
Abstract
Graph-based algorithms have aroused considerable interests in recent years by facilitating pattern recognition and learning via information propagation process through the graph. Here, we propose an unsupervised learning algorithm based on propagation on bipartite graph, referred to as Propagation in Bipartite Graph (PBG) algorithm. The contributions of this approach are threefold: 1) we present an iterative graph-based algorithm and a straight-forward bipartite representation for textual data, in which vertices represent documents and words, and edges between documents and words represent the occurrences of the words in the documents. Additionally, 2) we show that PBG is more flexible and easier to be adapted for different applications than the mathematical formalism of the generative models, and 3) we present a comprehensive evaluation and comparison of PBG to other topic extraction techniques. Here, we describe the strategy employed in PBG algorithm as a problem of maximization of similarity between latent vectors assigned to vertices and edges and demonstrate that the proposed strategy can be improved by assigning good initial values for the vectors. We notice that PBG can be parallelized by a simple adjustment in the algorithm. We also show that the proposed algorithm is competitive with LDA and NMF in the task of textual collection modelling, returning coherent topics, and in the dimensionality reduction task.
Keywords
Introduction
Data has increased faster than ever before and a massive amount of new information has been created and shared in daily base. The most common way of storing such information is employing textual format, such as journals, web pages, reports, memos and social networks. Therefore, the development of powerful interactive mining tools remain as relevant research topic to deal with textual data. An important task when exploring collections of documents is understanding the semantic information conveyed by texts, so that relevant concepts, themes, and topics present in the collections can be unveiled.
Many applications rely on unsupervised strategies for grouping textual documents, among them probabilistic topic modeling, a suite of algorithms that aims at discovering and annotating large collections of documents with thematic information [5]. These algorithms model each document as a mixture over a fixed set of underlying topics, in which each topic is characterized as a distribution over words. The topic probabilities can be indirectly inferred through the maximization of the log-likelihood of the data to be generated [6]. However, the mathematical technicality of these approaches hamper the exploration of new assumptions, heuristics or adaptations that might be useful in many real scenarios. From a practitioner’s perspective, the inclusion of heuristic knowledge into a probabilistic model and derivation of an effective and implementable inference algorithm are hard and tiresome tasks. Therefore, there is room for development of simple descriptive algorithms which allow easily incorporation of heuristic methods and adaptations for unsupervised tasks.
Topic modeling are useful in the sense that, empirically, they lead to good models for document collections, where topics tend to place high probability on words that represent concepts, and documents are represented as expressions of those concepts. Perusing the inferred topics is effective for model verification and for ensuring that the model is capturing the practitioner’s intuitions about the documents. Moreover, producing a human-interpretable decomposition of the texts can be a goal by itself, as when browsing or summarizing a large collection of documents.
In this spirit, much of the literature comparing different topic models presents examples of topics and examples of document-topic assignments to help understand the model’s mechanics. Topics can also help users discover new content via corpus exploration [5]. The presentation of these topics serves, either explicitly or implicitly, as a qualitative evaluation of the latent space, but there is no explicit quantitative evaluation of them. Instead, researchers employ a variety of metrics of model fit, such as perplexity or held-out likelihood. Such measures are useful for evaluating the predictive model, but do not address more exploratory goals of topic modeling. The mathematical and formal assumptions proposed by topics models, empirically, lead to good models of documents. However, fitting a mathematical model do not address the more exploratory goals of topic modeling: producing a human-interpretable decomposition of the texts. On the other hand, heuristic approaches have been widely used for solving problems more quickly, or finding better solutions. In some tasks, traditional topic extraction algorithms converge slowly, which requires many iterations, so that their peak performance can be reached. Their slowness is mainly due to their batch nature, in which parameters are updated only once after each iteration of the data. In such cases, a heuristic method based on incremental update can potentially speed up learning and performance. In other cases, heuristics can be combined with optimization algorithms to improve solutions.
Another important text extraction task is data representation, in which the vector space model (VSM) has been the usual approach. Nevertheless, more expressive representations, such as bipartite graph for representing relations between documents and words, can be employed. In such intuitive and straight-forward representation, vertex represents document or term, and edge correspond to the occurrence of a word in a document, i.e. there are edges only between pairs of vertices of different types (document or word). Eventually, a weight can be assigned to the edge according to the frequency of the word in the document.
The description of algorithms over a graph representation offers several advantages, since graph representations (1) avoid sparsity and ensure low memory consumption, (2) enable an easy description of operations for inclusion of the topological structure of a dataset, (3) enables an optimal description of the topological structure of a dataset, (4) provides local and global statistics of the dataset structure, and (5) enables the extraction of patterns which are not extracted by algorithms based on vector-space model [11, 33, 13].
Graph-based algorithms are commonly used in a semi-supervised learning schema, in which some labeled objects propagate their labels to other objects through the graph structure via transductive classifications [44, 33, 42, 3]. However, the appropriate use of the richness of information conveyed by those graphs may lead to unsupervised algorithms that, through a suitable propagation schema, group objects densely connected, keeping in different groups sparsely connected objects.
Here, we proposed an algorithm referred to as Propagation in Bipartite Graph (PBG), which uses a bipartite heterogeneous graph representation for unsupervised tasks such as topic extraction and soft clustering. We present its mathematical foundation and empirically compare PBG with other techniques for topic extraction. The strategy adopted in PBG is a combination of two traditional optimization techniques for topic extraction, namely Nonnegative Matrix Factorization (NMF) [23] and Latent Dirichlet Allocation (LDA) [7]. We combine their optimization procedures in a simple and descriptive algorithm based on a bipartite graph representation. This algorithmic approach enables the combination of heuristics, optimization procedures and the graph representation of a document collection for improving the unsupervised tasks such as topic extraction and document clustering.
The rationale behind the proposed graph-based unsupervised algorithm is the association of latent information for each vertex and edge and their appropriate propagation until convergence. Such latent information is kept in a
The main contributions of this article are three fold: we present 1) the use of bipartite graph representation and iterative propagation for the unsupervised learning process, 2) a description of PBG as a simple implementable algorithm that combines the inference process of Latent Dirichlet Allocation (LDA) and optimization steps of Nonnegative Matrix Factorization (NMF), and 3) a comprehensive evaluation and comparison of PBG and topic extraction techniques.
We also discuss the behavior of the algorithms for different datasets and the empirical evaluation shows our algorithm returns consistent results, which makes it a competitive alternative and a new exploratory possibility to the state-of-the-art unsupervised algorithms for textual exploration.
The remainder of the paper is organized as follows: Section 2 reviews some basic concepts and provides an overview of the standard topic modeling approaches; Section 3 introduces a topic extraction method that uses propagation in bipartite graphs and its implementation; in Section 4 we compare the computational aspects of algorithms for LDA, NMF, and our proposed algorithm PBG; Section 5 reports results from an empirical study on a large test suite; finally, Section 6 summarizes the results and discusses other potential applications and future work.
Related work and background
Topic Modeling has many applications in natural language processing and information retrieval [37, 5]. The main application is related to summarizing the most important themes in a domain that pervade a large unstructured collection of documents. Topic models can organize the collection according to the discovered themes.
A topic model typically consists of a set
Considerable research on topic modeling has focused on the use of probabilistic methods, where a topic is viewed as a probability distribution over words, with documents being mixtures of topics [37]. Alternative non-probabilistic models, such as those based on matrix decomposition, have also been effective in the task of topic extraction [38]. In fact, each paradigm has its own strengths and weaknesses [36]. Among these topic models, we choose those most popular methods for topic modeling: non-probabilistic NMF and probabilistic LDA methods. LDA and NMF are two traditional and well formalized techniques to extract topics from a corpus.
LDA is a Bayesian generative topic model for documents. The basic idea is that documents are represented as a random mixtures over latent topics, where each topic
NMF is a matrix factorization method which factorizes a matrix, in which all the elements have non-negative values, into two matrices with elements having non-negative values. NMF for documents factorizes a document-term matrix
Later in Section 4 we discuss in more details the computational aspects of LDA and NMF to theoretically justify the similitude between our proposed algorithm PBG and these well-formalized techniques. Before that, we introduce PBG as a label propagation procedure in bipartite graph.
The general idea of label propagation in a graph is well-established in literature [42, 43, 44, 21] and it is closely related to techniques for message passing and inference of probabilistic models [30, 16, 27, 32]. In [30] is investigated the approximation performance of belief propagation in an inference schema, and the experimental results suggest that propagation can yield accurate posterior marginals. In [27] is proposed a distributed variational message passing scheme for learning conjugate models, and the theoretical analysis support the favorable behavior observed in experiments with financial datasets. In [40], LDA is represented as a factor graph within the Markov random field framework. Factor graph is a bipartite graph representing the factorization of a probability distribution function and latent variables, and there is a relationship between factors functions and variables [4]. Diversely to what we propose here, traditional message passing methods do not use bipartite graph as a descriptive approach and data representation. In addition, the computational problem in message passing approach is still based on approximate inference and parameter estimation.
Considering computational aspects of topic extraction problem, probabilistic topic models depend on learning algorithms to infer latent topics. Various learning algorithms have been developed, including collapsed Gibbs sampling, variational inference, maximum a posteriori estimation, and belief propagation. These algorithms, varieties of LDA inference, are based in a generative approach framework for modeling high-dimensional sparse count data. In [2] is provided empirical and theoretical comparison between these inference algorithms, and the conclusion found is that they are closely related, i.e. depending on the update equations and hyperparameters employed their performance differences diminishes. Then, it is expected similar experimental results between our method and the inferences algorithms for LDA. Nevertheless, the proposal presented is a simple descriptive approach, with equivalent theoretical results compared to inference and matrix decomposition algorithms. Besides, it is suited for incorporating new heuristic and available problem information.
Topic extraction using propagation in bipartite graph
In this section, we present the problem formulation, the general notation, and the mathematical and computational foundations of the proposed unsupervised algorithm based on a bipartite graph. The PBG (Propagation in Bipartite Graph) algorithm is an unsupervised label propagation algorithm based on the update equation of NMF and LDA. Our proposed algorithms can be seen as a mixture of these two techniques, later in Section 4 we discuss in more detail this issue. We assume the KL-divergence as similarity measure to optimize the similarity among latent information of documents, terms and their links in the topic extraction process.
The collection of documents is represented by a bipartite graph. In the bipartite graph representation
Optimizing the divergence between latent information vectors
The assumption of PBG is that the divergence between latent information of documents in
Local propagation to vertex 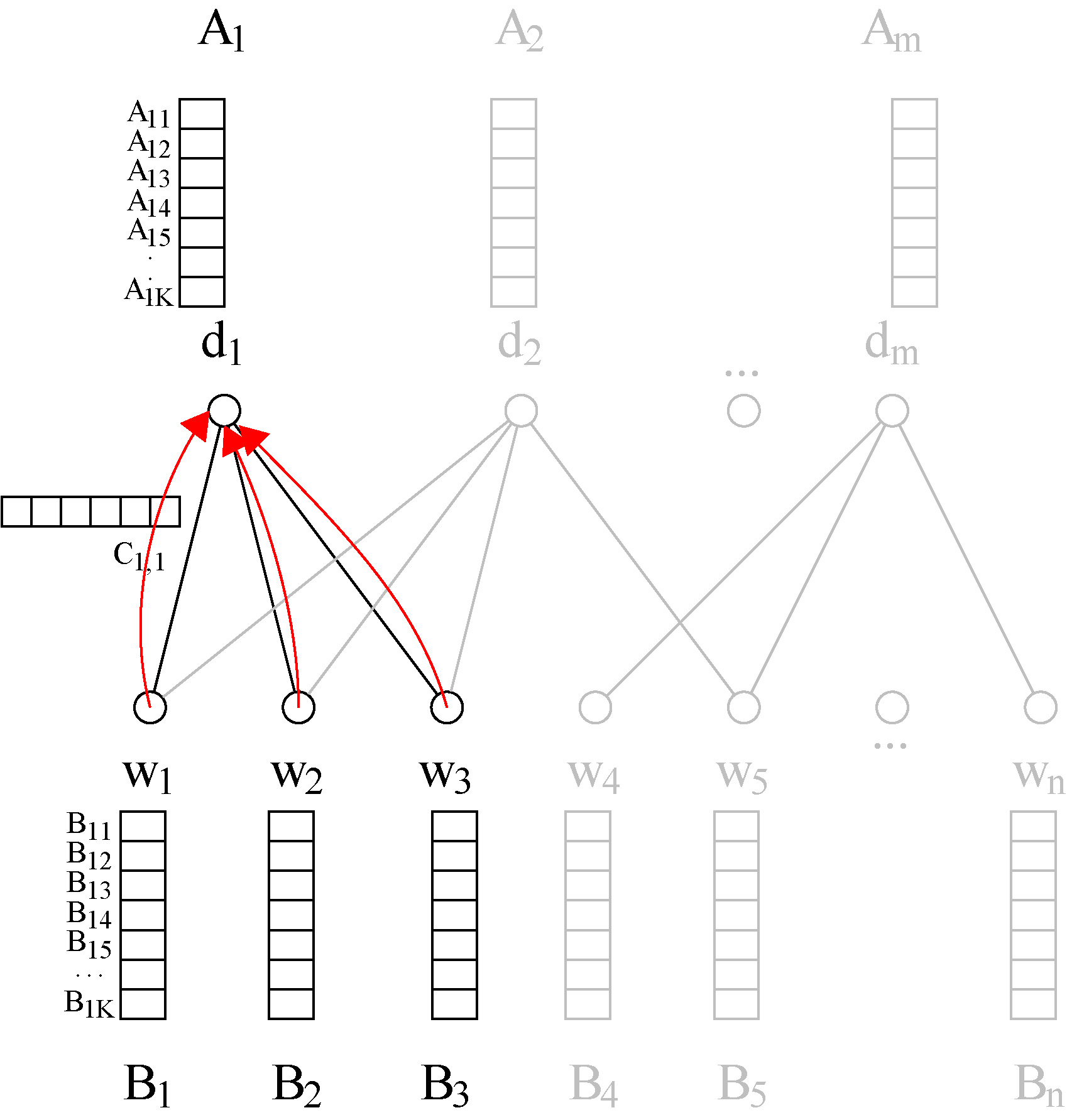
The rationale behind our proposed algorithm is that the larger the frequency
where
A high value for
The latent information vectors for the whole set of vectors can be obtained by optimizing this equation to each pair of vertices linked by an edge, thus giving rise to the following cost function for the graph
The induction of the latent information of
where we have dropped the arguments of
Setting this derivative to zero yields the maximizing value of the edges vector
As the sum of values in vector
Next, we maximize Eq. (1) with respect to
where the subset
We take the derivative with respect to
Setting this equation to zero yields a maximum at:
Finally, we maximize Eq. (1) with respect to
By taking the derivative
Setting this equation to zero, and solving
Normalizing the value of
The iterative updates in Eqs (7), (10) and (13) that minimize Eq. (3) are the basis for the Propagation in Bipartite Graph (PBG) algorithm described in the next section.
The idea of PBG algorithm is to propagate latent information throughout vertices’ neighborhoods. Assuming that the latent information vectors of terms and documents are randomly initialized. The iterative updates are performed in two different manners: (1) local updates, which account for propagations through the neighbourhood of each vertex, and (2) global updates, which propagate latent information throughout the entire bipartite graph and can be interpreted as a spreading of the information from local to global structures of the bipartite graph. The PBG algorithm is summarized in Algorithm 3.2. The local propagation is described in Algorithm 3.2 and the global propagation is described in Algorithm 3.2.
PBG AlgorithmInputInput bipartite graph
Local PropagationlocalPropaglocalPropagprocproc functionfunction ForEachforeachdoend
Global PropagationglobalPropagglobalPropagprocproc functionfunction ForEachforeachdoend
The propagation procedure of PBG algorithm (Algorithm 3.2) needs as input the set of documents
The global propagation is performed for every vertex
Global propagation to word 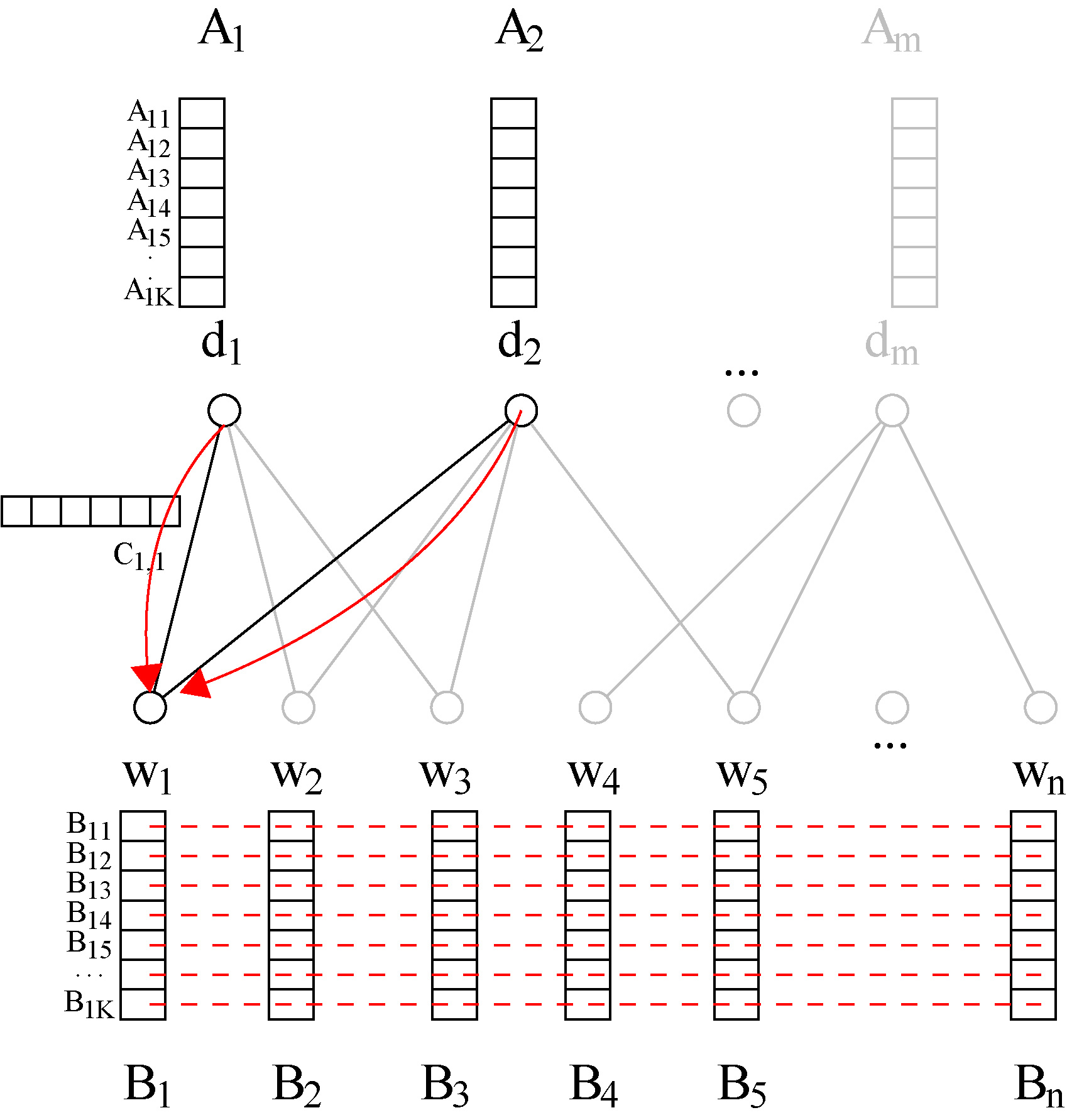
The rationale behind the proposed algorithm is to locally concentrate the latent information of each word of a document
We apply the local and global propagations until a maximum number of iterations is reached or until the latent information of documents remains the same in two successive iterations.
The complexity of the PBG algorithm is determined by the maximum number of local propagation
The PBG algorithm is an approximate solution to the optimization problem established by LDA with variational inference and NMF with KL-Divergence. At the same time, it is a heuristic method based on label propagation. Thus, it can take advantage of any label propagation heuristic and the trivial representation of textual documents as bipartite graph. Here, we show two examples of using heuristic to improve both performance and quality of results. The first improvement is the generation of initial solution. Initial labels can be provided by any available heuristic. Here they were created by using clustering algorithms. The second improvement takes advantage of local structure of the graph to perform parallel processing of the documents.
Initializing latent information
Here, we describe how to create initial values for vectors
Thus, in order to assign good initial values, we have used an initialization based on clustering of documents. In general, the proposed initialization applied by PBG algorithm can be described as: (1) compute the clustering
Regarding the clustering algorithm used to initialize vectors
Here we adopted the
Parallel PBG for topic extraction
Another modification is a parallel computing algorithm for the topic extraction of textual documents. The proposed parallel PBG scheme is introduced to reduce the computational load of local propagation using a parallel computing technique. The approach is based on performance of PBG algorithm into subgraphs created from subset of documents. We split the set of documents into
On the other hand, global propagation can not be parallelized since it requires one iteration over the structure of bipartite graph representing the entire collection of documents. Then, global propagation is performed after the end of the all local propagation threads. Before global propagation, the results of each thread have to be joined to describe the overall local propagations in the entire graph. Although this operation appears costly, the global propagation iterate only once over the entire structure of bipartite graph. The parallel version of the PBG algorithm is summarized in Algorithm 3.3.2.
[] Parallel PBG algorithmInputInput bipartite graph
Comparing PBG with LDA and NMF
The PBG can be related to technical aspects of NMF and Variational Bayesian (VB) Inference algorithm for LDA. Here we discuss this equivalence.
The equivalence between NMF and PLSI (Probabilistic Semantic Indexing) have been discussed in several works [9, 17]. Ding and colleagues [14] demonstrate that both NMF and PLSI optimize the same objective function, but they are different algorithms and converge to different local minima. Girolami and Kabán [18] demonstrate that LDA is a full Bayesian counterpart and a maximum-a-posteriori view of PLSI.
Here, we extend the equivalence between NMF and LDA described in [12] and indicate the computational aspects that were used to found our proposed algorithm. In order to relate these methods, we describe NMF and LDA focusing on their algorithmic point of view and optimization procedures.
Latent Dirichlet Allocation (LDA)
LDA is a generative topic model for documents. The basic idea is that documents are represented as a random mixtures over latent topics, where each topic
Given the parameter
where
A wide variety of approximate inference algorithms can be considered for LDA, including variational inference and Markov chain Monte Carlo (MCMC). Here, we describe the variational inference algorithm because it is described as a optimization problem, as well as NMF algorithm.
The main idea behind the variational method is to use a distribution with its own parameters replacing the posterior distribution
where
In fact, it is not possible to minimize the KL-divergence directly. However, bounding the log likelihood of a document,
ELBO
where
where
This section is a brief description of LDA derivatives by variational inference method. Here, we are interested in computational aspects of LDA inference algorithm, then we focus on update equations described in Eqs (18)–(20). In next section, we briefly describe the NMF updates equations derivatives. Based on these descriptions, we make a comparative analysis of these two methods and justify our method based on bipartite graphs.
The NMF method approximately factorizes a matrix of which all the elements have non-negative values into two matrices with elements having non-negative values. NMF for documents factorizes a document-term matrix
The factor matrices
where
The simplest technique to solve the optimization of Eq. (22) is by Gradient descent method. Gradient descent-based method can be implemented by the following “multiplicative update rules”
The update rules in Eqs (23) and (24) described the computational aspects of NMF in algorithmic term. Correspondingly, the computational aspects of LDA inference algorithm (Eqs (18)–(20)) can be compared with NMF in terms of optimization updates rules. This is described in details in the next section, and then it is demonstrated the similitude of these methods with our proposed method PBG.
The correspondence between NMF-KL and variational inference algorithm for LDA follows the fact that they try to minimize the divergence between word frequency, document-topic and topic-word statistics. To clarify the relationship between NMF and LDA, we describe NMF-KL as a relaxation of variational problem. The equivalence is reached when a relaxation of functions
.
The objective function of NMF with KL-Divergence is a approximation of ELBO
In practice, LDA and NMF use iterative algorithms to reach a feasible solution. Theoretically, these updates are based on distinct methods and different mathematical foundation. However, we can indicate similarities in the update equations of NMF-KL, Eqs (23) and (24), and the LDA with Variational Inference, Eqs (18)–(20). These similarities were used to found the PBG algorithms and the graph propagation procedure.
Plot of linear function 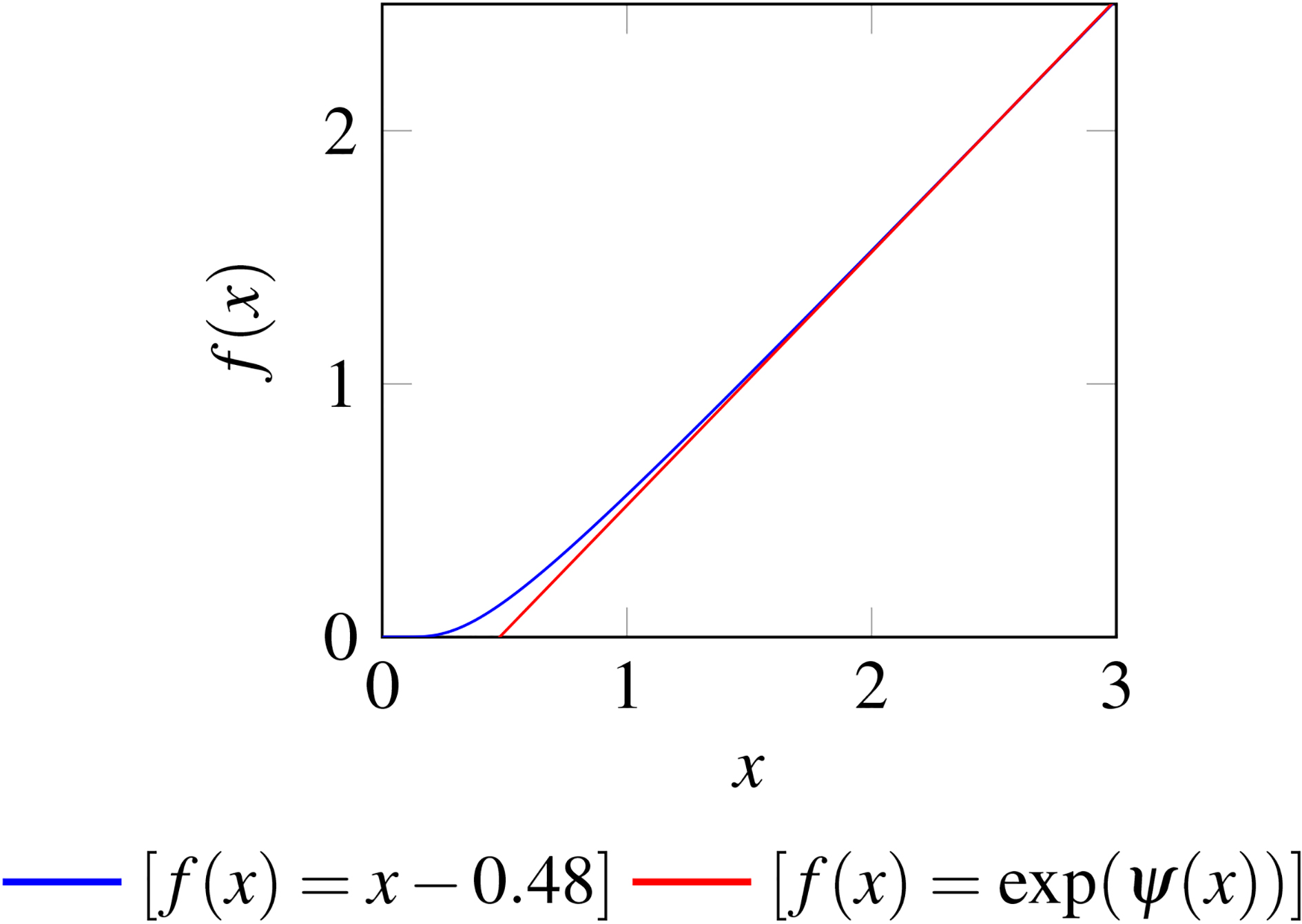
Firstly, we extend the value of
Thus, the value
Now, we describe the equivalence between document-topic value
Note that the updating equation of factor
The update equation of factor
By Eq. (28), we note that the value of
Equivalence between update equations of algorithms PBG, NMF, and LDA. The item a) it is related to the topics statistics for each word in each document; item b) it is related to document-topic statistics; and item c) it is related to topic-word statistics
The equivalence of update equations of the algorithms NMF, LDA, and PBG are summarized in Table 1. This equivalence extends the theoretical analysis between objective function of NMF and LDA, as described in [12], and indicate the computational aspects of their update algorithms similar to the propagation procedure described in PBG algorithm. Note that for update equations of NMF and LDA, it is possible to keep topic statistics for each word in each document, and to propagate this statistics to variables relating document and topics, and variables relating topic and words. Once understanding the propagation of these variables values during the processes of topic extraction, it is possible to realize the inspiration of PBG in using a suitable data structure based on graph to propagated these statistics.
The vectors
Collection of documents used in experimental evaluation. The column
is the number of documents, the column
is the number of unique words, and the last column
is the number of terms
Collection of documents used in experimental evaluation. The column
The bipartite graph was created for each collection and the PBG algorithm was applied to demonstrate its ability to extract latent patterns. The results were the vectors
The documents used in this experimental evaluation have labels for the task of supervised learning. However, we have hidden the labels to fit the collection in an unsupervised context. The labels were used only to assist the evaluation of results in the task of document representativeness.
We evaluated three versions of PBG algorithm: PBG with
The Normalized Pointwise Mutual Information (NPMI) was used as a measure of association between words that describe a topic. It was useful to measure the coherence of a set of words generated by a topic extraction algorithm. Another measure was the accuracy of vector
The number of topics was set to
The Python implementation of LDA with variational inference and hyperparameters optimization is available at
The Python implementation is available at
A strictly fair process of comparison between the proposed algorithms and probabilistic topic models algorithms is difficult, since probabilistic models traditionally use evaluation metrics based on likelihood and perplexity. In addition, perplexity or likelihood values are not necessarily correlated with human judgment about the semantic coherence of topics [31]. Therefore, we evaluate the topics coherence by the NPMI measure which approximates the human evaluation [31, 39].
In the absence of any general guarantees of convergence, we conducted an experimental analysis to indicate the convergence of PBG algorithm. Figure 4 shows the relationship between values of the objective function, defined in Eq. (1) (
Best accuracy values obtained by algorithms for Dataset 20ng
Best accuracy values obtained by algorithms for Dataset 20ng
Value of objective function (Eq. (1)) for each iteration of PBG algorithms for datasets 20ng (left), classic4 (middle) e Dmoz-Business (right).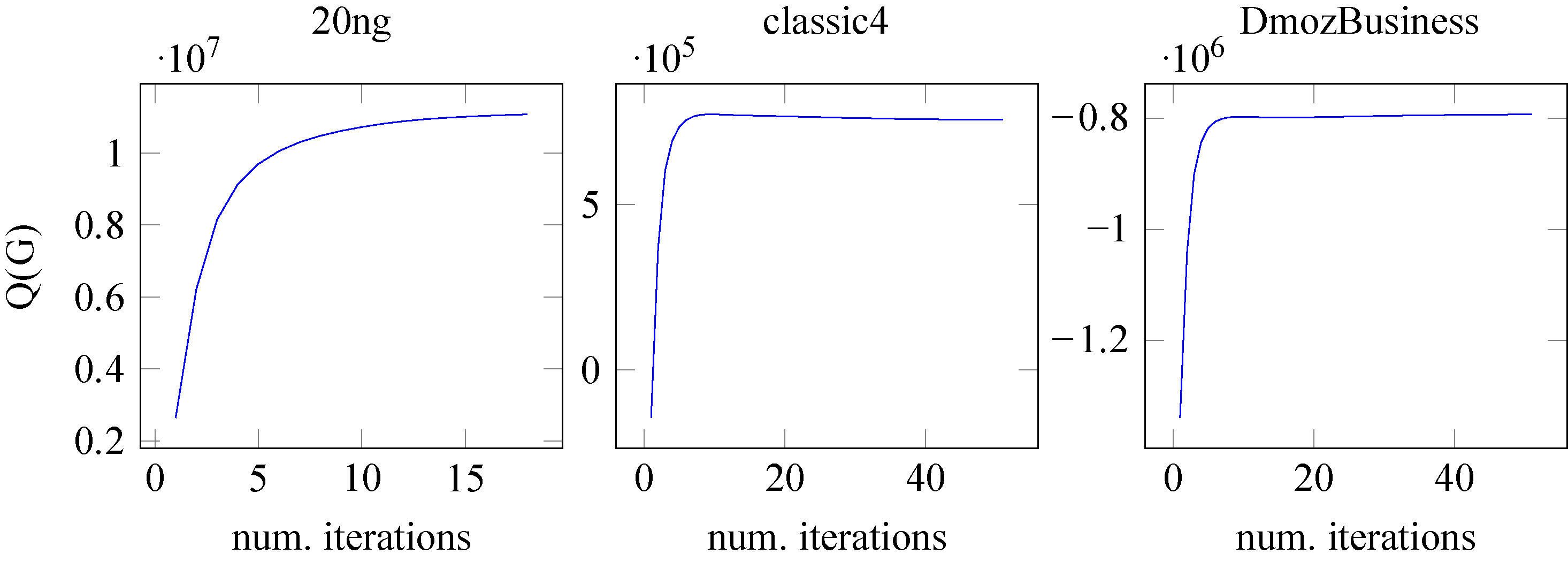
In this section we evaluate the representativity of a vectors
Weka 3: Java Data Mining Software
Tables 3–5 show the best accuracy for datasets 20ng, classic4, and Dmoz-Business, respectively. PBG algorithm captures better document characteristics than LDA in 100 iterations. The results indicate PBG as an effective method for dimensionality reduction task, hence a promising approach to tackle this problem. Especially, when the problem has an easy and straightforward strategy for graph construction, as in document-terms graphs. It is possible to further explore this representation to include heuristic knowledge to enrich the process and obtain better results.
Best accuracy values obtained by algorithms for Dataset classic4
Best accuracy values obtained by algorithms for Datasets Dmoz-Business Dataset
The critical difference diagram, Fig. 5, illustrates the statistical significance test obtained by comparing the results. Difference among algorithms connected with a line is not statistically significant. Thus PBG with heuristic initializations are superior with statistical difference compared to LDA. This result validates the hypothesis that the inclusion of heuristics in propagation process can lead to better results. It also demonstrates that to employ heuristic knowledge in PBG can be straightforward.
Critical difference diagram considering the best accuracy for each algorithm.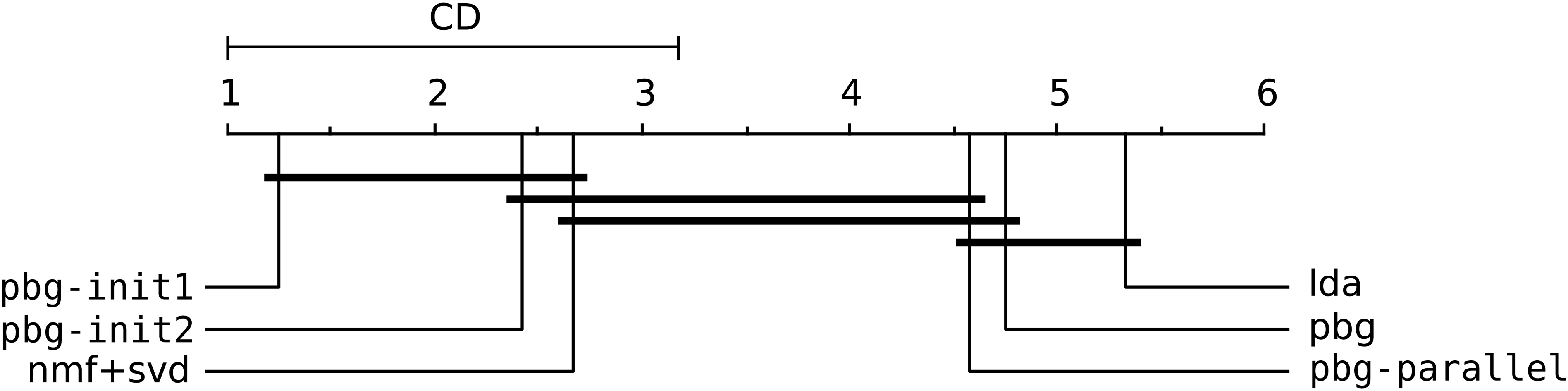
Figures 6–8 illustrate the values of accuracy versus time for all algorithms and datasets. Each series illustrates a specific algorithm behaviour. They are grouped by number of topics
Classification accuracy obtained during execution of algorithms used on this experimental evaluation. The features vectors (latent information vectors 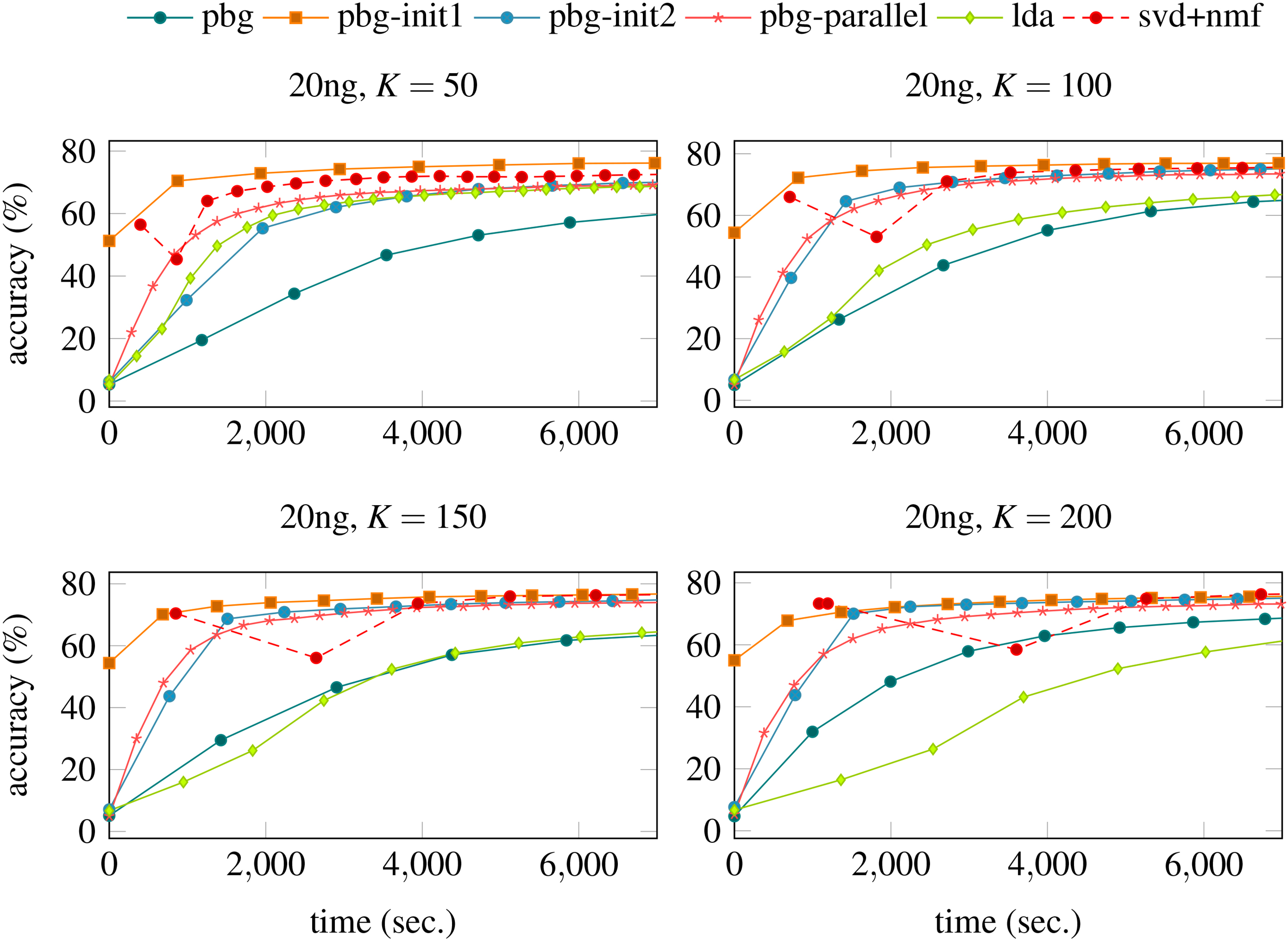
Classification accuracy obtained during execution of algorithms used on this experimental evaluation. The features vectors (latent information vectors 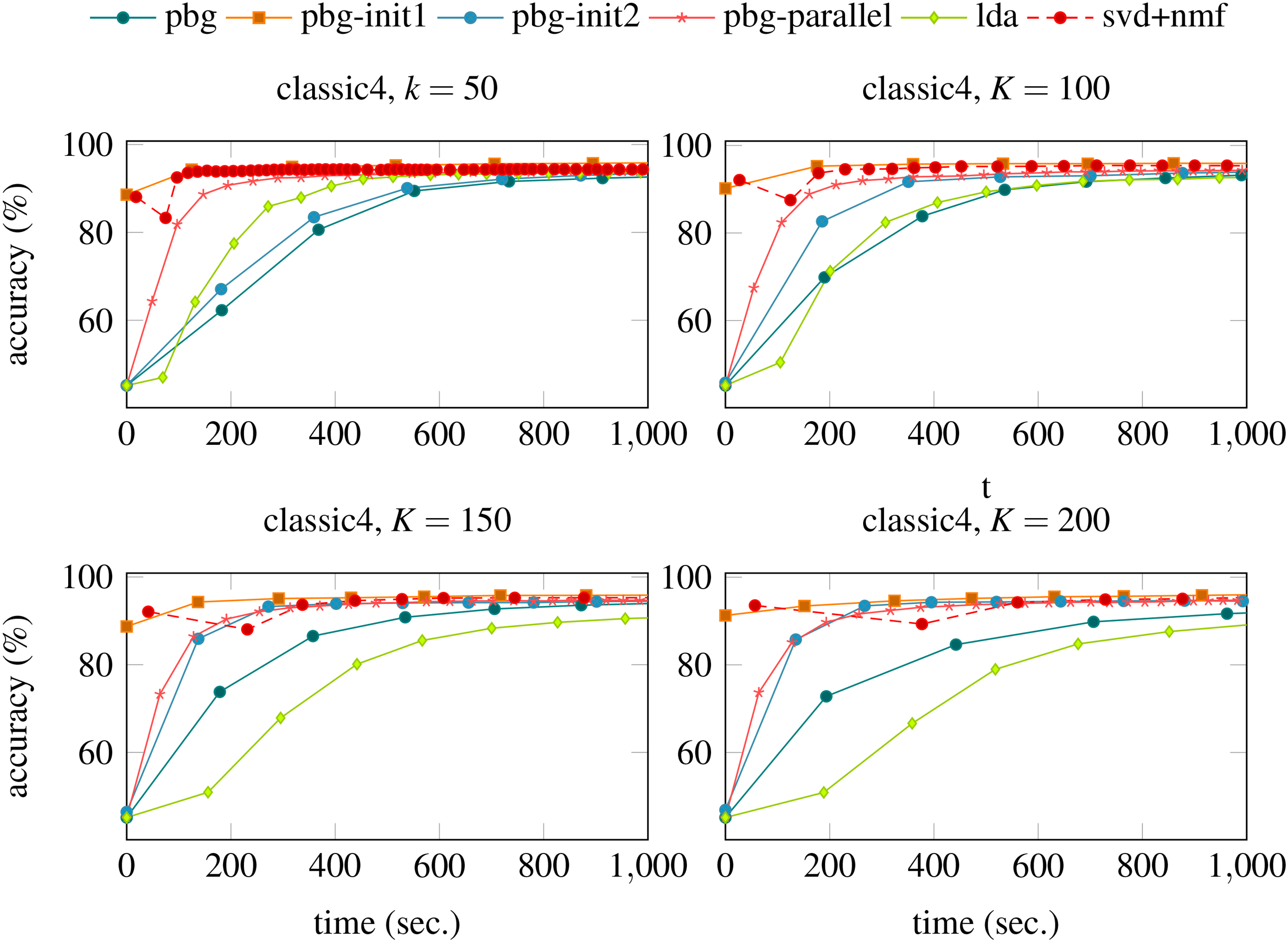
Classification accuracy obtained during execution of algorithms used on this experimental evaluation. The features vectors (latent information vectors 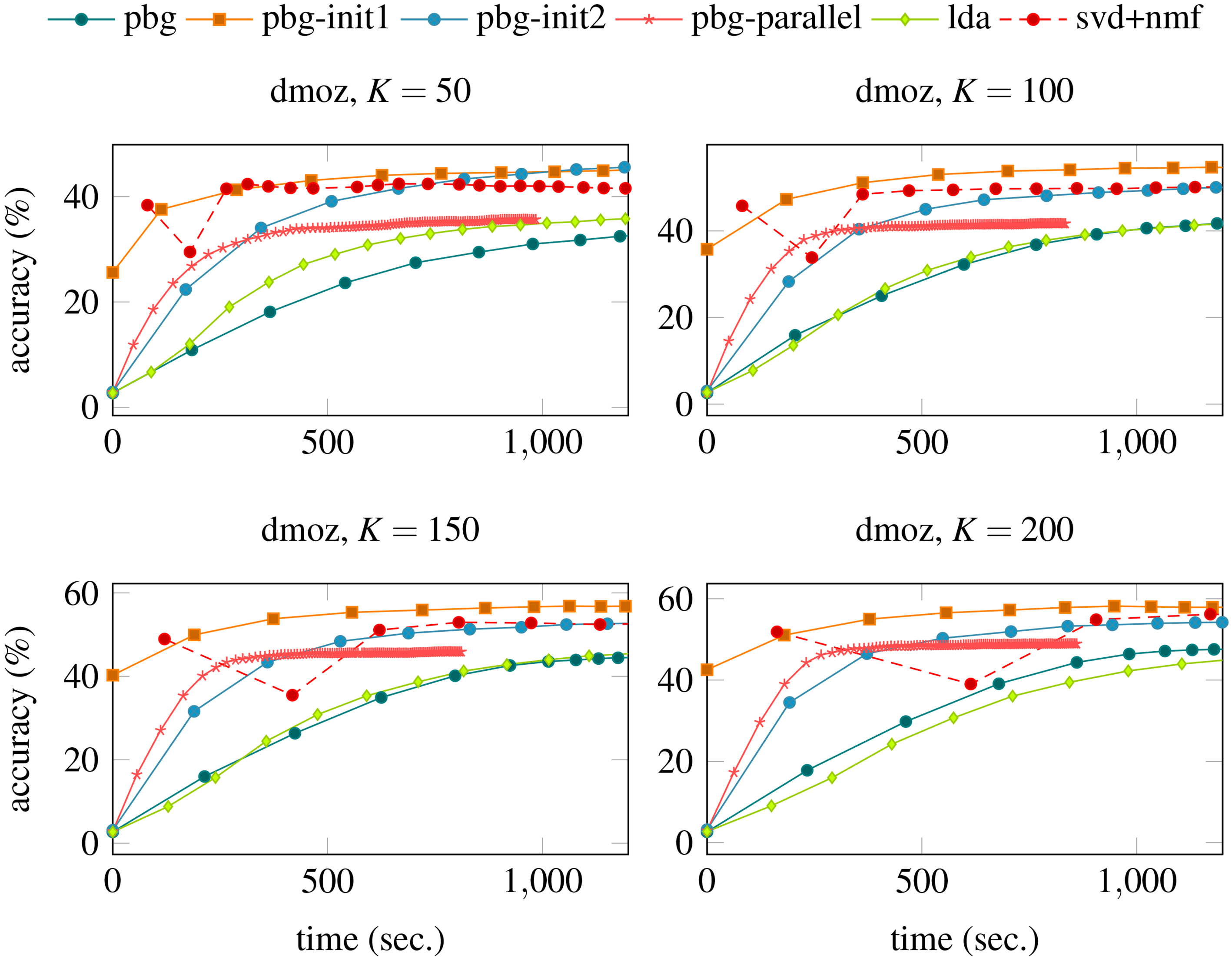
In Figs 6–8 we note that the first point (at the begin of first iteration) of the series related to algorithm svd
Figures 6–8 show that LDA converges faster with
Finally, these experiments indicate that even with inclusion of simple heuristics, such as clustering-based initialization and parallel processing, the results of PBG can be improved in the task of feature extraction. In addition, the proposed method achieves competitive results compared to methods as LDA and NMF.
Another experimental evaluation was carried out in the topic extraction task. A topic is a set of words that frequently occur in a semantically related documents and can be used to describe its thematic structure. Formally, a topic
such as
Automatic method to quantify the coherence of topics and their semantic interpretation has been the target of several studies [10, 31, 22]. Here, to compare the quality of the topics obtained by PBG with those obtained by LDA and NMF, we use the metric NPMI (Normalized Pointwise Mutual Information).
NPMI is based on the association between pairs of words using external data [31, 22]. This method is correlated with human perception about topic coherence, and indicates how well words in the topic describe a theme. In [31], words correlations were extracted from Wikipedia pages,4
We use documents from Wikipedia of the year 2008. These documents are freely available at
Average value of NPMI obtained by algorithms used on this experimental evaluation
The results of the NPMI are shown in the Table 6. The results indicate that NMF obtains more coherent topics than LDA. The NPMI values of NMF are the highest for many datasets and number of topics. Despite this, PBG (and its variations) achieved good results, reaching better NMPI values in some data sets. These results indicate the viability of PBG as a competitive method, and a promising new technique for the topic extraction task.
In this paper, we presented Propagation in Bipartite Graph (PBG) algorithm, an unsupervised algorithm based on label propagation that considers a collection of documents modeled as a bipartite heterogeneous graph. The proposed algorithm propagates the latent information vectors associated to vertices and edges in a bipartite graph considering unlabeled documents. The mathematical background of PBG is a simplification of update iterations of algorithms for NMF and LDA methods. This simplification makes the PBG algorithm a descriptive and intuitive option for practitioners to implement and expand its heuristics for topic extraction and unsupervised learning tasks. The proposed algorithm also obtained better document characteristics than LDA and NMF, indicating PBG as an interesting method for dimensionality reduction. While in the tasks of topic extraction, PBG obtained more coherent topics when it is evaluated by an automatic method as NPMI.
In future studies we intend to elaborate an online version of PBG algorithm, to use clustering algorithms to determine how many topics are appropriated in dataset collection, and to explore more heuristics to improve the results obtained by propagation in bipartite graph. We also intend to incorporate other types of objects relations as document-document or term-term besides the document-term relations and analyze the impact in the coherence of topics.
Footnotes
Acknowledgments
This work has been partially supported by the State of São Paulo Research Foundation (FAPESP), grant 2015/14228-9 and 2011/23689-9, the Brazilian Federal Research Council (CNPq), grant 302645/ 2015-2, and the Brazilian Federal Agency for Support and Evaluation of Graduate Education (CAPES).