
Abstract
In the last decade, the world has witnessed remarkable technological development, especially in artificial intelligence, which helps researchers find solutions to problems of concern to the individual and society, mainly, the huge propagation of hate speech with the increased use of social media platforms. In this study, we aim to enhance the detection of Arabic hate speech on social media by addressing challenges related to imbalanced datasets through data augmentation techniques. Several machine learning algorithms and the DziriBert, a pre-trained transformer model, are implemented on the Tunisian Hate Speech and Abusive Dataset (T-HSAB). The proposed approach achieves good results, improving the detection of hateful comments on Arabic social media using the Synthetic Minority Over-sampling Technique (SMOTE). Notably, the DziriBert model exhibits remarkable proficiency in detecting hate speech, achieving an accuracy of 82%. Random Forest (RF) and Linear SVC outperform the state of the art approaches, achieving the best result.
Introduction
In today’s Internet age, with the widespread use of social media platforms and the misunderstanding of freedom of expression, confronting the huge use of hate speech is of utmost importance. It requires more effort, especially for the Arabic language as a low-resource language. So, there is a lack of studies on Arabic hate speech detection [1, 2, 3, 4, 5]. Researchers aim to collect the various definitions of hate speech as a complex phenomenon [6]. The United Nations defines hate speech as “offensive discourse targeting a group or an individual based on inherent characteristics such as race, religion or gender, …”.
We investigate the advancement of Artificial Intelligence, Deep Learning, Machine Learning, Natural Language Processing techniques and data augmentation methods to provide an overview of hate speech detection on social media research. Notably, researchers have presented a deep summary of approaches including machine learning, deep learning, and transformers [7]. Further, they have reviewed the different challenges and difficulties that can be related to the structure of social media posts, the complexities and nuances of each language, mainly, the characteristics of Arabic script [8, 9], the cultural references [7], and their multiple dialects. It can also relate to the use of stereotypes, figurative language, and sentences semantic. Furthermore, the limitations related to imbalanced datasets [7, 10], the ratio of hate content [6], and the small sizes. All of that drive the embrace of data augmentation and oversampling methods [10] as a response to these challenges. Our work aims to address the gaps of the scarcity of Arabic studies focusing on text data augmentation as a technique to tackle the imbalanced dataset problems in text classification tasks, specifically hate speech detection. Hence, we propose an approach that aims to enhance the Arabic hate speech detection on social media using Machine Learning and Bert transformer models, based on Natural Language Processing techniques as a key tool for text classification tasks [2, 3, 4], outlining the SMOTE as a data augmentation technique to overcome the imbalance of the dataset.
The rest of the paper consists of an overview of recent research about hate speech detection on social media since 2017 is presented in Section 2. Then, our proposed approach, the dataset, data preprocessing, features extraction, data augmentation technique, and least, the Machine Learning and Deep Learning models are investigated in Section 3. Last but not least, the different results and discussion are outlined in Section 4. Lastly, a conclusion is given, and directions for future work are suggested in Section 5.
Related work
We want to provide an overview of recent studies about hate speech detection on social media using numerous machine learning (ML), deep learning (DL), and pre-trained transformer models implemented on both English and Arabic datasets. With the huge amount of data, it seems complicated to the data generation process, further, it’s hard to control the content. Which encourages users to assault others because of their areas, cultures, races, or who have different colors, psychologies, and religions [11].
In [12], the authors aimed to resolve the spread of racist speech on the Twitter platform, and to build a healthy and safe space. Watanable et al. [11] have chosen to implement their system on the Weka tool kit based on the ML algorithm “J48graft” on the merged dataset consisting of three corpora. The highest accuracy is obtained by the J48graft, which equals 87.4% for the binary classification, and 78.4% for the ternary classification with the extraction of sentimental and semantic features. J48graft outperforms Support Vector Machine (SVM) and Random Forests (RF). Devi et al. [12] have dealt with the problem of racism detection on social media with the ensemble learning algorithm eXtreme Gradient Boosting (XGBoost) implemented on the Twitter Sentiment Analysis dataset. XGBoost with word2vec obtained the highest result with 69% accuracy compared to RF, LR, and SVM, which are the popular ML algorithms [11, 13]. Gharbi et al. [14] provided an approach that uses the ML classifiers (Naive Bayes (NB), SVM, RF, LR) [13] and deep learning models (ARBERT, MARBERT (Monolingual Models) and XLM-R (Multilingual Model)) with Bag of Words (BoW). RF and LR had the highest result by an F1-Score
With the wide propagation of hate speech on online platforms and the increasing numbers of social media users, the authors in [15, 16] proposed an approach aimed at fighting this issue using advanced, easy-to-implement and efficient technologies in which they created a system based on ML algorithms implemented on Arabic dataset from Kaggle with a size of 24,783 tweets combining NB and DecisionTree (DT) algorithms with (n-grams +BoW+TF-IDF) as a features extraction technique. This system has improved the task of Arabic hate speech detection, reaching a high accuracy of 88.7% and an F1-score of 88.5%. In [15], the authors proposed an approach based on ML and Natural Language Processing (NLP) techniques to tackle the spread of hate speech on Arabic social media using SVM, NB, DT, and RF. This later achieved the best result with Term Frequency-Inverse Document Frequency (TF-IDF) as a feature extraction technique. The data that was used in this study has a size of 3696 tweets after preprocessing; it was collected from Twitter, mainly related to areas like sports, religion, racism, and journalism. The study of [17] stands on ML as a solution to contribute to the research community interested in the subject of hate speech as a real real-world problem, who proposed an approach to detect abusive language in which the RF model with bigrams has achieved an accuracy equal to 94%, it was implemented on a dataset from Kaggle having 159,571 comments divided into six classes, which are toxic, severe toxic, obscene, threat, insult, and finally, identity hate.
Replacing the handcrafted ML method with the DL models can lead to better results which resolves the problem related to feature extraction to become full automatically [18, 19]. There is fear of freely communicating and expressing their beliefs and opinions due to the huge use of abusive language by users on social media toward others who are different from them, which makes a need to develop a robust detector of offensive language on social media. In [20], the authors implemented recurrent Neural networks (RNN), a DL model, with the user’s tendency towards offensive language related to his tweet’s historical as a feature extraction tool, on a public English dataset. The model achieved an F1-score reaching 0.9320. Alsafari et al. [3] proposed the development of the convolutional neural networks (CNN) with mBert on Arabic hate and offensive speech dataset, sized 800,000 collected short texts from Twitter. The proposed system achieved the best result with an F-Macro = 87.03% for binary classification, compared to other models. The research of Lee et al. [13] investigated a DL-ensembled approach based on sentiment analysis for racism detection on Twitter. They hybridized the three DL models, the gated recurrent unit (GRU), CNN, and RNN obtaining a new model named Convolutional Recurrent-Neural Networks (GCR-NN) that succeeded in detecting racist tweets with an accuracy of 0.98%, outperforming numerous machine learning algorithms (K-Nearest Neighbors (KNN), RF, SVM, LR, DT) and DL models (CNN, RNN, GRU, Long Short-Term Memory (LSTM)).
Another research study interested in Arabic hate speech detection [21] provided a DL approach using the RNN model that obtained the highest accuracy of 99.73% with DRNN-1 for binary classification, compared to multiple ML and DL models, on a newly created dataset, composed of 4203 comments collected from social media sites. Elzayady et al. [22] aimed to propose an efficient approach for creating an Arabic hate speech detector, overcoming the challenges related to the imbalance of the dataset using the oversampling methods and a focal loss function further to traditional loss functions and implementing the Quasi-recurrent neural networks (QRNN) to fine-tune the transformer-based models, MARBERTv2, MARBERTv1, and ARBERT. Furthermore, they proposed ensemble learning that outperformed the state-of-the-art approaches. In [23], the authors proposed an approach for detecting hate tweets on Arabic social media, based on implementing the Bidirectional Long Short-Term (BI-LSTM) and CNN, which have achieved the best accuracy of 92.20% and 92.10% respectively, outperforming numerous ML algorithms. The authors implemented the models on the Arabic dataset, collected from the Twitter platform, and it included 15K tweets and 14 features. Another study [24] aimed to investigate Arabic hate speech detection on social media, trying to address the problem of the imbalanced dataset with the data augmentation technique. The used dataset was provided by The OSACT5. Fine-tuning the QARiB model implemented on the data-augmented, the F1 score has increased significantly, reaching the best result of 0.49 in comparison with other pre-trained DL models.
As an attempt to address the spread of hate speech on Algerian social media and to enhance the Arabic research on this issue [25], proposed a method Based on the application of a pre-trained transformer model, in which they had fine-tuned the dziriBert model implemented on a collected Algerian dataset from multi-platforms, YouTube, Twitter, and Facebook, with a size of 13.5K and two classes annotated as ’hateful’ and ’non-hateful’. Linear SVC, Gzip
Recent studies highlighting some points that can be taken into consideration:
Word embedding as a feature extraction technique can ameliorate the DL approaches [3, 21]. Data augmentation improves the models’ performances, by tackling the problem of imbalanced datasets [28]. Two or more DL models enhance performance more than a single DL model [6, 13]. Bert-based transformer models have achieved significant advancement in various NLP downstream, as text classification tasks [29]. Mainly, when they are ensembled with data augmentation [28] pointing out hate speech [10].
State of the art racism detection studies
State of the art racism detection studies
1
In this section, we propose a study investigating end-to-end hate speech detection system based on the ML approach starting with the data presentation and implementing the appropriate preprocessing data techniques and goes through extracting the main features of the data. After that, we apply the SMOTE data augmentation technique to resolve the data imbalance. Last but not least, we train algorithms on the augmented training set and test them on the test set. Finally, we implement the DziriBert as a pre-trained transformer model.
Data preprocessing
NLP is considered a fundamental key in ML project generation. As a crucial step before model implementation, data preparation is essential. This involves employing data preprocessing techniques and conducting a thorough cleaning process, which significantly enhances the performance and the accuracy of models [13]. However, it is important to note that certain preprocessing steps may not always be appropriate, particularly when dealing with Arabic datasets. It is crucial to consider the potential impact of preprocessing steps on Arabic text, recognizing the need for careful evaluation and adaptation to ensure optimal results [30].
Cleaning Data: removing the punctuations, the emojis, the other letters, the empty lines, the repeated characters, and other language letters Tokenization: each sentence, text, or phrase is divided into small units named tokens [2], each token has an index used to differentiate from each other, based on the Tokenizer API from TensorFlow Keras.
Features extraction
This process concerns the extraction of features from the text and then converting them to the right form to be understood and interpreted by the machine. We choose the TF-IDF with ML algorithms as feature extraction techniques throughout this study.
Term frequency-inverse document
TF-IDF attempts to scale the relevance of each word in the sum of the textual dataset [31], calculating the TF and the IDF and multiplying them as shown in Eq. (1).
with
The TF-IDF technique is considered as a solution to problems related to values generated by the bag of words technique, which are only 0 and 1 however TF-IDF can generate 0, 1, and other fractional values between 0 and 1. That outlines the importance of words in such a document.
With the lack of Arabic datasets [32, 33] and the associated challenges, such as their limited sizes, 55% of the available dataset sizes are considered small, along with the need for improving the annotation quality and the imbalance of classes [6]. Consequently, the preprocessing techniques are embraced [33] and the alternative performance metrics are considered as potential solutions by researchers. Indeed, the accuracy metric is an inappropriate choice for the imbalanced datasets [34] and is beneficial to be replaced by the ROC curve [35], others tackled the dataset imbalance using the data augmentation technique.
Data augmentation is a method that aims to generate more training data, synthetically, which gains effort time, and costs [27, 36], prevents overfitting, and improves the model’s efficiency [36]. It achieved remarkable performance in many domains, as well as health care, citing the study of [37] that proved the effectiveness of data augmentation with transfer learning in Breast cancer histopathological image classifier. Further, [36] has used the Imbalanced Data Augmentation (IDA) technique, which helps prevent the imbalanced classes problem and improves the model’s capability to classify texts, providing the best F1-score compared to recent approaches.
In addition, it has been used on many NLP tasks, named entity recognition [27] and spam detection [38], in which they proved the effectiveness of data augmentation applied to the task of spam detection with a significant increase in the macro F1 score from 58% to 89%, achieving the best-of-the-art result, and mainly text classification [39, 40, 41]. One of the popular and efficient techniques is SMOTE [42] which will be used in our approach.
SMOTE: Synthetic minority over-sampling technique
The over-sampling technique called Synthetic Minority Over-sampling Technique (SMOTE) is characterized by its simplicity, superior performance [35], and Effectiveness, which made it popular [42]. It works on over-sampling the minority class, in which it aims to create and generate synthetic minority class samples. The process of SMOTE is to take the minority class sample everytime, then the synthetic examples are introduced along the line segments joining any/all of the k minority class nearest neighbors randomly, following the algorithm described below [35].
The ratio of tweets per class.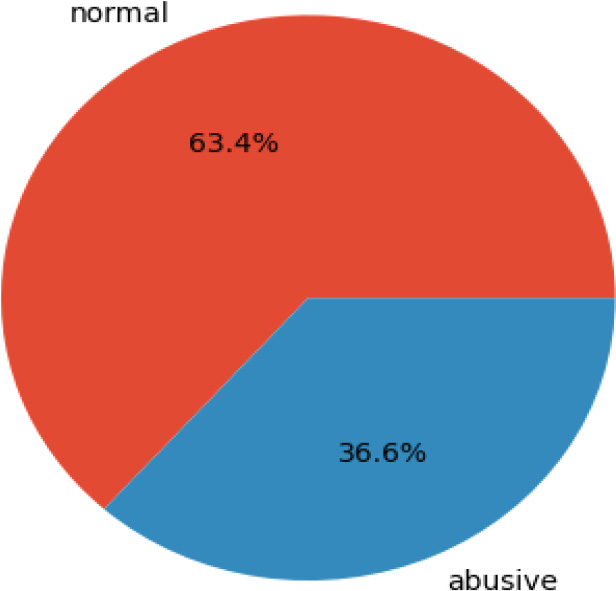
An imbalanced dataset has classes that are not approximately equally represented [35] which is the same case with the T-HSAB dataset as it appears in Fig. 1, indeed, the abusive class is the most important in the hate speech classification task, but it has a low ratio of Tweets per class in comparison with the normal class.
Several researches has investigated the hate speech detection problem on social media using popular ML algorithms, such as DT, LR, SVM, RF, and NB, which have been proven efficient in such tasks [17].
Logistic regression
A supervised machine learning algorithm is described as the most used algorithm for its ease of implementation and quickness [43], naming it as a shallow neural network [44]. It works to take the inputs and predict probabilistic output values that vary between 0 and 1, using the sigmoid function defined in Eq. (3).
Linear SVC is one of the most efficient versions of the popular ML algorithms, based on a kernel linear function that focuses on finding the optimal hyperplane to differentiate between classes, separating the space between dimensions of classes, and maximizing the distance between them using its linear function [45], which helps it to improve its performance on classification tasks. It is also the simplest and fastest type of SVM algorithm. Farther, it differs from LR in such a way that the results of Linear SVC are based on a probabilistic interpretation. But both are linear algorithms [45].
Random forest
RF is a supervised ML algorithm, which is composed of an ensemble of decision trees. [46] implemented the RF-based SMOTE combined with the Pointwise Mutual Information (PMI) technique to detect cyberbullying tweets, in which this model has obtained the best result, outperforming NB, kNN, DT, and SVM. [47] used the SMOTE technique to address the imbalanced classes with RF for the same task and achieved the best result. Furthermore, the RF model has also led a good accuracy in other domains such as heart disease prediction with an accuracy of 83.70%, surpassing other ML algorithms [48].
Multinomial naive bayes
Multinomial NB is a type of Naive Bayes classifier, which is a probabilistic and supervised ML algorithm. It prefers the dataset with a large size. Besides, it stands on the dependencies between attributes and the Bayesian theorem [49], which has much importance in enhancing the model’s performance. It is used by [50] to classify hate speech, achieving a good recall equal to 93.2%.
DziriBert
DziriBert is the first Algerian language model, a pre-trained transformers model developed by [51], which has been implemented on more than one million Algerian tweets as a multilingual dataset. It has reached better results, mainly, with the Arabizi writing where the Roman script is used, outperforming other Bert-based models such as AraBERT, mBERT. It is recommended to fine-tune the DziriBert on other NLP tasks, for instance, hate speech detection [51], which can lead to a good result. Indeed, [25] developed the DzaraShield that is a DziriBert-based model on an Algerian dataset for detecting hate speech on social media achieving a good result. Another study [52] aimed to investigate the fine-tuning of the DziriBert model to improve the Arabic Algerian Offensive and Abusive Language Classification.
DziriBert’s parameters
DziriBert’s parameters
After applying the preprocessing data, and splitting the T-HSAB dataset into a training set with a 75% ratio, a validation set of 15%, and a test set of 15%, to evaluate the model’s performance, with the number of samples of 4216, 903, and 904 respectively, we implement the DziriBert model, indeed, using the tokenizer dziribert encode function to encode the text into tokens, this process is called tokenization. The histogram above represents the distribution of sequence lengths in the test set, selecting the maximum length of 502 that will be used in the model’s parameters regularization, and applying the same process of encoding and tokenization on the train set and validation set. Table 2 displays that the DziriBert model goes through a training process using a batch size of 16, where the model’s parameters are updated based on the computed loss. The learning rate scheduler utilizes a warmup period of 500 steps, gradually increasing the learning rate to help in convergence, more effectively. During evaluation, the model performance was determined on batches of size 32. The training and evaluation processes span a total of 5 epochs, ensuring multiple passes through the training dataset for effective learning. To prevent overfitting, a weight decay of 0.01 is applied, which adds a penalty term to the loss function. The model handles input sequences with a maximum length of 502, either truncating or processing longer sequences accordingly. These configurations enable the DziriBert model to train efficiently, learn effectively, and achieve optimal performance in classifying abusive and normal comments.
The distribution of sequence lengths in the test set.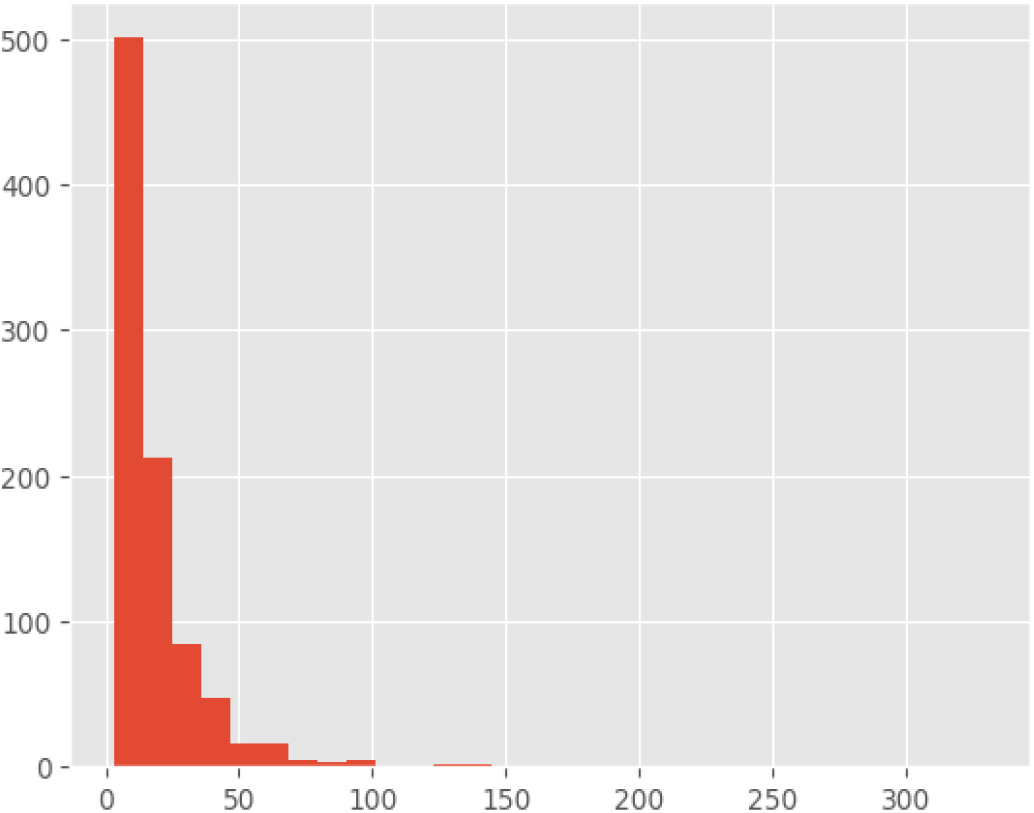
Providing an overview of the training loss and validation loss, described on the plot bellow, where the training loss curve is decreasing to approaching 0, counter to the validation loss curve that is increasing to adjacent 1.2.
Plot of training and validation loss.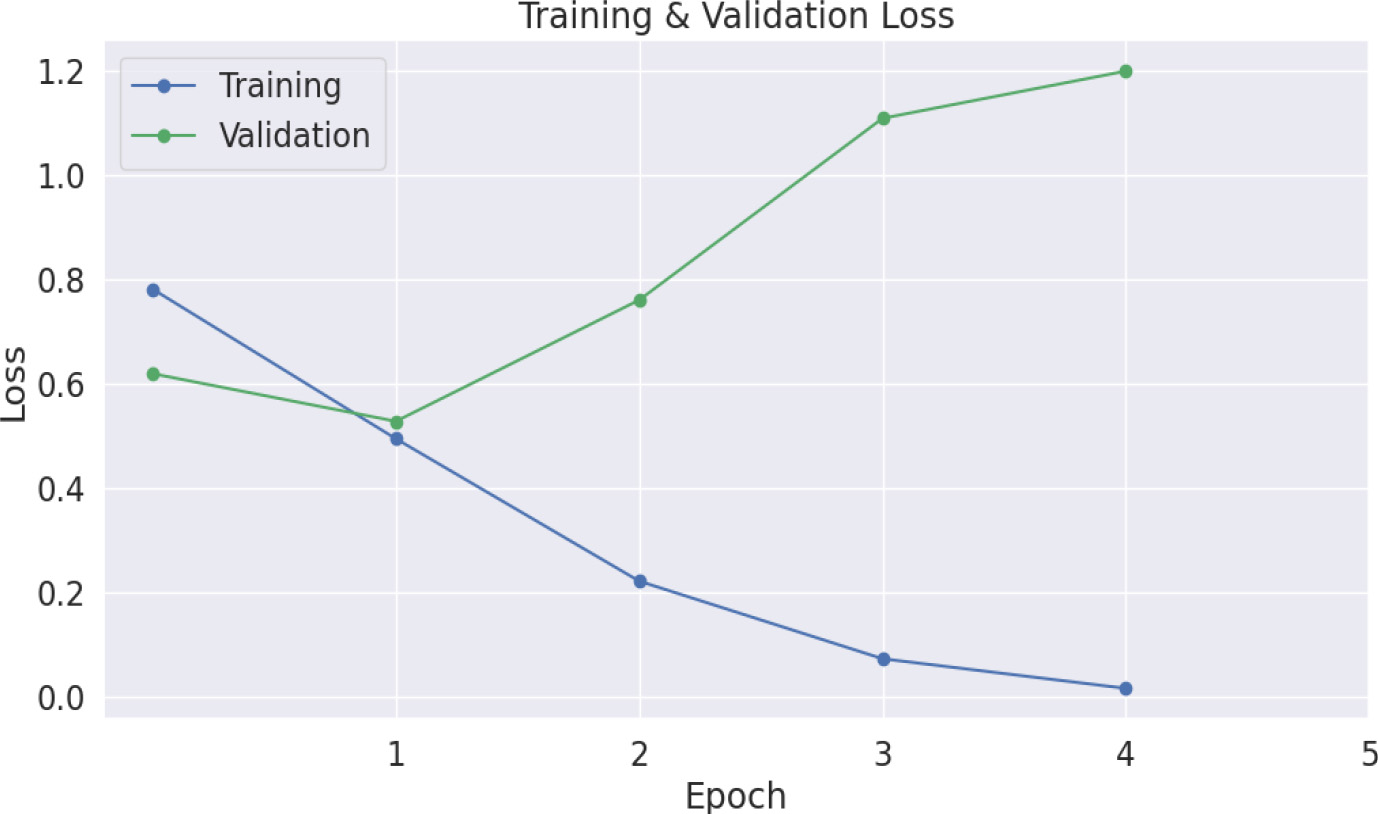
In this section, we outline the experimental results focusing on the effectiveness of the used methods in handling the imbalance of classes to address the misclassification of abusive samples that appeared in the training set less than the normal samples [53]. This can increase the models’ performances for Arabic hate speech prediction, throughout this study.
Dataset description
Samples from the dataset.
Results of machine learning algorithms with TF-IDF
Class distribution.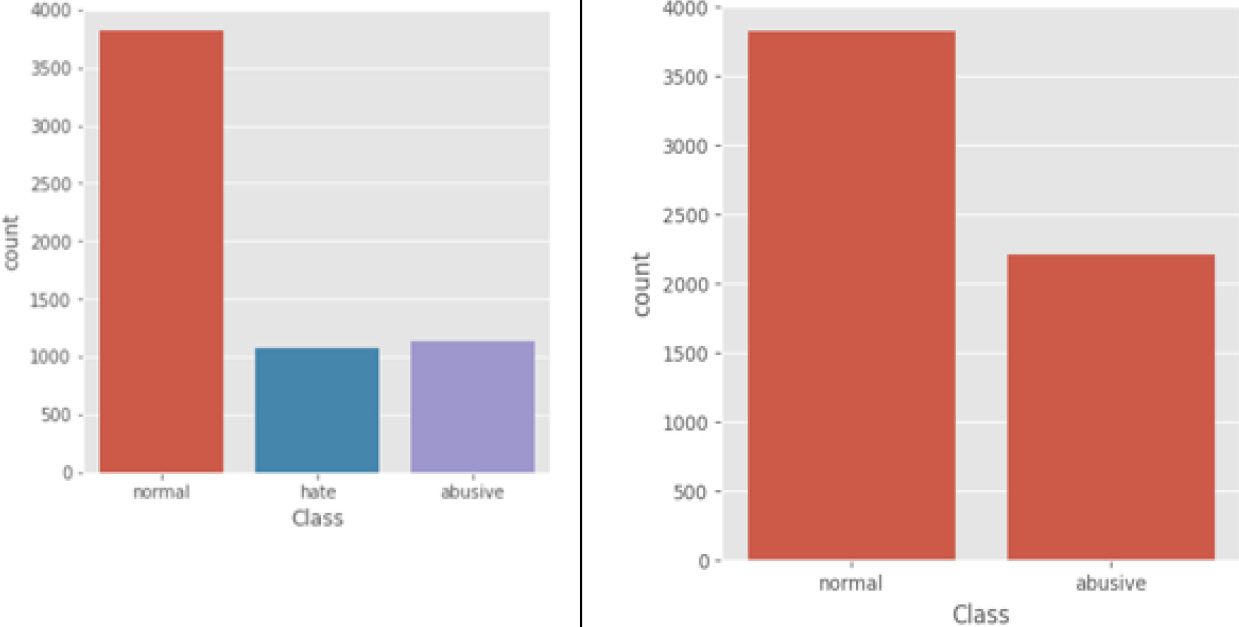
The T-HSAB Tunisian Hate Speech and Abusive Dataset is composed of 6024 textual samples, written in the Tunisian dialect and annotated as Hate (1077 samples), Abusive (1126 samples) or Normal (3820 samples).Some examples of hate and normal comments are presented in Fig. 4. The class distribution of comments is illustrated in Fig. 5, in which we can observe the imbalance of classes, indeed, we have only a 36.6% ratio of samples presenting the abusive class, whereas, the large ratio of samples had been labeled as normal by of 63.4%, as shown in the ratio’s figure, consequently, that imbalance will negatively affect the models’ performance. So, we’d like to provide a solution that handles this issue.
The selection of the appropriate evaluation metric is at most important, mainly when dealing with an imbalanced dataset. Accordingly, the precision metric is one of the suitable measures for this situation [54]. Implementing various machine learning algorithms with TF-IDF in the task of detecting abusive comments, achieves accurate predictions, as is shown in Table 3, Linear SVC and RF correctly predict all samples of both classes, achieving a precision equal to 100%. Further, LR and multinomial Naive Bayes achieve a precision reach of 90.8% and 94.2% respectively. By the application of SMOTE as a data augmentation technique to oversample the abusive class, the training set has increased from 6023 to 7640 samples. LR and multinomial NB have scored a significant increase in their performance of hate speech detection, with 8% and 4%, respectively, which concludes the beneficial impact of the SMOTE technique ensembled with LR and Multinomial NB machine learning algorithms, contrary to the case of RF and linear SVC that have a decrease of 3% and 2% respectively. The results are presented in Table 3.
DziriBert model result
Although the DziriBert model is fine-tuned to trait the Algerian dialect, it proves its capability to detect hateful comments written in the Tunisian dialect, achieving good performance with an accuracy of 80% and 82% for multi-class and binary classification, respectively, which encourages us to work hard to enrich Arabic studies as well as create larger and more balanced datasets, develop a pre-trained transformer model specialized for the Tunisian dialect.
Introducing the confusion matrix as an evaluation of the model’s performance and presentation of the number of samples correctly and wrongly predicted for the two classes. Based on the confusion matrix shown in Fig. 6, the DziriBert model proves a reasonably good performance in differentiating between abusive and normal comments, with a higher accuracy in identifying normal comments compared to abusive comments because of the imbalance size of classes which should be resolved and can be handled with data augmentation technique to oversampling the minority class.
Comparison with state of the art approaches for Arabic languages
Comparison with state of the art approaches
Comparison with state of the art approaches
CM of DziriBert model.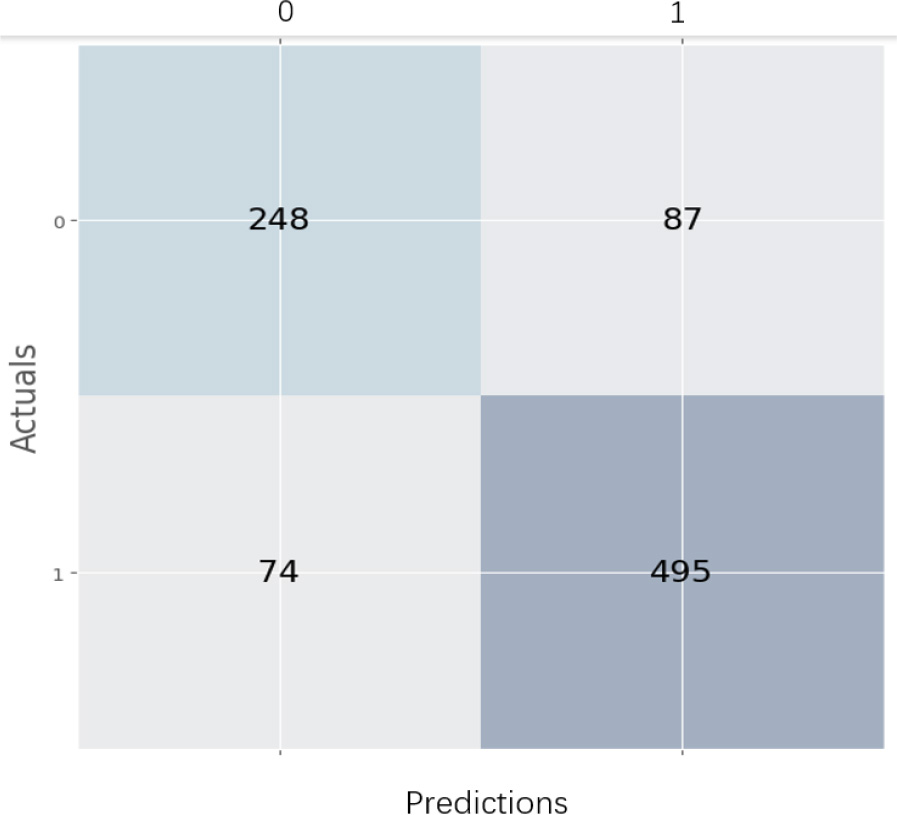
Table 4 introduces a comparison with state of the art approaches for the Arabic language focusing on studies that used the T-HSAB dataset or those using the same ML algorithms, DL and transformers models. Indeed, LR, Multinominal NB, RF, Linear SVC and DziriBert models have been used in our study on the T-HSAB dataset highlighting the efficiency of our method, with the comparison below, in which:
Our study outperforms the results of [4, 14, 56, 57] based on NB, RF, LR, and Linear SVC implemented on T-HSAB, with an accuracy of 98% improved by the use of SMOTE technique and precision of 100%. Our models succeeded in outperforming the hybridization of BERT+BI-LSTM [57] implemented on the combination of T-HSAB and L-HSAB that had achieved only an accuracy of 89.8%. Linear SVC achieves an accuracy higher than the result that had been obtained by our recent study [30]. Our study surpasses the results of [55, 50, 16, 17] based on LR, Multinominal NB, NB+DT, and RF, implemented on different datasets. Our approach based on DziriBert achieves a good result that outperforms the same model in the study of [51] by an accuracy of 82%. The DziriBert model has achieved accuracy slightly lower than the study of [25].
Our study achieves the best result with ML algorithms and succeeds in providing good accuracy with the DziriBert model, considering the size of our dataset, noting that a Bert-based model needs a large dataset.
In this decade, the increasing prevalence of online hate speech has necessitated the urgent need for effective hate speech detection tools and strategies to combat this real-world problem and create a safer and more inclusive online environment for all. Taking into consideration, the necessity and importance of addressing the imbalance problem related to Arabic hate speech datasets, we aimed to conduct a solution to tackle the imbalances dataset and enhance the model’s performance, throughout this study, focusing on the suitable evaluation metric in such case, as a first idea, then we implemented the SMOTE data augmentation technique to generate new samples for the minority class, which improves accuracy of LR and Multinominal NB algorithms, Last, we implemented the DziriBert model on the T-HSAB dataset, achieving good results. We will continue with the same approach of applying the data augmentation with the DziriBert model, supporting the advancement of NLP tasks for the low-resource Tunisian dialect, mainly hate speech detection. Nonetheless, continuous refinement and improvement of the model’s accuracy remain a crucial endeavor to enhance its effectiveness in combating hate speech.