
Abstract
Under the influence of COVID-19, detection and identification of moving targets are very important for personnel management. A lot of research work has improved the accuracy and robustness of the moving target tracking method, but the recognition accuracy of the traditional target tracking method in complex scenes (lighting changes, background interference, posture changes and other factors) is not satisfactory. In this paper, in view of the limitations of single feature representation of target objects, the method of fusion of HSV color features and edge direction features is used to identify and detect moving targets. In each frame of the tracking process, the weight of each feature is adjusted adaptively according to the proposed fusion strategy, and the position of the target is located by using the method of double template matching. Experiments show that the proposed tracking algorithm based on multi feature fusion can meet the requirements of moving target recognition in complex scenes. The method proposed in this paper has a certain reference value for personnel management under the influence of COVID-19.
Introduction
As one of the research hot-spots in the field of computer vision, moving object tracking has a wide range of applications, such as automatic video navigation, video retrieval, traffic monitoring, human-computer interaction and so on [1, 2]. Although target tracking has been studied and made great progress in the past decades, it is still a very challenging task when the target is in a complex scene [3].
How to design a model which can overcome the interference factors is an important factor to a good tracking system, and the appearance model directly affects the final tracking results [4]. In the real complex dynamic scene, it is difficult to describe the moving target by using a single feature to adapt to the changes of the target and the scene [5, 6]. By using the complementarity between different features, multiple features can be fused to express the appearance of moving objects, so as to achieve more robust tracking [7]. Although many researches have proved the effectiveness of data fusion in the field of moving target tracking, due to the different importance of different features in expressing the target object in each frame in the dynamic and complex environment, it is necessary to adapt to the changes of target appearance and background [8].
Multi feature fusion
The necessity of feature fusion
The method of data fusion can take advantage of the complementarity between different features. At present, it has been proved to be an effective method of moving target tracking. It is an effective method to express the appearance model of the target with multiple features extracted from different perspectives [9]. The global features are robust to pose changes and motion blur, but global features are not suitable to describe the target in the scene of illumination changes, occlusion and background interference, while local features are just the opposite.
In view of the simplicity and effectiveness of color features, this section uses color features to express moving objects. In image processing, RGB model is the most common color space. It uses three color channels R, G and B to represent any color and gray level. It is commonly used in color display and image processing. However, in the field of computer vision, RGB is not so stable, because RGB color is easily affected by light. Compared with RGB color features, HSV color space is more stable to the change of illumination, and can better reflect the nature of color, and the calculation is simple. Many methods proposed by the researchers have proved that HSV color features have good robustness and effectiveness in the field of computer vision.
The single color feature sometimes can not describe the target well when the target object suffers obvious appearance changes. In some cases, different positions of the same image may have similar color segment information, which is not conducive to accurate tracking of moving targets. In order to prove the above point, this section extracts the color histogram information in different ways. It can be seen from Figs. 1 and 2 that different targets may have the same information. In this case, using a single feature to describe the appearance of the target is difficult to design a robust tracking system, and even lead to tracking drift and other problems. Therefore, we can consider fusing multiple feature expression objects to make up for the shortcomings of a single feature.

Selected target and corresponding HSV color histogram.

Selected target and corresponding HSV color histogram.
In the field of computer vision, local features have better separability than global features in describing target objects [10]. In order to extract edge direction histogram information, edge detection is needed first, and Canny operator is recognized as the best edge detection operator at present. The edge direction histogram distribution information of different positions of the same image is also extracted. It can be seen from Figs. 3 and 4 that the distribution information of edge direction histogram in different positions of the same image is quite different, which shows that the edge direction histogram feature has high separability to the target [11, 12].
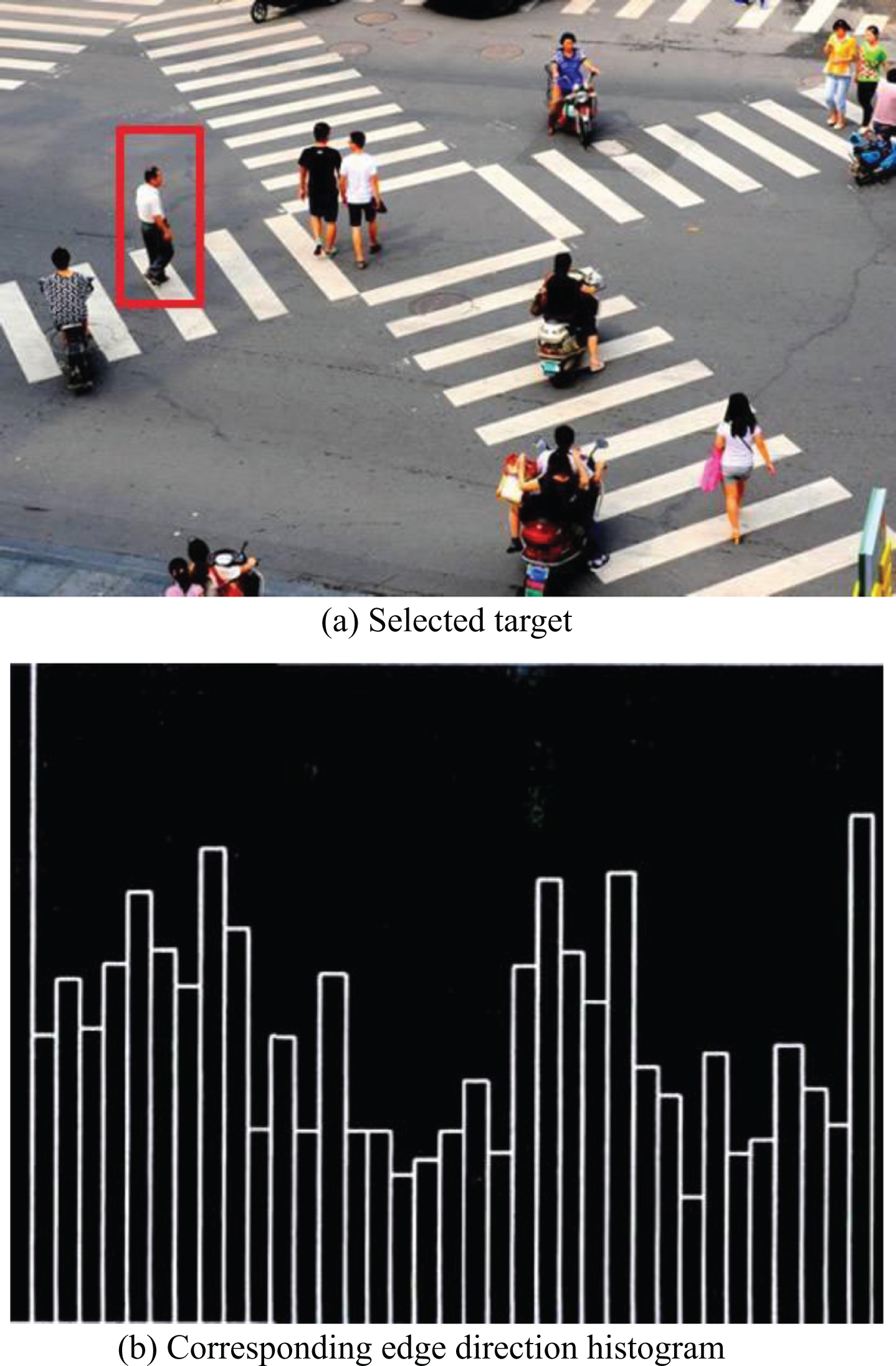
Selected target and corresponding edge direction histogram.
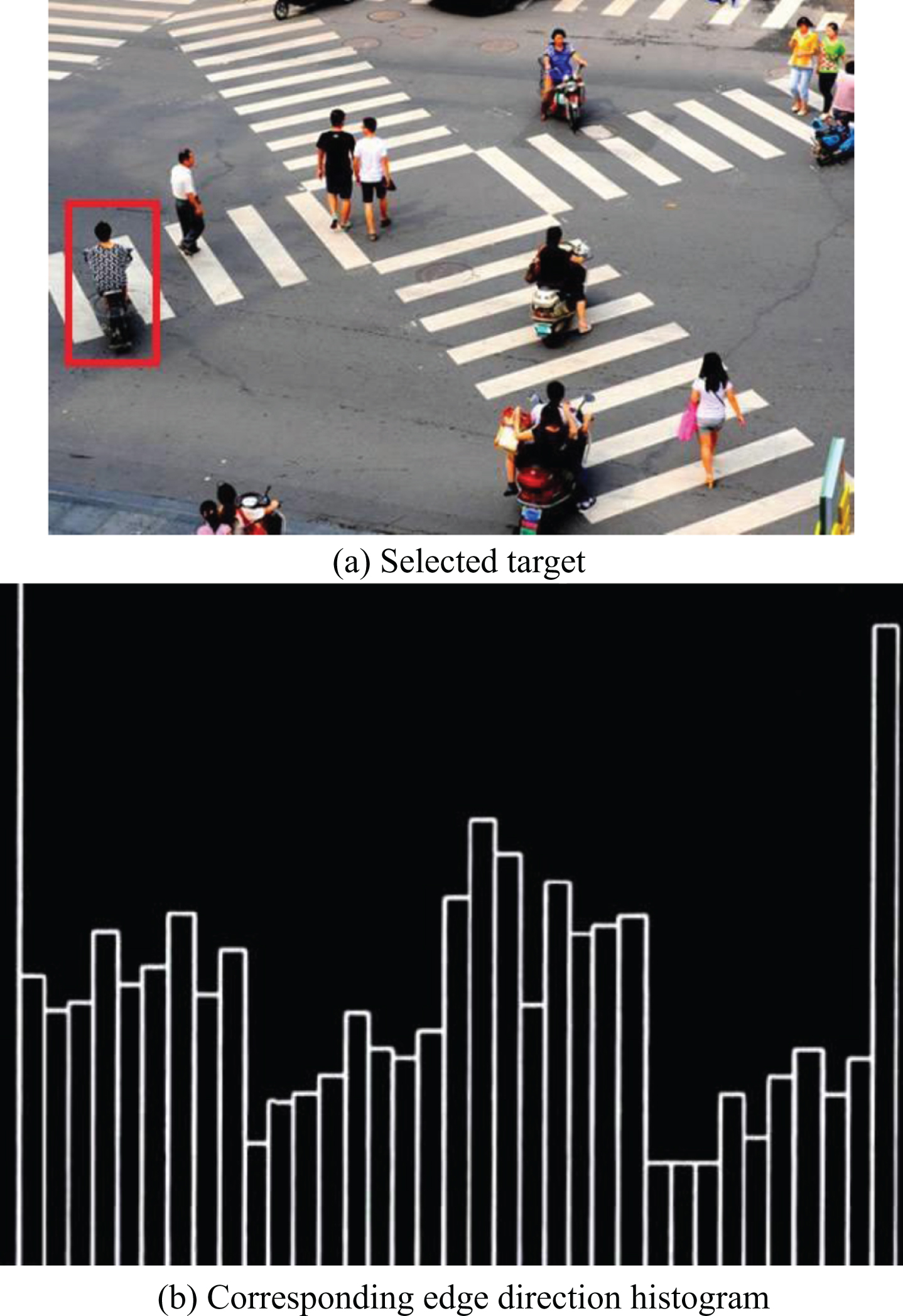
Selected target and corresponding edge direction histogram.
In a certain frame, HSV color feature are used to describe some candidate areas of the current frame, and then the similarity between these candidate areas (in this section, the similarity is calculated by the number of pasteurization system). Obviously, the greater the difference of similarity calculated based on a certain feature, the stronger the discrimination ability of this feature, as shown in Fig. 5a). In the blurcar video sequence, some candidate regions are selected. The Table 1 shows the eigenvalues of different images. In other words, HSV color features can not distinguish the target object from the background, but edge direction features can do this. However, in the Pedestrian 1 video sequence shown in Fig. 5b), the situation is just the opposite. It can be seen from Table 2 that the similarity value calculated based on the proposed HSV color feature expression is quite diverse when the similarity value calculated is very similar. That is to say, in the video sequence Pedestrian 1, the HSV color feature has better discrimination ability than the edge direction feature.

Selected video sequence.
Similarity of BlurCar video sequences
Similarity of Pedestrian 1 video sequence
It can be seen that in some complex and dynamic scenes, a single feature may not be able to make the target recognition well.
According to the realization process of the target tracking system, the target tracking method architecture can be divided into three parts: target initialization, target appearance modeling, motion prediction. Target initialization refers to the selection of interested moving targets at the beginning of target tracking. There are two common ways to select moving objects: manual selection and automatic selection. The former uses rectangle or ellipse frame which is slightly larger than the target to select the whole target area in the first frame, while the latter uses detection algorithm to select the target. Appearance modeling refers to what features are used to represent the target. Common moving target features include: color, texture, edge, motion and so on. How to select appropriate target features according to specific scene is the key factor of tracking performance.
By extracting effective features to represent the target, we can distinguish the interested moving target and background. Target feature extraction refers to the use of some salient features of moving targets to represent the target, which can be divided into two parts. Diverse features are used to build a robust appearance model. Statistical model is to use statistical learning method to build an effective mathematical model, in order to effectively distinguish the target and background. Motion prediction is a dynamic state evaluation problem. After getting the position of the target in the previous frame, the target features are extracted, and the position of the target is determined in the next frame by using a target tracking algorithm. The classical prediction methods include linear regression prediction algorithm, prediction algorithm based on meanshift, Kalman filter prediction algorithm, particle filter prediction algorithm, prediction algorithm based on discrimination learning and prediction algorithm based on sparse representation.
The research shows that the effectiveness of the tracking algorithm can be summarized as follows: the success or failure of tracking mainly depends on the separability between the target object and the background. If the target object is easily distinguished, a simple tracker based on single feature can be used to locate the target. On the contrary, if the target object is in a complex dynamic environment or its appearance changes greatly, the use of single features is often not so effective. Considering the complementarity of different features, it is an effective method to integrate multiple features or allocate the feature weight adaptively.
Generally speaking, researchers hope to distinguish the target object from the background as much as possible through the method of multi feature fusion. As a classical pattern classification method, the inter class dispersion of samples is as large as possible and the intra class dispersion of samples is as small as possible, so that these categories can be distinguished as much as possible. In fact, variance in statistics is an important indicator of the degree of dispersion between samples. Based on Fisher criterion, the similarity between target template and all candidate targets is calculated based on two different features, and then the variance of similarity is used to evaluate the discrimination ability of corresponding features. If the variance based on a certain feature is larger, it means that all candidate targets are more scattered, that is to say, this feature can better distinguish these candidate targets or its discrimination ability is stronger. Therefore, features with stronger discrimination ability are given greater weight. The multi feature fusion strategy will be described in detail later.
Adaptive multi feature fusion strategy
In this paper, based on the similarity between the target template and all the candidate targets, the variance in statistics is used to allocate the weight of each feature adaptively. The larger the variance calculated based on a feature, the stronger the discrimination ability of the corresponding feature, so the feature will be given a larger weight.
For example, in a certain frame, if the variance calculated based on color feature is smaller than that calculated based on edge direction feature, it indicates that in this frame, the discrimination ability of color feature is not as strong as that of edge feature, that is, the target object and background cannot be distinguished well. Therefore, at this time, the importance of color features to target expression is not great, so we should assign a small weight to color features. On the contrary, the edge direction feature should be given a larger weight. In addition, if the variance calculated based on color feature and edge direction feature is similar, it indicates that the discrimination ability of the two features is similar at this time. At this time, the two features have certain and similar importance in target expression. Therefore, the two features should be given similar weights to better express the appearance of the target.
In this section, because the method of bimodal matching proposed in this paper should be used as the main optimization function, we need to calculate online similarity and offline similarity respectively. Assuming that K candidate targets are obtained in a certain frame, the similarity of K candidate targets is calculated as follows:
Tcol _ line and Tedge _ online are online target models described by HSV color feature and edge direction feature respectively, while Tcol _ offline and Tedge _ offline are offline target models described by HSV color feature and edge direction feature respectively, and Ckcol and Ckedge are the K candidate block models described by HSV color feature and edge direction feature respectively. Obviously, the larger the pasteurization coefficient is, the higher the similarity between the target model and the candidate block is.
In order to get the importance of different features, we need to calculate the variance of the above similarity. The formula is as follows
Among them,
In different scenes, HSV color feature and edge direction feature have different discriminability in representing moving objects. Therefore, in the process of target tracking, when two features are fused to describe the target appearance model, an effective method is needed to express the discrimination performance of different features. Suppose ωcol_online and ωedge_online represent the weight of HSV color feature and edge direction feature respectively in the case of online template matching. Similarly, ωcol_offline and ωedge_offline represent the weight corresponding to HSV color feature and edge direction feature in offline template matching respectively. In this paper, the weight of each feature is allocated according to the variance calculated above. Take the case of online template matching (the case of offline template matching is similar), the weight of each feature is calculated as follows:
It can be seen from the above formula that the larger the variance of the similarity of the corresponding feature is, the greater the weight is given to it. On the contrary, the smaller the variance of similarity of corresponding features, the smaller the weight. If the variance of the two features is very close, it can be considered that the weight of the two features is 1. Take online template matching as an example, the weights of the two features are normalized:
Among them,
That is to say, among all candidate blocks, the candidate block should be selected.
The template updating system adopts pure client technology architecture mode. SSD detection model is packaged and stored locally. The spatial, attribute and enhanced information of all geographic objects are stored in the local database SQLite. The template updating system mainly includes four modules: image processing, position and attitude calculation, spatial data query and enhanced information. The image processing module includes acquiring image, running SSD model and outputting detection results. The position and attitude calculation module includes acquiring GPS and calculating attitude. The spatial data query module includes the query of the surrounding area and calculation direction, and the enhanced information module includes the display of attribute information, the display of virtual object information and the realization of human-computer interaction.
The online template is updated as follows:
The best candidate target of the current frame is used as the latest online template. The online template can not describe the appearance of the target well due to over learning, the offline template can be updated to improve this situation.
Assuming vectors p = p1,p2,...,pk and q = q1,q2,...,qk, the babbitt distance between vectors p and q is defined as follows:
The offline template is updated as follows:
Among them, d (Tcol_offline, Tcol_online) and d (Tedge_offline, Tedge_online) are the pasteurization distance. The threshold value 0 is used to determine whether the offline template needs to be updated. Through many experiments, the empirical value of θ is set to 0.3. In other words, firstly, the pasteurization distance between the online template and the offline template based on HSV color feature and edge direction feature expression is calculated. When the smaller of the two distances is larger than the threshold θ, it means that the distance between the offline template and the online template of the current frame is larger, so it is necessary to update the offline template, because the offline template can not describe the target object well.
Considering the influence of different lighting conditions on tracking registration, the test is carried out in different time periods of the day. Record the current time, the type and probability of detection, and the time taken for detection. A data table is designed to store the test information. The test information is stored every time when the test is carried out, and the statistics are made in different time periods.
In order to better explain the robustness and accuracy of the algorithm proposed in the plain-text, this section analyzes the tracking success rate Sr and the center position error of the Pedestrian 2 video sequence. It is worth noting that the Pedestrian 2 video sequence has challenges such as pose change, background interference and scale change. Table 3 illustrates that tracking methods based on single feature expression (including color and edge features) or fixed feature weights cannot accurately locate the target position, and even when another person walks out of a nearby car, the three algorithms all miss the target object. On the contrary, the adaptive multi-feature fusion method proposed in this paper maintains good robustness and high tracking accuracy throughout the tracking process.
Comparison of Tracking Success Rates of Pedestrian 2 Video Sequences (%)
Comparison of Tracking Success Rates of Pedestrian 2 Video Sequences (%)
The tracking success rate SR of Pedestrian 2 video sequences are listed in the Table 3. The tracking success rate SR of the tracking method based on single feature expression or fixed feature weight is relatively lower than that of the method proposed in this paper. Figure 6 shows a graph of center position error CLE of pedestrian 2 video sequence. The CLE curves of single feature tracking (using only color or edge features) and fixed weight tracking are higher than those of 8 TM-MF. Especially when the target has serious background interference, the CLE results of other methods suddenly increase, while the CLE of ATM-MF basically maintains the original size.
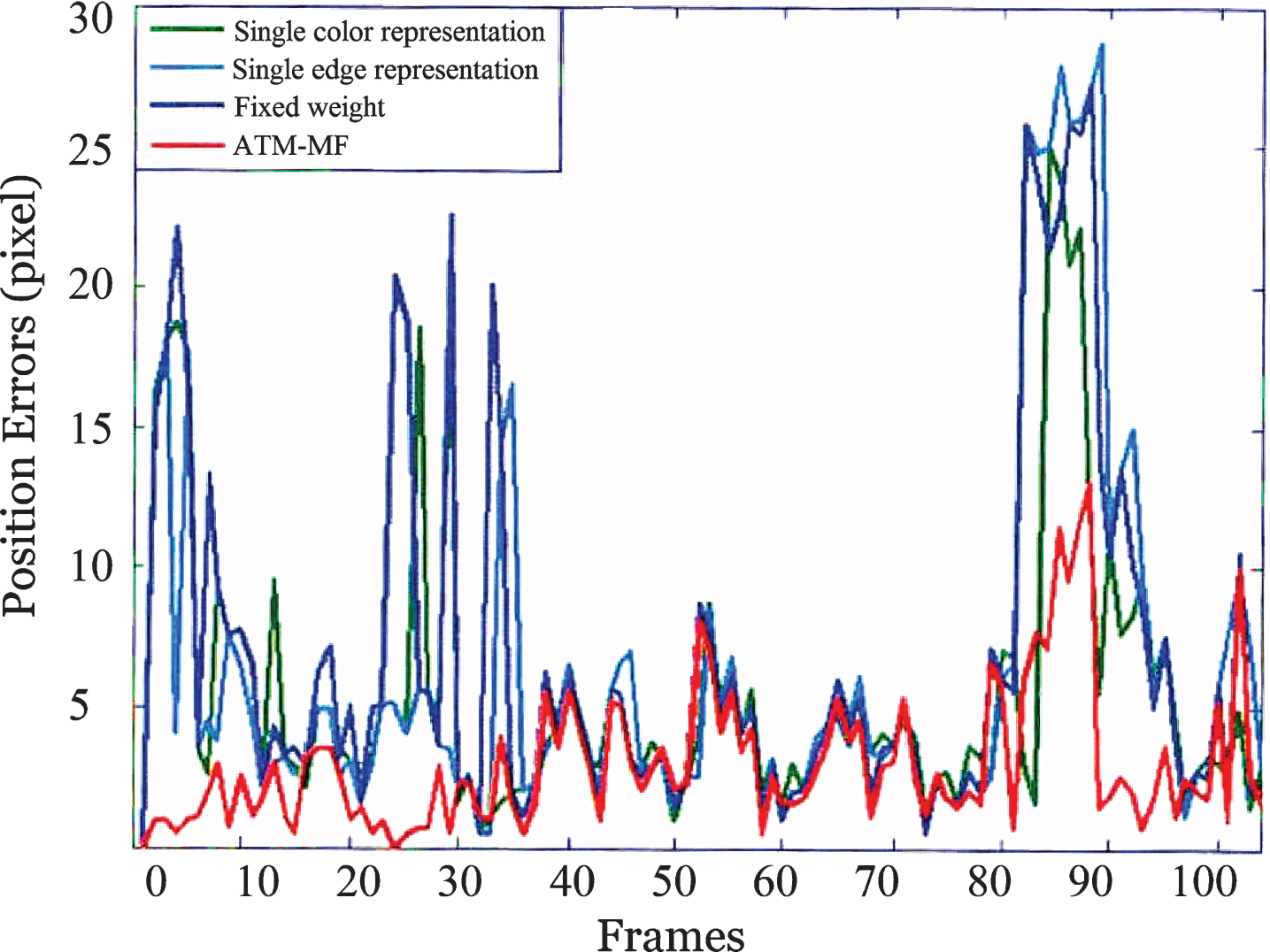
CLE Comparison Table for Center Position Error of Pedestrian 2 Video Sequence.
In this paper, in view of the limitations of single feature expression of target object, the necessity is analyzed. In each frame of the tracking process, the weight of each feature is adjusted adapt to the fusion data. Finally, through a large number of experiments, the effectiveness and robustness of the proposed tracking algorithm based on multi feature fusion are verified from three aspects. The method proposed in this paper has a certain reference value for personnel management under the influence of COVID-19.
Footnotes
Acknowledgments
This work has been supported by the major project of Henan higher education teaching reform research and practice project “based on” double high “, focusing on” five fusions", innovating and practicing the” five forces “talent training mode of Higher Vocational Education (approval No.: JG [2020] No. 27).