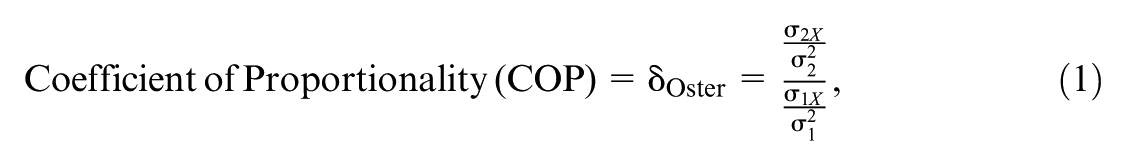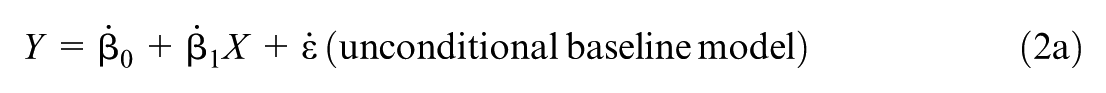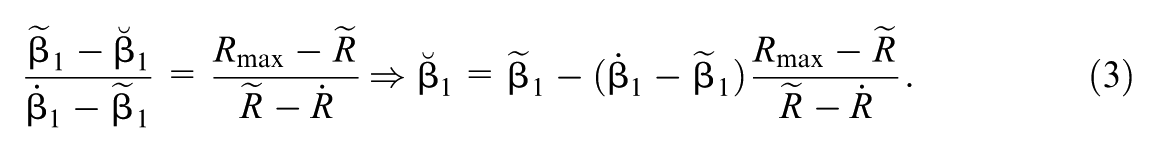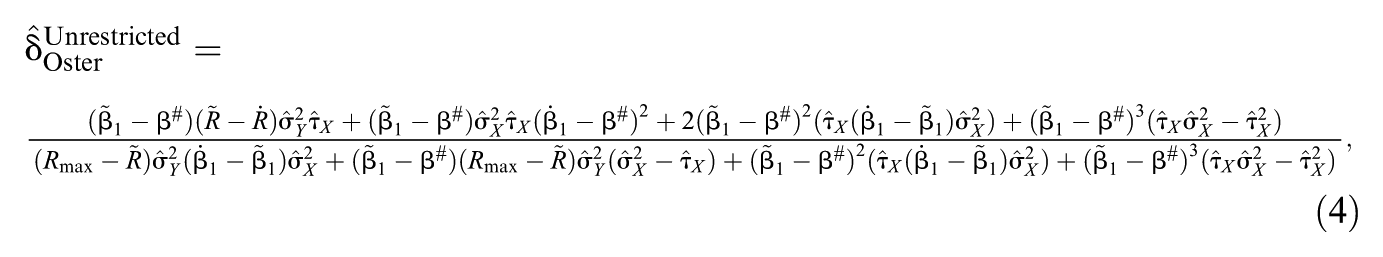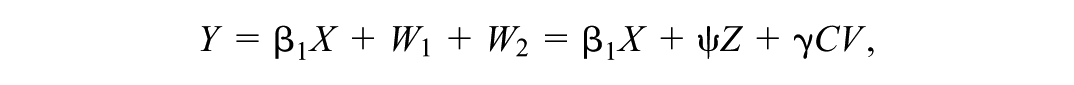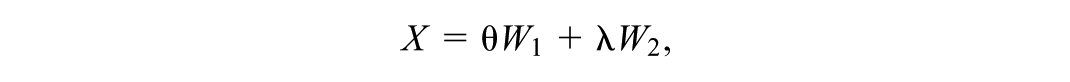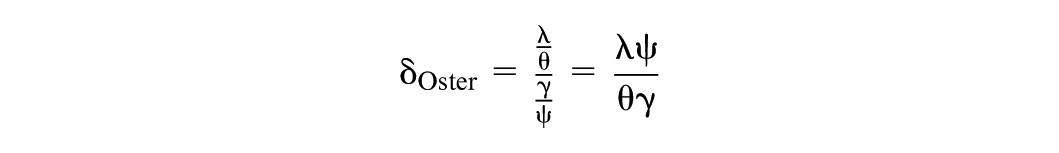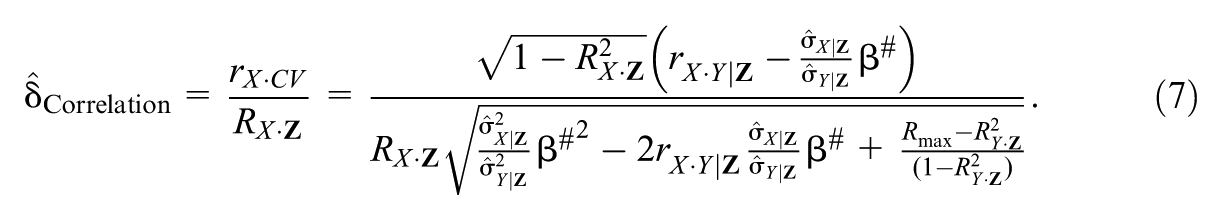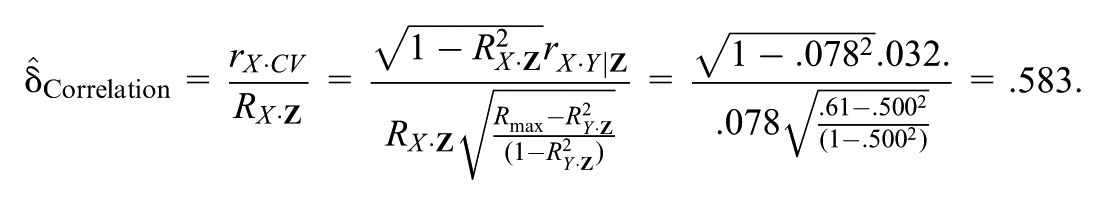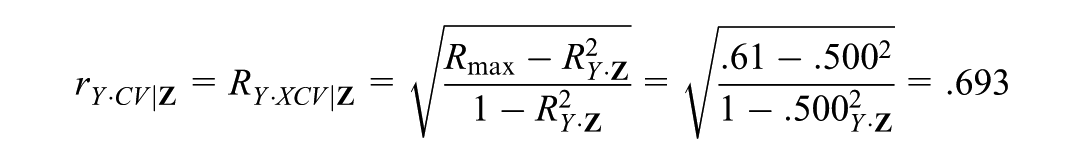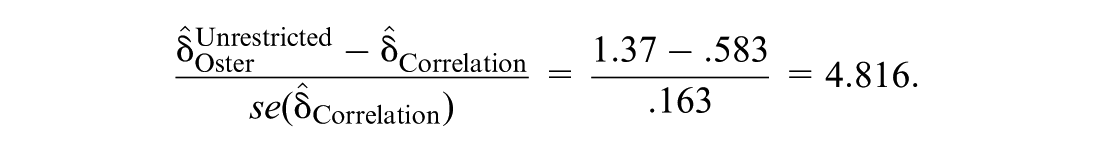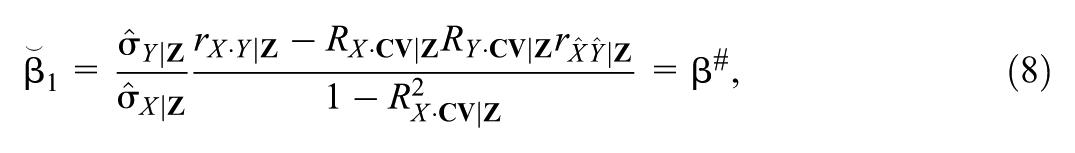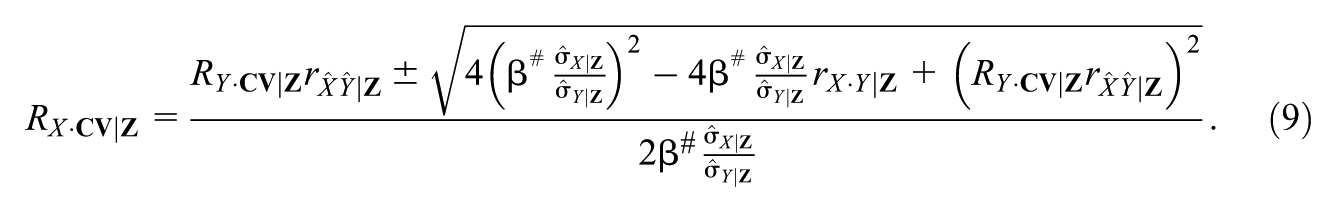Sensitivity analyses can inform evidence-based policy by quantifying the hypothetical conditions necessary to change an inference. Perhaps the most prevalent index used for sensitivity analyses is Oster’s Coefficient of Proportionality (COP) which expresses how strong selection on unobserved covariates would have to be relative to selection on observed covariates to nullify an estimated effect. But Oster has been critiqued based on its two-stage conceptualization of the COP and its estimation of the COP based on coefficient stability across estimated models. In this article, we reconceptualize the COP as a function of unobserved covariates’ correlations with the focal predictor (e.g., treatment) and with the outcome. Our correlation-based approach addresses the critiques of Oster while preserving the comparison of selection on unobserved covariates to selection on observed covariates. As importantly, our expressions do not depend on analysts’ subjective choices of covariates to include in a baseline model, are adapted to a threshold for inference based on statistical significance, and can be directly calculated from conventionally reported quantities (e.g., estimated effect, standard error) through the Konfound packages in R or Stata or the R-shiny app https://konfound-project.shinyapps.io/konfound-it/. Thus, for most published studies in the social sciences our correlation-based COP index can be easily applied and intuitively interpreted.
Cornfield et al. (1959) initiated sensitivity analysis in public policy to interpret inferences regarding the effect of smoking on lung cancer. In the context of lack of randomized experiments many questioned the effect of smoking on lung cancer. For example, R. A. Fisher (1958) argued “both characteristics [smoking and lung cancer] might be largely influenced by a common cause [genotype]” (p. 108). Cornfield et al. countered by calculating that to reduce the estimated effect of smoking on lung cancer to zero, an unobserved covariate “would need to be a near perfect predictor of lung cancer and about nine times more common among smokers than among nonsmokers” (as paraphrased by Rosenbaum, 2005, p. 1809). Sensitivity analyses like that of Cornfield et al. identify the specific properties, extreme in the example of smoking and lung cancer, of an unobserved covariate necessary to nullify an estimated effect.
In education research, Oster’s (2019) technique has recently been used to interpret inferences regarding effects of early college on postsecondary outcomes (Edmunds et al., 2020), dual enrollment on college credits (Edmunds et al., 2024), gifted programs on academic achievement and other outcomes (Redding & Grissom, 2021), universal early childhood education and care for toddlers on academic achievement (Zachrisson et al., 2023), single-sex classrooms versus coeducational classrooms on the mathematics achievement gap (Paredes, 2022), and attending community college on employment and earnings (Marcotte, 2019). In each case, the sensitivity analysis helps those interpreting the inference weigh the strength of the evidence relative to concerns about potentially omitted variables.
While Oster’s (2019) COP has potential to help stakeholders interpret inferences, several critiques have recently been raised based on the scaling in a two-stage conceptualization of a data generating process (Basu, 2023; Cinelli & Hazlett, 2020) and estimation based on coefficient stability relative to a baseline model (Diegert et al., 2022; Masten & Poirier, 2022). In this article, we draw on longstanding literature on sensitivity analysis (Frank, 2000; Mauro, 1990; see reviews in Frank et al., 2023 or Middleton et al., 2016) to address the critiques by reconceptualizing the COP as a function of unobserved covariates’ correlations with the focal predictor (e.g., treatment) and with the outcome. Our correlation-based approach addresses the critiques of Oster’s COP by leveraging Ordinary Least Squares (OLS) estimation for linear models while preserving the comparison of selection on unobserved covariates to selection on observed covariates. As importantly, our expressions do not depend on analysts’ subjective choices of covariates to include in a baseline model, are adapted to a threshold for inference based on statistical significance, and can be directly calculated from conventionally reported quantities (e.g., estimated effect, standard error) through the Konfound packages in R or Stata or the R-shiny app (https://konfound-project.shinyapps.io/konfound-it/). Thus, for most published studies in the social sciences, our COP index can be easily applied and intuitively interpreted.
In Section 2, we present the background of the COP including Oster’s intuition and estimation of the COP, and an empirical example. In Section 3, we present critiques of Oster’s COP in detail. In Section 4, we turn to the derivation and verification of our correlation-based COP which addresses the critiques of Oster (2019). In Section 5, we apply the correlation-based COP to the empirical example and then in Section 6 we compare the correlation-based COP with Oster’s COP in the empirical example and through simulation. In Section 7, we revisit our key assumptions (single versus multiple unobserved covariates, orthogonality of observed and unobserved covariates, and threshold specified without regard to sampling variability). In Section 8, we consider recommended practices and interpretation of the COP before making our final conclusion.
2. Oster’s COP: δoster
In this section, we present the intuition behind Oster’s (2019) COP based on a two-stage approach to express the dual components of confounding, and Oster’s conceptualization of coefficient stability to estimate the COP. We then present application to Oster’s example of the effect of Low birthweight and preterm on infant IQ.
Altonji et al. (2005) established the basis for Oster’s COP by expressing the dual components of confounding in terms of commonly used two-stage econometric techniques—one stage to predict the outcome, Y, and a second to predict selection into the focal predictor, X. Formally, let W1 represent the prediction of the outcome Y based on observed covariates Z, and W2 the prediction of Y based on unobserved covariates CV. Noting selection bias occurs when “… the treatment or control status of subjects is related to unmeasured characteristics that themselves are related to the outcome…” (Barnow et al., 1980, p. 1), a key contribution of Altonji et al. (2005) was to use a logistic regression to benchmark how strong selection into the focal predictor X (e.g., a treatment) based on W2 must be relative to selection based on W1 to nullify the estimated effect of X on Y (for other benchmarking techniques, see Rosenbaum, 1986; Cinelli & Hazlett, 2020; Frank, 2000; Veitch & Zaveri, 2020). Applying this insight to their empirical analysis of the effect of attending a Catholic school on student outcomes, Altonji et al. (2005, p. 176) concluded that, “the normalized shift in the distribution of the unobservables [selection based on W2] would have to be 3.55 times as large as the shift in the observables [selection based on W1] to explain away the entire CH [Catholic High School] effect. This seems highly unlikely.”
where is the covariance between X and W2, and is the variance of W2. Similarly, is the covariance between X and W1 and is the variance of W1. Therefore, the COP can be can be interpreted as the ratio of the prediction of X based on the unobserved covariates to the prediction based on the observed covariates , accounting for the relationships to Y through W1 and W2. Moreover, because W1 and W2 are defined in the prediction of Y, they express the observed and unobserved covariates on a common scale defined by the variance of Y.
2.2 Estimation of δoster
Oster (2019) developed an estimator for δoster based on coefficient stability observed by an analyst across the following three models estimated from a sample:
There are no distributional assumptions about the error terms (ε) in each model except when defining a threshold for decision-making based on statistical significance (see Subsection 7.3).
Note that each model in Equation 2 is conceptualized in terms of estimated values represented by ., ~, or ⏝ depending on the covariates an analyst adds, or considers adding, to the model. But each model has a population analog. For example, the population analog for Equation 2c is with β1 representing the effect of X on Y conditioning on observed and unobserved covariates in the population. If one also considered the observed covariates to be sampled from a set of covariates (e.g., Altonji et al., 2005) then only Equation 2c would be a true population model assuming that the union of Z and CV is the population of covariates.
Oster (2019) used the change in estimated effect from 1 to from Equation 2a to Equation 2b and corresponding change in explained variance (aka the coefficient of determination, R2) to estimate δoster. To represent Oster’s estimation strategy, first define 2 as the R2 for Equation 2a and as the R2 for Equation 2b. Importantly, Oster’s derivation assumed a maximum (Rmax) in the final model in Equation 2c that could be less than one. Consistent with challenges to determinism based on human agency and free will (e.g., Strawson, 2008), some variance in the outcome may be unexplainable even accounting for all conceivable observed and unobserved covariates (Oster, p. 201, developed an empirical guideline for Rmax based on randomized studies see Subsection 8.1.2). Using these quantities, Oster derived an intuitive estimator for β1 in Equation 2c:
The estimator leverages intuition based on coefficient stability: “the ratio of the movement in coefficients is equal to the ratio of the movement in R-squared ” (Oster, 2019, p. 193).
While the expression in Equation 3 is intuitive, it is restricted by the assumption that selection on unobserved covariates equals selection on observed covariates (it is also restricted by the assumption that the relative contribution of each unobserved covariate to X is the same as its contribution to Y, which we will discuss in Subsection 7.1). Oster relaxed the two assumptions to derive an unrestricted estimator for β1 as a function of δOster defined in Equation 1. This allowed Oster to create a sensitivity index by identifying the value of δOster that would generate a specified value of .
Specifically, Oster (2019) solved three equations for three unknowns (based on the stability of estimated effects and R2 across the models in Equation 2) to derive an expression to estimate δOster that would generate a threshold value of = β# for a specified Rmax yielding:
where is the estimated residual variance in X after conditioning on Z. Note that β# may equal zero nullifying the estimated effect, but it also may be a non-zero threshold for inference. Most importantly, is an index of sensitivity. The larger the value of necessary to reduce to β# (for specified Rmax), the more robust the inference regarding β1.
2.3 Example Application: Effect of Low Birthweight and Preterm on Infant IQ
To illustrate the use of the COP throughout the article, we focus on the most robust inference (defined by ) among the examples used in Oster (2019, Table 3, Panel A, Column 3), regarding the effect of Low birthweight and preterm on infant IQ. The inference is of scientific importance representing the implications of birth conditions throughout schooling and the life course (e.g., Breslau et al., 1994). Furthermore, if Low birthweight and preterm affect IQ, then policy might attend more fully to corresponding prenatal medical and postnatal educational supports (Gross et al., 1997; National Research Council, 2000).
For the baseline model (Equation 2a, including the covariates age and child female), Oster reported = −.188, and = .004. For the intermediate model (Equation 2b, including five additional covariates: mother Black; mother age; mother education; mother income; mother married), Oster reported and . For the final model Equation 2c, Oster specified β# = 0 and . Based on these values, Oster reported = 1.37 based on Equation 4 indicating that selection on the unobserved covariates would have to be more than one-third stronger than selection on the observed covariates to reduce to 0 with of .61.1
where W1 = Z and W2 = γCV. Note that technically Oster considers W2 as wholly representing the unobserved covariate without a parameter (i.e., = 1), but we use Cinelli and Hazlet’s formulation W2 = CV.
with W1 and W2 already representing the relationships of the covariates to Y (through and γ). Using the previous two expressions for Y and X, Cinelli and Hazlett (2020, Equation 27, p. 64) then re-express δOster:
The middle expression shows how Oster’s formulation of the COP scales selection on unobserved covariates (λ) to that on observed covariates (θ) relative to their corresponding contributions to Y (through γ and ψ). Cinelli and Hazlett then showed that representing the dual relationships associated with a confounder through the two sets of coefficients for Y and X can lead to counter-intuitive results. Consider = = q and = q/2 (where q is any real number) in which case selection on the CV (λ = q/2) is half that of selection on Z (θ = q), but δOster = 1 (Basu, 2023, p. 10 draws the corresponding conclusion that a benchmark of δOster = 1 is problematic).2
The second critique of Oster (2019) is based on as an estimator for δOster (Masten & Poirier, 2022). The expression for in Equation 4, based on solving a system of three equations in three unknowns, yields cubic dependence on both β# and . As a result, the dependence of on β# is non-monotonic and may exhibit discontinuities. Specifically, Masten and Poirier (2022) showed that the value of necessary to produce a sign change can be different from, and smaller than, the value of necessary to nullify the estimated effect by making it equal to zero. This is counterintuitive; someone seeking to reduce the estimated effect of to zero might perceive an inference to be highly robust, while someone seeking the more extreme reversal of sign (even just to an estimate of small magnitude but opposite sign than ) might perceive the inference to be fragile (see Masten & Poirier, 2022, p. 3; see also Basu, 2023).
4. Recasting the COP in a Correlational Framework: δCorrelation
In this section, we present a definition and estimator of a correlation-based COP, δCorrelation, that address the critiques of Oster (2019).
4.1 Notation
Following the presentation of Oster’s COP, we use Greek letters to represent population parameters that define δCorrelation. We use ^ to represent an estimated value with two exceptions. First, we use ., ~, and ⏝ to differentiate among the estimates in Equation 2. Second, following convention, we use r to represent a sample correlation between two scalars. To be consistent, we use to represent the coefficient of determination from model Equation 2b in a sample including the observed covariates Z, equivalent to Oster’s ; and we use = to represent the coefficient of determination from model Equation 2c also including the unobserved covariates CV. We then use “|” to represent partialled for, or residualized on (Cinelli & Hazlett, 2020, p. 48). For example, rX·Y|Z represents the sample correlation between X and Y partialled for, or residualized on, the observed covariates Z. Also using the “|”, represents the sample standard deviation of X conditional on Z and represents the sample standard deviation of Y conditional on Z. See Table 1 for the notation used throughout.
Notation Used in the Main Text
Term
Definition
X
Focal predictor, or independent variable
Y
Outcome, or dependent variable
Z
Observed covariate (Z for multiple observed covariates)
CV
Unobserved covariate (CV for multiple unobserved covariates)
W1
Function of observed covariates Z weighted by their prediction of Y
W2
Function of unobserved covariates CV weighted by their prediction of Y
β1
Effect of focal predictor X on outcome Y. Estimate from baseline model: ; estimate from intermediate model including observed covariates: ; estimate from final model also including unobserved covariates:
ε
Error term for a model predicting Y
β#
Threshold value for making an inference about β1
ρ1·2
Population correlation between variable 1 and variable 2. The term r is used in a sample. For example, rX·Y is the correlation between X and Y
r#
Threshold value for making an inference about a correlation
ρ1·2|3
Correlation between variable 1 and variable 2 partialling for (i.e., conditioning on, residualized on) variable 3. The term r is used in a sample (e.g., rX·Y|Z is the correlation between X and Y partialling for Z)
P1·2
Multiple correlation between a variable and a vector. R1·2 used in a sample (e.g., RX·CV is the multiple correlation between X and CV), 0 < R1·2 < 1
Rmax
Specified maximum R2 for a model using X, Z, and CV to predict Y
σ1
Standard deviation for variable 1. used for a sample. For example, is the sample standard deviation of X
σ1|2
Standard deviation for variable 1 conditioning (or residualized) on 2. used for a sample. For example, is the sample standard deviation of X after conditioning on Z
σ12
Covariance of variables 1 and 2. used for a sample
δOster
Coefficient of Proportionality based on Oster’s formulation in terms of W1 and W2.
Unrestricted estimator of δOster
δCorrelation
Coefficient of Proportionality based on correlational framework
Estimate of δCorrelation
Frank’s Impact
The product of two correlations associated with a covariate. For example, rX·CVrY·CV is the impact of the CV on the relationship between X and Y in a sample
Df
Degrees of freedom used for an inference
Se()
Standard error of an estimated effect
Sample correlation between (the predicted value from regressing X on the elements in CV conditioned on Z) and (the predicted value from regressing Y on the elements in CV conditioned on Z)
4.2 Definition of δCorrelation
As we noted in presenting the intuition behind Oster’s COP, one of Oster’s (2019) contributions was to express the COP in terms of OLS estimates of the General Linear Model (GLM). Correspondingly, our COP is conceptualized in terms of the linear relationships among the focal predictor, outcome, and covariates, and we assume OLS will be used to estimate the GLMs in Equation 2. This allows us to derive closed form expressions for the relevant correlations and COP.3
Specifically, we define δCorrelation as the ratio of two (multiple) correlations:
where of PX·CV represents the population correlation (the square root of the coefficient of determination) between X and the vector CV and PX·Z represents the population multiple correlation between X and Z. For the square root of coefficients of determination, we assume 0 < PX·CV < 1 and 0 < PX·Z < 1 to ensure the directionality of the impact on β1 (Frank, 2000).
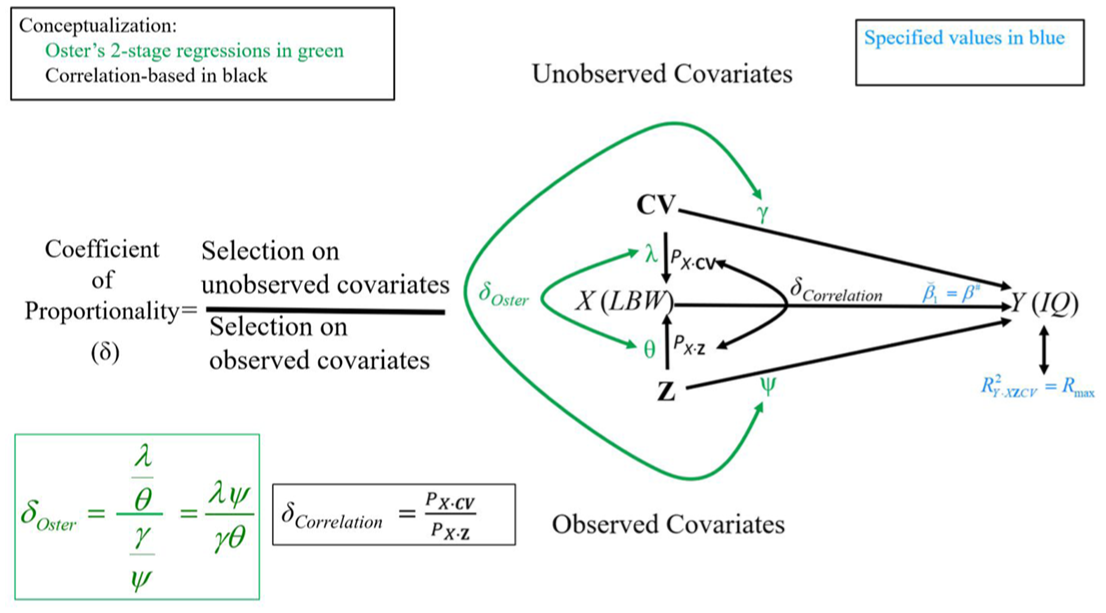
The difference in conceptualization between δOster and δCorrelation is shown in Figure 1. The core of the figure features a Directed Acyclic Graph (e.g., Pearl, 2009) focusing on the effect of X on Y, with observed covariates Z at the bottom and unobserved covariates CV at the top. Note that arrows lead from both sets of covariates to X and Y indicating Z and CV are causally prior to X and Y at the bottom left of Figure 1. Both δOster and δCorrelation are defined by the ratio of selection on unobservables (CV) to selection on observables (Z). But δOster is conceived through a two-stage approach, ultimately expressing selection into the treatment (X) through λ and θ scaled by each set of variables’ relationships to Y (defining γ and ψ in Section 3). This creates the counterintuitive results noted by Cinelli and Hazlett (2020). In contrast, δCorrelation is a function only of scale-free correlations between X and its predicted values based on CV or Z. Selection on unobserved covariates is twice as strong as on observed covariates if PX·CV is twice as large as PX·Z. Although PX·CV and PX·Z are not directly functions of associations with Y, we will show in Supplemental Appendices A and B that, for a given correlation between X and CV, the relationship of CV to the outcome Y (PY·CV) is essentially determined by specification of Rmax. Furthermore, in Supplemental Appendix C, we verify that our correlational framework can reproduce the data generated through Oster’s two-stage process, showing how a correlation-based formulation accounts for differences in variances of covariates that motivated Oster’s (2019, pp. 189–192) formulation. The two correlations associated with the CV can be recombined through the product PX·CV PY·CV, which Frank (2000) referred to as the impact of a confounding variable. Finally, the scalar results can be generalized to multiple observed covariates as in Subsection 7.1.
Difference in conceptualizations of the coefficient of proportionality: δOster versus δCorrelation.
4.3 Initial Assumptions for Estimation
We make four assumptions for our initial derivation of an expression for Correlation to estimate δCorrelation. The first assumption simply explicates a characteristic of the unobserved covariates as confounders. The next two assumptions state stronger conditions which we relax in Section 7. The final assumption concerns the evaluation of an estimated effect relative to an absolute threshold rather one based on sampling variability, which we also relax in Section 7.
The first assumption is that . That is, that the unobserved covariates add explanatory power to Y after residualizing on Z. This assumption is consistent with conceptualizations of the elements in CV as omitted confounding variables that are related to Y as well as to X (Barnow, Cain & Goldberger, 1980; Frank, 2000; Oster, 2019). Implied by is that > 0 (at least some variance in Y is not explained by Z). This assumption is required for the general calculation of Correlation to yield real numbers (Supplemental Appendix A) as well as to establish that the relationship between Correlation and is continuous and strictly negatively monotonic (Supplemental Appendix D).
Second, in initial derivations, we treat CV as a single covariate, CV. Like any variable in a model, the CV may be a weighted combination of variables. Moreover, in Subsection 7.1, we show that using a single CV defined as an index of multiple unobserved covariates weighted by their relative contributions to the outcome (W2) is conservative in terms of avoiding overstating the robustness of the inference, protecting the null hypothesis of zero effect.
Third, we assume CV is orthogonal to the elements in Z, expressed as RCV·Z = 0 (see Oster, 2019, p. 192). Intuitively, if RCV·Z ≠ 0, then some of the impact of the unobserved covariate CV on the estimate of β1 would be accounted for by the observed covariates in Z, weakening the challenge to the inference based on omission of the CV (Frank, 2000). In the empirical example, the relationship between Low birthweight and preterm (X) on IQ (Y) might be challenged based on an unobserved covariate of caloric intake (CV—Kramer, 1987). But the challenge is weaker if caloric intake is already partly accounted for by measured covariates including income and education (Z). Following Mauro’s (1990, p. 316) intuition: “clearly, the effect of omitting CV on the regression coefficient of the primary predictor (X) is much greater when the correlation between the omitted variable and the covariates is small.” In Subsection 7.2, we show that assuming RCV·Z = 0 is generally conservative in terms of protecting the null hypothesis.
Fourth, in initial derivations, we assume that the threshold for inference, β#, is specified independent of statistical inference based on a standard error. In Subsection 7.3, we leverage our correlational framework to develop expressions for rX·CV|Z and rY·CV|Z required to nullify the statistical inference for β1, accounting for the change in standard error as well as in the estimated effect if an unobserved covariate were added to a model.
4.4 Estimation of δCorrelation
Oster’s (2019) expression in Equation 4 for based on solving three equations for three unknowns exhibits a non-monotonic relationship between and the corresponding estimate of as critiqued by Masten and Poirier (2022). We address this critique by deriving expressions for the COP that satisfy two fundamental relations:
The relation in Equation 6a, defines a threshold for an inference, β#, such that an inference based on the intermediate regression in Equation 2b is invalid if in Equation 2c is less than or equal to β#. The relation in Equation 6b indicates that the total variance in Y explained by X, Z, and CV in Equation 2c has a maximum value that may be less than one: = Rmax, Rmax < 1 (this includes Altonji et al.’s, 2005, special case of Rmax = 1). The relationships in Equation 6 thus represent Oster’s (2019, p. 198) goal to identify “…the value of δ [COP] that would produce β = 0 [β# = 0] under the assumed Rmax….”
Proposition 1. Define
Under this definition, . That is, that is a consistent estimator of δCorrelation.
Proof. As in Supplemental Appendix A, we first use the Frisch–Waugh–Lovell (Frisch & Waugh, 1933; Lovell, 1963) decomposition to condition all terms in Equation 2c on Z. We then express the two relations in Equation 6 for and as functions of two unknowns associated with the unobserved confounding variable CV:. Solving the two equations for two unknowns yields an expression for that we then use to obtain based on Supplemental Appendix B (under the assumption that the observed and unobserved covariates are orthogonal, which is relaxed in Subsection 7.2). Then is obtained by dividing by the sample quantity . Given the properties of OLS estimates (e.g., Johnson & Wichern, 2002, p. 151), and ; therefore, .
The expression in Equation 7 shows the relationship between Correlation and Rmax (the targeted value of ). Specifically, the larger the value of Rmax the smaller the Correlation and the less the selection on the unobserved covariate (rX·CV) relative to on observed covariates (RX·Z) required to nullify the inference regarding β1. In the birthweight example, the larger the expected final variance in IQ that could be explained by observed and unobserved covariates, the less the relative selection into Low birthweight and preterm on the unobserved covariate necessary to nullify the estimated effect on IQ. Correspondingly, the larger the value of Rmax, the less robust the inference regarding β1. This implies that specifying Rmax < 1 may allow interpreters of an inference to identify when there may be enough evidence to act pragmatically even if all is not, or cannot be, known about a phenomenon (Frank et al., 2023, Holland, 1986).
We have already shown how the definition of δCorrelation addresses Cinelli and Hazlett’s (2020) critique of δOster by expressing the COP in terms of scale-free correlations. The expression for Correlation in Equation 7 then addresses Masten and Poirier’s (2022) critique of Oster (2019) because Correlation is a continuous and monotonic (quadratic) function of assuming (Supplemental Appendix D). That is, the values of Correlation associated with the smallest possible difference between and creating a sign change are adjacent to the values that reduce to zero. Therefore, someone seeking to change the sign of the estimated effect would have a similar sense of the robustness as someone seeking to nullify the estimated effect.
Note that our calculation of Correlation depends only on the specified values of Rmax and β#, the sample correlations rX·Y|Z, RX·Z, and RY·Z, as well as the sample ratio (for β# = 0, is not needed). That is, unlike , our COP Correlation does not depend on an analyst’s subjective choice of baseline model. As we show in the empirical example and simulations below, and the corresponding interpretation of an inference can be highly sensitive to the choice of baseline model, a point we return to in Subsection 8.1.3.
4.5 Verification of Correlation Through Simulation
In Supplemental Appendix E, we use simulated data to verify the set of expressions for rX·CV|Z and rY·CV|Z (used to generate Correlation) in scenarios in which the exact results are known across 36 scenarios generated by varying values of β#, (), , and ( or Oster’s Rmax). For results, all the calculated values of were within .001 of the specified β# and the calculated values of were all within .001 of the specified values of Rmax using the Lavaan procedure in R (used for generating OLS estimates of linear models from covariance matrices—Rosseel, 2012). The results were even more accurate if we calculated and using direct function based on Supplemental Appendix A. Thus, the results in Supplemental Appendix E verify the closed form expressions for rX·CV|Z and rY·CV|Z to produce the specified values of β# and Rmax in Equations 6a and 6b.
The full set of simulation results in Supplemental Table E1 help us interpret the expression for Correlation in Equation 7. Confirming our interpretation of Equation 7, the smaller the Rmax, the larger the value of Correlation. Inferences may be interpreted as more robust when not all of the variance in an outcome can be explained. Furthermore, although Equation 7 is not a direct function of , Table E1 reveals that the greater the difference between and β#, the larger the value of Correlation, reflective of the stronger covariate necessary to nullify the inference when far exceeds the threshold for inference (β#).
5. Application of δCorrelation: Estimated Effect of Low Birthweight and Preterm Status on IQ
In this section, we apply our correlation-based framework to the example of the effect of Low Birthweight and Preterm Status on IQ,4 and we recover the correlations that combine through their product to define the impact of the of the unobserved covariate on the estimated effect.
5.1 Calculation of Correlation
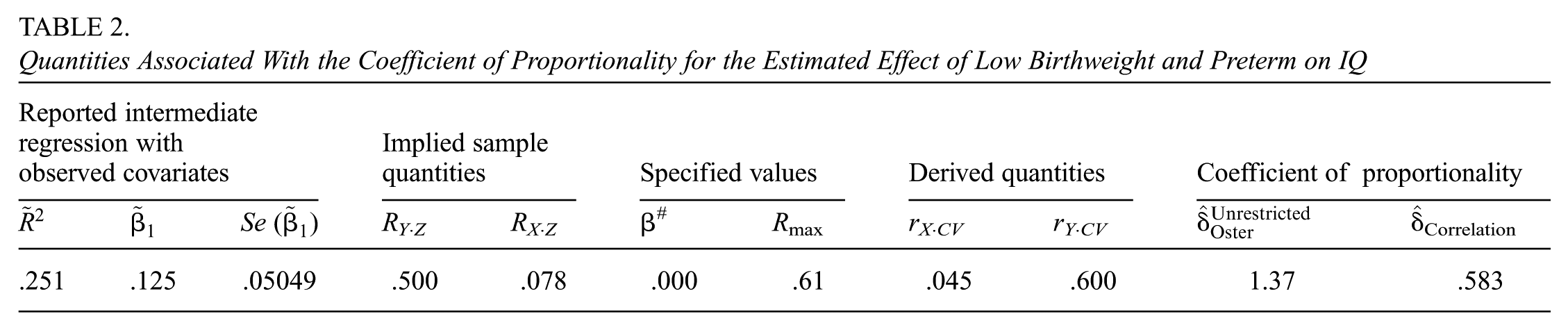
We calculate Correlation for the running example of the estimated effect of Low birthweight and preterm on IQ based on conventionally reported quantities in Oster (2019). We also show how the relations defined in Equation 6 are satisfied through the dual components of the CV—the correlation with X and the correlation with Y (corresponding commands and output for the Konfound packages in Stata and R are provided in Supplemental Appendix F). In Supplemental Appendix G, we calculate: based on Oster’s reported quantities of =.05049 (italicized digits inferred—see Supplemental Appendix G), = .251, , , and df = 6,165. Then from Equation 7, for the specified β# = 0:
The correlation between an unobserved covariate and Low birthweight and preterm would have to be about 58% that of the very modest multiple correlation associated with the observed covariates (RX·Z = .078) to nullify the estimated effect of Low birthweight and preterm on IQ for specified Rmax = .61. We note this result is obtained under the assumption that the unobserved covariates are orthogonal to the observed covariates (RCV·Z = 0). But in Supplemental Appendix H, we show that for Correlation < 1 as in this example, there is no value of RCV·Z that would make Correlation smaller; Correlation = .583 is a conservative expression of the robustness of the inference. A summary of reported, implied, specified, and derived quantities as well as the COPs is provided in Table 2.
Quantities Associated With the Coefficient of Proportionality for the Estimated Effect of Low Birthweight and Preterm on IQ
Reported intermediate regression with observed covariates
Implied sample quantities
Specified values
Derived quantities
Coefficient of proportionality
Se ()
RY·Z
RX·Z
β#
Rmax
rX·CV
rY·CV
Correlation
.251
.125
.05049
.500
.078
.000
.61
.045
.600
1.37
.583
5.2 Recovery of rX·CV and rY·CV Defining the Impact of the Confounding Variable
To better interpret the two components of confounding in the empirical example, we recover rX·CV and rY·CV from Correlation. First, from Equation 7, . Then, for = β# = 0 model (Equation 2b) reduces to . Therefore, all the variance explained in Y|Z is due to CV|Z and:5
The dual components relating the confounder to the outcome as well as the focal predictor can then be reintegrated through the product: rX·CV rY·CV, which Frank (2000) referred to as the impact of a confounding variable. In the example, impact = rX·CVrY·CV = .045 × .600 = .027. The product rX·CVrY·CV represents the dual aspect of confounding as each component is important in proportion to the size of the other—the strength of the covariates’ relationship to X (rX·CV) is important to the extent that the covariates are related to Y (rY·CV) and vice versa.6 Correspondingly, products are key to OLS adjustments for covariates (see Equation 8 below as in Cohen & Cohen, 1983, pp. 84–85) and similar products have been used for sensitivity analyses using propensity scores (Hirano & Imbens, 2001; Hong, Yang & Qin, 2021), mediation (Imai, Keele & Yamamoto, 2010), and linear models (Cinelli & Hazlett, 2020). Finally, following the intuition of a COP, the product rX·CV rY·CV can be benchmarked against observed covariates as in Equation 1 or Equation 5 by comparing how large rX·CV rY·CV must be relative to RX·ZRY·Z to nullify an inference (see Lonati & Wulff, 2024, for careful consideration of the use of such benchmarks). In the empirical example, RX·ZRY·Z = .078 × .500 = .039. Therefore, the impact of the unobserved covariate would have to be about 70% (.027/.039 = .699) that of the observed covariates to nullify the estimated effect of Low birthweight and preterm while generating a final R2 in Equation 2c model of .61. This assessment of the robustness based on impact is similar to the level of robustness represented by Correlation = .583.
6. Differences Between and Correlation
In this section, we evaluate the difference between and Correlation in both the empirical example, and in the multiple simulated scenarios we used to verify Correlation. The results show clearly discernable and meaningful differences between the two that would affect interpretations and inferences.
6.1 Example of Estimated Effect of Preterm and Low Birthweight on IQ
Note that Correlation = .583 is less than half the value of = 1.37, as reported by Oster (2019). That is, the COP based on the scale-free correlational framework suggests that the estimated effect could be nullified even if selection on the unobserved covariate were only 58% of that on the observed covariates. In contrast, = 1.37 implies that selection on the unobserved covariate would have to be more than one-third greater than selection on the observed covariates to nullify the estimated effect. These are markedly different assessments, falling on either side of Oster’s (2019, p. 191) threshold of one for determining whether an inference is robust.7 Furthermore, we evaluate the difference between and Correlation relative to the sampling variability in Correlation. Specifically,
That is, the difference between and Correlation is more than four times the standard error of Correlation. Ultimately, the differences in conceptualization and calculations between and Correlation have implications for the scientific understanding of the effects of Low birthweight and preterm on IQ and corresponding policy.
We consider four explanations for the difference between of 1.37 and Correlation of .583. The first may be that Correlation is too small because = .050 was assumed rounded from .05049. We consider this unlikely: Setting to something smaller than .05049 would reduce RX·Z below .078, questioning the quality of the observed covariates in representing the selection process. For example, setting would be consistent with Oster’s reported = 1.37 based on Equation 4. But the corresponding RX·Z would be .050 with the observed covariates explaining less than three-tenths of a percent of the variance in X. Furthermore, even for , Correlation = .908, which is still less than one, and one-third smaller than of 1.37.
The second explanation for the difference between and Correlation is that, in our notation, compares rX·CV|Z (conditional) to RX·Z (unconditional)—see Diegert et al. (2022)—whereas Correlation compares rX·CV (unconditional) to RX·Z (unconditional). But note that rX·CV (unconditional) = 0.04535913, while rX·CV|Z (conditional) = 0.0454969 (expressed to eight digits). Using rX·CV|Z instead of rX·CV would produce Correlation = .585 instead of Correlation = .583, which is not a meaningful change and would lead to the same substantive comparison with .
A third, strong, explanation for the difference between and Correlation is that is sensitive to the choice of baseline model. Oster’s (2019) estimate of = −.188 was from a baseline model (Equation 2a) that included two covariates (child is female and age). Instead, we may estimate for a model with no covariates under the assumption that the strength of child is female relative to age in predicting Low birthweight and preterm is proportional to the relative strength of child is female in predicting IQ (leveraging the result in Subsection 7.1 on multiple unobserved covariates).9 Using this assumption, in Supplemental Appendix I, we obtain: . Correspondingly, from Equation 4, = .487, much closer to the correlation based Correlation = .583.10 Thus, in this empirical example, the dynamic is strongly affected by the choice of baseline model in contrast to the static correlation-based Correlation, which does not depend on the baseline model.
The last explanation for the difference between and Correlation is that the two are defined on different scales as in Equation 1 for and Equation 5 for Correlation. To investigate the importance of scale, in the next subsection, we compare and Correlation in the simulated scenarios of Subsection 4.5 (which also include different choices of baseline model and which are not dependent on rounding in reported quantities).
6.2 Comparison of and Correlation Through Simulation
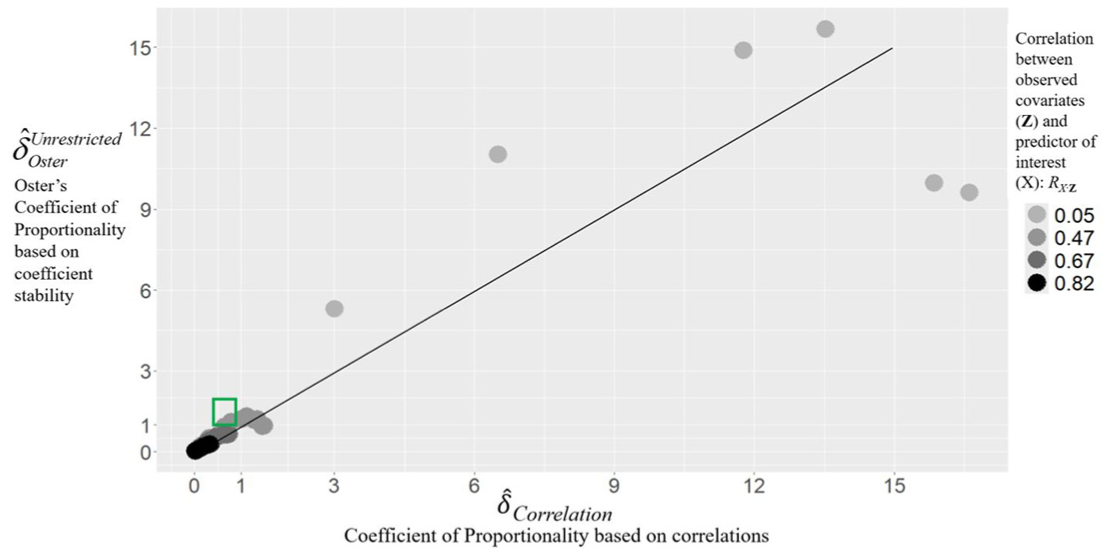
To calculate in the simulated scenarios of Subsection 4.5, we use an unconditional baseline model for which = rX·Y (σY/σX) with and .
Given the values of , , and , and the other simulated values, we calculated based on Equation 4. This allows us to graphically compare with Correlation as in Figure 2. There is high agreement; the two are correlated at .902. But the difference in scales between and Correlation is consequential. About 89% (32/36) of the points are above the 45-degree line, implying characterizes the inference as more robust (less conservative) than Correlation. Specifically, in the green box, > 1 > Correlation (as in the running empirical example). In these scenarios, one would infer from that the inference regarding β1 is robust using Oster’s (2019, p. 191) threshold of equal selection but not so from Correlation.
Coefficient of Proportionality based on coefficient stability versus correlations.
As in the empirical example, we leverage sampling variability in Correlation as a function of rX·CV to evaluate the difference between and Correlation. As reported in Supplemental Table E1, the difference between and Correlation is more than twice the standard error of Correlation in more than 80% (30/36) of the scenarios (i.e., in 22 scenarios, the difference is more than four times the standard error of Correlation); the differences between and Correlation are clearly discernable.
Examination of the results in Supplemental Table E1, sorted by , shows that in general, and Correlation are least in agreement when Rmax is small. Specifically, the four smallest (negative) values and four largest (positive) differences occur for Rmax < .5. Although one important insight from Oster (2019) is that one may not be able to explain all of the variance in Y even if one had access to every conceivable covariate, this logic can be taken too far in calculating , which is highly responsive to small values of Rmax.
In an alternative set of scenarios, we added .1 to rX·Y thereby increasing the change in estimated effect between the baseline (Equation 2a) and intermediate (Equation 2b) models but decreasing the change in R2 between the two. In these alternative scenarios, and Correlation were correlated only at .60. Thus, the difference between and Correlation appears to be due to the extreme responsiveness to coefficient instability relative to change in R2 inherent in Oster’s (2019) conceptualization of the COP. Note Se() > Se(Correlation) because is a function of 1 and in Equation 2a in addition to the terms in Equation 2b.
7. Revisiting Assumptions for Correlation
In this section, we revisit our initial assumptions made in Subsection 4.3 to support a more general application of the COP. Specifically, we evaluate the assumption that the there is only a single unobserved covariate, the unobserved covariate is orthogonal to observed covariates, and that the threshold is specified as absolute without regard to sampling variability.
7.1 Multiple Unobserved Covariates
Oster (2019, pp. 191–192) represented unobserved covariates with a single index, W2, the predicted value of Y based on all the unobserved covariates. Correspondingly, for initial derivation, we assumed a single unobserved covariate, CV. This allowed us to express the conditions necessary to generate a specified value of (β#) and maximum (Rmax) in model (Equation 2c) in terms of rX·CV|Z and rY·CV|Z.
Our initial derivations can be directly extended to multiple unobserved covariates CV by drawing on Knaeble and Dutter (2017) and Knaeble et al.’s (2020) expression for statistical control based on multiple covariates. Applying the result to in Equation 2c yields (leveraging the Frisch–Waugh–Lovell decomposition to condition on Z):
where is the correlation between (the predicted value from regressing X on the elements in CV conditioned on Z) and (the predicted value from regressing Y on the elements in CV conditioned on Z), with −1 < < 1.
Although is not observed, we can leverage Equation 8 to show that our expression for Correlation in Equation 7 as a function of a single covariate is conservative. For β# = 0, the numerator in Equation 8 must equal 0 (assuming ) and therefore . Correspondingly, the minimum value of RX·CV|ZRY·CV|Z occurs for = 1. When = 1 (in which case ), the regression weights using the elements in CV to predict X are proportional to those when predicting Y. As a result, RX·CV|ZRY·CV|Z can be represented by a single CV* based on the predicted value of X or Y. Equation 8 can then be rewritten replacing RX·CV|ZRY·CV|Z with rX·CV*|ZrY·CV*|Z. Furthermore, for β# = 0, rY·CV*|Z is completely determined by Rmax and RY·Z (see Subsection 5.2). As a result, for , rX·CV*|Z would have to be greater than RX·CV|Z to satisfy Equation 8, making Correlation larger. Therefore, for β# = 0 assuming a single CV represented by CV* is conservative in the sense of producing a small value of Correlation, protecting a null hypothesis of zero effect.
For β# < 0 (implying a sign change in the estimate of β1 from Equations 2b to 2c for rX·Y|Z > 0), solving Equation 8 for yields
Note that is monotonic and decreasing in for β# < 0. Therefore, the minimum RX·CV|Z for flipping the sign of also occurs for = 1.11,12 The result can be extended to the assumption of non-orthogonality in the next subsection because Knaeble and Dutter’s (2017) expression applies to the numerator for the partial correlation in Supplemental Appendix H (Equation H1).
7.2 Unobserved Covariate is Not Orthogonal to Observed Covariates
Oster (2019, p. 192) assumed the unobserved covariate (W2) is orthogonal to the observed covariates (W1). In our notation, this implies RCV·Z = 0 (for similar assumptions, see Altonji et al., 2005, p. 169; Cinelli & Hazlett, 2020, p. 53; Frank, 2000, p. 165; Ichino et al., 2008, p. 316). The assumption that RCV·Z = 0 is necessary to obtain rX·CV from rX·CV|Z and therefore Correlation in Equation 7.
In Supplemental Appendix H, we show for a single observed covariate the assumption rCV·Z = 0 is always conservative (in the sense of minimizing Correlation) for Correlation < 1. For Correlation > 1, the results in Supplemental Appendix H also show that rCV·Z = 0 is conservative except in the extreme of our simulated scenarios (reported in Supplemental Appendix E) in which rX·Z < .05 (the observed covariate explains a small amount of variation in X) or rCV·Z > .92 (observed covariate essentially subsumes the unobserved covariate). Thus, assuming rCV·Z = 0 will typically lead to a conservative interpretation of the inference, in the sense of making it more difficult to overturn the null hypothesis of no effect. In Supplemental Appendix E, we also report Max(rCV·Z), the maximum value of rCV·Z for which Correlation is a minimum, and thus conservative. The result can be adapted for multiple observed covariates via Subsection 7.1.
7.3 Threshold Based on Statistical Significance, Statsig
Although Equation 7 is expressed for any specified threshold β#, separate expressions are necessary to calculate the conditions necessary to nullify a statistical inference (e.g., associated with p < .05) regarding β1. This is because statistical significance is typically a function of the standard error for which would change with the inclusion of omitted covariates. To develop an expression based on statistical significance, in Supplemental Appendix J (including application to the empirical example and R code) we define and solve two equations for = Rmax and rX·Y|Z = rcritical (the value of a partial correlation associated with p = .05) for the two unknowns rX·CV and rY·CV, leveraging the fact that the p-value for a partial correlation equals that for the corresponding regression coefficient (Cohen & Cohen, 1983). Ultimately, this generates an expression for Statsig that accounts for sampling variability, one of the most commonly used thresholds for inference (Frank et al., 2023).13
We apply the result in Supplemental Appendix J to the inference regarding the effect of Low birthweight and preterm on IQ. For Oster’s (2019) specified Rmax = .61 and given the other quantities reported by Oster, the partial correlations of rX·CV|Z = .0195 and rY·CV|Z = .6928 would generate , , with associated with p = .05 for df = 6,165. Concurrently, rX·CV|Z = .0195 and rY·CV|Z = .6928 generate corresponding to as in Oster’s specification (see Section 5 and Supplemental Appendix E). Note that the standard error of .0364 for this calculation is smaller than the standard error of 0.050 Oster reported for the observed data. In this sense, the expressions in Supplemental Appendix J account for how the standard error would change if unobserved covariates were added to the model. To calculate the corresponding Statsig, we first calculate (drawing on Supplemental Appendix B, with extra digits to dif-ferentiate rX·CV from rX·CV|Z). Then for RX·Z = .078, Because the threshold for rejecting a null hypothesis of zero effect as greater than zero, Statsig of .249 required to reduce the estimated effect below the threshold for statistical significance is less than Correlation of .583 required to reduce the effect to zero. That is, Statsig will typically be more conservative (smaller) than Correlation.
8. Discussion
Beginning with the effects of smoking on lung cancer (Cornfield et al., 1959), sensitivity analyses have shaped debates about causal inferences that can inform policy or practice. In this article, we contributed to the development of the COP which expresses sensitivity in terms of how strong selection on unobserved covariates must be relative to that on observed covariates to nullify an inference (Altonji et al., 2005). Specifically, we have built directly on Oster’s (2019) contributions to the COP in specifying a maximum variance explained if all conceivable covariates were included in a linear model. But we have extended Oster’s application of the COP by reconceptualizing it within a correlational framework. Thus, we wrote, “the correlation between an unobserved covariate and Low birthweight and preterm [rX·CV] would have to be about 58% that of the very modest multiple correlation associated with the observed covariates (RX·Z = .078) to nullify the estimated effect of Low birthweight and preterm on IQ.” The second component of confounding, the relationship of the unobserved covariate to the outcome, is then expressed through a separate correlation (rY·CV) that generates a final specified R2 (e.g., R2=.61 in the empirical example). Importantly, we showed how the dual components of confounding can then be incorporated through the product, rX·CVrY·CV, defining the impact of a confounding variable (Frank, 2000).
Our reconceptualization of the COP addresses the critiques (e.g., Cinelli & Hazlett, 2020; Diegert et al., 2022; Masten & Poirier, 2022) of Oster (2019) because it is expressed in terms of scale-free correlations and establishes a continuous monotonic relationship between the COP and the estimated effect of the focal predictor. Furthermore, because our COP is rooted in static correlations, our expressions do not depend on an analyst’s specification of a baseline model, are adapted to a threshold for inference based on statistical significance, and can be directly calculated from conventionally reported quantities (e.g., estimated effect, standard error). Furthermore, the assumptions we have made (there is a single unobserved covariate; the unobserved covariates are uncorrelated with the observed covariates) are conservative in terms of protecting the null hypothesis. Finally, using the Konfound package in Stata or R (or the R-shiny app: https://konfound-project.shinyapps.io/konfound-it/), our COP index can be easily applied and intuitively interpreted for most published studies in the social sciences.
8.1 Recommended Practices
8.1.1 Carefully Examine Extent of Selection on Observed Covariates
A by-product of our conceptualization of the COP in terms of correlations is a preliminary calculation of the multiple correlation between the focal predictor and observed covariates (RX·Z). Although covariates can gain impact strength through their relationship to the outcome (Frank, 2000), a small value of RX·Z partly undermines the claim that strong covariates were already accounted for and therefore conservatively represent selection on unobserved covariates (e.g., Altonji et al., 2005, pp. 176–177; Oster, 2019, pp. 195–196). The value of RX·Z = .078 in the empirical example suggests modest selection on the observed covariates at best. Because RX·Z appears in the denominator of our COP in Equation 7, we especially caution against over-interpretation of the COP when RX·Z < .05 (and ). In such cases, one might simply report the correlations associated with the unobserved covariate necessary to produce the specified estimated effect and R2 without expressing as a ratio to the limited selection on observed covariates.
8.1.2 Consider a Minimum Value of the Maximum R2
One of Oster’s (2019) key contributions is to consider a limit on the explanatory power of a model even if all conceivable covariates were observed and included. In deriving our expression for Correlation, we adopted Oster’s (2019) emphasis on realistic expectations for variance explained in terms of or Rmax. Specifically, Oster (2019, p. 201) established a guideline based on the finding that most (97%) inferences from the randomized studies analyzed would have been sustained for , the variance explained in the outcome by the focal predictor (X) and the observed covariates (Z). While Oster’s logic and empirical validation are sound, we note that small values of could generate unrealistically small values of Rmax, leading the robustness of the inference to be overstated (the smaller the value of Rmax, the larger the COP indicating a more robust inference). As a guideline, one might consider an absolute minimum Rmax of .15, noting that in our simulations performed poorest for Rmax < .15. Moreover, it seems reasonable that one should be able to explain at least 15% of the variation in an outcome if all conceivable covariates could be observed and included in a model.
8.1.3 Specification of the Baseline Model
Oster proved the consistency of using null baseline models including no covariates as in Equation 2a. The proof applies to from baseline models that include covariates only if changes in estimated effects and R2 when observed covariates are added to a non-null baseline model are proportional to changes relative to a null baseline model (see Section 2.1). This seems unlikely and an added strong assumption to evaluate.
Opportunity to exploit the baseline model is greater for the COP index than for conventional model specifications because it is not clear what should be included in the baseline model. Oster (2019) did not include baseline covariates in the derivation of the COP but included what some may consider essential covariates in baseline models in empirical examples. In the running empirical example in this article, choosing an unconditional baseline model produced = .487 versus = 1.37 using a baseline model with two covariates (mother age and child female); the choice of baseline model had a marked effect on the interpretation of the robustness of the inference. In applications of Oster’s COP, Paredes (2022, footnote 41) controlled for gender and an indicator for coeducational schools at baseline; Edmunds et al. (2024, Supplemental Materials) cited Altoni et al. (2005) to include only “essential or parsimonious” controls at baseline, but Marcotte (2019, Table 2 column 4) controlled for a more extensive set of covariates. Redding and Grissom (2021) included fixed effects for students, although Oster (2019) did not. Because the different specifications can affect the stability of the estimated focal effect as well as the R2 (e.g., fixed effects can dramatically increase R2), the direction and magnitude of bias in the estimation of δOster based on these choices is unclear.
8.1.4 Interpretation of the COP
In general, we avoid specific cut-offs for sensitivity indices (Frank et al., 2023; Frank et al., 2025) because the indices are intended to inform dialog regarding the strength of evidence relative to study design and controls. If an absolute threshold were pre-specified (e.g., Correlation > 1), a COP value exceeding that threshold could preempt dialog even for studies with weak designs (e.g., studies in which observed covariates are poorly theorized, defined, or measured). Note that unlike other indices, the COP already has the advantage of being defined relative to a benchmark of observed covariates, facilitating an intuitive interpretation based on existing knowledge of a phenomenon. We do also encourage interpreters of inferences to carefully consider the threshold they choose for making an inference, noting that using statistical significance as a threshold will typically be more conservative in terms of protecting the null hypothesis than using a threshold of zero.
9. Conclusion
Even if one follows all recommended practices and uses a baseline model with no covariates, other critiques of Oster (2019) still apply. Cinelli and Hazlett’s critique based on the scaling of δOster and Masten and Poirier’s (2022) critique based on the non-monotonic and discontinuous relationship between and the corresponding estimated effect are difficult to resolve within Oster’s framework. Because the correlational framework is not vulnerable to the same critiques, can correspond with the two stage regression data generation, does not depend on the specification of the baseline model, and is expressed in terms of the OLS calculations conventionally applied to model (Equation 2c), it is difficult for us to imagine a scenario in which Oster’s would be preferred to Correlation as presented here.
Ultimately, like Cornfield et al. (1959), our intent is to inform causal inferences from nonexperimental studies. But we emphasize sensitivity analyses do not, in and of themselves, establish the quality of a model or change an inference. Sensitivity analyses should only be applied after one has maximally leveraged the data and design to estimate the best model possible. What sensitivity analyses can then do is formalize and quantify the hypothetical conditions necessary to nullify an estimated effect to inform debate and corresponding policy based on the strength of evidence. Thus, we re-express the COP based on selection into the treatment in terms of correlations associated with observed and unobserved covariates to make it accessible to as broad a set of stakeholders as possible.
Supplemental Material
sj-pdf-1-jeb-10.3102_10769986261422704 – Supplemental material for Quantifying Sensitivity to Selection on Unobserved Covariates: Recasting the Coefficient of Proportionality Within a Correlational Framework
Supplemental material, sj-pdf-1-jeb-10.3102_10769986261422704 for Quantifying Sensitivity to Selection on Unobserved Covariates: Recasting the Coefficient of Proportionality Within a Correlational Framework by Kenneth A. Frank, Qinyun Lin, Spiro Maroulis, Shimeng Dai, Jihoon Choi, Nicole Jess, Hung-Chang Lin, Yuqing Liu, Sarah Maestrales, Ellen Searle and Jordan Tait in Journal of Educational and Behavioral Statistics
Footnotes
Acknowledgements
The authors acknowledge Brian Knaeble for his thoughtful comments on earlier drafts of this manuscript.
Authors’ Note
This article was presented on August 6, 2025 at the Joint Statistical Meetings, Nashville TN.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by U.S. Department of Education Institute for Education Sciences through R305D220022 to Michigan State University. The opinions expressed are those of the authors and do not represent views of the Institute for education Sciences or the U.S. Department of Education.
ORCID iD
Kenneth A. Frank
Supplemental Material
Supplemental material for this article is available online.
Notes
Authors
KENNETH A. FRANK is MSU Research Foundation Distinguished Professor of Sociometrics at Michigan State University. His methodological interests in sensitivity analysis (), causal inference, and social network analysis are driven by his substantive interests in how people draw on their networks to make collective decisions (in organizations and communities).
QINYUN LIN is a Senior Lecturer in Health Science Statistics at the School of Public Health and Community Medicine, University of Gothenburg, Sweden. Her research focuses on causal inference, spatial epidemiology, and sensitivity analysis, with applications to health and educational inequities and the social and contextual factors shaping population outcomes.
SPIRO MAROULIS is Professor and Director of the Martin School of Public Policy and Administration at the University of Kentucky. He is a computational social scientist with a particular focus on public policy and management, innovation, social networks, and causal inference.
SHIMENG DAI is a research associate and project manager at Michigan State University. She received her PhD in Measurement and Quantitative Methods from Michigan State University. Her research focuses on computational social science, STEM education, randomized controlled trials, social network analysis, and natural language processing.
JIHOON CHOI is a PhD student in the Measurement and Quantitative Methods program at Michigan State University. His research interests are in causal inference, with a methodological focus on sensitivity analysis for observational studies and empirical applications to postsecondary educational effectiveness.
NICOLE JESS is a Statistician at Michigan Fitness Foundation, where she conducts program evaluation and research in public health and community settings. She specializes in survey development, latent variable modeling, and quasi-experimental designs, with a focus on supporting evidence-based decision making.
HUNG-CHANG LIN recently received his PhD in Strategic Management from Michigan State University. His research examines the role of language and emotion in markets, particularly investor evaluations of executive communication, with broader methodological interests in natural language processing.
YUQING LIU is a postdoctoral researcher on the Urban-Rural Dialogue project in the Department of Community Sustainability at Michigan State University. Her research includes survey development, program evaluation, and social network analysis of dialogues about urban-rural identities, aiming to improve identity awareness, relationships across differences, bias interruption, and equity-oriented action
SARAH MAESTRALES, Ph.D. (Michigan State University), consults with EdTech startups and educational organizations on AI integration, data workflows, and evaluation practices. Her current work examines how statistical modeling and measurement methods can be used to improve the efficiency, evaluation, and implementation of GenAI systems in educational and applied research settings.
ELLEN SEARLE has a Master’s in Psychology from Michigan State University and is currently pursuing a master’s in data science from the University of Pittsburgh for training that can be applied across the social sciences as well as sport.
JORDAN TAIT (PhD Michigan State University) is an Assistant Teaching Professor in the Information Systems and Analytics Department in the Farmer School of Business at Miami University Oxford, Ohio. In this role, he coordinates Business Statistics. His research interests include sensitivity analysis, social network analysis and students’ self-efficacy.
References
1.
AlbergA. J.ShoplandD. R.CummingsK. M. (2014). The 2014 Surgeon General’s report: Commemorating the 50th Anniversary of the 1964 Report of the Advisory Committee to the US Surgeon General and updating the evidence on the health consequences of cigarette smoking. American Journal of Epidemiology, 179(4), 403–412.
2.
AltonjiJ. G.ElderT. E.TaberC. R. (2005). Selection on observed and unobserved variables: Assessing the effectiveness of Catholic schools. Journal of Political Economy, 113(1), 151–184.
3.
BarnowB. S.CainG. G.GoldbergerA. S. (1980). Issues in the analysis of selectivity bias (Vol. 4). University of Wisconsin, Inst. for Research on Poverty.
4.
BasuD. (2023). A critical assessment of a popular econometric method for sensitivity analysis. Available at SSRN 4540836.
5.
BerridgeV. (2006). The policy response to the smoking and lung cancer connection in the 1950s and 1960s. The Historical Journal, 49(4), 1185–1209.
6.
BonettD. G. (2008). Meta-analytic interval estimation for bivariate correlations. Psychological Methods, 13(3), 173–181. https://doi.org/10.1037/a0012868
7.
BreslauN.DelDottoJ. E.BrownG. G.KumarS.EzhuthachanS.HufnagleK. G.PetersonE. L. (1994). A gradient relationship between low birth weight and IQ at age 6 years. Archives of Pediatrics & Adolescent Medicine, 148(4), 377–383.
8.
CarnegieN. B.HaradaM.HillJ. L. (2016). Assessing sensitivity to unmeasured confounding using a simulated potential confounder. Journal of Research on Educational Effectiveness, 9(3), 395–420.
9.
CinelliC.HazlettC. (2020). Making sense of sensitivity: Extending omitted variable bias. Journal of the Royal Statistical Society: Series B, 82(1), 39–67.
10.
CohenJ.CohenP. (1983). Applied multiple regression. Correlation Analysis for the Behavioral Sciences. Lawrence Erlbaum.
11.
CornfieldJ.HaenszelW.HammondE. C.LilienfeldA. M.ShimkinM. B.WynderE. L. (1959). Smoking and lung cancer: Recent evidence and a discussion of some questions. Journal of the National Cancer Institute, 22(1), 173–203.
12.
DiegertP.MastenM. A.PoirierA. (2022). Assessing omitted variable bias when the controls are endogenous. arXiv. arXiv preprint arXiv:2206.02303.
13.
EdmundsJ. A.UnluF.FureyJ.GlennieE.ArshavskyN. (2020). What happens when you combine high school and college? The impact of the early college model on postsecondary performance and completion. Educational Evaluation and Policy Analysis, 42(2), 257–278.
14.
EdmundsJ. A.UnluF.PhillipsB.MulhernC.HutchinsB. C. (2024). CTE-focused dual enrollment: Participation and outcomes. Education Finance and Policy, 19(4), 612–633.
15.
FisherR. A. (1958). Lung cancer and cigarettes?Nature, 182(4628), 108.
16.
FrankK. A. (2000). Impact of a confounding variable on the inference of a regression coefficient. Sociological Methods and Research, 29(2), 147–194.
17.
FrankK. A.LinQ.MaroulisS. J. (2025). Causal inferences from observational studies in education policy: Towards pragmatic social science. In Cohen-VogelL.ScottJ.YoungsP. (Eds.), Handbook on education policy research (pp. 479–510). The American Educational Research Association.
18.
FrankK. A.LinQ.MaroulisS.MuellerA. S.XuR.RosenbergJ. M.HayterC. S.MahmoudR. A.KolakM.DietzT.ZhangL. (2021). Hypothetical case replacement can be used to quantify the robustness of trial results. Journal of Clinical Epidemiology, 134, 150–159.
19.
FrankK. A.LinQ.XuR.MaroulisS. J.MuellerA. (2023). Quantifying the robustness of causal inferences: Sensitivity analysis for pragmatic social science. Social Science Research, 110, 102815.
20.
FrankK. A.MaroulisS.DuongM.KelceyB. (2013). What would it take to change an inference?: Using Rubin’s causal model to interpret the robustness of causal inferences. Education, Evaluation and Policy Analysis, 35, 437–460.
21.
FranksA.D’AmourA.FellerA. (2019). Flexible sensitivity analysis for observational studies without observable implications. Journal of the American Statistical Association, 115, 1730–1746.
22.
FrischR.WaughF. V. (1933). Partial time regressions as compared with individual trends. Econometrica: Journal of the Econometric Society, 1, 387–401.
23.
GastwirthJ. L.KriegerA. M.RosenbaumP. R. (1998). Dual and simultaneous sensitivity analysis for matched pairs. Biometrika, 85(4), 907–920.
24.
GrossR. T.SpikerD.HaynesC. W. (1997). Helping low birth weight, premature babies: The infant health and development program. Stanford University Press.
25.
HiranoK.ImbensG. W. (2001). Estimation of causal effects using propensity score weighting: An application to data on right heart catheterization. Health Services and Outcomes Research Methodology, 2(3), 259–278.
26.
HollandP. W. (1986). Statistics and causal inference. Journal of the American Statistical Association, 81(396), 945–960.
27.
HongG.QinX.YangF. (2018). Weighting-based sensitivity analysis in causal mediation studies. Journal of Educational and Behavioral Statistics, 43(1), 32–56.
28.
HongG.YangF.QinX. (2021). Did you conduct a sensitivity analysis? A new weighting-based approach for evaluations of the average treatment effect for the treated. Journal of the Royal Statistical Society: Series A (Statistics in Society), 184(1), 227–254.
29.
HosmanC. A.HansenB. B.HollandP. W. (2010). The sensitivity of linear regression coefficients’ confidence limits to the omission of a confounder. The Annals of Applied Statistics, 4(2), 849–870.
30.
HsuJ. Y.SmallD. S. (2013). Calibrating sensitivity analyses to observed covariates in observational studies. Biometrics, 69(4), 803–811.
31.
IchinoA.MealliF.NanniciniT. (2008). From temporary help jobs to permanent employment: What can we learn from matching estimators and their sensitivity?Journal of Applied Econometrics, 23(3), 305–327.
32.
ImaiK.KeeleL.YamamotoT. (2010). Identification, inference and sensitivity analysis for causal mediation effects. Statistical Science, 25(1), 51–71.
33.
ImbensG. (2003). Sensitivity to exogeneity assumptions in program evaluation. American Economic Review, 93(2), 126–132.
34.
JohnsonR. A.WichernD. W. (2002). Applied multivariate statistical analysis. Prentice Hall.
35.
KnaebleB.DutterS. (2017). Reversals of least-square estimates and model-invariant estimation for directions of unique effects. The American Statistician, 71(2), 97–105.
36.
KnaebleB.OstingB.AbramsonM. A. (2020). Regression analysis of unmeasured confounding. Epidemiologic Methods, 9(1), 20190028.
37.
KramerM. S. (1987). Intrauterine growth and gestational duration determinants. Pediatrics, 80(4), 502–511.
38.
LinD. Y.PsatyB. M.KronmalR. A. (1998). Assessing the sensitivity of regression results to unmeasured confounders in observational studies. Biometrics, 54, 948–963.
39.
LonatiS.WulffJ. N. (2024). Hic Sunt Dracones: On the risks of comparing the ITCV with control variable correlations. Journal of Management, 52, 0149206324 1293126.
40.
LovellM. C. (1963). Seasonal adjustment of economic time series and multiple regression analysis. Journal of the American Statistical Association, 58(304), 993–1010.
41.
MarcotteD. E. (2019). The returns to education at community colleges: New evidence from the Education Longitudinal Survey. Education Finance and Policy, 14(4), 523–547.
42.
MastenM. A.PoirierA. (2022). The effect of omitted variables on the sign of regression coefficients. arXiv. arXiv preprint arXiv:2208.00552.
43.
MauroR. (1990). Understanding LOVE (left out variables error): A method for estimating the effects of omitted variables. Psychological Bulletin, 108(2), 314.
44.
MiddletonJ. A.ScottM. A.DiakowR.HillJ. L. (2016). Bias amplification and bias unmasking. Political Analysis, 24(3), 307–323.
45.
National Research Council. (2000). From neurons to neighborhoods: The science of early childhood development. National Academies Press.
46.
OsterE. (2019). Unobservable selection and coefficient stability: Theory and evidence. Journal of Business & Economic Statistics, 37(2), 187–204.
47.
ParedesV. (2022). Mixed but not scrambled: Gender gaps in coed schools with single-sex classrooms. Journal of Research on Educational Effectiveness, 15(2), 330–366.
48.
ParkS.EsterlingK. M. (2021). Sensitivity analysis for pretreatment confounding with multiple mediators. Journal of Educational and Behavioral Statistics, 46(1), 85–108.
49.
PearlJ. (2009). Causality. Cambridge University Press.
50.
ReddingC.GrissomJ. A. (2021). Do students in gifted programs perform better? Linking gifted program participation to achievement and nonachievement outcomes. Educational Evaluation and Policy Analysis, 43, 01623737211008919.
51.
RiceJ. A. (2006). Mathematical statistics and data analysis. Cengage Learning.
52.
RobinsJ. M.RotnitzkyA.ScharfsteinD. O. (2000). Sensitivity analysis for selection bias and unmeasured confounding in missing data and causal inference models. In M. E. Halloran & D. A. Berry (Eds.), Statistical models in epidemiology, the environment, and clinical trials (pp. 1–94). Springer.
53.
RosenbaumP. R. (2002). Observational studies. Springer.
54.
RosenbaumP. R. (1986). Dropping out of high school in the United States: An observational study. Journal of Educational Statistics, 11(3), 207–224.
55.
RosenbaumP. R. (2005). Sensitivity analysis in observational studies. Encyclopedia of Statistics in Behavioral Science, 4, 1809–1814.
56.
RosenbaumP. R.RubinD. B. (1983). Assessing sensitivity to an unobserved binary covariate in an observational study with binary outcome. Journal of the Royal Statistical Society: Series B (Methodological), 45(2), 212–218.
57.
RosseelY. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48, 1–36.
58.
StrawsonP. F. (2008). Freedom and resentment and other essays. Routledge.
59.
U.S. Department of Health, Education, and Welfare. (1964). Smoking and Health: Report of the Advisory Committee to the Surgeon General of the Public Health Service. Washington, DC: US Department of Health, Education, and Welfare, Public Health Service (Public Health Service Publication No. 1103).
60.
US Public Health Service. Office of the Surgeon General, United States. Office on Smoking, Center for Chronic Disease Prevention, & Health Promotion (US). Office on Smoking. (1989). Reducing the Health Consequences of Smoking: 25 Years of Progress: A Report of the Surgeon General, Centers for Disease Control. Rockville, Maryland.
61.
VanderWeeleT. J.DingP. (2017). Sensitivity analysis in observational research: introducing the E-value. Annals of Internal Medicine, 167(4), 268–274.
62.
VeitchV.ZaveriA. (2020). Sense and sensitivity analysis: Simple post-hoc analysis of bias due to unobserved confounding. Advances in Neural Information Processing Systems, 33, 10999–11009.
63.
ZachrissonH. D.DearingE.BorgenN. T.SandsørA. M. J.KarolyL. A. (2023). Universal early childhood education and care for toddlers and achievement outcomes in middle childhood. Journal of Research on Educational Effectiveness, 17, 1–29.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.