
Abstract
Recognizing a singing melody from an audio signal in terms of the music notes’ pitch onset and offset, referred to as note-level singing melody transcription, has been studied as a critical task in the field of automatic music transcription. The task is challenging due to the different timbre and vibrato of each vocal and the ambiguity of onset and offset of the human voice compared with other instrumental sounds. This paper proposes a note-level singing melody transcription model using sequence-to-sequence Transformers. The singing melody annotation is expressed as a monophonic melody sequence and used as a decoder sequence. Overlapping decoding is introduced to solve the problem of the context between segments being broken. Applying pitch augmentation and and adding noisy dataset with data cleansing turns out to be effective in preventing overfitting and generalizing the model performance. Ablation studies demonstrate the effects of the proposed techniques in note-level singing melody transcription, both quantitatively and qualitatively. The proposed model outperforms other models in note-level singing melody transcription performance for all the metrics considered. For fundamental frequency metrics, the voice detection performance of the proposed model is comparable to that of a vocal melody extraction model. Finally, subjective human evaluation demonstrates that the results of the proposed models are perceived as more accurate than the results of a previous study.
Keywords
Introduction
Automatic music transcription (AMT), which refers to converting an audio signal into the form of a symbolic score, is one of the most important research topics in the field of music information retrieval (MIR). Among the symbolic score forms, expressing notes with onset and offset time and pitch is referred to as note-level representation. Many attempts have been made to transcribe a singing melody into note-level representation, but this remains a difficult task. In vocal melodies, the onset and offset are often not apparent. Contrary to the exact pitch of instruments such as a piano, pitch vibrato appears in various patterns depending on the style of the vocalist. Moreover, for a vocal melody in polyphonic audio with accompaniment, it is necessary to distinguish vocal timbres from mixed pitch patterns.
High-quality audio data with annotations are essential for adopting machine learning techniques in AMT. Manual note-level singing melody annotation requires musical ability to recognize pitch and onset/offset timing of vocal notes and is time consuming. Nevertheless, many attempts have been made to annotate music by using experts [1, 2] or with machine learning techniques [3, 4]. DALI dataset was presented as a result of matching the karaoke melody data and the audio of 5,358 songs [4]. However, because there was no human verification of the results, the dataset contained wrong annotations, such as octave and timing errors, and its quality was improved by cleansing the data [5]. MIR-ST500, a large-scale dataset of 500 songs constructed by combining AMT technology and manual annotation, was recently released [6]. It is a high-quality annotation data obtained by employing humans to verify the results of automatically recognized pitch and note segmentation
Fundamental frequency (F0) analysis for melody pitch recognition has been conducted predominantly for automatic singing melody transcription. The most popular traditional approach to pitch tracking is pYIN [7], which adds a probabilistic model to the result of YIN algorithm [8]. Recently, pitch tracking using deep learning has been actively researched [9, 10, 11], with one attempt to recognize only the vocal F0 after detecting vocals from polyphonic audio [12]. However, the results of pitch tracking cannot be converted into the form of note-level annotation due to the absence of notes’ onset and offset information. The consecutive onsets of the same pitch cannot be distinguished.
An amplitude-based note segmentation heuristic was developed and used in Tony software to convert F0 to note-level annotation [13]. In [14], pitch tracking and note segmentation were performed using deep learning and the results were combined to enable note-level transcription. In [15], pitch estimation results were converted from frame-level to note-level by quantizing F0 results to the nearest MIDI pitch and with rhythm quantization based on tempo estimation [16].
However, combining note segmentation and pitch tracking is complicated and incomplete. An end-to-end piano transcription Transformer has been proposed [17], breaking away from the necessity of combining the individual recognition results of onset, offset, and pitch. The authors demonstrated the best performance in note-level piano transcription through a sequence-to-sequence Transformer [18] that predicts a sequence of tokens representing absolute time, note velocity, and note pitch.
This paper proposes a note-level singing melody transcription Transformer to recognize the monophonic singing melody from polyphonic audio signals. Monophonic note event tokens are defined to express a monophonic melody as a sequence of event tokens. Furthermore, we propose three techniques to enhance the transcription performance, namely overlapping decoding to resolve a context breakage between segments in decoding, pitch augmentation to enlarge the training dataset, and adding noisy dataset with data cleansing.
The experimental results imply that combining the proposed methods significantly improves the performance. The proposed model outperforms other models in note-level singing melody transcription regarding note-level evaluation metrics. Through the analysis of F0 estimation evaluation metrics, we show that the voice detection performance of the proposed model is comparable to that of a previous study. Finally, the visualization of the results and subjective listening test demonstrate that the proposed methods are effective in achieving better transcriptions.
Related work
Note-level singing transcription
For note-level singing transcription, it is essential to recognize the pitch, onset, and offset of each note. Tony [13] enabled interactive annotation of melodies from monophonic audio recordings. It supported note-level transcription by first performing pitch tracking using pYIN [7] and then converting the F0 results into note-level annotation with hidden Markov model [19]. Furthermore, consecutive notes of similar pitch were segmented by applying the amplitude-based onset segmentation heuristic.
Omnizart [20] provided various AMT functions based on deep learning, such as vocal transcription, chord recognition, drum transcription, and beat tracking. Its vocal transcription module for polyphonic music adopted a hybrid network comprising frame-level pitch extraction and note segmentation models. The authors used pretrained Patch-CNN [21] for pitch tracking and improved the previously proposed note segmentation model using Pyramid-Net with ShakeDrop regularization [22] and virtual adversarial training [23].
The downside of various note-level singing transcription datasets is that the amount of data is small or the annotations are inaccurate. Wang et al. [6] proposed a large-scale dataset for singing transcription consisting of 500 pop songs (MIR-ST500) by setting some labeling criteria and obtaining annotations from non-experts. With the proposed dataset, they proposed a singing transcription model that recognizes onset, silence, pitch, and octave for each time frame using EfficientNet-b0. EfficientNet-b0 [24] is a convolutional neural network model that showed state-of-the-art performance on image classification, while keeping the model size small compared to other models. The proposed model in this work was also trained and evaluated with MIR-ST500. Furthermore, although Wang et al. [6] stated that DALI has inevitable errors, we make use of the dataset as an additional noisy dataset.
Kum et al. [15] proposed a semi-supervised learning method to solve the problem of insufficient note-level labeled data in singing transcription from polyphonic music. The authors generated pseudo-labels by applying pitch and rhythm quantizations to the results of a vocal pitch estimation model. The proposed singing transcription model was trained with unlabeled audio data and the pseudo-labels. Furthermore, the repeatedly applied self-training using the teacher-student framework [25] led to additional performance improvement. They showed that the use of unlabeled data in addition to labeled data can improve the performance of the singing transcription model.
Donahue et al. [26] designed a system that produces lead sheets from music audio. The authors claimed that using the audio feature of Jukebox [27] as input instead of spectrogram features led to significant performance improvement when training a Transformer [18] for melody transcription. However, only the performance for note onset was reported; the specific training technique was not disclosed. This paper proposes a note-level singing transcription Transformer and analyzes its performance using various metrics.
Transformers for music transcription
Model architecture of Transformer [18], a self-attention-based sequence-to-sequence model.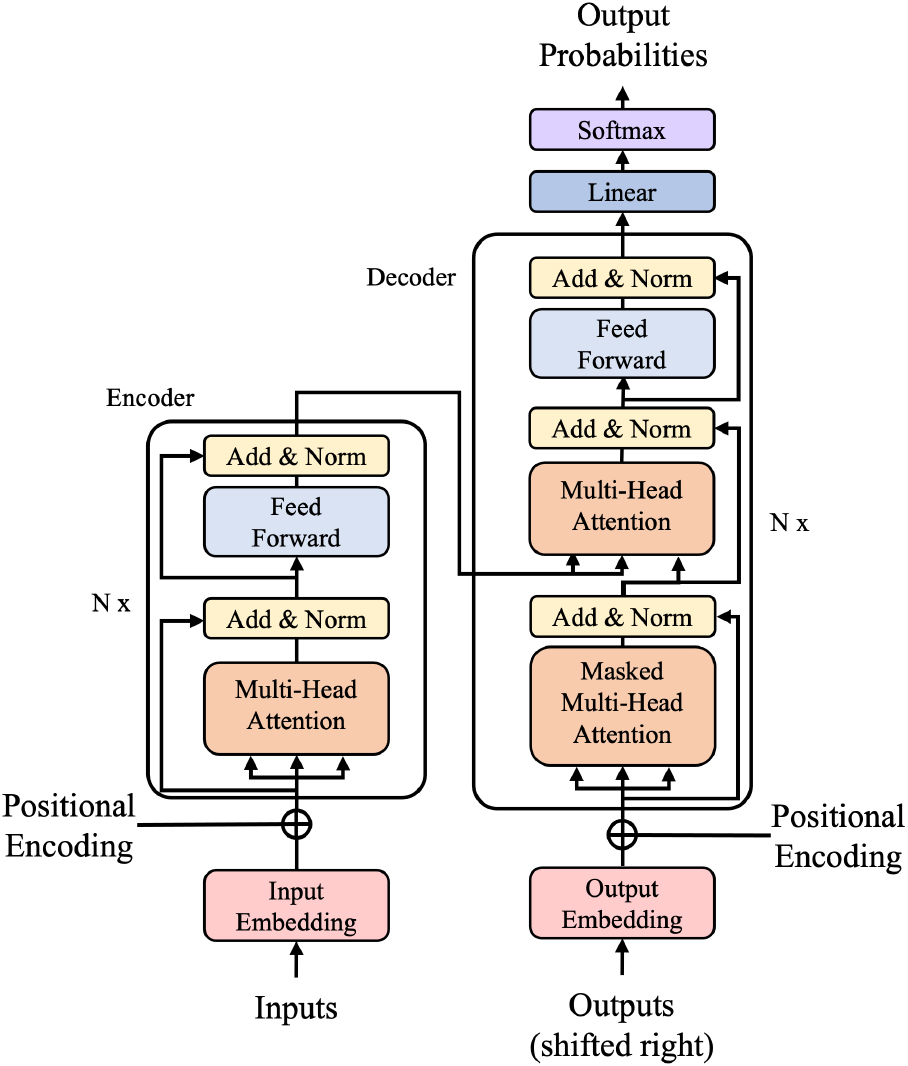
As depicted in Fig. 1, Transformer [18] is an attention-based network that relies only on attention mechanism without any recurrent or convolutional architecture. Utilizing multi-head attention together with position-wise fully-connected feed-forward network, it showed significantly faster training speed and achieved better performance than recurrent or convolutional networks for translation tasks. Since Transformer demonstrated outstanding performance in various tasks dealing with sequential data, it was also often used for music transcription tasks.
The sequence-to-sequence Transformer has achieved state-of-the-art performance in the task of piano transcription [17]. Despite the different lengths of audio feature and musical event token sequences, the authors proposed to use audio features as the encoder input and train the decoder to predict the output tokens autoregressively. A polyphonic piano performance was represented as a sequence of tokens where the token set consists of absolute time, note, velocity, and end of sequence (EOS). The results of the experiment comparing relative time-shift and absolute time tokens demonstrated that the latter performed better in piano transcription, due to the prevention of error accumulation. Following the results, we also adopted absolute time tokens for data representation.
In [28], a multi-task AMT Transformer was proposed, confirming that transcription of arbitrary combinations of instruments is possible by training various note-level instrument datasets simultaneously. The musical event sequence used in the decoder consists of instrument, note, on/off, time, drum, end tie section, and EOS. The instrument tokens enable distinguishing notes of different instruments. Moreover, the authors introduced an end tie section token as a method of conveying information about notes that were not turned off in the previous segment. The multi-task AMT Transformer obtained high-quality transcription results on various instrument datasets, but the task of singing transcription was not covered.
In this paper, referring to [17, 28], a sequence-to-sequence Transformer is applied to note-level singing transcription. While [17] focused on polyphonic piano transcription, this paper approaches the problem of monophonic singing melody transcription.
We propose a sequence-to-sequence note-level singing melody transcription Transformer and some techniques to improve the performance.1
An example of a monophonic note event sequence. Time tokens indicate the absolute positions of the events in the audio segment. A pitch token represents either an onset event of one of the 128 MIDI pitch numbers or an offset event.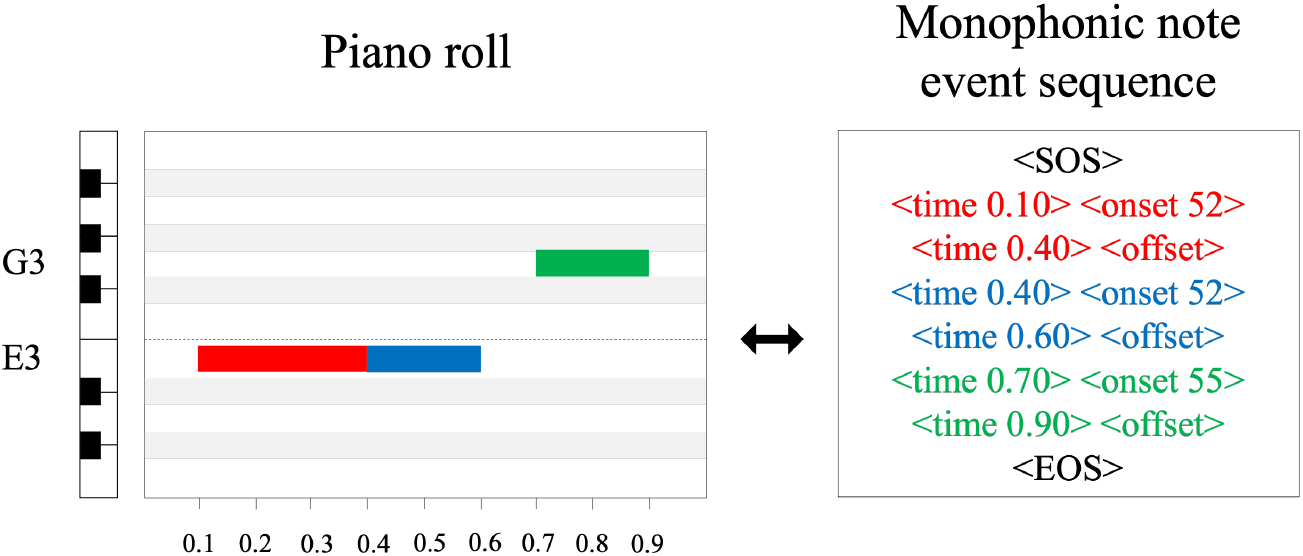
In this paper, a monophonic melody is represented as a sequence of musical event tokens. Each token in the event token set belongs to one of the following types: time, pitch, start of sequence (SOS), EOS, or padding (PAD).
By fixing the length and time resolution of an audio segment at
The magnitude values of STFT were utilized as the input audio representation. The audio sample rate was 16 kHz, and the window size and the hop length of STFT were 2,048 and 160, respectively. The length of the unit time frame was 10 ms. The STFT parameters previously used in singing melody F0 estimation [12] were referenced.
In training phase, the audio signal is randomly cropped into sections of
Model architecture
Overall structure of the proposed note-level melody transcription model. Transformer encoder and decoder are similar to those of the original Transformer [18].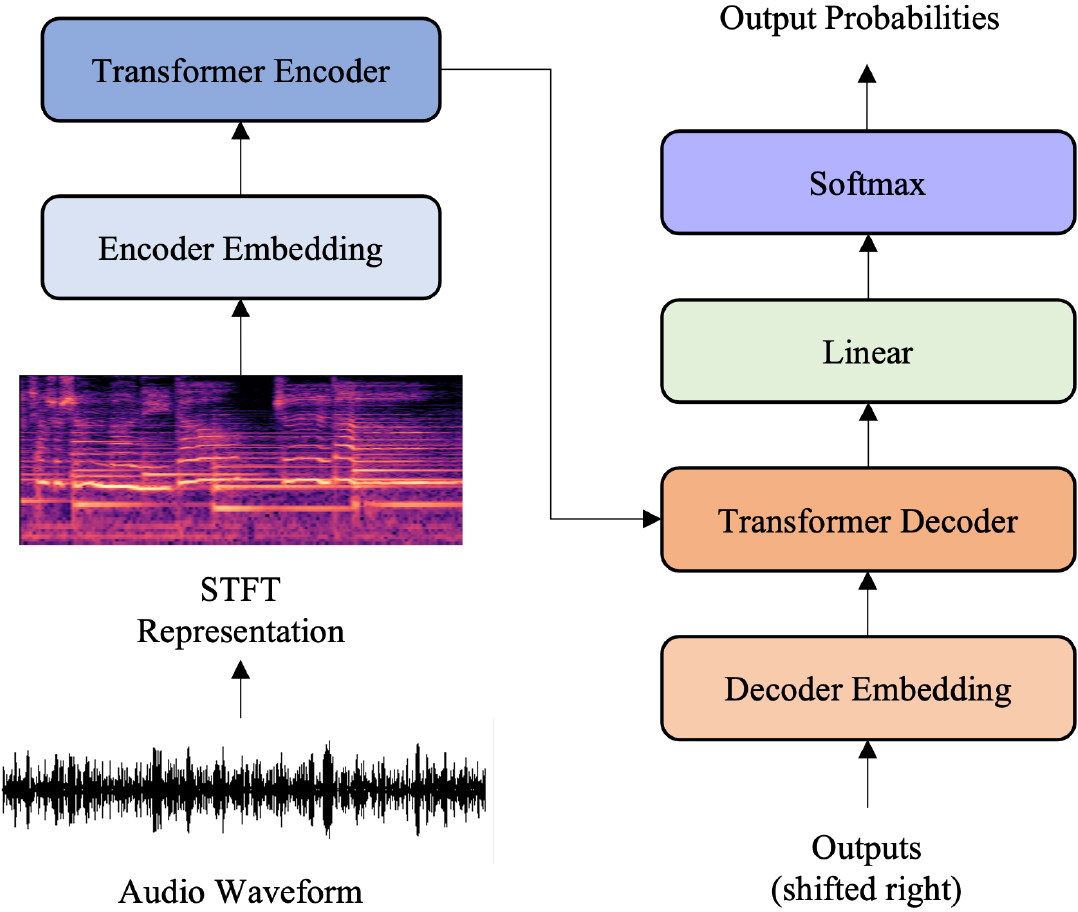
The structure of the proposed note-level singing melody transcription model is depicted in Fig. 3. While [17] adopted T5 [29] as the network architecture, our model resembles the original Transformer [18] with some modifications to the embedding layers.
Detailed structures of (a) encoder and (b) decoder embedding layers. In the encoder, layer normalization is first applied to normalize the STFT magnitude values. Both encoder and decoder embedding layers apply layer normalization after adding the positional encoding.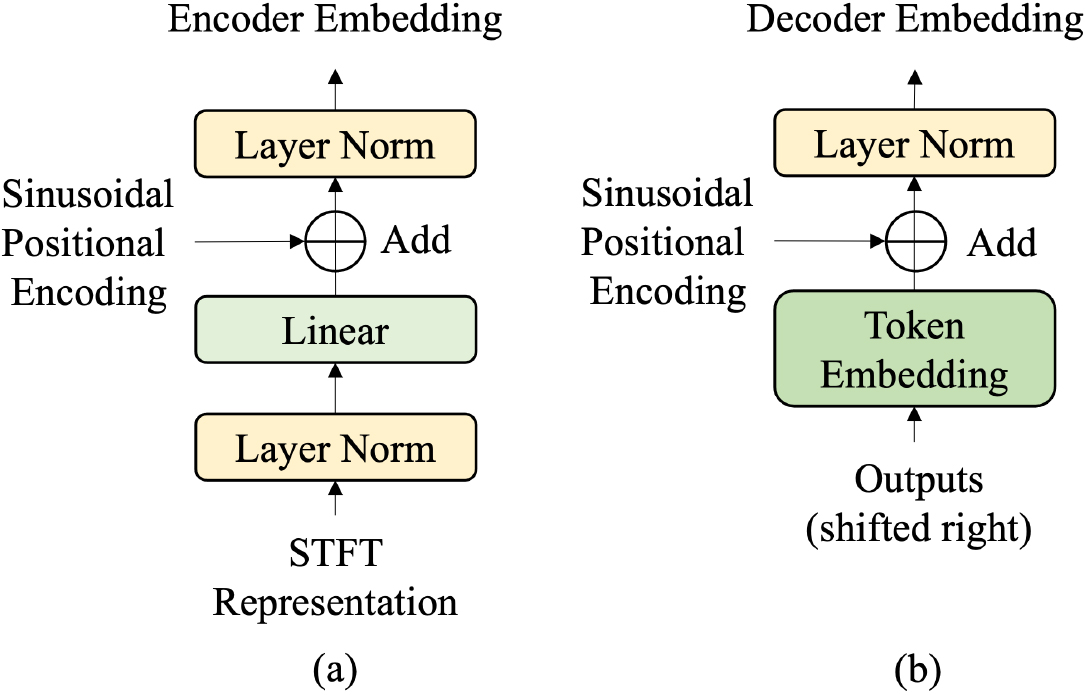
Since the input of the encoder is STFT, layer normalization [30] is first applied to normalize STFT magnitude values. After adding sinusoidal positional encoding, another layer normalization is applied given that the warm-up stage can be omitted by pre-normalization [31]. Figure 4 shows the resulting embedding layer architectures of encoder and decoder.
At the inference phase, the event tokens are decoded autoregressively. The encoder receives an audio signal of
Several maskings are applied when computing the subsequent token probabilities, to ensure that the recognition result is a monophonic melody. Time and pitch tokens are forced to be decoded alternately by masking one type after another. When time tokens are to be predicted, tokens that indicate the previous time are masked. For the prediction sequence to end within a limited length, the last token of the decoder output is forced to be EOS.
Overlapping decoding
Illustration of the difference between overlapping and non-overlapping decoding. 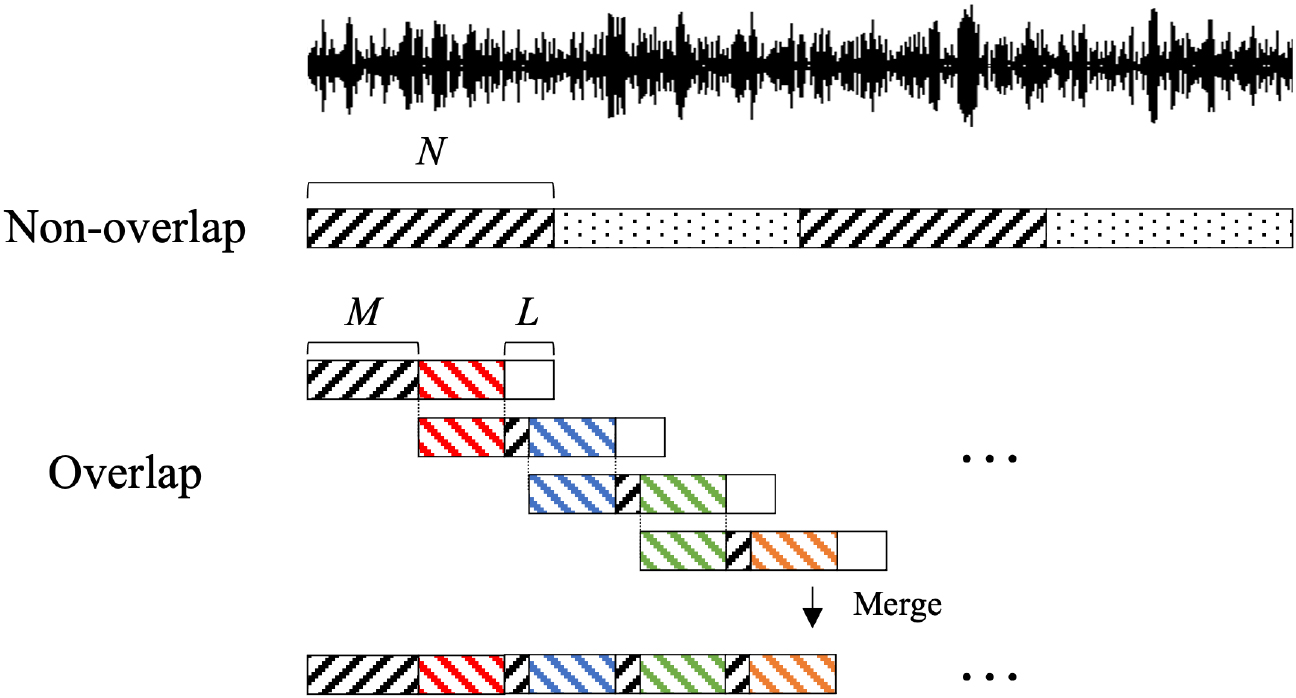
In [17], non-overlapping audio segments were recognized separately and the results were combined to transcribe longer audio signals. Such non-overlapping decoding has a problem in that the context of the previous segment is lost. For example, if a segment is truncated after a note onset but before its offset, decoding should be performed in the next segment without the note’s onset information.
We propose overlapping decoding in this paper to overcome the limitation. With overlapping decoding, successive segments overlap for a certain length of time. This prevents the context from being disconnected by transferring some of the results recognized in the previous segment to the next segment. Among the notes recognized in the previous segment, notes that overlap with the next segment are replicated to the next segment by modifying the time tokens to match the absolute time within the next segment. These notes act as a prior sequence when autoregressively inferring the next segment’s notes. And to avoid discontinuity in the transcription results, a certain length of time in the end of the overlapping region is discarded and inferred again in the next segment.
As depicted in Fig. 5, the hop size between segments is
As training a deep learning model requires a large amount of data, data augmentation is one of the most common attempts to improve performance [32]. Various augmentations such as pitch shifting and time stretching has been widely adopted in previous studies in the field of MIR [33]. Especially in AMT, since acquiring the pair of music audio and high-quality label data is very costly and time consuming, data augmentation is one attractive option to enlarge training data.
To be more specific, pitch augmentation refers to shifting the entire pitch of an audio clip several semitones up or down. Through pitch augmentation, various pitch tokens can be uniformly exposed during the training process. This prevents the output probability distribution of pitch tokens from being biased to some common tokens, resulting in less overfitting and generalization of the model.
In this work, a Python library designed to apply effects to the audio signal, pysndfx,2
A large amount of training data is required to develop a model with robust performance, but obtaining high-quality labeled data is laborious. Although DALI [4] is a noisy dataset with incorrect labels, some of the songs are labeled correctly, and it would be a more valuable dataset if one could distinguish between the correct and incorrect songs. When examining the DALI dataset, it turned out that the most common label errors were octave error and time shift. Therefore, we manipulated the label in terms of octave and time shift and compared it with the F0 estimation [12] result, and classified it as data that can be used for training if it exceeds a threshold.
Specifically, data cleansing was performed by shifting the annotation in both pitch and time axes and comparing with the recognition result of F0 estimation [12]. The sliding window sizes were 1 octave and 10 ms for pitch and time, respectively, in the ranges of
Experiments
Dataset
In this paper, two public datasets were used: MIR-ST500 [6] and DALI [4]. MIR-ST500 is a dataset with note-level annotations of vocal melodies for polyphonic audio signals. It consists of 500 songs, and only 474 songs were available at the time of the experiments. The dataset was split into three sets: songs numbered from 1 to 350, 351 to 400, and 401 to 500, which were used for training, validation, and testing of the experiments, respectively. To enable direct comparison with previous studies [6, 15], we used the same data split as the publication of the dataset. As for the test data split, all 100 songs were available without missing data, and was used for the ablation study and comparison with other models.
DALI is another note-level singing melody annotation dataset for polyphonic audio signals. It is the largest public singing transcription dataset currently available. A total of 4,927 songs were available, but the dataset has many incorrect labels because it was annotated automatically [6, 5]. Therefore, data cleansing described in Section 3.7 was applied. Consequently, 858 songs were left, which were used only for training to verify the effect of the additional noisy dataset.
MedleyDB [34], an F0 dataset which differs from a note-level dataset, was also evaluated for performance evaluation and comparison. The test data split of [35] was adopted, and only 12 songs were used as in [12, 25]. The F0 annotations of vocal melody in polyphonic audio were used as labels.
Experiment configurations
Specific hyperparameters of Transformer are summarized in Table 1 and other configurations used in the experiment are as follows. The model was trained with cross entropy loss function. The Adam optimizer was adopted, with an initial learning rate of 0.0001 and a batch size of 12. The learning rate was decayed with a factor of 0.5 if the validation loss did not decrease for more than 3 epochs, and the experiment was terminated if the loss did not decrease for 10 epochs. The number of time tokens was 1,025, enabling representation of 0 to 10.24 seconds with a time resolution of 10 ms. Adding 128 pitch onset tokens and offset, SOS, EOS, and PAD tokens to the token set results in a total of 1,157 tokens. The duration of the audio input
Hyperparameters of Transformer
Hyperparameters of Transformer
The transcription metrics of mir_eval [36] were used for the evaluation of note-level singing melody transcription. Four types of metrics were selected: onset time, offset time, onset with pitch, and note-level which considers all of the onset, offset, and pitch. A threshold was set according to each criterion to evaluate the transcription results, and is considered correct if the difference between the predicted value and the groundtruth is less than the threshold. In this paper, the thresholds for onset time, offset time, and pitch were 50 ms,
Additionally, F0 estimation evaluation metrics were used to evaluate the voice detection and pitch-only transcription performance. The melody metrics of mir_eval were used as the evaluation metrics for F0 estimation. Note-level labels and predictions were converted into F0 sequences with the time resolution of 0.01 seconds. For time frames not included in any note, the frequency was set to 0 Hz (unvoiced). Voicing recall rate (VR) and voicing false alarm rate (VFA) were used as metrics to evaluate voice detection. Raw pitch accuracy (RPA) and raw chroma accuracy (RCA) were used as metrics to evaluate pitch tracking. Overall accuracy (OA) was used as a metric to evaluate the performance of voice detection and pitch tracking simultaneously. The threshold to judge the correctness of the pitch was set at 50 cents. Equations (1)–(5) are defined to compute each metric. The number of voiced frames and the total number of frames in the reference are denoted by
EfficientNet-b0 [6] was chosen as a comparative model to train and test on MIR-ST500 dataset. The metrics were computed from the public prediction results of the test dataset released by the authors. JDC
Tony [13] and Omnizart [20], which are public note-level singing transcription models, were also selected as comparative models. The transcription result of Tony, a public software, was analyzed by exporting the result to MIDI. Vocal audio separated using Spleeter [37] was given as an input to Tony because the performance of singing transcription dropped significantly for polyphonic audio. The singing transcription result of Omnizart was obtained using a public source code library.
For the comparison model of vocal melody F0 estimation, JDC [12] was chosen. It can recognize a vocal melody from polyphonic audio with its voice detection module. The pre-trained model shared by the authors was used for performance evaluation.
Human evaluation
In order to analyze whether our proposed model achieved significant performance improvement, we asked people to evaluate the results. The transcription result was converted into a MIDI piano sound source and was played along with the original audio. In addition, the piano roll was provided as an image so that the results of transcription could be visually evaluated.
A total of three transcription results were evaluated: ground truth, EfficientNet-b0 [6], and the propsed model. Since ground truth is the most accurate transcription result, it was used as a criterion for accurate transcription when people listened to it and evaluated it. EfficientNet-b0 was selected as a comparison model because it showed the highest note-level F1 score among comparison models. In the test dataset of MIR-ST500, 140-160 seconds of 10 songs (410.mp3, 420.mp3, …, 490.mp3, 500.mp3) were used. For the same section of 10 songs, the results of three models were provided in random order so that people could listen and evaluate the performance.
The criteria for evaluating performance were evaluated in terms of note onset, offset, pitch, and overall. The transcription performance was scored on a 5-point scale ranging from 1 (poor) to 5 (good) for each criterion. Experimental subjects were recruited from Amazon Mechanical Turk [38], and only the results of those who evaluated the ground truth as the highest overall average score were collected for the reliability of the experiment. As a result, the results evaluated by 32 people were collected.
Results
Ablation study
Performance evaluation results of models for MIR-ST500 dataset
Performance evaluation results of models for MIR-ST500 dataset
The experimental results of note-level singing transcription are summarized in Table 2. Ablation studies were conducted to confirm the effects of overlapping decoding (OD), pitch augmentation (PA), and adding noisy dataset with data cleansing (AD).
First, the F1 score of note-level is improved by 0.013 by introducing OD. The performance improvement in the offset F1 score is more noticeable than onset, which is plausible because the onset of the previous segment is no longer lost. For non-overlapping decoding, determining an offset event is problematic because it is not possible to know whether the pitch onset event has occurred in the previous segment.
Adding PA led to a significant improvement in note-level F1-score by 0.09. PA increases the amount of training data due to exposure to pitch classes that do not appear frequently, preventing overfitting. Figure 6a implies the relevance between PA and overfitting. The validation loss increases after 25 epochs for the vanilla Transformer, implying overfitting. In contrast, although the training loss decreased slowly with PA, the validation loss continued to decrease without overfitting.
One of the notable results is that by including DALI dataset in the training data, the performance of the note-level F1 score improved by 0.01. Even though training and testing on only DALI resulted in poor performance, AD demonstrated a performance improvement. The effect of DALI dataset can also be found in Fig. 6. Figure 6b demonstrates the training loss decreasing more slowly with AD. Moreover, as illustrated in Fig. 6a, the validation loss continuously decreased along with the training loss. AD is beneficial because it prevents the model from memorizing the training data and generalizes the model performance.
Although the label data of MIR-ST500 are accurate, adding PA and AD were effective in performance improvement. Since PA and AD have the effects of increasing the training data, we expect that the performance can be further improved with larger datasets.
(a) Change in loss according to the epoch for each data split in each experiment. (b) Training loss according to the number of steps. Red indicates vanilla Transformer, green indicates Transformer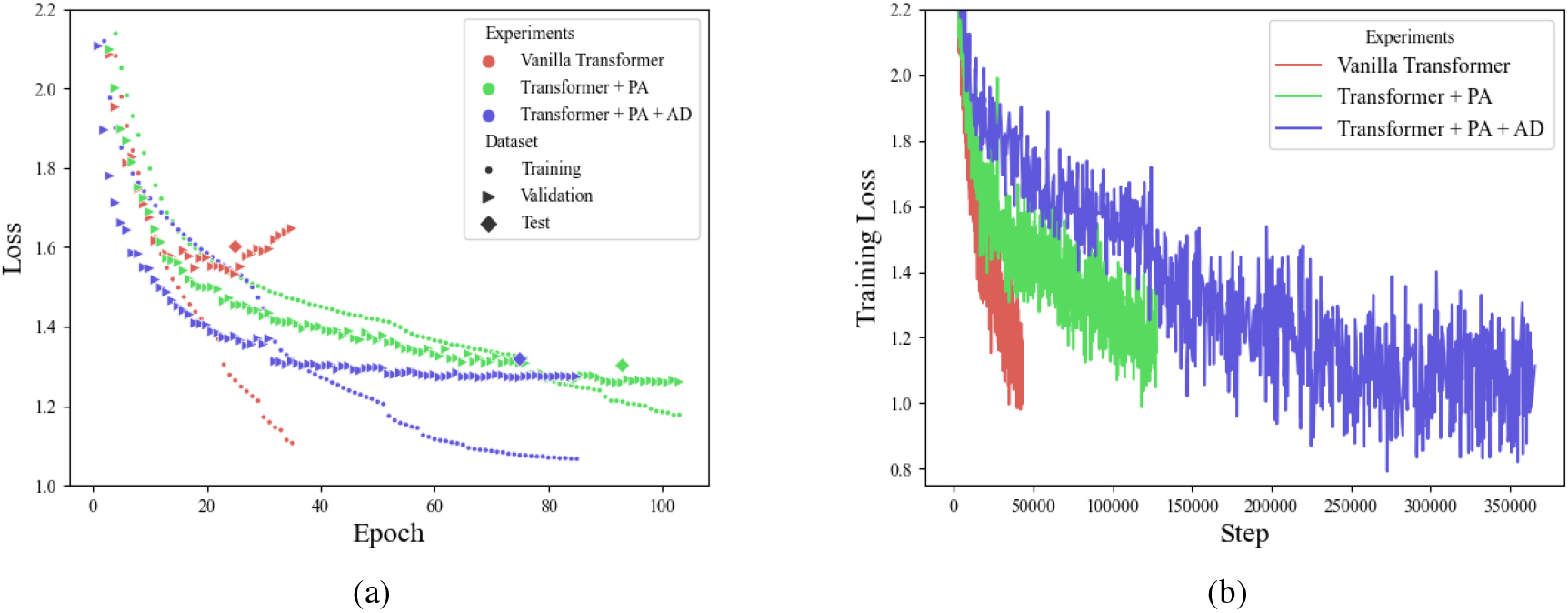
The results of comparing different state-of-the-art note-level singing transcription models with MIR-ST500 test dataset are also reported in Table 2. The proposed model outperformed the comparison models for all the metrics considered. There was a significant performance improvement in which the note-level F1 score increased by 0.1 or more compared with other models. This can be attributed to the performance improvement in the sequence-to-sequence model structure and the methods specialized for note-level singing transcription. Tony and Omnizart achieved poor performance because they were not trained with MIR-ST500. Compared with EfficientNet-b0, vanilla Transformer achieved a higher offset F1 score. Consequently, predicting the musical note sequence in the decoder is more advantageous than predicting for every time frame because the offset of the vocal melody is often ambiguous.
Transcription performance distribution analysis
Box plots representing the distribution of the proposed model performance on MIR-ST500 test dataset. The y-axis indicates the F1 score.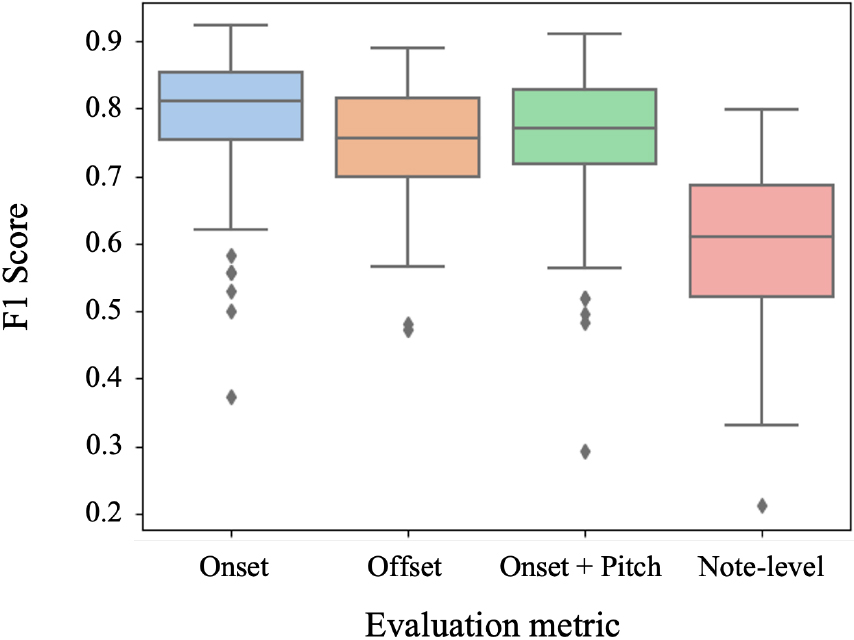
The proposed model’s evaluation results on MIR-ST500 test data are visualized in Fig. 7 as box plots. The onset prediction achieved a higher F1 score than the offset prediction, supporting the assumption that offset in vocal melody is ambiguous. Compared with predicting only the onset, adding pitch prediction resulted in a lower F1 score, which is predictable. The difference between the two is insignificant, implying that the pitch prediction can be considered accurate if the onset prediction is successful. In contrast, the note-level F1 score was noticeably low because note-level prediction requires accurate prediction of onset, offset, and pitch for a single note. Moreover, the transcription performance varies significantly depending on the song. Regarding note-level prediction, the proposed model successfully transcribed one song with the highest F1 score of 0.8 while reporting the worst performance of 0.21 for another. Some of the plausible reasons why the results vary widely depending on the song are discussed in detail in Section 6.2.
F0 evaluation results of the proposed model and JDC [12]
F0 evaluation results of the proposed model and JDC [12]
Table 3 presents the results evaluated by F0 metrics. For metrics related to voice detection, the proposed model performed better in VR, and JDC performed better in VFA. This result can be interpreted as caused by training the proposed model to achieve a high recall rate, increasing false alarm rate. However, the difference in VFA between the proposed model and JDC is subtle, implying that the voice detection of the proposed model is comparable to JDC.
For pitch-related metrics, namely RPA and RCA, and the overall performance metric OA, the results were contradictory depending on the dataset. With MIR-ST500, the proposed model outperformed JDC, whereas with MedleyDB, JDC achieved superior results likely caused by the difference between the annotation and prediction method. For example, the results of note-level and F0 annotations may exhibit significant differences in vibrato notes or note transitions with dragging pitch. A vibrato note is covered over several semitones with F0 annotation, but in note-level, it is annotated as a single pitch level. For note transitions with dragging pitch, F0 annotation expresses each pitch change in detail, whereas only two notes are remained at note-level. In such cases, the evaluation results are likely superior when the annotation and prediction coincide. Furthermore, whereas RPA and RCA differ by more than 0.4% for JDC, the proposed model exhibits almost no difference, suggesting that the proposed model commits fewer octave errors.
Visualization of ablation study
Visualization of the transcription results of “460.mp3” in the MIR-ST500 test dataset. The onset is indicated in dark color for each note. In (b), (c), (d), and (e), the ground truth label, prediction, and the shared part are shown in red, blue, and orange, respectively.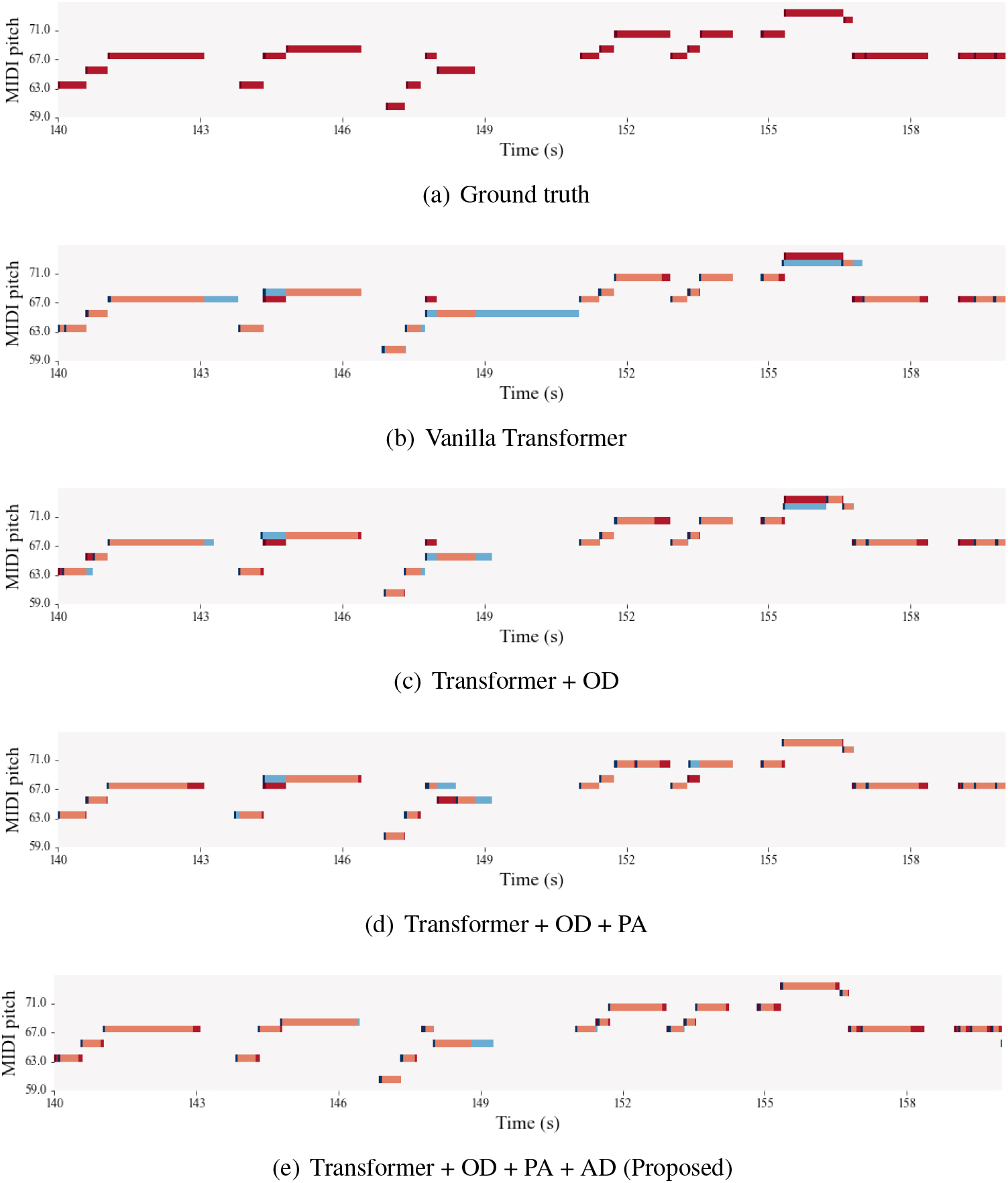
Visualizations of note-level singing melody transcription results for test examples from MIR-ST500 dataset. The STFT representation is expressed as a spectrogram. The annotated labels and prediction results are depicted as solid blue lines and dotted cyan lines, respectively, according to the pitch and time of the notes. In (a), most of the prediction results and correct annotations are consistent, and in (b) and (c), they are not.
Through qualitative ablation studies, we analyzed the effects of introducing OD, PA, and AD to vanilla Transformer. Figure 8 is a visualization of the transcription results for a test song in the MIR-ST500 dataset. While Fig. 8(a) represents the ground truth label of singing melody transcription, (b), (c), (d), and (e) are images expressing the ground truth label and the recognition results together.
Figure 8(b) and (c) are the transcription results of the same model but different decoding strategy. The former is the result using non-overlapping decoding, while the latter is the result of applying OD. The biggest difference between the two is the offset of notes. In Fig. 8(b), regarding the two notes at 143 and 149 seconds, respectively, the notes do not end and continue until the onset of the next note. On the other hand, in Fig. 8(c), the offset of the corresponding notes were predicted after few time frames, resulting in a relatively accurate transcription. The reason for missing the note offset in non-overlapping decoding is that the presence of a note onset in the previous segment is unknown due to the context loss problem. Through the proposed OD, the context loss problem was mitigated and note offsets were captured.
Figure 8(d) is the transcription result of the model with PA added. Compared to Fig. 8(c), the timing of the onset in the notes around 140 seconds is slightly more accurate. And for the note at 156 seconds, pitch transcription with PA was correct whereas the model without PA predicted the wrong pitch. These visible differences explain the significant improvement of the evaluation metrics in Table 2.
Figure 8(e) is our proposed model applying OD, PA, and AD altogether. The notes at 144, 148, and 153 seconds, which were all incorrect notes in Fig. 8(d), were recognized correctly. Most of the recognition results match the ground truth label, and there are no well-marked blue colored notes except the note at 149 seconds. The example shows that the proposed methods are effective in improving transcription performance, in accordance with the quantitative results in Section 5.1.
In analyzing the results in more detail, some examples of spectrograms of test songs along with the annotated labels and prediction results are visualized in Fig. 9. Figure 9(a) illustrates the spectrogram of the best transcription results with an F1 score of 0.8. Most notes were accurately predicted with respect to onset, offset, and pitch, except the offset of the last note. The result is explainable through several aspects of the music audio: the vocal voice is audibly clear, the accompaniment sound is relatively calm, and there are few chorus voices.
In contrast, Fig. 9(b) and (c) are examples of poor performance. In Fig. 9(b), most of the notes’ onsets and offsets are inaccurate, with some notes even missing. The low F1 score of 0.33 can be explained as caused by the vocal’s whisper-like singing style, obscuring the onsets and offsets of the singing notes.
Some specific pitch prediction errors are examined in Fig. 9(c), in which the F1 score was 0.35. One of the most common prediction errors was the octave error. For example, for the notes at 97 and 101 seconds, the model predicted the pitch as D#4 and F4, whereas the ground truth pitch labels were D#5 and F3. Moreover, the prediction result of the G4 note at 96 seconds was C5: the pitch class itself was incorrect. One reasonable explanation is that because the chorus vocal is heavily inserted in the song, the loud chorus was the predominant cause of pitch inaccuracy. At 98 seconds, there were some non-existent notes in the prediction results, likely because the model detected instrument sound as the vocal melody.
Based on analyzing the examples of the prediction results, the results are more accurate when the singer’s voice is clear and the chorus and instrument sounds are quiet. In contrast, because the proposed model is a monophonic singing melody transcription model, the performance was poor for multi-vocal audio.
Human evaluation
The results of human evaluation of singing melody transcription can be seen in Table 4. The score of ground truth, which is an accurate transcribed answer, is the highest in all aspects. Our proposed model showed the second best performance in all aspects, following ground truth. In particular, the proposed model regarding onset received a score of 3.89, close to the ground truth’s 3.90, which is significantly ahead of EfficientNet-b0. For offset, pitch, and overall scores, the proposed model achieved slightly higher scores than EfficientNet-b0.
The average scores evaluated by humans for the results of each model. Numbers next to the scores denote the standard deviations
The average scores evaluated by humans for the results of each model. Numbers next to the scores denote the standard deviations
In terms of overall scores, a notable gap still remains between ground truth and AMT models. In order to be recognized as perfect transcription by humans, performance improvement through additional research and data collection is required.
This paper proposed a monophonic note-level singing transcription model using a sequence-to-sequence Transformer that advances state-of-the-art singing transcription on MIR-ST500 dataset. Accordingly, we introduced a method of representing monophonic melodies as musical event sequences and approached singing melody transcription through sequence-to-sequence task. The overlapping decoding turned out to be effective for note offset prediction by preserving sequential context information. The transcription performance was also improved by introducing pitch augmentation and adding noisy dataset with data cleansing, having effects in preventing overfitting and training a robust model. Visualization of the transcription results enabled qualitative analyses to investigate the effect of each of the proposed techniques. Subjective human evaluation showed that the results of our proposed model were perceived as more accurate than those of a previous study.
Nonetheless, the fundamental solution to improve the performance of singing melody transcription is to collect sufficient training data. In the future, more automatic melody alignment studies need to be conducted to provide additional annotation data. Furthermore, one limitation of this paper is that the goal was constrained to monophonic melody transcription. Because songs with multiple voices are prevalent, it is necessary to expand the scope of the note-level transcription to polyphonic melodies, which we leave to future work.
Footnotes
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government, (MSIT) (No. NRF-2019R1F1A1053366). The Institute of Engineering Research at Seoul National University provided research facilities for this work.