
Abstract
In this paper, we present an extractive approach to document summarization based on Siamese Neural Networks. Specifically, we propose the use of Hierarchical Attention Networks to select the most relevant sentences of a text to make its summary. We train Siamese Neural Networks using document-summary pairs to determine whether the summary is appropriated for the document or not. By means of a sentence-level attention mechanism the most relevant sentences in the document can be identified. Hence, once the network is trained, it can be used to generate extractive summaries. The experimentation carried out using the CNN/DailyMail summarization corpus shows the adequacy of the proposal. In summary, we propose a novel end-to-end neural network to address extractive summarization as a binary classification problem which obtains promising results in-line with the state-of-the-art on the CNN/DailyMail corpus.
Introduction
Nowadays, automatic summarization is an important issue in the current world due to the great amount of information in different formats that is accessible. It is necessary to develop techniques that help us to tackle that huge amount of information. For this reason, there is an increasing interest in some areas of speech and text processing to develop techniques that allow the users to find, read, understand, or process the documents. In this context, automatic summarization can be an important aid because it provides a condensed version of documents that reduce the time to explore or analyze them.
Summarization techniques [13, 29] are usually classified as extractive, where some sentences (or other units) are selected from the documents, and abstractive, where the final summary is a sequence of generated sentences. Regarding the different approaches used to document summarization, some works are based on unsupervised learning techniques by considering statistical word features [2], topic modeling such as Latent Semantic Analysis [4], graph based approaches such as LexRank [5], among others [13, 29]. There are also systems based on supervised learning techniques such as Conditional Random Fields [27], Support Vector Machines [1] or Neural Networks [3, 26].
Summarization systems are not limited to text input tasks, there are some other works that address the problem of adapting these techniques to audio recordings as input, typically broadcast news, lectures or meetings [6, 12]. These systems have to tackle with specific problems derived from the errors generated by the speech recognition phase such as misrecognized words, or errors in punctuation marks.
Progress in summarization research has been influenced by the organization of evaluation conferences and the collection of corpora for training and test purposes. It can be highlighted theDocument Understanding Conferences (DUC) 1
, which were integrated later in the Text Analysis Conference (TAC) 2 These conferences were mainly oriented to evaluation tasks, therefore they provide corpora that were not large enough to be used in the estimation of some corpus-based models. This is the case of deep learning models, that are based on supervised learning techniques. Unfortunately, the construction of an appropriate corpus for this purpose is not an easy task, because it is necessary a great human effort to generate thousands of manual summaries, or to design new approaches to obtain these summaries in a semiautomatic way. An important resource for the corpus-based models is the recently created CNN/DailyMail summarization corpus, originally constructed by [7] for the passage-based question answering task, and adapted for the document summarization task [3, 21]. It consists of news stories from CNN and DailyMail and contains 312,085 document-summary pairs.In the last few years, approaches based on Neural Networks have been applied to summarization, taking advantage of their powerful capabilities to learn extremely complex functions. The most widely used approaches are based on encoder-decoder architectures modeled by Recurrent Neural Networks that had provided good results in translation tasks. Generally, in these approaches, the encoder processes the source sequence as a list of continuous-space representations and the decoder generates the target sequence. Some of these approaches also incorporate attention mechanisms. In particular, Cheng and Lapata [3] proposed an attentional encoder-decoder approach for extractive single-document summarization and Nallapati, Zhai and Zhou [20] presented an extractive summarization approach based on sentence classification using Neural Networks. In both works, they applied their approaches to the CNN/DailyMail corpus since its large size makes it attractive for training deep Neural Networks.
In this work, we propose an extractive approach to text summarization which is based on Siamese Neural Networks with Hierarchical Attention mechanisms using distributed vector representation of words. Siamese Neural Networks are capable of learning from positive and negative samples. In our approach, we provide the network with positive and negative document-summary pairs; a positive pair is a document and its summary from the training set and a negative pair is a document and a summary of other different document randomly extracted from the training set. The Siamese Network is trained as a classifier to distinguish whether a summary is correct for a document or not. Furthermore, this model is enriched with an attention mechanism that provides the final score associated to each sentence of the input document. This way, given a document, the model assigns weights to the sentences, which allows us to establish a ranking, and to select the most salient sentences to build the summary. In summary, we propose a novel end-to-end neural network to address extractive summarization as a binary classification problem. In comparison to other deep learning approaches, our system requires a training time of only a few hours. On the other hand, some deep learning approaches require adapting the training corpus before training their models e.g. to convert the abstractive reference summaries to extractive labels as in [20]. This adaptation is not necessary in our approach that uses the training corpus in a straightforward way. We have performed some experiments on the CNN/DailyMail corpus that confirm the promising behaviour of our approach to the summarization problem.
Our system addresses the extractive summarization task as a classification problem. Specifically, it learns whether a summary x′ is correct for a document x or not. We consider that a summary x′ is correct for a document x when they have similar semantics. In order to represent such semantics, we use Hierarchical Attention Networks (HAN) composed by Bidirectional Long Short Term Memory (BLSTM) [8, 25] networks.
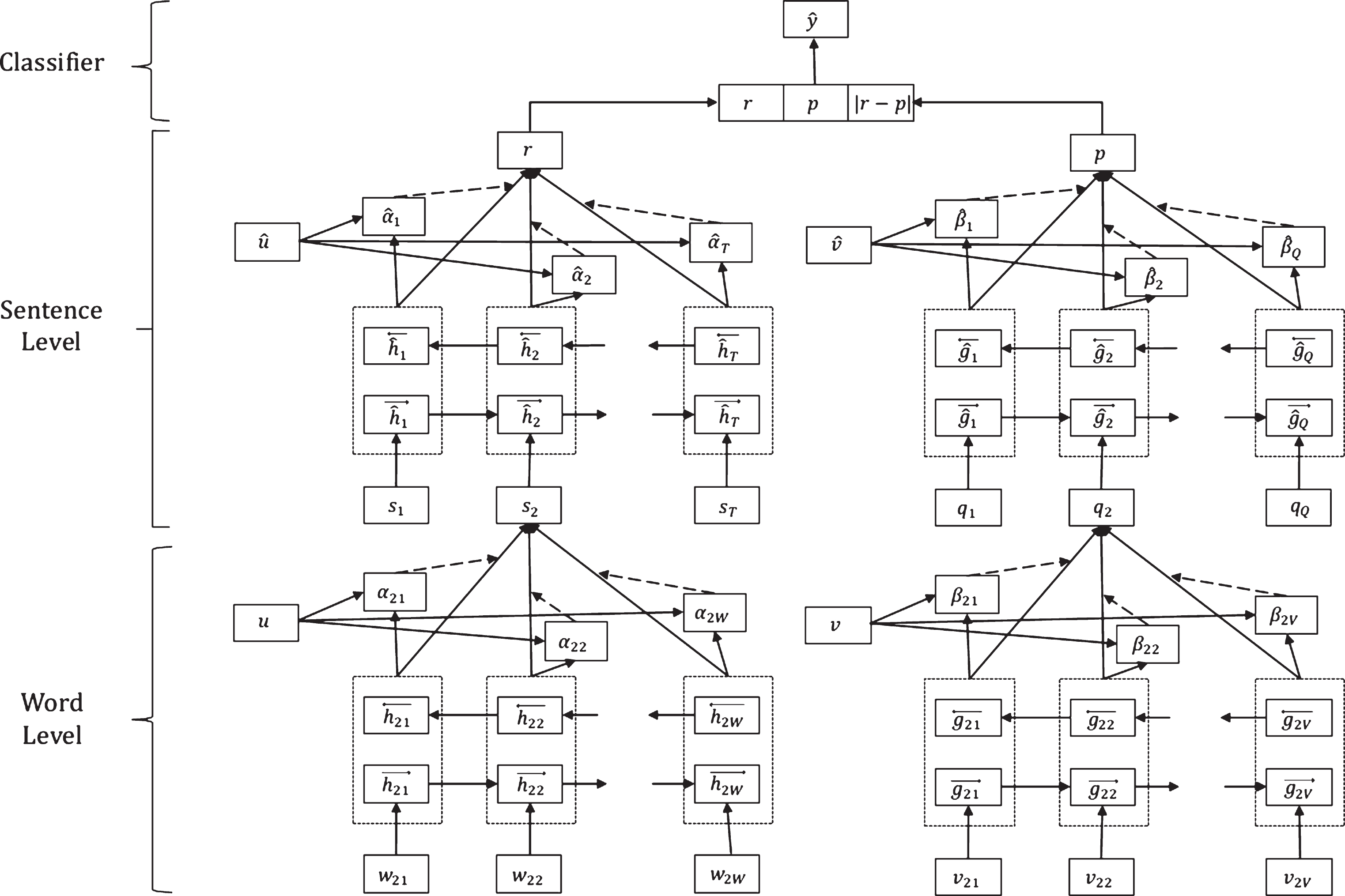
The Siamese Hierarchical Neural Networks (SHA-NN) architecture scheme.
This kind of network allows us to extract a vector representation of documents from the representations of their sentences. Moreover, the representation of each sentence is obtained from the representations of their words. As word representation we used Word2Vec word embeddings estimated from Google News [17, 18].
We use HAN to process both documents and summaries, where all the BLSTM share their weights, i.e. we use the same BLSTM to process documents and summaries, but the attention mechanisms have different weights. Finally, once the representations of documents and summaries are obtained, we follow an approach similar to [19] where the representationof documents and summaries with the difference between them are concatenated. We call this approach Siamese Hierarchical Neural Networks (SHA-NN) and its architecture scheme is shown in Fig. 1.
Let
From
where
From
where
where
The vector representations of the document
In order to train the model, for each document we built a positive pair
In this work, we used batches of 64 document-summary pairs (32 positive pairs and 32 negative pairs). Moreover, we considered that one train epoch was reached after processing 500 batches (32,000 samples in each epoch). We made this consideration with the aim of observing the model behaviour with finer granularity.
In order to carry out document summarization with SHA-NN, once the network has been trained to distinguish correct summaries for documents, some of its estimated parameters could be used to select the document sentences that will compose the summary. That is, for the summarization process, given a document, a forward pass is performed to obtain the weight of each document sentence
Corpus
For the experiments, the CNN/DailyMail
. corpus, which is a combination of the CNN and the DailyMail corpora, was used. This corpus was originally constructed by [7] for question answering and modified by [3] and [21] for extractive and abstractive summarization respectively.To make a fair comparison with other works, we used the anonymized version of DailyMail corpus, which consists of 196,961 training documents, 12,148 validation documents and 10,397 test documents. Additionally, we carried out other experiments with the combination of CNN/DailyMail corpus (anonymized version), which consists of 287,227 training documents, 13,368 validation documents and 11,490 test documents. In Table 1, several features of these two corpora are shown.
Average number of sentences and words (including words per sentence) in the training set
The ground truth summaries provided by this corpus are abstractive. They are built by the concatenation of all the highlights associated to the documents.
Recently, due to the impact of neural networks in the Natural Language Processing community, a large number of approaches based on Deep Learning for Text Summarization have been proposed. Most of the proposed approaches address the summarization problem from an abstractive perspective and are based on encoder-decoder models with attention mechanisms [15, 28]. The main problems of these systems are the generation of repeated words and the inability of producing words out of the training vocabulary (especially name entities). For this reason, more recent approaches propose coverage mechanisms and Pointer Networks to deal with these problems [26].
However, the extractive summarization has not been deeply explored and only a few works address it [3, 20]. ([26] can be seen as a hybrid between abstractive and extractive).
In this section, we discuss the works with which we have compared our system. To our knowledge, they are the only works that used the CNN/DailyMail corpus to perform summarization from an extractive perspective.
In [3], the authors propose an encoder-decoder model combined with attention mechanisms for extractive summarization. However, they report their results using a subset of 500 samples from DailyMail corpus. For this reason, we do not compare our system with them.
In [20], the authors present a Hierarchical Attention Network to choose sentences from the document as a sequence classification problem. They used two different summary sets to train their system. The SummaRunner-Abs system is trained using the summaries provided by the corpus. The SummaRunner-Ext system is trained from new summaries obtained by a greedy algorithm that transforms the CNN/DailyMail abstract summaries into extractive summaries, choosing a set of sentences from the document that maximize the similarity with respect to the abstractive summary.
SHA-NN and SummaRunner-Abs are similar systems since both are based on a sentence ranking without the need of converting the abstractive summaries in extractive summaries. However, the main difference between them is that they address different classification problems. In our case, the aim of the classification is to distinguish whether a summary is correct for a document or not, whereas SummaRunner-Abs system addresses a sequence classification problem in order to select sentences. Moreover, our criterion of sentence selection is based on a hierarchy of activations on the sentence level, instead of a classification for each sentence of the document. Furthermore, it is necessary to highlight that SHA-NN system is able to extract the most salient words of the documents due to the use of word and sentence level attention mechanisms.
Regarding [26], they proposed a hybrid approach based on Pointer Networks and encoder-decoder models with attention mechanisms. In the summarization process, the network can choose between generating a new word from the vocabulary or copying a word from the source document. Moreover, in order to address the word repetition problem, the authors enrich the system by using a coverage mechanism based on the attentions of previous timesteps, for each decoder timestep.
In addition to these systems, we compare the results of the SHA-NN system to another extractive approach which is not based on neural networks, TextRank [16]. Moreover, we provide results using two straightforward mechanisms: Lead-K, that extracts only the first K (tipically K = 3) sentences of the document, and Random-K, that randomly extracts K sentences from the document.
Experiments
We carried out two different experiments, one for each corpus. We evaluated the performance of our system in the experiments by using variants of the ROUGE measure [11]. Concretely, Rouge-N with unigrams and bigrams (Rouge-1 and Rouge-2) and Rouge-L were used. Although in the literature there are some proposals to evaluate automatic summarizations without using the gold standard [14, 24], in order to compare our system to other approaches in the same conditions, we evaluated it with ROUGE statistics using the gold standard provided by the DailyMail and CNN/DailyMail corpora.
In the experimentation we used d1 = d2 = 512, BatchNormalization [9] between each pair of layers, and Adam [10] as algorithm to minimize the cross entropy. From the ranking of the document sentences based on
The experiments consisted in two steps. First, the network is trained, and second, the trained network is used to process a new document by means of a forward pass, in order to obtain the weights
In the first step, we trained our system with the goal of distinguishing correct summaries for a given document, i.e. we used the SHA-NN system to solve the classification problem. In this step, we selected the best epoch for the model evaluated on the validation set. The cross entropy at each epoch for DailyMail and CNN/DailyMail corpora are shown in Figs. 2 and 3.
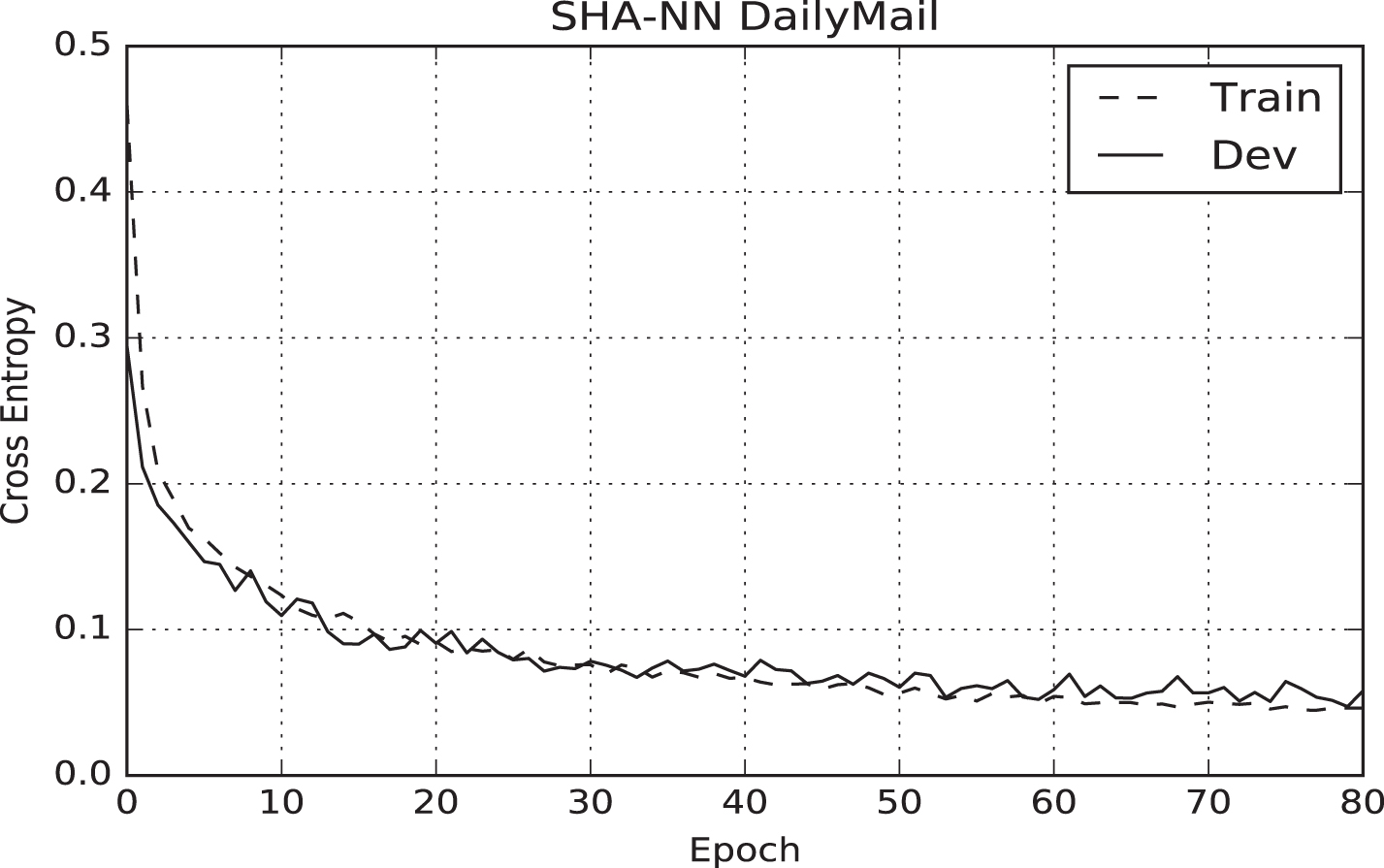
Training and validation loss on DailyMail.
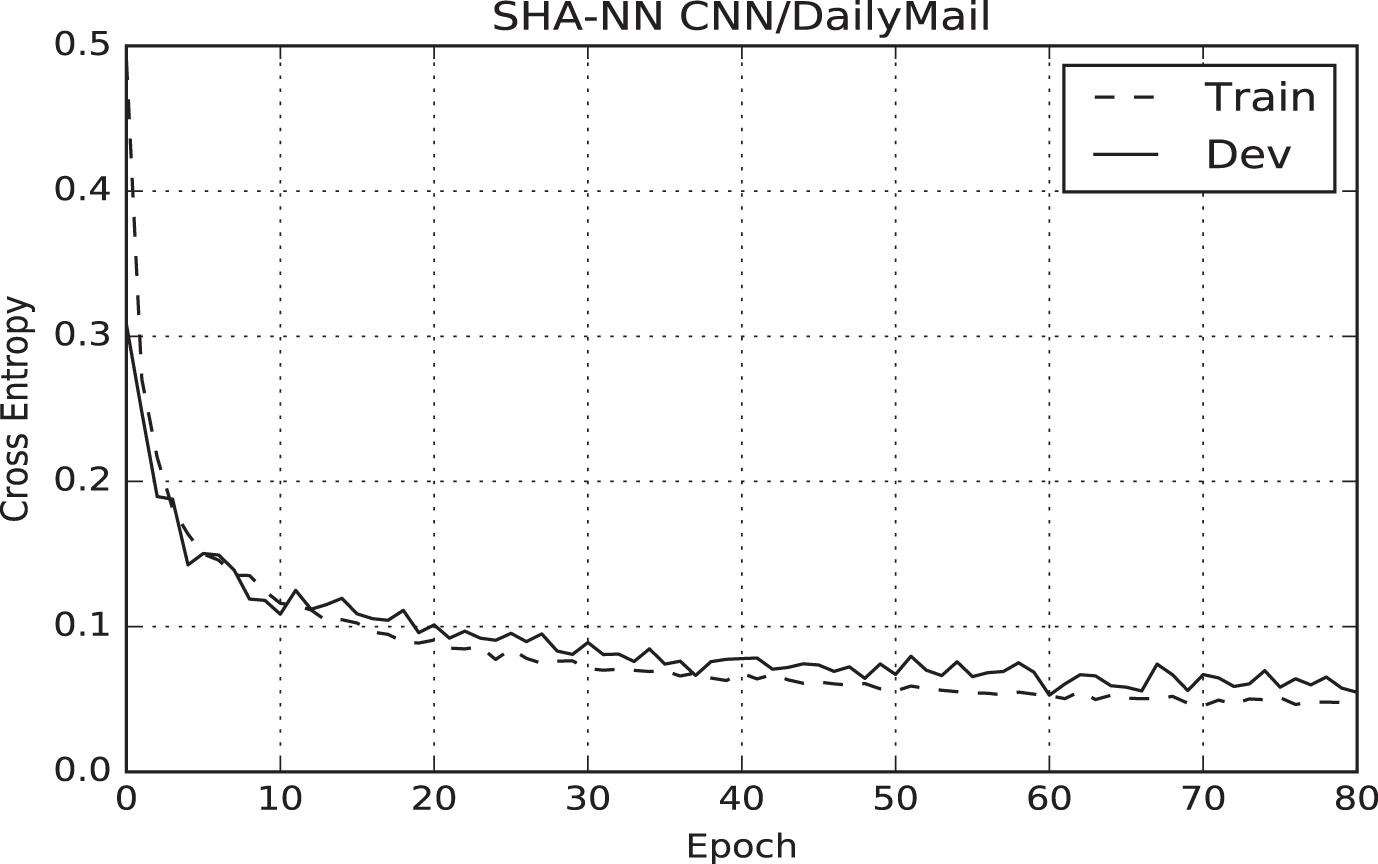
Training and validation loss on CNN/DailyMail.
Regarding to DailyMail corpus, the best model was obtained after 65 epochs, trained with 2,080,000 positive and negative pairs. This process took 5 hours on a single Nvidia Titan X GPU. With respect to CNN/DailyMail corpus, the best model was obtained after 70 epochs, trained with 2,240,000 positive and negative pairs. This process took 5.5 hours. Therefore, our model stands out in training speed compared to other systems such as [21] who took a few days to reach convergence on a single Tesla K-40 GPU.
In the second step, once the network was trained, it was possible to use it for extractive summarization.With the aim of comparing our system to other systems, we carried out two experiments, both for DailyMail and CNN/DailyMail corpora.
In all the result tables, the results labeled with † were obtained in the experimentation we done in our laboratory, while the results labeled with ⋄ and ‡ are provided in [20] and [26] respectively. In [20], they use the anonymized and preprocessed version of the corpus, and in [26] they use the non-anonymized version of the corpus. It is important to mention that we have not used any kind of preprocess, for this reason, the experiments with Lead-3 do not get the same results compared to [20].
Tables 2 and 3 show the results of our system (SHA-NN) on the DailyMail corpus compared to other works, at 75 and 275 bytes for the evaluation with limited length Rouge recall.
Results on DailyMail corpus with respect to the ground truth at 75 bytes (limited length Rouge recall)

Extractive summarization with a test sample of CNN/DailyMail corpus (DailyMail subset).
Table 2 shows that our system provides results that are slightly worse than those provided by the best version of the SummaRunner system, however, it exceeds both the reference systems, the Lead-3 and the Random-3, as well as the results of the TextRank system. These are the results when the evaluation is made with respect to the ground truth at 75 bytes. When the evaluation is made with respect to the ground truth at 275 bytes, see Table 3, the results of our system are slightly worse: the results of TextRank and Random-3 systems are widely surpassed, however those of the Lead-3 system are only slightly improved.
Results on DailyMail corpus with respect to the ground truth at 275 bytes (limited length Rouge recall)
Table 4 shows the results on the CNN/DailyMail corpus in terms of Rouge F1 using full-length summaries.
Results on CNN/DailyMail corpus with respect to the ground truth (full length Rouge F1)
As Table 4 shows, only the best version of the SummaRunner system is able to slightly outperform the results of its Lead-3 reference system. Our results when the evaluation is made with respect to the ground truth (full length Rouge F1) are worse than those provided by our Lead-3 reference system. That is true also for the best version of the Pointer Gen system.

Extractive summarization with a test sample of CNN/DailyMail corpus (CNN subset).
When the length of the phrases of the summary considered for the calculation of the ROUGE, grows a deterioration of the results provided by all the compared systems is observed. We hypothesize that it can be due to the fact that it is the third of the sentences provided as the summary those that includes a greater number of errors with respect to the reference summary.
When evaluating the performance of the systems, it must be taken into account that we have compared extractive summaries against those of the reference that are abstractive. Moreover, we suspect that the abstractive summaries have been elaborated mainly using the first three sentences of the documents.
Figures 4 and 5 show two examples of summarization using the proposed SHA-NN system. We provide the Document, its Ground Truth summary, the three sentences extracted by our system (bold font), and the weights assigned to each sentence by our system.Fig. 4 shows a good summarization example, where the sentences with highest weights contain the most information of the Ground Truth. Figure 5 shows another example, where the two sentences with the highest weights (sentences 1 and 3) are correct compared to the Ground Truth. However, the sentence with lowest weight (sentence 2) is not correct. Additionally, if our system considered more sentences for the summary, in this example the sentences 4 and 5, then the summary would contain almost all the information of the Ground Truth.
We have presented an approach based on Siamese Neural Networks for summarization tasks. It has been shown the adequacy of the proposed learning methodology to capture the relevance of words and sentences in order to extract the more salient sentences of documents. Our system also allows for the use of the training corpus in an easy way, taking advantage of positive and negative training samples. Experimental results confirm the promising behaviour of our proposal, they are in-line with the state-of-the-art. Additionally, our system requires a low trainingtime.
As future works, we will study other kinds of deep learning architectures in order to process documents and summaries. In this work, we only experimented with extractive summarization at sentence level, however, as the model also assigns weights to words, we can take advantage of these information to enrich the sentence selection criterion. We will study the evolution of our proposal to tackle with abstractive summarization based on the weights obtained at word level. Furthermore, it could be interesting to explore the use of SHA-NN as sentence selector to feed abstractive models. Additionally, when we have adequate corpora in other languages we will also study the portability of our approach.
Footnotes
Acknowledgements
This work has been partially supported by the Spanish MINECO and FEDER founds under project AMIC (TIN2017-85854-C4-2-R). Work of José-Ángel González is also financed by Universitat Politècnica de València under grant PAID-01-17.