
Abstract
At present, the teaching of architectural art in China is still relatively traditional, and there are still some problems in the actual teaching. Based on this, this study combines the Naive Bayesian classification algorithm with the fuzzy model to construct a new architectural art teaching model. In teaching, the Naive Bayesian classification algorithm generates only a small number of features for each item in the training set, and it only uses the probability calculated in the mathematical operation to train and classify the item. Moreover, by combining the fuzzy model, the materials needed for architectural art teaching can be quickly generated, and the teaching principles and implementation strategies of architectural art are summarized. In addition, this paper proposes an attribute weighted classification algorithm combining differential evolution algorithm with Naive Bayes. The algorithm assigns weights to each attribute based on the Naive Bayesian classification algorithm and uses differential evolution algorithm to optimize the weights. The research shows that the method proposed in this paper has certain effect on the optimization of architectural art teaching mode.
Keywords
Introduction
Art education plays an important role in cultivating people’s aesthetic consciousness and innovation ability and is an important part of human education. Public art education refers to non-professional quality education for non-art majors, also known as general education. The “Guidelines for the Public Art Curriculum of the National Colleges and Universities” issued by the Ministry of Education clearly states: “Public art curriculum is an important part of China’s higher education curriculum system, it is the main way for ordinary higher education institutions to implement aesthetic education, and public art curriculum teaching is the central link of art education in ordinary higher education institutions.” In 2014, the Ministry of Education issued the “Opinions of the Ministry of Education on Promoting the Development of School Art Education”. The opinion pointed out: “Ordinary colleges and universities need to open public art courses for all students in accordance with the “National General Colleges and Universities Public Art Curriculum Guidance Program” and incorporate credit management. Schools that are allowed to do so must offer a wide range of art electives for students to choose from. The promulgation of this series of policy documents reflects the state’s high regard for public art education [1].
Art education strives to pursue a teaching method that can stimulate students’ interest in art, improve students’ ability to innovate, and realize the educational philosophy of “Lide”and “Shuren”. Since the reform of education, in order to comply with the trend of international education and actively respond to the various educational goals and teaching concepts put forward by the international education community, Chinese educators have been experimenting with various teaching models to adapt to social change and development. The new era brings us not only progress, but also more challenges. Facing the challenges of modern education, China is fundamentally developing the capabilities of students, constantly enriching its own education system, and establishing a comprehensive and comprehensive education system framework to create a good learning environment for students. Therefore, the study of teaching reform theory has a certain influence on China’s educational progress [2]. However, the variety of teaching modes makes teachers difficult to teach before, and the pressure from various aspects has to be formalized or lost in the role of teachers. Traditional teaching methods and methods do provide teachers with a clear teaching idea and process. However, in the specific practice, the inevitable drawbacks are also found: the formalization of teaching, the fixed teaching ideas, the ineffective classroom effect, and the shallow understanding of students’ knowledge. Although the traditional teaching methods have certain applicability and have different influence on teachers, in the modern educational context, it is especially important for teachers to choose the appropriate teaching style based on the development of students’ core literacy [3].
Related work
Regardless of the size of the selected training set, the Naive Bayesian classification algorithm only produces a small number of features for each item in the training set, and it only uses the probability calculated in the mathematical operation to train and classify the project. Therefore, the algorithm is widely used in real life, for example, detecting spam pages when users go online or helping users to analyze related resources of customers [4]. At the same time, experts and scholars in related fields are constantly studying how to effectively improve the classification performance of Naive Bayes classifiers. On the basis of the assumption that the conditions are independent of each other, Abel J H proposes an improved Bayesian classification method, which adjusts the probability [5]. Manescu R et al. [6] proposed combining the weighting operation and the selection operation, and then applying it to the Naive Naive Bayesian classification algorithm of Naive Bayes. Lucchino E C [7] proposed an attribute-weighted Naive Bayesian algorithm with weights representing the importance of attributes. Torregrosa-Jaime et al. proposed an attribute-weighted Naive Bayesian algorithm that uses weights to represent the degree of influence of attributes on categories [8]. J Strzałkowski proposed a feature-weighted Naive Bayesian algorithm that uses attributes to represent the conditional probability after decomposition [9]. Amani N [10] proposed a tree extended Bayesian classification algorithm, which stipulates that each node can have a parent node in addition to the decision node, wherein each non-decision attribute belongs to at most one parent node. The algorithm allows certain dependencies between attributes, which reduces the impact of conditional independent hypotheses on the classification performance of Naive Bayesian classification. Lei Z et al. proposed a two-layer Bayesian model based on mutual information [11]. Tiejun C [12] proposed a feature-weighted Naive Bayesian algorithm that uses weights to represent the influence of attributes on categories. Pengyuan S extended the Bayesian structure and proposed a Bayesian network. The Bayesian network consists of a directed acyclic graph and a corresponding conditional probability table. A Bayesian network is a set consisting of nodes of various attributes. It contains the directed edges existing between the nodes of each attribute and the conditional probability corresponding to its corresponding state [13].
On the big dataset, the Naive Bayesian classification algorithm is not very accurate in classifying the data but combining it with other methods can effectively improve the classification accuracy. For example, the Shungo S algorithm [14] combines a decision tree with a Naive Bayesian algorithm. When there is a strong correlation between attributes, the classification effect of the decision tree is better. Otherwise, the classification effect of Naive Bayes is better. Therefore, the combination of Naive Bayes and decision trees can greatly improve the accuracy of classification. Based on the NBTree algorithm, Bergero adds attribute weighting to it [15] and uses the weight to represent the interdependence of attributes, so that the algorithm is closer to reality, and the classification accuracy of the algorithm is also improved. In addition, the Naive Bayesian classification algorithm can be combined with association rules, clustering, Boosting methods, fuzzy sets, decision trees and other theories to compensate for the lack of conditional independent assumptions. Through the combination, each algorithm will play its own advantages and complement each other. For example, the BNB algorithm proposed by Thomas A [16], which uses the adaptiveness of Boosting, marks the test samples, and then adds them to the training set, and continues to train the next classifier with this training set. The BLNBT algorithm proposed by Andrews C J [17] also uses the Boosting algorithm. The CNB classifier [18] proposed by Vilalta. R uses a clustering method. The NFNB classification algorithm proposed by Nurnberger. A [19] combines neural networks with Naive Bayes.
Relevant theory of bayesian method
Foundation of probability theory
(1) Conditional Probability and Multiplication Theorem
In the sample space S, assuming that A and B are two random events, under the condition that event A occurs, the probability of occurrence of event B is called the conditional probability (also called posterior probability) of event B in the case of given A, which is recorded as p (B|A). Correspondingly, p (A) is called unconditional probability (also called prior probability). The conditional probability can be calculated by:
The multiplicative theorem of probability can be obtained from the conditional probability:
Assuming there are n events A1, A2, ⋯ A n , n ⩾ 2, there are:
(2) Probability Formula and Bayes’ Theorem
In the sample space S, assuming that A is a random event, B1, B2, ⋯ B
n
is a division of S, and p (B
i
) > 0 (i = 1, 2, ⋯ n),
The formula (4) is called the full probability formula.
Bayes’ theorem can be obtained from the definition of conditional probability and the full probability formula:
(3) Independence of events
We assume that A, B are two random events. The probability of occurrence of general A and B is influential with each other, namely g. p (B|A)= p (B) exists only if this effect does not exist. At this time, there are:
Then, A and B are called independent events.
Similarly, for n number of events A1, A2, ⋯ A
n
, n ⩾ 2, if there is (7)
A1, A2, ⋯ A n is called an independent event.
The Naive Bayes Classifier (NBC) is one of the most widely used models in Bayesian classifiers. The model description is shown in Fig. 1.
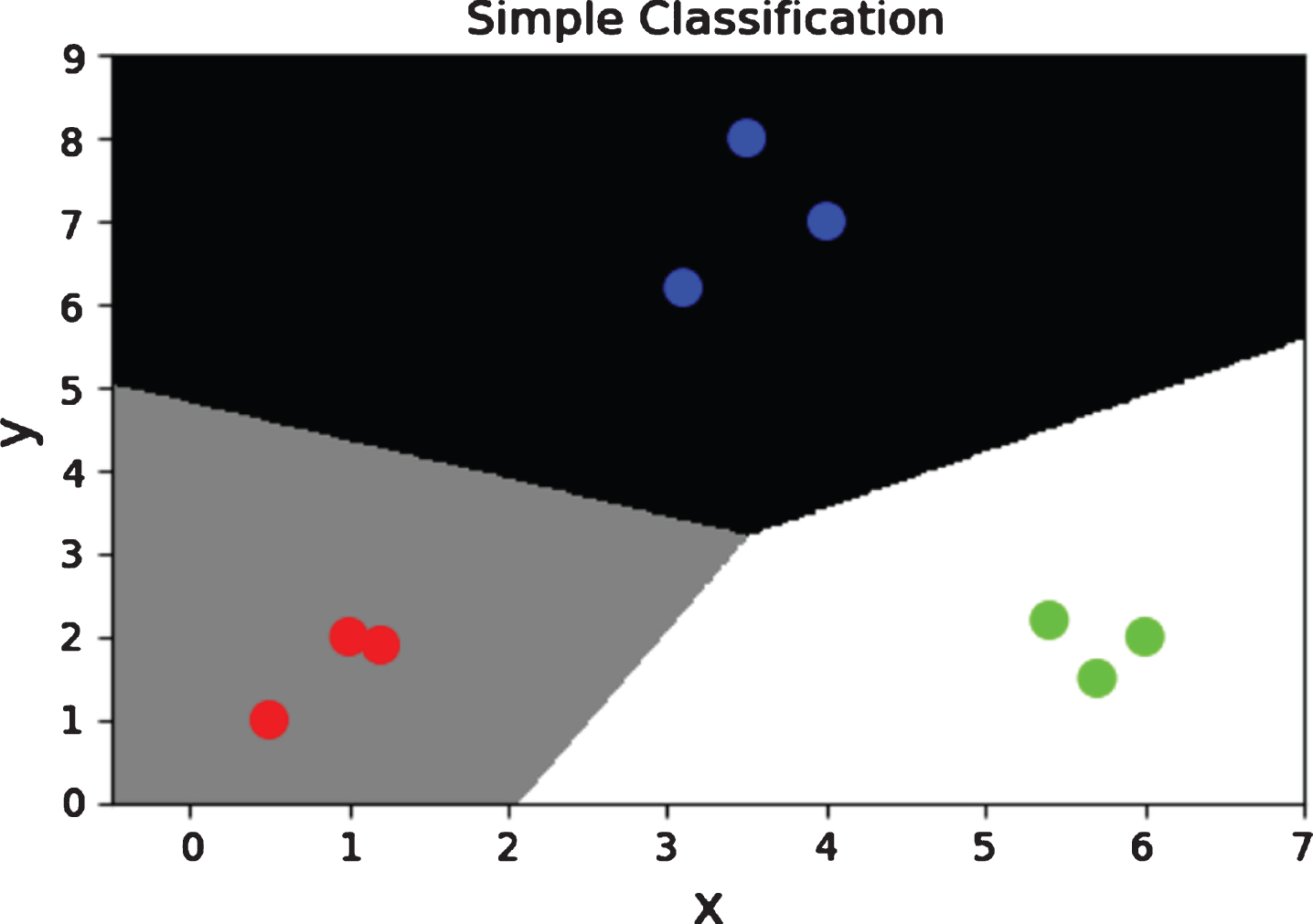
Structure diagram of the Naive Bayesian classification model.
We assume that there is a variable set U ={ A, C }. Among them, A ={ A1, A2, ⋯ A n } includes n number of condition attributes, and C ={ C1, C2, ⋯ C m }c contains m number of class labels. The Naive Bayesian classification model assumes that all conditional attributes A i (i = 1, 2, ⋯ , n) are used as child nodes of the class variable C. A given sampleX ={ a1, a2, ⋯ a n } to be classified is assigned to class C i (1 ⩽ i ⩽ m), when P (C i |X)> P (C j |X)(1 ⩽ i, j ⩽ m, j ≠ i).
According to Bayes’ theorem, there are:
If the probability of the class in the data set is not known in advance, the probability of each category can be assumed to be equal. That is:
According to this assumption, P (C
i
|X) is maximized, otherwise P (X|C
i
)P (C
i
) is maximized. Since P (X) is constant for all categories, there are:
Due to the assumption that the conditional attributes of the Naive Bayesian classification algorithm are independent of each other, there are:
In the formula, If the attribute A
k
is discrete, If the attribute A
k
is a continuous value, it is generally assumed that it obeys a Gaussian distribution. Then, For the sample X to be classified, we calculate the conditional probability P (C
i
) P (X|C
i
) for each category C
i
∈ C separately. The sample x belongs to the category C
i
only when
➀ The required data set is preprocessed, including attribute value discretization and missing value padding;
➁ The number S of training samples, the number S i of samples of class C i , the sample attribute of class t, and the number S ik of samples whose sample attribute A k of class C i is a k are counted.
➂
➃ The classification result
Data preprocessing
Data is a form of expression of people’s understanding of the objective world. It serves as a carrier of information and has a variety of manifestations. The amount of information contained in different forms of data is also different, reflecting the difference in people’s perception of the objective world. Data can be divided into qualitative data and quantitative data. From another perspective, data can also be divided into different measurement scale levels. Qualitative data is also called category data, and they can be divided into different categories based on certain characteristics of the data. Sometimes qualitative data can be sorted meaningfully, but arithmetic operations such as addition, subtraction, multiplication, division, and remainder cannot be performed on qualitative data. Quantitative data can also be viewed as numerical data, which can be used to order quantitative data or perform arithmetic operations on them. Quantitative data can be further divided into discrete data and continuous data. Discrete data cannot take any value on the axis, but can only be taken at specific points, such as the number of students in a school, the number of universities in a country, and so on. Continuous data can take any value on the axis. A typical example is the height of a tree, the weight of a watermelon, the length of a rope, and so on.
In the information age, the amount of information is growing at an explosive rate every day, and the amount of data that needs to be stored is growing. However, due to different needs, the storage format of the data is different, which brings a lot of inconvenience to the storage and analysis of the data. Large-scale data includes both incomplete data and noise-containing data, and there may be data inconsistencies. These unfavorable factors may affect the normal processing of data, thus reducing the value of data to people. Therefore, in order to improve the quality of data mining, especially before processing large amounts of data, it is necessary to pre-process the data, so as to more effectively extract valuable information from the data. Currently, commonly used data preprocessing methods include: Data integration; Data cleaning; Data transformation; Data reduction.
In order to facilitate the verification of the classification algorithm proposed in this paper, we process the data into the form of Fig. 2:
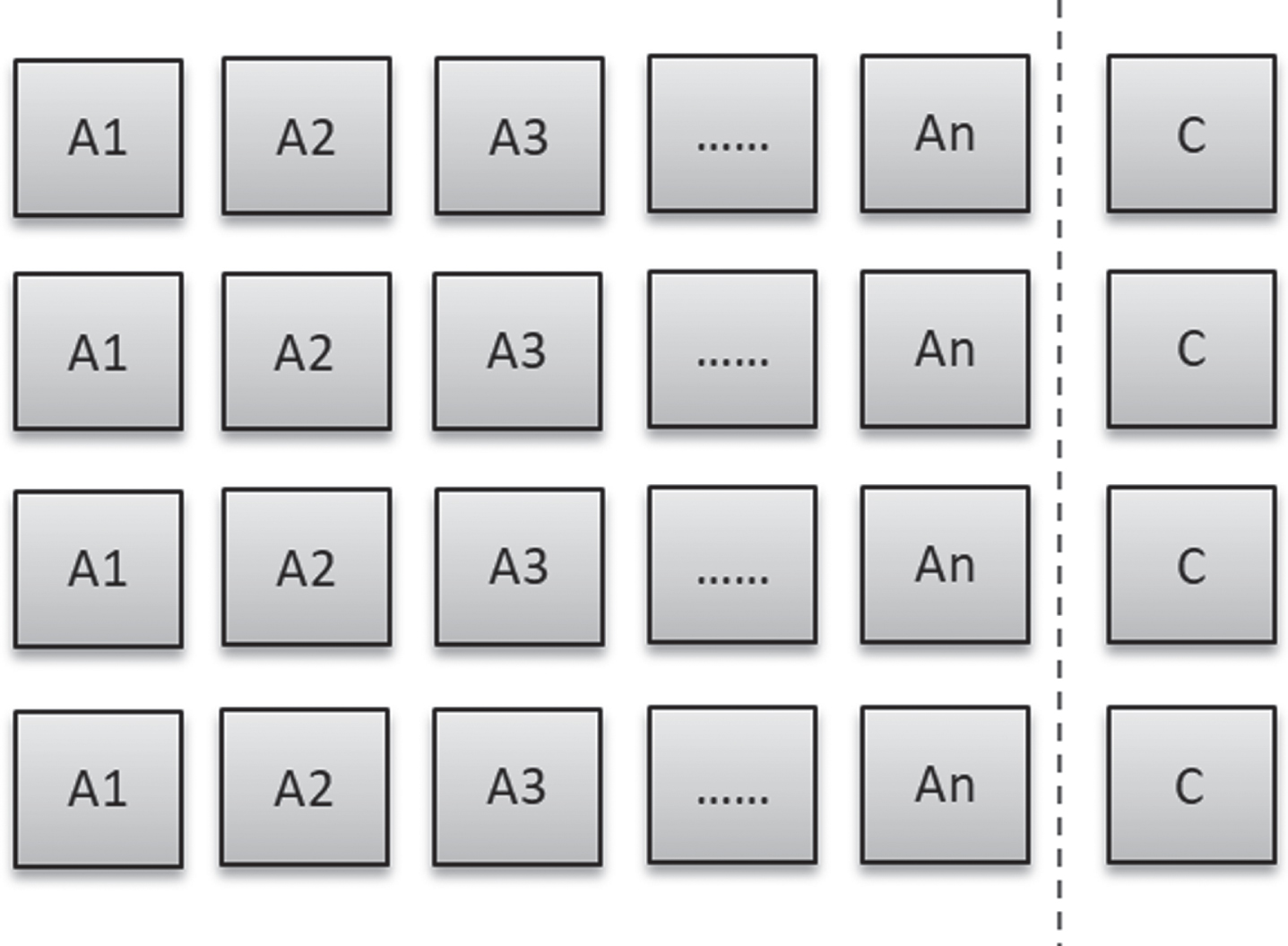
Sample tuple structure.
Among them, A1, A2, ⋯ A k is the attribute, k is the number of attributes, and C is the class label. The attribute and the class tag together form a sample of data, and the collection of samples constitutes the data set. In the classification algorithm research, the data set generally includes a training set and a test set. We store the data set in a text file and store one sample data in one line.
The classifier model is done on top of the training data set. The Naive Bayesian classification algorithm has been introduced in detail in Chapter 2. The basic idea of NBC is to predict the unknown data samples to the category corresponding to the highest posterior probability based on Bayes’ theorem.
D is the training data set, and A = A{ 1, A2, ⋯ A n } is a set of attribute variables, including conditional attributes of n numbers, and C ={ C1, C2, ⋯ C m } is a set of class variables containing categories of m numbers. Then, a training sample can be expressed as X ={ a1, a2, ⋯ a n , C i }.
In order to get the Naive Bayesian classification model, we first need to obtain the prior probability P (C i ) = N i /N of a certain category C i on the training data set. In the formula, N represents the total number of samples in the training data set, and N i represents the number of samples belonging to class C i in the training data set. Then we need to calculate the conditional probability parameters of the attribute. For discrete value attributes, we can count the number n ijk of samples of attribute A j with value a k in the sample belonging to category C i . If the attribute is a continuous value, there are two ways to deal with it. One method is to discretize the continuous value, and then calculate the conditional probability by processing the discrete value attribute. Another method is to count the distribution of the value of the attribute A j in the sample belonging to category C i . Gaussian distribution is usually used to simulate, and Gaussian distribution parameters θ ij of attributes are calculated by sample data.
. That is, the mean and variance of the sample are used to estimate the model parameters. In the formula, μ
ij
,
The weighted Naive Bayesian classification algorithm weighs the importance of different attributes by assigning different weights to different conditional attributes, thereby improving the classification accuracy. The formula for calculating the posterior probability of the Naive Bayesian classification algorithm based on attribute weighting is as follows:
Equation (14) contains product operations and power operations, and the computational overhead increases greatly as the number of attributes increases. To this end, we can use the natural logarithm operation on equation (14), convert the product into addition, and convert the exponent into a product operation. The converted formula is as follows:
In the formula, w k represents the weight of the attribute A k . Comparing equations (1) and (14), it can be found that the difference between weighted NBC and NBC is that a weight w k is given when calculating the conditional probability P (a k |C i ) value of each attribute. In fact, we can also regard NBC as a specific weight for all weighted NBC attributes with a weight of 1.
The conditional probability P (a k |C i ) can be obtained from the conditional probability parameters obtained on the training data set:
If A j represents a discrete attribute, P (a k |C i )= n ijk /N i . In the formula, n ijk represents the number of training samples in class C i that have the value a k on the attribute A j .
If A
j
represents a continuous attribute, it is generally assumed that it is subject to a Gaussian distribution. Then, there are
In the formula, g (a k , μ C i , σ C i ) is the Gaussian density function of the property A k , and μ C i andσ C i are the mean and the standard deviation, respectively.
The weighted Naive Bayesian classification algorithm is classified by the following formula:
A key issue in the weighted Naive Bayesian classification algorithm is how to determine the size of each attribute weight. The weighted Naive Bayesian classification algorithm proposed in this paper uses differential evolution algorithm to optimize attribute weights, and each attribute A i corresponds to a weight w i . In the process of using the differential evolution algorithm to optimize the weights, the individual X i ={ w1, w2, ⋯ w k } is used to represent the weights. In the formula, k is the number of attributes, multiple individuals form a population pop ={ X1, X2, ⋯ X n }, and n represents the size of the population. Classification accuracy is one of the important indicators to measure the performance of the classifier. The accuracy of the classification determines the performance of the classifier. Therefore, the fitness function of the differential evolution algorithm uses the classification accuracy of the classifier.
The random method is used to initialize the population pop so that the variables in each individual satisfy w i ∈ (0, 1). In each iterative optimization process, each individual is treated as a possible optimal weight, and substituted into formula (16) to predict the category of training data. It should be noted that the weights are normalized when they are substituted into the weighted Naive Bayes formula, so that the sum of the weights is 1. Since the category of the training data is known, the classification accuracy of the weighted Naive Bayes classifier on the training data set can be obtained when the categories of all the samples on the training data set are obtained, and each individual in the population can obtain a classification accuracy rate. After the end of an iteration, the optimal individual can be found, then the population is updated, and the next iteration optimization process is repeated, and the iterative process is repeated until the specified number of iterations is reached. The optimal individual finally found is used as the optimal attribute weight of the classifier.
Classification prediction
Through the above training process, a Naive Bayesian classification model with weights can be obtained, and then the unknown data can be classified and predicted. Since the static parameters of the model already contain the prior probability of the category, the posterior probability of the attribute, and the weight, it is only necessary to calculate the posterior probability that the unknown data belongs to each category according to the WNBC classification formula (16), and then select the category with the highest probability as the prediction category of the unknown data.
Algorithm process
Determining the size of attribute weights is one of the main tasks of attribute weighted Naive Bayesian classification algorithm. The weighted Naive Bayesian classification algorithm based on differential evolution algorithm uses DE algorithm to search for suitable attribute weights in search space. Once the size of the appropriate weight is determined, the classification model can be used for classification. The main process of the algorithm is described in detail below: Data preprocessing. On the training data set, the classifier model is trained, including calculating prior probabilities and conditional probability parameters. The population pop ={ X1, X2, ⋯ X
n
} is randomly initialized and gbest = 1. Each individual in the weighti = Xi population represents a combination of attribute weights and normalizes the weighti. Each individual predicts the classification accuracy of the data set, that is, the fitness value FitVal of each individual is calculated. The fitness value FitVal (Xi, g + 1) of each individual is compared with the individual fitness value FitVal (Xi, g) of the previous generation. If FitVal (Xi, g + 1) > FitVal (Xi, g), the descendant individual Xi, g + 1 replaces the parent individual Xi, g into the next generation, otherwise, the parent individual enters the next generation. The fitness value g of each individual is compared with the global optimal value. If FitVal (Xi, g + 1) > FitVal (gbest), gbest = i. Individual Xi in the population is updated. The step jumps to step (4) and the loop iterates until it converges, or the population reaches the maximum number of iterations.
After the above training process, a set of weights can be obtained, and then the set of weights can be used to predict the data of the unknown tag according to the attribute weighted Bayesian classification algorithm.
Design principles of architectural art
Principle of openness
The principle of openness refers not only to the opening and transparency of space, but also to how the architectural space of contemporary art museums can be more inclusive and open, and to accommodate more audiences in today’s contemporary art context and in the increasingly unconstrained world of art and life. First of all, the open spatial form is opposite to the closedness. The openness of the architectural space of the museum mainly reflects the open and free communication of the inner and outer space and increases the attraction and affinity of the space through the form of the boundary of the architectural space and the performance of the material.
In the division of indoor space, whether it is a functional space or an indoor auxiliary space, the building is divided as much as possible in a flexible form, without emphasizing the specific division of different functional spaces. At the same time, the definition of space in the building is as blurred as possible, and there is no blocking between the indoor space and the space on the line of sight, and it is transparent and coherent (Fig. 3, Fig. 4). The rotating panel partitions on the second floor of the building can be closed or opened to create a flexible space for viewing, and also form a barrier and control flow, providing a varied exhibition environment for the exhibition to meet the needs of different exhibitions.
Rotating partition wall (self-painting).

Building effect simulation.
Secondly, architecture emphasizes the integration of art and life. Contemporary art puts forward the slogan of “everyone is an artist” and “life is art”, which brings the distance between life and art closer. This means that the architectural space of the museum should focus on the needs of visitors in functional planning, meet the physiological and psychological needs, enhance the sense of service, and transform the museum into a space-conscious place that focuses on people’s emotional experience and pleasure. For example, the design of functional spaces such as art galleries and cafes in the museum, and the two main functional spaces face Hee Street, and can also operate independently during the retreat of the museum (Fig. 5, Fig. 6).
The plane of the art store of the art gallery.
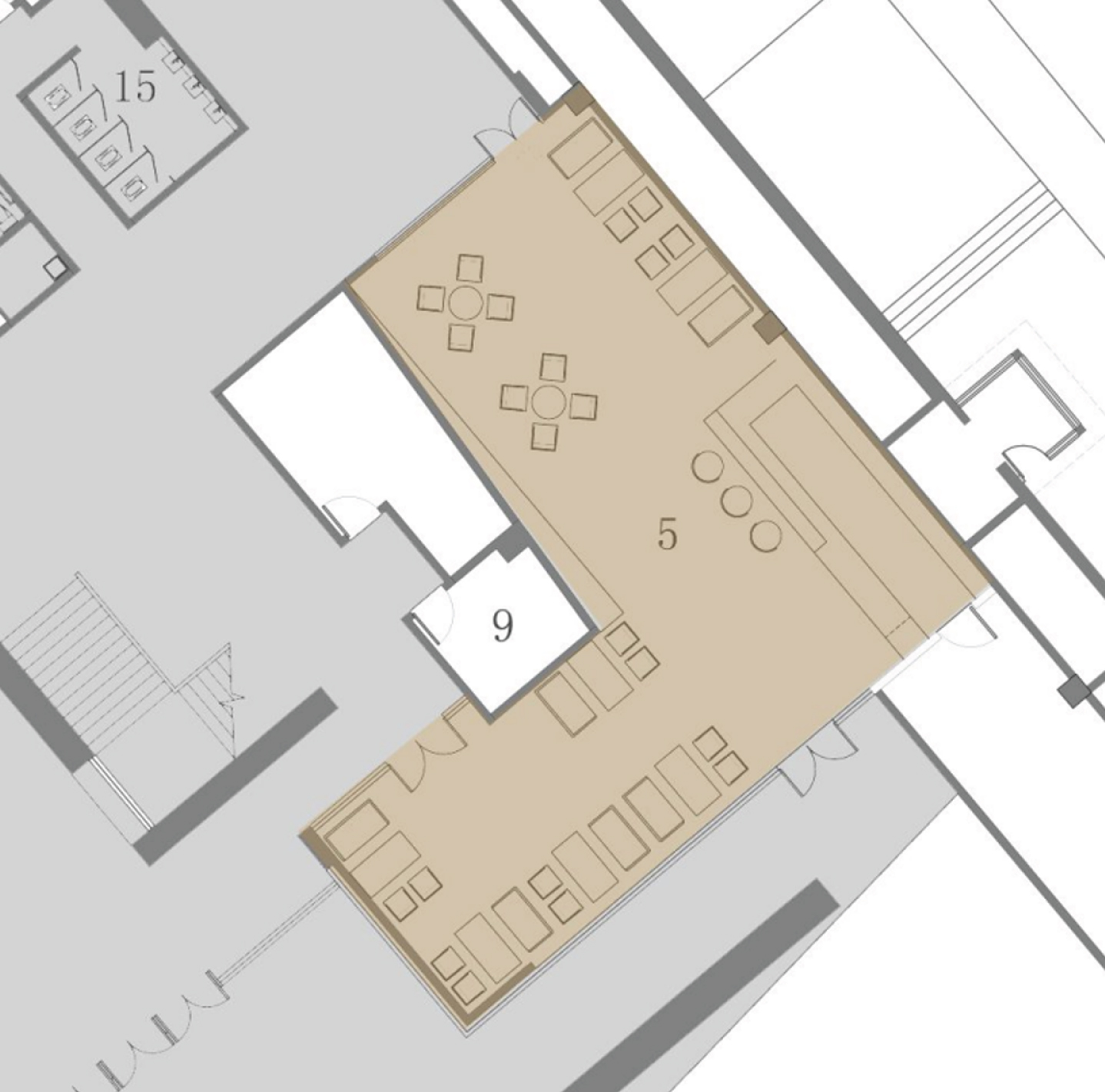
The plane of art café of the art gallery.
The architectural space incorporates contemporary art and human visual perception, forming a close connection between space and people, art and people, space and art. This requires that in the design of the architectural space, it is necessary to consider not only how the architectural space accommodates contemporary art works and the way contemporary art is presented, but also the spatial cognition generated by the experience of people in the architectural space. The principle of dynamism emphasizes the changes in the movements and experiences of visitors in the space process, and focuses on the communication between the works and the visitors formed in the space.
In the actual case of the museum, the interaction is mainly reflected in how the space setting better meets the communication and communication between the person and the displayed work. Moreover, the design of the exhibition hall is not only a square structure with regular rules, but also under the influence of contemporary art, it forms a combination of viewing and moving lines (Fig. 7, Fig. 8). The exhibition hall on the first floor of the museum is 10 meters high, and the first and second floors are connected by a folding walkway. Visitors can take a tour of large installation art and sculpture exhibits. In this way, not only visitors can interact with the exhibits in all directions, but the artist can also arrange the display effects according to the form of the scene to achieve a more perfect combination. The exhibition space on the first and second floors of the museum transitions from a low space to a high space and is combined with the tour line to form a close communication between visitors, space and exhibits.

One-floor installation hall (self-painting).

Display space of one and two floor (self-painting).
The museum building space contains two levels of content, namely the physical space level and the behavioral space level. Physical space refers to space size, space shape, and space capacity. It is particularly embodied in the distribution of the various functional spaces of the museum and the distribution of the shape and size. It can be seen from the layout of the art museum of the Sichuan Academy of Fine Arts that in the orange and purple-red exhibition area, its shape and size are gradually increased from one layer to two layers, and then gradually become independent in three layers and four layers. In the organization of the tour line, because the hall and the entrance are places where people flow more concentrated, different traffic flows are set on the first floor, namely the flow directions of the elevator, the main staircase passage, the slope exhibition hall passage, and the folding slope exhibition hall passage, which satisfy the visiting and viewing modes of various regions (Fig. 9).
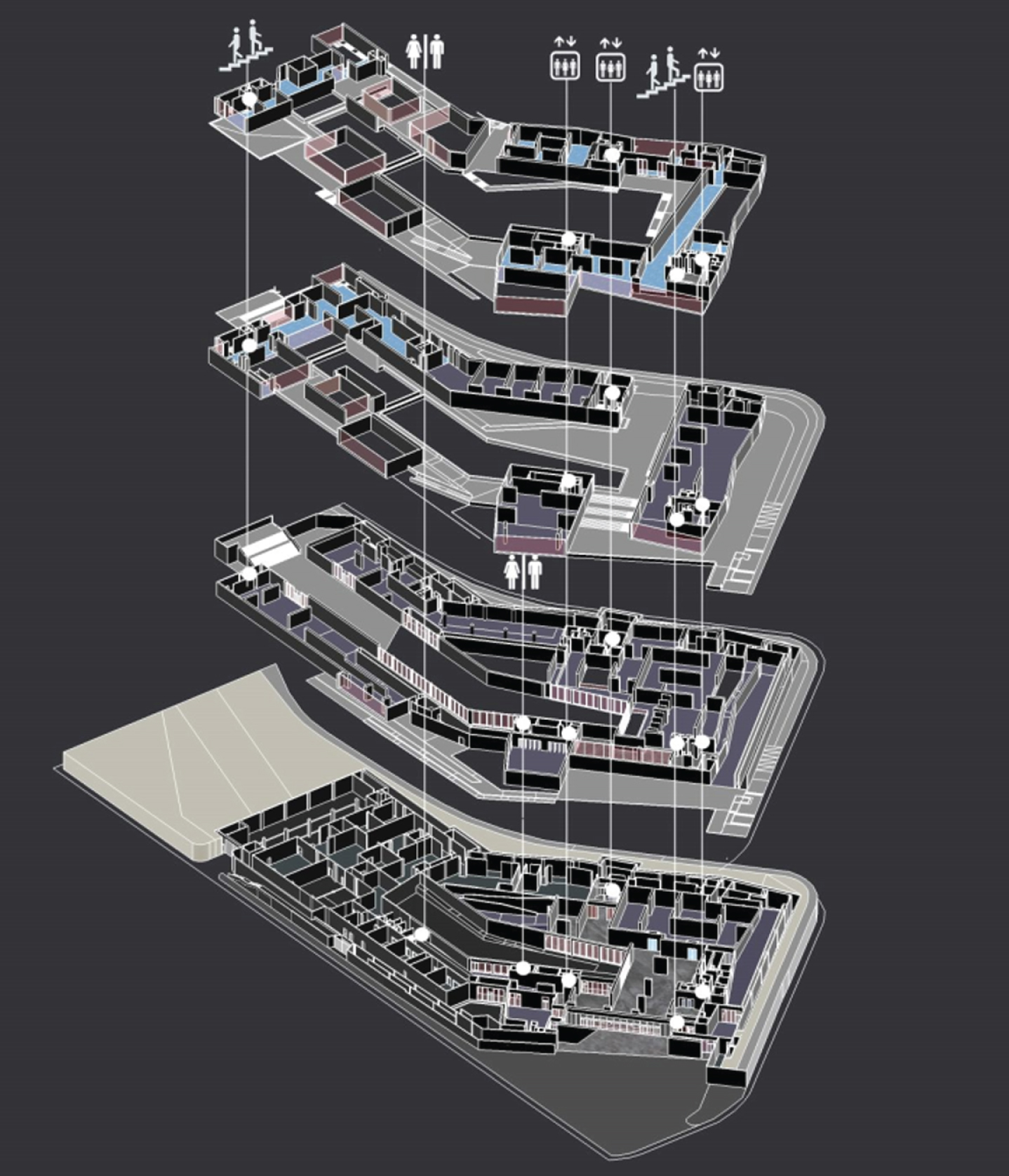
Moving line organization from one layer to four layers (self-painting).
In the ambiguity caused by the change in quantity, we find two specific forms of existence, one is the ambiguity of function, which can also be called the ambiguity of space. This means that in a certain space, its spatial function cannot be defined by a single conventional function but is generated by a combination of multiple functions. Another type of path blur we call, when people enter a network of traffic systems, they fall into path blur. When the path is shorter, the more likely the choice is, the more obvious the path blur is.
In the design process of a building, designers usually pre-set the user behaviors of each room and set a name for them, such as corridors, bedrooms, living rooms, restaurants, study rooms, etc. For these spaces with different “tags", architects usually sum up a set of spatial paradigms to simplify thinking, but this simplification is mechanical, modular, and non-human. Once the space has “production drawings”, the same bedroom, corridor, living room, etc. are produced one after another. “As long as things get more and more superfluous, then the sense of loss and emptiness will increase, and conscious builders feel restless about such a situation.” When such malpractices gradually emerged over time, the exploration of a group of architects led to people’s thinking about the possibility of spatial function.
The function-blurred space is opposite to the “tagged” space. This type of space provides more possibilities for use and reflects a functional ambiguity. This ambiguity caused by “polysemy” is one of the ways in which ambiguity exists in architecture (Fig. 10).
From traditional plane to modern plane ambiguity.
Smith’s famous work, CorwnHall, is a bold practice of his “universal space” theory (Fig. 11). The first floor of the building is a huge open hall. In order to achieve the purpose of space purity, he did not set the weighing column and the weighing wall in the hall but suspended the roof in the hanging ridge on the roof. The interior functions of the building are arranged around, and only a few light partitions are used to separate the functions. Mies tries to create a universal space that can accommodate a variety of activities. Mies re-tested the general space in the 1954 Covnentin Hall program. This is a non-separated integrated space that can accommodate 50,000 people. It has a side length of 82.3 meters and a building area of 46,500 square meters. In this unfinished solution, Mies still tries to solve multiple functions with a large space (Fig. 12).

Design concept image of the school building.

Design of the building skeleton.
Faced with the basic context of current education, in the specific implementation stage of the curriculum, classroom teaching is difficult to completely get rid of the double-basic mode of traditional art teaching, and teachers and students are accustomed to teachers to listen to students to listen to this teaching mode. Course teaching based on the concept of modern science and technology education is a new and open teaching mode. The effective development of teaching mode requires a democratic and open teaching environment, flexible and flexible teaching methods, and active and enthusiastic participation of students. For the new art teachers, due to the lack of their own art education literacy, the teacher’s theme orientation of the course makes the students’ thinking naturally limited to a certain art field, forming a habitual classroom atmosphere such as “this class is cutting paper” and “let us draw sketch still life” “Is this not a logo design”? At this time, students often lose interest and curiosity about art learning, and students’ enthusiasm for class participation is weak, which runs counter to the generative classrooms that modern educational concepts hold.
This study is aimed at the application of Naive Bayesian classification algorithm and fuzzy model in architectural art teaching. Through the previous literature reading, the theoretical basis and application mode of mixed learning are summarized, and the teaching effect of the algorithm is studied. By applying this method to the teaching of architectural art, the teaching effect can be effectively improved.
The application research on hybrid learning is not uncommon, and the main application fields are mostly in the fields of language and computer technology. However, there are very few research practices in implementing mixed teaching in the teaching of public art courses. Based on the Naive Bayesian classification algorithm and fuzzy model, this paper constructs a hybrid teaching design process model of the new public art curriculum, and carries out teaching practice, which makes a new exploration for improving the teaching quality of public art education curriculum.
The research of domestic scholars based on the intelligent teaching interactive platform is still in its infancy, and some scholars have studied the interactive platform with English and computer. This study further expands the scope of application of science and technology in the education industry.
This paper designs a hybrid teaching design process model and tests this hybrid teaching design process model in teaching practice, which can provide some ideas and methods for follow-up scholars.
Conclusion
In the past few decades, China has taken a step in art education, and has a systematic contribution of educational concepts, academic theories, and educational practice models as a carrier, and has become a classic for future development of art education. China’s art education has developed rapidly under the impetus of strong social demand, and it has ushered in a period of opportunity that has never existed in history. In order to accomplish the goal of aesthetic education, creative classrooms are promoted. The generative classroom is based on the students’ problems and is the test of the wisdom of teachers’ education. When carrying out thematic teaching, teachers need to pay attention to scientifically grasp the whole classroom teaching process, allow students to imagine the sky, and pay attention to guiding students to imagine the way. However, in the course of the course, the following situations often occur: the classroom teaching style of the teacher is very novel, and the students’ participation in the classroom is highly motivated, but the students do not have a positive and prosperous art classroom. In this case, the art class seems to be full and lively, but in reality, the students are doing nothing, and the concept of the curriculum education is not effectively implemented. The ideal generative classroom is to try to transform students’ cognitive changes into evaluable and measured external behaviors through classroom participation.