
Abstract

Who Invented the Diesel Engine?
Rudolf Diesel, of course, you say. Not so fast, says Bruno Latour (1987) in Science in Action. Latour recounts the meandering connections, people, experiments, and prototypes that led to those sturdy, efficient internal combustion engines without spark plugs that sit in your Volkswagen Jetta or Kenworth 18-wheeler—and bear scant resemblance to the sketches on Diesel’s patent. It took Diesel and the engineers from Maschinenfabrik–Augsburg–Nürnberg (MAN) 4 years to produce a working prototype, too unreliable for practical use and already morphed from a constant temperature to a constant pressure device. Over the next 3 decades, after Diesel’s patent expired, hundreds of engineers across laboratories and workshops experimented and innovated, posed designs and new ideas, and shared and learned from others’ models and theories in conversations and demonstrations. Latour describes this network of “actors”—people, prototypes, articles, and patents—which, connection by connection, trial by trial, encountered myriad challenges and developed methods for tackling them to transform a brilliant if unworkable insight into practical machines.
Likewise does educational measurement progress. Yan, von Davier, and Lewis’s edited volume Computerized Multistage Testing (CMT) gathers the developments that have brought a brilliant if unworkable insight a half-century ago to a practical testing methodology to balance the efficiencies of adaptive testing and the control of assessment design for real-world applications. After a brief description of multistage testing, the following sections offer some observations on the actor network from which it arises, summarize the contents of CMT, and comment on users and uses it seems to suit.
What Is Multistage Testing?
Figure 1 shows a three-stage design (CMT, p. 6). In this example, all examinees are administered the set of tasks labeled Module I in Stage 1. Stage 2 of examinees’ tests continue down a path that depends on their performance in Stage 1, say to the easier items that constitute Module J or the harder items of Module K. Again their performance thus far determines the next stage. Examinees who have taken Module J are routed to either still-easier Module L if they have not done well or medium-difficulty Module M if they have. Examinees who have taken Module K are similarly routed to Module M or to still-harder Module N. There are four possible paths in this design, each constituting a different effective test form. Because the modules and the procedures are designed to present the examinees with items that are adapted to their ability and therefore more informative, nearly the same precision can be obtained with fewer items per examinee by administering the same fixed form to everyone.
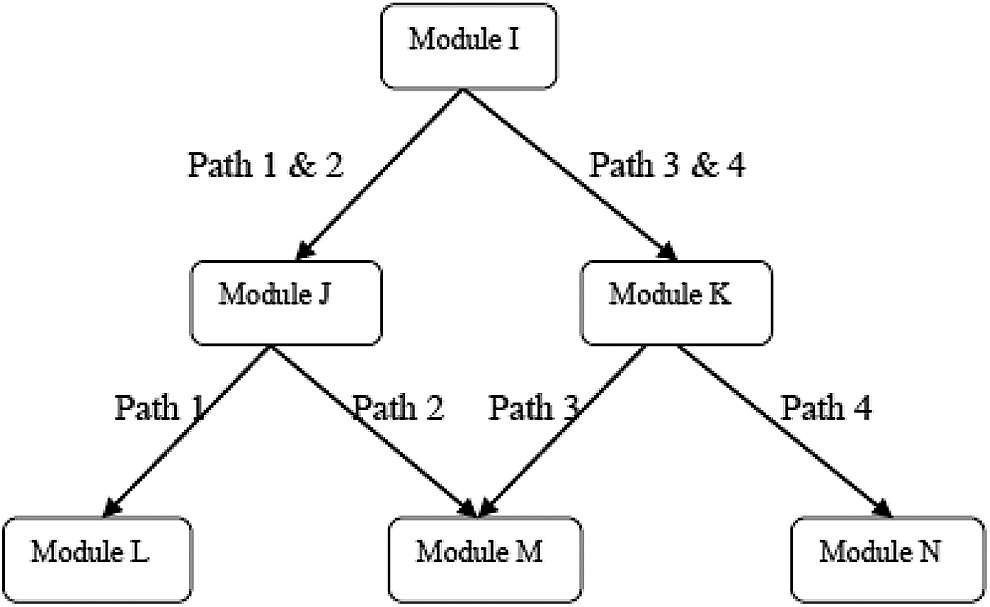
A three-stage test.
One limiting case has only one stage and administers all examinees the same items in the same order. This is a familiar single-form fixed test. At the other extreme, each module is a single item and a routing decision is made after every response. This every-item adaptive testing is nowadays implemented as computerized adaptive testing (CAT; van der Linden & Glas, 2010; Wainer et al., 2000). Countless variations lie between, with different numbers of stages, numbers and compositions of modules at each stage, and different procedures for routing and scoring examinees. A common branching structure can be replicated as “panels” with parallel modules in each position, and an examinee’s test is a path on one panel.
The chapters in CMT explore these possibilities, some from theoretical standpoints of efficiency and optimality and others tackling practical challenges such as content balancing and test security.
How Did Multistage Testing Come About?
Tracing the connections among the authors, the papers, the references, and applications in CMT with Latour’s actor-network theory would make a fascinating dissertation. Along with CAT and nonadaptive sequential testing, multistage testing is a kind of response-contingent testing (RCT). The 1905 Binet-Simon test was an individually administered RCT, as the examiner moved up or down a fixed sequence of items ordered by age-related difficulty until they became too hard or too easy for a child. Hick (1951) drew on emerging information theory to suggest that examinees should be presented items they had 50–50 chances of answering correctly. Cronbach and Gleser (1957) explored RCT for adaptive placement and selection decisions. There were a fair number of nodes in the RCT actor-network early on but not many connections. “For the past twenty-five years,” Robert Wood observed in 1973: this idea has exerted a more or less continuous fascination on the educational research community, and there has probably always been someone working on it. Yet with the greatest respect to all concerned, these enquiries have never really amounted to anything of practical significance. It is indicative of the state of the art that response-contingent testing has been reinvented so many times.… (p. 529)
The RCT network was initially dense around every-item CAT, with notable impetus from the work of Frederic Lord (1970) and a CAT research program supported by the Office of Naval Research (ONR) and led by David Weiss. This program pulled in human actors, funding researchers, and their grad students. It generated statistical theory, alternative approaches, informative simulation results on what worked, and prototype applications. Perhaps most importantly, it richly connected this work through a series of ONR-sponsored conferences and the resulting proceedings. The following years saw applications of CAT in important large-scale testing programs such as the Armed Services Vocational Aptitude Battery, the Graduate Records Examination (GRE), and the National Council Licensure Examination for nursing licensure.
Although individual-item CAT has the greatest potential efficiency under a given model, a model is never exactly right. Applications were troubled by considerations outside the model but endemic in real-world contexts and live examinees: controlling the content, format, and timing requirements of the collections of items examinees received, for example; balancing the exposure of items in a pool; allowing examinees to change their answers or to skip them to return to later; reducing spurious results from examinees who start badly or answer randomly when time runs short at the end of a test. Attention began to turn to multistage testing, which gave developers greater control of the content and the conditions of each examinee’s test yet could achieve most of the efficiency gains of individual-item CAT.
What Is in Computerized Multistage Testing?
CMT is itself a formidable agent. There are 27 chapters, organized into six parts, by 43 contributing authors. The chapters link back to the RCT literature and connect richly to writing on numerical optimization, decision theory, and the pervasive measurement issues of validity, reliability, fairness, and security. There are too many chapters to list and discuss individually, so overviews and highlights of the main sections will have to suffice.
Section I, Test Design, Item Pools, and Maintenance, is a solid introduction to multistage testing, laying out concepts and terminology. The editors’ overview chapter (Chap. 1) is a great quick start, and Zenisky and Hambleton’s survey of current research (Chap. 2) prepares the reader for the more detailed chapters that follow. The remaining chapters in Part I push further into areas that have seen less attention. Veldkamp’s chapter (Chap. 3) on item pool design, for example, brings optimization machinery to bear on the design of item pools to support the assembly of modules. In early work, the item pool was presumed, but creating tasks (including the possibility of automated task creation, as was done in the British Army Recruitment Battery; Irvine, 2013), is critical to an organization that wants to develop an ongoing multistage test program. Similarly, Luecht’s chapter (Chap. 5) on designing and implementing large-scale multistage testing systems tackles practical issues that arise when vast numbers of examinees are tested in real time with important consequences, and crashes and security breaches cost money and hurt people.
Parts II and III dig deeper into developments at the core of multistage testing. They reflect the blend of the considerations of fixed-form test assembly and the dynamic nature of single-item CAT. The parts are Test Assembly, which is the up-front design work for numbers, lengths, and composition for modules, stages, and panels, and Routing, Scoring, and Equating, which is the design of the real-time processes that take place for each examinee as they proceed through the paths in the resulting design. Significant advances have taken place in both areas.
The Zheng et al. chapter (Chap. 6) opens Part II with an overview of assembly in multistage testing. Given a design, assembly for multistage tests draws heavily on optimization techniques, specifically integer programming to select items for modules that balance considerations of information, content balancing (usually along many dimensions), format and expected response time allocations, item exposure, and joint appearance of items. Construction can be simultaneous across modules, stages, and panels. A given design requires heavy computations, and comparing designs requires extensive simulations. Subsequent chapters describe more recent work. For example, van der Linden and Diao (Chap. 7) describe how a “shadow test” approach offers improvements over look-ahead-one assembly algorithms, and Han and Guo (Chap. 8) describe multistage tests that assemble each examinee’s successive modules in real time. These strategies are impossible without powerful real-time processing.
Weissman’s chapter (Chap. 10) on IRT-based multistage testing opens Part III, laying out the statistical foundation of most designs (again connecting with early theoretical work in Lord, 1971). Haberman and von Davier (Chap. 15) delve into the statistical aspects more deeply. The remaining chapters address special topics, such as the editors’ chapter (Chap. 11) on a tree-based regression alternative for smaller applications that retains many of the benefits of multistage testing without IRT. Other chapters address multistage tests that optimize categorical decisions and that are based on multidimensional IRT or diagnostic models.
Part IV, Test Reliability, Validity, Fairness, and Security, is critical to using multistage tests in practice, for as Messick (1994) reminds us, “[V]alidity, reliability, comparability, and fairness are not just measurement issues, but social values that have meaning and force outside of measurement wherever evaluative judgments and decisions are made” (p. 13, emphasis original). These chapters explore the forms that these familiar properties take in an unfamiliar form of testing, focusing on reliability using the IRT framework (van Rijn, Chap. 16) and classical test theory (Livingston & Kim, Chap. 17); validity, fairness, and differential item functioning (Zwick & Bridgeman, Chap. 18); and test security and quality control (Lee, Lewis, & von Davier, Chap. 19).
Part V, Applications in Large-Scale Assessments, shows multistage testing in action. The examples span a well-chosen array of settings: the tree-based regression approach with small samples (Chap. 20); the high-stakes GRE Revised General Test of broadly defined abilities (Chap. 21); a certification examination for American Institute of Certified Public Accounts (illustrating a mix of task types from multiple-choice to simulations, Chap. 22); a K–12 achievement test (Chap. 23); a fielded demonstration in the National Assessment for Educational Progress (NAEP, Chap. 24), a large-scale educational survey of populations rather than individuals; and operational use in the Program for the International Assessment of Adult Competencies (Chap. 25), where the focus is item exposure rates. In each chapter, the authors not only describe how they employed the technical ideas addressed earlier in the book, but how they developed and tested their designs in the context of the populations, the constraints, the purposes, and the social contexts of their applications.
The final two chapters have a somewhat different character. I will return shortly to Han and Kosinski’s discussion of software tools for simulation (technically the last chapter in Part V, Chap. 26). In the final chapter (the only chapter in Part VI), Bejar (Chap. 27) considers the past and future of multistage testing in educational reform. His review draws out more of the connections in the historical actor-network graph and looks ahead to possible future connections for multistage testing. One direction is using multistage testing not simply to efficiently address a given objective (e.g., measuring individuals, estimating population distribution, and making decisions) but to address multiple purposes in the same assessment system. Modules and routing rules would then optimize selection (or construction) of modules that might, for example, both provide estimates of broad population characteristics and ground more precise estimates for individuals only in domains selected adaptively for them. A second direction is using automated generation and automated scoring of tasks on the fly, with modules constructed as frameworks that would wholly or in part administer tasks that were complex and interactive but selected or generated to be at difficulty levels and addressing substantive content that enabled optimal engagement from most students. This is an exciting possibility, which depends all the more on computational capabilities and a principled framework for the design of tasks and interpretation of task performances.
Who Is Computerized Multistage Testing for?
The chapters of CMT reflect work comparable to that of the engineers at MAN. Some are syntheses of existing work but many reflect ongoing work inside the black box, to understand the pieces, to create new methods, and to connect to other pieces of the assessment systems and the social systems they are embedded in. It is written by engineers for engineers. The chapters are quite readable—assuming the reader is familiar with statistics and IRT at the level of the Journal of Educational and Behavioral Statistics and Applied Psychological Measurement. It promises to become a very dense node in the actor network associated with multistage testing, for it pulls together much of what is known about the topic at a moment it has come of age. It is key for any measurement scientist seeking to become more familiar with multistage testing, or to develop an application, or to learn about it as a student or to help students learn about it. If this is the kind of book you like, you will like this book.
On the last point, CMT is not written as a textbook. It has individually authored self-contained chapters, some differences in notation, some overlap, and no exercises. It would however serve as a basis for a seminar course for advanced students. It is here that the chapter on software tools for simulation (Chap. 26) is particularly useful. Chapter after chapter describes extensive computations and simulations, to find and compare designs tuned to the particulars of an application. There are many factors to balance and no simple solution to guide their simultaneous configuration. A difference in one factor can lead to a notably different optimal design. Carrying out tailored simulations is necessary. Using the software described in the chapter (and in a few years, its successors), students can try out the ideas and techniques, using either local sources or publically available item banks such as those of NAEP.