
Abstract
MRI image segmentation, a challenging task in medical diagnostics aids in extracting the summarized information of the anatomy of the human brain, thereby offering the potentiality for accurate treatment of the disease. The purpose of this work is to elevate the performances of different optimization techniques that are used in automated segmentation procedures. The performance of four algorithms was evaluated quantitatively over the genetic algorithm-based segmentation, which is the prevailing approach in automated segmentation. The upshot exhibits the accuracy and performance of various optimization techniques with a genetic algorithm.
Introduction
Image segmentation is one of the rudimentary techniques in drawing out the contours of the image by which recognition of the objects in the image is made less complicated as stated by [27] Sudipta Roy Samir Kumar Bandyopadhyay, [14] Kailash Sinha and G.R. Sinha. In common, the assessment of segments involving user assistance approaches that involves techniques like supervised evaluation and subjective evaluation of the segments. Apart from the challenges of supervised based approach, it is obligatory to automate the segmentation that minimised the burden of the radiologist and more over the unsupervised based approach lean to generate accurate results as it works with a dynamic range of an image.
In [1], Nandhi and [18] Nursuriati Jamil et al. has proposed a morphological operations basedapproach, D. Selvaraj, R. Dhanasekaran [4] has proposed an approach intensity based on thresolding. Noha EI et al. in the article [17] has suggested a semi-automated technique through graph cuts segmentation approach in which the value of pixel distance is measured from the edges to designate them to the suitable segment. But the distance based methods may hardly converge towards the best possible number of segments in case of a wrongly chosen centroid and how ever the pixels are to delegated by considering the degree of belongingness through membership rather than the distance.
Geng-cheng et al. in his paper [9] had proposed a seeded region growing approach for automated segmentation of brain MRI images, but this mechanism has a considerable limitation in picking the initial seed point, especially in case of a noise image If the initial seed point is incorrect, it doesn’t yield a worthy outcome. And the technique is susceptible to initial seed point.
In the article [6], Goshal et al. had performed segmentation of the MRI image through a watershed technique that it is very accurate for segmentation of large images with numerous segments but the main pit fall of this technique is that many of the times it leads to over segmentation which is not appropriate for segmentation of the brain images as the MRI image constitutes brain fluids, tissues, and neurons which are recognised with different intensities and over segmentation. Under such circumstances, it may not fetch the best results. P. Singh et al. in the article [20], segmenting the MRI through Fuzzy C Means(FCM) algorithm that is efficient in semi-automated segmentation of MR image but the computational time for FCM is exceptionally high, As it need to evaluate the membership of each pixel with respect to cluster centers for pixel assignment.
As proposed by Angelina et al. in the article [24], the automated way of segmenting the MRI image for the non-invasive way involves more efficient techniques like region growing and region merging which is more liable to the initial seed points.And the objective function for the seed point identification would also be moderately complicated that needs to be more robust enough.
The paper is organized as section-II Image preprocessing to banish the salt and pepper noise, section-III presents stages of automated segmentation and Section IV presents about the genetic algorithm based variable string length based clustering, Section-V presents the work of Support vector Machine for optimisation, Section-VI presents the working of Particle swam optimisation for refining the segmented Section-VII presents the working of Teacher Learner Based Optimization. Section VIII is for data analysis of the MRI brain image segmentation utilising divergent optimisation approaches and exacting results of the different optimisation techniques. And section IX is the Conclusion and Section 10 is about the Future Scope.
Image preprocessing to eliminate salt and pepper noise
While the MRI image is being transformed, there is a chance of salt and pepper noise added to the image, as stated by K. V. R. Teja et al. in [13]. If any such image is segmented without performing preprocessing it may lead to misinterpretation. So the image has to be preprocessed before segmentation of the image.
Images with salt and pepper noise Q. Chen, in [21], will have the extreme intensity values either 255(Bright) representing the salt noise or 0(dark) representing the pepper noise. Here we use a 3×3 scanning technique to get the intensity of center pixel m(i, j)
When (i + x, j + y) ≠ (i, j) and p (i, j) gives the luminance difference. Now we recover the pixel intensity using the harmonic mean by using the following formula
r(i, j) recovered pixel, and a(i, j) is the average of 4 connected pixels and c is the weighted constant.
In general, a complete automated tumor diagnosis system CAD(computer aided diagnostics) is distantly accurate in terms of tumor estimation under certain initial assumptions, but for more accuracy, results the results could be further refined through the evolutionary algorithms. Automated image segmentation involves the following strategy for the identification of lesions and tumors. In the initial stage, the image is preprocessed to detach the noise, and then the features were extracted based on which the segmentation is progressed, and the obtained segments were assumed to be the initial clusters. The pixels are considered as initial population, and further refinement is performed for accurate identification of tumor/damaged index in the brain by further iterating it as shown in Fig. 1.
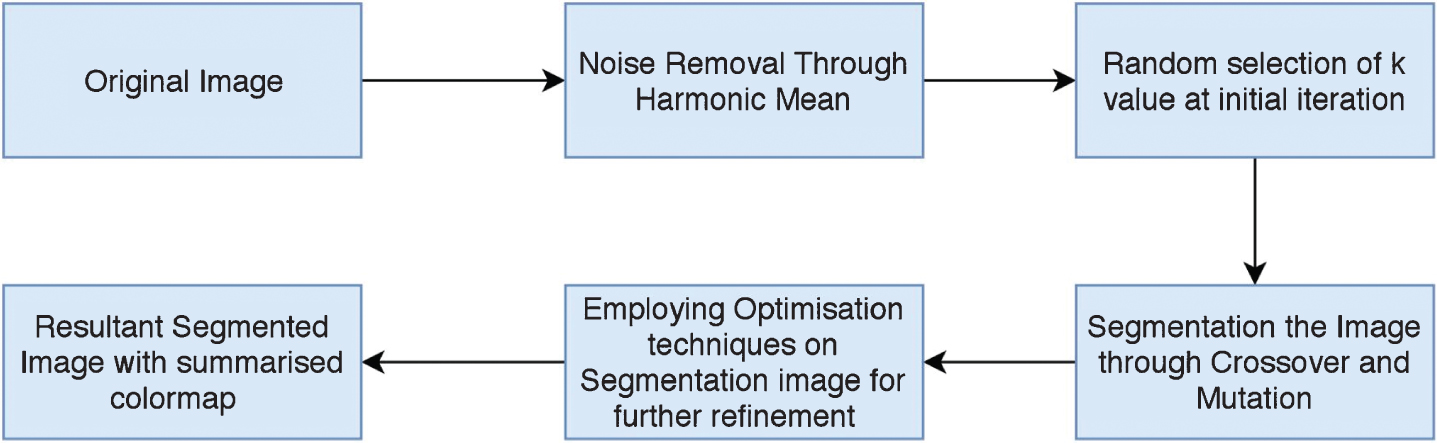
Block diagram of the segmentation procedure follows commonly in all the procedures.
Image segmentation could be fruitful and effective through automated image segmentation technique. The automated approaches would automatically assess the appropriate number of segments through the genetic algorithm as ststed by Nicoara et al. [16] and. In this mechanism, a variable string length based approach, as stated by Chou et al. in the article [3], Das S., [5] and KarimaBenatchba, MouloudKoudil [15] has deployed Genetic Algorithm for segmenting the image in their work. The degree of belongingness of the assigning to the concerning segment would be decided by applying line symmetry based approach by making use of an index. And hence, in each iteration, the index value has been optimised to outreach the global best solution. It folds a variable number of image segments, i.e. the optimal value of K. However, the algorithm could be implemented on the cluster of diverse size and shape as stated by Singh Vijendra, Sahoo Laxman, in the article [26].
Selection operator
The Selection operator decides the individual elements, i.e., segments that are selected for crossover purpose based on the computed fitness value. Then the chromosomes are continuously updated through the fitness of an individual in each iteration. Finally, the number of copies of a chromosome that goes into the mating pool for subsequent operations is proportional to its fitness.
Crossover operation
Crossover operation is executed among a group of parent chromosome to produce a child chromosome as an offspring. The Crossover probability is a ratio that determines the number of chromosomes that will be selected to perform the crossover operation. The crossover probability would be reduced as the number of iteration were increased with the idea that the best chromosomes, i.e., segments, would remain the same and would propagate to the next generation.
The Line symmetric distanced as stated by Sriparna saha in the article [25], where ls(z, c) over a symmetric point be Z, and the relative center is C is set by 2 × C - Z and this is denoted by Z*. Let the Knear neighbors of Z* could be located at a Euclidean distance of des = 1, 2, 3, 4 ... ..Knear. Then
Where d ed (z,c) will be the Euclidean interval from the point Z to the center C. And d sym , constitute line symmetric measure. However, from the above equation, it is drawn that the I value of ‘i’ lies between 1 and the best Knear value. So the knear value which we are going to choose must be optimal. In the case of 1, there will be no influence on Euclidean distance and incase the uppermost value is too large then it may lead to a un-deterministic state. Hence the upper bound is chosen close to 2. Knear value is hugely rely on the population distribution.
After crossover operation is performed the pixels are assigned based on the point symmetric approach, and then mutation is performed on the resultant chromosomes of crossover based on mutation probability (0.01), that is proportion of the maximum likeness that an arbitrary elements of considered chromosome that would be flipped into a new set of chromosome for the next iteration.
Least squares support vector machine based automated MRI segmentation
SVM is one of the numerous supervisory learning approaches as experimented by X. Wang et al. [29], J. Xiao and Y. Tong [12] employed in generalised linear classification, SVM could be employed in optimising the segmentation by classifying the pixels among multiple segments and assigning them to the best optimal closest segment. Initially, the image with a random K number of segments is obtained by assigning the pixels to the centroid, which is a closest by line symmetric distance. Support vector machine will maximise the predictive accuracy at the same time avowing the over fit of data. Support Vector Machine could be defined as a mechanism that uses theoretical scope of a linear function a multi-dimensional feature space that working on the top of the trained image from an optimisation theory which is driven by statistical learning theory.
In SVM based MRI image segmentation as ststed by Fahd Mohsen et al. in the article [7] and I.Lizarazo. in the article [11], training samples are acquired, and the various dimensions were identified. From the identified set of dimensions, a few features were considered like intensity, texture or a boundary pixel and then based on the features the entire image is segmented. SVM need the training images, as much the algorithm is trained, the more the accuracy in segmentation. In the training phase, the decision function to decide the pixels fitness among the segments is evaluated by f(x,d,w) is given by
From the equation, w is the weighted constant. And d is the dimension, i.e. the features that each pixel holds and xpis the Pth pixel in the segment.
Support Vector Machine aims in estimating the crucial point the hyper plane that maximises the least gap between any two pixel centroids. The equation for the hyper plane could be given as the following through quadratic equation
Under the rule, the value of
Particle swarm optimisation is one of the prominent approaches as experimented by S. Ait-Aoudia et al. [23] and VasupradhaVijay et al. [28] in optimisation mechanisms. It an ideology influenced by the group of birds flying in search of food where the destination is not exactly known, but in every iteration, they converge towards the piece of food. In each iteration, a new particle is selected based on the p best which is assumed to be the local best value and the g best which is assumed to be the global best value that picks the best value among all the particles. The same assumptions are applied to the pixel segments for further optimisation of the segmented image for better results.
In PSO, everything we assumed as a swarm and particles, where a swarm is a group of particles which is applied in image segmentation by assuming the image segment which is resultant of variable string length based segmentation and each swarm consists of seed points with X coordinate and Y coordinate. And the resultant segmented image is further upgraded through computed fitness function that decides the g best . In each iteration, the velocities and vectors are updated. The above said procedure is repeated until the stopping criteria are attained where no further bounces from the segment.
The PSO algorithm retains to reduces the ambiguity of boundary and unallocated pixels and maximises the number of segmented regions as follows
Where
W1, W2: Represents the weights for the function.
P n : Represents the number of pixels in the image
P x i: Represents the number of assigned pixels to the ith particle.
S n : Represents the number of seeding points
S i : Represents the number of segmented regions.
In some scenarios, when the fitness function is evaluated, the pixel may be shared by more than one segmented region that leads to inappropriate regions that are too large or too small. To address such a situation the above discussed equation is further optimised as below
Where
N r : Is the representation for a number of pixels in the region ‘r’.
C: Is decided as follows
C (v) = 1 if Pmin < v < Pmax
else 0 otherwise.
Upon conducting multiple iterations to optimise the solution, the global best solution at the final iteration is picked to be the best result.
In particle swam optimisation, the resultant segmented image of the genetic algorithm is further optimised by identifying the centroid pixel within the swam, i.e. in the segment and the fitness is computed for every pixel in the segment. The pixel which is having the highest fitness is the current iteration is assumed as the local best and based on the threshold value the pixels in the same segment are repositioned. Few pixels will be rescheduled to other segment based on the distance from the centroids of the neighboring segments. This is practiced for a few iterations until the stopping criteria are achieved.
Teacher learner based optimization based segmentation
Teacher leaner based optimisation is an optimisation algorithm that is experimented by B. S. Khehra and A. S. Pharwaha [2], Harmandeep Singh Gill et al. [10] for the recognise and escalate the segment, In which it implicates twin stages, i.e. teaching stage and learning stage. TLBO had a special significance among the rest of the two mechanisms, i.e. Particle swam optimisation and support vector machine. In either of the later approaches are probabilistic approaches that involve control variables like initial population strength, and a number of generations. Moreover few optimisation techniques need an algorithm specific parameters. Particle swarm optimisation assumes an inertia weight and cognitive parameters, and even the genetic algorithm needs mutation and crossover rates. However, TLBO algorithm does not need any algorithm specific initial parameters.
It is applied to the resultant image from the genetic algorithm, which further optimises the accuracy of the results that aid in tumor recognition, as stated by P Naga Srinivasu et al., [19].
Initialisation
The notations that were used in TLBO,
N: Denotes the number of learners in the particular class
CO: Denotes courses offered.
MI: Represents the maximum number of iterations.
Let P be the arbitrary loaded initial population from the search space that is constrained by the matrix of N rows denoting the learners and Columns denotes the courses provided represented by co. The jth variable of the ith learner is defined by [3]
Teacher stage the mean of every subject for all the learners in the class at generation G is considered to be the mean parameter. eMG is given as
Always the learner with the minimum
Teaching Factor T
F
Generally set either 1 or 2 that decides the degree of change that has to be made to mean value. Anyway, it is not passed as the input parameter for the algorithm. The value of T
F
could be randomly computed from
The latest value
In this stage, the learner will learn from the teacher as well as from the co-learners by random interaction with them increases their knowledge. Let us assume for a learner
The above said approach is convenient for the refinement of segmentation by re arranging the pixels based on the Euclidean distance. In each iteration, a new centroid pixel is picked based on the fitness of the pixel in the particular segments. And all other pixels in the corresponding segments are updated in each iteration concerning the local best pixel which is assumed as the centroid. TLBO is applied to the resultant image of Genetic algorithm. Teaching factor that is estimated in the current iteration is used in computing the fitness with random weights. In each iteration fitness of every individual is upgraded.
This is continued till no further modification were possible, which is estimated by a deviation less than 0.011 and finally the refined image is fed to estimate the damaged index in the human brain.
Performance analysis
The three optimisation techques for optimisation are evaluated over an MR image of sizes 256×256 and 512×512, which is corrued by an impulse and spike noise while rendering the image. The performances of the three techniques were evaluated over the peak signal to noise ratio, mean square error and root mean square error for both the noise free image and a noisy free image with a varying noise levels followed by IQI which must be high indicates the quality of Image, and the results were tabulated as follows in Tables 1, 2 and 3. It could be observed from the obtained results the performance of TLBO is more satisfactory than the counterparts that can be seen from the graphs that are presented in Figs. 2 and 3.
Tabulated values of PSNR, MSE, RMSE, IQI for the segmented image preprocessed through Harmonic mean and without zharmonic through Genetic Algorithm alone over a varied noise
Tabulated values of PSNR, MSE, RMSE, IQI for the segmented image preprocessed through Harmonic mean and without zharmonic through Genetic Algorithm alone over a varied noise
Tabulated values of PSNR, MSE, RMSE, IQI for the segmented image preprocessed through Harmonic mean and without harmonic mean alongside with PSO optimisation over a varied noise
Tabulated values of PSNR, MSE, RMSE, IQI for the segmented image preprocessed through Harmonic mean and without harmonic mean alongside with SVM classifier over a varied noise
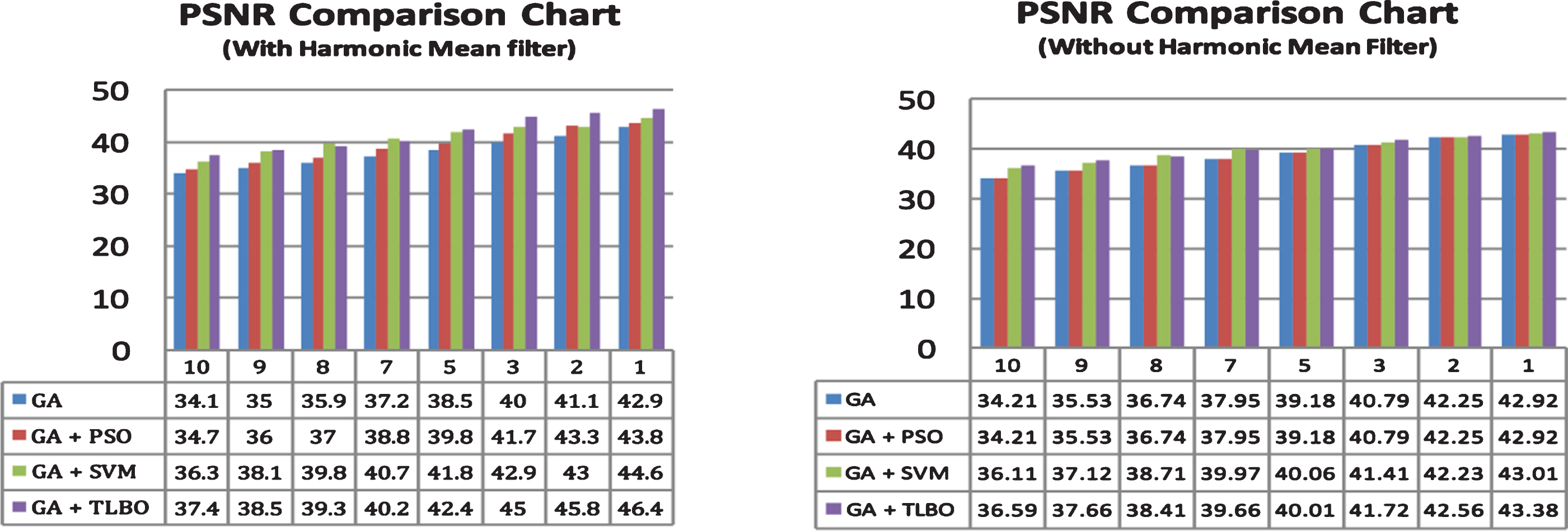
The above graphs represent the PSNR for all the three approaches using PSO, SVM, TLBO alongside with the genetic algorithm through harmonic mean and without harmonic mean. From the above graphs, it is clear that TLBO with GA had exhibited better performance over its counterparts.
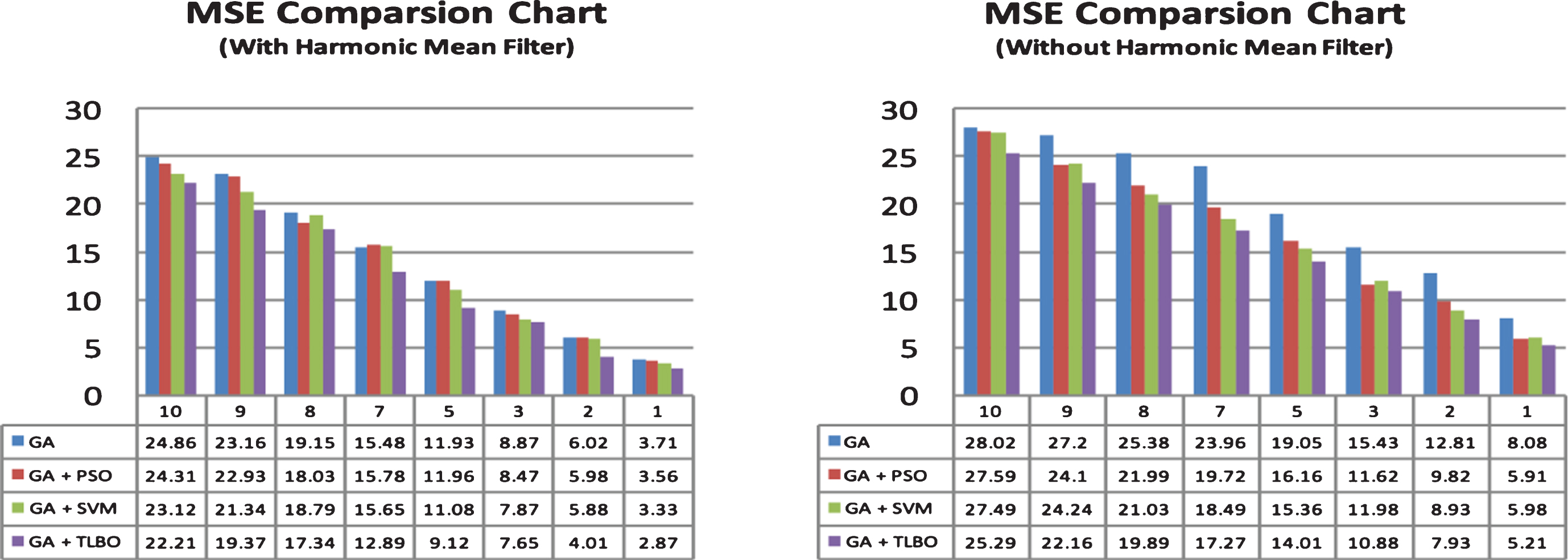
The above graphs represents the MSE for all the three approaches using PSO, SVM, TLBO alongside with the genetic algorithm through harmonic mean and without harmonic mean. From the above graphs, it is clear that TLBO with GA had exhibited better performance and holds the lowest value with the least noise variance value.
From the Tables 1–4 it is understood from the experimental study that the performances of the optimisation techniques seem to be much better when compared to Genetic algorithm alone. Moreover the TLBO based approach has exhbitted a better performances over the other algorithms, where the PSNR and IQI values of TLBO is comparitively high even at significant noise level and MSE, RMSE values are slightly low when compared to that of the other approaches. The values of IQI that are assessed among various approaches are plotted over a graph that can been seen in Figs. 4 and 5.
Tabulated values of PSNR, MSE, RMSE, IQI for the segmented image preprocessed through Harmonic mean and without harmonic mean alongside with TLBO over a varied noise

The above graphs represent the RMSE, which is directly proportional to the MSE for all the three approaches using PSO, SVM, TLBO alongside with the genetic algorithm through the harmonic mean filter. TLBO with GA is proven to be exceptionally better than the other approaches stated above.
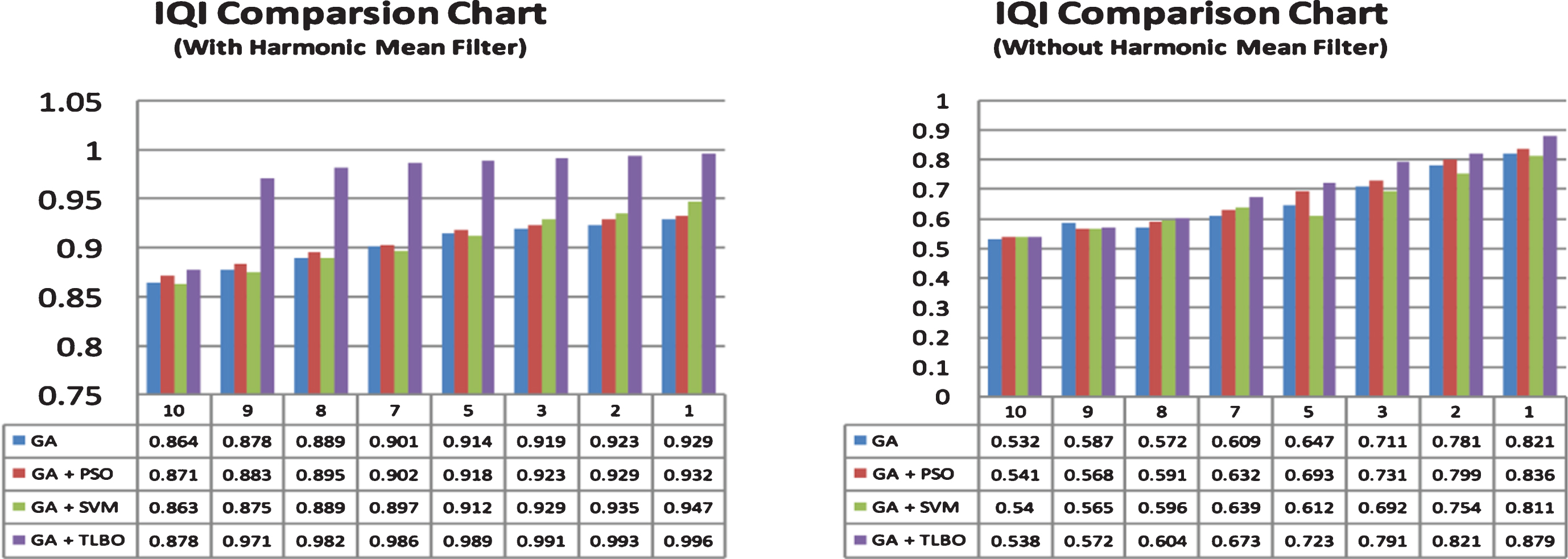
The above graphs represents the image quality index (IQI) for all the three approaches using PSO, SVM, TLBO alongside with the genetic algorithm through harmonic mean and without the harmonic mean filter. The quality of the image through TLBO and the GA nowhere matches with the other approaches.
From Fig. 6 is the graph representing the execution time for the different approaches over an MR image of size 256×256 and 512×512. It is observed from the statistics data in either of the cases the TLBO based approach has taken comparatively marginal time than its counterparts. At times the execution of the PSO based approach and TLBO are identical, but the resultant images of TLBO are more favorable when compared to its counter parts.
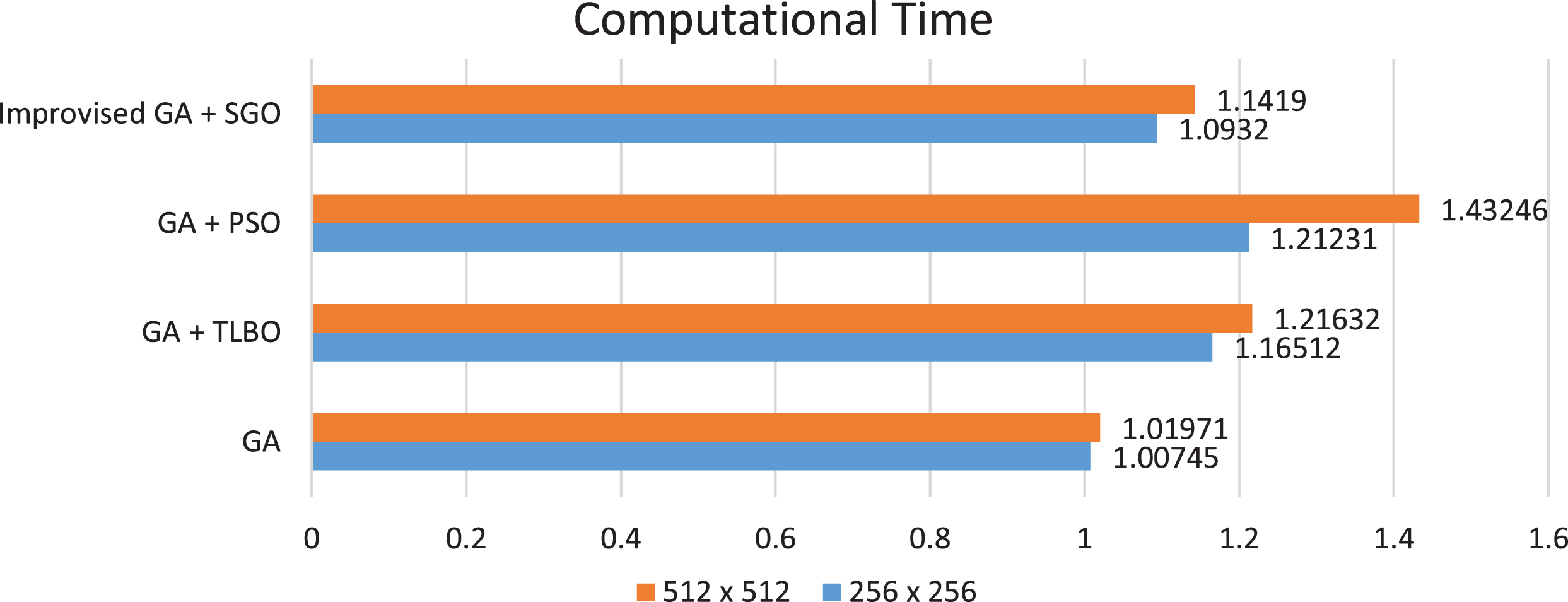
The above bar graph represents the computational time that each algorithm has taken to segment the 256×256 and 512×512 size image with a noise variance of 6. From the above graph, the computational time of GA with TLBO is comparatively low than the PSO and SVM based approach. However, its greater than GA alone but the outcome of GA with TLBO is comparatively better than GA alone.
All the afore mentioned algorithms are implemented over the MR images of size 256×256 and 512×512 with varying noise levels and the computational time for the TLBO is comparatively better the SVM classifier. However, the computation time of TLBO based approach is almost close to the computational time of the PSO algorithm. Still in many cases TLBO has exhibited better performance than its counterpart.
It could be obsereved from the Figs. 7 and 8 that few of the regions in the MR image seems to be having multiple regions in the image MR with identical intensities that would lead to a misinterpritatoin of the damaged region. It could be seen from the afore mentioned figures the SVM based segmented image seems to have multiple smaller regions along with the damaged region and PSO has fiewer and the TLBO based segmentation approach is having an almost negligible number of non-damaged regions higlited when compared to SVM based approach. However, it is advisable to perform skull region removal as stated by P Naga Srinivasu et al. in the article [8] for better identification of the abnormality in the humnan brain through segmentation. The following are the resultant images of the three approaches

The above figure constitutes the segmented image over a noise neutralised input and the color mapped image at divergent intensity levels by which one can easily recognise the effectiveness of the optimisation algorithm in converging towards the automation of lesion identification over iterations.
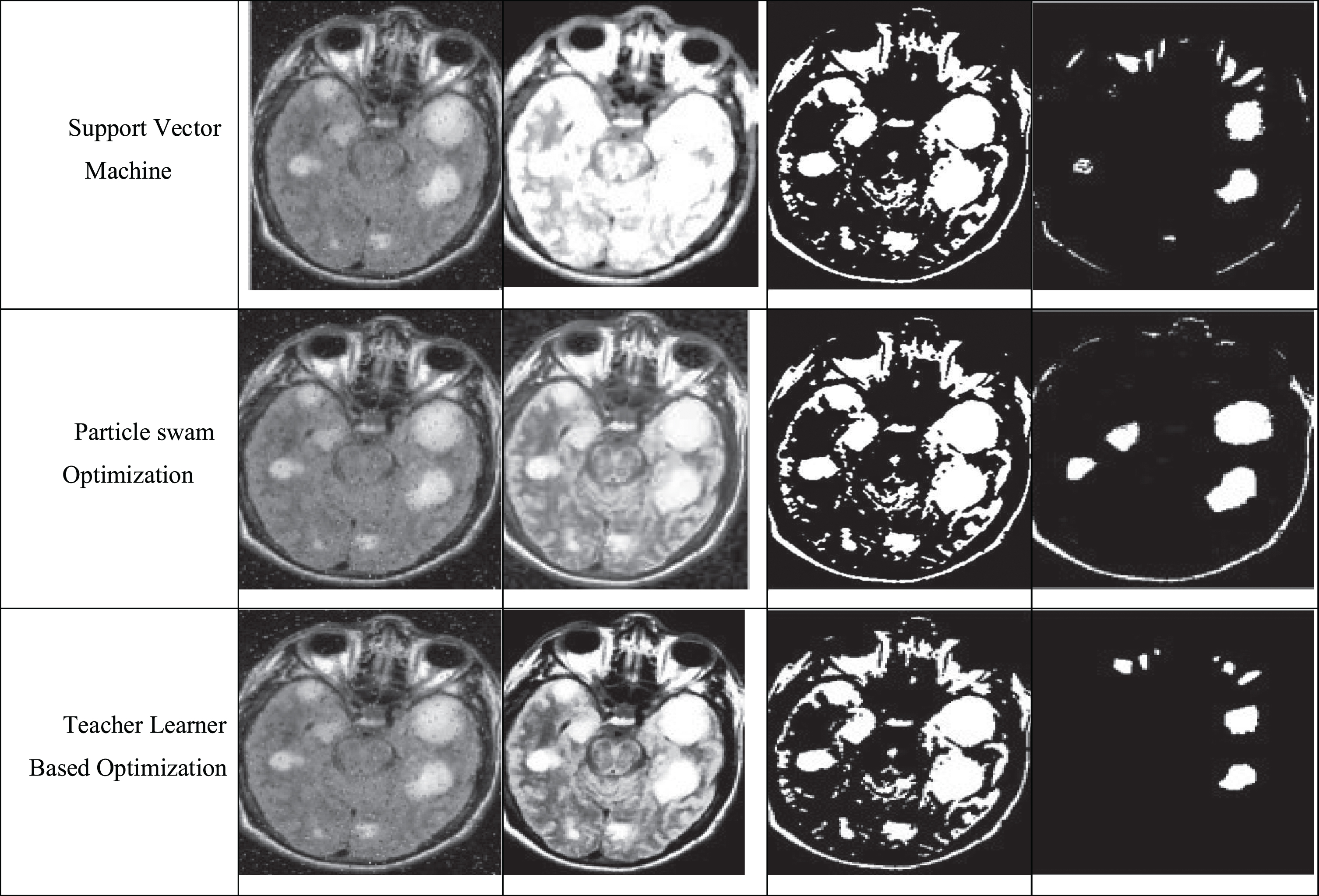
The above figure constitutes the segmented image over a noisy image as input and the color mapped image obtained by segmenting the image. Noise image doesn’t generate the result as good as noise free input.
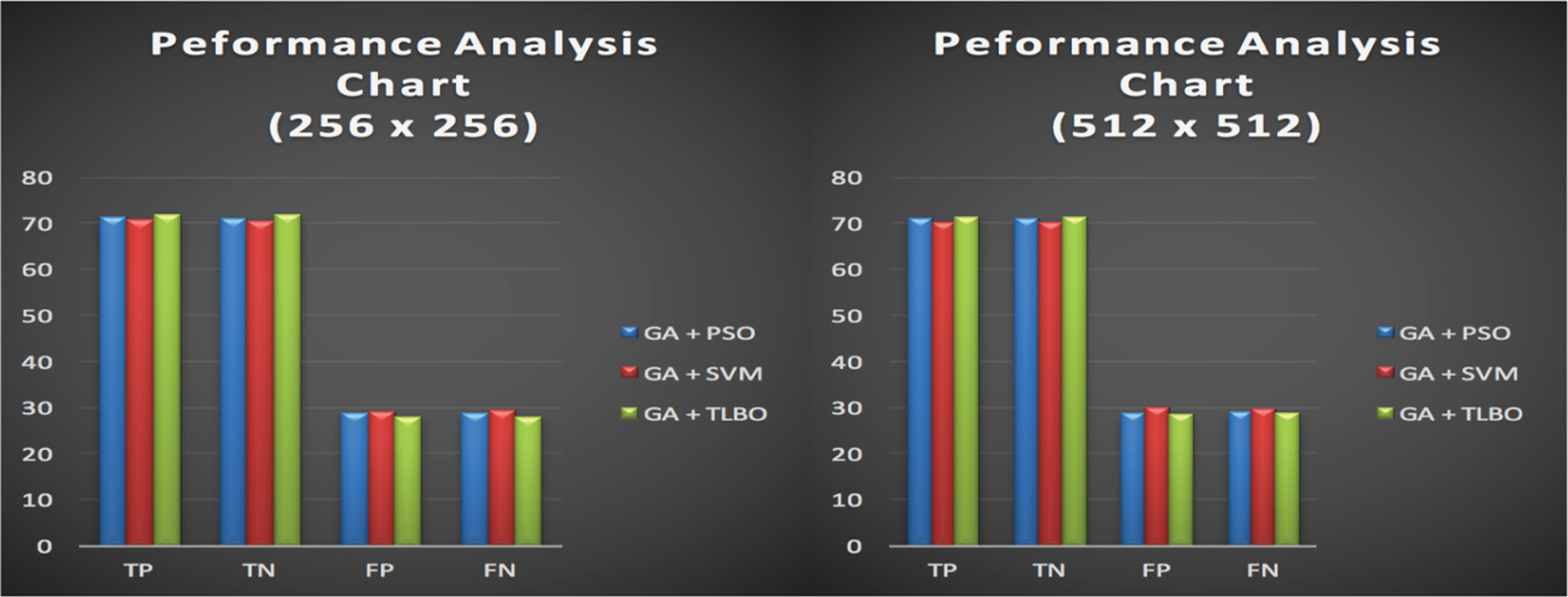
The performances of the proposed approaches have been assessed through accuracy measuring parametrs like True Positive(TP), True Negative(TN) that designates how many times does a particular algorithm can correctly recognise the damaged region from the segmented image and the algorithm can recognizing the non-tumorous tissues as normal tissues respectively, which is desired to be maximum for a well formulated mechanism. And False Positive(FP) and False Negative(FN), that determines how many times does the specific algorithm fails to correctly recognise the damaged region from the segmented MR image assuming the normal region to be the damaged region and FN determines the number of times does that the algorithm fails in identifying the non-tumoros region as the tumorous region.
The performance evaluation metrics are being implemented over the afore mention approaches that are discussed earlier in this session to evaluate the performances, and the accuracy of all the approaches seems to be nearly the same with minor dissimilarirties. The experimentation that is carried on the images of size 256×256 and 512×512 have been presented in Table 5 below.
The above table represents the performance of the various segmentation approaches
On experimentation, it is observed that the accuracy of the algorithms seems to be identical with minute differences, And all the algorithms have exhbitted better performances of the smaller size image, i.e. MR image of size 256×256 over the MR image of size 512×512. Among all the three experimented approaches, the Teacher Learner Based approach has exhbitted a better performance. However, the computation time for the Genetic Algorithm with Teacher Learner Based optimisations seems to be better than its counter parts, The value of the evaulated metrics are tabulated below in Table 5 for noise normalised images. And the performance of the algorithms over a noise normalised images are much better when compared to that of the experimentation over the noise images. And Fig. 9 is the graph that is generated from the Table 5 where GA with TLBO has exhbitted the better performance.
The above bar graphs represents the performances of various approaches over varied size MR Images.
In our detailed examination of all the three optimisation techniques PSO, SVM, and TLBO with Genetic Algorithm. It is observed that all three mechanisms work in a better way rather than Genetic algorithm alone. Genetic algorithm with TLBO with an improvised noise reduction strategy has unveiled a divergent result. In few instances with a varied noise impulse over the image, all the three had exhibited an identical performance in tumor detection. And the TLBO based optimisations have conusmed less computational efforts, and it doesn’t have any algorithm specific perameters that helps in ease of converging toward an optimal number of segments.
The working algorithms were evaluated over a wide range of images with varying noise levels and contrast ratio for evaluation of damaged index. The above said mechanisms could be well mechanised by calculating the membership along with the line symmetric based approach for assignment of pixels into the segment. In certain conditions, the borderline pixels or the equidistance pixels may be assigned inappropriately, to circumvent such interpretations the weighted optimisation technique is cooperative. Parameterized TLBO algorithm could address the above said problem in a better way than a standalone approach.
The genetic algorithm supports in estimating the divergent segments that converge to the best possible number of segments. And the optimization techniques would re-arrange the pixles in the segment with respect to the local best segment centroid and the global best centroid. And the stopping criteria must be choosen with at most care for better termination of the algorithm.
Future scope
It is observed on the practical implementation of the afore mentioned approach, the Genetic Algorithm itself needs a considerable amount of computational efforts to identify the best possible number of segments and applyimg the optimisation techniques like PSO, SVM and TLBO would obvisouly consume more computational efforts and dignosis latency. It is atmost essential to design an algorithm that could perform better with minimal computatoional efforts. In such scenario it advisable to have a mechnism with enhanced category of the Genetic Algorithm with two point crossover that reduced the time of generating the offspirings, or the entire process of this could also be replaced with multi-objective function based approaches that consumes less computational efforts. It is recommended to mechansie an approach that woould work with all varieties of the medical MR images that include T1-Weighted, T2-Weighted and PD weighted MR images.
It is also advised to have a robust pre-processing algorithm that can reduice the noise as well as preserves some of the crucial information related to the objects in the image like edge information and texture based data. In the earlier algorithms only the noise is being addressed that would smoothen the image where some minute regions that are clucial in tumor identification had gone missing. It is advisable to mechanise an approach that can work effieciently over a noise image.