
Abstract
High Blood Pressure (HBP) is one of the major triggering factors for many health-related issues such as brain stroke, heart stroke, kidney failure, eye damage, etc. The victims of HBP are drastically increasing day by day across the globe. The prediction of HBP in advance is more beneficial to control the Blood Pressure (BP) rather than using BP control medications. So this paper focused on an intelligent fuzzy classification model called Association based Fuzzy rule Miner (AFM) to predict HBP. Although they are numerous parameters that contribute to HBP, the impact of Bio-Psychological factors on HBP is always worth noting. This paper considered biological factors obesity level, cholesterol level, age, and Psychological factors anxiety level and anger level of a person for experimental analysis. The proposed Model initially converts the crisp data set into the fuzzified data set. Later, the association rules are extracted using apriori algorithm based on conditions imposed as constraints. In the final step the extracted association rules for each decision class separately together constructs AFM, which predicts whether a person is a victim of HBP or not. The experiments are conducted on a real-time dataset of 1000 records, where 600 records are used for training and 400 records are used for testing. The AFM has shown 90.75% accuracy, which is for better than the accuracy of existing classifiers such as Random Forest, Naïve Bayes, Simple logistic regression, J48, and PART.
Introduction
In the present day’s many people around the globe are suffering from High Blood Pressure (HBP) also called Hypertension. There may be numerous reasons for elevated blood pressure in people, but bio-psychological factors [1, 2] are always worth noting. So we focused on age, obesity, cholesterol, anger and anxiety levels of a person to predict the blood pressure (BP) of a person. BP is the most often measured and the most intensively studied parameter in medical and physiological practice [3]. If the measured BP is more than the normal range, then it is called HBP [3]. Although there exist different machine learning techniques to classify medical data, the proposed AFM has selected a fuzzy-based approach to predict, whether a person is a victim of HBP or not. Fuzzy logic is an approach used to compute the degree of truth rather than the precise value of truth [4]. Fuzzy is a branch of mathematics, comes under the umbrella of artificial intelligence. It is sometimes also called a soft computing method. The fuzzy theory was introduced by L.A. Zadeh in 1965 [4].
Existing work on HBP prediction
Existing work on HBP prediction
In fuzzy controlled systems, the initially crisp data set is collected, and it is converted into fuzzy data set using linguistic variables and fuzzy membership function, it is called as Fuzzification [4]. In general, all fuzzified values of the crisp data set are distributed in the interval of [0, 1]. After fuzzification, fuzzified rule base and inference engine are used to get the fuzzy output, the fuzzy output obtained in this stage is converted back as crisp output using the defuzzification process [5, 6].
This section covers the existing work on blood pressure and also explains the way the data set is collected, details of the data set, the way how a data set is converted into the required form for the experimental analysis. Table 1 unfolds that the existing approaches on blood pressure prediction are considered only a single attribute, and they concluded that the attribute considered for blood pressure prediction, blood pressure are positively correlated. But the combined quantitative influence of biopsychological factors on blood pressure does not experimented in the literature. The quantitative influence of biopsychological factors on blood pressure is using a fuzzy approach is addressed in this paper. Table 2 explains the paper title of Table 1.
The architecture of the fuzzy controlled system.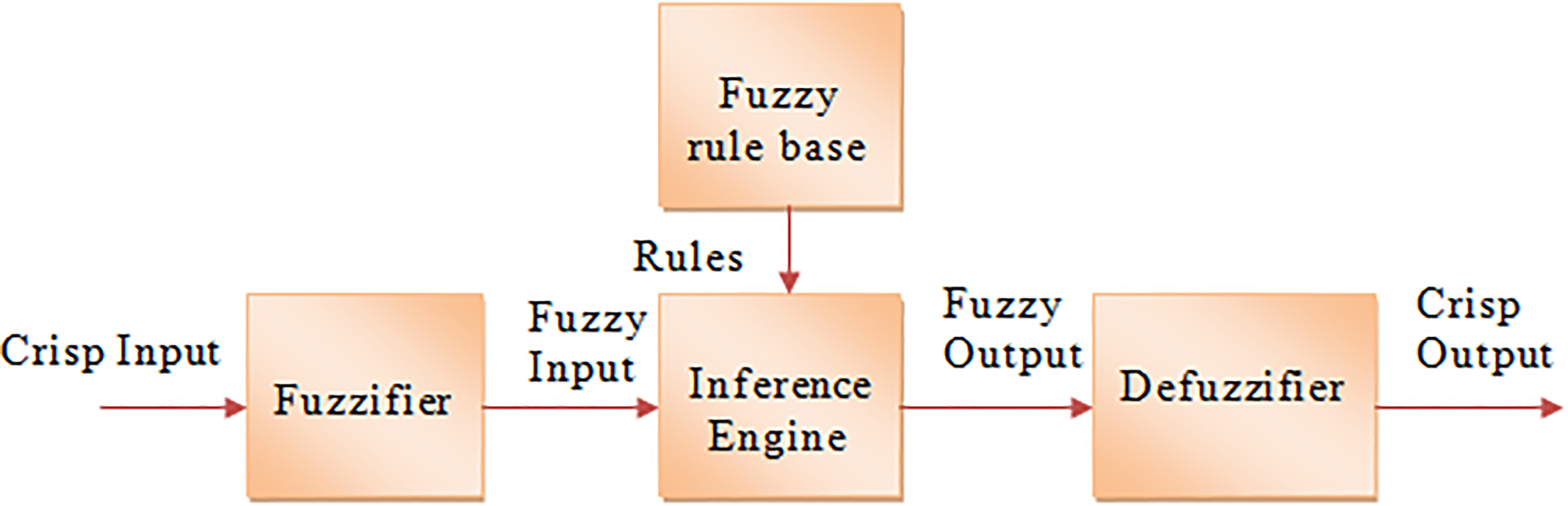
Paper title of Table 1 and its abbreviation
Fuzzified values of age, anger and anxiety levels
Fuzzified values of obesity, cholesterol levels
Initially, in the data conversion process, the biological parameters such as age, obesity level, cholesterol level, psychological parameters anger level and anxiety levels are considered as fuzzy linguistic variables. Linguistic terms of each linguistic variable are identified as shown in Tables 3 and 4 [7]. This fuzzification is done based on the scientific and medical reports available on the web [8, 9]. For example, linguistic terms of fuzzy linguistic variable anger level are considered as {healthy, mild, serious, extreme}. The sample data copy after fuzzification is shown in Table 5. The fuzzy value for overlapped values of each attribute is assigned based on the degree of membership value of the attribute. In data set collection process anxiety, anger levels are measured on the scale of [0, 3], but age, cholesterol, and obesity levels are measured on different scales. In order to bring the whole data on to the scale of [0, 3], age, obesity level, and cholesterol level are normalized using a min-max normalization technique.
A sample copy of fuzzified data set
A sample copy of fuzzified data set
The fuzzy membership function is used to calculate the fuzzy membership value or degree of membership value of the selected attribute in the interval [0, 1] [10, 11, 12]. The triangular, trapezoidal, and Gaussian functions are the most often used fuzzy membership functions [13]. Equation (1) represents the triangular function used for the experimental analysis where
The advantage of the triangular membership function which represents the linear relationship between the crisp value of the selected attribute and its degree of membership value as continuous increasing function as well as continuous decreasing function from a certain specific point [14]. If the age of a person is young, the membership value of age is increasing up to age reaches 30 in the range of [15, 40] and then the membership value is decreasing, The degree of membership value of each attribute is calculated using the membership functions as shown in Table 4.
Here, the degree of membership value represents the fuzzified value of the attribute in the interval [0, 1]. The continuous data set is then replaced by fuzzy linguistic terms using membership functions. For the overlapped areas for example age in the range of 15–20, both the membership values with respect to very young and young are calculated, the crisp value is then replaced by the fuzzified value of age for which membership value is high.
Fuzzy membership value of age.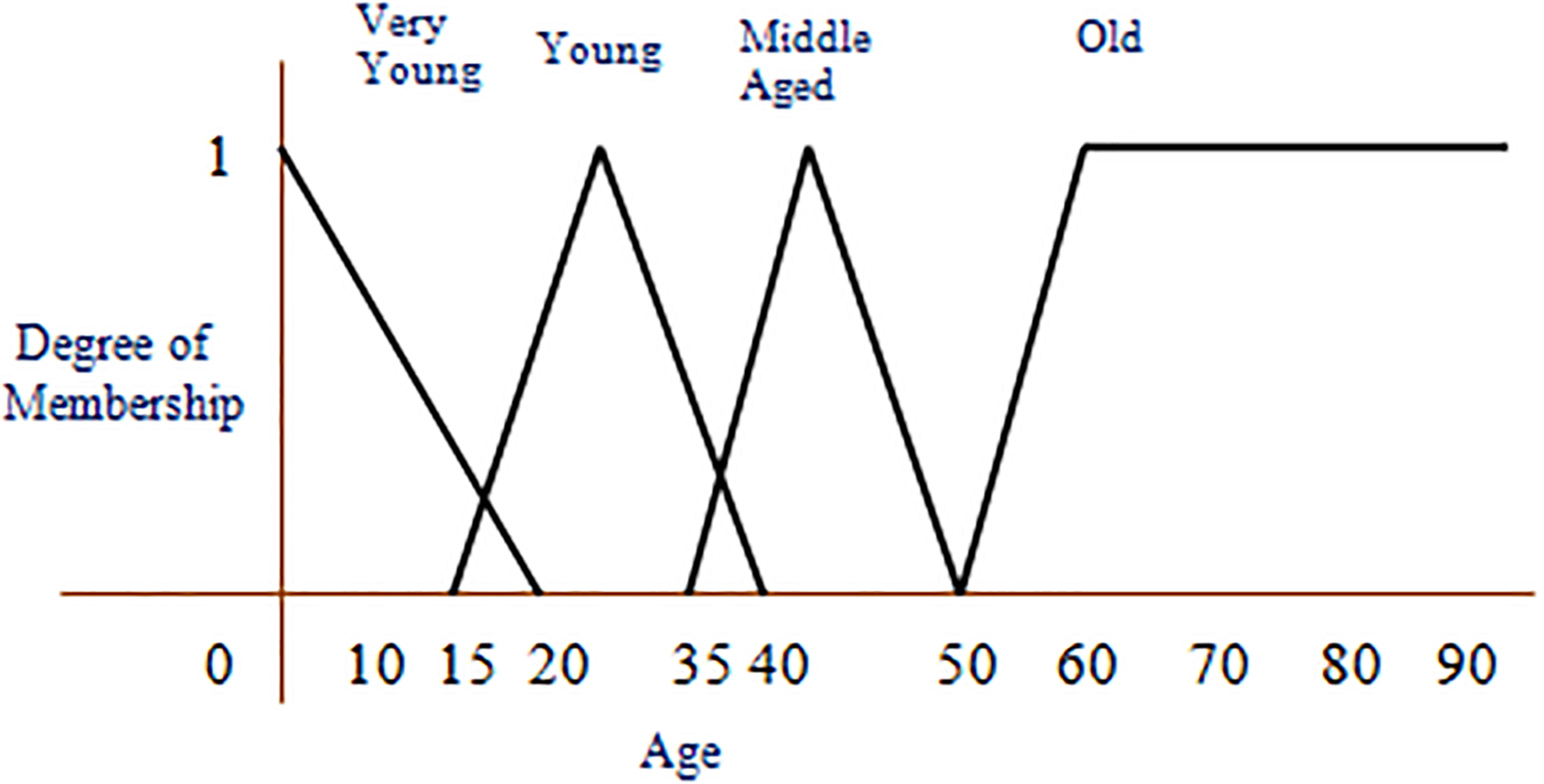
Fuzzy membership value of obesity level.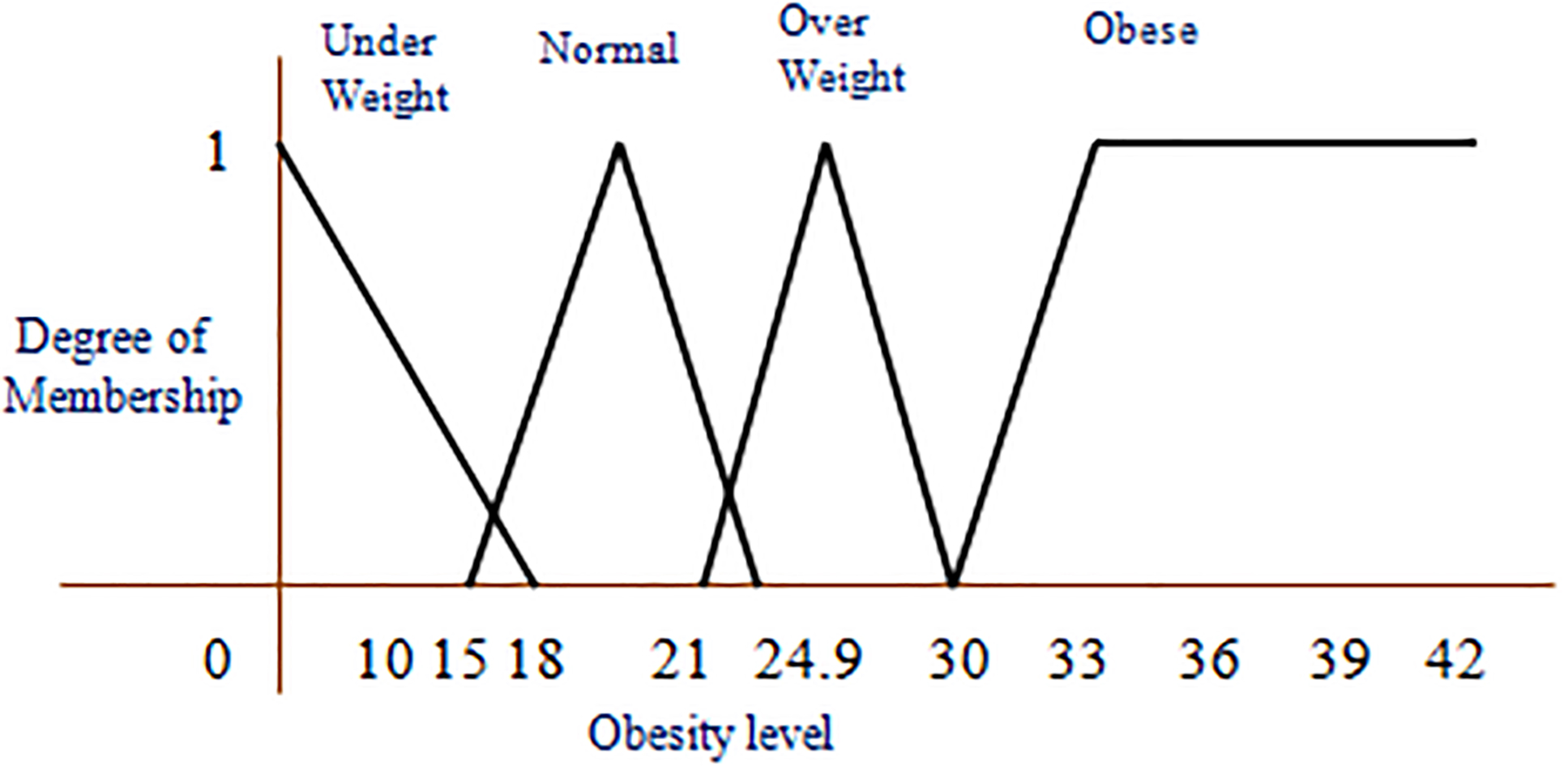
Fuzzy membership value of cholesterol level.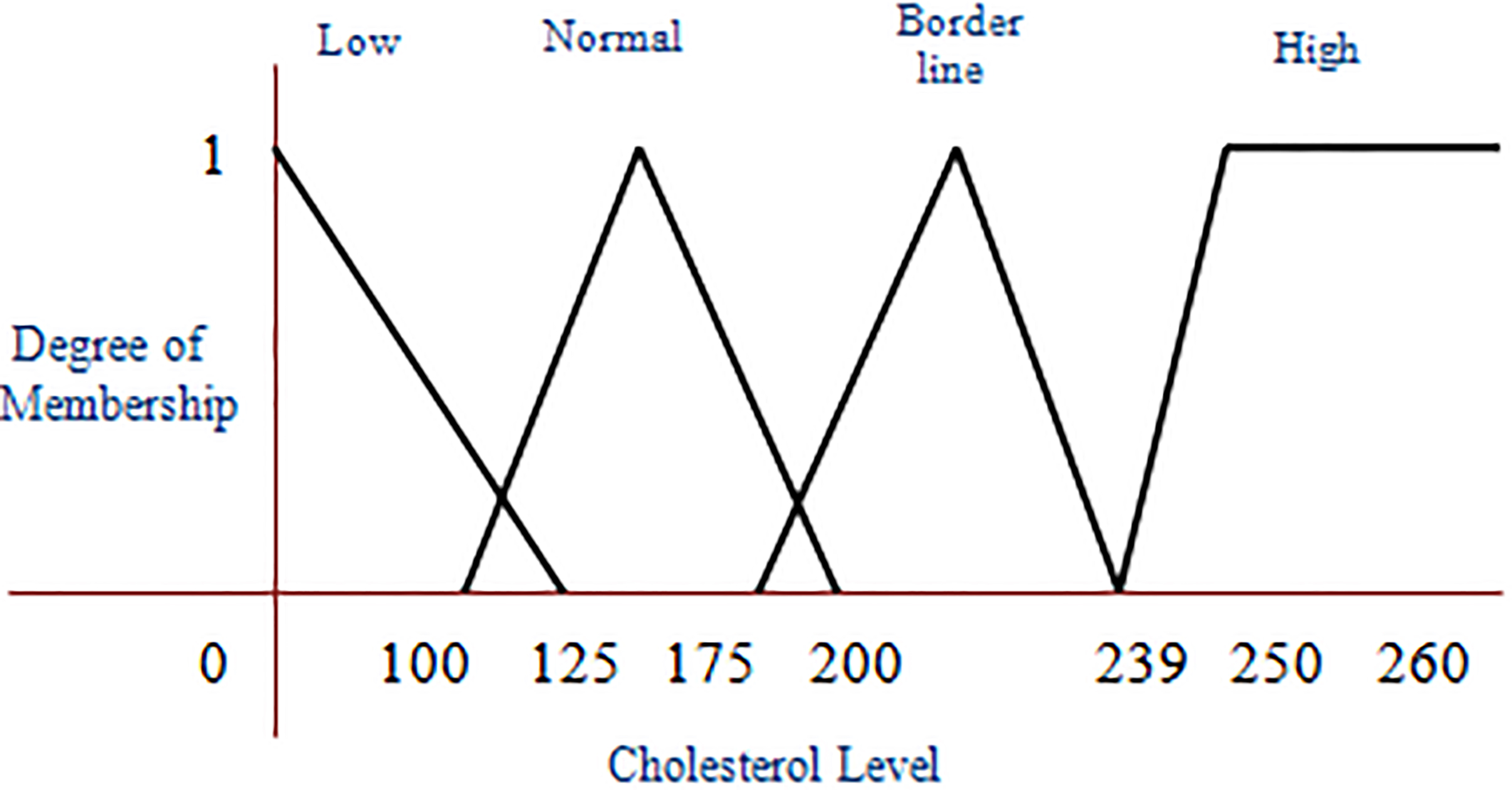
Fuzzy membership value of anger level.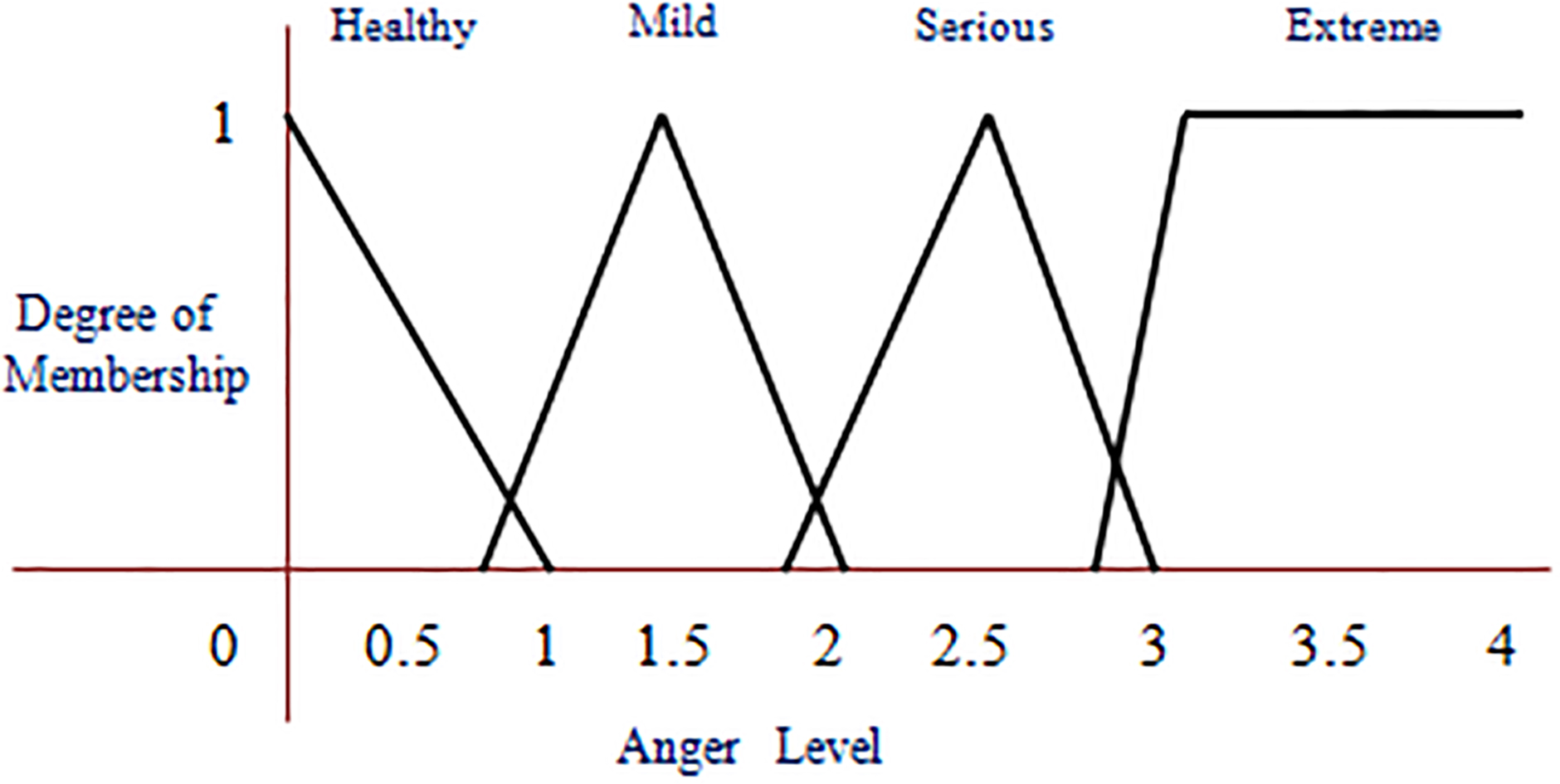
The crisp values of each attribute considered to build the AFM are fuzzified and they are shown in Figs 2–5. The crisp value for age young is actually in the range (0, 30), middle-aged is (31, 50), old is more than 51. As age is fuzzified as shown in Fig. 2, it is unfolded for one more dimension called very young, and also enabled the overlapped areas. The crisp values of each attribute in the overlapped area now have 2 membership values, the crisp value is replaced by a fuzzy value for which the membership value is more. The AFM has taken a triangular membership function to fuzzify the crisp data for each attribute in each range. The degree of membership values of an attribute are increasing up to the middle of the range, and then after decreasing towards zero. The AFM considered the special case of trapezoidal function i.e., L-function to obtain the membership values of age in the range old, obesity level in the range obese, cholesterol level in the range high, anger level in the range extreme, and anxiety level in the range panic.
Fuzzy membership value of anxiety level.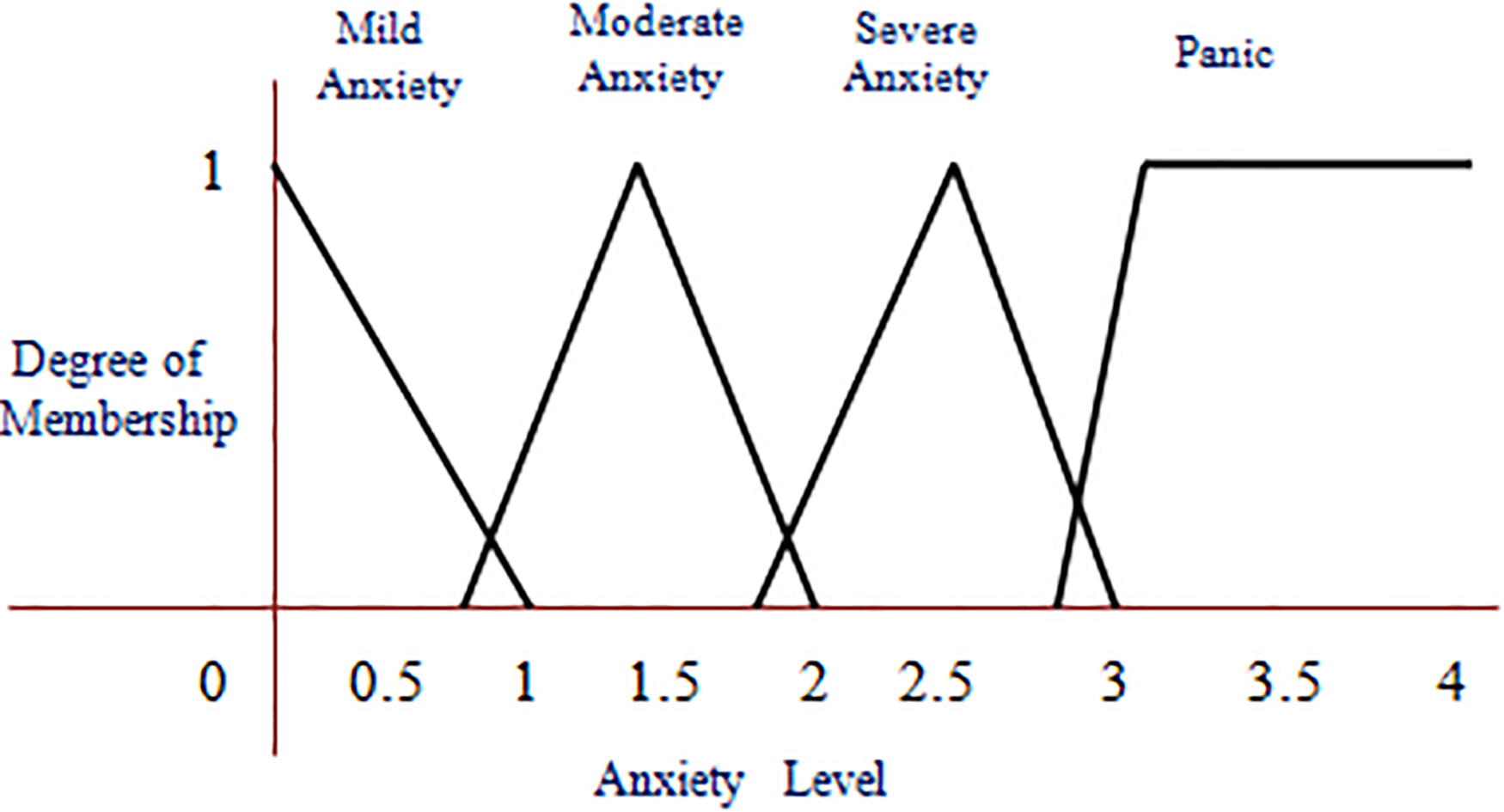
Fuzzy membership function
This section presents the approach used to build the AFM classifier to predict whether a person becomes victim of HBP or not using bio-psychological factors. First and foremost, it converts the crisp data set into fuzzified data set using fuzzy linguistic terms as shown in Table 5.3. The fuzzy linguistic terms of the bio-psychological factors considered for experiments are shown in Figs 2–6. In order to train the AFM, the data instances of YES class and NO class are separated. Now apriori is executed to generate association rules for each decision class separately, the generated rules are pruned using the coverage of the rule. Support Count (SCount) and Specified Confidence (SC) is set during the training phase of the AFM. In the last phase, the AFM is built using the extracted rules from apriori, and it is used to predict the class label of test instances supplied.
Proposed architecture of the AFM
The architecture of the proposed system is as shown in Fig. 7 as given below. Here the term modified apriori is used as we are pruning the rules generated from apriori using the coverage of the rule.
The architecture of proposed AFM.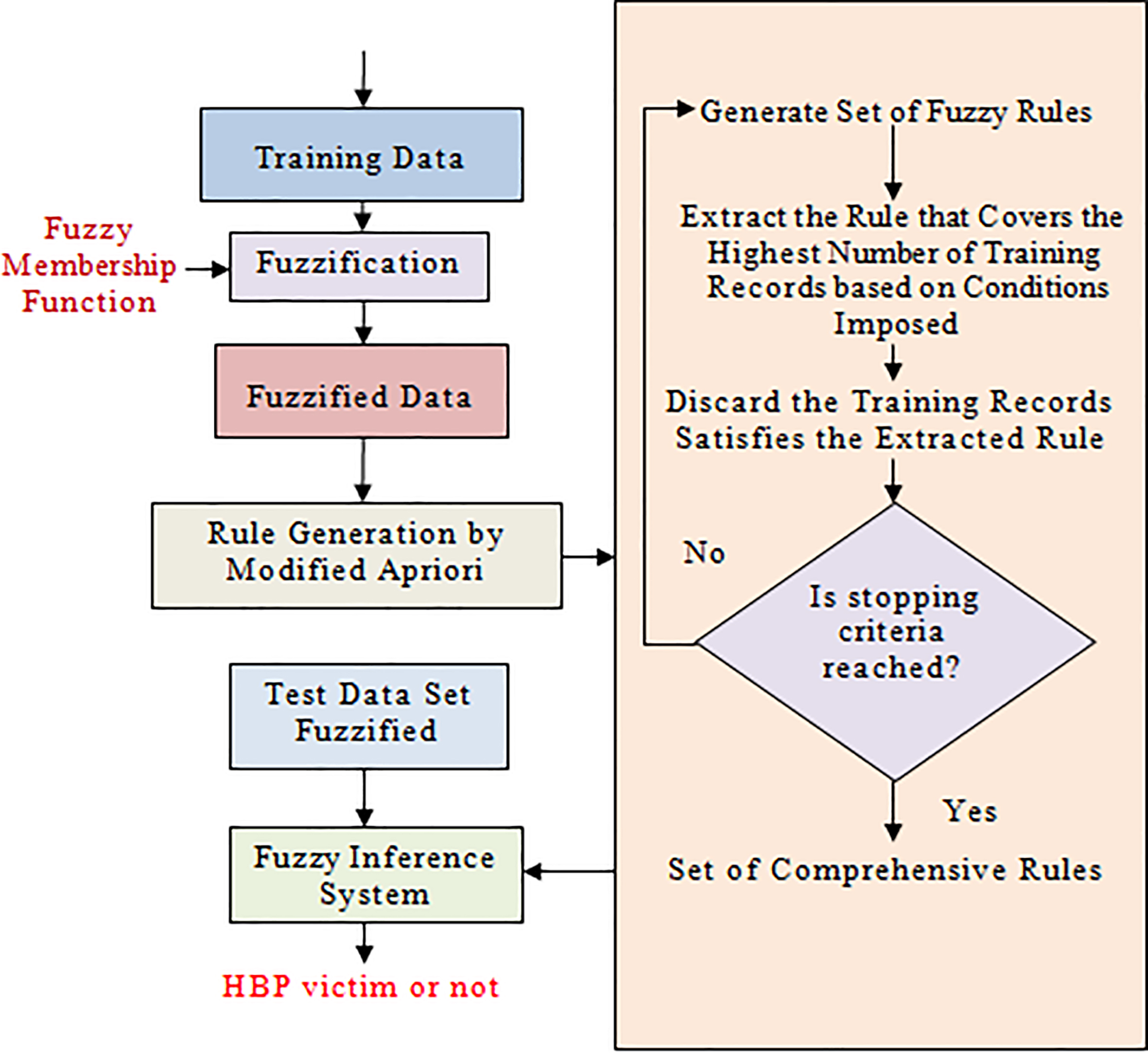
This chapter proposed an intelligent association based fuzzy rule miner to predict high blood pressure using bio-psychological factors named the AFM. It is an intelligent classifier that extracts the association rules generated from apriori using the coverage of a rule [15]. The generated rules are extracted for each decision class separately using the training data set. Extracted rules are used as classification rules in the next stage to classify the input test instances.
Yes class rules extraction
Initially, all the association rules are generated on the basis of support count and confidence specified during the training phase of the classifier using apriori. Yes, class rules extraction means the extraction of rules that satisfies the below-mentioned conditions imposed on the antecedent part of the rule, where the consequent part of the rule is always Yes. Condition 1: While extracting yes class rules the algorithm looks for the rule that covers the highest number of training records. Condition 2: Rules are generated from frequent itemsets based on support count, the first extracted rule is from only rules generated from 1-item frequent itemset, and the next extracted rule is from the rules generated from the 2-item frequent itemset and so on that satisfies condition 1. If no such rule is generated, decrease the support count and repeat the same or consider the rule generated from previous frequent item set that satisfies Condition 1. This is followed to improve the reliability and accuracy of the rule, during the training phase of the classifier. Condition 3: At each step generate the top 10 rules say N, pick up the best rule means that satisfies the above 2 conditions, and remove the records covered by the rule from the training data. If no best rule is found, increment N by 10 each time and repeat the process, stop the above algorithm only if the leftover training records are less than 5% of total training records after removing the records covered by the extracted rule in the current iteration.
No class rules extraction
Initially, all the association rules are generated on the basis of support count and confidence specified during the training phase of the classifier using apriori. No, class rules extraction means the extraction of rules that satisfies the below-mentioned conditions imposed on the antecedent part of the rule, where the consequent part of the rule is always No. Condition 1: While extracting No class rules the algorithm looks for the rule that covers the highest number of training records. Condition 2: Rules are generated from frequent itemsets based on support count, the first extracted rule is from only rules generated from 1-item frequent itemset, and the next extracted rule is from the rules generated from the 2-item frequent itemset and so on that satisfies condition 1. If no such rule is generated decrease the support count and repeat the same or consider the rule generated from previous frequent item set that satisfies Condition 1. This is followed to improve the reliability and accuracy of the rule, during the training phase of the classifier. Condition 3: At each step, generate the top 10 rules say N, pick up the best rule means that satisfies the above 2 conditions, and remove the records covered by the rule from the training data. If no best rule is found, increment N by 10 each time and repeat the process, stop the above algorithm only if the leftover training records are less than 5% of total training records after removing the records covered by the extracted rule in the current iteration.
Experimental results and discussion
Experimental analysis is done on a real-time data set of size 1000 people. Each person data is considered one record. Each record consists of anxiety level, anger level, age, cholesterol level, obesity level, SBP, and DBP. Age, cholesterol level and obesity level are considered biological factors, whereas anxiety level and anger levels are considered psychological factors. For comparative analysis of the proposed AFM classifier, the existing classifiers supported in WEKA are considered. As WEKA processes the input data using ARFF (Attribute Relation File Format). The data collected is converted into an arff file format in the data preprocessing phase. The proposed AFM is implemented in JAVA. The total data set is divided into two sets. One is a training set and another is a test set. The proposed AFM considered 60% data for training and 40% data is for testing.
Rules extracted using modified apriori
Initially, Yes class and No class records are separated from the training data set. And then, apriori is executed to extract association rules based on the supplied support count and confidence. Initially, support count and confidence are set at 1. At support count 1, no rules are generated so the value is subsequently decreased by 0.1 in each iteration using a recursive approach. However at confidence 1 and support count 0.6, there exist many association rules, so confidence is set at 1 and support count is set at 0.6. The fuzzified and defuzzified rules are given below.
Fuzzified rules extracted
If ((anxiety If ((obesity If ((cholesterol y If (cholesterol Confusion matrices of different classifiers
Accuracy of different classifiers
Performance measures of the different classifiers
Accuracy of different classifiers.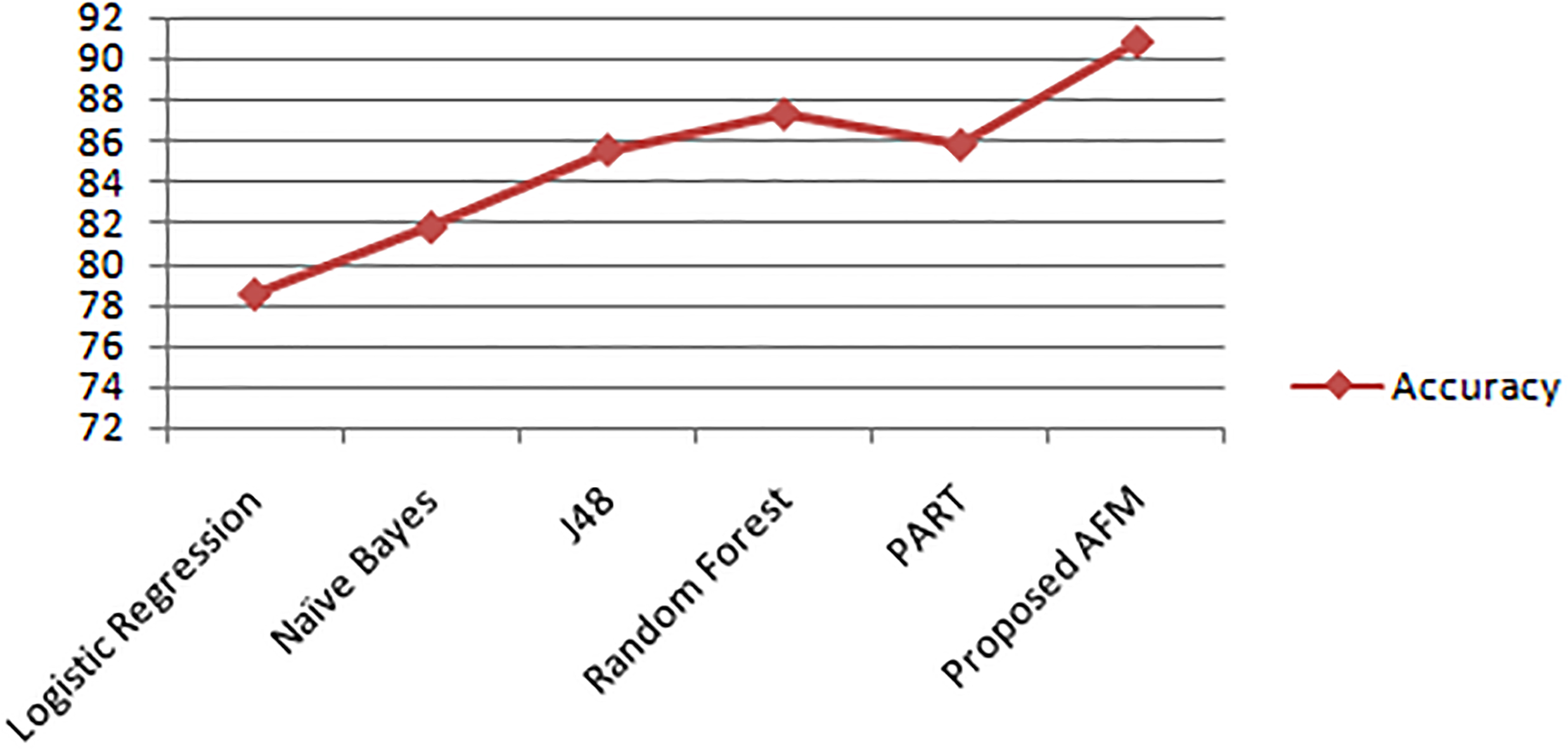
If ((obesity
If (age
If (obesity
Performance of Yes class using the proposed AFM.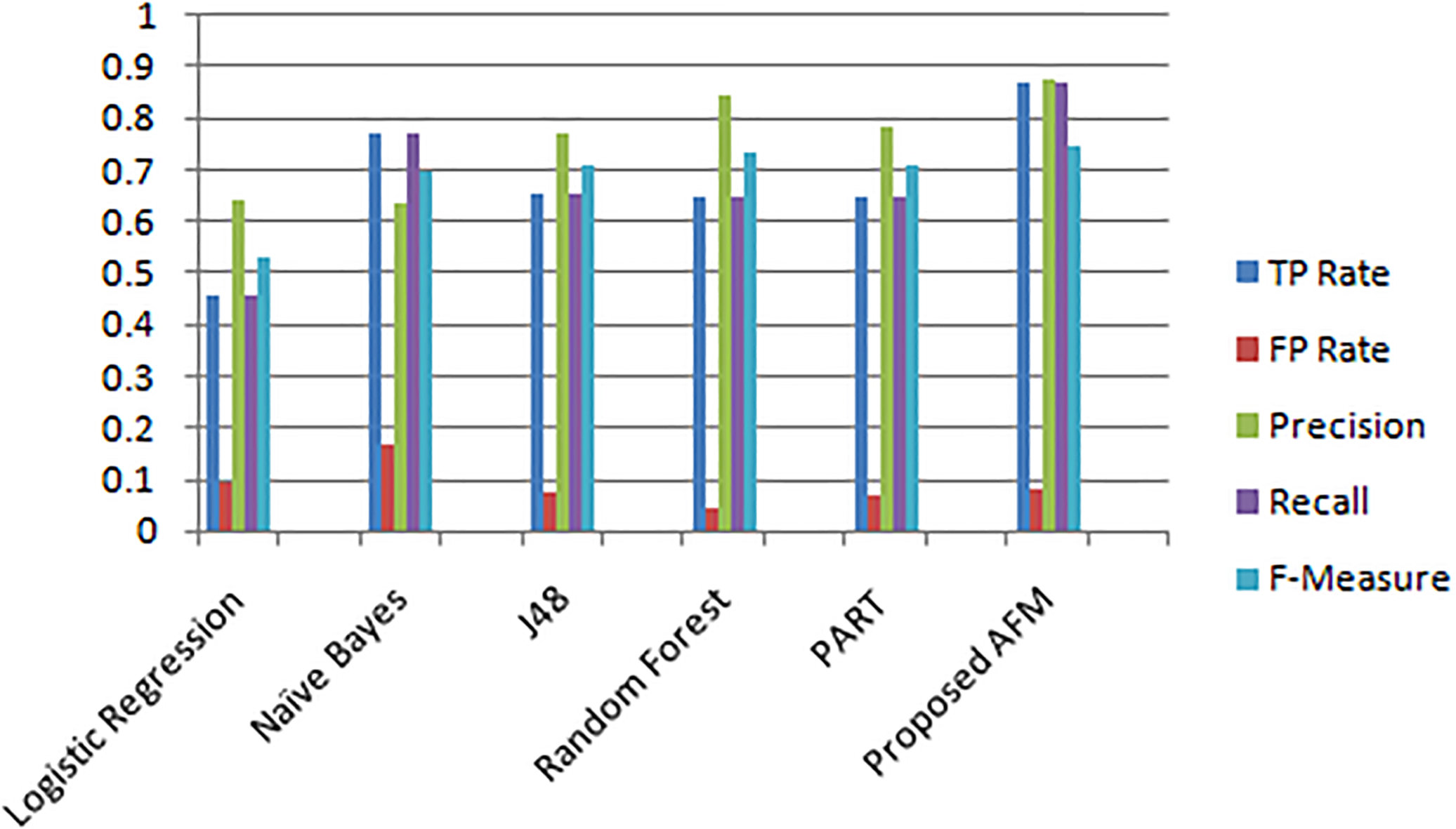
Performance of No class using the proposed AFM.
If ((anxiety If ((obesity anxiety If ((cholesterol anger If (cholesterol If ((obesity If (age If (obesity
The performance of the classification system is normally evaluated using the data present in the confusion matrix. The confusion matrix is a two-dimensional matrix that contains the information about actual and predicted classifications done by the classification system. Table 5.5 shows the confusion matrices of the proposed different classifiers and the proposed AFM. In the training data set out 400 records, 108 are Yes class records and 292 are No class records. The proposed AFM predicted 94 out of 108 Yes class records as Yes, 269 out of 292 No class records as No. The accuracy of proposed and different classifiers is shown in Table 8 and in Fig. 8.
Performance evaluation of the proposed AFM
If Positive class is considered, the TP Rate of a classifier represents the fraction of positive class records predicted as positive, and it shows how good the classifier is in predicting positive class records.
FP rate represents the fraction of negative class records predicted as positive, it shows how the error rate of the classifier is in predicting negative class records. The precision of the classifier shows how exact the classifier is in predicting positive class records. The F-measure is harmonic mean of the precision and recall represents the overall performance of the classifier with respect to the positive class.
If Negative class is considered, True Negative (TN) Rate represents the fraction of negative class records predicted as negative, and it shows how good the classifier is at predicting negative class records. False Negative (FN) rate represents the fraction of positive class records predicted as negative, and it shows the error rate of the classifier in predicting positive class records. The precision of the classifier shows how exact the classifier is in predicting negative class records. The F-measure is harmonic mean of the precision and recall represents the overall performance of the classifier with respect to Negative class. The performance measures of the experiments conducted are shown in Table 7. Figure 8 shows the performance details of the proposed AFM with respect to Yes class. Figure 9 shows the performance details of the proposed AFM with respect to No class.
Comparative study of AFM with existing classifiers
In this paper, it has been proposed a new model named AFM to predict the victims of HBP using real-time data set. The FM considers bio-psychological factors to predict the class label attribute. The experimental results are compared with classifiers supported in WEKA. The proposed AFM has outperformed in terms of F-measure, accuracy comparatively with logistic regression, naïve baye’s, j48, Random Forest and PART. The proposed AFM has also shown the improved performance in terms of TP rate, FP rate, precision for each decision class as shown in Table 9.
Conclusion
This chapter proposed an intelligent AFM to predict the HBP based on bio-psychological factors. Age, cholesterol level, obesity level are considered biological factors, and anxiety level, anger levels are considered psychological factors. The proposed approach initially generates association rules using apriori, later association rules are pruned based on the coverage of records. The extracted association rules are used to build the AFM. The real-time data sets of 1000 records are considered for experimental analysis. The AFM is trained using 60% of data and it is tested using 40% data. The proposed AFM has shown improved performance in terms of accuracy, TP rate, FP rate, precision, and F-measure comparatively with existing classifiers supported in WEKA like simple logistic regression, Naïve Bayes, j48, Random forest, and PART. The proposed approach has shown 90.75% accuracy in classifying the test instances.
The objective of this paper is to find the influence of biopsychological factors on blood pressure of a person. Biological factors such as age, obesity level, cholesterol level are collected from the medical laboratory, the anxiety level, anger levels of same people are collected from the response obtained from a set of predefined questionnaire. From the Experimental evaluation, we draw the following conclusions: 1. The extracted rules by the AFM are simple to understand, and they are very useful for technical and nontechnical communities to manage BP rather than using BP medications. 2. These rules can be used by an individual to keep him/her blood pressure in a healthy range. 3. From the experimental results, it is so vivid that people with higher anxiety levels (is severe) in the range between (2, 3) are more prone to the HBP. 4. In the people of overweight even their cholesterol level is in the normal range (108,184), but their anxiety levels are moderate (0.9, 1.9) and higher are prone to the HBP. 5. If the cholesterol level of a person is in a healthy range and if he is not anxious, he is less prone to the HBP. 6. However, young people aged between 18 and 37 are less prone to HBP. 7. If a person’s anger level and anxiety level is close to zero (Normal) and even if he is overweight and having cholesterol level in borderline (185,239), the person is less prone to HBP.