
Abstract
Explainable recommendations enable users to understand why certain items are suggested and, ultimately, nurture system transparency, trustworthiness, and confidence. Large crowdsourcing recommendation systems ought to crucially promote authenticity and transparency of recommendations. To address such challenge, this paper proposes the use of stream-based explainable recommendations via blockchain profiling. Our contribution relies on chained historical data to improve the quality and transparency of online collaborative recommendation filters – Memory-based and Model-based – using, as use cases, data streamed from two large tourism crowdsourcing platforms, namely Expedia and TripAdvisor. Building historical trust-based models of raters, our method is implemented as an external module and integrated with the collaborative filter through a post-recommendation component. The inter-user trust profiling history, traceability and authenticity are ensured by blockchain, since these profiles are stored as a smart contract in a private Ethereum network. Our empirical evaluation with HotelExpedia and Tripadvisor has consistently shown the positive impact of blockchain-based profiling on the quality (measured as recall) and transparency (determined via explanations) of recommendations.
Keywords
Introduction
Crowdsourcing platforms are open, distributed collaborative systems that enable the general public “users” to carry demanding jobs which otherwise would be carried out by paid employees or contractors. Recommendation engines in large e-commerce crowdsourcing platforms entice users by suggesting products based on past customer feedback, current user preferences and interactions, and inter-user similarities. However, the majority of these recommendations are left unexplained, leaving users clueless about their rationale and could eventually lead to distrust of the platform. Therefore, there is a growing need to provide explainable recommendations in order to increase user confidence, but the formulation of explanations is not a trivial task. For example, Besnard et al. [1] employ an ontology-based approach to represent causal statements and then apply several patterns of inference on the ontological information to generate explanations.
According to Tintarev et al. [2], an explanation is any content added to the recommendation that aims to increase transparency, trust, and decision-making effectiveness and generate high quality recommendations [3]. The explanation of recommendations should arguably be sine qua non for crowdsourcing platforms, as they are largely based on past customer feedback.
Traditional recommendation systems have been benchmarked against single user perceptions only using metrics such as precision, recall, or novelty [4] and applying either collaborative or content-based filtering to generate recommendations. However, it has become self-evident that such evaluations ought to consider a more comprehensive search space and, ideally, take into account additional system parameters and group aspects to cross-validate and eventually explain recommendations [5].
Consequently, modern recommendation filters rely on inter-user and inter-item similarities – also known as user-based or item-based filters [6, 7] – to generate a list of items ordered descendingly according to the predicted ratings, the so-called recommendations. To focus on the perspective of a given active user, the recommendation pipeline may include pre- and post-recommendation filters in order to further tailor recommendations to the user’s profile. Specifically, pre-filters use the current user context to reduce the initial search space, whereas post-filters refine the ordering of the list of items from the perspective of the user. In the latter case, the final items order considers not only the value of the predicted ratings, but also other relevant user profile dimensions such as Trust and Reputation (T&R) [8].
In this context, this paper explores the generation of explanations for different types of recommendation systems, using, as case studies, two data sets from the tourism domain namely HotelExpedia and TripAdvisor, via blockchain profiling. Crowdsourced from the Expedia and TripAdvisor tourism sites, these two data sets have been processed incrementally as data streams.
Blockchain (see Section 2.1) has been considered a promising technology with intrinsic properties such as security, authenticity, traceability, and transparency. Especially suitable for environments that require temporal order storage, blockchain ensures data remain authentic and certified by distributed entities rather than a single central authority [9]. This work relies on blockchain to create authentic, traceable, historical profiles used to explain opaque recommendations by means of a private blockchain distributed network (i.e., including several nodes). This design choice grants: (i) a temporal database where past transactions remain recorded in the chain of blocks; (ii) an immutable database where, once a transaction is written in a block, it remains stored in a Merkle tree connected to previous blocks through interdependent hashes; and (iii) a distributed, replicated database, which is harder to infiltrate thanks to the blockchain consensus.
In order to address the explainability and transparency challenges, we focus on two research questions:
Can we improve the quality and transparency of existing online collaborative filters by means of an external a posteriori-filter? Can we use the evolving incremental trust and reputation (T&R) profiles of raters for this purpose?
Transparency is particularly relevant for existing crowdsourcing platforms which incorporate opaque recommendation engines such as Expedia or TripAdvisor. In addition, the evolving T&R profiles can be stored in a blockchain to provide authenticity, traceability and historical logging. These profiles can then be used to reorder the output of opaque collaborative filters and to explain the top recommendations presented.
This article significantly expands and refines our previous work reported in Leal et al. [10] by furnishing a novel method to marshal and enable trust and reputation on incremental profiles using blockchain smart contracts. Such chained historical data are then used to improve the quality and transparency of recommendations for different recommendation filters, namely, memory-based [8] and model-based [11].
In a similar fashion to Jiang-Adeli’s work [12], our system has adopted an engineering approach to forecast the behaviour of incremental profiles under specific operating conditions by using memory- and model-based filters. Given their tamper-proof nature, smart contracts aim to ensure complete data authenticity, i.e. avoid the manipulation from unethical stakeholders as well as user and data provenance.
The main contribution of this work is to rely on engineering-inspired historical stream-based profiling with the help of blockchain to provide explanations and higher quality recommendations. We have performed a series of experiments on representative data sets from two major tourism crowdsourcing platforms (HotelExpedia and Tripadvisor), used as case studies. Our results show noteworthy advantages when using Recall@10 and Target Recall@10 (TRecall) as evaluation metrics. Moreover, from a systems point of view, we have evaluated the blockchain performance in terms of latency and throughput, measured as transactions per second (t/s). The results show not only a positive impact of historical profiling in recommendation, but that trust chained profiles underpin the creation of authentic, traceable and explainable recommendations.
The rest of this paper is organised as follows. Section 2 reviews the background on explainable recommendations, blockchain, traceability, smart contracts, and the current contribution. Section 3 presents a motivational example concerning explainable recommendations in crowdsourcing platforms. Section 4 describes the proposed method for the creation of explainable recommendations. Section 5 presents the experiments performed and the results of the empirical evaluation. Finally, Section 6 summarises and discusses the outcomes of this work.
Explainable recommendations have been discussed in the literature for distinct domains, as part of the ongoing endeavour for Explainable Artificial Intelligence [13, 14] which aims to both improve prediction accuracy and allow humans to understand and have confidence in artificial intelligence systems. Whilst enhancing recommendations with explanations can significantly expand the overall search space by introducing additional user actions, the overall user engagement should arguably be improved ultimately benefiting the given recommendations and user confidence.
Recommendation explainability in fashion has proved to be particularly popular due to the subjective nature of the domain. E-commerce platforms have looked at regions within a picture to explain a given recommendation, e.g., using a multimodal attention convolutional neural network to extract specific features within a fashion shot [15, 16]. Other researchers have employed a semantic extraction network, where two tasks are divided in distinct semantic attributes (items), and then a convolutional neural network classifier is used to represent and classify the items [17]; quantified the influence of different visual regions with a combination of human-interpretable features [18]; used fuzzy logic to build adaptive personalised profiles [19]; or employed proximity alignment of co-purchasing networks to provide online recommendations [20].
Within the food industry, researchers have adopted graphs to describe the hierarchy of preferences of a user [21]. To enhance predictions they used an attention layer where profiles are updated using a hierarchical propagation mechanism and the explanations are generated using a dynamic programming method to determine the usefulness of each feature. Other approaches use deterministic Markov decision process combined with knowledge graph to produce explainable recommendations [22]. Via a reinforcement learning mechanism, their proposed system learns to predict potential items of user interest, such that history can serve as an explanation for the prediction. Other works propose a knowledge-aware path recurrent network model to exploit knowledge graph for recommendation [23]. This graph model can represent semantics and entity relations between users and songs. The sequential dependencies within a path, allows to infer the rationale of a user-item interaction and prediction.
A social network approach has proposed an explanation mechanism for recommendation systems that uses the concept of viewpoints [24]. A viewpoint is the combination of a concept, topic, and sentiment of a sentence, since Natural Language Processing (NLP) techniques can provide useful insights on reviews and explain a recommendation. Similarly, other research groups combine different user sentence vectors into a unified embedding, which are used in the final rating. The attention weights encode the relevance of different review sentences, which can provide rating prediction explainability [25].
In songs and multimedia, recommendations have long employed different techniques including tag-based methods coupled with digital signal processing [26]. To enable explainability, a matrix factorisation combined with a deep learning model have been used to elucidate the recommendations of songs [27]. To produce the explanations the authors used a forward propagation of segments to explain the prediction. Additionally, the explainability of a recommendation can be achieved using rule based learning model from knowledge graph [28]; or using multi-armed bandits to produce recommendations and a reward function that predicts the user engagement of an item with an explanation on a given context [29]. The latter has been developed by the Spotify research team who discusses how their bandits system learns and predicts satisfaction (e.g., click-through rate, consumption probability) for any combination of item, explanation, and context. They also put particular emphasis on the ability to enable logging and contextual retraining in their implementation as a way to “learn from mistakes”.
Specifically, this paper focuses on explaining online recommendations from crowdsourcing platforms. Crowdsourcing platforms not only advertise offers, but also promote the voluntary feedback sharing, which influences the behaviour of the other customers [30]. However, this crowdsourced information, which is voluntarily and freely shared, raises questions about its reliability. Therefore, it is relevant to assess the reliability of crowdsourced information, namely, by using trust and reputation models. Service reputation can be inferred from the reputation of the service contributors, which, in turn, can be based on the analysis of the individual contributions, e.g., reviews or ratings. Therefore, higher reputation indicates higher service quality, allowing, for example, the provider to increase the price [31]. Hence, rater trustworthiness can be derived from the crowdsourced rating stream. This can be achieved together with collaborative recommendation filters, decision trees or neural networks classifiers. Regardless of the technique, the designed system must ensure data authenticity, traceability, and transparency as well as work online and scale well. To maintain authenticity and traceability, the pairwise trust between raters or the stream of ratings can be stored in the blockchain. Considering transparency, the chained pairwise trust and decision trees have a clear advantage over black box neural network models since the explanations are immediately available in the blockchain [10] or are by default embedded in the path from the tree root to the selected leaf [32, 33]. Nevertheless, there are post hoc complex explanation techniques that can be used together with deep neural networks [34]. When it comes to stream processing, while there are online neural network algorithms [35, 36, 37], decision trees [38] and recommendation filters [39] are typically faster. Ultimately, offline neural networks algorithms, such as [40, 41, 42], could be adapted for stream processing with considerable effort. Considering scalability – an essential characteristic for big data processing – there are distributed implementations of both recommendation filters [43], decision trees [44] and deep neural networks [37, 45, 46, 47].
Blockchain
A blockchain, a data structure built as a persistent linked list of records, groups records into blocks which are concatenated via metadata with blocks of the previous chain into a continuous timeline. Each block contains a timestamp with a cryptographic hash of the previous block, and the transaction data (generally represented as a Merkle tree). Due to the use of cryptographic techniques, data contained in a block can only be altered by modifying all subsequent ones. Such property enables its application in distributed environments, where the blockchain data structure acts as a non-relational public database containing irrefutable historical information.
By using an appropriate consensus protocol, it is possible to keep the integrity of the data across all the network nodes without the need of a central trusted entity [48]. As a result, blockchain technology maintains a reliable system state, achieved and strengthened by the member nodes themselves, even in environments where a minority of nodes pursue some malicious behaviour.
There are several types of protocols to reach consensus in a blockchain network such as Proof of Work, Proof of Stake, and Proof of Authority. In particular, this paper explores Proof of Authority (PoA). In PoA-based networks, transactions and blocks are validated by approved accounts, also known as validators, in an automated process that only requires authority nodes to remain secure. Presently, PoA is considered more robust than Proof of Stake and much more efficient than Proof of Work [49]. Besides, this protocol has been implemented recently in the Ethereum network [50]. This implementation is highly scalable for private networks with diverse requirements in terms of quality of service and service level agreements [51, 52].
History, traceability and transparency
The development of Artificial Intelligence based systems should ideally be guided by Accountability, Responsibility and Transparency (ART) design principles [53], i.e., systems should explain and justify their decisions (accountability), incorporate human values into technical requirements (responsibility) and describe the decision-making process and how data is used, collected and governed (transparency). With its transparency, traceability, trust, immutability, desintermediation, and security characteristics [54], blockchain is arguably one of the most promising techniques to achieve ART compliant data processing as data history stays automatically imprinted in the chain of blocks. Having been tested in different applications and industries, blockchain technologies have proved to intrinsically grant (i) decentralised immutable and traceable reputation; (ii) unique users, i.e., only registered users can contribute with ratings or reviews; and (iii) portable and transversal reputation [55].
Smart contracts
Szabo [56] proposed the term smart contract to refer to a computer program which uses algorithmic protocols to ensure the execution of the terms of a contract for securing relationships on public networks. Blockchain technologies enable the implementation of smart contracts in distributed environments without the need of a trusted central authority [57]. A smart contract is composed of dedicated data structures and methods, whose execution are stored as immutable transactions in the blockchain [58].
Due to the intrinsic properties of blockchain technologies such as history, traceability, transparency and security support [59], there is an increased interest in the use of blockchain and smart contracts to implement distributed trust and reputation management systems with the goal to improve the trustworthiness of the information, privacy and security of such systems [60].
Blockchain smart contracts have been employed by trust based systems and/or reputation based systems in a variety of areas such as autonomous systems [61], multi-agent systems [62], fair payments with reputation for cyber physical systems [63], crowdsourcing [64], recommender systems [65] and crowdsourcing-based recommendation systems [10]. Smart contracts have been used to calculate and manage the trust [66] and reputation scores [62, 64], and also to store the trust and reputation values in the blockchain via the contract’s variables [64, 10].
In contrast to the previous works that use smart contracts, our approach employs smart contracts to store historical, traceable inter-user trust profiles with the aim to enable explainable and higher quality recommendations.
Contribution
This work proposes a novel method to explain and refine stream-based collaborative recommendations, supported by blockchain technology. The research addresses the problem of making collaborative recommendation engines transparent, a key feature for any state-of-the-art recommendation/search engine. The proposed method stores profiles in the blockchain not only to keep the history, immutability and traceabilility of the contents, but also to generate trustworthy explanations and improve the quality of recommendations.
Top 3 explainable recommendations for an active user
Top 3 explainable recommendations for an active user
The application of blockchain together with trust and reputation to crowdsourcing platforms is relatively new [67]. The works found in the literature include trust [68, 69] and reputation [70, 64]. Regarding the blockchain, a few use the Ethereum open source framework [70, 69, 64] and one relies on a proprietary solution [68]. This review shows that most crowdsourcing platforms disregard processing transparency. In particular, in the tourism domain where crowdsourcing is extremely popular, no such mechanisms are found in the prevailing platforms.
The proposed method builds incremental trust and reputation profiles (supported by smart contracts) and explores historical data to achieve both decision-making transparency and increased recommendation quality. Moreover, it was designed to be implemented as a plugable module, to be composed by several distributed nodes, and integrated with existing opaque collaborative filters via a post-recommendation filter.
The main contribution focuses on incremental profiling with look-back refinement to provide authentic and trustworthy explanations and higher quality recommendations, improving the user experience.
Recommendation and explanation engine. Module A represents the standard recommendation engine. Module B portrays the novel explanation module (Blockchain, T&R profiling with look-back refinement, and post-filtering).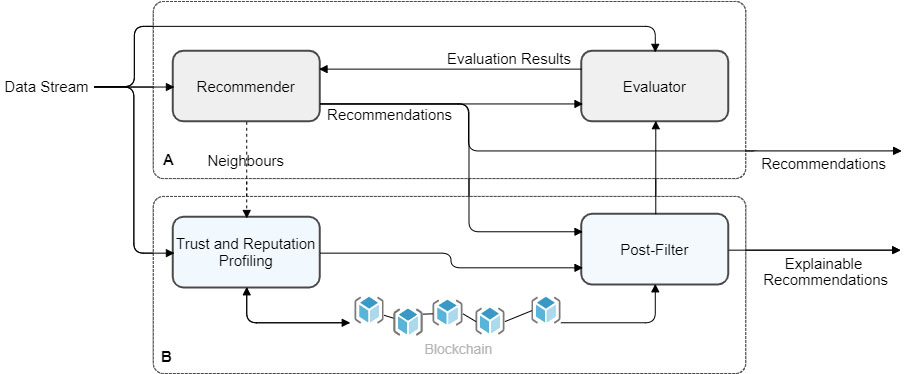
Algorithmic transparency is not a mere ethical concern since it contributes to improving the user experience and confidence on AI-based systems. The proposed method relies on T&R incremental profiling and on the transaction history kept by blockchain to improve the quality of recommendations and to explain the top recommendations. Table 1 presents an example concerning explanations based on Incremental Trust & Reputation Profiling. The active user can click on the questions Why?, Who?, and Which? and the system is able to present the corresponding explanations. These explanations present the user with the reasoning collaborative filters apply to generate personalised recommendations, which is largely based on the set of pertinent item co-raters. Consequently, our method uses the chained inter-user trust and the derived system-wide reputation of the pertinent item co-raters to provide the active user with the reasons behind any item recommendation.
The post-filter reorders and provides explanations for the top
Proposed method
The proposed method explores blockchain technologies to maintain the authenticity, history and traceability of the trust and reputation models.
In this context, we developed a new plugable module – module B – incorporating blockchain-based profiling and trust and reputation post-filtering. As illustrated in Fig. 1, the proposed module can be deployed together with opaque stream-based collaborative filters – module A – to explain recommendations. The blockchain-based profiling integrates a private Ethereum network adapted from Leal et al. [10].
Module B includes an Incremental T&R profile updater, the smart contract holder (private Ethereum network) and the post-filter, whereas module A contains the collaborative recommendation filter, and the evaluator (Root Mean Square Error and/or Recall@N metrics). Our method applies incremental updating (data streaming), i.e., the profiles and models are updated every time a new rating event occurs. In the case of memory-based filters, module B works independently from module A, whereas, in the case of memory-based filters, every time a new event is processed by the module A, the filter shares with module B the set of pertinent neighbours.
Profiling
Profiling is a core component of a recommendation system as it has a direct impact on the quality of recommendations. The type and complexity of profiles depend on the available information sources. This work relies on multi-criteria rating profiles to predict personalised ratings (collaborative filters) and on blockchain inter-user trust profiles to reorder and explain predictions. Specifically, in stream-based recommendation, these profiles are continuously updated and refined.
Rating-based
Rating-based crowdsourcing platforms often allow the classification of services according to different criteria, e.g., overall, cleanliness or staff ratings. In this work, the collaborative filters adopt the Personalised Weighted Rating Average (PWRA). Proposed by Leal el al. (2017) [71], this rating-based profiling combines existing multiple criteria ratings into a single rating. Equation (1) displays the PWRA
Trust is a one-to-one relationship based on the outcomes of direct interactions, whereas Reputation is a many-to-one relationship built upon indirect interactions such as hearsay. Trust and Reputation profiles can be built and employed with both memory and model-based collaborative filters by means of an a posteriori recommendation filter. Therefore, we apply a cascade post-filter to first sort the predictions by rating, then by trust and, finally, by reputation. The aim is to simultaneously improve the quality of recommendations and support the generation of explainable collaborative recommendations.
The trust network corresponds to a multigraph, i.e., a directed graph with up to two edges between the same pair of nodes, representing a trustor and a trustee. These entities can be two users or one user and one item. A directed edge indicates the one-way trust the source node (trustor) has in the target node (trustee). In this context, three situations may occur between the pair of nodes: (i) there is no edge between the nodes; (ii) there is only one directed edge; or (iii) there are two directed edges, each with its own value.
Memory-based filters
Leal et al. (2018) [8] proposed a trust and reputation model for memory-based filters which quantifies the trustworthiness between the active user and its neighbour users by analysing their mutual influence. It takes into account the number of times the active user selects, from the top ten recommendations, recommendations based on a given neighbour. The social reputation of an user is derived from the trust attributed to the user by the set of pertinent neighbours.
Trustworthiness (
Neighbour-based reputation (
System-wide reputation (
Algorithm Appendix, presented in Appendix Appendix A. Algorithms, describes the Memory-based Incremental Trust and Reputation profiling. The algorithm is invoked whenever a new rating event occurs.
Model-based filters
Leal et al. (2019) [11] designed a trust-based profiling approach for model-based filters that quantifies the relatedness between the active user
Trustworthiness (
System-wide user reputation (
Algorithm Appendix, included in Appendix Appendix A. Algorithms, describes the Model-based Incremental T&R profiling. Its execution is triggered by the arrival of a new rating event.
Cascade post-filter
sorts sequentially by rating, trust and, finally, reputation, the predictions generated after each event arrival. To do so, it derives the trust and the reputation that the active user has in the predicted item rating from the trust between the active user and the pertinent item raters. The pertinent users from the perspective of the active user are, in the case of memory-based filters, the subset of the neighbours of the active user who co-rated the item, whereas in the case of model-based filters, they are the subset of relevant item co-raters in whom the active user trusts, at least, as much as the average system-wide reputation.
Item trust (
Item reputation (
Trust and reputation models aim to help the user navigate through a large search space by suggesting relevant items and, thus, improving the user experience. However, when the models are centrally stored, they can be easily manipulated, e.g., to meet hidden interests. Therefore, this paper explores a blockchain-based solution to ensure the authenticity of the profiles supporting explanations. The proposed solution represents T&R models as smart contracts in the blockchain. The smart contract holds a hash table containing the corresponding profiles and supports a collection of transactions to alter and access the stored model as illustrated in Fig. 2.
Smart contract structure.
Specifically, the trust smart contract stores the trust between neighbours or co-raters obtained with Eq. (2) or Eq. (5), depending on the collaborative predictor employed. These values are updated with each incoming event, therefore allowing tracing over time. Algorithm Appendix A. Algorithms, included in Appendix Appendix A. Algorithms, shows the contents of the Trust Smart Contract.
Every time some trustor chooses an item due to a trustee, the incremental trust of the trustor in the trustee is updated and stored in the blockchain. This event-driven storage of the incremental trust in the blockchain constitutes yet another source of relevant information – the trust time series. This historical trust data can be used to refine further individual profile, resulting in the look-back refinement.
Figure 3 plots the incremental trust and reputation with and without look-back refinement for two HotelExpedia users, where user 121 is the trustor and user 104 is the trustee. Figure 3a shows the evolution of the incremental trust user 121 has in his neighbour 104 (
Incremental T&R profiling with and without look-back refinement. (a) 
The incremental and historical data can be combined to refine the inter-user trust and, after, derive user-item trust and system-wide user and item reputation. This work considers statistical linearisation (Eq. (9)), recursive statistical linearisation (Eq. (10)) and slope sign changes reinforcement (Eq. (11)). The resulting profile is called the incremental profile with look-back refinement or simply refined profile.
Equation (9) provides the linearised statistical trust and reputation profiles (
Equation (10) displays the recursive linearised statistical trust and reputation profiles (
Equation (11) presents the sign changes refined profiles (C) based on the slope sign changes of the incremental profile. In this case, the current incremental profile value is reinforced by the ratio of value increases to value decreases plus equal values, where
Explainable recommendations address the question of ‘Why has this item been recommended?” by sharing with the user the reasons for the recommendation. In a transparent system, it is important to explain the recommendation process, clarifying if it took into account the user’s preferences or rather hidden interests. In this context, the proposed method relies on the chained models to reorder and explain recommendations following the approach proposed by Leal et al. [10].
The proposed method associates and stores in a smart contract the one-way trust each user (trustor) maintains in each of his influential users (trustees). This set of users corresponds, in the case of memory-based filters, to the top nearest neighbours and, in the case of model-based filters, to those users with a larger number of relevant co-rated items. Once the collaborative filter generates predictions for the active user, the post-filter sorts the list and presents the top
The idea of using trust models as part of a broader recommendation explanation was introduced by O’Donovan and Smyth (2005) [72]. Table 2 exemplifies the type of support information available to generate explanations for the active user
Aggregated explanation data
Aggregated explanation data
Detailed explanation data
These generic explanations can be further detailed by specifying the individual contributions of each co-rater
The proposed method is empirically evaluated by calculating incrementally for each incoming event the following metrics:
Incremental root mean square (RMSE), defined by Takács et al. (2009) [73].
Incremental Recall@N, proposed by Cremonesi et al. (2010) [74], computes the classification accuracy based on a sample of 1000 randomly selected items never rated by the active user plus the newly rated item by the active user. The sample is then sorted by descending prediction value and the top
Incremental TRecall@N, proposed by Veloso et al. (2017) [75] computes the classification accuracy similarly with the approach of the incremental Recall@N. However, it counts a hit only if the prediction is close to the target rating, i.e., within a radius of
The performance of the blockchain is assessed using the following metrics [76]:
Throughput to determine the number of successful blockchain transactions per time unit.
Latency to establish the time delay between the submission and completion of a blockchain transaction.
Experiments and results
The empirical evaluation focused on the assessment of stream-based explainable recommendations with smart contract profiling. The implemented stream-based recommendation engines include a collaborative memory-based filter [8] and a collaborative model-based filter [11]. The accuracy and classification accuracy were evaluated using RMSE, Recall@10 and TRecall@10. The aim was to analyse the performance of: (i) PoA consensus algorithm; (ii) rating-based (PWRA); and (iii) post-filtering with trust-based (T&R) profiling. Specifically, the profiling experiments contemplated incremental profiling with and without look-back refinement (with the three look-back refinement versions).
The experiments were conducted on an OpenStack cloud instance with 16 GiB RAM, 8 CPU and 160 GiB of hard-disk space. The blockchain technologies employed were: (i) Go-ethereum1 as Ethereum client; (ii) Solidity2 as smart contracts language; and (iii) Web3J3 as Java Application Programming Interface. The configuration of the implemented private Ethereum network is composed of two miner nodes. In the case of PoA, the private Ethereum network was configured with a block period of 2 s and a block gas limit of 0
The models are incrementally updated with each incoming stream event. The default trustworthiness is initialised at 0%. The
The implemented application programming interface (API) with Ethereum offers three transactions. The uniform resource identifier (URI) of each transaction, including the input parameters, and responses are summarised in Table 4. Parameter
Blockchain API
Blockchain API
The proposed method was evaluated with the incremental protocol and different data sets, profiling approaches and recommendation filters. Specifically, we used the HotelExpedia and TripAdvisor data sets to perform the experiments. The data sets were ordered temporally and the events were processed sequentially without initial models.
HotelExpedia was gathered by Leal et al. (2017) [77]. After discarding the anonymous users, the resulting data set contains 50603 hotels, 1090 users and 214342 reviews from 10 different locations. Each user classified at least 10 hotels and each hotel contains at least 10 reviews. The average and standard deviation of the number of hotels rated per user is 197
TripAdvisor was collected by Wang et al. (2010) [78]. It includes 9114 hotels, 7453 users and 127517 hotel reviews. Each user classified at least 10 hotels and each hotel contains at least 10 reviews. The average and standard deviation of the number of hotels rated per user is 17
Results
The results of the experiments are depicted in Table 5. They compare the average incremental accuracy, classification accuracy and processing time of the different approaches.
Comparison of Memory- and Model-based approaches. The table contains the results of: (i) baseline method (PWRA); (ii) baseline method
T&R post-filtering
blockchain using PoA; and (iii) baseline method
incremental T&R with look-back refinement
blockchain using PoA. The results show a positive impact of incremental profiles in terms of Recall@10 and TRecall@10 in both recommendation models. Since our solution acts a posteriori, RMSE remains unchanged
Comparison of Memory- and Model-based approaches. The table contains the results of: (i) baseline method (PWRA); (ii) baseline method
Collaborative filter (CF); Post-filter (PF); Look-back refinement: Statistical (S); Recursive (R); Sign changes (C).
The first set of experiments was performed with the HotelExpedia data set. The memory-based collaborative filter employs
The second set of experiments was performed with the TripAdvisor data set. The model-based filter employs Singular Value Decomposition with Stochastic Gradient Descent (SVD-SGD). Similarly, the first experiment corresponds to the baseline method, namely SVD-SGD model-based collaborative filter with incremental updating and rating-based (PWRA) profiling. Experiments two and three use this baseline method to generate predictions and apply four post-filter variants, corresponding to the incremental T&R and three refined incremental T&R blockchain profiles.
T&R incremental profiling: Improvement with look-back refinement
As expected, the prediction accuracy remains unchanged since the collaborative filter is the same. Blockchain profiling slows the execution as it requires time to mine the blocks. In our Ethereum network with PoA the average mining time is 2 s per block.
Overall, the results of coupling a T&R post-filter to collaborative filters show that:
Incremental T&R reordering improves the quality of the default recommendations. Recall@10 increases 176% for HotelExpedia and 37% for TripAdvisor and the TRecall@10 136% for HotelExpedia and 38% for TripAdvisor.
Incremental T&R with Look-back refinement reordering improves further the quality of recommendations. Table 6 displays the improvement obtained with Eq. (9). HotelExpedia shows an approximate increase in Recall@10 and TRecall@10 of 4%, and TripAdvisor an increase in Recall@10 and in TRecall@10 of 44%.
Profiles, when stored as smart contracts, maintain their history immutable and traceable at the cost of time, and can be used to provide trustworthy explanations. When compared with the baseline method, the average increase in processing time per event was: (i) 2.2 and 2.7 times for the incremental and refined versions with memory-based filtering; and (ii) 0.11 and 0.30 times for the incremental and refined versions with model-based filtering.
Chi-square test results
To statistically analyse the memory- and model-based results with and without look-back profiling, we performed a Chi-Square Test of independence. This test considered, as rows, the five profile categories, and as columns, the R@10, TR@10 and latency metric categories presented in Table 5. The five profiling approaches are the baseline, without post-filtering, and the four PoA blockchain profiling post-filtering variants, resulting in 8 degrees of freedom. These variants include, first, the incremental T&R profiling and, then, the statistical, recursive and sign changes look-back refinements. The Chi-Square Test examines, then, for each data set and collaborative filter, the relationship between the different types of profiles and the three evaluation metrics. Table 7 presents the Chi-Square Test results of the memory and model experiments, which show that, in both cases, the values of the metrics depend of the profiling variant.
Finally, we determined the latency and throughput of the implemented private Ethereum network using PoA. These experiments were repeated four times.
Table 8 displays the results in terms of average latency and throughput as well as the number of transactions on the private Ethereum network with both data sets.
Ethereum performance results
Ethereum performance results
Crowdsourcing platforms rely on voluntary contributions, such as ratings, reviews or views, to generate recommendations. While research has shown that richer profiles improve the accuracy of the recommendations, these recommendations are mostly opaque to the end-user. To address this problem, this work explores the generation of trustworthy explanations supported by blockchain technology. Our proposal explores: (i) incremental trust and reputation profiling with look-back refinement; (ii) the storage of inter-user trust in a blockchain smart contract; and (iii) post-filtering as a means to improve and explain collaborative recommendations.
The proposed incremental updating method can be applied to any crowdsourced platform that provides recommendations. In order to evaluate our method, we have used HotelExpedia and TripAdvisor data sets to test and evaluate it using incremental RMSE, Recall@10 and TRecall@10 as evaluation metrics.
The post-filter reorders the recommendations, in the memory-based case, based on the trust between the active user and his neighbours as well as the system-wide reputation of his neighbours; and, in the model-based case, on the trust between the active user and his co-raters together with their derived system-wide reputation.
When we compare the incremental T&R profiling with and without look-back refinement, we can see a clear improvement of the recall-based metrics. This improvement was achieved exclusively by using the new look-back method to reorder the list of recommendations issued by the collaborative filter. In the case of the model-based filter, the increase was 40% higher than with memory-based. This can be explained by the fact that
Concerning blockchain technology, and as a proof of concept, we have analysed the average latency and throughput per transaction and the average execution time per event. The blockchain latency was less than 5 ms/t with a throughput of at least 210 t/s. These values can be used as an indication of the expected blockchain performance when both the experiments and the blockchain are deployed within the same network. Nevertheless, the obtained latency was a good result for the Ethereum blockchain network. The average execution time per event is considerably higher with memory-based filtering and HotelExpedia (2.2 and 2.7 times higher for the incremental and refined versions) and higher with model based filtering and TripAdvisor (0.38 and 0.44 times higher for the incremental and refined versions). This indicates that the price to pay for a distributed, temporal, traceable and immutable database is latency.
To sum up, this paper presents a novel explanations module for crowdsourcing collaborative filters. This plugable module, supported by incremental trust and reputation profiling with look-back refinement, improves the quality of recommendations and explains the recommendations to the end-user.
As future work, we intend to identify and minimise the impact of malicious users (human or bots) in collaborative recommendation by exploring blockchain as the system-wide data gatekeeper. In this new role, it will hold individual profile smart contracts between each user and the platform, comprising all profile features, instead of just T&R. Finally, decision trees or neural networks classifiers, using single or ensemble models, can be used to predict and classify rater trustworthiness directly from the crowdsourced rating stream. However, to maintain data authenticity and traceability, those classifiers should be supported by blockchain solutions; this is another research direction.
Footnotes
geth.ethereum.org/.
solidity.readthedocs.io/.
docs.web3j.io/.
Acknowledgments
This work was partially financed by: (i) the ERDF – European Regional Development Fund through the Operational Programme for Competitiveness and Internationalisation – COMPETE 2020 Programme within project POCI-01-0145-FEDER-006961, and by National Funds through the Portuguese funding agency, FCT – Fundação para a Ciência e a Tecnologia, within project UIDB/50014/2020; (ii) the Xunta de Galicia (Centro singular de investigación de Galicia accreditation 2019–2022, also financed from ERDF); and (iii) the Irish Research Council within the framework of the EU ERA-NET CHIST-ERA project SPuMoNI: Smart Pharmaceutical Manufacturing
Appendix
Memory-based incremental trust and reputation
User generated event
Updates
*[h]Update the trustworthiness of
()
*[h]Update neighbour-based reputation of
()
()
[h!t] Model-based: Incremental trust and reputationUser generated event
Updates
()
*[h]Update system-wide reputation of
()
()
()
()
*[h]Update the raters of
*[h]Returns the subset of pertinent co-raters of
FMainupdatePertinents FnFunction:
()
Appendix A. Algorithms
Algorithm Appendix describes the Memory-based Incremental Trust and Reputation profiling. The algorithm is invoked whenever a new rating event occurs and needs access to the current set of items
Algorithm Appendix describes the Model-based Incremental Trust and Reputation profiling, which is triggered by the arrival of a rating event
Algorithm Appendix A. Algorithms describes the Trust Smart Contract. The smart contract maintains a hashtable with as many entries as users. In turn, each user entry keeps an individual hashtable holding trustee data. The smart contract implements two transactions: (i) updates the trust the trustor has in the trustee; and (ii) retrieves the current trust the trustor has in the trustee. In this incremental setup, the trustor corresponds to the active user
Structstruct {}
[!t] Trust Smart Contract Store trust transaction:
Store/retrieve
*[h]Trustee data structure
TrusteeDS
*[h]Trustor hashtable: holds the trustee data of all trustees of
TrustorHT
*[h]User hashtable: aggregates the trustor hashtables of all users mapping(uint => TrustorHT) user;
*[h]Creates or updates
FMainupdateTrust FnFunction:
*[h]Retrieves
FMaingetTrust FnFunction: