
Abstract
In today’s rapidly emerging computing environment, cloud computing has become a significant trend for the delivery of IT business services, and representes a potential technology resource choice that offers cost effective and scalable processing. However, Distributed Denial of Service (DDoS) attacks continually target cloud services and resource availability, rendering the cloud unavailable to the detriment of both cloud providers and users. In previous research, feature selection, has revealed its importance in the recognition of irrelevant and redundant features, which increases detection rates and decreases processing speeds toward the evaluation of intrusive patterns, while reducing computational complexity. In this work we propose a Hybrid Filter-Wrapper Feature Selection HFWFS method for DDoS detection, which takes advantage of both filter and wrapper methods, to identify the most irrelevant and redundant features in order to form a reduced input subset. Subsequently, it applies a wrapper method to achieve the optimal selection of features. To evaluate the performance of our proposed model, we used two datasets (NSL-KDD and UNSW-NB15) and a Random Tree classifier. The results indicated that the proposed model may reduce the number of features from more than 40 to nine, while maintaining high detection accuracy, in contrast to well-known feature selection methods.
Introduction
The adoption of cloud computing has been a lively topic of discussion over the last few years. The NIST has advanced the most commonly employed definition of the cloud-computing approach as an approach that facilitates expedient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that may be rapidly provisioned and released with minimal supervision efforts, or service provider interactions. There are three primary service models, namely Software as a Service (SaaS), Infrastructure as a Service (IaaS), and Platform as a Service (PaaS) [4, 8]. The emergence of the cloud computing approach serves as a motivating factor for both industry players and academia to embrace the model in order to host a wide range of functions, ranging from highly computationally rigorous functions down to lightweight services.
Concomitant with the drastic increase in the popularity of cloud computing, attention has shifted toward security issues that have been introduced since the model was operationalized. One such issue comprises Distributed Denial of Service (DDoS) attacks. A Denial of Service attack is one that has the purpose of preventing legitimate users from engaging with a specified network resource, such as a website, web service, or computer system [30]. A Distributed Denial of Service (DDoS) attack is a coordinated assault on the availability of services of a given target system or network, which is launched indirectly through multiple compromised computing systems known as zombies [30, 25]. Such attacks have continued to propagate both in size and sophistication, and extortion has been identified as one of the main underlying motives [21].
Generally, DDoS detection systems are based on the assumption that the behavior of intruders is different from that of legitimate users, which may be categorized into two primary approaches; misuse based, or anomaly based. Misuse detection, also known as signature-based detection, is based on the storage of all features of known attacks in a knowledge database in order to identify an attacker; the reason why it is efficient for the detection of known attacks. Alternatively, anomaly based techniques employ the behavioral changes of users in the network, where any deviations from normal or expected behavior is considered to be associated with an intruder .
One of the key issues with DDoS detection systems relates to response times, due to the increasing volume of information and data that must be processed in real time [23, 9, 55, 54]. Utilizing feature selection can deal with such issues; it improves classification accuracy and reduces computational complexity by identifying only the critical and relevant attributes from a dataset. Feature selection is utilized in various areas such as statistical pattern recognition, machine learning, and data mining [11]. There are three principal categories of feature selection, including algorithms, filter, wrapper, and embedded methods [31].
Filter feature selection methods apply a statistical measure to assign a score to each feature. Features are ranked by the score, and are either selected to be kept or removed from the dataset. The methods are often univariate and consider the feature independently, or with regard to a dependent variable (e.g., Chi squared test, information gain, and correlation coefficient scores) [33, 49, 48]. Wrapper methods, on the other side, consider the selection of a set of features as a search problem, where different combinations are prepared, evaluated and compared to other combinations. A predictive model is employed to evaluate a combination of features and assign a score based on model accuracy (e.g., recursive feature elimination algorithm.). Lastly, embedded methods learn which features best contribute to the accuracy of the model while the model is being created. The most common type of embedded feature selection methods are regularization methods (LASSO, Elastic Net, and Ridge Regression).
Recent studies have shown that the combining of feature selection methods can improve the performance of classifiers by identifying features that are individually weak, but strong as a group [44], removing redundant features [48], and determining features that have a high correlation with the output class. In this work we propose a hybrid feature selection that combines both filter and wrapper. We present a Hybrid based Filter and Wrapper Feature Selection (HFWFS) method that combines the output of Chi-square, Info Gain, Gain Ratio and WrapperSubset
This paper presents a novel hybrid feature selection strategy using filter and wrapper feature selection model for DDoS detection on Cloud environment, which combines filter methods (Chi-Square, InfoGain and GainRatio) and a wrapper based on greedy step-wise search method, in order to select important features and to significantly reduce the feature set while maintaining or improving classification accuracy using a Random Tree classifier. We specify the main contribution of our work as follows:
Novelty. The proposed approach inserts the reduced and substantial attributes obtained by filters into a wrapper phase where a predictive model is used to evaluate different combination and to get the most relevant subset of features to identify DDoS attack in Cloud environment. Effectiveness. The hybrid algorithm takes the efficiency of filters and the accuracy of wrappers, so we can improve the classification accuracy and we decrease the processing time of wrappers. The selected features by our model show the best detection accuracy compared with existing feature selection approaches. Robustness. Our proposed feature selection approach is tested on two different datasets NSL-KDD and UNSW-NB15 data sets. On both datasets the hybrid model produces an improvement in detection accuracy compared to other approaches.
The remainder of the paper is organized as follows: related work is presented in Section 2, while the proposed HFWFS method is described in Section 3. In Section 4, the classification algorithm and benchmark datasets are presented. In Section 5, our experimental findings are discussed. Section 6 concludes the paper.
Due to the continuous expansion of network traffic data volume and the high dimensionality of the feature space, feature selection is becoming an essential phase toward building intrusion detection systems [2]. In any intrusion attempt there are a number of behavioral patterns and interrelations that are unique and recognizable. Since these patterns are hidden within irrelevant and redundant features, it is often difficult to discover them. Feature selection methods have been applied in classification problems to select a reduced feature subset from the original set to achieve faster and more accurate classification, and to eliminate less relevant features [42]. The selection of the correct feature can be quite a challenging task; several methods have been proposed to resolve this issue, while discarding redundant, irrelevant, and noisy features [22].
Mukkamala and Sung [36] proposed a novel feature selection algorithm to reduce the feature space of the KDD Cup 99 dataset, from 41 dimensions to six dimensions, and evaluated these six selected features using an IDS based on SVM. The results showed that the classification accuracy increased by 1% when using the selected features. Chebrolu et al. [35] investigated the performance of a Markov blanket model and decision tree analysis for feature selection, which showed the capacity to reduce the number of features in KDD Cup 99, from 41 to 12 features. Chen et al. [50] proposed an IDS based on Flexible Neural Tree (FNT). The model applied a pre-processing feature selection phase to improve the detection performance. Using KDD Cup 99, the FNT model achieved 99.19% detection accuracy with only four features.
Huang et al. [46] present an anomaly detection model based on quantum wavelet neural network and normalized mutual information feature selection, the method is used to select best feature combination from a given sample features sets. Experiment results using KDD99 data set showed a reduction of features from 41 to 20 which is still an important number that affect the train and execution time, even the model achieve a detection accuracy of 98.88 when dealing with DoS attack. In [28] authors present an intelligent water drops (IWD) algorithm for feature selection, a nature inspired optimization algorithm with support vector machine as a classifier. Experiments conducted using KDDCUP99 dataset, the model was able to reduce the number of features to 9 features while maintaining the detection accuracy at 99.09%.
Wang and Combault [47] used Information Gain to extract and rank nine of the most important attributes as input values to train and detect a DDoS attack in the network traffic. The results obtained using a C 4.5 and Bayesian network indicated that the detection accuracy remained the same or was even improved. Bolon-Canedo et al. [44], proposed a new method for combining discritizers, filters, and classifiers to improve the classification performance for both binary and multi-class classification problems. This method was applied to the KDD Cup 99 dataset, where the results obtained showed an improved performance, while reducing the number of features.
The Group Method for Data Handling (GMDH) comprises a supervised inductive learning method [53]. The KDD’99 dataset was preprocessed using Info Gain, Gain Ratio, and GMDH to rank features, and the results of the detection rates achieved 98%. Lin et al. [37] developed an anomaly based intrusion detection strategy that combined SVM, Decision Tree, and Simulated Annealing (SA). SVM and SA identified the most critical features from the KDD’99 dataset to detect new attacks toward improving the detection accuracy of SVM and DT. Feature selection and multi-agent intrusion detection were implemented onto an Industrial Control System (ICS) [12]. The NSL-KDD data set was used to compare the performance of the proposed method to common feature selection techniques (Info Gain, Gain Ratio, Relief, and Chi-square).
Sindhu et al. [39] addressed the challenge of identifying important features by employing a wrapped based feature selection algorithm, and realized an IDS with a neuro tree to achieve a higher detection accuracy. Zhang et al. [11] proposed a feature selection approach based on a Bayesian Network classifier with the aim of decreasing the attack detection time, and to improve the classification accuracy, as well as the true positive rates. The performance of this proposed approach was evaluated with the NSL-KDD dataset, and compared with other commonly used feature selection methods. The authors of [16] have combined a Correlation-based Feature Selection (CFS) technique and ANN for DoS detection. The method consists of collecting the incoming network traffic, selecting relevant features for DoS detection the CFS method and classifying the network traffic into DoS traffic or normal traffic. The proposed method achieved satisfactory results on both UNSW-NB15 and NSL-KDD datasets.
Clustering is an unsupervised technique that is also used for feature selection. Data with similar characteristics are placed in a group called cluster. The task of feature selection involves two steps, namely partitioning the original features set into a number of homogenous subsets (clusters) and selecting a representative feature from each cluster. A K-Means method that creates mutually exclusive clusters, which effectively helps in identification of significant features for the attack, has been used in [34] to build a multi-measure approach containing filter, wrapper and clustering methods, that work in parallel in order to generate a rank of features by assigning a multi-weight to each feature. The experimental studies show that the less important features as identified by the proposed approach does not affect the performance of most of the classifiers in detecting DoS and probe attacks in various types of network datasets. Li et al. [51] proposed a gradual feature removal method that processed the dataset prior to employing the combining cluster method, ant colony algorithm, and SVM to classify network traffic as either normal or abnormal.
On the other hand, some research has been conducted on the detection of DDoS attacks on cloud computing. Wang et al. [45] proposed a graphic model based attack detection technique that may deal with the dataset shift problem in the era of cloud computing. Xu and Shelton [19] employed a continuous time Bayesian network model, which considered temporal sequences of events, to construct both network-based and host-based intrusion detection systems. Osanaiye et al. [31] proposed an ensemble-based multi-filter feature selection method that combined the output of four filter methods to achieve an optimal selection. Experimental evaluation performed using the NSL-KDD dataset and decision tree, revealed that the detection rate and classification accuracy was enhanced, while the number of features was reduced from 41 to 13.
The aim of this paper is to present an algorithm that supports data mining and security detection for Cloud DDoS attacks with minimal features for real time response. HFWFS is method that filters and combines the output of filter and wrapper methods to identify the most relevant features selected by each technique. The performance of a suggested feature selection algorithm was evaluated using a NSL-KDD dataset, which represented an improved version of the original KDD Cup 99 and UNSW-NB15 datasets; a recent dataset generated at the Australian Center of Cyber Security (2015). We implemented our HFWFS method using Weka data mining software [10], and used the Random Tree classification algorithms to classify the incoming network traffic as normal, or as a DoS attack.
A hybrid feature selection method HFWFS
Filters vs wrappers
As mentioned above, filter methods carry out the feature selection as a pre-processing phase. The information of a set of features might be calculated by the distances between classes, or via statistical measures over a training dataset. Figure 1 shows that Filters possess three primary stages: initially, feature subsets are generated, whereafter the features are scored and a threshold is determined in order to remove the features that are below a certain threshold. Finally, the testing step proceeds through the use of a learning algorithm, where the results include the testing results of the selected features. The filter model is more rapid than the wrapper approach. and results in an improved generalization as it acts independently of the induction algorithm. Hence, filters are often applied to feature selection in high-dimensional data.
The filters.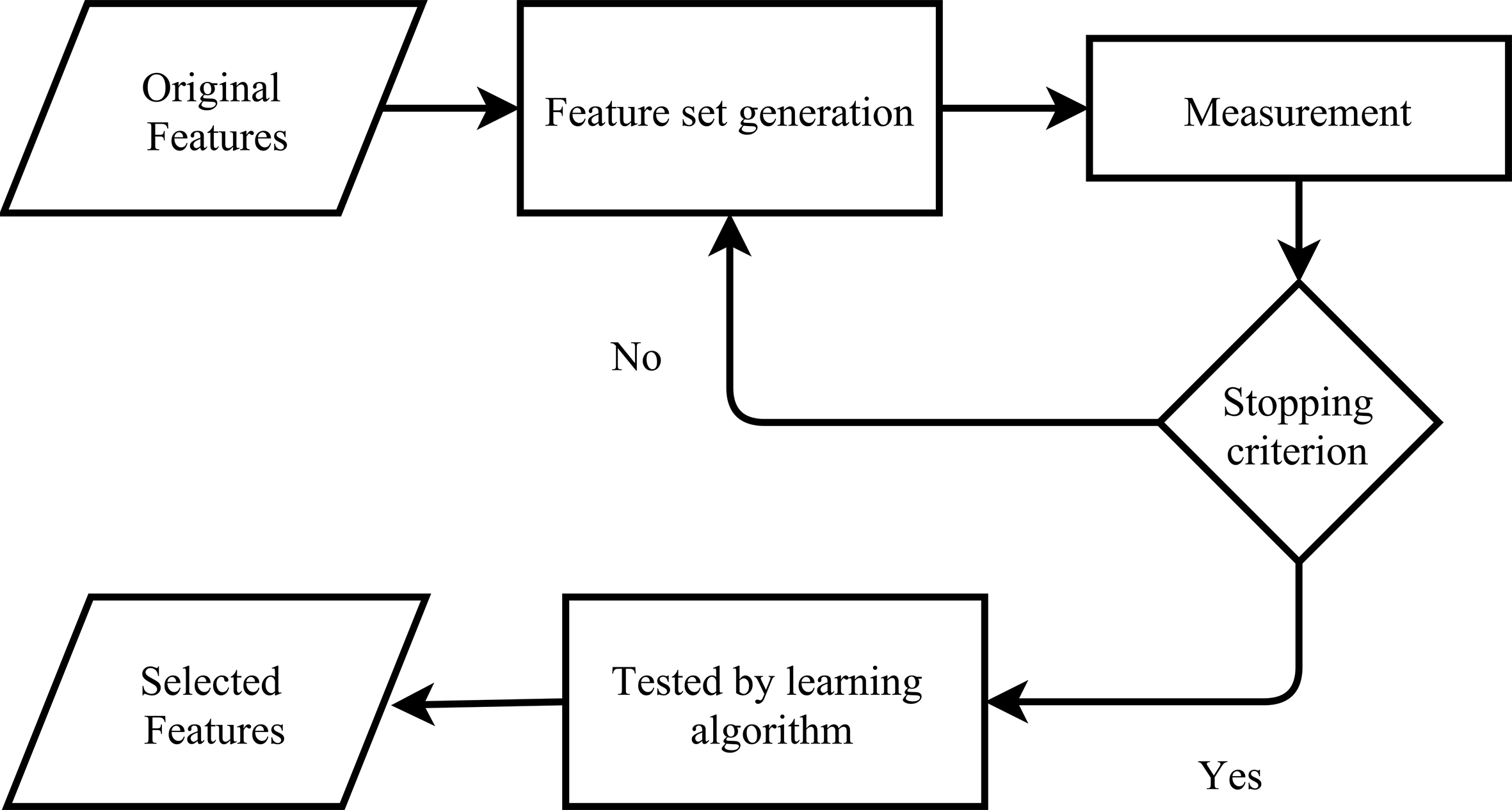
The working procedure of wrappers is the same as that of the filters, with the exception that the measurement stage is replaced by a learning algorithm Fig. 2. This cause the wrappers perform slowly; however, they can achieve improved feature selection results in most cases. The stop criterion might be through a predefined number of selected features, or when the performance begins to degrade [15].
The wrappers.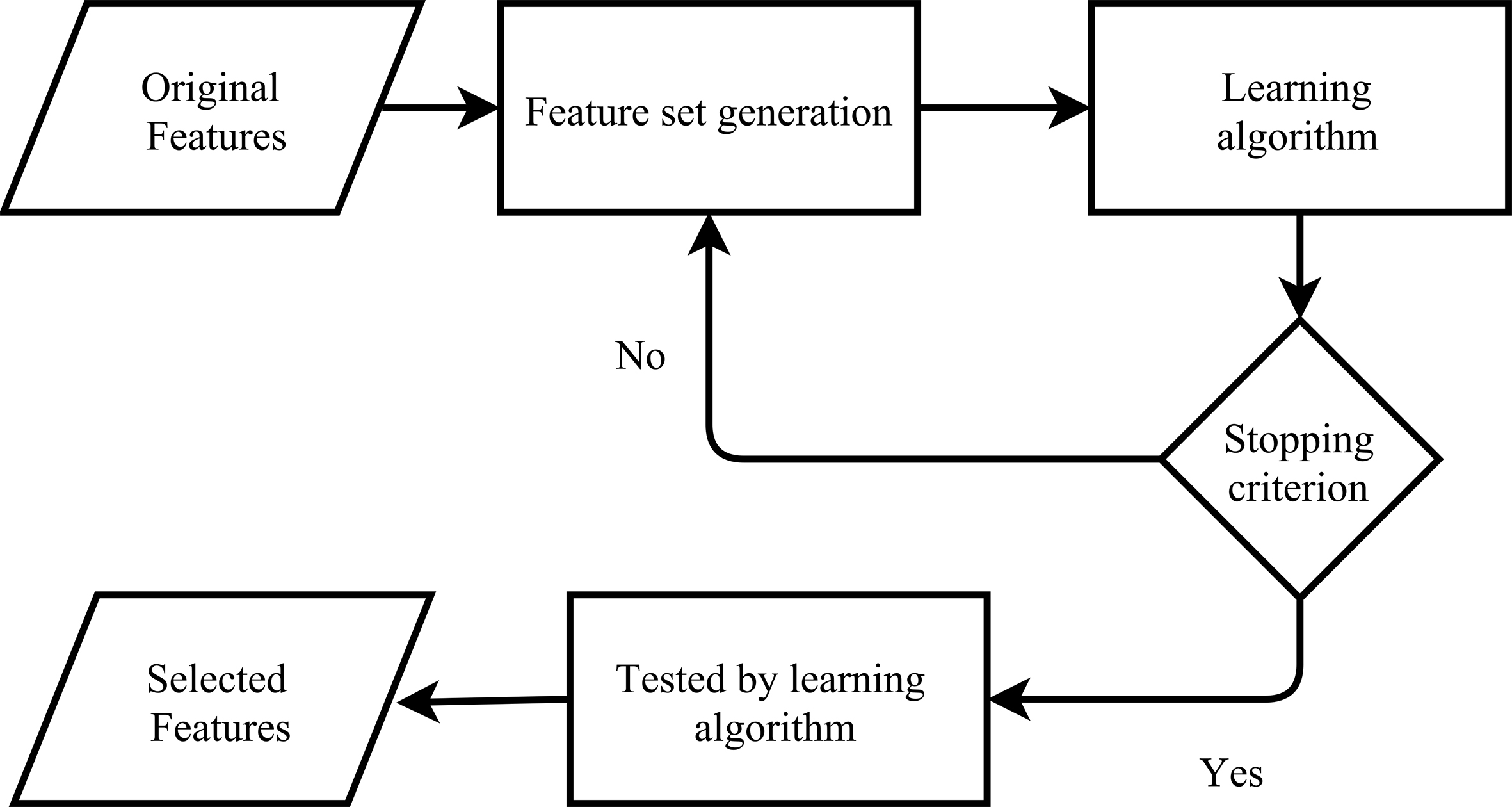
In this section, we describe our proposed hybrid filter wrapper method. We initially used Chi-square, Info Gain, and Gain Ratio methods to eliminate a large number of irrelevant and redundant features, with the aim of reducing the complexity of the search space. Secondly, we applied a wrapper method to find a smaller set of features than those obtained through filters. The proposed method utilized the filter method efficiency and high classification accuracy of wrapper methods to complete each other’s selections. Figure 3 depicts an overview of the proposed hybrid Filter-Wrapper method for feature selection.
A flowchart of the proposed hybrid feature selection method.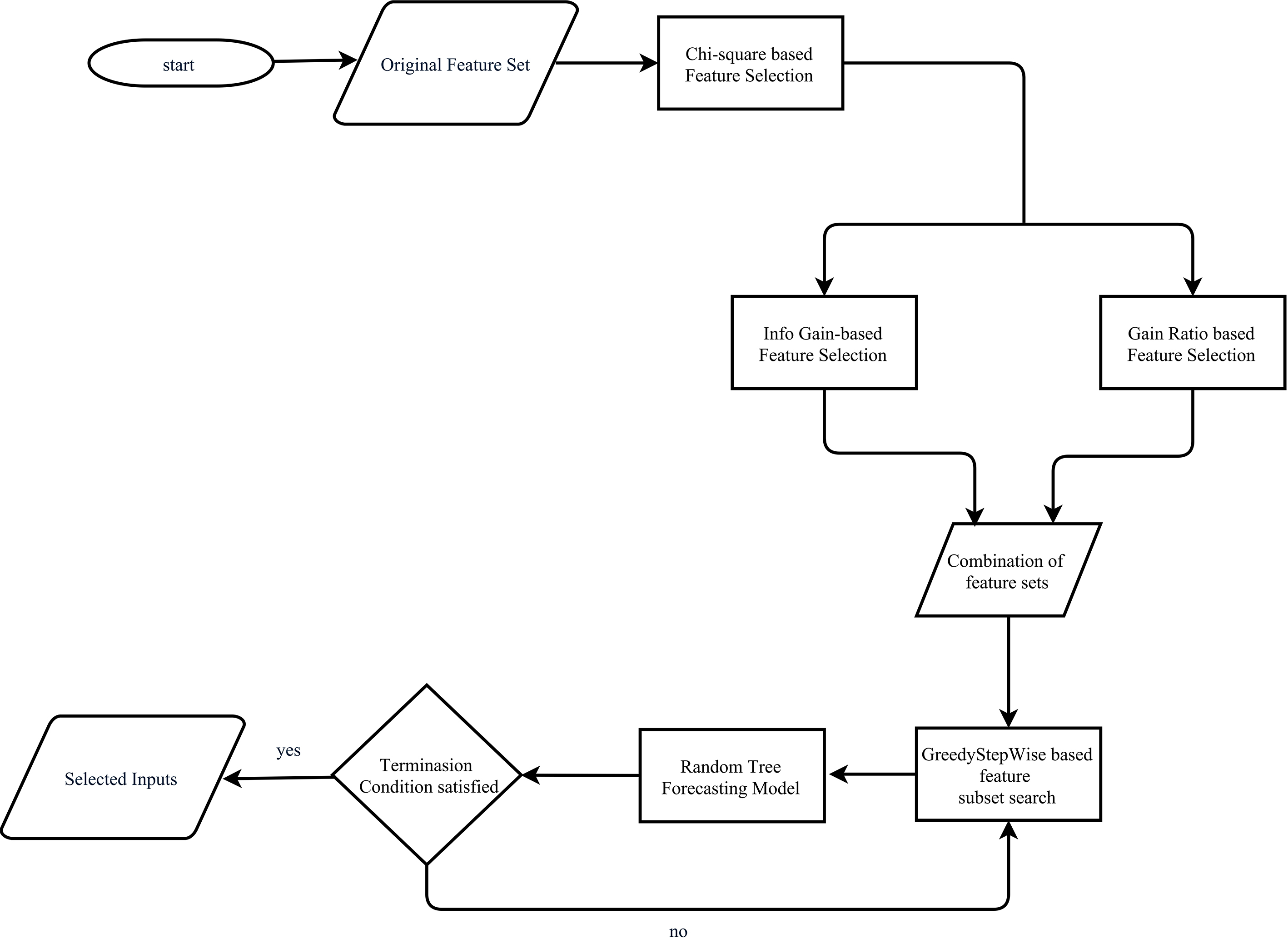
where
Information Gain (IG) (Quinlan, 1986) is one of the filter feature selection methods that is used as a criterion for the determination of relevant attributes from a set of features. The information gain reduces the uncertainty associated with identifying the class, when the value of the attribute is unknown based on information theory. The higher information gain of a feature is more important than the feature is for the detection of the class category. Uncertainty is determined by the entropy of the distribution, sample entropy, or estimated model entropy of the dataset. The entropy of variable
In Eq. (2)
Based on this measure, it is clear that features
The gain ratio technique was introduced to improve the bias IG toward multi-valued attributes, by taking the number and size of branches into account when selecting an attribute. The intrinsic information of a given feature may be determined by the entropy distribution of the instance value. The gain ratio of a given feature
where
Note that
The wrapper feature subset evaluation conducts a search for a viable subset using the learning algorithm itself as a portion of the function. In this work, repeated 5 cross-validation was used as an estimate for the accuracy of the Random tree classifier. A greedy stepwise forward search was employed to procure a list of attributes, ranked according to their overall contribution to the accuracy of the attribute set with respect to the target learning algorithm [3].
HFWFS algorithms characteristics
HFWFS algorithms characteristics
The proposed HFWFS method for feature selection has two primary objectives. The first is to identify the most irrelevant features that may properly improve the classification accuracy and reduce the computational complexity of the wrapper method; the second is to identify a small set of features with minimum redundancy, which can reduce the computational cost of the modeling process without reducing the classification accuracy.
In the initial step, we applied Chi-square to rank the feature set of the original dataset the score is averaged as given by Eq. (1). Features above the threshold were considered as the most critical features, which were selected to create a new subset for the second filter, the Algorithm 1 details the tree steps of the Chi-square filter. In the second step, Info Gain and Gain Ratio filter methods were used separately to rank the resulting output of the Chi-square and to select those candidate features that were more information rich.The selected features of the two filters IG and GR were combined. Algorithm 2 describes the combined model. The relevance of the feature in a subset within the combined model is defined as given in Eqs (4) and (5). Subsequently, we exploited the wrapper method using a greedy stepwise forward searching algorithm and machine learning model to identify a small set of features that might result in higher classification accuracy. Algorithm 3 describes the search and evaluation of a subset. Wrapper methods are not suitable in dealing with a dataset that contains an enormous number of features. The previous filters reduced the complexity of the search space; hence, wrappers may be applied with less computational effort. Figure 1 shows the proposed HFWFS method, and the HFWFS method is constructed through the algorithms presented below.
Table 1 summarize the HFWFS algorithms and their characteristics and Fig. 3 shows the hybrid feature selection procedure. Three filter models were preliminarily selected in order to remove the most redundant or irrelevant features. Chi-square was initially used to reduce the dimensions of dataset, followed by Info Gain and Gain Ratio, which were used separately. The two resulted feature sets were combined as a preprocessed feature set for the next fine tuning step. In the second step, the wrapper model was applied to improve classification accuracy, while reducing dimensionality using the Random Tree classifier.
Currently, there are only a few publicly available datasets for the evaluation of intrusion detection. Among these datasets, the NSL-KDD and UNSW-NB15 datasets have been commonly cited in the literature to assess the performance of the HFWFS feature selection method. NSL-KDD comprises a new revised version of KDD Cup 99 that has been proposed by Tavallaee et al. [41]. This dataset addresses some problems included in the KDD Cup 99 dataset, such as a vast number of redundant records in the KDD Cup 99 data. As in the case of the KDD Cup 99 dataset, each record in the NSL-KDD dataset is composed of 41 different quantitative and qualitative features. Despite all improvement over KDD Cup 99 dataset, the NSL-KDD dataset still suffers from several issues, such as the existence of large numbers of redundant records and its high complexity. Further, NSL-KDD does not represent actual existing networks. However, it may still be applied as an effective benchmark data set to assist researchers with comparing different intrusion detection methods. To overcome these limitations, Nour and Slay [27] created the UNSW-NB15 data set in the Cyber Range Lab of the Australian Centre for Cyber Security (ACCS), which represents a hybrid of modern realistic normal network activities and synthetic contemporary attack behaviors from network traffic.
NSL-KDD dataset
The NSL-KDD dataset, an improved version of KDDCUP 99 that has been widely cited in the literature for intrusion detection [37, 11, 14] was used to validate our proposed algorithm. NSL-KDD is a labelled benchmark dataset derived from KDDCUP 99 to improve its flaws. NSL-KDD is made up of 41 features that are labelled as either normal or attack, and NSL-KDD comprises both training and testing datasets. The attacks are grouped into four categories: DoS, Probe, U2R, and R2L. Table 2 describes the NSL-KDD feature dataset.
NSL-KDD dataset features
NSL-KDD dataset features
UNSW-NB15 dataset Features
As previously mentioned , the UNSW-NB15 data set was created [27] at the Cyber Range Lab of the Australian Centre for Cyber Security (ACCS) using the AXIA Perfect Storm tool to create a hybrid of modern normal and abnormal network traffic. This data set includes nine families of attack: Fuzzers, Analysis, Backdoors, DoS, Exploits, Generic, Reconnaissance, Shellcode, and Worms. In addition, the UNSW-NB15 dataset is decomposed into training and testing sets and contains 49 features Table 3 [26]
Experimental results
In this section, we deployed our proposed HFWFS method to pre-process the dataset toward the selection of the most important features for the Random Tree classification algorithm, which classifies data as either normal or attack in cloud computing. Our analysis was carried out using Weka [44], which contains a collection of machine learning algorithms for data mining tasks. The parameters for classification in the experiments were set to the Weka default values. We employed the NSL-KDD and UNSW-NB15 datasets with the distribution presented in Table 4, in order to evaluate the performance of our HFWFS method and random tree classifier using train and test datasets. All experiments were performed on a 2.5 GHz Intel Core i5 CPU with 8 GB of RAM.
Normal and DoS Distribution on NSL-KDD and UNSW-NB15
Normal and DoS Distribution on NSL-KDD and UNSW-NB15
HFWFS applied to NSL-KDD
HFWFS applied to UNSW-NB15
We applied the HFWFS method for feature selection to determine the most relevant features of the NSL-KDD and UNSW-NB15 datasets. Following the application of our Algorithm 3.1.1 using the Chi-square filter method, we selected 22 of the most important features from the NSL-KDD and UNSW-NB15 datasets (Tables 5 and 6, respectively). Subsequently, we engaged Algorithm 3.1.2 by applying Info Gain and Gain Ratio and selected the nine most prevalent features for each method (Tables 5 and 6) after which we combined the results to obtain 14 relevant features. Finally, we applied the final portion of our Algorithm 3.1.3 using a wrapper method, which was based on a Greedy Step Wise search. We selected nine of the most important features from both NSL-KDD and UNSW-NB15 datasets (Tables 5 and 6). In order to compare our model with the filter methods used in our approach we selected nine of the most important features for each method. Tables 7 and 8 reveal the nine selected features from NSL-KDD and UNSW-NB15 datasets, respectively, using the HFWFS method, Chi-square, Info Gain, and Gain Ration. We employed these features as input for the training and testing of the Random Tree classification algorithm.
Feature selection using filter methods on NSL-KDD dataset
Feature selection using filter methods on NSL-KDD dataset
Feature selection using filter methods on UNSW-NB15 datase
Classification accuracy for feature selection methods.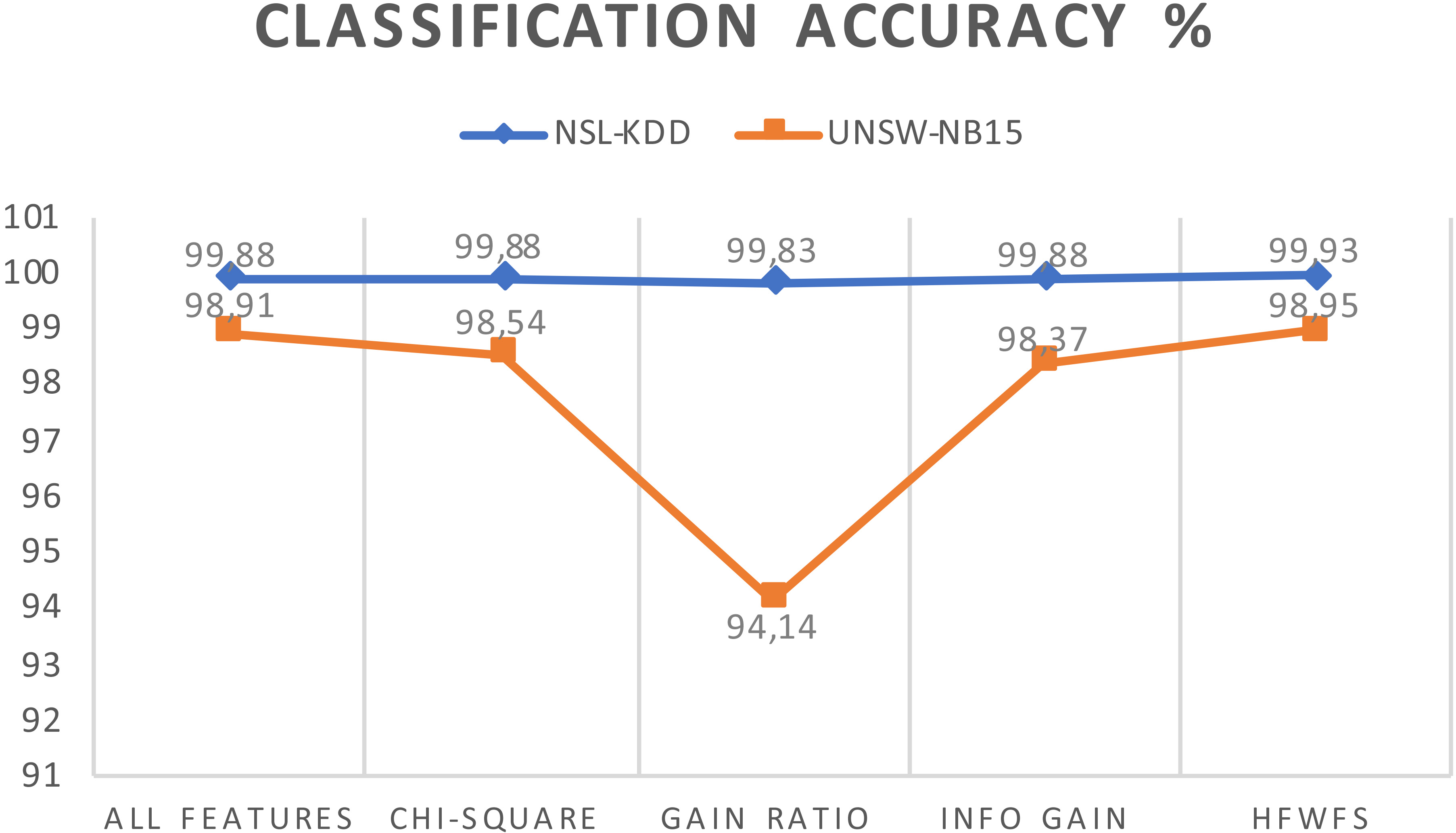
Several experiments were conducted to evaluate the performance of the proposed HFWFS method. For this purpose, different metrics are applied, including accuracy and false rate positive (FAR). The measure of these metrics involved the quantification of: true positive (TP), as representing the actual number of attacks that were classified as attacks, true negative (TN), being the number of actual normal records classified as normal, false positive (FP), was the number of actual normal records classified as attacks, whereas false negative (FN) was the misclassification of a test sample as normal, when it was actually an attack. In this work, we compared the accuracy, false alarm rate, timeline for building and testing the model of our proposed HFWFS method with each filter method, and the full dataset feature using the Random Tree classification algorithm. Furthermore, we compared the time required to build the classification model, which was the duration of the classifier’s learning process after applying each feature selection method. Tables 9 and 10 present the results of the performance measure of the Random Tree classifier using both datasets with all features, with the nine features that were selected using our proposed HFWFS method.
Classification accuracy
Classification accuracy pertains to the number of correct predictions made divided by the total number of predictions made, multiplied by 100 to convert it into a percentage. This may be determined by:
Figure 4 depicts the classification accuracy across different filter feature selection methods and the HFWFS method. Our proposed method presents a slight increase in classification accuracy, by 0.05% and 0.04%, on the NSL-KDD and UNSW-NB15 datasets, respectively.
Performance measure using NSL-KDD dataset
Performance measure using NSL-KDD dataset
Performance measure using UNSW-NB15 dataset
False alarm is the amount of normal data that has been misclassified as an attack. This may be determined by:
Figure 5 illustrates the false alarm rate of the full feature set and different filter feature selection methods. The UNSW-NB15 dataset Gain Ratio produced the highest false alarm rate, while the full feature set had the lowest rate at 1.07%. Our method generated a false alarm rate of 1.3%. Our method presented the lowest rate with 0.088% when dealing with the NSL-KDD dataset.
False alarm rate for feature selection methods.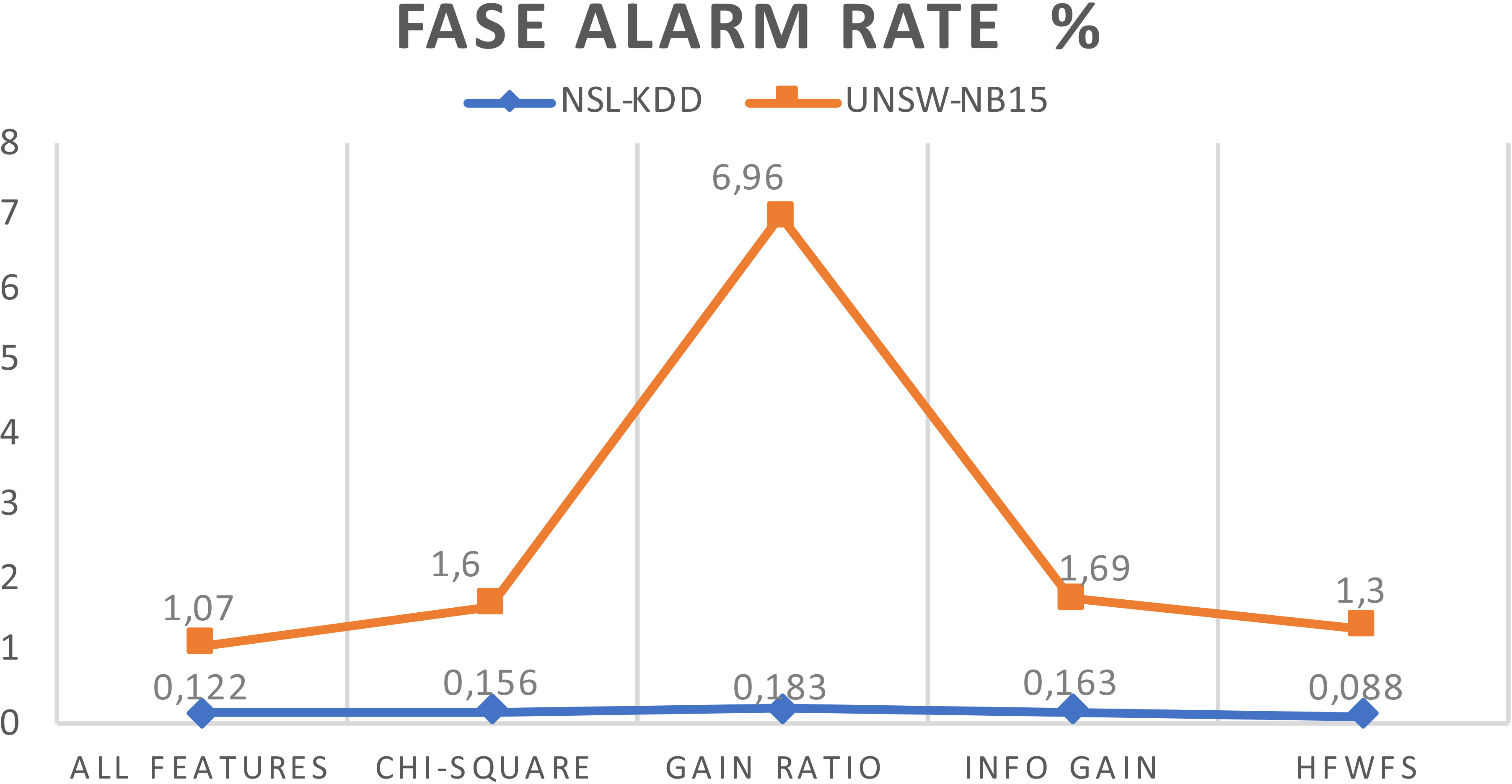
Figure 6 presents the time required to build our model across different filter selection methods and the full feature set. The results indicated that the use of full features had the worst learning time at 1.73 s and 1.03 s, respectively, with NSL-KDD and UNSW-NB15, due to the important number of features that the classifier had to process. When compared with other filter methods, our proposed method presented the best time, at 0.64 s and 0.35 s.
Time to buil the model for feature selection methods.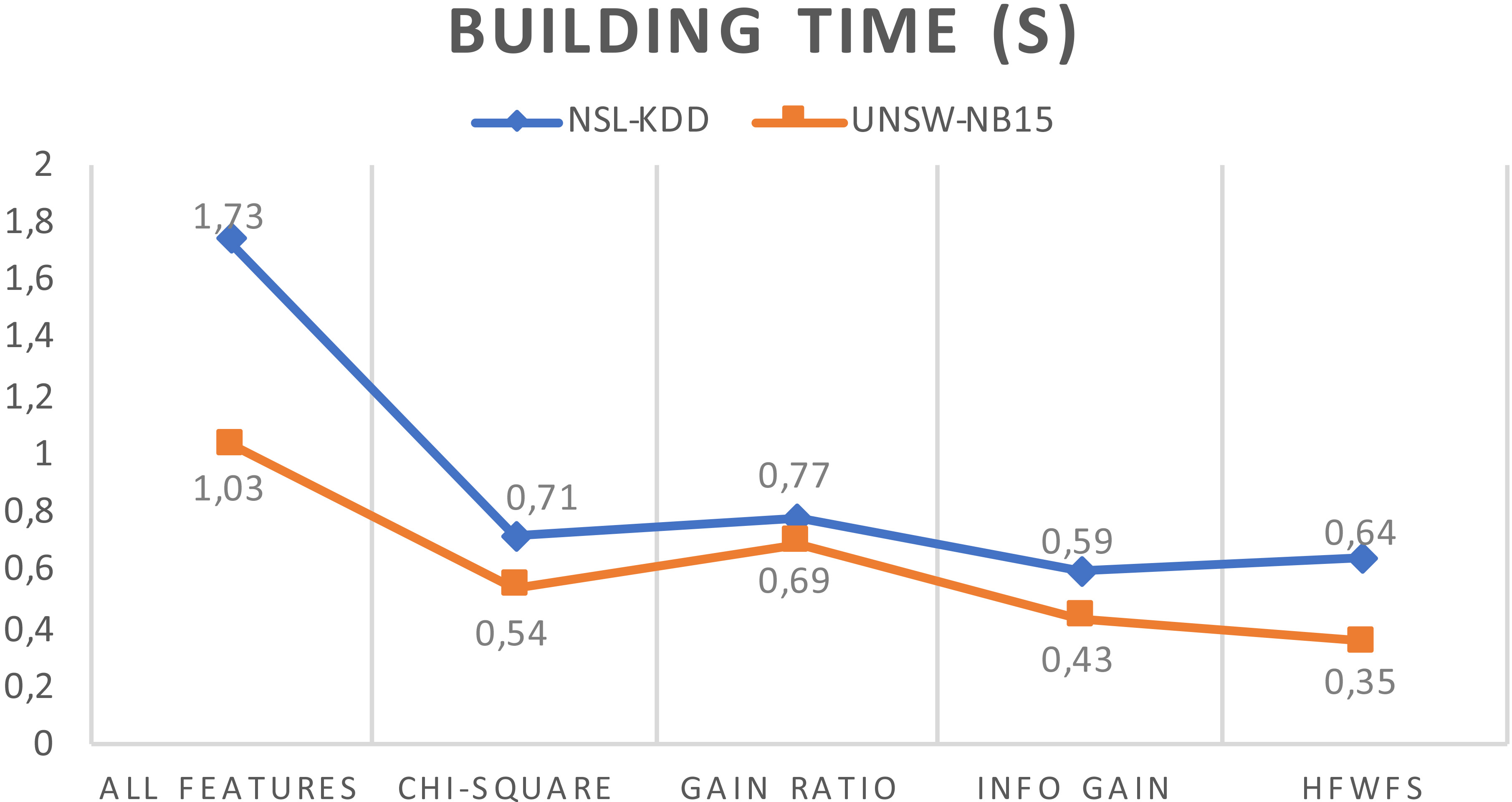
Figure 7 depicts the time required to test the model across different filter selection methods and the full feature set. Our proposed method showed the best time to test the model at 0.36 s with NSL-KDD, and 0.26 s with UNSW-NB15, and as expected, the full features sets presented the worst time to test the model.
In order to demonstrate the performance of the HFWFS, we compared our method using the Random Tree classifier with some state-of-the-art approaches that have been tested using the NSL-KDD dataset, and Table 11 reveals the resulting comparison.
The comparison with other methods (using NSL-KDD)
The comparison with other methods (using NSL-KDD)
Time to test the model for feature selection methods.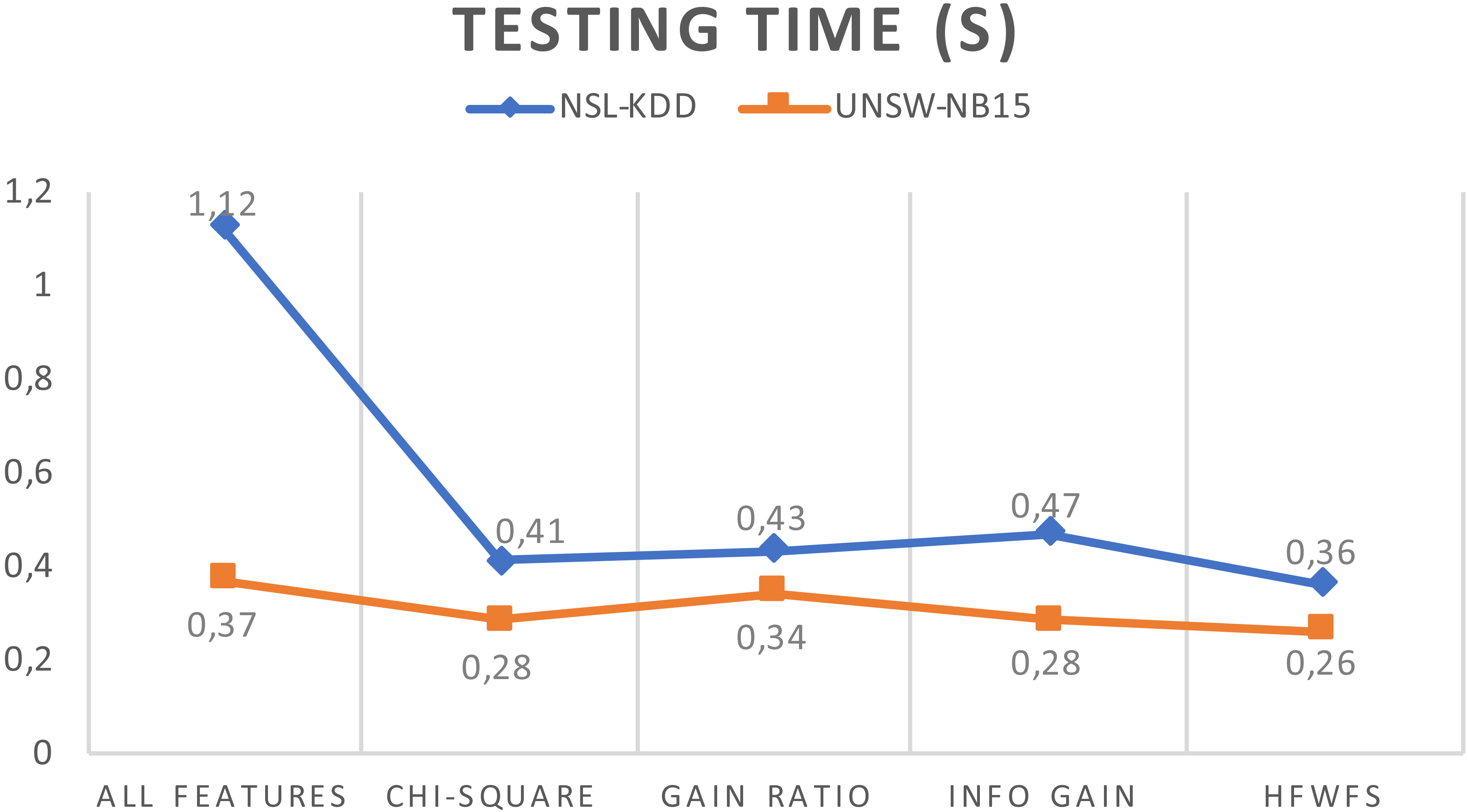
With regard to the performance measure in Tables 9 and 10 using NSL-KDD and UNSW-NB15 dataset respectively, the comparison of results shows that our method appears to have the best accuracy, execution and test time and less False Rate Alarm. Table 11 compares our proposed method with other existing feature selection methods on the NSL-KDD dataset. The results show advantage of our method in classification accuracy and execution time. MMIFS proposed in [6] reduced features to 8 with a low classification accuracy of 84.11% and high execution time of 10 s when compared to our method [20] used domain knowledge with the practical significance and the feasibility of each feature for selecting it. Thus, from the total 41 features on NSL-KDD, they selected 9 features for DoS layer. It was notable that our hybrid feature selection, with 99.93% classification accuracy and 0.64 second to train the model, performed better than feature selection based on domain knowledge and other model presented in Table 11. However, all these results suggests that HFWFS feature selection approach using Random Tree classifier is a feasible scheme for building reliable intrusion detection systems for DoS attack.
Real-time and efficacious DDoS attack detection systems in cloud computing have become a necessity, which has translated to the increased complexity of detection techniques. Filter and wrapper methods for feature selection present several advantages and weaknesses when identifying important features. In this study, we proposed a new feature selection mechanism which utilized the advantages of both filters and wrappers. Our HFWFS method greatly decreased the number of features, from more than 40 features for both datasets to nine. Further, the accuracy, as well as the time to build and test the model was improved. We initially compared our method with the full set, and with nine selected features using other filter methods. The results indicated that the classification accuracy obtained using our method was an improvement over other filter methods for both NSL-KDD and UNSW-NB15 datasets. Additionally, our method presented the best time to build and to test the model, which made our HFWFS an effective hybrid feature selection method with less complexity. As shown in Table 11 we conclude that the use of the nine features selected using our method in conjunction with the Random tree classifier provided the best results in terms of classification accuracy and the time required to build the model, in contrast to the other approaches presented in Table 11.
Conclusion
In this paper we proposed and tested a hybrid feature selection mechanism to address the massive complexity of DDoS attack detection in cloud computing. The idea was to initially utilize the efficiency of filters, followed by the accuracy of wrappers. Chi-square, InfoGain, and GainRatio were first employed to remove the most irrelevant and redundant features toward the formation of a reduced subset. A wrapper method was then applied to improve the classification accuracy and to identify a small set of features. The performance of the hybrid mechanism was evaluated using two different datasets (NSL-KDD and UNSW-NB15). Experimental results showed that the proposed approach, on one hand, was more efficient than individual filter feature selection methods, and on the other hand, identified fewer features than other proposed feature selection methods, while the overall efficacy was improved.