
Abstract
Associative rule mining is a technique for discovering common patterns and correlations in data sets from different databases, including relational, transactional and other types of data repositories, such as relational databases. Different types of patterns exist in data mining such as frequent patterns, extended patterns, regular patterns etc. Many searches have focused on finding the frequent patterns and very little work has been carried out on negative or rare patterns. It has also been observed that only those items which are positively correlated(frequent) are been executed by various algorithms but very less attention is been given to negatively correlated items. Negatively correlated items also called infrequent items are the items which negate with each other. The items which do not satisfy the minimum threshold value generally are always been ignored by many researchers. Mining of Negative association helps in business such as for customer segmentation, in risk management as well as in medical field. So the main aim of writing this paper is to provide a short overview of various research issues involved in finding out positive and negative associations.
Keywords
Introduction
Data mining is a method for discovering patterns and relationships in enormous datasets, and two of the key purposes of data mining are to explore ever-larger databases and improve market segmentation. Data mining techniques might be used by businesses to anticipate future trends and make better business decisions. Relational, transactional, or other types of databases are used in association rule mining to discover patterns, correlations, relationships, or causal structures that are common across different types of data. Using association rule mining algorithms, it is feasible to identify hidden truths in enormous datasets and mine transaction databases for intriguing linkages between groups of things [1]. The purpose of association rule mining is to discover interesting and strong associations between variables. An object that has been acquired or sold is referred to as having a positive connection (i.e., items that are present and observed). A non-linear restriction that must be properly controlled for negative association arises when products bought individually or in combination are examined in market basket analysis and clustering, classification, and association rule mining are examples of data mining approaches [2]. The process of combining positive item sets with field data to produce negative relationships is known as association analysis. Association rule mining and frequent item set mining are two popular and widely studied data analysis techniques for a range of applications [3]. Negative Affiliations relate to associations that reject the existence of something, and in contrast to positive rules, negative rules define a property that is present in a dataset to be missing [4]. Negative association rules are those that form links between the present and absent items. Items that are not bought while others are might be illuminating, and substantial study has been done on the extraction of association rules from transactional databases since their beginnings, making item set mining or association rules mining essential in understanding buying behavior [5, 6]. Market basket analysis is used in association rule mining to learn about customers’ purchasing behavior by looking at what they put in their shopping carts. Although it has been demonstrated to increase revenue in several corporate businesses [7]. The Association rule can be determined with the support and confidence parameters [8] There is a negative correlation, and it is also regarded as a negative association when the values of one variable decrease as the values of the other increase. A transaction database with an excessive number of components and infrequent pattern sets is a good candidate for negative association rule mining since the approach diagnoses the crisis and optimizes the rule generation process. The Negative Association Rule reminds us that a record containing a given linguistic phrase will not have another linguistic term connected with it [9].
The negative rule requires more time and space to write, but it is more accurate than the standard mining association rule. For each transaction, an association rule scours the database and compresses it into a more compact version. There are statistical and non-statistical features to the association rule mining issue in a database. The study goal is to establish k-way correlations between products bought by customers and establish associations between those items. Most typical association pattern mining models utilize the frequency of sets as a quantifier for association level, which is employed in association.
Types of association rule mining
Associative rule mining is a method for finding correlations between items in a vast database of cases and drawing interferences on how to separate subsets of things that affect the existence of other subsets of things. Finding patterns and connections across a broad variety of databases, including relational, transactional, and other data repositories could be accomplished using the association rule mining technique. The method involves searching for these patterns, correlations, links, and causal structures. Popular and extensively studied association rule learning is a technique for identifying interesting relationships between variables in huge datasets. Association Rule mining relies on identifying frequent sets in a huge database to maximize the scalability of algorithms and find frequent sets that lead to valuable association rules [10]. Positive and negative association rules were the foundations of association rule mining.
Positive association rule
Positive association rule mining extracts frequent things or collections, but it might also eliminate many valuable items or collections because of their poor support. These infrequent items or item sets might cause large negative association rules and a powerful positive association is referred to be a positive relationship between two item sets [11]. The positive association rule is said to be positive, available in the form of A
Negative association rule
Negative association rule correlation is defined as the values of one variable decreasing as the values of the other increase. A positive connection is formed when the lift value is higher than 1, a negative relationship is formed when the lift value is less than 1, and a neutral relationship is formed when the lift value is equal to 1. Genetic operators and fitness function assignments are used to create negative association rules in databases. There is a lack of attention paid to negative dependencies in most quantitative association rule mining techniques [15, 16]. Algorithms have been created in a variety of approaches to construct negative association rules. It is difficult to discover negative norms because of the large variety of potential negative standards. This leads to millions of negative rules that a manager could not find helpful, and the goal of this exercise is to discover just interesting negative association rules that managers act on [17].
Application of association rule mining
It is possible to do association rule mining on data sets stored in relational or transactional databases as well as other types of data repositories to look for patterns, relationships, linkages, and causal structures that are common among them. Data analysis might be used to discover commonalities among the datasets. Association rule mining is a powerful technique for uncovering hidden links and connections within massive datasets. This rule establishes the frequency with which a certain item will be used throughout a transaction. Men’s and women’s risk for cardiovascular disease might be better understood with the use of association rule mining [18]. The use of association rules in data mining methods is critical for consumer behavior research and forecasting. It is possible to discover previously undiscovered patterns of purchasing behavior that might be leveraged to design more effective marketing campaigns via association rule mining. Clinical diagnosis might benefit from the use of soft set-based association rule mining and the adoption of association model assessment for the discovery of characteristics that might be utilized to enhance patients’ health from the illness schistosomiasis is now being employed by algorithms [19].
Data mining
The purpose of database mining is to discover patterns in large datasets that might be both helpful and amusing. The Apriori technique is used to find common groups of items (symbols) that occur together often in a database of customer transactions in this study. Due to its capacity to uncover patterns that can be recognized in big datasets, grasped by people, and used for evaluating data and making decisions, pattern mining technologies have grown more popular. The fact shows that frequent item sets are used in pattern mining, and they became popular because of their wide range of uses.
For detecting patterns in data, Association rule mining (ARM) is an alternative method that doesn’t take into consideration the sequential order of occurrences. It is thus impossible to employ these algorithms on data that contains temporal or sequential ordering information. If the sequential link between events or objects is ignored, important patterns in the data might be missed or patterns of limited use might be uncovered. In terms of the development of new computational and algorithmic techniques, Frequent Pattern Mining (FPM) is one of the data mining challenges that has received the most attention. Apart from frequent patterns, there are some extended patterns, such as rare patterns, negative patterns which aim to extract more insightful and meaningful information from the data [20]. Feature selection is also one of the critical steps in association data mining, aimed at identifying the most relevant attributes or variables that contribute significantly to the patterns or associations within the dataset [21]. We can also accompany association mining with opinion mining where we want to uncover patterns or associations within opinions or sentiments expressed in text [22].
Review of literature
The following study expands on enhancing the mining of association using several algorithms. Several researchers explain their findings as seen below.
Subrata Datta and Kalyani Mali (2021) [23] provides a novel framework of significant association rule mining with high associability which is built upon the concept of flexible dissociation. Rule pruning is a critical step in this framework. It involves the process of refining discovered association rules by leveraging the flexible dissociation concept while ensuring a certain level of confidence in the association. Pruning helps eliminate redundant or less meaningful rules, allowing the retention of only the most relevant and significant ones. This paper introduces the SARMHA- (Significant Association Rule Mining with High Associability) framework on account of support, confidence and flexible disassociation.
Jabbour and his colleagues (2018) [24] mentioned that one of the most basic issues in data mining is figuring out how to use methods like association rule discovery to find patterns of transactions with the omitted ones being intended as a contraindicative norm. A negative connection is fully mined as possible, and it is commonly linked with a new measure such as lift or conversion to restrict the set of extracted association rules, and in a satisfiability (SAT) approach is used. The result shows that the non-linear limitations imposed a unique technique, the search space must be pruned, and its efficiency examined.
I.Berin Jeba Jingle and J. Jeya A. Celin (2017) [25] proposed that efficient positive and negative association rule can be mined with the help of an artificial bee colony algorithm. In this, frequent and infrequent item sets are generated by using the Apriori multilevel and multi-support algorithm(Apriori_AMLMS) and then from these infrequent item sets PAR and NPAR are derived which becomes input for the optimized ABC algorithm. In this generating the positive and negative association rule (GPNAR) an algorithm is used for certain parameters such as comprehensibility, time, support and confidence.
Peddi Kishor and Dr. Sammulal Porika (2016) [26] found that it is essential to use association rule mining in large databases to find patterns that relate to different dataset components. Standard rules of association only consider objects that have been transacted in the dataset. In this paper the Yules correlation coefficient formula is used with the help of which we can generate negative rules without the need of finding out infrequent sets thus avoiding the need of scanning the database again.
Youcef Djenouri and his co-workers (2014) [27] investigates the extraction of metarules as a means to effectively prune irrelevant rules in association rule mining. The emphasis lies in clustering association rules specifically designed for handling large datasets. Various interdependencies among rules within the same cluster are identified using a meta-rules algorithm. Then a pruning strategy is applied which reduces redundancy and retain the most effective rules for each cluster k-Means algorithm is used to identify independent cluster.
Jose A. Diaz-Garcia and his team (2022) [28] suggested a brief overview of applications of association rules in the field of social media. The paper also narrates the strengths and weakness of using association rules to solve various tasks of textual social media. As social media mining deals with large amount of unstructured data which do not require labelled datasets so focus is also shifted to using unsupervised techniques.
Chandrasekar Ravi and Neelu Khare (2014) [29] demonstrated EO-ARM algorithm as most efficient algorithm for finding out positive and negative association rules by scanning the database only once irrespective of size of dataset it identifies the frequent item sets by using two dimensional matrix which resemble to k-Map the algorithm was also compared with standard Apriori algorithm in which it was proved that execution time in EO-ARM is much less when compared to Apriori. The algorithm was executed in MATLAB Results show that the use of the projected correlation measure, EO-ARM is more efficient than the normal Apriori method when it comes to execution time and several rules created.
John Tsiligaridis (2013) [30] explained a set of strategies for finding both positive and negative association rules in databases via mining association rules, with a focus on the negative ones. The Apriori classical association rules method is adapted to identify two types of Negative Association Rule (NAR) approaches: Constrained negative association rules (CNR) and Generalized Negative Association Rules (GNAR). The result shows that there is a series of formulae dependent on the tree’s height. Binary tree rules construction (BTRC) was developed for GNAR which can compute negative rules without creating any additional tuples.
Weimin Ouyang (2013) [31] examined that an important approach in data mining is association rule mining. The Mining Positive and Negative Association Rule over sliding window (MPNAR-SW) technique is used in market-basket analysis to identify goods that are either complementary or conflicting. Experiments were carried to find out negative associations over data stream.
Sikha Bagui and Probhal Chandra Dhar (2019) [32] presented a Hadoop implementation with the Apriori algorithm to mine both the positive and negative associations in big data. Map reduce jobs are used to find the frequents item sets from database. The results showed that there were more negative associations found as compared the positive associations, also different datasets with different slave nodes with different block sizes gave the best runtime performance.
Thanh-Long Nguyen and his associates (2017) [33] proposed the CP-Miner algorithm for mining colossal patterns. CP-Miner mines colossal patterns using the CP-tree and pre-processing methods to reduce the search space. CP-Miner, PCP-Miner and BVBUC algorithms were applied to compute patterns of nodes and prune nodes without loss of information in order to mine colossal patterns.
NVS Pavan Kumar and his co-workers [34] presented the work on studying the negative association across all distributed locations in order to determine the regular or global nature of patterns which can also be helpful for business operations. Organizations which are working in global market sometimes also need to carry out data mining operations on distributed data sources which can either homogeneous or heterogeneous so to mine such kind of distributed database we require some databases to be executing in parallel.
Rakesh Duggirala and P. Narayana [35] proposed a method from which association rules can be mined from coherent rules. These coherent rules require only knowledge of propositional logic. Coherent rules were analysed and the rules which were derived from these were being compared with other algorithms. In this positive and negative association rules can be derived without the knowledge of support threshold value.
E. Bala Krishna, B. Rama, A. Nagaraju [36] proposed a new Improved FP tree (IFP– Tree) and a Frequent Sequence Mining algorithm (FISM) to mine negative association rules. The proposed novel approach produced useful and valid negative association rules. The approach which they have defined is definitely capable than the existing FP–Growth based algorithms. The improved algorithm was implemented without generating candidate item sets.
Hetal Jadhav and Kinjal Thakar [37] proposed a new modified Apriori algorithm which helped to find out negatively associated data items within a realistic execution time. The main aim for using modified Apriori algorithm was to reduce space and time complexity in distributed environment on large databases so as to find out the negative association.
Sajid Mahmood and his colleagues [38] describes the methodology for finding the frequent and infrequent item sets and generation of association rules based on these item sets. The experiments were done on medical blog dataset. The positive and negative associations are identified which can help doctors to reach to conclusion among presence or absence of a particular disease.
K. S. Ranjith and A. Geetha Mary [39] proposed privacy preserving data mining technique for spatiotemporal database for mining negative association rules. Privacy became the important factor while mining association rules. The paper also focused on encryption technique of cryptography where partial support for all distributed sites were calculated.
Bemarisika Parfait and her co-workers [40] proposed an efficient method of counting the support primitive called as reduction-access-database and for generating the association rules a new technique called as reduction-rules-space was introduced. Different problems for positive and negative association rules were studied for big data.
Bowei Wang and his co-workers [41] proposed the discovery of association rule by using FP-Growth algorithm which mines both positive and negative frequent patterns. PNFP-Growth seems to be a strategy aimed at enhancing the quality of pattern discovery or data mining results by considering negated items in the analysis process. Experiments were carried out on public dataset from UCI Machine learning repository.
Toung-Long Nguyen and his co-workers [42] proposed a method to extract colossal patterns with length constraints also an attempt was made to shorten the candidates during the extraction process. Minimum and maximum constraints problem was also highlighted in this study. The Length constraint for colossal pattern (LCCP) algorithm was compared with other existing algorithms such as PCP-miner-POST1 and PCP-Miner-POST2 in order to prove the effectiveness of study. The algorithm was helpful in determining whether colossal patterns satisfies the length constraints. The constraints which were not helpful for improving the mining time and does not satisfy the length constraint were eliminated by the algorithm.
Akbar Telikani and his colleagues [43] proposed an approach in which an emerging research of evolutionary computations of Association Rule Mining (ARM) were discussed. Various applications on different types of ARM approaches were discussed such as Market basket analysis, Recommendation systems, computer networks etc. The paper also discusses different types of patterns extracted from large datasets in ARM.Statsistical analysis of different ARM approaches along with their evolution was also narrated in this paper.
Ping Qiu and his co-workers [44] carried out the task to determine whether data sequence contains negative sequence or not and then proposed NegI-NSP algorithm to calculate the support of negative sequence. In this work, two loose constraints were introduced frequency constraint and 1-length-neg element format constraint. Several experiments were carried on synthetic and real data sets in order to compare the performance of NegI-NSP with the baseline approach e-NSP.
Mikhail Moshkov and his colleagues [45] proposed a method to reduce the problem of study of association rules for a dispersed set of single information system with equal set of attributes to study of association rules. The work also shows how a joint information system can be built in a polynomial time. Study of association rule was carried out on transaction data.
B. Rini Rathan and Dr. K. Swarupa Rani [46] implemented a MapReduce model for mining frequent patterns from uncertain data which can be expressed in terms of probabilities. To carry out the mining of these frequent patterns different datasets were taken into consideration. To improve the efficiency of the work MR-Growth algorithm is modified and data is represented in the form of compact tree. The paper also focusses on comparing sequential and map reduce strategies for uncertain data mining. Implementation was being carried out on Java platform.
Moksha Shridhar and Mahesh Parmar [47] presented an efficient mining based algorithm for rule generation. In this study Apriori algorithm is carried out in order to improve precision and recall system. Implementation of different time executions has been carried out with different support and confidence parameters and a comparison of Apriori and regression is being done on highest value of time. In this paper simulation of Apriori with regression is also carried out in .NET framework. The main focus of carrying out this research work was to find locating associations within the item sets. The work was carried out on the partitions of dataset rather than full dataset which results in reduction of time.
Anindita Borah and Bhabesh Nath [48] provided a concise overview of mining rare pattern from synthetic and real datasets. Previous extensive review of what work on rare pattern mining is done is also being narrated in this study. Comparison of frequent and rare pattern mining is also carried out. It has been observed that only a limited attempt has been made by rare pattern mining techniques from data streams, graph database and sequential pattern as compared to frequent pattern mining techniques. The substantial rare patterns in various domains can be recognized.
Summarize the reviewed literature
Summarize the reviewed literature
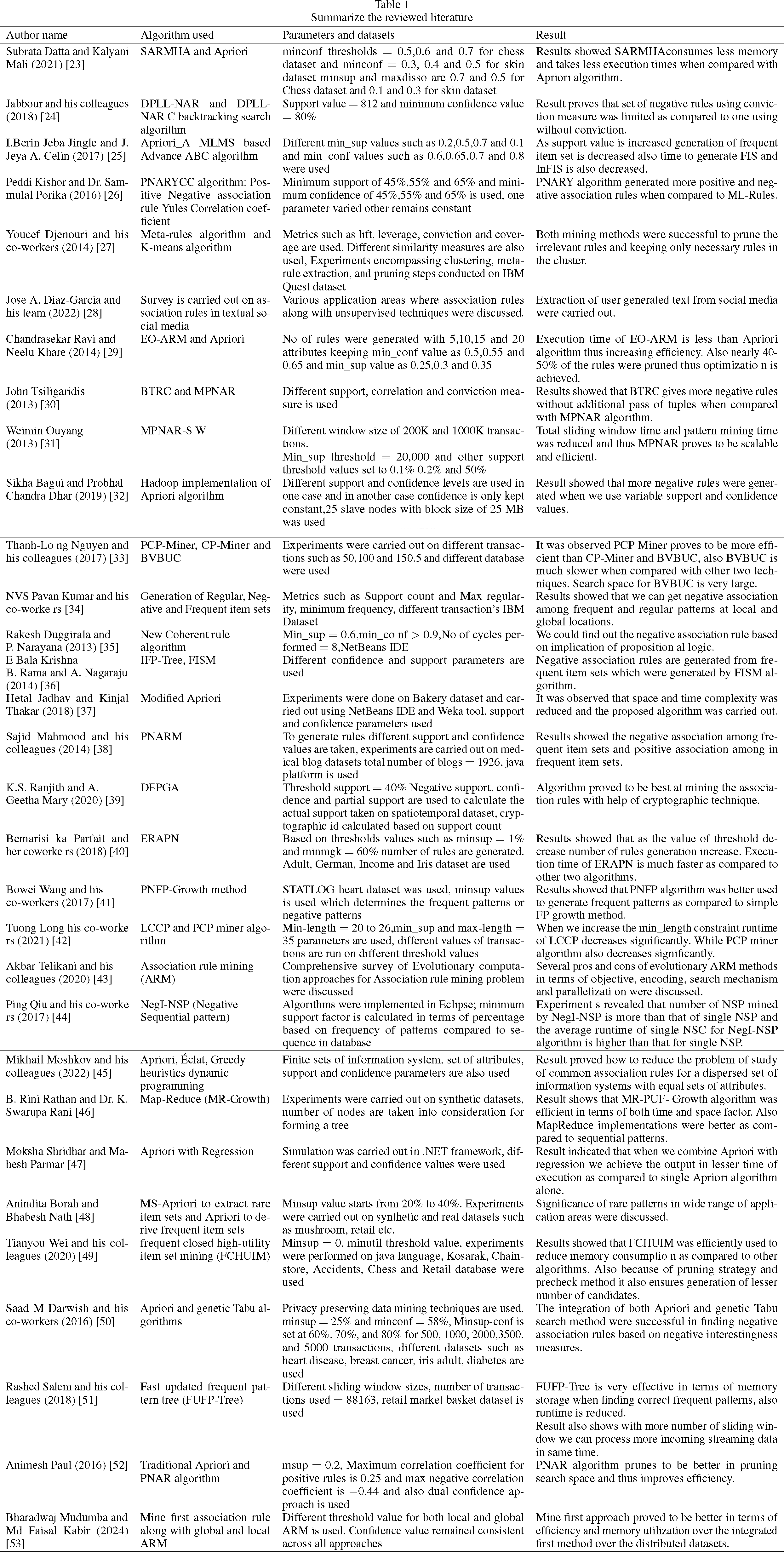
Tianyou Wei and his colleagues [49] presented an algorithm that is used to mine the frequent closed-high utility item set (FCHUIM) to reduce the search space. Experiments were carried out on synthetic and real datasets and the precheck method and nested list structure was also introduced. FCHUIM eliminates the need of scanning the database and provides a summarized list structure for retrieving the utility list.
Saad M. Darwish and his co-workers [50] focused on implementing data mining techniques in the domain of health care. In this study, an investigation is carried out on metaheuristic-based data cleaning for healthcare data in order to keep patient privacy safe. The main purpose of this study was to protect the patient’s data from to be revealed in unauthorized manner. Several privacy preservations in data mining (PPDM) techniques were carried out to keep patient information hidden. The proposed method uses negative interestingness to explain the success of negative association rules.
Rashed Salem and his colleagues (2018) [51] proposed a technique to mine an association rule from streaming data. The technique uses the FUFP-Tree algorithm, that reduces the number of traverses between tree nodes while extracting an association rules between items. In this study, the sliding window approach is also used to divide incoming data equally to all available windows in order to avoid congestion.
Animesh Paul [52] uses the positive and negative association rules (PNAR) algorithm which reduces the degree of redundant and contradictory rules to generate association rules with the help of correlation measure and dual confidence approach.
Bharadwaj Mudumba and Md Faisal Kabir [53] collected data from different varied sources and local association rules were discovered by mining approach and then those rules were integrated with global association rule mining. Class based association rule mining is used where the dataset contains multiple classes or categories, and we want to understand how different attributes are associated within each class separately.
There is a wide range of authors who used the technique and presented their discoveries, as can be found in Table 1.
Computational cost and complexity becomes one of the challenge to face in association rule mining. Support and confidence thresholding, pruning techniques, Top-K rule mining, feature selection and various other techniques can be used to manage complexity and computational cost associated with large scale association task. Generation of large number of rules in association rule mining can pose another challenge in terms of analysis and interpretation. To overcome this generation of large number of rules of association clustering and classification methods can be used. Optimization of association rule can also be used by reducing the search space of all the generated rules as well as applying the pruning techniques. By applying the optimization strategy one can enhance the efficiency of association rule as well as generate the different or extended patterns from the data.
Conclusion and future scope
Association analysis is the act of merging positive item sets with field data to develop negative links. The goal of this process is to construct association rules which is another name for the rules that govern how associations are formed. A mining technique is required to improve the quality of negative associations. Pattern mining have always considered the frequent pattern mining over the years and neglected the rare or negative ones. This study demonstrates different algorithms which were used for mining positive and negative associations. In Future, we can apply some of the data mining techniques or integrate some of the algorithms on extended patterns which are rarely used in order to get negative association items which can be used for better decision-making in marketing strategies. In the future, researchers have conducted an extensive investigation of a variety of algorithms and approaches that are now available for the mining of patterns. They want to include the context of the characteristics into the work to improve the quality and effectiveness of the developed association rules. Tools for mining negative association rules would be added to the source as a further research.