
Abstract
Speech Recognition is one of the prominent research topics in the field of Natural Language Processing (NLP). The Speech Recognition technique removes the barriers and makes the system ease for inter-communication between human beings and devices. The aim of this study is to analyze the Automatic Speech Recognition System (ASRS) proposed by different researchers using Machine learning and Deep Learning techniques. In this work, Indian and foreign languages speech recognition systems like Hindi, Marathi, Malayalam, Urdu, Sanskrit, Nepali, Kannada, Chinese, Japanese, Arabic, Italian, Turkish, French, and German are considered. An integrated framework is presented and elaborated with recent advancement. The various platform like Hidden Markov Model Toolkit (HMM Toolkit), CMU Sphinx, Kaldi toolkit are explained which is used for building the speech recognition model. Further, some applications are elaborated which depict the uses of ASRS.
Introduction
Human beings communicate with each other through hand gestures, facial expressions, and speech. More specifically, speech is considered as the fundamental means of conversation in human use to express thought, feeling and share information among each other’. Speech is produced by using a stream of air from the lungs and lifting up with the help of the trachea, mouth, and nasal cavity [1]. During this process, the airflow is changed by various linguistic organs like vocal cords, lips, teeth, tongue, Palate, and cavities of nose and mouth. The changes in the airflow make the speech of each human being different and unique. It also varies according to the pronunciation of words, tone, vocal cords, pitch, gender, age, etc. Speech, being an artistic type of biometric feature, consists of several letters and words. However, recognizing these spoken words and speaker is the primary task in ASRS [2, 3].
Speech Recognition is the process of identifying human speech or the ability of the machine to determine the spoken words. Four different steps are used to recognize the speech, firstly the speech is analyzed, then it is divided into parts, changing into a machine-readable format, and finally, an algorithm is used to match the most suitable pattern by which the speech is recognized. The ability of the machine to understand the speech signals and act accordingly is often termed an ASRS [4]. Over the past few decades, significant progress has been done in this area. Some speech recognition software has finite vocabulary size, and can only recognize words or phrases, whereas some software can work on natural speech irrespective of the accent and language of the speaker.
Search process flowchart.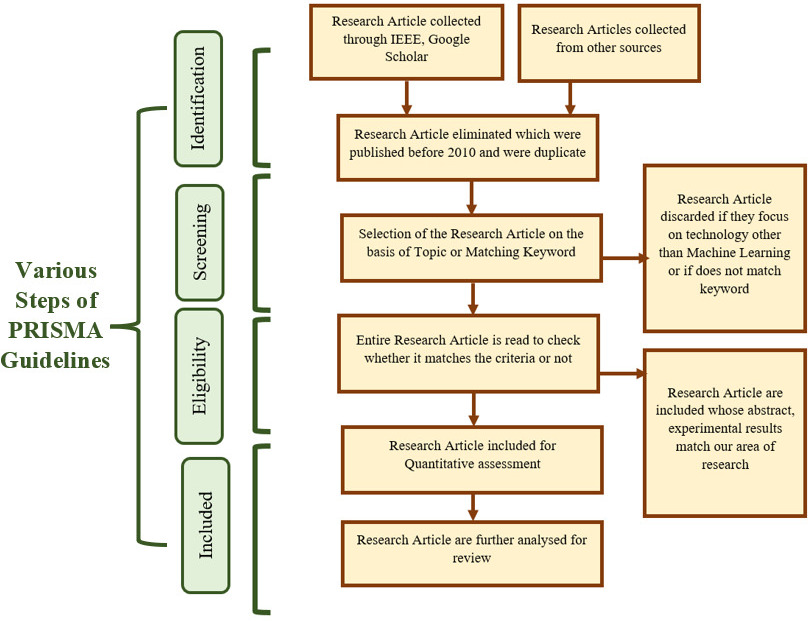
An ASRS consists of three parts, Vocabulary, Acoustic Model (AM), and Language Model. Vocabulary is made up of audio words, AM, is used to show the relationship between the audio and phonemes by extracting features from the speech sample, and Language Model, makes the system to understand what the speaker is saying and helps to recognize the speaker. The Vocabulary size for the speech recognition system varies in sizes i.e., small, medium or large [5, 6]. The Small size has 1 to 100 words or phrases, the medium size has 101 to 10,000 words or phrases and the large size has more than 10,000 words or phrases respectively. AM is a technique in which the features from the speech are extracted. The commonly used model is Hidden Markov Model (HMM) [7]. On the other hand, the language model also helps in speaker identification. Various Deep learning models such as Deep Neural Network (DNN), and Convolutional Neural Network (CNN) are used to identify the speech easily [8, 9]. Apart from this, various open-source platforms like KALDI toolkit, HMM toolkit, Julius, ISIP, and CMU Sphinx are also used for Speech recognition [10]. This study represents a comprehensive literature review on ASRS in Indian and foreign languages. The main objective of this research article is to explore different types of techniques used to recognize the speech of various languages. Further, a systematic review of the latest work done in the field of ASRS is presented with various platforms and applications used to build these systems.
The sections of this research article are organized as follows. Section 2 presents the approach utilized for the literature review process. Section 3 summarizes the literature describing the various speech recognition models in different languages of both Indian and Foreign languages. Section 4 focuses on the research methodology, which includes the framework and platform used to build an ASRS. All the investigations are discussed in Section 5. In Section 6, future scope is discussed for ASRS. Finally, this research work is concluded in Section 7.
Inclusion and exclusion parameters
Inclusion and exclusion parameters
In the review process of this research paper, the standard guidelines of Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) have been followed.
The entire work is carried out by exploring articles from Google Scholar, IEEE Xplore, Elsevier, and ResearchGate. The keywords have been used to explore the research article such as “Speech recognition”, “Automatic Speech recognition system”, “Feature extraction”, “Hidden Markov Model (HMM)”, “Speech processing”, “Types of speech”, and their combinations. Further, in this section steps of PRISMA are followed (Ref. Fig. 1) for incorporating the research article in this research work.
In the identification process, the articles issued before the year 2010 are eliminated, i.e., the article issued after the year 2010 is acknowledged and passed to the screening process. In the screening process, the articles are again eliminated based on title or abstract. The specific papers which match our findings proceed to the next step. In the Eligibility step, the whole reading of the research article is done, and depending upon that the papers are included or excluded for the final study.
The articles are selected in this study based on various quality evaluation parameters such as Period, Investigation, Comparator, Methodology, and Design of Study based upon which the paper is excluded or included. Table 1 depicts a detailed description of these parameters based on Inclusion and Exclusion standards followed. Additionally, the research article considered in this work, primarily focuses on HMM model and Artificial Neural Network (ANN) where the main experimental outcome is accuracy for the ASRS Model.
Literature review
The first attempt to recognize Speech was made in the year 1950s and, Bell Laboratories develop the first isolated digit recognition standalone system in 1952. Since then, researchers have used various techniques and technologies to develop voice recognition system. This section provides a summary of prominent research work done by many researchers using various ASRS for the Indian and Foreign languages.
ASRS for Indian languages
The research work in the Indian languages such as Assamese, Bengali, Gujrati, Hindi, Malayalam, Marathi, Odia, Punjabi, Tamil, Bodo, Kashmiri, Kannada, Manipuri, Nepali, Sanskrit, Telugu, and Tamil is elaborated in this sub-section. It includes the ASRS built by using the Trigram language model, HMM, Support Vector Machine (SVM), KALDI toolkit, Sphinx toolkit, Neural network, Differential Evolution (DE) algorithm and etc.
In [11], Madhavaraj and Gansena (2022) presented two different approaches to increase the performance of ASRS using DNN and Multitask-DNN. The model was built by using Low- Resource setting (LRS) which includes 40 hours of transcribed speech for Tamil, Telugu, and Gujarati languages, and a Medium-Resource setting (MRS) which includes 160, 275, and 135 hours of speech data for Tamil, Kannada and Hindi languages. The efficiency of the model was calculated in terms of Word Error Rate (WER). In LRS, the model showed WER of 9.66%, 7.2%, and 15.21% and MRS showed the WER of 15.0%, 17.54%, and 16.06% respectively. In [12], Kumar and Aggarwal (2021) present two techniques to improve the efficiency of ASRS in the Hindi language. The model was built using SincNet-CNN and Light Gated Recurrent Unit (LiGRU) techniques. The overall accuracy of the model was calculated in terms of WER of 5.5%. In [13], Barkana and Patel (2020) showed the differences and similarities between spectral and time-domain characteristics of vowel production for English words when spoken by Hindi speakers. The author used a One-way Analysis of variance (ANOVA) approach where the speech samples of both male and female speakers were examined based on Pitch, tonality, harmonicity, etc. In [14], Guglani and Mishra (2020) improved the performance of ASRS in the Punjabi Language using Kaldi toolkit in terms of word error rate. The work is carried out on pitch-dependent and probability of voicing (POV) estimated features. The model shows better results as compared to other features such as Yin, SAcC, and FVV. The WER of Yin pitch, SAcC pitch, and Kaldi pitch was 69%, 67.5%, and 64.25% respectively. In [15], Kumar et al. (2019) presented a Kannada language speech recognition model in a different noisy environment. The model was built by using Kaladi toolkit and performance is calculated in terms of WER. The total WER evaluated by the model was 4.21%.
In [16], Anoop and Ramakrishnan (2019) developed a speech recognition model for large vocabulary continuous speech in the Sanskrit language. A Speaker independent model was built using HMM toolkit and Java swings for the graphical user interface. The author achieved Word and Sentence accuracy of 89.64% and 58.76% respectively. In [17], Ghosh et al. (2019) stated an approach for the recognition of words in Bengali script. The model was based on the Recurrent Neural network (RNN) and HMM technique. A comparative study between both techniques was shown and stated the accuracy of RNN is better than HMM. In [18], Kumar et al. (2019) worked to recognize Telugu Isolated words which were recorded by various Male and Female Speakers. The feature extraction and classification technique used for building the model were Teager energy operator delta spectral cepstral coefficients (T-DSCC) and DNN. The authors achieved an accuracy of 97.32%.
In [19], Regmi et al. (2019) demonstrated a speech recognition model for the Nepali language. An RNN-based model is combined with Connectionist Temporal Classification (CTC) algorithm to train data for audio signals. A collection of 67 characters of the Nepali language was used to covert speech into text format. In [20], Upadhyayaa et al. (2018) proposed a model to improve the robustness of the Hindi Speech recognition system including both Audio & Visual features. The Visual and Audio features were extracted using Histogram of Oriented Gradient (HOG) and Mel Frequency Cepstral coefficients (MFCC). A comparative study between the extracted features is presented and showed 12.3%-word recognition accuracy. In [21], Kakodkar and Borkar (2018) presented an acoustic speech processing model for the Sanskrit language using the spectral component of MFCC. A customized dataset was used and processed over 13 coefficients which showed an improved accuracy. In [22], Patel et al. (2018) developed a keyword search system and a speech recognition system for the Manipuri language. The baseline model was based upon Gaussian Mixture Model-HMM (GNN-HMM) and DNN-HMM technique. A comparative analysis of both techniques was done by using a small dataset. The DNN-HMM based architecture provided a better result as compared to GNN-HMM and the WER of 13.57% was calculated. In [23], Digamberrao and Prasad (2018) suggested an approach for author recognition in the Marathi Language. Two different models were built by using SMO with a rule-based decision tree approach. The performance was evaluated based on standard parameters such as recall, precision, f-measure, and accuracy. The overall accuracy achieved by the model was 80%. In [24], Bhowmik et al. (2018) presented a report on the classification and detection of speech patterns for Bengali continuous speech. Two models were designed for the classification and detection of speech samples based on the DNN framework. The speech data was collected from multiple speakers. The model showed improved performance and achieved an accuracy of 86.19%. In [25], Dua et al. (2018) stated an approach by using the DE algorithm to optimize the number and spacing of filters in the ASRS of the Hindi language. The performance of the model was evaluated using MFCC, Gammatone Frequency Cepstral Coefficient (GFCC), and Basilar-membrane Frequency-band Cepstral Coefficient (BFCC) feature extraction techniques with and without DE algorithm in both noisy and clean environments, respectively. The author showed that the BFCC systems perform 0.4% to 1.0% better than GFCC and 7% to 10% better than MFCC.
In [26], Ajees and Idiculaa (2018) discussed a neural network-based Named Entity Recognition (NER) system for the Malayalam language. The representation of words as vectors leads to precise classification and outperforms all the existing methods. The overall accuracy achieved by the model was 95.3%. In [27], Darekara and Dhandeb (2018) proposed an ANN-based architecture for recognizing emotions in speech signals for Marathi Language. The performance of the recognition model was analyzed on various measures like Accuracy, Sensitivity, Specificity, and Precision. In [28], Mane and Kulkarni (2018) proposed a model based on Customized-CNN (CCNN) for Marathi Language. The model has the ability to learn the features automatically and predict the class of numerals from a wide-ranged dataset. Using the large data set, the author achieved an accuracy of 94.93%. In [29], Mauryaa et al. (2017) implemented a speaker recognition model for Hindi speech samples using MFCC–Vector Quantization (MFCC-VQ) and MFCC-GMM for text-dependent and text-independent phrases. The ability of the model to recognize text-dependent phrases is more as compared to text-independent phrases. The accuracy achieved by the model using MFCC-VQ MFCC-GMM technique was 85.49% and 94.12% respectively.
In [30], Ssarma et al. (2017) implemented a speaker-independent isolated word speech recognition model in the Nepali language based on the HMM technique. The system is trained upon the specific set of words collected in-room environments by various speakers. The accuracy achieved by the model is 75% for the specific words from the collected dataset. In [31], Kumar et al. (2017) presented a speaker-independent speech recognition system for continuous words in the Telugu language. The features were extracted using a combined MFCC and Discrete Wavelet Packet Decomposition (DWPD) technique and then, classified with the help of HMM-based on DNN. Finally, the model attains an accuracy of 91.89% with a shallow error rate.
In [32], Bhardwaj et al. (2017) implemented a speaker-independent speech recognition system in Kashmiri Language based on the Sphinx tool which recognized the spoken words of both Male and female speakers. The accuracy calculated by the model was 78.3% when analyzed over a small dataset. In [33], Qasim et al. (2016) presented accent-dependent and independent models for Urdu speech recognition. Two models were built by collecting the speech samples based upon the accent and non-accent of the speaker’s voice respectively. Both models were trained and tested by showing a comparative analysis. An accuracy of 92.56% was achieved. In [34], Mishra et al. (2016) presented a model capable of recognizing the voice in the presence of environmental noise. The model was based on a Quantile-based Dynamic Cepstral Normalization-MFCC (QCN-MFCC) along with baseline MFCC featured for Vowel classification. The MFCC features were tested over context-dependent and context-independent classification and showed 5.97% and 5% of improvement respectively. In [35], Mohamed and Lajish (2016) worked on recognizing vowels in Malayalam Language using non-linear speech parameters such as Maximal Lyapunov Exponent (MLE) and Phase Space Anti-Diagonal Point Distribution (PSAPD). The accuracy achieved by using MLE was 74.39% and PSAPD was 80.44%. In [36], Vijayendra and Thakar (2016) developed a speech recognition model for the Gujarati language. The author addresses two different structures of neural networks such as two-layer and three-layer. The speech data was collected by using a regular and in-ear microphone. The speech data collected using the in-ear microphone showed better results than a regular microphone. In [37], Rajisha et al. (2016) developed a system capable of recognizing emotions in speech for the Malayalam Language. The model used MFCC, Short time energy, and Pitch as the feature extraction technique and pattern classifier as ANN and SVM. A parallel study between two classifiers was presented, and a conclusion is drawn by showing the accuracy achieved i.e., 88.4% and 78.2% for the ANN and SVM model respectively.
In [38], Sunija et al. (2016) showed a comparative study of different classifiers such as ANN, SVM and Naïve Bayes to recognize the Malayalam language. The features classified using these techniques were MFF, pitch and energy. In addition, a parallel analysis of these techniques is presented. The Accuracy achieved by using ANN, SVM and Naïve Bayes Classifier was 90.2%, 88.2% and 84.1% respectively. In [39], Mannepalli et al. (2015) presented an approach to recognize a speaker in the Telugu language. The speech samples were extracted by the MFCC technique, and classification is done by GMM. The model showed 91% accuracy based on the accent of the speech. In [40], Das et al. (2015) proposed a model to recognize each word of the sentence by using SVM for Odia language. An SVM-based Part of Speech (POS) tagger was developed using small tag sets. The results were calculated and compared with ANN-based POS Tagger. An SVM-based POS showed better results as compared to ANN-based POS Tagger by achieving an accuracy of 82%. In [41], Agarwalla and Sarma (2015) described Machine Learning ways such as ANN and DNN for extracting Assamese speech samples from large datasets. The model performance is calculated based on mood, dialect, speaker, and gender in a noisy environment. The accuracy achieved to recognize the speech sample was 92.7%, 95.5%, 96.33%, and 87.22% for Speaker, Dialect, Gender, and Mood respectively.
In [42], Kannadaguli and Thalengala (2015) presented an approach for speaker-dependent phoneme recognition in the Kannada language by using random pattern recognition and acoustic speech sound schemes. The model was based on HMM technique where the sample of speech features was used and then the performance was analyzed. In [43], Pokhariya and Mathur (2014) developed a speech recognition model in Sanskrit Language. The model was built by using HMM toolkit, and the performance was tested by using two types of speakers, one, who is involved in both testing and training, and second, the speaker is involved only in testing. The overall accuracy of 97.2% was achieved by the model. In [44], Narayan and Chakraverty (2014) removed the ambiguities in the speech corpus of Hindi language. The model was built by using ANN approach. The effectiveness of the proposed approach was analyzed and showed an accuracy of 91.03%. In [45], Thakuria et al. (2013) developed a speech recognition model for Bodo Language by using the HMM Toolkit. The model was trained for continuous speech collected from the male speakers only. The model’s ability to recognize voice was challenging as it was sensitive and varied according to spoken methods and scenarios. In [46], Das et al. (2013) presented a speech recognition model for the Bengali Language. The speech characteristics reduce with age and model accuracy decreases with time. Hence, an adaptive speaker model was built to improve the accuracy of the recognition of speech. The model was experimented by using different methods such as Vocal tract length normalization (VTLN), Maximum likelihood linear regression (MLLT), Maximum Posteriori (MAP), and Linear discriminative analysis (LDA). The accuracy achieved by the model is 90.3%. In [47], Thakuria et al. (2013) proposed a speech recognition system to recognize speech in a Noisy environment for Bodo Language using HMM toolkit. The dataset was divided into training and testing. Various experiments were performed and performance was calculated based on digit and alphabet accuracy. The overall accuracy achieved by the model in recognizing digits was 90.6% and the alphabet was 70.17%. In [48], Sarma and Sarma (2013) presented an approach to recognize phonemes of Assamese words. A combination of three types of ANN structures such as RNN, Self-Organizing Map (SOM), and probabilistic Neural Network (PNN) was used to build the algorithm. A comparison analysis of the proposed algorithm and conventional Discrete Wavelet Transform (DWT) is presented. In [49], Vimala and Radha (2012) described a speaker-independent Isolated speech recognition system for Tamil Language. The author primarily focused on a small dataset and developed the system by using HMM components such as feature extraction, AM, pronunciation dictionary, and language model. The overall accuracy achieved by the model was 88%.
In [50], Kuriana and Balakrishnanb (2012) worked on Context-dependent tied, Context-dependent, and context-independent models for the continuous speech recognition system for the Malayalam language. The author analyzed, compared, and evaluated these three models using HMM & MFCC techniques. The author concluded that the context-dependent tied model was better than the other two AM by showing an accuracy of 80.3%, 81.5% and 76.4% for Gaussian mixture 4,8 and 16 states for each HMM. In [51], Mohamed and Nair (2012) proposed HMM/ANN-based hybrid model for continuous Malayalam speech recognition. The model performance was evaluated on small vocabulary and speaker-independent continuous Malayalam speech corpus. The promising results in recognizing words and sentences in the continuous speech was shown and the accuracy achieved for recognition of word was 86.67% and the sentence was 66.67%. In [52], Hegde et al. (2012) developed an Isolated Word Recognition (IWR) Model to identify spoken words in the Kannada language. As, the main goal of the speech system is to recognize the speech by removing all constraints like environment, type of speaker, accent, language, and so on. The author presented the SVM technique in the combination of MFCC feature extraction to achieve a good accuracy rate considering all the above-mentioned constraints. The overall accuracy achieved by the model was 79%. In [53], Ashraf et al. (2010) developed an Urdu language speech recognition model. The work on the model was carried out by using Isolated words. A comparative study between the proposed model and the existing model was presented by the author. In [54], Beg et al. (2008) presented an approach for recognizing spoken Urdu Language words using Neural Networks. The features were extracted by collecting samples from various speakers. The model was implemented by using Linear Predictive Coding (LPC) and Cepstral analysis. An average accuracy of 96.6% was achieved by the model.
ASRS for foreign languages
Some researchers have worked to develop ASRS in the foreign language as well. This section represents the work done in the languages such as Arabic, Chinese, Dutch, Japanese, Persian, Russian, Romanian, Turkish, French, German, Italian, Spanish, and Tibetan. Various techniques and algorithms that were used to develop ASRS such as DNN, HMM, Sonic tool, Sphinx tool, and Word-state DBN algorithm are also described in this section.
In [55], Ivanko et al. (2022) presented an automated lip-reading visual speech recognition system in the Russian language. The model was built by using two datasets namely Lip-Reading in the Wild (LRW) and the Russian Audio-Visual Speech in Cars (RUSAVIC) dataset. The model showed an overall accuracy of 88.7%. In [56], Lakushkin et al. (2018) developed a Russian language speech recognition system. A speech-based text search from a large collection of videos was shown and accuracy was calculated in terms of WER of 22%. In [57], Menacera et al. (2017) presented a speech recognition system named Arabic Loria Automatic Speech Recognition (ALASR) based on DNN for the Arabic Language. The model was built to investigate several other models and trained under extreme conditions. The accuracy of the model was calculated in terms of WER of 24%. In [58], Alsharhan and Ramsay (2017) discussed an algorithm to recognize the spoken words in Arabic language. Using two different Arabic sentences dataset was tested and showed an improvement in the recognition rate from 9% to 11.3%. In [59], Pan et al. (2010) worked on Tibetan language speech recognition. The author derived active learning, semi-supervised learning, and supervised learning methods for the Language. A comparison between these three languages was shown and calculated overall accuracy of 97%.
In [60], Bahou et al. (2017) proposed a methodology for understanding spontaneous Arabic speech. The method consists of two steps, i.e., processing of the words and segmentation. By using SARF system, the data was processed and tested. The result was obtained in the form of Recall 73.45%, Precision 81.97% and F-measure 77.48%. In [61], Li et al. (2015) presented a comparative study on the performance of the Large Vocabulary Continuous speech recognition system in the Chinese Language. A comparative analysis of the model was depicted when trained with DNN and GMM techniques respectively. 20% more accuracy was achieved by using DNN technique as compared to GMM. In [62], Schiopu (2013) showed the use of a statistical model for building ASRS. The author worked for Romanian Language and presented an isolated word speech recognition system based on HMM and ANN. The accuracy achieved by using HMM model was 83.33% and ANN was 60.63%.
In [63], Karpov et al. (2013) built an ASRS for the Russian Language with a large Vocabulary. The authors used statistical and knowledge-based approaches for building an AM. A combination of syntactical and statistical analysis was used for building a Language Model. The experiments were performed on two different types of speech samples of Russian languages. The model showed a WER of 26.9%. In [64], Pirhosseinlooa et al. (2012) worked on Persian Speech recognition systems and described the use of discriminative criteria for training AMs using Discriminative linear transforms (DLT). Under discriminative criteria, minimum phone error (MPE) and maximum mutual information (MMI) were investigated. The conclusion showed that the MPE-based DLT shows better results than MML-based DLT. In [65], Yang et al. (2011) described speech recognition software to recognize German-language video lectures. The work was carried out by generating and collecting speech data from German video lectures. The model was built by using Sphinx 4, Julius, HMM toolkit technique and showed a WER of 12.8%.
In [66], Chien and Chueh (2010) discussed AM and Linguistic modeling (LM) for speech recognition systems in the Chinese Language based upon the maximum entropy principle. A comparative study between Discriminative Maximum entropy-based on AM (DME-AM) and DME-based on LM (DME-LM) is shown by using various parameters. The performance of DME-LM technique outperforms DME-AM. In [67], Zhang et al. (2008) worked on the Continuous Speech Recognition model for large Vocabulary in Chinese Language. The authors presented three main features: a flexible dataset, AM, and a language model. The model was built on the basis of HMM and Minimum Description Length (MDL) based on Successive State Splitting (SSS) technique and showed an accuracy of 90%. In [68], Niculescu and Jong (2008) work to develop a speech recognition system for Spanish broadcast news. The model was built by using SONIC recognizer and focused on certain aspects. It was built by using written language or read speech and the model requires more training for both language and speech. The accuracy was calculated in terms of WER of 39.2%. In [69], Salor et al. (2007) developed speech corpus and recognition tools in the Turkish Language. The accomplished work fulfilled two objectives, i.e., built a speech corpus for a standard triphone-balanced microphone, and develop speech recognition tool which aligns speech to text.
In [70], Furui et al. (2005) presented the work to increase the recognition accuracy of spontaneous speech in the Japanese Language. A large-scale spontaneous speech corpus was used for the experiment. The authors showed a comparison between speaking spontaneous speech and reading a transcription of spontaneous speech. The recognition of speaking rate was relatively 10% higher than reading spontaneous speech. In [71], Heuvel et al. (2003) worked to improve the recognition rate in the Dutch Language. The authors showed two experiments based on stressed and unstressed vowels in continuous speech. Context-dependent words were used in the first experiment and context-independent words in the second. A comparative analysis of each experiment was shown and concluded that stress does not affect the recognition rate. In [72], Carki et al. (2000) described a speaker-independent LVCSR engine for the Turkish Language. The author incorporated the LVCSR engine with a multilingual recognition engine in the Global phone framework. The proposed system yields a decrease in WER of 16.9%. In [73], Adda et al. (1997) worked on speech recognition tools in the French Language. The work was carried out on various types of normalizations for French texts. The impact was calculated by using Lexical coverage and Language Modeling perplexity. The result was carried out in terms of WER of 11.2%. In [74], D’Orta et al. (1987) developed an ASRS in the Italian Language. The system was developed at IBM Italy Scientific Center in Rome. This speaker-dependent system was able to recognize in real-time natural language sentences dictated by the speaker only, and the speech includes short pauses. The average accuracy achieved by the model was 96%.
Investigations
During the study of Indian and Non-Indian languages for ASRS, the following investigations are discovered. The possible solution (PS) for all investigations is explained in Section 5.
Investigation 1: What are different types of datasets or speech corpus which are used by the ASRS to recognize the speaker?
Investigation 2: In which language the various researchers worked to develop the Automatic Speech Recognition (ASR) model and in which year these studies have been published?
Investigation 3: What are the different Acoustic and Deep learning methods? State different dataset split ratios of ASRS for the Training and Testing phase.
Investigation 4: What are the different factors which evaluate and affect the performance of the ASRS?
Investigation 5: Which AM is best suited for the ASRS?
The Framework for ASRS is presented in this section along with its various components.
Framework for ASRS
Framework of ASRS.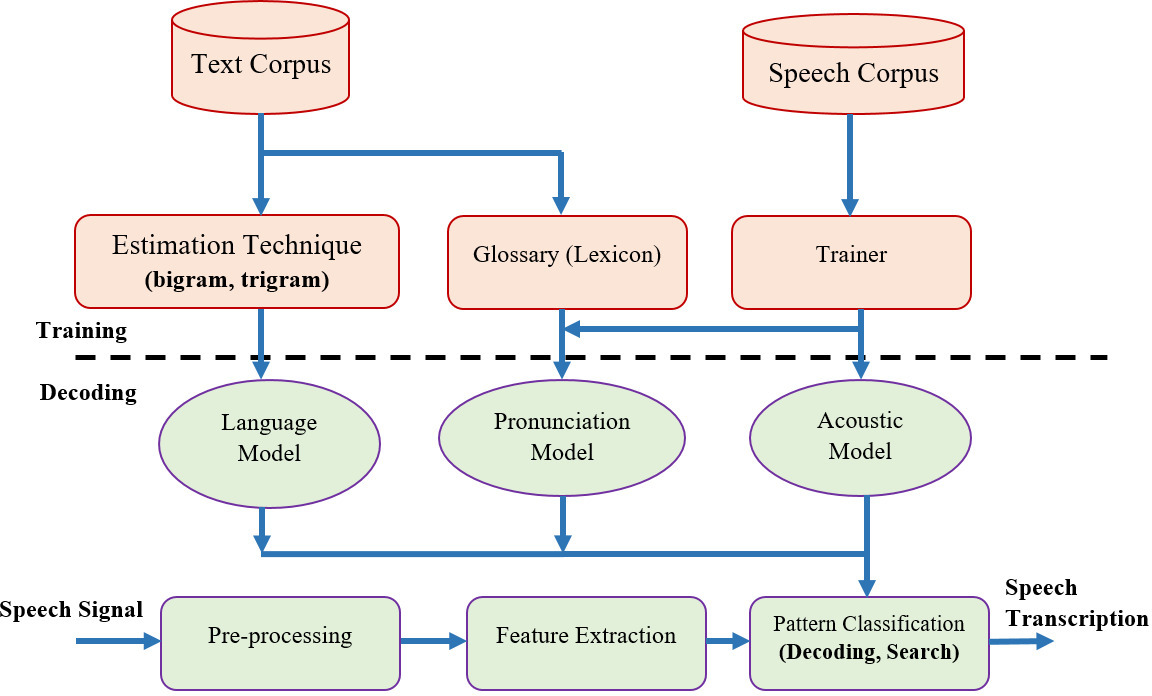
The Framework for ASRS is designed in such a way that provides accurate results in a noisy environment as well. An ASRS mainly revolves around three essential components: Language Model, AM, and Feature Extraction. The architecture for ASRS is depicted in Fig. 2. A brief description of each component is also mentioned in this section.
Corpus is the collection of text (written or spoken) that is either small or large. In linguistics, a text corpus is an enormous and organized arrangement of writings used to analyze, check events, test hypotheses, and validate standards [75]. Depending upon a particular scenario, a corpus is specific and modest such as records, sentences, conference data and etc.
Speech corpus
It is a collection of Speech audio files and text transcriptions (the visualization of spoken language in written format). In other words, a cluster of the speech signal and its interpretation, document, and metadata is termed the speech corpus [75, 76]. The speech corpus can be broadly divided into two categories:
Read Speech: It includes data from Word Records, News communicates, Number series, and Excerpts from books.
Spontaneous speech: It includes data from,
Exchange and gatherings-free discussions among two individuals, Narratives-one individual recounting a story, Map-assignments- two individuals, where one individual guides the other individual, Appointment-undertakings- where two individuals are given individual schedules and meet according to their free time.
There are four different classes of a speech signal,
Isolated Words: It is single word or utterances given to the recognition framework at a particular interval of time [77].
Connected Words: It allows multiple utterances to run at the same time.
Continuous Speech: It is a naturally occurring type of speech such as the speech spoken by the user.
Spontaneous Speech: It is a natural non-rehearsed type of speech.
The Speech corpus is standardized as shown in Table 2, depending upon various specifications the ASRS is built.
The most widely used estimation technique is “
Standardization of speech corpus
Standardization of speech corpus
One way to calculate the probability is to take a large corpus and counts the occurrence of “the person is ill so he should take” is followed by the word “medicine”, which is a tedious task, so to overcome this, the chain rule of probability is used, where the entire sequence of the word to occur is computed like
On the other hand, the n-gram technique computes the word by using the history of last few words rather than taking entire history. Therefore, the general equation for estimation:
Unigram:
Bigram:
Trigram:
For example, if the sentence is “This is Machine and BD book”:
Unigram: this, is, machine, and, BD, book; Bigram: this is, is machine, machine and, and BD, BD book; Trigram: this is machine, is machine and, machine and BD, and BD book respectively.
Lexicon or Glossary plays a vital role in training, conversion, or recognition of speech. The AMs is built by acknowledging the words or lexical things known to the framework. It works on two principles, (1) For each pronunciation the vocabulary item is chosen and defined, (2) representation of word pronounced. Each lexical has more than one pronunciation and the accuracy is depended on the number of lexical taken from the word list. When both principles are given equal weightage, the performance of the system is more accurate and precise [80].
Trainer
The main aim of ASRS is to predict the pronounced word from the recorded speech waveforms corpus. The prediction of the word is done with the help of HMM as it finds the sequence of states (phonemes) from the actual articulated sound [81]. On the other hand, HMM is also used to compute the likelihood in order to find the hidden sequence by estimating certain parameters.
Computing likelihood: Given
Finding Hidden Sequence: Given
Estimating the parameters: A sequence of observations (
Language model
The task of a language model is to assign a probability to any sequence of words. It is a model which predicts what will be the next word in the sequence. It is used to translate the input audio and recognizes the new word with respect to the words which are already recognized [82]. There are two types of language models: the Neural Language Model (used in NLP) and the Statistical Language Model (used in HMM,
Pronunciation model
It is the procedure of handling pronunciation variation which occurs when the speaker speaks. It depends on two things: phonetics and phonology [83]. Phonetics is the study of human sounds made during communication and Phonology is a classification of these sounds. There are two different methodologies for pronunciation modeling, firstly, encoding semantic information to pre-determine pronunciations of words, and second, getting options directly from the corpus (pronunciation corpus).
AM
It is a collection of statistical visualization of each distinct sound that makes a word. Each representation is called a phoneme [84]. For example, if a language has 50 distinct sounds, then there are 50 different phonemes. In other words, an AM is the representation of the connection between sound and phonemes. The model is created by using a large speech corpus and aims to recognize speech.
Pre-processing
Pre-processing refers to the removal of noise and silence from the speech signal. In speech signal processing, the speech signal
Speech signals are pre-processed by using various methods. Some of the techniques are described as under:
Speech Detection: The speech signals are divided into various segment such as voiced and unvoiced speech. Voiced speech refers to the actual speech and unvoiced speech refers to the utterance before and after a speech.
Pre-emphasis filtering: It is a standard technique of speech pre-processing in which a high-pass filter is used to differentiate between the low and high frequencies of the speech signal. The High frequencies signal is highlighted whereas the low-frequency signal is reduced.
Framing: It involves segmenting the speech signal into various components. Each component is of equal length.
It is considered as the heart of an ASRS. This technique helps the model to identify the speaker by extracting various features from the speech sample such as tone, pitch, gender, age, and accent [85]. LPC, MFCC, Relative Spectral (RASTA), and Probabilistic Linear Discriminate Analysis (PLDA) are various types of feature extraction techniques described as under:
LPC: This method is used to illustrate the speech signal in the compressed form. It is based on assumptions and gives accurate results depending on the speech parameters. LPC represents the present speech by the combining linear past speech sample. It is calculated by the formula mentioned in Eq. (4),
where
MFCC: It converts the normal frequencies of the speech sample into Mel-Scale frequencies which are further used to extract the feature and identify the speaker [86]. The various steps followed during this conversion are, first, Windowing of the input signal, where the signal is divided into frames, second, Discrete Fourier transform (DFT) is applied to each frame to calculate spectrum frequency, further, the spectrum frequencies are wrapped on Mel scale and inverse Discrete cosine transform (DCT) is calculated. In brief, these steps are explained as, Pre-emphasis, a filtering technique that highlights the sound having a high frequency. It is used to remove the glottal effect (change in the speech vibrations) from the speech signal and form the vocal tract parameters. It is done through the transfer function as shown in Eq. (5).
where The next step is Frame Blocking and Windowing, the speech signal is divided into sliding frames. Initially, the speech signal is assumed stationary for short time intervals such as 20 milliseconds or 30 milliseconds and is divided into overlapping frames for the analysis. Further, the hamming window
0 Now, for a particular time, signal s is extracted as shown in Eq. (7),
Until now, the frames are formed and the speech signals are emphasized. Now, DFT is used to calculate the frequency of each frame as mentioned in Eq. (8),
0 After frequency calculation, the triangular filters are applied to extract the frequency bands on a Mel-scale as shown in Eq. (9),
where
RASTA: It is a filtering technique used to sharpen the speech signals recorded in a noisy environment. It is built to work along with Perceptual Linear Prediction (PLP) pre-processing technique. The formula mentioned in equation 10 is used to calculate the filter,
PLDA: This technique is an extended version of LDA which handles complex data. It is a generative type of model which presumes the given data sample is produced for the distribution purpose. The distribution is based on two factors, (1) various data representation, and (2) parameter calculation [87].
It helps in the identification of the speaker. Patterns refer to the acoustic features extracted from the input speech signal [88]. This technique is similar to the “TREE” data structure where decisions are made by eliminating some patterns while processing. Some of the pattern classification techniques are as follows:
Dynamic Time Wrapping (DTW): It calculates the best wrapping path between two data points of the sound pattern. The wrapping path is the distance between two patterns (whose comparison it to be done). The smaller the distance, the more alike the patterns [89]. The DTW algorithm also computes the similarity between two data sequences which vary in speech and time. The best result is obtained by finding the best match between the two data sequences.
GMM: It is a multi-variant normal distribution model. It helps to model a system with two different states and train GMM matching to those component states. When an input signal is received the likelihood for each component is determined [90]. Further, the obtained likelihood predicts whether the input signal is a valid speech or noise. GMM distribution is calculated by using feature vector(x) and M Gaussian Mixtures as shown in Eq. (11),
The primary purpose of ASRS tools is to use an algorithm to identify the speaker. Some of the tools are mentioned below:
CMU Sphinx: This tool was developed at Carnegie Mellon University and is popularly known as the Sphinx tool. The toolkit includes two things: SphinxTrain, an AM trainer, and Speech recognizer series such as Sphinx2, Sphinx3, Sphinx4, and PocketSphinx. The tool uses HMM and
Sphinx2: This is the performance-oriented type of recognizer and uses in real-time applications such as exchange frameworks, language learning frameworks, end-point- ing, incomplete hypothesis generation, and dynamic language model exchange. Sphinx3: It is used for non-real-time-recog- nition. The recognizer uses a continuous HMM representation technique for AM. Further in combination with SphinxTrain, it is used with other modeling techniques such as MLLR, VTLN, and so on. Sphinx4: It is an alternative version of Sphinx engine. Various enhancements are done in this recognizer to make it work for speaker adaption model. PocketSphinx: It is mainly built for embedded systems and is based upon Advanced RISC Machines (ARM) processor. Various features provided by this recognizer are efficient and fixed-point arithmetic algorithms for GMM computations.
Kaldi toolkit: The name KALDI was introduced by Legend Ethiopian goatherder. The toolkit is written in C
HMM Toolkit: The primary purpose of HMM toolkit to recognize the speech and is useful for other task also such as character recognition, speech synthesis, and sequencing of DNA. HMM toolkit consists of several tools or programs (more than 20) and a set of library modules [94]. The library modules keep track whether all the tools are working uniformly or not. The relation between tools and libraries of HMM toolkit is depicted in Fig. 3.
HMM toolkit.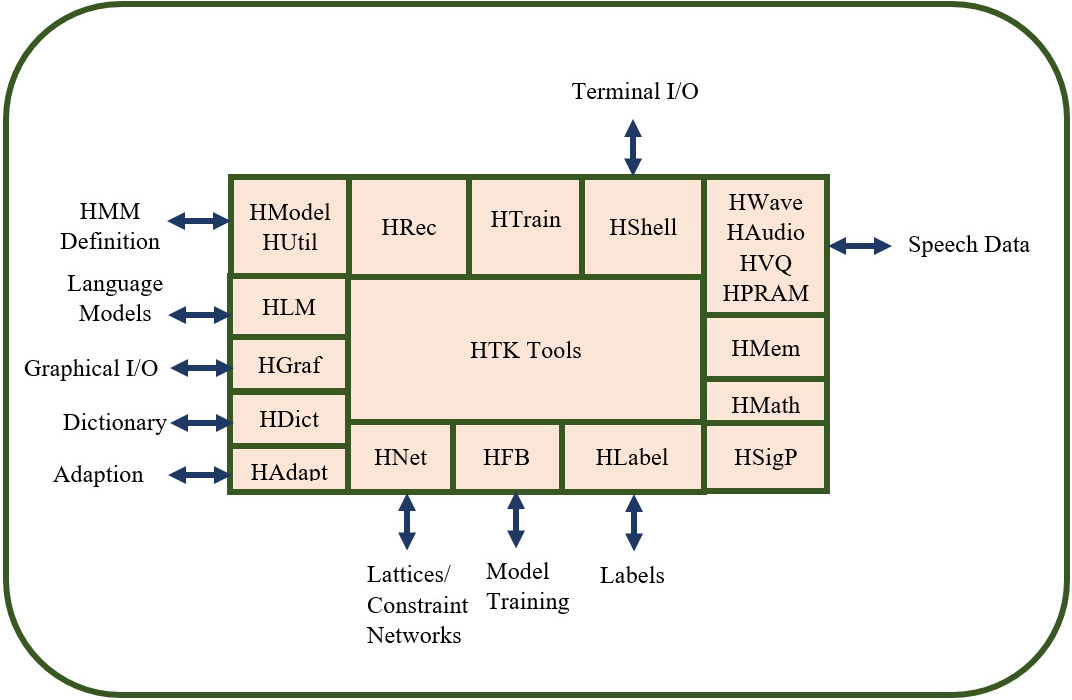
A brief discussion of libraries and tools of HMM Toolkit is mentioned below:
The HTM Library: The library consists of nearly ten modules that work as an interface between the outside world and the HMM toolkit tools. It provides various support functions such as HDBase, a training database, HGraf a graphical interactive interface, HLabel Input/output label file, HMath an additional mathematical support library, HMem for Memory management, HModel definition of HMM and input/output, HParse for grammar, HShell interface for Operating system, HSigP library for Signal processing routines and HSpIO Speech input/output data file. The HTM Tools: The tools are used to build HMM-based systems. There are more than 20 tools available. Some of the main tools are HAlign which perform Alignment, HCode which analyzes the speech using LPC, MFCC, and so on, HDed Dictionary editor in Batch Mode, HERest Baum-Welch embedded re-estimation, HHEd its HMM editor in Batch Mode, HInit Model initialization by using segmental k-means (Isolated unit), HLed Label file editor in Batch mode, HList a type of list which contains all the data file contents, HRest Baum-Welch Isolated unit re-estimation, HResults tool for result analysis, HSLab Simple label file editor (interactive), HSource used to generate the data by using HMM which is a statistical source, HVite Isolated and Connected Viterbi decoder.
After rigorous analysis of different researchers’ works, various investigations come out as discussed in Section 3.3. The PS with respect to investigations discovered is described in this section.
Investigation 1: What are different types of datasets or speech corpus which are used by the ASRS to recognize the speaker?
PS1: The ASRS requires a variety of datasets in huge amounts to produce a good result. The dataset must contain sample speeches of different speaker and categorized as a General speech recognition dataset, Speaker identification dataset, Multilingual speech dataset, Speech command dataset, and Conversational speech recognition dataset [8]. The selection of the dataset is depending upon the ASRS system required to build. General Speech Recognition is the dataset containing English speech samples where each speaker is from a different country and has a different native language. The Speaker identification dataset identifies the gender of the speaker, i.e., whether the speech is of a male or female speaker. The Multilingual dataset contains a short audio clip of a single speaker in ten languages such as Dutch, Russian, Chinese, French, Finnish, Spanish, Greek, German, Japanese, and Hungarian. It is a one-second duration clip having single word utterances such as Stop, yes, Go, On, Off, no, True, and False. The Speech command dataset is a small dataset that identifies a single utterance from a set of 10 words. At last, the conversational speech recognition dataset contains a dataset recording in different parts of a house. The minimum length of each recording is of 2 hours. Some open-source Speech corpus names are “Yes-no,” which contains 60 recordings of an individual saying Yes or No, and “TED-LIUM,” corpus from TED talks used as a training corpus in the English speech recognition system, “MUSAN,” a corpus which consists of Speech signals, noise, and music, “Crowdsourced High-quality speech data set,” which consists dataset of various languages such as Catalan, Nigerian English, Chilean Spanish, Kannada, Gujarati, and many more.
Year-wise analysis of research papers.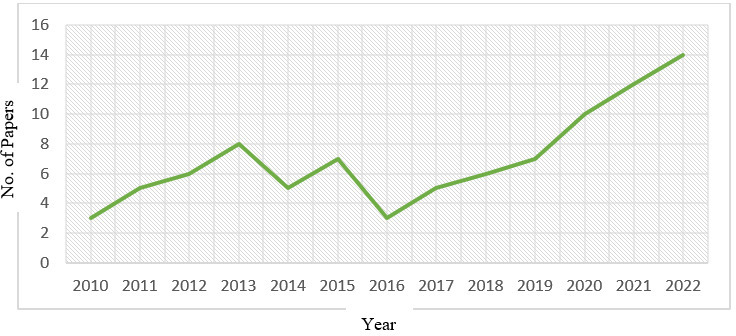
Indian language-wise distribution of research papers.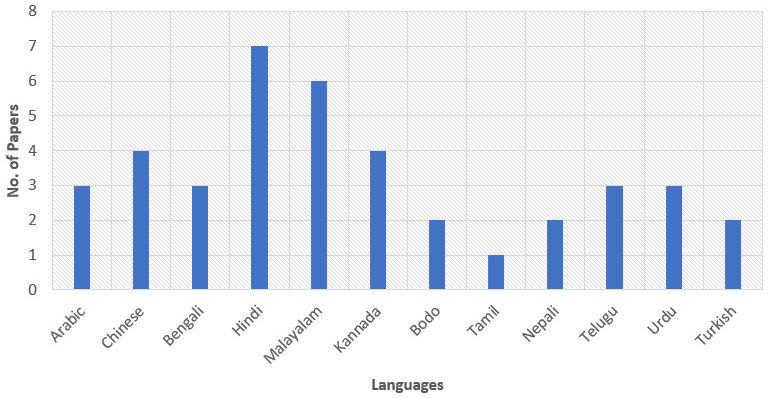
Investigation 2: In which language the various researchers worked to develop the Automatic Speech Recognition (ASR) model and in which year these studies have been published?
PS2: To analyze the ASR model built in different languages mentioned in different research’s work are considered. The ML technique and ASR models are the major keywords in finding the work done by different researchers from year 2010 to 2022. Figure 4 shows the year-wise analysis that concludes the highest number of works is done in a particular area from 2019 to 2022. Figures 5 and 6 depict the Indian and Foreign languages respectively used by different researchers to build ASRS using ML.
Foreign language-wise distribution of research papers.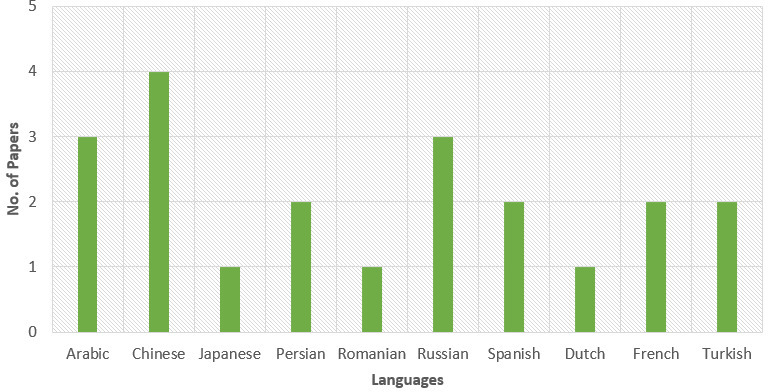
Various deep learning & acoustic methods for speech recognition.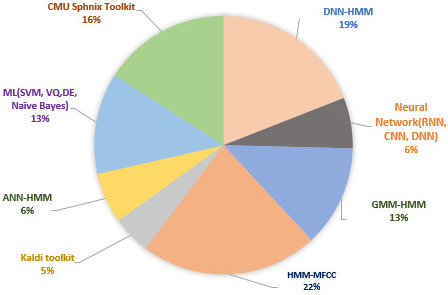
Investigation 3: What are the different Acoustic and Deep learning methods? State different dataset split ratios of ASRS for the Training and Testing phase.
PS3: The training and testing data of ASRS are divided into three ratios such as 70:30, 60:40 and 50:50 respectively. However, these ratios are not followed exactly it may vary according to the model formulation [96].
Depending on various parameters such as number of utterances, male or female speakers, and so on, the speech corpus is divided into these ratios. On the other hand, the Acoustic and Deep Learning method uses HMM for feature extraction. The AM in the speech recognition system is capable to predict all the variations in the sounds such as channel, and speaker. In contrast, Deep learning is used for classification purposes. It is a versatile technique to extract the features and act accordingly. Figure 7 shows various deep learning and acoustic methods for Speech Recognition.
Investigation 4: What are the different factors which evaluate and affect the performance of the ASRS?
PS 4: The factors used to evaluate the performance of the ASRS are Accuracy, Efficiency, and Speed. Speed is the real-time factor that estimates the time taken to recognize speech, Accuracy is calculated in terms of Word error rate, Sentence error rate, Single-word error rate, or Command success rate, and Efficiency of the speech recognition system is depended upon various features such as age of the speaker, gender, Environment (from where the speech has been recorded like café, school, train, bus and so on), Background Noise, Pronunciation, tone, pitch, behavior, microphone used for the recording, the distance between the speaker and the microphone and many more [1]. Some of the factors that affect speech recognition’s accuracy are the type of speech (isolated speech, continuous speech, and discontinuous speech), the vocabulary size, speaker-dependent and independent speech, and spontaneous speech. In addition, when the vocabulary size is more, the chances of error are more. E.g., if the vocabulary size is 20 or 30 words then it is recognized perfectly whereas at 5000 or 10000 words, the error chances are more. Therefore, these factors play a vital role in recognizing the speaker in the Speech recognition system as if one factor is affected, the performance of the ASRS is directly affected.
Investigation 5: Which AM is best suited for the ASRS?
PS 5: The AM is the central part of the ASRS. It represents the connection between the speech signal and phonemes that makes the whole speech [12]. Various types of AMs used to recognize speech are End-to-End AM, HMM-GMM AM and HMM-DNN AM respectively, where HMM is a statistical model, GMM and DNN are probabilistic models. Each model has some advantages over the other AM. The AM for Speech recognition is selected based on the type of speech. The HMM/DNN is considered as the best-suited AM used for ASRS as it yields higher performance.
ASRS is one of the emerging fields which allows human beings to connect with computers. It is useful in various areas such as Workplaces, Healthcare, Industries, Business, Marketing, Banking, and so on [95]. In Workplace, ASRS is used to increase productivity and perform various tasks without the inclusion of other person/machine. Some of the tasks are such as scheduling a meeting, recording minutes, searching for documents on a computer, dictating the information which is to be implemented in a document, giving voice commands to print the document, setting up video conferences, making employees cab or bus arrangements, designing graph or tables using the data available, and so on. In the field of Banking, ASRS aim to assist the customers efficiently. It improves banking in various ways, such as commanding a system to make payments, receiving information about a transaction made in a particular account, knowing the balance in an account without logging into the account, and so on. In Healthcare, the efficiency of the medical system is improved by providing immediate and Hands-free access to the patient’s history. Various other benefits of speech systems are such as it helps to quickly find the medical records of patients, improve the workflow, based upon primary symptoms suggest seeing which doctor, staff are given reminders of the task, paperwork is reduced, administrative information like the number of patients in the hospital and on each floor, it also helps to access the content of the health care digitally, the data which is to be validated or supplied to or by the medical institutes and so on. In Marketing, voice-based search helps marketers to reach their customers efficiently. It helps to increase marketing and impacts people’s way of interacting with different devices, and their ways to analyze new data. In Education, according to the population, 80% of the students learn through their vision or from the environment around them whereas the rest 20% of students who are blind and have low vision, the ASRS helps them to learn and grow. Also, these systems are used for security purposes in schools or colleges. Based on someone’s voice characteristics (tone, pitch, frequency, dynamics, intensity, pronunciation), a digital profile of the employee is created within the organization, which in turn will help to authenticate the employee whether he/she belongs to the particular organization or not.
Conclusion
Automatic Speech recognition helps to understand human dialect and identify the voice based on features like tone, pitch, gender, age, background noise, and accent. In this work, PRISMA guidelines are followed to do rigorous analysis. Indian and Foreign language studies are considered to recognize speech. Further, a framework for ASR model is discussed where it is divided into two phases such as training and decoding. The training phase includes the text and speech corpus, estimation technique, lexicon, and trainer. On the other hand, the decoding phase includes the three models (Language model, Pronunciation model, and AM). It shows how the speech signal uses pre-processing feature extraction and classification techniques to identify the speaker. Thereafter, an overview of various platforms which are used to build an ASR recognition model with some of its applications is discussed. This work will help researchers to analyze the existence of various tools and parameters used for the analysis of ASRS along with the technology.
Footnotes
Conflict of interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Funding statement
The author(s) received no funding for this study.