
Abstract
We consider the problem of cumulative reward maximization in multi-armed bandits. We address the security concerns that occur when data and computations are outsourced to an honest-but-curious cloud i.e., that executes tasks dutifully, but tries to gain as much information as possible. We consider situations where data used in bandit algorithms is sensitive and has to be protected e.g., commercial or personal data. We rely on cryptographic schemes and propose
Keywords
Introduction
The stochastic multi-armed bandit game is a sequential learning framework where a learning agent aims at maximizing its cumulative reward while successively interacting with an uncertain environment. At each time step, the agent chooses an action (a bandit arm) from a fixed set of actions with unknown associated values. The environment responds with a stochastic feedback (reward) drawn from the distribution associated with the chosen action. The agent uses the received feedback to update its estimate of the values for the chosen action and to decide which action to choose next. The agent has to continuously face the so-called exploration-exploitation dilemma and decide whether to explore by choosing actions with more uncertain associated values, or to exploit the information already acquired by choosing the action with the seemingly largest associated value. Cumulative reward maximization has been already extensively studied for several multi-armed bandit settings (see [7] for a survey) and for various applications, from clinical trials, to online advertising and recommendation systems. In this paper, we address the security concerns that occur when outsourcing the cumulative reward maximization data and computations to the cloud.
Our scenario is inspired by the machine learning as a service cloud computing model, for which security is known as a major concern [6]. As a motivating example, assume:
∙ A data owner: a company that wants to monetize some collected data, while keeping ownership over it. The collected data may be a large quantity of surveys on customer preferences for several products. By product, we mean any type of object or service. The K bandit arms are the surveyed products and only the data owner knows their associated rewards, based on the collected surveys.
∙ A data client: a company that wants to spend some budget to use some of the data owner’s data. The data client may be a small company that cannot afford doing its own surveys, but wants to estimate the income that it could generate for the products surveyed by the data owner. The cumulative reward captures such information because it sums the rewards produced by each product. The budget N is the number of data owner’s surveys used to compute the cumulative reward and the bandit algorithm has to decide how to choose these N surveys in order to maximize the cumulative reward. A larger budget gives a higher accuracy for the largest cumulative reward. The data client only sees the cumulative reward, without knowing the values associated to each arm.
We assume that the interaction between the data owner and the data client is done using the cloud (as shown in Fig. 1), where both data and computations are outsourced. The data owner does the data outsourcing, and the data client interacts directly with the cloud, by sending the budget and receiving the obtained cumulative reward. The outsourced data may be sensitive (e.g., personal, commercial, or medical data). We want the outsourced learning algorithm to be run while protecting data against unauthorized access. The problem that we address is how to allow the data client to obtain precisely the same cumulative reward as with a standard bandit algorithm, Upper Confidence Bound (UCB) [4,7], within a reasonable computation time and while preserving the data security. Indeed, the outsourced data can be communicated over an untrustworthy network and processed on some untrustworthy machines, where malicious cloud users may learn sensitive data that belongs only to the data owner.

Outsourcing data and computations.
The privacy-preserving cumulative reward maximization is a hard problem. To solve it, the authors of [16,25,30] use differential privacy introduced in [13]. However, in these approaches, the returned reward is not the same reward obtained for the data client’s budget using standard algorithms. This happens because differential privacy guarantees depend on noise being injected in the input/output. We take a complementary approach by relying on cryptography instead of differential privacy. To the best of our knowledge, our approach is original and its goal is to give security guarantees, while obtaining the same output as standard (non-secure) algorithms. The security for obtaining the same output has a price because the computation time may increase because of cryptographic primitives that are time-consuming in practice. More precisely, we require that the data owner (which can be seen as an oracle knowing the reward functions associated with each arm) encrypts her data before outsourcing it to the cloud. Then, the cumulative reward maximization algorithm is run directly in the encrypted domain, and the (encrypted) output should be exactly the same as for standard UCB, with the cost of an increased computation time.
From a theoretical point of view, the problem could be straightforwardly solved by using a fully homomorphic encryption scheme [17], which allows to compute any function directly in the encrypted domain. However, it remains an open question how to make such a scheme work fast and be accurate in practice. Indeed, the state-of-the-art fully homomorphic systems (SEAL1
Consequently, our challenge is to rely on simpler cryptographic schemes and design a multi-party protocol with several cloud node participants such that each of them can only learn the specific data needed for performing its task and nothing else e.g., if a participant does in clear computations on real numbers, these computations concern data of only one arm, and no other participant has access to this piece of data. Our protocol returns exactly the same cumulative reward as UCB, while satisfying desirable security properties such as: only the data client can see the cumulative reward, which cannot be learned by any cloud node participant nor by an external observer. We precisely characterize our security model and security guarantees later on in the paper. To achieve our goals, we rely on indistinguishable under chosen-plaintext attack (IND-CPA) cryptographic schemes: symmetric encryption AES-GCM [1,28] and asymmetric partially homomorphic Paillier’s scheme [27]. We formally prove the security of our protocol and we precisely characterize the number of needed cryptographic operations.
Summary of related work and positioning of our contribution
Related work. Each line in Table 1 corresponds to a standard problem in stochastic multi-armed bandits. The most popular problem is cumulative reward maximization and UCB is a standard algorithm for solving it [4,7]. There is a recent line of research on enhancing algorithms such as UCB with differential privacy [16,25,30]. There are some fundamental differences between this line of work and our work based on cryptography. On the one side, the running time overhead of differentially-private algorithms is negligible, whereas our approach has an overhead in computation time coming from the use of cryptographic primitives. On the other side, the cumulative reward returned by differentially-private algorithms is different from the output of standard UCB. Indeed, to obtain differentially-private guarantees for a bandit algorithm, noise is added to the algorithm input or output. Thus, the cumulative reward obtained using a differentially-private algorithm is different from that obtained by the algorithm without privacy guarantees. This is reflected in the regret analysis of the algorithms (where the regret is given by the difference in the cumulative reward obtained by a learning agent and the best cumulative reward possible obtained by always playing the best arm): the regret of differentially-private bandit algorithms have as overhead an additive [30] or multiplicative factor [16,25] with respect to the regret of their non-private version. In contrast, our cryptography-based algorithm is guaranteed to return exactly the same cumulative reward as standard UCB.
The second line in Table 1 corresponds to a different bandit problem that is best arm identification [3], equivalent to minimizing the simple regret, that is the difference between the values associated with the arm that is actually the best and the best arm identified by the algorithm. From the cryptography point of view, there exists a multi-party protocol [11] that enhances the Successive rejects algorithm [3] for best arm identification with security guarantees that are similar to the ones from this paper. Naturally, the algorithms that are secured (Successive rejects [3] in [11] and UCB [4] in this paper) solve different problems, thus the corresponding secure protocols are different and cannot be reduced to one another.
All related works discussed thus far are for standard stochastic bandit models. Securing cumulative reward maximization algorithms using cryptography has been recently studied for a different bandit model i.e., linear bandits [10], where the arms are vectors and the rewards are unknown linear functions of the arms. The corresponding secure protocols are again different and cannot be reduced to one another.
Regarding the secure multi-party computation literature, we are not aware of any other work considering multi-armed bandits or which could be easily reduced to be used in the context of multi-armed bandits, hence to the best of our knowledge there is no other protocol that is genuinely close to ours. According to Moti Yung’s keynote in CCS 2015 [31], an important factor that one should take into account when designing a secure multi-party computation protocol is “Generality vs. specificity: Secure computation is a general scheme; in reality one has to choose an application, starting from a very real business need, and build the solution from the problem itself choosing the right tools, tuning protocol ideas into a reasonable solution, balancing security and privacy needs vs. other constraints: legal, system setting, etc.” This is precisely our approach: we start with an important and interesting problem setting that to the best of our knowledge is not previously considered in the secure multi-party computation literature (i.e., cumulative reward maximization in stochastic multi-armed bandits), then we design secure multi-party protocols that are guaranteed to return exactly the same result as a standard algorithm, while aiming at a reasonable cryptographic overhead. Several partial or fully homomorphic encryption schemes have been designed to solve the following problem: perform computations over encrypted data [15]. For example, such cryptographic tools have applications to various problem settings from the control domain [14,22,24,29]. The main difference between this line of research and our paper is on the type of manipulated data and the subsequent needed computations, as we detail next. On the one hand, they manipulate vectors of encrypted elements on which they perform linear algebra operations. Their approach is to rely on some homomorphic encryption scheme (generally Paillier) that can already do some computations directly in the encrypted domain, and then find a way to securely run some other computations specific to the concrete problem that they study. On the other hand, our data is not vectors of elements that can be manipulated in the encrypted domain. Indeed, multi-armed bandits are a model of interactive learning, where data comes sequentially, based on an interaction with an unknown environment. In the case of the UCB algorithm that we secure in our paper, the unknown environment is K Bernoulli distributions associated to the bandit arms. To generate a reward for an arm i i.e., a call
Moreover, since multi-armed bandits are a reinforcement learning model hence a machine learning model, a problem setting close to ours is the one of federated learning [21]. Indeed, federated learning is a machine learning paradigm where multiple entities collaborate in solving a learning problem, under the coordination of a central orchestration server. In a very recent federated learning survey [21], secure multi-party computation and homomorphic encryption are mentioned as standard cryptographic techniques to deal with the privacy and security issues in the presence of honest-but-curious adversaries. As mentioned in [21], “to date, federated learning has primarily considered supervised learning tasks where labels are naturally available on each client. Extending FL to other ML paradigms, including reinforcement learning, semi-supervised and unsupervised learning, active learning, and online learning all present interesting and open challenges”. An example of such challenge that we address because it occurs in multi-armed bandits is that there is less data that is available and comes only by interaction with the unknown environment and under a fixed budget.
Summary of contributions and paper organization. This paper is an extension of our conference paper [12], which is to the best of our knowledge the first one to propose a secure multi-party protocol based on the UCB algorithm. We next discuss the organization and contributions of this paper.
In Section 2, we introduce some basic notions: standard UCB algorithm and some cryptographic tools. Then, Section 3 is the core of our contribution:
We propose We show that We analyze the theoretical complexity of We propose the
In Section 4, we include a proof-of-concept empirical evaluation that confirms the theoretical complexity, and shows the scalability and practical feasibility of our protocols, on synthetic and real-world data. Finally, we conclude our paper and outline directions for future work in Section 5.
The main novel content of this paper w.r.t. its conference version [
12
] consists of non-trivial theorems and proofs (Section
3.3.2
), as well as the presentation of the
We first recall the UCB algorithm [4]. Then, we briefly present two cryptographic schemes that we use to build our protocols: Paillier asymmetric encryption scheme and AES-GCM symmetric encryption, which are both IND-CPA secure. For ease of readability, we provide in Table 2 a summary of our notation, presented according to the order of appearance in the paper.
Table of notation
Table of notation
Upper confidence bound (UCB). UCB is a class of algorithms commonly used when facing the exploration-exploitation dilemma. Each bandit arm is associated with a distribution whose mean is unknown to the learning agent. When pulling an arm, the agent observes an independent reward drawn from the distribution associated to the chosen arm. Specifically, we consider rewards drawn from Bernoulli distributions with expected values
To guide the choice of the learner, arm scores have been proposed [2] to construct upper confidence bounds (UCB) based on the empirical mean of arm-specific rewards and the number of arm pulls. In the class of UCB algorithms, an important breakthrough was the introduction of algorithms with a finite-time analysis [4]. Specifically, in the UCB algorithm [4] presented in Fig. 2, for each arm i, the score

UCB algorithm [4].
Next, we introduce a few security tools, while aiming to provide enough background to formally prove the security of our protocols. Before introducing the two cryptographic schemes, we point out that each of them has a security parameter λ that is input to key generation. By
Paillier asymmetric encryption [
27
]. It is an asymmetric partial homomorphic encryption scheme defined by a triple of polynomial-time algorithms
Paillier’s cryptosystem is additive homomorphic. Let
AES-GCM symmetric encryption. AES [1] is a NIST standard for symmetric encryption that encrypts messages of 128 bits. To encrypt messages larger than 128 bits, we use AES with a symmetric encryption mode. Among all existing modes we chose GCM (Galois Counter Mode) [28], which has been recently added to TLS 1.3.3
IND-CPA (INDistinguishability under chosen-plaintext attack) [
5
]. Let
Both cryptographic schemes mentioned earlier in this section are IND-CPA: (i) Paillier is IND-CPA under the decisional composite residuosity assumption [27], and (ii) AES-GCM is IND-CPA under the assumption that AES is a pseudo-random permutation [5]. In our theorems, the notion of “better than random” is consistent with the aforementioned IND-CPA property. We also point out an additional notation used in the proofs. Similarly to Landau Big O notation, where by convention
All theoretical security properties of our protocols also hold if we choose any other IND-CPA symmetric scheme instead of AES-GCM, and any other additive homomorphic IND-CPA asymmetric scheme instead of Paillier. Our choice to rely on the aforementioned schemes is due to practical reasons. AES-GCM is very efficient in practice and implemented in standard libraries for modern programming languages. Paillier is also supported by a number of libraries that can be used in practice.
We define the security model in Section 3.1. We propose our secure protocol
Security model
As outlined in Introduction and in Fig. 1, we assume that the data (i.e., the reward functions associated to K bandit arms) and the computations (i.e., the cumulative reward maximization algorithm) are outsourced to an honest-but-curious cloud. This means that the cloud executes tasks dutifully, but tries to extract as much information as possible from the data that it sees. Our model follows the classical formulation in [19] (Ch. 7.5, where honest-but-curious is denoted semi-honest), in particular (i) each cloud node is trusted: it correctly does the required computations, it does not sniff the network and it does not collude with other nodes, and (ii) an external observer has access to all messages exchanged over the network.
The data client indicates to the cloud her budget N and receives the cumulative reward R that the cloud computes using the K arms outsourced by the data owner and the data client’s budget N. The data client does not have to do any computation, except for decrypting R when the data client receives this information encrypted from the cloud. We expect the following security properties:
No cloud node can learn the cumulative reward. The data client cannot learn information about the rewards produced by each arm or which arm has been pulled at some round. By analyzing the messages exchanged between different cloud nodes, an external observer cannot learn the cumulative reward, the sum of rewards produced by some arm, or which arm has been pulled at some round.
We give a brief intuition for each property. Property 1 implies that only the data client can see in clear the cumulative reward for which she spends a budget. Property 2 ensures that the data client can see only the information for which she pays, and nothing else. Otherwise, depending on the difficulty of the bandit problem, the data client could estimate the arm values based on the contribution of each arm to the cumulative reward, which would leak information that should be known only by the data owner. Property 3 states that if some curious cloud admin analyzes all messages exchanged over the network, then she should have no clue on any input, output, or intermediate data that is used by the cumulative reward maximization algorithm.
We design a multi-party protocol that satisfies the aforementioned properties by exchanging only encrypted messages, and by splitting the computations among several cloud node participants, each of them having access only to the specific data that it needs for performing its task and nothing else. The challenge is to efficiently split the computations among as few cloud participants as possible, while minimizing the time needed for cryptographic primitives.
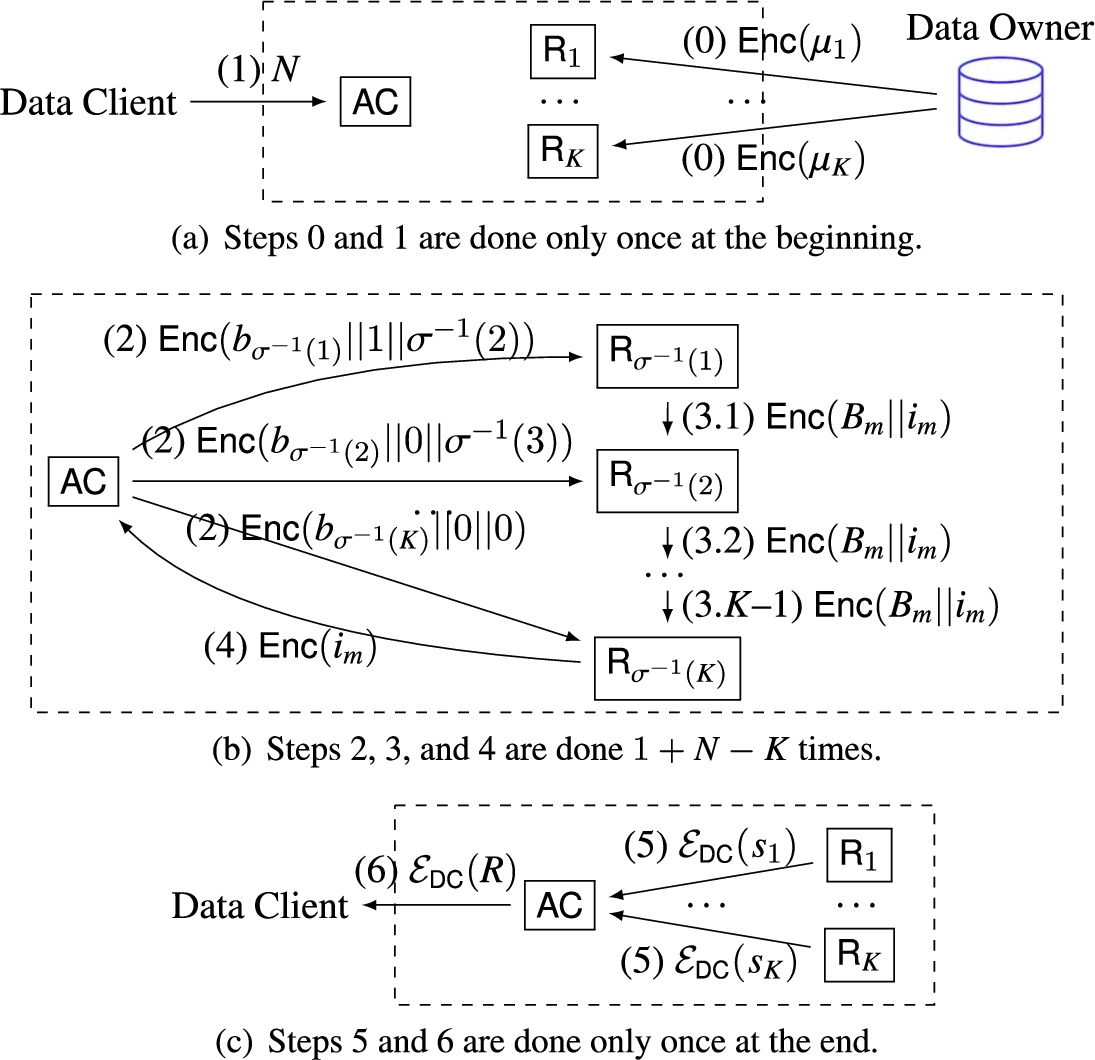
Overview of
In Fig. 3, we present an overview of
It suffices to do the AES key exchange among the concerned nodes only once before starting the actual protocol. This can be done by relying on a standard key exchange protocol e.g., Authenticated Key Exchange. The key agreement is already done when starting the actual protocol, and has no impact on our protocol’s steps detailed in the rest of the section.
Fig. 3(a) (steps 0 and 1). For
Fig. 3(b) (steps 2, 3, and 4). This is the core of the protocol, being done during
Fig. 3(c) (steps 5 and 6). After spending the data client’s budget, each arm node sends to
Step 0. We recall (cf. Fig. 2) that the data owner knows
Step 1. The data client sends her budget N to
Pseudocodes of Steps 2, 3, and 4 are presented in Fig. 4.
Step 2. It corresponds to everything except the last two lines in Fig. 4(a) and has

Pseudocode of
Step 3. This step corresponds to everything except the last two lines in Fig. 4(b). Note that the variable t stores how many arm pulls have been done in total since the beginning of the protocol. As discussed for Step 0, each arm initialized
Step 4. This step corresponds to the last two lines in Fig. 4(b) (the last arm node in the ring sends
Step 5. Once the budget is spent and no more arm has to be pulled, each arm node
Step 6. The node
Next, we analyze the correctness (Section 3.3.1), security (Section 3.3.2), and complexity (Section 3.3.3) of
Correctness
We point out that
Security
In Table 3, we summarize what each participant in No cloud node can learn the cumulative reward and additionally: Only Only arm node Only An external observer cannot learn the cumulative reward, the sum of rewards for some arm, or which arm has been pulled at some round.
These properties subsume the list of desirable security properties listed in Section 3.1.
What each participant of
knows and does not know, with pointers to the relevant theorems
What each participant of
Next, we provide formal statements and proofs for the security properties of We recall (cf. Section 3.1) that the participants are honest-but-curious and do not collude. By collusion we mean that cloud nodes put together all their data. If at least 2 of the During the ring computation (cf. Step 3 in Section 3.2), each arm learns an intermediate max value By negligible in λ, we denote that our security theorems are always asymptotic i.e., they describe the behavior when the security parameter λ of the cryptographic schemes becomes infinitely large.
Before discussing the security properties for each participant, we introduce some additional notation needed for the theorem statements:
We next provide theorems that state each non-trivial property from Table 3. We first state an useful lemma, which intuitively says that guessing the cumulative reward with probability better than random is equivalent to guessing the sum of rewards of some arm with probability better than random.
Let
⇐ Assume that
⇒ If
Security of
For an arm
Before Step 5 of
Since
We next prove the property for the last round i.e.,
Let us build an IND-CPA game, in which
To do so,
As input for the IND-CPA game, If If If If the output of Otherwise (probability If If the output of Otherwise (probability
By aggregating the aforementioned cases, the probability α of success of
As a corollary, by Lemma 1 and Theorem 1, we infer that
Security of
At the end of round
After round t, an arm i can either guess randomly (with a success probability of
For an arm
If an arm i has been pulled
As a corollary, by Lemma 1 and Theorem 3, we infer that
Security of
For each round
The data client does not receive any message until the end of
For an arm
Similarly to the previous proof, we observe that the data client
External observer. An external observer sees all messages exchanged between nodes, from which we show that she cannot learn which arm is pulled at some round (Theorem 6) or the sum of rewards for some arm (Theorem 7).
For each round
By construction of
An external observer (denoted
We next show that by using the adversary
As input for the IND-CPA game, If If Otherwise (probability If If Otherwise (probability
By aggregating the aforementioned cases, the probability α of success of
For an arm
The external observer collects
The goal of the adversary is to extract at least a bit of information from either m or n. The entropy of this system is minimal when
Let us prove that the advantage of a PPT adversary in this latter case (having to guess a bit about m from
We assume, toward a contradiction, that there exists a PPT adversary
We use this adversary to create another adversary If If If If If not (happens with probability
By aggregating these cases, the probability α of success of
As a corollary, by Lemma 1 and Theorem 7, we infer that the external observer cannot learn the cumulative reward with probability better than random.
We detail in Table 4 the number of cryptographic operations used in each step of
Number of cryptographic operations used in
Number of cryptographic operations used in
We propose the

to
The idea of
We show in Fig. 5 the modifications to Step 3 and 4 of
In
At each round t, the arm node
We show that the overhead due to cryptographic primitives is reasonable, hence our protocols are feasible. More precisely, we show the scalability of our protocols with respect to both parameters N and K through an experimental study using synthetic and real data. We compare:
UCB-M = UCB with multiple participants among which the computations are split, in the spirit of
We implemented the algorithms in Python 3. For AES-GCM we used the Cryptography library5
As expected, in each experiment, all four algorithms output exactly the same cumulative reward. The property that our secure algorithms return exactly the same cumulative reward as standard UCB is in contrast with differentially-private multi-armed bandit algorithms [16,25,30], where the returned cumulative rewards are different from that of standard UCB. Consequently, a shallow empirical comparison between these works and ours boils down to comparing apples and oranges: (i) on the one hand, the running time of differentially-private bandit algorithms is roughly the same as for standard UCB and is never reported in their experiments, whereas (ii) on the other hand, for our algorithms the cumulative reward is always the same as for standard UCB and consequently there is no point for us in doing any plot on the cumulative reward. Nevertheless, we carefully analyzed all experimental settings (N, K, μ) used in the related work, that we adapt for our scalability experiments, as we detail next.
Scalability with respect to N. In this experiment, we rely on scenarios from the related work [16,30] to fix K and μ, and to vary N. In Fig. 6, we show the results for two such scenarios. We repeated the same experiment for four other scenarios, which yielded very similar results that we do not include here to avoid redundancy. We vary N from
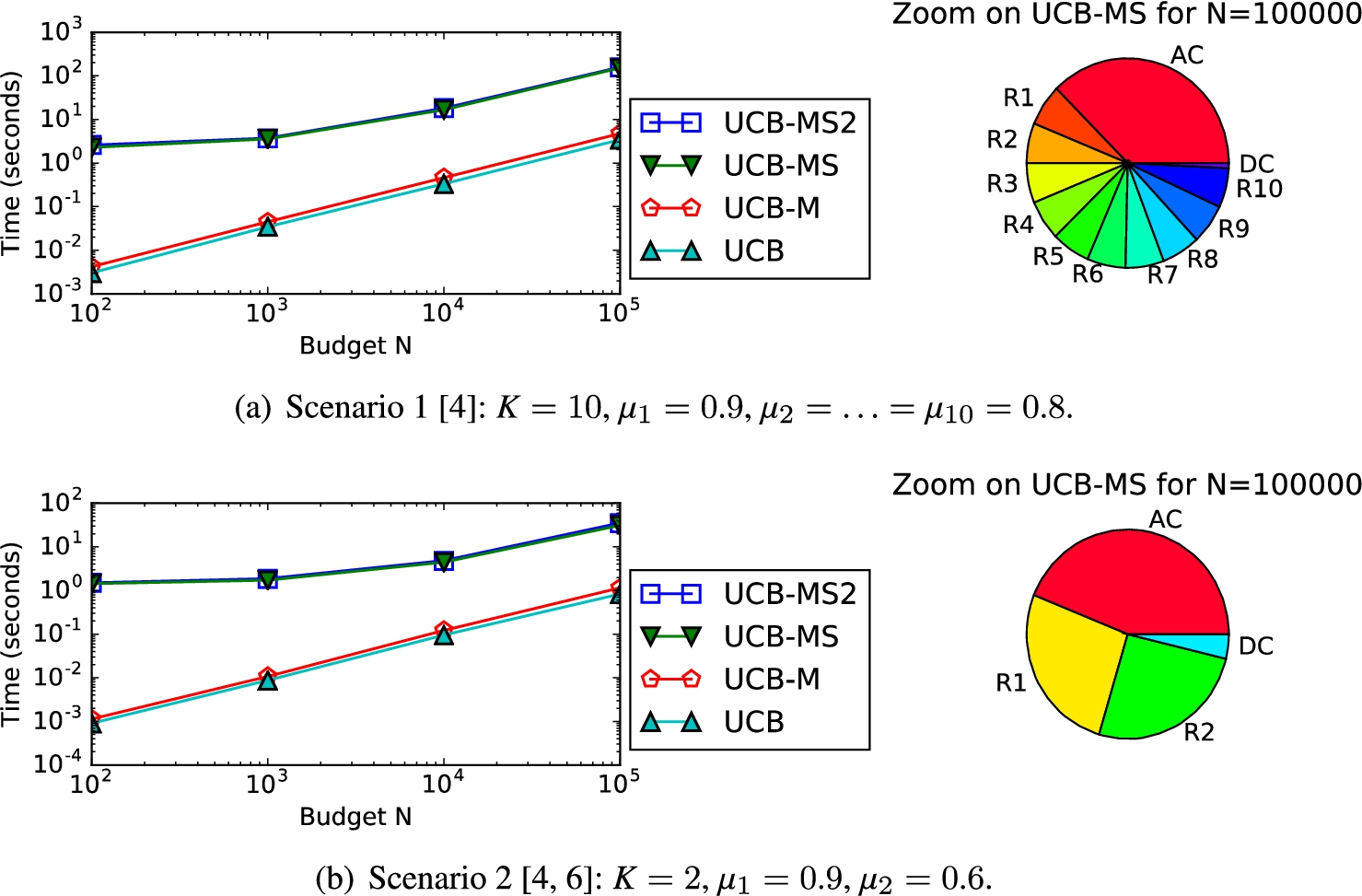
Scalability with respect to N. In the zoom, we do not show
Scalability with respect to K. In this experiment, we fix
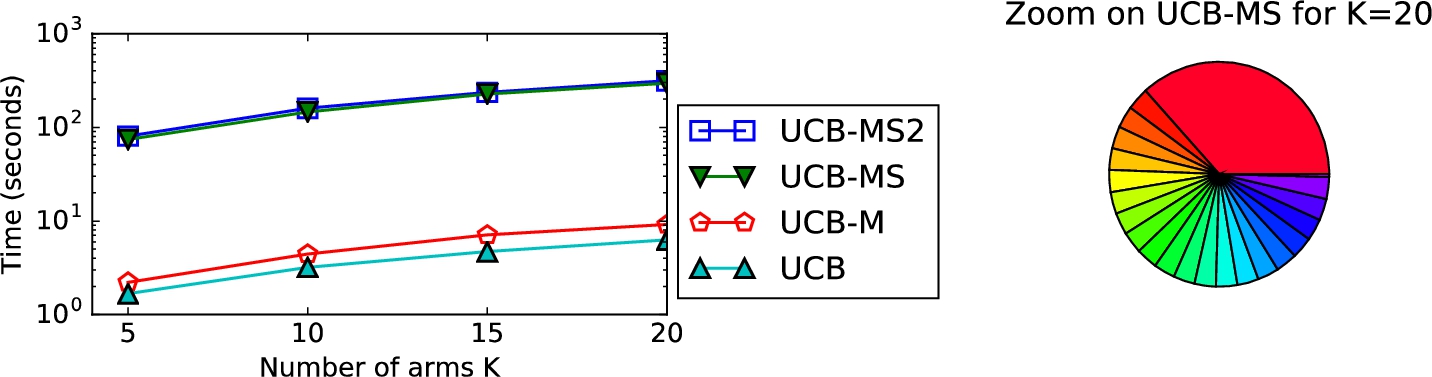
Scalability with respect to K, for fixed
Real-world data. We also stress-tested our algorithms on real-world data, using the same data and experimental setup as [23].
More precisely, we use data from Jester8
Jester-small:
Jester-large:
MovieLens:
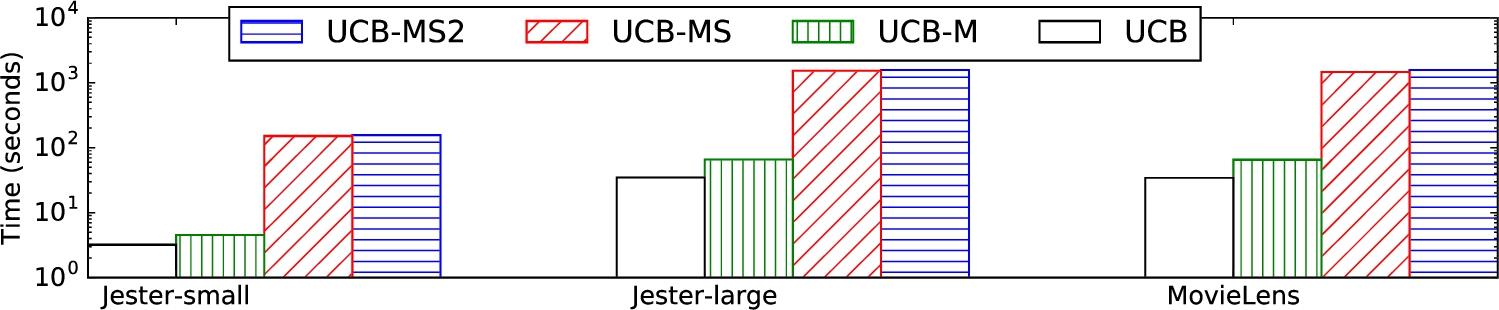
Running times on three real-world data scenarios from [23].
Positioning with respect to FHE. The main computations done by the UCB algorithm are: pull a bandit arm (i.e., draw a random number and compare it with the expected value to decide whether the reward is 0 or 1), compute arm scores (i.e., sum, multiplication, sqrt, ln), and decide what arm to pull next (i.e., compute an argmax over arm scores). A fully homomorphic encryption (FHE) scheme basically supports homomorphic addition and multiplication, and all other computations require some effort to be specified since they should be encoded using additions and multiplications.
A possible FHE version of the UCB algorithm is to encrypt the input
To give a rough idea on a loose lower bound of the UCB computation time in a FHE scheme, we focus on the comparisons required for arm pulls and argmax computations. Running the UCB algorithm for some K and N requires N comparisons for the pulls, and
We analyzed a state-of-the-art article for efficient homomorphic comparison methods, published at ASIACRYPT 2020 [9]. Among all algorithms and variants presented there, if we take the one that provides the best compromise between fast running time and small chance to make an error in the comparison result (i.e.,
Take for instance
We recall (cf. experiment Scalability with respect to N) that for
We tackled the problem of cumulative reward maximization in multi-armed bandits, in a setting where data and computations are outsourced to some honest-but-curious cloud. We proposed
As future work, we plan to extend our scenario such that multiple data clients concurrently submit budgets to the cloud and receive corresponding cumulative rewards. In such a scenario, parallelism between nodes could be leveraged to improve the system’s throughput.
Footnotes
Acknowledgments
We thank the anonymous reviewers whose suggestions helped improve and clarify this manuscript. This work was mostly done while Radu Ciucanu and Marta Soare were affiliated with INSA Centre Val de Loire / Univ. Orléans / LIFO, France. This work has been partially supported by MIAI@Grenoble Alpes (ANR-19-P3IA-0003) and two projects funded by EU Horizon 2020 research and innovation programme (TAILOR under GA No 952215 and INODE under GA No 863410).