
Abstract
Information retrieval process is an inference for the real-world user communication, which is based on the concept of storing, representing and searching information. Moreover, it utilizes the repository in order to retrieve the stored information in an effective way. The processing of such system is not an easy task; also, its complexity depends on the quality of searched information. The information that would be retrieved depends on the query formed by the user. The fuzziness of human brain is extremely high as every person has different cognitive skills, opinions, thinking, perception, situation, intention, intuition and domain; these varied attributes results in a fuzzy query by the user for any information need, thus it can be said that different types of user have different query apprehension. In order to provide efficient and relevant results to the user according to the information need, the foremost requirement is to understand the users’ query. In this paper, hybrid of Vector Space Model with fuzzy logic inference has been implemented. The purpose of the system is mapping of the Vector Space Model with cognitive skills of the user using the fuzzy approach. The similarity between the documents has been computed using the fuzzy logic in order to evaluate the query results based on the graininess of the user.
Introduction
Information Retrieval (IR) is a process of extracting relevant documents as per the information need of the user. A lot of data is created everyday by the user intentionally or unintentionally. Data is stored in unstructured format and extracting information from this big pool of data isa tedius and complex task. Various information retrieval algorithms are proposed in literature for retrieving information which assists in retrieving relevant information from the repository [17]. The most commonly known are:
Boolean Retrieval [25] – It deals with the matching of exact queries. The matching is done based on the Boolean operators such as AND and OR. The term is either significant or insignificant when the IR system is boolean. Significant here refers to the terms that occur atleast once whereas, insignificant terms are those that donot occur even once in the document. It is one of the oldest model for IR systems, known for its simplicity. But the model fails when it comes to the exression formulation according to the grading scale (extended boolean model). This lead to the need of a model that would deal with the user query which is fuzzy in nature.
Vector Space Mode [25] – VSM model calculates the TF-IDF for each document and converts them into a vector to search the relevant documents. This model is advantageous as it improves the retrieval performance by arranging the documents according to the similarity to the user query and also allows partial matching of the query with the documents. With these added functionalities the model does not posses simplicity.
Probabilistic Model [25] – This model was proposed by Robertson and Johnes who calculates the probability of finding a document
A document contain numerous terms, where each term has different level of significance. But there is no way by which one term can be entitled more significant than the other. The information retrieval of the documents is majorly based on the way the document is represented and the query that the user gives. The representation of the documents is centered around the most basic constituent of the document, that are the terms. Further, the query that the user gives is based on these terms. The user query can be expressed through various methods in which the use of logical operators (AND, OR) is one of them [4]. These operators allows the user to use combination of terms in order to give more efficient query. It is assumed that the terms in the users’ query are completely relevant to the needs of the user. But this assumption is not always true, there is some imprecision in the users’ query. A user has some thought process running at the back of his brain about what exactly he wants to search. According to Ingwerson a user is usually categorized in three groups namely – that are verificative, consicious topical and ill defined. Each type of user formulates the query in different way [5].
Formulating a query based on the thought plays a major role in retrieving the document. The search will be more refined if the query formed is such that it clearly expresses the need. The imprecision can be caused due to the vague knowledge of the user about the subject to be searched and assumption that the document representation is partial. This imprecision (partial significance of the terms) cannot be handled by the boolean IR system. In order to retrieve relevant documents from the set of whole documents, it is necessary that the system is capable of handling uncertainity. The VSM model provides the score that reflects the relevence of the document w.r.t. the given query. This ranking can be used for developing the membership function in the range of 0 to 1, leading in gradual transition from membership to non membership which would be abrupt in case of boolean retrieval system. Thus, fuzzy set theory to devlop the fuzzy inference system which could better coorelate the thinking pattern of the user as per the catergories given by ingerwerson. The keywords that represent the document is the focus in the IR research. Non topical attributes characterization can also be used for the document eventhough it may sometimes cause imprecision. There has to be a system that would handle the uncertainity caused by the vague queries by the user and the imprecise values. A fuzzy IR system works on the fuzzy set theory that considers both the vagueness in query predicates as well as the uncertainity in database record. In this paper, the Logic based model has been combined with Vector Space Model using fuzzy logic. This hybrid model improves the performnace and flexibility of the system and also simplifies it.
The paper is divided as follows: User graininess description, background of fuzzy IR and vector space model has been described in Section 2. It also covers the hybrid model used in the research. Section 3 provides the experimental design based on the hybrid of fuzzy IR with the vector space model including the dataset, tools, model implementation and the result evaluator. Section 4 presents the results obtained from the implemenation of the hybrid model and also covers the major discussions of the study; and Section 5 presents the conclusion of this work.
Background
IR is basically a system that provides a platform to the user to import their query in order to retieve the information from the unstructured repository to fulfil their information needs. The user tries to formulate a query as per knowledge, which might not be treated structured by the repository for retrieving relevant documents.
Graininess of the user
An IR system is designed for retrieving information, it discusses about the uncertainty of the data and query formulation but never discusses the diversity of the user. Every user has a different set of varying cognitive skills (thinking, opinion, thought process, and perception decision making etc.) which affects the query given by the him. Thus, it is important to understand the state of mind of the user. Cognitive Informatics provides better understanding of the complexity of the users [22]. These informatics simplifies researchers to have a better understanding of users’ searching pattern and query formulation [6].
Fuzzy information retrieval system.
Vector space model stages.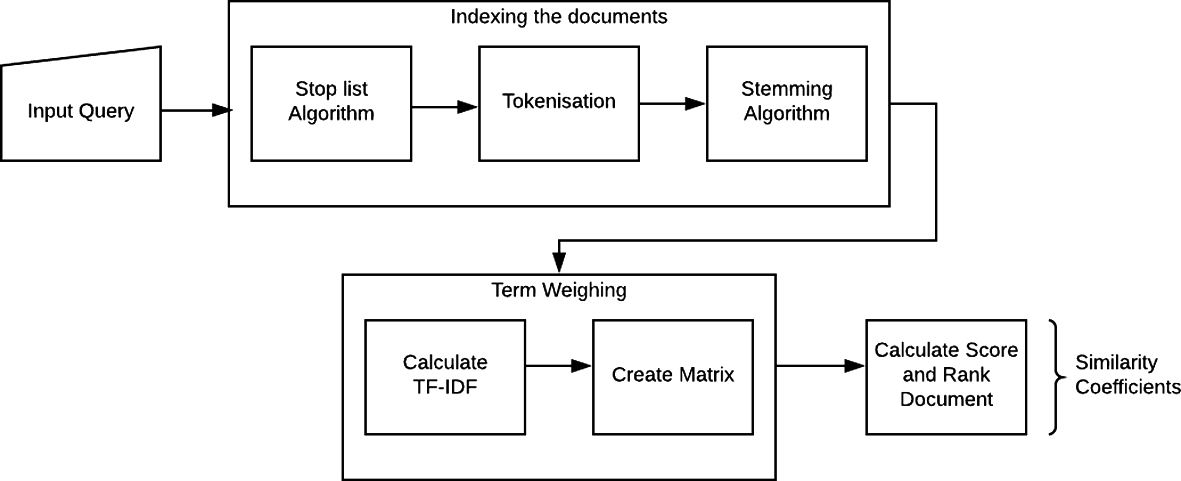
Graininess is a concept to break the modules into smaller chunks, grains or terms such that each particular grain plays an important role [7]. User graininess categorizes the user in three, namely: verificative user, conscious topical and ill defined user. Table 1 gives the information about the types of user. The graininess of the cognitive information retrieval can be used to understand the users’ need in the context of executive functions (flexibility, theory of mind, anticipation, decision making, problem solving, working memory etc.), motor skills and perception.
Also, different retrieval methods can be used for different users.
Types of user with their information need/intentions and cognitive skills
The fuzzy IR set model basically has two elements, queries and documents [1]. These elements are represented by set of indexed terms. The documents together are stored in repositories. The queries are put on these repositories which brings out the matched documents. This matching is approximate that results in the vagueness. Further, each document has degree of membership which the system can effectively display [14].
Whenever a query is given, a term co-relation matrix is created which is then normalised using various algorithms [Ref]. The documents are categoried on a relevance scale based on the similarity in the terms of the query and the document. As the similarity between the elements increases the document weight increases too. Fuzzy IR informs the user about the validity of the document relevance to a query entered by the user [13, 23]. The following Fig. 1 shows a fuzzy IR system.
Vector space model
Vector Space Model (VSM) is an algebraic model of information retrieval that is used to represent text documents in the form of vectors. It was given by Salton et al. in 1975. It ranks the document depending upon the score of each query in that particular document. The major goal of VSM model is to rank the documents that contains the query most frequently. In this model, every document
The following steps are involved in VSM model that plays a crucial role in indexing the repository and for query processing:
Indexing the documents (ID) – The foremost step while indexing the documents is the removal of non significant words from the document vector. Indexing basically finds out the term frequency which can either high or low in range.
Term weighing (TW) – In this stage the resultant frequency from the prior stage is used in order to find out the weight of terms. There are 3 main factors that affect the term weight: term frequency factor, collection frequency factor and length normalisation factor. All the factors are multiplied to get TW as outcome. Whenever a query has to be processed, the recall and precision can be evaluated based on the factors mentioned above.
The TW for document vector
Each dimension of the vector corresponds to a term that is assigned by a weight called TF-IDF weight [1]. TF is term frequency of the document that contains the most frequently occurring terms and IDF is inverse document frequency of the document that are less frequent in the documents [15, 16]. Thus TF can be mathematically expressed as in Eq. (2):
And IDF is given in Eqs (3) and (4):
where,
Similarity coefficients (SC) – Similarity coefficients are the resultant of document vector and query vector. In order to measure the SC the angle between the two vectors has to be calculated. The similarity of each document
The result file obtained from the above steps which is the outcome of TF-IDF of the topic file. Further, the result file is used in the final evaualtion of the documents retrieved. The evaluation can be measured through various formulas, amongst which the major two are the recall and precision. Recall is the fraction or percentage of relevant documents that were retrieved and precision is the fraction or percentage of retrieved documents that are relevant. Figure 3 shows the venn representation of recall and precision.
Venn diagram of recall and precision.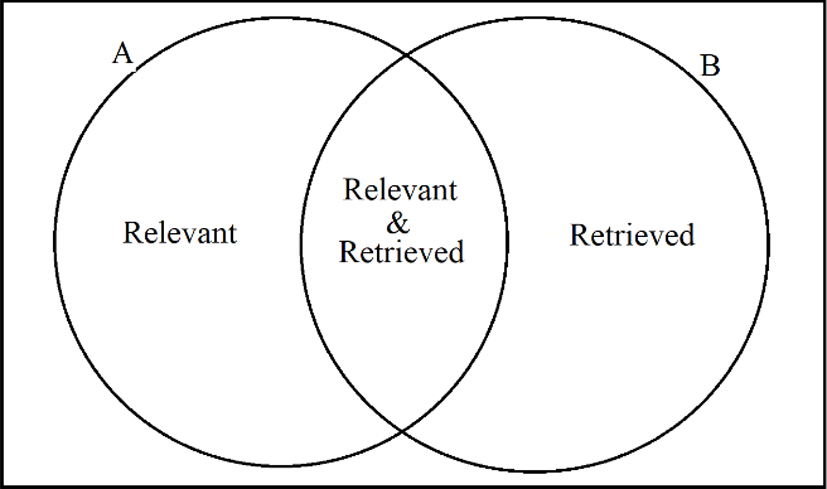
Mathematically, recall and precision can be expressed as shown in Eqs (5) and (6):
VSM gives us the TF-IDF values depending upon the specific term that has occured in a document frequency. Also, fuzzy logics are used to find the ranking of the particular document that are ranked previously by the user and stored as meta data. These soft computing techniques are being used majorly in decision-making applications with inexact and undefined knowledge. These applications of fuzzy approach is emerging consistently in area of reasearch [2]. Combining these techniques together will formularize a logic based model that will improve flexibility and performance of the vector model [3]. The fuzzy logic expresses relevance as a degree of membership that ranges between 0 to 1. The documents with relevance greater than 0.5 are considered as highly relevant, the documents with relevance 0.5 is considered as somewhat relevant and documents with relevance less than 0.5 are considered as less relevant for any search term. This will reduce the dimensionality of the vector space and the results that are more relevant would be collected in accordance to the page contents using vector space model. In Eq. (4), if
In the proposed Hybrid Model, the system access the database according to the query the user has phrased. The model is the combination of VSM and Fuzzy Logic. VSM preprocesses the dataset using stemming algorithm, removing stop words and indexing the terms and then it applies TF-IDF algorithm on topic files. After the above steps, result file is evaluated by Qrel file that gives the recall and precision. Fuzzy Logic categorizes the user query as well as their results based on the cognitive skills [22]. The output generated by fuzzy system indicates the type of user that feeds the quires. It is an efficient way to categorize the users depending upon the score of TF_IDF model. Different rules are generated based upon the membership functions of the fuzzy system. These rules decide the ultimate output of the system [13]. The model proposed in this study (Convergence of Fuzzy Inference with VSM) is given in the Fig. 4.
Flow chart depicting the hybrid model.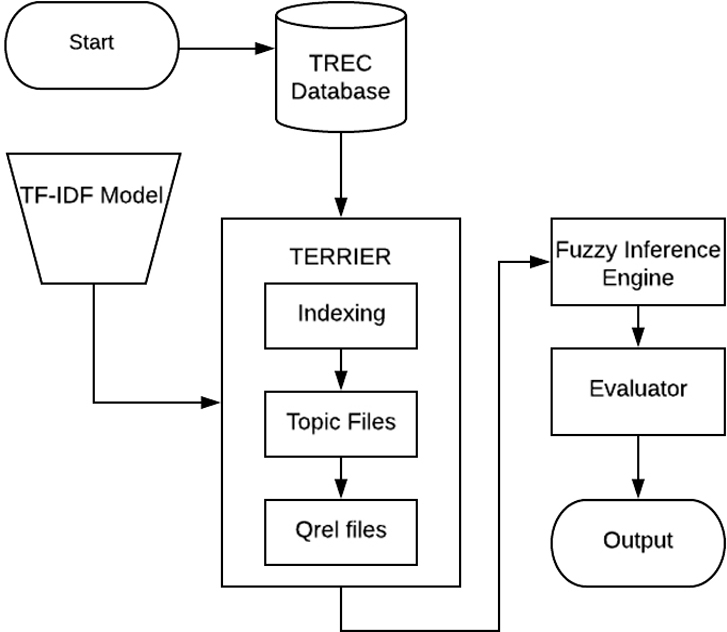
To implement and validate the model experiment was conducted which has been given in detail in the next section.
The hybrid model makes use of the Text Retrieval Extraction Conference (TREC) dataset that has been evaluated and analysed using Terrier and Matlab.
Dataset
The dataset that is used in the experiment was collected from Disk-1 Text Retrieval Extraction Conference (TREC) sponsored by Defense Advanced Research Projects Agency (DARPA) and National Institute of Science and Technology (NIST). Disk 1 consists of data from five newswires namely, Associated Press (AP), Department of Energy abstracts (DOE), Federal Register (FR), Wall Street Journal(WSJ) and Ziff-Davis (ZIFF). They contain document and their respective DTD (Document Type Definition).
The topic files for evaluating the result was collected from [9, 10] and evaluation file was collected from [11]. Topic files are basically the query files and Qrel files are the relevance judgment files according to which the evaluation is done.
Tools used
Terrier. Terrier is a highly flexible, well organized, and efficient open source engine that can deploy documents at a large scale. It is a hasty platform for research and experimentation in text retrieval. It is completely written in java and hence easy to use. It is an effective, efficient, flexible, multi-lingual, extensible and interactive tool for the researcher of the field information retrieval [11].
Indexing. Terrier processes the transformed data through indexing. The indexing is a four step process that includes the following:
Collection. Documents. Term pipelines. Indexer.
Trec Disk 1 Corpuscomplied details
Firstly, the collection of documents is injected in the system. After having the collection of documents, an automatic indexing runs on these documents to create indexes upon which the further search is performed. During indexing, some preprocessing steps are applied on the documents such as removing of stop words, stemming of words etc. Thenuser identifies its information need and in accordance to this, generates a query statement. The system processes the query against the created index and returns a number of potential feedback with the score calculated for each document. The user selects the feedback generated by the system to access the documents. Figure 5 shows a block diagram for creating Index and searching relevant items.
Topic files. In Terrier supporting dataset format which is used as an information need that is “topic” to differentiate it from a “query” which is a data structure represented in the retrieval system. There are various statements of the topic in Terrier along with number of fields.
Qrel files. In order to test the relevance of topic files, relevance judgement files are made. They are often mistaken as the query files. But the qrel files are the batch files that are created with the opinion of experts.
Matlab. Matlab provides a toolbox for fuzzy logic implementation. It computes the inference engine rules, verifies the changes and analyses the parameters. It also provides a flexible environment in order to improve integrity of the system even though there are changes in the parameters of inference rules and membership.
Creating index and searching relevant items.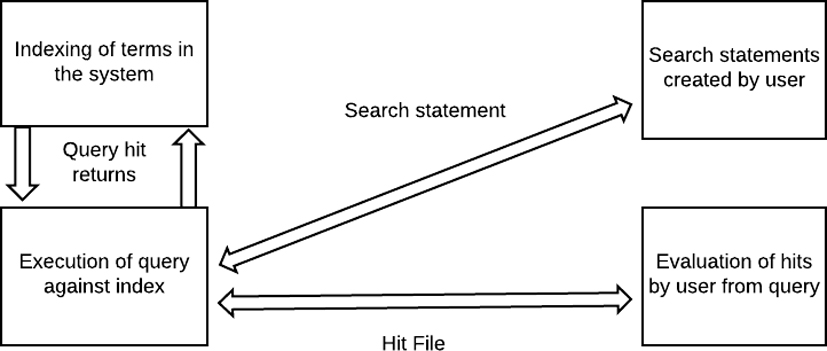
Information Retrieval is about retrieving the results against the queries generated by the users. Disparities in the ranking system of TF-IDF are mostly used by the search engines as a major means to score a document and rank a document for any given user query. The idea behind the fundamentals of Fuzzy System is to deal with the vague values rather than crisp values. MATLAB was used to create an inference engine that deals with words. The authors evaluated the TF and IDF for each query then further generated the rules using the fuzzy system. The generated rules indicates the relevance of the query and based upon this, the user is classified as verificative, conscious topical and ill defined. A fuzzy system was build that takes input P1, P2, Pn where, Pn is the evaluation score of TF_IDF model for query. The fuzzy rule based classifier generates flexible and useful structures [7]. Figure 6 shows a graphical model of fuzzy TF-IDF [20, 21].
TF_IDF score count with average
TF_IDF score count with average
Rule set of the Fuzzy_TF_IDF system for different types of user
Fuzzy_TF_IDF.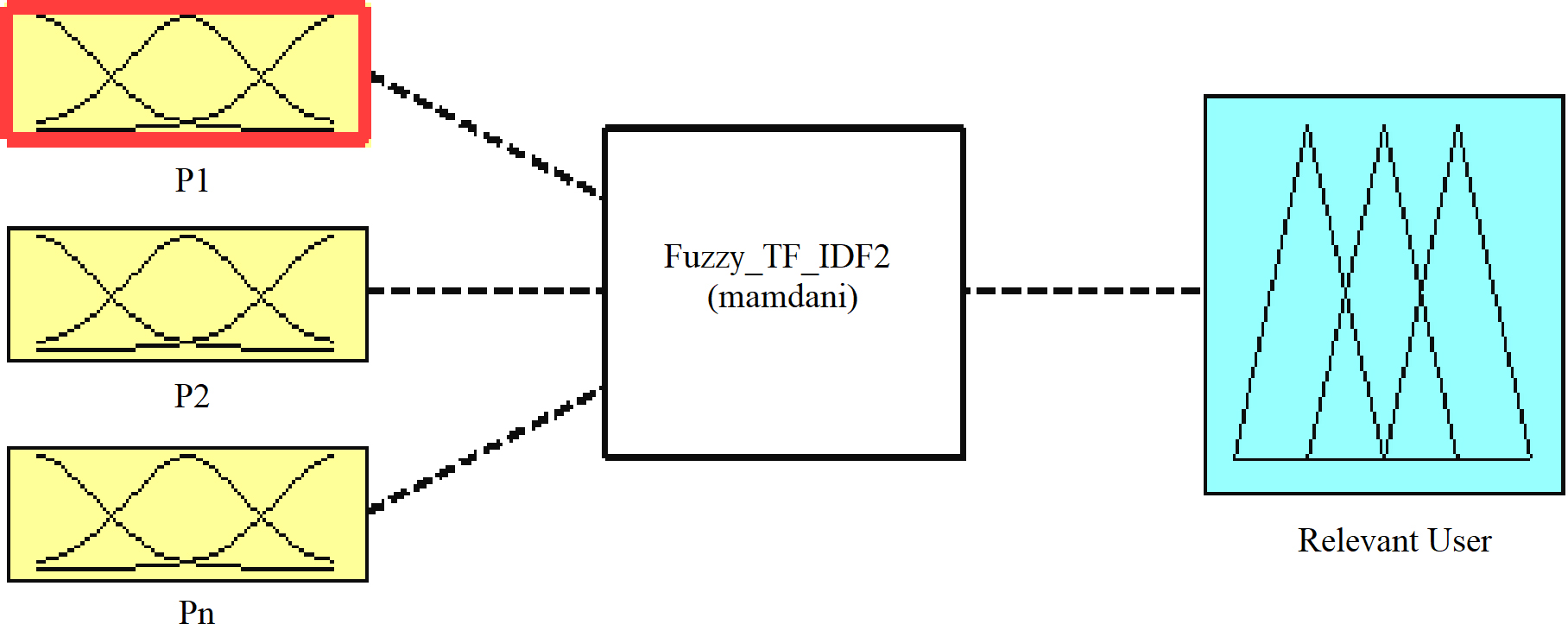
To evaluate the effectiveness of TF_IDF with fuzzy model, data from the NIST TREC Disk 1 was used that is mentioned in Table 2.
Baseline system. Terrier 3.5 [11] Open Source Tool with query expansion module was used as a baseline search engine. Terrier is an open source, high performance, full featured text search engine written entirely in java. The queries were fed into the system. TF_IDF was used to generate the scores. The scores that were generated was divided into five different levels to differentiate the types of users. Maximum score obtained was 31.84 and Minimum score obtained was 1.24. The fuzzy TF_IDF regulates the relationship among the user and TF_IDF score which maps these two factors.
Table 3 shows the TF_IDF score count with average of the scores obtained in that particular query. Further, Fig. 7 depicts the graph for sum, rank count and rank score average.
Sum, rank count, and rank score average.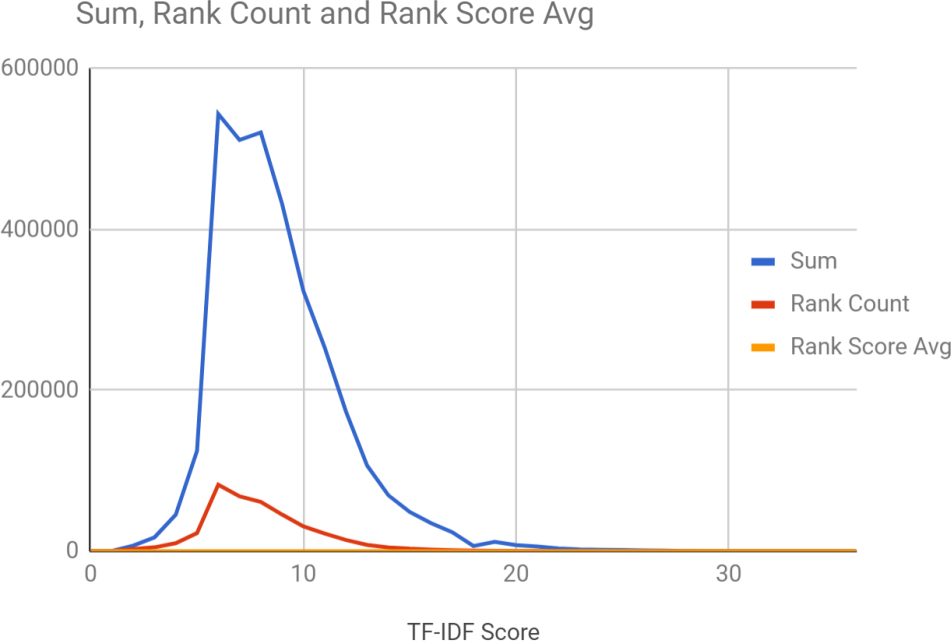
Fuzzy TF_IDF Rules:
Different rules were generated by classifying the type of the users. TF_IDF rules were generated. Scores of TF_IDF was given as input through the fuzzy system and corresponding results were generated. Here having knowledge or shortage of knowledge to determine weights of the effectiveness of users can affect the overall ranking.
Refer Table 4 for the rule set of fuzzy TF_IDF system.
Membership function.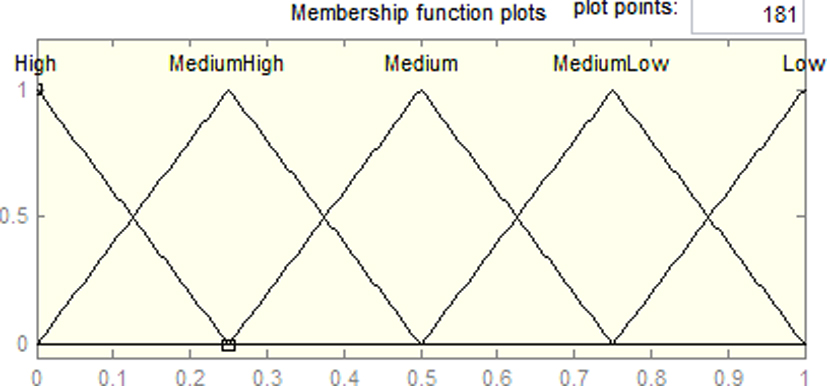
Figure 8 illustrates the membership functions used in Fuzzy TF_IDF.
As discussed, there are three types of user in cognitive information retrieval who has their focus and reason for searching. Some users are clear about what they want while others are confused about their own thoughts. Thus, fuzzy modeling is an area that deals with this vagueness when user’s perspective is not clear.
The resultafter evaluating the data is:
Evaluation of qrel file
Table 6 gives the precision @N along with their scores. A comparison is done with the precision score evaluated for standanrd VSM model with the proposed hybrid model. The result shows a significant improvement, this improvement can be well understood by the gain.
Comparision of precision @N of TF_IDF and hybrid model
The table can be well understood with the graph as shown in Fig. 9.
Comparison chart of retrieved relevant terms with score.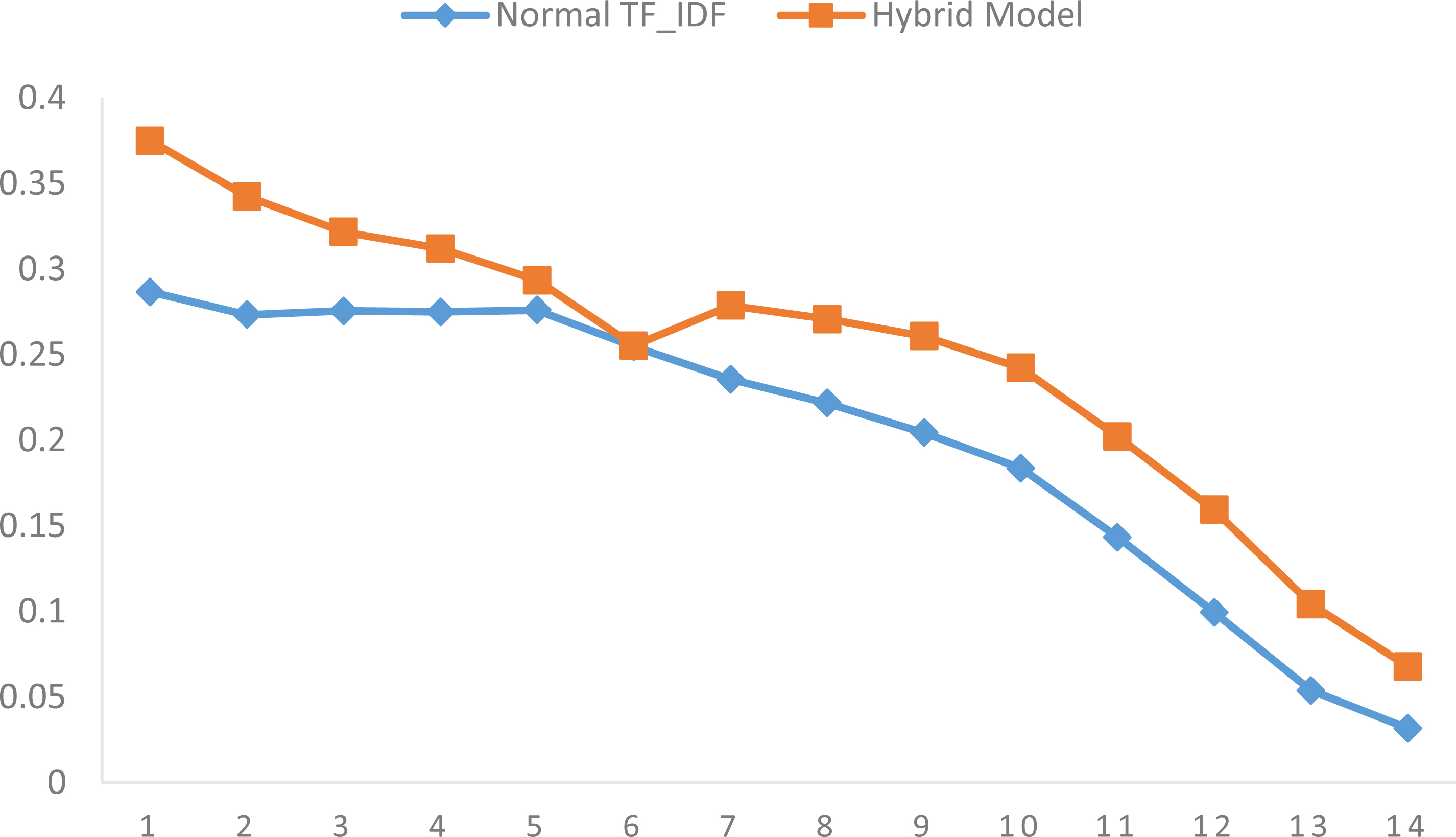
In this paper a hybrid information retrieval model has been propsed by converging vector space model in user’s cognitive skills into a fuzzy inference system. The VSM model produces automated rank list as an output that is based on term weighted score. The human perception and thinking creates significant variation in the retrieved information. Cognitive information retrieval models were used for understanding the psychology of human brain, how it thinks and perceives information and categorizes the users accordingly. In this paper the users were categorised into three groups, namely: verificative, conscious topical and ill defined and their needs were taken as a base to create a rule set that can give more precise the retrieval for a given query. As the categorery of the user do not have the fixed boundaries, a fuzzy logic based inference system was desinged. The six rules were framed for each user and TF_IDF score. The output of the inference system delivered new ranking which out-performed the normal TF_IDF score based on the performance evaluation using precision and recall. In the future, the work can be extended further using query expansion technique where the selection of a suitable query expansion apporach is used based on type of user and would also be combining more information retrieval models with other machine learning algorithms.