
Abstract
The rise of the cloud computing model has resulted in more than terabytes of data being stored in the cloud platform every day on the Internet. Mining valuable information from these massive data has become an emerging industry direction, but the current Intrusion-detection system (IDS) has been unable to adapt to large-scale log information mining. Therefore, an association rule mining algorithm based on MapReduce parallel computing framework is proposed. Firstly, the frequent itemsets mining algorithm Apriori is analyzed, and the MapReduce model is used to parallelize and improve it to more efficiently complete the mining of frequent itemsets. Secondly, the parallel Apriori is designed to run on IDS. Finally, the simulation experiment was carried out by building an open source cloud computing framework Hadoop cluster. Finally, the simulation experiment was carried out by building an open source cloud computing framework Hadoop cluster. The results show that the proposed method has higher detection efficiency when processing massive data, and requires less processing time.
Keywords
Introduction
With the continuous development of cloud computing technology, a large amount of data information has been generated in various industry sectors. This large amount of data information has gradually evolved into an important asset of IT Internet companies. Many research institutions and research scholars have made big data the focus of research [1, 2]. As we all know, everything has both positive and negative aspects, as well as in the era of big data. On the one hand, we compare it with a small amount of data, the data we get does not give us the expertise and value, and the mad growth of massive data brings great pressure. For example, intrusion detection technology has developed rapidly in recent years, and the ability to deal with scale, sudden attacks and intrusions is also increasing. However, the mad growth of massive data has also brought great pressure. Using data mining to find useful information in any amount of arbitrary data can not only summarize the past but also predict the future. In the network security problem, its efficient and fast features have great potential.
As a main research direction in data mining algorithms, association rules have become a hotspot in data mining research [3, 4]. At this stage, association rules have many algorithms that generate frequent itemsets. However, when these algorithms generate frequent itemsets, the number of times the connection database generates candidate itemsets is more, which reduces the execution efficiency and increases the time cost. In the early 1990 s, the classic Apriori algorithm [5] proposed by R. Agrawal and R. Srikant added vivid colors to the analysis and processing of data. The idea is to find the relationship between different items from the historical transaction database. The core is to obtain the frequent itemsets by repeatedly scanning the data items and discover the relationship between the items and the items. At present, there are many improvements to the parallel of the Apriori algorithm.
The Apriori algorithm in the association rule model is mainly used in a large number of historical transaction data to find frequent patterns and associations between items. However, given the inherent deficiencies of the Apriori algorithm, when the amount of data is large, its defects become more and more obvious. At this point, using the Apriori algorithm to analyze and process the data will consume a lot of time and memory space [6], making the efficiency low, so in order to achieve the important goal of data mining technology improvement, it is necessary to complete the computing power. Khalili A proposed a key state determination method for industrial intrusion detection systems based on Apriori algorithm [7]. Bhandari A et al. proposed an improved Apriori algorithm for frequent pattern trees and applied it in data mining [8].
Therefore, in view of the low efficiency of the traditional algorithm in the intrusion detection system in dealing with massive data, the popular Hadoop system framework and classic Apriori algorithm are selected to parallelize the frequent itemsets mining Apriori algorithm in the Hadoop framework, solving the problem of reducing the processing speed due to the increase of data volume. The IDS simulation experiment is carried out by building a Hadoop cluster. The results show that the improved Apriori algorithm of Map Reduce parallel has higher detection accuracy and less time in processing massive data.
Hadoop framework analysis
Distributed framework
Hadoop is a framework of different software libraries (also called functional modules that are part of the Hadoop job). The most important ones are Common, HDFS, Map Reduce, which are also called the narrow Hadoop [9]. The creativity of the open source world is limitless, and other products of the Hadoop system have sprung up, which together constitute a vibrant Hadoop framework. Hadoop is also known as the Hadoop ecosystem in certain circumstances. The Apach Hadoop project is mainly used for the development of open source software. It is characterized by distributed computing, good scalability and good reliability. For the task requirements of distributed computing, a complete data stream is usually split into multiple different job streams. A complete Hadoop distributed application framework has four characteristics: 1) scalability; 2) fault tolerance; 3) high security; 4) high efficiency. Currently, the distributed Hadoop platform mainly uses a massively parallel programming framework, including Distributed File System (HDFS) and Map Reduce. HDFS is primarily responsible for data storage. Map Reduce is primarily responsible for parallel processing tasks. The distributed Hadoop framework is shown in Fig. 1 [10].
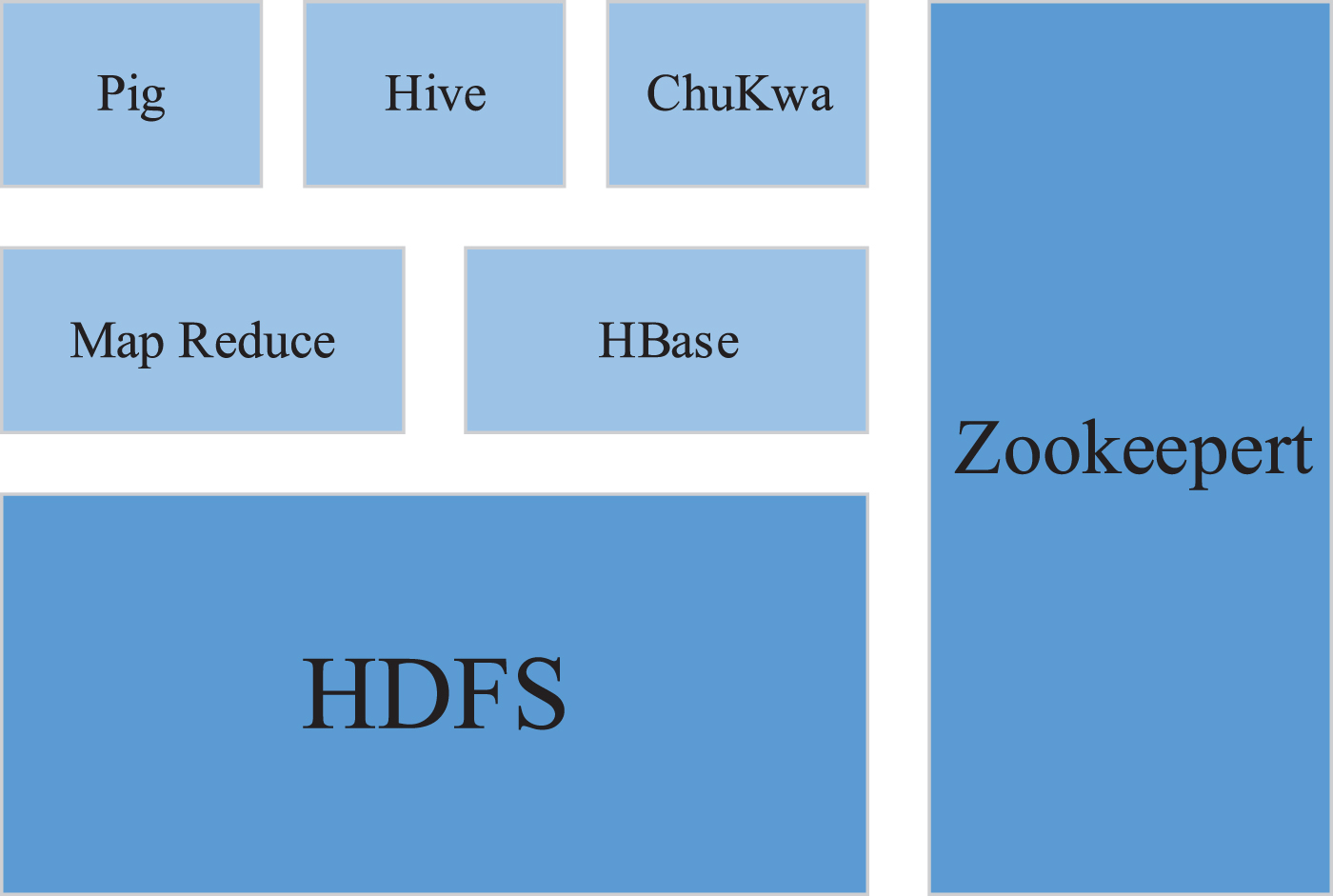
Distributed Hadoop Framework.
Map Reduce is the cornerstone of the data analysis processing model, and its model structure is simple and easy to understand. In this paper, the DAG graph, the Directed Acyclic Graph, is used to represent the Map Reduce job stream. In the Hadoop platform, the commonly used MapReduce architecture is shown in Fig. 2 [11]. The Map operation and the Reduce operation are the two core operations of Map Reduce. No matter how complex the Map Reduce job is to be performed, it goes through these two phases.
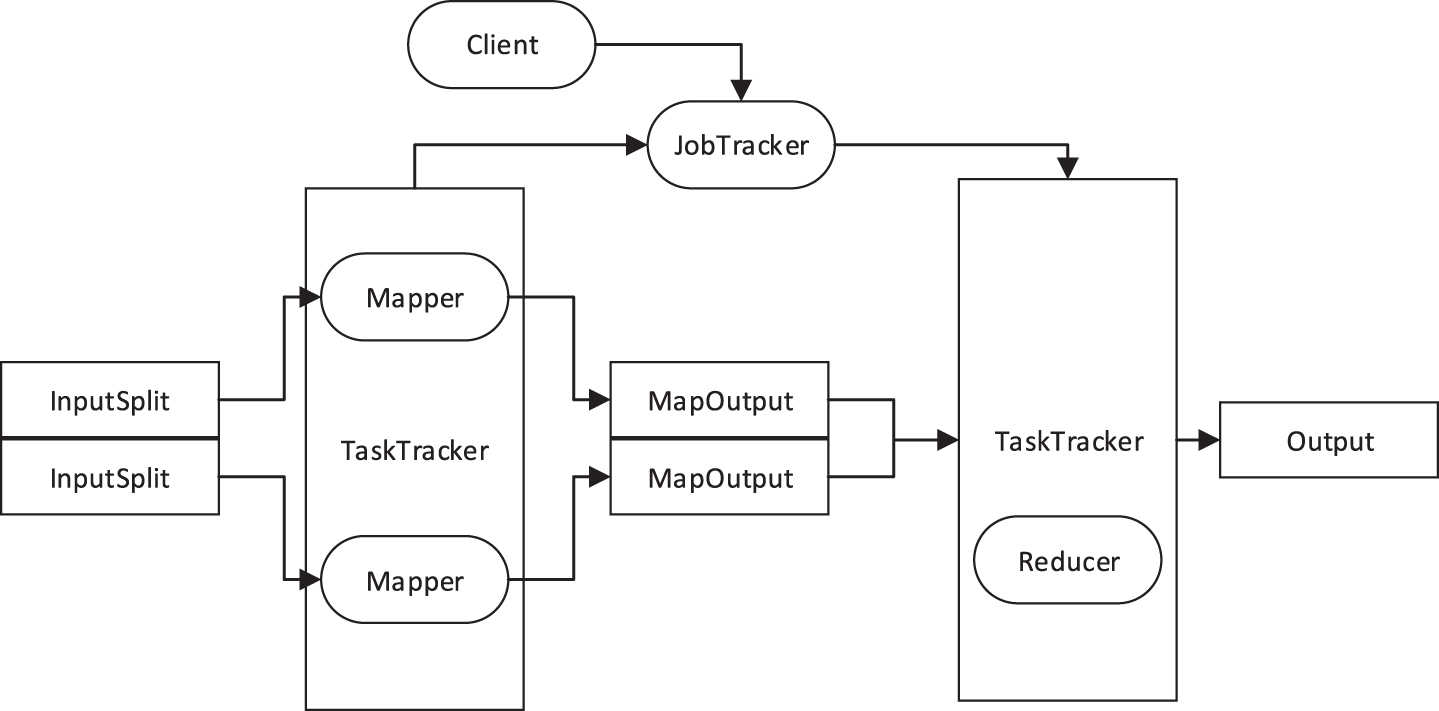
MapReduce architecture.
Each job stream under the Map Reduce framework can be represented by a Map Reduce job. All the jobs required for the task constitute a DAG diagram [12]. Each edge in the DAG graph represents the relationship between two jobs. The representation of the job stream in the DAG diagram is shown in formula (1).
Where W represents the set of job streams obtained after processing, Wname represents the name of the task, Map and Reduce represent map and reduce processing operations, respectively, Param is the configuration parameter required for the task. Input and Output represent the data source type of the input and output tasks. E represents the edge between two jobs in the DAG diagram. DAGinfo is the special identification information of the DAG. The Map processing in formula (2) can be expressed as follows:
Where Mname represents the name of the map processing, InK and InVal represent the type of key-value pairs entered during the Map process, OutK and OutVal are the key-value pair types of the output. Properties represents the property parameters required for the Map processing. The Reduce processing in formula (2) can be expressed as follows:
Where Rname represents the name of the Reduce process, and the representation of other parameters is consistent with the Map.
The representation of E is as shown in formula (5).
Path indicates the transmission path of the data stream, StartTk indicates the current task, and EndTk is the subsequent task.
The data mining model based on Hadoop is shown in Fig. 3. It mainly includes: 1) Dynamic interaction layer, which communicates with users through the interface as a bridge. 2) Business application layer, which performs command and control of all business processes between the interaction layer and the data mining platform layer. 3) Data mining platform layer, which is the core layer, mainly completes data processing tasks, including parallel data mining algorithm module, workflow module, data loading module, and storage module. 4) Distributed computing platform layer, using Hadoop framework to achieve HDFS storage and MapReduce work execution.
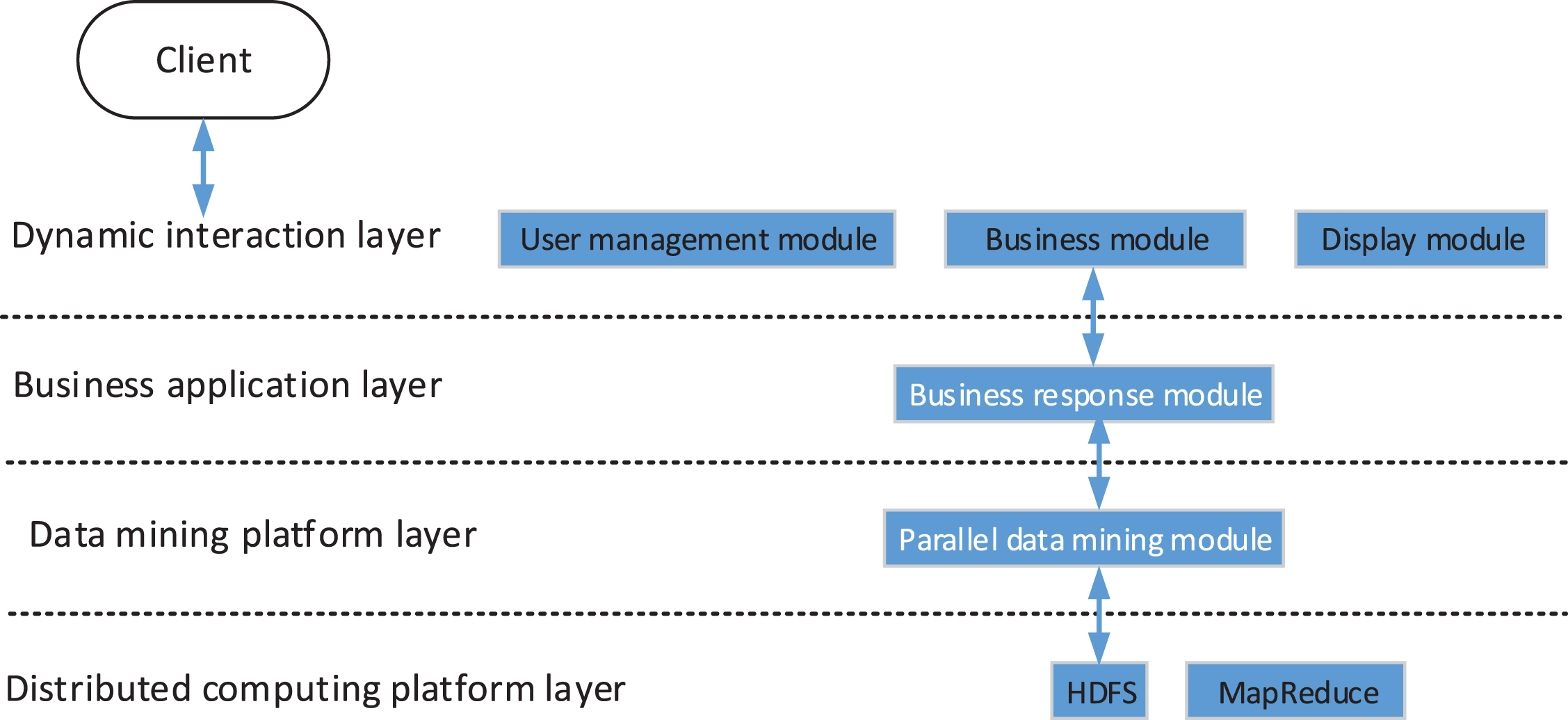
Hadoop-based data mining model.
Association rules represent some hidden relationships between two things under one rule. The purpose of data mining algorithms is to discover these hidden relationships [18]. Association rules can be used to represent, where X is the premise of the association rule and Y is the follow-up of the association rule. In addition, the association rule algorithm has a definition of support and confidence, and the calculation formula is as shown in formula (6):
Among them, A and B represent different events.
The correspondence between the degree of support and the confidence can be calculated by the probability formula (7).
The main idea of the typical Apriori algorithm is to use the prior knowledge of frequent itemsets to complete the iterative calculation by layer-by-layer search [13, 14]. The general mining step for implementing association analysis with a typical Apriori algorithm is [15]: Set the required minimum support degree min_Sup and minimum confidence min_Conf; sequentially connect and scan the data set, determine the support number of each item, and select the frequent itemsets 1 that meet the requirements by the minimum support set in step 1; randomly combining two frequent itemsets 1 to generate candidate frequent itemsets 2, and then sequentially connecting the data sets and completing the support degree calculation of the candidate frequent itemsets 2, and finally filtering the frequent itemsets 2 according to step 2; Repeat step 3 until an empty highest order frequent itemsets is generated; Output the result and the algorithm ends.
The Map Reduce system adopts the M/S (Master/Slave) structure mode, that is, the master node/slave node structure mode, the master node is operated by the Job Tracker, and the slave node is operated by the Task Tracker. In the DAG graph model, in order to allocate the appropriate job stream to all processing nodes, this paper uses the parallel Map Reduce job stream processing technology [16], the specific implementation mechanism is shown in Fig. 4. In order to implement the traditional Apriori algorithm in the cloud platform Hadoop framework, this paper performs MapReduce parallelization processing on the Apriori algorithm flow, which is shown in Fig. 5.
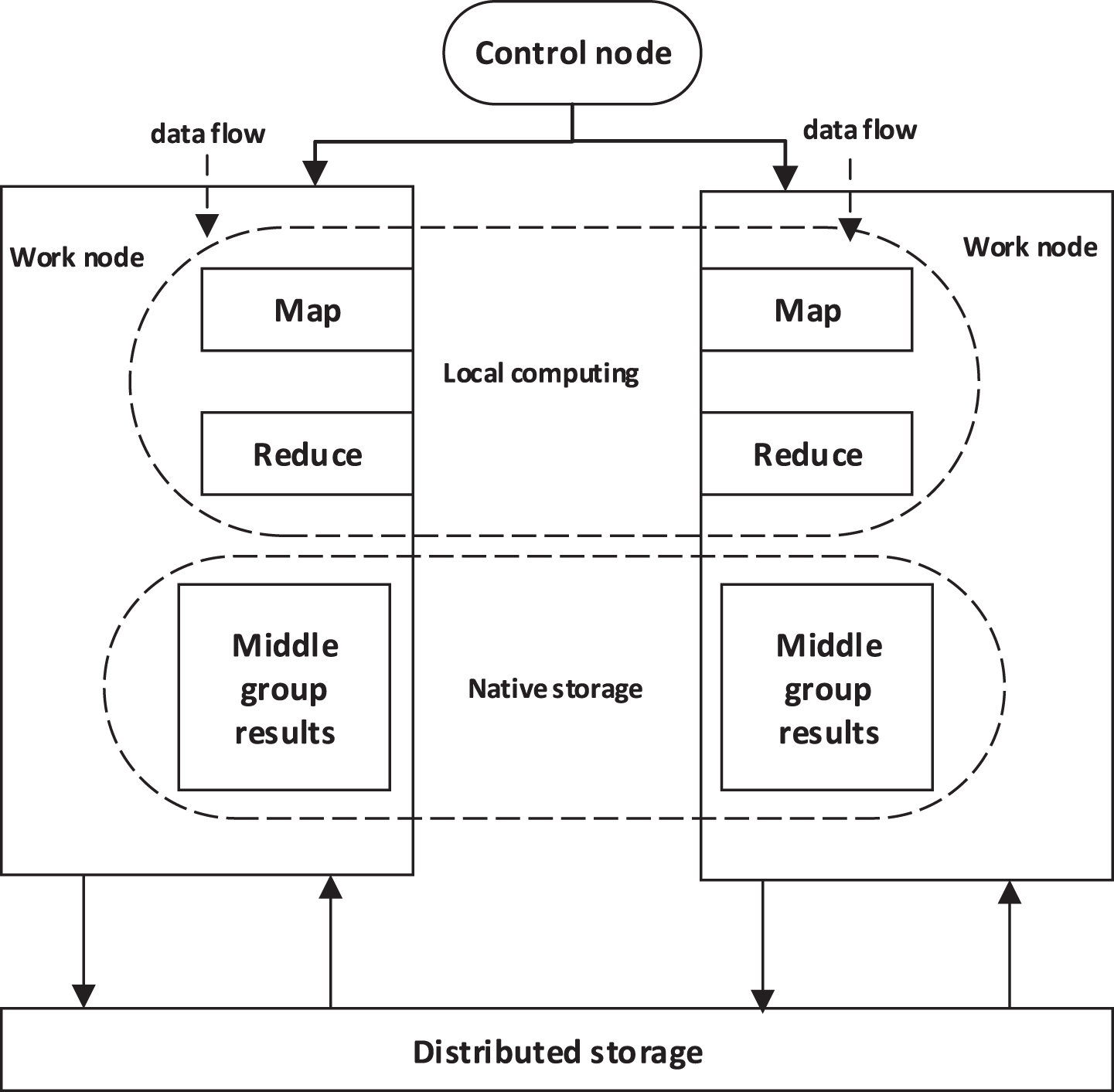
MapReduce parallel working mechanism.
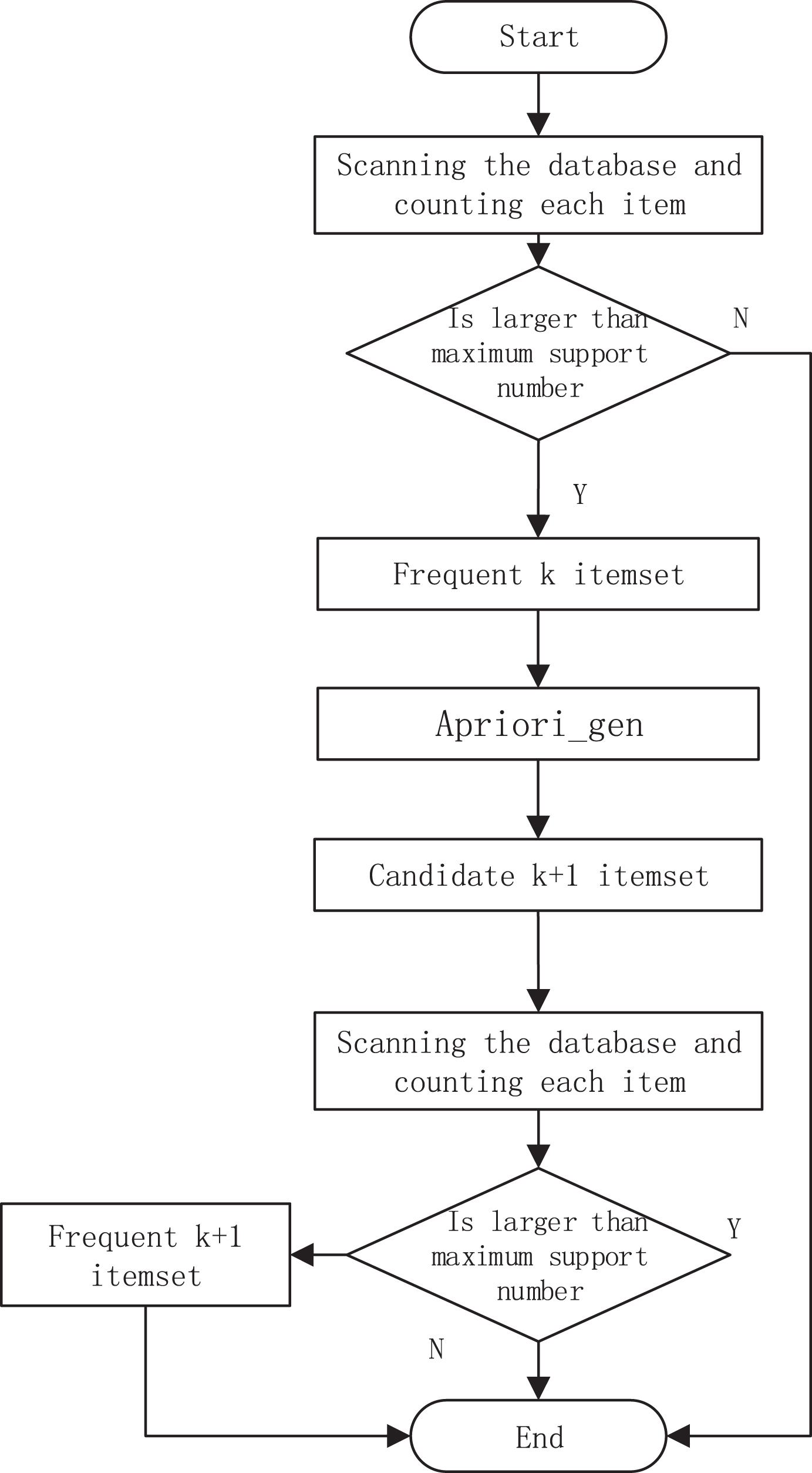
The flow of MapReduce-based parallel Apriori algorithm.
The algorithm follows a top-down approach, starting with the first level of conception and the last level. Use Map Reduce to generate a large number of frequent itemsets, including hierarchical intersections at different conceptual levels. For each level, the Map Reduce function generates a frequent set of items, including the intersection of that particular level. This approach will iterate until you can’t find more frequent itemsets in that level. In the data entry process, there are three main classes used, Input Format, Input Split, and Record Reader. Among them, Input Format divides the input data once, and the type of each data block that is divided is Input Split. The task of the Record Reader is to parse each split Input Split type of block into multiple key-value pairs and send it to the Map.
In the first round of Map Reduce tasks, the Map function outputs the first candidate set for each slice. The Recude function stipulates the output of the Map function, that is, counts and accumulates, and compares it with the minimum support threshold (min, Sup) to get the first frequent item set. In the kth round Map Reduce task, enter < key, value > . The task custom key value < key, value > is shown in Table 1 below.
Description of the key value
Description of the key value
When using Hadoop for data processing, each line in the file is treated as a transaction record, and each entry in the line is separated by a space symbol. After the user submits the file to HDFS, the data in the file is divided into a number of data blocks with a default size of 64MB. Each round of iterations executes a Map Reduce Job, each Map node processes multiple data blocks, outputs a candidate set, and its support. The Reduce task continues to process the output of the Map task, and all key-value pairs with the same key value are reduced, and finally the complete support of the itemsets is obtained.
The parallel reduction structure design concept is used to complete the Map Reduce function design, including the map() and reduce() functions, to run on the Hadoop distributed platform and improve the running speed. The specific distributed process is as follows:
1) Map stage
2) Reduce stage
If i is the number of transactions in the original data set D, j is the average length of each transaction record. Using the traditional Apriori algorithm to obtain the time complexity T1 = O (i * j) of L1, the total time complexity is:
Where Lk-1 represents all sets of k-1 items greater than the set minimum support threshold and C k represents the set of candidate k items.
For the Apriori algorithm based on MapReduce, if the cluster has a node and each node operates a data block, the total time complexity required to obtain the frequent itemsets is:
As can be seen from formulas (8) and (9), the MapReduce-based Apriori algorithm greatly reduces execution time. And the more the number of cluster nodes, the greater the efficiency.
Experimental environment configuration
The specific parameters of the test platform are: 6 computing nodes, with Intel i7 processor, CPU clocked at 3.2 GHz, 8GB memory. All service nodes communicate with each other through the Intel 82574 L dual Gigabit Ethernet port. The 2.2.0 version of Hadoop is installed on all service nodes, and the JDK version is 1.8.0 [17]. One of the nodes is set to Jobtracker, and the other five compute nodes are set to tasktracker. Each tasktracker has 1 reduce work slot and 2 map work slots. The IP allocation information of each server node is shown in Table 2.
Node allocation information table
Node allocation information table
The Linux operating system is installed on all service nodes. The installation location of hadoop-1.1.2 tar.gz is (HADOOP_HOME): usr/local/hadoop, which is extracted and completed. At the same time, conFig. and modify the environment variables in the profile file, as shown in Fig. 6.

Profile file configuration diagram.
In order to compare the computational efficiency of the Apriori mining algorithm of MapReduce parallelization and the traditional Apriori algorithm, this paper uses the kddcup.data_10_percent_corrected dataset to conduct experiments. KDD Cup This data set is the most commonly used standard test set for network intrusion detection systems [18]. It is also the most representative and influential intrusion detection data set in academic circles at home and abroad. The records in this data set are divided into two major parts: the data set used for training and the data set used for testing. Among them, the trained data has a specific identifier, and the test data is not identified. The test data also contains some attack types that are not included in the training data, making the system’s detection more realistic and reliable. The amount of kddcup.data_10_percent_corrected is only 10% of the KDD Cup99 data set. The data set has a total of 494 021 data records, of which 97,278 normal data, and various attack data are shown in Table 3.
Experiment attack types
Experiment attack types
Considering that different types of intrusion data have different numbers of attributes and units of measure, in order not to affect the results of the mining analysis, the data must be normalized in the data preprocessing stage:
Where ide represents a parameter with a value of 2. dis represents a parameter with a value of 1.5. min _ col and max _ col represent the minimum and maximum values of the j-column attribute, respectively.
Simulate attack packets and save them to a log file. A total of approximately 2,000 attack packets were recorded to measure the effectiveness of system pre-tests. The system’s pre-detection engine discards packets that are considered normal to reduce unnecessary abuse detection. The performance evaluation of the intrusion detection algorithm mainly uses the Error Detection Rate (EDR) of the anomaly detection [19]. Through this indicator, the detection effect of the algorithm can be well measured.
Test results of traditional IDS
Detection results of IDSD using MapReduce parallel Apriori
The running time comparison between the traditional Apriori mining algorithm and the Map Reduce-based Apriori algorithm is shown in Table 6. The running time comparison is shown in Fig. 7. It can be seen from Fig. 7 that when the amount of data is small, the Map Reduce-based Apriori algorithm does not show obvious advantages, and its running time is even slower than the traditional Apriori mining algorithm. However, with the increase of data volume, Map Reduce-based Apriori mining algorithm gradually shows its advantages. Especially when the amount of data is too large, the traditional Apriori mining algorithm cannot complete the calculation. However, the Map Reduce-based Apriori mining algorithm makes full use of its parallel advantages, and its speed is not affected by too much data factor. In addition, after solving the problem of load imbalance, it can be seen that the proposed Map Reduce-based Apriori mining algorithm is better than the improved data placement strategy proposed in [20], as shown in Table 6 and Fig. 7. This shows that the proposed method has significant improvements in processing big data.
Running time of each algorithm
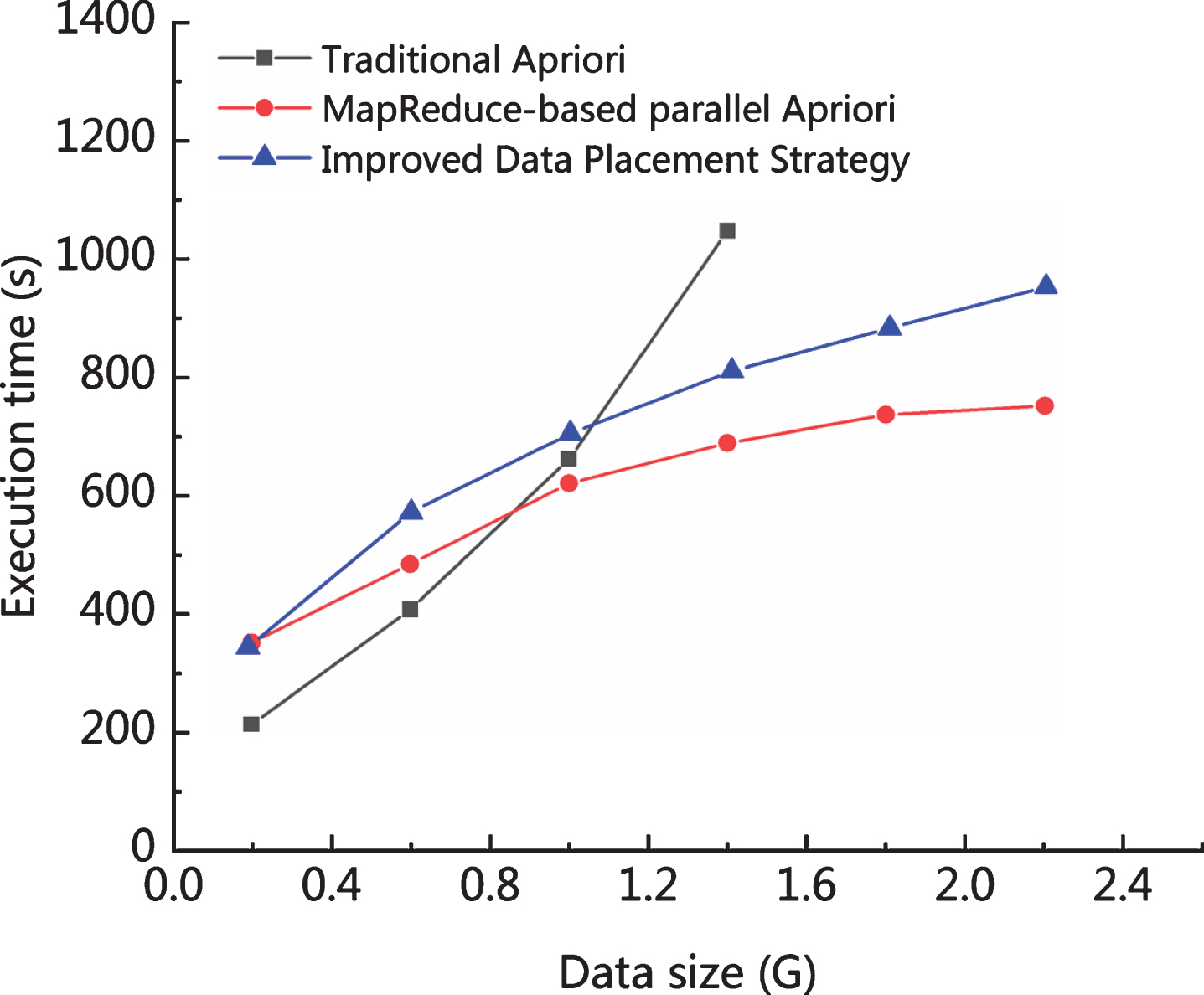
Running time of each algorithm.
In order to further verify and analyze the impact of the proposed method on execution time, the execution time when the service node changes is tested. Fig. 8 is an execution time diagram of different service nodes processing the same amount of data.
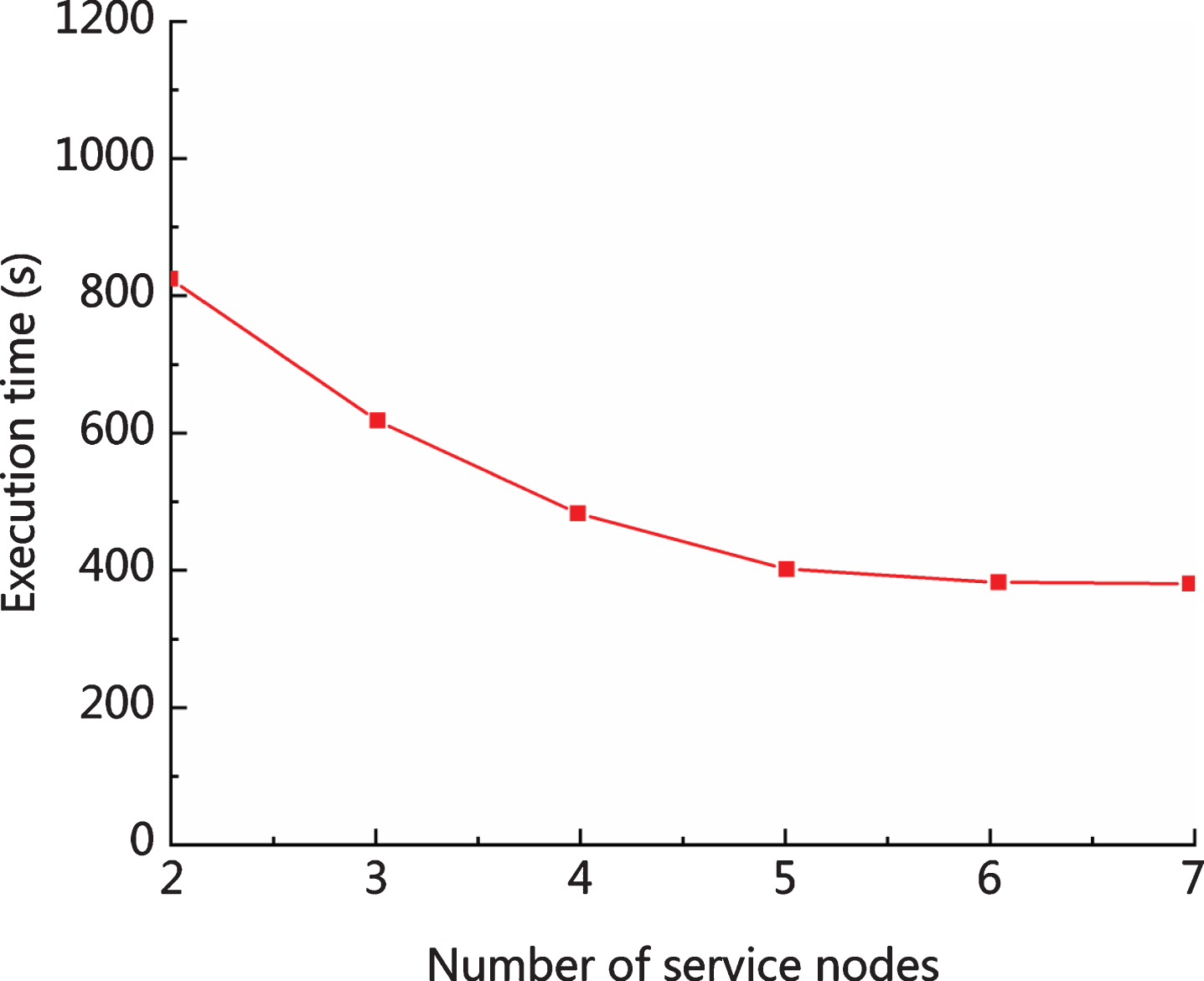
Execution time when the number of service nodes changes.
It can be seen from Fig. 8 that when the same amount of data is processed, the efficiency of the proposed algorithm involved in processing the data becomes higher and higher with the addition of the service node. When the service node reaches a certain amount, the execution time increases slowly and finally stabilizes. The experimental results show that the improved MapReduce parallelization of Apriori algorithm based on Hadoop is feasible. It also proves that the method utilizes the advantages of clustering, can process data in parallel and efficiently, and improves the efficiency of association rule mining.
Finally, the simulation experiment was carried out by building an open source cloud computing framework Hadoop cluster. The results show that the proposed method has higher detection efficiency and reduces running time when processing massive data. However, the KDD Cup IDS accuracy test results show that the proposed method does not significantly reduce the false positive rate. This is because there is no improvement to the mining rules of the Apriori algorithm. Further research will be carried out in the future, such as using FP_growth mining instead of Apriori association mining.