
Abstract
Caption generation requires best of both Computer Vision and Natural Language Processing. Due to recent improvements in both of them many efficient models have been developed. Automatic Image Captioning can be utilized to provide descriptions of website content or to engender frame-by-frame descriptions of video for the vision-impaired and in many such applications. In this work, a model is described which is utilized to generate novel image captions for a previously unseen image by utilizing a multimodal architecture by amalgamation of a Recurrent Neural Network (RNN) and a Convolutional Neural Network (CNN). The model is trained on Microsoft Common Objects in Context (MSCOCO), an image captioning dataset that aligns captions and images in the same representation space, so that an image is close to its relevant captions in that space and far away from dissimilar captions and dissimilar images. ResNet-50 architecture is used for extracting features from the images and GloVe embeddings are used along with Gated Recurrent Unit (GRU) in Recurrent Neural Network (RNN) for text representation. MSCOCO evaluation server is used for evaluation of the machine generated caption for a given image.
Introduction
The world relies on what gets seen. Vision modality therefore is an integral part of communication of information. But when it comes to describing it in Natural Language Text it becomes cumbersome. This is due to the limitation in the difference of representing the modalities, as the structure of both are different. This in turn makes emulation of human abilities to represent details of an image in simple text, a difficult task. The complexity further increases when we require efficiency of the representation. However a lot of approaches have been introduced to have a correspondence among the modalities so that they can represent each other. This often helps to generate more details about any of the involved modalities span the modality alone. The recent research are benefited by large datasets those have pairing of images and their descriptions. The progress that Image Caption Generation has achieved, is mostly delved out of three main techniques:
i) Template based - The main idea here is to identify as much detail as possible about the image components such as objects, their attributes, relationship with other objects. Then further parse the sentence into phrases and learn their correspondence with the image components using models like Conditional Random Fields (CRF) [1]. Finally putting them in a fixed template as Subject-Verb-Object to generate captions. These methods perform poorly as the dependency on template limits them to generate variable length sentences.
ii) Retrieval or Transfer based - These leverage the distance in the visual space to retrieve images which are similar to the test image and then modify and combine their captions to form the semantically similar caption for the test image. These models are highly dependable on the training or seen data and need additional steps like modification and generalization to output the final caption. Also they fail to generate novel captions.
iii) Language based - These models offer greater flexibility of producing more human like captions by being independent of either templates or training data. They learn the probability distribution over a common semantic space of both image content and text. The semantic space offers measurement efficiency of both the modalities by reducing the individual structure in to a common representable platform through which the individual distance can easily be delved out. Further it offers more flexibility of representing components of both modalities to have better correspondence among them. Language based models are the main inspiration behind recent improvements in caption generation, which is undoubtedly due to the success of Neural Networks which makes the representation of the modalities in semantic space much easier. These work in a sequential encoder decoder methodology to generate output sequence from input sequence. As RNNs have proved to be efficient for text representation they are measuredly used for novel caption generation whereas CNNs have outperformed any other category for image representations, thus making it a safe bet for image encoding and decoding.
This work simplifies the existing approaches for Image Caption Generation by means of introducing a much efficient approach through generated embedding of both the modalities. It also helps in either way retrieval as the generated embeddings correspond to each other.
The paper is structured as follows. Section 2 gives an overview of various caption generation models. Section 3 describes our caption generation model followed by analysis of result in Section 4. Section 5 concludes with some overview of the model and directions for future work.
Related works
Caption Generation models rely on both the aspect of feature extraction from images by different Image Processing methods and further analyzing the features to obtain the relation among the detected image fragments in terms of Natural Language Text. Earlier methods of Caption Generation mainly focused on generating sentences from the combinations of image annotations. The generated captions through this are the result of proper image understanding as well as Natural Language Generation. Evaluation of image sentence correspondence mapped on to an intermediate meaning space represented by (object, action, scene) template has been described in [2]. Through the intermediate space they were able to represent either modality from the other. Similar to this, work in [3–5] also finds objects from images along with their attributes and relation among the objects to establish a template based relation among the two modalities. However these are hard bounded to the template and are limited to the spatial or corpus based relationship among the objects identified in the image. A deviation from these approaches with densely labeled images, which incorporate object, attribute, action, and scene annotations to generate description was proposed in [6]. A three stage approach was followed in [7] without explicitly labeling the images, in the first stage they mapped the features extracted from each region of image to words likely to be present in caption. This was followed by a Maximum Entropy in Language Modeling on a set of training image descriptions to produce likelihood sentences in second stage, further followed by a re-ranking stage.
Retrieval based approaches associate an image with top ranked description among the candidate descriptions of similar images. These candidate descriptions can then either be used directly (description transfer) or a novel description can be synthesized from the candidates (description generation). The retrieval of images and ranking of their descriptions can be carried out in two ways: either from a visual space or from a multimodal space that combines textual and visual information space. The first approach represents the query image as visual features and compares its similarity with the images in the candidate set which are retrieved based on their features in the feature space. Finally the candidate image description are re-ranked or their fragments are combined as per certain rules and assigned to the query image. Im2Text model [8], GIST [9], Tiny Image [10] are based on this approach. The second approach projects features of both image and text on to a common semantic space known as multimodal space. This helps to retrieve one modality given the other. Models described in [11–13] build common multimodal space for image and text based on the training set of image and its corresponding description pair. Our work mostly relates to this approach.
Most of the recent methods are based on Recurrent Neural Networks, inspired by the successful use of sequence-to-sequence training with deep recurrent networks in machine translation [14–16]. The first deep learning method for image captioning was proposed in [17]. The method utilizes a multimodal log-bilinear model that is biased by the features from the image. The feed-forward neural network was replaced in [18] with a Recurrent Neural Network. In [19] a Long short-term memory (LSTM) network was used, which is a refined version of a vanilla Recurrent Neural Network. Unlike models of [17, 18], which feed in image features at every time step, in [19] the image is fed into the LSTM only at the first time step.
Top-down approaches followed in [19, 20] used modern CNNs for encoding and replaced feed forward networks in [2] with recurrent neural networks, in particular LSTMs. The use of these models on video captioning tasks was demonstrated in [21]. One of the main contributions of the work in [19] showed that a LSTM that did not receive the image vector representation at each time step was still able to produce state-of-the-art results, unlike the earlier work in [2]. The common theme of these works is that they represented images as the top layer of a large CNN and produced models that were end-to-end trainable.
Bottom-up approaches implemented in [22] trains a CNN and bi-directional RNN, that maps images and fragments of captions to the same multimodal embedding, demonstrating state-of-the-art results on informational retrieval tasks. Secondly, a RNN is trained that learns to combine the inputs from various object fragments detected in the original image to form a caption. This improved on previous works by allowing the model to aggregate information on specific objects in the image rather than working from a singular image representation. However, these models were not end-to-end trainable. Recently there has been a resurgence of interest in image caption generation, as a result of the latest developments in deep learning [18, 23]. Several deep learning approaches have been developed for generating higher level word descriptions of images. Convolutional Neural Networks have been shown to be powerful models for image classification and object detection tasks. In addition, new models to obtain low-dimensional vector representations of words such as word2vec [24], and Global Vectors for Word Representation (GloVe) [25] and Recurrent Neural Networks can together create models that combine image features with language modeling to generate image descriptions. In [26] a novel decision-making framework for image captioning was introduced where two separate networks were used. One to provide local guidance for predicting the next word as per the current state and another to provide global and lookahead guidance by evaluating all possible extensions of the current state. Attention mechanism used in [27] enables attention to be calculated at the level of objects and other salient image regions which has produced state-of-the-art result on MSCOCO dataset [28]. Our model differs in the sense of producing captions based on nearest neighbor embedding of feature from the modalities.
Caption generation model
The model differentiates among relevant and irrelevant captions by projecting image and its captions to same embedding space and further measuring their distance to cast the most similar embedded caption as the corresponding caption for the image. Since the model is purely based on vector semantics, it permits both way retrieval, as relevant images for any input caption can also be identified.
Dataset description
The model uses MSCOCO 2014 training dataset, each with 5 corresponding captions for training. The model’s performance is evaluated both on MSCOCO 2014 validation set with 5 captions each and on MSCOCO 2014 testset respectively. The details of the dataset is shown Table 1.
Details of MSCOCO 2014 Dataset used
Details of MSCOCO 2014 Dataset used
The model is based on retrieval based approach which retrieves the most similar caption of an input image based on the embedding generated. The model embeds image and its corresponding caption into vectors which can be compared with the input image embedding, to produce its closest caption and vice-versa. The main idea is to train the model to distance the image embedding from irrelevant captions embedding whereas the relevant captions embedding are treated closer to the image. Figure 1 describes the model which accepts three inputs, an image feature (the output of the ResNet-50 [29] model), embedding of a correct caption and a noise caption respectively. As mentioned, the model gets trained to have minimum distance between similar vectors and thereby maximizes the distance between dissimilar vectors in embedding space. As initial stage both image and caption text are embedded. Then dot product is computed between embedding vector of image with actual caption and also between image and a noise caption which is selected randomly from the dataset. The model is trained to distance noise captions from image by using the max-margin loss function. As both the modalities needs to be converted into vectors, efficient neural based techniques are used to produce the embedding.
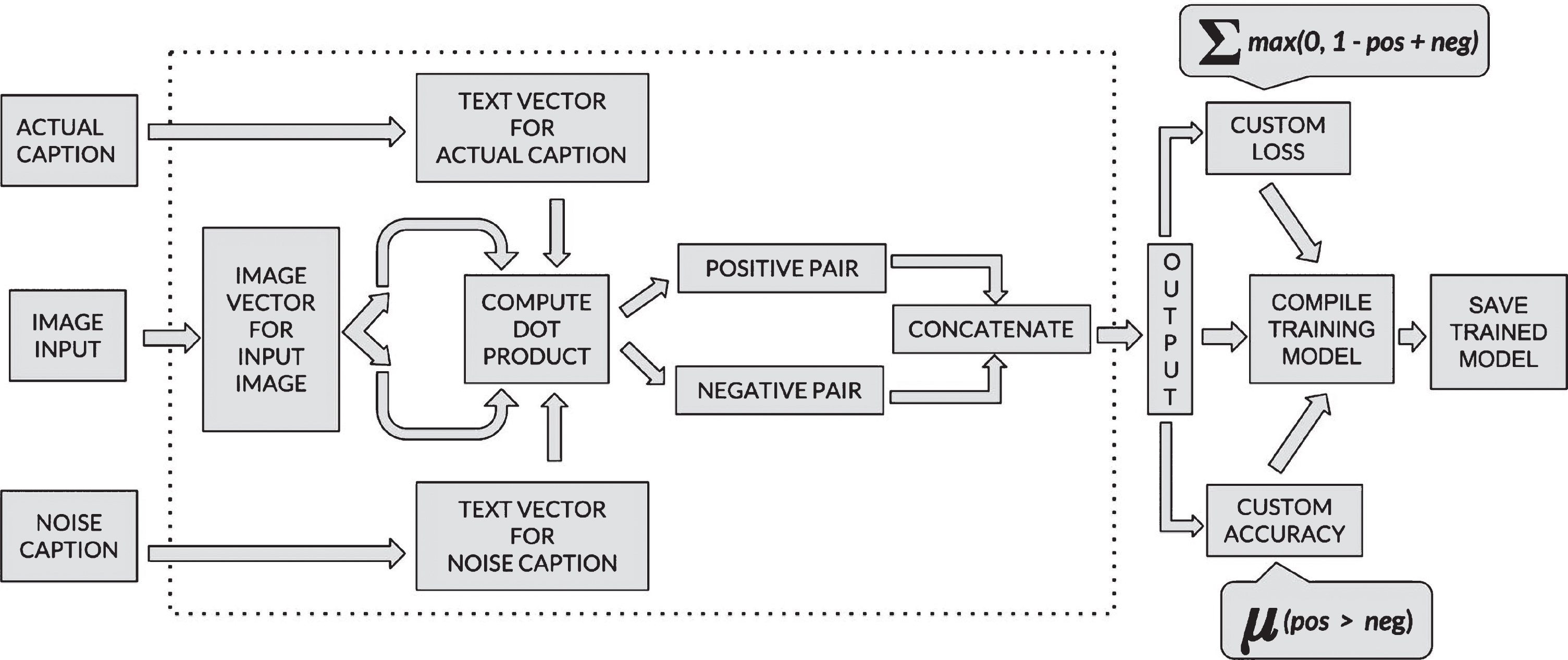
Model architecture.
CNN architectures have proved to be efficient enough in Computer Vision related tasks. So following the work by [16] the image representation model exploits CNN architecture for embedding images. It utilises the ResNet-50 [29] structure of the Imagenet Large Scale Visual Recognition Challenge [30]. The last layer of the structure is removed to retrieve the embedding matrix of shape (82783, 2048) from the images. The image representation model is shown in Fig. 2.

Image representation model.
The captions for images are initially tokenized, lower-cased and stripped of its punctuation as part of the preprocessing task using NLTK [31]. Also the texts are converted to integer sequences of the same size by padding upto 16 characters for each caption. Preprocessed texts as array of integers are now fed into the GRU based text representation model initialized with Glove embeddings trained on 6 billion tokens from Wikipedia 2014 and Gigaword 5. Figure 3 shows the process followed for text embedding generation.
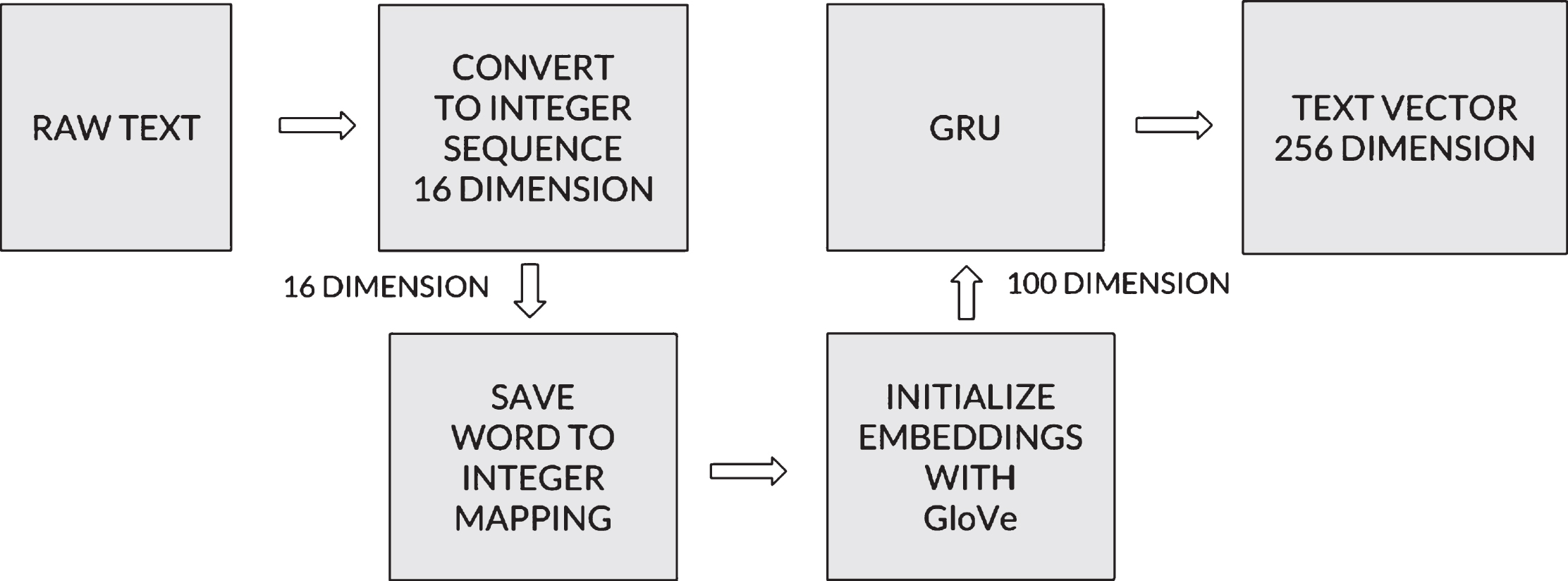
Text representation model.
The model gets trained based on maximum margin loss on positive and negative pairs of image and caption. It computes the dot product for the positive and negative pairs and aims to maximize the score for positive pairs. For this the maximum-margin loss function is used as represented in eq (1).
Here p i refer to the score of the positive pair of the i-th image and n i refers to the score of the negative pair of that image. The neural embedding model appears in Fig. 4.
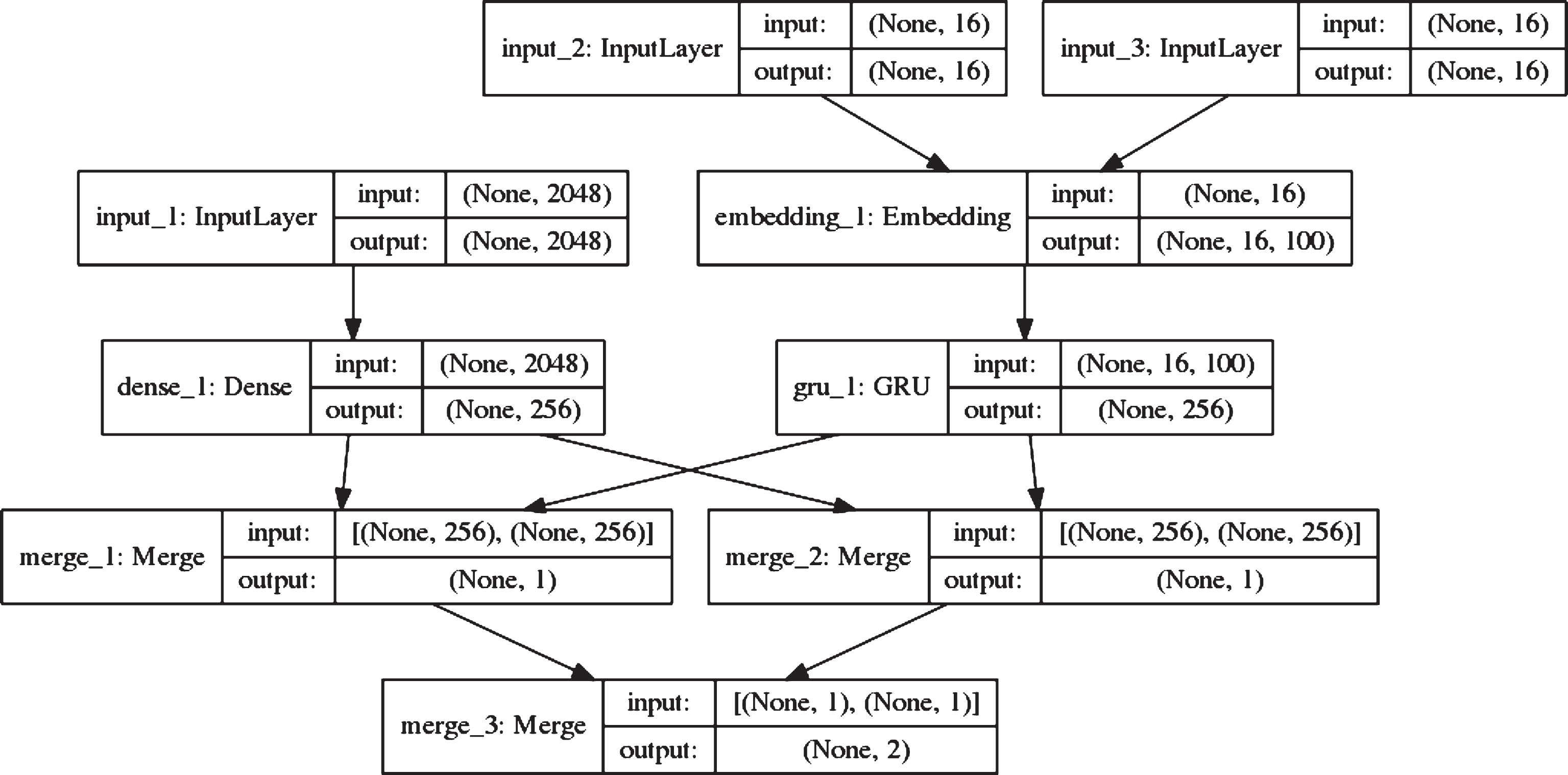
Neural embedding model.
The model was trained for 500 epochs on a single Nvidia Quadro K420 GPU using checkpoints on best accuracy and the best accuracy was produced in 174th epoch. The step time for each epoch was about 2 seconds and it took around a week to train the model. The accuracy and loss plots for the model are shown in Fig. 5 and Fig. 6 respectively.
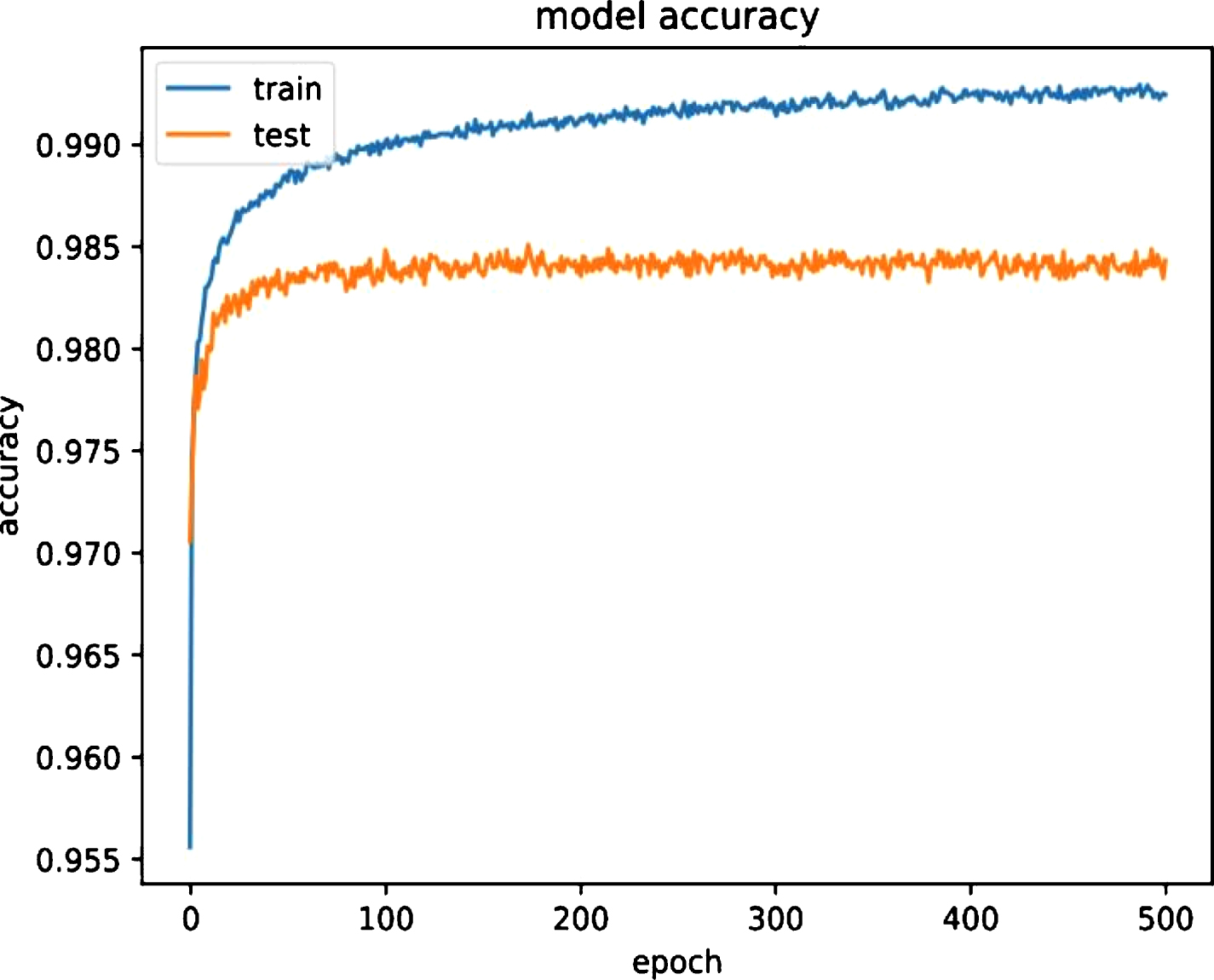
Accuracy plot over 500 epochs.
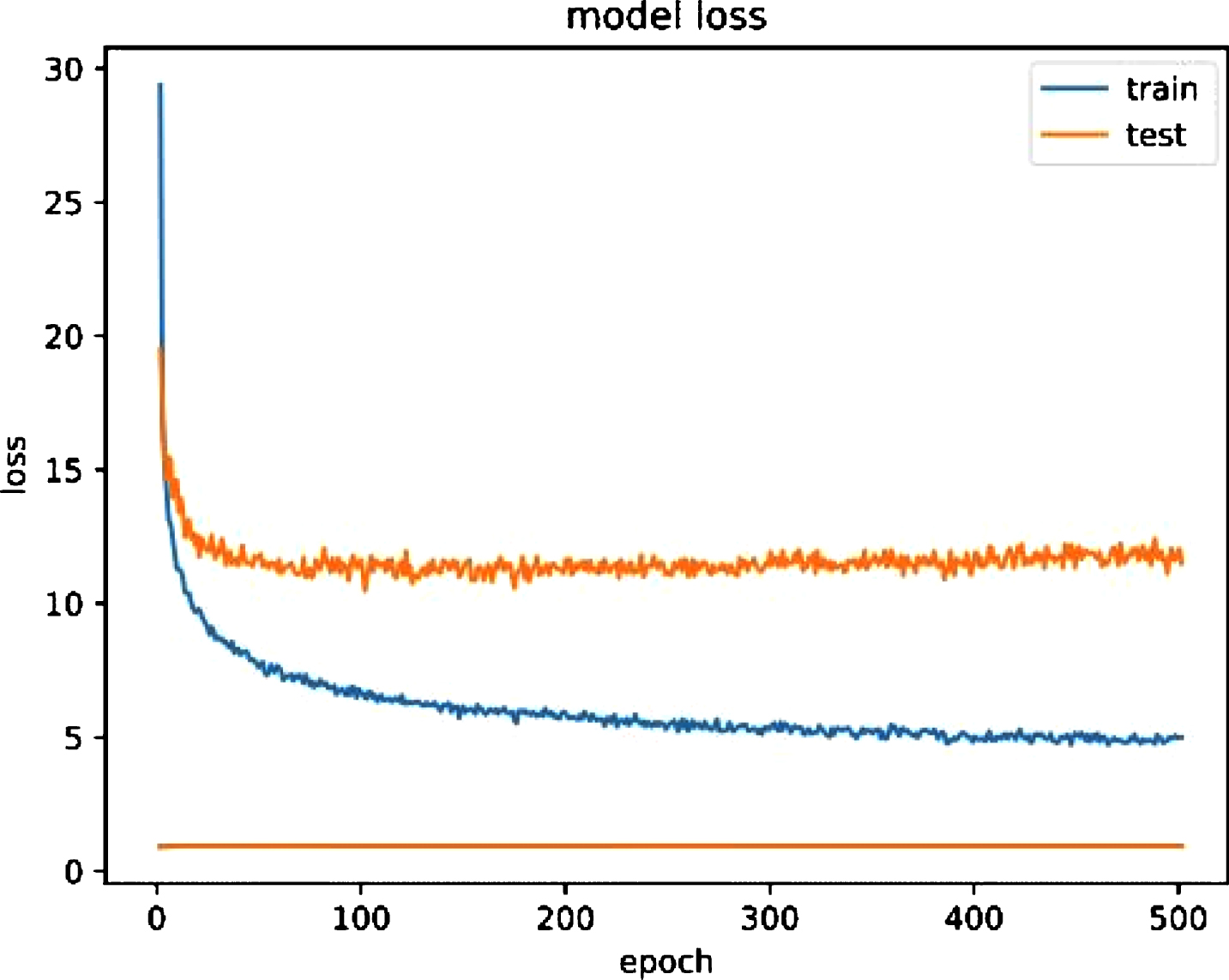
Loss curve plot over 500 epochs.
The diagram in Fig. 7 describes the typical steps involved in generating a caption for any novel input image. The neural embeddings generated through the image and text representation models create an embedding space where each vector is reduced to same size of 256 dimension. For any raw image its embedding vector is projected onto the embedding space and the nearest vector from the common embedding space is retrieved as its relevant caption.
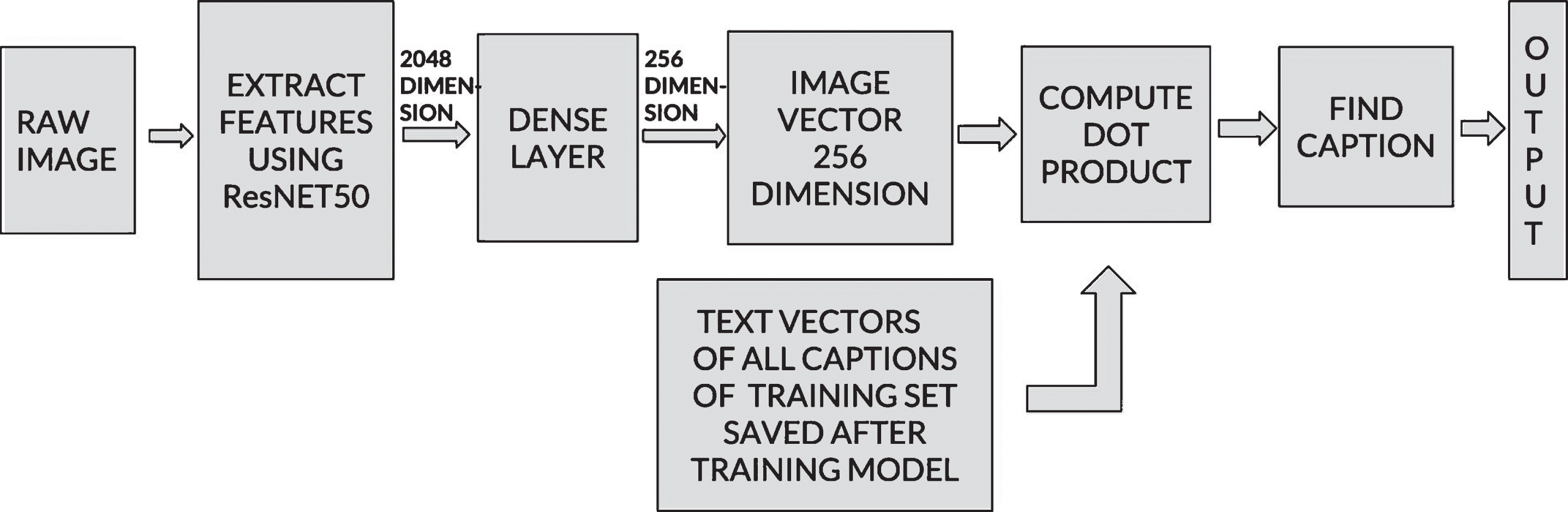
Caption generation procedure for any input image.
Evaluation metric
The effectiveness of the model is tested on 40,775 images contained in the MSCOCO 2014 test dataset. Also to avoid overfitting the model, MSCOCO validation dataset is used consisting of 40,504 images. As in machine translation, the Bilingual Evaluation Understudy (BLEU) [32] Score is the main metric used to evaluate image-to-text translations. The BLEU-n score computes a modified n-gram precision for words in the candidate translation compared to the reference translations. In particular, the n-gram precision is computed by taking the count of each n-gram in the reference translation, and clipping this count by the maximum number of times that the n-gram appears in a reference translation. This clipped count is divided by the unclipped count in the reference translation to produce a score. CIDEr [33], Meteor [34], Rogue-L [35] are also used for evaluation purpose in this work.
Qualitative analysis
The model produces better result when objects in the training images correspond to similar objects in the test image whereas it slightly faults when totally untrained objects come up. Performance of the model can be seen in Figs. 8–10 which are produced on MSCOCO validation dataset.

Successfully generated relevant captions by the model.

Partially successful result from the model.

Un-successful result generated by the model.
Results shown in Fig. 11 shows the performance of the system on some of the images from MSCOCO Testset whose context were learned, thereby producing relevant captions. However the result slightly defaults when it gets totally unseen images as shown in Fig. 12.

Successfully generated captions from MSCOCO Testset.

Partial-successfully generated captions from MSCOCO Testset.
The model generalizes very well for unseen images which can be observed from the results of unseen images in test set. This can be observed from the Table 2 in Section 4.3 where the performance on unseen test image was nearly same as that of validation dataset which shows that our model is generalized for unseen images. Also, since the batch size was kept high (256), the gradient updates during training were done after every batch of 256 images was seen, thus resulting in a more generalized model. Hence the model is able to generate captions for images which are semantically similar in context. Since the automatic metrics look for exact matching of tokens for evaluating captions, so even if the model generated a caption which is semantically correct, the performance was not very high due to the use of different words in the caption than expected in ground truth captions. This can be observed from the results of BLEU/CIDEr/METEOR/ROGUE-L metric of c40 in test set, where the caption generated by system is tested against 40 ground truth captions instead of just 5 ground truth captions, c5 as in validation dataset which concludes that our model gathers much semantic information during captioning and hence score increases when number of ground truth captions are high, which can be seen in Table 3.
Performance comparison of the model on MSCOCO val2014 and test2014
Performance comparison on MSCOCO test set
The system results are reported using COCO captioning evaluation tool which reports metrics such as BLEU, Meteor, Rouge-L and CIDEr. Table 2 shows the comparison of individual scores for metrics obtained from the MSCOCO evaluation server on validation set and test set respectively where 5 images were held for ground truth caption(c5). Table 3 shows the comparative analysis of performance on the evaluation metrics on MSCOCO Testset, where system generated caption is evaluated against 5 ground truth captions in c5 and 40 ground truth captions in c40. The higher value of c40 against c5 for all metrics prove that our model carries more semantic information and hence performance is high when varieties of captions are used to describe the same scenario. Hence, the model is highly robust for novel image captioning.
Error analysis
The system generates relevant captions for images in those cases where the model sees objects in the similar context. As the model gets trained on the whole image as feature input, it cannot detect the individual objects present in the image resulting in the generation of partial and unsuccessful result. As in cases it can identify the ‘tennis court’ context but fails to identify whether the player is a male or female. Similarly it clearly fails to identify a skate park whereas it has identified the beach which is in the context but not in attention.
Conclusion
The model describes neural embedding based method to project image and its corresponding captions to the same vector space. The max-margin loss function utilized, reduces the distance between image and its relevant caption. The model generates better captions for images in seen context. As future prospective attention based mechanism for generating object based features from image along with Recurrent Neural Network based method for text generation will be used to improve the performance of the model. Also, a better image model will be used for identifying local and global features from image which will aid in generating more accurate captions.
Footnotes
Acknowledgement
We acknowledge the anonymous reviewers for their valuable suggestions for improving the paper.