
Abstract
Large amounts of data are generated by the intelligent transportation system (ITS) everyday. It exceeds the storage and processing capacity of conventional systems, and also doesn’t fit the structures of current database. Therefore, it is necessary to use efficient methodology addressing the challenges. Vehicle logo recognition (VLR) is a significant application in ITS. VLR is difficult due to the geometric distortions as well as various imaging situations simultaneously. However, traditional methods and hand-crafted features have many limitations. Convolutional neural network (CNN) enjoys the success in many machine vision tasks. Inspired by the excellent performance of CNN, we design and develop a novel VLR distributed system framework based on Hadoop ecosystem and deeplearning. We propose a Mapreduce based CNN called MRCNN to train the networks, which significantly increases the training speed and reduces the computation cost simultaneously. Furthermore, unlike previous classical CNN starting from a random initialization, we propose a novel genetic algorithm (GA) global optimization and Bayesian regularization approach called GABR in order to initialize the weights of classifier, which help prevent the overfitting and avoid the local optima. Compared with other algorithms, the proposed method performs best and increases the recognition accuracy with good initial weights optimized by GABR. The results show that the distributed system framework and proposed algorithms are suitable for real-world applications of VLR.
Keywords
Introduction
Large amounts of data in intelligent transportation system (ITS) present challenges to processing the information. Therefore, the use of great computing power to speed up the training process has shown significant potential in ITS. However, the harvesting of valuable knowledge and intelligence from ITS is difficult [1].
Deep learning refers to a set of machine learning techniques that learn multiple levels of representations in deep architectures [2–5]. In recent years, most deep learning algorithms were designed for single machine. With the arrival of Big Data age, this does not hold any more. It is impossible to train a deep neural network by only one machine with CPU, GPU and limited storage. Therefore, distributed architecture with clusters of machines is a better choice [6–8]. Strategies of such deeplearning have been developed for the forward and backward propagations, such as data parallelism or model parallelism or both two. It is significant to develop high performance computing (HPC) infrastructure in order to build the deeplearning system that is scalable to massive data [9, 10].
ITS plays an important role in the machine vision application areas with techniques such as computer vision and deeplearning. In real applications, vehicle frontal view images [11] are captured by traffic cameras in many places such as highway, checkpoints and intersections. A great many of features are utilized such as Sobel edge, direct normalized gradients, locally normalized gradients, and Harris corner. Psyllos et al. [12] utilized SIFT features to recognize the logo, manufacture and model of vehicles.
Vehicle logo, as an important vehicle feature, can provide the ITS with useful information to category different vehicles [13], which can be applied in the highway monitoring or public security, such as illegal vehicle and incident detection. Besides, vehicle logo recognition (VLR) can also provide government and business with valuable statistics for intelligent city planning or other commercial use.
Therefore, it is necessary to recognize vehicle logo automatically in order to meet demand from practical processing situation. There are two main challenges: one is that large amounts of data generated by intelligent transportation system should be stored and processed properly, the other is that recognition accuracy and efficiency should be increased for real-world applications.
Wang et al. [14] proposed a vehicle logos detection method using edge features. A solution for VLR using “Modest AdaBoost” was presented by Sam and Tian [15]. SIFT features was utilized by Belongie [16] and Psyllos et al. [17] to recognize the vehicle manufacturer. Yu et al. [18] designed a “Bag-of-Words” model for VLR in which SIFT is used to extract robust features. Dai et al. [19] applied SVM to the binary image recognition of vehicle logo.
However, the above methods are still limited. They are based on handcrafted features. Recently, hand-crafted features are often utilized, such as HOG, SIFT and so on. However, these approaches indicate their limitations for vehicle logo since images can be easily influenced by geometric distortions. In addition, hand-crafted features are not discriminative enough.
Convolutional neural network (CNN), as a method of deep learning, is able to automatically learn multiple stages of invariant features for the specific task and has enjoyed the success in a great deal of applications [20, 21]. CNN shows strong robustness against geometric distortions due to the hierarchical learning structure, such as shifts, scaling and inclination. Furthermore, unlike many traditional methods, CNN can learn features automatically, which is suitable for real-time applications.
Recently, CNN has demonstrated excellent performance on various visual tasks, including the classification of two-dimensional images. CNNs were firstly introduced in Fukushima [22]. CNNs have recently outperformed some other conventional methods, even human performance [23], on many vision related tasks, including image classification [24], scene labeling [25], house number digit classification [26], and face recognition [27]. CNNs have been demonstrated to provide even better classification performance than the traditional SVM classifiers [28]. The hierarchical architecture of CNNs is gradually proved to be the most efficient and successful way to learn visual representations [29].
Huang et al. [13] proposed a CNN based VLR system. However, the training of CNN and system are deployed on single machine. As described above, it is not suitable for larger samples. To address the problems, the distributed infrastructure and parallel computation are preferred.
Although CNN achieves excellent performance in VLR, the training of CNN is time consuming, which is inadequate to the real-world applications [30–32]. In addition, the VLR systems need to be trained with frequently updated training samples. To address this problem, we propose a distributed VLR system and MRCNN training algorithm dramatically increasing the speed of CNN training. With the arrival of big data age, the designed and developed distributed VLR system is also capable of handling this challenge.
On the other hand, the training of fully connected layers may suffer from overfitting problems and local minima [33, 34]. To address this problem, Bayesian regularization and genetic algorithm (GA) global optimization are combined in the training procedure. GA is significant as it has powerful ability to avoid local optima. We utilize GA global optimization in order to initialize the weights of classifier in CNN. The combination of neural network and GA efficiently increase the recognition accuracy with good initial weights optimized by GA. A Bayesian approach can potentially avoid the above pitfalls in training neural networks [35]. Bayesian principle can not only automatically infer hyperparameters by marginalizing them out of the posterior distribution, but it also naturally accounts for uncertainty in parameter estimates and propagates the uncertainty to predictions. Furthermore, Bayesian techniques are often more robust to overfitting since it averages over values of parameters rather than choosing a single point estimate.
The major contributions of this paper are as follows. A distributed Mapreduce based CNN training algorithm (MRCNN) is designed. Unlike other CNN methods deploying on single machine, the proposed distributed system significantly reduces the training cost and increases the processing efficiency simultaneously. The proposed distributed framework satisfies the requirement of real-world logo recognition tasks, such as dealing with frequently updated training samples generated by monitors. It also improves the storage ability and system scalability. Compared with traditional methods utilizing hand-crafted features, the developed architecture automatically extracts features to provide better recognition accuracy and achieves higher qualified performance. Moreover, unlike classical CNN suffering from over-fitting problems with random initialization, a pre-training strategy called GABR is proposed to further increase the flexibility, robustness and recognition accuracy of CNN model.
The rest of paper is presented as follows. The distributed systems are detailed in Section 2. In Section 3, the experiment and comparisons are presented. Finally, this paper is concluded in Section 4.
Framework of distributed VLR system
The distributed VLR system is illustrated in Fig. 1. It consists of two stages: offline training and online recognition. In the offline training stage, training samples are trained from feature extractor to the classifier. In the recognition stage, vehicle logo is segmented from new images and then sent to the trained framework for recognition.
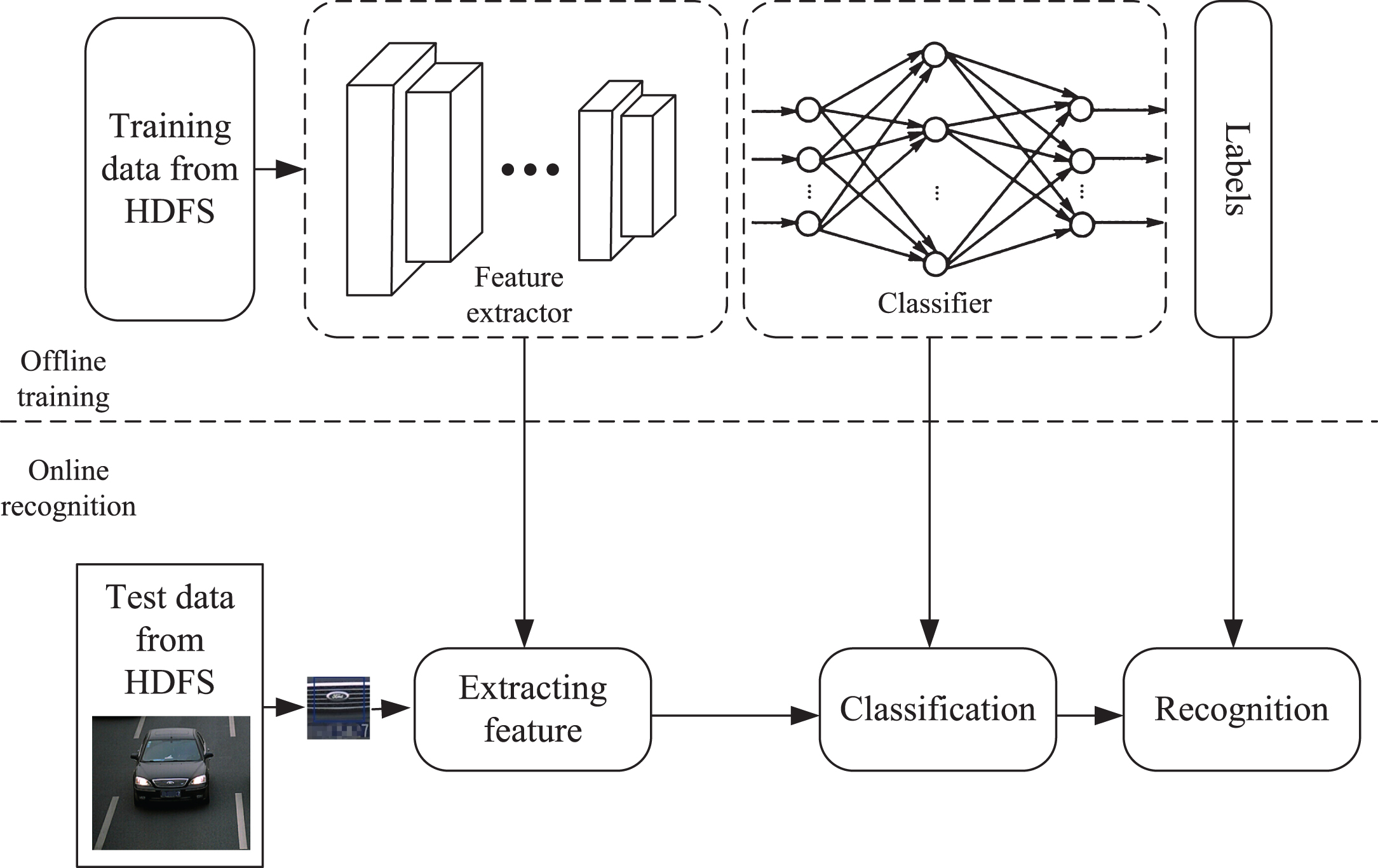
Overview of distributed VLR framework.
Hadoop has attracted substantial attention from both industry and scholars alike. Instead of relying on expensive hardware to store and process data, Hadoop enables distributed processing of big data on large clusters of commodity servers. Apache Hadoop framework has become an ecosystem. Hadoop ecosystem has many advantages and is particularly suitable for data management and analysis. Hadoop allows hardware infrastructure to be scaled up and down easily to accommodate hardware changes.
MapReduce draws a lot of attentions as a powerful tool for building specific applications. Hadoop distributed file system (HDFS) is characterized as a distributed file system that can store a large number of files on clusters. It utilizes the advantage of data locality in order to move computations to data nodes rather than bring data to computation nodes. We store the training image data by HDFS.
Mapreduce based CNN
The training of CNN is time consuming; we propose MRCNN training algorithm dramatically increasing the speed of CNN training.
As shown in Fig. 2, we propose a framework supporting data parallelism, where multiple replicas of the same CNN model are utilized to optimize a single objective.
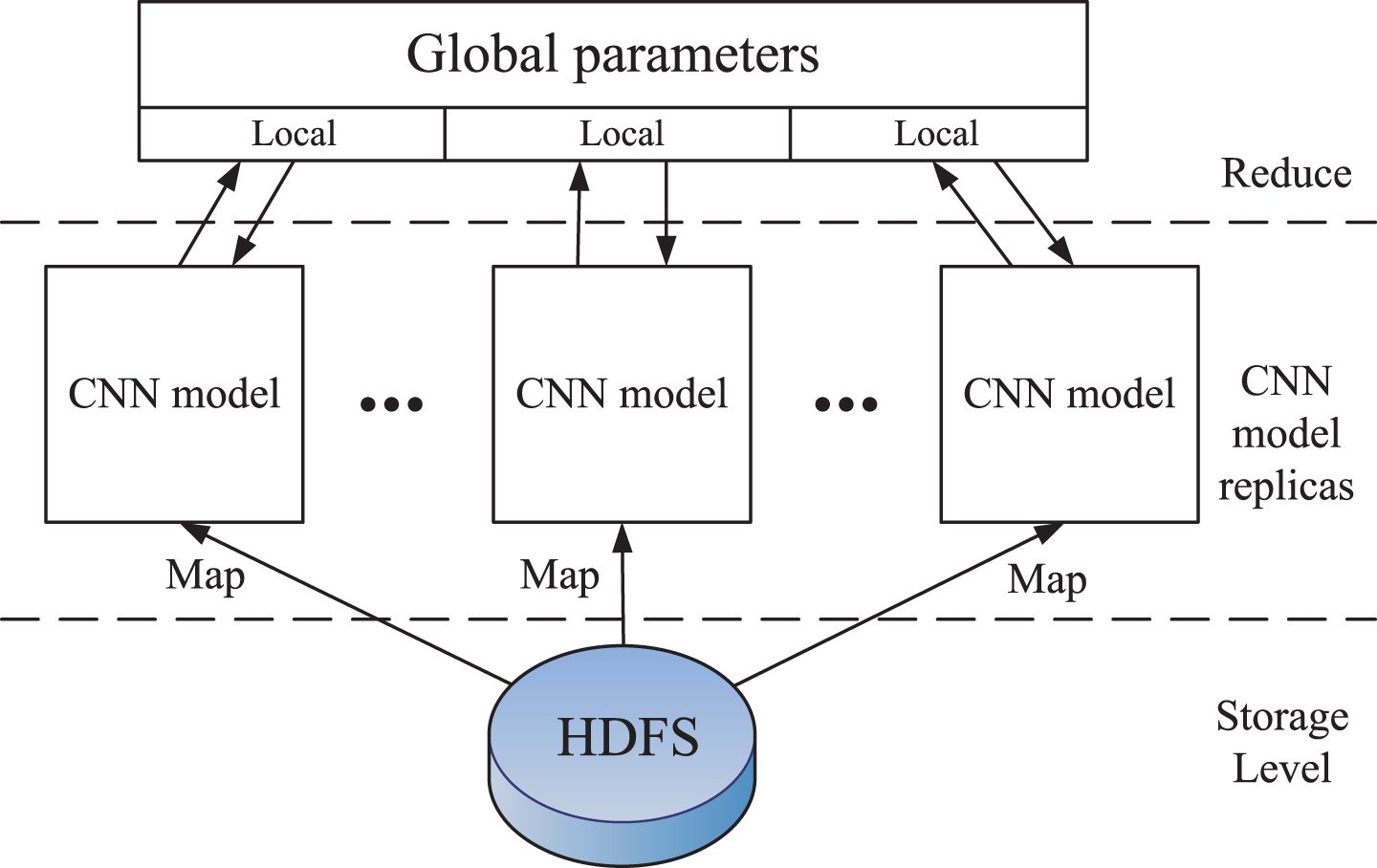
Architecture of Mapreduce based CNN.
We employ a set of CNN model replicas to simultaneously address a single optimization problem. We leverage the concept of a centralized parameter server in which model replicas update and share their parameters. It takes advantage of the distributed computation within each individual replica.
In a sense, the optimization algorithms implement an intelligent version of data parallelism using HDFS and Mapreduce. It allows us to simultaneously process training samples in each of the CNN model replicas, and periodically combine their outputs to optimize the objective function.
In the parallelized implementations of optimization algorithm, training data is distributed to many machines and each machine is responsible for calculating the gradient on a specific subset of training data samples. The gradients computed are sent back to a central server stored on HDFS that is suitable for data processing.
The MRCNN is implemented as follows:
All data generated by monitors are stored in HDFS, as shown in Fig. 3.

The image originally captured from the monitoring system.
The method detecting the vehicle logo was described in [13]. Figure 4 shows the approach detecting the vehicle logo.

The method detecting the vehicle logo.
Firstly, the vehicle license plate is identified with LPL module. Then, the area in the blue box above license plate is segmented, as shown in Fig. 5a. The size of image is 100×100 pixels in order to contain more types of vehicles such as Audi logo with wide size, as shown in Fig. 5b. Meanwhile, the images shown in Fig. 5 are samples for deeplearning in training set and test set.

Segmented vehicle logo. (a) logo with common size, (b) loge with wide size.
CNN composes of mainly two parts: feature extractor and classifier. CNN starts with two altering layers named convolutional and downsampling layers. The sequence of convolutioand and downsampling can be repeated many times.
Followed by a nonlinear activation, several feature maps are constructed. The outputs from the last downsampling layer will be constructed as feature vector. And then the feature vector is sent to the classifier.
A nonlinear activation is given by
One weakness that fully connected layers exhibit is their tendency to strongly overfit the training data [36, 37]. CNN is composed of alternating convolution and pooling layers. The convolutional layers extract patterns on local regions of the input images by convolving a filter over the pixels of input image. After calculating the inner product of the filter at every location in the image, a feature map for each filter is constructed in the layer.
The objective function F is given by
The posterior probability of W is given by
According to [38], the values for α and β can be computed as follows:
Then, Bayesian regularization procedure can be summarized as follows:
The back propagation algorithm training neural network starts at random initialization, which often results in local optima. GA is significant as it helps avoid local optima. In addition, proper initialized parameters make the optimization process more effective. We utilize GA global optimization in order to initialize the weights of classifier in CNN. It efficiently increases the recognition accuracy with good initial weights optimized by GA.
GAs are based on biological process in which new and better populations are developed during evolution. The strong ones selected have more opportunity to pass their genes to next generations by reproduction. Weak and unfit species are faced with extinction by natural selection. GA has two operators that generate new solutions from existing ones: crossover and mutation. By utilizing the crossover, genes of good chromosomes are expected to appear more frequently in the population, leading to an overall good solution.
The mutation operator introduces random changes into chromosomes, playing a critical role in GA. In other words, the mutation operator allows for global search of the design space and prevents the algorithm from getting trapped in local minima.
The length of 1-D vector generated by CNN extractor is n1. The number of neurons in hidden layer is n2. The output layer contains neurons representing the class of categorized vehicles. Therefore, the length of chromosomes is (n = n1 × n2 + n2 + n2 × n3 + n3). We take 1/F as the fitness function, where, F is (βE D + αE W ). After selection, crossover and mutation, the best individual is found. Then, we decode chromosomes into weights in each layer of neural network. The algorithm is described in Fig. 6.
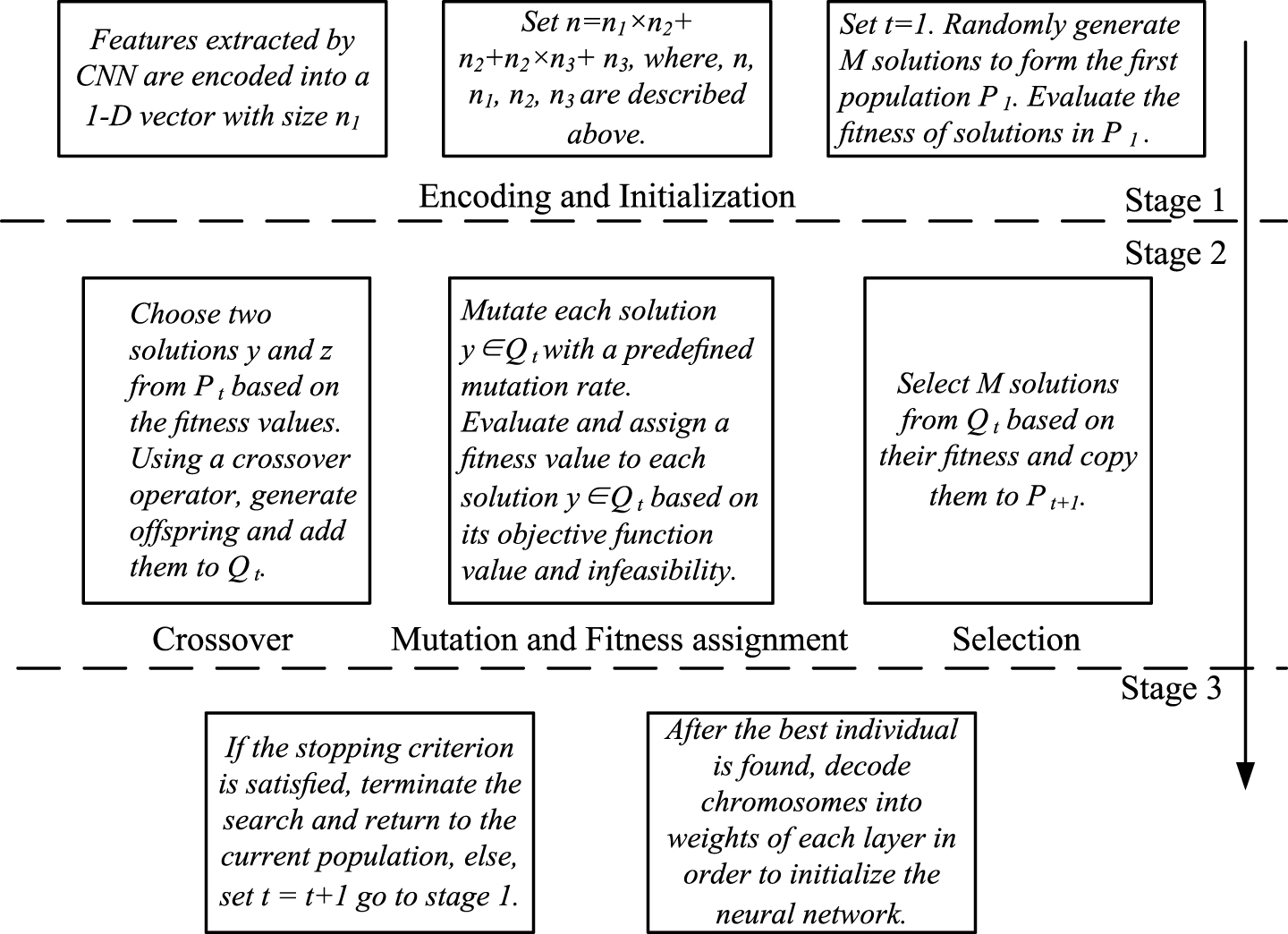
Weights initialization by GA global optimization.
Our experiments were performed on a cluster of machines that has 1 master and 3 slaves. The master was configured to use 4 CPU, 2.0 G Hz of each CPU, 4GB of RAM. Each salve was configured to use 4 CPU, 2.0 G Hz of each CPU, 8GB of RAM and 500 G disk spaces. All our experimental data are stored in HDFS, with the replication factor is 3.
Data sets description
After data pre-processing described above, 9000 from 9 manufacturers are generated. Each manufacturer has 1000 images with 100×100 pixels. In distributed VLR system, the parameters of CNN are shown in Table 1.
Architecture and construction of CNN
Architecture and construction of CNN
In the data sets, 7200 images are utilized as training samples, while other 1800 images are used as test samples. For each type of vehicle, 800 images are training samples and other 200 images are test samples.
We utilize CNN, CNN with GABR, and SIFT with SVM in order to compare the classification accuracy. SIFT with SVM is a traditional machine learning approach based on hand crafted feature. CNN is a deeplearning architecture automatically learning feature representation with random initialization. The proposed method is CNN framework with a pre-training strategy. The three methods are applied to the data sets. Then, the precision of VLR are shown in Tables 2, 3 and 4.
VLR accuracy by CNN+GABR
VLR accuracy by CNN+GABR
VLR accuracy by CNN
VLR accuracy by SIFT+SVM
As shown in Table 3, VLR by CNN in more accurate than traditional machine learning approach SIFT with SVM. It reveals that the feature representation of CNN is more powerful than hand-crafted features. According to Table 2, the weights optimized by GABR increases the accuracy of VLR in CNN. It shows that the proper weights initialization is significant to CNN and can improve the performance of CNN. The comparison of three methods is shown in Fig. 7.
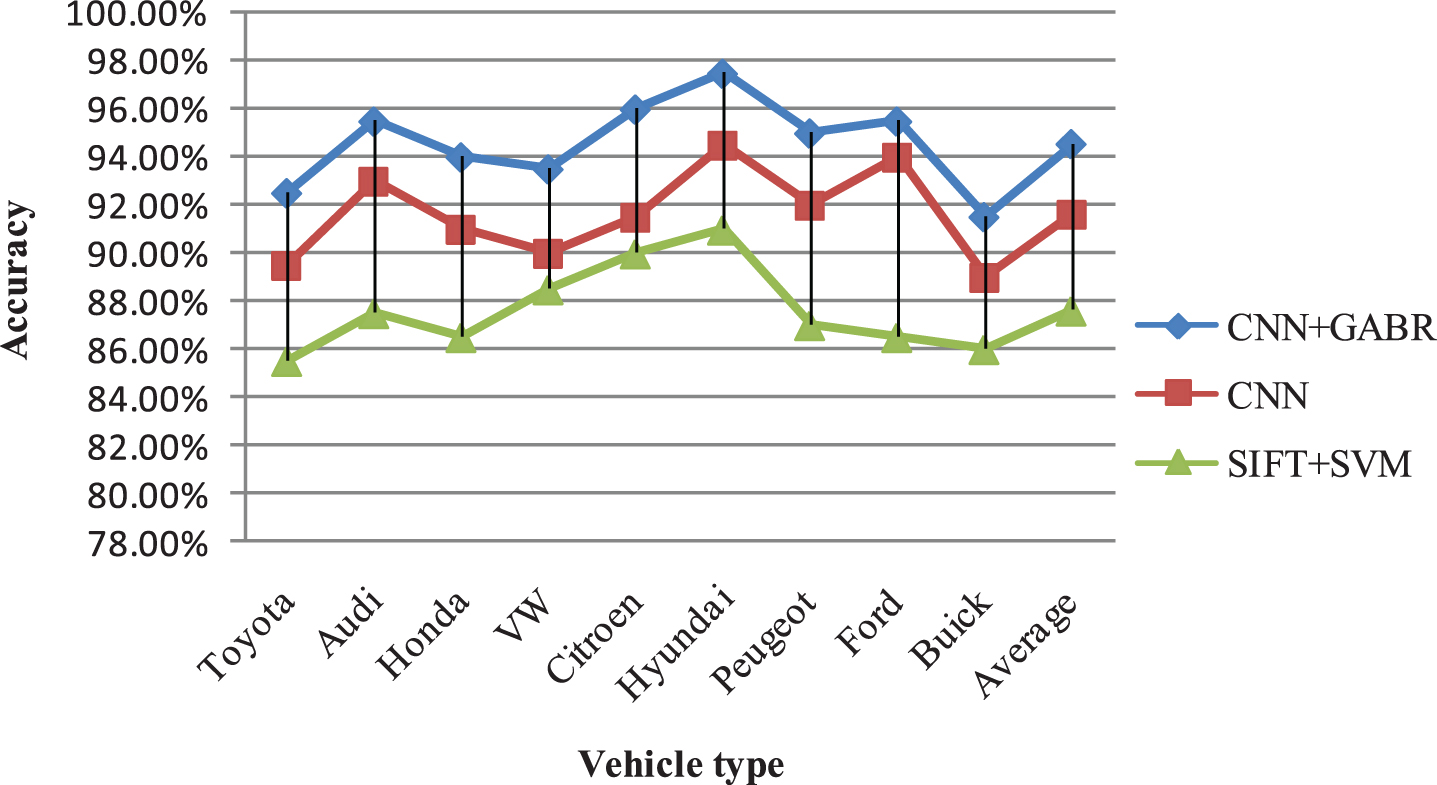
Comparison of accuracy in VLR system by CNN+GABR, CNN and SIFT+SVM.
In addition, unlike traditional CNN method focusing on the accuracy of VLR without considering the computational cost and system scalability, the proposed distributed framework and MRCNN efficiently reduce the computational cost and increases the training effectiveness simultaneously. The computational cost comparison between CNN and distributed CNN is also provided in Table 5.
Comparison of computational cost
As shown in Table 5, distributed CNN significantly increases the training speed and reduces the computation cost simultaneously. It is more suitable for real-world logo recognition tasks, such as dealing with frequently updated training samples generated by monitors. Note that the Mapreduce based framework is also efficient and effective to the large-scale data environment.
Our algorithms are also applied on the data set extended by [17, 39]. As shown in Table 6, CNN performs better than traditional approach. However, the computation cost of CNN makes it unsuitable for real world application. Therefore, distributed CNN is a more suitable choice.
Comparison with other methods
To evaluate the robustness of CNN model and pre-training strategy, we compute the accuracy by different percentage of training samples with and without pre-training. In addition, we select another technique called weight decay for comparison, considering that the training of traditional CNN encounters some limitations such as overfitting and local minima.
The results are reported in Table 7 and Fig. 8. It reveals that the pre-training strategy helps traditional CNN achieve better performance in classification accuracy.
Average accuracy with different number of convolution layers
Average accuracy with different number of convolution layers
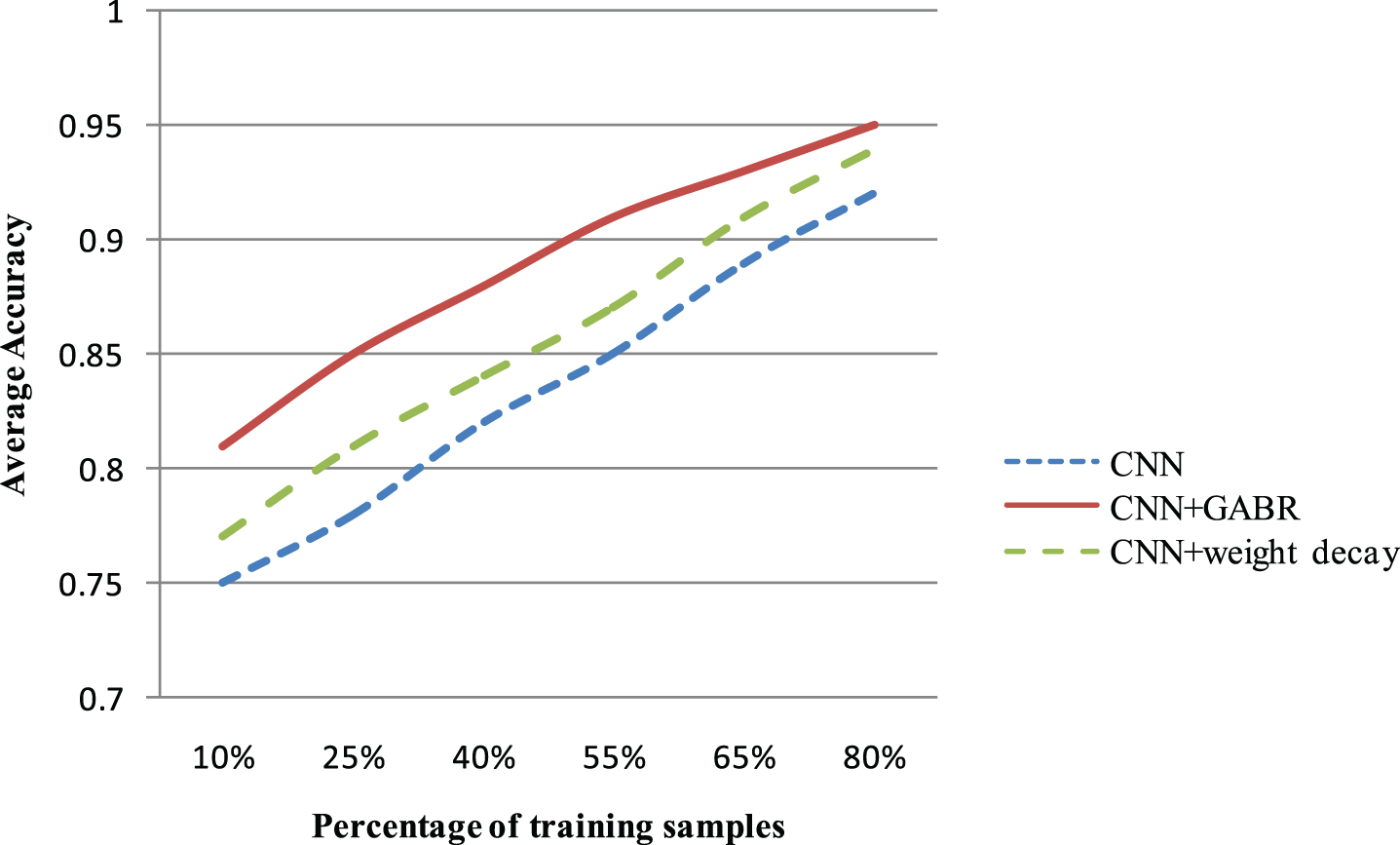
Robustness evaluation of CNN model in different percentage of training samples.
Compared with weight decay, the proposed method is more robust even with only 10% of training samples. It shows that the CNN model must control its parameters properly when trained from varied training samples. The balance between model complexity and size of data sets should be properly controlled.
As shown above, the observation demonstrates that the proposed method performs more robust due to the automatic adaption of varied training samples and different model structures. It helps the CNN model control the parameters adaptively according to the scale of training sets, which is more suitable for dealing with frequently updated training samples.
Previous CNN method mainly focused on the accuracy of VLR without considering the computational cost and system scalability. In contrast, the proposed distributed system framework is more sufficient for real-world applications. Unlike other CNN methods deploying on single machine, we design MRCNN to efficiently reduce the computational cost and increases the training efficiency simultaneously. Besides, we propose GABR approach initializing the weights of classifier to prevent the overfitting and avoid local optima. Compared with traditional CNN approach by random initialization, the results show that good initialized weights are important to CNN performance. The proposed method is more flexible, robust and increases the recognition accuracy. The distributed system framework and proposed algorithms are suitable for VLR tasks of ITS. Furthermore, considering the scalability of distributed system, it can be scaled up and down easily to more and more machines in order to accommodate larger data.
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
Acknowledgments
This work is supported by National Natural Science Foundation of China under Grant U1435220.