
Abstract
In order to allow users to incorrectly identify images by manipulating them using deep neural networks, this paper analyses the shortcomings of deep learning for image classification. It also develops a game that uses this technique. In the game, players can select one of their preferred product categories, causing the model to classify other product categories incorrectly as the one they selected. The goal of this game is to demonstrate to players the limitations of AI. We evaluate these programs based on their overall effectiveness, user satisfaction, and achievement of their objectives. The results show that this program is a successful method for arousing curiosity and stimulating thought. They can learn to appreciate the limitations of AI and the need to prioritize AI security in their daily activities.
Introduction
In many fields, including computer vision [1, 2], autonomous driving [3], video games [4], and others, AI and deep learning are used, but most people only focus on their advantages. Despite the fact that most people are aware of the numerous benefits of successful deep learning, few are concerned about the negative consequences of attacking them. Therefore, those who are unaware of this phenomenon often idealize deep learning. They create theoretically applicable scenarios without understanding the consequences. Although functional visualization technology was developing, Amodei et al. stated that it was still quite abstract for individuals without a foundation in the underlying technology [5]. The public’s lack of comprehension of these systems worsened as they spread in popularity. However, sophisticated systems were challenging to comprehend for those without relevant training and experience. It is crucial that those without technical knowledge comprehend the interesting ways in which deep learning has some drawbacks.
The main goal of this study is to present a project that will help users who lack these skills comprehend the fundamentals and limitations of deep learning in image classification. A game program called Similarity Attack Game aims to disrupt neural networks. The user can specify another item in the game, which leads the neural network to mistakenly identify the image as that item. The attack is carried out by making very small adjustments to certain pixel points, rendering them invisible to the human eye. Researchers have attempted such attacks using tools such as one pixel attack [6], Houdini [7] and Carlini and Wagner Attacks [8]. Users can use this as an engaging way to learn more about neural networks, deep learning, and their flaws. The project’s secondary objective is to improve user comprehension by analysing and modifying the game’s improvement process. The application’s ultimate goal is to increase users’ understanding of AI or deep learning and their shortcomings.
Game design
This project’s design objective is to expose AI’s shortcomings. Deep learning is a crucial component of AI and has many critical applications (e.g., image recognition, speech recognition, visual translation, etc). In this project, we use an adversarial attack to demonstrate a fascinating phenomenon: the outcomes following the categorization of the same image recognition model may vary when we discern two identical images with our eyes. This project was inspired by Modas et al. [9], Su et al. [6] and Dong et al. [10]. Users can take away from this finding that AI is not perfect and that mistakes can have negative effects.
Since non-professional users make up the majority of the target audience, a well-designed interface is required. Users may find simple code files to be inconvenient. To fulfil this objective, the project ultimately created an Adversarial Attack mini-game. Instead of being largely entertainment-focused, the game takes a few steps to explain to consumers some of the limitations of AI in image classification.
The entire procedure can be broken down into the three steps below:
Image classification identifies the chosen image. The user can see that the image is correctly classified in this step. A deliberate adversarial assault on the image. The class for hack can be specified by the user. For instance, the user can define that after the hack, the model would identify the chosen cat image as a tiger image. Show the user both the original and the hacked versions of the image. The user will discover that the eye is incapable of telling two images apart. The hacked image is classified and predicted again by the same means. The user can see that the image has been incorrectly classified in this step. By discovering that AI misclassifies images, the user can discover that it has flaws as well.
Technical implementation
The specific implementation of this project is examined in light of the design concepts previously mentioned. This section primarily introduces the programming language, model, associated dependency library, and philosophy utilised in the technical execution of the project.
Language of programming
The design was chosen to use Keras as the primary dependency library. Because it is an open-source artificial neural network library developed in Python that serves as a high-level API for designing, testing, implementing, and visualizing deep learning models for Microsoft-CNTK, Theano, and Tensorflow. The Keras library enables the use of numerous models. Later on in the project, designing user interaction is also made simple with Python. Based on these advantages, Python was selected as the programming language for this project.
Inception-V3 model
Inception-V3 is a more traditional and widely used model. This system aids in the detection of smaller objects. By factoring and dimensionality reduction, the neural network maintains good quality at a relatively cheap computational cost. Lower parameter counts, more regularisation, a batch normalisation assistance classifier, and label smoothing work together to enable this model to train a high-quality network on a relatively moderate training set [11]. It adheres to the following general design principles:
Steer clear of features that resemble bottlenecks. The dimension should be gradually decreased from input to output, according to features. The information scale is only partially represented by the dimension represented by the feature, which leaves out some crucial elements like the correlation structure. High-dimensional data is better suited for in-network local processing. Increasing the non-linear activation response concurrently convolution networks can gradually decouple more features, which speeds up network training. Lower-dimensional embeddings can be used for spatial aggregation with little loss in representational power. The network’s depth and width must be balanced. The network operates at peak efficiency when the ratio of filters per layer to total layers is balanced.
This is a highly thorough and widely utilized model that will be used to both health care and transportation [12, 13]. Furthermore, there are numerous scenarios in which this model will be applied. It is persuasive to use this model as a target in the project due to its universality. More non-professional users will be able to comprehend the concepts the project is attempting to convey if a counterattack is implemented using this model. Because rather than breaking down deep learning and the use of neural networks, the project’s primary goal is to help users understand that AI is somewhat brittle.
Implementation specifics
The implementation is divided into two main parts. The image classification section is the first, and image modification is the second (i.e., tampering with the image causes the model to misclassify it). The next section goes over interface implementation.
Classification of images
The Keras application first imports the Inception V3 model. We don’t need to use a lot of images to train the model because it is already well-trained. Convert the image to a NumPy array after it has been loaded, and then add a fourth dimension for batch size. In order to make classification predictions, classes list from the public ImageNet dataset are combined (1000 classes have been trained).
Image manipulation
A classifier functions by identifying a boundary dividing various objects. Figure 1 displays a simple two-dimensional classifier that learns to differentiate between green and red balls.
Principle of simple classifier.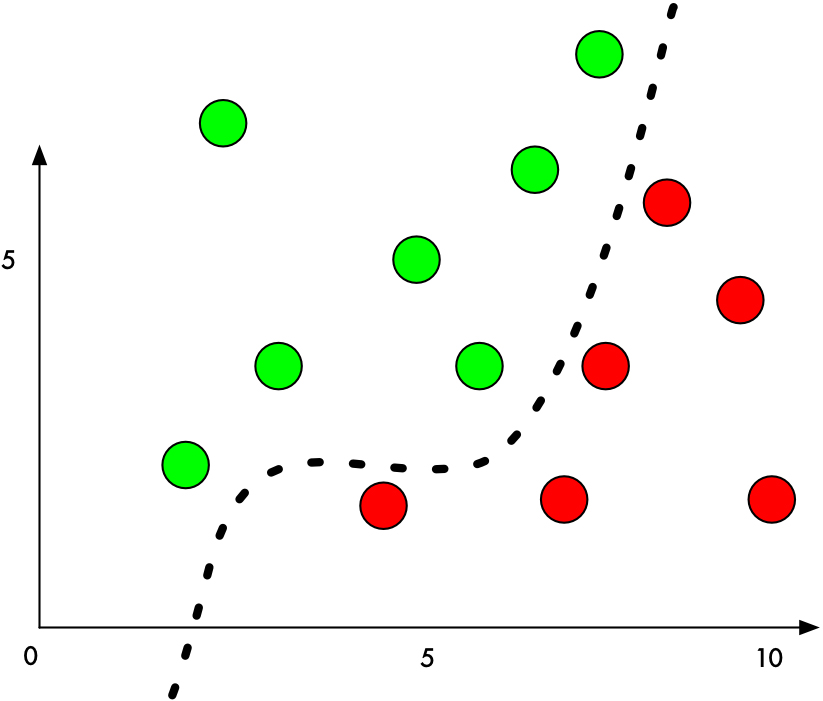
When it is operating normally, the classifier will be more precise. It locates a line that precisely divides each green ball from each red ball. The alteration we make to some of the image’s pixels is equivalent to increasing the Y value of one of the red balls next to the boundary by a small amount, as shown in the following figure.
Principle of spoofing classifiers.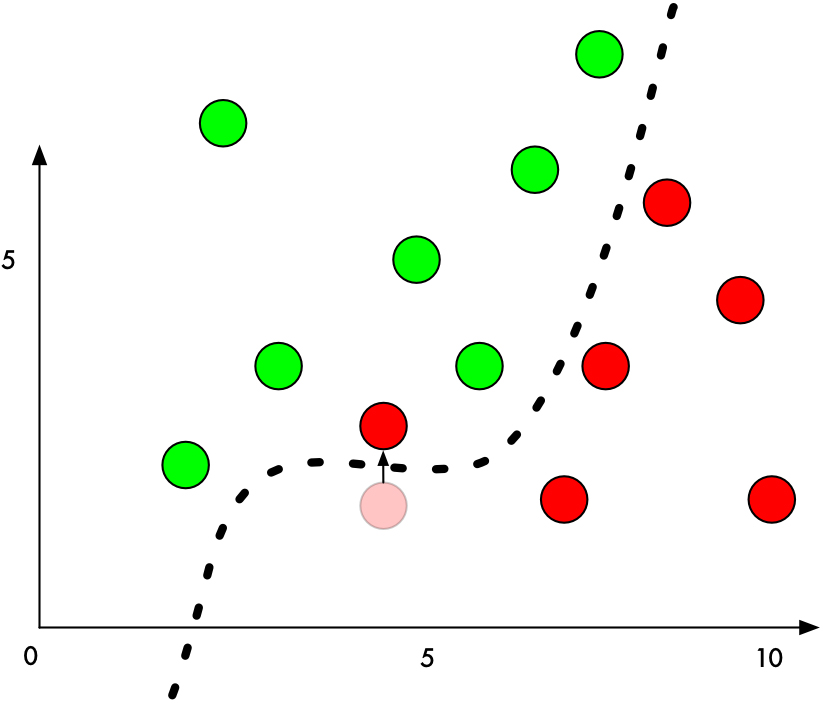
We simply need to know where to push the ball across the line in order to cause the classifier to misclassify. Move as little as possible if you don’t want to be too obvious. Each “ball” is each pixel that needs to be classified in deep neural network-based image classification. Thousands of pixels make up the entire image. This indicates that a variety of values can be altered and pushed outside the bounds of classification. If we edit the pixels in an image in a way that is not apparent to the human eye, we can deceive the image classification model without changing the way the image looks.
The attacked process determines how close the image is to the target class before grabbing the gradients it can use to move it even closer. The process is illustrated below, and it involves repeatedly iterating on the image to achieve the ultimate goal of fooling the model.
Attack process.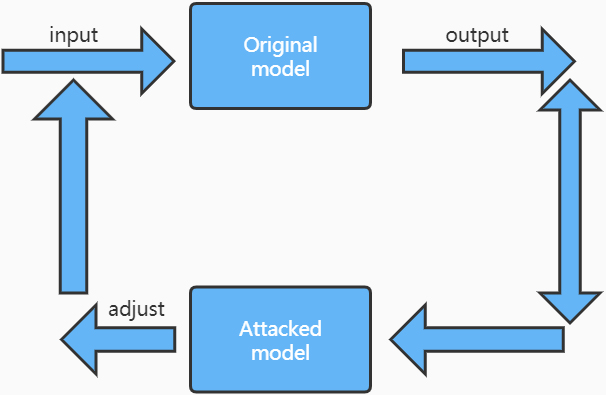
The interface to Python’s common Tk GUI toolkit is the Tkinter module. It works with Windows and Macintosh computers as well as the majority of Unix platforms. Controls like buttons, labels, and text boxes are available in Tkinter. Tk is an easy implementation for some straightforward interface designs.
Interface design is an iterative process. The first step is the implementation of fundamental functionality. The initial version is then enhanced after several iterations of gathering user comments and suggestions. The process of designing a program interface involves three iterations. Users are then given access to each design iteration so they can use it and provide feedback and comments so it can be improved. The analysis will be expanded in this section according to the three iterations.
Version 1
The program’s initial iteration is made to carry out fundamental tasks. A main page, a prediction page, and an image tampering page will all be included in the program. Because the goal of this iteration is to make sure that the program’s fundamental mechanisms can be deployed and used without issue, other functionality is viewed as superfluous. It should be possible to load, predict, alter, and predict the image normally. Below are a few screenshots of the program in action. We will compile all user feedback after this program is used by users, then design and enhance the second version.
Main page V1.
Prediction page V1.
Three of the most frequently cited flaws are as follows:
The program does not begin with an introduction. The program makes no indication that the image is predicted or altered. After tampering with the image, two images were not displayed side by side. After it has been altered, an image cannot be seen clearly with the naked eye.
Version 2
The second round of the program’s interface design is iterated based on user feedback. This round’s goal is to attempt to address all of the user-posted queries, and the problems brought up must be resolved. The following page after the home page contains an introduction to the program. When predicting and fiddling with the execution of the image, a progress indicator will also show up in the user interface. Before predicting the modified image on second time, the programme displays both the original and the modified versions of the image initially. The user must then manually click the “re predict” button to enter the second prediction. Several screenshots of the UI in this iteration are shown below. Customers will utilise the updated programme and provide new feedback.
Prediction page V2.
Comparison page V2.
Users believe that the issues raised in the previous iteration have largely been resolved. However, they still believe that the interface could be improved. They believe the interface isn’t visually appealing enough, and the main issue is that it lacks a background image or color. They also emphasized the need for some interface modifications, such as the introductions page’s design. And one of the users suggested that a final interface be added with a return to the program’s beginning or an opt-out option.
Main page V3.
Introduction page V3.
Version 3
The final iteration will be this one. As this is the final version and won’t change much going forward, we are constantly seeking user suggestions during the design process. The majority of users’ preferences determine the color choice. The program also includes a page for comparing two images at the same time, enabling users to review the differences between the two images after identifying the altered image. Users have the option to restart the game or close the application from this page. The following are some of the final interfaces.
Hack page V3.
Comparison page V3.
Program assessment
The program was first given to 20 users to test for usability. As a result, it operated flawlessly on 17 computers, only three of which required a resolution adjustment to fully display the interface. The integrity of the altered images is then assessed. We have tested the tampering on 500 sets of images and the results are all good, three groups are displayed below. Each group’s first image is left alone, while the user-specified second image is changed to a specific type. In this program, using square images gives better results.
The first group.
The second group.
The third group.
The results show that it is challenging for the human eye to discern that the tampered image has changed categories.
The user will use the final version and finish the SUS after three iterations. SUS [14] offers a “quick and dirty” trustworthy instrument for gauging usability. It consists of 10 questionnaires that give respondents a choice between 5 statements (ranging from Strongly agree to Strongly disagree). It can be used to evaluate a wide range of goods and services, including hardware, software, mobile devices, websites, and applications.
Scale for system usability
Ten questions were presented to users, with responses ranging from Strongly Agree to Strongly Disagree:
I believe that frequent use of this system is something I would like. I thought the system was overly complicated. The system seemed user-friendly to me. I believe that in order to use this system, I would require the assistance of a technical person. This system’s various functions seemed to be well integrated, in my opinion. This system seemed to me to be far too inconsistent. The majority of people, in my opinion, would pick up on this system very quickly. I found the system to be incredibly difficult to use. When using the system, I was very comfortable. Before I could start using this system, I had a lot to learn.
Even items are negative, while odd items are positive. Even items receive a score of “5-original score,” while odd items receive “original score-1.” The SUS score is calculated by multiplying the total number of items by 2.5.
The average SUS score for ten users is 81.5, according to statistics. This indicates that the program is effective because the score is relatively high. The program’s actual function, however, is not extensive or complicated. It might also contribute to the high score.
Conclusion
Artificial intelligence is now used in many fields as a result of the quick advancement of science and technology. Today’s world uses deep learning technology extensively for image recognition. The majority of people have great faith in AI. They are unaware, though, that a malicious attacker could manipulate an image and cause the model to incorrectly classify it by exploiting a deep neural network’s flaw.
In this instance, a simple program called Similarity Attack Game is created to alert users to the possibility of AI and deep learning errors. The program will give a targeted assault that produces two distinct forecasts by changing the initial image the user selected. The system has also been somewhat evaluated, and the results show that it can meet the requirements for function and interface design. The project’s objectives have been accomplished with good results as well. These kind of games can help users comprehend that AI and deep learning have different points of view and that they should approach these cutting-edge technologies with “questionable” suspicion.
In the future, we also can expand our programs by combining wireless big data and machine learning techniques. It may be more scalable and better deployed in online environments [15, 16].
Future work
Naturally, this project still has some shortcomings, but they merit discussion and future improvement. First off, some photos may have a slight blur after being altered by this program, especially if the final classification is not quite as similar to the original. At this time, image processing typically takes a long time. Additionally, the technology used in this paper is weakly robust and can only fool the Inception-V3 model. Future work should focus on improving the speed and quality of image tampering, and more research should be done on how to make tampered images fool more models.
Second, there is much room for improvement in the way this program interacts and designs its interface. Future versions of the interface should be more enticing and adaptable rather than having a fixed-size window. Simultaneously, systems that are simpler to distribute and use, like a web application or a mobile application, should be designed. At the same time, we should pay attention to the usage. Only when more users use it can we achieve the goal of this project. In the future, we also need to spend more resources on promotion and use.
Finally, we need to consider how to defend against these hostile assaults. Technology advancement is always based on ongoing offense and defense. At the same time that many helpful artificial intelligence technologies emerge, malicious individuals target them. For these technologies to withstand attacks, they must be improved and upgraded. Artificial intelligence can be applied to our daily lives in a safer and more reliable manner in this way. Therefore, it is important to continue talking about and researching how to make deep learning and artificial intelligence better able to withstand attacks in all directions.