
Abstract
In human-computer interaction the automatic face sensing and recognition of facial expressions is still a challenging task of affective computing, psychology and biomedical applications. The main goal of this paper is to increment a recognition rate of approaches for unobtrusive face sensing and automatic interpretation of emotions. The proposed approach explores local scale invariant feature transform descriptors for extraction of face key points used for face detection, recognition and then for encoding facial deformations in terms of Ekman’s Facial Action Coding System (FACS). Real-time face tracking and recognition is provided by quadratic discriminant analysis and Bayesian approaches as classification tools. Based on detected fiducial points, the accurate automatic recognizing six prototypical human facial expressions as well as detecting affective states in real-time scenes is provided by fuzzy inference system based on the proposed reasoning model. Carried out experiments demonstrate that Ekman’s FACS traditionally used in affective computing may be extended to interpretation of non-prototypical compound emotions using Plutchik psychological model of emotional responses. Conducted tests with faces from standard databases confirm that the proposed approaches for analysis of local image features provide robust, quite accurate, fast and low computational cost face sensing and facial expression interpretation.
Keywords
Introduction
Automatic face sensing and recognition are very helpful for affective computing, autonomous robot navigation, environment inspection, marketing studies and consumption, distance education, vehicle guidance, security monitoring, control, surveillance, education, etc. The ability to recognize a human in live video, track his face and interpret his emotional state is still open problem of unobtrusive sensing in machine vision [1–4]. The artificial tool for automatic face detection and recognition must have capacity to extract relevant features from images representing a region of interest in suitable manner for fast and accurate processing; generate inferences providing high precision recognition sometimes based on incomplete information; classify and interpret the obtained data and learn from examples providing generalization that will be applied to its future improvement [1, 6].
In general, the classification methods for pattern analysis take advantage of the generative and discriminative models. Pattern classifiers based on the generative models such as Principal Component Analysis (PCA), Non-negative Matrix Factorization (NMF) or Independent Component Analysis (ICA) provide suitable image data representation by model-based approaches, shape-based approaches and appearance-based approaches. Classifiers based on discriminative models such as Support Vector Machines (SVM), decision-generalization boosting or Linear Discriminant Analysis (LDA) take optimal decisions by using data directly assigned to labeled objects (feature vector). So, generative classifier models learn the joint probability of object of interest using information from class of images with similar features, while discriminative classifier models provide classification of objects directly from feature descriptors [1, 5–7].
Although the versatile analysis of methods based on generative and discriminative classification models has been widely discussed in scientific literature, most of them are not directly fitted to face processing tasks because the theoretical assumption of the classification process frequently does not take into account many specific conditions presented in complex machine vision applications [6, 9]. Additionally, most of the used approaches still require relatively heavy computing resources and operate on low speed and recognition accuracy particularly, when multiple objects within real time scenes must be processed.
Recently, deep neural networks have received a lot of attention particularly, in fields like face sensing and analysis of human emotional states. However, the principal disadvantages of the modern deep-learning approaches are significant complexity of the training process as well as requirements to use standard databases with thousands of manually labeled images for specific applications [1–3, 6]. Therefore, the main objective and a theoretical contribution of this paper is to propose appropriate, fast and accurate approach for applications that provide real-time face detection, tracking, recognition and facial expression classification.
It is important to mention that currently, wellbeing centered technologies for more natural communication between computing artefacts and users are focused on expanding traditional sensing by applying unobtrusive and noncontact techniques, which include automatic recognition of human emotional states [3, 11]. That is why, an experimental evaluation of the proposed approach for face feature detection, processing and recognition have been carried out by specially designed framework for automatic interpretation of basic emotions that represent behavioral, cognitive and physiological reaction towards relevant events occurred in live test videos. This is considered as a practical contribution of this paper.
The paper is organized as follows. In the next section an overview of recent trends and new advances in face sensing methods are discussed. Then, the proposed approach for face detection, tracking and recognition by scale invariant descriptors is introduced. The description of the adopted model for facial expression recognition is also discussed in this section. Further, the evaluation of obtained experimental results is provided analyzing the robustness of proposal and designed framework for face feature extraction and recognition invariant to changing ambient conditions. Finally, a critical discussion of performance of prototypical facial expression interpreter is presented comparing it with existing face feature processing approaches and systems.
Related works: Face sensing using pattern recognition approaches
In order to specify the requirements for development of specific approach or algorithm for face sensing and facial expression interpretation, some potential pattern recognition techniques are evaluated. Nowadays, the most widely used approaches for pattern recognition may be subdivided in some groups such as template matching, knowledge-based and appearance-based methods. The first group exploits template matching techniques that analyze the correlation between reference template and image test regions during its displacement to every possible position in that image. These techniques find regions of interest similar to templates with their description of shape, position and orientation. Among formal quantitative similarity measures used in template matching approaches, the sum of absolute differences, the sum of squared differences and the normalized cross correlation are distinguished. The first two metrics provide very simple and fast enough analysis of template matching but some factors like robustness against noise, tolerance to deformation, feasibility of matching process in images with distortions, size and orientation variations must be taken into account as possible disadvantages. In contrast, pattern analysis using normalized cross correlation is much slower than previous techniques and requires high computational efforts. However, this metric is more precise and robust particularly, applying it to images with non-uniform illumination [2, 12].
The second group of knowledge-based approaches are characterized by dimensionality reduction manipulating region of interest as whole entity with distinct to others features and core components. Using formalism for knowledge representation and fuzzy reasoning these approaches, under controlled conditions, improve the accuracy of pattern recognition without significant increment of processing time; however, they require a well structured environment [1, 13].
The last group of pattern recognition approaches exploits appearance of tested pattern usually represented by its different 2D views. Among these approaches, the local and global appearance-based techniques are distinguished. The local approaches describe regions of interest by corners, edges, boundaries, shapes, surfaces, etc. These spatial features are easily extracted and processed in images with presence of noise and do not strongly depend on scale, orientation, position, and changes in viewing direction providing robust pattern recognition under different illumination conditions. These techniques are known as Scale Invariant Feature Transform (SIFT), Entropy Based Salient Region detector (EBSR), Difference of Gaussian Points (DoG), Harris and SUSAN corner detectors, gradient-based techniques and others. The disadvantages of these approaches are the complexity of processing great amounts of data and simplicity of local features themselves [14–16].
In contrast, the global approaches turn an image into a lower dimensional data set covering the information content of the whole image or patch. The analysis of global image features such as integral color, mean values, histograms, entropy, gradient moments, multiresolution features, subspace data and others do not require complex and time consuming processing. The advantages of global approaches are their capability of image data modeling and processing in more suitable and simple way that allows reconstructing the original image. However, the dimension of image encoding data is enlarged considerably as well as required training and evaluation processes of global approaches in real-time applications are limited in use. On the other hand, the local feature-based approaches provide fast and accurate description of region or its small neighborhood by certain invariance properties to image distortions, scale variations, illumination changes, object of interest occlusions and others [9, 18].
Taking into account a previous analysis and expected relevant conceptual and practical contributions to the field of real-time face recognition, some design requirements have been established using the following generic methodology: A novel tool for face sensing should to solve a problem of exact detecting a region of interest with faces and provide certain estimation of their location and orientation with possible presence of glasses, hat, occlusions, variable facial expressions, change of viewing direction and others impairments; On the image enhancement step the low quality images with poor resolution and variations in color depth must be preprocessed; For applications, where face analysis in live video is required, the frame by frame face monitoring and prediction must be implemented using object tracking techniques; The feature extraction process must be adjusted to face sensing providing high accuracy of pattern processing and recognition; The time interval for face recognition in live video is limited, that implies development of high speed approaches particularly, for processing multiple subjects in real-time scene.
For evaluation of novel face recognition approaches the well-known standard image databases must be used instead of proper face databases usually presented in scientific reports. Non-standard ad hoc databases make difficult comparative quantitative performance validation of proposed solutions. Currently, there are many standard data bases used for face feature processing like CAS-PEAL face database with 99,594 gray-scale images on 1040 individuals with 15 different illumination conditions [19]; Yale extended B that operates on 16128 of 640×480 gray scale images of 28 persons with 9 poses and 64 different illumination conditions [20] and others, such as LFW of University of Massachusetts, VidTIMIT Database, FRAV3D Database, FERET DB, UMB database of 3D occluded faces, Project-Face In Action (FIA), NLPR Face Database, etc. [21]. For evaluating efficacy of facial expression recognition the standard Kanade’s CMU-Pittsburgh AU-Coded Facial Expression and Pantic’s databases have been used. Particularly, Kanade’s DB consists of 2105 digitized image sequences (640×490 or 640×480 pixel arrays with 8-bit gray-scale or 24-bit color values) from 182 adult between the ages of 18 and 50 years of varying ethnicity [22, 23].
Proposed approaches for face sensing and facial expression recognition
For accurate face feature extraction and processing simple and fast approach using local appearance-based descriptors is proposed and described in this section. The face recognition using local feature analysis in specific conditions provides better performance than global approaches during detection, tracking and interpretation of faces from ad-hoc and standard databases [1, 18]. An approach based on local face feature extraction is applied for automatic facial expression recognition using the proposed original emotion analysis model implemented into software platform with uniform interfaces and services.
Face recognition using local feature approach
The proposed approach for face sensing consists of face detection, tracking, feature extraction and recognition steps. To provide fast detection of regions with faces without previous image preprocessing, the Viola-Jones technique is recommended on the first step [24]. Using the adaptive boosting algorithm, the Haar features of a face are correctly extracted even though there are variations in face viewing position about±20°. Particularly, the extended rotated Haar feature set of Lienhart and Maydt is recommended for significant reduction of computational complexity and time for face detection. It also improves a classification process through the boosted cascade of simple feature classifiers providing the efficient cascade decision tree [25].
On the second step, face searching must be executed only on the space domain, where face location is predicted based on its locations in a previous frame. The proposed solution consists in spatially and temporally manipulating regions with a detected face from the first step (see Fig. 1(a)) generating a searching window for the next frame defined by increasing each rectangular side by 2/3 of its previous length as it is shown by white rectangle in Figs. 1(b)–1(e). The increment of face region size is defined by the average walking speed of human translation that is less than 5 km/h. Providing face searching only within the window (white rectangle) reduces significantly amount of processed data. If an object similar to a face is found in the white rectangle, it is then enclosed by inner rectangle, used only for visualization purposes and then, the third step is used to assure that inside the inner block there is a face. The face, found in the inner block, is highlighted by a black one and the same process is then applied to the next frame. If white rectangle has no face, such as in the case of Fig. 1(d), a face detection process is started again within the whole image.

Face detection and tracking by applying the proposed approach: (a) Detected face region rounded by rectangle. (b) Generating white rectangle, where face searching process is applied. (c) Pink rectangle shows region, where face is recognized and detected face is highlighted by black rectangle. (d) Particular case, when there is no face within white rectangle. (e) Correct face tracking in images with variable illumination, changes of face size and its translation.
The proposed face tracking process is characterized by simplicity, high speed and robustness to variable lighting conditions and slight face occlusions. For example, in Fig. 1 correct face tracking in images under variable illumination, face size changes and its translation is presented.
Previous to a local feature extraction step, the image enhancement based on histogram equalization is applied to a region with face as well as compensation of non-uniform illumination is provided by subdividing an image in some regions with the corresponding compensation coefficients. The proposal consists in splitting a face region into 16 regular blocks and the average intensity of each block is computed. This average value is assigned to all pixels into the corresponding block. After image smoothing by bilinear interpolation, its complement is derived and then it is used for compensation of non-uniform illumination in the enhanced image, which is obtained by adding original image to the complement of the smoothed image.
The local face feature extraction step consists in eye sub-region detection, applying the adaptive boosting algorithm. After detecting a group of pixels, that represent eyes, other sub-regions (second eye, nose and mouth) are found based on standard face measures.
An explanation of the proposed solution, for face sub-region detection, is given in the following algorithm, where variables (x,y) are used to designate the coordinates of the top left and bottom right corners of the rectangles highlighting the left and right eye as well as nose/mouth sub-regions. The applied algorithm returns necessary information about the position of eyes and nose/mouth sub-regions, as it is shown in Fig. 2.

Eyes/mouth/nose sub-region detection and description by feature vectors pti [i].
On the step of face local feature extraction and description, the SIFT Scale Invariant Feature Transform is used. Particularly, each key point of SIFT is described by four parameters: coordinates of location in image, scale, dominant position and feature vector [13, 26]. Thus, the proposed extraction of SIFT descriptors is subdivided into the following procedures:
The first procedure is used for detection of scale-space maxima and minima. It consists in construction of a pyramid of scaled images smoothed by a Gaussian filter in order to find a set of points that are candidates to be SIFT key points. The scale-space representation is described by the function, according to Equation (1):
where convolution of original image I (x, y) with Gaussian G (x, y, σ) is computed with different values of variance σ. A pyramid of Gaussians is obtained by subtraction of scales as Equation (2):
where k is a constant factor for differences in scale that are grouped in octave. The input of the following octave is the previous octave subsampled by factor of 2. Thus, the characteristic SIFT key points are found on different scales. The procedure is finished after computing the maximum and the minimum of Difference of Gaussians D (x, y, σ) according to Equation (2), comparing each of 27 pixels with its neighbors from current and two adjacent scales in the 3×3 window [26]; In the second procedure, the previously detected points of interest are evaluated to measure their stability according to scale and location, eliminating points with low contrast, vulnerable to noise or misplaced at edges of objects. So, stability is determined by level of the pyramid of Gaussian
Finally, the point is accepted as a candidate for the next procedure if the value of The next procedure is used for extraction of gradient magnitude g (x, y) and angle of gradient vector θ ; (x, y) for all non-rejected points according to Equations (4) and (5):
The last procedure is applied to each point generating a feature vector. Each of eye/nose/mouth sub-regions is divided into 16 blocks, where the maximum value of gradient vector orientation is estimated for each block. Thus, the dominant gradient vector direction is mapped to one of 8 directions with difference in 45°. Finally, the SIFT point descriptor is formed by 128 elements representing the union of 8 directions of each of 16 regions with specification of key point location (x, y), magnitude and scale.
Figure 3 illustrates the application of local SIFT feature extraction applied only to eyes, nose and mouth sub-regions. Figure 3 on the left shows detected eye sub-region, in the middle depicts SIFT key points and on the right presents grouped points in regions of interest.

Local SIFT feature extraction within eye/nose/mouth sub-regions as well as detected points used for face recognition.
The introduced approach of face local feature extraction has some advantages such as independence of key points from scale, rotation and partial occlusions, robustness to noise and variable illumination, low processing time and simple comparison of feature descriptors during recognition process. Each face is indexed by SIFT key point descriptors
Particularly, for face recognition the following strategy for SIFT descriptors matching is proposed to apply. It consists in computing the Euclidean distance ED between SIFT key points restricted only to eye/nose/mouth sub-regions according to Equation (6):
A grade between two faces is defined by a similarity vector C1. There exists at least one element s
i
in the similarity vector C2. Similarity vectors of faces, which passed first criterion must satisfy the following relation: C3. Faces, which passed the first criterion, must additionally satisfy the following relation:
To improve the face recognition process and to determine the identity of a recognized person, the Bayesian approach is used in live videos. It describes probability P (f i |s) of face f i with features s from several image frames applying the following Equation (7)
where P (f
i
) is the face probability, also known as the prior probability that a randomly chosen face belongs to the i-th subject. At the initial step it is taken as raise0.7ex1 / - lower0.7exnfor n registered faces. The relationship between consecutive frames is considered by taking P (f
i
)
t
at instance t equal to P (f
i
|s) t-1 at the previous instance t - 1. Particularly, P (s|f
i
) is obtained from similarities s
i
of vector
The last relationship, used for face recognition, is shown in Equation (9), where the maximum value of the global probability vector
Assuming that a face feature vector s is drawn from a normal or Gaussian distribution corresponding to face f i , with mean vector μ i and covariance matrix Σ i , the conditional density function is defined in Equation (10) as
Plugging this density function for the i-th face into Equation (7) and performing some algebraic manipulations reveals that the Bayes classifier assigns an unknown face to subject i-th for which
The obvious advantages of the proposed solution, based on the local SIFT face feature descriptors, includes the reduction of the processing time due to the fact that feature extraction and face matching processes are carried out only on small sub-regions as well as the improved accuracy of face recognition in live video is provided by the Bayesian approach.
There are several relevant scientific reports for estimation of human emotional states based on unobtrusive physiological measures such as facial expressions, voice, gestures. However, their principal disadvantage is sensitivity to noise that may be overcome by using different high accuracy approaches and classification techniques. Particularly, for inferring human affective states, just six prototypical emotions like happiness, surprise, sadness, anger, fear and disgust are consistently recognized by facial expressions because all the people express them in the similar manner [1, 4]. The facial expressions are measured by visually detected displacement of fiducial points or landmarks that currently are defined by the Action Units (AUs) of Ekman's Facial Action Coding System (FACS). Particularly, Ekman's forty-four AUs represent the simplest visible muscular facial motions, which cannot be broken down into more simple units [11, 27].
The common disadvantages of facial expression recognition methods are the presence of errors during image spatial sampling, restrictions to small number of well-defined and separated faces without occlusion, sensitivity to scaling or rotation of analyzed regions, low precision of recognition if faces in image have week borders or complex background as well as the detection and selection of fiducial points are frequently made manually [1, 29]. Therefore, exploiting the proposed local SIFT face feature descriptors, a face finding and extraction of required landmarks may be done in fully automated manner providing reduction of complexity of emotion classification in real-time applications.
The precision of emotion analysis approaches depends on correct selection of action units. After various experiments with existing applications for facial expression recognition, only six relevant facial action parameters in eye/nose/mouth regions, which ensure the correct description of prototypical emotions, have been adopted in the proposed facial model introduced in Table 1.
Facial expression cues adopted for analysis of facial expressions
Facial expression cues adopted for analysis of facial expressions
For testing efficacy of landmark estimation by local SIFT, the Kinect based emotion interpreter has been designed. In the Kinect’s Face Tracking software developer kit (SDK) six Ekman’s AUs have been implemented as it is also shown in Table 1. Described in section 3.1 approach detects required landmarks, which are converted to AU values in the range [–1, 1] by Kinect Codification Facial Stocks implemented in.NET-based application. It provides fuzzyfication of landmark displacement and definition of the corresponding membership function used for indexing facial deformations. So, the fundamental process of fuzzy reasoning is quantification of AU intensity by measuring the range of geometrical displacement of selected facial action. Finally, for interpretation of emotions according to Ekman’s FACS the combinations of AUs presented in Table 2 are used, where value 0 for all AUs corresponds to neutral facial expression [11, 27]. The advantage of this kind of reasoning is a simple calibration of recognizing process as well as fuzzy logic is more intuitive approach than others without far reaching complexity and required training.
AUs and Kinect values used for classification of prototypical emotions
To reduce relative subjectivity and lack of psychological meaning of intensity levels of emotions, the statistical analysis of previously indexed facial actions in standard Cohn-Kanade’s and Pantic’s face databases has been carried out [22, 23]. It was a base for defining fuzzy inference engine implemented in Kinect-based framework, which identifies the particular prototypic emotion as a combination of detected facial actions quantified as it is shown in Table 2. The interpretation of emotions is based on defuzzyfication process that uses Plutchik’s psychological model, which describes compound facial expressions as combination of prototypical emotions (see Fig. 4 on the left) [30]. Therefore, the non-prototypical facial expressions like awe, enjoyment, hope, pride, relief, anxiety, shame, hopelessness, boredom, etc. may be recognized providing more natural communication between computing artefacts and users.
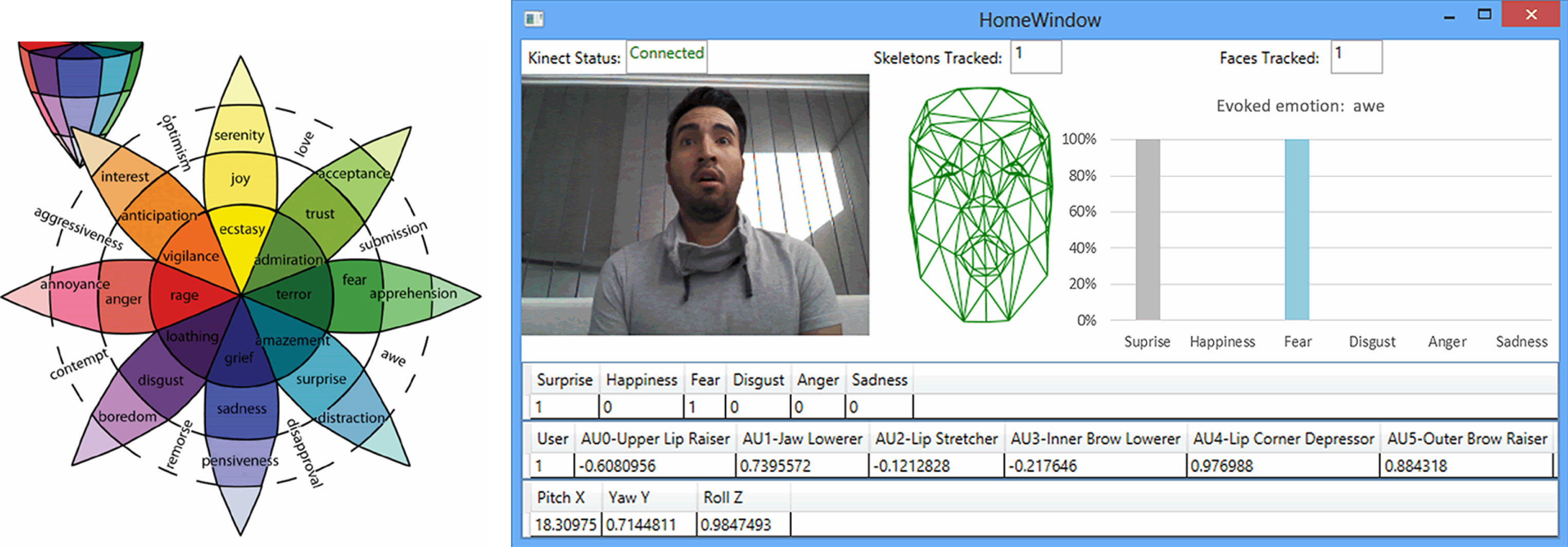
Plutchik’s wheel model of compound emotions [30] (on the left) and a Kinect session with detected AUs and interpreted emotion awe as combination of prototypical facial expressions surprise and fear of high intensity (on the right).
For instance, on the user interface of designed Kinect-based emotion interpreter presented in Fig. 4 on the right, the computed numerical values of six AUs are shown, which specify a presence of surprise and fear facial expressions of high intensity. Finally, according to Plutchik’s model (Fig. 4 on the left), the compound emotion awe is detected as combination of two prototypical facial expressions.
Despite of Kinect-based emotion interpreter uses limited number of AUs, the accurate recognition of facial expressions is provided due to high precision face feature extraction by SIFT approach.
The proposed approach based on local appearance-based face feature descriptors has been implemented and tested in real-time applications on a computer with CoreDuo processor of 3.3 GHz with 4 GB of RAM applying four sets of experiments. In the first group of tests, an analysis of system capability to reject new faces that are not in the database has been assessed.
The second set of tests is used for estimation of the accuracy of recognition of known faces, which are registered in a database. The next group of conducted experiments demonstrates the system accuracy of recognition of known faces in Yale B and CAS-PEAL standard databases. The last tests have been carried out in order to evaluate how well the proposed approach, implemented on the Kinect-based emotion interpreter, detects and recognizes facial expressions.
The first set of experiments has been used for evaluation of system performance during the real time recognition of faces of 10 unknown (nonregistered in database) persons, who are approaching to camera one by one from 5 to 1 meter. During this process, from conventional Pan-Tilt Canon VCC5 CCD camera with a resolution of 640×480, about 100 frames are captured for each analyzed person. During the first 50 frames, which are used for initial trial, the identity of the approaching person is unknown to the system. However, after processing these images, new faces are automatically incorporated to a database. Thus, in the next 50 frames, the recognition of known (registered in database) persons is provided in the second trial.
Examples of captured frames for one person and their subdivision into frames with unknown and known individuals are shown in Fig. 5. In the conducted tests, the indoor environment has no any special controlled illumination and person may use glasses, hat or face may be rotated in range about±20°.

In the first line 50 frames contain unknown face and next 50 images are processed as already registered face in database; the second line shows recognized face (frames 51–100), when it is already incorporated to BD as known one.
The analysis of efficiency of a system to recognize unknown faces in live videos is provided in this group of experiments by applying the proposed three criteria of matching C1, C2 and C3 presented in the previous section. The obtained results are shown in Table 3 for different values of thresholds vector
Average precision of correct rejection of unknown faces that are not registered in database
Likewise, the second set of experiments has been carried out with individuals that have been registered in a database. The obtained results are resumed in Table 4. As it can be seen in Table 4, the precision of 100% has been achieved by applying criterion C1 with a scheme of relative probability (C1-R) taking into account only 11% of similar SIFT points. With an increment in the percentage of SIFT key points in a face used for generation of the threshold vector, the accuracy of recognition is increased but the recall is decreased. The obtained precision rates for unknown as for registered person in face DB are quite competitive with well-known systems. For instance, for unknown persons the proposed SIFT-based approach provides recognition accuracy between 86.7% and 99.4% (see Table 3) and for known person precision takes values from 96.6% with a recall around 57.3% to 100% with a recall around 41.9% (see Table 4) depending on selected matching criterion, threshold and probability scheme.
Average precision/recall of known face recognition registered in ad hoc DB
The third group of experiments is proposed to evaluate how invariant is the local feature-based approach to diverse images with known individuals from standard Yale B and CAS-PEAL face databases. Table 5 resumes the average precision and recall for recognition of faces grouped in some sets, where Set 1 contains 20 images of four individuals taken from Yale B database, Set 2 includes images from 4 individuals additional to those in Set 1 and so on, concluding with Set 7 containing faces of 28 individuals.
Average percentage of precision and recall of face recognition registered in standard face DBs
The precision of face recognition varies from 99% to 94.5% with increasing number of processed faces in standard databases. These results are quite similar to the ones obtained in the second group of experiments with faces from an ad hoc database (see Table 4). It means that the approach is invariant to diverse images to be processed. Due to the fact that the average recall lies in the range between 19.8% and 46% , the percentage of relevant images is small indicating that the approach accepts only the restricted set of images with similar faces.
Table 5 also shows that the recall is affected more with the increased number of frames to be incorrectly rejected. Additionally, the average time for face detection, tracking and recognition has been computed and it does not overcome one second per frame. Thus, because the average number of frames required for taking decision concerning a subject identity is about 2.5 [13, 24], the recognition of any individual requires less than 3 seconds.
The fourth set of experiments has been carried out for evaluating facial expression recognition by Kinect-based emotion interpreter, when key points used for definition of action units have been estimated by the proposed local face feature extraction approach. The obtained results are compared to the model reported in [11], which estimate facial expressions without previously applied SIFT key point extraction. Fig. 6 shows better performance of Kinect-based emotion interpreter with approach for local face feature extraction. The improvement about 3.5%–5% is appreciated for the same metrics computed according to Equations 11–14: accuracy, precision, recall and specificity that represent percentage of correct interpretations, correct positive predictions, correctly identified positive instances and correctly identified negative instances, respectively.
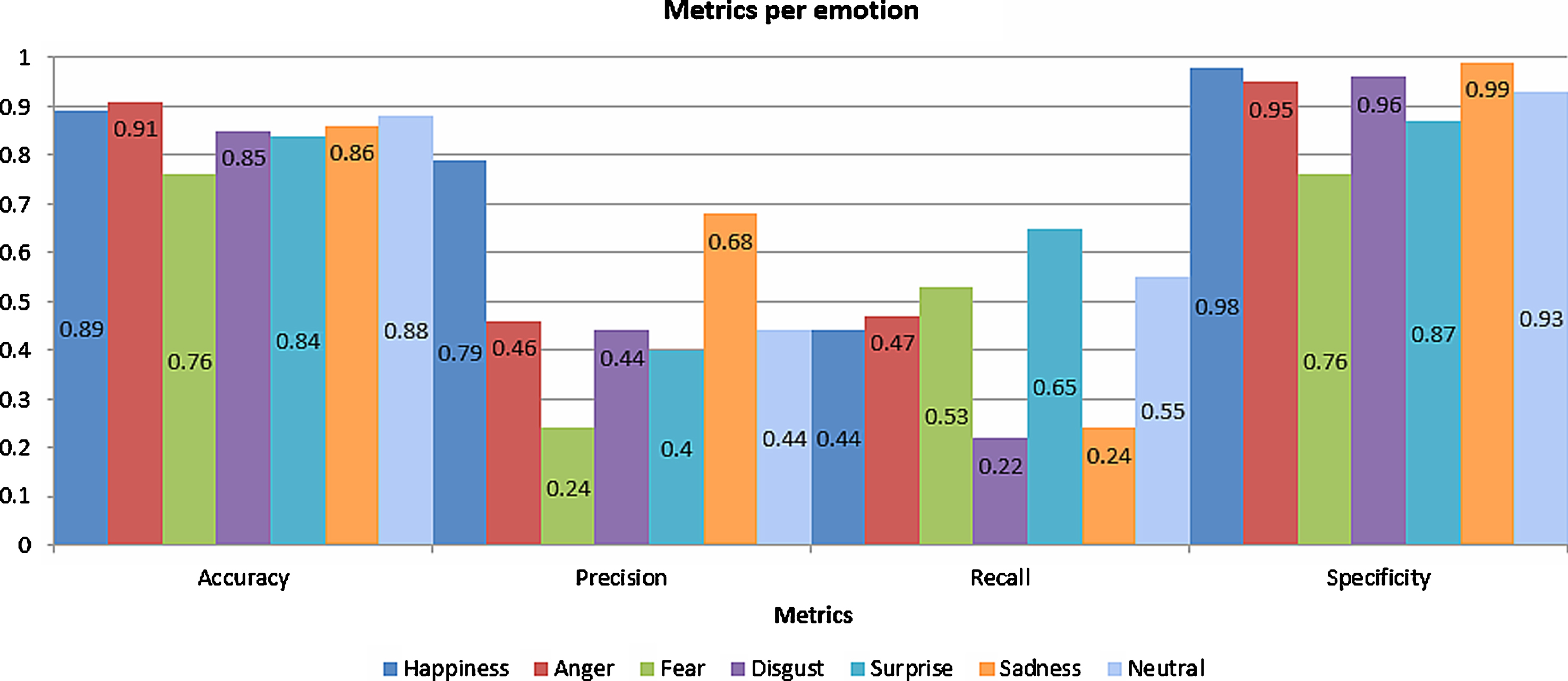
Performance analysis of Kinect-based emotion interpreter with local face feature extraction approach.
The variables used in Equations 11–14 are: TP (true positive) is a case, when a system interprets emotion correctly or FN (false negative) incorrectly. A case, when an emotion was identified as something that was not, is interpreted as FP (false positive) and a case, when real emotion was not interpreted as emotion, is considered as TN (true negative).
Despite of high complexity of automatic face detection and recognition processes a performance of the proposed approaches is competitive with those from recent scientific reports. For example, several algorithms, similar to the proposed approach, based on Viola-Jones method, using Haar feature extraction, achieve face detection rate between 50% and 70% on in-house tests [29], between 76.1% and 93.9% using MIT-CMU face database [24] and the achieved precision and recall around 97±2% and 20% , respectively [31].
Several well-known systems for face sensing based on generative PCA and discriminative LDA models provide high precision for recognition. For instance, Huang in [18] reports average recognition rates on the ORL database from 92.07% to 99.0% , using Top-level’s Wavelet Sub-Bands - TWSBF approach combining it with classical PCA and LDA, respectively.
By employing an explicit 3D face modeling in order to apply a piecewise affine transformation and derive a face representation from the nine-layer deep neural network, Taigman in [2] reaches an accuracy of 97.35% on the Labeled Faces in the Wild (LFW) dataset. Finally, Kamencay, in [8], describes a CCA Double method that fuses canonical correlation analysis (CCA) to learn the mapping between 2D face image and 3D face data as well as a PCA algorithm. However, the achieved recognition rates is quite low (around 80%) for the entire TEXAS database. Very satisfactory results are obtained by other methods particularly, by Sum of Absolute Differences SAD, Coarse-To-Fine CTF, 1D template matching and reducing image data MID algorithms that achieve improvement in pattern recognition up to 64.47% , 72.58% , 95.65% and 92.21% , respectively [12]. The feature encoding methods used for face recognition reach 90.89% on histogram of oriented gradients HOG, 94.57% for SIFT, 96.75% for space-time GABOR filter [16] and 96.76% of accuracy using CNN on databases such as CK+, JAFFE and BU-3DFE [3].
The designed Kinect-based emotion interpreter also provides quite acceptable facial expressions recognition similar to relevant reports about emotion sensing systems. For example, the achieved recognition rates are 72% by Esau’s emotion fuzzy classifier, 85% by FaceReader, 86% by Pantic’s expert system, 91.6% by eMotion system and 92.4% by SHORE framework [4, 28]. It is important to mention that recent emotion analysis systems explore deep-learning that in general, may outperform conventional approaches [1]. However, complex system architecture, significant time-consumuing training process and obligatoriness to operate with extensive databases must be taking into accout before selection of appropiate approach particularly, if real-time applications for face sensing are required to design.
In this paper local appearance-based image feature transform have been explored and evaluated with the principal goal to expand traditional methods for face detection, tracking and recognition. As result, an approach for fast, scale invariant and simple face sensing, indexing and interpretation have been proposed that may be considered as conceptual contribution. The obtained experimental results confirm high accuracy of face recognition, which lies between 95% and 99% using ad hoc and standard face databases. Designed Kinect-based framework with SIFT key point extraction has been used for recognition of prototypical facial expressions achieving average recognition rate about 85%. The conducted tests with Plutchik’s psychological model demonstrate that a framework also interprets both prototypical and compound emotions composed by multiple facial expressions. Therefore, Ekman’s model of well-recognizable six prototypical facial expressions traditionally used in affective computing may be extended to interpretation of complex emotional states based on analysis of non-prototypical emotions. It may be considered as practical contributions of the paper.
However, still low accuracy of recognition is due to a limited number of AUs used for representation of complex emotions, the simplicity of Plutchik's model and subjectivity of perception of facial expression by human. The introduced approaches have sufficient merit to be used as promising techniques for generation of novel high performance applications, where face feature detection, tracking, processing and recognition of facial expression are required.
Footnotes
Acknowledgments
This research was partially supported by FP7 European Grant (Cloud computing-based Advisory Services towards Energy-efficient manufacturing Systems).