
Abstract
Text sentiment analysis is an important natural language processing (NLP) task and has received considerable attention in recent years. Numerous deep-learning based methods have been proposed in previous literature in terms of new deep neural networks (DNN) including new embedding strategies, new attention mechanisms, and new encoding layers. In this study, an alternative technical path is investigated to further improve the state-of-the-art performance of text sentiment analysis. An new effective learning framework is proposed that combines knowledge distillation and sample selection. A dually-born-again network (DBAN) is presented in which the teacher network and the student network are simultaneously trained through an iterative approach. A selection gate is defined to deal with training samples which are useless or even harmful for model training. Moreover, both the DBAN and sample selection are further improved by ensemble. The proposed framework can improve the existing state-of-the-art DNN models in sentiment analysis. Experimental results indicate that the proposed framework enhances the performances of existing networks. In addition, DBAN outperforms existing born-again network.
Introduction
Text sentiment analysis is a key component in various text mining applications [1, 2]. Its goal is to accurately classify given a text sample into different categories, which are usually set as three-level {positive, neural, negative} or five-level {very negative, negative, neutral, positive, very positive}. Deep neural network (DNN) has become an extensively used learning technique in sentiment analysis because it does not require hand-crafted features and has a remarkable performance [3, 4, 5]. Numerous methods have been proposed in previous papers. These existing methods focus on the modification of network modules including new embedding [6], new attention [7], or new encoding layers [8, 9]. In addition, a few studies have attempted to leverage additional knowledge to further improve performance [10, 11]. Promising results have been obtained along these technical paths.
Rather than introducing new effective DNN models or utilizing extra domain knowledge, the deep leaning community also emerges some novel and effective techniques to improve classification performances of existing DNN models. One of such techniques is knowledge distillation, which refers to the distillation of knowledge from a trained teacher network to guide the training of a student network without modifying the network structures. Numerous applications [12] of distillation in computer vision demonstrate that knowledge distillation enhances the performance of a student network. Furlanello et al. investigated a special case of knowledge distillation [13], namely, born-again network (BAN), in which the teacher and the student networks share the same structure. BAN has been proven to be effective in solving various problems.
Apart from knowledge distillation, noisy-label learning is another extensively used learning strategy without keeping eyes on new learning models. Labels in some training data may contain errors due to label difficulty or annotators’ carelessness [14]. Several studies have proposed solutions to deal with noisy labels [15]. This work brings the main idea of noisy-label learning for sample selection. The motivation for sample selection is that a small-proportion of training samples may play a negative role in the model training and these samples can be seen as noisy.
In addition, ensemble learning [16] combines a set of existing basic learning methods to produce a more effective model. Ensemble learning has been integrated in knowledge distillation [17] to provide valuable knowledge to supervise a student model.
Inspired by the above progress in machine-learning strategies, we propose a new learning framework rather than single learning model design for sentiment analysis in this paper. First, a new dually-born-again (DBAN) learning approach is proposed, in which the teacher network and the student network are trained simultaneously in each iteration. They share the same network structure and most parameters. Second, several existing sentiment analysis models are used and their outputs are combined to guide the learning of the teacher and student networks inspired by knowledge distillation. Further, a selection gate is defined to deal with training samples which are useless or even harmful for model training. Experiments on two benchmark data sets indicate that the proposed framework can improve the learning performance of the existing state-of-the-art DNN-based sentiment analysis models. Our work is innovative in the following aspects:
A new learning framework is proposed to further improve the performance of existing DNN models for text sentiment analysis. This framework is inspired by the related studies on knowledge distillation, noisy-label learning, and ensemble learning. A new born-again learning approach is proposed. Our approach simultaneously trains the teacher and student networks with mixed supervised signals. This approach is more effective and efficient than the existing born-again strategy. To further improve the quality of the training samples, ensemble outputs are used to construct a selection gate that can filter samples that are relatively difficult to learn or even harmful.
Knowledge distillation
Knowledge distillation is initially designed for model compression [18, 19]. Knowledge of distillation usually refers to the distribution outputs of each training sample of a teacher model. This method borrows the knowledge from a cumbersome but high-performance model (teacher) to develop a simple model (student). The teacher model can be an ensemble of models and the student model can be a single model. Various experiments have shown that the class probabilities produced by a teacher model are better than the original ground-truth labels in training of a student model [20]. Knowledge distillation has been used in various natural language processing (NLP) tasks including neural machine translation [21]. To the best of our knowledge, knowledge distillation has not been applied to sentiment analysis.
Furlanello et al. proposed a new knowledge distillation strategy, in which the teacher and the student models share the same structure [13], to improve the performance of an existing DNN. They are optimized iteratively (teacher
Text classification
Numerous text sentiment classification methods have been proposed in previous literature and can be divided into three categories. The first category is rule-based. Rule-based methods are also known as lexicon-based methods in which dictionary of three kinds (positive, negative, negation) of the key words are compiled. A set of rules are subsequently constructed based on the appearance and positional relationships between key words. The second category is (conventional) learning-based. One-hot word-level features are constructed and fed into a shallow learning model (e.g., SVM and Adaboost). The third category is deep learning-based. CNN and long short-term memory (LSTM) are often used to encode input texts and a softmax classifier is used to predict the sentiment category [3, 22]. Previous deep learning-based methods have focused on new network structures, new attention mechanisms, or the utilization of domain knowledge. Our study adopts a new technical path to further improve the state-of-the-art sentiment analysis performance.
Noisy-label learning
Noisy-label learning assumes that a small proportion of labels in training data are errors caused by labeling noise [14]. The majority of the noisy-label learning methods attempt to model the labeling noise and than infer the ground-truth labels [23]. Some other methods assume that there is an additional small-size training set with high-quality labels [24]. Knowledge distillation has been used in noisy-label learning [15]. This study attempts to leverage the ensemble learning to deal with samples that are difficult to train. These samples can be considered with noisy labels or ambiguous. Our study focus is not on learning with noise samples, but on improving the performance of the existing DNN models by mining more information of samples. The difference between our study and noisy-label learning methods is that noisy-label learning attempts to model the labeling noise and than infer the ground-truth labels, but our model attempts to improving the performance of the existing DNN models by finding out the difficult-to-train samples.
Methodology
Text sentiment analysis can be formulated as follows. Given a piece of input texts
The overall learning framework
This study aims to design a learning framework to improve the performance of a mainstream existing DNN model. Accordingly, a dually-born-again network and sample selection are leveraged. DBAN can facilitate the performance of a single DNN model. Meanwhile, sample selection can select samples that are useless or even harmful for model. Both DBAN and sample selection can further improve by ensemble learning. Besides, no domain knowledge is used in the entire process. Let
Overview of the whole learning framework.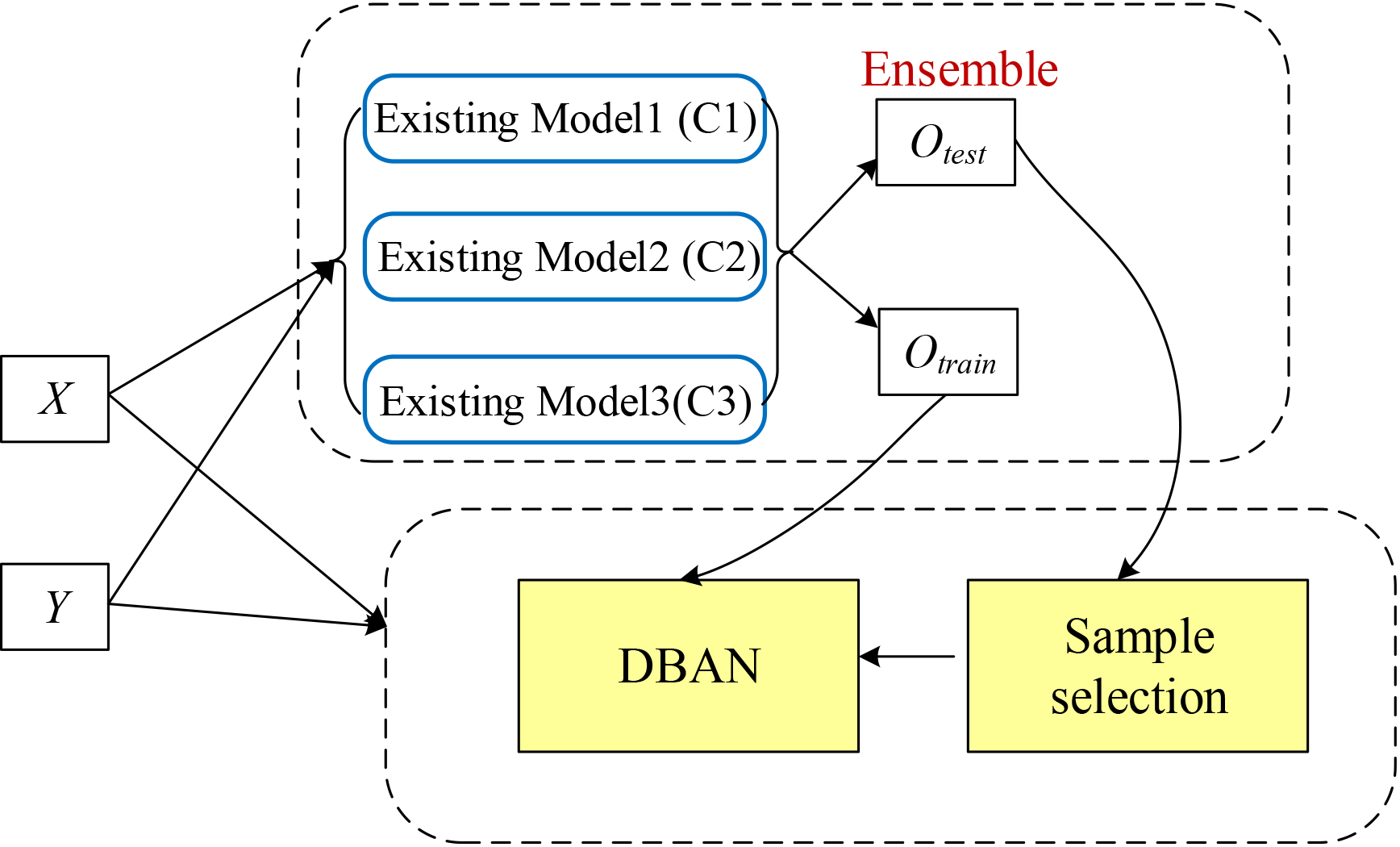
Our model comprises three major modules, namely, DBAN, sample selection, and learning model ensemble. The outputs of the model ensemble are taken as input for both the DBAN module and the sample selection module.
The first module, the DBAN, contains two sub-networks, namely, teacher network and student network. These two networks share most structure and parameters except the last softmax layer. The loss functions of the two networks are detailed in the following subsections.
The second module, sample selection, attempts to exclude training samples which are useless or even harmful for training. The sample selection is implemented via a selection gate. The selection gate is
The third module, ensemble learning, has two important roles in the entire learning framework. This module has two outputs (see Fig. 1), namely,
The primary goal of knowledge distillation is to compress models while retaining the prediction performance as good as possible. BAN is a special type of knowledge distillation and its goal is to produce improved model parameters for an existing model rather than compressing the existing model. This study also aims to improve the performance of an existing sentiment analysis model without modifying the structure of the model.
The existing BAN merely involves one DNN structure to be learned. BAN iteratively borns a new student model. The newly born student model is subsequently used as the teacher model to born the next new student model. After
The learning procedure of existing born-again network (BAN). The left image shows the first step and the right image shows the 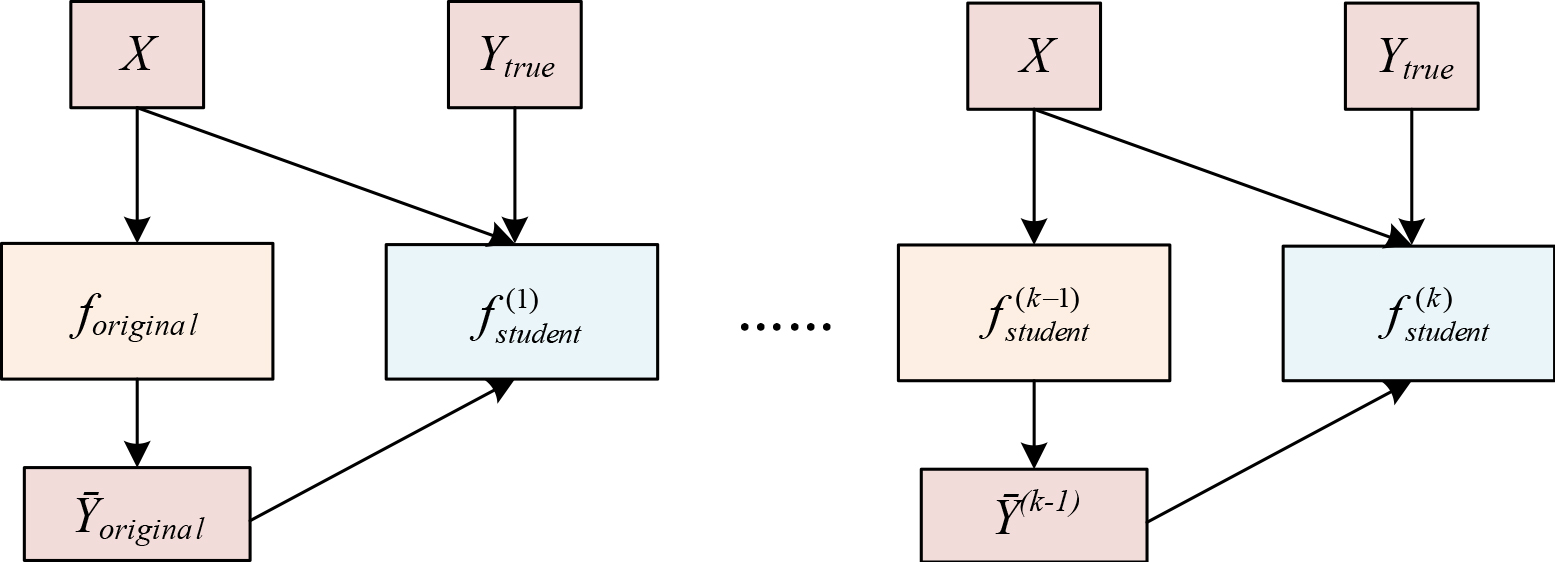
BAN needs to train the student network from scratch (all parameters are required to be re-initialized) in each step,1
Our experimental results indicate that the performance of the student network could not be improved if the parameters of the student network are initialized by copying those of its teacher network.
The graphical model of DBAN is shown in Fig. 3. The teacher and the student networks share the same network structure and most of the parameters. Only the last layers of the two networks are different.
The final supervised labels for teacher network is the mixture of ground-truth labels
The learning procedure of DBAN. The left shows the first step and the right shows the 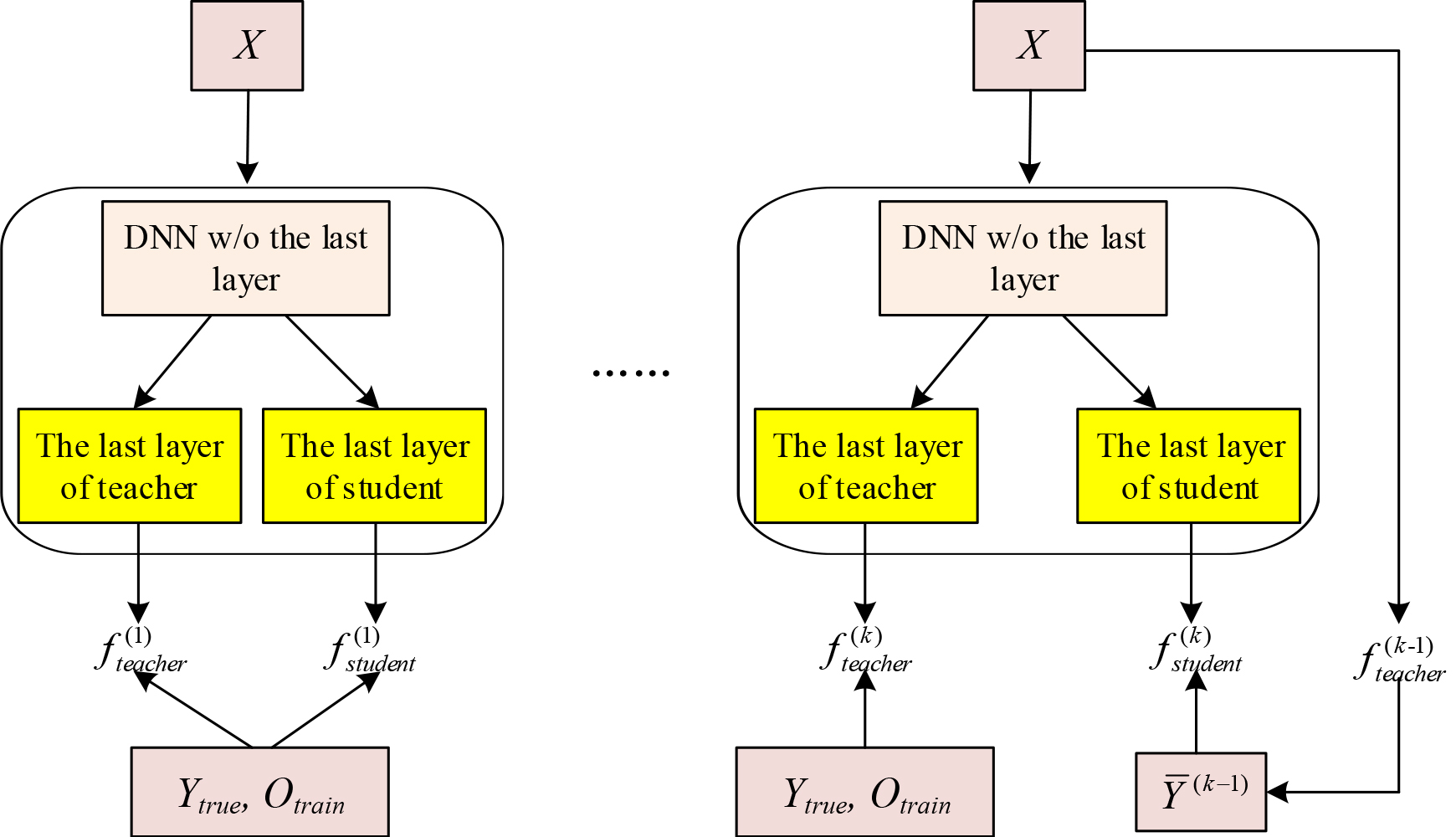
In the initialization step, the teacher and student networks are trained based on the sample set
where
where
In the
In the implementation of the network training, the first step runs
[h] InputInput ReturnReturn training set
In addition to the difference in parameter initialization strategy for student network training, there are two major differences between BAN and DBAN, as listed below:
In DBAN, the teacher network and the student network are trained simultaneously. However, BAN trains the teacher network and the student network separately. In DBAN, the teacher network and the student network share most parameters. In BAN, the parameters between the teacher network and the student network are independent.
Classification errors are inevitable in machine learning. The reason that classification errors of an involved model occurs mainly lies in the following aspects: (1) The classification capability of a model is not ideal. In practice, it is nearly impossible to construct a perfect model with 100% classification accuracy. (2) A few samples may play a negative role in training because several text semantics are reasonably vague or obscure to understand even by human beings. (3) A few labels are errors. Label inconsistency and labeling errors are inevitable in text sentiment annotation. These samples are harmful for the model learning. Intuitively, if text samples that are vague/obscure semantics or labeling errors are known in mode training, then these difficult-to-train samples can be excluded or given substantially low weights during the training stage. Therefore, the performance can be improved.
In order to identify the difficult-to-train samples, we made statistics on the error rates in terms of the maximum value of the softmax output on test data. The results shown in Fig. 4. The y-axis in Fig. 4 shows the error rates, while the x-axis shows the range of the maximum value of the softmax output. An increasing trend can be observed in Fig. 4. The error-classified samples are usually with lower maximum values of the corresponding softmax outputs. Alternatively, the maximum distribution outputs partially reflect the samples which are difficult to classify, thereby motivating us to conduct (difficult-to-train) sample selection based on maximum distribution output. The pseudo code of sample selection for one model is provided in Algorithm 3.3.
[h] InputInput OutputOutput training set
The relationships between the maximum value of the softmax ouput and the errors.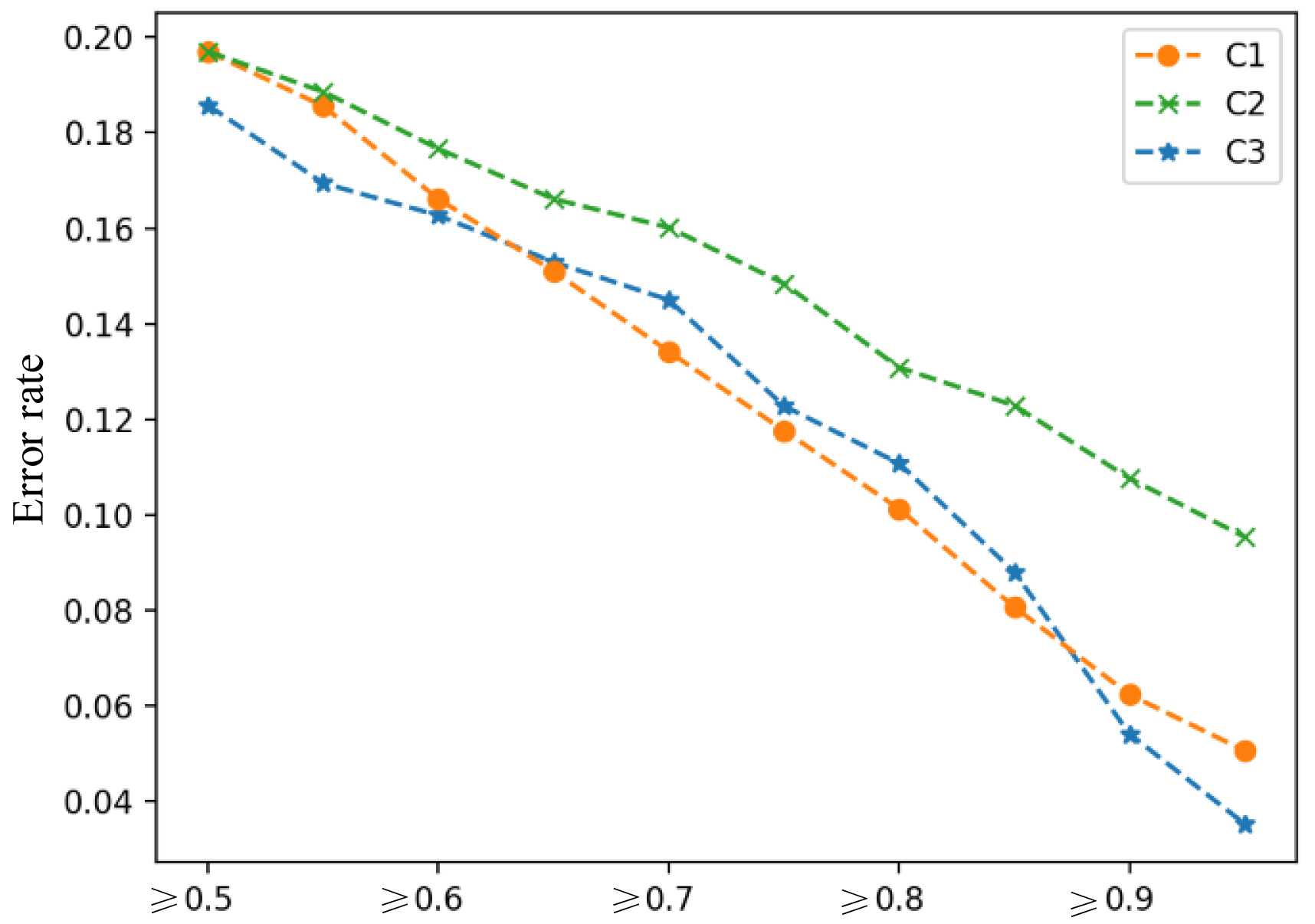
By considering sample selection
The last term is a sparse constraint that is used to prevent the loss from becoming zero if all the samples’ selection-gate values equal to zero. The sparse constraint is reasonable because the proportion for the samples unsuitable for training is usually small.
Ensemble learning is effective toward improving prediction performances without applying novel models. It has been used in a number of NLP tasks [25]. Although an ensemble of models is usually more effective than a single model, it is usually in larger-size and more time-consuming. Therefore, this study does not attempt to design an ensemble for the final sentiment analysis. Instead, we use a single model for our final sentiment analysis while utilizing the ensemble in the training stage. As previously mentioned, ensemble learning plays two important roles in the whole learning framework according to its two different outputs. The first role is the supervised information for DBAN; the second role is for sample selection. These two roles are implemented by two forms of outputs of the ensemble models, i.e.,
The approaches of generating 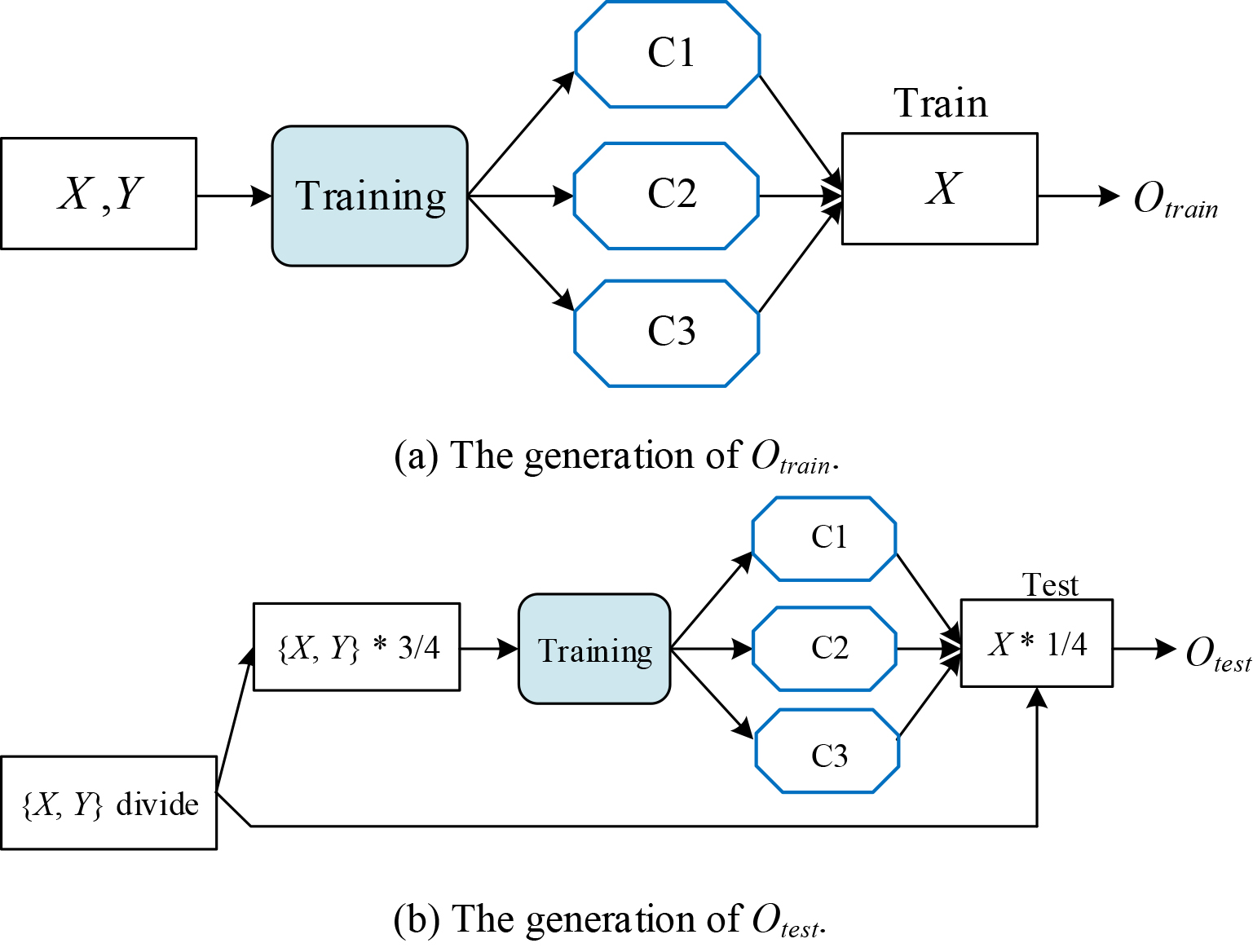
Figure 5 explains how outcomes
The three models here is just for illustration. The number of models can also be 4, 5, etc..
In Fig. 5b, the data
or
where
Data sets
To demonstrate the effectiveness of our proposed method, as most previous works [3, 11, 26], we conduct experiments on two benchmarks, namely, movie reviews (MR) [27] and Stanford Sentiment Treebank (SST) [28]. Table 1 shows statistics of the two datasets.
Details of the experimental data sets
Details of the experimental data sets
Train/Dev/Test: train/development/ test set.
MR: MR is a collection of movie reviews in English. Each sample in the MR dataset is divided into two categories, namely, negative and positive.
SST: The original SST data set provides phrase-level annotations. However, our experiments only considered the sentence-level annotations. Each sentence are classified into five categories (i.e. very positive, positive, neutral, negative, very negative).
In order to comprehensively evaluate the performance of our proposed method, the following state-of-the-art sentiment analysis DNN models are considered for comparison:
All word vectors in our experiments are initialized by Glove [31]. The vocabulary size is 1.9 M, while the dimension of each word vector is 300. The setting of hyper-parameters is mainly based on the original papers. All the LSTM hidden states are set to 300. The dropout rate is 0.5. The L2 regularization of CNN is 0.8, while that of LSTM-CNN is 0.4. The learning rate of CNN and LSTM-CNN is set to 0.01, while the batch size is set to 64. For LR-LSTM, the learning rate is set to 0.1, while the batch size is 25. The code of LR-LSTM is released by Qian et al. [11]. The other methods are implemented by Tensorflow.4
The accuracies of the competing models on MR and SST
The accuracies of the competing models on MR and SST
Our proposed learning framework consists of several new modules (i.e., ensemble, DBAN, sample selection). By training existing DNN models using our proposed learning framework, the following new models are obtained:5
Note that the ensemble module is the basis module for both sample selection and DBAN. It is not independently used here, whereas its effectiveness is verified in an independent subsection.
Table 2 shows the experimental results of competing models on the two benchmark data sets MR and SST. The results verify that the classification accuracies of existing models (i.e., CNN, LSTM-CNN, LR-LSTM, ELMo and BERT
On the MR data set, SD
Note that for selection sample, the results of using Eq. (3.5) are slightly better than those of using Eq. (8). Therefore, Eq. (3.5) is used in all experiments.
The training time of DBAN and BAN
The accuracy comparison between DBAN and BAN
The variations of the accuracies under different values of 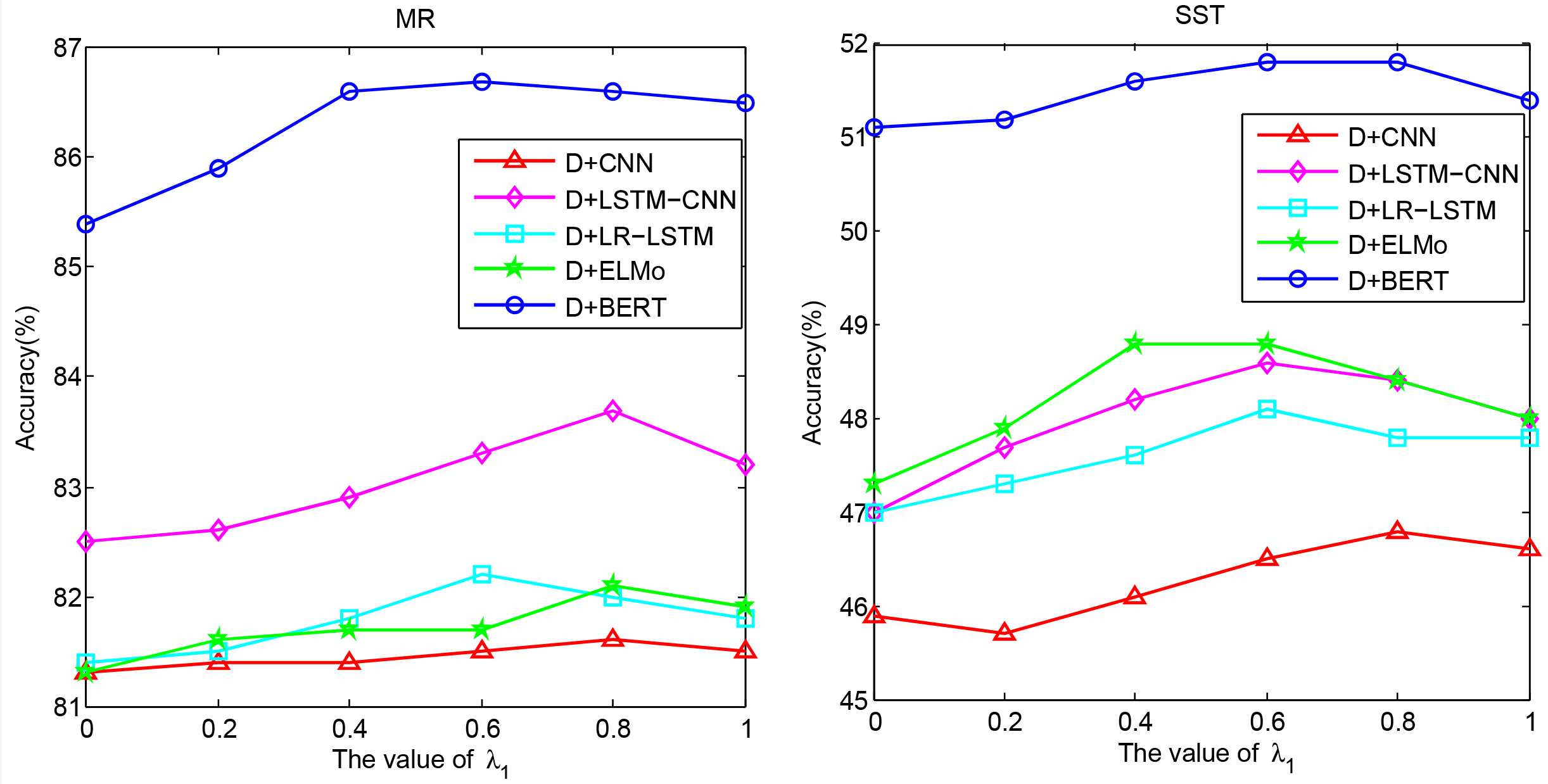
To further reveal the effectiveness of DBAN, we compared DBAN and BAN with the five existing DNN models, namely, CNN, LSTM-CNN, LR-LSTM, ELMo and BERT
The results shown in Table 3 indicate that DBAN is generally better than BAN. As previous stated, the training with BAN is time consumption as the network parameters should be re-initialized in each step. The training time of DBAN and BAN is recorded during learning and the results are shown in Table 4. Therefore, DBAN requires less training time than BAN, and the performance is better than BAN.
Experiments on the ensemble module
In DBAN, the output (
The accuracy comparison when different inputs for sample selection are utilized
The accuracy comparison when different inputs for sample selection are utilized
In order to verify the influence of ensemble learning in sample selection, we conducted experiments on the two benchmark datasets by using different inputs for the sample selection module. The results are shown in Table 5. When
Sample selection has rarely been analyzed in previous studies. To further illustrate that a few training samples play a negative role in training, we cite several typical examples from training sets, the weights of which are extremely minimal.
“I’ve never bought from telemarketers, but I bought this movie”. The weight value is 0.002. The review contains implicit information that indirectly expresses the affirmation of the movie. “The biggest problem with this movie is that it’s not nearly long enough”. The weight value is 0.025. The text implicitly expresses the love for the movie, and does not actually say that the movie is considerably short. “The movie is not as terrible as the synergistic impulse that created it”. The sentence contains negative words, and the weight value is 0.265. It implies that the model cannot considerably judge the sentiment of the text containing negative words.
The sentiment labels of the preceding samples are difficult to judge. That is, these samples add considerable burden to the training. Hence, reducing the weights of these samples benefits the training because “less is more” in real applications.
This paper investigates a new learning strategy to increase the sentiment analysis accuracy of a given deep neural network. Our proposed learning strategy is mainly based on BAN learning which is a special case of knowledge distillation. To mitigate the defects of existing BAN, a new learning approach, namely, DBAN, is presented and the teacher and student networks are trained simultaneously. The ensemble of existing DNN models is used for two goals. The first goal is to provide substantially effective knowledge to network training in DBAN; the second goal is to perform sample selection to improve the quality of the training data. The experimental results verify the effectiveness of the proposed learning strategy as well as the three independent modules, namely, DBAN, sample selection and ensemble. The performances of three typical DNN models are enhanced after using our learning strategy.
In our future work, we will extend the proposed learning framework for more NLP tasks such as opinion mining and machine translation.
Footnotes
Acknowledgments
This work is supported by the Frontier science and technology innovation project (2019QY2404), Zhejiang Lab Fund (2019KB0AB03), and Tianjin Nature Science Fund (19JCZDJC31300).