
Abstract
Hand gesture recognition is widely used in human-computer interaction (HCI) and has attracted substantial researching attentions. This paper aims to develop low-complexity and real-time solutions of dynamic hand gestures recognition using RGB-D depth sensor for natural human-computer interaction applications. We combine Euclidean distance between hand joints and shoulder center joint with the modulus ratios of skeleton features to generate a unifying feature descriptor for each dynamic hand gesture. And then, an improved dynamic time warping (IDTW) algorithm is proposed to obtain the final recognition results, which applies the weighted distance and a restricted search path to avoid the huge computation in conventional DTW and improves the recognition performance. Experimental results show that the proposed algorithm of dynamic hand gesture recognition not only achieves higher average recognition rate of 96.5% and better performance in response time, but also is robust to uncontrolled environments. Finally, according to our hand gesture recognition solutions, we develop one real-life HCI applications to control a virtual coalmine environment, which operates accurately and efficiently.
Keywords
Introduction
In the last few years, great attentions have been paid to Human-Computer Interaction (HCI) for developing easy-to-use interfaces by facilitating natural communication and manipulation skills of humans. Such interfaces allow users to unobtrusively interact with an application, without the need for specialized and costly equipment. They also support a natural, real-time interaction and are adaptable to the user without imposing tedious calibration procedures. In addition, they are robust against lighting condition and cluttered background. These various requirements and their inherent complexity still provide significant challenges for researchers [1].
Among different human body parts, the hand is the most effective interaction tool because of its dexterity. Adopting hand gesture as an interface in HCI affords users the ability to interact with computers in more natural and intuitive ways, which allows deploying a wide range of applications such as virtual reality, computer games, and sign language recognition. As a consequent, currently hand gesture recognition is no surprise to become one of the active research areas in natural HCI [1–3]. The principal components of hand gesture recognition are data acquisition, hand localization (e.g., segmentation and tracking), hand feature extraction, and gesture recognition based on identified features. The classic solution for data acquisition is color cameras that have already been successfully employed for gesture recognition tasks [1]. These solutions are, however, sensitive to clutter, lighting conditions, and skin color. Video capture has the extra challenge related to the speed of movement. In terms of 3D motion capture at the level of the fingers, possible solutions include optical marker systems, accelerometers, magnetic trackers, and data gloves. These require extensive calibration, limit the natural movement of the fingers, and are generally very expensive.
Recent development of depth sensors, e.g., Kinect sensor, provides a robust solution to hand gesture recognition. Data captured by Kinect, in RGB-D (color and depth information) form, are often used as a source for hand gesture recognition. In spite of many recent successes in applying the Kinect sensor to face recognition, human body tracking and human action recognition, it is still an open problem to use Kinect sensor for hand gesture recognition in natural HCI. Due to the low-resolution and inaccuracy of the Kinect depth map, it is difficult to detect and segment a hand gesture from an image with this resolution. In such a case, the segmentation of the hand is usually inaccurate, thus may significantly affect the recognition step [4].
The motivation in this work is to perform robust, real-time dynamic gesture recognition using RGB-D depth sensor, which can be used in natural HCI applications, with the aim of developing an interactive system for controlling virtual coalmine environment. To recognize dynamic hand gesture, we combined Euclidean distance between hand joints and shoulder center joint with the modulus ratio of skeleton feature vectors to generate a unifying feature descriptor for each dynamic hand gesture. An improved dynamic time warping algorithm (IDTW) was proposed to obtain the final recognition results. Conventional dynamic time warping (DTW) method measures similarity by using the distance between the reference sequences and test sequences. The distance between two elements oftentimes gives equal weights to all dimensions of a sequence sample. However, all body joints involved in a dynamic hand gesture are not equally important in computing the distance between two sequence samples. The proposed IDTW method used weighted distance, which reflects a joint’s moving displacement in a dynamic hand gesture. In addition, IDTW applied a restricted search path to avoid the huge computation caused by high inclination search in DTW. Moreover, we offered an IDWT interface that allows the user to train the system with his/her desired gestures and rapidly test its performance. Due to the fact that our system is based on RGB-D data, cluttered backgrounds, lighting conditions, clothing, or skin color have little impact on the system performance. Finally, on top of our gesture recognition algorithm, we build one real-life HCI applications to control a virtual coalmine environment in Section VI. The proposed system operates accurately and efficiently in uncontrolled environments and is applicable to other HCI applications.
Related work
The recent development of depth cameras, such as Microsoft Kinect, Creative Senz3D or Mesa Imaging Swiss-Ranger etc., opens up new avenues for hand gesture recognition and is increasingly becoming an active topic of research [5]. Related work on how the depth information can be efficiently utilized and how the depth camera can be incorporated in the hand gesture recognition system has received the most attention [3]. In the following subsections, we focus on typical work on feature extraction and classification algorithm for hand gesture recognition based on depth data extracted by depth sensors.
Different approaches can be employed for feature extraction of gesture recognition. One commonly used technique for feature extraction is based on depth-data [1, 5–7]. Specifically, depth data can be used to extract the hand region as the area of the body closer to the camera and then to identify the hand regions (fingers, palms, and wrists) by using geometric size, and finally extract a set of features descriptors which characterize the shape and the pose of the hand gestures. Depth data also allow an initial segmentation to extract SIFT features that can be hierarchically quantized in a vocabulary tree to recognize the hands performing different gestures such as drawing the numbers from “one” to “ten” in [8]. Though the depth-data based method is insensitive to lighting conditions and cluttered background, but it still has some limitations, such as the assumption of the hand is the closest object to the camera.
The skeleton based approaches to features extraction for hand gesture recognitions model temporal dynamics explicitly and consequently have become much more popular in the last years. This technique can be divided into two categories: position features based on the 3D coordinates of the joints and orientation features based on the angular information of the joints [3, 10]. The number of total skeleton joints varies from 15 to 20 to represent the whole human body, according to the selected platform. In [11], seven upper body joints out of the total 20 provided by the Kinect are kept to recognize 8 aircraft gestures used by the military air force. Each coordinate is normalized with respect to its maximum and minimum values. A simple geometric transformation is applied in [12] to the hand coordinates to set the reference system centered on the human torso, instead of the default sensor-centered reference frame. This transformation provides invariance to the starting point of a physical gesture. In [13] a Kalman filter is applied to sequences of joint coordinates to estimate the hand position since the application requires a precise localization of hand movement in a human manipulation interface for robot teleoperation. Also in [14], in order to make the skeletons scale invariant, the hip center joint is first placed at the origin of the coordinate system. Then, a skeleton template is taken as a reference and all the other skeletons are normalized such that their body part lengths are equal to the corresponding lengths of the reference skeleton.
Orientation features based on the angular information between joint vectors have the great advantage of maximizing the invariance of the skeletal representation with respect to the camera position and of reducing the dimensionality of the search space while retaining the character of the motion. Angles between specific pairs of direction vectors are computed to obtain the corresponding joint angles in [15]. In [16], a novel angular skeleton representation is used to map the skeleton motion data into a smaller set of features, which reduces the overall entropy of the signal and removes the dependence on camera position. The set of joint angles represented only by the inclination and azimuth terms are transformed in [17] in high-order features. The time series data is converted into a distance matrix of joint angle similarities between each of the angles along the entire action time series. Different distance measures are applied and these new feature representations are shown to outperform the initial feature set. The Euler angles have been largely used to describe the orientation of a rigid body in a 3-dimensional Euclidean space [18]. Another way to model orientation information is by means of unit quaternions which represent a system of numbers that extends the complex numbers [19].
After the feature extraction step during which features relevant for the gesture typology are selected, classification algorithm step has to be carried out for the hand gesture recognition task. This problem is largely considered as a supervised classification process. Different methods can be used to generate gesture models [3]. Due to the characteristics of mocap data, the extracted features are often time series signals, and DTW is widely applied to calculate distances between motion sequences [1, 20–23]. In [9], a weighted DTW algorithm is proposed, which uses a weighted distance in the cost computation. The weights are chosen so as to maximize a discriminant ratio based on DTW costs. The weights are obtained from a parametric model which depends on how active a joint is in a gesture class. The model parameter is optimized by maximizing the discriminant ratio. In [21] the set of gestures are preliminary characterized by the sequences of key poses; then a DTW distance between two sequences of key poses is defined by combining the Euclidean distance between couples of key poses in all the possible alignments of the test and reference sequences. Hidden Markov Models (HMM) also is a very common choice for gesture recognition as they model sequential data over time [2, 23–26]. However, most of the sequence data cannot be expressed as a series of independent events and defining states for gestures is not an easy task since gestures can be formed by a complex interaction of different joints. Compared to DTW, HMM requires more training data and demands more cumbersome and complex computation. [2, 23] used a huge gesture data to test and evaluate the two algorithms.
As far as static gesture recognition is concerned, Support Vector Machines (SVM) [6, 20] and multiclass SVM approaches are used broadly [15, 28]. In [6], based on the depth information, the region of hand is extracted using an adaptive square. Once the features of the hand are extracted, the static hand gestures are classified using SVM. In addition, artificial neural networks (NNs) represent another alternative methodology to solve classification problems in the context of gesture recognition. In [10], Extreme Learning Machines (ELM) is applied to classify motion on a frame level and make the final classification decision considering the whole sequence.
There are other prominent works reviewed in [3]. However, most of the existing solutions for hand gesture recognition are designed for hand properties (hand contour, hand palm center, fingers, and hand trajectory). Overall, there are only very few solutions for hand gestures recognition that work on hand, wrists, elbow, arm, and shoulder for natural HCI applications. The objective of this paper is to develop an improved, low-complexity, and real-time solution for the recognition of dynamic hand gestures executed by one or multiple hands from depth data returned by a Kinect sensor. Experimental results show that our hand gesture recognition system not only operates accurately and efficiently, but also is robust to uncontrolled environments and hand gesture variations in orientation, scale, articulation, and shape distortions.
Framework of dynamic gesture recognition
The proposed framework for dynamic gesture recognition is shown as in Fig. 1, including hand tracking, feature extraction, and gesture recognition.
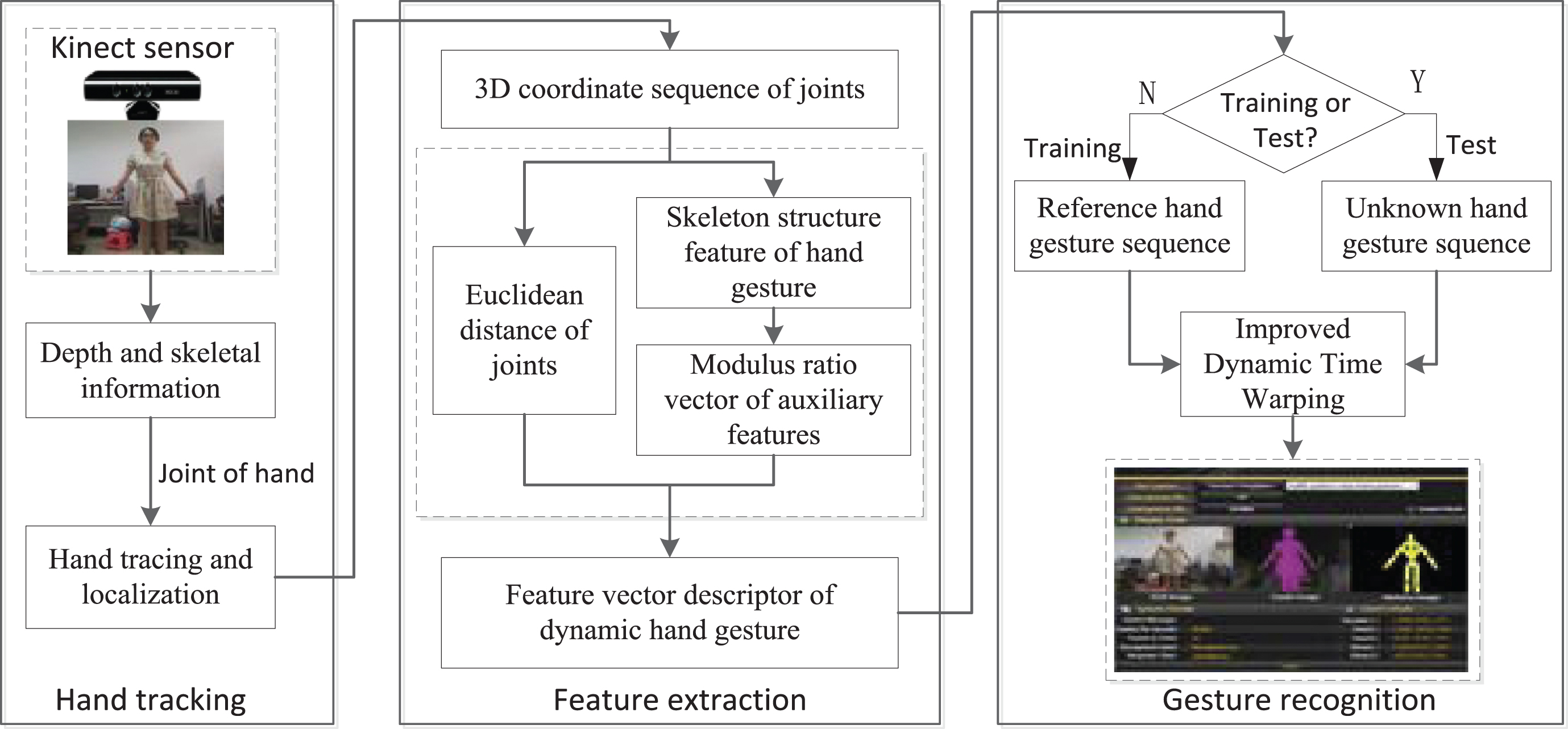
The proposed framework of dynamic gesture recognition based on Kinect.
We firstly apply Microsoft Kinect sensor to obtain the depth data and 3D coordinate information of hand joints (including hands, elbows, shoulders, etc.). The depth and joints information is used to generate a 3D motion trajectory of hand gestures to realize hand tracking and localization.
The acquired joints information (3D coordinate sequence) of hand gestures is then used to extract the geometric feature of dynamic hand gestures by calculating the Euclidean distance between hand joints. Meanwhile, in order to further describe the relative position features of hand gesture to the body, we create an auxiliary feature vector based on human skeleton structure of Kinect sensor. According to the Euclidean distance between hand joints and the modulus ratio of feature vectors, we can generate a unifying feature vector descriptor to represent each dynamic hand gesture.
Finally, an improved dynamic time warping algorithm (IDTW) is built to obtain the final recognition results by calculating the similarity between test gesture sequence and template gesture sequence. The proposed approach allows the user to train a reference (template) sequence of dynamic hand gesture. In order to ensure real-time behavior, reference gesture sequence is limited to 40 images. When the training is finished, these images are saved in an XML file. During recognition, once a sequence of new images representing a dynamic hand gesture is made available by the Kinect, the IDTW algorithm module is activated to recognize it based on the similarity between the observed gesture and each reference gesture.
Hand detection, including hand localization, segmentation and representation, is a non-trivial problem in gesture recognition. In order to ensure real-time, natural experience in HCI system, hand tracing and positioning methods should be robust to the cluttered backgrounds and various lighting conditions. In this work, hand tracking and localization algorithm fully takes use of the depth information and skeleton tracking provided by Kinect to describe the real-time coordinate of hand joints and further to generate a 3D motion trajectory. Meanwhile, to transform the coordinate system of the depth and skeleton image to that of the color image, some calibration parameters are adjusted so that the depth pixels can match the color pixels.
Feature extraction
Dynamic hand gestures not only contain three-dimensional position information, but also involve time information. Therefore, the joint coordinate sequence of dynamic hand gesture should be transformed into a feature vector which can be used in training and recognition of classification model. In most of the previous research, direction, position and speed are the most commonly used gestures features in dynamic gesture recognition system. In this work, we focus on recognizing dynamic hand gestures for natural HCI in virtual reality applications. The movements of hands and arms relative to the body are then of greatest interest. For a higher gesture recognition ratio, we adopt Euclidean distance of hand joints and the modulus ratio of human skeleton structure as the main feature of dynamic gesture recognition algorithm.
Normalization of human hand joints
The coordinates of hand gestures from Kinect are generally provided with respect to the Kinect reference system. They depend on different factors, such as person’s height, arm length, distance and orientation of the gesture with respect to the Kinect sensor. Therefore, the extracted hand gestures usually have different scales due to various distances from the Kinect to hand. Moreover, different rotations caused by the body postures also can impact the skeleton model in a different way. Hence, in order to minimize the impact of these variations, normalization steps are required in different gesture executions. The second pre-processing stage removes the rotational distortion caused by different orientations of humanbodies.
In order to ensure the translation invariance and scalability of the feature vector for dynamic hand gesture cognition, the 3D coordinate information joints obtained by Kinect is firstly normalized by calculating the Euclidean distance between hand joints and shoulder center joint. In addition, we construct four auxiliary feature vectors of skeleton structure from hand to head and spine. On this basis, the feature vectors’ modulus ratio of skeleton structure is calculated using skeleton coordinates. Finally, a unified feature vector for dynamic hand gesture recognition is constructed based on the Euclidean distance of hand joints and the modulus ratio of skeleton structure feature vectors. All feature vectors are normalized with the distance between the left and the right shoulder to account for the variations due to a person’s size.
In this work, the Euclidean distance between the hand joints, including hand left, hand right, elbow left, and elbow right, and the shoulder center joint are concretely used to represent the geometric feature of dynamic hand gestures. The normalization stage translates all skeletons to the center of the field of view, which subtracts the shoulder center joint position from the hand joint positions.
Let three-dimensional coordinate of shoulder center joint s and hand joint j in Kinect coordinate system, at t time, be P
st
(x
st
, y
st
, z
st
) and P
jt
(x
jt
, y
jt
, z
jt
), respectively. The Euclidean distance between joint s and joint j can be calculated by Equation (1).
In order to further describe the position features of hand gesture relative to the body, five auxiliary feature vectors are constructed as , , , , and . Their modulus are , , , and , respectively, which describes the distance between the hand and the head and the spine. Then these feature vectors are further normalized by using the distance between the head and the spine. Therefore, the modulus ratio of the auxiliary feature vector is calculated to create a modulus ratio feature vector by Equation (2).
According to the Euclidean distance between hand joints and shoulder center joint, and the modulus ratio of feature vectors of the skeleton from Kinect, we can analyze the normalization effect of three-dimension coordinates and the dynamic process of hand gesture. The motion trajectories for the hand gesture of ‘Draw a circle’ are illustrated in Fig. 2(a), which shows the dynamic process of the Euclidean distance between four joints (i.e. hand left, hand right, elbow left, and elbow right) and shoulder center joint. In addition, for this hand gesture, we record the modulus ratio of the feature vector five times and illustrate its dynamic process in Fig. 2(b). It can be seen that the modulus ratio of the same feature vector for a specific hand gesture has similar dynamic change process.
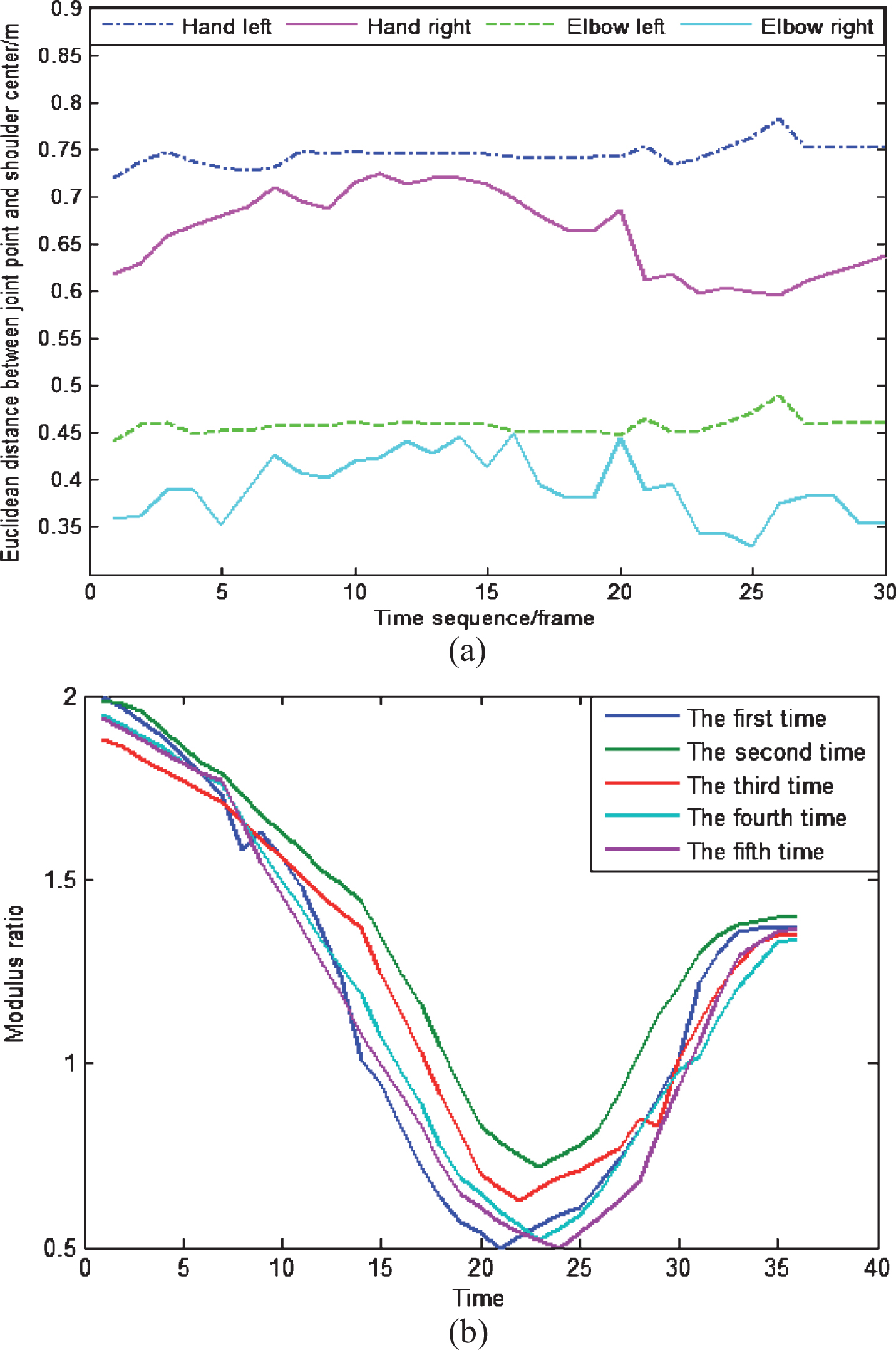
The dynamic features of dynamic hand gesture of ‘Draw a circle’. (a) Trajectories of the Euclidean distance between hand joints and shoulder center joint; (b) The change process of the modulus ratio of the feature vector from hand right to head.
Once the Euclidean distance of hand joints and the modulus ratio of auxiliary feature vectors are obtained, we can further construct a unifying gesture feature vector to represent the dynamic hand gesture by combining this two different gesture feature vectors. For the hand gesture feature of the jth frame image, the unifying feature vector Z
j
can be described by Equation (3).
Z
j
actually is an eight-dimensional descriptive vector of hand gesture feature, including the Euclidean distance between four hand joints (i.e. hand left, hand right, elbow left, and elbow right) and shoulder center, and the four modulus ratios of auxiliary skeleton feature vectors. In order to ensure real-time behavior of the system, the length of a dynamic hand gesture sequence is limited to 40 images. Therefore, the unifying feature vector for a dynamic hand gesture are described by Equation (4)
DTW not only requires fewer samples and a simpler computation but also improves the continuity and timeliness of the system to meet the requirements of the vast majority application while under the condition of similar recognition rate.
DTW algorithm
In our case, let template gesture sequence be and gesture sequence be , m ≠ n, l i is the ith frame image of the template gesture and S j is the jth frame image of the test gesture sequence. They have same internal dimension defined by Equation (3). According to Equation (4), L i and S j can be expressed as Z Li , and Z Sj , respectively.
The basic idea of the DTW algorithm is to align the two sequences L and S in time via the best path to make the sum of cost minimum and this path must pass through all the points of sequence S. Therefore the transfer function F for aligning L and S can be defined by Equation (5).
Furthermore, the optimal warping path can be illustrated as follows:
The similarity between two sequences can be defined by the total cost D of the warping path T between L and S with respect to the distance function d (L
i
, S
j
), which is the sum of all distances between mapped sequence frames, defined by Equation (8).
The computation and time complexity of conventional DTW algorithm will greatly increase with the length of gesture sequence in the iteration process. Moreover, in a typical hand gesture recognition problem, hand joints used in a hand gesture can vary from gesture class to gesture class. Hence, not all joints are equally important in recognizing a hand gesture. In this work, we present an improved DTW algorithm (IDTW) by restricting the wrapping path and using a weighted distance in the cost computation.
Firstly, in order to reduce the DTW computational complexity and increase the reliability of DTW’s dissimilarity measure, some global constraints have been imposed to the wrapping path. In this paper, we use a well-known global constraint parallelogram band to constrain search path [29], which can effectively limit the warping amount, i.e., slowing down or speeding up of a sequence in time. In the parallelogram, the maximum slope is 2 and the minimum slope is 0.5.
On the other hand, the conventional DTW algorithm gives equal weights to all dimensions of a sequence sample. However, in typical dynamic hand gesture recognition, hand joints can vary from one gesture class to another gesture class. Therefore, we propose a weighted DTW algorithm that uses a weighted distance in the cost computation. Different from the weighted DTW algorithms in [21], the weights in this paper are obtained based on a joint’s moving displacement in a dynamic hand gesture. To infer a joint’s weight in a trained template gesture we compute its total displacement by Equation (9)
According to Equation (10), if joint j remains static in performing hand gesture w, its weight is zero. On this basis, to incorporate these weights the final DTW distance between template gesture sequence L and test gesture sequence S is transformed as:
Several experiments were performed in order to test the proposed methods for dynamic hand gestures recognition. All experiments were done on an Intel Core(TM) i-7-4790 3.60 GHz CPU with 8 GB of RAM. Kinect for 3D sensor was used as data acquisition device. Visual Studio 2010, Kinect SDK-v1.8 and C# programming languages were employed as the programming tools.
Dataset
To validate the proposed algorithm for dynamic gesture recognition, we used two experimental hand gesture datasets: (1) a set of eight standard traffic cop gestures, shown in Fig. 3(a); (2) a set of eight 3D dynamic gestures, trained and generated by our volunteers according to the UDLR-8 dataset, as illustrated in Fig. 3(b). The hand gesture symbol and its description are listed in Table 1.
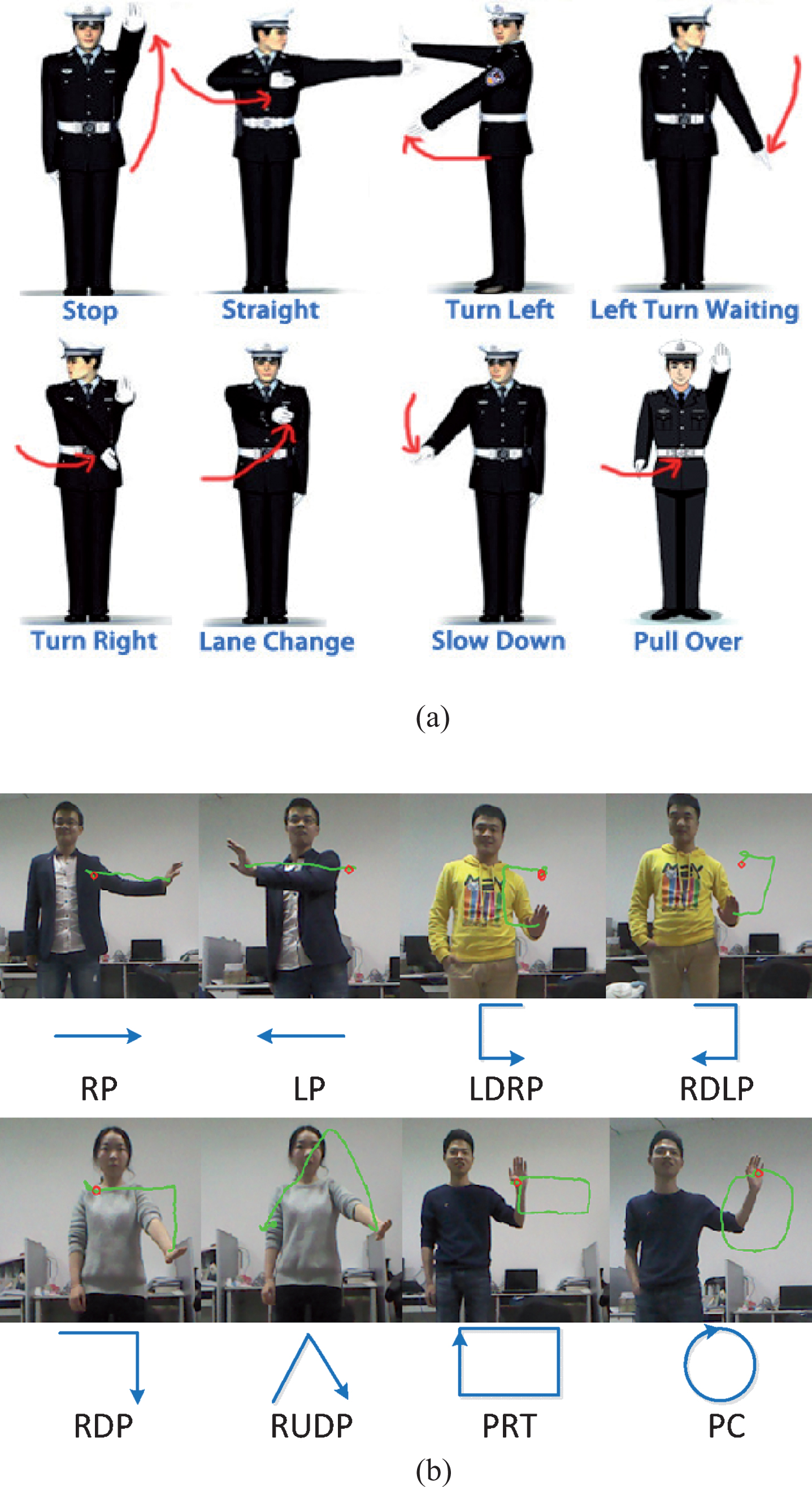
Experiment gesture dataset. (a) Traffic police command gesture dataset; (b) UDLR-8 gesture dataset.
Hand gesture symbol and its description
In this paper, we have developed a graphical interface for hand gesture recognition that allows the user to easily train his/her desired gestures and to rapidly test recognition algorithm, shown as inFig. 4.
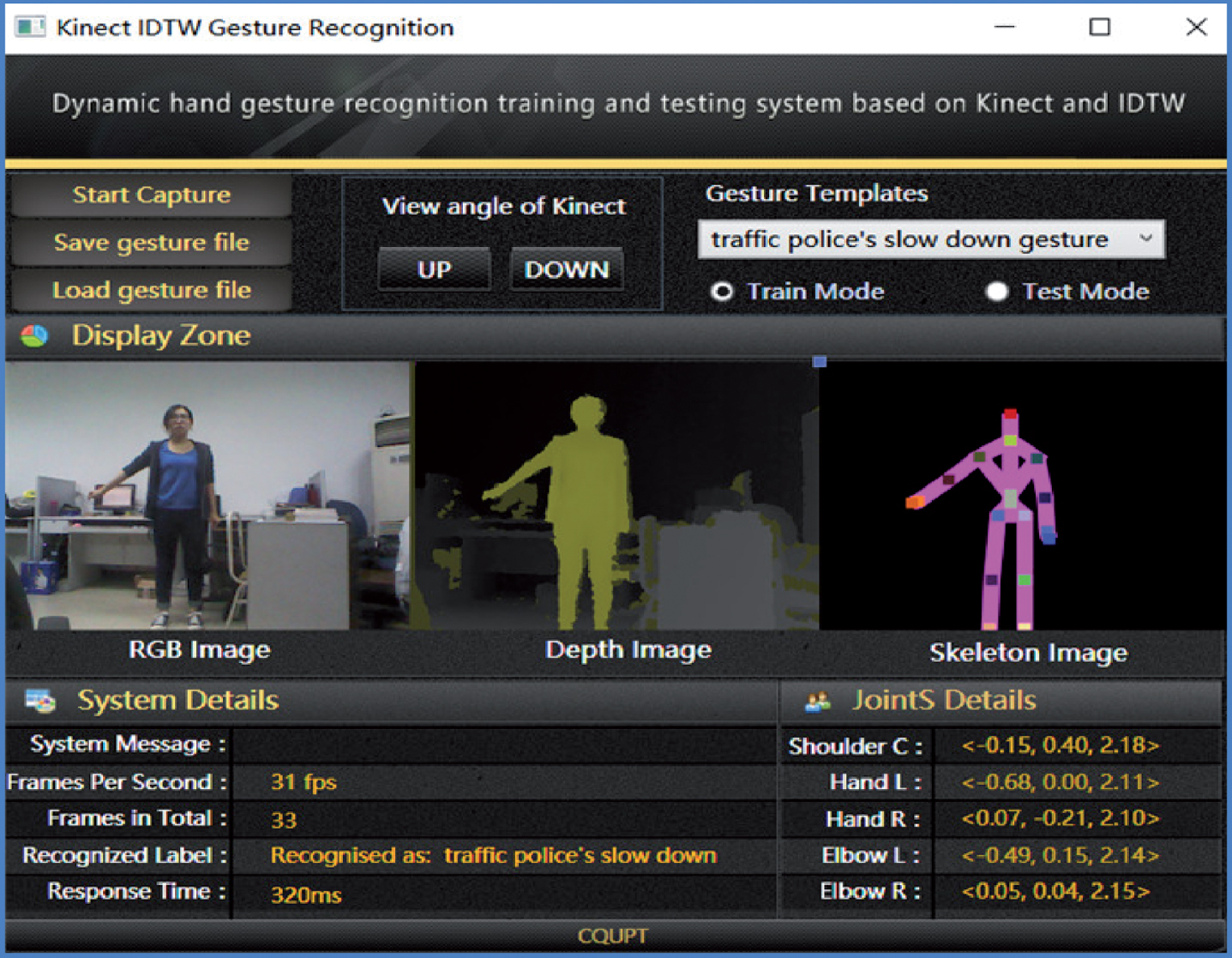
The interface of dynamic gesture training and testing.
IDTW interface contains two modes: sample train mode and gesture test mode. The main interface is divided into five zones: sample selection combo box, image display zone, system details zone, joints details zone, and operation buttons zone. User can select the hand gesture sample to train or test by clicking the drop-down button of sample selection combo box. Image display zone can show RGB image, depth image, and skeleton image. System details zone mainly display system messages, frame rate (FPS), frames in total, recognized hand gesture, and system response time. Joints details zone mainly shows the three-dimension coordinates of hand joints including shoulder center, hand left, hand right, elbow left, and elbow right. Operation buttons zone is used to capture gesture, save gesture file, load gesture file, and adjust the view angle of Kinect sensor.
We invite ten volunteers, including four females and six males, to train the template gestures according to the experimental dataset introduced in Section 5.1. Before training, each volunteer is asked to read the gesture introduction and is allowed to practice each gesture once or twice. Each gesture will be trained five times by each of the ten training users. For each volunteer, the specific training steps are as follows.
volunteer selects a gesture sample by clicking the drop-down button of sample selection combo box in the ITDW interface in Fig. 4.
volunteer stands in front of Kinect (about 1800 mm from the Kinect) and presses the ‘Start Capture’ button. Three seconds later, he/she begins to perform the selected hand gesture in Step 1 according to gesture introduction. Finished the performance, he/she clicks ‘Save Gesture File’ button to save the performed gesture sample file.
volunteer repeats Step 1 and Step 2 until all sixteen gesture samples are performed.
volunteer repeats Step 1, Step 2 and Step 3 four times.
All volunteers perform hand gesture samples according to Step 1, Step 2, Step 3, and Step 4. Therefore, each gesture has 50 different trained templates and 16 hand gestures in our experimental data set have 800 gesture templates in total.
For each gesture, we select ten samples from the fifty trained templates randomly and invite another ten volunteers to test the proposed recognition algorithm. In the test process, basic operation steps are similar to that of the training process introduced in Section 5.2. Volunteers select a test gesture by clicking the drop-down button of sample selection combo box in the IDTW interface and perform it. The recognized results of the selected gesture will be shown in system details zone in IDTW interface. Each gesture will be tested ten times by each of the ten volunteers. Therefore, the total test number of each gesture is one hundred. A gesture is considered unrecognizable if the IDTW interface displays a wrong recognized result within a predefined interval after test user finished his/her performance. We carried out test experiment under the normal light condition and the weak light condition to verify the performance of recognition algorithm.
The test results for traffic command gestures and our UDLR-8 gestures are shown in confusion matrix in Fig. 5(a) and (b), respectively. We can further observe that the average recognition rates of the proposed IDTW algorithm for traffic command gestures and our UDLR-8 gestures are 97% and 96.5%, respectively. According to our test results, the hand gesture recognition rates are almost same under different lighting conditions and cluttered background. In addition, the IDTW algorithm for dynamic gesture recognition is mainly based on the human joint information and skeleton features obtained by Kinect, therefore, the recognition results also are independent of different test users’ sizes.
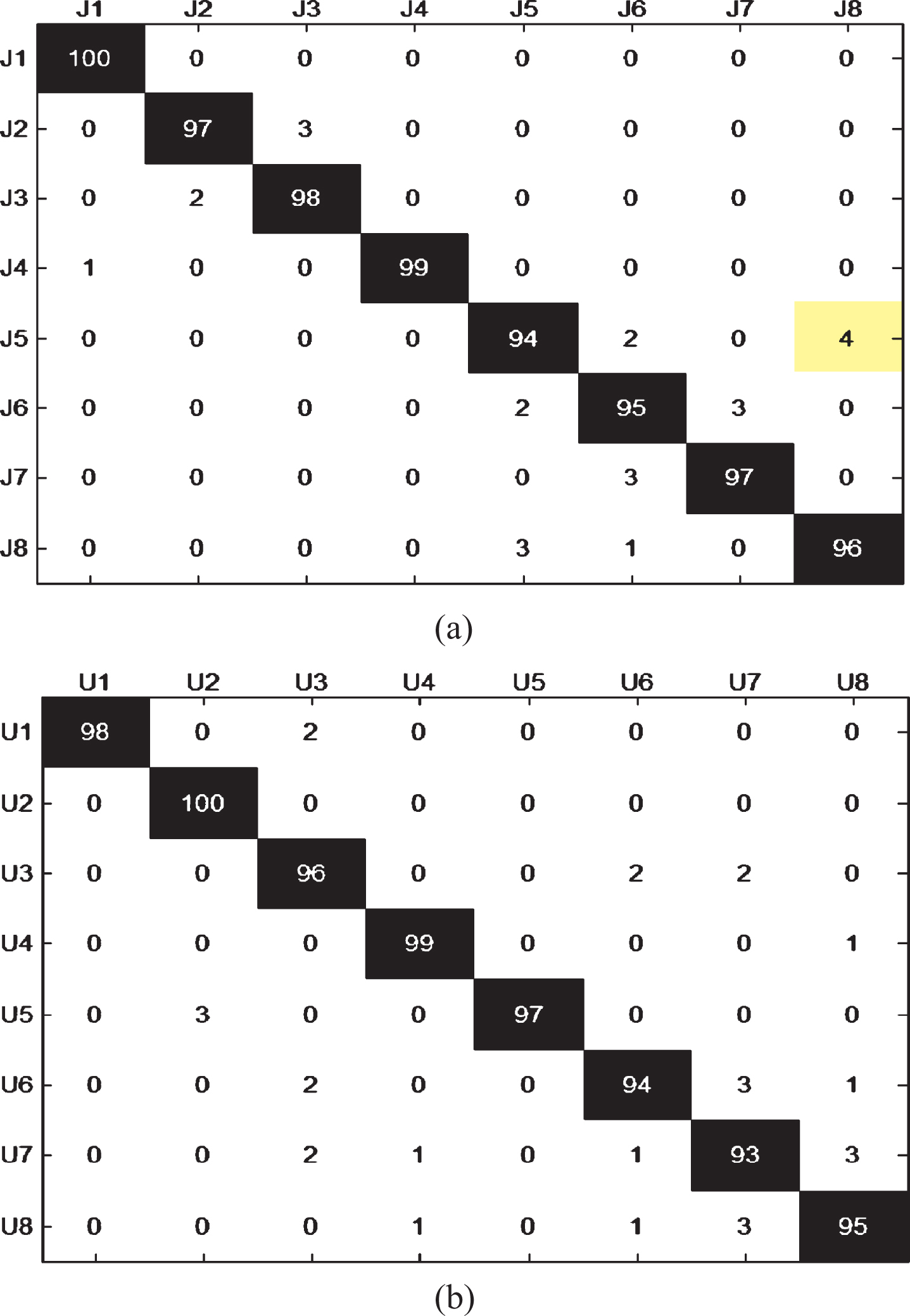
IDTW recognition results. (a) The confusion matrix for traffic command gestures; (b) The confusion matrix for our UDLR-8 gestures.
The average recognition rate of traditional DTW algorithm for traffic command gestures and our UDLR-8 gestures is shown in Fig. 6(a) and (b). We can observe that the recognition rate for each hand gesture of IDTW solution in Fig. 5 is higher than that of DTW in Fig. 6. Moreover, the overall average recognition rates of DTW algorithm for traffic command gestures and our UDLR-8 gestures only are 92.6% and 91.4%, respectively, which is less than that of IDTW in Fig. 6.

DTW recognition results. (a) The confusion matrix of traffic command gesture dataset; (b) The confusion matrix of our UDLR-8 dataset.
Figure 7 illustrates the comparison of the IDTW algorithm with the DTW algorithm on the response time. As one can observe, the average response times of the IDTW algorithm and the DTW algorithm on the traffic command gesture dataset are 358 ms and 460 ms, respectively, while that of on the UDLR-8 gestures dataset are 370 ms and 462 ms, respectively. The average response time of each hand gesture is less than 97 ms IDTW algorithm versus DTW algorithm.
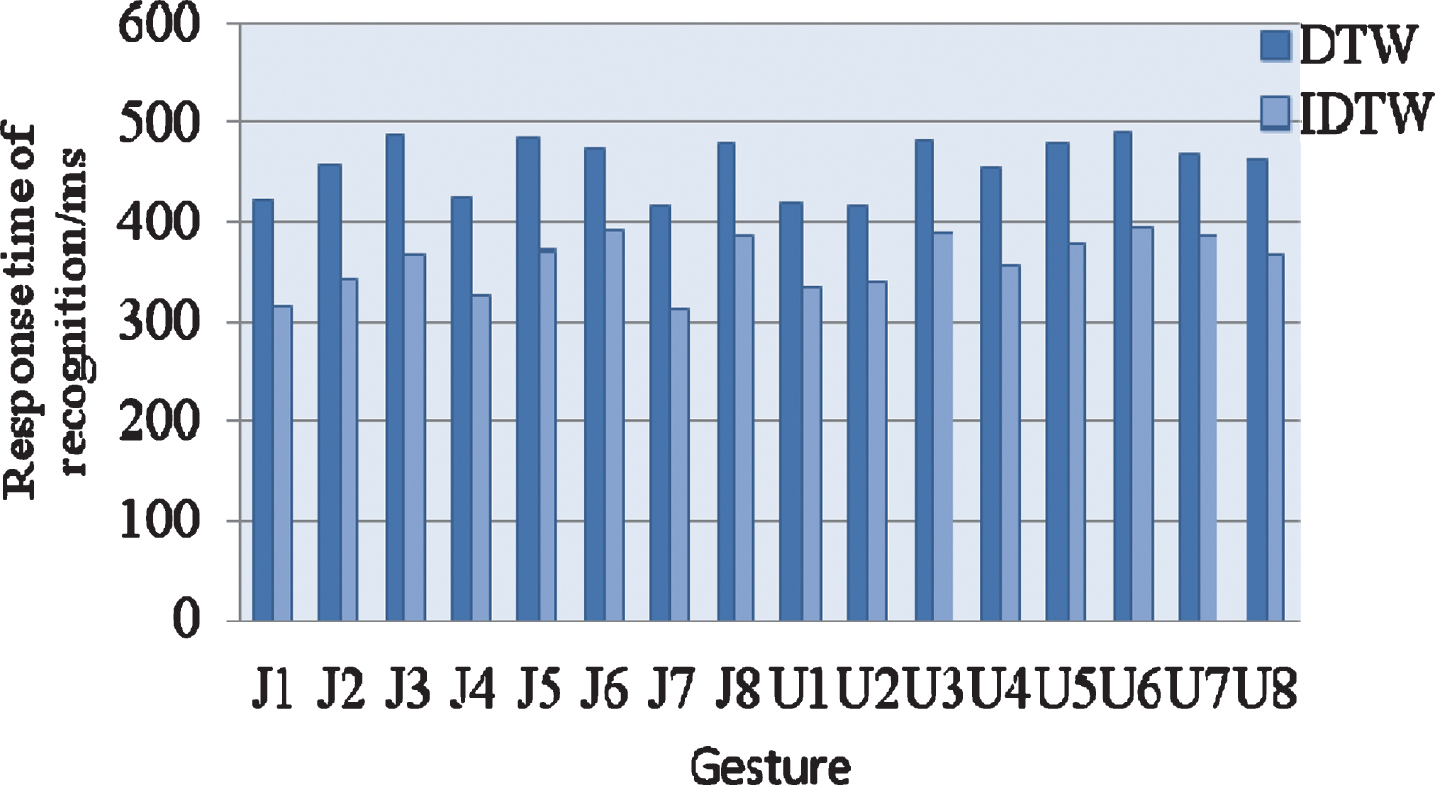
The response time comparison of DTW and IDTW.
According to test results as shown in Figs. 5–7, the proposed IDTW algorithm not only improves the total recognition rate and reduces the recognition response time, but also is robust to un- controlled environments such as different lighting conditions, cluttered background, and different user sizes.
For the purpose of comparison, we have also implemented other two methods in the literatures, which are the improved weights DTW algorithm (W-DTW) similar to [21] and the hidden Markov models (HMM) in [26], and tested their performance on the same database. The results of this comparison are shown in Table 2.
Comparison on traffic gesture dataset and UDLR-8 dataset
Inspecting Table 2, we can observe that the average recognition rates of the IDTW algorithm and the W-DTW approach on traffic command gesture dataset are 97.0% and 94.3%, respectively. It also can be observed that the performance of proposed IDTW solution with 96.5% average recognition rate on UDLR-8 dataset outperforms that of the W-DTW with 93.9% average recognition rate on the same dataset. Meanwhile, on our UDLR-8 dataset the average recognition rate of the HMM is 95.0% and slightly lower than that of our proposed IDTW method, which is 96.5% average recognition rate. Moreover, on UDLR-8 dataset the highest and lowest recognition rate of the IDTW algorithm can be 100% and 93% when U2 and U7 respectively while on the traffic command gesture dataset the highest and lowest recognition rate of the IDTW algorithm can be 100% and 94% when J2 and J5, respectively.
The test results further show the proposed IDTW algorithm has a higher recognition rate compared with some typical methods in the literatures. Certainly, in this paper this comparison gives only a general idea of the performance, because these compared algorithms are implemented and tested on the specific scenarios and some specific parameters of the compared algorithm are not completely open in the reference literatures.
According to our hand gesture recognition algorithm, we have developed an interactive application to control virtual coalmine so as to verify the proposed solutions of hand gesture recognition. The interactive system obtains the depth data and joint information of human hand using Kinect sensor and runs the proposed algorithms of dynamic hand gesture recognition. According to recognition results of the predefined hand gestures, the interactive system sends real-time control command to virtual environmentengine and realizes the interaction with the virtual coalmine. Considering the principle of ergonomics and daily habit of human communication, we have defined 10 interactive hand gestures. Figure 8 shows the typical interactive scenario with virtual mine according to hand gesture recognition.
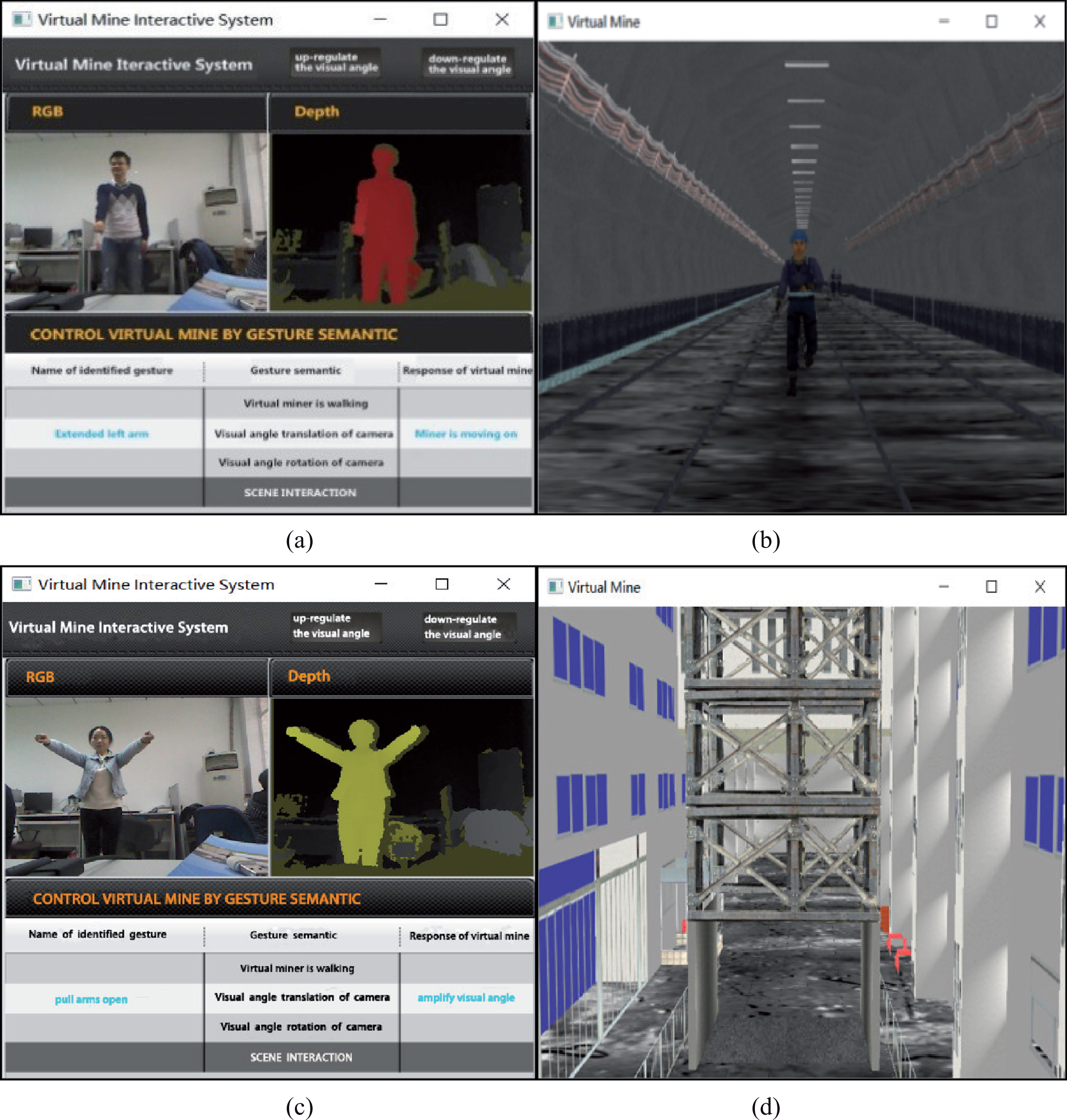
Natural interaction with virtual coalmine.
Figure 8(a) and (c) are the interactive interface of hand gesture recognition, which displays user hand gesture, the depth image in Kinect, the recognized hand gesture, command semantic of hand gesture, and the system response to user hand gestures. Figure 8(b) and (d) are the interactive results of virtual coalmine to the hand gestures in Fig. 8(a) and (c), respectively.
In Fig. 8(a), the user is stretching his left arm forward. Figure 8 (b) shows that virtual miner is walking due to the hand gesture of ‘up-regulate the left arm’. In Fig. 8(c), the user is opening outward both hands straight. Figure 8(d) shows that the camera moves forward to enlarge angle of view of virtual coalmine. The virtual coalmine system runs accurately in real time. It is feasible to build more interesting and practical HCI applications on top of our hand gesture recognition algorithm.
In this paper, we presented a framework for dynamic hand gesture recognition using RGB-D data collected by Kinect with the aim of developing a natural HCI application. We combined Euclidean distance between hand joints and shoulder center joint with the skeleton features to generate a unifying feature descriptor for each dynamic hand gesture. To recognize the hand gestures, we designed an improved dynamic time warping algorithm (IDTW) for dynamic hand gesture recognition. The proposed IDTW algorithm used weighted distance and applied a restricted search path to avoid the huge computation caused by high inclination search in conventional DTW. Moreover, we offered an IDWT interface that allows the user to train the system with his/her desired gestures and rapidly test its performance.
Experimental results show the average recognition rates of the proposed IDTW algorithm on the traffic command gestures dataset and our UDLR-8 gestures dataset are 97% and 96.5%, respectively. Due to the fact that our solutions are based on RGB-D date, the cluttered backgrounds, lighting conditions, and different user sizes have little impact on the overall performance. Meanwhile, the average response time of test hand gesture is less than 97 ms the IDTW algorithm versus the DTW algorithm. In addition, compared with the traditional weight DTW algorithm and HMM algorithm in reference literatures, the IDTW algorithm also has higher average recognition rate and better performance.
In the future, we will further improve the overall performance of dynamic hand gestures recognition by extracting more robust and discriminative features and optimizing the recognition algorithm, especially by integrating deep learning algorithm [10] within the proposed framework. Moreover, we will enhance the HCI functions of virtual coalmine by designing more effective and practical interaction hand gestures.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (61374093) and Chongqing Research Program of Basic Research and Frontier Technology (No. cstc2015jcyjA40009 and No. cstc2015jcyjA40007).