
Abstract
To deal with the systematic risk of financial institutions and the rapid increasing of loan applications, it is becoming extremely important to automatically predict the default probability of a loan. However, this task is non-trivial due to the insufficient default samples, hard decision boundaries and numerous heterogeneous features. To the best of our knowledge, existing related researches fail in handling these three difficulties simultaneously. In this paper, we propose a weakly supervised loan default prediction model WEAKLOAN that systematically solves all these challenges based on deep metric learning. WEAKLOAN is composed of three key modules which are used for encoding loan features, learning evaluation metrics and calculating default risk scores. By doing so, WEAKLOAN can not only extract the features of a loan itself, but also model the hidden relationships in loan pairs. Extensive experiments on real-life datasets show that WEAKLOAN significantly outperforms all compared baselines even though the default loans for training are limited.
Introduction
In order to decrease the systematic risk of banks and financial administrations, the analysis of credit risk and the decision making for granting loans is one of the most important operations for financial institutions. Basing on the background and financial situation of the applicant, every loan proposal should be carefully considered. For the rapid increasing of online applications, it is intractable to evaluate all loans artificially. Thus, predicting whether a loan is going to be defaulting automatically is becoming an extremely urgent task and draws much attention of the researchers. Although numerous methods were proposed for this task [3, 36], almost all of them are fully supervised which assumes that the training data is adequate to learn the prediction model. In the real-world, there exist some scenarios where only limited default loans are available that leads these methods failing in learning a decent model. For example, a new P2P lending start-up which has almost no historical data for training and previous models from other companies may not be suitable for its business. Directly using these models would lead to poor accuracy. How to learn a prediction model in such weakly supervised situation is a new problem and has not be well-studied.
Nevertheless, weakly supervised loan default prediction is not a trivial task. It is facing three challenges that prevent the existing models yielding accurate results: (1) Limited default samples. The default samples in training data are paltry compared with the total number of loans, which leads to insufficient supervised information for obtaining a well-trained prediction model; (2) Hard decision boundary. Loans in the training set are binary labeled. But the likelihood of which a loan would be defaulting is more useful than the binary result in real-world, such as determining the interest rate; (3) Heterogeneous features. The features describing a loan consist of multiple aspects that have different data types, such as numerical, textual, categorical and so on. It is challenging to model these types of features in a unified manner.
To better understand these three challenges, we conduct some statistical analysis on three months loans in LendingClub and give some examples in Fig. 1. Because of the charge-off loans need about half a year to discover, we omit them in weakly supervised prediction although they are default. As illustrated in the left part of Fig. 1, only 8% of loans are defaulting. It means that, even though the total number of loans are huge i.e., 42346 loans, the default samples only take a tiny fraction of them, i.e., 3387 default loans, which is not sufficient for model training. The situation would be even worse if the available loans were in an extreme short period. For data labels, just like the examples that are shown in the right part of Fig. 1, loans are only be labeled with 0 indicating not a default loan, or 1 indicating a default loan. The prediction model trained from such hard decision boundary can barely capture how likely a new loan would be defaulting. Moreover, data types of loan features are various. It contains not only the numerical features such as income and age, but also the categorical feature such as sexual. In addition, the features also contain some textual data such as the mail address. All this information should be gathered together for yielding accurate predictions.

Illustration of challenges in weakly supervised loan default prediction.
Although many research efforts have been conducted for predicting the default loans, none of them is able to address all the up-mentioned challenges. Traditional loan prediction methods can be categorized into two lines: classification-based methods [27, 28] which model this problem as a binary classification problem, and regression-based methods [4, 19] that learn numerical credit scores for evaluating the risk of loans. Because of the interpretability, we argue that credit scores are more appropriate than the result of 0-1 classification. However, methods in these two categories hold the assumption that the training data have adequate default loans for model optimization. This assumption is not always hold in our problem. For training sufficiently, a batch of semi-supervised models [5, 38] have been proposed for efficiently utilizing the information of normal loans to optimize the prediction model. Nevertheless, these models only support numerical input and fail to capture the full information in heterogeneous data types. Nowadays, with the emerging of deep representation learning [10, 35], these challenges are promising to be solved in one unified model.
In this paper, we propose a weakly supervised default loan prediction method, namely WEAKLOAN. It learns an accurate prediction model from a small number of default samples while supporting various types of features and yielding the numerical risk score of a loan systematically. The main idea of WEAKLOAN is based on the deep metric learning framework which constructs a metric to measure the similarity between two given samples. By doing so, WEAKLOAN can not only extract the features of a loan itself, but also model the hidden relationships in loan pairs. Both of the two aspects are critical for predicting the default probability of a loan and are good for learning the risk score of a loan in weakly supervised setting.
WEAKLOAN is composed of three key building-blocks: feature encoding module, metric learning module and score calculating module. By involving a deep neural network based encoding module, input features consisting of various data types are firstly transformed into a numerical embedding vector, and further fed in a multi-layer perception for generating the loan encoding. To learn the encoding module effectively, WEAKLOAN reorganizes the training data as loan pairs and employs two orthogonal objective functions for optimization. In this way, the scale of training data is quadratic increase and the hidden relationships lying in different categories of loans are modeled explicitly. Once the encoding and metric learning modules are well-trained, WEAKLOAN predicts the risk score of a new loan based on the result of its pairs with some pre-selected reference loans. The numerical risk score contains the useful information of both the predicted loan itself and the reference ones, which solves the hard decision boundary problem. After that, a per-defined threshold of the risk score is employed to predict whether a loan is defaulting. Moreover, we also provide a method for determining the threshold in new datasets. By integrating these modules, WEAKLOAN is able to predict the default loans effectively and efficiently, even though the labeled default loans are limited.
The main contributions of the paper lie on these aspects: The loan default prediction task is formulated as a weakly supervised learning problem with limited available default loans for model training, that fits the reality perfectly. We propose a weakly supervised default loan prediction model, WEAKLOAN, by employing deep metric learning, which can handle three challenges systematically in loan prediction problem, including limited default loans, hard decision boundary and heterogeneous features. Extensive experiments on different scale of datasets show that WEAKLOAN is superior to compared baselines, especially when the number of labeled default loans is small.
The rest of this paper is organized as follows: Section 2 introduces the related works. Section 3 gives the problem statement and overview of WEAKLOAN, and interprets the technical details. We validate the effectiveness of WEAKLOAN in Section 4. And this work is concluded in Section 5.
Existing works that are related to this paper can be categorized into three groups: supervised loan default prediction methods, semi-supervised loan default prediction methods and deep metric learning. Methods in the first two groups aim at to train a precise prediction model for evaluating the default risk of a new loan. For the third group, we specify some deep metric learning models which are related to the architecture of WEAKLOAN.
Supervised loan default prediction
Several methods are proposed to predict the default risk of a loan in supervised learning setting, such as [2, 36]. Authors of these works assume that there exist sufficient labeled default loans can be used to learn a perfect model. However, this assumption does not usually hold in real world. For solving the data unbalance problem, Chen et al. employs a diversified sensitivity under-sampling to reorganize the training data and yields better result compared with the baselines [36]. New models [33], such as LSTM, are utilized to model the sequential influence of the activities of applicants. Furthermore, some boosting techniques [28] are proposed to train the prediction model accurately. Although extensive supervised learning methods are available for predicting the default risk of loans, the labeled default loans are usually scarce in real-world, which leads all these methods failing to learn a decent model in weakly supervised setting. Perez-Martin et al. propose a logistic regression-based model for estimating the credit risk of P2P lending platform in China [6]. Non-parametric statistical method is used to identify the borrower’s characteristics and extract the features.
Nevertheless, all these works rely on sufficient labeled loans to train the prediction model. In real world, the labeled data is expensive and hard to get. Omitting the influence of unbalance data labels would lead the model failing to yield accurate prediction result.
Semi-supervised loan default prediction
To deal with the limited default data, recent years have witnessed an increasing amount of semi-supervised algorithms [18, 38] for loan default prediction. Methods in this group hold an assumption that there has a subset of training data being labeled (with both normal loans and default loans) and sufficient unlabeled loans. Under this setting, Livieris et al. [18] propose a semi-supervised learning boosting method for evaluating the default risk. Li et al. [38] employs a semi-supervised SVM to optimize the decision super-planes for predicting loan default. Xiao et al. [22] utilize the semi-supervised ensemble algorithms to learn a better set of parameters of the prediction model.
Methods in this group treat the unlabeled loans as normal loan. We argue that obtaining the labeled normal loans would be rather expensive due that it takes several months or years to validate whether a loan is normal. Otherwise, these unlabeled loans could also be defaulting, which provides error supervised information in model training. This situation limits the usage of up-mentation methods.
Deep metric learning
Apart from these loan default prediction methods, WEAKLOAN is highly related to metric learning [1, 24], which is a paradigm that learns a metric for sample pairs (or triplets) according to the pre-given supervised information. With the emerging of deep learning [25, 37], deep metric learning, which replace the feature selection module with a deep neural network, has been studied and aroused much attention [14, 17]. In recent years, there exist some efforts that extend deep metric learning methods to solve weakly supervised learning problems [16].
Although many deep metric learning-based methods are used for weakly supervised tasks, methods for weakly supervised loan default prediction have not been well studied. This is the motivation of this paper.
Methodology
In this section, we first define the weakly supervised default loan prediction problem. After that, the architecture of WEAKLOAN is overviewed and the details of the three key components in WEAKLOAN will be specified respectively. Moreover, the complexity analysis of WEAKLOAN will be given at the end of this section.
Problem Definition
Given a set of historical loan dataset
Overview of WEAKLOAN
As shown in Fig. 2, WEAKLOAN is a deep metric learning based framework that is suitable for weakly supervised setting. It has been tested to be able to learn a better model compared with other supervised and semi-supervised methods [11, 15] in other tasks. To adapt it on weakly supervised default loan prediction and solve the existing challenges, our solution is decomposed into three sub-procedures in WEAKLOAN.
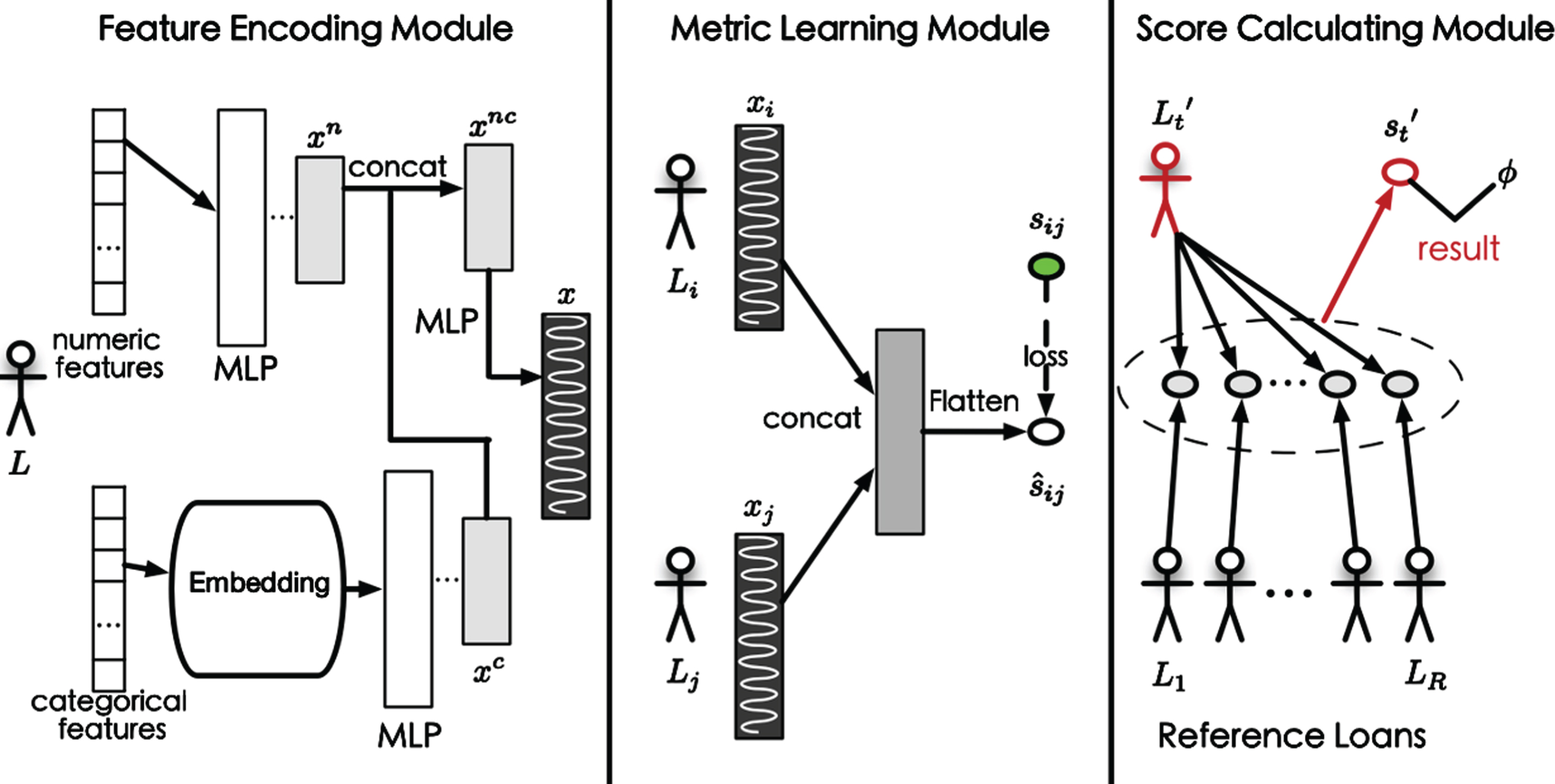
Overview of WEAKLOAN. Feature Encoding Module is to learn the potential features from various data types of loans; Metric Learning Module constructs loan pairs and explores the relationships in these pairs based on labels; Score Calculating Module will predict the default probability of a loan according to its relationship with other reference loans.
Firstly, to fully utilize the information of loans and deal with heterogeneous modality of data, the features of each loan L = [f1, …, f K ] are encoded into a fixed-length distributed vector by a deep neural network-based feature encoding module. Multiple feature types are supported by the encoding module, including numeric and categorical. It can be easily extended to other types such textual and image.
Secondly, to solve the limited default sample and increase the size of training data, the training loans in
Thirdly, for predicting the default score of a new loan
After that, we can obtain the label of a new loan by comparing its risk with a threshold. The threshold is determined by the data distribution and can be estimated with the training data.
Taking L = [f1, …, f
K
] as the input, WEAKLOAN transforms L
n
to a representation vector x
n
that encodes multiple types of features. According to the type of features, the input can be divided into several groups, including the numeric feature group
As shown in Equation 1, the numeric features are encoded into a representation vector by a multilayer perceptron (MLP). For categorical features, WEAKLOAN first employs an embedding metrics M
c
to learn the representation of each class, and then transforms the class embeddings with a MLP to obtain the encodings. Finally, the different types of encodings are concatenated together to generate the encoding of L. Note that, in order to balance the influence of different features, we initialize the dimension d of every feature equally and learn the weights of them by employing a neural network, namely, ∀i ∈ [1, a] and j ∈ [1, b],
This feature encoding method can be easily extended to other types of features. Assuming that a feature f g is an image, we can employ a Conventional Neural Network (CNN) [3] to encode it into a d dimensional vector and concatenate it with existing features encoding x nc . If there is a feature f t that presents as a sentence, we can first extract its keywords and embed these keywords with the pre-trained word vectors [21]. Then, these word embeddings can be easily transformed into a d dimensional vector by using RNN [31] or BERT [20] and encoded in the same way as other features.
To optimize the parameters, especially the weights of MLPs in Equation 1, a metric learning framework is conducted in WEAKLOAN. The metric learning module takes a pair of loans as the input and outputs a default score which indicates how likely the input loans contain default loans. Next, we first specify the generation of loan pairs and then detail the metric learning architecture and optimization method respectively.
Reorganize training data into loan pairs
Due to the limited labeled loans in training data and imbalance of data labels, WEAKLOAN reorganizes the training data into loan pairs and utilizes the label of these pairs to guide the model optimization. According to the binary label of loans, there exists three kinds of the loan pairs: (default, default), (default, normal) and (normal, normal) denoted as
Once the pairs are generated, we specify the default scores of them. Assuming that the default scores of
In metric learning procedure, the objective function is defined to minimize the output of WEAKLOAN and the ground truth default score. Specifically, WEAKLOAN consumes a pair of loans (L
i
, L
j
) and first encodes the two input loans by the features encoding module to generate its representation vector x
i
and x
j
. Then, the representation vectors are fed into a fully connected flatten layer to calculate the default score
For model training, WEAKLOAN directly fits the estimated default score with the ground truth s
ij
. The loss function of the metric learning part is:
Although the default scores of loan pairs are able to predict accurately, the risk score of one specific new loan
Specifically, with the reference loans
The select reference loans are determined by what kinds of defaults are willing to be detected. In this paper, we give a naive selection policy which randomly chooses equally-sized default and normal loans, R/2 loans are default and the other R/2 are normal. The risk score can be rewrote to:
In usage,
Moreover, we propose a Gaussian Mixture Model (GMM) to estimate the proper value of φ. Specifically, we first utilize the well-trained WEAKLOAN to calculate all the risk score of loans in the training dataset and obtain a risk score list S = [s1, s2, . . . , s
n
]. Assuming that S is sampled from a GMM that contains two Gaussian components, one denoting as
Beyond accuracy, the complexity of a default loan prediction method is also not to be neglected. High complexity limits the usage of the prediction method, especially in P2P online lending. For predicting the risk score of a new loan, the most complex part of WEAKLOAN lies in the feature encoding module. By involving the reference loans, the complexity of WEAKLOAN is O ((R + 1) · α) where R is the number of references and α is a const that indicates the complexity of feature encoding. However, this complexity can be rather reduced if we fix the reference loans and pre-compute the representation vectors of these references before predicting new loans. In this way, the complexity of WEAKLOAN is O (1) which is suitable for online lending.
Experiments
In this section, we aim to answer the following evaluation questions: EQ1: Can WEAKLOAN predict the default loans more precisely than existing state-of-the-art baselines? EQ2: How the performance of WEAKLOAN is under different numbers of training loans? EQ3: How the threshold φ and the number of reference loans R influence the performance of WEAKLOAN?
All the experiments are conducted in a high-end server Dell T7920 with two Nvidia 2080Ti GPUs. Both our methods and the compared baselines are implemented with Python 3.7. We utilize PyTorch 1.3.1 to build and train the WEAKLOAN model. For the performance evaluation, we directly use the metrics provided by sklearn package. Next, we first introduce the experiment settings and then analyze the experimental results to answer up-mentioned questions.
Experiment settings
Dataset
The datasets that we used in this paper are loans from LendingClub 2 , which is an American peer-to-peer lending company that provides the “bridge” between investors and borrowers. The dataset contains complete loan data for all loans issued through 2007-2015, including the current loan status (Current, Late, Fully Paid, etc.) and latest payment information. The total dataset has about 2.3 million loans and there exists a 145-dimensional feature set for each loan, including credit scores, number of finance inquiries, address and so on. The distribution and some statistics of the dataset are illustrated in Fig. 3. As shown, the default loans only take a small fraction of the whole dataset. In our experiments, we also regard the late loans and call-off loans as default loans. The experimental dataset is public available at here 3 .
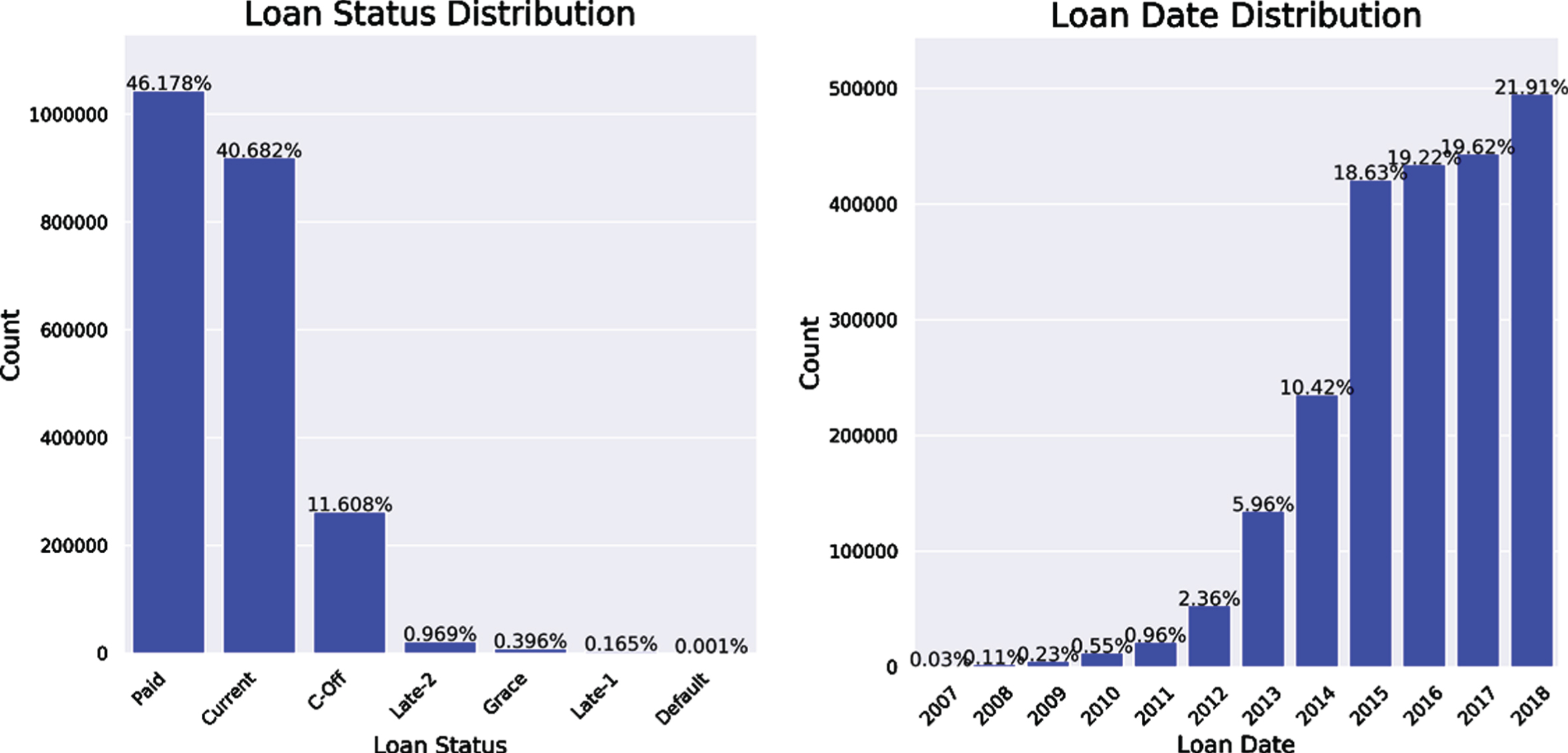
Statistics of the LendingClub dataset.
For simulating the weakly supervised scenario, we only use a small number of loans as the training data and take the other loans as the test data for evaluation. As shown in Fig. 3, the loans distribute unevenly over time. We first shuffle the dataset and calculate the average number of loans in one day. Then, five sub-datasets: one day
Sub-datasets to train the prediction model
In order to show the superior of WEAKLOAN, we compare it with several existing baselines for default loan prediction. These baselines can be categorized into two groups: supervised methods which contains SVM, Logistic Regression, Naive Bayes (NB) and Multi-layer Perceptron (MLP); and semi-supervised methods that includes S3VM. We also test the boosting method [26], but omit the result because it classifies almost all loans into normal. Naive Bayes (NB): This model assumes that the loans are conditional independent given the labels. We choose multinomial distribution to estimate the likelihood of dataset and maximize the likelihood to optimize model parameters. SVM [9]: Directly taking the features as input, SVM is a classic method for max-marginal classification which learns a classification super plane to decide whether a loan is default. Logistic Regression (LR) [6]: It is a model that transfers the linear combination of input features with a logistic function and generates the classification result based on the output of the function. Multi-layer Perceptron (MLP) [2]: This method models the classification problem with multilayer neural networks and outputs the probability of each class for one specific loan. Semi-supervised SVM (S3VM) [38]: Given a small training set of labeled loans and sufficient unlabeled loans, S3VM is an inductive learning algorithm that estimates the classification function at all possible values and then uses the fixed function to deduce the classes of the unlabeled loans.
To clarify the existing works related to default loan prediction, we summarize the data, methods, evaluation metrics and results that reported in their original papers. All this information are organized in Table 2. As shown, Li et al. [38] use the same dataset with us. They achieve over 0.9 accuracy which is better than the performance we reported in Fig. 5. This is because method in [38] utilizes 70% data for training which contains over one million loans. In this paper, we focus on weakly-supervised setting and only use at most 45 k loans for training.
Summary of the baselines
Summary of the baselines
In this paper, we employ four commonly used metrics, including precision, recall, accuracy and F1-score, for evaluating the performance of WEAKLOAN with the compared baselines. Given a set of test loans, the classification results are classified into four groups: true positive (TP), true negative (TN), false positive (FP), and false negative (FN), where the true/false indicate whether the loan is classified correctly and positive/ negative indicate whether the classification result of a loan is default or normal. Then, these four evaluation metrics can be formulated as follows:
The hyperparameters that need to be set in WEAKLOAN consisting of three parts: (1) the value of default score s dd , s dn and s nn ; (2) the number of reference loans R; and (3) the decision threshold φ. For the default scores, we empirically set s dd = 1, s dn = 0.5 and s nn = 0.1. For R and φ, we employ grid search to select the best values. More details of parameter studies are available in Section 4.4. Because that the test loans are accessible in our experiments, we empirically use φ that has the highest performance for evaluation and do not report the results of its estimation method.
In model training, we utilize the commonly used optimizer Adam [12] to learn the parameters. According to the recommendation, the learning rate is empirically set to 0.01. For each subdataset, we train WEAKLOAN in 50 epochs and select the model performing best on the test data to report.
Features selection
Before conducting the experiments, we first select a subset of relevant features from the LendingClub dataset which contains 146 different features for each single loan. Exploration data analysis (EDA) was employed to find what features are relevant to the default loan prediction task. Specifically, two rules are used for feature selection: (1) mutual exclusivity, which regularizes that the features are independent of each other. (2) relevance, which selects the features that are able to contribute to the prediction of default loan. For the first rule, we employ correlation matrix of these 146 features and choose independent ones as the candidate features. Figure 4 illustrates part of the results of this procedure. As shown, the loan amount is highly correlated with installment, and grade, subgrade and interest rate are correlated with each other, i.e., the correlation coefficients are approximate to 1. Therefore, we choose loan amount and interest rate as the selected features. For the second rule, we further filter the candidate features to obtain the relevant features by calculating the correlation coefficient between these features and the label. After that, the relevant features subset is returned, which consists of 7 features to learn the prediction model by WEAKLOAN. The result of these features and some loans can be found in Table 3.

The correlation matrix of the selected features.
Data samples of the selected features
In this section, we aim to answer the first two EQs. We compare the performance of different baselines and WEAKLOAN in various scales of training data. The results of these experiments are reported in Fig. 5. From these results, we can observe that: For the performance of default loan prediction, WEAKLOAN achieves great improvement compared to other state-of-the-art baselines in most cases in terms of precision, accuracy and F1-score, demonstrating the effectiveness of our proposed framework. With the increase of training loans, the performance of all methods first increases and then becomes stable. And WEAKLOAN outperforms all compared baselines significantly on precision, accuracy and F1-score, which indicates the superior of WEAKLOAN in weakly supervised setting. It also proves that WEAKLOAN is able to yield accurate prediction, even though the default samples in training data are insufficient. Among the compared baselines, supervised methods inferior to the semi-supervised method S3VM, especially when the number of training loans is small. It is because semi-supervised methods consider the nature of training data and yield better evaluation results of default loans, validating that the loan prediction task is suitable to be solved by semi-supervised or weakly supervised learning methods. WEAKLOAN outperforms the compared baselines including the semi-supervised methods. It is because WEAKLOAN involves heterogeneous features and models the interaction of these features to the prediction. Within supervised methods, MLP is the strongest baselines, but it still inferior to WEAKLOAN. MLP can be treated as a variant of WEAKLOAN without the metric learning module. This result proves that the deep metric learning module in WEAKLOAN can not only learn a soft decision boundary for default loans but also capture the hidden relationship of labels, which is useful for generating more accurate predictions. One interesting fact observed in the second sub-figure in Fig. 5 is that the recall of WEAKLOAN does not perform well compared with NB and MLP. It is because these two methods prefer to classify all loans to be the default loans. As shown, the precision of them is relatively low which means they cannot detect decent default loans.
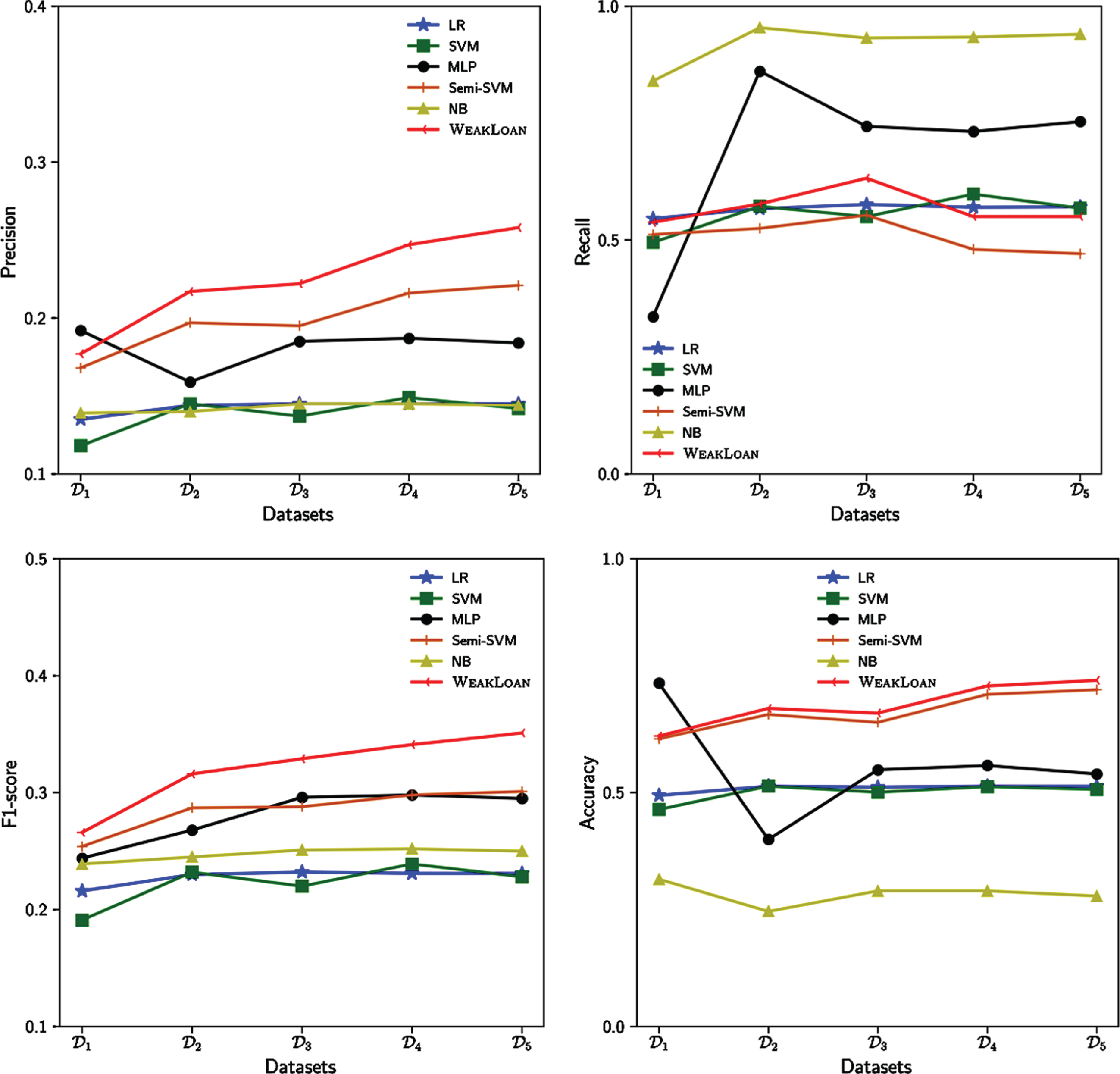
Results of performance comparison.
Overall, WEAKLOAN performs best on three evaluation metrics, precision, accuracy and F1-score, compared with the baseline models. Although it is inferior to NB and MLP on recall, we can still claim that our proposed WEAKLOAN is able to explore enough useful information from heterogeneous features in limited default loans for training, and produce numerical scores to predict their default probabilities.
To answer the third EQ, we compare the performances of WEAKLOAN under the different parameter settings. Specifically, we vary the values of φ and R, and get different results of WEAKLOAN. Due to the space limitation, we only report the results under F1-score which is able to represent the performance of WEAKLOAN comprehensively.
Influence of φ
The results of parameter φ are illustrated in Fig. 6. From these results, we can observe that with the increase of φ, the performance of WEAKLOAN first increases and then decreases violently. The reason is that high threshold will lead to an amount of false default loan alerts. The F1-score is dominated by these loans. This phenomenon is helpful in selecting the threshold φ on different datasets.
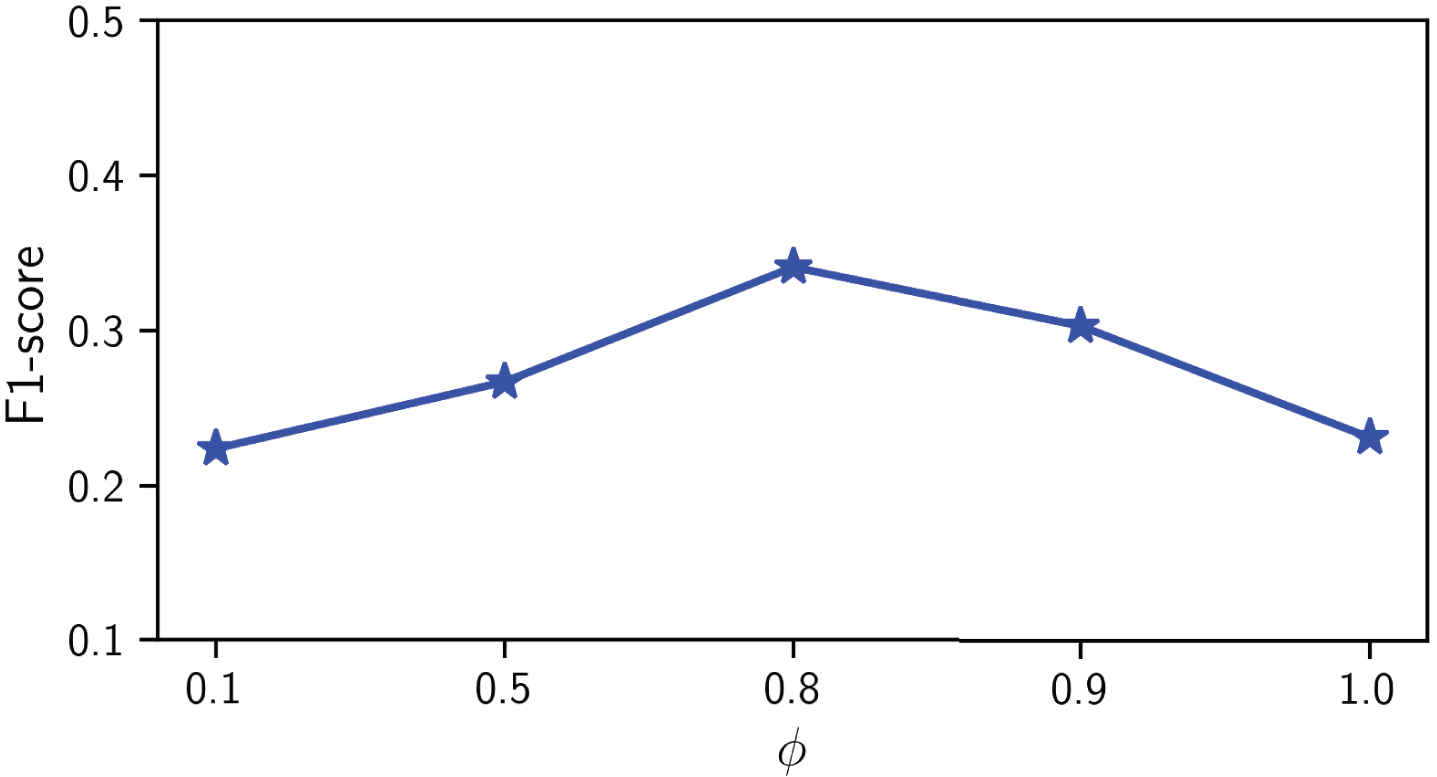
The effectiveness of φ.
The results of parameter R are illustrated in Fig. 7. From the results, we can observe that with the increase of R, the F1-score of WEAKLOAN first increases, suggesting that sufficient reference loans can improve the performance of default loan prediction. After the first increase, the performance becomes stable and then decreases slightly, which is useful from a practical point of view to select parameters.
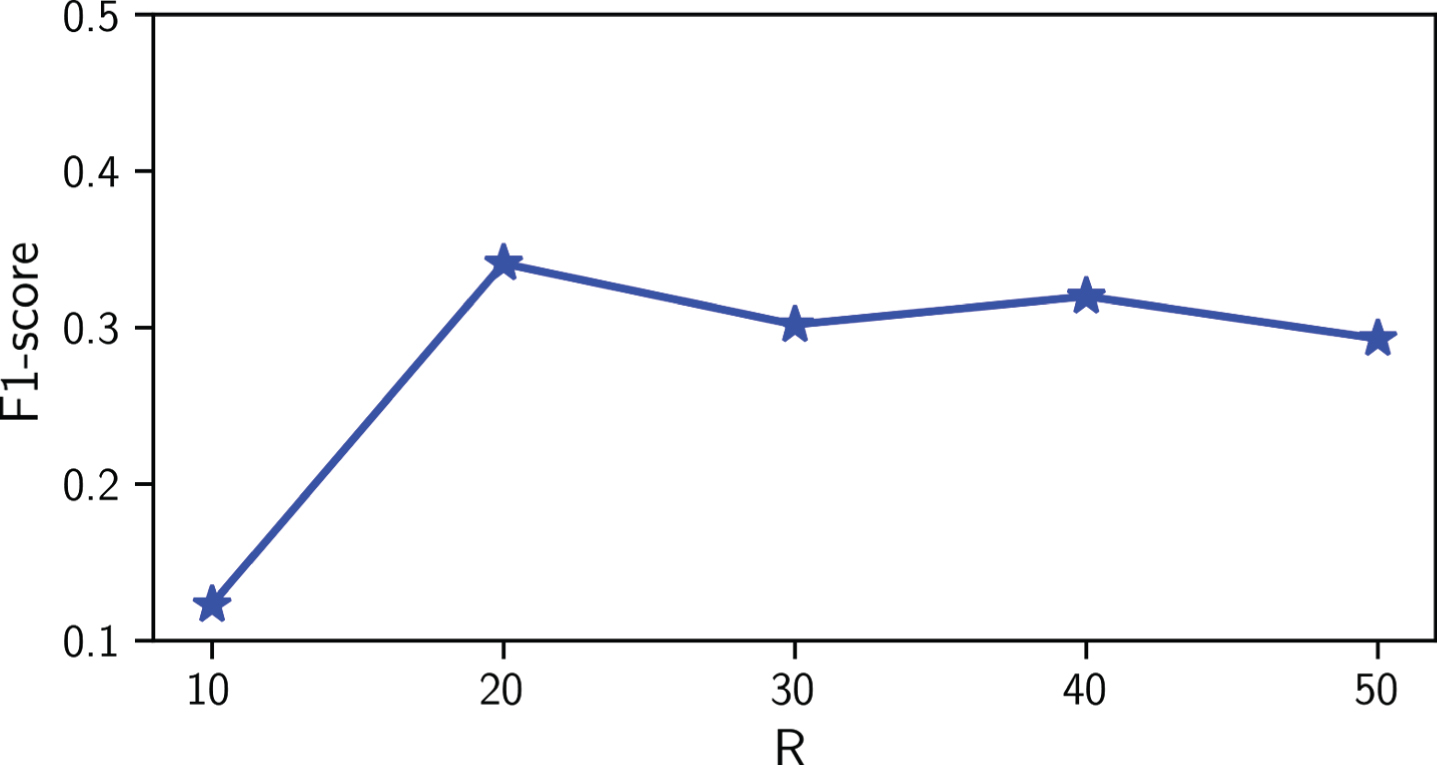
The effectiveness of R.
In this paper, we investigate how to address three challenges, namely insufficient default samples, hard decision boundaries and numerous heterogeneous features, in loan prediction task. Along this line, we formulate this task as a weakly supervised loan default prediction problem, and propose a framework WEAKLOAN based on deep metric learning to solve it. Specifically, WEAKLOAN consists of three modules: feature encoding module can model the loan features from multiple types, metric learning module can capture the hidden relationship in loan pairs, and score calculating module outputs the probability that a loan may be defaulting. The experimental results show that WEAKLOAN is superior to the compared baselines on both efficiency and effectiveness. For future research, we plan to explore the influences of different sampling policies of reference loans.