
Abstract
Soft consensus is a relevant topic in group decision making problems. Soft consensus measures are utilized to reflect the different agreement degrees between the experts leading the consensus reaching process. This may determine the final decision and the time needed to reach it. The concept of coincidence has led to two main approaches to calculating the soft consensus measures, namely, concordance among expert preferences and concordance among individual solutions. In the first approach the coincidence is obtained by evaluating the similarity among the expert preferences, while in the second one the concordance is derived from the measurement of the similarity among the solutions proposed by these experts. This paper performs a comparative study of consensus approaches based on both coincidence approaches. We obtain significant differences between both approaches by comparing several distance functions for measuring expert preferences and a consensus measure over the set of alternatives for measuring the solutions provided by experts. To do so, we use the nonparametric Wilcoxon signed-ranks test. Finally, these outcomes are analyzed using Friedman mean ranks in order to obtain a quantitative classification of the considered measurements according to the convergence criterion considered in the consensus reaching process.
Introduction
A group decision making (GDM) problem ends when the experts choose among a set of alternatives those ones that will be a solution. Usually, together with the solution obtained, it is convenient to know the degree of agreement reached by these experts [8, 18, 54].
Facing the classical notion of consensus as a full agreement among individuals that form a group of decision -experts-, Kacprzyk et al. [21, 24] introduce the concept of soft consensus to model the agreement process in GDM problems. This concept allows the definition of soft consensus criteria which are the basis of numerous consensus approaches [1, 33, 53]. In such a way, consensus measures assessed in [0,1] are introduced, where 0 means null consensus, 1 means total consensus, and values in (0,1) mean diverse partway consensus situations [4, 19]. Then, a process of reaching consensus could be established as a multistage process iteratively developed and made up of several discussion and consensus rounds [12, 20]. In each round we consider the existence of a coordinator of the process -moderator-, who evaluates the consensus levels existing among the experts through soft consensus measures. Fixed a particular consensus threshold, a consensus level is less than that threshold means that a large discrepancy among experts’ opinions is observed. In such a case, the coordinator would propose that the experts discuss their opinions so as to make them closer. In the case that an acceptable consensus level has been reached, it could be possible to make use of a selection process so as to get the ending solution [4, 19].
Given a set of alternatives in a GDM problem, experts can express their preferences in different ways such as: fuzzy preference relations [12, 23], multiplicative preference relations [20, 45], linguistic preference relations [1, 39], hesitant fuzzy preference relations [46, 47] or intuitionistic fuzzy preference relations [27–29, 50].
In addition, different approaches to consensus can be considered according to different criteria [4, 19]. One of this criterion is the coincidence among the experts’ preferences. In this case, soft consensus measures act on the preferences expressed by the experts, and consequently, their computation is build around the concept of similarity among preferences [4, 19]. We should point out that the specific metric (distance function) utilized to assess the similarity could influence the convergence of the consensus processes so as to get a solution admissible by the majority of experts. Another criterion is the coincidence among the solutions expressed by the experts. In this case, the coincidence is computed by comparing the positions of the alternatives observed in the individual solutions and the collective solution. We should point out that this coincidence approach provides a more realistic measure of consensus among experts [19, 20].
In this paper we use frequently employed fuzzy preference relations that we have already handled in previous papers [12, 20] to analyze the behavior of the two aforementioned consensus approaches in GDM problems. We present a comparative study between both approaches. Two-sample statistical tests are used to study the differences among five of the distance functions most commonly used in modelling soft consensus in GDM problems: Manhattan, Euclidean, Cosine, Dice, and Jaccard distance functions [12], and the consensus measure over the set of alternatives called C x [20]. Using the nonparametric Wilcoxon test [12, 42] significantly different results were found in most of the GDM problems between the consensus model based on the use of distance functions and the model based on the consensus measure C x . An in-depth analysis of this behavior also allowed us to specify concrete relations between some distance functions and the consensus measure C x , as well as indicate conditions under which both considered models could be interchanged in the calculation of the degree of consensus when dealing with a situation as the one analyzed in this paper. In addition, by using Friedman mean ranks we draw a ranking of the different measures according to the degree of consensus whose application can control the speed of convergence of the consensus process.
To do so, Section 2 introduces the main concepts and results in GDM problems. In describing the consensus process two approaches are considered: the one according to soft coincidence among preferences and the one in accordance with the coincidence among solutions. Section 3 shows the framework required to evaluate the distinct distance functions. Section 4 exposes and discusses the main results of this research. Section 5 includes a practical example of the use of the compared distance functions and consensus measure for the same GDM problem to illustrate their application. By last, Section 6 shows the conclusions.
Preliminaries
GDM problem framework
GDM problem is modelled by assuming a collection of possible alternatives X = {x i , i = 1, …, n} (n ≥ 2) which are assessed by the members of the group, i.e. experts, E = {e i , i = 1, …, m} (m ≥ 2), and then, the goal is to get a consensus resolution in accordance with the most of the preferences expressed by the experts [7, 56]. Fuzzy preference relations are widely utilized in the literature to depict the expert preferences [15, 43].
Sometimes, some rational criteria are required, as for example, the additive reciprocity property: p ji + p ij = 1 for all i, j in {1, …, n}.
In this situation, the solution process of a GDM problem consists of obtaining a set of solution alternatives, X sol ⊂ X, from the preferences expressed by the experts. This solution process is found on two dissimilar processes [9, 35]: selection and consensus. The solution collection of alternatives is deduced thanks to the selection process while the consensus process is employed to increase the level of accord amongst experts before obtaining that solution.
Selection process
Two procedures configure the selection process when dealing with a GDM problem [3, 38]: an aggregation procedure of expert preferences and an exploitation procedure of that aggregated preferences.
By aggregating all single fuzzy preference relations, namely, {P
i
, i = 1, … , m }, one collective relation of preference, namely,
Yager defines an interesting procedure to determine the vector W through fuzzy linguistic quantifiers Q [52]. Each weight w
k
could be computed by the following expression:
Then, we could compute every collective preference value
In this paper we use three fuzzy linguistic quantifiers: “at least half”, “most of” and “as many as possible”, with the parameters (0, 0.5), (0.3, 0.8) and (0.5, 1) for (l, u), respectively.
By exploiting the collective preferences on the alternatives we achieve a whole ranking of them, which allows us to attain the solution collection of alternatives. To do it, we could apply any degrees of choice of alternatives. We employ the following two degrees of choice of alternatives [12, 20]: Quantifier guided dominance degree:
Quantifier guided non dominance degree:
QGDD
i
represents the degree in which each alternative dominates a fuzzy majority of the rest of the alternatives while QGNDD
i
depicts the level where each one of the alternatives is not dominated by a fuzzy majority of the rest ones.
The solution X sol is then achieved by means of the application of the two choice degrees in such a way that those alternatives with higher choice degrees are chosen.
In a consensus process we have to define a coincidence criterion to calculate those consensus measures that allows us to lead to the process of reaching consensus. This is a dynamic process (see Figs.1 and 2) in which a previously agreed consensus value and/or number of rounds serves as control of the process. If any of these values is exceeded, the process ends and, if not, a feedback mechanism provides advice to experts in order to approximate their positions.
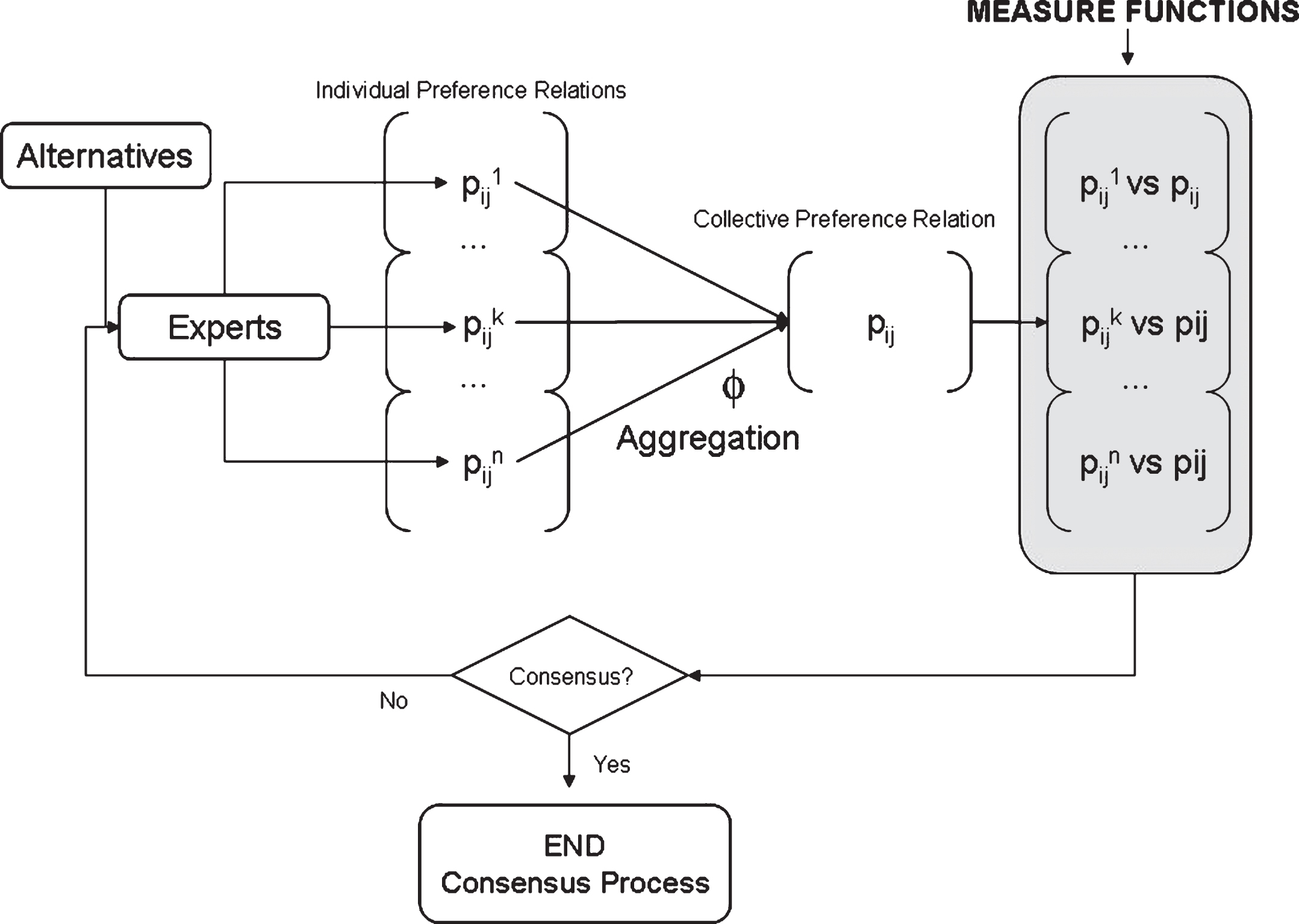
Consensus Model based on distance functions.
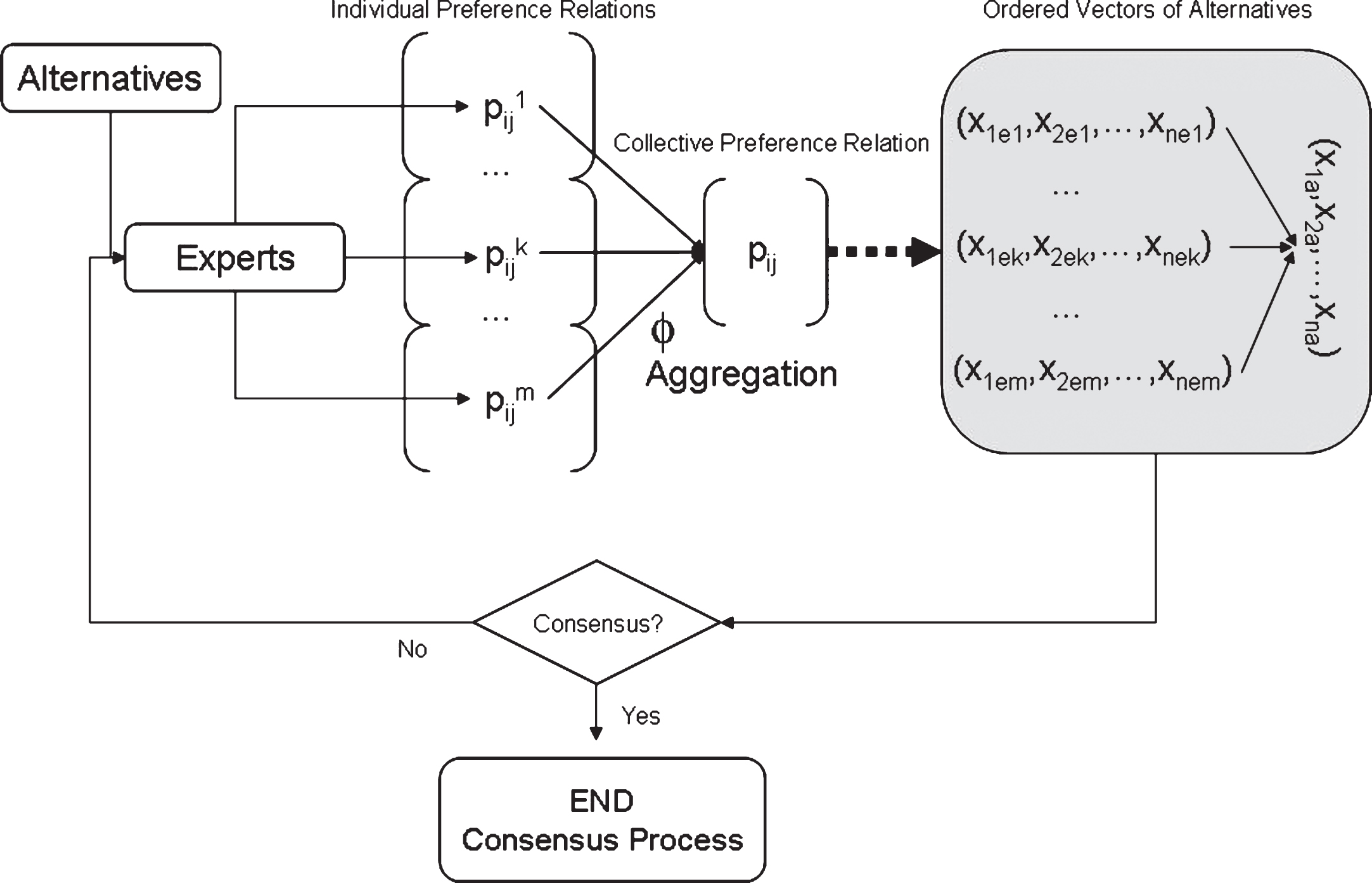
Consensus Model for C x method.
Two of the main approaches that can be used in a consensus process are the notion of soft coincidence among preferences and the concept of the coincidence among solutions [4, 19].
In GDM problems it is very extended to consider consensus as an iterative procedure where, after several rounds of discussion, accord is achieved. Then, it is assumed that the process of reaching consensus is led by two consensus measures [5, 6]: the consensus measure to evaluate the level of consensus in every one of the rounds of discussion and the proximity measure to lead to the discussion stage. Furthermore, these consensus measures allow us to discover information about the consensus state at every level of representation, namely, pairs of alternatives, alternatives and complete relation. In such a way, the degree of agreement among experts is determined by computing the similarity existing between their preferences by means of distance functions [4, 5, 19].
It is very easy to transform a similarity s to a distance d bounded by the unit value, and one possibility could be the following: d = 1 - s [14]. Then, the different consensus degrees utilized to control the consensus phase are deduced by merging the similarity of the values of preference supplied by the experts for every two alternatives. On the other hand, the proximity measures used to generate feedback used in the discussion rounds are determined by evaluating the similarity that there exists between the preferences expressed by every expert inside the group and the preferences in the collective.
This paper is focussed on the consensus degrees that we compute in a consensus process. The consensus degrees are obtained as follows: Given an expert, r, the similarity between his/her preferences and the corresponding preferences provided by the others experts inside the group is represented in an individual similarity matrix, A consensus matrix, CM = (cm
ij
), is defined as
being φ the OWA operator introduced in Definition 2. Consensus degrees are determined in the feasible levels of computation in the following way: Consensus on the pairs of alternatives: This degree of consensus, called cp
ij
, is computed for every two alternatives (x
i
, x
j
), and it represents the accord among all the experts on the two alternatives:
Consensus on alternatives, ca
i
. It is used to evaluate the accord among all the experts on the alternative x
i
. This consensus degree is obtained through the aggregation of the degrees of consensus of all the pairs of alternatives affecting alternative x
i
:
Consensus on the relation, cr. This consensus degree is used to evaluate the global accord among all the experts. This degree of consensus is derived from fusing the degrees of consensus on alternatives:
In this study our interest is focused on the consensus degree obtained in the level 3.
In order to support experts to agree a particular solution so that their individual positions converge, a consensus level γ ∈ [0, 1] is set beforehand. The decision-making session ends as the required consensus level is reached, cr ≥ γ, and then, by applying the selection procedure the solution is achieved. In another way, a group discussion session is performed so as to permit the change of preferences to experts. In this discussion session, a feedback mechanism build around both measures of adjacency and a collection of recommendations is applied to aid the experts in modifying their preferences as displayed in Fig. 1.
The rules used to provide advice to experts are based on a comparison between the individual and collective preferences:
DR.1. If
DR.2. If
DR.3. If
More details can be consulted in [20, 31].
As it is pointed out in [12] the consensus reaching process depends on the particular distance function used to calculate the similarity [10, 56]. As then, in this paper we consider the distance functions that are defined below.
An alternative approach to the aforementioned consensus process consists of measuring consensus by considering the position of the alternatives in each particular solution expresed by the experts [20]. This model takes into account two different criteria: a consensus measure that calculates the accordance among experts so as to conduct the consensus process to the ultimate solution and a proximity measure which calculates the accordance among particular experts’ opinions and the opinion in the group so as to conduct the debate of the group in the process of consensus. Both measures compare solutions, the individual and the collective, instead of the respective preferences as in the model described in subsection 2.3.1. By comparing the position of the alternatives in each solution, this comparison procedure allows to reflect the real consensus situation at each moment of the consensus process. This means that, at each step of the process of consensus, the first thing to do is to apply the selection process to obtain a temporary collective solution, and then measure the closeness of that solution to the individual solution [20].
Let
The adjacency of each expert for each alternative, p
i
(x
j
), is calculated by means of the comparison of the position of that alternative in the experts’s particular solutions, {V
i
; i = 1, …, m }, and its position in the collective solution, V
c
, through the function [20]:
The degree of consensus for all experts on each alternative x
j
is derived from:
Finally, the consensus measure over the collection of alternatives is calculated by accumulating the values C (x
j
):
The above model is represented in Fig. 2.
When the consensus measure C x has not reached the required level of consensus, a feedback mechanism indicates the experts to change their opinions in a similar way to the one described in the Section 2.3.1. In this case, the rules used to make experts change their opinions are based on a comparison between individual and collective solutions. This way, for the ith expert, e i , the opinion is changed using the following rules:
R.1. If
R.2. If
R.3. If
More details can be consulted in [20].
In this paper we examine whether the use of the aforementioned approaches produces differences which are significant in measuring the consensus and accelerating the convergence of the process of consensus. Following the study carried out in our previous paper [12] we consider the distance functions d i , i = 1, …, 5, given in Equations (11)–(15) to handle the model based on the soft coincidence among preferences, and the consensus measure C x given in expression (17) to deal with the model based on the concordance among solutions [20].
As mentioned before, two approaches can be considered to calculate soft consensus measures: concordance among expert preferences and concordance among individual solutions. In the first approach, the coincidence is obtained by evaluating the similarity among the expert preferences by means of distance functions, and in the second one the concordance is calculated by measuring the similarity among the solutions proposed by these experts using the consensus measure C x .
Following the guidelines presented in [12], the hypothesis we are testing in this paper can be established as follows: The application of Manhattan, Euclidean, Cosine, Dice and Jaccard distance functions versus the consensus measure C x in GDM problems do not produce significant differences in the measurement of consensus
To test this hypothesis, we generated ten sets of fuzzy preference relations in a ramdom way for every one of the possible combinations of alternatives: four, six and eight, and experts: four, six, eight, ten and twelve. Moreover, the distinct distance functions, d i , i = 1, …, 5, given in equations from (11) to (15), and the consensus measure over the collection of alternatives, C x , given in Equation (17), were successively used to size up consensus at the relation level, employing the OWA operators introduced in Subsection 2.2. We compared every distance function with the consensus measure over the collection of alternatives, d i vs C x (i = 1, …, 5), so that we finished handling two related samples.
The problem of two related samples can be adressed from two points of view: parametric and nonparametric. In the parametric case, the t-test is applied provided that the assumption of normality and independence distribution of the difference scores can be assumed [26, 37]. This way, the t-test could be applied to the problem we are dealing with if these hypothesis could be assumed on the population from which the random sample of fuzzy preference relation is selected. But, we have no information that could allow to identify the nature of the population from which the random sample of fuzzy preference relations is selected and we have any knowledge about any of its parameters. Therefore, we conclude that nonparametric test are most appropriate in our experimental study.
For continuous data and two related samples, the main nonparametric tests available are the sign test and the Wilcoxon signed-rank test [12, 42]. Since the Wilcoxon signed-rank test incorporates more information about the data it is more powerful than the sign test, and so it is preferable to be used in our study.
As a further step, it would be very interesting to be able to discriminate among the distance functions d i , i = 1, …, 5, given in Equations (11)–(15), and the consensus measure over the collection of alternatives C x , given in Equation (17). This discrimination procedure can be achieved through the mean ranks used in the nonparametric Friedman test to deal with several related samples [17, 37]. The ranking that can be achieved when these mean ranks are considered will allow to emphasize the magnitude of the differences between the aforementioned functions for the calculation of the consensus values.
In the following subsections we describe in detail these two statistical techniques to better understand their application in the subsequent study.
Wilcoxon signed-ranks matched-pairs test
Let X1, X2, …, X
n
denote a n-size random sample from a distribution function F which is continuous, let p denote a value in
A problem of symmetry and location consists in testing the hypothesis H0 : ξ0.5 (F) = ξ0 and F is symmetric against the hypothesis H1 : ξ0.5 (F) ≠ ξ0 and F is not symmetric. A nonparametric statistical technique known as Wilcoxon signed ranks test supplies a hypothesis test that considers the measure of the differences between the observed values and the quantile in H0 with the aim of performing a problem of symmetry and location.
Let H0 : ξ0.5 (F) = ξ0 be the null hipothesis and let D i = X i - ξ0, i = 1, 2, …, n, be the differences to the hypothesized value. Under H0 positive and negative differences are expected to be dispersed, so that the expected number of negative differences will be n/2 and negative and positive differences of equal absolute magnitude should take place with the same probability.
Let |D
i
|, i = 1, 2, …, n, be the absolute values of D
i
, i = 1, 2, …, n, and let us rank them from 1 (for the smallest) to n (for the largest). If T+ denotes the sum of ranks assigned to those
So, T+ and T- are linearly related and provide equivalent rules. A large value of T+ indicates that most of the larger ranks are assigned to positive
This way the test rejects H0 : ξ0.5 (F) = ξ0 to accept H1 : ξ0.5 (F) > ξ0 if T+ > c1; equivalently, if t0 denotes the observed value of T+, it rejects H0 if p0 = P H 0 [T+ ≥ t0] ≤ α, being α the significance level of the test. The test rejects H0 to accept H1 : ξ0.5 (F) < ξ0 if T- > c2 or p0 = P H 0 [T- ≥ t0] ≤ α, being t0 the observed value of T-. And the test rejects H0 to accept H1 : ξ0.5 (F) ≠ ξ0 if T+ > c3 or T- > c4 being values c i the critical region borders, or, equivalently, if p0 = 2(smaller tail probability).
Under H0, the common distribution of T+ and T- is symmetric about the mean E [T+] = n (n + 1)/4 with variance var [T+] = n (n + 1) (2n + 1)/24. For large n, the standardized T+ has approximately a standard normal distribution.
If the available data are matched-paired, {(X i , Y i ) , i = 1, …, n}, being derived from applying two treatments to the same set of subjects, to test H0 : ξ0.5 (FX i -Y i ) = ξ0 against the possible alternatives Wilcoxon’s test is carried out in the same way as in the case of one sample by taking D i = X i - Y i - ξ0 [12].
Friedman mean ranks
The analysis of data resulting from k-related samples can be performed using various nonparametric techniques. One of them addresses the problem as an extension of the two-way analysis of variance for a randomized block design when the assumption that distributions are continuous replaces the assumption of normality.
Let (Xi1, …, X ik ), i = 1, …, n, be a random sample from a k-variate continuous type distribution function. The data may be arranged in n rows (blocks) and k columns (treatment/measure). The observations in different rows are independent and those in different columns are dependent. The observation x ij then corresponds to the ith block and jth treatment/measure, j = 1, …, k and i = 1, …, n.
In order to test the hypothesis that measure effects are all equal against the hypothesis that measure effects are not all equal, the Friedman procedure [37] involves replacing each observation in a block by its rank. The rank of the jth observation in the ith block, R (x ij ) = R ij , is the value from 1 to k obtained by consecutively numbering the observations X ij , j = 1, …, k. So, for each block, the observed values are sorted for each measure and ranked from 1 (the lowest value in the block) up to k (the highest value of the block). Hence ranks are assigned separately for each block.
Let R
j
denotes the sum of ranks for jth measure, j = 1, …, k,
Experimental analysis
In order to develop our study we configure a set of ten GDM problems randomly elaborated for every feasible mixtures of expert numbers: four, six, eight, ten and twelve, and alternatives: four, six and eight. Three executions were done for each one of these GDM problems. In each execution we use one of the three distinct OWA operators aforementioned to calculate the consensus degree. In what follows, we summarize the results obtained by applying the results mentioned above, the Wilcoxon statistical test and the Friedman mean ranks.
Statistical test results
Table 1 shows the p-value for each one of the distances used in our experimental study versus C x . To better understand this table and the following ones, from now on, d1 is denoted by “Ma”, d2 by “Eu”, d3 by “Co”, d4 by “Di” and, finally, d5 is denoted by “Ja”. In view of the results, it follows that the hypothesis tested and displayed in Section 3 is rejected.
Wilcoxon signed-ranks matched-pairs statistical test results
Wilcoxon signed-ranks matched-pairs statistical test results
The comparison between different distance functions and C x to measure consensus produces significantly different results in all possible combinations used in the experiment. In particular, we observe a p-value less or equal than 0, 05 (predetermined significance level α) in all cases. In fact, in four of the cases the p-value is lower than 0, 001 (α), except for the Jaccard distance function, where the p-value is 0,013.
We note that, at the relation level, measurement of consensus is affected significantly by the use of a different distance function in comparison with C x . Results differ significantly depending on the distance function to be compared. Obviously, the comparison of different distance functions, for which significant variation has been established, could affect the convergence of the consensus process at this level.
Moreover, it can be observed that the results of the C x consensus measure and the Jaccard distance function are similar. This fact leads us to think that the consensus measure C x can be used as an alternative to the Jaccard distance function in the considered situation, and also that a consensus model based on the coincidence among solutions could replace a model based on the among experts preferences and vice versa in the calculation of the degree of consensus when dealing with a situation like this one.
Let us now analyze the results derived from Friedman mean ranks according to quantifiers, experts and alternatives.
Table 2 shows mean ranks of all methods according to the linguistic quantifiers considered in this study: “at least half”, “most of” and “as many as possible”. As regards to the first linguistic quantifier, we observe that the Jaccard distance function is closer to C x than the rest of distance functions. In this case the Jaccard distance function achieves bigger values than C x . We also note that as for the linguistic quantifier “most of”, C x is positioned between the Jaccard and Dice distance functions. In this situation the Jaccard distance function is nearer to C x than the Dice distance function. Regarding to the linguistic quantifier “as many as possible”, it can be seen that C x is positioned between the Jaccard and Dice distance functions as in the previous situation but, in this case, C x is nearer to the Dice distance function.
Mean ranks according to quantifiers
Mean ranks according to quantifiers
Table 3 shows mean ranks for different methods and different number of experts considered in this study. In this case C x is situated between the Jaccard and Dice distance functions except for the 4 experts case where the results are different from the ones obtained from 6 experts. We also note that, in all cases except the above-mentioned 4 experts case, C x gets values closer to the Jaccard distance function than the Dice distance function.
Mean ranks according to experts
On the other hand Table 4 shows mean ranks of different methods for the three possible number of alternatives proposed in the study. We observe that the behavior of C x is very stable in all cases. It can be pointed out that the values of C x are situated between the ones of the Jaccard and Dice distance functions.
Mean ranks according to alternatives
Table 5 shows mean ranks for all methods and samples. It can be observed that the Jaccard and Dice distance functions are closer to C x in their mean rank positions than the rest of functions, being Jaccard the closest one.
Global mean rank
In summary, we perceive that at the level of relation the evaluation of consensus depend on the distance functions which are used instead of C x . Therefore, the utilization of distinct distance functions could influence the convergence of the consensus reaching process at the level of relation. Furthermore, the results obtained suggest that the Jaccard distance function is the best option versus C x method, and the second option should be the Dice distance function.
The experimental study performed in this paper allows us to visualize a ranking of the different distance functions useful for their application as it is illustrated in Fig. 3. Most of metrics reach a consensus speed faster than C x , so if we want a faster convergence to consensus we would measure consensus on preferences with Manhattan, Cosine or Euclidian metric.
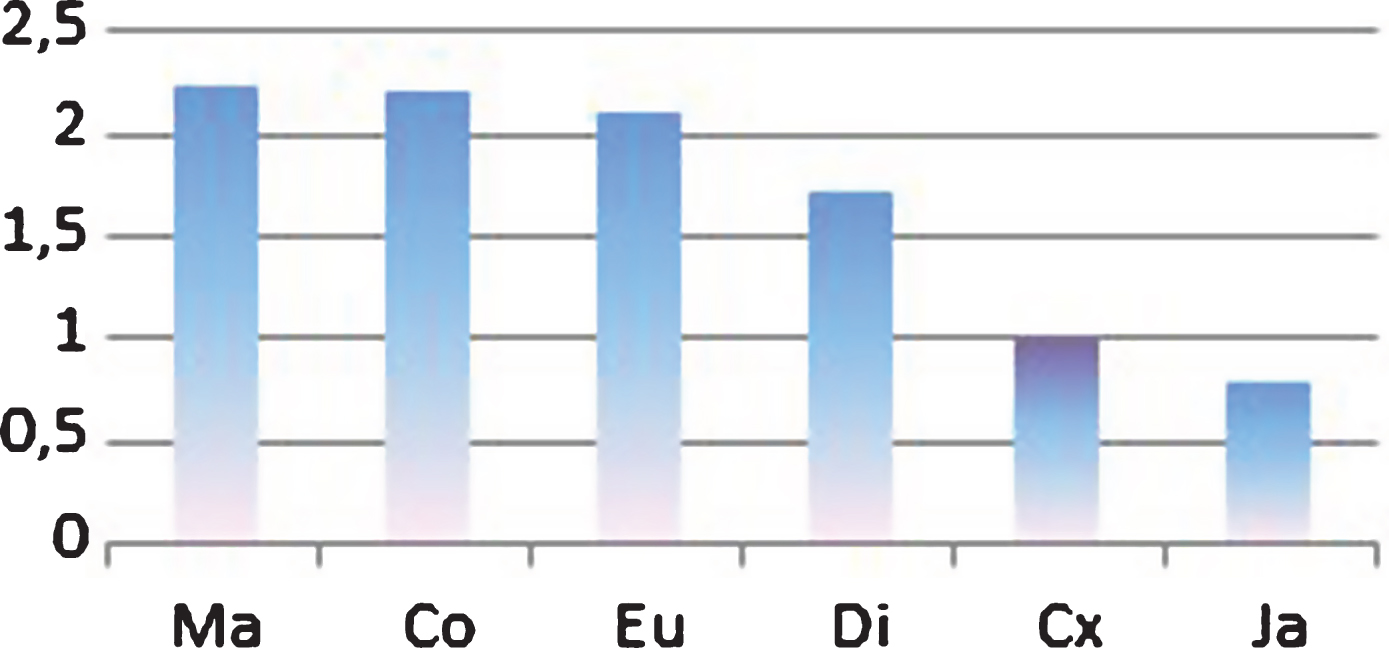
Global consensus speed.
If required in a consensus process, the values of C x model on the set of solutions could be substituted for those provided by the the appropriate distance function on the alternatives.
These results are coherent with the ones obtained in [12] but in this paper we also obtain a quantitative classification for the considered methods.
Finally, note that the values obtained for the consensus measure C x are placed between the values obtained for the Dice and Jaccard distance functions. This way, it seems to be confirmed that C x can be considered a different measure but comparable with the measures already analyzed [12], being the values of C x closer to those of the Jaccard distance functuion and being able to replace or be replaced by them.
As an application of the study carried out let us consider the example introduced in our previous paper [12]. A GDM problem with four alternatives and four experts is performed using the OWA operator guided by the linguistic quantifier “as many as possible” and a consensus threshold γ = 0.75. It is assumed that the initial set of individual fuzzy preference relations are the same as the ones that appear in Example in [12].
First round
At the relation level, the Jaccard distance function provides a consensus degree of 0.43, C x of 0.49 and the Cosine distance function of 0.66. The global consensus degree is lower than the threshold consensus level, so that experts receive feedback to modify their preference relations.
Second round
The new fuzzy preference relations are the same that appear in [12]. Using the Cosine distance function the consensus degree results in 0.81 which is greater than the threshold consensus level and the consensus process ends. However, if the Jaccard distance function or C x are used, it would be necessary to continue with the consensus reaching process since the consensus degree levels are 0.53 and 0.61 respectively.
Third round
The new fuzzy preference relations are the ones that appear in [12]. The Jaccard distance function results in a consensus degree level of 0.60 and C x of 0.65.
Fourth round
The new fuzzy preference relations appear in [12]. Using C x we would have had a consensus degree level of 0.79 which is greater than the threshold consensus level and the consensus process ends. However, using again the Jaccard distance function we need to continue with the consensus reaching process since the consensus degree level would be 0.69.
Fifth round
The new fuzzy preference relations areappear in [12]. The Jaccard distance function results in a consensus degree level of 0.78, the consensus reaching process stops and the selection process is activated to derive the solution of consensus.
Conclusion
We have analyzed the behaviour of two widely used consensus models based on two types of coincidence in GDM problems with fuzzy preference relations. In the first case the coincidence is obtained through similarity measured among expert preferences by using several distance functions. We have considered five distance functions commonly used in measuring experts’ preferences: Manhattan, Euclidean, Cosine, Dice and Jaccard. In the second case, the coincidence is derived from similarity calculated through the individual solutions provided by expert preferences. We have used the consensus measure C x on the set of solution of alternatives. We have presented a comparative experiental study based on the utilization of Friedman mean ranks and the nonparametric Wilcoxon’s test. The results are interesting since our experimental study has shown that the consensus model based on the use of distance functions compared with the model based on consensus measure C x produce significantly different results in most of the GDM problems performed. However, the similarity between the results of the C x consensus measure and the Jaccard distance function unveils two relevant elements. On the one hand, a consensus model based on the coincidence among solutions can replace a model based on coincidence among expert preferences and vice versa in the calculation of the degree of consensus when dealing with a situation such as the one contemplated in this paper. On the other hand, the consensus measure C x can be used as an alternative to the Jaccard distance function in the considered situation. The analysis of the results allows to draw a ranking of the different measures used according to the degree of consensus. In addition, this classification can be successfully used to control the speed of convergence of the consensus process.
Footnotes
Acknowledgments
The authors would like to acknowledge the FEDER financial support from the project TIN2016-75850-R.