
Abstract
Relation extraction is one of the core tasks of natural language processing, which aims to identify entities in unstructured text and judge the semantic relationships between them. In the traditional methods, the extraction of rich features and the judgment of complex semantic relations are inadequate. Therefore, in this paper, we propose a relation extraction model, HAGCN, based on heterogeneous graph convolutional neural network and graph attention mechanism. We have constructed two different types of nodes, words and relations, in a heterogeneous graph convolutional neural network, which are used to extract different semantic types and attributes and further extract contextual semantic representations. By incorporating the graph attention mechanism to distinguish the importance of different information, and the model has stronger representation ability. In addition, an information update mechanism is designed in the model. Relation extraction is performed after iteratively fusing the node semantic information to obtain a more comprehensive node representation. The experimental results show that the HAGCN model achieves good relation extraction performance, and its F1 value reaches 91.51% in the SemEval-2010 Task 8 dataset. In addition, the HAGCN model also has good results in the WebNLG dataset, verifying the generalization ability of the model.
Introduction
With the current high-speed development of internet technology, all kinds of data and text information show exponential growth. In response, information extraction technology has evolved swiftly to meet the critical need of deriving essential information from vast texts. Relation extraction, as an important task in information extraction, has received extensive attention from research scholars in recent years, providing important support for subsequent tasks such as knowledge graph construction [1], question and answer systems [2] and recommender systems [3]. The goal of the relation extraction task is to identify entities from unstructured textual information, determine the relationships between the entities, and ultimately to present the entity relationships in a structured form, which can support different application domains. For example, in the biomedical field, tuples of relationships between drugs and diseases can be obtained from the biomedical data through relation extraction, which can be used to determine whether there is an inhibitory or facilitatory relationship between the two, thus assisting in the development of drugs. The structured relational triples can usually be represented as (subject, relation, object). For example, in the sentence “The train
Currently there are two main types of deep learning based relation extraction methods: pipeline extraction and joint extraction. The pipeline approach means that the relation extraction task is partitioned into two parts to carry out named entity recognition and relation extraction. Initially, the textual information is processed to identify entities, and then the relationships between the entities are predicted. Zhou et al. [4] proposed a feature-based pipeline relation extraction method that integrates words, semantic knowledge and syntax, resulting in a significant enhancement in extraction performance. Zhu et al. [5] designed a graph neural network model with generative parameters, which enables reasoning about entity relationships by encoding unstructured information as parameters and transferring information in different network layers. The advantage of these methods is that the relation extraction is performed in two steps, and the model can be adjusted accordingly to the extraction characteristics of different parts. The limitation is the lack of interaction between the two stages, leading to an error propagation issue. Mistakes made during the named entity recognition model can adversely affect the relation extraction process due to the absence of parameter interaction, ultimately affecting the accuracy of the overall task.
Subsequently, researchers introduced the joint extraction model, where the joint extraction method enables sharing between training parameters as a way to enhance the link between entity recognition and relation extraction. Miwa et al. [6] proposed an end-to-end structure joint extraction model. In this model, the Bi-LSTM layer of the relation extraction can share the training parameters with the entity recognition part, and then combine it with dependent syntactic structures to extract relationship features. Wang et al. [7] proposed a joint decoding relation extraction model based on table filling, where encoders and decoders can be shared between two subtasks to facilitate information interaction. This type of methods solve the problem of error accumulation of the pipeline method. However, it also has certain defects, when it recognizes entities that do not have predefined correspondences, it will lead to entity redundancy and cause noise, which will have an impact on the accuracy of entity relationship extraction. In general, existing models have made great strides in the task of relation extraction, but challenges remain. Different positions, different lexemes, etc. play different degrees of importance for the model when performing feature extraction, and if they are not differentiated during relation extraction, they will affect the weights obtained for important information.
Therefore, in this paper, we propose a relation extraction model HAGCN (Heterogeneous Graph Convolutional Network and graph Attention mechanism), as shown in Fig. 1. In the HAGCN model, we build the word nodes and relation nodes in the graph structure based on the pre-trained language model BERT (Bidirectional Encoder Representations from Transformers); then taking the advantage of the heterogeneous graph convolutional neural network structure to aggregate information from different nodes, the information about each node in the graph structure is iterated through the information update mechanism, and relation extraction is performed after the nodes are updated. In summary, the main contributions of our work are as follows:
We propose a relation extraction model HAGCN based on a heterogeneous graph convolutional neural network and graph attention mechanism, which achieves good relation extraction performance with F1 value of 91.51% in SemEval-2010 task 8 dataset. In addition, the experimental results conducted on the WebNLG dataset outperforms most advanced models, which demonstrates the generalization ability of the proposed model. In order to solve the problem of insufficient acquisition of semantic features, this paper builds a heterogeneous graph convolutional neural network layer, and at the same time constructs two different types of nodes for the graph structure inputs through BERT, so that the model can adequately acquire semantic information and enhance the model expression. To distinguish the varying degrees of contribution from each node’s information in the graph structure, this paper adds the graph attention mechanism to assign different weights to the nodes, which can more accurately capture the correlation between node labels to improve the performance of relation extraction. We propose an information updating mechanism that can enable the model to efficiently learn a representation suitable for the relation extraction task.
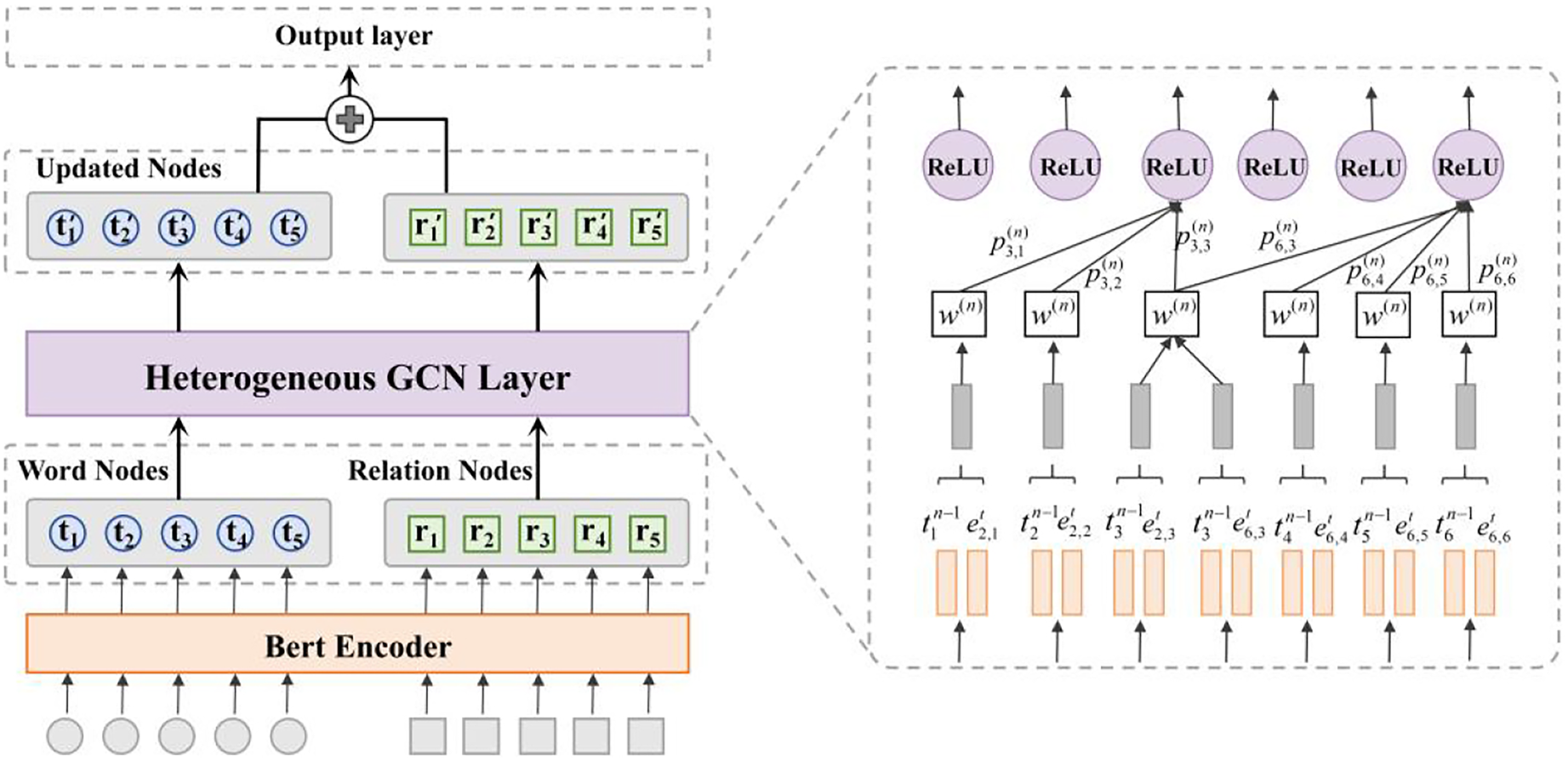
The structural model of HAGCN.
Previously, rule-based relation extraction methods primarily relied on rules written by experts in various domains in accordance with the characteristics of the data text. The SRA approach proposed by Aone et al. [8] implemented entity-relationship extraction from text based on pre-written rules. Humphreys et al. [9] employed syntactic analysis to feed information into manually labeled rules, enabling the identification of semantic relations between entities. However, rule-based methods face challenges such as the need for extensive data labeling, high costs, and limited portability. Subsequently, methods based on machine learning began to be popularized. These approaches typically extract relevant features from the text, including syntactic information, feature vectors, etc. Classifiers such as maximum entropy and support vector machines are then assigned the same semantic relationships to match entities, resulting in a trained relation extraction model. Kambhatla et al. [10] first used the maximum entropy modeling, and it also fused syntactic information, entity type information and semantic features in the text at the same time, as a way to realized the prediction of entity relationships. Zelenco et al. [11] applied kernel functions in the parsing structure, combining support vector machines and kernel functions thus realizing the classification of entity relations and accomplishing the task of relation extraction. However, traditional machine learning models have many limitations, including incomplete construction of features, time-consuming, and poor migration, all of which have a significant impact on the subsequent accuracy of relation extraction.
With the gradual maturation of deep learning algorithms, more and more deep neural models are being applied to relation extraction. Recurrent neural network (RNN) was the first neural network models to be applied to entity relationship extraction. Socher et al. [12] proposed MV-RNN model, which captured the meanings of neighboring words through the combination of matrix and recurrent neural networks. This approach provided a deeper understanding of textual information and to improve entity relationship extraction accuracy. Long Short Term Memory (LSTM) is a kind of recurrent neural network, the basic principle is similar, the difference is that the gate mechanism is introduced into LSTM, so as to control each neural unit to forget or retain the text information, which solves the problem of long term dependency to a certain extent. Xu et al. [13] proposed the SDP-LSTM method for relation extraction, which utilised the shortest dependency paths between entities as a way of obtaining heterogeneous information, avoiding the effects caused by irrelevant words in a sentence effectively. Liu et al. [14] presented for the first time the use of Convolution Neural Network (CNN) in a relation extraction task, which includes coded embedding of near-synonyms and fusion of word features to enrich the neural network. The performance achieved on the ACE dataset showed substantial improvements over previous methods. The rapid development of graph neural networks and their own structural features have brought them into the limelight in the field of natural language processing. Quirk et al. [15] introduced a cross-sentence relation extraction method, which used multiple paths in the graph structure to represent the part of speech and syntactic features, so as to more fully extract the textual features and then complete the relation extraction. Guo et al. [16] integrated the attention steering mechanism into graph convolutional neural networks. The whole model relied on trees as inputs, while automatically selecting more valuable information for relationship judgement through soft pruning, thus achieved cross-sentence relation extraction and large-scale sentence-level relation extraction.
The rapid development of pre-trained language models in recent years has profoundly influenced field of relation extraction and natural language processing in general. Prters et al. [17] introduced the pre-trained ELMo model, effectively leveraging contextual semantic information to address the challenge of word polysemy. Radford et al. [18] proposed a generative pre-trained model, GPT, in the same year, which had better performance in resolving long distance dependencies and extracting semantic representations by pre-trainied and fine-tuning the downstream tasks. Devlin et al. [19] presented the BERT unsupervised pre-trained language model, which employed the Transformer encoder structure for feature extraction, while bi-directionally encoding the text, allowing the model to better access contextual information and significantly improve the accuracy of natural language processing downstream tasks. Wei et al. [20] proposed CASREL, a BERT-based relation extraction model, where BERT is used in the encoding part to obtain contextual semantic information, and in the decoding part to identify the head and tail entities through the parameter sharing mechanism, thus effectively completing the relation extraction process. Eberts et al. [21] proposed a spanning joint relation extraction model based on BERT as the core for entity identification and filtering. This model advanced relation extraction through enhanced negative sampling and local contextual representation.
The above advanced methods have respective advantages and achieved good performance, however, there are insufficient extraction of semantic information. Furthermore, in the unstructured text, there will be multiple relational tuples, and there may be one entity in two relational tuples. Therefore, enhanced feature extraction is beneficial to reduce redundancy and distinguish the relationships between different entities, which is important for unstructured text relation extraction. The HAGCN model proposed in this paper considers the semantics and properties of different nodes, strengthens the weight allocation of important information, and enhances the aggregation of feature information, thus improving the feature extraction ability of the model.
The HAGCN framework
In this paper, we propose a relation extraction model HAGCN based on heterogeneous graph convolutional neural network and graph attention. Firstly, BERT is used as a word embedding method to construct two kinds of nodes in the graph structure, and then a heterogeneous graph convolutional network is used to aggregate the information of the nodes to further extract the semantic representations of the context. At the same time, we added graph attention mechanism in it to assign higher weights to important information, and finally iterated the node information through the information updating mechanism to obtain more accurate contextual information and complete the relation extraction. The specific model structure is shown in Fig. 1, and in the overall model, we denote the dependency type of
Pre-trained input layer
In the input layer, this paper employs the pre-trained language model BERT for encoding. BERT utilizes the Word Piece method when pre-processing the data to split the vocabulary, separating the words themselves from the tense representations, which can effectively reduce the size of the word list and improve efficiency, as well as improve word differentiation and accuracy. During input processing, two special tags [CLS] and [SEP] are inserted into the text sentences, where the [CLS] tag is added in front of the first sentence and the [SEP] tag is added at the end of each sentence to segment the data text. The input of BERT is composed of three embedding layers: Token Embedding, Segment Embedding and Position Embedding. The final input representation is shown in Fig. 2. The sequences in the text data are firstly tokenized, and then go through the token embedding layer, segment embedding layer and position embedding layer in turn to get the corresponding embedded representations. The accumulation of all these embedded representations constitutes the input representation of BERT.
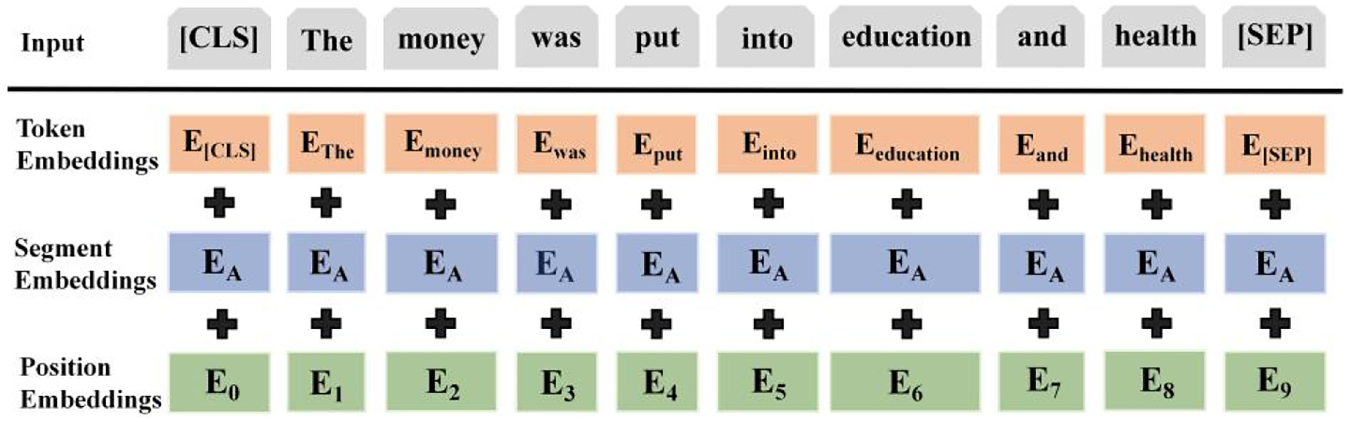
Word embedding representation of the BERT model.
In order to more fully utilize the interaction information generated by the nodes in the graph structure, we encode the words in a sentence as vectors and embed the relations as a vector. This is used to obtain richer information to construct the inputs of the graph structure. In the proposed HAGCN model, we construct two types of representations: word nodes and relation nodes. Below is a detailed introduction to these two types of nodes.
Word nodes: For a sentence S in the given data text, we use the BERT pre-trained model to encode the contextual information, and the embedded information obtained from the training is represented as word nodes, as shown in Eq. (1). Where
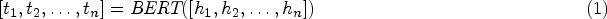
Relation nodes: In this paper, we designed two types of nodes, word and predefined relationship, and encode each type of relationship, as a way to strengthen the constraints of the relationship information on the extraction process, which improves the overall performance. We use
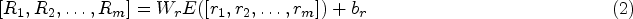
In texts across various domains, the relationships between entities are often complex, and there may be more than one relationship between the same entities, expressing only one kind of edges and nodes will affect the extraction accuracy. Therefore, we utilize heterogeneous graphs to achieve the purpose of distinguishing between different relationships by modelling the relationships of multiple edges and nodes effectively.
The core idea of Graph Convolutional Neural Networks (GCN) is to extract important features from data through convolutional operations, achieving good performance in the field of natural language processing. The advantage is that in each GCN layer, the information of each node in the graph can be aggregated with the neighbouring nodes by connecting with each other, which can effectively capture the information characteristics of the nodes in the graph. Inspired by the graph convolutional neural network part proposed by Zhang et al. [30], we build the model of this paper, and subsequent related improvements based on it.
When extracting features by Graph Convolutional Networks, if a graph is given with
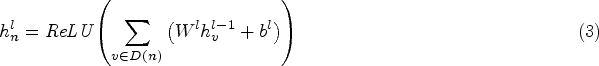
The heterogeneous graph convolutional neural network layer aggregates information from different types of nodes to extract the important information in the text. However, in GCNs, the adjacency of each node is represented as a matrix, assigning equal weights to all neighboring nodes. This approach overlooks the fact that different neighbor nodes often vary in their level of importance to a central node. Therefore, in this paper, the Graph Attention Network (GAT) is added and used to assign different weights to different nodes, thereby enabling the model to aggregate more significant information.
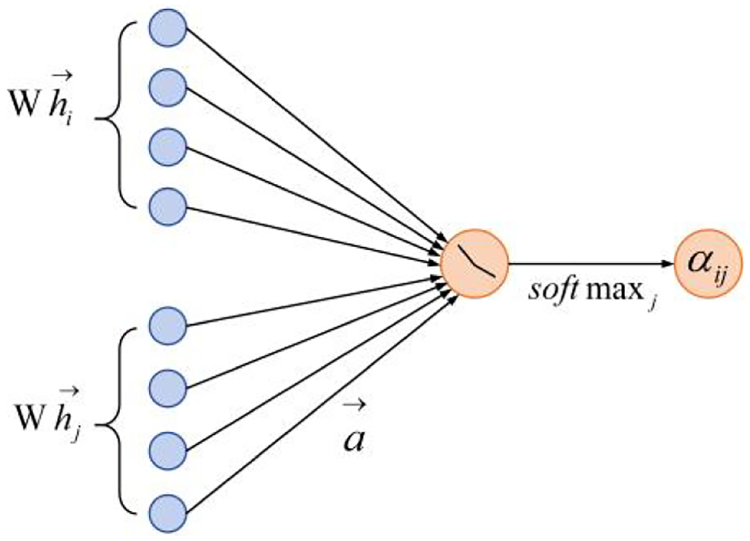
GAT working principle diagram.
The working principle of GAT is shown in Fig. 3, where the adjacency matrix
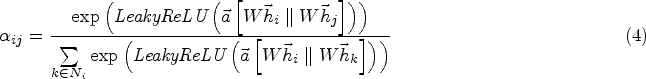
Where LeakyReLU is a nonlinear activation function,
After performing the normalised attention coefficient calculation, the final output feature vector

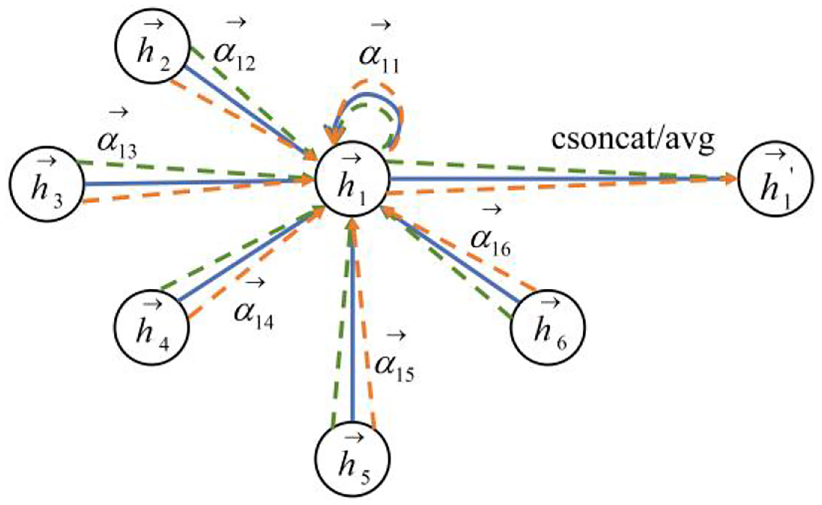
Graphical attention network.
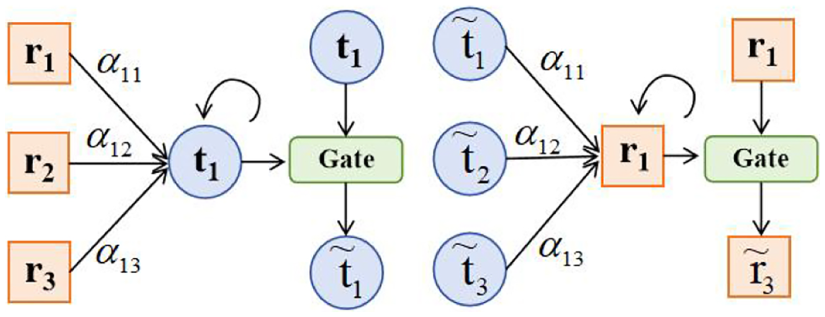
Node update process.
We propose two node representations in the graph-structured network model, furthermore, in order to semantically fuse word nodes and relation nodes, we propose the information update delivery module. As shown in Fig. 5, the word node aggregates information about all the relationships around it, and updates the relationship nodes using the new node representations obtained by updating the information, as a way to make the node information more suitable for a particular task. The specific process is as follows, firstly, we define all the relation nodes as the neighbors of the word nodes, and update the word nodes through GCN, as shown in Eq. (6):

where

When we get the new word node representation




For the relation extraction task, we aim to identify relationships between entities in a given text. In this paper, we take the average vector of the start and end positions of each target entity as the entity representation, classify the individual representations of the relationship nodes. In the output layer, we use the updated information of word nodes and relation nodes in the graph structure for classification. After obtaining the entity representations, we predict the entity relationships, here we will classify them with multiple labels, which are calculated as shown in Eqs (12) and (13). Where
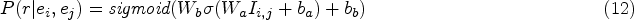

Datasets
In this section, we evaluate the effectiveness of our proposed method on the public dataset SemEval-2010 task 8 [22], which is widely used and recognized in the field of entity relation extraction. The SemEval-2010 task 8 dataset has a total of 10,717 instances and contains “9
Statistics for various relationship types on the SemEval-2010 task 8 dataset
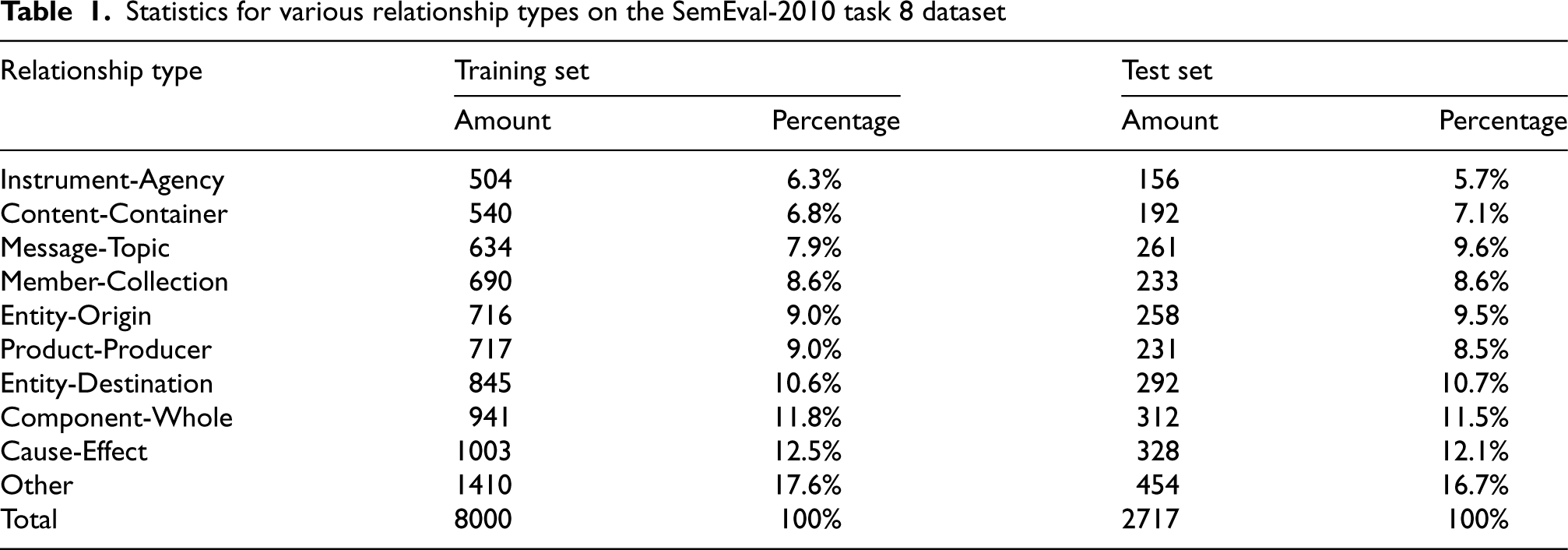
Statistics for various relationship types on the SemEval-2010 task 8 dataset
The experimental models in this paper are designed under the PyTorch framework. For the pre-trained model BERT, we use the original integrated model. The baseline model and the improved models listed in the experimental process use the hyper-parameter settings as shown in Table 2.
Model experiment parameter setting
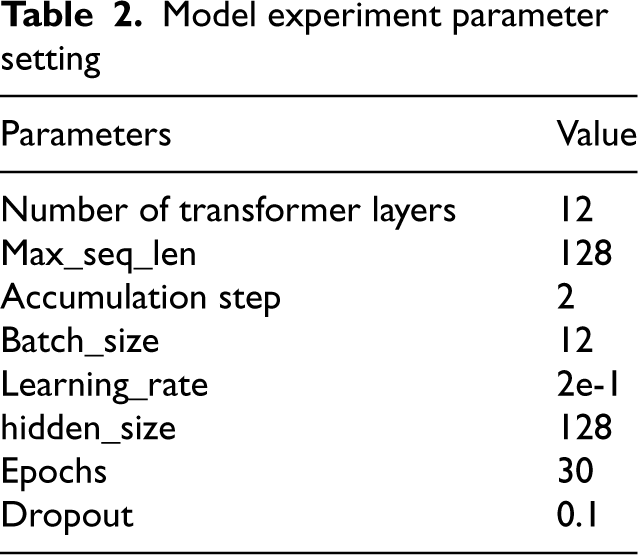
Model experiment parameter setting
In this paper, we use the evaluation metrics commonly used in the field of relation extraction: precision (P), recall (R) and F1 value. The F1 value is a synthesis between precision and recall, moderating the different effects of the two, which can be viewed as an average of the weighted values of the model’s accuracy and recall. It is an evaluation of the total system performance, therefore, we select F1 value as the final evaluation index. The specific calculation method is shown in Eqs (14)–(16), where TP denotes a true positive sample, FP represents a false positive sample, and FN is a false negative sample. Precision is the ratio of true positive samples predicted by the model to the total number of predicted positive samples. Recall is the ratio of predicted true positive samples to the sum of predicted true positive and false negative samples.



In this subsection, we analyze the validity of each component of the HAGCN model. In this paper, we propose a relation extraction model HAGCN based on heterogeneous graph convolutional neural network and graph attention. It is used to solve the problem of incomplete feature extraction in relation extraction. There are various kinds of feature information in relation extraction, including bidirectional semantic information, long-distance dependency features, syntactic features, etc. For example the semantic representation of the current word is correlated with the semantic representations of both the preceding and following information. If only the semantic representation of the extracted word alone is obtained, the deeper feature representations brought by the context are often missed, making the feature extraction incomplete, and thus the result of imprecise classification occurs. Therefore, it is necessary to fully utilize the feature information. BERT has good performance in extracting semantic features between contextual words. Therefore, BERT is used as a baseline model to compare and analyze the HAGCN model, and the important parts of the model are mainly introduced. The ablation experimental results are shown in Table 3.
Ablation comparison of our experimental model

Ablation comparison of our experimental model
In this paper, we enhance BERT by incorporating a heterogeneous graph convolutional network module, so that the model can automatically obtain the information of neighboring nodes of the target node, and make the node features enriched with more comprehensive syntactic structure information and contextual semantic features. As a result, the F1 value is improved by 2.94% from the baseline model. Additionally, we combine BERT with graph convolutional networks and heterogeneous graph convolutional networks, respectively, in our experiments, the results are shown in rows 3 and 4 of Table 3. The F1 value of adding a heterogeneous graph convolutional network is 0.84 percentage points higher than the result of adding a graph convolutional network, further proving the effectiveness of incorporating the heterogeneous graph convolutional network module.
Effectiveness of GAT
Different words in various positions and with different attributes play distinct roles in relation extraction. To distinguish the importance of these words, we utilize graph attention to assign different weights to them. By calculating their contribution values and allocating varying probability weights, the model is enabled to aggregate information more effectively, producing improved graphical representations. In the comparison of the experimental results, the F1 value increases by 1.21% after adding the graph attention mechanism, which verifies that the graph attention mechanism can better capture the key information in the context, thereby enhancing the accuracy of relation extraction.
Effectiveness of node update
In the graph structure, each node can complement and utilize each other through a message-passing process. Before entity extraction, each word node can update its information in conjunction with the associated relationship nodes, integrating their semantic information. Getting a node representation that is more suitable for relation extraction can make it easier to extract the relationships between entities. In the experimental comparison, when we add the node information update, the F1 value improves by 0.68%, proving the effectiveness of the fused relationship representation and word representation during the node information update.
Number of heterogeneous GCN layers
To determine the impact of the number of layers of the graph convolutional neural network on the performance of relation extraction, we comparatively analyse the results of using different numbers of heterogeneous graph convolutional network layers on the SemEval-2010 task 8 dataset. Table 4 gives the experimental results and time dimensions with different heterogeneous GCN layers on the SemEval-2010 task 8 and WebNLG datasets. It can be seen that the experimental results are better when the number of layers is 2 or 3. Figure 6 shows the comparison of the experimental results of different layers, we can infer that when the number of layers L
Results of different numbers of heterogeneous GCN layers
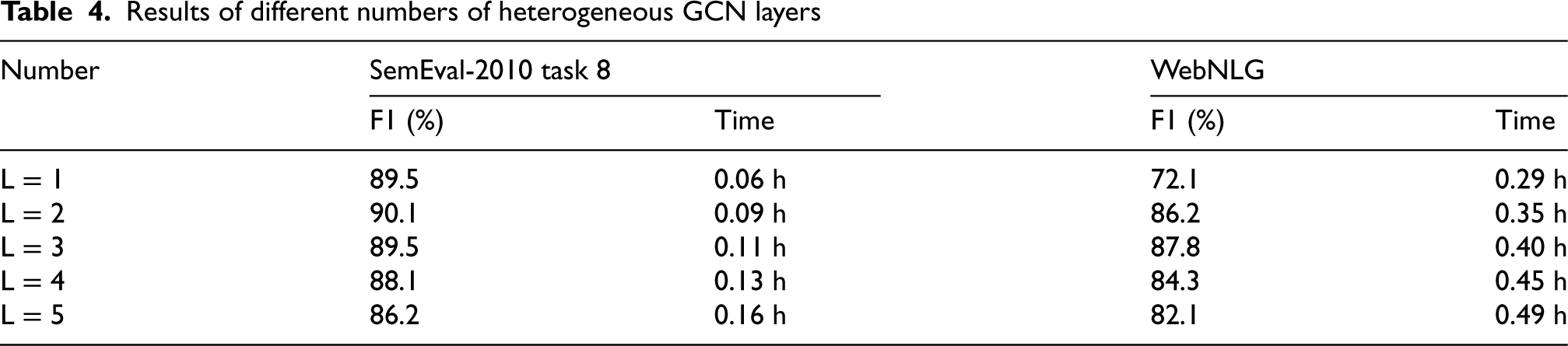
Results of different numbers of heterogeneous GCN layers
In order to verify the overall effectiveness of our proposed HAGCN model, we compared it with the current state-of-the-art models, and the specific results are shown in Table 5.
The overall performance of various models on Semeval-2010 task 8 dataset
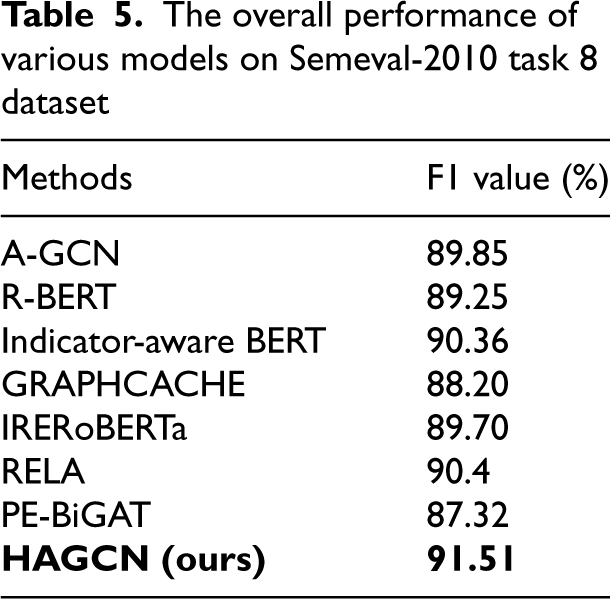
The overall performance of various models on Semeval-2010 task 8 dataset
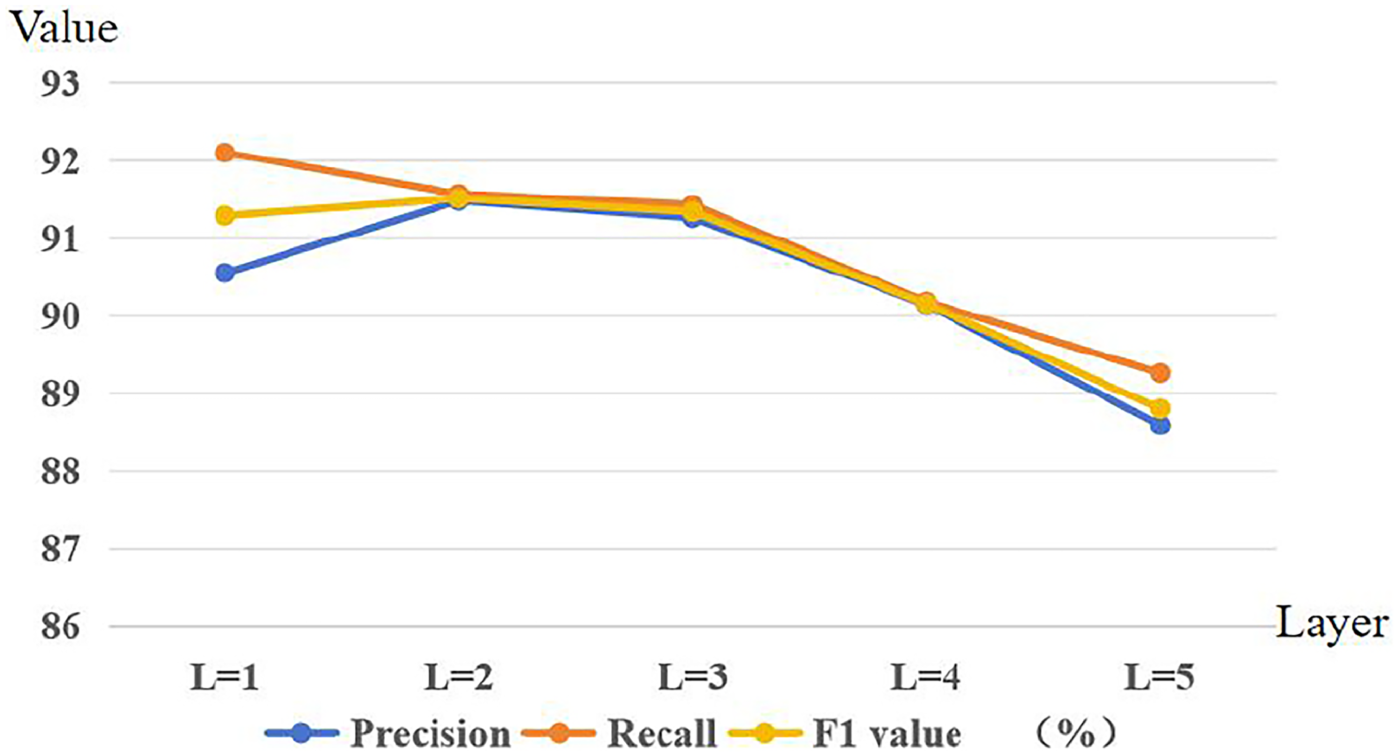
Comparison of results by layer.
A-GCN [23]: The model proposed a relation extraction method based on dependency information and attention graph convolutional neural networks, which allowed it to dynamically learn different dependencies, and its F1 value on the Semeval dataset reached 89.85%. R-BERT [24]: The model was based on the pre-trained language model BERT, and combined with the location information of the target entity to propose the R-BERT relation model, which achieved an F1 value of 89.25% on the Semeval dataset. Indicator-aware BERT [25]: In this method, an indicator-aware neural model was presented, a syntactic indicator was defined, and the pre-proposed indicator was used to improve the relation extraction while enhancing the extraction of contextual relation features, achieving an F1 value of 90.36% on the Semeval dataset. GraphCache [26]: In this method, a graph caching module is introduced based on graph neural network. It learns the entity relationship representation by propagating features across sentences, the F1 value on the Semeval dataset was 88.2%. IRERoBERTa [27]: This approach is built on the pre-trained language model RoBERTa and combines type-tagged entity representations with confidence-based classification to enhance entity detection. The F1 value on the Semeval dataset was 89.7%. RELA [28]: Li et al. proposed a relation extraction model that improves accuracy by extending relationship names, which utilized automatic labeling enhancement to improve the overall results. The F1 value in SemEval-2010 task 8 dataset reaches 90.4%. PE-BiGAT [29]: Deng et al. proposed a relation extraction model based on cue augmentation with BiGAT, which encodes syntactic graphs using a combination of intra-graph and inter-graph information transfer to improve the overall performance.
Our model improves the F1 value by 1.66% and 3.31% compared to the above models over the two graph-structure based A-GCN and GraphCache models. Compared to R-BERT, Indicator-aware BERT and IRERoBERTa, which are based on pre-trained models, the F1 values are improved by 2.26%, 1.15%, and 1.81% respectively. Compared with the two recent models based on information enhancement, the F1 values are improved by 1.11% and 4.19%, respectively. The above models have their own characteristics, but they do not fully capture semantic features and sufficiently utilize contextual information. Considering the context-awareness of pre-trained language models, we employ BERT for word embedding representation, constructing word nodes and relation nodes. We leverage a heterogeneous graph convolutional neural network model for semantic feature extraction and introduce graph attention to assign higher weights to crucial information, thereby enhancing the accuracy of relation extraction. The experimental results demonstrate the effectiveness of the proposed HAGCN model.
Comparison of the results under the different categories
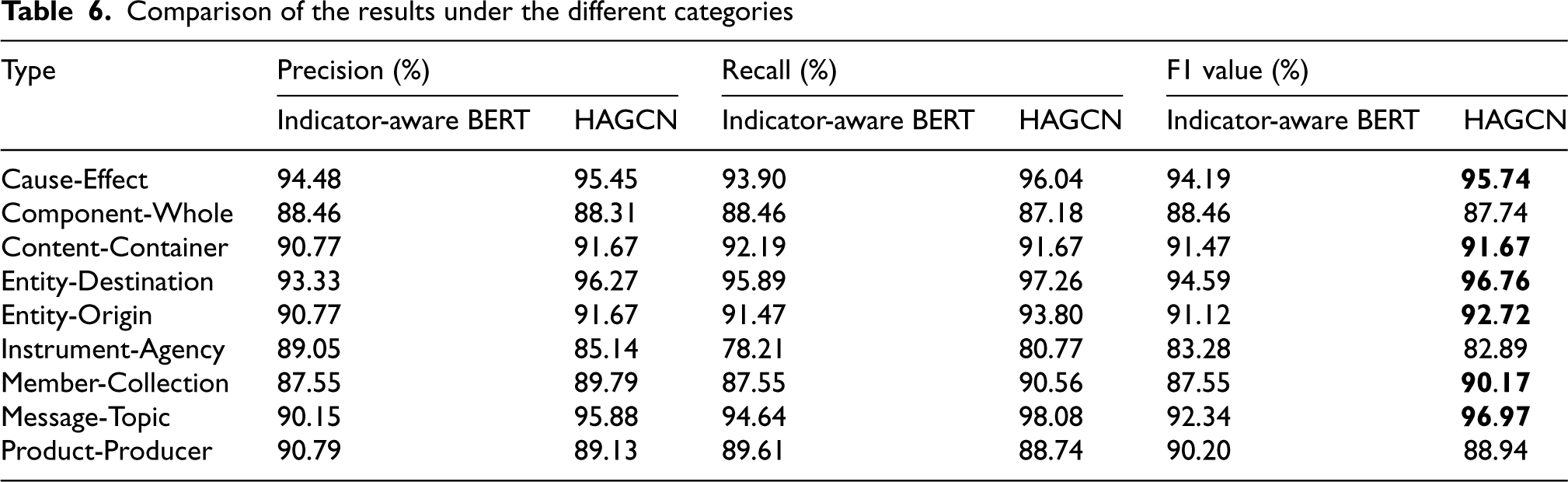
To demonstrate the effectiveness of the HAGCN model, we have analysed the performance improved by each part of the model (Table 3) and also compared the overall performance of the model with current state-of-the-art models (Table 5). In addition, we compare the individual entity category results with the state-of-the-art Indicator-aware BERT model as shown in Table 6. The results show that six of the various relationship types are significantly higher than the comparison model. It suggests that HAGCN has a robust capability to learn node representations, demonstrating more comprehensive extraction of textual semantic features. In addition, a comparison of the data shows that the “Instrument-Agency” type shows low performance in all models. Considering the distribution of entity types in the dataset, we infer that the imbalance in training data distribution is one of the factors affecting relation extraction performance. In future work, we will further explore how to enhance the performance of relation extraction tasks in the context of data scarcity.
In order to validate the effectiveness of the model as well as its generalization ability, we conduct experiments on WebNLG, a commonly used dataset in the relation extraction domain. The WebNLG dataset was originally created for natural language generation tasks and adapted for relation extraction by Zeng et al. The WebNLG dataset consists of 5019 training sentences, 500 validation sentences and 703 test sentences containing 171 predefined relations. Our experiments follow Zeng et al.’s test set under the same setup for F1 score comparisons, as shown in Table 7.
The overall performance of various models on WebNLG dataset
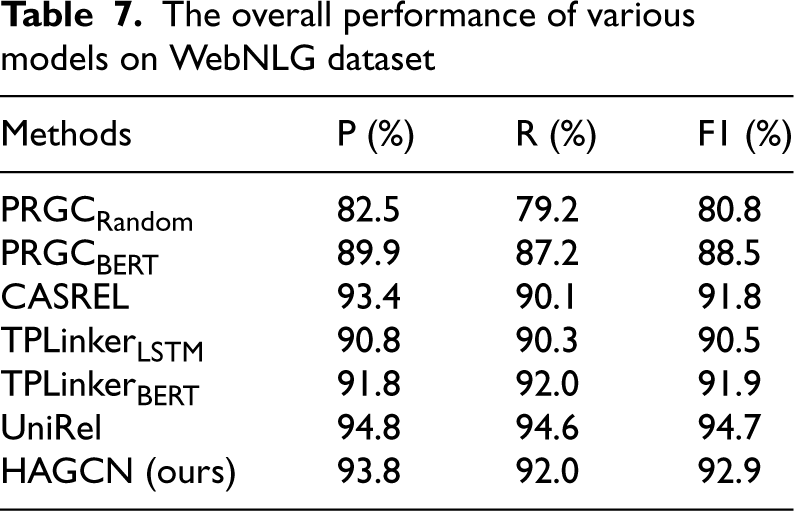
The overall performance of various models on WebNLG dataset
PRGC [32]: Zheng et al. proposed a relation extraction model utilizing latent relationships and global correspondences, which mitigates the effect of redundant information to some extent and is successfully applied to several complex scenarios. CASREL [33]: Wei et al. proposed a new cascading binary labeling framework that can efficiently extract relational tuples with an F1 value of 91.8% on the WebNLG dataset. TPLinker [34]: Wang et al. proposed a single-stage joint extraction model, which avoided exposure bias by sharing overlapping relationships of entities and thus improved relation extraction performance. UniRel [35]: Tang et al. designed natural language sequences that jointly encode entities and relations to fully utilize their contextual relevance, and their F1 value on the WebNLG dataset reached 94.7%.
On the WebNLG dataset, we compare the proposed HAGCN model with the current better models, and the F1 values are improved by 12.05% and 4.45% compared to the PRGCRandom model and PRGCBERT model, respectively. Compared to the CASREL model, TPLinkerLSTM and TPLinkerBERT F1 values are improved by 1.1%, 2.4% and 1%, respectively. The above comparison can assist in proving the effectiveness of our proposed model. However, it can be seen that there is still a gap between our proposed model and the Unirel model, which has the most excellent results so far. The Unirel model has a greater advantage in joint coding of entities and relations, while our proposed model focuses on capturing node information more comprehensively and solving the problem of insufficient feature extraction. In our future research, we will also focus on the consideration of expressing semantic information more accurately through joint encoding.
The HAGCN model proposed in this paper captures semantic features more comprehensively by constructing two kinds of nodes, which obtain advanced performance on the SemEval-2010 task 8 and WebNLG datasets. However, it still has some limitations. In the actual relation extraction dataset, there exists a certain proportion of nested relations, and there may be ambiguity problems when obtaining node information. In addition, observing the SemEval-2010 task 8 dataset used for relation extraction, the proposed model is not effective in extracting the “Instrument-Agency” relationship category. However, since this category accounts for the lowest percentage of the data volume, it did not affect the overall performance of the model. Other advanced models also performed poorly in this category. More research should be conducted in this aspect in the future.
Conclusion
In this paper, we propose a relation extraction model HAGCN based on heterogeneous graph convolutional neural network and graph attention mechanism. Initially, using BERT for word embedding, we construct word and relationship nodes, which are then aggregated using a heterogeneous graph convolutional network to further extract contextual semantic representations. Furthermore, we add graph attention mechanism to assign higher weights to important information. Finally, through an information updating mechanism, we iteratively refine the node information to accurately capture contextual details for relation extraction. The validity of the model is validated in the generic domain relation extraction dataset SemEval-2010 task 8. To solve the problem of low precision of relation extraction due to uneven distribution of relation types, we will focus on the effect of unbalanced data distribution on constructing graph nodes and further explore the sample less relation extraction problem in our future work.
Footnotes
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No. 62006108, 61976109), Postdoctoral Research Foundation of China (No. 2022M710593), Scientific Research Project of Liaoning Province (No. LJKZ0963), Key Research and Development Project of Science and Technology Department of Liaoning Province (No. 2022JH2/101300271), Liaoning Revitalization Talents Program (No. XLYC2006005), Liaoning Province General Higher Education Undergraduate Teaching Reform Research Project (Liaoning Education Office [2022] No. 166), Liaoning Normal University Undergraduate Teaching Reform Research and Practice Project (No. LSJG202210), Ministry of Education Industry University Research Cooperation Project (No. 220802755304633), Liaoning Provincial Key Laboratory Special Fund.