwhelming number of products and services that benefit from consumers' repeat purchasing behavior, there are relatively few academic studies in the social interactions literature that focus on this aspect. Exceptions include the study of peer influence on doctors' prescription behaviors (Iyengar, Van den Bulte, and Lee 2015; Nair, Manchanda, and Bhatia 2010), the study on the impact of in-group friends on golfers' repeat purchase behaviors (Hartmann 2010), the study on the impact of peer login behaviors on users' login (Trusov, Bodapati, and Bucklin 2010), and the correlation of content generation and consumption in smartphones among friends (Ghose and Han 2011). We contribute to the sparse literature in this area by investigating the influence of friends in a repeat usage context when usage is visible to others through online social networking tools.
Finally, existing studies focusing on social influence have tended to examine products and services characterized by high risk, high uncertainty, or coparticipation. Typical examples include new drugs treating critical diseases, high-tech products requiring information search, or activities involving partners or counterparts. Recent evidence has shown, however, that social interactions also affect sales of more typical consumer packaged products (Du and Kamakura 2011). Similarly, Toubia, Goldenberg, and Garcia (2014) use individual-level data to show that social interactions play a key role in improving penetration forecasts for consumer packaged goods. Our current setting represents yet another usage context: the services area in which products contain little to no risk or uncertainty, and social effects may operate differently. We thus contribute to the literature by studying the role of social influence on repeat usage in a service context.
The Nature of Social Influence
The existing literature on social interactions has proposed several underlying mechanisms, most of which can be organized into the following categories: (1) competitive concerns (in which not adopting may result in a status disadvantage), (2) performance network effects (in which benefits increase with the number of adoptions), (3) informational influence (to learn about the product's risks and benefits), and (4) normative influence (to reinforce the legitimacy of new products) (for a review on social mechanisms, see Van den Bulte and Lilien 2001). 1 The institutional context and empirical data suggest that competitive concerns and performance network effects are unlikely to be operating. People who do not wear a pedometer at work will probably not experience a status disadvantage; in addition, the benefits of walking while carrying a pedometer will not increase with the number of users. To elaborate, competitive concern operates as a driver of social influence when rivals who have adopted the innovation would gain a competitive edge over someone who has not adopted it (Burt 1987; Hannan and McDowell 1987; Van den Bulte and Lilien 2001). In our research context, the wellness program is designed to improve individual employees' welfare, and adopters are unlikely to experience any status advantage compared with nonadopters. 2 Consequently, the research setting and rich data allow us to rule out the first two processes; we thus focus on the informational and normative influences as possible processes operating in our context.
We look to the classical social influence theories for our research setting and empirical data; however, other mechanisms might operate. For example, Gardete (2015) proposes omission neglect, product contagion, and goal balancing as additional theories.
We obtain additional empirical support that competitive concern is not present in our case. Specifically, we construct the variable of competitive concern measuring the proportion of a focal participant's friends with higher status than him or her each week and find that social influence is unrelated to such a status variable. We thank an anonymous reviewer for this line of thought. Note that status achievements can create competitive concerns in other settings, such as where status is work-related and such information signals an employee's performance relative to colleagues. We leave this issue for further research to examine.
Prior work has suggested that informational influence is dominant in reducing uncertainty in a new product adoption context. Such informational influence could operate in a repeat usage context as well, in which learning from experience may be slow, with uncertainty remaining even after early product experiences. Iyengar, Van den Bulte, and Lee (2015), for instance, suggest that for a risky prescription drug, physicians can rely on the judgment of peer physicians in making repeat decisions. This finding suggests that although impact of informational influence may decrease as customers proceed from trial to repeat, influence may still play a role in driving usage.
Normative influence, in contrast, is dominant when conforming to in-group expectations or norms. Rather than decreasing over time, such a need for conformation may in fact grow more pronounced as the participant becomes more involved and the in-group expands (Gardete 2015; Iyengar, Van den Bulte, and Lee 2015). Indeed, the repetitive nature of consumption behavior might lead to increased susceptibility to social influence, such that normative influence may lead to herding behavior (Banerjee 1992; Muchnik, Aral, and Taylor 2013). These findings indicate that normative social influence is more likely to exert a greater influence on repeat purchase than on initial adoption decisions. 3
It may be argued that social support or group support might be operating in our setting because physical activities may be challenging over a prolonged period, and social support helps participants persevere in these activities. Indeed, both drivers of social interactions yield the same outcome; namely, social interactions become more critical as participants gain experience. However, we posit that social support is unlikely to be at work for the following reasons. First, social support is the perception of being part of a social network incorporating mutual assistance and cooperation (Rosenbaum and Massiah 2007; Taylor et al. 2004; Wiesenfeld, Raghuram, and Garud 2001). It is unlikely that wearing a pedometer requires the urge to seek such mutual assistance and obligations. Second, social support has been shown to work for serious and rather stressful activities ranging from cessation of drug or alcohol use to preparation for exams, activities that consumers may otherwise procrastinate (Felsten and Wilcox 1992; Giles et al. 2005; Steptoe et al. 1996). Given the casual setting of an optional wellness program offered at the workplace, participating is unlikely to cause the kind of stress that would require group support. Finally, it is difficult to disentangle both drivers empirically unless additional detailed data such as psychographics are available. We thus preclude social support as a driver of participation and instead focus on normative influence.
Note that our research setting and empirical data (in a nonexperimental setting) do not offer an a priori prediction regarding the effect of informational or normative influence. To explore the mechanisms operating in this context, we analyze social influence contingent on people's usage patterns and thus seek preliminary evidence regarding the nature of social influence in repeat usage.
Monetary Incentives and Comparison with Social Interactions
Much of the existing literature incorporating marketing actions in social interaction studies has found the impact of the former to be limited in the presence of the latter. For example, sales calls are effective in encouraging adoptions but not in driving subsequent prescriptions (Iyengar, Van den Bulte, and Lee 2015; Iyengar, Van den Bulte, and Valente 2011; Nair, Manchanda, and Bhatia 2010) while the impact of direct marketing diminishes over time in smartphone adoption (Risselada, Verhoef, and Bijmolt 2014). We contribute to this literature by comparing the effect of monetary incentives, another popular marketing tool, with social influence on repeat usage.
Monetary incentives are known to work effectively for increasing survey responses (Hansen 1980), encouraging word of mouth (Wirtz and Chew 2002), and shaping behavior (Jenkins et al. 1998). When offered by reward and loyalty programs, in particular, the incentive is often based on the extent of repeat purchasing, unlike other marketing actions such as detailing. Thus, consumers perceive each use and consumption experience as a sequence of related decisions rather than independent transactions, which in turn motivates consumers to invest extended efforts over time (Kivetz and Simonson 2002; Lewis 2004). This suggests that people who have been rewarded before are more likely to engage in similar behavior again, resulting in a positive impact of monetary incentives on purchase (Lichtenstein, Netemeyer, and Burton 1990).
Nevertheless, several studies have shown that the positive relationship between monetary incentives and performance may fail to hold. Gneezy and Rustichini (2000) show that monetary compensation can yield lower performance when factors other than money and effort play a role in decision making. For example, performance on intelligence tests and donation collection is lowered when meager compensation is offered in return. Furthermore, Vohs, Mead, and Goode (2006) show that when people are primed with money, they become self-sufficient, resulting in a tendency to isolate themselves and be insensitive to social activities. We thus investigate the effect of monetary incentives on repeat usage in the presence of social interactions.
Interestingly, much of the research, whether focusing on adoption or repeat usage behavior, has incorporated marketing efforts in their analyses as control variables, under the argument that ignoring their effects could cause social interactions to be overstated because of correlated effects (e.g., Van den Bulte and Lilien 2001). We posit that the reverse could be true as well. That is, ignoring social interactions could cause marketing effects to be overstated. Research comparing these two factors at an aggregate level has shown that social effects may actually have a stronger impact than traditional marketing actions (e.g., Trusov, Bucklin, and Pauwels 2009). We may therefore expect that, in the presence of social interactions, monetary incentives may also have a lower (or even insignificant) impact, and that ignoring the former may overstate the impact of the latter.
Summary and Our Objectives
Existing studies have offered limited insights on social effects in repeat decisions and the effectiveness of monetary incentives in the presence of social interactions. We fill this gap by investigating the impact of social interactions and monetary incentives together at an individual level in a repeat purchase context. Finally, we explore the nature of social influence by examining its interactions with usage behavior.
Table 1 lists the aforementioned relevant research, offering a comparative view based on factors such as the type of behavior studied, the type of social interactions at work, the type of marketing effort employed, and whether individual-level marketing data are used. Note that we focus on studies using individual-level social interaction data (i.e., based on actual interpersonal ties) consistent with our area of interest. Next, we discuss the details of our data set.
RELATED LITERATURE USING INDIVIDUAL-LEVEL SOCIAL INTERACTION DATA

Data
Our data are from an online wellness program deployed in an international consulting company. According to the U.S. Department of Labor, more than 90% of companies with 200 or more workers have employee wellness programs (Mattke, Schnyer, and Van Busum 2012), and the use of social tools in such programs has indeed become fairly common. The ultimate goal of these programs, which frequently offer some form of rewards, is to increase employee welfare by encouraging exercise, healthy eating, smoking cessation, and clean living in general, which in turn is expected to increase productivity and reduce health care costs.
The company ran the program in its U.S. offices for approximately five months between March 28 and August 30 of 2011, with 5,107 participants across 76 U.S. offices. In the beginning of the program, each participant signed up online through a website. Once registered, users were required to purchase a pedometer for approximately $30 to participate. The pedometer keeps track of the number of steps taken in hourly intervals (e.g., “200 steps taken between 1 P.M. and 2 P.M. on May 12th”). It is also USB enabled, and client software is provided to participants that automatically uploads pedometer readings to their online accounts. Each participant has a specific online user account and an assigned identification number through which activities can be tracked. Figure 1 shows a screenshot of the main page of the online user account.
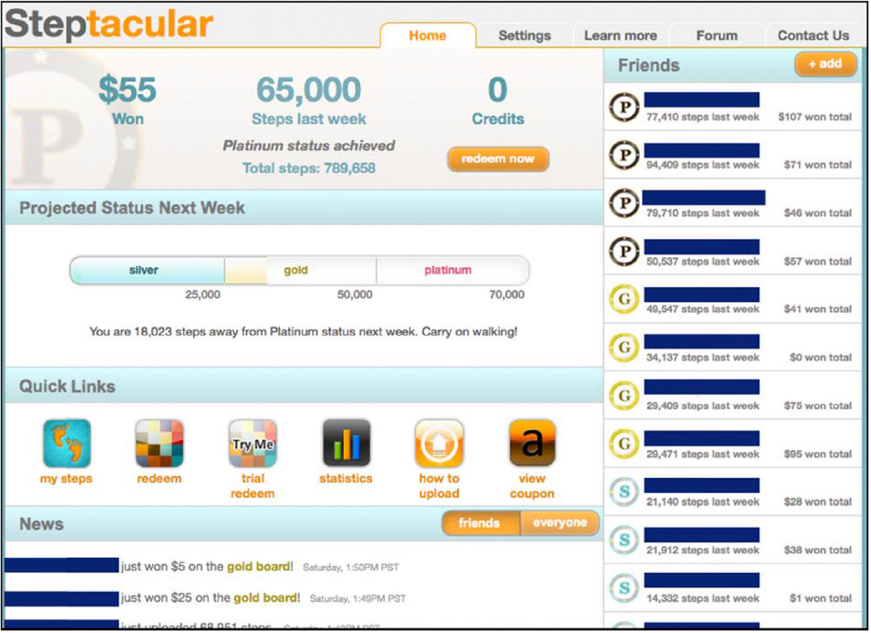
ONLINE USER INTERFACE: MAIN PAGE OF THE ONLINE USER ACCOUNT
We highlight three important features of the online user interface involved in the program. First, participants can track their own activity: the main screen displays the total number of steps walked since the beginning of the program, over the previous week, and since the beginning of that week. Each week starts on Monday and ends on Sunday. Second, participants earn credits as they upload their steps. Similar to a points-based rewards program, readings from the pedometer are converted into online credits through a mathematical formula that increases credits with the number of steps walked. Participants can track their credits and subsequently redeem them for cash. Participants also have a “status” that is updated every week. Depending on how much they walk in a given week, they attain a silver, gold, or platinum status in the following week. Third, the online networking tool for the program was introduced on May 4 (37 days after the launch of the program). The tool allowed each participant to “friend” other participants in the program by sending an invitation through the web page. Friendships are mutual, as is the case with the majority of social networking sites including Facebook and Google Plus (hereinafter, we refer to such “friends” in the wellness program simply as friends). Participants can track their friends' activities through the “friends” interface in their account page. Every time a participant logs in, (s)he observes friends' previous week activities (i.e., how much they walked and the reward they claimed in the previous week; see Figure 1).
Our data set includes the four key pieces of information that are crucial for our analysis. First, we have access to each participant's pedometer information (i.e., number of steps taken on an hourly basis as recorded by the pedometer, along with the timing of upload). Second, our data include the amount and the timing of the rewards claimed by each participant. From this information, we can extract participants' daily activities such as hours pedometer used, steps walked, and rewards claimed in a given day. Third, we have access to each participant's friend list at a given time. In other words, we can track when a pair of participants adds each other to their friends' lists. This information enables us to construct each participant's friend network in the program.
Finally, our data include information on each participant's office location. This allows us to identify whether the participants share the same geographical office with their friends. In our data set, participants may have friends in the same and/or in other offices. We can thus divide a given participant's friends into two mutually exclusive categories: same-office friends who share the same office with the participant, and out-of-office friends who do not share the same office. The participant has online interactions with friends because (s)he observes their activities through the website after adding them to his or her friend list. We use this information to identify the effect of online interactions on a participant's behavior. Note that the participant shares the workplace with same-office friends and could potentially see them daily throughout the program. We control for this contemporaneous workplace correlation in the model.
Over the course of the program, 2,980 of the registrants uploaded their pedometer data at least once. Of these participants, 1,166 had at least one friend in their friend lists. The time period we use in our analysis is May 4 (when the online networking tool is launched) through August 30 (when the program officially ended). For our sample, we selected the participants who added at least one friend, signed up for the program before April 10, and actively participated (i.e., used the pedometer and uploaded steps) until the end of the program. 4 Our sample includes a network of 334 participants from 43 U.S. offices with a total of 39,746 daily data points. 5 Table 2 includes descriptive statistics for the selected sample of participants. Participation was lowest in April, the first month of the program, and there is a nondecreasing trend in both participation levels and rewards claimed in the following months.
We use April 10 as the threshold because we observe that 90% of the participants with at least one friend signed up in the first two weeks of the program. Such a selection also enables us to exclude participants' “warm-up” periods (i.e., they become used to the program and start accumulating credits for rewards) from our analysis to better capture our effects of interest.
Note that because of our sample selection criteria, a small proportion of participants are excluded from the network. However, we also test and find that inclusion of these participants does not result in any significant changes in our results and interpretation.
DESCRIPTIVE STATISTICS

Notes: Standard deviations are in parentheses.
Drawing on the final friend lists of the participants, the average number of friends in our network is 2.26, of which .72 represents out-of-office friends and 1.54 represents same-office friends. Figure 2 shows the degree distribution, which follows a power law as commonly observed in most social networks. Figure 3 presents the collection of social interactions for the selected sample using the final friend lists. Straight lines represent connections between same-office friends, and dashed lines represent connections between out-of-office friends.

DEGREE DISTRIBUTION FOR THE SELECTED SAMPLE OF PARTICIPANTS

SOCIAL INTERACTIONS FOR THE SELECTED SAMPLE OF PARTICIPANTS
Model
We first discuss the conceptualization of our key model components including the nature of social interactions we study, followed by our treatment of the potential identification problems that are common in such networked data analysis. We then present our full model specification and the variables used for the empirical analysis.
Model Components
Dependent variable
In conceptualizing our model, we gauge people's participation in the wellness program on the basis of their pedometer usage. That is, we use the number of hours the pedometer is used in a given day as the dependent variable. Note that we utilize this measure rather than the number of steps walked because it is the conscious act of carrying the pedometer that represents a commitment to participate, while the steps walked may be a function of a person's daily routine, natural orientation, and habits. 6
Both measures (number of steps and hours pedometer used) are be highly correlated with a r = .7 (p < .001). In our robustness check, we also use the number of steps as an alternative measure and find its estimates to be consistent.
Friend determination
As several studies have noted, it is crucial to obtain exogenously defined social network information when studying social interactions (Hartmann et al. 2008; Manski 1993; Nair, Manchanda, and Bhatia 2010). We follow a data-based approach in that we directly use the friendship data from existing social networks (e.g., Goldenberg et al. 2009; Katona, Zubcsek, and Sarvary 2011; Trusov, Bodapati, and Bucklin 2010). In our case, we assume that a participant is only influenced by friends represented in his or her friend list, and we use that to define the social network. We then separate these friends into two disjoint groups—same-office friends and out-of-office friends—as discussed in the “Data” section. Note that there could be other participants who share the same office but are not in each other's friend list. We assume that such coworkers who are not on friend lists will have negligible influence on the participants with respect to this program. We support this assumption in two ways: first, face-to-face interviews with 15 randomly selected participants confirmed that only coworkers with whom the participants interact in general (irrespective of the program) are actually added to their friend lists. Second, it is reasonable that in such large offices (mostly with more than 50 employees), the remaining same-office participants may indeed have little contact with or influence on each other.
Social interactions
Social interactions in our data consist of observing each other's activities through the website. Participants mainly observe their friends' previous-week activities in their personal accounts; we thus assume that online interactions will influence participants' future behavior. We find further support for this in the literature, in which, given their discontinuous nature, online social interactions are typically considered to have significant impact on future behavior (e.g., Moe and Trusov 2011; Trusov, Bodapati, and Bucklin 2010). Overall, a participant will have online interactions with both same-office and out-of-office friends listed in his or her friend list. Furthermore, we are able to distinguish the impact of social interactions emanating from same-office and out-of-office friends on participants' repeat usage behavior. Next, we next discuss the potential identification problems that are common in networked data analysis.
Identification Issues
A common problem with this kind of data is distinguishing correlation from causation regarding a person's actions and his or her friend's behaviors. Correlations could arise from three main factors: endogenous group formation, correlated unobservables, and simultaneity (Hartmann et al. 2008; Manski 1993; Moffitt 2001). In the following subsections, we discuss how we handle these issues through our model specification and unique data set.
Endogenous group formation
Identification problems could result from endogenous group formation when people with similar tastes and preferences form social groups (Hartmann et al. 2008; Moffitt 2001), such that the observed correlation in behaviors could actually be due to omitted (unobserved) individual characteristics. Endogenous group formation could occur in our context if participants add people with similar walking and participation preferences to their friend lists. It may then be difficult to identify whether the observed correlation reflects friends' influence on the participant's behavior or friends' commonalities with the participant.
Such endogenous group formation is not a credible threat to the internal validity of our empirical findings, as the following discussion shows. First, the institutional setting indicates that participants who are already “friends” in an offline world are reproducing ties in an online network setting. That is, our case is more similar to a static offline network, in which existing friends' activities become available online over a certain time period. In addition, as mentioned previously, our interview with participants confirms that they are likely to have preexisting ties with those in their friend lists in an offline world prior to the introduction of the networking feature. 7 Second, we take advantage of having panel data and specify individual-specific fixed effects to control for unobserved individual-level differences in tastes and motivations to participate in the program (Ghose and Han 2011; Hartmann 2010; Hartmann et al. 2008; Nair, Manchanda, and Bhatia 2010; Narayanan and Nair 2013). Doing so not only is in line with the recent studies in the literature but also enables us to separate out the common unobserved individual-specific effects from the error term, which could solve the endogeneity problem.
Note that our friendship formation mechanism is different from that of “new” ties in other contexts (e.g., Snijders et al. 2010) dealing with the “partner selection” issue for the following reasons. First, the website interface does not allow participants to see other “nonfriend” users or their activities; thus, participants cannot add friends contingent on others' participation performance. Second, the online program does not encourage users to explore new connections (unlike Facebook, which interactively shows a “people you may know” list). Instead, mutual friendship is formed when one participant sends an invitation through the website and the other accepts it; this in turn suggests that participants who are already offline friends reproduce ties online in this wellness program. Finally, we empirically test the potential impact of “who is being added” as a robustness check. Specifically, we measure the difference in the steps walked last week between a focal participant and his or her newly added friends at a given week (i.e., the steps of a focal participant – the steps of the newly added friends at a given week). Results show that “who is being added” is not statistically significant while other variables remain qualitatively identical.
Finally, we argue that if the correlation in the behaviors of a given participant and his or her friends were only due to similarities in tastes and preferences, the introduction of the online networking tool would be unlikely to drive any significant changes in the participant's relative activity levels. Recall that the online networking tool in the program was introduced 37 days after the launch of the program, before which participants were not explicitly exposed to their friends' activities through the website; therefore, there were no online interactions among participants. Although participants could be having offline interactions (at least with same-office friends) during this time period, they are still not exposed to the details of friends' activities through the website (i.e., online interactions). A comparison of pedometer usage for each participant with his or her friends' pedometer usage before and after they add each other to their friends' lists offers some early insights. We observe that, on average, the gap between pedometer usage of participants and their friends significantly decreases for both out-of-office and same-office friends (average difference in means before friendship = 5.75, average difference in means after friendship = 4.61; p < .001). In other words, the pedometer usage of participants and their friends becomes more similar after they begin having online interactions (i.e., add each other to their friend lists). This increased similarity in pedometer usage (after the networking tool is introduced) could well be reflective of the social influence in our sample, which we further explore and validate through our model specification.
Correlated unobservables
There could be other sources of correlation, not observable to us, but nevertheless responsible for driving the behavior of participants in the same network (Moffitt 2001). Unlike most of the existing studies focusing on product adoption or usage, there are no significant external marketing efforts that could result in such correlations because the focal program is internal, controlled by the company. However, there could be other unobserved factors based on location and time that could result in a correlation in participants' behavior (Nair, Manchanda, and Bhatia 2010). For instance, participants who work in the downtown area may have a tendency to use the pedometer more because they might be walking more or using public transportation because of parking difficulties. Similarly, participants may have a tendency to use the pedometer more over time as they become familiar with the program or may adjust their usage on the basis of the weather and holidays. We thus control for time and location effects in our empirical model.
Simultaneity
Simultaneity issues arise when a participant's and friends' actions could be contemporaneously interdependent (Moffitt 2001; Nair, Manchanda, and Bhatia 2010). For instance, throughout the day, a participant could potentially observe his or her same-office friends' activities (e.g., whether they are carrying the pedometer or taking a walk), even coparticipating in them (e.g., walking to a restaurant together for lunch) or having face-to-face discussions regarding the program. We incorporate the simultaneity aspect by specifying spatial correlation between the participant and his or her same-office friends. Inclusion of spatial dependence is considered one way of incorporating contemporaneous social interactions in a model (Anselin 2002; Lee, Liu, and Lin 2010; Manski 1993). We discuss the model details in the next subsection. Note that such a simultaneity issue may be less of a concern for online interactions (with both same-office and out-of-office friends) because these interactions mainly consist of observing friends' previous-week activities through the website (see Figure 1).
Model Specification
We observe the hours that a pedometer is used in a given day only if the participant uses the pedometer that day. Because the pedometer does not record any information when it is not used in a given day, we simply observe zero for those days. Because of the nature of our dependent variable, we specify a spatial Tobit model for a given day t and for n participants as in Equations 1 and 2. Let yit be the number of hours pedometer is used by participant i on day t:

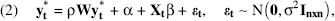
We also use a weight matrix specification with 0–1 entries, where the total influence is allowed to increase with the number of friends. Given that the final model performs worse with such a specification and our results and interpretation do not significantly change, we decided to keep this normalized specification.
In this specification, ρ is the spatial coefficient based on physical proximity, and it represents the strength of the contemporaneous correlation between a participant and her same-office participants' activity levels.
9
α = [α1,α2,…,αn]′ is the vector of individual-specific fixed effects for n participants. Denoting k as the number of covariates, 
Note that exposure to same-day activities of the same-office participants is not directly measured but indirectly inferred by using the contemporaneous correlation term for the network of same-office friends.
Covariates (Xt)
We divide the covariates in Equation 2 into five categories: (1) individual characteristics, which include a participant's observed and unobserved propensity to participate in the program; (2) monetary incentives, which represent the effect of monetary rewards; (3) online social interaction effects, which capture the effect of participants' exposure to friends' activities through online interactions; (4) network characteristics, which include the effect of participants' network size to capture additional friend effects; and (5) time and location effects, which include unobserved time- and location-specific effects common to all participants in a location at a given time period. Controlling for all of the known major factors helps us identify social interaction effects from other sources of correlation.
Individual characteristics
We specify individual-specific fixed effects, αi, to control for the unobserved individual-level differences in preferences and motivations to participate in the program. As mentioned in the identification issues section, this specification also helps tackle the endogenous group formation problem. To control for observed characteristics, we include HPSMiw(t), the number of hours the pedometer is used since Monday in the week of day t. This variable captures a participant's natural tendency to participate in the program in a given week as well as his or her desire for a higher program status in the following week. Note that participants can see how much they walked since Monday and how much they need to walk to upgrade their status in their online account. Finally, this variable further allows us to control for potential state dependence in a participant's behavior.
Monetary incentives
The effect of monetary incentives is measured by MREiw(t)–1, the average daily monetary reward earnings ($) that participant i claimed in the previous week of day t, where w(t) represents the week of day t. This variable captures the effect of monetary rewards on a person's participation level. If the participant earned monetary rewards in the previous week, this can raise the expected value of future rewards and thus motivate current pedometer usage.
Online social interaction effects
We divide online social interaction effects into two categories based on the participants' office locations. Online interaction effects of out-of-office friends capture the influence of out-of-office friends through online interactions. Similar to prior studies, we operationalize influence as the weighted sum of a participant's (out-of-office) friends' activities (e.g., Iyengar, Van den Bulte, and Valente 2011; Trusov, Bodapati, and Bucklin 2010; Van den Bulte and Lilien 2001). For participant i on day t, the variable is defined as

We also define online interaction variables using friends' reward earnings (rather than pedometer usage) and include them in our analysis. We found no significant effects of online interactions in this case.
Similarly, we introduce online interaction effects of the same-office friends to capture the influence of the same-office friends through online interactions. Again, we operationalize influence as the weighted sum of a participant's (same-office) friends' activities. For participant i and day t, the variable is defined as

Network characteristics
We include the size of the network of participant i on day t, NSizeit, by counting friends in a participant i's network on a given day. This variable captures additional friend effects that evolve over time and influence the participant's behavior. For instance, if a participant is part of a large connected network, (s)he might be more actively involved in the program.
Time and location effects
We use monthly dummies to control for unobserved time effects that could be common across all participants. Thus, Dk is equal to 1 for month k and 0 otherwise, where k = 1–3. We define May as the base month. Because this is a new program, we expect to see an increase in participation levels as participants acclimate to the program over time.
There are 43 office locations; therefore, it is not practical to use a dummy variable approach as we did to capture month effects. We construct a proxy variable to further capture unobservable location effects that could be common across all participants in a particular location at a given day. For this purpose, we use the average activity levels of all the participants (not only limited to our sample) in a particular location at a given day. We define the location effect for participant i on day t as follows:
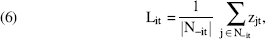
where N–it is the set of all other participants in participant i's office on day t, and Zjt is the number of hours that participant j uses the pedometer on day t. Thus, this mean variable captures unobservable location and time-specific effects.
Final Empirical Model and Estimation
To incorporate these variables, we rewrite Equation 2 for participant i on a given day t to obtain our final empirical model as in Equation 7.
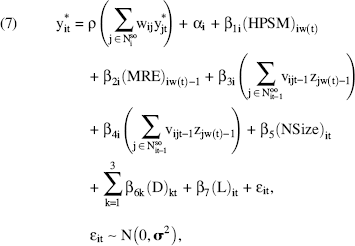
where β2i represents the impact of the rewards program on a person's participation, and β3i and β4i capture the out-of-office and same-office friends' influence through online interactions, respectively. 11 Overall, analyzing these three coefficients will offer insights on the impact of peer influence in the same versus different workplaces as well as on the comparison of social influence with the effect of marketing program.
Note that for both rewards and online interactions, we include only one lagged week effect. We also test for potential carryover effects from additional lags by using an exponential smoothing specification similar to Trusov, Bodapati, and Bucklin (2010). Results show that participants give a weight of 86% or more to the first lag (previous week) for both variables. Because the current model with only the previous week's effects also performs better, we present this specification.
Table 3 reports the parameter estimates of the four empirical models including our full model (Model 4) as well as three benchmark models (Models 1–3). Model 1 includes all but social interactions and monetary rewards and serves as a base model with contemporaneous correlation and control variables. In Model 2, we introduce the impact of social interactions emanating from same-office and out-of-office friends, whereas Model 3 includes the reward effect. Model 4, our full model specified in Equation 7, incorporates both kinds of online interactions in addition to monetary rewards. A comparison of these models will help us identify the model that best explains participation behavior as well as study the relative impact of these variables in the presence/absence of others.
ESTIMATION RESULTS

Notes: We included fixed effects for participants but do not report these values. Parameters in bold indicate significance at the 95% level. We used May as the base while coding for month dummies.
Bayesian inference may provide computational superiority in estimating limited dependent variable models (e.g., Tobit, probit) compared with likelihood-based methods. Estimation of such models may require dealing with integration in multiple dimensions. However, in the case of Bayesian inference, this complexity can be avoided by data augmentation methods used in the presence of a censored dependent variable (as is the case in our study; see Chib 1992). Therefore, we use simulation-based Bayesian inference to obtain parameter estimates of our spatial Tobit models. Specifically, we use Markov chain Monte Carlo methods utilizing data augmentation and a hierarchical Bayesian approach to incorporate heterogeneity in certain parameters (β1i, β2i, β3i, β4i) to simulate parameter draws from the posterior distributions. We implement the Metropolis–Hastings algorithm within Gibbs sampling with a uniform prior specification for parameter r for the spatial Tobit models (LeSage 1997, 2000) and conjugate priors for the other parameters. We ran a Gibbs sampler for 15,000 iterations for all the four models. We checked for convergence by monitoring the properties of the draws over iterations and choose a burn-in period of 5,000 iterations. We use the remaining 10,000 draws to calculate posterior means and 95% posterior intervals for parameters of all the models.
Findings and Implications
We first discuss our empirical findings and then conduct what-if scenario analyses to study the relative effects of social interactions and monetary incentives. Finally, in line with prior literature, we explore the nature of social influence.
Empirical Findings
We discuss our results from the estimations of the four models in Table 3. As the table shows, the log-marginal likelihoods reveal that Models 2 and 3 outperform Model 1, and Model 4 (the full model as specified in Equation 7) offers a better fit than the other models. The detailed discussion of each model and comparisons among them offer insights on the impact of various factors on participants' behavior. (Please note that our discussion centers on the results reported in Table 3. We do not repeatedly reference the table to avoid interrupting the narrative.)
Model 1 shows that the contemporaneous correlation effect among the same-office coworkers is significant and positive (ρ = .2313). This indicates that physical proximity among same-office friends plays a significant role in driving simultaneous interdependency in repeat usage behavior. This also suggests that the effect of simultaneous interactions among physically proximate participants needs to be controlled for to accurately measure the effect of same-office friends' online social interactions.
The control variables exert significant influence on the hours of pedometer usage. Specifically, participants tend to use the pedometer more on any day of a given week if they have been actively using it since the beginning of that week (β1 = .0234). This captures people's natural tendency to participate in the program and their desire to upgrade their program status so that they can claim more rewards in the following week. The network size has a significant and positive impact on pedometer usage, indicating that if the participant is part of a larger network, (s)he has a greater tendency to participate in the program (β5 = .1863). 12 Negative coefficients for the month dummies indicate that there is a decrease in pedometer usage (β61 = –.1730, β62 = –.8180, β63 = –.8795). 13 The time-location effect is also significant and positive (β7 = .5254). These time- and location-related effects (β61–β63, β7) suggest that the correlation between a participant and his or her friends' pedometer usage could be attributed to the friends' influence through online interactions. Note that the estimates of the control variables remain almost identical across all four models; we thus focus on only the key variables in discussing Models 2–4.
Previous performance may affect the evolution of online social networks: participants are more likely to add friends in their online network as they walk more and become more comfortable with the fact that friends are observing their performance. In our robustness check, we use the control function approach with the lagged network size as an instrument and estimate a model while controlling for potential endogeneity between walking and network size. All the empirical results remain qualitatively identical.
Because the online networking tool was introduced in May, participation might have been relatively higher that month, resulting in the smaller estimates for June to August. The estimate for June is significantly larger than those for July and August, whereas the estimates of the latter two months are not different from each other. These findings are not surprising, because participation in the program may have stabilized after the first couple of months. Moreover, the two summer months are popular vacation times (e.g., 4th of July), which might also affect their participation.
Models 2 and 3 include social influence and monetary reward, respectively, in addition to the existing variables in Model 1. First, Model 2 shows the significant and positive online social interaction effects by out-of-office friends (β3 = .0345), whereas the same-office friends exert insignificant influence on pedometer usage. Thus, a person's participation in a given week is influenced by out-of-office friends' pedometer usage in the previous week. This finding is intuitive in that the participant regularly observes out-of-office friends' previous week activities in his or her online account. However, same-office friends' previous week activities have no influence after we control for the same-day activities by the same-office friends (β4 is insignificant). This seems logical on deliberation, given that participation in the program involves wearing the pedometer continuously throughout the day, making it highly likely that these same-office friends are coworkers who know and perhaps see each other every day at work. As such, the social impact among same-office friends is captured through simultaneous pedometer usage of friends in the same office rather than observation of previous week's activities online. Thus, although β4 is insignificant, contemporaneous correlation is positive and significant (ρ = .0843). Notably (and expectedly), the magnitude of the correlational impact decreases from .2313 to .0843 when we include online interactions.
Next, we explore the effects of monetary rewards in Model 3. As we discuss in the “Related Literature” section, monetary incentives offered in reward programs are a widely used marketing tool, but they have received little attention in the field of social interactions. Our empirical findings show that there is a significant and positive effect of monetary rewards on pedometer usage (β2 = .0887). 14 Clearly, offering monetary incentives still boosts continued participation. Unlike previous studies that uncover the presence of marketing actions in adoption only and at the early stage of product life cycles (Iyengar, Van den Bulte, and Lee 2015; Nair, Manchanda, and Bhatia 2010; Risselada, Verhoef, and Bijmolt 2014), we find that monetary rewards can be effective in repeat usage as well. Our finding adds empirical evidence to the literature in that the positive effect of reward incentives in driving repeat usage sustains in the presence of social interactions.
Participants earn rewards based on the amount of walking they do, and these rewards may affect subsequent walking, causing a potential endogeneity problem. As a robustness check, we estimate models while controlling for potential reward endogeneity using the control function approach with the lagged rewards as an instrument. All the empirical results stay consistent.
Model 4 represents our full model and includes both online interactions and monetary rewards. Online social interactions with friends play a significant role in driving repeat usage, and the social influence primarily emanates from out-of-office friends rather than same-office friends (i.e., β3 = .0370; β4 is insignificant). We see (as in Model 2) that the same-office friends' influence is mainly explained by the contemporaneous interdependency among proximate offline friends (ρ = .0843). Finally, monetary rewards claimed in the previous week significantly increase pedometer usage (β2 = .0572). Note that the impact of monetary incentives is still significant in repeat behavior despite the presence of significant social influence. Furthermore, when compared with Model 3, there is a decrease in the impact of monetary rewards. This suggests that when social interactions occur, omitting such effects may overstate the effects of monetary incentives. Clearly, both social interactions and monetary rewards have a positive impact on participation in the wellness program. To quantify their relative effects, we consider various scenarios and perform what-if analyses through simulations.
What-If Analyses and Implications
In the following subsections, we explore four “what-if scenarios. In addition, we investigate the participation levels that result when the firm's offering for the service program varies.
No social interactions, no monetary rewards
The firm offers neither social networking tools nor monetary rewards, and participants' intrinsic tendency to walk is the main driver of their behavior.
Social interactions only
The firm offers social networking tools, but not monetary rewards. That is, the program does not incur continued expense to encourage usage.
Monetary rewards only
The firm offers monetary rewards contingent on participants' pedometer usage. This used to be widely implemented in the wellness programs offered in the industry before the popularity of social networking tools.
Both social interactions and monetary rewards
The firm offers social networking tools along with monetary rewards, with the expectation that they create synergistic participation.
We simulate the expected participation levels for each scenario during our data window, and the estimates for each scenario are taken from the corresponding model in our estimations presented in Table 3. 15 To this end, we follow the actual process in our data as closely as possible. For instance, we assume that the participants' friendship networks are the same as in the actual data and use a dynamic weight matrix when generating online interaction variables, whereas the weight matrix for the contemporaneous correlation is taken as static. We also generate monetary reward earnings in line with the actual observations in our data. To generate a new sequence of rewards, we assume that people will redeem all the available credits for cash on the exact dates given in the actual data using a linear relationship between the number of hours of pedometer usage and reward earnings. 16 Table 4 shows total hours of pedometer usage per person and total rewards claimed per person across alternatives of the firm's offerings.
We thank an anonymous reviewer for this suggestion. Details of the simulation process are as follows. The initial values of the independent variables (rewards earned last week, online interaction variables and hours walked since Monday) are initialized as zero. Given a sequence of covariates up to (and including) day t, we generate the dependent variable for day t + 1 using Equation 7 along with the corresponding parameter estimates. In turn, the values of the dependent variable up to (and including) day t + 1 determine the value of hours walked since Monday as well as same-office and out-of-office online interactions at day t + 1. This is then used to generate the value of the dependent variable for day t + 2.
More specifically, we assume that people will claim their rewards on the exact dates given in the actual data. For instance, if a person claims rewards on days t1, t2, and t3 in the actual data, (s)he claims rewards at the same times in the simulated data as well. Moreover, we assume a linear relationship between the number of hours the pedometer was used and reward earnings. In other words, the reward conversion ratio is calculated based on the number of hours the pedometer was used and amount of rewards earned between two consecutive reward claim dates in the actual data. Finally, we assume that the person will redeem all of his or her credits for cash if (s)he claims rewards on a given day.
SIMULATION RESULTS FOR WHAT-IF SCENARIOS
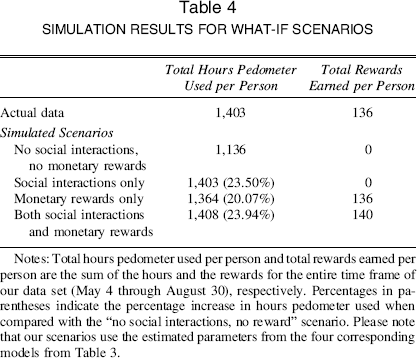
Notes: Total hours pedometer used per person and total rewards earned per person are the sum of the hours and the rewards for the entire time frame of our data set (May 4 through August 30), respectively. Percentages in parentheses indicate the percentage increase in hours pedometer used when compared with the “no social interactions, no reward” scenario. Please note that our scenarios use the estimated parameters from the four corresponding models from Table 3.
Our what-if analyses provide several notable findings. First, the simulated data of the current version of the program is very close to the original data, indicating that our full model replicates aggregate behavior of the participants well. Second, when using “no social interactions, no monetary rewards” as the base case, the hours of pedometer usage is larger in the other three scenarios by more than 20% (1,136 vs. 1,403, 1,364, 1,408); this substantial improvement confirms the strong impact of the firm's offerings on participants' repeat usage. Third, the wellness program with “social interactions only” induces participants to walk more than the program with “monetary rewards only” (1,403 vs. 1,364, respectively). Clearly, either enabling social interactions or offering monetary rewards has the potential to sustain and improve people's participation levels even in the absence of the other program feature; however, social interactions are perceived as more effective than monetary rewards. This effectiveness is noteworthy because the firm needs to spend $136 per person as rewards in the “monetary rewards only” case, whereas the “social interactions only” case incurs no such costs. Finally, the “both social interactions and monetary rewards” scenario performs best, with a 23.91% increase over the base scenario. Its benefit over “social interactions only,” however, is marginal (a .44% increase) because monetary incentives exert little influence in the presence of social influence, despite its statistical significance. Indeed, companies should be cautious because the impact of monetary rewards might be minimal in the presence of online social interactions; as a result, the cost of offering monetary rewards might exceed the incremental benefit that such incentives could provide.
The findings from what-if analyses, together with the empirical models, offer managerial implications for firms utilizing social interactions as well as monetary incentives as part of their marketing strategy. Online interactions positively influence repeat usage behavior, and companies can potentially benefit from leveraging online social networking platforms among their target population. Our analysis also indicates that monetary incentives have a significant and positive, though smaller, impact—even in the presence of social interactions—in encouraging repeat usage. Monetary incentives, in that case, may not be as effective as one might expect, and companies in similar contexts might consider shifting some of their resources from current rewards programs to ones that could enhance social interactions among consumers. Given the popularity of reward programs, along with the fact that businesses are increasingly encouraging their customers to use social channels where users can influence each other, the implications from our research context could be generalizable to a broad range of contexts.
The Nature of Social Influence
Our empirical findings and simulation analyses find strong support for the social effect. In line with recent studies, we explore the nature of these social effects and investigate the “hows” and “whys” of social interactions contingent on individual-level susceptibility and usage behavior (Gardete 2015; Iyengar, Van den Bulte, and Lee 2015; Nitzan and Libai 2011). As discussed previously (see the “Related Literature” section), informational or normative influence is likely to operate in our research setting. Informational influence refers to social learning in which information obtained from others updates one's belief about products/services, whereas normative influence arises from one's desire to conform to in-group norms. If the informational driver is at work, we posit that the social effect will diminish as participants learn more about the program through their own experience and rely less on others. However, if the normative influence is at work, the social interaction effect will become more prominent over time as participants get more involved in the program and walking with a pedometer establishes itself as an in-group norm. We empirically investigate the nature of social influence by adding interactions to gain deeper insights into the main effects.
We operationalize the extent to which a participant has engaged him- or herself in the program using two variables: the intensity (total time of use) and consistency (variability of use) of pedometer usage. 17 We postulate that the higher the intensity of usage, as measured by the cumulative hours in log form that the pedometer was used until the previous week of day t since signup, the greater the participant's engagement in the program. We further posit that the consistency in usage reflects a consistent motivation to participate in the wellness program. We measure the consistency of pedometer usage using the standard deviation in weekly usage hours in the moving window of four weeks prior to the focal week. We estimate the full model after adding the interactions between the social effects and the two usage-related variables. Because the impact of monetary incentives might also vary as a function of the participant's engagement in the program, we further add the interactions between the reward effects and the two usage variables. Finally, we compare the social effect with the reward effect.
We use the total time of pedometer usage in our empirical models instead of the time since joining the program because the participation benefit primarily depends on the time of pedometer usage rather than the tenure time. Note, however, that we also ran the analysis with the tenure variable, and results were qualitatively the same. In addition, we address any potential correlations between the two usage variables and current period errors as follows. First, we use the lagged cumulative time in log form. Second, we run the Hausman endogeneity test using the lagged values of the two usage variables as instruments and confirm that neither the intensity measure nor the consistency measure is correlated with current-period error terms.
Table 5 presents models that include the additional interaction effects between social interactions and monetary rewards, on the one hand, and intensity and consistency of usage on the other. Intensity and consistency variables are mean-centered, so the linear effects of social interactions and monetary rewards are the effects pertaining to the average participant. Models 1 and 2 show the estimation results of the models incorporating interactions with social influence and monetary rewards, respectively. Model 3 presents our full model with all the interactions included. Finally, given that the novelty of wearing pedometers may wear off over time, we also estimate Model 4, which includes additional time interactions with social influence and monetary rewards using a continuous week variable. 18 Model 3 outperforms the other three models with the largest log-marginal likelihoods, and the signs and significances of estimates (other than one insignificant coefficient in Model 4) remain consistent across all four models. Therefore, we focus on Model 3 for our analysis and interpretation, followed by a brief discussion of Model 4.
We use the continuous week variable to control for any time effects because social interactions and monetary rewards are also week-specific variables. As robustness checks, we estimate Model 4 with different time variables such as a continuous day or month variable and a log-transformed week variable. We also test Model 4 after excluding the month dummies and/or week main effect. All the empirical results of the key variables remain qualitatively identical.
RESULTS FOR THE NATURE OF SOCIAL INFLUENCE

Notes: We included fixed effects for participants but do not report these values. Parameters in bold indicate significance at the 95% level. The parameter estimate δ32 in Model 1 is significant at the 90% level. We used May as the base while coding for month dummies. Inconsistency is expressed in hundreds of units to avoid reporting small estimates.
The strength of social influence varies across pedometer users with different repeat usage patterns. More specifically, the main effects of online social interactions on the average participant are not significant (δ3 and δ4), but participants with intensive usage are less susceptible to the online social influence emanating from both out-of-office and same-office friends (δ31 = –.1460, δ41 = –.2441). These results suggest that participation experience accumulated over time creates “expertise,” which in turn makes participants rely less on information obtained from others when assessing the program. This is consistent with the finding of informational influence in Iyengar, Van den Bulte, and Lee (2015) that shows that physicians with high confidence in their judgment are less susceptible to social influence. Furthermore, participants with a consistent usage pattern are more sensitive to the online social influence (δ32 = –.1580, δ42 = –.1788). This implies that relative to inconsistent users, consistent users of pedometers are more likely to pay attention to the program and put greater weight on updating benefit information on the basis of social interactions. Together, these empirical findings (1) show that social influence decreases for more intense and inconsistent users and (2) suggest, given our previous arguments, that informational influence is more likely to be at work than normative influence. 19
Note that the descriptive statistics in Table 2 provide further support for informational influence. If normative influence operates, participants would try to follow the in-group norm by wearing pedometers longer and walking more. However, the average usage hours of program participants is approximately 12 hours per day and the average steps walked lies between 600 and 650 per hour without any increasing time trend over May to August.
The main effect of rewards on the average participant is significant and positive (δ2 = .0536), and participants with high usage volume seem less susceptible to monetary rewards (δ21 = –.1388). This may imply that more engaged participants are likely to be internally motivated by the benefits they experience rather than by the external motivation of monetary incentives. In other words, intense users of pedometers care about the activity itself and health improvement and are less influenced by the company's marketing efforts. 20 Notably, high consistency in repeat usage also decreases susceptibility to marketing actions (δ22 = .3460). Inconsistent participants have a more difficult time maintaining usage momentum and might then become more reliant on external incentives. Note that for higher-intensity users, the impact of external factors (social influence and monetary reward) will decrease. However, in the case of consistent users, whereas social influence will have a positive impact, monetary rewards will have a negative one. Clearly, any strategy targeting participants to increase usage must take into account the variation in consistency of usage. For example, companies may want to reallocate their marketing efforts for less engaged participants and adjust the reward scheme upward.
Previous studies have shown that the effect of direct marketing on high-technology product adoptions decreases from the product introduction onward (Risselada, Verhoef, and Bijmolt 2014), and the elasticities of brand advertising and personal selling become smaller along the product life cycles (Albers, Mantrala, and Sridhar 2010; Lodish et al. 1995). Our finding also indicates that the monetary incentive loses its attractiveness over time when participants become more engaged, which is well aligned with these previous findings.
As mentioned previously, the effects of social interactions and monetary rewards can change over time as the novelty of wearing pedometers wears off. Indeed, Model 4 shows that social influence emanating from same-office friends declines over time, whereas that from out-of-office friends is not subject to such time effects. After we control for the latter, Model 4 offers findings consistent with Model 3. That is, social interactions are less effective for intense and inconsistent users (δ31 = –.1322, δ41 = –.2499, δ42 = –.2038), and monetary rewards work better for less engaged and inconsistent participants (δ21 = –.1326, δ22 = .3078). 21
In the exception noted previously, Model 4 yields an insignificant interaction effect between the consistency of usage and social influence by out-of-office friends, whereas Model 3, in the absence of wear-out effects, produces a significant interaction. Notably, this result implies that in terms of the susceptibility to online social influences by out-of-office friends, there is no difference in social influence between consistent and inconsistent participants (when controlling for time effects).
In summary, this empirical examination of the social influence process serves as evidence to support the existence of an informational influence mechanism. Social influence still has an impact in the repeat usage service context (a nondurable that poses little to no risk or uncertainty), and people may still seek informational guidance in this setting. Note that this is consistent with the recent empirical findings that social influence can affect the diffusion of low-involvement consumer packaged goods (Du and Kamakura 2011; Toubia, Goldenberg, and Garcia 2014). Our process evidence helps shed light on how and why social influence is at work; we contribute to the research by uncovering possible mechanisms driving social interactions.
Conclusion and Further Research
This article adds to the growing literature on social interactions and their implications. First, consistent with prior literature, we find that online social interactions have a significant impact on consumers' repeat usage behavior. In particular, we find that people are more influenced by online interactions emanating from distant friends after we control for contemporaneous correlation among same-office coworkers. Second, we show that monetary incentives have a significant, though lesser, impact on encouraging repeat usage and that ignoring such interactions may overstate the impact of monetary incentives. Third, our scenario analyses suggest that when both social interactions and monetary incentives coexist, the former may be sufficient for sustaining participation. A company might benefit substantially from shifting its marketing strategy from monetary incentives to deploying social networking tools and encouraging social interactions.
Fourth, we offer theoretical contributions to the field of social influence. That is, we find that informational influence is the likely theoretical driver of participation in our context of repeat usage in a low-risk setting. We also demonstrate the significant effect of traditional marketing actions such as monetary rewards in today's hyperconnected era. This understanding of the nature of social effects will help generalize our findings to other contexts with similar underlying drivers. Finally, we offer managerial implications for businesses trying to leverage social influence. From a practical perspective, the implications for the relevant companies are particularly distinct. The success of the program is not related as much to the size of the participant group recruited as to the continued usage by the participants. Because we find social interactions to be particularly significant, implications would be in the form of continuous engagement by the company to support interactions among group participants. Depending on the relative size of the impact of monetary rewards, such encouragement could come at the cost of the rewards or even using a creative tie-in of rewards and interaction.
Although this study answers a few questions, it also gives rise to several more. For example, the online social network data we used did not have the advanced direct communication technologies such as messaging common in Facebook and other social platforms. While such limited interaction is common for platforms developed with specific purposes in mind (e.g., reading enthusiasts using Goodreads to share reading history), it would be worthwhile to see whether a more interactive platform would affect the findings. If so, companies may want to add to their platform capabilities or offer greater connectivity by leveraging third-party social media sites.
Note that the nature of impact of the variables we consider could differ in the context of product purchase or consumption. Further research could investigate how product and service characteristics affect the impact of these variables. For example, will monetary rewards play a greater role in general if the decision to be made is the purchase of a product from a company website? It would be also fruitful to investigate the impact on our results if the parameters capturing the effects of monetary rewards and social interactions are allowed to be dynamic. It could be that the relative impact of the various program features changes so that online interactions become more critical. Next, our research implies the possibility of endogenous behavior: (1) participants earn rewards for walking, but rewards can also motivate participants to walk more, and (2) participants with good records might invite a greater number of friends to their online social networks. We confirm that our empirical results hold even after we control for such potential reward and network endogeneity. Nevertheless, it would be worthwhile to validate and elucidate these possible endogenous behaviors in different contexts.
Finally, we use social influence theories to explore the possible drivers of repeat usage that may be operating. As such, we try to disentangle normative and informational aspects of influence in our context by modeling interactions of two usage variables. Nevertheless, there may be other means of disentangling the key drivers. Furthermore, other drivers may also be operating as a function of different contexts. For example, when status is work related and such status information signals an employee's performance relative to colleagues, competitive concerns may be a relevant driver. We leave these questions for future research to explore.