
Abstract
In this paper a strategy for incorporating a flexible and reliable high-level inference module in service robots is presented. This module is a part of the robot’s cognitive architecture which coordinates perception, inference and action within the robot’s communication and interaction cycle. The present approach relies on an explicit representation of the structure of the task performed by the robot. There are three kinds of inferences that the robot can use opportunistically along the task: (1) diagnosis, (2) decision making and (3) planning; each kind can be used in specific situations of the task structure or performed in arbitrary situations with recovery purposes when there is an interaction failure. In this latter case the three kinds of inference are performed sequentially in what we call the daily-life inference cycle. The inference cycle allows the incorporation of basic emotions in the robot’s behavior. A case study incorporating these functionalities in the robot Golem-III is presented. The paper is concluded with a reflection on the opportunistic use of inference schemes to support flexible and robust behavior, including the expression of emotions, in service robots.
Keywords
Inference and task structure
The purpose of service robots is to assist people in their common chores at home, the office or other daily life contexts. Practical service robots of the future will need to be flexible to operate successfully in diverse scenarios. In order to deploy the perceptual, inferential, emotional and motor behavior effectively the robot needs to be situated or in context –unless there is a direct link between a particular stimulus and a particular action and the behavior is reactive. For the present discussion a situation is a pair consisting of (i) a state of the world involving a set of individuals with their properties and relations at a particular spatial position and time, and (ii) a knowledge structure containing the expectations of the robot about the potential intensional actions that can be performed by other agents or the natural events that can potentially occur in the situation in conjunction with the potential actions that should be performed when a particular expectation is satisfied. Expectations and actions in situations are propositional representations that result from interpretations of the information sensed in the world and produce intentional behavior respectively. Actions can be external, like motor behavior, or internal, like making conceptual or deliberative inferences [24]. For the present discussion a robot is situated if its knowledge state in (ii) is coherent with the state of the world in (i). For an extensive discussion of these notions see [22].
The present notion of situation allows to represent the task structure as a directed graph of situations that the robot needs to unfold in order to achieve its goal. The task structure can also be thought of as a script or protocol that characterize the behavior of an agent, like a waiter or a supermarket assistant.
The notion of task structure allows also a simple representation of the emotional state of the robot. This is achieved by assigning a particular “emotive value” to the expectation that is met in a situation and performing and appropriate coherent emotional action. For instance an expectation with a low emotional value that is met in a situation may trigger the expression of a sad or angry facial expression.
Human behavior for accomplishing these kinds of tasks is extremely complex but we can expect that simplifying it through simple but flexible parametric protocols is feasible in practice. We refer these simplified descriptions as practical tasks [22]. From these definitions it follows that the robot is situated all the way if it is able to achieve a practical task by successfully unfolding the graph of situations specified in the task structure.1 For modeling all this functionality we have developed the Interaction-Oriented Cognitive Architecture [21] which is described in Section 4.1. These notions are adopted implicitly or explicitly by most current operational service robots.
Opportunistic inference
The model of behavior sketched above needs to consider the case in which none of the robot’s expectations is met in a situation. The explicit representation of the task structure is the product of analysis and characterizes the standard dynamics of the application domain, but in a constantly changing world there are agents performing actions and natural occurring events that cannot be considered beforehand. When these happen the normal flow of behavior is interrupted, the robot loses its ground, gets out of context and is no longer situated. At this point the goals of the tasks need to be posponed, and the robot’s priority is to get situated again and be able to resume the interpretation of the task structure. There are several possible strategies to this effect. One is to relay on a number of recovery protocols that take into account possible failures that can occur in the domain. These protocols may also be the product of analysis, and robust behavior should be supported by a large number of them. However, there may also be more extreme failures that cannot be predicted through analysis, and inference is required for dealing with them.
Suppose, for instance, that the robot gets back to its house from work –by following the situations of an appropriately defined task structure– and there is a puddle in front of the door. Suppose that this is not considered in the task structure and the robot has no recovery protocol for meeting with this eventuality. One possibility is to ignore the water and get wet with potential costly consequences for the robot’s integrity; however, a better strategy consists in engaging in an inference cycle consisting on a diagnosis, a decision making and a planning stage. The diagnosis consists on making an abductive inference from the effect (i.e. the puddle) to its plausible causes. For this a set of diagnosis rules need be available. For instance, if it rained there is a puddle or if a pipe is broken there is a puddle. From the actual observation and the diagnosis rules the robot may infer that it rained or a pipe is broken.
The importance of the diagnosis is that the premises of the diagnosis rules are also the premises of the decision making rules through which the robot decides what to do next. Suppose that the robots has a set of decision making rules including if it rained sweep the water and if a pipe is broken fix it. So, making a particular diagnosis conditions a decision making process to attend the initial unexpected observation. Decision making rules are also based on the preferences and “values” of the robot, and involved an underlying ethical layer of behavior.
Furthermore, when a decision has been made, the consequence of the relevant decision rule becomes the goal of a plan to achieve such decision. If the diagnosis is that it rained the goal of sweeping the water involves getting the broom, going to the puddle and sweeping the water, but if the diagnosis is that a pipe is broken the plan may involve inspecting the pipe, finding the leak, closing the faucet, plug the hole, sweeping the water, and opening the faucet. Once the plan is induced the robot can proceed to its execution and review the situation after one or more steps of the plan have been performed. The inference cycle can be invoked recurrently as many times as needed until the ground is recovered and the robot is able to get back to the situation in which it was within the task structure and complete its journey home. We call this the daily life inference cycle that is performed opportunistically on demand when the flux of common events of the schematic behavior deviates from its normal course. The knowledge required to support these kinds of inferences is incomplete and non-monotonic, and the inferential machinery needs to be supported by an appropriate non-monotonic knowledge-base system, as the one developed for this purpose within our project [24]. Service robots should be equipped with this inferential abilities in order to cope with the myriad of incidents that may happen in the world that cannot be predicted through analysis.
Outline of the paper
A literature revision of work related to inference in service robots is presented in Section 2. The definition and implementation of the daily-life inference cycle is presented in detail in Section 3. The cycle is illustrated with an scenario in which the robot performs as an assistant in a supermarket. This is a practical task that is modeled through an appropriate task structure. The diagnosis, decision making and planning rules and schemes for this scenario, in conjunction with the heuristics and search strategies for exploring the problem space for each of the three kind of inferences, are described in detail. The representation and deployment of emotional behavior in the context provided by the task structure is presented in Section 4. A demo to illustrate the present scenario has been fully implemented in the robot Golem-III and the Interaction-Oriented Cognitive Architecture, which are described in Section 5. The paper is concluded with an overall reflection in Section 6.
Related work
Making inferences has long been one of the recurring abilities in autonomous robotic systems. This ability is particularly important for service robots, which operate in complex and dynamic environments, because it allows them to cope with uncertainty, enables more robust, flexible and autonomous behaviour, and greatly simplifies task programming. In this section, we summarize some related work on inference in robotics with especial focus on service robots. The reader is referred to [15] for a broader review on the topic.
Inference in service robots has been focused on task planning using logical inference. For example, Brennet [5] relies on classical planners to decide what actions the robot has to perform given the user’s command. A decision-theoretic task planning based on READYLOG was incorporated to the cognitive architecture of the service robot Caesar [25] and was tested on the RoboCup@Home competition. The READYLOG-based planner allows the integration of qualitative reasoning and human-robot interaction. Task planning using non-monotonic inference based on Answer Set Programming (ASP) was proposed by Chen et al. [6]. Thanks to the use of ASP, this inference system can handle common-sense reasoning and planning in a unified way. The proposed system was demonstrated in the the KeJia robot using standard RoboCup@Home tests as well as other complex tasks. A large body of research on inference on service robots has been devoted to task planning using spatial and/or temporal information coupled with semantic information (e.g. [11, 20]). Bidot et al. [4] proposed a hybrid planner which takes into account high-level actions and low-level motions and geometric information.
There have been also many robotic systems incorporating decision-making. For example, the CRAM [3] architecture combines the CRAM Plan Language (CPL) and KNOWROB’s knowledge processing system to make decisions and create plans for complex manipulation tasks. Lemaignan et al. [19] designed a human-aware deliberative architecture for social robots for decision-making and planning in collaborative tasks where humans work together in the same space with robots to achieve a shared task. Interestingly, in the proposed architecture, components interact bidirectionally and take into account intentions, beliefs, perspectives, skills of the human partner as well as the actions she/he has performed to achieve the shared task. An interactive decision-making framework was introduced by Agostini et al. [1] which allows the robots to incrementally learn to take decisions and make plans from human instructions given by human operators.
Probabilistic approaches such as Partially Observable Markov Decision Processes (POMDPs) and variants, have been integrated into several robots to provide decision-making and planning capabilities and have been applied to navigation [9] and grasping [14]. Schmidt-Rohr et al. [26] modified the Bayesian forward filter of POMDPs to better model uncertainty in low-level components when taking decisions. POMDPs have also been used in service robots to learn decision making and planing from human demonstrations [27]. Zhang et al. [31] combined logical and probabilistic inference for task planning. Specifically, hierarchical POMDPs are used for modelling low-level sensing and navigation where the belief distributions are initialized and revised based on the domain knowledge using ASP.
Most of the existing deliberative inference systems in service robots have been mainly designed for task planning and decision-making. Surprisingly, diagnosis has been scarcely explored. Among the few related works is the diagnosis module proposed by Becker et al. [2], which uses abductive reasoning methods to create hypotheses about past events that explain some changes in the current state of the world. The diagnosis module is used on demand and was developed using the KnowRob Knowledge Processing Framework and demonstrated on a delivery application. To the best of our knowledge, the closest work to ours is the three-layer architecture of the Dora robot [13], which integrates decision-making, planning and diagnostics. However, as opposed to our proposed approach, decision and planning are not explicitly decoupled. To the best of our knowledge, the high-level inference module for service robots proposed in this paper is the first integrating diagnosis, decision-making and planning in a sequential fashion and accessed on demand by the robot in unexpected situations.
Inference in the robot Golem-III
The implementation of the inference cycle is now discussed in detail. For the sake of clarity and practicality, the diagnosis, decision making and planing stages will be described in terms of the supermarket assistant domain.
The supermarket assistant domain
Consider the scenario in which the robot Golem-III is an assistant in a supermarket. Golem-III has two responsibilities (i) it must arrange and carry items from a warehouse room to specific shelves according to the category of the items, and (ii) it must interact with customers, bringing the items they request. Furthermore, the supermarket employs one human assistant, having the same responsibilities than the robot, and three shelves, namely Shelf 1 of drinks, Shelf 2 of food, and Shelf 3 of bread.
The human assistant states that he will place a soda, a beer, a soup and a package of biscuits in their respective shelves. By this statement, the state of the world for Golem-III is that a soda and a beer are in Shelf 1, a soup is in Shelf 2 and a package of biscuits is in Shelf 3. Unfortunately, the human assistant got distracted and made some mistakes by placing the soup in Shelf 1 and the soda in Shelf 3; although, the beer and the biscuits were correctly placed in their respective shelves. He additionally put a package of cereal in Shelf 2 without informing Golem-III of this action.
Next, a customer meets Golem-III and requests a soda, so the robot goes to Shelf 1 to fetch it. Once Golem-III reaches Shelf 1, it observes a soup and a beer there, and no soda. Thus, the robot becomes aware that the state of the world is not coherent with the information it senses from the environment. Since a failure has occurred, an inference cycle must be done to get Golem-III situated again in order to complete the customer’s request.
Diagnosis
Obtaining the diagnosis is an abductive process that considers two inputs: the current observation O n , and a collection R of rules of the form A → O, where A is an action that produces an observation O. The result of these two inputs is an action An-1 at the moment n - 1, such that An-1 produces O n by following a rule in R. Now, the observation On-1 is considered as well as R to obtain action An-2, and so on. Unseen observations about the state of the rest of the world may be considered to complete the diagnosis, so more observations O i and actions A i are added with respect to possibly a different set of rules. The diagnosis process generates a tree with explanations of the current information perceived from the world, and by applying some heuristics the best path is taken.
By examining a shelf, the rules R for the supermarket domain are: If assistant P moves to shelf N with items in his hands, then P places items on shelf N. If an assistant places item I on shelf N, then I is on appropriate shelf N. If an assistant misplaces item I on shelf N, then I is on wrong shelf N.
From the observations of Shelf 1, Golem-III can determine that the human assistant’s last action was to misplace a soup in Shelf 1, before that he placed a beer in this same shelf, and prior to this he moved to Shelf 1. The diagnosis so far is D = [misplace (soup), place (beer), move (shelf1)]. For more actions that would be added to D, Golem-III considers a set S of possible previous actions performed by the human assistant related to the unobserved shelves and objects. The robot then chooses elements of S, resulting in the diagnosis being branched. Such a choice depends on the rules that the last action of D introduces. For instance, move (X) cannot be preceded by other move (Y) action.
Let S be {move (shelf2), move (shelf3), misplace (soda), place (biscuits)}, since the last action of D is move (shelf1), the previous action done by the human assistant might be either misplace (soda) or place (biscuits). Once a choice is made, it is removed from S. This process continues repeatedly until there are no more elements in S. Figure 1 depicts a partial diagnosis tree for the supermarket assistant domain.
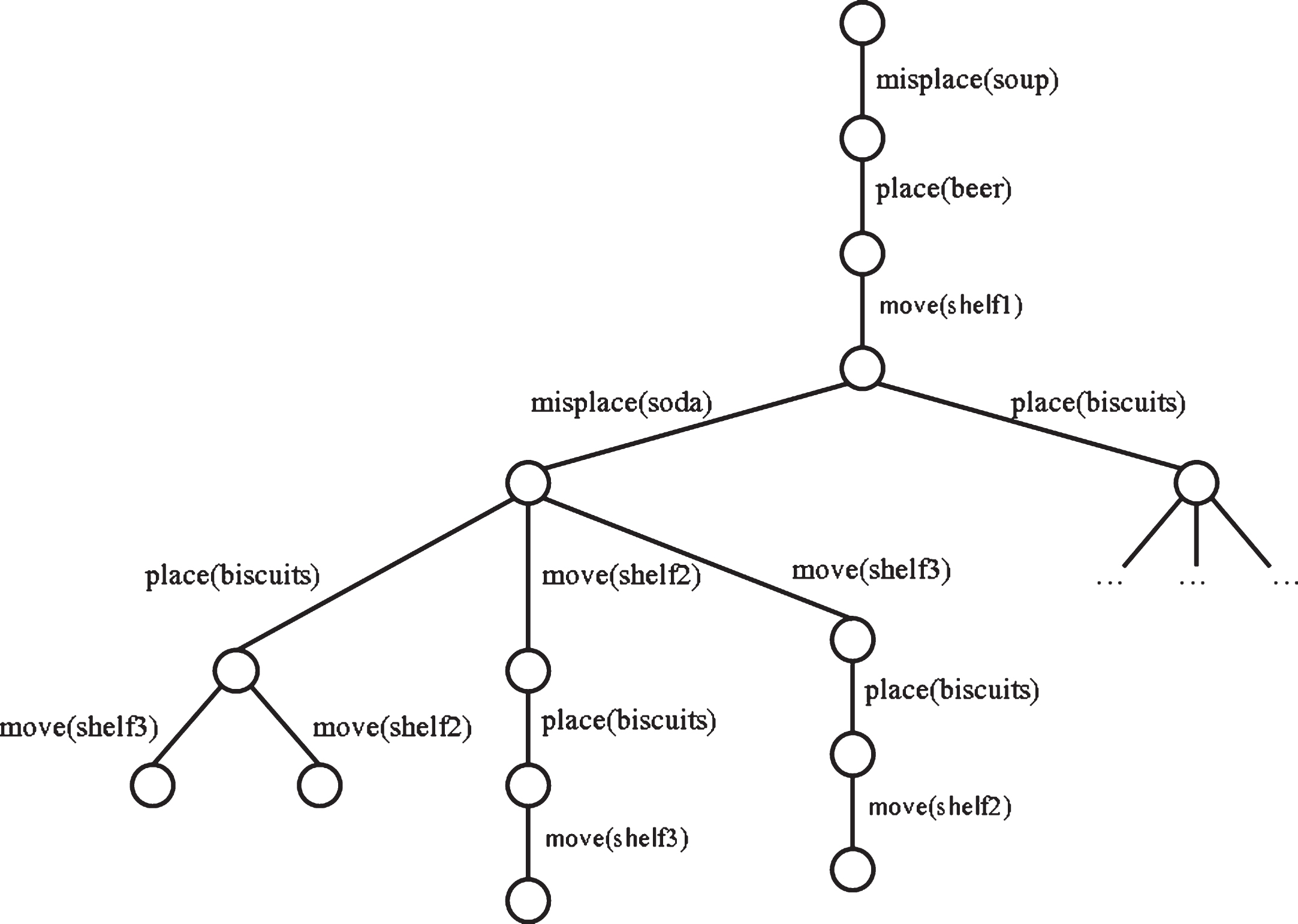
A partial diagnosis tree for the supermarket assistant domain.
From a diagnosis tree, the best path from a leaf to the root is selected by taking into account three heuristics: The number of items wrongly placed in the path. Items in erroneous locations decrease the chances of a path of being selected. The similarity between the distribution of objects in the shelves reported by the human assistant and that found within a path. Note that the distribution does not mind whether an object was placed in the correct shelf or not. For instance, [2, 1, 1] is the distribution reported by the human assistant, and [1, 2, 1] is the one in a particular path. A path with a similar distribution to the one reported by the human assistant increases its chances of being selected. The number of objects in the path. The more objects placed within a path, the more likely it is of being selected.
The selected path, traversed from bottom to top, becomes the final diagnosis that will be the input for the decision making stage. For the supermarket assistant domain the diagnosis is: the human assistant went to Shelf 3 and placed the biscuits; next, he went to Shelf 2 and misplaced the soda; finally, he went to Shelf 1 and placed the beer and misplaced the soup.
The decision making process considers two values: the diagnosis D obtained in the previous stage and a set of rules
Given the diagnosis of the previous stage, the decision rules If an assistant placed (or misplaced) the soda on shelf N, then bring the soda from shelf N to the customer. If an assistant misplaced item I on shelf N, then rearrange I to be placed in the correct shelf.
So, the goal actions that Golem-III might carry out are: bring the soda from Shelf 2 to the customer, rearrange the soda to be placed in Shelf 1, and rearrange the soup to be placed in Shelf 2. A clear restriction is that actions on the same object are not allowed. For instance, it is inconceivable that our decision involves bringing the soda to the customer and rearranging the same soda to be placed in Shelf 1. With this consideration, the decision making tree for the supermarket assistant domain is given in Fig.2. When evaluating a path, Golem-III focuses on two values: A bonus β is granted for each bring action included in the path. A bonus γ is granted for each rearrange action included in the path.
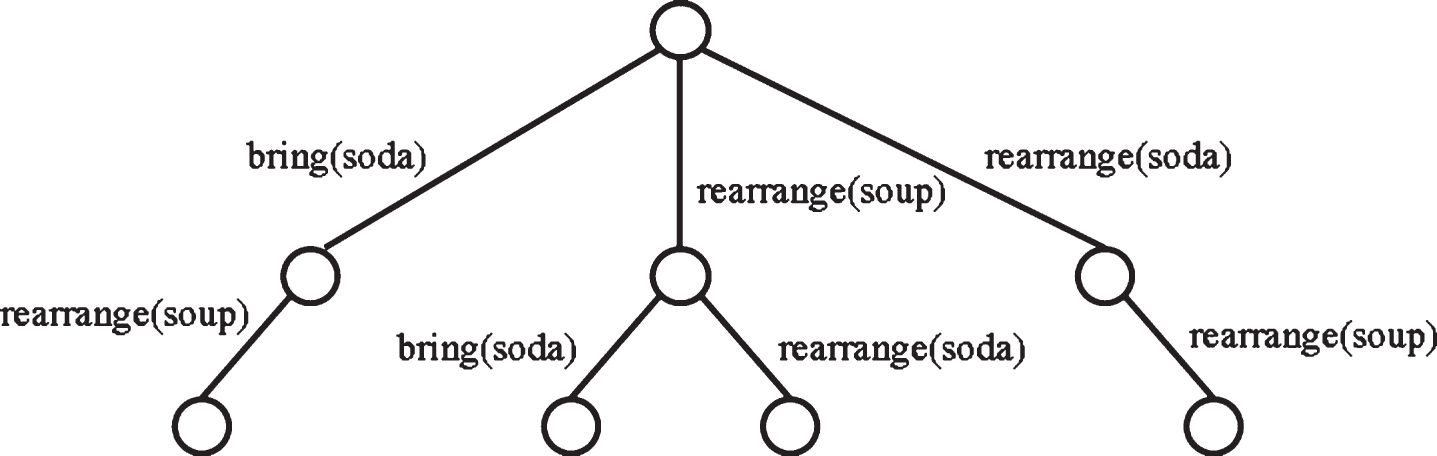
The decision making tree for the supermarket assistant domain.
The relation between β and γ will determine whether Golem-III pays more attention to completing the request of the customer, provided β > γ, or to preserving the order of items in the shelves, provided γ > β.
The path with the highest evaluation becomes the decision that will be the input for the planning stage. For the supermarket assistant domain it turns out that the decision is: Golem-III will rearrange the soup to be placed in Shelf 2, and bring the soda from Shelf 2 to the customer.
Each individual goal action returned by the decision making process is decomposed in primitive or atomic actions, which are all put together in a bag B. To build the planning tree, primitive actions are drawn from B in such a way that consecutive possible actions do not create a conflict with one another. Hence, certain constraints or rules are needed. The plan for achieving the goals of the decision from the preceding stage is the best path found by a search algorithm on the planning tree, whose computations take pertinent values previously assigned to primitive actions within the tree.
Back to the supermarket assistant domain, the primitive actions for rearranging the soup are
Also, the primitive actions for bringing the soda to the client are
Golem-III puts together the primitive actions in a bag B. Next, the planning tree is built by using the constraints that each kind of action imposes on the action that might follow. For instance, suppose that the action move (shelf1) is performed, this implies that: A move (X) is not possible because move (shelf1) just took place, that is, any move (X) is prohibited immediately after a move (Y) action is completed. A search (soda) is not considered because Golem-III only searches for items in the shelf where it thinks such items are. According to its current state of the world, the soda is in Shelf 2, and Golem-III is located in Shelf 1. A grasp (X) is not possible because, for such an action to be carried out, it must be immediately preceded by a search (X) action. A release (X) is not possible because, for such an action to be executed, it must be preceded by a grasp (X) action.
Hence, assuming that move (shelf1) was performed, the only plausible next action in B is search (soup), which becomes ineligible for future choosing.
Consequently, Golem-III produces the planning tree, that Fig. 3 shows in part.
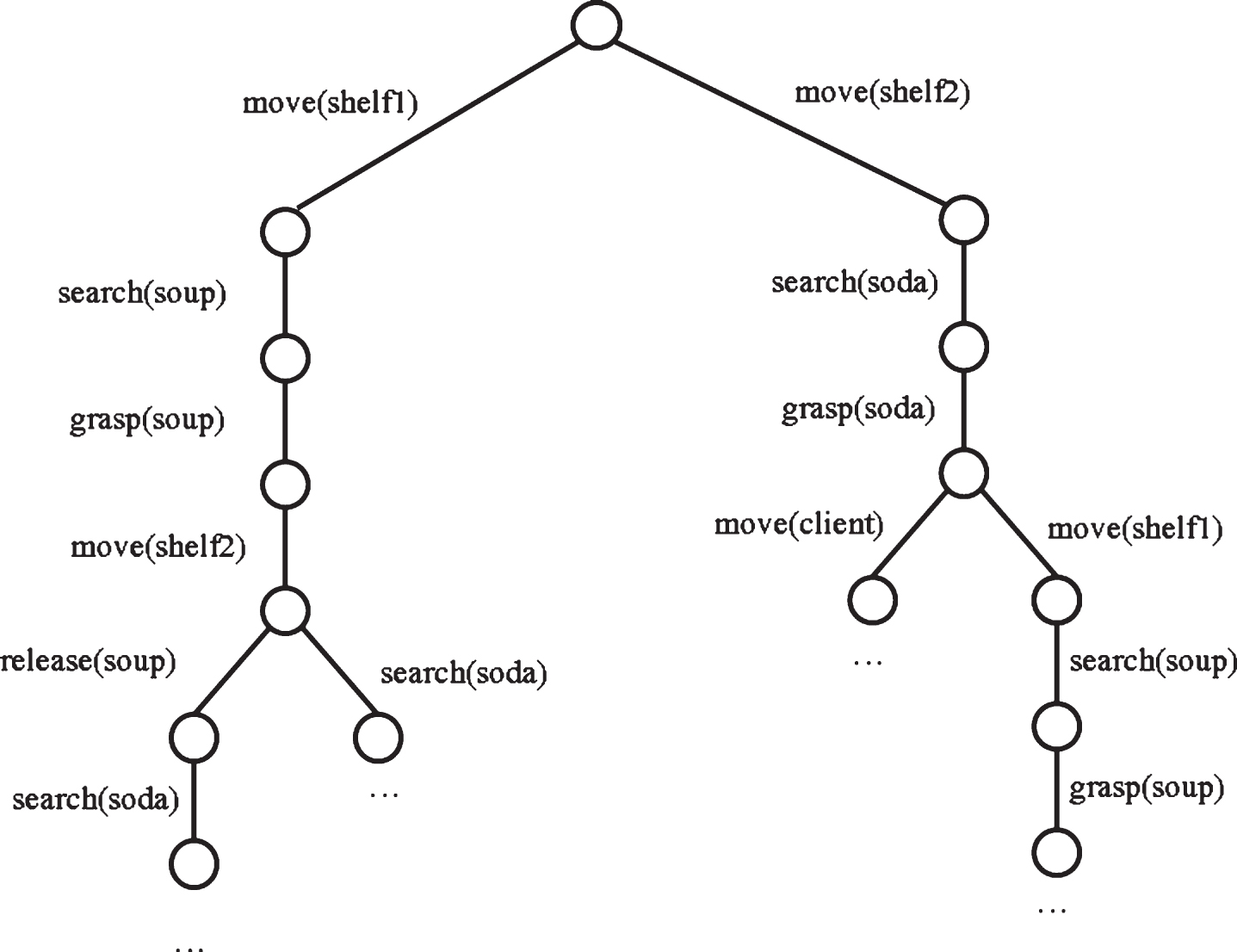
A partial planning tree for the supermarket assistant domain.
To choose the best plan, Golem-III associates to each primitive action in the planning tree a probability of success, a cost in time, and a reward. With these values, different search algorithms were tested, such as Breath-First Search (BFS), Depth-First Search (DFS) and A*; however, for this particular problem, finding an admissible heuristic, and proving that it works correctly is not trivial for A*.
For the supermarket assistant domain the plan is: Golem-III will move to Shelf 1, find the soup and grasp it. Then it will move to Shelf 2, release the soup, find the soda and grasp it. Finally, it will move to the client and release the soda to him.
This finishes the inference cycle Golem-III engaged to when realizing that the soup was incorrectly put in Shelf 1 and the soda was not there. The resulting measures taken to situate Golem-III again into the actual world will not lead it to complete the task, since it will encounter additional failures in Shelf 2 and Shelf 3; therefore, more calls to this inference cycle will be needed. The whole execution of this task, involving Golem-III engaging in several inference cycles, can be seen in the video at http://golem.iimas.unam.mx/opportunistic_inference.
The expression of emotions has been used in service robots to enhance human-robot interaction (e.g., Lisa Robot [28] and Bender Robot [29]). This is of interest since the effect of emotional behavior during human-robot collaboration helps to enhance activities in daily life environments. Facial expression is a common mechanism to display emotional behavior; it shows individual motivation and makes behavior understandable and predictable. Also, it helps to synchronize, organize and complete social interactions [18]. Many expressive robots focus on a set of universal facial expressions. Ekman’s proposes the following: happiness, surprise, fear, disgust, sadness and anger [8]. It has been shown that expressive robotic systems favor feedback and linkage with people [7, 12]. Furthermore, facial expressions help to communicate an emotional and mental state which is expected to be consistent. Thereby, facial expression of emotions can be a window to an internal condition in the system.
The expression of facial gestures with minimal resources is useful when explicit or unclear situations arise during the interaction. The robotic head in Golem-III is able to communicate five of the six universal facial expressions (all but disgust). The emotional behavior in our robot is regulated by the cognitive architecture. The activation of gestures is the result of the diagnosis and the premises of the decision in the system, also, an emotion in the robotic face informs about a new inference cycle. The facial gestures and the situations in which these are expressed are as follows: Happy: The objective was completed or the conditions are consistent with the hypothetic state of the world. Surprise: The world is not as expected in the situation (i.e., no expectation is met in the world). Sadness: The expectations to complete the current objective are low and the diagnosis inference needs to be started. Angry: An adverse condition is still present in the environment and the daily-life inference cycle needs to be continued. Fear: The system is not able to complete the task and a help recovery protocol needs to be invoked.
The five facial emotions expressed by Golem-III, as well as the neutral expression, are shown in Fig. 4. Additionally, Golem-III is able to perform transitions from an emotional state to another (e.g., sad to angry) and also dynamic gestures which differ from static ones in that they consist on a sequence of expressions with incremental intensity [16, 30].

Facial emotional expressions: neutral, happy, surprise, sadness, angry and fear.
The interaction-oriented cognitive architecture
Golem-III is a realization of the conceptual model presented in [22] and its behavior is regulated by the Interaction Oriented Cognitive Architecture (IOCA) [21]. The IOCA architecture specifies the types of modules which integrate the system. A diagram of IOCA can be seen in Fig.5.
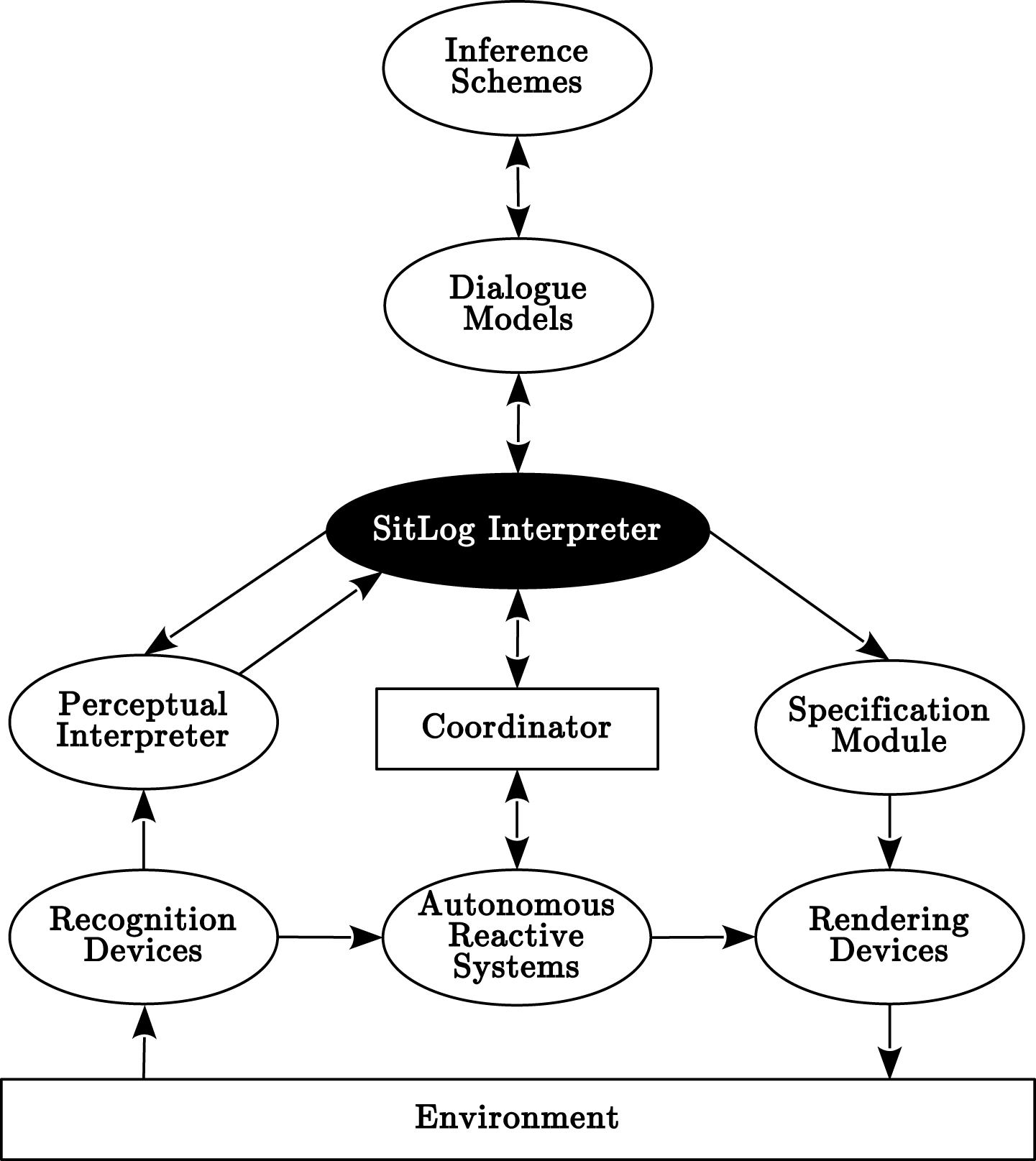
Inference Module in the Interaction-Oriented Cognitive Architecture.
Recognition modules encode external stimuli into specific modalities (e.g., speech into transcriptions, images to SIFT features). Interpreter modules assign a meaning to those messages from different modalities (e.g., from transcriptions to a semantic representation). On the other side, Specification modules ground global parameters to values that are able to be rendered at a low-level (e.g., “kitchen” to [x, y] coordinates). Render modules are in charge to execute the actions (e.g., perform navigation actions to arrive to the kitchen). The dialogue manager is in charge of managing the execution of the task. It is based on SitLog [23], a programming language designed for task description, developed within the context of the Golem project.
Reactive behaviors, such as obstacle evasion or the emergency stop, do not require any task context. Thus, management from the top dialogue manager is unnecessary. To achieve this, recognition and render modules are tightly joined into Autonomous Reactive Systems (ARSs) that can communicate to the dialogue manager directly by a coordinator.
The robot Golem-III is shown in Fig. 6. Its lower half, which houses the hardware used for navigational purposes, is an Adept MobileRobot’s Research PatrolBot robotic base. Its upper half, which houses the rest of its hardware, is an in-house-built robotic torso. In Table 1, a brief summary is presented of its hardware and the software libraries used.

The Golem-III Service Robot.
Software Libraries and Hardware used by the Golem-III Modules
Service robots of the future will need to exhibit flexible and robust behavior to assist people in their normal daily-life chores in real environments. Procedural or schematic models of behavior offer direct and effective performance but small deviations of the expected state, actions or events of the world can cause that the robot losses its ground, gets out of context and is unable to act. One way to face these problems is to embed beliefs, intentions and desires explicitly within the interaction and communication cycle and perform inferences upon these objects continuously, in a model that favors a think-to-act style of behavior. However, the computational resources to implement this latter model in real time are too expensive and may not be available in practice, limiting the actual use of service robots. A trade-off between these two extreme cases is to model the robot’s behavior schematically through the explicit representation of the task and communication structure, which is also a representation of the context –so the robot can achieve its goals by “visiting” the situations specified in the task structure without performing explicit inference– but at the same time providing a set of inference schemes that can be used on demand when required, in particular when the expectations of the robot are not met in the current situation. When this happens the robot can invoke the use of such inference patterns to reason about the situation of the world and engage in a think-to-act cycle until a situation in which the expectation are met, the context is recovered, interpretation and action are grounded, and the robot can proceed with the task through schematic behavioral patterns again. We call this “opportunistic inference” and our methodology, experiments and current results suggest that this interaction-reasoning strategy offers a very good compromise to support effective interaction with robust behavior.
This compromise also supports the implementation of a natural model of emotional behavior. The emotions expressed by the robot can also be specified within the task structure, providing additional feedback to users, so they can behave cooperatively and contribute to the task and help the robot to reach their goals. Conversely, the expression of negative emotions when something goes wrong with the task, specially when the expectation are not met and the robot gets out of context, is an important capability to motive the user to behave proactively, and facilitate that the robot gets back on track. Furthermore, particular kinds of inferences often have a concomitant kind of emotion, that can be expressed when instances of such inferences occur. We have capitalized these capabilities in demonstrative scenarios of the robot Golem–III with promising results.
In this paper we have also introduced the daily-life inference cycle for service robust, consisting on making a diagnosis for hypothesizing why the world is not as expected in a particular situation, a decision making inference in order to decide what to do to fix the problem and a planning inference to define how to achieve such decision. Each of these three kinds of inference has been studied intensively in knowledge representation in AI by their own, but is not common to address their study systematically within the daily-life inference cycle. In the field of service robots planning inference is a common topic of study, especially for navigation and manipulation, and decision making is also commonly study, specially in sub-symbolic approaches involving reinforcement learning; however, diagnosis or abductive inference has been addressed very seldom in service robots, as discussed in Section 2. Providing the setting in which the use of this kind of inference is useful in practice, and relating diagnosis, decision making and planning systematically to support robust behavior in service robot is a promising approach, which to our knowledge is a novel contribution to the field of service robots.