
Abstract
The increasing demand for mobility in our society poses various challenges to traffic engineering, computer science in general, and artificial intelligence in particular. Increasing the capacity of road networks is not always possible, thus a more efficient use of the available transportation infrastructure is required. Another issue is that many problems in traffic management and control are inherently decentralized and/or require adaptation to the traffic situation. Hence, there is a close relationship to multiagent reinforcement learning. However, using reinforcement learning poses the challenge that the state space is normally large and continuous, thus it is necessary to find appropriate schemes to deal with discretization of the state space. To address these issues, a multiagent system with agents learning independently via a learning algorithm was proposed, which is based on estimating Q-values from k-nearest neighbors. In the present paper, we extend this approach and include transfer of experiences among the agents, especially when an agent does not have a good set of k experiences. We deal with traffic signal control, running experiments on a traffic network in which we vary the traffic situation along time, and compare our approach to two baselines (one involving reinforcement learning and one based on fixed times). Our results show that the extended method pays off when an agent returns to an already experienced traffic situation.
Introduction
Traffic congestion is a well investigated phenomenon in traffic engineering, having various deleterious consequences: air pollution, decrease in speed, delays, opportunity costs, etc. The increase in transportation demand can be met by providing additional capacity. However, this might not be economically or socially attainable or feasible. Thus, optimizing the use of the existing infrastructure is key. One way to accomplish this is by employing control techniques, notably the adaptive control of traffic signals. We stress that optimizing such a controller is not trivial since the problem is very constrained, given that minimum and maximum green times need to be observed, and the control policy needs to be fair to all traffic directions in order to deal with starvation.
Several approaches to adaptive control exist (see, e.g., [22] and the surveys mentioned ahead). Among them, approaches based on reinforcement learning (RL) are gaining popularity. In these approaches, learning agents are normally in charge of controlling the signals at a single intersection, in a decentralized way, i.e., each agent learns independently and without a central agent in charge of all intersections. We remark that for centralized approaches, where there is a single controller in charge of computing optimal actions for the whole set of intersections, deep learning is more popular. However, due to robustness issues (central point of failure, communication failures), it is desirable to avoid centralized solutions. Besides, centralized approaches assume a central entity in charge of the control, which needs to collect all information from all intersections, and needs to determine an action for each controller at the intersections, thus violating the autonomy of the individual controllers. To circumvent this, in this paper we deal with multiple agents (signal controllers) learning independently in a decentralized way.
One important aspect of such learning task is that traffic signal control is a highly non-local phenomenon, i.e., it is affected by actions of other agents. This is what makes multiagent RL much more challenging than single agent RL. Another challenge is the fact that the state space is very large (thus RL algorithms like Q-learning converge more slowly) and continuous (appropriately discretizing continuous states is a difficult problem).
That being said, alternatives to tackle these matters, like function approximation, come with some drawbacks. They make the learned policy harder to comprehend, and generally require that the agents gather a large amount of data to be able to successfully generalize and apply their collected experiences.
To tackle large continuous state spaces in an efficient way, in [11] we have started investigating the use of a method that avoids the usage of function approximation, while also dealing with discretization in a more effective way. For this purpose, a learning algorithm based on k-nearest neighbors (k-NN) [17,18] was used, which estimates the value of a state by calculating a weighted average of the Q-values of the k closest previously visited states. However, given that the agents may not have k good experiences, in the present paper we allow agents to transfer their experiences.
The reader can find details of the proposed method in Section 4, where it is described in a general way, as we believe the framework can be applied to several multiagent RL problems. Then, in Section 5 we discuss how to apply the method to the domain of traffic signal control. Our results are presented and discussed in Section 6. The underlying concepts used in this paper (e.g., on RL and RL-based signal control), as well as the related literature are discussed in Section 2 and Section 3, respectively. A conclusion and a discussion on future research lines appear in Section 7.
Background on traffic assignment and reinforcement learning
This section briefly presents underlying concepts on RL and on traffic signal control.
Reinforcement learning
In RL, an agent learns how to act in an environment interacting and receiving a feedback signal (reward) that measures how its action has affected the environment. The agent does not a priori know how its actions affect the environment, hence it has to learn this by trial and error (in an exploration phase). However, the agent should not only explore; in order to maximize the rewards of its action, it also has to exploit the gained knowledge. Thus, there must be an exploration-exploitation strategy that is to be followed by the agent. One of these strategies is ε-greedy, where an action is randomly chosen (exploration) with a probability ε, or, with probability 1-ε, the best known action is chosen, i.e., the one with the highest value so far (exploitation).
In the exploitation phase, it is assumed that the agent has sensors to determine its current state and can then decide on an action. The reward is then used to update its policy, i.e., a mapping from states to actions. This policy can be generated or computed in several ways.
For the sake of the present discussion, we concentrate on a model-free, off-policy algorithm called Q-learning [30], which estimates so-called Q-values using a table to store the experienced values of performing a given action when in a given state. Hence Q-learning is a tabular method, where the state space and the action space need to be discretized.
In RL, the learning task is usually formulated as a Markov decision process (MDP), that defines the sets of states and actions, a transition function, and a reward function. Since the transition and the reward functions are unknown to the agent, its task is exactly to learn them, or at least a model for them.
In Q-learning, the value of a state
When there are multiple agents interacting in a common environment, the RL task (thus, multiagent RL) is inherently more complex because agents’ actions are highly coupled and agents are trying to adapt to other agents that are also learning. Besides, several convergence guarantees no longer hold. However, in many real-world problems, where the control is decentralized, it might not be possible to avoid a multiagent RL formulation, as for instance the scenario we deal with in the present paper, namely control of traffic signals, whose basic concepts we briefly review in the next section.
Before, we mention that in systems in which learning agents are allowed to communicate, there has been some research on how to improve effectiveness and efficiency by allowing transfer of knowledge among agents in multiagent systems. While there are many ways to consider transfer learning techniques, as well as many dimensions of this task, in the present paper we deal with transfer of experiences. The interested reader is referred to [24,25] for more details on multiagent transfer learning.
RL-based traffic signal control
Besides safety and other issues, one aim of a traffic signal controller is to decide on a split of green times among the various phases that were designed to deal with geometry and flow issues at an intersection. This can be done in several ways (for more details, please see a textbook such as [22]). In this paper, the controller is given a set of phases and has to decide which one will receive green light.
A phase is defined as a group of non-conflicting movements (e.g., flow in two opposite traffic directions) that can have a green light at the same time without conflict.
In its simplest form, the control is based on fixed times, whose split of the green time among the various phases can be computed based on historical data on traffic flow, if available. The problem with this approach is that it may have difficulties adapting to changes in the traffic demand. This may lead to an increase in the number of stopped vehicles. To mitigate this problem, it is possible to use an adaptive scheme and thus give priority to lanes with longer queues (or other measures of performance). Adaptive approaches based on RL were developed, as we discuss next.
Related work
Traffic control techniques stem mainly from the areas of control theory and operations research. See for instance [21,22]. More recently though, techniques from artificial intelligence and multiagent systems have also been employed, especially in connection with RL. RL is used by traffic signals to learn a policy that maps states (usually queues at intersections) to actions. Due to the number of works that employ RL for traffic control, the reader is referred to surveys [9,16,19,31,34].
In any case, these surveys show that there has already been a significant contribution of RL techniques to control of traffic signals. However, issues of scalability and performance remain open, especially if tabular methods are used, as for instance the aforementioned Q-learning. Tabular methods require discretization of the state space. The finer such discretization is, the poorer the computational performance tends to be, since agents need to visit an increasing number of state-action pairs that are associated with the learning task at hand.
Therefore, the remaining of this section discusses alternative ways to tackle these issues, which are discussed in the literature.
A first line of research does use tabular methods, changing the level of discretization of the state space, which leads to different levels of performance of the learning task. In this class, well-known works include [6,8,12,33], among others.
A second class of works avoids using tabular methods such as Q-learning. Rather, they propose the use of function approximation. For instance, [2] uses tile coding. Recently, many studies have used deep neural networks to approximate the Q-function (e.g., DQN [29]). However, non-linear function approximation is known to diverge in multiple cases [7,26]. In order to address these shortcomings, [5] proposed the use of linear function approximation, which has guaranteed convergence and error bounds.
A third research line employs clustering methods together with some kinds of RL-based approach in order to tackle the large or continuous state space. For instance, in [1] a hierarchical multiagent system is used, which has two levels: the physical intersection one and the region level. In the former agents use RL to find the best policy and send local information to an agent at region level. At this level, the locally collected information is used to train a long short-term memory (LSTM) neural network for traffic status prediction. The agents in the above level can control the traffic signals by finding the best joint policy using the predicted traffic information.
Finally, another way to tackle the issues that arise from large and continuous state spaces appeared in [17,18], in which a temporal difference learning algorithm based on k-nearest neighbors was presented. RL approaches based on this technique have been used in different domains, like robot motion control [13] and video streaming [14]. More recently, we have studied the use of this technique also in traffic signal control, with preliminary results presented in [11].
In any case, one needs to stress that a multiagent setting is inherently non-stationary, making the learning task even more challenging.
This paper also deals with transferring of experiences among agents, which is related to transfer learning. Since learning a task and adapting to changes in dynamic environments are usually computationally expensive in real-world applications, one solution is to profit from other agents knowledge. Transfer learning is a method to deal with this. Multiple agent can share their experiences, policy or any other knowledge through learning. The knowledge can be transferred from expert agents or more experienced agents [23]. It can also be advice-based transfer in which human teachers [20,28] or adviser agent [35]. In [10], an expert-free transfer learning was utilized in multi-agent reinforcement learning in which source agent is dynamically selected according to the performance and uncertainty measured using interactions. The readers are referred to [24,25,27] for more details on transfer in reinforcement leaning.
Combining and transferring nearest neighbors’ knowledge with Q-learning: General framework
As aforementioned, our approach aims at tackling two challenges. First, in many real world problems, the state space that is associated with an RL task is large and/or continuous. Therefore, the quality of the learning task depends on how the state is discretized.
The second challenge is how to improve the learning task by means of having agents communicating their experiences, so that agents that do not have a number k of good experiences can profit from having them transferred from other agents.
The remaining of this section details how to deal with these two challenges by means of combining Q-learning with k-NN, as well as by transferring experiences.
Temporal difference learning based on k-nearest neighbors
Essentially, the method estimates the Q-values of the current state by calculating the weighted average of the Q-value estimates of the k nearest states, based on the Euclidean distance. The closer a neighbor state is, the greater the impact its estimated Q-value have on the Q-values of the current state.
Once the Q-values are updated this way, each agent then selects an action based on an exploration strategy such as ε-greedy, transitions to a new state and receives a reward. Subsequently, it calculates a temporal difference (TD) error based on the reward and the expected value of the last and new state, and uses this error to update the Q-value estimates of all the k nearest states that contributed to estimate the Q-values of the previous state.
The next subsections details these procedures.
Estimating Q-values
Each dimension of the state space could be of a different order of magnitude. In order to avoid a bias (towards some of these dimensions) when computing the Euclidean distance between two states, we use normalization, as stated in Eq. (2), where
The agent keeps a record of each visited state and an estimate of the Q-values for each of these states. After normalization, the k nearest previously visited states according to the Euclidean distance are selected, in order to determine the k-nearest neighbors set.
A weight is then calculated for each state in the set, according to Eq. (3), where
The Q-value of a state-action pair is determined by an estimate of the expected value, in which the probabilities of each state in the
For each action a, the Q-value of the state-action pair (
This way, the method estimates the Q-values of the current state by calculating the weighted average of the Q-values of the nearest previously visited states.
Action selection and updating Q-values
Having the expected value of each action for the current state
Communicating agents transferring experiences
At every time step, each agent observes a new state and tries to select the k experiences (Q-values associated with such new state) that are nearest to this observed state. However, if the distance between any of these experiences and the current state is greater than a distance threshold Δ (a parameter of the model), then the agent requests experiences from other agents. These then select all experiences that are within the distance threshold of the requesting agent’s current state, and then send these experiences to the requesting agent. The requesting agent then recomputes the k nearest experiences, and estimates the Q-values for each action based on the standard k-NN-based algorithm.
Pseudo-code

Temporal difference learning based on k-nearest neighbors
A pseudocode for the overall procedure – combining Q-learning with k-NN and transferring of experiences – is presented in Algorithm 1.
At every time step, the agent observes a state and normalizes it according to Eq. (2). Then, a set
Each other agents selects all of the experiences that have a distance to the current state equal to or less than Δ, that is, all experiences e for which
Once
The problem of large and continuous state space arises typically in RL-based traffic signal control, where the possible formulations for states may consider queue length, density of vehicles, and also a handful of other features. The reader is referred to [32] for a discussion about popular formulations of the state space for this particular domain.
Next, we discuss the particular formulation of the RL task as used in the present paper, which is a popular one (e.g., [4,5,16]. Before, we introduce the actual traffic network used, in order to refer to it when we discuss how the RL task was formulate.
Scenario
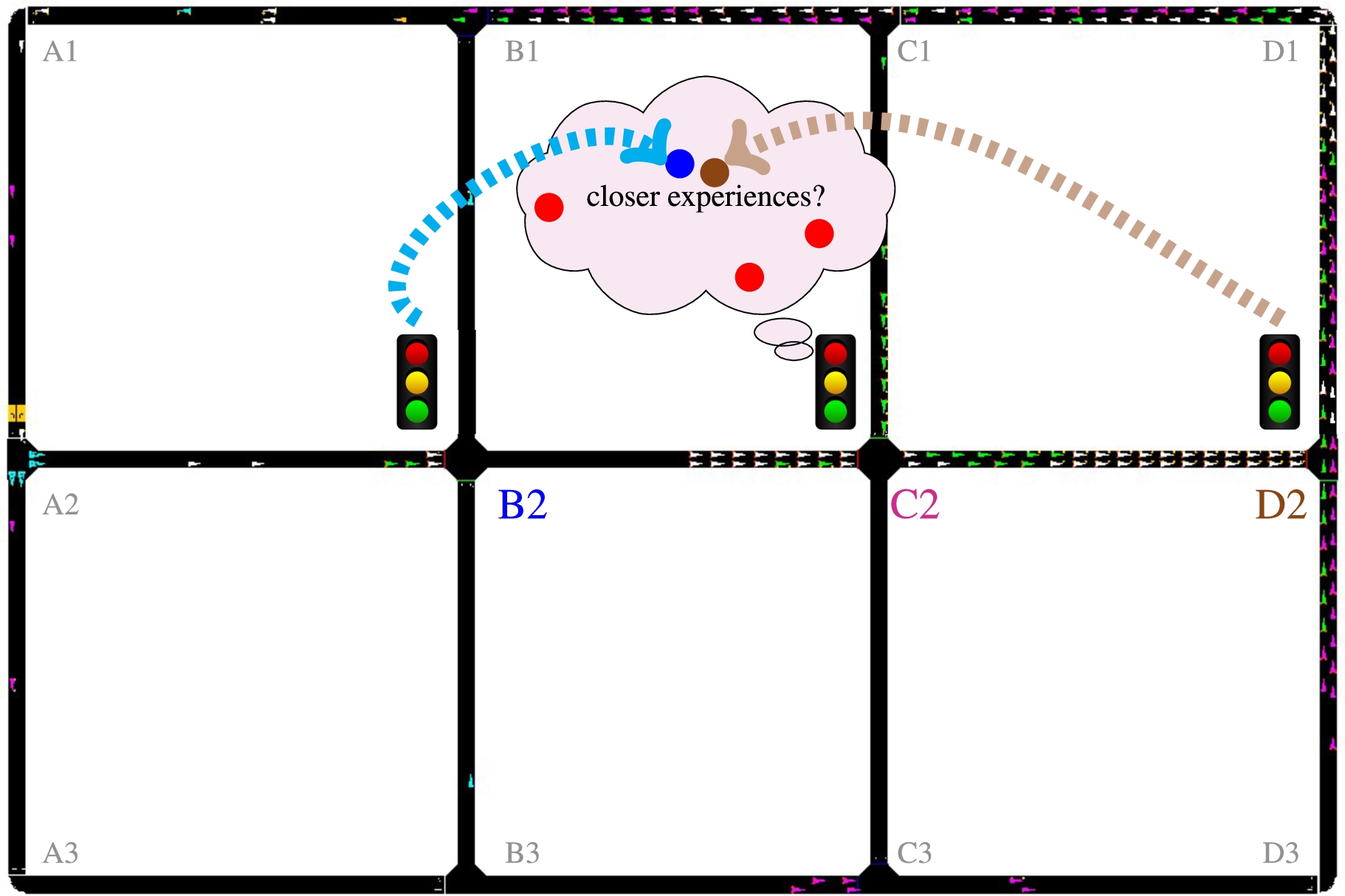
Road network used in the experiments. This figure also depicts a scheme of the communication among the traffic signal control agents (agent C2 lacks experiences and thus request them; agents B2 and D2 send their experiences).
To illustrate the application of our approach, we use the traffic network with 12 intersections depicted in Fig. 1. However, since the links are one-way, not all intersections require a traffic signal controller. This is the case of the four corner intersections, as well as intersections A2, C1, and B3. Other non-signalized intersections are B1 and C3. These two are regulated by a priority mechanism defined in the microscopic simulator used (SUMO), namely all vehicles decelerate before reaching the intersection and SUMO regulates the right of using the intersection. We did this in order to concentrate on the intersections defined by the arterial depicted in the middle of the figure, namely the one that starts at intersection A2 and ends at D2. In this arterial, there are three signalized intersections that are then controlled by a learning agent, namely B2, C2, and D2. Each of these agents learns using the method described in Section 4. More details on SUMO’s priority mechanism can be found at
We also stress that we have created this network with a particular feature in mind: the total number of vehicles is kept constant (except for the first steps, when they are still being inserted at the link B3-C3). This avoids many problems related to the network introduced in [4] and also used in [11], where it was not possible to fully isolate the behavior of the RL approach from SUMO’s mechanism for routing vehicles. In the network depicted in Fig. 1, there is a re-routing device right before intersection A2 that is responsible to re-route each vehicle from time to time. Essentially vehicles keep running in loops, never leaving the simulation. This allows us to control how the trips use the network, which is an important question we deal with here, as described next.
In [4,11] it was shown that the respective methods were able to adapt to change in traffic contexts or simply context. By context we mean that, from time to time, the way trips are distributed over the routes were changed. Note that this does not mean that the number of trips (vehicles) changes but, rather that each trip may use a different route, thus the use of the links, and, hence, of the intersections, differs along time. In the aforementioned papers, the task of setting and controlling the change in contexts faced difficulties because vehicles kept being consumed at their destinations, while new ones were generated, so that at any given time, the number of vehicles kept changing.
In the present paper we decided to have a more stable scheme. We generate a number of trips (200, which, for this network represents almost 50% of overall density, given that its maximum capacity is around 500 vehicles1
The network has 17 one-way links of 150 meters; each vehicle occupies 5 meters when queued.
As is often with RL problems, we use a multiagent MDP (MMDP) to formalize the learning task. In the traffic signal control domain, besides the set of agents, we need to define the other sets and functions that compose the MDP. Next, we define the state space, the action space, and the reward function.
Before, we make two remarks. The first is that the discussion ahead considers two kinds of time steps: simulation time and action time. The former corresponds to 1 second of real-world clock, whereas the latter is the time step in which the agent makes a decision about which action to select, given its observed state. In the present paper, one action time step occurs at each five seconds of the real-world clock. This makes sense as signal controllers never make decisions – which could change phases – at each second. All plots depicted in Section 6 refer to the real-world clock.
The second remark refers to classical parameters when controlling traffic signals, namely, the minimum and the maximum time they must remain green. They are referred to as minGreenTime and maxGreenTime, respectively.
State space
At each action time step t, each agent observes a vector
Be L the set of all incoming lanes. The density
Note that while it is common in the literature that only one feature be used (i.e., either density or queue), here we employ both as this was shown to be more efficient (see [4]).
Action space
Each learning agent chooses a discrete action
Reward function
Let
Changing the demand along the simulation horizon
As aforementioned, a particular challenge in the present work is that the demand changes during the simulation time because vehicles are re-routed from time to time. In the present paper, this is done each 5000 simulation steps, as follows.
Consider the following set of routes:2
Route
There are two different contexts that keep being alternating during simulation time. For both contexts flows are distributed between links as given in Table 1.
Probability of a vehicle to be re-routed to each route, according to a given context
This probabilities result that, in context 1, most of the traffic flows horizontally at the arterial A2 to D2, whereas in context 2, there is more vertical traffic at B2 because links B3 to B2 and B2 to B1 have a higher flow. Also, there is more vertical traffic at C2.
Each simulation runs for 20,000 seconds and switches contexts every 5,000 seconds; thus there are three changes in context (Context 1 → Context 2 → Context 1 → Context 2).
As aforementioned, the experiments were performed using a microscopic traffic simulator, namely SUMO [15] (Simulation of Urban MObility). In the scenario depicted in Fig. 1, agents are homogeneous, i.e., they have the same set of available actions.
Setting the values of the learning parameters
The value used for minGreenTime and maxGreenTime were set to 10 and 50 seconds respectively. Also, as aforementioned, one action time step corresponds to five seconds of real-life clock time, and contexts change at each 5000 simulation steps.
As for the learning parameters, after experimenting with other values, we have set
Regarding the k-NN method,
Finally, regarding the transfer of experiences, we also tried several values for the distance threshold Δ; here we show results for
Results and discussion
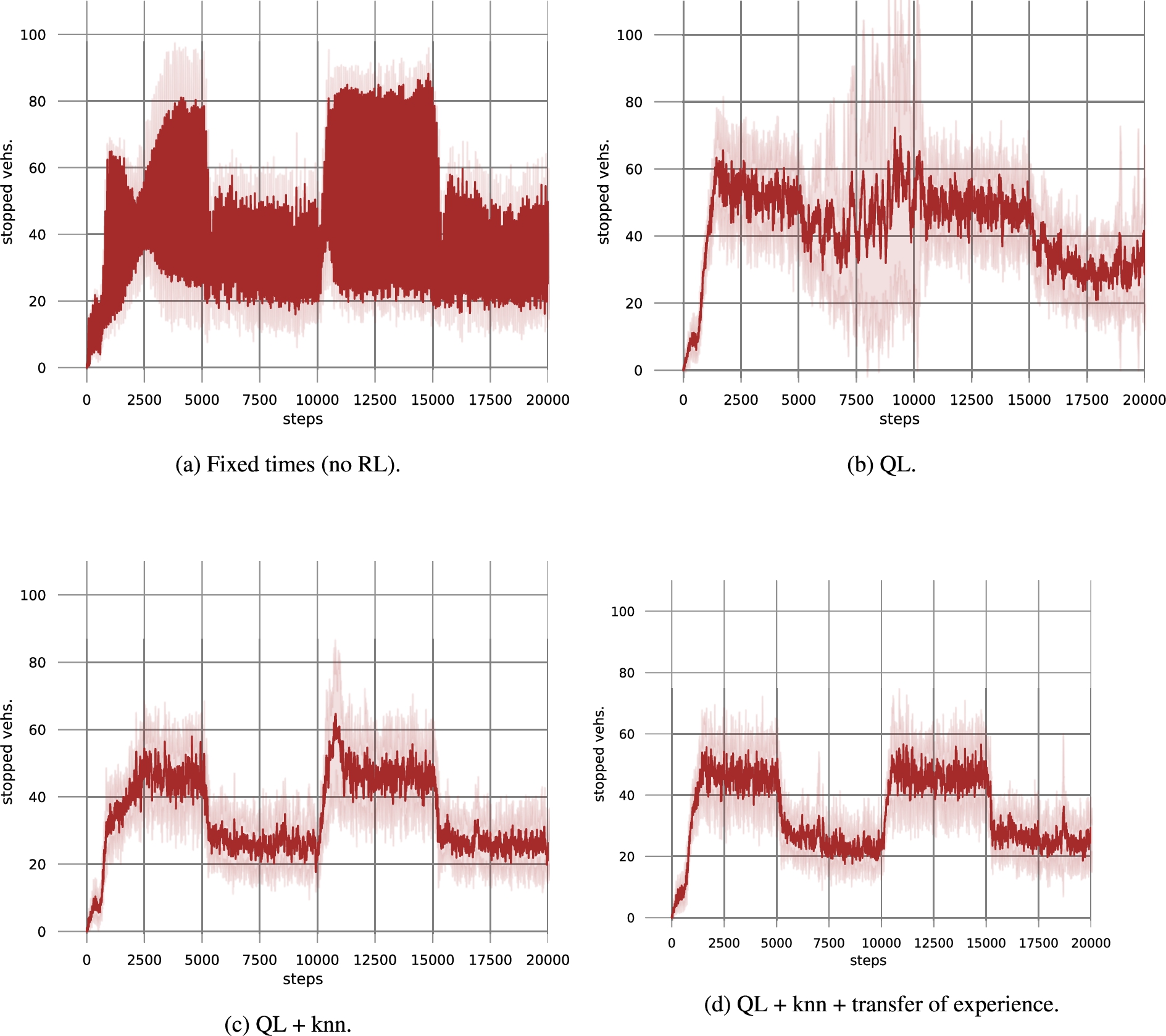
Comparison of the number of stopped vehicles in the network.
We compare our method to two baselines: fixed times and when only tabular Q-learning is used. For the former, we use a cycle of 90 seconds, splitting green time equally, so that each phase receives green for 42 seconds, and there is a 3 second red and yellow signal after each phase change. These values were computed by SUMO. For Q-learning, the values of α, γ, ε and the decay on ε mentioned in the previous section were used. In all cases, we have run 10 repetitions in order to show the deviations from the mean value.
We measure the number of stopped vehicles along time. For the two baseline situations, plots are depicted in Fig. 2a and Fig. 2b. For the sake of clarity, we show each situation in one plot, so that deviations are easily spotted.
One can observe that using fixed times (Fig. 2a) yields lots of oscillations, not only when contexts are changed, but virtually at all times. This is due to the fact that the rules to deal with the traffic volume are fixed, but the traffic volume itself changes.
The use of Q-learning without k-NN and/or communication among the agents does not produce such oscillations (see Fig. 2b) but: (i) it results in higher number of stopped vehicles, (ii) it does not adapt well and fast after there is a change from context 1 to context 2, and (iii) it produces the highest deviations (see shadow in lighter color).
Figure 2c shows the result when k-NN is used in conjunction with Q-learning. It is possible to notice that there is a reduction in the number of stopped vehicles – especially when there is a change to context 2 (at time step 5,000), which shows that the use of k-NN is able to adapt fast to such change. Notice also the reduction in the deviations (shadow) as compared to Fig. 2b.
Finally, Fig. 2d covers the result when agents communicate in order to transfer experiences when necessary. This is the case when they find themselves in states for which they do not have k good (meaning below the distance threshold) estimates to compute the Q-value. This is especially the case in the beginning of each never experienced context (i.e., at the initial time steps, as well as around step 5,000 when there is a change in context).
By comparing Fig. 2d to Fig. 2c, we do not see an improvement of performance: up to step 5,000, values are actually not much different. The fact that agents are still exploring with very high probabilities (as ε starts at 1.0) means that agents have values that are not necessarily good estimates for a Q-value, thus the transfer of such experiences do not improve the performance. However, once the environment goes back to context 1 (around 10,000), it is possible to see that transferring experiences pays off, even if the improvement is not big.
Overall, the number of stopped vehicles is lower when using transfer of experiences, in comparison to when k-NN is used without such transfer. And k-NN in conjunction with Q-learning does result in a better performance, when compared to when (tabular) Q-learning is used without k-NN. Moreover, all of them over-perform fixed times, as expected, given that this method does not adapt to changes in context.
In this paper, we discuss how multiagent RL can be combined with k-nearest neighbors to estimate Q-values. This approach is particularly useful to deal with issues that arise when the state space is continuous and thus, a poor discretization may lead to poor performance. Further, we propose experience transfer among agents, in order to account for lack of good experiences. Besides proposing this approach, we illustrate its use with a scenario stemming from the area of traffic signal control, where we also deal with changes in context, i.e., in the traffic flow patterns.
Our results show that, compared to two baselines (one stemming from standard RL, i.e., a tabular method) the proposed approach performs better in terms of quality (less stopped vehicles), speed of convergence, and also presents less oscillations.
As discussed, transfering experiences led agents to improve their performance in a limited way, i.e., in given changes of context (but not in all). This may be due to the fact that agents have not yet found good estimates for some Q-values. Therefore, as a next step, we plan to extend the approach to incrementally cluster the agents’ experiences in order to have more abstract representation of the Q-values. This in turn can be helpful when sharing knowledge among the agents, since they may be able to do this at a higher abstraction level. Regarding the experiments, we intend to use scenarios in which agents are heterogeneous (e.g., they have a different set of actions that arise due to different set of phases).
Footnotes
Acknowledgements
We are thankful to the anonymous reviewers. This work is partially supported by FAPESP and MCTI/CGI (grants number 2020/05165-1) and by CAPES (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brazil, Finance Code 001). Vicente N. de Almeida was partially supported by a FAPERGS grant. Ana Bazzan is partially supported by CNPq under grant number 304932/2021-3, and by the German Federal Ministry of Education and Research (BMBF), Käte Hamburger Kolleg Cultures des Forschens/ Cultures of Research.