
Abstract
English text is difficult to recognize under the interference of blurred background, so it is necessary to improve the fixed-point tracking technology of English text. Based on machine learning algorithms, this paper studies the fixed-point tracking model of English reading text based on mean shift and multi-feature fusion. The target tracking algorithm based on mean shift obtains the description of the target model and the candidate model by calculating the pixel feature probability in the target area and the candidate area. Then, it uses the similarity function to measure the similarity between the initial frame target model and the current candidate model, selects the candidate model that maximizes the similarity function, and obtains the target model mean offset vector. Finally, it continuously iteratively calculates the offset vector based on this vector, and finally converges to the true position of the target, thereby achieving the effect of tracking. In general, it is verified that the model constructed in this paper works well through control experiments.
Introduction
In the intelligent reading of English text, it is necessary to use the text tracking technology to locate and recognize the text, and to classify and recognize the text to understand the meaning of the text. Since text location recognition technology is based on image recognition, English text will be difficult to recognize under the interference of blurred background. Therefore, it is necessary to improve the fixed-point tracking technology of English text.
In traditional image feature extraction, because Haar features (edge features, linear features, center features, and diagonal features) are extracted quickly and can express a variety of edge change information of objects, and can be quickly calculated using integral graphs, they are widely used. The local binary mode expresses the texture information of the object more and has good adaptability to uniformly changing illumination. Histogram of Oriented Gradients (HOG) encodes the edges of objects by using histogram statistics, which has stronger feature expression ability and is widely used in object detection, tracking, and recognition. Traditional feature design is often driven by the experience of researchers, and the update cycle is often long. The detection accuracy can be further improved by combining and tuning different features or describing objects from different dimensions. For example, ACF detection combines 20 different feature expressions [1].
Text classification is one of the important issues in the field of natural language processing. Most traditional supervised learning methods assume that data samples are in single-label form, that is, one sample corresponds to one category label. However, in real life, it is often not so ideal, and a data sample usually expresses extremely complex multiple semantics. The extraction of text features in traditional multi-label classification methods often requires manual intervention, which is prone to noise and labor intensive. In recent years, deep learning methods have achieved very good results on single-label text classification tasks [2]. However, the multi-label text classification model based on deep learning at home and abroad is still in the research stage. In view of the poor effect of existing deep learning models in mining label correlation, some scholars have proposed to regard the problem of multi-label text classification as label sequence generation and achieved good results [3]. For multi-label text classification, the label set corresponding to each sample can be regarded as a label sequence. Moreover, multi-label labeling for text can be regarded as label sequence generation, and the recurrent neural network and its variants have been applied to various sequence modeling tasks.
Related work
In the method based on Boosting, Boosting obtains a sample subset by operating on the sample set, and then uses a weak classification algorithm to train a series of base classifiers on the sample subset, and then weights and merges these base classifiers to form a strong classifier. The tracking algorithm based on AdaBoost ensemble proposed in the literature [4] considers foreground and background information and selects more discriminative features online to form several weak classifiers to achieve target tracking. Since the selection of positive and negative samples depends on the performance of the classifier, if the classifier is continuously updated, it may lead to the accumulation of errors and eventually cause drift problems. The literature [5] proposed a semi-supervised CovBoost online update algorithm to solve the drift problem in the tracking process. This method can effectively use auxiliary samples and unlabeled samples to train the strongest classifier, so that it can successfully deal with significant changes in the target and background. The literature [6] proposed a multi-instance learning method for target tracking. This method uses Boosting for feature selection and trains the classifier with positive and negative samples in packs to reduce sample ambiguity. The literature [7] proposed a boosting online tracking algorithm based on multi-core functions. The base classifier is a support vector machine and each base classifier uses different features and kernel functions. The algorithm emphasizes the dual selection of features and kernel functions. Because the CF algorithm requires a lot of training data, it cannot be used in target tracking because of its slow calculation speed. The literature [8] proposed a target tracking algorithm based on adaptive correlation filter, and applied correlation filter to target tracking for the first time. Since then, tracking algorithms based on correlation filtering have been fully developed. The literature [9] improved the MOSSE algorithm, applied the circulant matrix to the sampling and proposed a kernel tracking algorithm based on the cyclic structure, and then introduced the kernel function into the filtering algorithm to propose a multi-channel kernel-related filtering algorithm. The CF algorithm uses Fourier transform to greatly improve the tracking speed of the algorithm, but it does not have the ability to estimate the scale. The literature [10] proposed a robust scale tracking algorithm DSST algorithm. In the algorithm, the one-dimensional filter is used to estimate the scale of the target, the two-dimensional filter is used to estimate the position of the target, and the three-dimensional filter is used to locate the target in the scale space. The literature [11] proposed a multi-feature fusion scale adaptive algorithm based on the KCF algorithm. The algorithm samples the candidate regions with different scales and finds the scale box with the largest response value. In recent years, deep learning has shown strong feature learning capabilities. The literature [12] improved on the VGG-M model and added a production network between the last convolutional layer and the first fully connected layer, so as to achieve the purpose of enhancing the positive samples in the feature space. The deep model trackers cannot benefit from better and deeper convolution features. Aiming at this anomaly, literature [13] believed that it is caused by the difference in characteristics between shallow and deep features. Therefore, it treated the two features differently and used them for different purposes. Among them, deep features are responsible for robustness, shallow features are responsible for accuracy, and the two detection response maps are adaptively fused in the final stage.
Deep learning is widely used in the field of natural language processing. Compared with traditional machine learning methods, it does not need to manually design features, can automatically learn and extract text features, and achieve better results than traditional methods. The literature [14] proposed the BP-MLL method, which used the neural network model for multi-label text classification for the first time and used the fully connected network and ranking loss for classification. The literature [15] used adagrad and dropout to accelerate convergence and prevent overfitting during training and used the cross-entropy function as the objective function. The literature [16] used the pre-trained word2vec word vector to capture the word order and used it on CNN and GRU directly for multi-label text classification, which improves the classification performance compared to the traditional bag of words model. The literature [17] initialized the output layer of CNN with the co-occurrence relationship between category tags to obtain the correlation between tags. The literature [18] proposed a fusion mechanism of CNN and RNN. It uses the output of CNN as the input of RNN to capture the semantic information of the text, and then predict the category. The literature [19] used the Encoder-Decoder model in machine translation for multi-label classification and proposed a formula for calculating the joint probability of labels and generating category labels in order. The literature [20] used reinforcement learning for multi-label text classification and proposed an Encoder-Decoder model based on deep reinforcement learning, which treats category labels as sets to reduce the dependence between labels. The above models are mostly based on CNN and RNN network structures. However, the pooling operation of CNN causes information loss, and RNN will cause gradient explosion or gradient disappearance as the length of the sequence input increases. The capsule network not only obtains the position information of the words in the text, but also captures the local spatial characteristics of the text. BiLSTM not only adds a gating mechanism, but also captures the contextual order information of the text [21]. In addition, considering that the importance of words in the text sequence has different effects on the classification results, literature [22] introduces an attention mechanism. Attention mechanism is a selection mechanism used to identify keyword information, which is widely used in neural machine translation tasks. It considers the difference in word contribution of the input text, highlights the role of key inputs on the output category label, and assigns higher weights to words with large contributions and lower weights to other words.
Scale-adaptive target tracking algorithm based on mean shift and kernel correlation filtering
Target model: To represent the target, first, a feature space is selected. The reference target model is represented by its probability density function in the feature space. For example, the reference model can be selected as the color probability density function of the target. Without loss of generality, the target model can be regarded as centered at spatial position 0. In the subsequent frame, the target candidate is defined at position y, and is represented by the probability density function p (y). Both probability density functions are estimated from the data. In order to meet the requirements of low computational cost imposed by real-time processing of discrete density, m–bin histogram should be used. Therefore, we have the target model [23]:
The candidate models are:
The target model can be expressed as the probability value of all color features in the target area. We set
Among them, C is the normalization constant, n is the number of pixels in the target window, and k (x) is the kernel function used to weight the pixels. At the same time, h is the bandwidth of the kernel function, and δ (x) is the 1-dimensional Kroneckerdelta function. Function b (x) maps the pixels of the coordinates to the feature space: μ is the color feature of the target model.
Similarly, the distribution density
The Bhattacharyya coefficient is used to measure the similarity between the target histogram and the candidate histogram, so as to obtain the candidate area that maximizes the Bhattacharyya coefficient. This area is the target area [25].
The specific process is shown in Fig. 1:
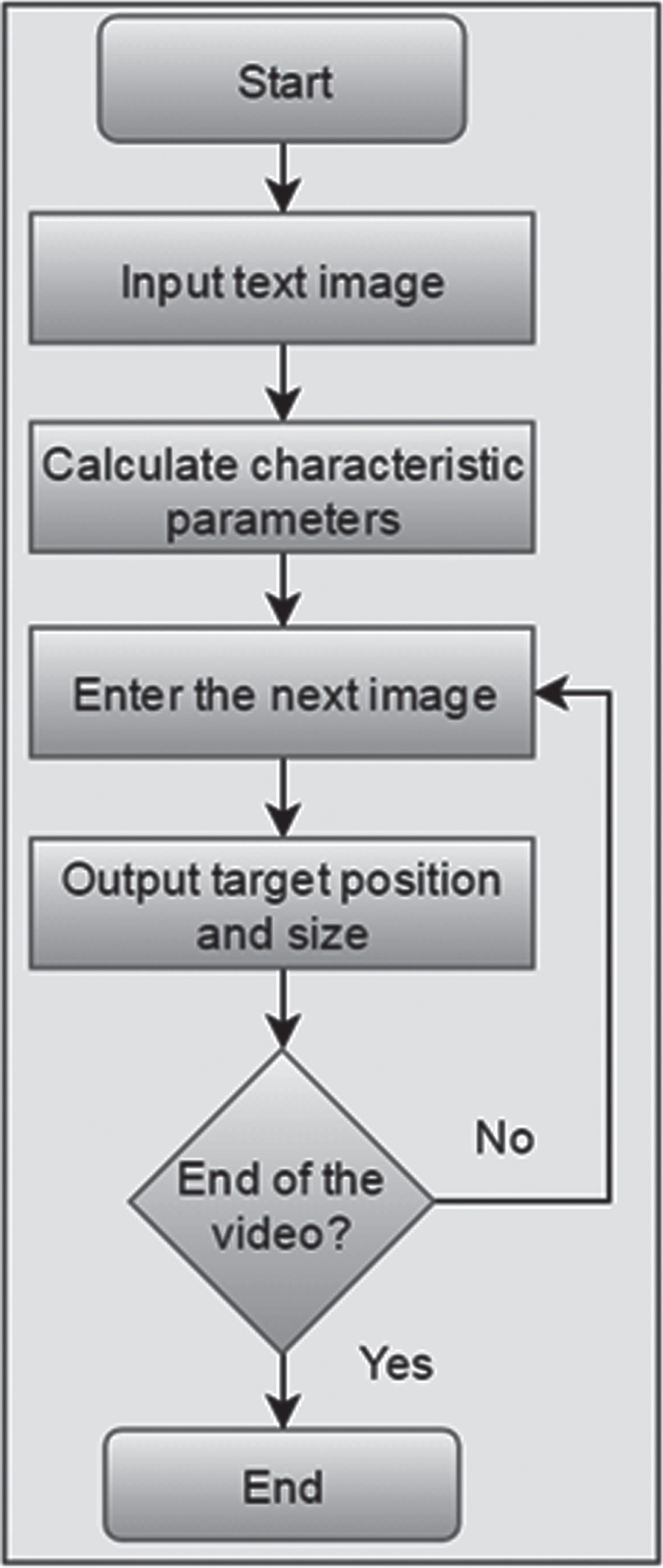
Flow chart of mean shift algorithm.
The core idea of the kernel correlation filtering algorithm is to cyclically shift the sample points in the target area to obtain additional samples to train the classifier, so as to solve the problem of insufficient samples in target tracking. However, at the same time it will bring huge computational cost to the training of the classifier. Therefore, the KCF algorithm introduces the discrete Fourier transform in the calculation [26].
For the convenience of notation, this section uses a single-channel one-dimensional signal to introduce a circulant matrix. First, the n × 1-dimensional target block X is selected as the basic sample. Then, the classifier is trained using basic samples (positive samples) and virtual samples (negative samples) obtained by cyclic shift. The one-dimensional translation of the vector is simulated by the cyclic shift operator, which is a permutation matrix, and its form is as follows:
In this formula, each row of the circulant matrix is obtained by shifting the previous row by one unit to the right.
The above formula is used to cyclically shift the target image sample X to obtain the training sample set.
Training sample X
i
is assigned label y
i
(y
i
obeys Gaussian distribution). The training process of the classifier can be described by the following formula:
That is, the optimal W is found so that the cost function (the above formula) is the smallest. Among them, there is:
Among them, α
i
is the coefficient of training sample X
i
, and φ (X
i
) represents the mapping of training sample X
i
to a high-dimensional feature space function. The correlation and similarity of any two samples p and q in the high-dimensional feature space are [27]:
Among them, k () is the Gaussian kernel function. The kernel function can be used to solve the complex problem of high-dimensional matrix dot product calculation. At this time, the solution of W is converted to the solution of weight coefficient α:
Among them, there is α = [α1, α2, ⋯ , α
n
] and K is the kernel matrix.
Equation (12) is Fourier transformed:
Among them,
First, the trained classifier is used to detect the newly input image Z. Second, the target center of the previous frame of the image z is the center. Finally, the image z is used as a reference, all the image blocks of the target candidate area are obtained through cyclic shift, and the HOG features of these candidate areas are calculated, and then the probability of becoming the target area is calculated by the following formula.
The candidate area x′ with the largest probability value is selected as the target area of the current frame. The model update is to cyclically shift x′ to obtain a new training sample set, which is used to update the parameter α required for classifier training in the next frame. The update rules are as follows:
Among them, β is the learning rate of the updated model and is a fixed value, α pre is the classifier parameter of the previous frame, and αx′ is the classifier parameter of the current frame.
Improved kernel related filtering algorithm
The circulant matrix introduced by the kernel correlation algorithm can increase the training samples and solve the problem of lack of samples in target tracking. However, it still uses a single scale size and does not improve the scale problem in target tracking. Therefore, we apply the scale search strategy in the SAMF algorithm to the kernel correlation filtering algorithm. First, the template size is defined as:
At the same time, a standard pool is defined:
We assume that the target window size is s
t
in the original image space, which samples k templates in {t
i
s
t
|t
i
∈ S } for the current frame to find a suitable target. The dot product in the kernel correlation function requires data of a fixed size. They use bilinear interpolation to adjust the sample size to a fixed template size s
T
, and the final response is calculated by the following formula:
Among them, z
ti
is a sample block of size t
i
s
t
, and its size is adjusted to s
T
. After the response function obtains the vector, the scale with the largest response value is found. Since the target motion is implicit in the response graph, the final displacement needs to be adjusted by t to obtain the true motion deviation. Because the registration size of all templates is the same, the update process is simple. Only two sets of data need to be updated, one is the weight coefficient and the other is the new sample X. As shown in the following formula, we linearly combine the new filter with the old filter as follows:
Among them, T = (α T , x T ) is the template to be updated.
The mean shift algorithm uses color distribution to express the appearance of the target, and then calculates the probability distribution of the target on the next frame of image. It converges to the final target position through continuous iteration. The mean shift algorithm has a good effect on partial occlusion. However, the target model only uses color features, lacks target spatial information, and does not adequately describe the target, which is prone to error positioning. The kernel-related filtering algorithm is not good for tracking occlusion and fast motion. However, the circulant matrix describes the target sufficiently, and the combination of the two can complement each other and achieve a better tracking effect. The speed of the mean shift algorithm is not as fast as the KCF algorithm. After combining the two, the speed is lower than that of the KCF algorithm. Therefore, the hybrid algorithm in this paper has only one layer. Algorithm fusion model as show in Fig. 2.
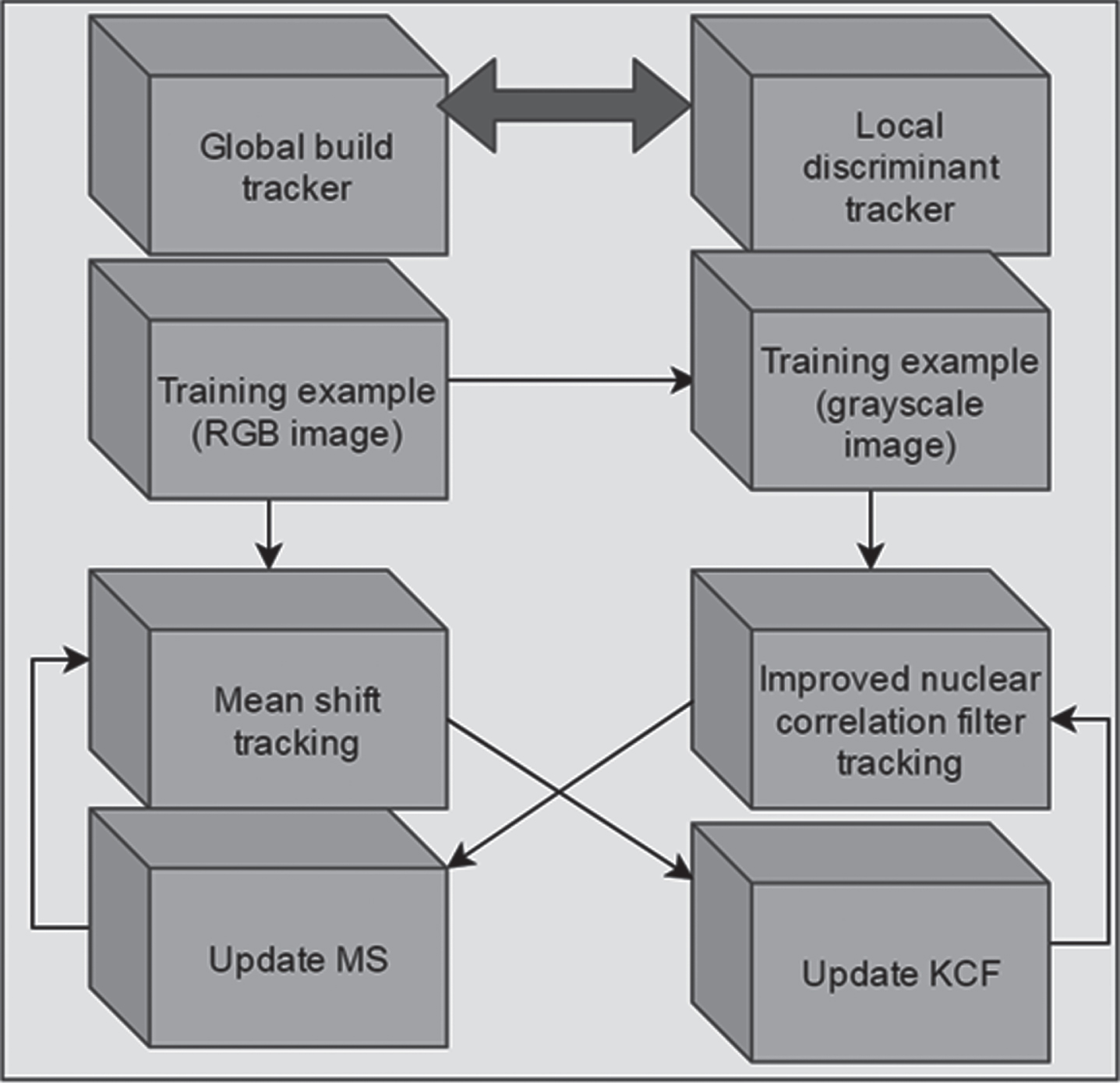
Algorithm fusion model.
The KCF algorithm does not solve some problems in target tracking, such as fast motion and scale changes. In order to solve these problems, this chapter proposes a scale adaptive algorithm of mean shift and kernel correlation filtering. For each frame of the video, the strategy adopted by this algorithm is to use the mean shift algorithm to make a preliminary judgment on the target to obtain the initial position of the target. Then, the improved kernel correlation filtering algorithm samples this position as input, finds the scale frame with the largest response value according to the scale strategy, determines the final target position, and finally updates the algorithm model. In order to ensure the speed of the algorithm for tracking the target, the algorithm in this paper has only one layer. The fusion model is as follows:
With the deepening of the research and application of the Internet of Things technology, the demand for edge computing that provides real-time, intelligent, and secure services in the vicinity of mobile terminal devices continues to expand. The huge deep neural network model can only be used on a limited platform and cannot be transplanted to mobile terminals and embedded chips with limited storage. On the other hand, large models also bring huge challenges to the power consumption and operating speed of the equipment. In the past two years, the industry’s development trend for deep learning is to place most of the applications in the cloud, and the equipment used is generally GPU. Cloud-based algorithms are far from enough, because in some application scenarios, calculations must be performed locally. Autonomous driving is used as an example. For traffic and road safety, data transmission and interaction must minimize the delay. Otherwise, the threat will be fatal. If Apple’s FaceID is only placed in the cloud, once the device has no network access, the user will not be able to use it. In industry applications such as smart homes, there are extremely high requirements for real-time, stability and privacy. In consideration of cloud data processing capabilities, network latency, and data security, edge computing, which decentralizes computing to terminal hardware, has developed rapidly. Deep neural networks are computationally intensive. Due to the huge amount of calculation and training data, and the need for a large number of parallel operations, most of the current model training part uses GPU. Multi-GPU parallel architecture is a common infrastructure solution for training. Although the multi-GPU solution is good, it is not suitable for many occasions. In inference scenarios such as using GPUs in security monitoring, data centers, robotics equipment, and mobile phones, power consumption and latency will be serious problems. ResNetS0 needs 7 GOPS to do a forward inference, and VGG16 needs about 30 GOPS. In contrast, the typical value of the computing power of the ARM processor of a mobile phone is 10 GOPS. Therefore, even if it is only a reasoning task, such a network cannot run on the mobile phone. Moreover, many current processors cannot support such large-scale parallel computing. However, if the terminal equipment is equipped with complex software and hardware equipment, it will increase the cost and hinder the popularization and promotion of the product. Deep neural networks are also storage intensive. The weight of each connection in the network may be reused many times, so the model’s memory throughput requirements will be hundreds of times larger than the size of the model itself, or even more. Putting high requirements on cache reading means that the system is prone to high latency. Storage intensiveness also brings about a problem, that is, the power consumption caused by storage will be 2 to 3 orders of magnitude higher than on-chip computing. Therefore, more effective identification methods need to be studied.
The DSST algorithm mainly uses two filters (position filter and scale filter) to achieve target tracking. One filter is used to determine the target position of the current frame, and the other filter is used to estimate the target size. The two filters are independent of each other, tracking the target more efficiently.
The DSST algorithm trains two filters of the same type. The one-dimensional filter is used to estimate the scale of the target, the two-dimensional filter is used to estimate the position of the target, and the three-dimensional filter is used to locate the target in the scale space. The algorithm uses d-dimensional feature mapping to express the target appearance. We set f to be the target block of training samples extracted from this feature map, and use f
l
to denote the z-th dimensional feature number of the target block f. Among them, there is l∈ { 1, ⋯ , d }. At this time, to determine the target position is to find an optimal correlation filter h, and each feature dimension contains a filter h
l
, which is obtained by minimizing the sum of square errors:
Among them, g is the response output of the filter, λ is the coefficient of the regular term, and there is λ ⩾ 0. ⊙ represents cyclic correlation. The solution of the above formula can be obtained as:
The regularization parameter alleviates the problem of zero frequency components in the F spectrum. The optimal filter is obtained by minimizing the output error of all training blocks. However, this requires solving the d × d-dimensional linear equation system for each pixel, which will cost a huge computational cost. In order to obtain a more reliable approximation, we can update the numerator
Among them, η is the learning rate parameter. The following formula is used to calculate the correlation score Y at the rectangular area z of the feature map. Then, the new goal state is found by maximizing the score Y:
The DSST algorithm learns a filter using HOG features, which is only used for target position estimation. To train the filter, the algorithm extracts the feature map f of the target block. Then, the algorithm uses the update filter h tran , and finally estimates the position of the target in the new frame by extracting the feature map 2 of the predicted target position. Then, it uses to calculate the correlation score Y.
DSST algorithm proposes a joint translation scale tracking method based on three-dimensional scale spatial correlation filter. The filter size is fixed at M × N × S. Among them, M and N are the height and width of the filter and S is the scale. To update the filter, the algorithm first calculates the feature pyramid of the rectangular area around the target. The pyramid is constructed so that the size of the target is M × N. The algorithm is trained according to its estimated ratio, and then the sample f is set as the rectangular cuboid of the feature pyramid. This cuboid size M × N × S is centered on the estimated location and size of the target. The algorithm uses a three-dimensional Gaussian function as the corresponding expected correlation output g. Finally, the scale space updates the tracking filter.
We assume that P × R is the target size in the current frame, and S is the scale filter size. The target J
n
of size a
n
P × a
n
R around the target is extracted, among them there is:
In target tracking, the scale difference between two frames is usually smaller compared to the translation of the target. First, the target position is determined by the position filter h tran . Then, the sample z is extracted from that position using the same process as f. By maximizing the correlation output between h scule and z, the target scale size is obtained.
Feature fusion
Color is a perspective space. It is a language label used by humans to describe colors. The representation of color labels in space is closer to human perception than in RGB space, so we convert RGB space into 11-dimensional color attribute space. The HOG feature extracts gradient information from a cell composed of a series of pixels and calculates the discrete direction to form a histogram. We use 31 gradient direction bins in the method. The HOG feature emphasizes the gradation of the image, and the Color Name (CN) focuses on the color information. These two features complement each other. Therefore, we fuse the 11-dimensional color feature and the HOG feature with the unit cell as 4 × 4.
As shown in Fig. 3, we assume that the size of the original image is 202 × 85 pixels. After extracting HOG features, it will be reduced to 50 × 21 pixels. In order to ensure the consistency of the dimension of the feature matrix, the original image is downsampled to 50 × 21. The 10-dimensional color features of the down-sampled image are extracted, and finally a 41-dimensional feature matrix is obtained by fusion by vector superposition.
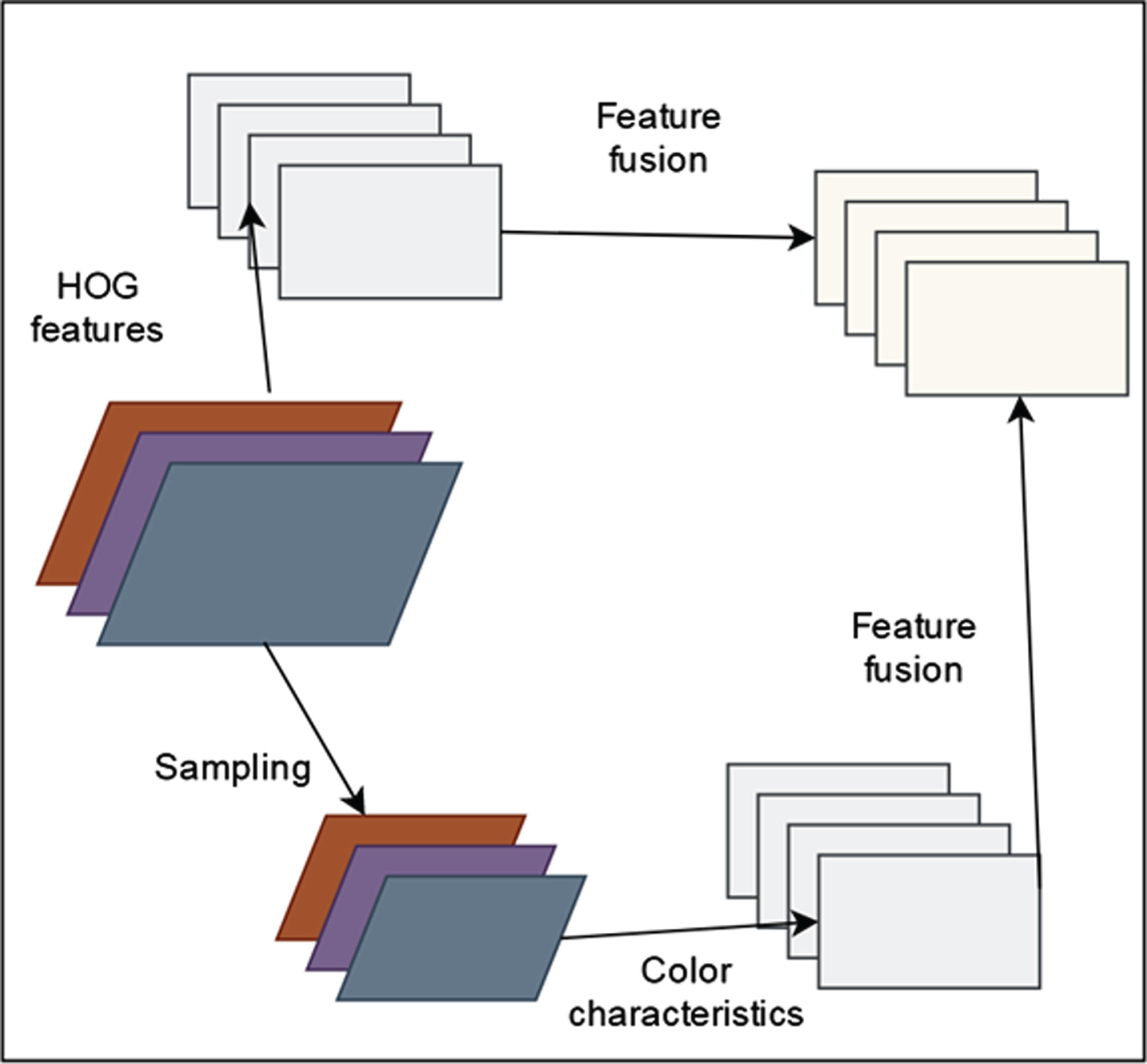
Feature fusion process.
In the target tracking process, errors will accumulate as the template is constantly updated. We hope to get the true position p
gt
of the target, but errors will occur in most cases. In order to reduce this gap as much as possible, this chapter proposes a scale-adaptive target tracking algorithm based on mean shift and multi-feature fusion. We first improve the DSST algorithm by fusing the color attribute features into the algorithm, and then linearly combine the mean shift and multi-feature fusion scale adaptive algorithm to determine the target position together. If it is assumed that the target position obtained by the mean shift algorithm MS in the t-th frame is
Among them, λ is the weight coefficient, and 0 < λ < 1. For a more intuitive understanding, the algorithm in this paper gives an algorithm flowchart as shown in Fig. 4:
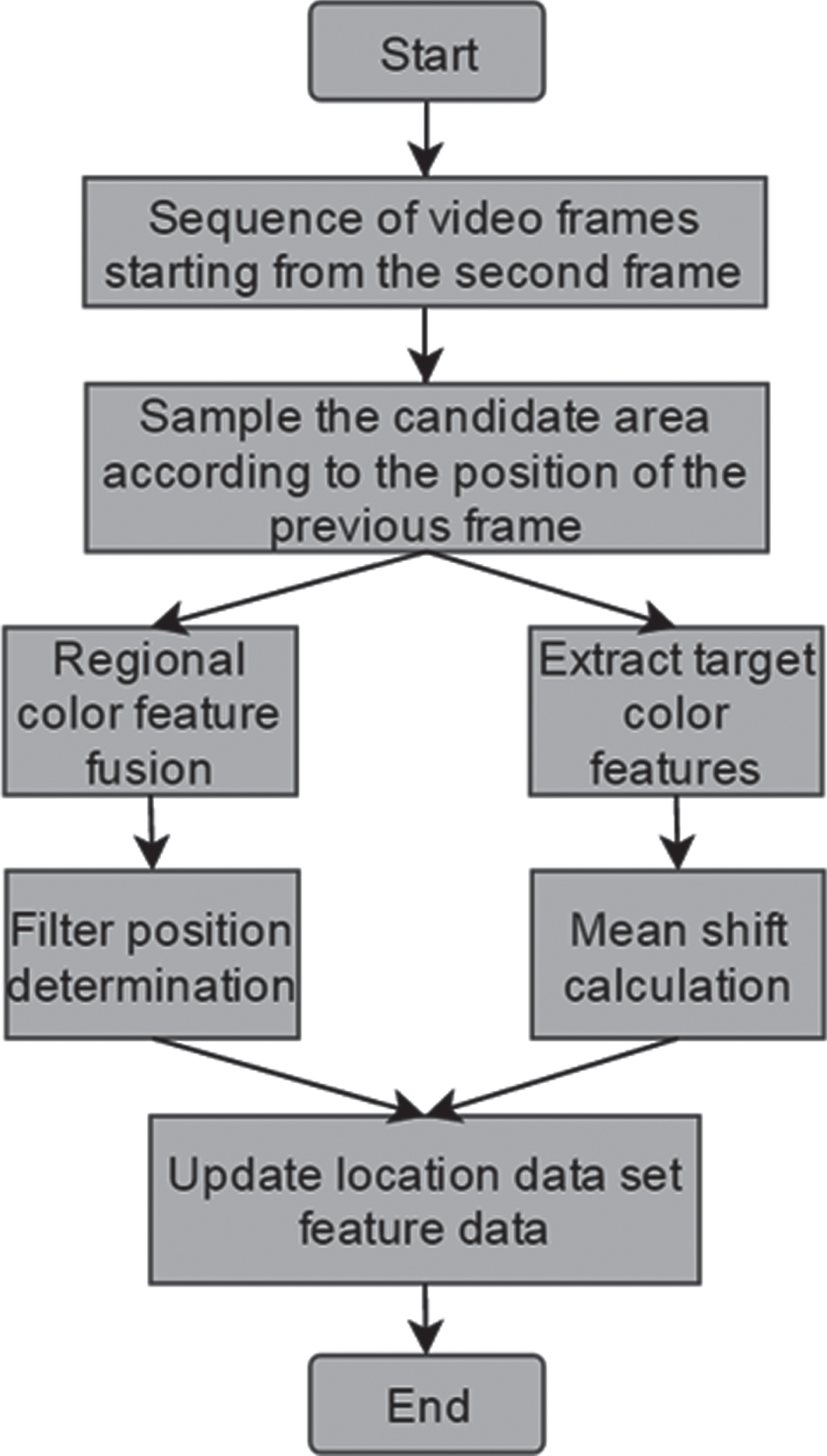
MSMF algorithm flow diagram.
This article uses Average Accuracy, Hamming Loss, One-error and AUC to evaluate the performance of the multi-label classification model. Average Accuracy evaluates the average score of the tags listed above a specific tag. Hamming Loss evaluates the scores of misclassified instances-label pairs. One-error evaluates the score of examples where the top label is not in the relevant label set. AUC is called the area under the ROC curve and is related to the label ranking performance of each instance. The larger the average accuracy and AUC value, the smaller the value of Hamming loss and One-error, and the better the model performance. In this experiment, we use English book information and news information collected by English websites as the identification objects. Table 1 shows the basic information of the data set. The data set consists of 11 top-level categories. According to different categories, different numbers of samples are randomly selected as training texts. Statistical diagram of the number of labels as show in Fig. 5; Statistical diagram of the number of instances in the data set as show in Fig. 6.
Basic information of the data set
Basic information of the data set
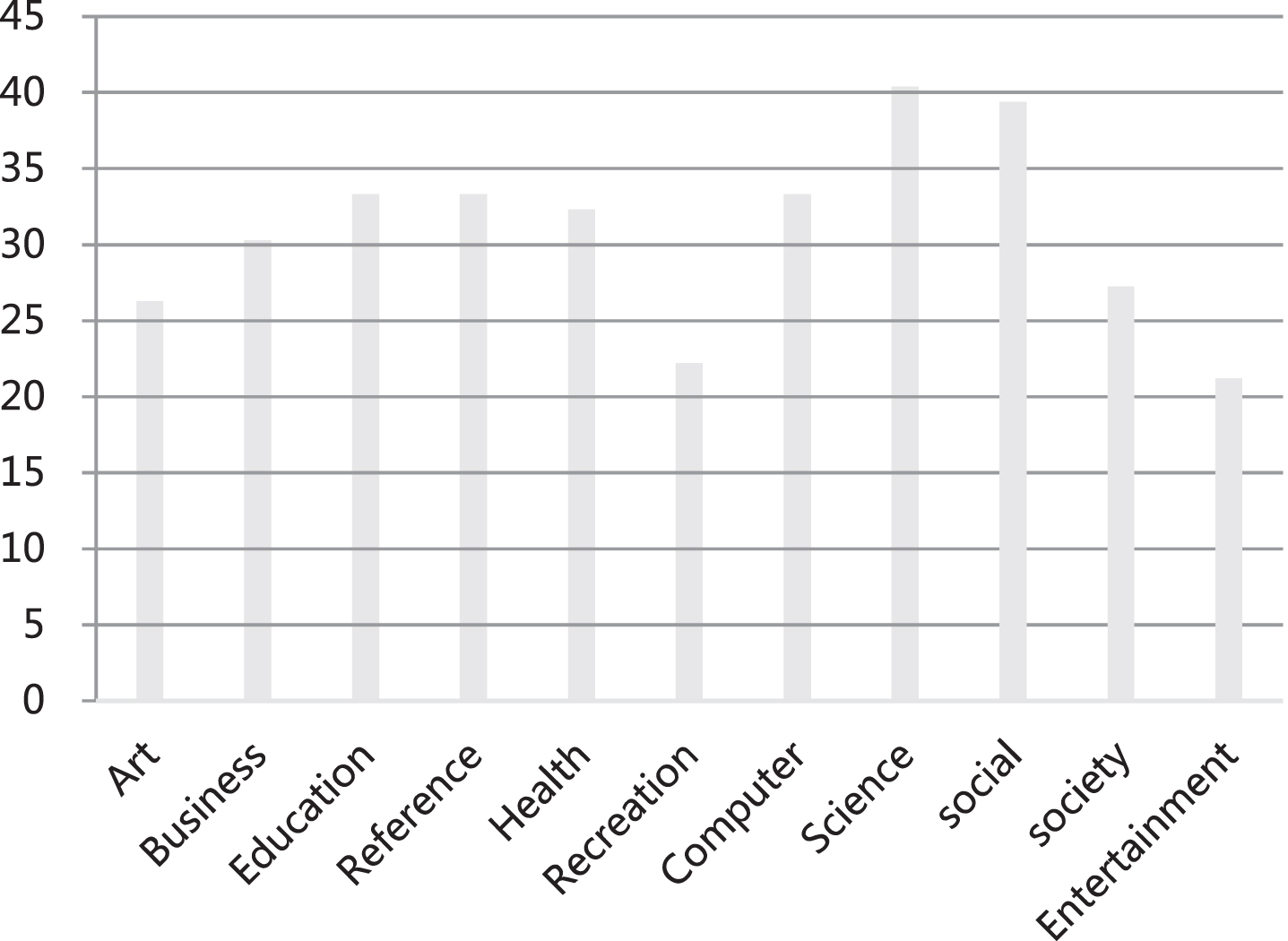
Statistical diagram of the number of labels.
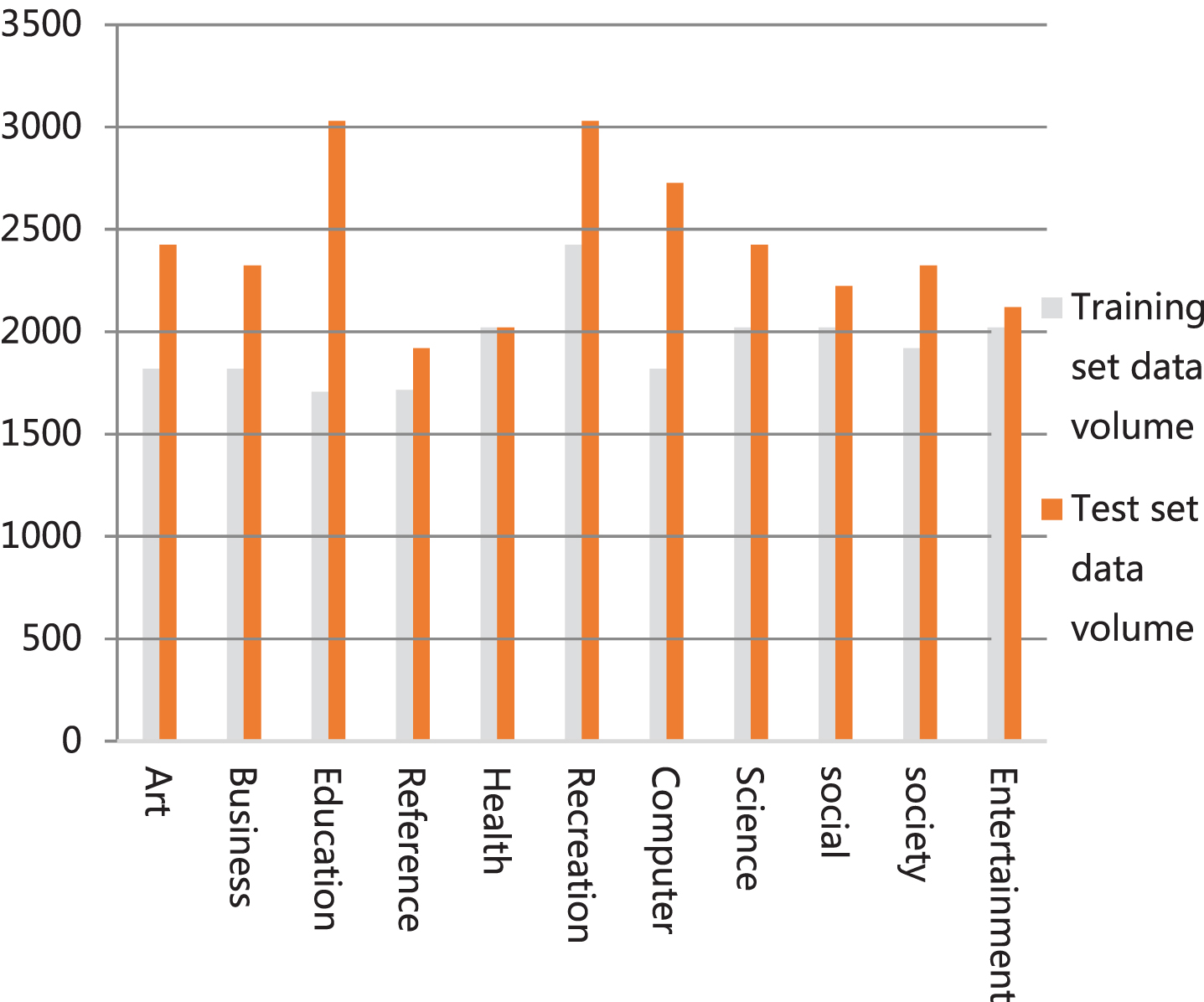
Statistical diagram of the number of instances in the data set.
Next, we perform text location on these data, and also use the above data set for text location tracking, and perform the statistics of Average Accuracy, hamming Loss, One-error and AUC respectively. The results obtained are shown in Table 2 to Table 5, and the corresponding statistical diagrams are shown in Fig. 7 to Fig. 10.
Statistical table of Average Accuracy
Statistical table of Hamming Loss
Statistical table of One-error
Statistical table of AUC
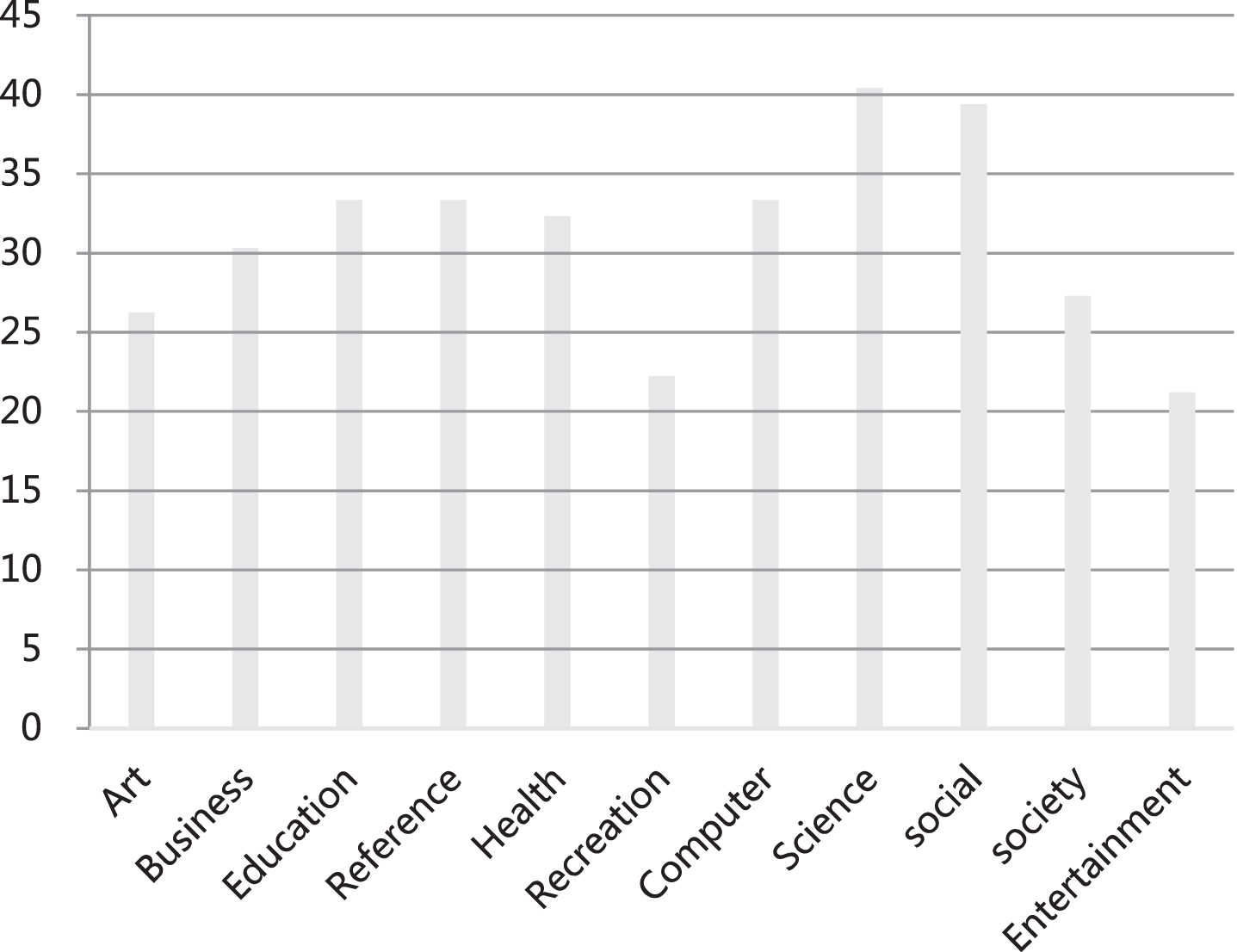
Statistical diagram chart of Average Accuracy.
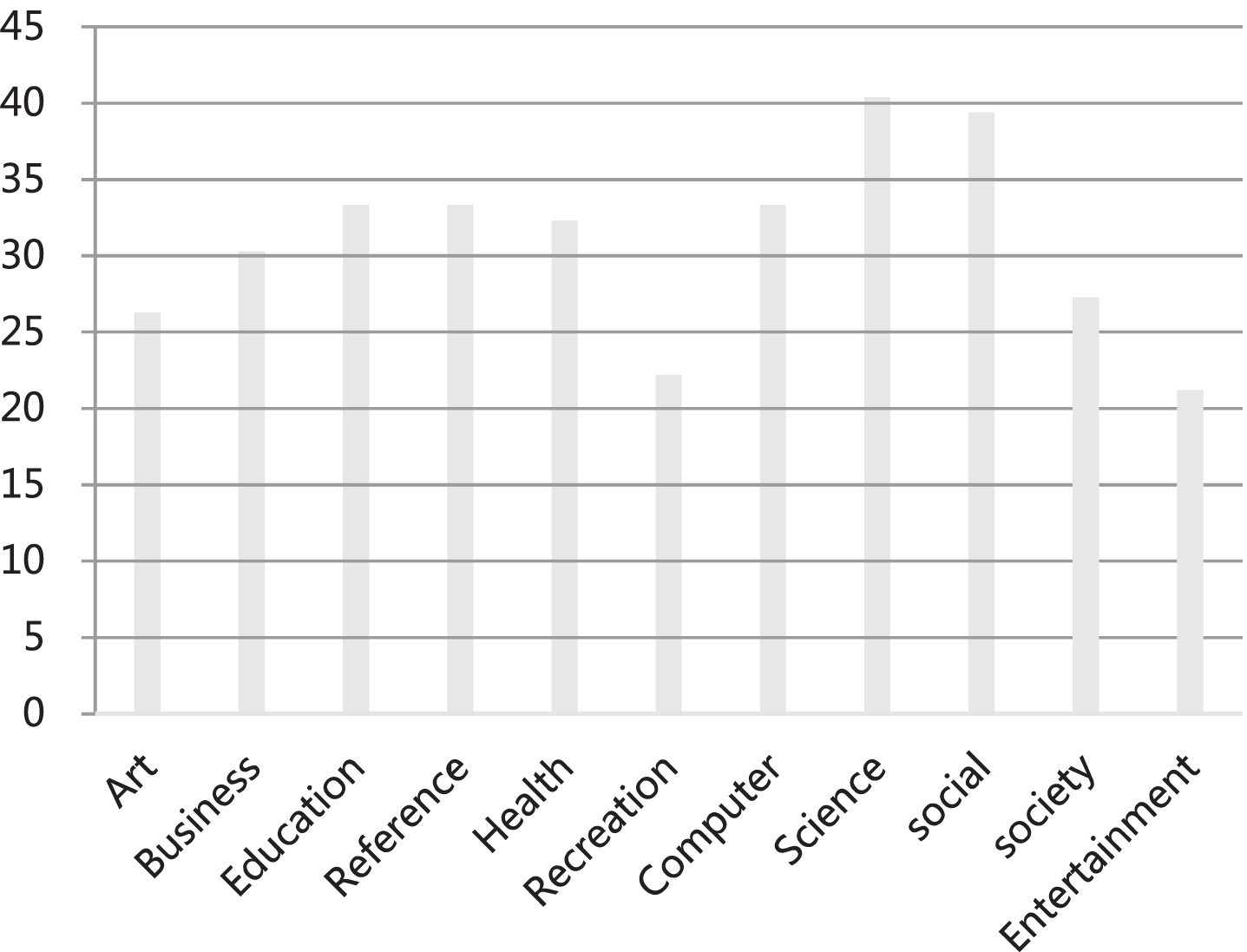
Statistical diagram of Hamming Loss.
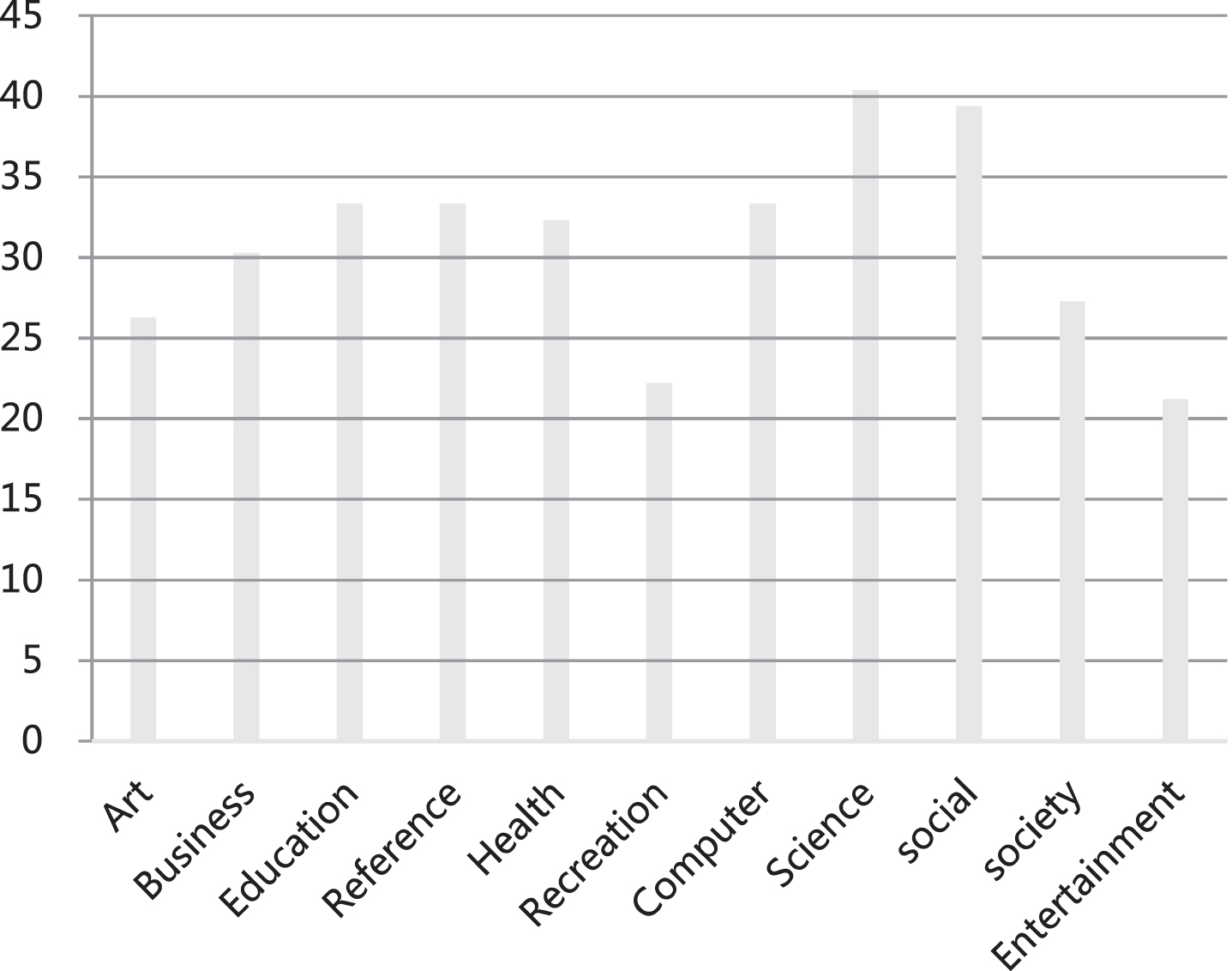
Statistical diagram of One-error.
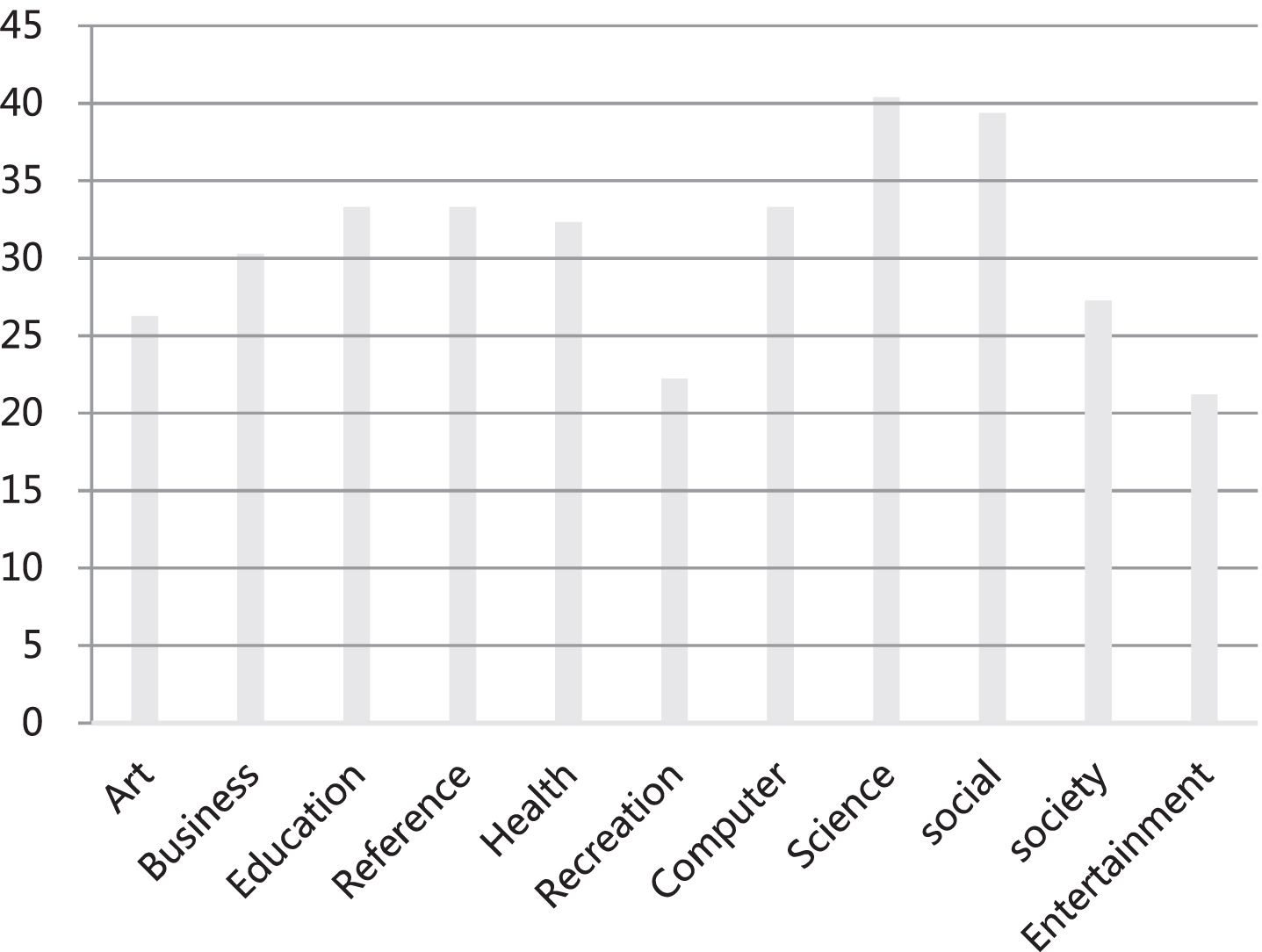
Statistical diagram chart of AUC.
From the above statistical results, it can be seen that the model constructed in this paper has good performance in all aspects, and its practical effects can be studied later.
As a medium of information transmission, English text is playing an increasingly important role in human life. In recent years, with the widespread popularity of various smart terminals and digital products, people can recognize texts through various smart devices. This paper uses artificial intelligence algorithm to track English reading text at fixed points. The mean shift algorithm uses color distribution to express the appearance of the target, then calculates the probability distribution of the target on the next frame of image and converges to the final target position through continuous iteration. Moreover, this paper uses the DSST algorithm to replace the gray-scale feature with the HOG feature and defines two filters for target appearance training and target scale estimation, which achieves a good tracking effect. In addition, this paper proposes a scale-adaptive target tracking algorithm (MSMF) based on mean shift and multi-feature fusion to solve the problem of partial occlusion and rotation of the target. The research results show that the algorithm in this paper has achieved better tracking results on the data sets with these characteristics.