
Abstract
Fashions and conspicuous consumption play an important role in marketing. In this article, the author presents a three-pronged framework to analyze fashion cycles in data composed of (1) algorithmic methods for identifying cycles, (2) a statistical framework for identifying cycles, and (3) methods for examining the drivers of such cycles. In the first module, the author identifies cycles by pattern-matching the amplitude and length of cycles observed to a user-specified definition. In the second module, the author defines the conditional monotonicity property, derives conditions under which a data-generating process satisfies it, and demonstrates its role in generating cycles. A key challenge in estimating this model is the presence of endogenous lagged dependent variables, which the author addresses using system generalized method of moments estimators. Third, the author presents methods that exploit the longitudinal and geographic variations in agents' economic and cultural capital to examine the different theories of fashion. The author applies her framework to data on given names for infants, shows the presence of large-amplitude cycles both algorithmically and statistically, and confirms that the adoption patterns are consistent with Bourdieu's theory of fashion as a signal of cultural capital.
Keywords
Fashion
Fashion, as a phenomenon, has existed and flourished since ancient times across a wide variety of conspicuously consumed products. The impact of fashion can be observed in all aspects of society and culture, including clothing, painting, sculpture, music, drama, dancing, architecture, and art (English 2007; Lipovetsky, Porter, and Sennett 1994). According to the prominent sociologist Blumer (1969), fashion appears even in redoubtable fields such as sciences, medicine, business management, and mortuary practices.
Fashion plays an important role in the marketing of many commercial products. For example, the U.S. apparel and footwear industry follows a seasonal fashion cycle, in the form of spring/summer and fall/winter collections. According to industry experts, a large chunk of the $300 billion that Americans spend on apparel/footwear annually is fashion driven rather than need driven. Fashion also influences the success of other conspicuously consumed products such as electronic gadgets, furniture, and cars (Liu and Donath 2006; Seymour 2008). For instance, the 1950s saw the rise and fall of the tailfin craze in car designs. Even though tailfins were completely nonutilitarian, they contributed to the phenomenal success of Cadillacs and other cars sporting fins (Gammage and Jones 1974).
Given the widespread impact of fashion and its economic importance, it is essential that marketers develop frameworks to reliably identify fashion cycles in data and examine their drivers. However, to date there is no empirical framework to study fashion cycles. Furthermore, no research has examined whether the cycles observed in data are consistent with any of the proposed theories of fashion. Indeed, apart from a few early descriptive works by Richardson and Kroeber (1940) and Robinson (1975), there is hardly any empirical work on fashion. In this article, I attempt to bridge this gap in the literature.
Framework for Analyzing Fashion Cycles
In the current research, I present a three-pronged framework to analyze fashions composed of (1) algorithms for identifying cycles, (2) statistical models for identifying cycles, and (3) methods for examining the drivers of fashion cycles. The first module consists of an algorithmic framework for identifying fashion cycles by pattern-matching the amplitude and length of cycles observed in the data to a user-specified definition of a cycle as satisfying certain minimum requirements on those dimensions. I also use algorithmic methods to characterize and identify recurring cycles, whereby each cycle is separated by a dormancy period that is allowed to be a function of the amplitude of the cycle. Taken together, these techniques enable me to characterize different types of cyclical patterns in data.
Although algorithmic identification of cycles is sufficient for many purposes, it suffers from user subjectivity. Thus, in the second module, I develop a statistical method to identify the presence of cycles. I define the conditional monotonicity property and derive the conditions under which a data-generating process satisfies this property. Specifically, an autoregressive process of order p (AR(p)) is conditionally monotonic if it is nonstationary and continues to increase (decrease) in expectation if it was on an increasing (decreasing) trend in the last (p – 1) periods. I then demonstrate that conditional monotonicity is necessary and sufficient to give rise to cycles.
A key challenge in estimating this model and establishing conditional monotonicity is the presence of potentially endogenous lagged dependent variables. In such cases, the two commonly used estimators—the random-effects estimator and fixed-effects estimator—cannot be used (Nickell 1981). Although theoretically, I can solve this by finding external instruments for the endogenous variables, it is difficult to find variables that affect the lagged popularity of a fashion product but not its current popularity. I address this issue using system generalized method of moments (GMM) estimators that exploit the lags and lagged differences of explanatory variables as instruments (Blundell and Bond 1998; Shriver 2015).
Finally, in the third module, I expand my framework to examine the drivers of fashion. Although various drivers of fashion have been proposed, two signaling theories have gained prominence because of their ability to provide internally consistent reasoning for the rise and fall of fashions: wealth signaling theory (Veblen 1899) and cultural capital signaling theory (Bourdieu 1984). While existing analytical models of fashion assume one of these social signaling theories and examine the role of firms in fashion markets, they do not test the empirical validity of either of these theories (Amaldoss and Jain 2005; Pesendorfer 1995; Yoganarasimhan 2012a). In contrast, I present empirical tests to infer whether the patterns observed in data are consistent with one of these theories. I use aggregate data on the metrics of wealth and cultural capital of parents in conjunction with state-level name popularity data and exploit the geographical and longitudinal variation in these two metrics to correlate name adoption to the predictions of the two theories.
Name Choice Context
I apply my framework to the choice of given names (i.e., names given to newborn infants). I chose this as my context for four reasons. First, the choice of a child's name is an important conspicuous decision that parents make; therefore, it is a good area in which to examine fashion and conspicuous choices. Second, to establish the existence of cycles in a product category, I need data on a large panel of products for a significantly long period. My context satisfies this data requirement: the Social Security Administration (SSA) is an excellent source of data on given names at both the national and state levels, beginning in 1880. Third, it is a setting in which large cycles of popularity are observed, which makes it ideal for this study. Figure 1 depicts the rise and fall of the most popular male and female baby names from 1980. Note that at their peaks, these names were given to more than 80,000 babies on a yearly basis, which hints at the presence of cycles of large amplitude in this data. Fourth, to examine the impact of social drivers of fashion cycles, I need both time and geographic variation in agents' status in the society, which is available in the form of metrics on economic and cultural capital through U.S. Census data. Together, these factors make the context of given names ideal for studying fashion cycles.

POPULARITY CURVES OF THE TOP FEMALE AND MALE BABY NAMES FROM 1980
Findings
Using this framework, I provide a series of substantive results. First, I establish the existence of large-magnitude cycles in the names data using algorithmic methods. Of the names that have appeared in the top 50 in at least one year since 1940, more than 80% have experienced at least one cycle of popularity, and a significant fraction (approximately 30%) of these has gone through two or more cycles. In data sets that include less popular names, the fraction of names with cycles is lower but still significant. For instance, of all female names that have been in the top 500 in at least one year since 1940, more than 75% have gone through at least one cycle of popularity. I also find that a significant fraction of names have gone through at least two cycles of popularity and find evidence for patterns shaped like  and
and  .
.
Second, I apply my statistical framework to the name choice data and show that it follows a second-order autoregressive (AR(2)) process that satisfies the conditional monotonicity property. I show that the names data exhibit nonstationarity (i.e., they have a unit root) and follow the direction of the movement from the last period, thereby satisfying the two conditions for conditional monotonicity. These results are robust across different types of data and model specifications. Thus, there is statistical evidence that the data-generating process satisfies properties that lead to cycles when sampled over significantly long periods of time.
Third, I exploit the longitudinal and geographical variations in cultural and economic capital to show that these cycles are consistent with Bourdieu's cultural capital signaling theory. I present three findings in this context. First, I show that states with higher average cultural capital are the first to adopt names that eventually become fashionable; they are then followed by the states with less cultural capital. Similarly, the states with higher average cultural capital are the first to abandon increasingly popular names. In other words, the rate of adoption is higher among the “cultured states” at the beginning of the cycle, whereas the opposite is true at the end of cycle. Second, I find that adoption among the cultured states has a positive impact on the adoption of the general population, while adoption among less cultured states has a negative impact on the overall adoption. Third, I do not find any such parallel results for economic capital. Taken together, these results provide support for Bourdieu's theory in the name choice context.
The results have implications for a broad range of fashion firms. First, my empirical framework enables firms to test for the presence of fashion cycles in their context. Second, it allows them to uncover the social signaling needs of their consumers, which in turn would help them target the right consumers at different stages of the fashion cycle. For example, if a firm finds that its products serve as signals of cultural capital, it can initially seed information with cultured consumers and then release information to the larger population in a controlled manner to maximize profits.
Related Literature
The current research relates to three broad streams of literature in marketing, sociology, finance, and economics. First, it relates to the theoretical literature on conspicuous consumption and fashion cycles. Karni and Schmeidler (1990) present one of the earliest models of fashion with two social groups, high and low. Agents in both groups value products used by “high types” but not those used by “low types.” In this setting, they show that fashion cycles can arise in equilibrium. Similarly, Corneo and Jeanne (1994) show that fashion cycles may arise out of information asymmetry. On a related front, Amaldoss and Jain (2005) study the pricing of conspicuous goods. Pesendorfer (1995) adopts the view that fashion is a signal of wealth (Veblen 1899), adds a firm to the mix, and goes on to show that a monopolist produces fashion in cycles to enable high types to signal their wealth. In contrast, Yoganarasimhan (2012a) presents a model in which agents want to signal that they are “in the know” or have access to information. In this setting, she shows that a fashion firm may want to strategically cloak information on its most fashionable products to allow for the signaling game between consumers.
Second, the current research relates to the macroeconomic literature on identification of business cycles from data pioneered by Burns and Mitchell (1946). Recent work has advocated the use of band-pass filters to separate cycles from short-term fluctuations and long-term trends under the assumption that cycles indeed exist and that cycle length falls under certain limits (Baxter and King 1999; Hodrick and Prescott 1997). These methods are designed to work with a small number of time series that exhibit similar behaviors. Furthermore, they do not offer any insights on the factors that give rise to cycles. My approach differs from these methods in three important ways: (1) I do not know whether a given name has gone through a cycle, and I do not limit the length of the cycles; (2) I have a very large number of names, and there is no co-movement or even similarity in the cycles across names; and (3) I am interested in exploring the underlying reasons for fashion cycles and thus need a methodology that can accommodate endogenous explanatory variables.
Third, the current research relates to the finance literature on identifying stock market bubbles using nonstationarity tests (Charemza and Deadman 1995; Diba and Grossman 1988; Evans 1991). The key difference between these articles and the current research is that they define a bubble as any long-term deviation from the stable mean of an autoregressive process. Thus, nonstationarity tests are sufficient to identify bubbles. In contrast, I am interested in fashion cycles, which are defined as long-term deviations characterized by consecutive increases followed by consecutive decreases (or vice versa) and are caused by social signaling. I show that nonstationarity is necessary but not sufficient to identify cycles, and I go on to define conditional monotonicity and demonstrate its ability to establish the presence of cycles. As with the previous methods, these cannot provide information about the drivers of fashion cycles.
This article also contributes to the literature on the measurement of social effects in marketing. For some recent developments in this area, see Chintagunta, Gopinath, Venkataraman (2010), Nair, Manchanda, and Bhatia (2010), Sun, Zhang, and Zhu (2014), Tellis, Niraj, and Yin (2009), Toubia, Goldenberg, and Garcia (2014), and Yoganarasimhan (2012b). Finally, this article relates to the literature on name choice, which I discuss in the next section.
The Naming Decision
How do parents choose names, and why does the popularity of a name change over time? These are interesting questions that have attracted the attention of researchers in various domains. Sociologists were among the first to study names, and early works in this area include Rossi (1965), Taylor (1974), Lieberson and Bell (1992), Lieberson and Lynn (2003), and Lieberson (2000). More recently, in a descriptive study, Hahn and Bentley (2003) show that naming patterns can be characterized using power-law distributions and random regenerative models. Similarly, Gureckis and Goldstone (2009) include the effect of past adoptions to build a predictive model of name choice. Berger and Le Mens (2009) show that the speed of a name's adoption is correlated with its speed of abandonment. Drawing on a survey of expecting parents, they argue that this phenomenon stems from negative perceptions of fads. Although these studies demonstrate some naming patterns and provide preliminary evidence on the sociological aspects of name choice, they do not empirically establish the presence of cycles in the data or examine drivers of these cycles—which is the focus of this article.
Next, I present a discussion of factors that potentially affect parents' naming decisions. Subsequently in the article, I discuss how the empirical model controls for these factors.
Name Attributes
The popularity of a name is likely to depend on its attributes. For example, short names are easy to speak and spell, which makes them attractive to many parents (e.g., John vs. Montgomery). Parents may also prefer names that symbolize positive imagery and qualities, such as bravery (Richard), charm (Grace), and beauty (Helen, Lily).
Familial and Religious Reasons
Traditionally, newborns were named after their relatives. For instance, first-born boys were named after their father or paternal grandfather and first-born girls after their paternal grandmother. However, Rossi (1965) finds that this custom has been on a decline due to the rise of nuclear families.
Religious beliefs can also influence name choice. Many long-term popular names such as Joseph and Daniel have Biblical origins. However, Lieberson (2000) finds no correlation between church attendance and popularity of Biblical names in the United States and the United Kingdom. Even though some Biblical names have remained popular (e.g., Samuel, Seth), their choice is likely driven by other considerations, because many others have declined in popularity (e.g., Michael, Paul).
Assimilation and Differentiation
Researchers have shown that names associated with an obvious ethnic or minority population can have a negative impact on a child's future employment and success (Bertrand and Mullainathan 2004). Recognizing this, minority parents may choose conventional names to avoid discrimination and integrate their children into mainstream society. Consistent with this theory, Mencken (1963) finds that names that were popular among Norwegian immigrants (e.g., Leif, Thorvald, Nils) suffered a rapid loss in popularity after their immigration to the United States.
In contrast, some minority parents may try to differentiate their children from the majority by choosing names that highlight their distinctive ethnic background. Fryer and Levitt (2004) find that African American parents chose increasingly distinctive names in the 1970s, often with African roots, to emphasize their “blackness.” Of course, neither of these effects are at play for non-black or non-ethnic names.
Celebrity Names
Popular entertainers, sports stars, and celebrities are often mentioned in the mass media, and this exposure can influence parents' name choices. However, prior research has refuted the idea that fashion cycles in names are caused by celebrities. First, many stars adopt names that are currently popular, which actually implies reverse causality. For example, “Marilyn” was already a popular name before Norma Jean Baker adopted it as her stage name (Marilyn Monroe), and the name actually declined in popularity in the following years. Second, not all celebrities' names become popular and not all names that become popular are those of celebrities. Third, in the few cases in which a name became popular around the same time as a rising celebrity, the resulting increase in its popularity has been minor compared with the magnitude of the usual cycles observed in the data. Finally, if celebrities cause popularity cycles in names, then, empirically, there should be no difference in the rate of adoption among different classes of people at different stages of the fashion cycle. For example, a celebrity theory cannot give rise to an adoption pattern in which wealthy or cultured parents are first to both adopt and abandon a name. For a detailed discussion of this idea, see Lieberson (2000).
Signaling Theories
Finally, parents may choose names to signal their (and their child's) high status in the society. Two kinds of signaling mechanisms can be at work.
Signal of wealth
Parents may choose certain names to signal their affluence. The wealth signaling theory would predict name cycles as follows: (1) wealthy parents first adopt certain names, which makes them signals of wealth; (2) less wealthy parents adopt these names in imitation of the wealthy, which dilutes their signaling values; (3) the wealthy abandon these names because they are no longer exclusive signals of wealth; and (4) when the wealthy abandon these names, their signaling value decreases even more, which leads to abandonment by the less wealthy. This entire process constitutes a fashion cycle.
There is some support for this theory in the literature. Some sociologists have argued that the use of middle names by the English middle class is an imitation of the British aristocratic practice (Withycombe 1977). Others have provided correlational evidence that suggests that names popular among the wealthy were later adopted by the less wealthy (Lieberson 2000; Taylor 1974). However, the evidence in these studies is suggestive rather than conclusive.
Signal of cultural capital
Parents may choose names to signal their cultural capital and artistic temperament, and such an incentive can also give rise to cycles in the popularity of names (following the same reasoning as that used in the context of wealth-based fashion cycles). Indeed, Kisbye (1981) provides some evidence for this theory. In his study of English names in nineteenth-century Aarhus (Denmark), he finds an increase in the use of English names in the earlier part of the century (corresponding with the introduction of English books by Shakespeare, Dickens, and others), followed by a decrease toward the end of the century. Kisbye argues that English names were first adopted by the cultured or well-read Danes. However, toward the end of the nineteenth century, the less cultured residents obtained access to these previously obscure texts and started adopting English names, which in turn diluted their signaling value and led to their eventual decline. Although Kisbye does not provide concrete evidence to substantiate this speculation, his study suggests that names can be used as a vehicle to signal cultural capital. Similarly, Lieberson and Bell (1992) and Levitt and Dubner (2005) also provide some correlational evidence for the cultural capital signaling theory. 1
Their evidence is purely correlational (i.e., they do not control for other factors that could simultaneously drive name choices). In a critical commentary on Lieberson and Bell (1992), Besnard (1995) counters that most of the names popular among the highly educated in the early parts of the cycles Lieberson and Bell studied were also popular among the larger population. In addition, he asserts that their findings are unlikely to be meaningful given their short time frame of 13 years. My own analysis suggests that name cycles are, on average, much longer than 13 years.
By definition, signaling theories require an action to be not only costly but also differentially costly across types for it to serve as a credible signal of the sender's type. Given that names are free, at the first glance neither of these signaling theories may be expected to work. However, this would be a naive inference because the cost of gathering information on the set of names popular among the high types (in wealth or culture) could vary with the parents' own wealth and cultural capital. There is considerable evidence on network homophily (McPherson, Smith-Lovin, and Cook 2001). Researchers have found that social networks are strongly homophilous on both wealth and cultural capital. For example, Marsden (1990) finds that approximately 30% of personal networks are highly homophilous on education, which is one of the strongest indicators of cultural capital (see the “Cultural Capital” subsection). This homophily has powerful implications for people's access to information. If cultured people live in similar neighborhoods, attend similar cultural events, work in similar environments, and interact more with each other than with those outside their group, it is easier for a cultured parent (vs. a less cultured parent) to obtain information on the names that other cultured people have given their children. Thus, network homophily can give rise to heterogeneity in signaling costs across classes of people, thereby enabling names to serve as signals of parents' types. In a subsequent section, I examine whether the name cycles are consistent with one of these two signaling theories, after controlling for the aforementioned alternative explanations.
Data
I use two types of data in this study: (1) data on popularity of names, and (2) data on the cultural and economic capital of parents. I elaborate on these in the following subsections.
Data on Names
The data on names come from the SSA, the most comprehensive source of given names in the United States. All newborn U.S. citizens are eligible for a Social Security Number (SSN), and their parent(s) can easily apply for one while registering the newborn's birth. Although getting an SSN for a child is optional, almost all parent(s) choose to do so because an SSN is necessary to declare the child as a dependent in tax returns, open a bank account in the child's name, and obtain health insurance for the child. 2 The SSA therefore has information on the number of children of each sex who were given a specific name, for each year, starting in 1880. The SSA was established in 1935 and became fully functional only in 1937. Many people born before 1937 never applied for an SSN, and the data from 1880 to 1937 constitute a partial sample of the names from that period. Therefore, I restrict my empirical analysis to the data from 1940 to 2009.
There is a small discrepancy between the number of annual registered births and number of SSNs assigned. This may be due to the fact that some infants die before the assignment of SSNs. Alternately, a small set of parents may choose not to participate in the process for personal reasons.
These data are available at both national and state levels. At the national level, for each name i, I have information on the number of babies given name i in time period t, which I denote as nit. Because the data of interest start from 1940, t = 1 denotes the year 1940. The name identifier i is sex-specific. For example, the name “Addison” is given to both male and female babies, but I assign different identifiers to the two Addisons. To preserve privacy, if a name has been given to fewer than five babies in a year, the SSA does not release this number for that particular year. In such cases, nit is treated as 0. The state-level data are available for all 50 U.S. states. nijt denotes the number of babies given name i in state j in time period t. As in the national data set, nijt is also left-truncated at 5, in which case I treat it as 0.
For each name i, I construct the following variables:
si = the sex of name i (si = 1 if i is a female name, and si = 0 if it is a male name),
li = the number of characters in name i, and
bibi = the number of times that name i appears in the Bible.
The SSA also furnishes data on the total number of SSNs issued to newborns each year both nationally and statewide. I use these data to construct the following variables:
Γsit = total number of babies of sex si assigned SSNs in period t, nationally. Thus, Γ0t and Γ1t are the total number of male and female babies born in period t;
Γsijt = total number of babies of sex si assigned SSNs in state j in period t;
fit = nit/Γsit is the fraction of babies of sex si given name i in period t; and
fijt = Γsijt is the fraction of babies of sex si given name i in period t within state j.
There are a total of 56,937 female and 33,745 male names in the data, but a small subset of these names account for a large portion of name choices. To focus the analysis on a representative sample of names, I work with the following four subsets of data:
Top50 data set: For each year starting with 1940, I collect the top 50 male and the top 50 female names given to newborns in the country. I then pool these names to form the Top50 data set.
Top100 data set: Same as the Top50 data set, but it includes names that have appeared in the top 100.
Top200 data set: Same as the Top50 data set, but it includes names that have appeared in the top 200.
Top500 data set: Same as the Top50 data set, but it includes names that have appeared in the top 500.
Table 1 shows the number of names in each data set by sex and also provides the fraction of total births that these data sets account for. For example, the Top500 data set contains a total of 1,468 female names, which together account for 60.99% of all female births from 1940 to 2009.
NUMBER OF MALE AND FEMALE NAMES AND THEIR CORRESPONDING PERCENTAGES OF BIRTHS (1940–2009)

Next, I examine the patterns in the name choice data. Table 2 shows the top ten female and male names for the years 1940, 1950, 1960, 1970, 1980, 1990, 2000, and 2009. It is clear that there is quite a bit of churn in popular names. For instance, of the ten most popular female names in 1990, only five remained in the top ten in 2000. To understand the patterns better, I plot the popularity of the top six female and males names from 1980 for the full span of the data (i.e., from 1880 to 2009; see Figures 2 and 3). The plots present clear visual evidence of cycles in the data.
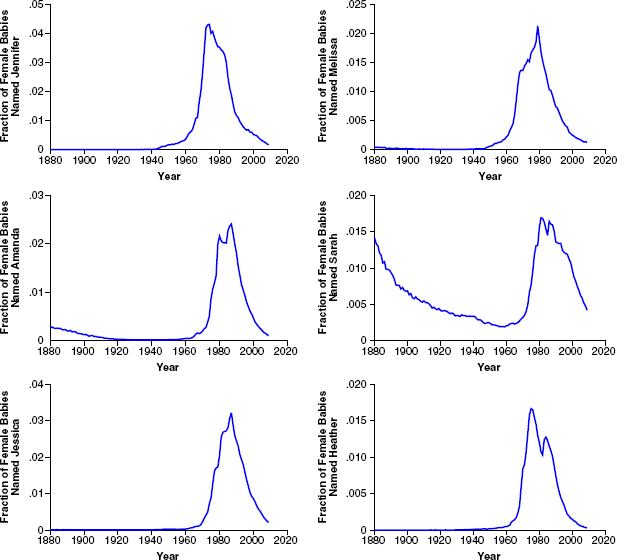
POPULARITY CURVES OF THE TOP SIX FEMALE BABY NAMES IN 1980

POPULARITY CURVES OF THE TOP SIX MALE BABY NAMES IN 1980
TOP TEN FEMALE AND MALE NAMES IN 1940, 1950, 1960, 1970, 1980, 1990, 2000, AND 2009

Data on Economic and Cultural Capital
To examine the two theories of fashion, I need data on the geographical (state-level) and longitudinal (yearly) variations in the economic and cultural capital of decision makers. I provide more information about these in the following subsections.
Economic capital
I use a state's median household income at period t as a measure of the economic capital of the decision makers from that state during t. The income data come from two sources: the decennial Census and the Social and Economic Supplements of the Current Population Survey (CPS). I retrieved data on the state-level median household income for 1970 and 1980 from the decennial census tables. 3 For 1984–2009, I obtained annual state-level data on median household income from CPS. To calculate values for the intervening years in which income data are not directly available (1971–1979 and 1981–1983), I use linear interpolation, which is reasonable because a state's median income rarely exhibits wide year-to-year fluctuations.
Although the Census Bureau has asked income-related questions since 1940, the wording used in the question formulation in 1940, 1950, and 1960 is different from that in use now (family vs. household income), making it difficult to combine the data from the former years with the current data set.
The original data are in current dollars (i.e., reported dollars). To obtain a normalized measure of wealth, I need to correct for both inflation over time and geographic variations in cost of living. I do this using the revised 2009 version of the Berry-Fording-Hanson (2000; BFH) state cost of living index. This normalized metric is denoted as Wjt, the adjusted median household income of state j in period t. It is obtained as follows:
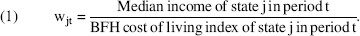
The BFH index is a measure of how costly a state is compared with a median state in 2007 (the index for the two middle states, New Mexico and Wyoming, is set to 100 in 2007). Table 3 lists the top and bottom five wealthiest states based on wjt for 1970, 1980, 1990, and 2000.

Based on adjusted median household income.
Based on percentage of adults with a bachelor's degree.
Cultural capital
Cultural capital is defined as a person's knowledge of arts, literature, and culture (Bourdieu 1984; Dimaggio and Useem 1974). The most commonly used measure of cultural capital is education attainment, especially higher education (Cookson and Persell 1987; Lamont and Lareau 1988; Robinson and Gamier 1985).
I use the percentage of adults in state j with a bachelor's degree or higher in period t as a measure of the educational attainment of decision makers from that state in period t. These data come from the U.S. Census Bureau (for years 1970, 1980, 1990, and 2000, and interpolated for intervening years) and the CPS (annually for 2001–2006). As in the case of income, the absolute number of people with a bachelor's degree is an imperfect metric of the relative cultural capital of decision makers in period t, especially because people have become more educated with time. Thus, for each state j in period t, I subtract the national average of the percentage of the adults with a bachelor's degree and use this as the measure of the cultural capital Cjt. Table 3 lists the most and least educated states (based on cjt) for 1970, 1980, 1990, and 2000.
Note that the metrics of economic capital and cultural capital are not directly comparable. The former is a relative measure of a state's wealth and is normalized across time and space. The latter is not normalized similarly. Wealth is used to procure scarce resources (e.g., housing, leisure), and therefore a relative metric of wealth seems reasonable. In contrast, education provides access to information goods that are not as scarce (e.g., the New York Times can print more copies if there is more demand), and thus an absolute measure seems appropriate. 4 That said, the substantive findings presented subsequently should be interpreted cautiously and with an understanding of how these metrics work.
I thank an anonymous reviewer for this suggestion.
Algorithmic Detection of Popularity Cycles
Definitions
Essentially, a cycle is an increase followed by a decrease (i.e., an inverted V-shaped curve such as that exhibited by the name Jennifer from 1940 to 2009 in Figure 2) or a decrease followed by an increase (i.e., a V-shaped pattern, such as exhibited by Sarah from 1880 to 1980 in Figure 2). Although it is easy to visually identify popularity cycles in a small set of names (e.g., Figures 2 and 3), visual identification is neither feasible nor consistent when analyzing a large set. Therefore, I next present a formal definition of a cycle, which I then use to detect and characterize cycles in the data. I begin by providing some terminology. Consider a sequence of T real numbers x1, x2,…, xT.
Operators 〈 and 〉 are defined as follows:
xi 〈 xj if xi < xj or if xi = xj∧i < j, and
xi 〉 xj if xi > xj or if xi = xj ∧ i > j.
A local minimum and a local maximum are defined as follows:
xi is a local minimum if xi 〈 xj for all i – τ ≤ j ≤ i + τ, and
xi is a local maximum if xi 〉 xj for all i – τ ≤ j ≤ i + τ.
Using this notation, a cycle is defined as follows:
A cycle C is a sequence of three values {xi, xj, xk} with i < j < k that satisfies the following conditions:
xi, xk are local minimas and xj is a local maximum, or xi, xk are local maximas and xj is a local minimum;
Len(C) ≥ L, where Len(C) = k – i is the distance between the first and last points of the cycle; and
Amp(C) ≥' M, where Amp(C) = min{|xi – xj|, |xj – xk|} is the amplitude of the cycle.
To be classified as a cycle, a bump or trough must be significant in both time and magnitude. I weed out insignificant deviations through two mechanisms: (1) A local maxima or minima has to dominate τ values to both its right and left (see Definition 2 and the first condition of Definition 3). Thus, a short-term increase in a curve that is on a decreasing trend is not classified as a local maxima and vice-versa. This ensures that I capture only consistent increases and decreases, not shocks in time. Furthermore, the total length of the cycle has to be at least L to ensure that I am capturing real patterns in the data and not shocks (see the second condition of Definition 3). (2) The amplitude of a cycle must be greater than a baseline value M (see the third condition of Definition 3). For example, if a name has followed an inverted V-shaped pattern but the magnitude is very small, then I do not classify it as a cycle.
Application of Algorithm to Name Choice Context
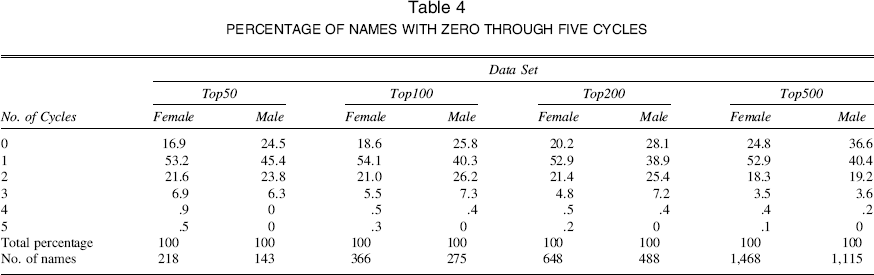
Next, I apply these definitions and the algorithm to identify cycles in the name choice context. Specifically, I set {M, τ, L} = {:00005, 4, 10} and analyze the time series of fit in the data sets of interest. 5 I perform my analysis on the Top50, Top100, Top200, and Top500 data sets and present the results in Table 4. Of the 361 Top50 names, more than 80% have experienced at least one cycle of popularity. Moreover, a significant fraction (30%) has gone through two or more cycles of popularity. This suggests the presence of recurring fashion cycles. In data sets with less popular names, the fraction of names with fashion cycles is lower, but still quite significant. For example, more than 75% of the 1,468 female names in the Top500 data set have gone through at least one cycle. Furthermore, over 20% of all names in Top50 have an amplitude of .005 or more, which implies that more than 10,000 babies were given these names at the peak of their popularity. For details on the empirical distributions of the length and amplitude of cycles, see the Web Appendix.
Note that if I set lower values of M, τ, and L, I would find more cycles in the data. By setting relatively high values of these parameters, I am setting a higher bar for classifying a bump or trough as a cycle. For a sensitivity analysis to varying τ and M, see the Web Appendix.
PERCENTAGE OF NAMES WITH ZERO THROUGH FIVE CYCLES
Notably, several names have gone through more than one cycle (for an example, see Figure 4). To better understand repeat cycles in names, I analyze the time it takes for cycles to repeat. I define “dormancy length” as the period between two popularity cycles in which the name is dormant or adoptions for the name are close to minimum. Formally,
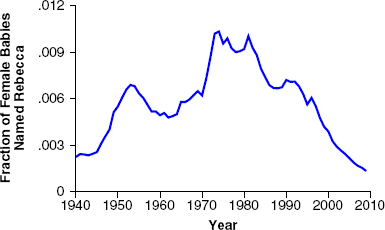
POPULARITY CURVE OF REBECCA
Given two adjacent cycles C1 = {xi, xj, xk} and C2 = {x1, xm, xn}, such that |xk – x1| < dt × Amp(C2), where dt < 1 is a dormancy threshold, the dormancy length is defined as 1 – k.
Table 5 provides the statistics for dormancy length when the dormancy threshold is defined as 10% (i.e., the change in values from the end of the first cycle to the beginning of the second cycle is less than 10% of the amplitude of the second cycle). For all four data sets (Top50, Top100, Top200, and Top500), the median dormancy period is between three and eight years. However, a large number of names also remain dormant for significant periods before experiencing a resurgence. For example, the 75th quartile of dormancy length for Top100 male names is 29. Furthermore, the dormancy periods are longer for female names compared with male names. Table 6 presents details on the main patterns of repeat cycles in the data. Different types of cyclical patterns are prevalent at varying frequencies. For instance, 13.6% of names in the Top100 data set have gone through a 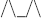 pattern, while 6.54% have gone through a
pattern, while 6.54% have gone through a  pattern. Together, these findings provide strong support for the presence of cycles in data.
pattern. Together, these findings provide strong support for the presence of cycles in data.
DISTRIBUTION OF DORMANCY LENGTHS BETWEEN CYCLES

Notes: This table presents name dormancy lengths (in years) between cycles. The dormancy threshold is defined as 10% (i.e., the change in values from the end of the first cycle to the beginning of the second cycle is less than 10% of the amplitude of the second cycle).
CYCLICAL PATTERNS IN THE DATA BY PERCENTAGE

Notes: Cycles were identified using the algorithmic definition of cycles.
A Statistical Framework for Identifying Cycles
In the previous section, I reported that the data present clear evidence of cycles. My efforts to identify and classify these cycles were algorithmic. I provided a specific definition of a cycle and identified patterns in the data that satisfied this definition. In this section, I establish the presence of cycles using statistical analyses. There are two main reasons for developing a statistical framework that goes beyond algorithmic methods. First, statistical methods are not influenced by user subjectivity, unlike the algorithmic methods, which require the values of τ, L, and M as user input. Second, statistical methods can include other explanatory variables that drive these cyclical patterns.
Fashion cycles differ from standard product life cycles (Day 1981; Levitt 1965) in two important ways. First, they can potentially reappear. Theory models of signaling-based fashions predict such recurring fashions (Corneo and Jeanne 1994), a prediction confirmed by casual observation (e.g., skinny jeans). Recall that even in this setting, a significant fraction of names go through multiple cycles of popularity. Second, fashion cycles have to be caused by social signaling. Both these properties must be satisfied for a cycle to be defined as a fashion cycle. For example, repeat cycles can occur without social signaling simply by being driven by a firm's marketing activities. Similarly, social signaling can occur in non-conspicuous arenas unrelated to fashion. Formally,
An adoption curve is defined as a social signaling-based fashion cycle if (a) it satisfies statistical properties that can lead to repetitive cycles over sufficiently long periods and (b) the cycles (if they exist) are caused by social signaling—either wealth signaling or cultural capital signaling.
An empirical framework that aims to identify the presence and cause of fashion cycles in data must provide researchers tools to establish the two properties in Definition 5. In this section, I focus on the first aspect of the problem—identifying the presence of cycles in data using statistical tests. In the next section, I outline the second part of my framework and present tools to test whether the cycles are indeed caused by social signaling.
Conditional Monotonicity Property
Observe that name cycles are inverted V-shaped rather than inverted U-shaped curves. In this respect, they resemble stock market and real estate bubbles rather than standard product life cycle curves. Finance literature has shown that bubbles occur when consumers' utility and actions depend on their expectations and beliefs about others' valuation of the product rather than the inherent attributes of the product (Camerer 1989). In such settings, small changes in consumers' beliefs and expectations can cause large shifts in behavior. Because consumers' behavior in fashion markets is also driven by their beliefs about what other consumers consider fashionable (Yoganarasimhan 2012a), it is understandable that the popularity cycles of names follow similar patterns.
Note that unlike financial economists, who are interested in bubbles, I am interested in cycles. A bubble is defined as an autoregressive process that does not have a stable long-term mean. In contrast, a cycle is an autoregressive process that shows a clear cyclical behavior or generates an inverted V-shaped curve. Traditionally, the finance literature has used nonstationarity tests to identify bubbles in data (Charemza and Deadman 1995; Diba and Grossman 1988; Evans 1991). However, I show that nonstationarity alone is not sufficient to generate cycles and therefore provide a more precise framework for identifying cycles using the concept of “conditional monotonicity.”
Let the popularity of a conspicuously consumed product i evolve as an AR(p) process (i.e., an autoregressive process of order p) as follows:
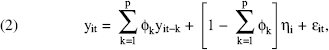
where
This simple framework can be easily expanded to include other time-varying and time-invariant explanatory variables. Equation 2 can be rewritten as follows:

where Φp(L) = 1 – ϕ1L – ϕ2L
2
… – ϕpLp, with L denoting the lag operator and
An AR(p) process is stationary if all the roots of the polynomial Φp(L) lie outside the unit circle. Under these conditions, a shock to the system dissipates geometrically with time, and the resulting process is mean-reverting and stable. For example, if the popularity of name i follows a stationary process, then shocks to its popularity (e.g., election of a president with name i, the sudden fame of a celebrity with name i) will dissipate with time, and its popularity will soon return to its long-term average. (For detailed discussions on stationary time-series models, see Fuller [1995] and Dekimpe and Hanssens [1995].) In an AR(1) process, the stationarity condition boils down to |ϕ1| < 1, and it can be written as yit = ϕ1yit–1 + (1 – ϕ1)ηi + ∊it. Figure 5 shows an AR(1) process with ϕ1 = .5 and ηi = 30. Note that this is a very stable process that oscillates around a constant mean of 30. The expectation of the tth realization of a stationary AR(p) series is a weighted mean of its last p realizations and the unobserved fixed effect ηi. Thus, every period, there is a constant pull toward the mean ηi, and this property makes a stationary process stable. Of course, an important implication of this stability is that a stationary process cannot give rise to popularity cycles significant in either time or magnitude.
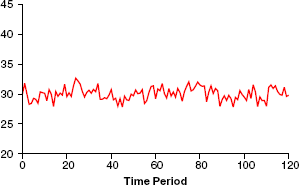
AR(1) STATIONARY PROCESS WITH ϕ1 = .5, ηi = 30
An AR(p) process is nonstationary if one or more of the roots of Φp(L) lies on the unit circle. When subjected to a shock, a nonstationary series does not revert to a constant mean, and its variance increases with time. If name choices are nonstationary, then shocks due to celebrities, politicians, and so on can cause long-term shifts in name popularity. An AR(1) process with ϕ1 = 1 is nonstationary and is referred to as a random walk process. It can be written as yit = yit–1 + ∊it ⇒ E(yit) = yit–1. Therefore, at any point in time, the process evolves randomly in one direction or the other. Although a random walk process is not mean-reverting, it also does not produce cycles of any significant magnitude, because its specification does not imply consecutive increases or decreases. Thus, nonstationary is not sufficient to generate cycles. Next, I define the conditional monotonicity property and describe its role in generating cycles. Let Δ be the first difference operator, such that Δyit = yit – yit–1.
P1: A nonstationary AR(p) process with roots 1, 1/c1, 1/c2,…, 1/cp–1, where p ≥ 2 and 0 < c1, c2,…, cp–1 ≤ 1, is conditionally monotonic in the following sense:
if
if
For a proof, see the Web Appendix.
According to P1, in a conditionally monotonic AR(p) process, there is a lower bound on E(Δyit) if the last p – 1 periods' changes satisfy the constraint
When p = 2, there is an AR(2) process, and
Next, I demonstrate the implications of conditional monotonicity for an AR(2) process (for a general proof for an AR(p) process, see the Web Appendix). Consider a nonstationary AR(2) process of the form yit = (1 + c1)yit–1 – c1yit–2 + γi + ∊it, where 0 < c1 ≤ 1 and

AR(2) CONDITIONALLY MONOTONIC PROCESS WITH ϕ1 = 1.5, ϕ2 = –.5, ηi = 30
Note that nonstationarity is necessary, but not sufficient, for conditional monotonicity. Nonstationarity is necessary because in stationary processes, the conditional expectation E(yit) remains dependent on ηi, which precludes making any general statements on the relationship between E(yit) and its past (p – 1) lags. For example, consider the stationary AR(2) process yit = ϕ1yit–1 + ϕ2yit–2 + γi + ∊it, where
Finally, a conditionally monotonic process needs to be observed for sufficiently long periods of time to generate cycles. Although the property is defined over the change in the yit from the last period, such changes need to be observed for a long-enough period to observe a full cycle or multiple cycles (as in Figure 6).
Application: Identifying Cycles in the Choice of Given Names
Model
Next, I expand Equation 2 to suit the specific context as follows:

where yit denotes nit, number of babies given name i in period t. This is modeled as a function of the following:
The last p lags of i's popularity. This captures the past trends in name i's popularity that can affect adoption by current parents.
Xit, time-varying factors that affect i's popularity. Here, xit consists of the number of babies of sex si born in year t and time dummies.
Zi, the time-invariant attributes of name i that affect its popularity: length, sex, and number of Biblical mentions.
A name fixed effect
A mean-zero shock ∊it that captures shocks to a name's popularity. This can stem from a variety of factors, including but not limited to the rise or fall of celebrities, entertainers, and book characters.
Furthermore, I make the following assumptions about the model:
E(∊it) = (γi × ∊it) = E(∊it × ∊ik) = 0 ∀ i, t, k ≠ t. I follow the familiar error components structure (i.e., en is mean zero and uncorrected to γi for all i, t). ∊it is allowed to be heteroskedastic but assumed to be serially uncorrected. Because this is an important and strong assumption, I test its validity after estimating the model using the Arellano-Bond (2) test.
E(xik × ∊it)=E(xik × γi)=E(zi × ∊it)=E(zi ×γi) = 0 ∀ i, k, t.
The time-invariant attributes of a name are assumed to be uncorrelated to both ∊it and γi. xit is assumed to be uncorrected to γi because the long-term mean of any name i is unlikely to be correlated with the total births of either sex in year t. Moreover, because the decision to have a child is unlikely to be influenced by shocks in the popularity of a specific name i, there is no reason to expect ∊it to be correlated to past, current, or future births.
Assumption 2 is specific to this context. In a different context, in which explanatory variables are predetermined or potentially endogenous, it can be easily relaxed (see the “Statistical Framework for Analyzing the Drivers of Fashion” section).
Although both xit and zi are uncorrelated to the shock and the fixed effect, the same cannot be said of the lagged dependent variables—the dynamics of the model imply an inherent correlation between the lagged dependent variables (yit–1, …, yit–k) and the unobserved heterogeneity γi if γi ≠ 0. Moreover, ys and ∊s are correlated by definition. Because the current error term affects both current and future popularity, ⇒ E(yik × ∊it) ≠ 0 if k ≥ t. However, past popularity remains unaffected by future shocks ⇒ E(yik × ∊it) = 0 if k < t.
Estimation
I rewrite Equation 4 as follows and use this formulation in the subsequent analyses:

where
If all the panels in the data set follow a nonstationary process, then
The two commonly used methods of estimating panel data models, random-effects estimation and fixed-effects estimation, cannot be used in a dynamic setting. The former requires explanatory variables to be strictly exogenous to the fixed effect γi, an untenable assumption if some panels are indeed stationary. The latter allows for correlation between γi and explanatory variables, but because it uses a within transformation, it requires all time-varying variables to be strictly exogenous to ∊it. This is impossible in a dynamic setting with finite T (Nickell 1981). Although theoretically, I can solve this problem by finding external instruments, it is difficult to find variables that affect lagged name popularity but not current name popularity. Therefore, I turn to the GMM-style estimators of dynamic panel data models that exploit the lags and lagged differences of explanatory variables as instruments (Blundell and Bond 1998). This methodology has been successfully applied by researchers in a wide variety of fields in marketing and economics (for details, see Acemoglu and Robinson 2001; Clark, Doraszelski, and Draganska 2009; Durlauf, Johnson, and Temple 2005; Shriver 2015; Yoganarasimhan 2012b). I briefly outline the method next.
System GMM estimator
First, consider the first-difference of Equation 5.

Note that first-differencing has eliminated the fixed effect γi, thereby eliminating the potential correlation between the lagged dependent variables and γi. However, first-differencing introduces another kind of bias. Now, the error term Δ∊it is correlated with the explanatory variable Δyit–1 through the error term ∊it–1. However, it is easy to show that lags and lagged differences of yit from time period t – 2 and earlier are uncorrelated to Δ∊it and can therefore function as instruments for Δyit–1 and Δ 2 yik. In addition, because Δxit is uncorrelated with Δ∊it, it can instrument for itself. Thus, I specify the following sets of moment conditions for Equation 6:



In theory, these moments are sufficient to identify ϕk and α as long as the process is not first-order nonstationary (Blundell and Bond 1998). However, a priori, it is not clear whether these moment conditions are sufficient for identification in the current context. So, following Blundell and Bond (1998), I also consider moment conditions for the level Equation 5.




xit and zi can instrument for themselves because they are uncorrelated to both γi and ∊it. Lagged differences of yit from period t – 1 and earlier can be used as instruments for yit–1 and Δyit–k. The moment conditions in Equations 10 and 11 hold irrespective of the stationarity properties of the process. They require only the initial deviations of the dependent variable to be independent of its long-term average, which is a reasonable assumption in most settings, including the current setting.
Stacking the moments results in a system GMM estimator that provides consistent estimates regardless of the stationarity properties of the process. I employ a two-step version of the estimator because it is robust to panel-specific heteroskedasticity and increases efficiency. However, the standard errors of the two-step GMM estimator are known to be biased. Windmeijer (2005) proposes a correction for this bias, and I follow his method to obtain robust standard errors.
Serial correlation and lagged dependent variables
A key assumption in the method in the previous subsection is that the error terms are not serially correlated. Serial correlation is problematic for two reasons. First, in the presence of serial correlation, the restrictions that I apply break down. For example, consider a scenario in which errors follow a moving average (1) process such that ∊it = ρ∊it–1 + uit, where E(uit) = 0 and E(uit × uik) = 0 ∀ k ≠ t. Then, for q = t – 1, Equation 10 can be expanded as E[Δyit–1 × (γi + ρ∊it–1)] = 0. However, this moment condition is invalid because Δyit–1 is correlated with ∊it–1. Similarly, the moment conditions in Equations 7, 8, and 11 also fail to hold in the presence of serial correlation. Second, the absence of serial correlation confirms the absence of omitted variable biases (for a detailed discussion on this issue, see the subsection “Controlling for Other Factors that Affect Name Choice”). Therefore, for all the models estimated herein, I test the validity of the instruments and the absence of omitted variable bias using the Arellano-Bond (1991) test for serial correlation.
Results and discussion
I estimate the model on the four data sets of interest (Top50, Top100, Top200, and Top500) and present the results in Table 8. The instruments for each of the level and differenced equations appear in the last four rows of the table. The GMM refers to the instruments generated from the lagged dependent variables, and standard refers to exogenous variables that instrument for themselves.
In all the models, I find that the coefficient of Δyit–2 is insignificant, implying that the process is AR(2). Thus, Equation 5 can be written as

This process satisfies the conditional monotonicity property if and only if μ = 1 and 0 < θ1 ≤ 1. Under these conditions, the two roots of the process are 1 and 1/θ1, where 0 < θ1 ≤ 1. Thus, for all the four models, I test the following two hypotheses:
H1: μ = 1.
H2:
Table 8 shows the results from the hypothesis tests. First, for all four models, I cannot reject the null of H1 (μ = 1). This suggests that the data-generating process is nonstationary and contains a unit root. Second, in all the models, I cannot reject the null of H2 (θ1 = .47). 7 Together, these results present clear evidence for the existence of cycles in the data because they demonstrate the conditional monotonicity of the underlying process.
In principle, this could be any positive θ1 between 0 and 1. Because my estimates show that θ1 ≈ .47, I use this specific number to show that the hypothesis that θ1 is positive and less than 1 cannot be rejected.
The Arellano-Bond test confirms that the model is not misspecified; I cannot reject the null hypothesis of no second-order serial correlation in first-differenced error terms (i.e., the tests present no evidence of serial correlation). This establishes the validity of my moment conditions and confirms the absence of omitted variable biases. Nevertheless, I include time-period dummies in all models. They control for unobserved time-varying variables such as education, income, urbanization, and religious preferences, which may affect name choice.
In all the models, the coefficient of z; is insignificant. This is understandable because in a truly nonstationary model, the impact of time-invariant observed attributes should also be zero, just as the impact of the time-invariant unobserved attributes is zero. Recall that
The results are robust to variations in model specification and data used. When I estimate the model with fit (the fraction of babies given name i in period t) as the dependent variable instead of nit (number of babies given name i in period t), the qualitative results remain unchanged. Similarly, the results are robust to the following changes in the data: (1) inclusion of all the names that have been in top 1,000 at least once (this data set can be referred to as Top 1000), (2) inclusion of a set of randomly picked names to the existing data sets, and (3) inclusion of observations prior to 1940 (i.e., analyzing all the data from 1880 to 2009 instead of focusing on the data from 1940 to 2009).
Statistical Framework for Analyzing the Drivers of Fashion
The previous two sections show that there is both algorithmic and statistical evidence for the existence of popularity cycles of large magnitudes in the data. In this section, using state-level variation in economic and cultural capital, I examine whether these cycles are consistent with one of the two signaling theories of fashion: (1) fashion as a signal of wealth and (2) fashion as a signal of cultural capital. I also consider and rule out a series of alternative explanations.
I begin with a visual example using the popularity curve of the name Heather (Figure 7). Panel A shows Heather's popularity in the three most and three least educated states. It is clear that Heather became popular in the more educated states (Massachusetts, Connecticut, and Colorado) before it took off in the least educated ones (West Virginia, Arkansas, and Mississippi). Similarly, note that it begins dropping in popularity in the highly educated states first. However, no such patterns appear in Panel B, which shows Heather's popularity cycles in the three most and three least wealthy states. This pattern also repeats in more recently popular names such as Sophia (Figure 8). Taken together, these patterns are suggestive evidence in support of the cultural capital theory. However, visual evidence from a few names is not conclusive, so I examine the data further for model-free patterns.

POPULARITY OF HEATHER IN THE MOST AND LEAST EDUCATED STATES AND THE MOST AND LEAST WEALTHY STATES

POPULARITY OF SOPHIA IN THREE OF THE MOST AND LEAST EDUCATED STATES AND THE MOST AND LEAST WEALTHY STATES
Preliminary examination of the data indicates that there are significant differences in when a name takes off and peaks across states. Table 7 compares the relative order of peaking in Colorado (high-cultural capital state) and West Virginia (low-cultural capital state). In the Top500 names, 71.33% of the names peak in Colorado before West Virginia (i.e., names tend to take off and peak in high-cultural capital states before low-cultural capital states). Nevertheless, even this finding is not conclusive because it does not control for other factors that affect name choice. So, hereinafter, I focus on empirical analysis.
RELATIVE ORDERING OF WHEN NAMES PEAK IN COLORADO AND WEST VIRGINIA BASED ON THE ALGORITHMIC DETECTION OF CYCLES

ESTIMATION RESULTS AND CONDITIONAL MONTONICITY TESTS

p ≤ .1.
p ≤ .05.
p ≤ .01.
Notes: The dependent variable is nit.
To confirm that the cycles in the data are consistent with social signaling, my empirical tests should confirm the following two statements:
The high types are the first to adopt a name, followed by low types. Similarly, high types are the first to abandon the name, followed by low types (i.e., the rate of adoption is higher among the high types at the beginning of the cycle, whereas the opposite is true at the end of cycle).
Adoption by high types has a positive impact on the adoption of the general population, whereas adoption by low types has a negative impact on the adoption of the general population.
In these statements, high types = wealthy and low types = poor if the wealth signaling theory is true, and high types = cultured and low types = uncultured if the cultural capital signaling theory is true. The following subsections present two models that test the validity of each of these statements.
A potential issue with using state-level data to make inferences on individual behavior is aggregation bias (Blundell and Stoker 2005; Stoker 1993). For an explanation of how an individual-level model aggregates to the state-level models employed in this section, see the Web Appendix. 8
States serve as the lowest level of geography in the data. Thus, all models in this section are specified at the state level. In a study on installed base effects in hybrid adoptions, Narayanan and Nair (2012) find that social effects tend to be stronger at lower geographical aggregations. So, this study's use of a relatively high level of aggregation should, if anything, reduce the likelihood of finding evidence in favor of social signaling.
Interacting Wealth and Cultural Capital with Past Adoptions
Model
I expand the model of name popularity to the state level as follows:
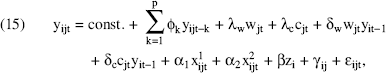
where
yijt = nijt, which is the popularity of name i in state j at time t;
Wjt and cjt are metrics of wealth and cultural capital of state j in period t;
wjtyit–1 and cjtyit–1 capture the interaction between the lag of the total country level adoption of name i and the wealth and cultural capital of state j, respectively;
zi is a time-invariant attribute of the name (discussed in the “Model” subsection);
εijt is an i.i.d mean-zero time- and state-varying shock that affects the popularity of name i in state j. It captures differential exposure and other random effects (e.g., the television show with a lead character named i may randomly be aired in one market before another, a local news item may mention name i in state j at time t).
This model can be augmented to include state-time dummies. However, I found no significant effects for such dummies, so I omit them here.
yit–1k terms are endogenous because yit–k is a function of yijt–k, which in turn is a function of γij ⇒ E(yit–k × γij) ≠ 0. Because the interaction terms wjtyit–1 and cjtyit–1 are functions of yit–1, I treat them as endogenous too. I modify the previous moment conditions to accommodate these changes and ensure that these correlations are not violated in the moment conditions. To avoid repetition, the estimation strategy is not described again. However, for each model estimated, I list the set of instruments for the level and first-differenced equations when presenting the results.
Results and Discussion
Model N1 in Table 9 presents the results from the estimating the model on the Top50 data set. Next, I discuss the estimates from this model (for robustness checks, see the “Robustness Checks” subsection. 9
Recall that name data are left-truncated at 5. At the state level, in Top50 names, 22.01% of the data are zero; in Top100, 29.54% of the data are zero; in Top200, 41.54% of the data are zero. I cannot tell how many of these are truly zeroes and how many are values less than five. If I include less popular names, a significant fraction of these zeroes are likely to come from truncation. Truncation can adversely affect the quality and significance of the estimates. Thus, to keep the estimates clean, I avoid less popular names and confine my analysis to the Top50 and Top100 data sets.
IMPACT OF ADOPTION BY HIGH AND LOW TYPES

p ≤ .1.
p ≤ .05.
p ≤ .01.
Notes: The dependent variable is nijt.
In Model N1, the mean effect of cjt is positive, and its interaction with past country level adoption cjt × yit–1 is negative. So the total effect of cjt is cjt (7:749 × 10–2 – 2:780 × 10–5 × yit–1). Recall that cjt is positive for states with high education and negative for states with low education (Table 3). For low values of yit–1 (≈ yit–1 < 2,787), the overall impact of cjt is increasing with education. Thus, at low values of yit–1, the impact of education is increasingly positive for states with education higher than the national average (cjt > 0) and increasingly negative for states with education lower than the national average (cjt < 0). This suggests that high-education states are more likely, and low-education states are less likely, to adopt a name at the early stages of the cycle (when its countrywide adoption is low). Conversely, for high values of yit–1 (approximately yit–1 > 2,787), the opposite is true. Here, the overall impact of cjt is increasingly negative for high-education states (cjt > 0) and increasingly positive for states with low education (cjt < 0). That is, high-education states are more likely to abandon a name as it becomes very popular, and the rate of abandonment increases with education. In contrast, low-education states are more likely to adopt a name as it becomes very popular, and this rate of adoption increases as education levels decrease.
The effect of the wealth metric, wjt, is the opposite of that of education—the mean effect of wjt is negative, while its interaction with past country-level adoption wjt × yit–1 is positive. This suggests that, after controlling for cultural capital, name cycles begin in the less wealthy states and then spread to the wealthier ones. Thus, the results do not support wealth signaling theory but are consistent with the cultural capital theory.
Controlling for other Factors that Affect Name Choice
Next, I explain how the model controls for other factors that affect name choice, as discussed previously. These include name attributes, familial and religious reasons, and celebrity names.
Name attributes
I control for time-invariant name attributes using observed variables such as length, number of Biblical mentions, sex, and an unobserved state-name fixed effect γij. γij captures state j's preference for the name as well as the name's origin, symbolism, ease of pronunciation, and so on. The inherent unobserved attractiveness of a name in a state can change over time and cause state-level trends in its popularity. Such trends are captured through lagged dependent variables (yijt–k).
Familial and religious reasons and assimilation/differentiation incentives
Familial and religious reasons as well as assimilation/differentiation incentives can be grouped under the heading of peer effects because they capture the impact of previous adoptions by others of same ethnicity, familial background, or religion on one's own adoption of a name (Nair, Manchanda, and Bhatia 2010; Shriver, Nair, and Hofstetter 2013). They are captured using lagged dependent variables. If lags are insufficient controls, the model would suffer from serial correlation, which is not so in this case. 10 Thus, in all models estimated, I take care to add enough lags of past adoption on the right-hand side to control for such time-varying name-specific effects. I verify the adequacy of these controls using the Arellano-Bond test, which confirms the absence of serial correlation.
A simple example illustrates the reasoning behind this finding. Consider a scenario in which parents' choices are influenced (among other things) by their need to fit in with a certain ethnic group. To this end, they may want to pick names that are currently popular in this group. Formally, let rijt–1 denote the number of babies from the ethnic group given name i in state j in period t – 1 and suppose that this number affects i's popularity in state j in period t. In the model, rijt–1 is indirectly controlled for through yijt–1 (which is a function of rijt–1), which is an adequate control. If it were not adequate, rijt–1 would be a true omitted variable that would appear in the error term as follows: ∊ijt, = δrijt–1 + uijt, where E(uijt) = E(uijt × uikt) = 0∀t, k ≠ t. Moreover, because the number of parents from the ethnic group choosing name i in period t – 1 is likely to be highly correlated to the number of parents from this group choosing name i at period t – 2, rijt–1 can be expressed as rijt–1 = ζrijt–2 + νijt–1, where E(νijt) = E(νijt × νijk) = 0 ∀ t, k ≠ t. In that case, E(∊ijt × ∊ijt–1) = E[(δrijt–1 + uijt) × (δrijt–2 + ujit–1)] = δ 2 (rijt–1 × rijt–2) = δ 2 ζ ≠ 0. Thus, if the lags of yijt–1 do not sufficiently control for name-specific time-varying factors that affect name popularity, the model would suffer from serial correlation.
Celebrity names
As discussed previously, a popular lay theory of name adoption is based on celebrity adoption. Although prior research has refuted this theory (Lieberson, 2000), in this subsection I explain how the model controls for celebrity adoptions.
First, the impact of newly popular celebrities on naming decisions is captured through time-varying error terms (Eyt). Once a celebrity is well-known, the lagged dependent variables account for the past unobserved effect of the celebrity's name on parents' choice (through either awareness of the name or adoptions by other parents). Again, the lack of serial correlation in the error terms ensures that these unobserved effects are adequately controlled for. More importantly, a celebrity-based theory cannot account for the differential rate of adoption (or abandonment) among different subsets of parents.
Robustness Checks
I conducted many checks to validate the robustness of the results and outline the key ones in this subsection. First, I reestimated the model with the Top100 data set to confirm that the qualitative results remain the same (see Model N2 in the Web Appendix). Next, according to Berry, Fording, and Hanson (2000), the BFH index does not sufficiently normalize the cost of living for Alaska, making it look wealthier than it really is. Therefore, I excluded it and reran the analysis to confirm that the results are similar to the previous ones (see Model N3 in the Web Appendix).
Impact of Adoption by States with the Highest and Lowest Cultural and Economic Capital
So far, the analysis has been restricted to analyzing the adoption patterns of a name within a state and relating it to the education and income of its residents. However, a given state may also be influenced by the adoption (or abandonment) of a name in high-/low-culture (or high-/low-income) states. This influence can help in the spread of names across states and explains the rise and fall of fashion cycles (see the “Deconstructing a Fashion Cycle” subsection). Next, I specify and estimate a model in which I examine the impact of the difference in the adoption levels in the most and least cultured (and wealthy) states on the rest of the states.
Model and results
Let
Let yijt denote the popularity of name i in state j in period t, where

The interpretations of yijt, γij, wjt, cjt,
Table 9 presents the results. Model P1 is estimated on the Top50 data set. The effect of
Note that these results extend those in the “Interacting Wealth and Cultural Capital with Past Adoptions” section by ruling out some alternative explanations. For instance, some prior work on name choice has suggested that certain parents prefer unique names (Lieberson and Bell 1992; Twenge, Abebe, and Campbell 2010). If preferences for education and uniqueness are correlated, then educated people should adopt unique names, which can potentially explain the positive interaction effect between education and past popularity. This positive interaction effect can also be explained using a novelty-based explanation; for example, educated people may prefer to be on the cutting edge (use novel names) and less educated people may prefer not to be on the cutting edge. However, neither of these alternatives can explain the finding that adoption by high-education states has a positive impact on others' adoption and adoption by low-education types has a negative impact on others' adoption (after controlling for name popularity [i.e., uniqueness or novelty]). These two findings are instead consistent with a vertical signaling–based explanation.
Deconstructing a fashion cycle
Finally, I combine Models N1 and P1 into Model P2 (see Table 9). The patterns from this model enable me to deconstruct culture-based fashion cycles: at the beginning of the cycle, when the name has not been adopted by anyone, the overall impact of cjt is positive, which implies that cultured parents are more likely to adopt the name. This effect in turn gives rise to a situation in which the number of cultured parents who have adopted the name is higher than the number of uncultured parents who have adopted it (i.e.,
Robustness checks
In this subsection, I present some specification checks to confirm the robustness of these results. First, the results are robust to changes in the data. In Model P3, I reestimate the model with the Top100 data set and find that the results are qualitatively similar (see the Web Appendix). Next, in Model P4, instead of
Managerial Implications
The findings have implications for marketing managers in the fashion industry. First, they provide an empirical framework to identify the drivers of fashion cycles in conspicuously consumed product categories. Second, they suggest that fashion should be seeded with consumers at the forefront of fashion cycles. For example, if consumers are interested in signaling cultural capital, the firms in that market should seed the product among the culturally savvy first. Over the last few years, seeding information with influentials has become a popular strategy among firms selling conspicuous goods (e.g., Ford hired 100 social media–savvy video bloggers to popularize its Fiesta car; Barry 2009; Greenberg 2010). However, finding effective seeds is a time-consuming and costly activity. In contrast, this study's findings suggest that fashion firms can use even simple geography-based heuristics (at the state level) to find seeds. Notably, the findings also have implications for constraining market expansion. For example, fashion firms may want to withhold the product from low–cultural capital consumers to keep the fashion cycle from dying too quickly by avoiding certain geographical areas.
The main empirical framework is fairly general. It can be easily adapted to data sets from commercial settings. The model, as specified in Equation 15, can be modified to accommodate such data by (1) including endogenous location-specific firm-level variables such as own price, advertisement, and promotions into
Conclusion
Fashions and conspicuous consumption play an important role in marketing. However, empirical work on fashions is close to nonexistent, and there are no formal frameworks to identify the presence of fashion cycles in data or examine their drivers. This article bridges this gap in the literature. First, I present algorithmic and statistical methods to identify the presence of cycles. In this context, I introduce the conditional monotonicity property and explain its role in giving rise to cycles. I also show how system GMM estimators can help researchers overcome potential endogeneity concerns and derive consistent estimates to establish the presence of cycles in data. Second, I apply my framework to the name-choice context and establish the presence of cycles in data. Third, I examine the potential drivers of fashion cycles in this setting, especially the two signaling theories of fashion. By exploiting longitudinal and geographical variations in parents' cultural and economic capital, I show that naming patterns are consistent with the cultural capital theory.
In summary, this article makes two key contributions to the literature on fashion and conspicuous consumption. First, from a methodological perspective, I present an empirical framework to identify the presence and cause of fashion cycles in data. The method is applicable to a broad range of settings wherein managers and researchers need to detect the presence of fashion cycles and examine their drivers. Second, from a substantive perspective, I establish the presence of large amplitude fashion cycles in names choice decisions and show that the patterns of these cycles are consistent with Bourdieu's cultural capital signaling theory.
The analysis suffers from limitations that serve as excellent avenues for further research. First, the context of the data may not be best to examine the theories of fashion, especially the wealth signaling theory, because names are costless. Thus, the magnitude and directionality of Bourdieu's (1984) and Veblen's (1899) effects are specific to this setting. Recall that given names are unique—they are not influenced by commercial concerns (advertisements, promotions, and so on) and are free (zero-price) for all potential adopters. This makes it difficult to extrapolate the point estimates in this research to other commercial settings. Second, because this study has only state-level data, the analysis is silent on within-state effects. It is possible that other types of peer effects are at play within smaller geographic areas that the cross-state analysis misses. Analyzing and documenting such effects would be a useful next step.
I conclude with the observation that while fashion is an important driver of consumption in the modern society, it remains an understudied topic in marketing. I hope that the empirical methods and substantive findings presented in this article will encourage other researchers to undertake empirical studies of fashions in the future.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.