
Abstract
In response to the concerns White raises in his technical comment on Rickles, Heppen, Allensworth, Sorensen, and Walters (2018), we discuss whether it would have been appropriate to test for nominally equivalent outcomes, given that the study was initially conceived and designed to test for significant differences, and that the conclusion of no difference was not solely based on a null hypothesis test. To further support the article’s conclusion, confidence intervals for the null hypothesis tests and a test of equivalence are provided.
Keywords
We appreciate the opportunity to respond to the concerns that White raises in his technical comment on Rickles, Heppen, Allensworth, Sorensen, and Walters (2018). White raises three interrelated concerns about our paper on the longer-term effects of an online credit recovery course:
He describes our paper as a “Nominally Equivalent Outcome” (NEO) study and, as such, suggests we should have conducted equivalency testing rather than traditional null hypothesis statistical testing (NHST).
He suggests we incorrectly accepted the null hypothesis of no effect based on an analysis that only supports a conclusion of failure to reject the null hypothesis.
He suggests we should have reported standard errors, confidence intervals, or some other quantification of the degree of uncertainty in the effect estimates.
We believe the applicability of the first two concerns are debatable for this particular study and deserve further discussion. At the same time, we acknowledge the need for a greater awareness of equivalence tests among education researchers. His last concern is valid, and we are grateful for the opportunity to report confidence intervals and provide evidence for equivalence.
In our experience of conducting and reviewing research in the field of education over several decades, it is rare to develop a study with the intent of testing equivalent interventions. Our study of online credit recovery was initially designed around a theory of action which posited that students may benefit from an online course where the content was more standardized, provided in a more interactive and graphically rich way, and allowed students to progress at their own pace, compared to the standard face-to-face course (see Heppen et al., 2017). Therefore, our a priori hypothesis at the start was that the online course may result in better student outcomes, and the study was designed to test for such differences. Upon finding significant negative short-term outcomes, the question then became whether significant negative effects were also seen in longer term outcomes. This is not to say that, upon seeing insignificant differences in longer-term outcomes, we should not subsequently test for equivalence, but to raise the question of whether a study should be recast as an equivalence study if it was not intended to be one. We are supportive of the suggestion to use equivalence tests in education research, and such methods seem particularly salient for studies focused on the application of educational technology in the classroom.
White’s second concern, that we incorrectly accepted the null hypothesis, raises a broader question about how to communicate education research in a way that balances the technical realities of the work with a need to make the writing accessible to inform the field of education, which includes the clarity and length of a manuscript. This is an on-going struggle in most applied research, where there is both an increasing concern about the “proper use and interpretation” of statistical results (Wasserstein & Lazer, 2016) and a need for “clear, concise, and low-jargon” writing (Clayton, 2015).
White’s concern that we accepted the null hypothesis of no effect is based on the one instance in the manuscript where we provide a broader, more colloquial synopsis of the findings within the discussion section. The statement that “students were no more or less likely to accumulate math course credits over time or graduate” if they took the online course or the face-to-face course was a statement of fact about our sample, among whom there was almost no difference in outcomes (0.1 difference in course credits, zero difference in graduation rate). We are comfortable concluding that the two groups had similar outcomes because that conclusion was not only based on a failure to reject the null hypothesis of no effect, but also on the small magnitude of the effects in our sample and the consistency in the results across the outcomes.
But we are glad White identified another way for us to support this conclusion, and for the opportunity to do so here in a way that neither confuses nor lengthens the original manuscript. To provide evidence that our conclusion was not frivolous within the context of a NEO study, we report the 90% and 95% confidence intervals in Figure 1, for our two primary outcomes. The 95% confidence interval aligns with the traditional NHST, where an interval that intersects with zero implies failure to reject the hypothesis of no effect. The 90% confidence interval aligns with the two one-sided test of equivalence (Barker, Luman, McCaluley & Chu, 2002), where the interval represents the range of differences within which we cannot reject the hypothesis of group equivalence (with α = .05). If the threshold for a substantive difference falls outside the 90% confidence interval, we have statistical evidence to conclude that the two groups are substantively equivalent given that threshold.
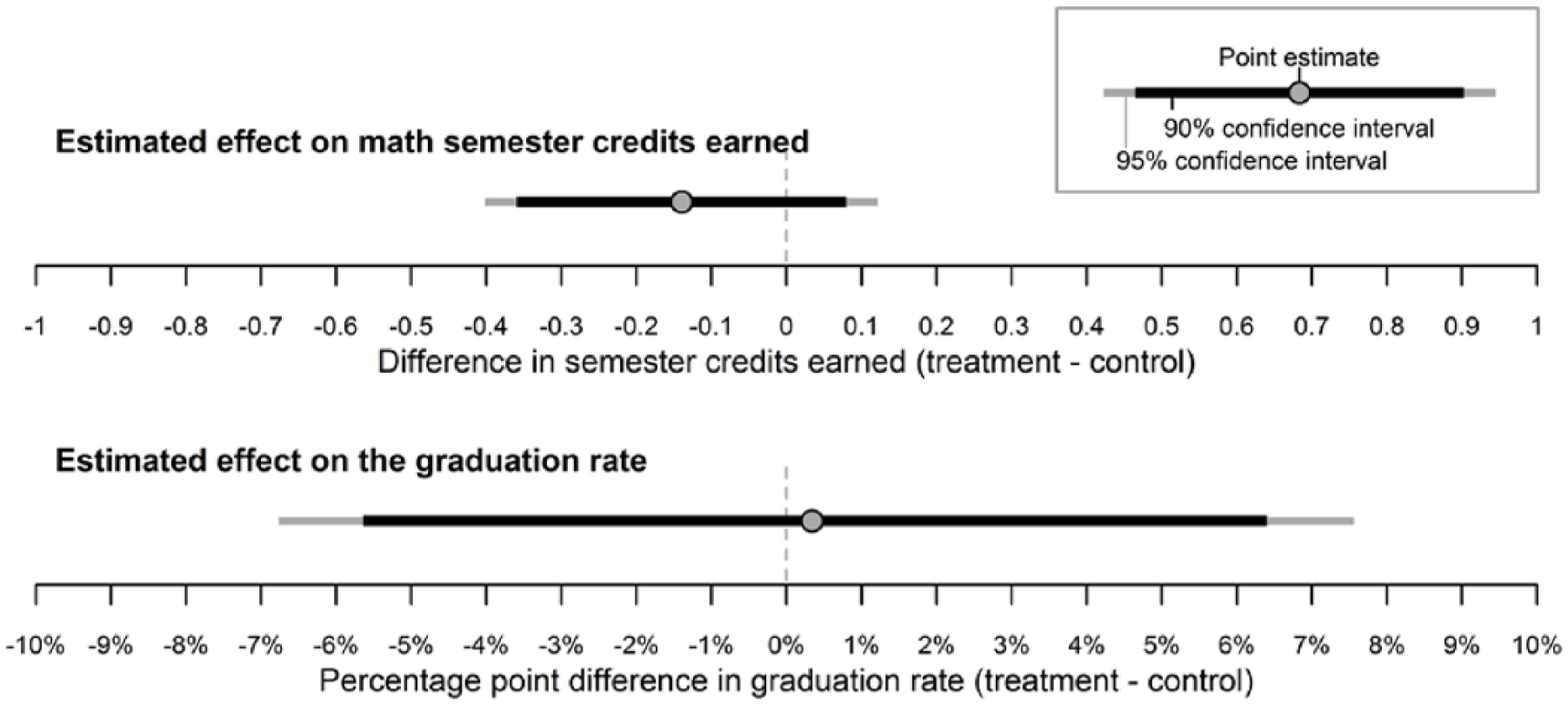
Confidence intervals for the treatment effect on math semester credits earned and high school graduation.
For the math semester credits outcome, the 90% confidence interval ranges from approximately -0.35 credits to 0.08 credits. Because we believe the difference should be greater than ± 0.5 credits to be of substantive interest, we can conclude that the groups are substantively equivalent. The 90% confidence interval for the dichotomous graduation rate outcome indicates more uncertainty in this effect estimate and includes ± 5 percentage points, which may be a reasonable threshold for a substantive difference. However, this threshold is at the outer edge of the interval and still unlikely. Given a point estimate near zero, and clear equivalence of the other outcomes which are direct antecedents to graduation, we think the most plausible conclusion is that the two groups are substantively equivalent.
To make education research policy relevant we believe it is desirable, particularly within the context of a discussion or conclusion section, to evaluate the weight of the evidence available to draw broader conclusions about the analysis, rather than relying on, or insisting on, a particular type of analysis. It is, however, also desirable for others to monitor our work to ensure we do not stray too far from the data in ways that make unwarranted claims. For this, we are grateful to White for raising concerns that both push and allow us to provide more nuance to the findings originally reported.