
Abstract
Illegal cyber activities can be curbed by means of authorship analysis which intends to identify the authors of a document by scrutinizing the writing style involved in it. One of the major threats associated with online media is the propagation of false statements on behalf of celebrities with the aim of tarnishing their public image especially as a part of online political campaigns. The scenario calls for the need of analyzing the authorship of documents with less contents and capturing the author style from among a large number of candidate authors belonging to the same domain. This is a less explored area of authorship analysis as the task is challenging because traditional methods fail to acquire accuracy when the contents of different authors are pertaining to same topic. Here we propose a method that accomplishes the task of analysis in such an environment, by employing psycholinguistic, lexical, and syntactic aspects of an author combined with word co-occurrences obtained by modeling the style word pattern of the text. The method identifies an author’s individualistic form of expression of emotional aspects, sociolinguistic aspects and word co-occurrences, to obtain an author-style pattern for each candidate author. An author-specific model is generated. The questioned document is fed into the different models so formed, and the final decision regarding the authorship is made based on the ensembled learning method. The experimental results of the proposed method has secured a precision of 0.98 in best case and 0.45 in worst case, thereby illustrating an improvement in the accuracy of authorship attribution of short texts, in comparison with the existing methods.
Keywords
Introduction
The huge potency of Internet in disseminating information around the globe has transformed it into an exorbitantly popular means of communication. This in turn has put the accountability of contents being shared to the question. The recent reports on cyber threats reveal a shocking rise in the rate of online content forgeries intended towards spreading terrorism, exploiting hacked accounts for fraudulent political promotions and illegal recommendations on behalf of public figures. Several cases of blog post plagiarism have also been reported. These are issues of prime importance that are yet to be addressed and they thrive on the anonymity offered by the Internet space. A means to unveil the identity of the person behind the mask, based on the writing style, is pivotal in furnishing immunity towards illegal cyber activities. Authorship analysis is a technique aimed at tracking down salient author characteristics that define a unique hallmark of that author. Hence it serves as a powerful means to confirm the authenticity regarding the author of an online post and thus can counter the acceleration of abusive cyber activities.
Authorship analysis has established its implication in the area of forensic linguistics where language is a crucial evidence [1]. The analysis is backed by the concept that there exists a unique writing style for each individual. The indication of these features is so inconspicuous that one needs to resort to adept statistical and computational methods to model the writing pattern followed by an individual. The major challenge in the area of authorship analysis of online forensic documents is the lack of enough content for analysis. This in turn spawns the challenge of lesser accuracy in the realm of forensic document analysis.
Efforts targeting authorship analysis of forensic documents have so far utilized lexical syntactic and semantic features [2–4]. However, these are far from perfect in terms of accuracy. This is mainly due to the fact that the author style cannot be completely captured by considering these customary features from limited text content. The improved accuracy also demands more data for an author and lesser number of candidate authors, which are not feasible in real scenario of authorship attribution. Few previous studies [5, 6] have experimented on a larger data set comprising several words available for training and have come up with lesser accuracy of analysis. This is mainly due to the fact that these methods resorted to lexical and syntactic features counts and frequent word usage based features. The task of obtaining relevant features becomes even more confronting in situations where authors in question write articles regarding the same topic. This is particularly significant in the analysis of questioned online documents that have been allegedly manipulated for political or professional benefits, because in such situations candidate authors are mostly from the same domain. Comparison of author styles in such scenarios becomes a daunting task when features used are mainly word based and character based as they mainly capture topic-based patterns. Traditional features do not suffice in such an environment of attribution. Most previous methods use word based and character based n-grams to perform attribution in such a scenario.
The proposed method aims at contributing a solution to the above-mentioned problem of authorship attribution among the candidate authors belonging to the same domain. The proposed method evaluates texts in terms of the frequent usage of emotional categories and style word co-occurrences by the author thereby contributing to the uniqueness of the pattern modeled for each author. The emotional orientation of a person remains consistent throughout his articles, but cannot always be taken for granted especially in cases where authors are from the same domain. Thus the proposed work also incorporates the orientation of style word patterns of the writer which are oblivious to the author but at the same time a prominent style marker. By attaining such a foolproof authorship attribution scheme, the research work contributes towards a system for providing a safe cyber realm where the author’s writing style becomes easily traceable.
The experiments have been performed using psycholinguistic, sociolinguistic, lexical, syntactical and frequent style word pattern based aspects of authors, which aid in dealing with short texts. The style word co-occurrences are obtained using Latent Dirichlet Allocation. Separate author models are created based on the features specific to each author. These models are constructed as SVM base ensemblers. The decision regarding the authorship is made based on the majority vote method for the SVM ensemblers. This has paved way for an improved result with a precision of 0.98 in best case and 0.45 in worst case in comparison with the state of the art methods. The paper advances by detailing on the existing methods that mobilized the proposed method in Section 2. Section 3 provides a detailed account of the proposed method. Section 4 briefs the experimental setup. Section 5 validates the result obtained. The paper concludes in Section 6.
Literature review
For the investigations related to authorship attribution of online forensic documents to get on the beam, it should lay focus on subtle manifestations of idiolectal variations among different authors. The proposed method throws spotlight on techniques to attribute authorship of short documents. The crux behind an identification approach out in front is the prudent choice of features. Conventional methods of authorship analysis dealt with stylometric features such as lexical, syntactic, semantic features and application specific features [12]. But the attribution techniques using these features alone do not hit the spot in the task of analyzing forensic documents. The techniques face limitations in stringent environment of analysis where the amount of content for analysis is less, the number of candidate authors is large and the authors belong to the same domain.
A new area of research points towards tracking the idiolect by considering the psycholinguistic aspects of an author. The recent work in this area by U. Athira et al. [13] studied the usages of formulaic sequences and parts of speech tags along with some lexical features using ensembled approach to contribute towards better attribution in authorship.
Many works have been conducted to establish the influence of author character on word usage. The authors of [31] provides a performance evaluation of authorship attribution using individual classifiers trained using traditional stylometric features along with social media specific features. It also analyses the performance based on voting algorithm that combines all classifiers.
In [15] Barbon et al. discuss about employing authorship analysis technique to detect forged twitter accounts. The features utilized are lexical, syntactic, idiosyncratic and content specific features.
The results obtained in above methods were considerable but with a degradation in performance with a large data set comprising lesser data available for each author.
Gill et al. illustrate that there exists a strong relation between the nature of an author and the words used by the author of a blog [16]. The usage of language throws light on the personality of the author [17]. Since these features determine the personality, they can for sure contribute as an efficient style marker for an author. The existing literature in the field of psychology; states there exist stylistic differences in documents written by individuals belonging to different gender groups [18]. The difference is also noteworthy in case of documents written by individuals of different age groups [19]. Similar studies have been conducted to contemplate the variations in linguistic characteristics of depressed individuals and normal individuals, which inferred an observable divergence in the usage of language [20].
The general issue associated with applying psycholinguistic factors mentioned in the above methods can be the close similarity of traits of authors with the same area of interest and similar kind of mental status. This is because; authors with similar mental status can make references to past, future and present in a similar manner. This can hinder the identification of the unique in traits among authors belonging to the same category. This is evident in the case of analyzing authorship of blogs written by cancer survivors, as can be seen in the “Results” section of this article. Here all the candidate authors suffer from similar mental plight, and they describe about similar events. Thus, using these factors alone cannot help in obtaining an author style. Hence, other means of chalking up the characteristics of an author must be resorted to.
Exquisite features of an author can be assimilated by examining the consistency of a userś word co-occurrence frequency. This is attained by topic modeling; that targets deducing patterns followed in a document by taking into account the usage of words [21]. Latent Dirichlet Allocation is a proven starting line for topic modeling [22]. The path of investigations pertaining to the applicability of topic modeling for authorship attribution is a less tread one. Rajkumar [23] discussed about author identification and gender identification using topic modeling. Another notable contribution made by Seroussi [24], describes three topic models to identify authors. The previous works in this regard relies on experiments on much larger dataset that comprised of more data for each candidate author. Further the above methods treat features associated with candidate authors as common without giving consideration to individualistic preferences. This can result in reduced accuracy as there can be patterns that are of importance to one author which might be irrelevant to other authors. Considering common features might not be an efficient means of capturing author-specific features. Thus, a technique using ensemble classifiers [25] is to be employed.
Ensembler classifiers combine together several base classifiers and combine the predictions made by the base classifiers. The method is particularly suitable in situations where expert decision has to be made by combining the classification capability of different aspects. The approach becomes substantial when the error rate associated with individual classifiers is less. The ensembler method by randomly sampling the feature subset uses different feature sets for the base classifiers [26].
The proposed method employs ensembling by considering individual models specific to authors as base ensemblers. A feature subset sampling method is used to generate an author-specific model. The proposed method culls out an effective means of authorship attribution by exploiting the variation of style word patterns and manifestations of psycholinguistic, lexical, and syntactic aspects specific to authors, thereby making attribution possible in the case of authors focusing on the same area of interest.
Proposed authorship attribution mechanism
The proposed method focuses on authorship attribution using ensembled classifier based on feature sets for individual authors. The system takes as input the documents of each author, and the documents are pre-processed to extract tokens. The tokens are made to undergo linguistic analysis. The emotional traits associated with each author are found out. This is done by estimating entropy based priority of each trait in distinguishing the concerned author from other candidate authors. The feature set so obtained is combined with the style word pattern. To obtain style word patterns the documents are examined for stop word patterns. The stop word usage of an author is subjected to topic modeling to obtain different style word patterns of an author. This is estimated for several number of topics (hence forth referred to as style word patterns). The optimal number of topics/patterns has been fixed by cross validation. The distribution of patterns within the document and the rank of the pattern for a particular topic are considered as features. The feature set obtained by combining style word patterns and emotional traits together forms the training data for generating a model for that author. The same is repeated for all authors. Thus, we get as many number of base classifiers as the number of candidate authors. The questioned document is supplied to these ensembled SVMs and the output is obtained using majority votes. The overall methodology can be depicted as in Fig. 1.
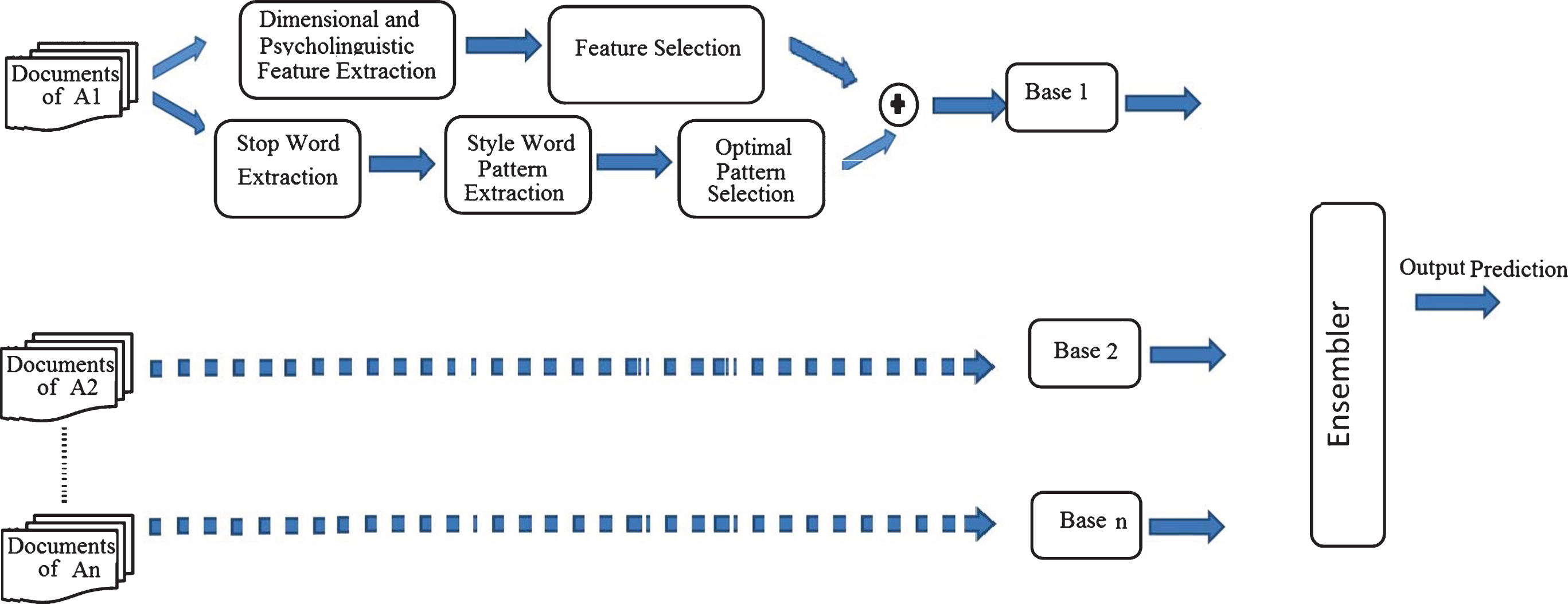
The process design of the proposed method.
The steps involved in the mechanism begin with data collection. The data collection phase is automated by an intelligent crawler that extracts relevant data of authors from online blogs. The next phase is the feature selection. The features used in the proposed approach are of three kinds namely, dimensional, psycholinguistic, and style word features. The relevance of these features, the method of extraction and selection of effective features can be explained in Section 3.1–3.5.
Dimensional features refer to the word, character, and grammar-based lexical and syntactic properties of a given text.The psycholinguistic features mainly portray a personś individualistic pattern of expressing emotional, intellectual and personal preferences. This mainly includes the word usage pertaining to sentiment-based, time-based, social affiliation based, passion based, interest based, and personality based references by an individual. The dimensional and psycholinguistic features have been chosen for the proposed work to support the hypothesis stated in this paper. The hypothesis can be stated as follows:
To support the hypothesis, an authorship attribution technique that imbibes the attributing property of psycholinguistic, lexical, and syntactic features has been adopted. The proposed approach departs from conventional approach of attribution by conducting the analysis in terms of the frequency of certain psycholinguistic categorical term usage. These categories are provided by Linguistic Inquiry Word Count (LIWC) dictionary [27], a resource of several categories of words as well as lexical dimensions of a document. The proposed method exploits the percentage of psycholinguistic category used by an individual as a feature set. The category weight associated with each category specified in LIWC is as follows:
The dimensional and psycholinguistic features considered for the proposed authorship attribution mechanism have been sketched in Fig. 2. Analysis of feature usage among different users shows considerable fluctuations in usage pattern followed by different writers. Thus it becomes important to resort to different features corresponding to different authors. The approach employs feature selection methods to get the best features for each author.
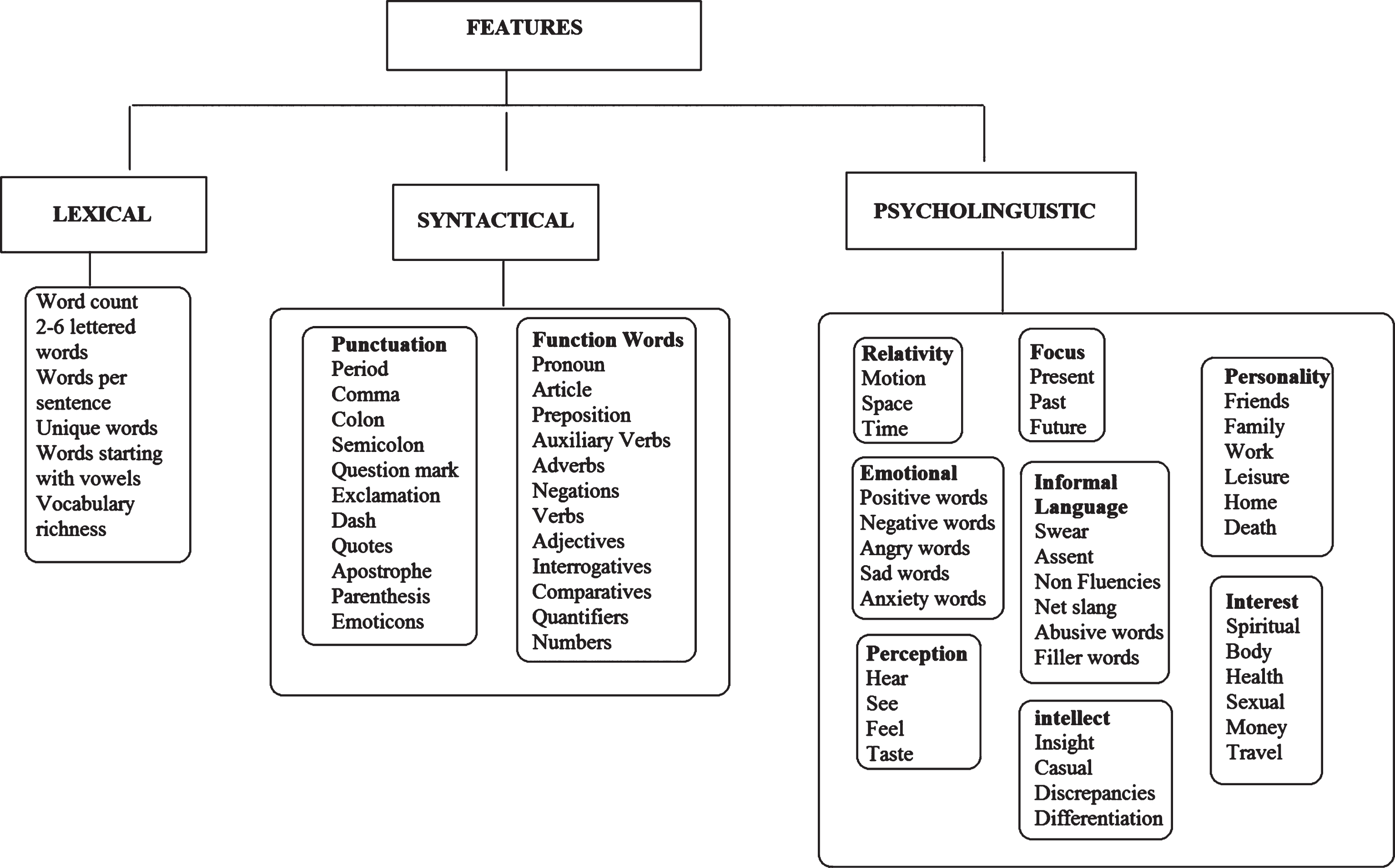
Dimensional and psycholinguistic features used for authorship attribution.
Feature selection is the process of refining the available set of features, so as to accommodate the most pertinent features suitable for defining an individual author style. Here, feature selection has been done to support another hypothesis which can be stated as follows:
Towards attaining evidence for the above hypothesis, experiments have been done with traits specific to each author. The traits refer to the lexical, syntactical, and psycholinguistic features to be considered for attribution task. The author-specific features have been estimated based on the entropy-based ranking of features in distinguishing an author from the other candidate authors. The irrelevant features with respect to a particular author need to be eliminated so as to retain the prime features that are pivotal in expressing an authorś identity. The attribute evaluator used in our work is information gain method [28]. The information gain associated with a particular attribute gives the importance of that attribute in deciding the target class of the instances in the dataset. The information measure used to evaluate the attribute is the entropy [29]. Entropy gives the uncertainty associated with a particular state. The information available from a dataset in the presence and absence of an attribute is taken into consideration.
Consider the dataset D with A = ai=1ton, and p
i
refers to the probability of instances in dataset D to belong to author class a
i
; the entropy E(D) of the dataset can be given as
The information gain associated with D for a feature F can be expressed as
The proposed approach is fueled by the concept that style words contribute more towards the attribution of authors than content words [27]. Content words refer to those words that are mainly involved in expressing the gist of a sentence. It includes adjectives, adverbs, regular verbs, or nouns. The style words refer to function words that determine a person’s writing style. The usage of function words varies as per authorś preferences. Thus, style word patterns form a major style marker in authorship identification.
The proposed method seeks for the frequent co-occurrence pattern of style words associated with each candidate author. To facilitate such an analysis, the documents have been modeled to elicit co-occurrence pattern of frequent style words-in use. The analysis has been conducted on documents which have been cleaned off to contain only stop words and function words. This has an added benefit of getting rid of certain content words that can interfere with the identification of authors tossing around related areas. The approach gets motivated by the fact that style words are used by all the authors, but the proportion of the usage varies from one author to the other. Thus it can be used to model the authorś writing behavior.
To track the frequent usage pattern of function words, we considered the distribution of these patterns over the documents of an author, as well as the distribution of common frequent patterns among all authors. Topic modeling approach has been applied on the documents to be analyzed for authorship. The method assumes that the documents are a mixed model of several topics. Here topics are formulated by frequently used function words, unlike other topic modeling cases where stop words are eliminated.
The following section gives an insight into the topic model used in this article to identify the patterns used by authors. The pattern of the function word usage is expressed as a probabilistic conditional distribution over the given set of function words. The latent distribution of the pattern structure in the documents concerning an author can be modeled using LDA (Latent Dirichilet Allocation) [30]. LDA can be sketched down in terms of mathematical representations.
General terms and representations
P(pat) represents the pattern distribution in a document. P(T/pat) computes the probability of term T to be a part of pattern pat. For a term indexed at i
th
position, random sampling of a pattern is performed from different likely patterns. The distribution of a term ti given by P(t
i
) in a document that contains in itself P patterns can be represented by the following equation:
The term φ
j
, the distribution of term in a pattern, is critical in determining the most pertinent term in a pattern. This can be estimated as follows
The estimation of the pattern distribution θ
d
in a given document d indicates the peculiar usage patterns associated with an author. A conjugate prior α determined over θ is given by the following equation
The typical value of α1 through α P is taken to be the same, so as to obtain a symmetric distribution. The value chosen for α determines the degree of smoothness and the optimal value for it is 50/P [21]. In our proposed work, the values of α chosen are 5,3.34,2 and 1. Another parameter considered for providing a smoothing in distribution of terms over a pattern is β. This value gives the granularity of the LDA model. The ideal value chosen for β is 0.1 [31].
The important patterns within a document The proportional contribution of all patterns within a document The frequency of words belonging to each pattern within a document.
The success of authorship attribution based on style word pattern depends on the number of style word pattern considered. This number varies with the dataset chosen for attribution. On the basis of experiments performed, we obtained different values of pattern numbers for different experimental settings. The optimal number of patterns was decided by cross validation. The experiments have been performed on different dataset for different number of patterns viz 5, 10, 25, 50, 75, 100, 150 and 200. The optimum number for each dataset has been determined on the basis of the performance guaranteed by each number of patterns.
Ensembled learning
The features obtained using the methods in the previous sections are combined together to form feature set associated with individual authors. Thus, we have a total of n feature sets, each associated with one of the n authors. This stipulates the need for an ensembler classifier. Since the final prediction of author class is made effective by combining the features together, it works in favor of supporting another hypothesis that can be stated as follows:
As an effort to prove H3, the proposed method combines the author specific features to obtain the parameters for each author.The approach followed is, associating each author with a specific subset of the major attribute list. The major attribute list comprises of all the dimensional and psycholinguistic features specified in Fig. 2 along with style word patterns identified for optimal number of patterns identified for a specific dataset.This approach works in favor of H2. Individual models are created for each author, based on the author-specific subset of attribute list. This is particular to the case of psycholinguistic features that are considered here. Out of the 98 psycholinguistic aspects used for analysis, some features might be applicable to some authors while they might not be suitable for attribution in case of other authors. Thus we infer a set of relevant attributes for each author.
Let {A1,A2...An} be a set of authors in a given dataset. Then the attribute list A xi associated with author A i can be given as
The consensus about the class of the questioned document is attained by taking summation of the weighted votes:
The hypotheses H1,H2 and H3 that define the influence of an individualś personality on his writing style,unique dimensional and psycholinguistic features that are pivotal in determining a personś writing style and the salient style marker constituted by the combination of dimensional,psycholinguistic, and style word patterns respectively. A novel means of obtaining individual author-based features obtained by relevant attributes identification using entropy score. The final prediction of attribution using ensembled learning performed on base ensemblers formed out of individual author models.
Experiments have been performed to empirically evaluate each stage of the proposed method namely dimensional and psycholinguistic feature extraction, feature selection, style word pattern extraction, optimal pattern identification, base ensembler formulation and ensembled prediction. These experiments have been conducted to prove the following set of accomplishments of the proposed work. The credibility of H1, H2 and H3 The better performance of authorship attribution using individual author based features Acceptance of the proposed approach in scenarios where there are many authors To prove that the proposed method is immune towards documents pertaining to similar themes To prove that the approach is applicable in case of documents that are short To prove that the proposed method considers optimum number of pattern usage for document to be analyzed for authorship
Data collection
These experiments were performed on two different types of data set so as to avoid biased conclusions. The set1 data set comprised of blogs collected from 5, 10, 20, and 50 authors belonging to different areas of interest. Five text documents of each author have been collected with around 200 words per text as well as 500 words per text. Set 2 data set has been prepared by collecting only the blogs written by cancer patients. 1
The data collection phase has been automated by means of an intelligent crawler that extracts posts from online blogs. The dataset has been prepared so as to scrutinize the scalability of the proposed method in cases where the candidate authors make point on similar topics. The mental plight associated with the authors in such cases is also same. As mentioned above, the authorship attribution approach proposed here has been tested on 5, 10, 20 and 50 authors each with five texts comprising of around 200 words. The same was carried out using 500 words per text. The variation in data set parameters has been incorporated to test the behavior of the proposed work in best case scenarios and worst case scenarios.
Stages of experiments
The initial set of experiments was conducted to prove the effectiveness of psycholinguistic, lexical and syntactical features in attributing authorship. All the data have been subjected to extraction of psycholinguistic, lexical and syntactic features as explained in methodology section. Experimentation phase proceeds further with the aim of obtaining optimum count of style word patterns of authors so as to secure best results. Then attribution using style word patterns is evaluated. Final experiments were performed by combining style word features corresponding to optimal number of patterns, with psycholinguistic, lexical and syntactical features. Then we proceed by performing attribution using combined features set (group based features) method and using individual author based feature method. This is in order to gauge the effectiveness of combined attribution over individual author-based attribution. The results have been analyzed to check the applicability of the proposed method in different scenarios. The final results have been compared against the existing methods to validate the effectiveness.
Results and discussions
The results of the different experiments performed on different stages can be explained as follows.
Dimensional and psycholinguistic feature extraction
The experimentation phase proceeds by performing experiments aimed at supporting hypothesis H1. Here different features specified in Fig. 2 have been considered and attribution has been performed using these features.
Feature selection
Experiments have been performed by individual author-based models. To prove H2, experiments have been conducted on group-based models also. In group based models, all the features in Fig. 2 have been combined together and then feature selection is performed on these combined features thereby resulting in a common feature set for all authors. Here we have only a single SVM Classifier. While in individual author-based model, a model trained on the psycholinguistic features associated with that author is formed for each author. The experimentation results are tabulated in Tables 1 and 2.
The accuracy of attribution using Psycholinguistic features for random blog authors
The accuracy of attribution using Psycholinguistic features for random blog authors
The accuracy of attribution using Psycholinguistic features for cancer blog authors
The experimental results are acceptable in confirming the hypotheses H1 and H2. The results prove that author based feature model gives better results in comparison with group based feature model. The accuracy is acceptable in cases of both best case and worst case scenarios. From this, it can be illustrated that psycholinguistic, lexical, and syntactical features can together contribute towards identifying an authorś writing style.
The empirical validation of hypothesis 1 using the above-mentioned experiments can be explained as follows. The lexical and syntactical variations in the writing style have been discussed in most of the previous works. The current work adds to this by incorporating new aspects of stylistic variations by including psycholinguistic features. This is done, considering the fact that an authorś rate of usage of words related to their interest is based on their attitude. For example, an introvert person is more intended towards explaining homely things in comparison with leisurely words. Passion-based difference will be evident from the difference in focus given for interests and perception. Focus of a person varies based on his/her inclination towards life and situations. Thus it can be clearly stated that a personś writing style is markedly influenced by his/her psycholinguistic aspects. Hypothesis 2 which states the variations in author traits to be considered for attribution can be remarkably validated by the results in Tables 1 and 2 which show improved results in case of author-based features in comparison with group-based features. This can be explained as follows. Based on authorś interests and affiliations, certain traits become more important for particular author while others play no role in their style identification. Acquiring those specific features and eliminating those features that do not take part in identification improves the results of attribution. In this way the experiments succeeded in proving H1 and H2 right. Since the attribution using individual author-based models shows better accuracy in comparison with group-based model attribution
Further analysis of the results shows that there is a degradation of results with a decrease in data set, as conceived from Tables 1 and 2. This can be associated with the lack of enough content for assimilating the psycholinguistic aspects of an author.
The results of Tables 1 and 2 also pronounce a reduced accuracy in case of attribution of cancer blog authors. This is owing to the reason that as the cancer patient blogs mainly focus on the victimś emotional disclosure and issues related to health, most of the articles follow the same pattern of theme-related aspects. Thus, psycholinguistic aspects cannot perfectly distinguish the writing styles followed in similar-topic articles. The reduction in performance can be compensated by incorporating style word patterns along with dimensional and psycholinguistic features.
The initial set of experiments of style word pattern identification begins with the identification of optimal number of style word patterns of authors. The best means of capturing author style is based on the number of the style word patterns to be considered for attribution which varies with the data set. To arrive at a preferred outcome, the attribution task has been subjected to experimentation under different number of style word patterns. Different settings of both data set (random authors and cancer blog authors) have been tested on 5, 10, 20, 50, 75 and 100 patterns respectively. The optimum number of patterns for each setting has been fixed by cross-validation based on the accuracy attained for attribution. The obtained results are delineated in Tables 3 and 4.
The accuracy of attributions corresponding to optimal number of patterns for Random author Data set
The accuracy of attributions corresponding to optimal number of patterns for Random author Data set
The accuracy of attributions corresponding to optimal number of patterns for Cancer Blog Authors Data set
The results of Tables 3 and 4 illustrate that style word pattern has a distinguishing capability in identifying authors writing articles on the same theme. But the performance degrades in situations where lesser data are used. This is because as the data lessen, the amount of style words obtained also reduces. This results in reduced accuracy in such situations. From the previous experiments it is evident that the style word markers, lexical, syntactic and psycholinguistic features can contribute towards identification of the author style. Hence, we aim at combining these features to exploit their attribution potential.
The inferences from the results of Tables 1–4 necessitate the reinforcement of attribution efficiency by the unification of all features discussed so far. Further, the results obtained for author-based features perform better than group-based features. Thus, the feature set associated with author-based model has been appended with pattern orientation features. The experiments using these features are tabulated in Tables 5 and 6.
The attribution using all features for random blog authors
The attribution using all features for random blog authors
The attribution using all features for cancer blog authors
The results obtained from experimentation as illustrated by comparing Table 1 with Table 5 and comparing Table 2 with Table 6 suggest that the proposed ensemble method using author-specific feature set improves the attribution. Tables 5 and 6 are a notable clarification for Hypothesis 3, as it clearly states that the ensemble method gives an improved result in cases of both data set. This is mainly because of the fact that, unlike the usual method of considering word-based features; here we consider style word patterns used by an author together with other dimensional and psycholinguistic features. The unison of these aspects makes the approach independent of the context of the topic being discussed as well as the emotional theme of the topic being explained but at the same time gathers necessary lexical, syntactic and psycholinguistic aspects that are particular to the author. The method followed here exploits the most obscured feature set of authors which they themselves are unaware of. This is combined together with the conventional strategies including frequent lexical and linguistic parameters. The combination is made in such a way that the features that are most specific to the authors are consolidated.
The attribution also shows improved results in the case of random authors. The attributions in case of random authors are more successful in the case of analysis using linguistic parameters as these features are more focused towards the term usages and psycholinguistic aspects which vary considerably with varying domains. Thus, analysis becomes more powerful using such features that can draw a clear distinction between author styles.
The results from Tables 5 and 6
Experiments have been performed to evaluate the performance of the method in comparison with the state-of-the-art methods. The method has been compared against various common methods that are based on formulaic sequences, topic modeling based and lexical methods. Table 7 gives a description about the existing startegies that have been experimented to analyze authorship. These are the methods against which the proposed method has been compared to evaluate its performance. The results of the comparison of experiments using the above mentioned methods against the proposed method are shown in Figs. 3–10.
Benchmark methods used for comparing the performace of proposed method
Benchmark methods used for comparing the performace of proposed method
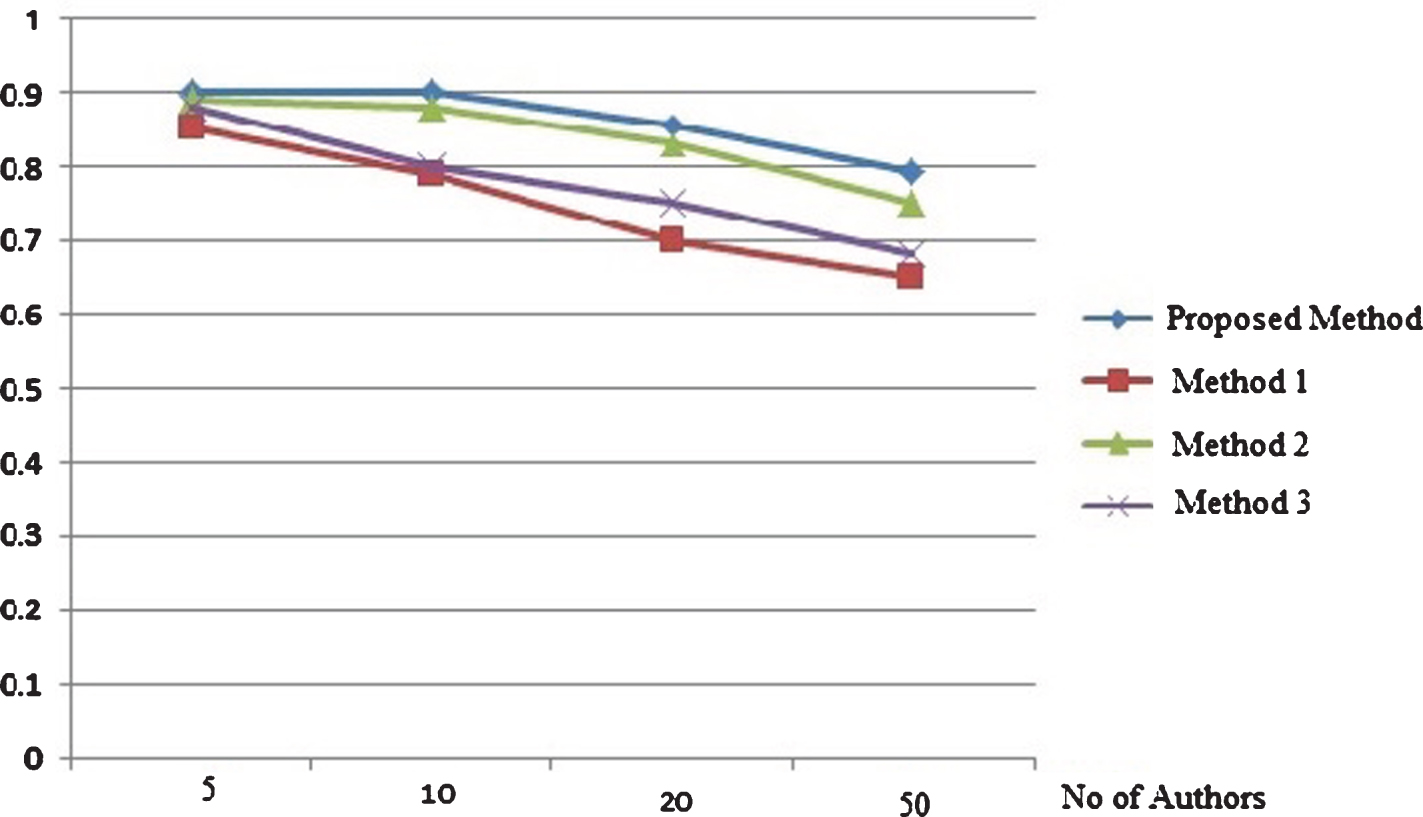
Precision based comparison on random authors dataset with (500 words per text).
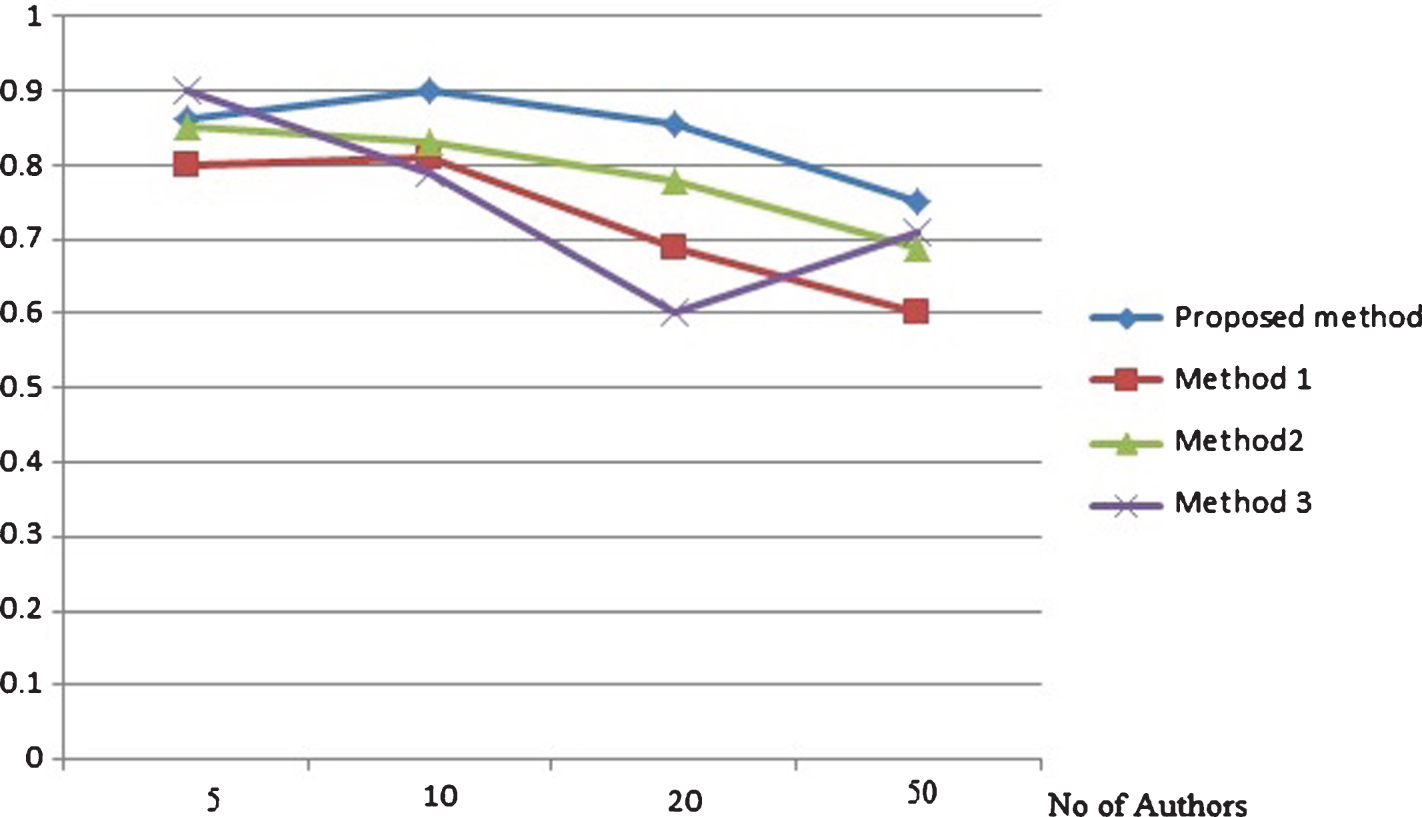
Recall based comparison on random authors dataset with (500 words per text).
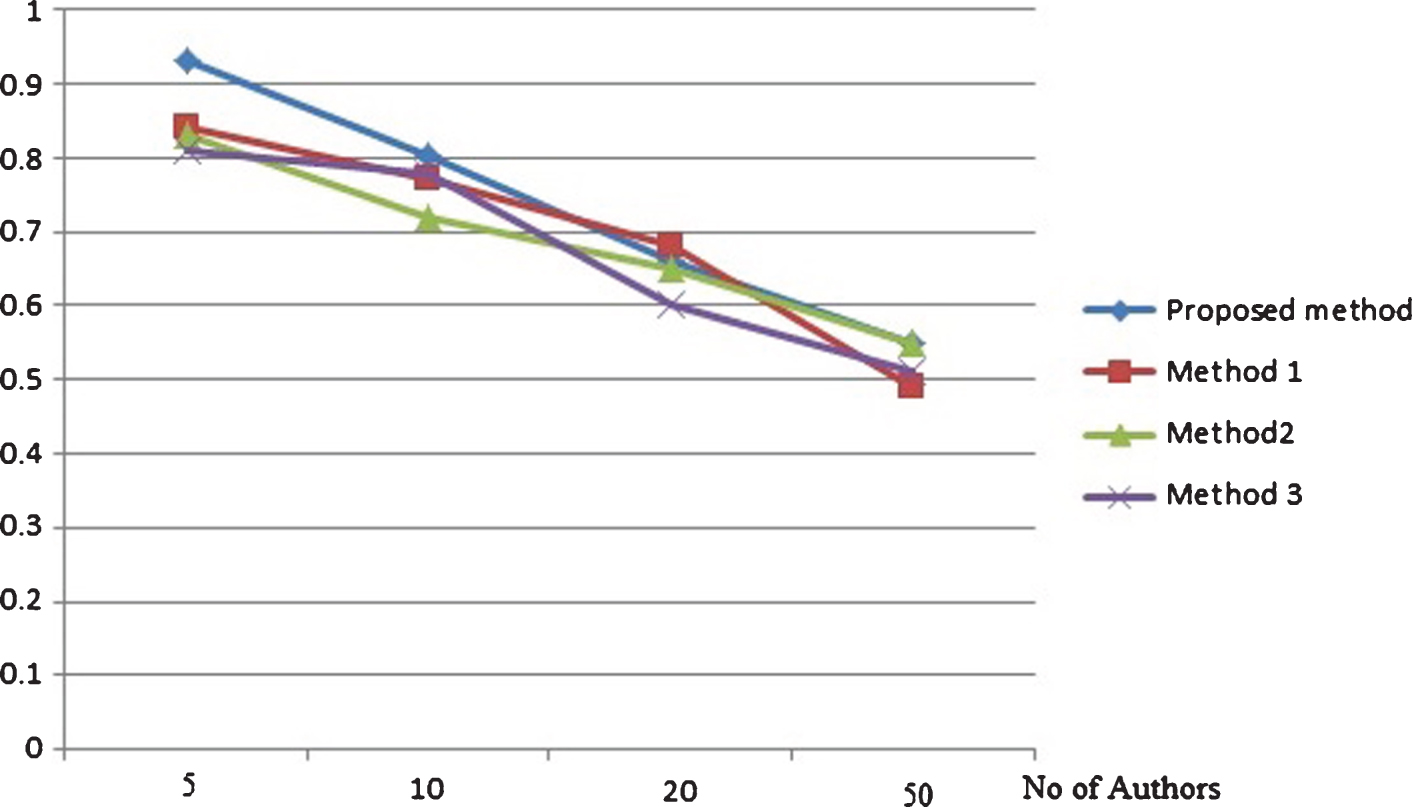
Precision based comparison on random authors dataset with (200 words per text).
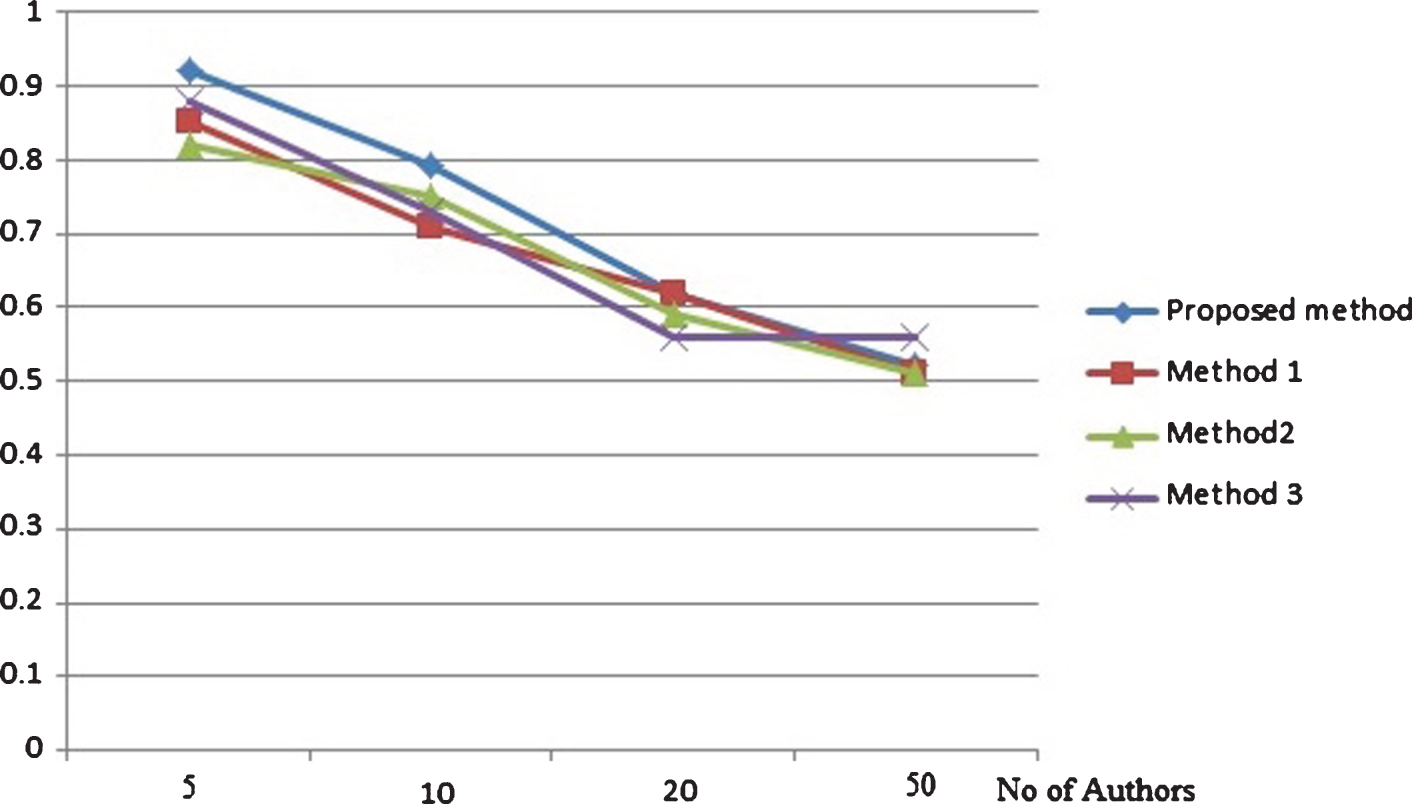
Recall based comparison on random authors dataset with (200 words per text).
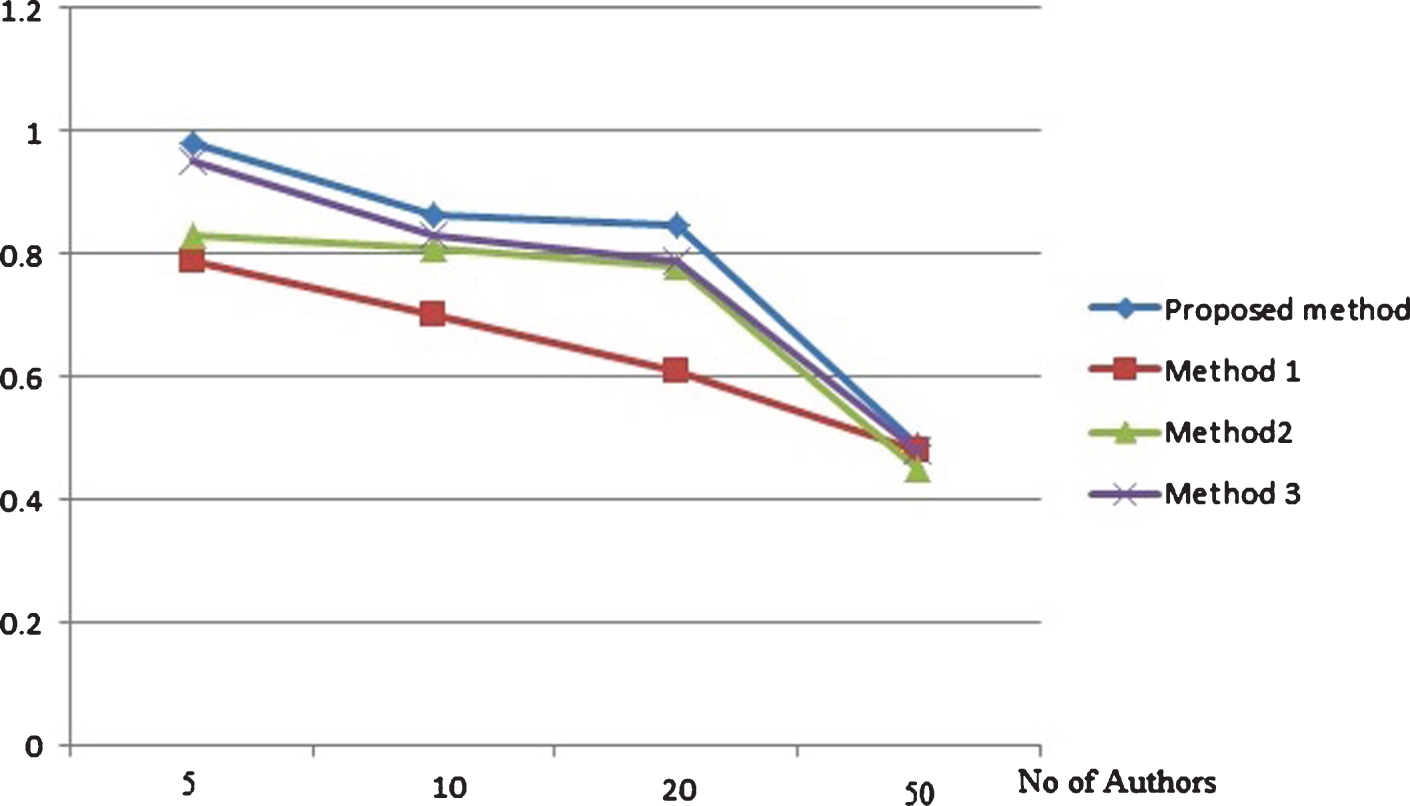
Precision based comparison on cancer authors dataset with (500 words per text).
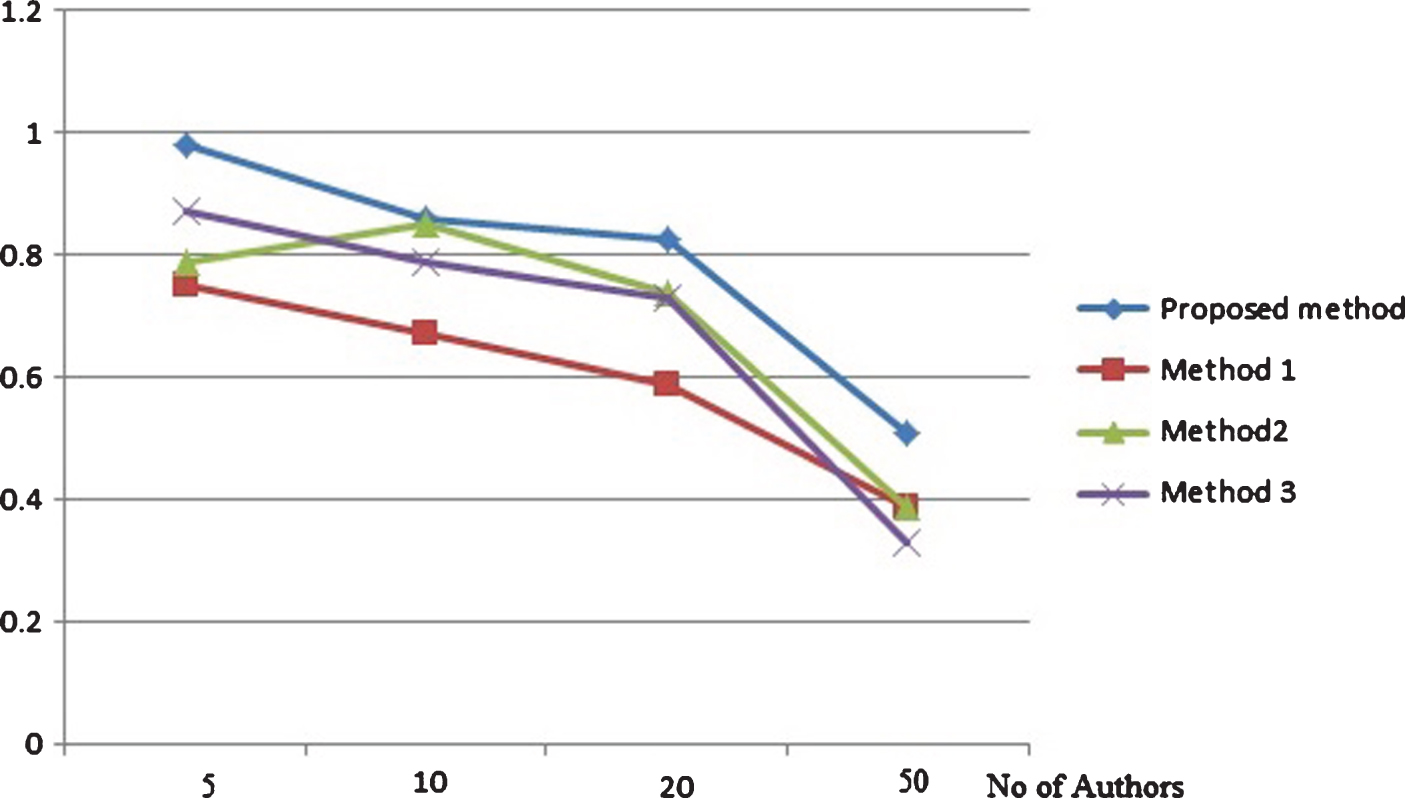
Recall based comparison on cancer authors dataset with (500 words per text).
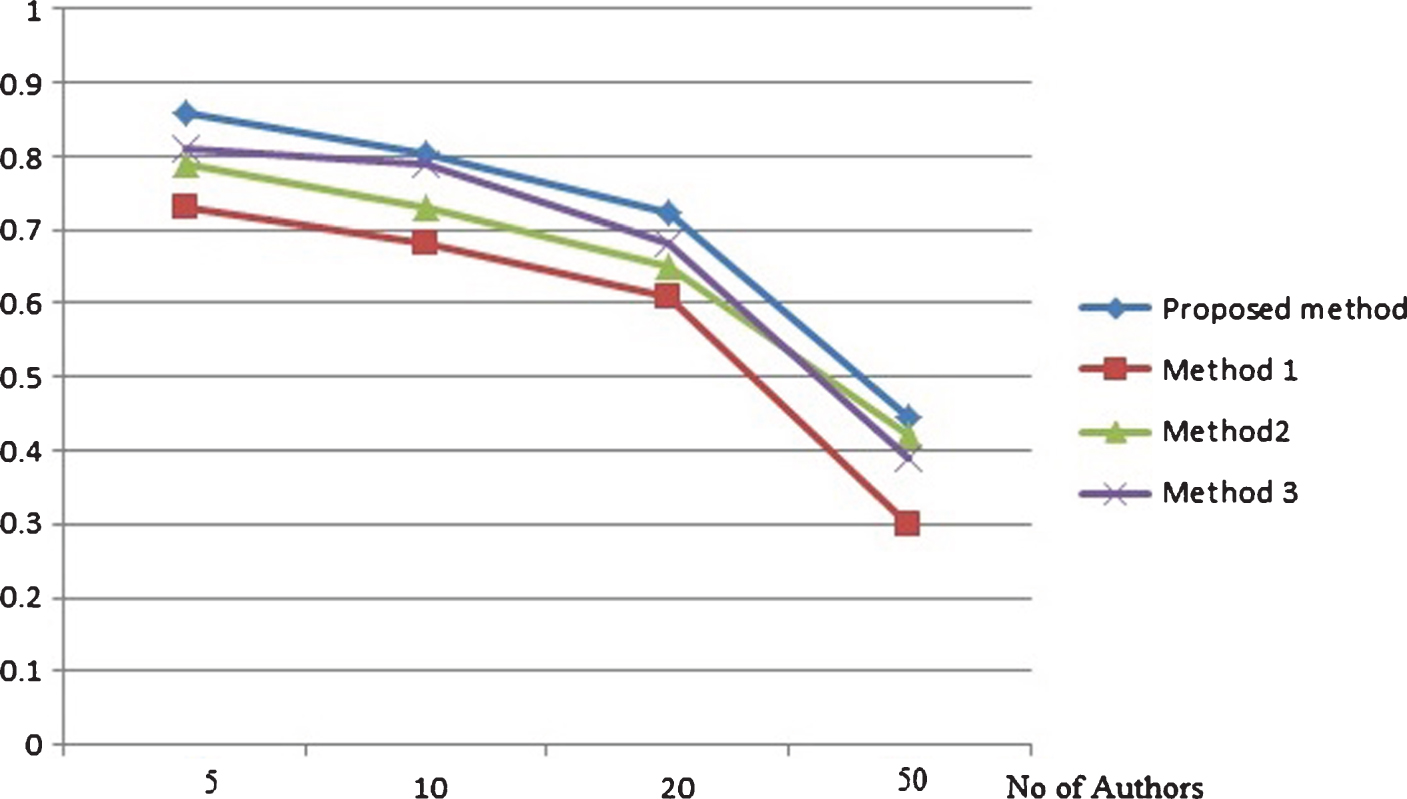
Precision based comparison on cancer authors dataset with (200 words per text).
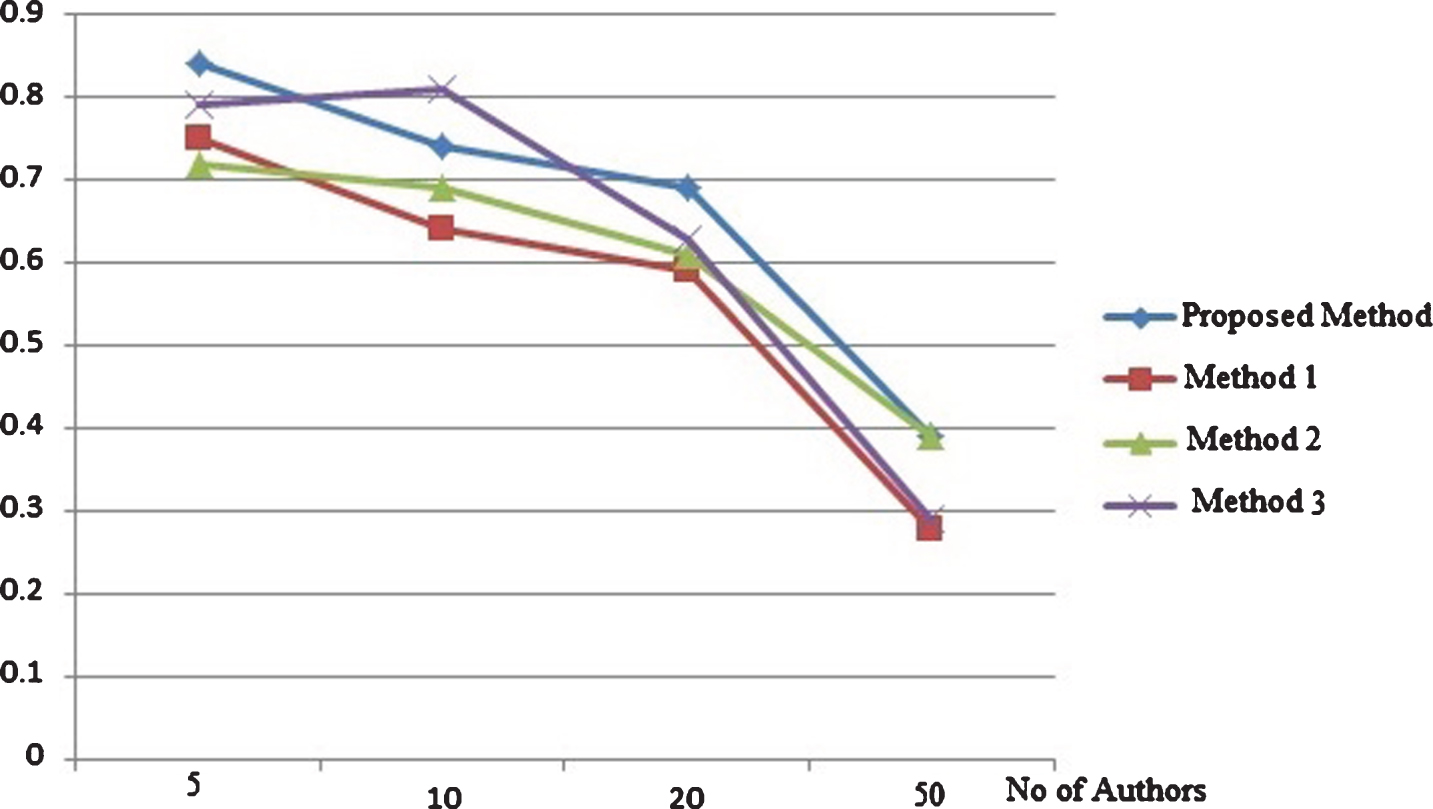
Recall based comparison on cancer authors dataset with (200 words per text).
Precision and recall based comparison on random authors data set with each author provided with 500 words per text are depicted by Figs. 3 and 4 respectively. The same metrics measured for the same data set with 200 words per text for each author is depicted by Figs. 5 and 6. From the results it is clear that the proposed method attains better results that existing methods in different cases of number of candidate authors in both the set ups of different words per text. The precision and recall based comparison of cancer blog data set with 500 words per text for each authors is provided in Figs. 7 and 8 respectively. The same metrics measured for the same data set with 200 words per text for each author is depicted by Figs. 9 and 10. The observed results from figures illustrate that the proposed approach attains better precision and recall in cases of different number of candidate authors and different number of words per text.
From Figs. 3–10, thus it is clear that in majority of the cases, the proposed method attains more precision and recall in comparison with existing methods. The proposed method works better in cases of less and more content available for analysis. The same result is observed for both the data set: random blogs and cancer blogs. This is because the feature chosen for analysis includes a combination of style word pattern and psycholinguistic patterns that are subtle manifestations of oneś writing style. The features make it more beneficial in identifying forged articles in online realm. The features used in our approach are less content-based, hence providing better accuracy. The results inferred from the above experiments prove that the proposed method performs better than the existing method. The performance of the method is even more evident in the case of cancer blog author data which ensures the applicability of the proposed method in the domain-specific dataset.
The proposed approach puts into use the psycholinguistic, lexical, syntactic, and frequently used style word pattern of individual author. The approach aims at finding individual author-based features, thereby strengthening the author pattern identification. The features so obtained are fed to base ensemblers. The final decision is made based on the majority weighted votes obtained for the test document. The conjunction of these features turned out to be a striking style marker in case of author styles followed in same-themed articles as well as random blog authors. In both cases, the individual author-based features are effective style markers. The method shows an improved performance in attribution of short documents in comparison with the existing methods hence making it applicable in forensic linguistic scenario. The method shows considerable performance in cases of large number of candidate authors with fewer documents per author. In spite of its meritorious performance in comparison with existing methods, the approach shows degradation in performance with decrease in contents available for analysis. The proposed work considers the scenario of attribution in case where training and testing corpus belong to same topic. Much discussions are going on in recent literature regarding cross topic authorship attribution where testing and training corpus are obtained from different topics. Our proposed method can be applied in the scenario of cross topic attribution, since the features are independent of the topic of candidate authors. The scope of the work can be improved by incorporating more features that captures tone based peculiarities of the author. This can improve the performance in case of very short texts.