
Abstract
With the development of speech recognition technology, human services in many fields have gradually been replaced by intelligent voice services. Natural language processing technology and speech recognition technology are gradually becoming the key technologies in human-computer interaction systems. However, there are still some problems in intelligent speech recognition. In view of this, this study uses English as the basic language to carry out research and combines support vector machine to construct intelligent English recognition and predic-tion system to obtain EEG signals related to Chinese speech. Moreover, this paper adopts wavelet packet decomposition and co-space mode to extract the features of the acquired EEG signals and uses the support vector machine model to classify and compare the signal features. The research results show that the recognition rate of the traditional algorithm is significantly lower than the speech recognition rate of the algorithm model, and the algorithm of this study basically meets the requirements of the actual use of the system.
Introduction
With the development of speech recognition technology, human services in many fields have gradually been replaced by intelligent voice services. For example, when a driver drives a car, the driver can use voice control technology to complete the inconvenient hand control such as making a call, sending a text message, etc. [1]. The research of speech recognition technology has two important directions: online speech cloud recognition and offline client speech recognition, and there are related application products in both directions [2].
Natural language processing technology and speech recognition technology are gradually be-coming the key technologies in human-computer interaction systems. The addition of natural language and speech recognition technology to smart homes will revolutionize the service of traditional smart homes. By using a smart home that supports natural language and speech processing, people can easily view home information and control home related equipment [3]. Applying natural language processing and voice technology to the smart home field can free home devices from long-term dependence on remote controls and buttons, improving home reliability, convenience, high-end, and livability. Moreover, it reflects the environmental protection and energy-saving quality in the human settlements [4] and can also meet people’s demand for intelligent applications [5] and has a good market prospect.
The DIVA model and the speech neuro-analysis system proposed by Prof. Gunther are de-signed for English speakers. The research and processing objects are 29 basic phonemes of English. Therefore, this neural analysis system has a high recognition accuracy for English pronunciation, but it cannot be applied to the pronunciation of Chinese and English Pinyin. Be-cause different languages have different degrees of activation of brain-related regions in the process of speech generation, the brain mechanism of speech processing is also very different [6]. In order to “read” the English thinking process and extract the speech of the English phonetics, it is necessary to conduct an in-depth analysis of the English phonetic brain mechanism to study the difference between it and the English phonetic process. Therefore, this paper explores the DIVA model by exploring the brain mechanism of Chinese pronunciation and finds a classification algorithm with high recognition accuracy for Chinese pronunciation EEG signals, which can be applied to the design of Chinese brain voice interface system.
Based on this, this study uses English as the basic language to carry out research and combines support vector machine to construct intelligent English recognition and prediction system, which lays a foundation for intelligent recognition and prediction of all subsequent languages.
Related work
The purpose of speech recognition is to transform human speech into a computer-readable code [7]. Voice is not only the simplest and most common tool for information exchange between people, but also an important means of communication between people and people. Speech recognition technology is a sub-discipline of pattern recognition, which involves psychology, linguistics, computer science and signal processing [8].
In the literature [9], Lin Wang introduced the status of foreign speech recognition research. The earliest computer-based speech recognition system was the Audrey speech recognition system developed by AT&T Bell Labs in the 1950s. At the time it was only able to recognize ten English numbers. In the 1960s, the development of computer and speech recognition theory promoted the development of speech recognition technology, and two important theories emerged: one is linear predictive analysis and the other is dynamic programming. The wave of speech recognition research began in the 1970s and has achieved certain results and achievements in the research of speech recognition. Moreover, two results have been proposed: First, dynamic time warping techniques: DTW, Warp Time, Dynamic. The second is the linear prediction coefficient technique: LPC, t Coefficien, and Prediction Linear. Dynamic time warping technology is a simple and effective classical speech recognition algorithm [10] and has been used until now. After the 1980s, the focus of research shifted from identifying small vocabularies to a large number of continuous speech recognitions, and the research methods also changed, from the traditional template-based model to the HMM-based statistical model [11].
After 1990, the speech recognition technology gradually matured and slowly moved from the experimental stage to the society. In 2009, Microsoft added voice recognition technology to its Windows 7 operating system, enabling users to experience the convenience of voice commands to control the computer. In 2011, Microsoft made a major breakthrough in deep neural network model technology and applied it to the search task of speech. In the same year, Apple’s mobile assistant Siri was first released. This feature was included in the iphone4S smartphone that was released in the same year, and human machine interaction further penetrated people’s lives. In 2013, Google launched the wearable product Glass, and users can use voice to operate it. In 2014, Apple officially released its first smartwatch, AppleWatch, which integrates voice control. In the same year, Microsoft bundled the voice assistant “Xiao Na” in its own operating system Windows10 [12].
Compared with the strong development momentum of foreign speech recognition technology, although the research on speech recognition technology in China in the early years is not optimistic, it has also achieved some important results. From the 1980s to the 1990s, information technology began to be popularized in research institutes and universities. At this time, the country began to pay attention to the research of speech recognition, increasing the investment in research funding. Moreover, research institutes such as the Institute of Automation of the Chinese Academy of Sciences, the Institute of Acoustics, and key universities have begun to study speech recognition technology. The National 863 Program listed speech recognition with English as a key research topic, and some of its research results: speech recognition engine for telecommunications, broadcasting, security, education, has been successfully accepted in 2011. At present, as the representative of domestic speech recognition, the speech recognition technology of IFLYTEK Company has achieved very good results especially for the speech recognition of some local dialects. The Baidu voice developed by Baidu Company has a recognition rate of 97% in a quiet environment [13].
Natural language processing research began with a machine translation system. In the mid-1960s, the United States translated several simple Russian sentences into English on the IBM M-701 computer. Although there are few Russian words (only 250) and only a few grammar rules, this is enough to illustrate the feasibility of machine translation [14]. In 1966, the National Foundation announced an important ALPAC report, and the content of this report is mainly that machine translation is not feasible at this stage, and the research work encounters difficulties that cannot be solved. After the publication of this report, machine translation re-search in many countries fell into a trough, and machine translation almost entered a state of rest in worldwide. After the release of the ALPAC report, machine translation researchers calmly reflected on the confusion. In the 1970s, several methods and theories for dealing with natural language knowledge were gradually proposed. These theories once ignited people’s interest in the study of natural language, and people have extended these methods and theoretical applications from the field of machine translation research to other fields of ap-plication [15]. After the 1980s, with the rapid promotion and popularization of information technology, the human-computer interaction of natural language has gradually entered the daily social life of people from the theoretical research in the laboratory stage. Since the 1990s, due to the development and popularization of Internet and communication technologies, natural language has seen many mature applications. Hutchins made a special report summarizing some of the research results of machine translation in recent years, and he believes that ma-chine translation development has entered a new stage. Domestic research on natural language started relatively late, and domestic research on English language understanding began in 1978. The purpose of our country’s research on natural language is mainly to deal with English, and the traditional English study in China is not aimed at automatically processing English language by computer. At the same time, because English is an idiom, it is impossible to directly apply the semantic and grammatical theories of Western language systems using the language of conformity, which makes the study of English natural language processing to face many difficulties. However, after the efforts of Chinese researchers, the research on natural language processing in China has also achieved many important results. The study of English language processing has gone through four important stages, and the focus of each stage of re-search is different: The first stage is based on morphological analysis. In the second stage, under the premise of studying semantic rules, the focus is the analysis of semantics. The third phase of the study is based on a corpus and uses statistical methods to analyze it. The fourth stage, that is, at this stage, on the basis of summarizing the research results of the previous stages, it is considered that the combination of the two methods of statistics and rules can achieve better results. In recent years, China has achieved considerable results not only in corpus research, English automatic segmentation, English information retrieval, but also in theoretical studies of computer linguistics [16].
Feature extraction of EEG signals
Feature extraction of EEG signals using wavelet packet decomposition
In recent years, wavelet transform is often applied to signal feature extraction and signal de-noising. The base of the wavelet transform has a shorter time duration than the sine wave base employed by the Fourier transform. The component of a signal is usually not 0 in many time intervals. Similarly, many important features of EEG signals and noise appear only in local small spaces. Moreover, these components are not like the Fourier base. Therefore, there is no efficiency in representation. The emergence of wavelet transform is precisely for this shortcoming.
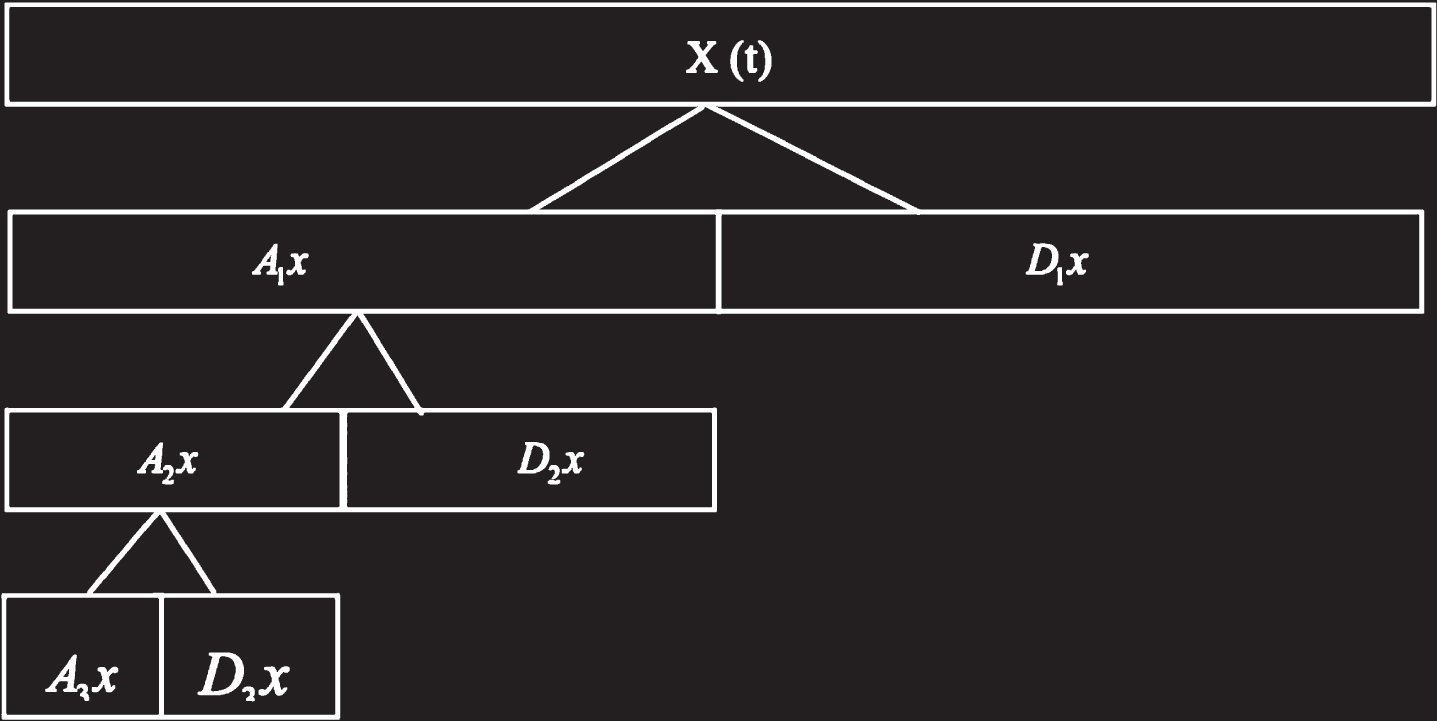
Wavelet decomposition is a signal feature extraction method with higher frequency domain resolution. Wavelet packet decomposition is an extension of wavelet decomposition. The wavelet packet decomposition is to further decompose the high frequency detail signal which is not processed by the wavelet decomposition after the wavelet transform, thereby further improving the frequency resolution. A schematic diagram of wavelet decomposition and wavelet packet decomposition of the signal is shown in Figs. 1 and 2. In the wavelet packet decomposition of the signal, since the orthogonal decomposition is employed, the two frequency bands generated after the decomposition do not overlap with the frequency bands before the decomposition. Since the bandwidth of the two generated frequency bands is halved, even if the adoption rate is reduced by half in the wavelet packet decomposition, no information is lost.
Wavelet decomposition of the signal.
Wavelet packet decomposition of the signal.
For any wavelet series:
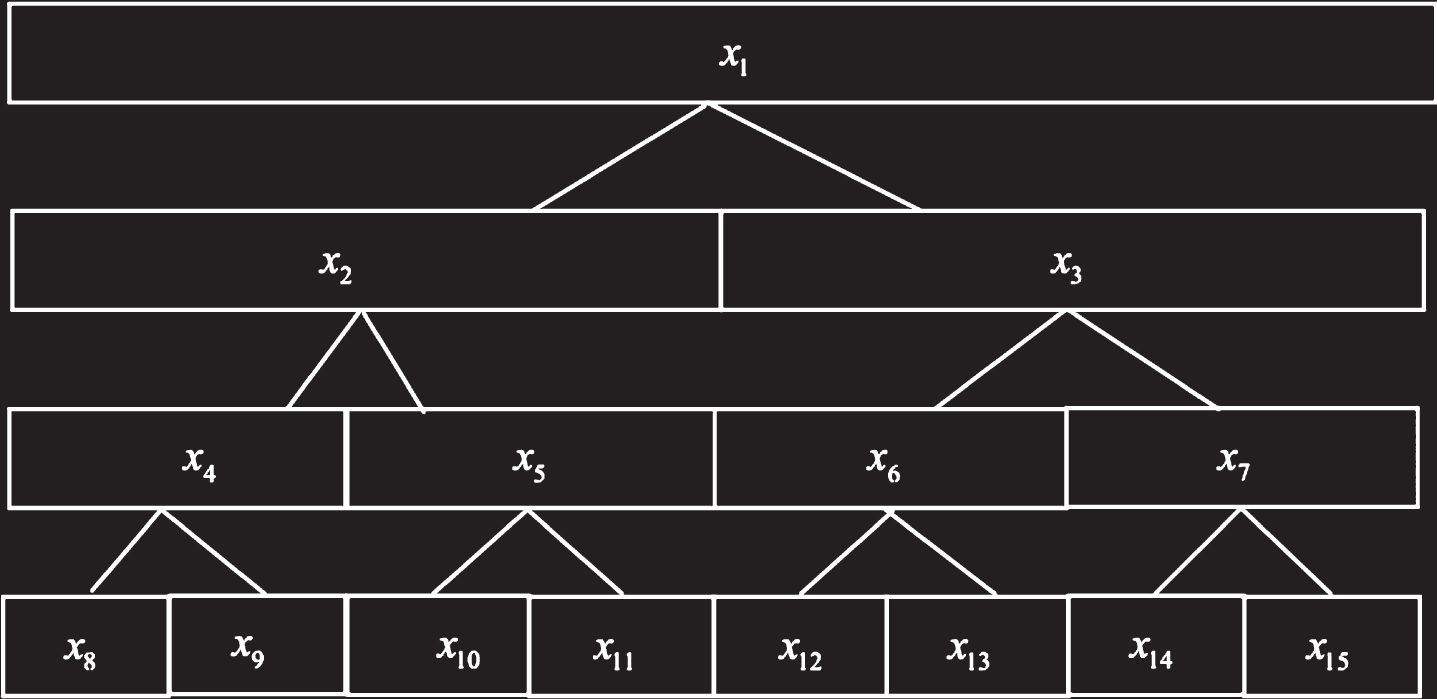
In the signal X (t), if j = 0, k = 0 and m = 0, which represents the undecomposed source signal X (t) at the resolution level j and is denoted as X1. Multi-layer wavelet packet decomposition can be performed. If we decompose the signal for the first time, that is, k = 1, m = 0,1, we can obtain the signal after the wavelet packet 1 decomposition, denoted as X2 and X3. The signal is further decomposed for the second time. At this point, k = 2, m = 0,1,2,3, and we obtain the signal after the wavelet packet decomposition, which is recorded as X4, X5, X6 and X7, and so on, as shown in Fig. 3.
Structure diagram of the wavelet decomposition tree.
The wavelet packet decomposition and reconstruction algorithm are as follows:
1) Equation (3) and Equation (4) show that a signal sequence s ={ x (k) , k ∈ z } is decomposed into two signal subsequences: an even sequence s e ={ s e (k) , k ∈ z }and an odd sequence s o ={ s o (k) , k ∈ z }.
2) By calculating equation (5 and 6), we can get the signal of each frequency band obtained after the wavelet packet layer is decomposed.
3) We reconstruct the wavelet packet according to the formulas (7, 8, 9 and10). In the reconstruction process, we reserve the corresponding frequency band signal and set the remaining frequency band signals to 0:
Each frequency band decomposed in the wavelet packet decomposition of the signal is independent of each other, and no redundant signal occurs, so the signal wavelet packet decomposition is energy balance. Equation (11) represents the energy E (n) in the wavelet packet band:
Studies have shown that EEG signals generated by brains collected using EEG scanners are non-stationary random signals, and wavelet packet decomposition can analyze such non-stationary random signals in both time and frequency domains. In the full frequency domain, the wavelet packet orthogonally decomposes the signal, and the wavelet packet decomposition can adaptively select the appropriate frequency band, which improves the time-frequency resolution of the analysis. Therefore, wavelet packet decomposition is an analytical method that is very suitable for EEG signals.
Studies have shown that the brain produces an EEG signal with a frequency range of 9–13 Hz in a state of calm and without any stimulus input. This signal is called rhythm. If the brain is stimulated, such as when the subject uses the brain to perform or simply imagines performing a muscle exercise task (sports, talking, etc.), the 9–13 Hz EEG signal rhythm will be significantly enhanced or weakened. Therefore, the general brain-computer interface system understands the instructions that the brain wants to emit by recognizing this change in rhythm. Because we need to focus on 9–13 Hz EEG signals, we use the Db2 wavelet function to perform 6-layer wavelet packet decomposition on the experimentally acquired EEG signals, and the signals are orthogonally decomposed into 32 independent bands of 0–7.8125 Hz, 7.8125–15.6250 Hz,... In this way, the 9 to 13 Hz sinusoidal signal is assigned to the corresponding second frequency band, and we take the decomposition coefficient and energy of the second layer as the feature vector.
In the brain-computer interface system based on motion imagination, the co-space mode is a widely used EEG signal processing method. The main feature of the co-space model in processing EEG signals is that the characteristics of EEG signals can be extracted based on multiple channels, and the co-space mode depends on a sufficient number of channels. If there is sufficient spatial domain information, the co-space model is ideal for extracting features of EEG signals. This method is based on the simultaneous diagonalization of two covariance matrices to design an optimal spatial filter to resolve the two EEG populations. It was originally used to detect abnormal EEG and has been successfully used in the classification of motion-related EEG in recent years. The basic idea of the co-space model is that the original EEG signal generates a new time series through spatial mode, and its variance is best suited to distinguish between two different types of EEG signals.
The advantage of CSP is that there is no need to pre-select the frequency band specific to the subject. The disadvantage is that it requires a large number of electrodes and multi-channel analysis of EEG. Moreover, the multi-channel EEG amplification system limits the use of CSPs in portable BCI systems, so further optimization of the number of electrodes is needed.
The principle of classifying EEG signals using the co-space mode algorithm is to find a projection of the optimal space, so that the power of the two types of signals is the largest. Therefore, it can estimate two spatial filters to extract the task-related signal components, and at the same time remove the task-unrelated components and noise.
We collect EEG signals through an EEG scanner, and the signal is represented as a matrix E of N * T. N is the number of channels, and T is a sample of all EEG signals collected by each channel. Then, the regularized space covariance of the EEG signal is as shown in equation (12):
Support vector machine model (SVM)
The support vector machine model is a statistically based machine learning algorithm. It was first proposed in 1992 and quickly gained the attention of researchers and developed rapidly. The support vector machine model is a generalized linear classifier, which is mainly used in the field of visual information acquisition and processing. The basic idea of the SVM model is to map the input vector to a high-dimensional feature space through a kernel function. The sample set given is:
The support vector machine model allows the hyperplane to separate the two types of data in the sample space by finding the optimal classification hyperplane of a sample space. The support vector machine model introduces an error penalty mechanism and performs trade-off optimization in the process of classification, so that the two separate types of data points are farthest from the classification surface. As shown in Fig. 4, the essence of the support vector machine model is to solve the quadratic programming problem with linear inequality constraints as shown in Equation (19), and obtain an optimal classification hyperplane, so as to obtain the decision function to classify the sample space.
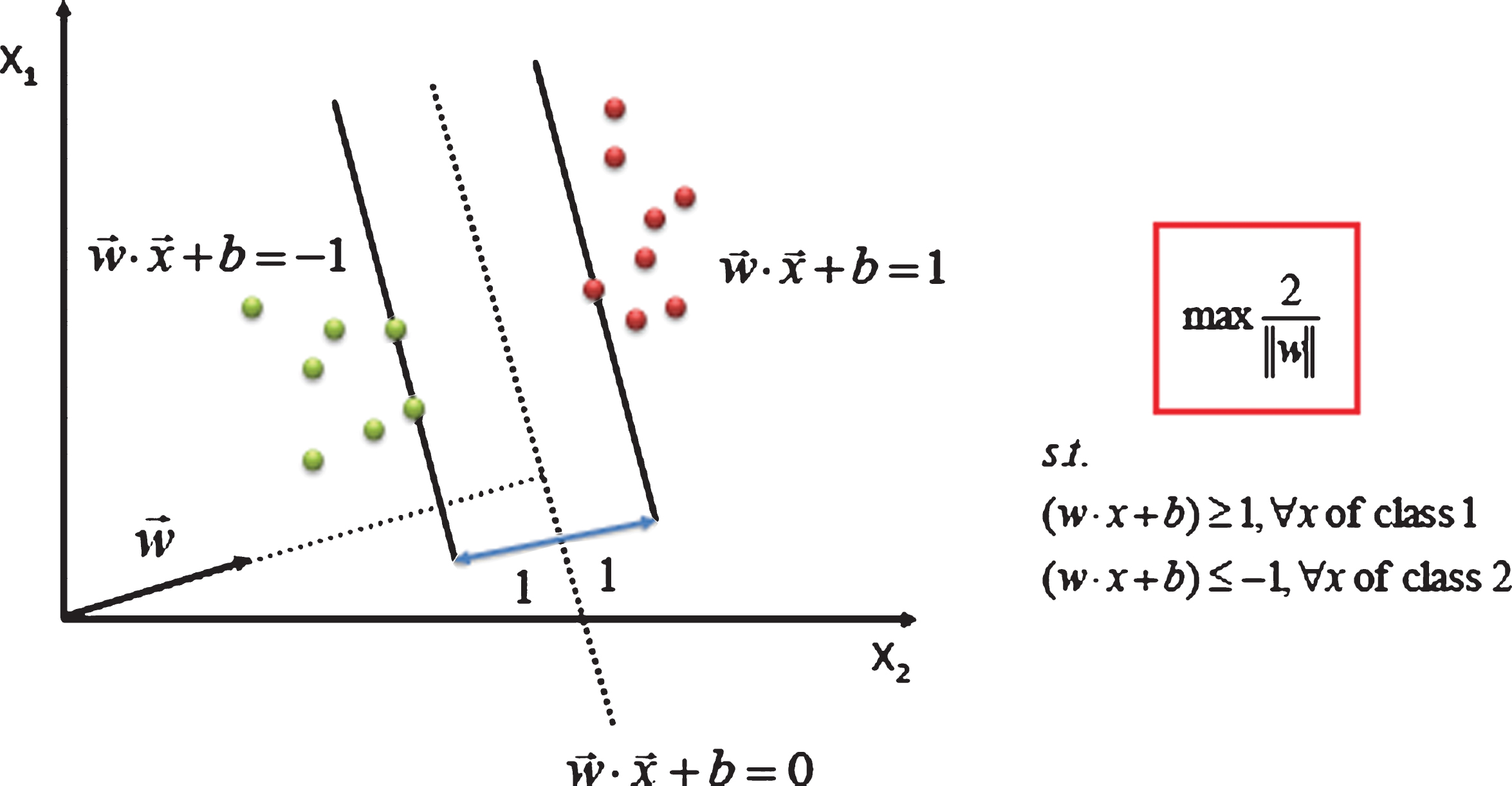
Schematic diagram of the classification of the support vector machine model.
The LibSVM toolbox is a simple, easy-to-use and fast and efficient SVM pattern recognition and regression software package developed by Associate Professor Zhiren Lin of Taiwan University. The SVM parameter adjustments involved in the software are relatively small, and many default parameters are provided. Moreover, the software uses these default parameters to solve many problems and provides interactive verification capabilities. In this study, we used the LibSVM toolbox to identify EEG signal feature vectors.
In order to test the performance of two EEG signal feature extraction methods in the speech brain-computer interface signal feature extraction module, we trained two support vector ma-chine models using wavelet packet decomposition and common space signal eigenvectors extracted from the co-space model algorithm, and tested the classification accuracy of two feature vector extraction models extracted by two support vector machine models. In this paper, we use the wavelet packet decomposition and co-space model algorithm to extract the features of 40 times a pronunciation and 40 times j pronunciation. We select the first 20 a pronunciation and the first 20 j-grams of EEG signal feature vectors as training sets to train two SVM classifiers. Moreover, we use two different algorithm-extracted feature vectors trained SVM classifiers to identify the remaining 20 feature vectors. The classification and recognition results of the feature vectors extracted by the SVM for the two algorithms are shown in Figs. 5 and 6.
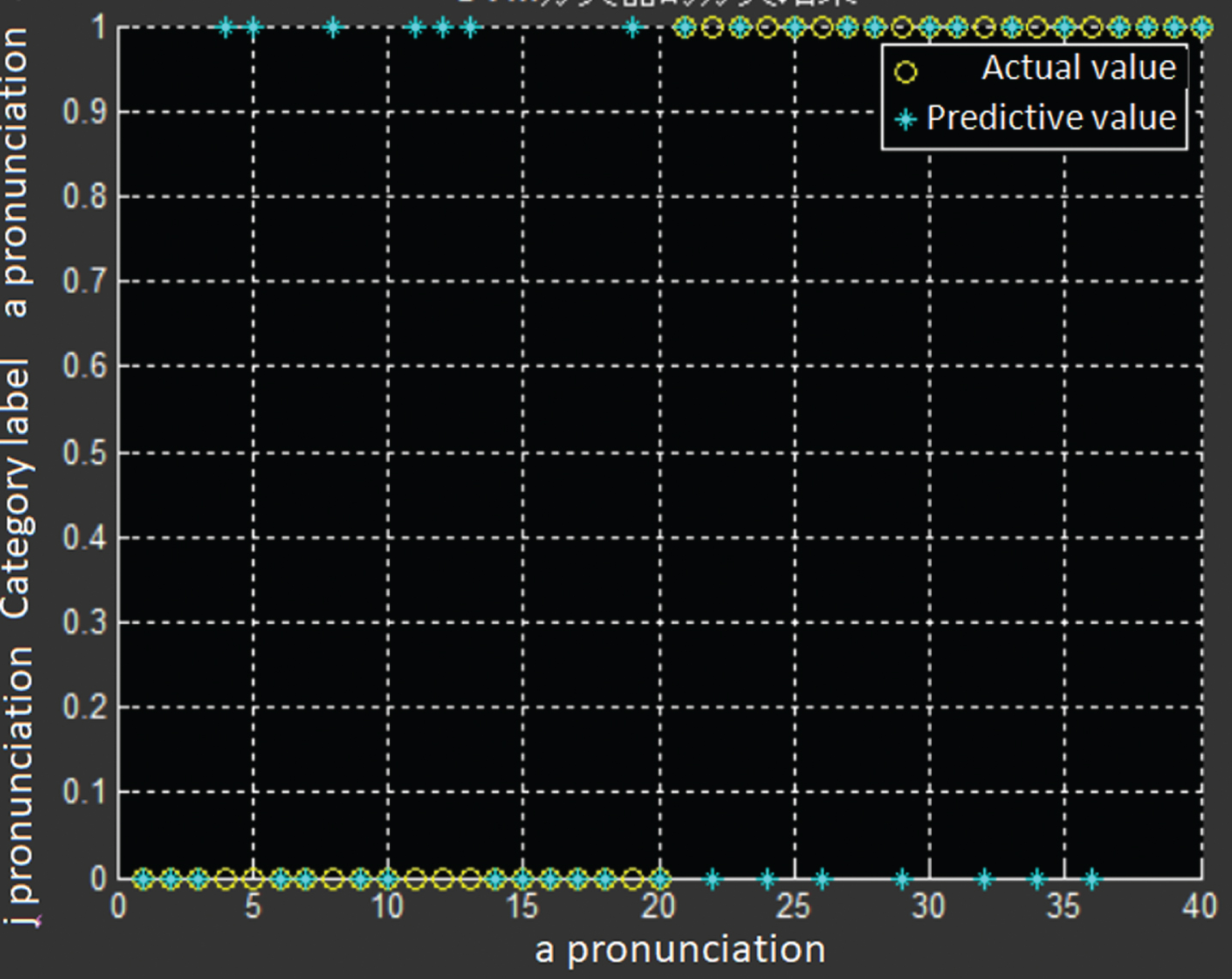
Recognition results of a training support vector machine model for extracting signal features using a co-space model.
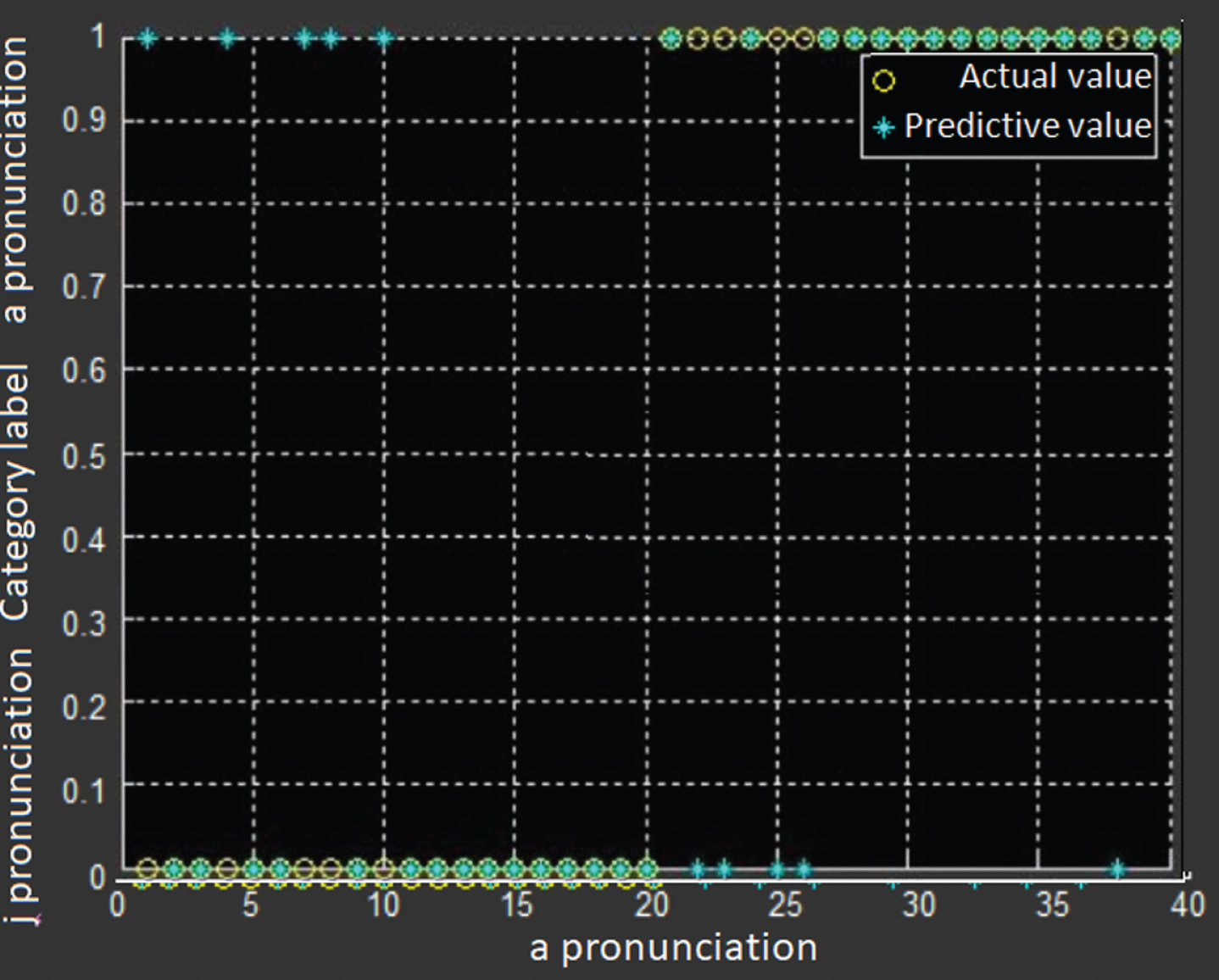
Recognition results of a training support vector machine model for extracting signal features using a wavelet packet decomposition.
We found that the SVM classifier trained by the CSP algorithm extracted the feature vector with 65% accuracy, while the SVM classifier using the wavelet packet 6-layer decomposition training has a recognition accuracy of 75%. Obviously, the feature vectors extracted by the wavelet packet decomposition algorithm have higher recognition accuracy. Then, the English speech brain-computer interface designed by wavelet packet decomposition algorithm will have better performance.
We found that brain regions activated by English phonetic pronunciation differed from brain regions activated by English pronunciation. According to the DIVA model for the definition of English-related brain regions and the Chinese-related brain regions obtained by fMRI experiments, we selected EEG signals collected by two electrodes located in different brain regions of channel 35 and 46 channel for recognition. Among them, 35 channels are located in the brain region of interest related to English pronunciation and 46 channels are located in the brain region of interest related to English pronunciation.
In this paper, we use the pronunciation of 40 English pinyin j and 40 English letters j collected in this experiment to take the experiment. We use the wavelet packet to decompose the ex-tracted feature vectors. Moreover, we used the pronunciation of the first 20 English pinyin j and the first 20 English letters j as training samples, and the last 20 pronunciations as test sam-ples. In addition, we compare the difference in the recognition accuracy of the support vector machine models in different channels, as shown in Figs. 7 and 8. We can clearly see that the data collected by the channel 35 has high recognition performance for EEG signals in English Pinyin pronunciation, the recognition accuracy is 70%, and the recognition accuracy for Eng-lish pronunciation is only 50%. The data collected by the channel 46 has high recognition per-formance for EEG signals in English pronunciation, and the recognition accuracy is 70%, while the recognition accuracy for English Pinyin pronunciation is only 55%. We believe that the reason is that when English-speaking people pronounce English Pinyin and English letters, there is a difference between the brain processing mechanism and the brain’s activation. The DIVA model considers the brain’s frontal and ventral pathways to be initiated dur-ing the processing of English speech. Moreover, the fMRI imaging studies we performed in Chapter 3 showed that the brain regions activated by the English speech task included the left parietal lobe and the left central anterior gyrus. Therefore, the results of the experiments in this chapter are basically consistent with the conclusions of the research in Chapter 3. This con-firms the prediction of the brain region initiation in the pronunciation process of the DIVA model and the research conclusions on the brain region initiation in the Chinese pronunciation.
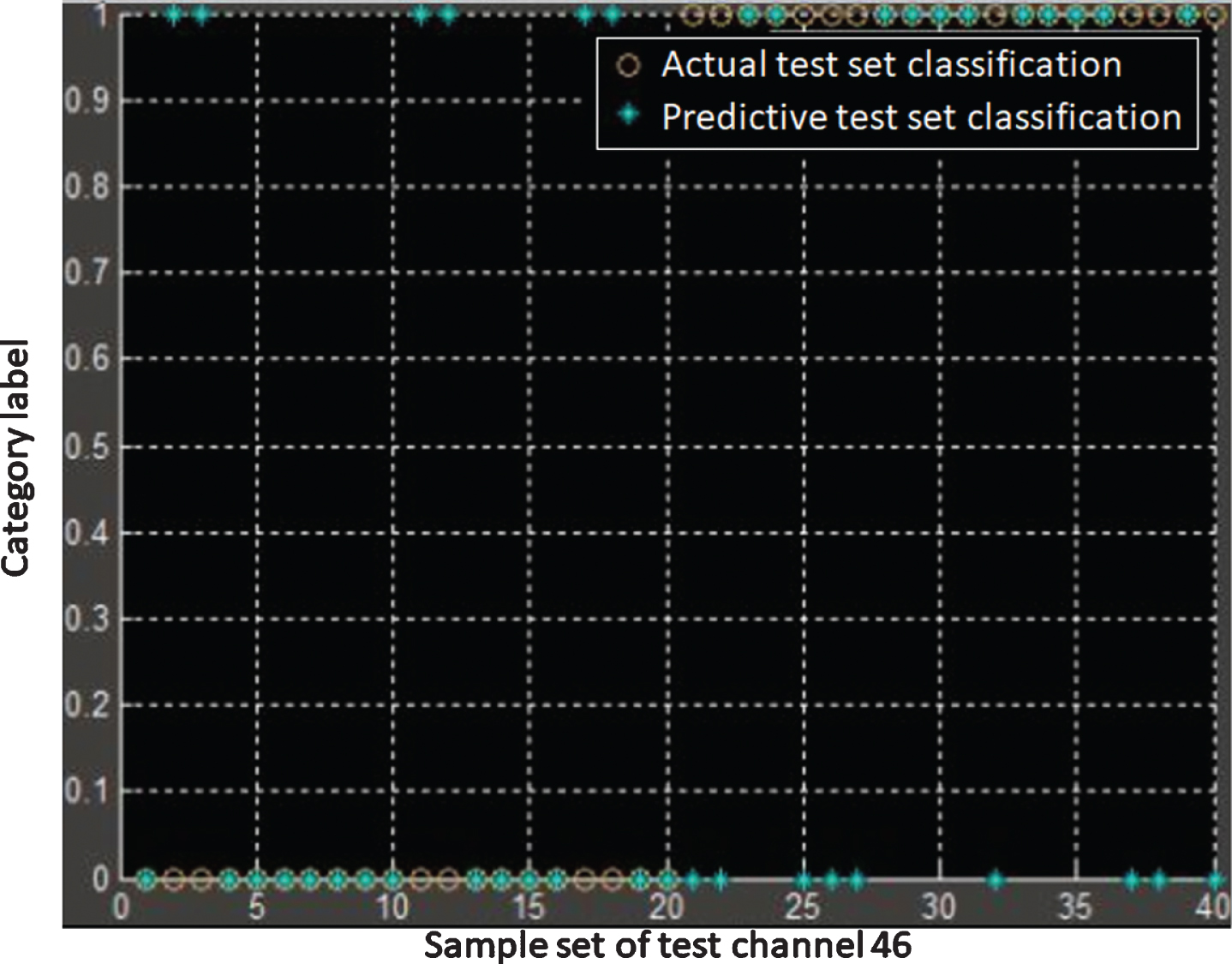
Results of recognition of the EEG signals acquired by channel 46.
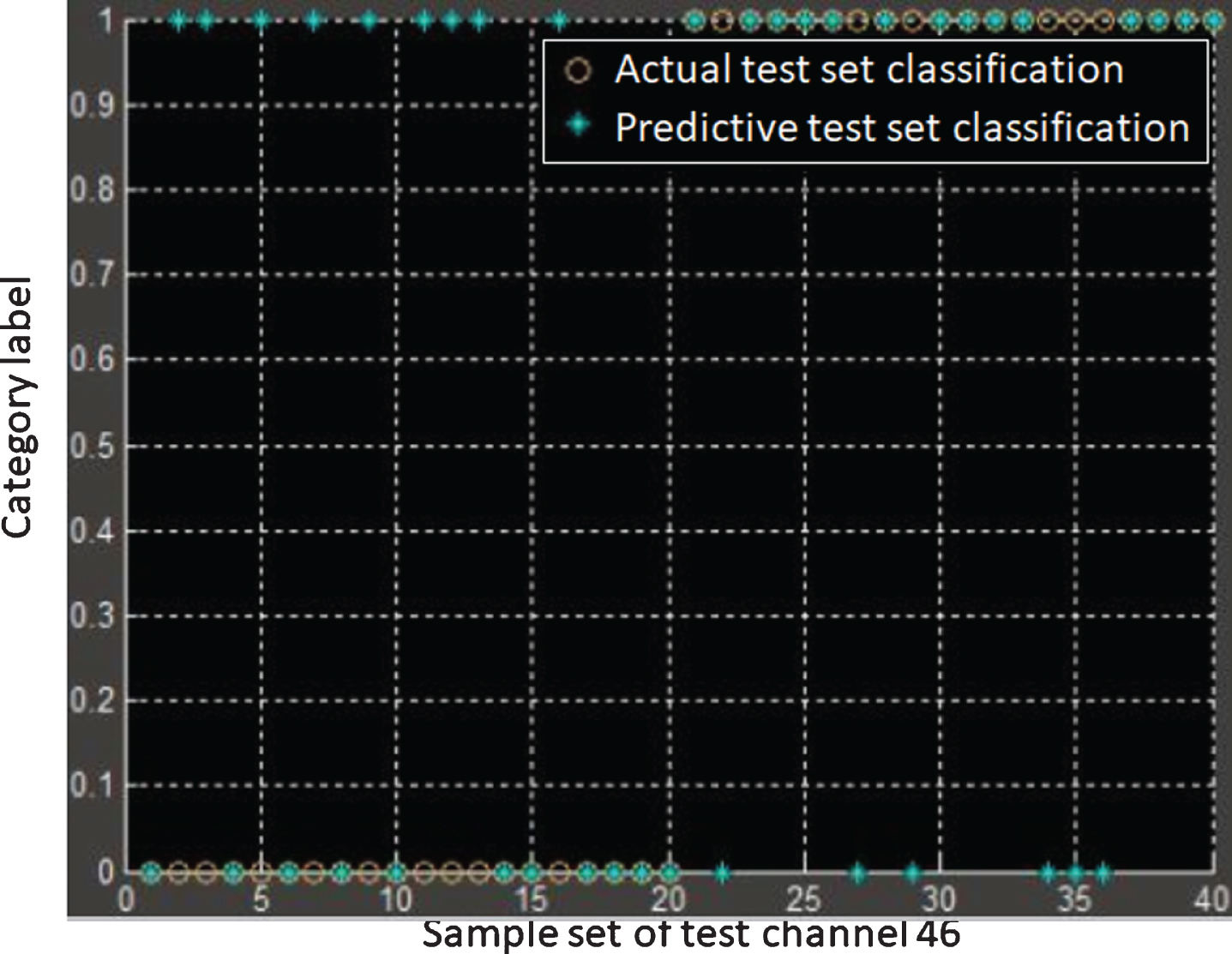
Results of recognition of the EEG signals acquired by channel 35.
In order to analyze the effectiveness of the adaptive algorithm, the corpus required for self-built training is built. The corpus uses Mandarin pronunciation, which takes 300 sentences from newspapers and dictionaries and 300 sentences from online news to form a total of 633 sentences. The tester’s age range is 35–25 years old, 1 male and 1 female from the northern region, and the other 2 are southerners. The voices of the four testers all have a certain local accent. Each of the four testers recorded 633 sentences, and then the error test was performed. Four testers (same as the previous section) performed independent 10 tests and randomly selected 45 instructions each time. The recognition rate using the traditional algorithm is shown in Table 1. The speech recognition rate using the algorithm model of this study is shown in Table 2, and the corresponding statistical graphs are shown in Figs. 9 and 10, respectively.
The English recognition rate of traditional English algorithm
The English recognition rate of traditional English algorithm
The English recognition rate of the algorithm of this study
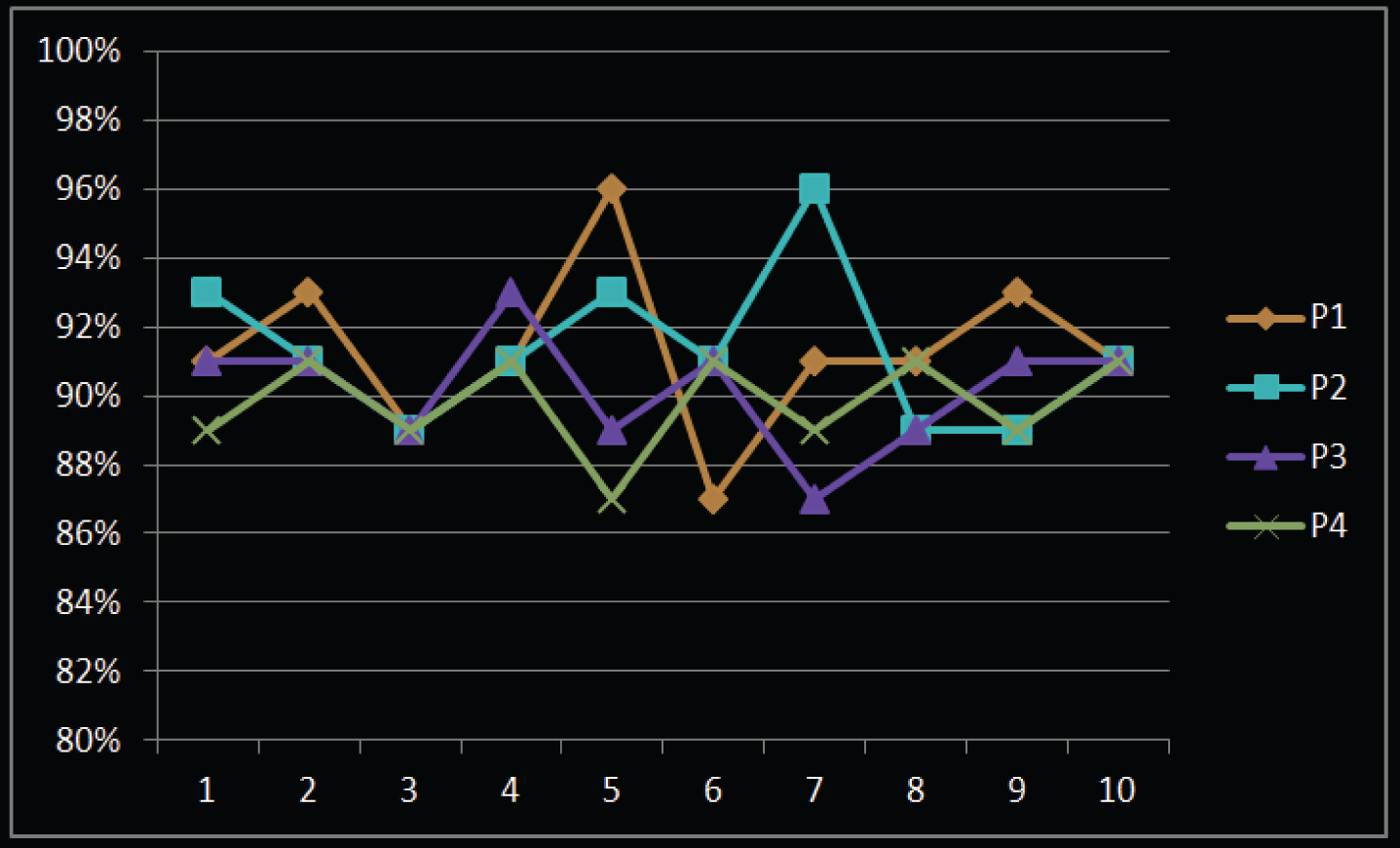
Statistical diagram of the English recognition rate of the traditional algorithm.
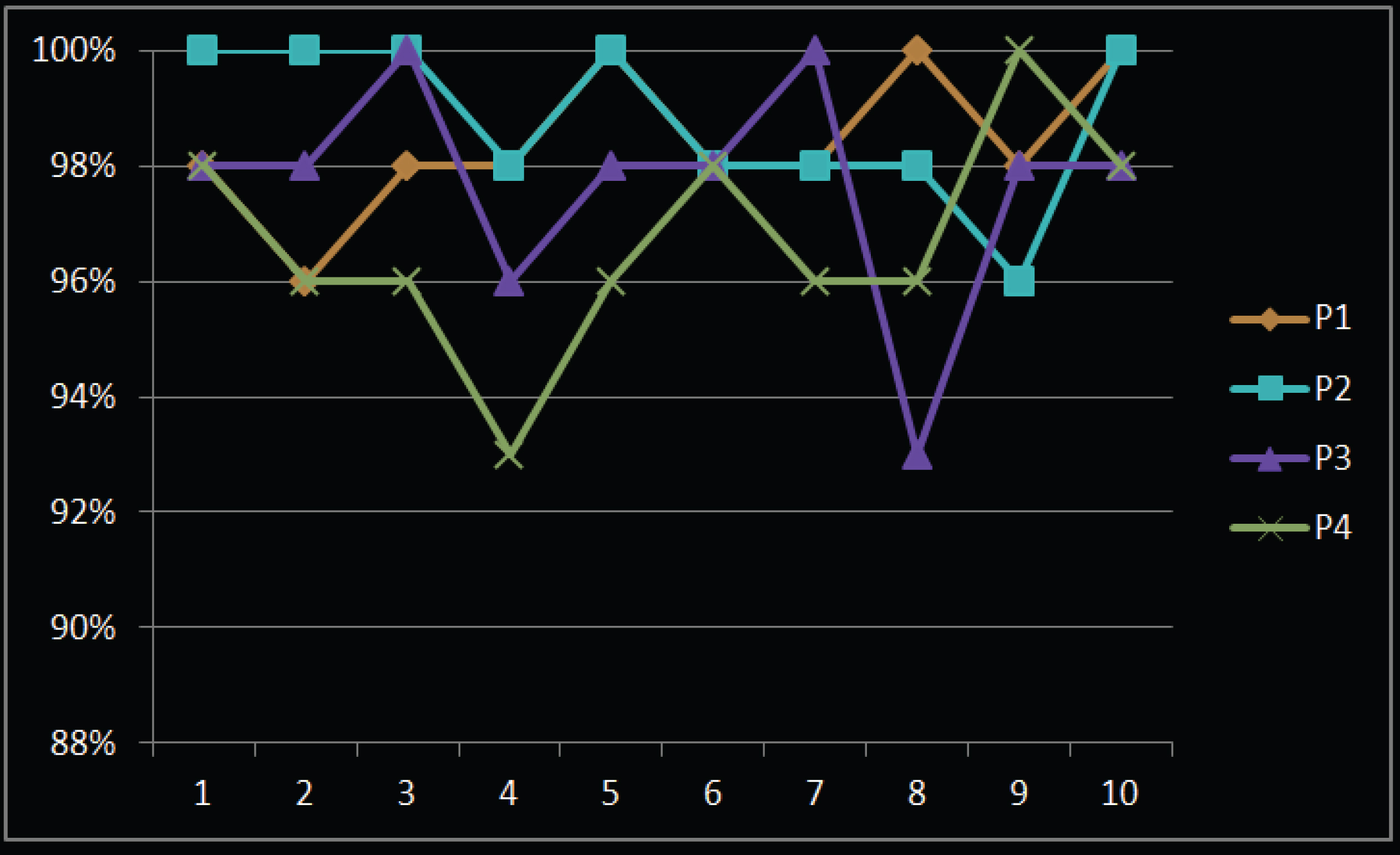
Statistical graph of English recognition rate of the algorithm of this study.
It can be seen that the recognition rate of the traditional algorithm is significantly lower than the speech recognition rate of the algorithm model in this study. The speech recognition rate of the algorithm model in this study is at least 96%. The client’s speech recognition rate can reach 90% when it can’t connect to the Internet, which basically meets the requirements of the actual use of the system.
When designing a speech brain-computer interface system for English pronunciation, the most important part is the two modules of signal feature extraction and recognition in the brain-computer interface system. In this paper, the EEG signal acquisition experiment of English phonetic pronunciation is designed, and the EEG signals in the brain region related to English speech in the process of English phonetic pronunciation are collected. This experiment used a non-invasive EEG signal acquisition program (EEG). The EEG signal has a low frequency-domain resolution but a low signal-to-noise ratio. Therefore, there are many disturbances such as eye movement artifacts and muscle movement artifacts in the signals collected by the experiment. Based on this, we first remove the obvious interfering signals such as ocular electricity and muscle movement by digital filtering and visual observation. Subsequently, this paper uses the independent component analysis method in EEGLAB to extract the main components of EEG signals, further removes the noise in EEG signals, and achieves good results, which provides help for signal feature extraction.
In the text classification task, the model innovatively uses the modularization of rules and uses the neural network to build a rule parser and some modules. The methods used by the model have good application value for upgrading existing rule systems and building neural rule systems that do not rely on large amounts of data.
The thesis conducts an in-depth study on the integration of machine learning algorithms, and on this basis, studies how to construct a modular system, so that the model can better maintain the advantages of rule system interpretability and flexibility. Moreover, this paper introduces the powerful learning ability and generalization ability of the support vector machine, and then applies it to the text classification task, and has achieved good results. However, there are still some problems in terms of word vector and system optimization that require further research and experimentation. Words with the same semantics have similar word vectors that bring generalization to the classification system. However, sometimes the similar meanings of the words covered by the word vector may not be similar to those expected by the mission objectives. Therefore, an error case analysis can be performed on the classification result, and after some words lead to misclassification, the word vector fine adjustment can be separately performed for these words. The word vectors of the two to be distinguished can be separately fine-tuned so that the difference between the word vectors of the two is increased, which reducing false positives.
Conclusion
Based on the research background, this chapter deeply analyzes the research status of related technologies of this subject and conducts a comprehensive analysis of the domestic and international research situation of related technologies.
This paper compares two EEG signal feature extraction algorithms. According to the characteristics of frequency domain and space of EEG signals, the EEG signals of Chinese phonetic pronunciation process were extracted by wavelet packet 6-layer decomposition and co-space mode. After that, this paper uses the support vector machine model to identify the feature vectors extracted by the two feature extraction methods. The results show that the wavelet packet decomposition has better recognition performance, which achieves the recognition accuracy of the English neuroanalytic system designed by foreign researchers based on the EEG signals collected by the cortical electrodes. It is proved that the method provided in this paper is a de-sign method of Chinese speech brain-computer interface system with better performance. The speech recognition system has only undergone simple processing, and the endpoint detection and feature parameter extraction are not very accurate, so the recognition rate is relatively low, and more time is needed to study the problem.
Footnotes
Acknowledgment
The study was supported by “Horizontal Project of Foreign Language Teaching and Re-search Press Corporation Ltd. and Zhejiang Wanli University, China (Grant No. HX2019075)”.