
Abstract
Gradient Boosting Decision Tree (GBDT) has been used extensively in machine learning applications due to its superiority in efficiency, accuracy and interpretability. Although there are already excellent and popular open source implementations such as XGBoost and LightGBM, etc., however, large data size tend to make scalable and efficient learning to be very difficult. Since sampling is an efficient technique for alleviate massive data analysis performance issues, we exploit sampling techniques to address this problem. In this paper, we propose the AdaGBDT approach which apply an adaptive sampling method based on Massart’s Inequality to build GBDT model and draws samples in an on-line manner without manually specifying sample size. AdaGBDT is implemented by integrating the adaptive sampling method into LightGBM. The experimental results showed that, AdaGBDT not only keeps a small sample size and has a better training performance than LightGBM, but also subject to the constraint of estimation accuracy and confidence.
Introduction
Gradient Boosting Tree (GBDT) [1] is one of the most popular algorithm in machine learning, which is the state-of-the-art solutions in many machine learning tasks. However, the increasing volume of data tends to make the conventional GBDT implementations to be inefficient because the construction of tree learner at each gradient boosting round need scan entire training data for each feature to find the optimal split points. Many optimizations are proposed in real application scenarios to tackle this issue and have achieved good performance. The two most representative GBDT implementations are XGBoost [2] and LightGBM [3]. Both of them implement histogram-based algorithm [4, 5, 6] instead of the inefficient pre-sorted method to split data instances. Moreover, LightGBM optimize the histogram-based algorithm by ignoring the zero feature values and reduces the cost of histogram building from O(#data) to O(#non_zero_data) for a feature [3]. However, this method still subjects to the problem of the fine balance between accuracy and efficiency.
To cope with the challenge posed by the data size, one possible approach is to take a random sample on data instances since the approximate response is acceptable for many machine learning tasks. Sampling is a critical technique widely used in statistical analysis and computer science. In machine learning area, researchers often use sampling technique to estimate the accuracy of the classifier or extract a random subset of the original data to reduce the number of data instances. Many off-the-shelf sampling methods are weight-based and are designed for AdaBoost [7]. In order to apply sampling techniques to GBDT, the work in [3] proposed a novel techniques GOSS to obtain samples in terms of the gradients which implicitly indicate the importance of data instances. The experimental results of LightGBM show that GOSS can bring nearly 2x speed-up by using only 10%–20% data and achieve better accuracy when maintaining competitive sampling ratio compared with Stochastic Gradient Boosting (SGB) [8]. GOSS need two parameters top_rate and other_rate as inputs to determine how much data instances with big gradients should be retained and how much data instances should be sampled from the rest. It is often difficult since the appropriate sample size is typically unknown.
Adaptive sampling is a promising solution target to the problem by drawing examples sequentially in an online manner without a pre-specified sample size. Compared with static sampling methods in which sample size is determined in advance, adaptive sampling scheme determines when to stop drawing examples according to random samples seen so far. It means sample size could be dynamically determined during the training procedure. There are already many studies in this area. Chen and Xu [9] conducted extensive research on adaptive boosting algorithm and proposed an efficient adaptive sampling technique for binary classification task, which uses significantly lower sample size while maintaining competitive accuracy and confidence when compared with most existing methods.
In this paper, we exploit sampling techniques to address the problem that large data size tend to make scalable and efficient GBDT learning to be very difficult. The major novelty and technical contributions can be briefly summarized as following: we propose the AdaGBDT approach which applies an adaptive sampling method based on Massart’s Inequality to build GBDT model and draws samples in an online manner without manually specifying sample size. Our AdaGBDT is implemented by integrating the adaptive sampling method into the popular GBDT implementation LightGBM. In order to achieve better usability than other works, our AdaGBDT approach provide users with accuracy level parameter
Background
In this section, we will briefly describe the related work of sampling scheme designing and off-the-shelf work on adaptive sampling techniques.
Related work
Currently, most of the existing GBDT algorithm toolkits such as XGBoost, pGBRT and scikit-learn provide a simple random sampling method. Such a static sampling method chooses a random sample subset to train the base learner at each iteration. LightGBM proposes a new gradient-based sampling technique GOSS to obtain sample subsets, which achieves a good balance between reducing data instances and keeps acceptable accuracy of decision tree. As is shown in [3], LightGBM outperforms other GBDT implementations. Therefore, we combine adaptive sampling with LightGBM for better performance requirement and use LightGBM as the baseline for our experiments.
GOSS sorts gradient values of the samples in a descending order in each iteration, then controls the proportion of instances with different gradients need to retain by parameters top_rate and other_rate. While GOSS require user to specify the sampling rate which is often to be difficult. Users do not know how much samples is full enough to insure the estimation accuracy and confidence. In this context, the well-known Chernoff-Hoeffding bounds are commonly used to determine sample size for data mining problems [12, 13, 14, 15]. It can be used both in a static way and dynamic way. In conventional batch sampling, sample size is pre-specified which is unnecessary large to make sure work well in any possible situations and keep a reasonable good accuracy and confidence. It lead to the sample size is overestimated in most cases of static sampling.
Adaptive sampling is used instead of the traditional static sampling due to its scalability whose stopping criterion is dynamically adjusted by random samples seen so far. Moreover, recent studies in [16, 17] shows that adaptive sampling holds lower sample size in contrast with conventional batch sampling, which holds the worst-case sample size even though current hypothesis is good enough.
Watanabe proposed an adaptive sampling technique Madaboost [17, 18, 19, 20], and applied it to boosting algorithm. These works show that adaptive sampling techniques can substantially improve the performance and scalability of ensemble learning. The adaptive sampling method proposed in [16] was based on Chernoff bound, which make the bounds tighter than method in [21, 22]. Furthermore, Jianhua Chen et.al developed an efficient ensemble learning method by combine Massart’s inequality and the techniques in [23, 24]. It significantly reduced sample size, meanwhile, keep comparable accuracy compared with work proposed in [21]. To achieve better efficiency and scalability for GBDT, we apply the method proposed in [21] to off-the-shelf implementation for GBDT.
In this paper, we work to apply the dynamic sampling technique to GBDT to speed up the training process in large-scale datasets scenario. We use adaptive sampling technique based on the Massart’s inequality [25] to optimize LightGBM. In next subsection, we will describe the problem definition which exist in most theoretical studies respect to sampling scheme designing.
Computer recovery boiler
The foundational problem in most sampling scheme designing is how to estimate the probability
Problem 1 – Control of absolute error
Design an adaptive sampling scheme which represents stopping criterion such that for any pre-specified
When termination condition is satisfied after seeing
Problem 2 – Control of relative error
Design an adaptive sampling scheme which represents stopping criterion such that for any pre-specified
When termination condition is satisfied after seeing
It can be clearly seen for the above definition that the bound of sample size can be worked out when the error, confidence level and samples seen so far are given.
AdaGDBT
In this section, we will present our AdaGBDT approach and detail its adaptive sampling technique [23] and implementation.
Sampling adaptively using the massart inequality
In [23], they utilize the
Then associate a simplified version of Massart Stopping Rule in [16] with the function
They conduct preliminary theoretical analysis on their method for controlling absolute error and relative error. For any pre-specified
Their theorem demonstrates there is an upper-bound
when we assume that true probability
For any pre-specified
In Eqs (1) and (2),
The method in [23] define
For any pre-specified
Associated with
Replace the
The justification and the proof for testing this condition can be found in [23]. Algorithm 1 describes the detailed procedure of the method. This algorithm run once in every iteration. Let
In order to improve the performance of LightGBM over the huge amount of data, we implement AdaGDBT which integrate the adaptive sampling algorithm introduced in last section into LightGBM, and make few modifications to the algorithm shown in Algorithm 1, which is for hypothesis selection using the Massart Inequality. We set 0.5 for the initial value of
During the implementation, we create a new class AdaGBDT which inherits GBDT interface in LightGBM. AdaGBDT implements TrainOneIter method to add adaptive sampling algorithm to it. The pseudo code is shown in Algorithm 2. Note that line 8 trains a tree which would lead to additional overhead when we get samples multiple times in a round. To avoid this we fix the calculation of the sample size. Actual sample size is calculated as:
LightGBM implements the histogram-based algorithm to find the best split points. The complexity of building histogram and finding split points for data with dense features is
Experiments
In this section, we report the experimental results with regards to LightGBM with adaptive sampling (i.e., AdaGBDT). Eight datasets are used in our experiments, which contain four artificial data sets and four publicly available data sets. The number of data instances and features are shown in Table 1. Our experiments only run the binary classification tasks and use binary error as measurement. All experiments run on single computer with two quad core i7-4790 CPUs and 16G memories.
Speed and accuracy comparison
In this subsection, we present speed and accuracy comparison between LightGBM and AdaGBDT. The artificial data sets used in experiments are generated by Matlab, which cover Gamma distribution, Gaussian distribution, Poisson distribution and Uniform distribution. Four publicly available data sets are from 26.
Datasets used in the experiments
Datasets used in the experiments
The first four artificial data sets consist of 500 features and 100K instances. We generate data sets with gamma distribution GammaDS by setting shape parameter to 2 and scale parameter to 500. Data set NormDS with Gaussian distribution is generated by setting the value of mean to 0 and the value of variance to 500. We set
Overhead of training (seconds)
The time consumption of training are presented in Table 2. We recorded the average time cost for one iteration of training process. The results in Table 2 show that AdaGBDT costs about 25%–50% of the time spent by LightGBM, meanwhile, only 0.15%–76.6% of data is used. The results demonstrate that our AdaGBDT successfully improved the performance of training by reducing the number of needed instances.
Accuracy comparison
The result of accuracy comparison are showed in Table 3. We set
Iteration-accuracy curve.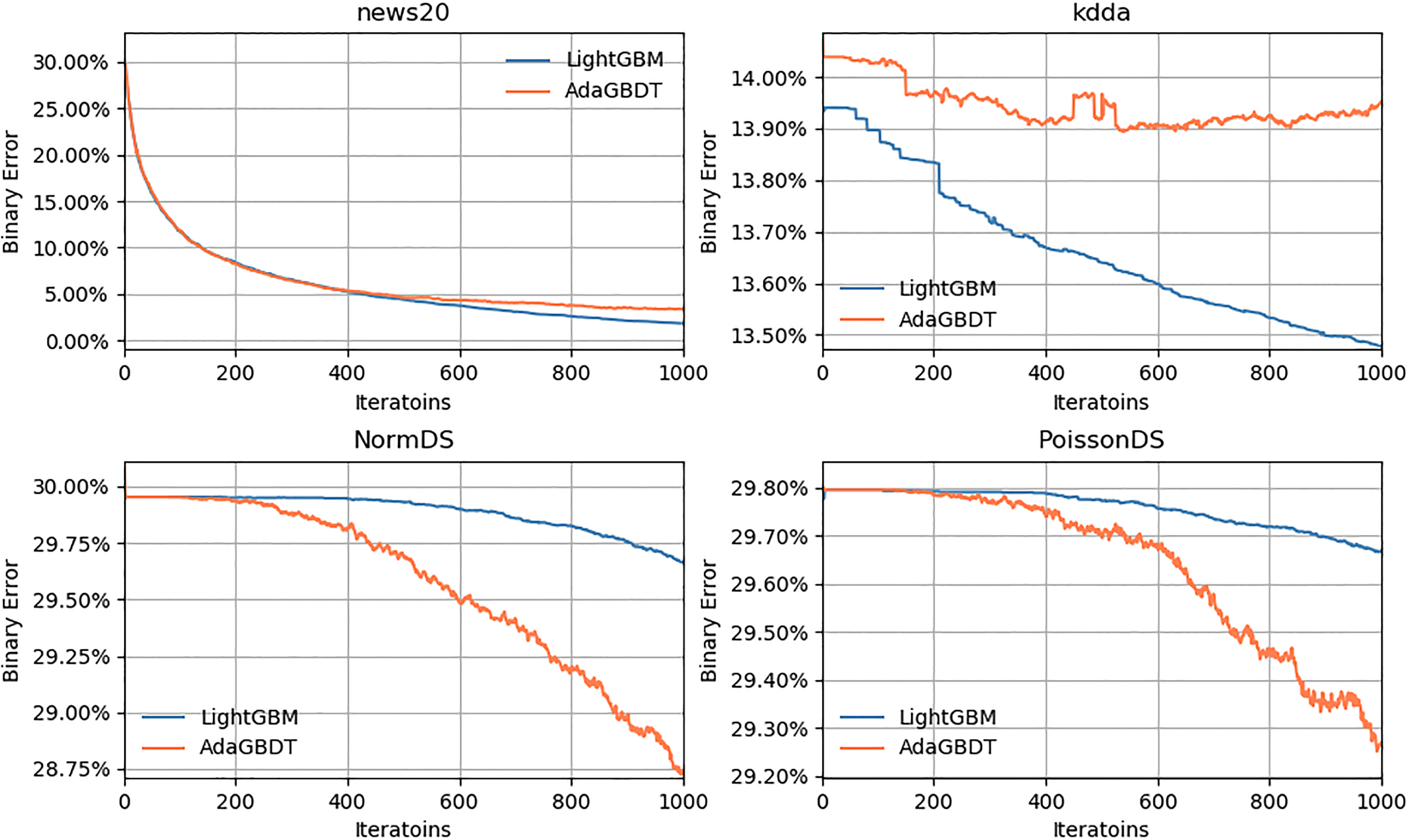
The training accuracy in each iteration on four data sets are showed in Fig. 1. Iteration-Accuracy curve. Note that the binary error of AdaGBDT is slightly higher than LightGBM for news20 and kdda datasets, but lower for NormDS and PoissonDS datasets. We can see AdaGBDT performs not very well on data with sparse features. Because there are very little information we can get from small samples with sparse feature space. The results demonstrate that our implementation works better with intensive data.
In this experiment, we compare the average training time of LightGBM and AdaGBDT at one iteration when running on data with different sample size and feature size. The datasets used in experiments are with four different distribution whose distribution type and corresponding configuration are same as the data sets described in Section 4.1.
Our experiment compare the time cost of training on 20 datasets for each distribution. In Fig. 2, data with same distribution consist of 200 features and the number of instances ranges from 50K to 500K at intervals of 50K. In Fig. 3, data with same distribution consist of 100K instances and the number of features ranges from 100
Time cost of training for different numbers of instances.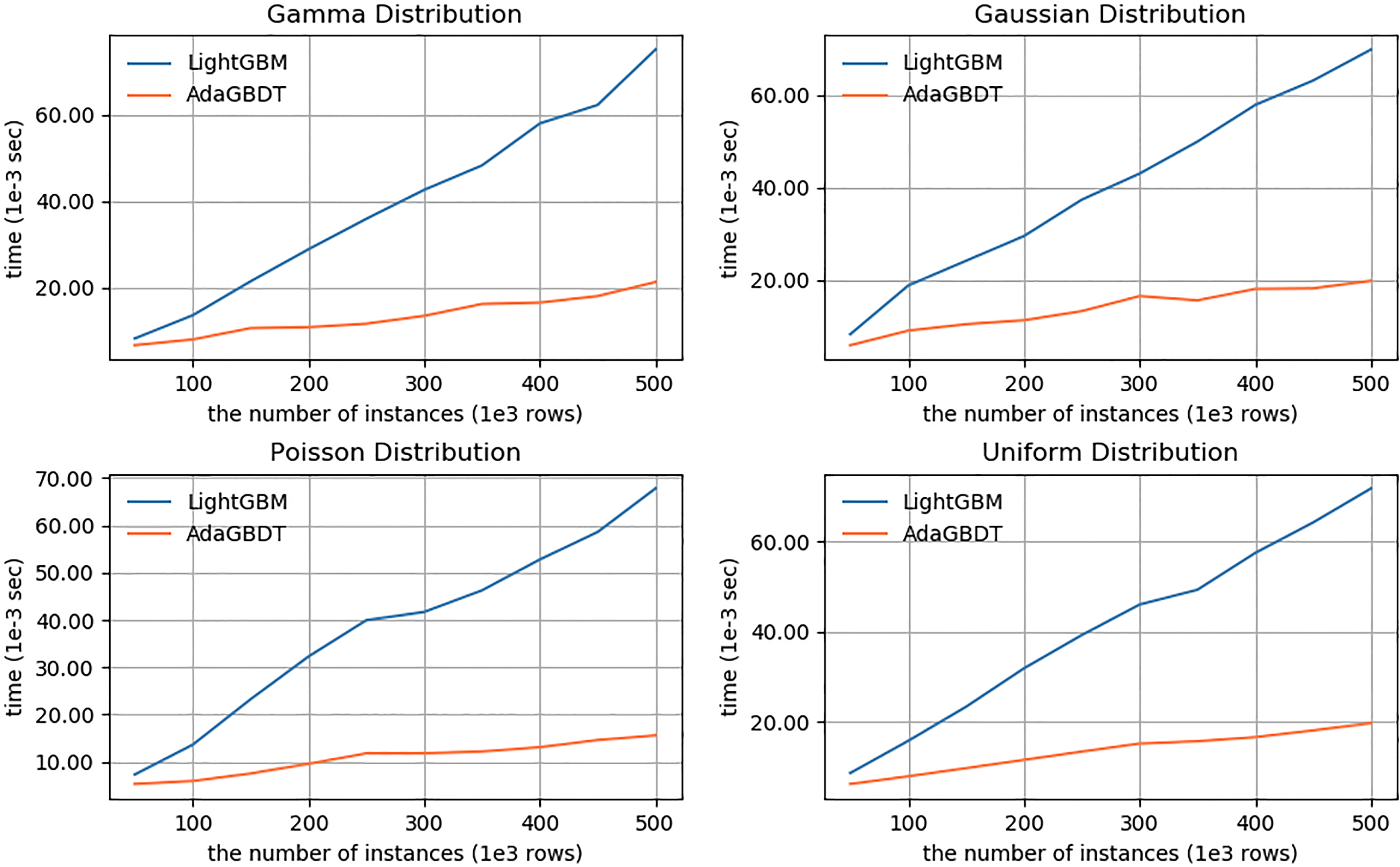
Time cost of training for different numbers of features.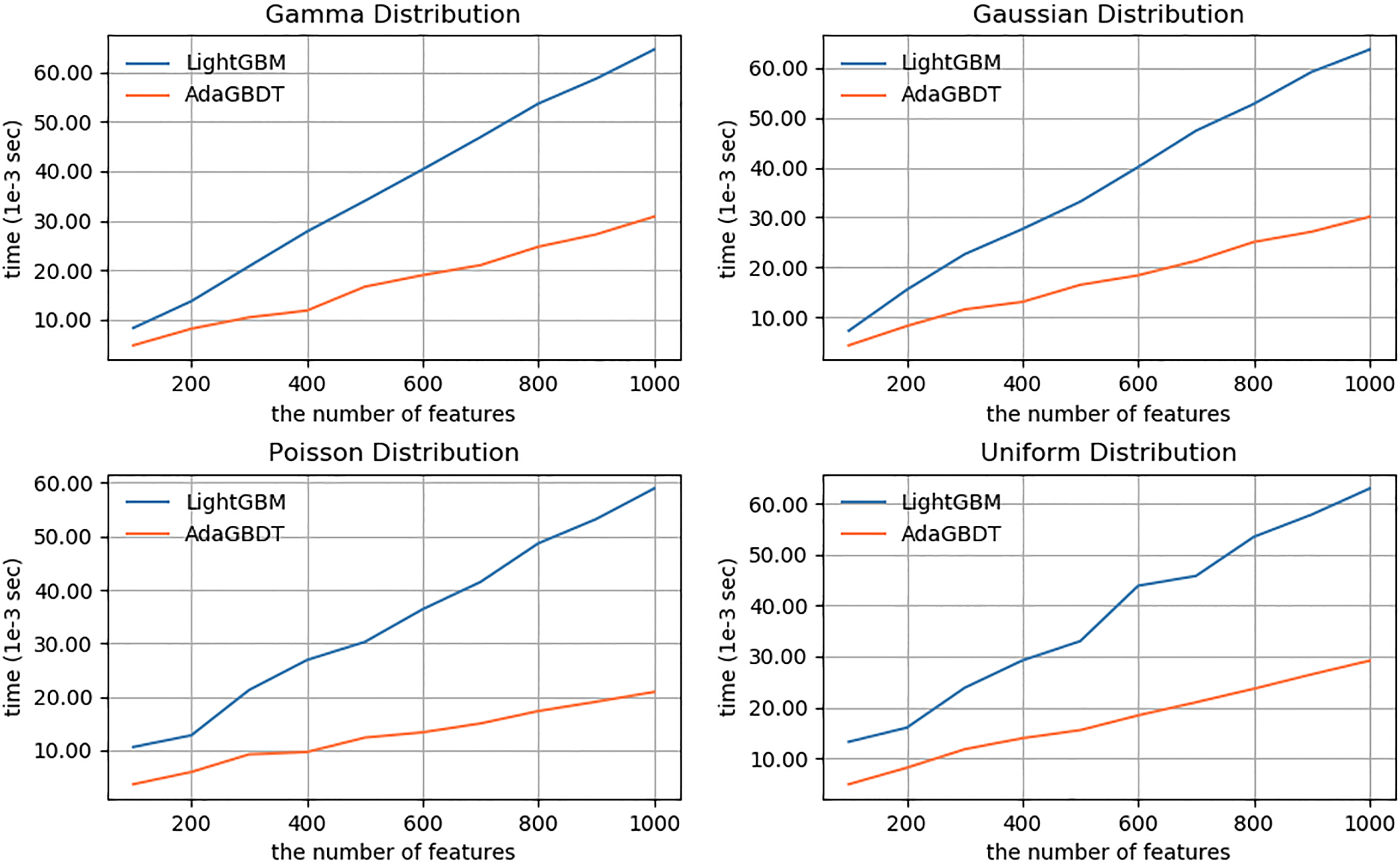
In this paper, we employ adaptive sampling method into LightGBM to reduce the number of data instances in an online fashion by drawing a subset of training data in every iteration of training procedure. Our AdaGBDT approach provide users with accuracy level parameter
Footnotes
Acknowledgments
This work was supported by the Fund by National Natural Science Foundation of China (Grant No. 61462012, No. 61562010, No. U1531246), The Innovation Team of the Data Analysis and Cloud Service of Guizhou Province (Grant No. [2015]53).