
Abstract
In recent years, affective computing has received much attention in the area of natural language processing and artificial intelligence. Sentiment orientation recognition of text is one of important parts in affective computing. A method is proposed to recognize the multi-label sentiment orientations of Chinese text based on three-way decisions. Firstly, sentiment orientation and intensity of sentiment words from texts are identified by sentiment lexicons, Tongyi Cilin and HowNet. Subsequently, sentiment orientation of text are divided into three domains, including positive, negative and boundary domain, according to their sentiment intensity and the appropriate decision-making thresholds. Lastly, sentiment orientations of texts in the boundary domain are distinguished pursuant to sentimental characteristics of sentences in texts. The results of experiments show that the method of multi-label sentiment analysis of Chinese text, based on three-way decisions, is effective for identifying sentiment orientations of texts.
Introduction
The dramatic development of Internet technology is rapidly changing the way of daily interpersonal communication. Personal blog, microblog, product comment and news comment, etc., has generated lots of online information with personal subjective feelings [1–3]. Most of the online information in texts tells something about users’ personal view, attitude and emotion, including pleasure, anger, sorrow and joy, reflecting people’s sentimental characteristics and sentimental changes [4–7]. So, text is no longer merely used to describe objective facts, but is more focused on expressing private opinions and feelings, thus text sentiment analysis technology is promoted and become a research hotspot in the field of artificial intelligence and natural language processing.
Sentiment analysis of text is meant to make a judgment on the sentiment orientation of the words, sentences and text through mining and analyzing the opinions, views, emotions, and other subjective information revealed in the text. Sentiment analysis of text is an important part of affective computing [8], which has posed a new challenge to natural language processing. According to the difference of objects, sentiment analysis can be classified into the sentiment analysis of word and phrase, the sentiment analysis of sentence and the sentiment analysis of text, three research levels from low to high [9]. This paper carries out sentiment analysis of Chinese text at these three levels based upon sentiment lexicon and sentiment orientation of sentences with topic feature, to identify the multi-label sentiment orientation of Chinese texts.
Sentiment analysis of text is a higher-grade form of expression in affective computing, for which there are two major research methods: supervised learning and unsupervised learning [10–14]. The method of unsupervised learning is to judge the sentiment category of text in accordance with the sentiment information of words or phrases in the text. Turkey [15] introduced a semantic orientation-based unsupervised method, and classified review articles according to the tendentious information of the commendation and derogation of word. Supervised learning method is a machine learning method by which texts are put under different sentiment categories. Pang et al. [16] first applied machine learning method to the sentiment classification of a text and made a comparison in three classification models as NB, ME and SVM. Naive Bayes classifier is a simple probabilistic classifiers based on applying Bayes’ theorem. ME states that the probability distribution which best represents the current state of knowledge is the one with largest entropy. SVM is a supervised learning model and can efficiently perform a non-linear classification. Jesus Serrano Guerrer et al. [17] review and compare some free access web services, analyzing their capabilities to classify and score different pieces of text with respect to the sentiments.
In China, Xu Linhong et al. [18] proposed an automatic identification mechanism that embraces semantic features and machine learning for Chinese text polarity. Xu Jun et al. [19] researched the sentiment classification of news and comments using Naive Bayes Method and Maximum Entropy Method, and summed up the superiority and inferiority of each method through a series of experiments. Wang Suge [20] proposed a text vector representation model with strength of sentiment orientation by the use of the data representation model in rough set theory, constructing a weighted rough membership function, and applied it to sentiment classification of Chinese text. Fuji Ren et al. [21–23] proposed some methods by using sentiment topic features to recognize the sentiment orientation of Chinese text over different level, such as words, sentences and documents.
In light of above problems, this paper brings forth a method for identifying sentiment orientations of Chinese texts based on three-way decisions. Sentiment orientations of texts are identified in two stages. First of all, they are classified into acceptance, rejection and delay according to affective characteristics of words. Next, sentiment orientations of Chinese texts delaying decision-making are further identified based on affective characteristics of sentences. Sentiment orientations of Chinese texts are judged by making full use of affective features of words and sentences, so as to reflect connections of these three levels (i.e. words, sentences and texts). The experimental result shows that sentiment analysis of text based on three-way decisions is a satisfactory one.
The structure of this paper is shown as follows: the second part presents a brief introduction of related theory; the third part gives a detailed description of sentiment orientation analysis of text based on three-way decisions; the fourth part describes the experimental process and the result analysis; the final part makes a summary of the full paper.
Related theory
Rough set theory
In 1982, Professor Pawlak, as a Polish scholar, put forward the rough set theory [24]. According to this theory, knowledge is represented and processed based on information forms. The knowledge of research objects is described according to their attributes and their values.
Then, IND (R) is an equivalent relation, a division at U and denoted as U/IND (R).
As a positive domain, POS R (X) is a set of objects that may be definitely included in the set X according to knowledge R . The negative domainNEG R (X) is a set of objects that may be definitely excluded from the set X according to knowledge R . In a sense, the boundary domain BND R (X) is an uncertain domain and means the classification that can’t be clearly defined according to knowledge R is within or beyond the scope of X .
Based on Pawlak’s classical rough set theory, Yao et al. [25, 26] proposed the rough set theory of decision making, made a semantic explanation on the basis of Bayes’ minimum-risk decision rule, depicted the probability domain by two thresholds and provided a practically effective method for threshold calculation. Based on decision acceptance or rejection, decision deferral is introduced into the three-way decisions model, thereby avoiding the losses from direct choice of decision acceptance or rejection.
For any object x ∈ U, it exists in two states, namely meeting or not satisfying given conditions. Thus, the set of objects U may be divided into two subsets, that is
Requirement 1:
Requirement 2:
For any object x ∈ U, the three-way decisions rules are as follows:
Rule A (Acceptance): If P (X| [x]) ≥ α, then x ∈ POS (X).
Rule R (Rejection): If P (X| [x]) ≤ β, then x ∈ NEG (X).
Rule N (Deferral): If β < P (X| [x]) < α, then x ∈ BND (X).
Where, threshold parameters α and β are calculated as follows:
Concerning Rule A, when the probability of x ∈ X is higher than α, acceptable rules may be created for the positive domain, and x may be included in the positive domain of X . According to Rule R, rejected rules will be developed for the negative domain when the probability of x ∈ X is below β, and x will be categorized as a part of the negative domain in X. For Rule N, x will be included in the boundary domain of X in case that the probability of x ∈ X ranges between α and β, while decision deferral means temporarily, no decisions are made.
Three-way decisions are made at the minimum costs. By calculating probability and thresholds of their categories, objects are categorized into positive, negative and boundary domains accordingly, which correspond to decision acceptance, rejection and deferral respectively. Being effective for processing and classifying data to reduce wrong decisions, the three-way decisions model may increase the accuracy of classification.
Sentiment orientation of texts is determined by sentiment characteristics of the basic elements included in text. In other words, sentiment information of words and sentences decide sentiment orientation of texts. Therefore, the core idea of this paper is that sentiment orientation of text is recognized from two different levels: words and sentences, which the three-way decisions model is applied. The detailed analysis procedure is shown here below.
Sentiment orientation analysis of words based on semantic similarity
It is fundamental for analyzing sentiment orientations of texts by identifying sentiment orientations of words and their intensity. In this paper, a method based on Tongyi Cilin [27] and HowNet [28] to determine correlations between unknown words and seed words according to their synonymous relations and semantic similarities, in order to identify sentiment orientations of unknown words and their intensity.
Establishment of sentiment lexion
In this paper, Ren_CECps Chinese sentiment corpus [29, 30] is adopted in the experiment. After processing and labeling 1,487 Chinese blogs, 11,255 paragraphs, 35,096 sentences and 878,164 words are included in Ren-CECps.
In Ren_CECps, all language information of Chines texts associated with sentiment expressions are labeled by hands at three levels, including texts, sentences and words. The sentiment label at the level of words are essential for annotating the whole Chinese sentiment corpus. Specifically, orientation and intensity of sentiments as well as parts of speech are labeled for words and phrases.
All sentiments are divided into eight most basic categories, including surprise, sorrow, love, joy, hate, expect, anxiety and anger. Sentiment types and intensity of texts, sentences and words are represented by an 8-dimension sentiment vector as follows:
The value of e i ranges from 0.1 to 1.0 and indicates sentimental intensity of a basic type of sentiments among the eight categories mentioned above. In this paper, sentiment words are extracted from training sets of Ren-CECps to make up a multi-label sentiment lexicon.
To analyze sentiment orientations of words, synonymous relations between unknown words and seed words of sentiment lexicon are determined by using Tongyi Cilin. If the unknown words are not included in Tongyi Cilin, the semantic similarities between unknown words and seed words shall be further measured by HowNet. In case that the unknown words exist in neither the Tongyi Cilin nor HowNet, the sentiment orientations of these words may be identified by the naive Bayes method introduced here below.
All words included in Tongyi Cilin are arranged in line with a tree-shaped hierarchical structure. In this dictionary, vocabularies are divided into three categories, including 12 in the division, 97 in the group and 1,400 in the class. The structure of Tongyi Cilin is shown in Fig. 1 as follows.
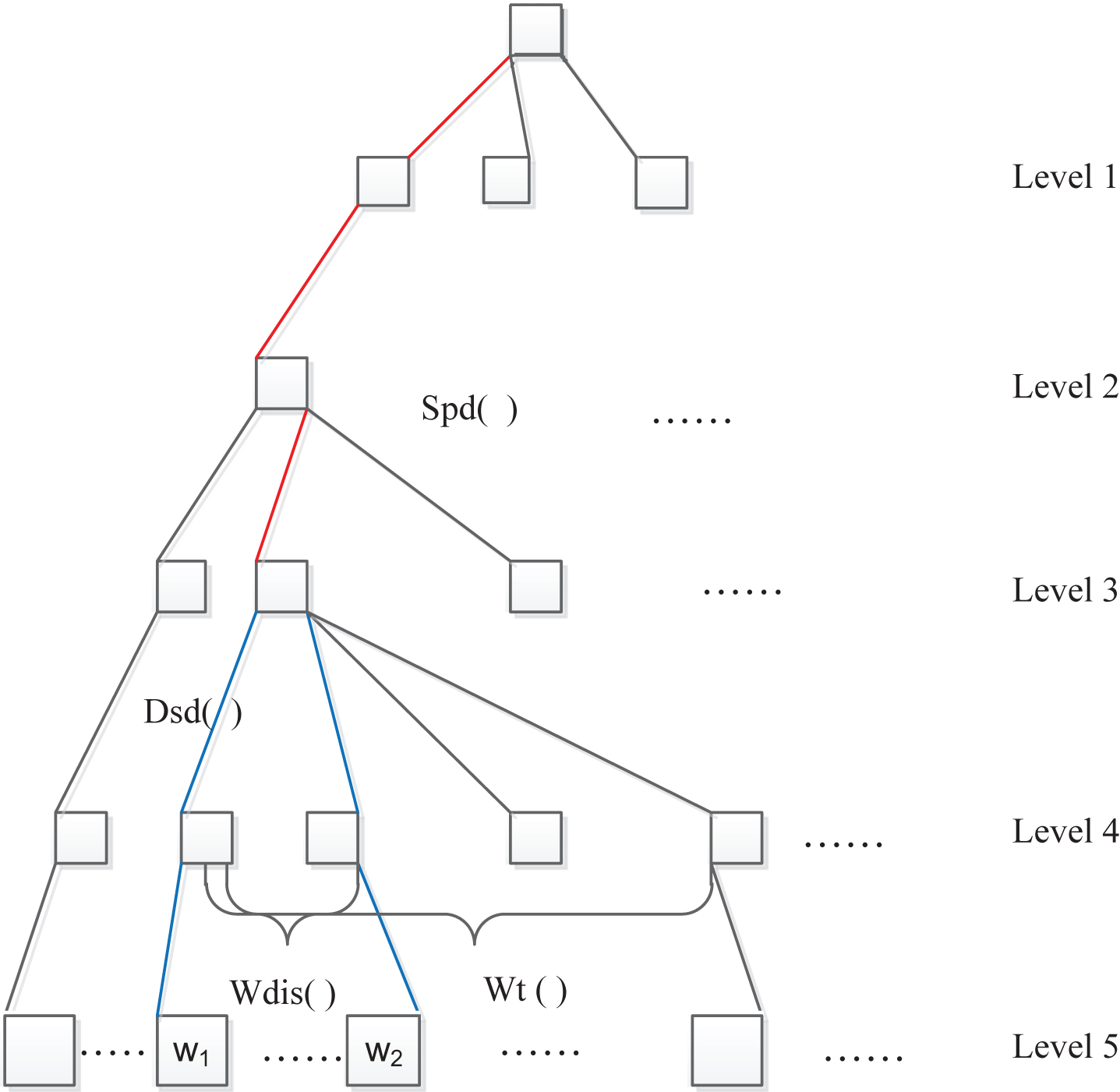
Structure of tongyi cilin.
Based on above definitions, the semantic similarity of w1 and w2 may be conveyed by Formula 8 as follows.
In case that two words w1 and w2 meet following requirements:
w1 and w2 belong to a common category l (w1) = l (w2), the semantic similarity between w1 and w2 may be further represented by Formula (9) as follows:
Where, α is a control parameter, Dnd (w1, w2) is used for measuring differences between w1 and w2, and Cld (Spd (w1, w2) +1) is an empirical parameter that indicates similarity of meaning items between w1 and w2 (i.e. Cld (2) > Cld (3) > Cld (4) > Cld (5)).
When w1 and w2 don’t belong to a common category, or one of them isn’t included in Tongyi Cilin, it will be inadvisable to calculate their semantic similarity by Formula (9), but by the HowNet-based semantic computation method, as shown in Formula 11.
Sentiment orientation of words may be determined by calculating semantic similarity of unknown and seed words. If the unknown words are not included in Tongyi Cilin and HowNet, it will be impossible to judge sentiment orientations and intensity of these words by measuring their semantic similarity. Under this situation, sentiment orientations of the unknown words may be identified by Bayes classifier.
Assuming that w is a sequence composed of several characters (c1, c2, ⋯ , c n ) and each character is characterized as a feature of the word, the probability of its sentiment orientation may be determined by the general expression for calculating the probability that all features belong to a type of sentiment orientations.
Where, P (e = k) may be calculated as follows:
Thus, the naive Bayes classifier may be conveyed as follows:
Model for multi-labeled emotion topic
A further study of Ren_CECps Chinese sentiment corpus shows that there is an inseparable relationship between the sentiments of sentences and the topic features of words. So based on this relationship, a multi-labeled emotion topic model (MLETM) [31–35] is proposed to identify the sentiment orientation of sentence. This model is shown in Fig. 2.
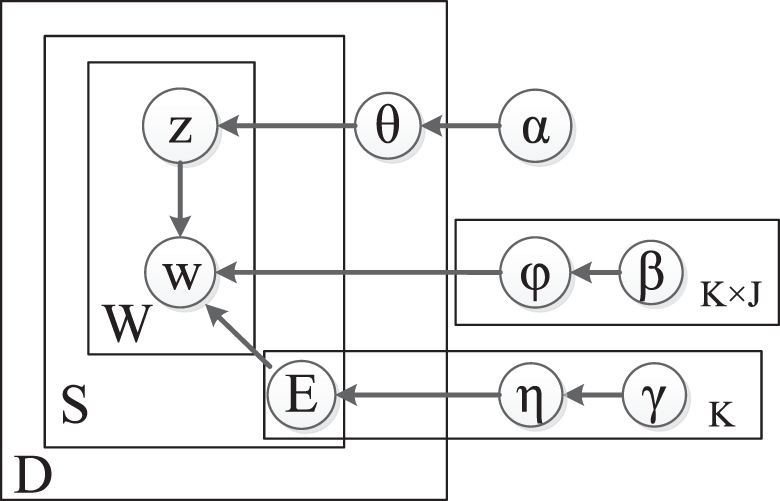
Multi-label emotion topic model (MLETM).
In Fig. 2, node denotes random variable, such as word node w, and directed edge describes the condition dependence between nodes, such as directed edge z → w. In the overall graphical model there are three types of variables: the categorical variable, the proportional variable and the observable variable. E, z and w represent nodes, known as categorical variables. To identify K - Class emotions of sentence in the text, we define K two-dimensional random variables E
dsk
to represent whether Sentence s in Text d has a kth emotion. As the ith word in Sentence s in Text d, w
dsi
is subject to a random distribution of φ → w, and also affected by Topic z and Emotion E. θ, η and φ are proportional variables, which respectively denote the prior probability of E, z and w. θ
d
is a J-dimension vector, and each θ
dj
refers to the prior probability of the jth topic in Text d. η is a K-dimension vector, which describes the prior probability of different sorts of emotions. φ is a K × J × N-dimension vector, which describes the prior probability of word.
According to the definition of MLETM, the directed edge in the model describes the condition dependence between random variables, and in accordance with the condition dependence, we hypothesized the probability.
For each sentence in the text, let there be K emotion classifiers E
dsk
, and suppose E
dsk
is independent from each other, and it affects the probability distribution of Word w together with Topic z
di
. Suppose Word w is subject to the classification distribution of Random Variable φ, and has condition dependence with Emotion E and Topic z; the formulas are shown below:
Support Topic z is a classification distribution of condition dependence variable θ, and the formula is shown below:
Since kth emotion classifiers E
dsk
are independent from each other, suppose E
dsk
are subject to the Bernoulli distribution of Parameter η; the formula is shown below:
For random variable φ, let
K-dimension random variable η is the prior probability of binary class emotion classifier E
dsk
. Suppose η follows Beta distribution, a conjugate distribution of the Bernoulli distribution of Parameter η, and the formula is shown below:
According to graphical model theory, many potential random variables are used to describe the potential characters needing to be predicted; in accordance with the hypothesis on probability distribution and the observable variable, we could derive the value of these potential variables. In MLETM, the value of E
dsk
in each sentence needs to be predicted, which describes the probability for Sentence s in Text d to possess Emotion k; meanwhile, this value has conditional dependence with other variables. The derivation formula is listed below:
Topic z di describes the topic probability distribution of the ith word in Text d. The formula is listed below:
According to the “bag of words” hypothesis, a text is deemed as a set of sentiment words and phrases, which are weighted to identify sentiments. The vector space model of a text may be expressed as D = {w1, w2, …, w
n
}, where n represents number of sentiment words and phrases, and w
i
is the ith sentiment word or phrase. w
i
is denoted by a 8-dimension sentiment vector
In order to facilitate weighting for identifying sentiment category of texts, Formula (26) is rewritten into Formula (27), which may be used for initially identifying sentiment category of text.
The problem on how to distinguish multi-label sentiment orientations of texts is converted into a problem concerning identification of several binary sentiment orientations. Based on three-way decisions, an object d is categorized as certain sentiment category or not. It may be ascribed to that category or excluded from it. Hence, the state set is defined as: Ω = {E k , ¬ E k }, where E k and ¬E k mean the x belongs to or is beyond E k . The action set is defined as: A = {a A , a R , a N }, which represent acceptance, rejection and deferral respectively. Based on experiences, the loss functions are shown in Table 1 as follows.
Loss functions for decisions of two states
According to Table 1, formulas 5 and 6, a pair of thresholds are calculated, α = 0.625 and β = 0.286. Thus, the decision rules are as follows for object d:
Rule A: If P (E k |d) ≥ α, d ∈ POS (E k ).
Rule R: If P (E k |d) ≤ β, d ∈ NEG (E k ).
Rule N: If β < P (E k |d) < α, d ∈ BND (E k )
P (E
k
|d) is calculated as follows:
When the object d adopts deferral rules, it means the object d is impossible to directly judge the emotion E k or not by weighing sentiment words. Then sentiment information of sentences in a text may be acquired by MLETM, and sentiment orientations of texts may be further discriminated based on sentiment characteristics of sentences.
For the object d delaying decision-making, a threshold θ is set according to sentiment characteristics of sentences, and handled as follows: If the emotional equivalence class proportion of the sentences with Emotion E
k
in Text x is equal or greater than θ, we judge that Text x has Emotion E
k
. If the emotional equivalence class proportion of the sentences with Emotion E
k
in Text x is less than θ, we judge that Text x doesn’t have Emotion E
k
.
The multi-label sentiment analysis framework of Chinese texts is illustrated in Fig. 3. Training process is in the left and testing process is in the right side. Moreover, sentiment lexicon, MLETM model and three-way decisions model are used to identify the multi-label sentiment orientation of Chinese texts. The judgment of the sentiment orientation of text falls into 6 steps, with more detail asfollows:
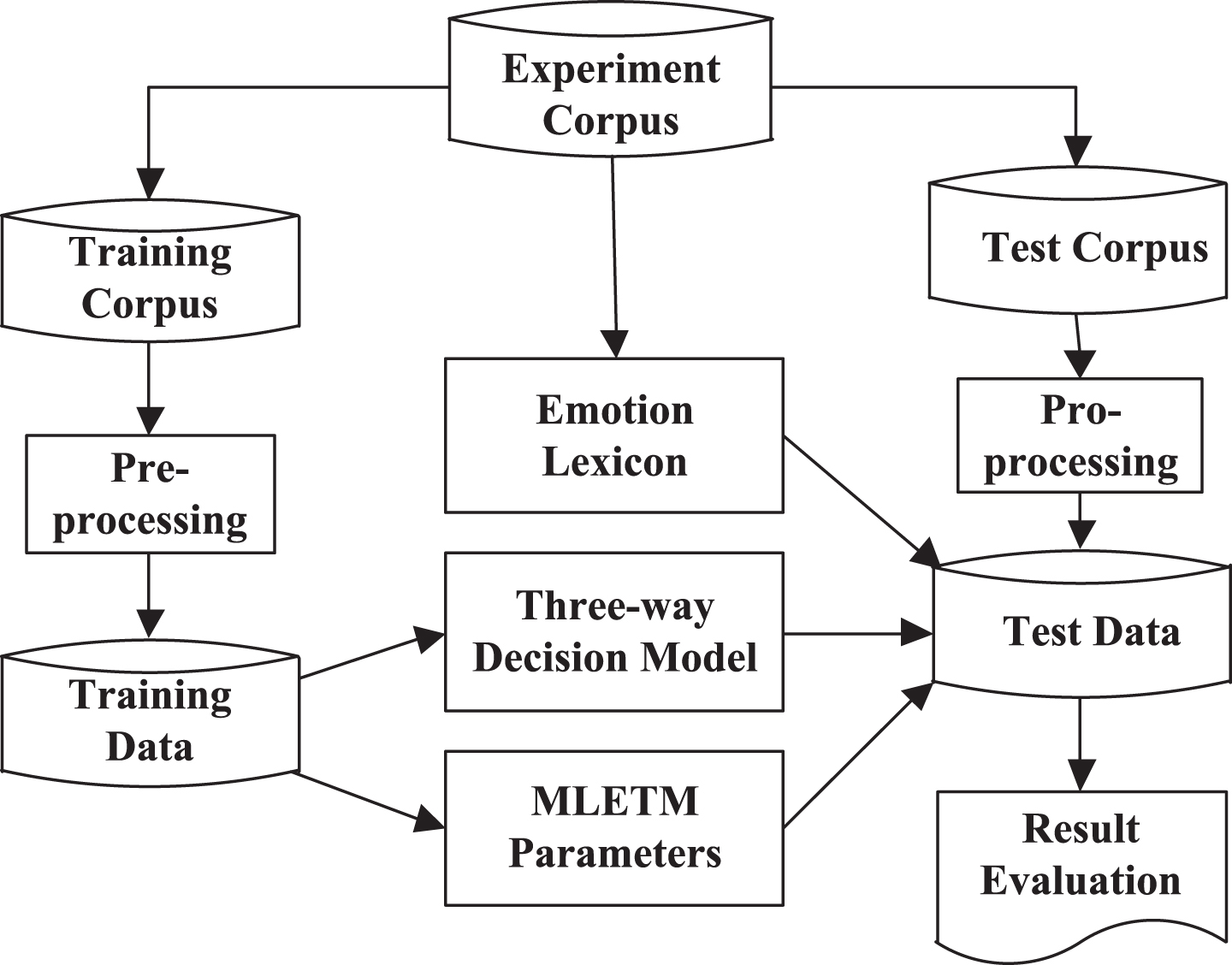
Multi-label text emotion analysis framework.
Experiment data
In this experiment, 1,000 blogs are randomly selected from Ren_CECps as experimental dataset, where each blog is tagged as a subset of 8 categories of sentiment (including surprise, sorrow, love, joy, hate, expect, anxiety and anger). The distribution of sentiment orientations of texts is shown inTable 2.
Distribution of sentiment orientations for texts
Distribution of sentiment orientations for texts
Pre-processing of the data set: 1) remove a few sentences without any emotion out of data set; 2) Remove the stop words out of all the sentences. 3) 800 documents of the dataset make up a training set, while the testing set is composed of the remained 200 documents.
The experiment in the paper is aimed at recognizing the multi-label sentiment orientations of texts, and the experiment result is evaluated with a label-based evaluation method [36, 37]. For some single label k, formula M (tp
k
, tn
k
, fp
k
, fn
k
) is used to evaluate the classification result. In the formula, tp
k
denotes correct identification of the number of the texts with emotion label k, tn
k
denotes correct identification of the number of the texts without emotion label k, fp
k
denotes false identification of the number of the texts with emotion label k, and fn
k
denotes false identification of the number of the texts without emotion label k. The macro-average and micro-average formulas of multi-labeled classification are listed as follows:
A method is developed for identifying sentiment orientations of texts according to affective features of words and sentences in combination with the thoughts of three-way decisions. The parameters of three-way decisions models may be set as: α = 0.625, β = 0.286 and θ = 0.5. All the above parameters are empirical values obtained from the training data set.
A multi-label sentiment recognition experiment on text is compared with Naive Bayes Method, sentiment lexicon method and the method based on three-way decisions respectively. Table 3 illustrates the macro-average and micro-average value in the three methods. The experimental result in Table 3 fully shows the superiority of the method based on three-way decisions in sentiment identification of texts.
Comparison of multi-label sentiment recognition
Comparison of multi-label sentiment recognition
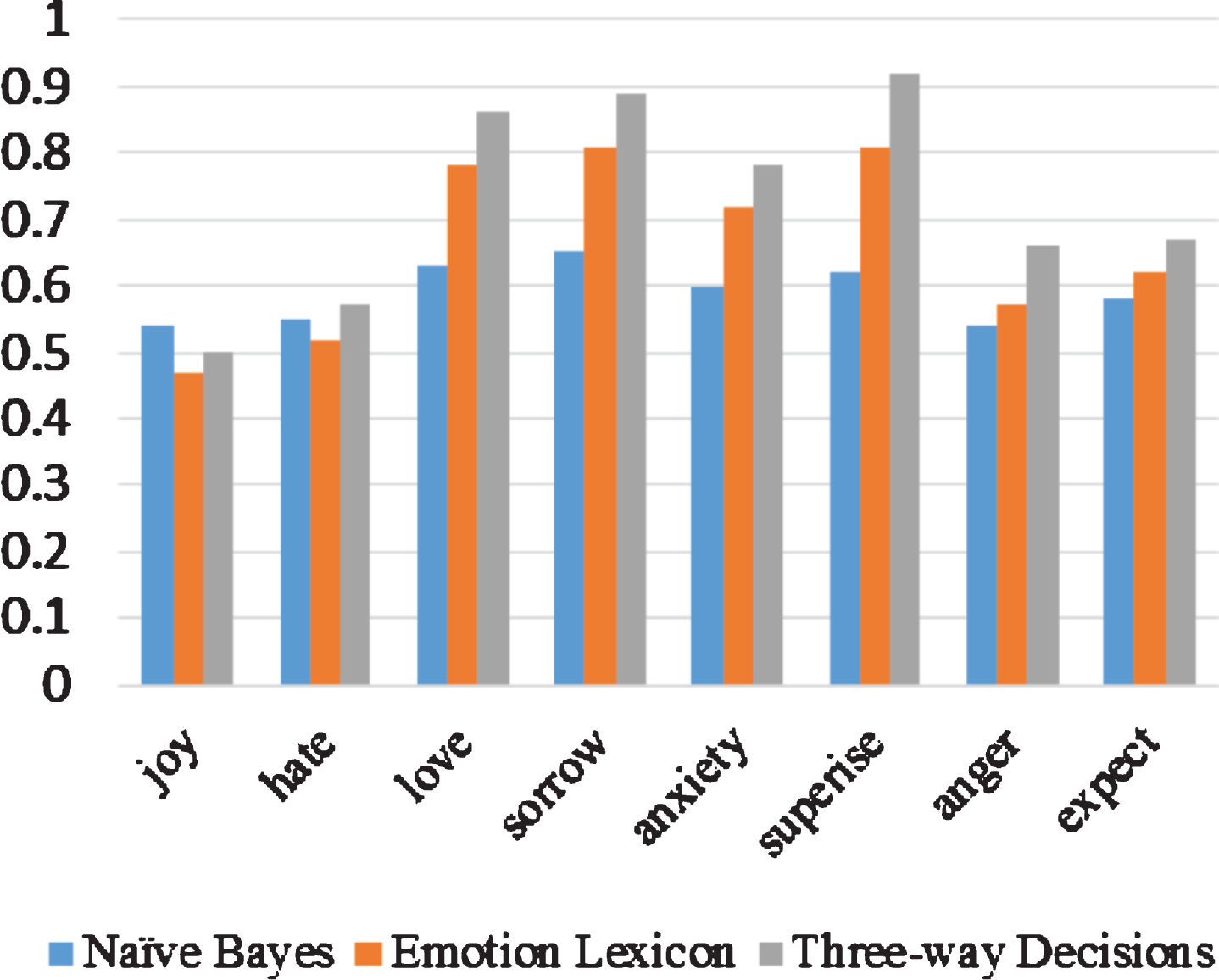
As shown in Fig. 4, the accuracy for identifying six basic sentiment orientations (including love, sorrow, anxiety, surprise, angry and expect) is higher than the accuracy for identifying joy and hate. The accuracy for identifying hate is low, fewer tests with sentiment orientation of hate are collected in corpus. As a consequence, models are not adequately trained, thereby impacting the accuracy of identifying hate.
A comparison of 8 basic sentiment orientation.
8 categories of basic sentiment orientations are identified by three different methods and corresponding experimental results are also shown in Fig. 4, from which it may be found that the three-way decisions method is advantageous in identifying a majority of sentiment orientations.
In this section, a discussion is made to evaluate the results of our experiments and find the factors which influence the result of the multi-label sentiment recognition of Chinese texts.
The good results of the experiments show that our method in recognizing the multi-label sentiment orientation of texts is better than Naïve Bayes and sentiment lexicon method in Table 3 and the accuracy of the single-label sentiment orientation of 8 basic category is over 50 percent in Fig. 4. But all of the above shows that the emotion of human beings is so complicated and the performance of experiments also have space to improve in the future. It inspires us to study new methods and find more meaning sentimental information to improve the performance of our model. It is another important factor that sentiment distribution is not balance in corpus, so that it influences the sentiment recognition of text and some sentiment orientations of text can’t be identified precisely, as shown in Fig. 4. It is a difficult and tough task for us in the future.
Conclusion
We made an intensive study on the problem of multi-label sentiment analysis and proposed a three-level (word, sentence and text) multi-label sentiment analysis method based on three-way decisions model. Ren_CECps Chinese emotion corpus is adopted for the experiment in the paper.
The method proposed in the paper for analyzing sentiment orientations of Chinese texts based on three-way decision identifies the sentiment orientations by fully taking advantage of affective features of words and sentences. The experimental results prove the superiority of this method. The method for analyzing sentiment orientations of texts based on three-way decisions takes affective features of words and sentences into account to jointly discriminate the orientations, which solve the problem regarding loss of sentiment information between levels. The risk cost is introduced into the decision making, so it is necessary to seek appropriate thresholds for making decisions, in order to adopt different decision making rules for texts.
At present, WeChat has become the most common online social media with great value for research and application in identifying sentiment orientations of texts. WeChat texts are mostly concise with fewer words and sentences, but rich sentiments, flexible structures and often special sentiment symbols of the internet. Therefore, it is somewhat challenging to identify diversified and complex sentiment orientations of WeChat texts by efficiently and accurately exacting affective features from them.
Footnotes
Acknowledgments
This research has been partially supported by National Natural Science Foundation of China under Grant No. 61432004, and JSPS KAKENHI Grant Number No. 15H01712.