
Abstract
Feature selection is one of the key problems in machine learning and data mining. It involves identifying a subset of the most useful features that produces compatible results as the original entire set of features. It can reduce the dimensionality of original data, speed up the learning process and build comprehensible learning models with good generalization performance. Nowadays, ensemble idea has been used to improve the performance of feature selection by integrating multiple base feature selection models into an ensemble one. In this paper, in order to improve the efficiency of feature selection in dealing with large scale, high dimension and imbalanced problems, a Min-Max Ensemble Feature Selection (M2-EFS) is proposed, which is based on balanced data partition and min-max ensemble strategy. The experimental results demonstrate that the M2-EFS can obtain higher performance than other classical ensemble methods in most cases, especially for large scale, high dimension and imbalanced data.
Introduction
Feature selection is an important preprocessing step in many machine learning applications, and it is often used to find the smallest subset of feature that maximally increases the performance of following learning model. Besides maximizing model performance, other benefits of applying feature selection include the ability to build simpler and faster models using only a subset of all features, as well as gaining a better understanding of the insight of data [1]. Feature selection techniques can be divided into three categories depending on how they interact with classifier. Filter methods directly operate on the data set, and provide a feature weighting, ranking or subset as output. These methods have the advantage of being fast and independent of the classification model, but at the cost of inferior results. Wrapper methods perform a search in the space of feature subsets, guided by the outcome of the model (e.g. classification performance on a cross-validation of the training set). They often report better results than filter methods, but at the price of an increased computational cost [2]. Finally, embedded methods use internal information of the classification model to perform feature selection (e.g. use of the weight vector in support vector machines). They often provide a good trade-off between performance and computational cost [1–3]. We have reviewed the recent advances of feature selection in survey paper [4].
Nowadays, the growth of the high-throughput technologies has resulted in exponential growth in the harvested data with respect to both dimensionality and sample size. Efficient and effective preprocess for these data becomes increasing important and challenging, and traditional feature selection is impractical for these data [5]. We will solve the feature selection problem of large scale imbalanced data efficiently using the ensemble idea. The ensemble feature selection involves creating a set of different base feature selectors and aggregating the results of all base feature selectors. There are three categories of methods for generating base feature selectors: one is to use Bootstrap strategy on the original data sets to obtain many data subsets, and then train different base feature selectors on these data subsets [6–11]. Another is to train base feature selectors using different feature selection algorithms on the original data set [12], or obtain different base feature selectors using a feature selection algorithm based on random strategy, such as genetic algorithm, random forward backward search. The last one is the combination of Bootstrap strategy and different feature selection algorithm [13]. The ensemble strategy for base feature selection results depends on the output type of feature selection [14]. For example, if the output is feature weights or feature ranking, the outputs of base feature selection will be summed by the linear combination method, and then to reorder the feature based the obtained feature weights or the ranking value and to obtain the final ensemble result [9–11]. If the output of feature selection is feature subset, the voting method will be used. That is to say, the times of feature being selected by base feature selection is counted, and then the final ensemble result is the feature subset with top largest number. The ensemble methods mentioned above are ineffective for the large-scale imbalanced data set. In this paper, the Min-Max Ensemble Feature Selection (M2-EFS) is proposed where the base feature selectors are produced based on data partition and the results are integrated by min-max strategy. M2-EFS can efficiently handle both large scale and imbalanceddata.
This paper is the expand of our previous work [15]. The rest of this paper is organized as follow. Section 2 introduces the proposed method M2-EFS. Section 3 presents the experimental results to show the effectiveness of our approach. Section 4 concludes this paper.
Min-Max ensemble feature selection M2-EFS
Nowadays, ensemble idea has been used to improve the performance of feature selection. Same to the ensemble models for supervised learning, there are two essential steps in ensemble feature selection: Creating a set of different base feature selectors with outputs and aggregating the results of all feature selectors. Each feature selector is always learned from a bootstrapped sample subset of original data. Some classical bootstrap strategies are bagging, random-based and equal-based, et al. The well-known aggregation strategies are voting,K-median, mean weight, and so on. However, these traditional ensemble feature selections did not consider the large scale imbalanced problem. To address the large scale and imbalanced issues, we propose a Min-Max Ensemble Feature Selection (M2-EFS) that consists of data partition and Min-Max ensemble strategy.
Data partition
Before the introduction of data partition, some notations used in this paper will be introduced. We use X = (x1, y1) , (x2, y2) , . . . , (x
n
, y
n
) to denote a data set X containing n samples. The k-th sample in X is
The main idea of data partition in M2-EFS is as follows. Suppose the original data set X is a binary classification problem consists of positive class X+ with label +1 and negative class X- with label -1.
Then, for large scale and imbalanced binary classification problem, we firstly divide X+, X- into N+, N- data blocks respectively. To achieve it, random based method, hyper plane based method and clustering based method can be used [17]. The results of partition is described as (2), (3),
After the partition, we will merge positive data blocks and negative ones above to obtain N+ × N- data subsets T, as shown in (4).
Now, we have introduced the partition of original data set. Then, for imbalance data sets, we could adjust the block number N+ or N- to generate a balance training sample subset Ti,j, i.e., the number of positive samples
For large scale imbalanced data processing, the data partition above usually divides the large scale imbalanced problem into several small balanced sub-problems. For each sub-problem, feature selection can be implemented independently. Therefore, M2-EFS could easily deal with each independent sub-problem in a parallel way and finally achieve the process of large scale problem. The time complexity of this part depends on the data partition strategy. For example, the time complexity of random partition strategy is O (n).
For N+ × N- training sample subset, classical feature selection algorithm is learned on each subset Ti,j and output N+ × N- base feature selection results. Suppose each base feature selection result is feature weighting as in (6).
The rule of minimal ensemble unit-MIN is to take the minimum weight value of each feature in different base feature selection results. These base feature selection results are derived from the training subsets containing the same positive samples and different negative samples. The rule of maximum ensemble unit-MAX is to take the maximum weight value of each feature in different feature selection results after the MIN operation. For this ensemble strategy, the time complexity is O (N+N-).
Now, we are at position to summarize the framework of M2-EFS and present its pseudo code, which are shown in Fig. 1 and in Algorithm 1, respectively.
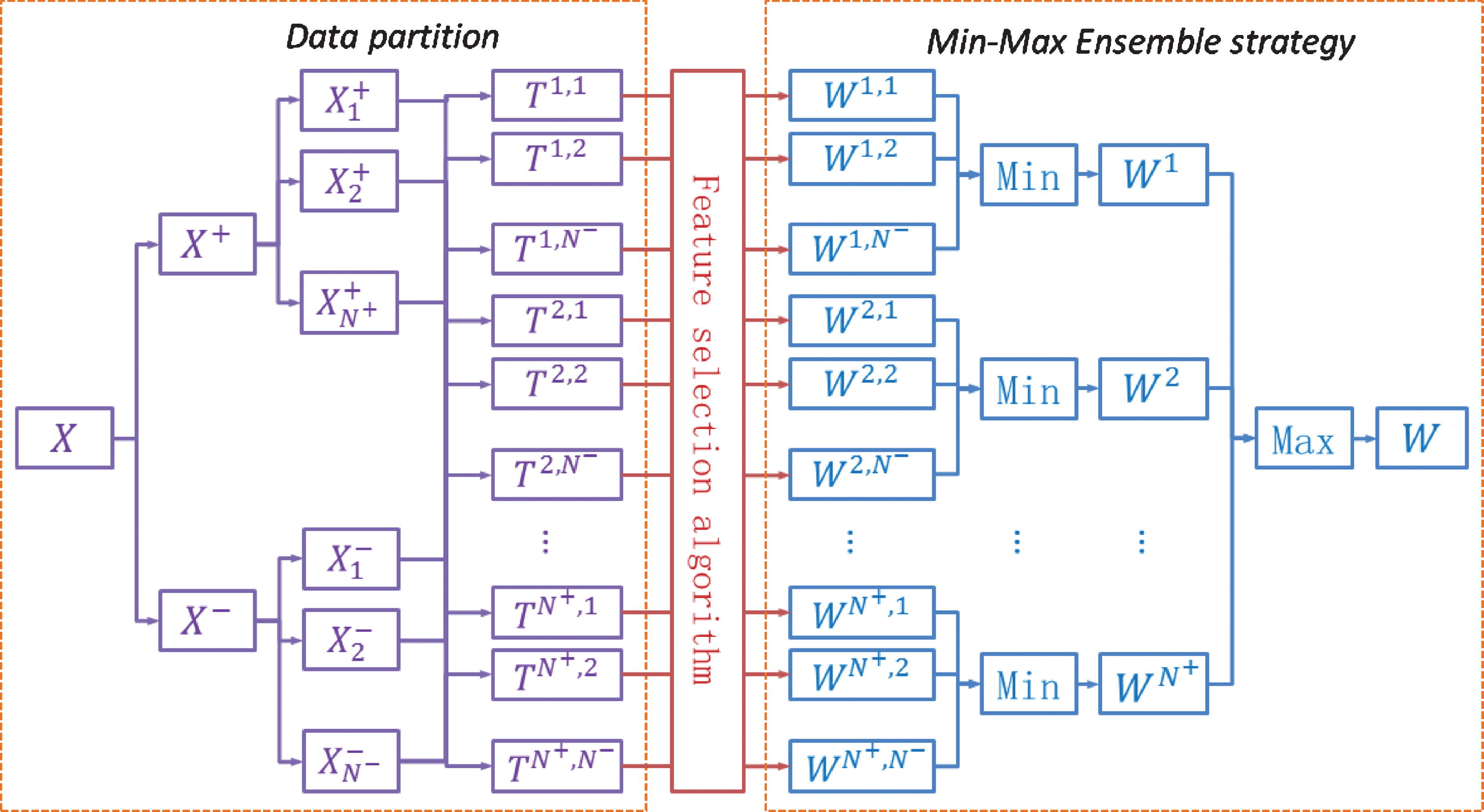
Min-Max Ensemble Feature Selection-M2 EFS model.
M2-EFS is similar to the integration of sampling methods with ensemble learning. However, both the sampling and the ensemble strategy of M2-EFS are quit different from others. The sampling of M2-EFS is task decomposition, instead of under-sampling the majority classes or over-sampling the minority classes for imbalanced data set. And the ensemble of M2-EFS is through a specially designed Min-Max network, different from the commonly used weighted voting or linear combination.
(1) Data partition phase:
(a) Compute N- using Equation (5).
(b) Transform X into binary classification X+, X-, and divide X+, X- using P
(c) For i = 1: N+
For j = 1: N-
End
End
(2) Min-Max ensemble phase:
(d) For i = 1: N+
For j = 1: N-
Wi,j = F (Ti,j)
End
W i = MIN (Wi,1, Wi,2, . . . , Wi,N-)
End
(e) Output W = MAX (W1, W2, . . . , W N + )
Both M2-EFS and other integration methods of sampling and ensemble can convert imbalanced data into balanced, thus eventually solve the imbalanced learning problem. However, M2-EFS has a notable merit of parallel learning, which is precise in facing large-scale data sets. The modules in M2-EFS are independent thus they can be learned individual, while the modules in Adaboost must be generated sequentially.
Experiments and results analysis
We like to evaluate M2-EFS on various data sets. Some common data sets are used to verify the effectiveness of the M2-EFS. Moreover, Internet traffic data set is also used to evaluate M2-EFS on large scale and imbalanced scenario.
Preliminary knowledge
Data sets
Five data sets are used in this experiment. Four data sets names, the size of each data set and their sizes of attribute are shown in Table 1. The PcMac is the data set about text recognition, the HIVA is a medical experimental data and the GINA is a data set about image identification. These three data sets are small scale with high dimensions. In addition, the HIVA is more imbalanced than other two. And the fourth data set Adult is large scale, low dimension and imbalanced [18, 21].
The summary of common data sets
The summary of common data sets
We also validate the performance of M2-EFS on Internet traffic data set, which is provided by A.W. Moore et al. in [22]. It consists of 20000 samples, 29 key features and 6 classes. This data set is not only large scale, but imbalanced rate is very high. The number of samples in some categories account for only 5% or less, which will result in severe under-fitting. The class names, the size of each class and their sample proportions are shown in Table 2. The training set and test set have been presented in [22], so we directly used them in the experiments.
The description of imbalanced Internet traffic data set
For imbalanced problem, the correct classification of minority class should be paid more attention. Then G-Mean metric is widely adopted in imbalanced classification, which treats the classification accuracy of each class equally. The G-Mean metric is defined as follows,
As introduced in Section 2, the traditional feature selection algorithm should be chosen to produce the base feature selector in ensemble feature selection. In our case, two well-known feature selection algorithms, i.e., Fisher score [23] and Relief [24], are utilized. Both of them belong to filter model with lower time complexity, and they are suitable for high dimensional data. The outputs of Fisher score and Relief are feature weights.
Fisher score is one of the most widely used feature selection methods. The key idea of Fisher score is to find feature weights such that in the data space spanned by the weighted features, the distances between data points in different classes are as large as possible, while the distances between data points in the same class are as small as possible. Then the criterion for Fisher score prefers features that have similar values for the samples from the same class and different values for the samples from different classes. Feature weights are obtained by computing the deviation of each feature from its mean value on all classes.
The Relief algorithm is considered one of the most successful feature selection algorithms due to its simplicity and effectiveness. The key idea of Relief is to iteratively estimate feature weights according to their ability to discriminate between neighboring samples.
Experimental results
M2-EFS is originally designed for two-class feature selection. For the multi-class problem in Internet traffic classification, the “one versus one” strategy is adopted to transform it into some binary problems. One class is considered as positive class, and the other one is considered as negative class. In our experiments, we will present the results of different ensemble strategies comparison on the data sets shown in Table 1 and Internet traffic data set, different ensemble feature selection algorithms comparison on Internet traffic data set and different strategies comparison for dealing with imbalanced problem on Internet traffic data set. For Internet traffic data set, to ensure the balanced training subset after data partition, the number of division blocks for each class are listed in last column (from left to right) of Table 2. 10-cross validation is adopted in the experiments. SVM [19] is utilized to classify the samples after feature selection, where its sigmoid value is set to 2, the loss function C is set to 32 and the SMO algorithm is used to calculate the parameters.
Validation of ensemble strategies
After data partition by hyper plane (HP), three ensemble strategies (i.e., Min-Max strategy, voting and K-median) are used to integrate the results of base feature selection trained on each block. The K-median clustering ensemble strategy is mainly based on the idea to choose K representative results from all base feature selection results as its output. In our case, only one representative result is needed, then K = 1. Voting method is to compute the frequency of each feature being selected from each base feature selection result.
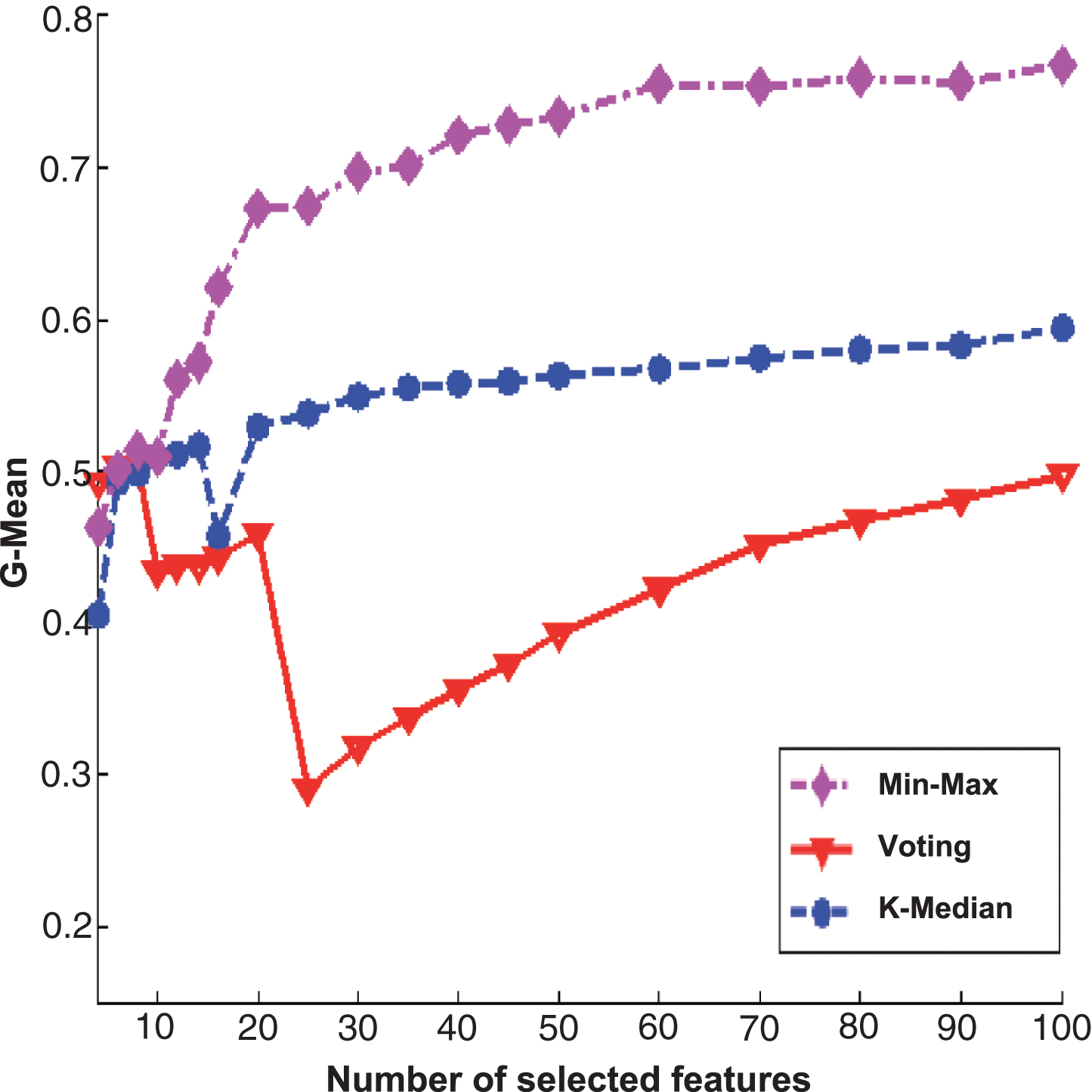
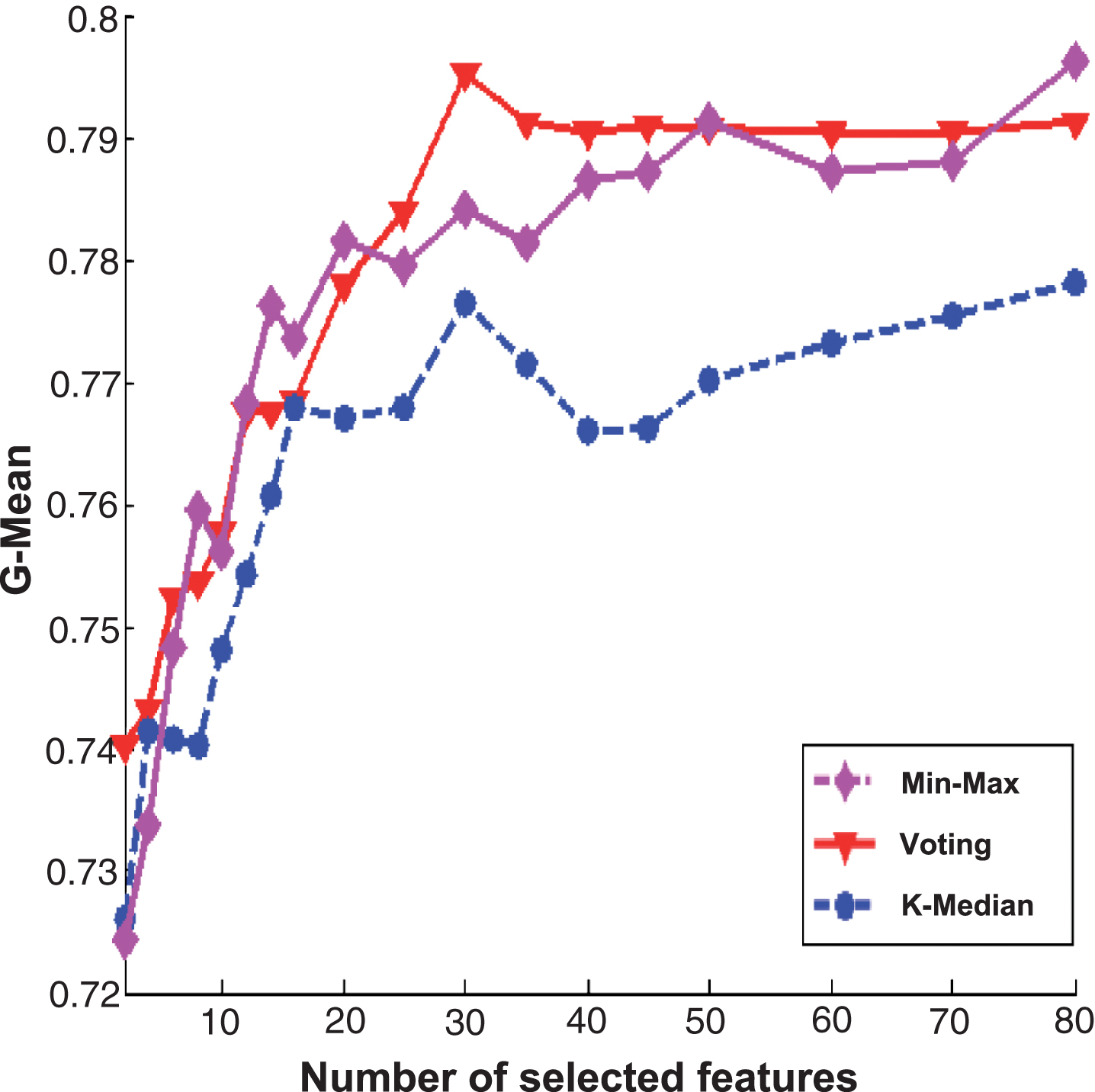
Figures 2 and 3 are the experimental results of PcMac data set, Figs. 4 and 5 are the results of GINA data set, Figs. 6 and 7 are the results of HIVA data set, Figs. 8 and 9 are the results of Adult data set. For feature selection algorithms, Figs. 2, 4, 6 and 8 show results for the Fisher score, while Figs. 3, 5, 7 and 9 are the experimental results for Relief algorithm. The X-axis is the number of selected features, and Y-axis is the G-Mean value. From the experimental results, we can observe that the performance of Min-Max ensemble strategy is better or similar to others in most cases. For the HIVA data set, the Min-Max strategy has obvious advantages compared to other ensemble strategies in the low dimensional space. This result should be attributed to the imbalanced property of the data set. When Relief is used as base feature selection algorithm, the Min-Max strategy has obvious advantages compared to other ensemble strategies in any number of selected feature space. However, for the Adult data set, the advantage of the Min-Max ensemble strategy is not obvious, which might be rooted in the low dimensions of the data set.
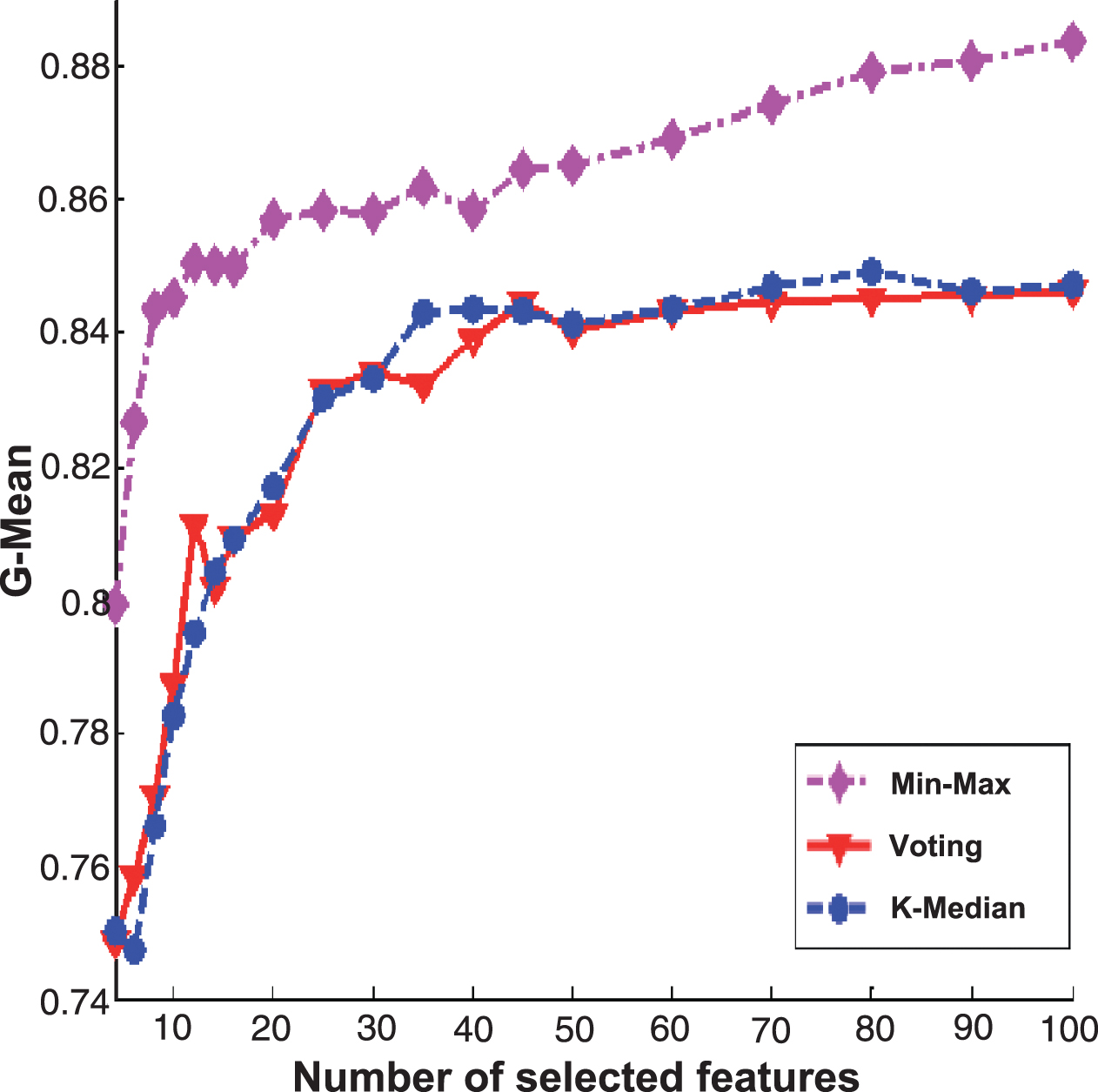
The experimental results of three ensemble strategies after data partition for Fisher score feature selection algorithm on PcMac data set.
The experimental results of three ensemble strategies after data partition for Relief feature selection algorithm on PcMac data set.
The experimental results of three ensemble strategies after data partition for Fisher score feature selection algorithm on GINA data set.
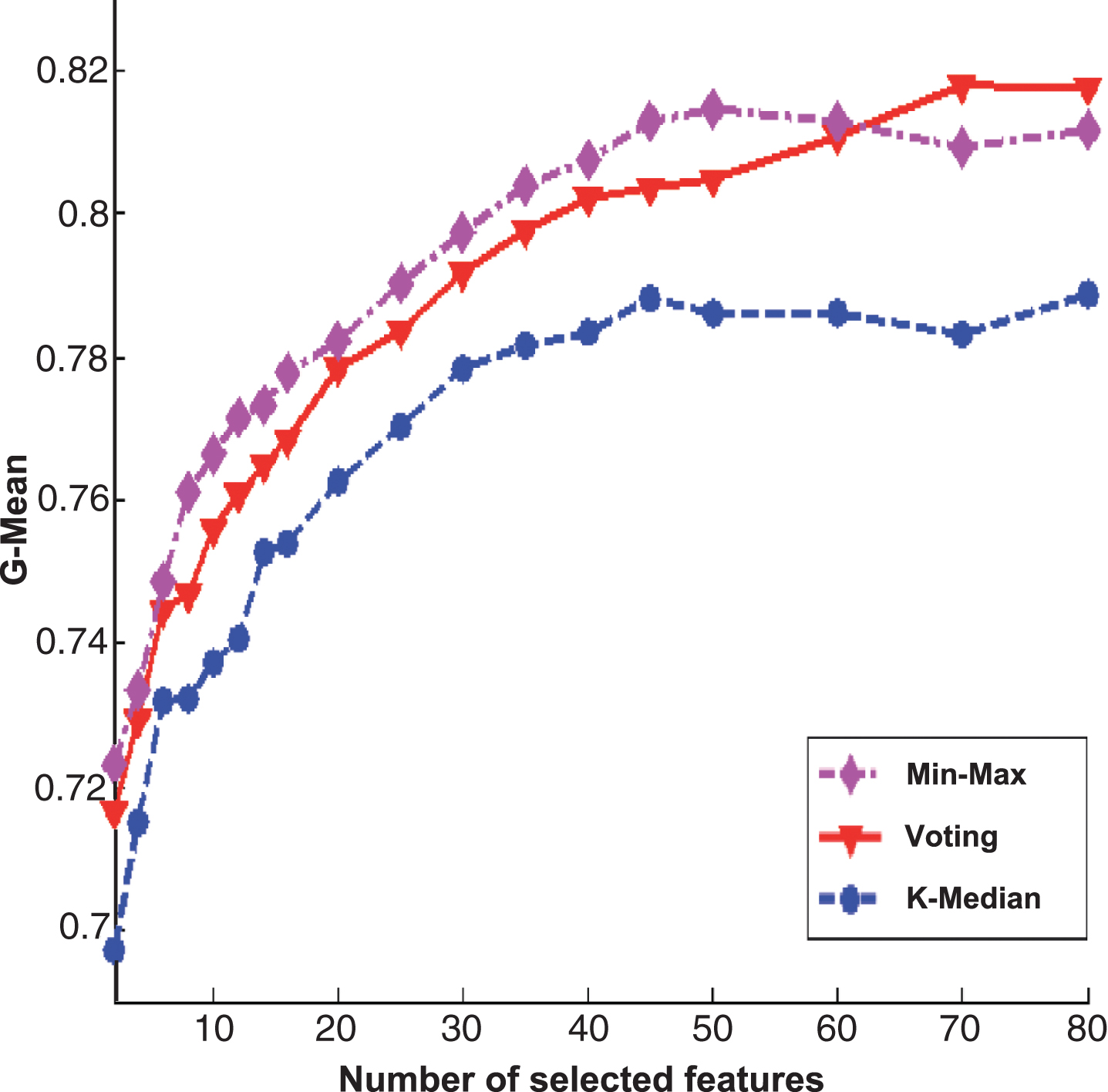
The experimental results of three ensemble strategies after data partition for Relief feature selection algorithm on GINA data set.
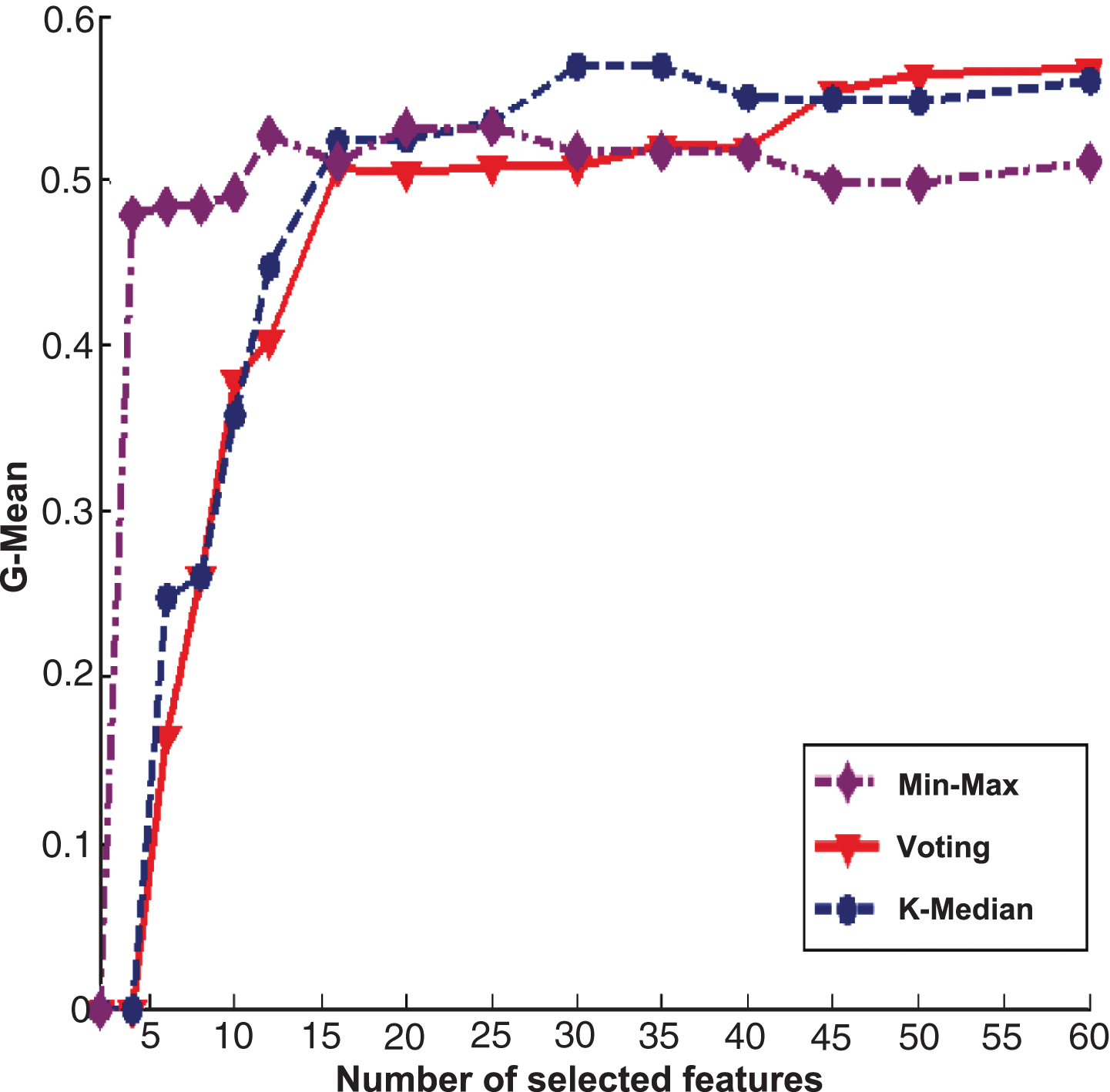
The experimental results of three ensemble strategies after data partition for Fisher score feature selection algorithm on HIVE data set.
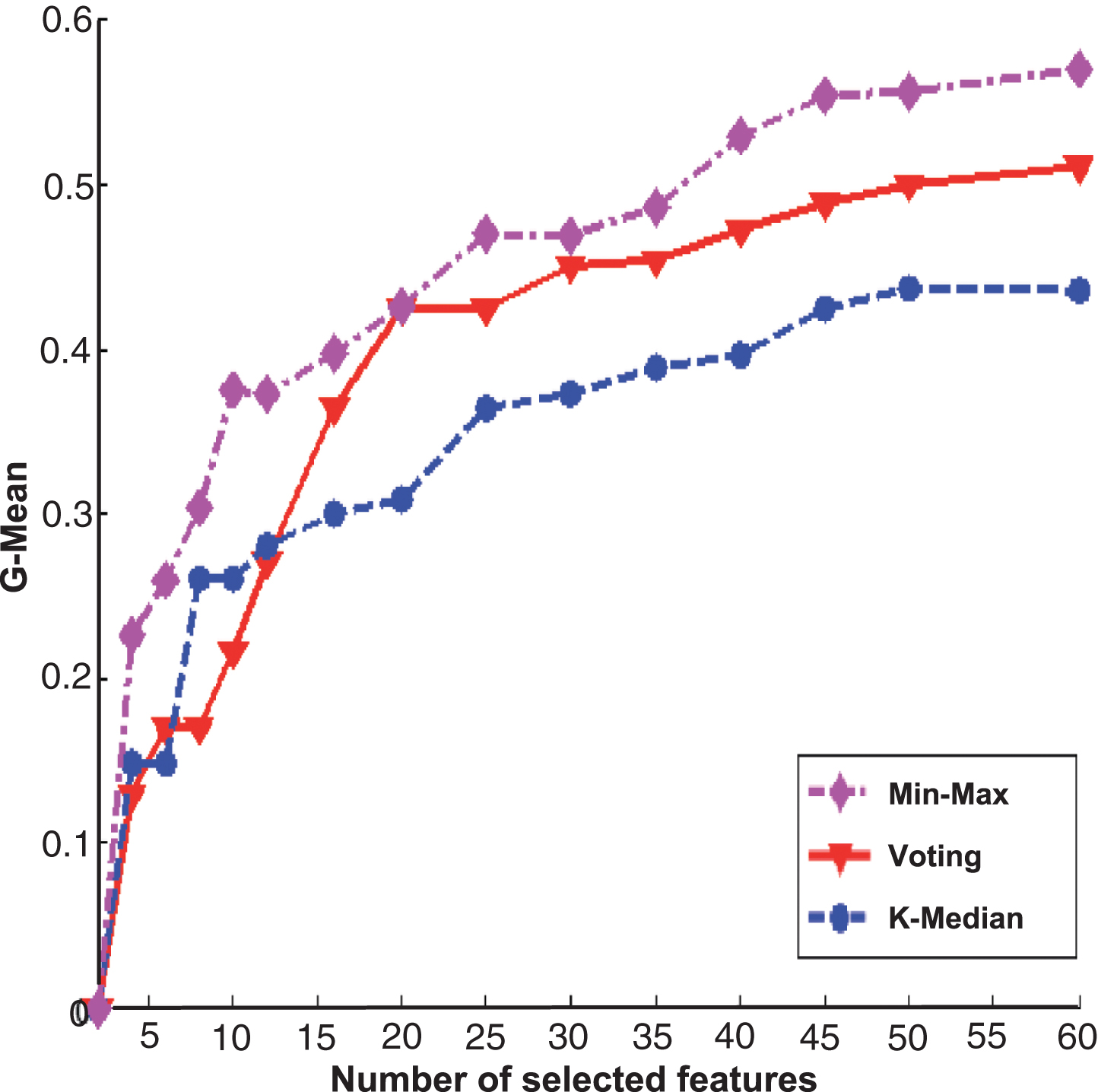
The experimental results of three ensemble strategies after data partition for Relief feature selection algorithm on HIVE data set.
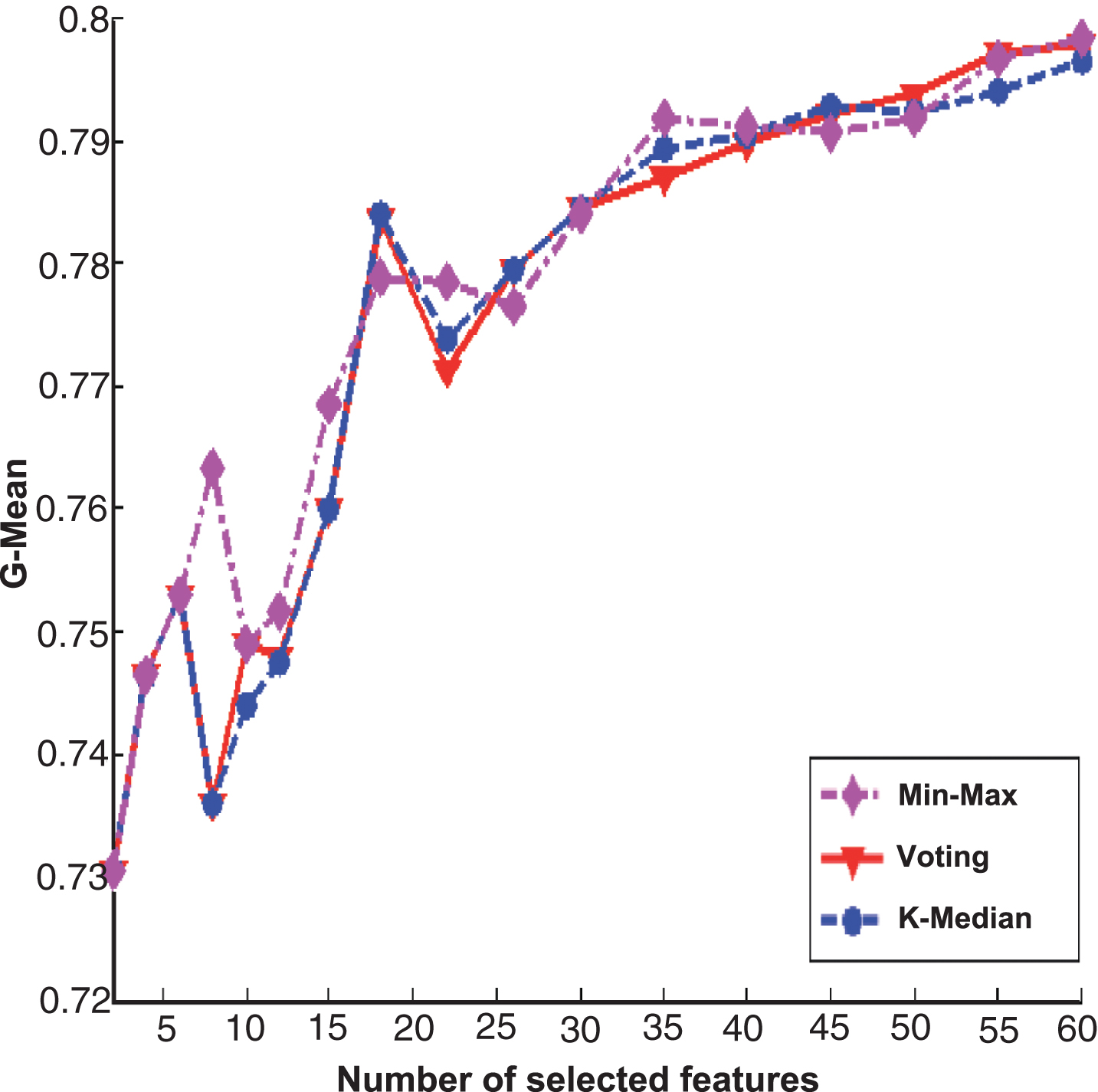
The experimental results of three ensemble strategies after data partition for Fisher score feature selection algorithm on Adult data set.
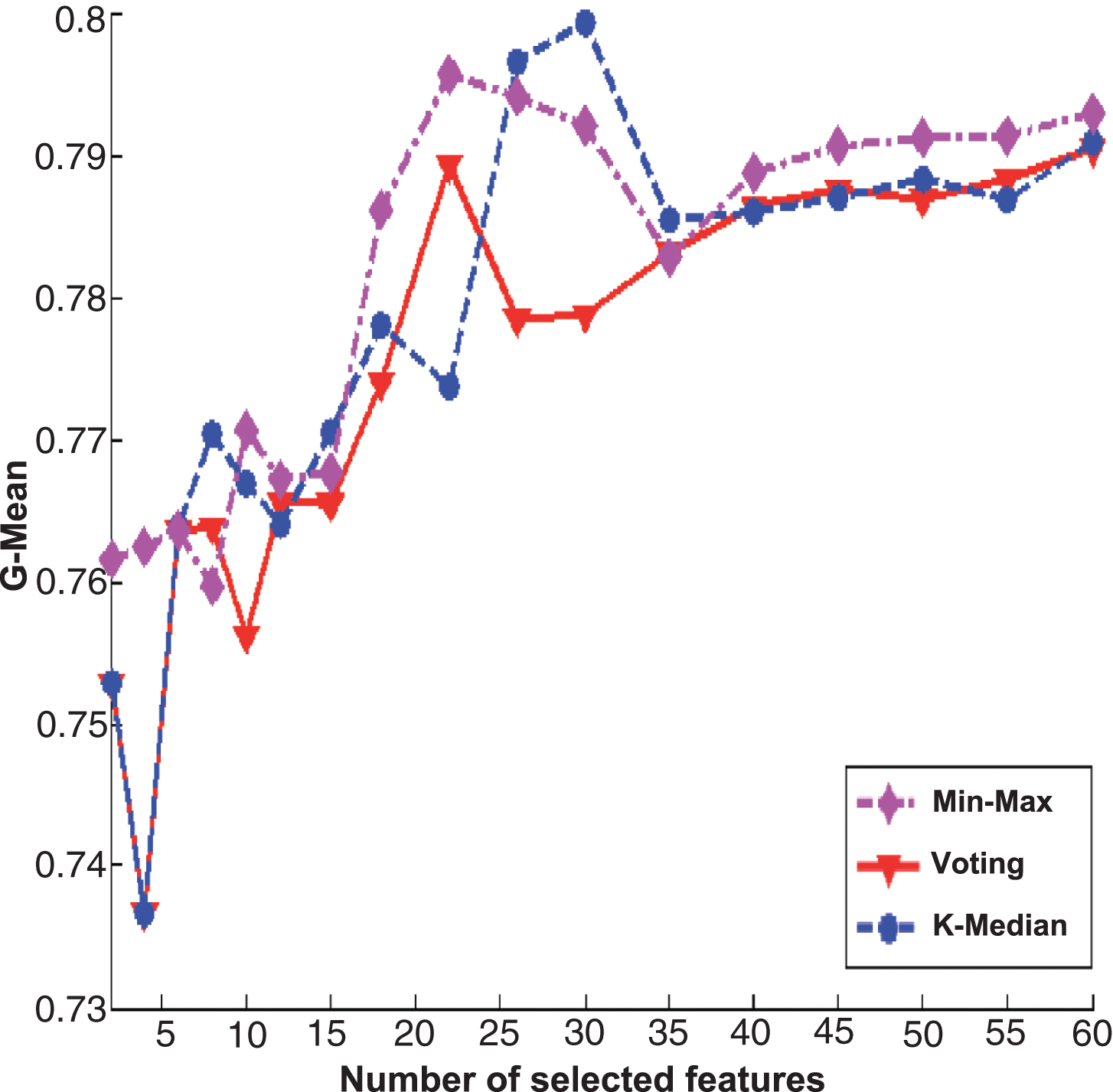
The experimental results of three ensemble strategies after data partition for Relief feature selection algorithm on Adult data set.
On the other hand, the same experiments are also conducted on Internet traffic data set. Figure 10 shows the results for the Fisher score algorithm, while Fig. 11 is the experimental results for Relief algorithm. From the experimental results, we also can observe that the performance of Min-Max ensemble strategy is better or similar to others in most cases.
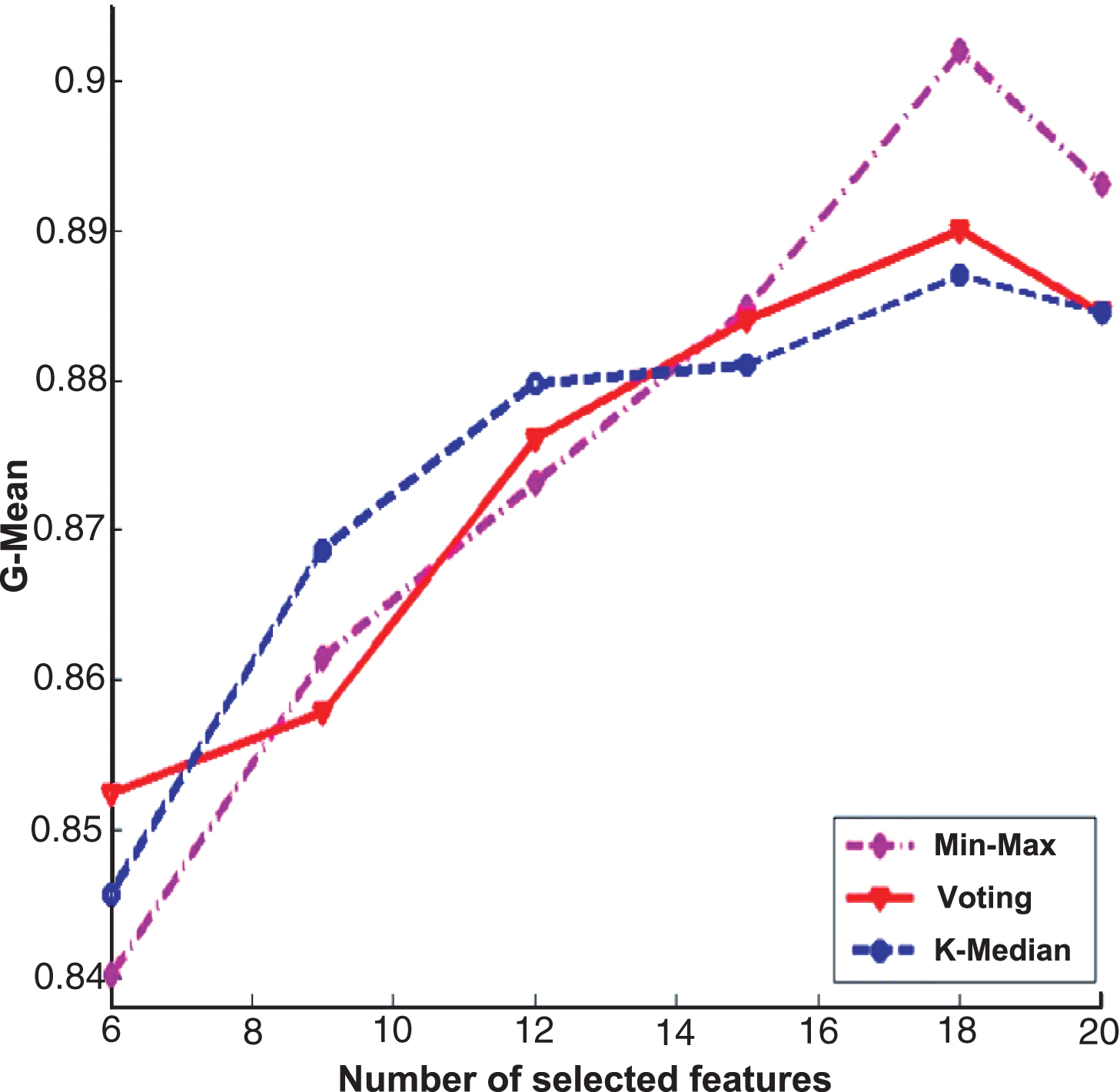
The experimental results of three ensemble strategies after data partition for Fisher score feature selection algorithm on Internet traffic data set.
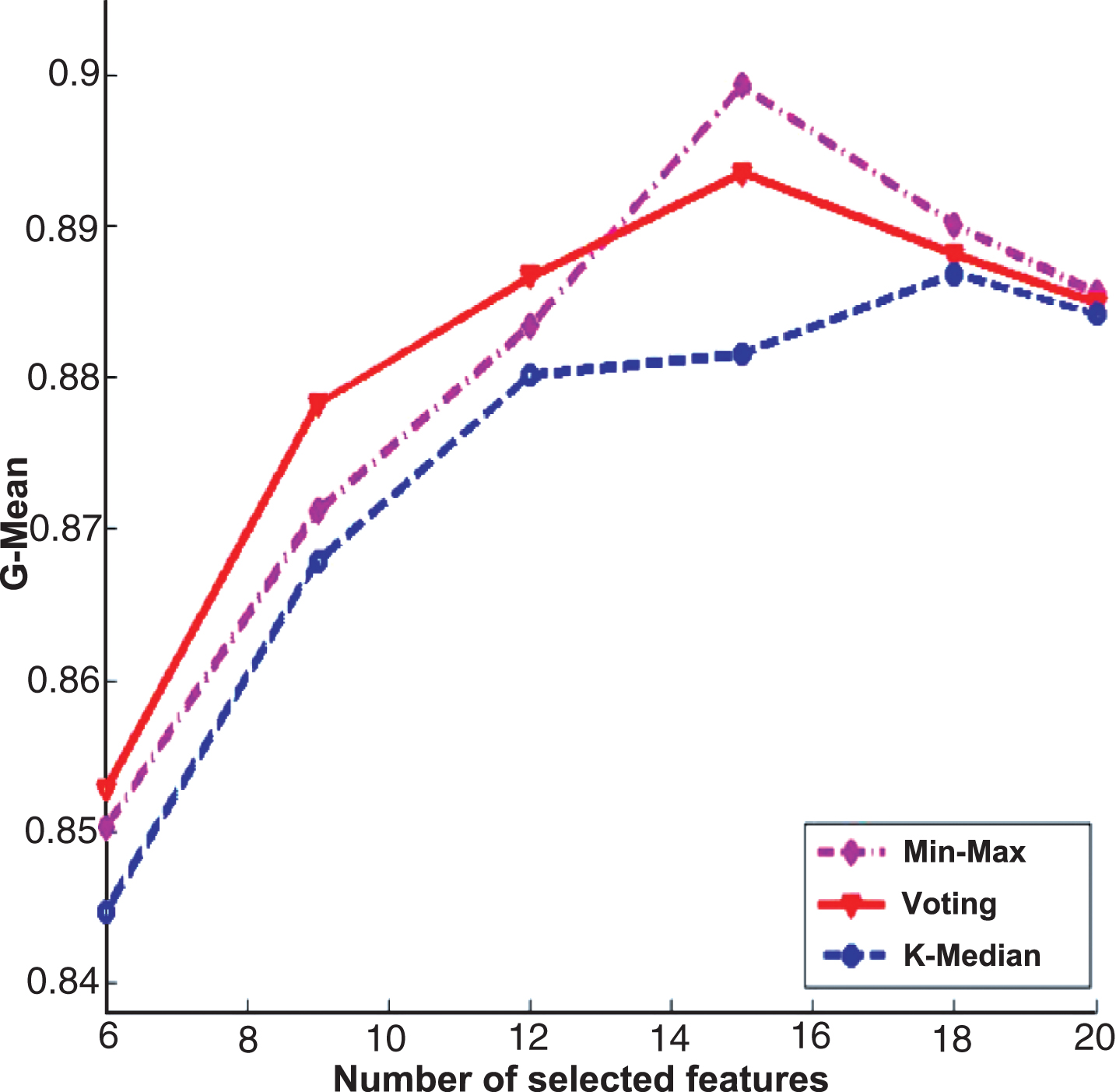
The experimental results of three ensemble strategies after data partition for Relief feature selection algorithm on Internet traffic data set.
We compare the M2-EFS with other traditional ensemble feature selection methods, i.e., bagging-voting and bagging-K-median, on imbalanced Internet traffic data set. Bagging-voting and bagging-K-median are classical ensemble feature selection algorithms that bagging is used to sampling data set and voting strategy or K-median strategy is adopted to integrate the outputs of base feature selectors. For M2-EFS, two partition strategies (hyper plane (HP), random partition (RP)) are explored, which leads to two methods, i.e., HP-M2-EFS and RP-M2-EFS. The base feature selectors are built by traditional feature selection algorithm Fisher score and Relief. The experimental results for Fisher score are shown in Fig. 12, while Fig. 13 is for Relief. The experimental results have shown that the bagging coupled with voting (bagging-voting) has better performance than bagging coupled with K-median (bagging-K-median). However, Regardless of the partition strategy, M2-EFS are always better than bagging-voting. Obviously, the combination of Min-Max strategy with hyper plane (HP-M2-EFS) has better performance than Min-Max combined with random data partition strategy (RP-M2-EFS).
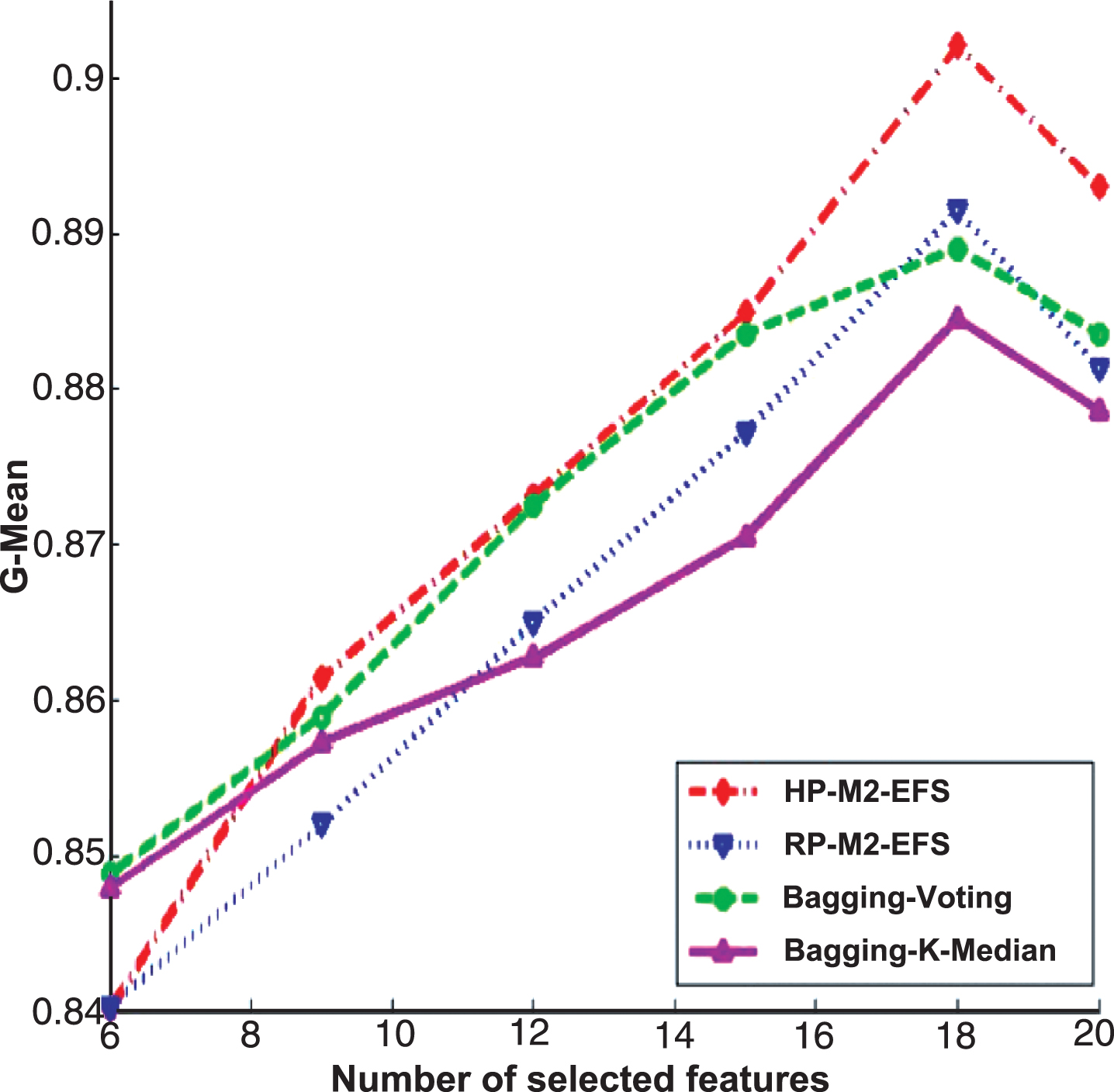
The experimental results of different ensemble feature selection algorithms for Fisher score on Internet traffic data set.
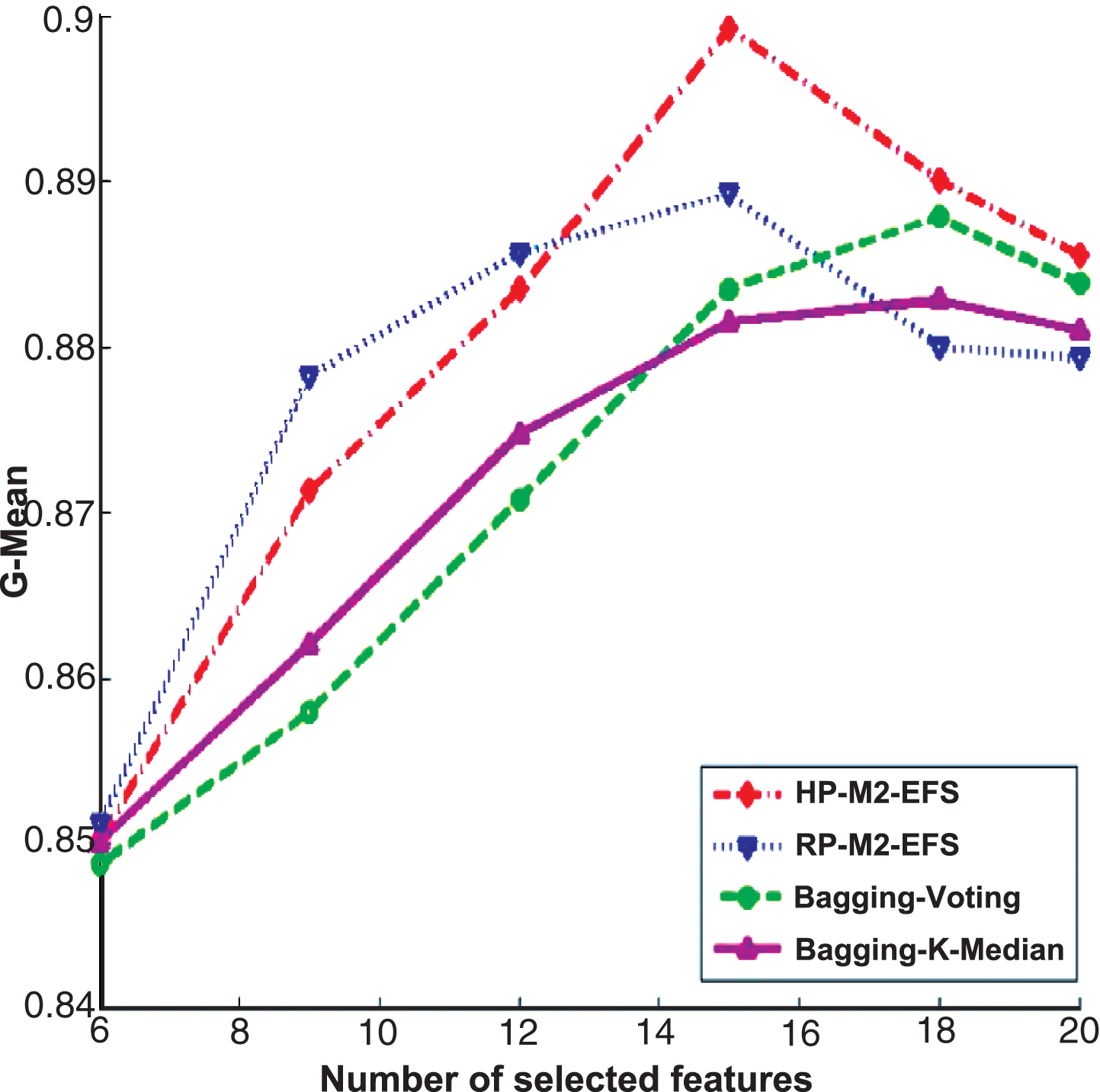
The experimental results of different ensemble feature selection algorithms for Relief on Internet traffic data set.
Moreover, two commonly used methods for dealing with imbalanced problem, i.e., the 1:1 Random undersampling (1:1 RUS) and 1:1.5 RUS, are compared with M2-EFS with HP partition strategy. 1:1 RUS is to make the number of samples in the majority class is same to the number of samples in the minority class through randomly sampling. And 1:1.5RUS is to make the number of samples in majority samples is 1.5 times as much as the number of samples in minority class. In the experiments, Fisher score is used to choose features for 1:1 RUS and 1:1.5 RUS, and it is also used to produce base feature selectors for M2-EFS. The number of selected features is 18 as example. The experimental results are shown in Fig. 14, where X-axis is different methods for imbalanced problems and Y-axis is the G-Mean value. From the experimental results, we can observe that M2-EFS is better than others, and M2-EFS is efficient to deal with imbalanced data sets.
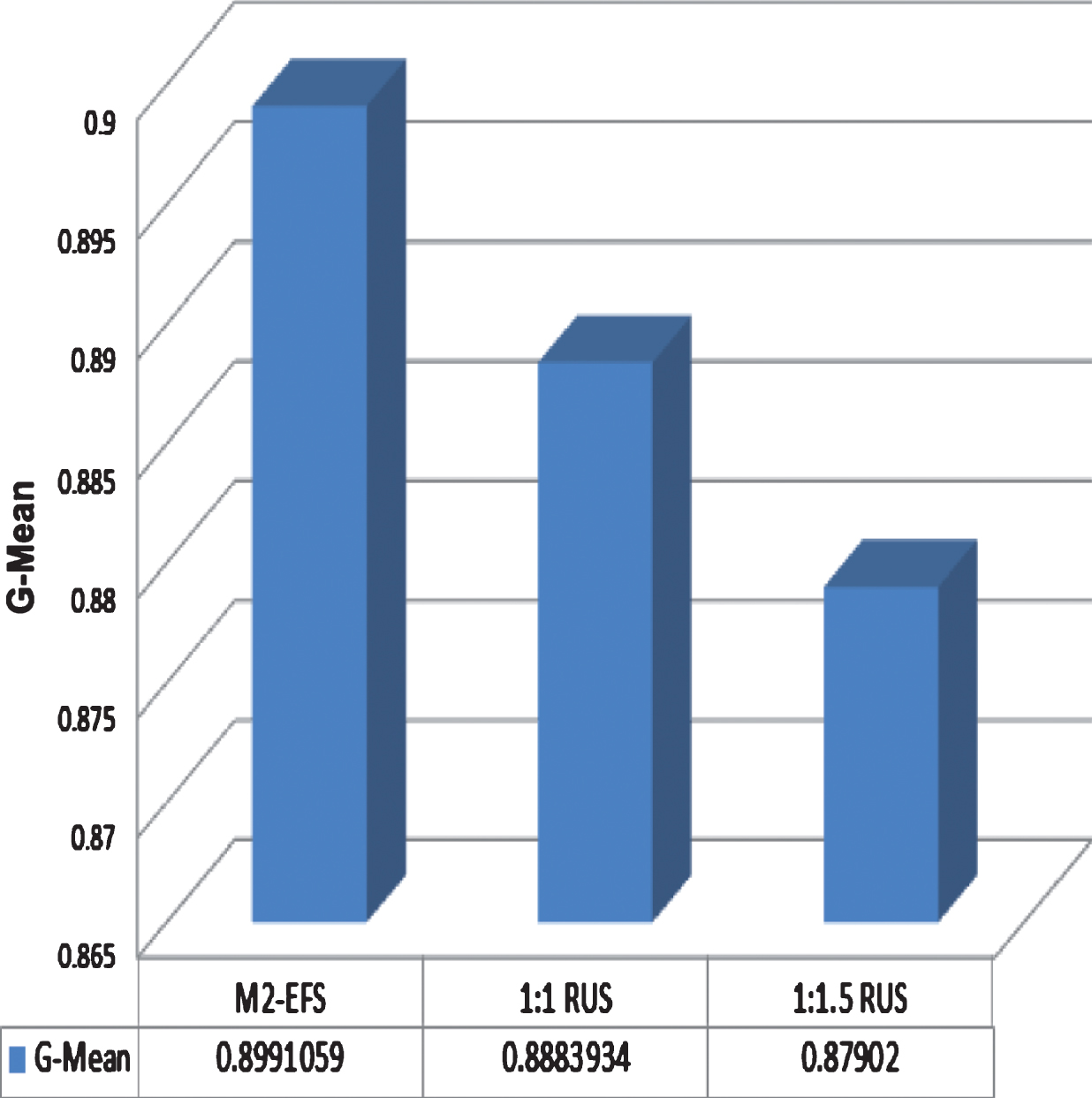
The experimental results of different methods dealing with imbalanced problem.
In this paper, the ensemble feature selection method based on balanced data partition and Min-Max strategy is proposed and validated on real world data set, such as the large scale imbalanced Internet traffic data set. The proposed method can efficiently deal with imbalanced data set through data partition. Since the training process of each base feature selector in the proposed method M2-EFS is independent, then it is easy to be parallelized and can handle large scale data. The various experiments have shown its higher performance than other methods.