Abstract
There are two mainstream strategies for image-text matching at present. The one, termed as joint embedding learning, aims to model the semantic information of both image and sentence in a shared feature subspace, which facilitates the measurement of semantic similarity but only focuses on global alignment relationship. To explore the local semantic relationship more fully, the other one, termed as metric learning, aims to learn a complex similarity function to directly output score of each image-text pair. However, it significantly suffers from more computation burden at retrieval stage. In this paper, we propose a hierarchically joint embedding model to incorporate the local semantic relationship into a joint embedding learning framework. The proposed method learns the shared local and global embedding spaces simultaneously, and models the joint local embedding space with respect to specific local similarity labels which are easy to access from the lexical information of corpus. Unlike the methods based on metric learning, we can prepare the fixed representations of both images and sentences by concatenating the normalized local and global representations, which makes it feasible to perform the efficient retrieval. And experiments show that the proposed model can achieve competitive performance when compared to the existing joint embedding learning models on two publicly available datasets Flickr30k and MS-COCO.
Introduction
Image-text matching aims at searching for those semantically relevant images given a query of type text and vice versa. It is a basic task in many multimedia machine learning tasks, e.g., image captioning, cross-modal information retrieval and visual question answering. However, the natural discrepancy between representations of text and image makes it challenging to capture semantic relationships between them. As illustrated at the left side in Fig. 1, to bridge the heterogeneous gap, joint embedding learning models [1, 2, 3, 4, 5, 6, 7, 8, 9] apply separate encoders to project both sentences and images into a shared feature subspace in which the semantic similarity is equivalent to the conventional metrics, e.g., Euclidean distance. Due to the mutually independent image and text encoders, joint embedding learning turns the retrieval problem into a vector-based ranking problem, which makes it feasible to efficiently retrieve targets among a huge amount of candidate items by precomputing semantic feature vectors of all database items. Kiros et al. made the first attempt that projecting both image and sentence into a common space and learned cross-modal representation with a hinge-based bidirectional triplet rank loss [10]. Liu et al. introduced a recurrent residual block to progressively enhance feature embedding [8], and applied a fusion module to integrate all output representations at each time step to a power representation which is mapped into the shared feature space using a fully connected layer. Faghri et al. further improved the retrieval performance by computing triplet rank loss with respect to the hard negatives in each mini-batch [4]. Semedo et al. proposed an adaptive maximum-margin strategy to adopt a dynamic margin value for computing the rank loss function at the training stage [11]. Some methods [12, 13] introduced instance-based classification loss to capture intra-modal discriminative information. Zhang et al. proposed the cross-modal projection matching loss and classification loss to minimize KL divergence and intra-modal classification loss w.r.t the projection on other modality [5], which can incorporate inter-modal correlation constraint into the intra-modal classification loss.
Additionally, some multi-modal learning tasks are also utilized to further fill the heterogeneous gap, such as cross-modal generation task [1, 3], adversarial learning tasks [9] and reconstruction task [14, 15]. Gu et al. proposed a model for learning a global feature embedding space and a grounded feature embedding space [6], and introduced a sentence generative module and an image generative adversarial module to supervise learning the grounded embedding. Hu et al. proposed a scalable multi-modal retrieval model [15] which projects each modality into a predefined common label space using individual auto-encoder. Therefore, the cross-modal representation of data from a new modality can be learned without retraining whole model. Besides, given a set of detected salient object regions in an image, Huang et al. learned a semantic concept and order representation by fusing a semantic unit representation and a referred global representation [7], and introduced a sentence generation module conditioned on the fusion vector to supervise the fused representation learning. Hong et al. first pretrained a general embedding model on several large multi-modal datasets, and then fine-tuned the pretrained model with respect to specific downstream task [2]. To enhance the discriminative power of learned joint representations, the existing models generally focus on introducing either novel loss functions as explicit constraints or additional auxiliary tasks as implicit constraints. However, these models only exploit the semantic relationships between holistic images and sentences for aligning cross-modal representations in the shared feature subspace, which fails to explore local semantic relationships which is important for understanding and matching semantic information better in the cross-modal retrieval task. In other words, due to the complexity of semantic concepts in practice, it is almost impossible to find a textual description which matches all potentially expressed semantic information in an image, vice versa. It means that the mismatched information generally exists between an image and its semantically relevant sentence to some extent, which is not completely in line with the widely adopted loss functions in joint embedding learning framework, e.g., hinge-based triplet rank loss. Therefore, it is necessary to introduce the local semantic information for alleviating the problem.
The demonstrations of joint embedding learning (left) and metric learning (right).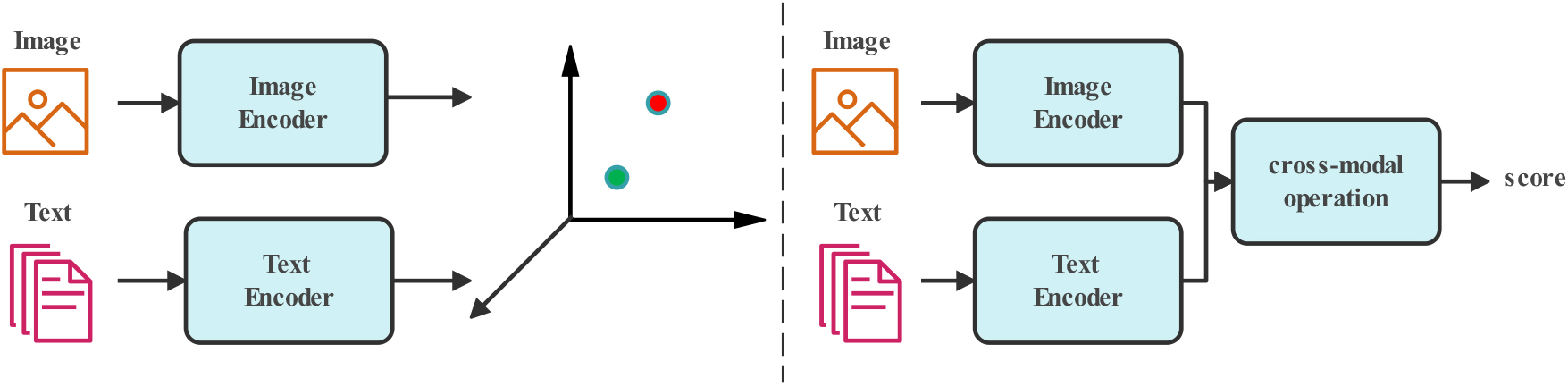
As illustrated at the right side in Fig. 1, the metric learning models learn a similarity function which directly output the similarity scores of all image-text pairs. Except for the modal-specific encoders, metric learning introduces specifically designed cross-modal operation to measure the semantic similarity, in which it is infeasible to find a feature space shared across all visual and textual database items. Much existing metric learning methods explore fine-grained semantic relationships at the level of image regions and words through attention mechanism [16, 17, 18, 19, 20]. Nam et al. proposed Dual Attentional Network [17] to capture fine-grained interplay between image and sentence through multiple time steps. Similarly, Chen et al. proposed matching image and sentence with recurrent attention memory through multiple time steps [21]. Lee et al. proposed the stacked cross attention mechanism [18] to capture the semantic similarity between all possible pairs of image regions and words to generate the power representations for semantic components belonging to both image and sentence. Ji et al. deployed an asymmetrical saliency-guided network [20] for generating powerful textual representations corresponding to each specific image. Zhang et al. proposed a context-aware network [19] to simultaneously capture inter-modal semantic correspondence and intra-modal semantic correlation. Yu et al. proposed heterogeneous attention model [16] with an adaptive-weighted hard negative rank loss.
Except for the attention mechanism, some methods [22] designed novel neural network architectures to adaptively control the information flow, which can help models attend to those objects with rich semantic information. Besides, some methods [23, 24] transformed image and textual data to the scene graph, and learn to measure the semantic similarity between heterogeneous graph data. In contrast to the joint embedding learning, the metric learning models generally involve complex interaction operation over multi-modal data, such as cross-modal attention mechanism and fusion strategy. In other words, it is impractical to find a fixed representation for each database item, which means it has to exhaustively compute the scores for all possible image-sentence pairs from the scratch. When dealing with a huge amount of data, e.g., social media and search engine, metric learning based methods will introduce unbearable computation burden and time cost at the retrieval stage.
In this paper, we propose a novel hierarchically joint embedding model to incorporate local semantic relationship into a joint embedding framework. The proposed model captures both local and global inter-modal semantic correlation by learning the joint local and global embedding space simultaneously. Concretely, the proposed model is the cascade of local and global semantic embedding module. The former takes as input a given image-sentence pair and outputs their local feature vectors in the shared local semantic subspace in which the local similarity is measured. Then the latter takes as input the set of local feature vectors and outputs the corresponding global semantic representations of images and sentences in the shared global semantic subspace. At the training stage, the local similarity label derived from lexical information of corpus is utilized to supervise training the local embedding module, by which we can incorporate local semantic correlation into the joint embedding learning framework. At the retrieval stage, the fixed semantic representation corresponding to each database item is generated by concatenating its normalized local and global representations. Our contributions are summarized as follows:
We propose a novel framework to introduce the local semantic alignment information into a joint embedding learning framework. And by concatenating the normalized local and global semantic representations, the proposed model still support the efficient retrieval as the existing joint embedding learning methods. In contrast to the existing methods, we design a novel local semantic alignment strategy for modeling local feature subspace. And the local similarity labels are easy to access from the lexical information of corpus with low time cost.
The proposed model aims at embedding both local and global semantic information into the cross-modal representations. Concretely, the distribution of joint local and global embedding spaces are inferred with respect to the training data simultaneously. And we derive the local similarity labels from the distribution of words in corpus, which are utilized to optimize the parameters of local embedding modules. And by concatenating the normalized representations in local and global embedding spaces, we can attain the fixed representations of all database items for efficient retrieval. In this section, we will introduce the proposed model from two aspects, model architecture in Section 3.1 and training strategy in Section 3.2.
An overview of the proposed hierarchical embedding model.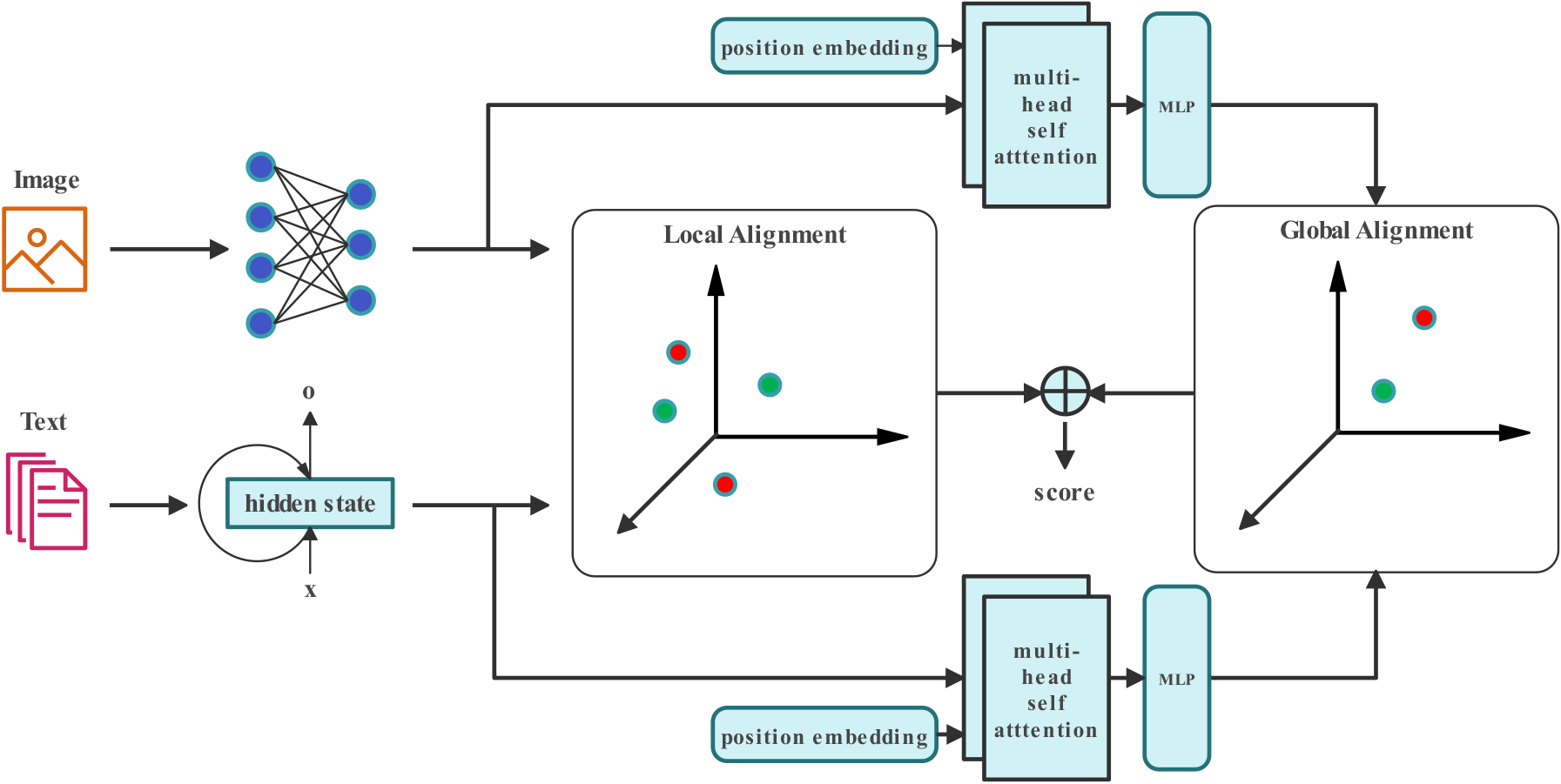
We present an overview of the proposed model in the Fig. 2. As illustrated in the Fig. 2, our model encodes local and global semantic information of images and sentences with two mutually independent embedding branches. And each branch is the cascade of local and global embedding modules. The local embedding module aims at extracting a set of semantic feature vectors for each database item. And an attention-based pool strategy is proposed to average of all feature vectors is normalized as the final local semantic representation which is further used to match the semantic information at the level of image regions and words. Given a set of local semantic feature vectors, the global embedding module aims to output the final global representation for measuring semantic similarity at the level of holistic image and sentence. Finally, local and global semantic representations are normalized and concatenated as the universe representation of each database item. We will detail the image embedding branch in Section 3.1.1 and the text embedding branch in Section 3.1.2.
Image embedding branch
Due to the great achievement in computer vision field, Convolutional Neural Network (CNN) [25, 26, 27] have been widely applied to encode image in various image-text processing tasks. We firstly apply a pretrained CNN model to represent an image as a sequence of feature vectors of which each corresponds to a specific region in the image. And the precomputed feature vectors are fixed during both training and retrieval stages. And then we project each feature vector into the shared local embedding space with the multi-head self-attention mechanism [28]. The core of self-attention mechanism is the scale dot product attention which is described in the Eq. (1), where the
Then, as illustrated in Eq. (2), the multi-head mechanism aims to concatenate the outputs of multiple parallel scale dot product attention operations and transform the output with single linear map.
where
To generate the powerful global semantic representation, we firstly apply the multi-head self-attention mechanism to further refine the local feature vectors. We view the global information as the fusion of natural semantic order and local semantic features. Therefore, it is pivotal to incorporate the semantic order information into the generation process of global representation. To make the global module position-sensitive, we add the learnable position encoding to the input sequence before feeding them into the attention module. Besides, we also adopt the average of local feature vectors as the query, which aims to attain single enhanced feature vector for each image. Then we apply a two-layers feedforward network to project the enhanced feature vector into the shared global semantic subspace. We sequentially insert the Gaussian error linear units (GELU) [30] and a normalization layer between two fully connected layers. The GELU activation function is defined as
As in prior work [28], we apply the combination of residual connection and normalization layers after both attention and FFN layers. For simplicity, the global encoder can be formulated as the Eq. (4), where residual connections and layer normalization are omitted,
Given a sentence
To generate the global representation of sentences, we adopt the same encoding process as in image embedding branch, which comprises a multi-head attention layer and a two-layers feedforward network. Similarly, the global encoder is formulated as
The proposed model requires optimizing the distribution of local and global embedding spaces simultaneously. Firstly, we define some necessary notations. Assume that a batch of training samples consists of
Learning local embedding
In our work, the local embedding modules aim to transform images and sentences into the corresponding sequences of feature vectors in the shared local embedding space. Consider that the spatial layout and word order information should have limited effect on measuring the local semantic similarity of an image-sentence pair, we propose a position-independent local alignment strategy to model the local embedding space. Instead of exploiting global alignment labels to implicitly infer local semantic relationships, we extract a set of motif tags from the lexical information of corpus (i.e., all sentences in dataset) to promote fine-grained local semantic alignment. Concretely, we firstly utilize the Stanford natural language toolkit to generate the part-of-speech tags of corpus and build a collection of all nouns and adjectives occurring in all sentences. And then we further clean the collection by merging some semantically relevant words into a group with respect to some lexical relationships, e.g., synonyms, comparative, plural, etc. Finally, we remove those groups which occur in all sentences with low frequency to attain a set of motif tags, and assign a label vector
Given a batch of samples equipped with label vector
Except for the intra-modal classification losses, we also introduce a matching loss to further explore the inter-modal semantic relationship. However, it is non-trivial to obtain sufficient fine-grained labels indicating the semantic relevance at the instance-level. Many prior works generally utilize global alignment relationship to guide learning local semantic information. For example, the most attention-based methods learn local semantic relationship by controlling the information flow with specifically designed architecture and a global rank loss. In this paper, we compute the local semantic similarity labels of all possible image-sentence pairs using the Eq. (11), where the
We estimate the local similarity of the image-sentence pair
From the Eq. (11), we can see that the range of local similarity label
We observe that the objective Eq. (13) only impose the target value to each image-sentence pair, which may be not sufficiently compatible with the local similarity label, i.e., the different ranges between
In contrast to the objective Eq. (13), the KL divergence loss tends to model the semantic relationships between one query and multiple candidate samples. In other words, unlike the smooth L1 loss function whose gradients with respect to all pairs of image and sentence embeddings are mutually independent, the gradients of KL divergence loss are dependent on all pairs of image and sentence embeddings in the batch. As in Eq. (15), we finally define the whole local align loss as the sum of intra-modal and inter-modal alignment losses, where
We define the semantic similarity score
Given a batch of samples
The
To investigate the generalization of the shared feature space, we design a common image-to-text generation task in this subsection. We implement the task with classical attentive encoder-decoder model. In our model, the encoder is actually the visual local embedding module. We implement the decoder with a one-layer GRU model. The input to decoder at each time step consists of two parts, the output of attention module and the prediction at the previous time step. The attention module aims to aggregate the outputs of encoder into a single vector at each time step, which help the decoder selectively attends to different part of outputs of encoder. Given the outputs of visual local embedding module
As shown in the Eq. (24), we apply the negative log-likelihood functions to train the decoder. The
In this section, we perform several experiments on two publicly available datasets to investigate and demonstrate the effectiveness of the proposed model.
Datasets and evaluation metric
We evaluate the proposed model on Flickr30k entities benchmark [32] and MSCOCO dataset [33]. Flickr30K contains 31,783 images collected from Flickr website, and each image is annotated with five sentences. As common in existing work [34], we use 1,000 images for validation, 1,000 images for testing and the rest for training. MSCOCO contains 123,287 images, and each image is annotated with five sentences. Following the work [4], the dataset is split into 113,287 training images, 5,000 validation images and 5,000 test images. We report the retrieval results for both average of 5 folds of 1000 test images and the full 5000 test images. The recall rate at top K (R@K) is used to measure performance of sentence retrieval (Sentence-to-image) and image retrieval (Image-to-sentences) tasks, which is defined as the fraction of queries for which the correct item is retrieved in the top K items. We also report the sum of all recall rates for illustrating comprehensive performance.
Experiment setup
We carry out experiments to evaluate the hierarchical embedding space model with Pytorch [35] framework. For fair comparison, we experiment with various pretrained CNN encoders which include VGG-19 [25], Resnet-152 [26], Faster R-CNN [27] and ViT models. For the first two encoders, we first rescale shorter edge of each image to 256 pixels and then generate ten
Both dimensions of local and global semantic representation are set to 768, i.e.
Comparison with state-of-the-art methods
In this section, we experiment with the proposed hierarchical embedding model to demonstrate its effectiveness. We compare it with several state-of-art joint embedding models which use identical splitting manner. The compared models include CMPM [5], LTBN [13], VSE
The retrieval results on Flickr30k are illustrated in the Table 1. Compared with other joint embedding models, the model BHES achieves best performance in R@10 on sentence retrieval and R@10 on image retrieval, and gains competitive results on other tasks. When focusing on the results of models with VGG-19, except for the SCO model, we can see our mode surpasses other models. Compared with the multi-classification label used in SCO model, the local similarity labels proposed in this paper are easier to access and introduce no extra computation burden at retrieval stage. When using the ResNet-152 encoder, our model also achieve competitive performance on all tasks. The comparison results on MS-COCO are illustrated in Table 2 (1000 test images) and Table 3 (5000 test images). Similar as the results on Flickr30k, the BHES model achieves competitive performance on both 1000 and 5000 test images. Compared with VSRN model, our model gains 1.5% improvement in the Sum when dealing with 1000 test images, even though our model perform worse on 5000 test images. Similar as the Resnet101 and VGG19 encoders, the ViT model also takes as input the adjacent patches with same size on the image, instead of the regions of interest detected by the Faster RCNN model. In contrast to the models built on either Resnet101 or VGG19, the model combined with pretrained ViT achieves better performance in all tasks on both Flickr30k and COCO datasets. As shown in the prior work, due to the large amount of training data and powerful attention-based architecture, the ViT model generally performs better than the common CNN models in some downstream visual tasks. However, it is still inferior to the model built on the regions of interest detected by the Faster RCNN model, which implies that performing visual semantic segmentation is likely beneficial to promote image-text matching. From the overview of results on both Flickr30k and MSCOCO, we can see the high-quality pre-computed image features significantly improve the retrieval performance on all tasks. And our model generally performs better on sentence retrieval than other models.
Comparison results with state-of-the-art methods on Flickr30k
Comparison results with state-of-the-art methods on Flickr30k
Comparison results with state-of-the-art methods on MS-COCO (1000 images)
Comparison results with state-of-the-art methods on MS-COCO (5000 images)
In this section, we perform several ablation experiments on Flickr30k dataset to understand better the effect of some components of the proposed model. These ablation versions are described as follows. To investigate the effect of local alignment module, we experiment with only the global alignment module (denoted as
Comparison results of ablation study on Flickr30k dataset
Comparison results of ablation study on Flickr30k dataset
The results of ablation experiments with various testing database
The comparison results of ablation study are illustrated in Table 4. From the results of model
Data masking and noise
Except for studying the effectiveness of models with various architectures, we also investigate the impact of testing database with different types of noise. We perform the following experiments with the baseline model HES (Faster RCNN). Concretely, we first randomly mask some words in a sentence with a predefined probability, and refer this modification as
The examples of sentence retrieval
The examples of sentence retrieval