
Abstract
Feature selection is an effective approach for solving the curse of dimensionality. Evolutionary computation, such as genetic algorithms, are extensively applied into feature selection. However, with the available algorithms, features aren’t screened before evolutionary computation starts and all of them are equal in status during the process of evolutionary computation. In this paper, a new algorithm that screens features before evolutionary computation starts, and makes full use of the screened ones during the process of evolutionary computation is proposed. In detail, important and useful features are found by scoring all features, and endowed with privileges in obtaining advantages comparing to other features during the forthcoming process of evolutionary computation, which is the first stage of our proposed algorithm. As for the second stage, we design a genetic algorithm with multiple sub populations, in which each sub population corresponds to a combination of important and useful features, and a competition mechanism between sub populations is introduced. As a result, important and useful features are further sufficiently used and extensively explored compared to the available algorithms, hence classification accuracies are increased. Experiments are performed with 8 datasets comparing to 11 state-of-the-art algorithms to validate our proposed algorithm. And the results show that our proposed algorithm outperforms the 11 state-of-the-art algorithms.
Introduction
With the development of information technology, tremendous amount of information can be collected, processed into data sets with many features, and applied to classification problem. However, too many features results high computational time. Although some features are important and useful (short for good features), some features may be unimportant, irrelevant or redundant, introduces noise and degrades classification performance. This is known as the curse of dimensionality [1, 2, 3, 4, 5, 6]. Feature selection (FS) is an effective method solving the curse of dimensionality, which selects appropriate subsets from features, removes unimportant, irrelevant or redundant features in order to reduce computational time, eliminates noise and improve classification performance [1, 7, 8, 9, 10, 11, 12].
Popular feature selection techniques fall into two broad groups: filter methods and wrapper methods [10, 11]. The former is independent of the classifier, removes unimportant, irrelevant or redundant by analyzing the features’ information. On the contrary, the latter employs a classifier, derives classification performance which is used to evaluate a feature subset [1, 3, 7]. Although filter methods are considered to be more general than wrapper methods, wrapper methods usually derives better classification performance than filter methods [1].
Filter methods have been widely discussed and many algorithms have been proposed. Feature Selection technique based on Feature Similarity (FSFS) removes redundancy by measuring similarity between features using a feature similarity measure [15]. Fuzzy rule based Feature Selection (FR-FS) is an algorithms which extracts fuzzy rules and selects appropriate features simultaneously [16].
Researchers have also widely studied wrapper methods and proposed many algorithms. The available algorithms fall into two broad groups: (1) Deterministic algorithms [17, 18, 19, 20, 21, 22], a deterministic feature subset can be derived if an algorithm is applied to a dataset; (2) Evolutionary Computation (EC) based algorithms [23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39], evolutionary computation, such as Genetic Algorithms (GA), Particle Swarm Optimization (PSO) Algorithms, Artificial Bee Colony (ABC) Algorithms, Genetic Programming (GP), and Ant Colony Optimization (ACO) Algorithms are applied to finding appropriate feature subsets, with which the final derived feature subsets are uncertain because of evolutionary computation’s randomness [1].
The main deterministic algorithms includes Sequential Forward Selection (SFS), Sequential Backward Selection (SBS) [19], Ranking Based method (RB-FS) [21], Graph Clustering with Node Centrality (GCNC) [22], etc. SFS adds features to an empty feature subset step by step. On the contrary, SBS removes features from a feature subset involving all features step by step. The two algorithms terminates when the adding or removing can’t increase classification performance [19]. However, with the two algorithms, once a feature is added or removed, it can’t be removed or added, which limits finding optimal feature subsets. RB-FS determines the number of selected features by building a convex hull in high-dimensional space firstly, then obtains a local optimal feature subsets by hill climbing algorithm [21]. GCNC regards all features as a graph and divides them into some clusters. Finally, feature selection is performed with node centrality based iterative search strategy [22].
The main EC based algorithms includes Modified Discrete Artificial Bee Colony (MDisABC) [1], Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D) [7], Fast Feature Weighting algorithm of Data Gravitation Classification (FFW-DGC) [23], Multi Objective Differential Evolution based FS (DEMOFS) [36], Binary Bat Algorithm for FS (BBA) [37], Binary Grey Wolf Optimization approaches for feature selection (bGWO) [38], Visibility density Modified Binary coded Ant Colony Optimization algorithm (VMBACO) [39], etc. MDisABC is a binary artificial bee colony (ABC) algorithm, which integrates evolutionary based similarity search mechanisms and another binary ABC variant [1]. MOEA/D is an algorithm for feature selection and weighting using a Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D), in which data points are projected into a hyper space. Then the distances of inter-class and intra-class are optimized by MOEA/D in order to select features [7]. FFW-DGC integrates data gravitation classification (DGC) model and fuzzy set to obtain optimal feature subsets and reduce computational time [23]. DEMOFS is a multi-objective feature selection algorithm based on differential evolution in order to increase classification accuracy and decrease the number of features simultaneously [36]. BBA is a wrapper algorithm based on the bats behavior that integrates the power of the bats’ exploration and the Optimum-Path Forest classifier’s speed [37]. bGWO is an algorithm for feature selection based on the binary version of the Grey Wolf Optimization (GWO) which is one of the latest bio-inspired optimization techniques [38]. VMBACO is an algorithm integrating a modified binary coded ACO and GA, in which the solution derived by GA is regarded as visibility or initial pheromone information [39].
As mentioned before, different features act different roles in classification. Although evolutionary computation have been extensively applied into feature selection, features are not discriminated before evolutionary computation starts, all features are equal in status during the process of evolutionary computation, and some individuals considered involve no good features with the available algorithms. As a result, good features aren’t sufficiently used and extensively explored, and computing resource is wasted. In this paper, we propose a method for screening good features by scoring all features before evolutionary computation starts, which is the first stage of our proposed algorithm. In the second stage, we design a genetic algorithm with multiple sub populations, in which each sub population corresponds to a combination of good features, and a competition mechanism between sub populations is introduced. As a result, good features are further sufficiently used and extensively explored compared to the available algorithms, hence classification accuracies are increased. The proposed algorithm is named as Feature Selection algorithm based on Feature Score and Genetic Algorithms (short for FS
The main contribution of the work are summarized as follows: (1) It is proposed for the first time that features should be screened before evolutionary computation starts (see the paragraph above); (2) a method for screening features is proposed (see Section 2);(3) a method for dividing multiple sub populations as well as the mechanism between sub populations are designed (see Section 3). We compare our proposed algorithm with available EC based algorithms to illuminate our contribution in Table 1.
The rest of the paper are organized as follows: in Section 2, we describe how to find good features; in Section 3, the GA algorithm is described in detail; Section 4 describes the experiments and analyses the results; finally, we conclude our work in Section 5.
The comparison of FS
GA and available EC based algorithms
The comparison of FS
As mentioned before, we propose a method finding good features by scoring before evolutionary computation starts. In detail, a certain number of feature subsets are generated entirely stochastically, and a classifier is employed to obtain classification accuracies of all feature subsets. Then the feature subsets with high classification accuracies (short for elite subsets) are found. For each feature, its score is the sum of the accuracies of all elite subsets involving it, and the features with high scores are regarded as good features. This is because, if a feature appears in elite subsets frequently, then a feature subset involving it obtains high classification accuracy with high probability. That is to say, the feature is good and feature subsets involving it should be focused on. If two features appear the same times in the elite subsets, the one involved by the elite subsets with higher accuracies is more important than the other. Therefore, the accuracies of elite subsets should also be considered.
Representation of feature subset
A feature subset corresponds to a binary string, in which each bit corresponds to a feature. If the feature subset involves a certain feature, the corresponding bit is ‘1’, otherwise ‘0’. Therefore, a feature subset s can be expressed as the following binary string:
where
For instance, the feature subset (F1, F3, F5, F7, F8) is represented as the binary string ‘10101011’, as shown in the following figure.
Representing feature subsets with binary string.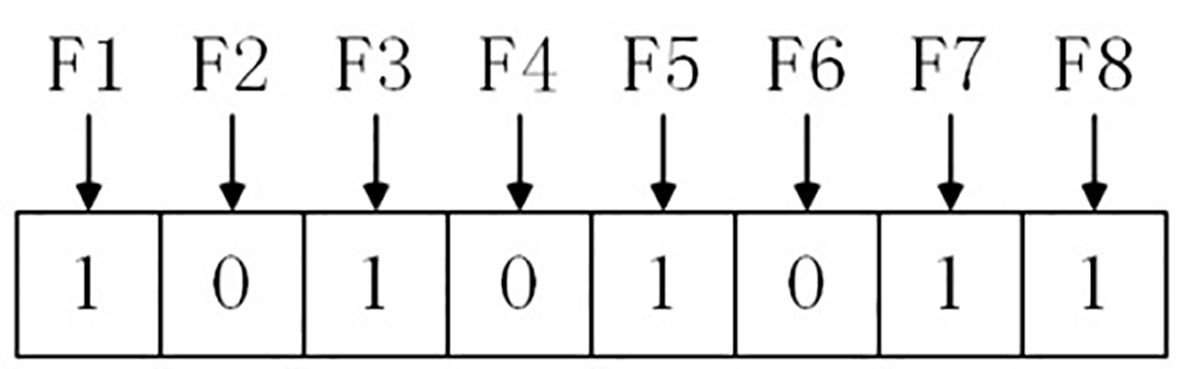
Scoring features
Our work mainly aims at improving classification accuracies. Hence, for
For feature
The higher a feature’s score is, the better it is. The features are sorted by their scores from high to low and the top num_good_fea features are regarded as good features. The value of num_good_fea is decided by the specific scores of features.
Computational complexity analysis
The time of this stage is mainly the duration of obtaining the individuals’ classification accuracies. The classification accuracies of
Genetic algorithms
In this section, we describe the second stage of our proposed algorithm. Genetic Algorithms (GA) is employed in this stage, in which each individual corresponds to a feature subset. As mentioned before, the feature subsets involving good features should be focused on. Therefore, the individuals considered during GA must contain one, some or all good features. To do that, GA with multiple sub populations is adopted and each sub population corresponds to a combination of good features. Individuals of a sub population must contain the combination of good features assigned to the sub population, and mustn’t contain good features out of the combination. To explore all possible individuals, the empty set of good features also corresponds to a sub population. That is, individuals of the sub population mustn’t contain any good feature. Good features don’t participate in crossover or mutation, while all other features participate in crossover and mutation. This ensures that individuals in a sub population involves the same and constant good features during the GA operations. A competition mechanism between sub populations is introduced, with which the sub populations with higher classification accuracies obtain more population sizes because high classification accuracies illustrates that the sub populations’ combination of good features is more excellent and should be explored intensively. Each sub population performs GA operations respectively and independently. And the only relationship between sub populations is the competition mechanism between them. In each round, the highest accuracy of all sub populations is regarded as the accuracy of the round, and the accuracy of the final round is regarded as the final accuracy.
The main steps of the GA are shown in the following figure, where NR is the number of GA’s rounds.
The main steps of the GA.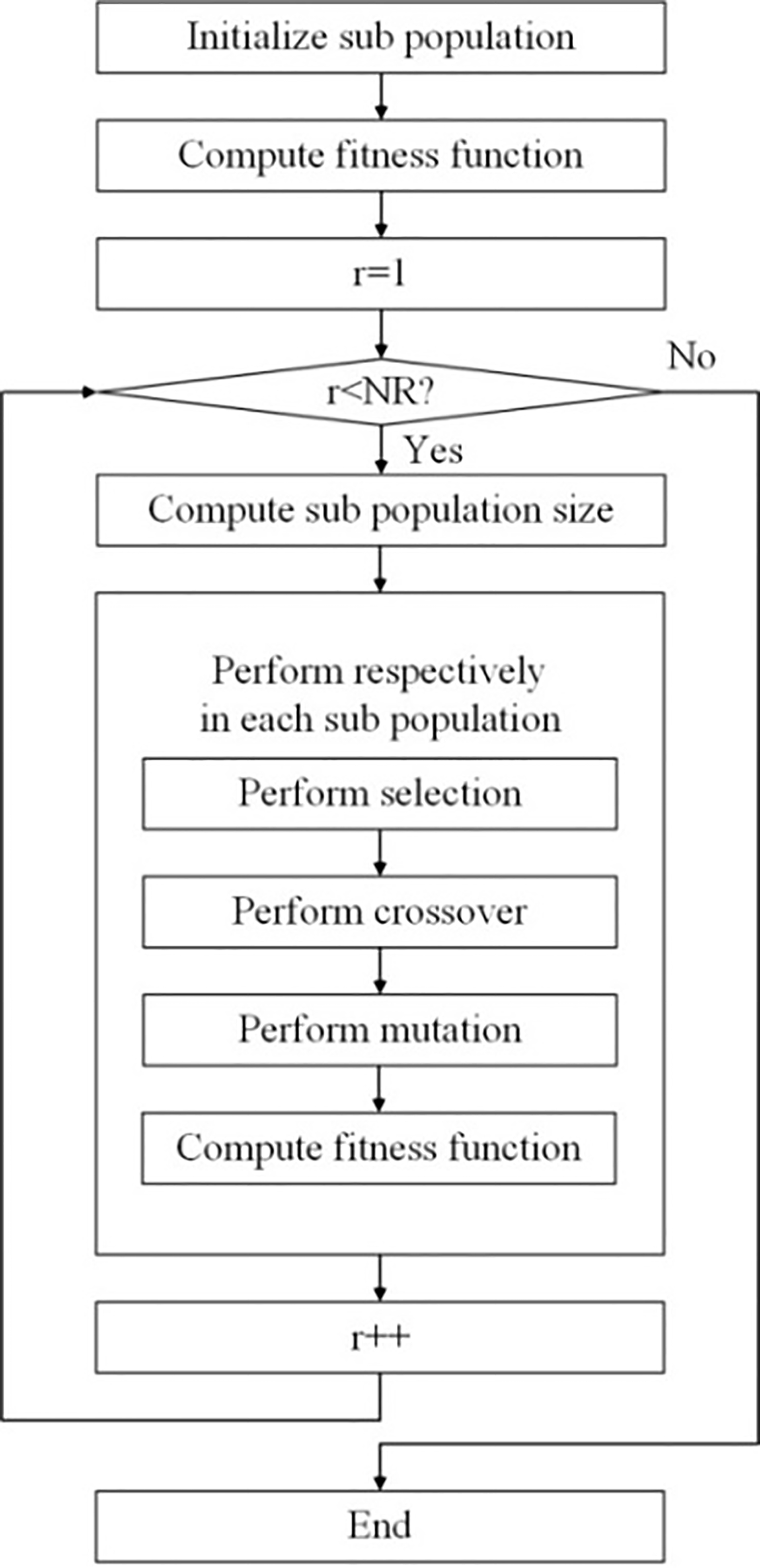
The genetic algorithm with multiple sub populations is employed in our proposed algorithm. Each sub population corresponds to a combination of good features. That is, the number of sub population is NM
The binary string is divided into two sections.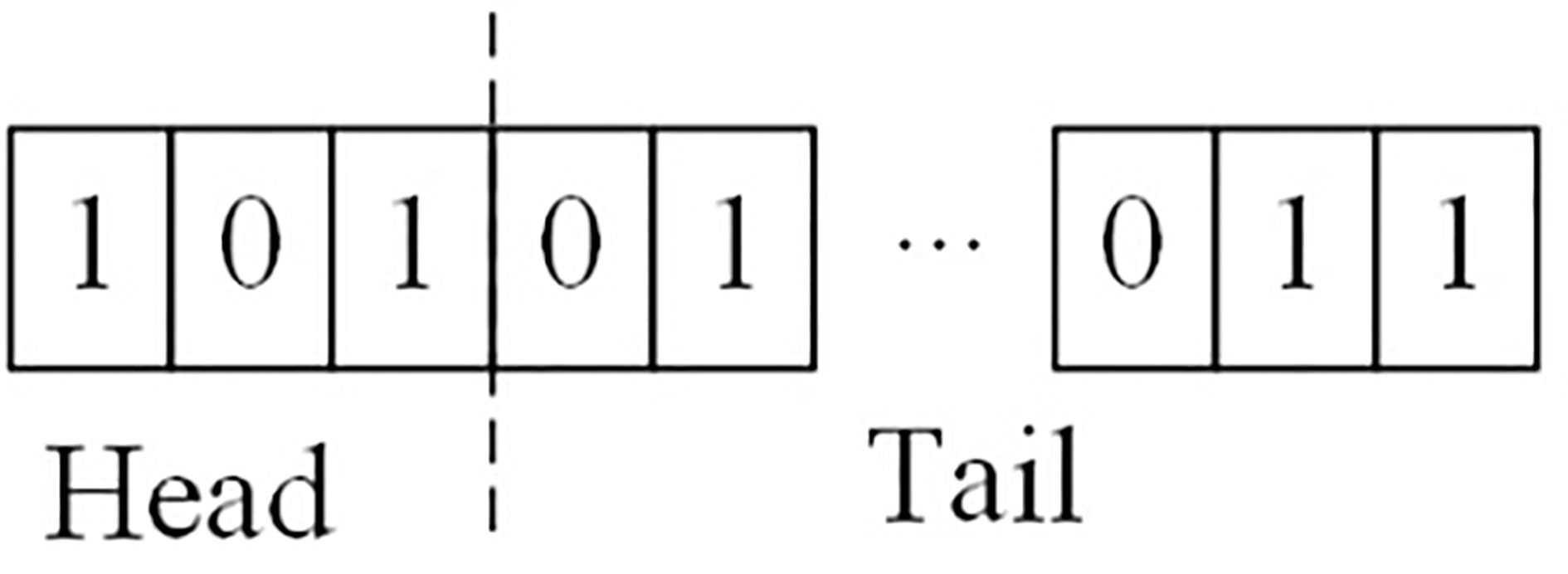
As mentioned before, a competition mechanism between sub populations is introduced. Before round
where Max(SP
All sub populations have the same initial size, which is computed as follows:
Due to the head of SP
Where Id(
For individual Id(
Roulette-Wheel selection method is employed by our proposed algorithm. In round
where mul_g is the coefficient used to decide the preponderance of the individual with more classification accuracy. A random number with the range [0,1) is generated, and the individual whose range the random number falls in is selected. The procedure repeats (Size(SP
As mentioned before, only the tails of individuals participate in crossover and mutation.
The probability that an individual is selected to perform crossover is pc. For selected individuals, they perform crossover in pairs. For two parents, a random number with the range [0,1) is generated for each bit of the tail. The two parents exchange their value of the bit if the corresponding random number is less than pc_bit. Crossover can be performed more freely with the method.
The probability that an individual is selected to perform mutation is pm. Some individuals with overwhelming superiority usually appears in the latter rounds and are selected too many times during selection. Hence, the value of pm increases pm_increase in each round to avoid the same individuals are evaluated repeatedly. For an individual selected to perform mutation, a random number with the range [0,1) is generated for each bit of the tail. The individual changes the value of the bit from ‘0’ to ‘1’, or from ‘1’ to ‘0’ if the corresponding random number is less than pm_bit. Mutation can be performed more freely with the method.
Computational complexity analysis
The time of this stage is mainly the duration of obtaining the individuals’ classification accuracies. The classification accuracies of T_Size
Experiments are performed with 8 datasets comparing to 11 state-of-the-art algorithms to validate our proposed algorithm.
Experimental environment
The software environment and of hardware environment of the experiments are shown in Table 2.
The software environment and of hardware environment
The software environment and of hardware environment
Eight real world datasets from the UCI machine learning repository are used in the experiments, as shown in Table 3.
The datasets used in the experiments
The datasets used in the experiments
The result of the first stage
The main parameters setting for each datasets
The average accuracy of different values of pc (%)
The average accuracy of different initial values of pm (%)
The experimental results of FS
The score for each feature of each dataset.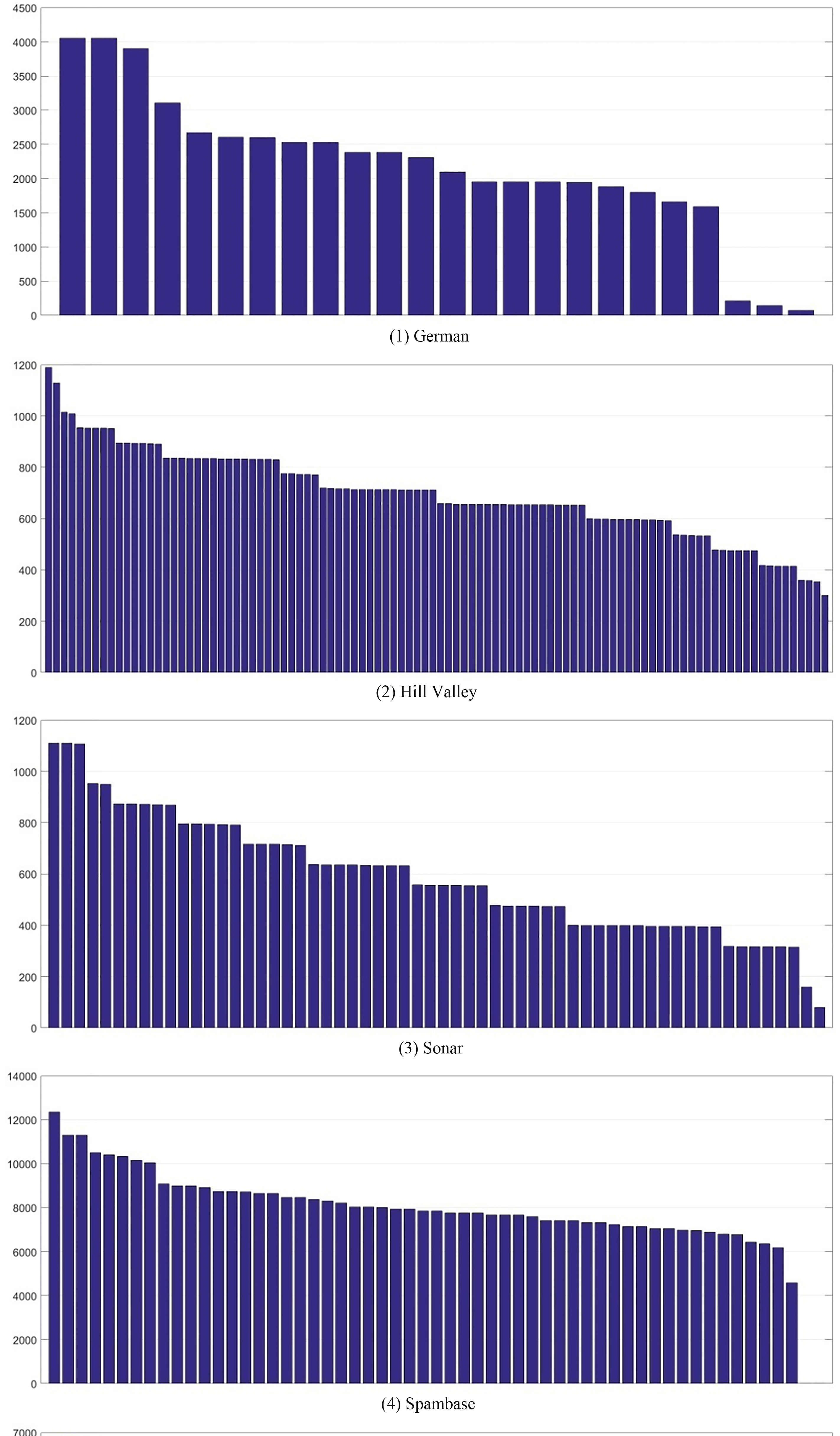
Conitnued.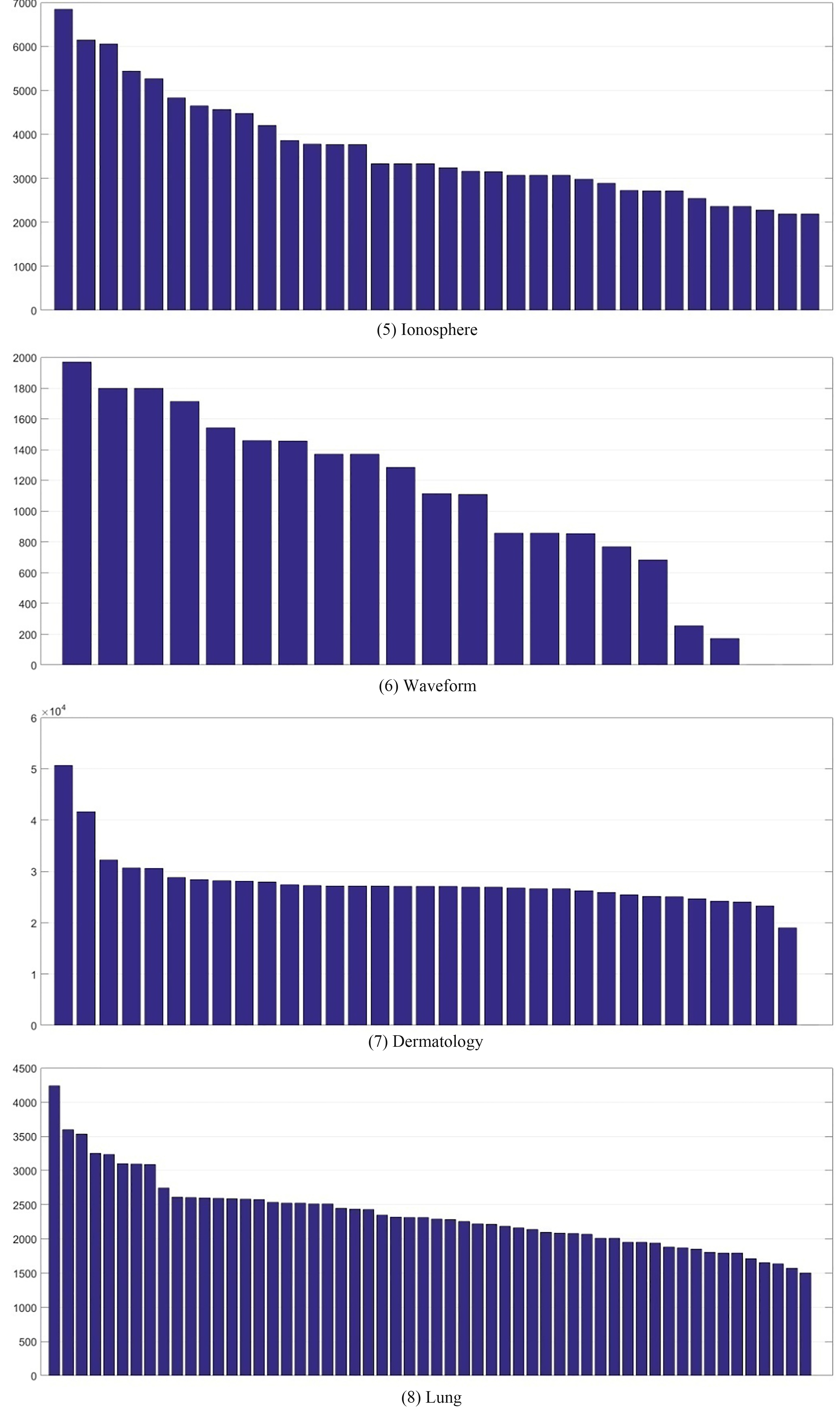
The rankings of the algorithms for each dataset (mean
The following state-of-art deterministic or EC based algorithms are compared with our proposed algorithm:
Sequential Forward Selection (SFS) [19] Sequential Backward Selection (SBS) [19] Ranking Based method (RB-FS) [21] Graph Clustering with Node Centrality (GCNC) [22] Modified Discrete Artificial Bee Colony (MDisABC) [1] Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D) [7] A Fast Feature Weighting algorithm of Data Gravitation Classification (FFW-DGC) [23] Multi Objective Differential Evolution based FS (DEMOFS) [36] Binary Bat Algorithm for FS (BBA) [37] Binary Grey Wolf Optimization approaches for feature selection (bGWO) [38] Visibility density Modified Binary coded Ant Colony Optimization algorithm (VMBACO) [39]
For binary classification datasets, the SVM with linear kernel is employed. For multiple classification datasets, logistic regression is employed because the SVM with linear kernel is not suitable for multiple classifications. And ten-folds cross-validation is adopted to compute all individuals’ accuracies.
Settings and results of the first stage
In the first stage of our proposed algorithm, 5000 random feature subsets are randomly generated for each dataset. The value of K in K-Means
Based on the scores above, good features of each dataset are screened and shown in Table 4.
The accuracy of each round in GA of FS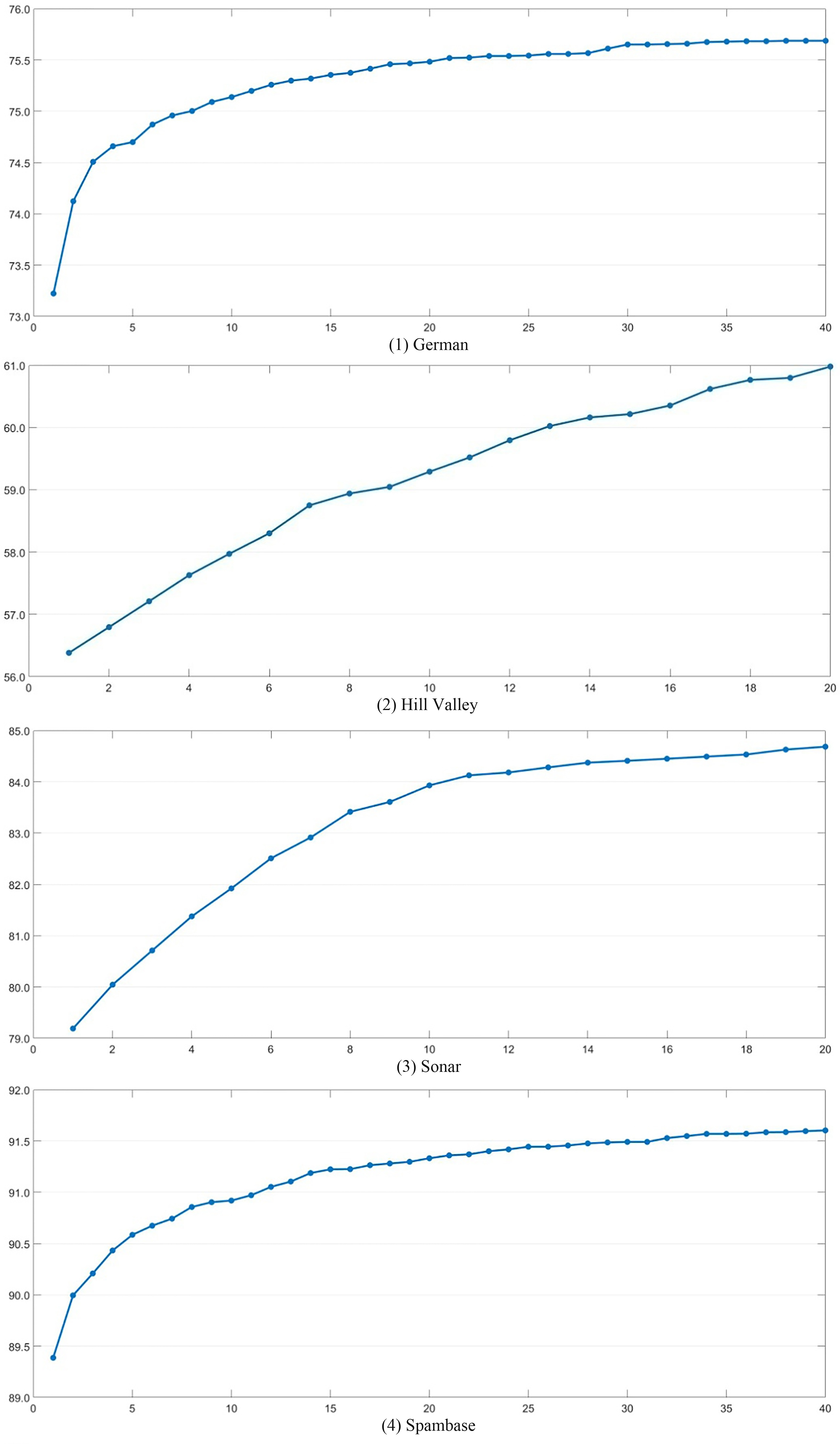
Continued.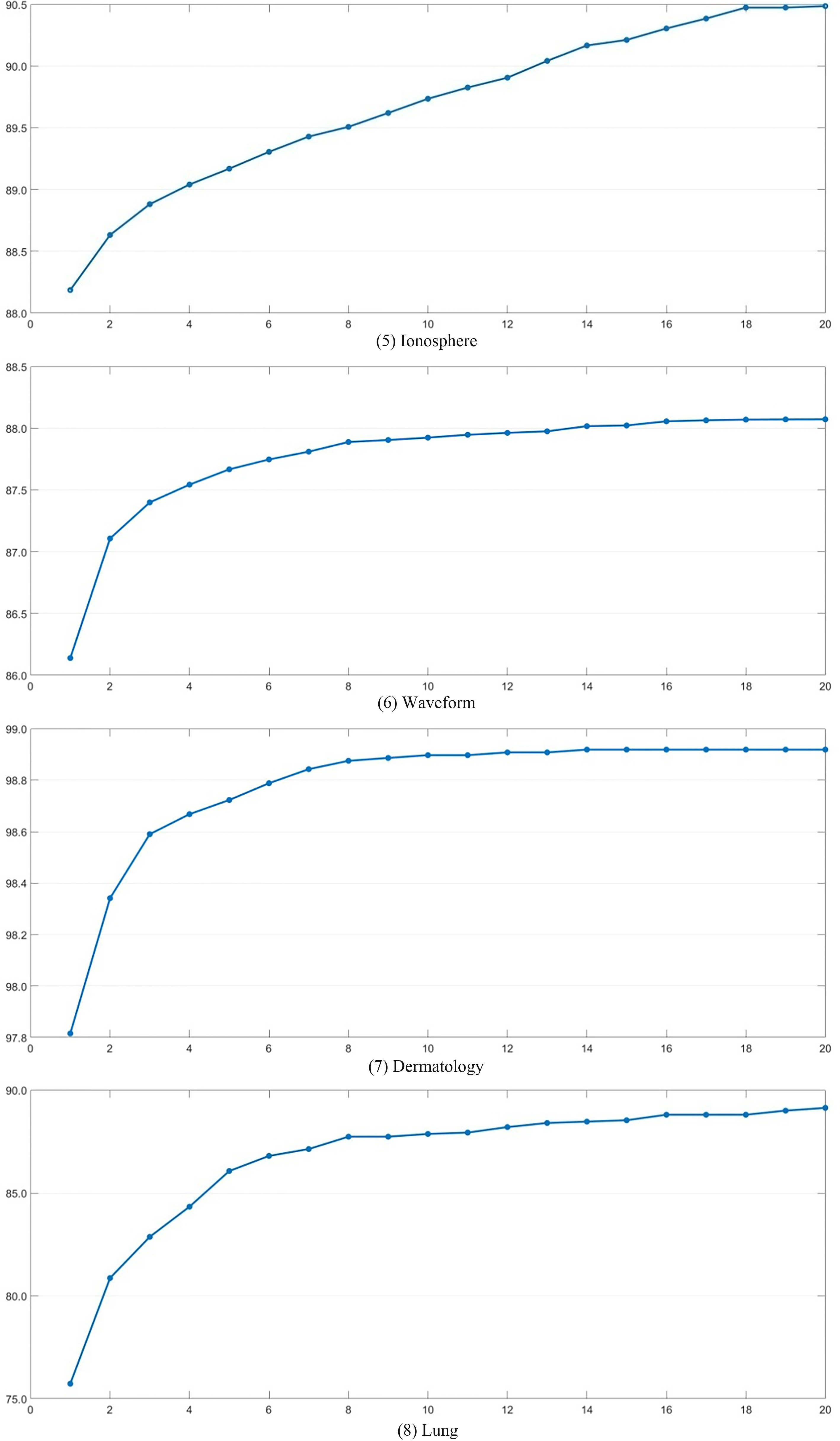
Firstly, we determine the optimal values of the parameters. Although big population sizes can obtain better accuracies, it is impossible to set big population sizes because the process of obtaining an individual’s classification accuracy is time-consuming, and the performance of our hardware is limit. Thus, we set the population sizes of different datasets from 320 to 640 based on their numbers of good features and sub populations. By experiments, we find that the accuracy of a dataset usually doesn’t increase or increase slowly after some generations. Thus, we set the numbers of rounds for different datasets, as shown in Table 5.
To determine the value of crossover probability pc, we perform the experiments with different values. For each value of pc, we run FS
As mentioned in sub Section 3.4, the value of mutation probability pm increases in each round. We also perform the experiments with different values to determine the initial value of mutation probability pm. For each initial value of pm, we run FS
For each dataset, we run FS
Table 9 shows the comparison of FS
The computational time of FS
GA for each dataset (hours)
The computational time of FS
The computational times of a run for each dataset with FS
Conclusion
With the available EC based algorithms, features aren’t screened before evolutionary computation starts and all of them are equal in status during the process of evolutionary computation. In this work, we propose a new algorithm that screens features before evolutionary computation starts, and makes full use of the screened ones during the process of evolutionary computation, which is named as FS
Footnotes
Acknowledgments
This paper is supported by the following scientific research projects of Mianyang Teachers’ College: QD2014A007 (no. 07165211) and 2014A07 (no. 07165212).