
Abstract
A bipartite network is a special kind of complex network that consists of two different types of nodes with edges existing only between the different node types. There are numerous real-world examples of bipartite networks, such as scientific collaboration networks and film-actor networks, among many others. Detecting the community structure of bipartite networks not only contributes to a deeper understanding of their hidden structure, but also lays the foundation for research into the personalized recommendation technology. Most existing algorithms, however, only focus on the detection of non-overlapping community structures while ignoring overlapping community structures. In this study, we developed a micro-bipartite network model, Bi-EgoNet along with an algorithm called Overlapping Community Detection using Bi-EgoNet (OCDBEN). This algorithm first extracts the sub-bi-community set from each Bi-EgoNet using similarity within the bipartite network and then constructs a global community structure by merging the sub-bi-communities using the double-merger strategy. We evaluated the OCDBEN algorithm with several synthetic and real-world bipartite networks and compared it with existing state-of-the-art algorithms. The experimental results demonstrated that OCDBEN outperformed existing algorithms in both accuracy and effectiveness.
Introduction
Community detection in complex networks have received significant research interest in recent years. Many methods have been proposed for one-mode networks [11, 42]. Community detection uses topological features of networks, such as Chang’s method’s use of Friend Intimacy [11] and Li’s method’s use of the maximizing likelihood function [21]. In addition to the topological features, researchers also consider other influence factors, such as social behavior and semantics [18] and background information [20]. Based on these community detecting methods, other researchers have proposed personalized recommender systems, including the Community-based Collaborative Filtering Recommender System (CCFRS) [32] and the Community-based Hashtag Recommender System (CHRS) [33].
Recently, research into bipartite networks has received attention. Bipartite networks are found in various fields including a scientific collaboration network of papers and authors [24], a movie-actor network of movies and actors [2], and the metabolic network [14] of reactions and metabolites. A bipartite network (also known as a two-mode or affiliate network) is an essential kind of complex network having two types of nodes and edges only between the different types of nodes. Fig. 1 shows a bipartite network example of South African companies [35] with shared leadership relations between persons and companies. The node types are indicated by different colors.
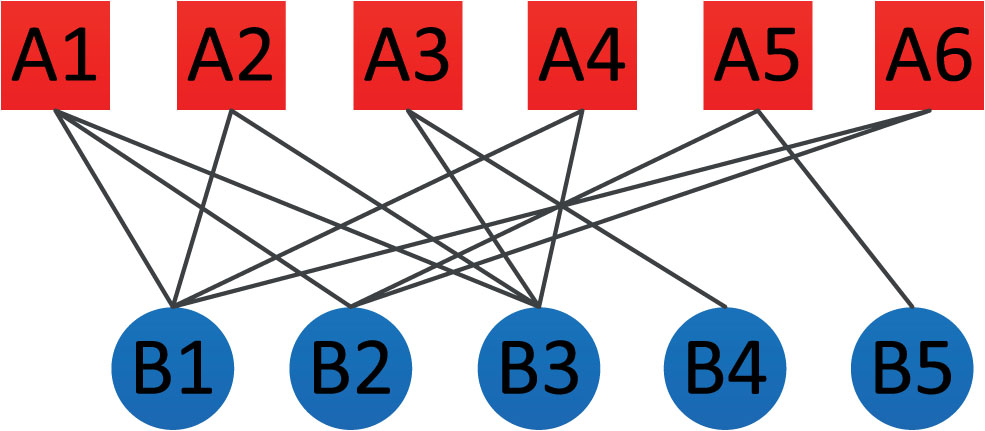
A bipartite network example of South African companies. Red nodes (A1, A2, . . . , A6) represent persons, and blue nodes (B1, B2, . . . , B5) represent companies. Each of the 13 edges between persons and companies indicates that the person has a leadership position in the company.
The community structure of bipartite networks features significant characteristics with tightly connected nodes within communities (intra-communities) and sparely connected between communities (inter-communities). Detecting community structure is helpful to excavate the hidden structured information in the network. In most real networks, an entity (nodes) has multiple attributes that means the entity can belong to more than one communities at the same time. However, in the traditional community detection algorithm, there are few researches on bipartite network overlapping community structure. So detecting overlapping communities in bipartite networks has more important significance and application value.
Recently, a large number of algorithms have been proposed to detect overlapping community structure in bipartite networks [8, 15]. These algorithms fall into two main categories: One method projects bipartite networks onto one-mode networks. Newman et al. [8, 40], however, have proven that the method of one-mode projection does not fully reflect the relationship strength of these nodes. One-mode projection results in a loss of information from the original bipartite network and the addition of information that does not belong to the original bipartite network. The second method addresses bipartite networks directly. This method simplifies the capture of essential network features compared to one-mode projection.
EgoNet [13] (also known as Egocentric Network) is a micro one-mode network model consisting of a single node and its neighborhood. The single node is called the Ego. Its neighbors are called Alters. Edges among of these nodes are called relationships. Fig. 2 depicts a typical EgoNet. Any node in a one-mode network can be the kernel of an EgoNet. Any one-mode network is composed of more than one EgoNet. EgoNet effectively enables detection of overlapping communities in one-mode networks [1, 5]. Inspired by EgoNet, we have designed a micro-bipartite network model named Bi-EgoNet. Within our method, we introduce a new OCDBEN (Overlapping Community Detection using Bi-EgoNet) algorithm to address bipartite networks directly from the micro-perspective. Our main contributions in this work are as follows: Bi-EgoNet, a micro-bipartite network model. We extend the micro-one-mode model, EgoNet, to a micro-bipartite network model. We believe Bi-EgoNet is the first to analyze bipartite networks from a micro-perspective. A new OCDBEN algorithm. OCDBEN is an overlapping community detection algorithm based on Bi-EgoNet. Compared to state-of-the-art traditional algorithms, our experiments show OCDBEN to be more accurate and effective. A new measurement method of modularity, EQ
b
EQ
b
extends the Q
b
measure and evaluates the modularity of overlapping community structures.
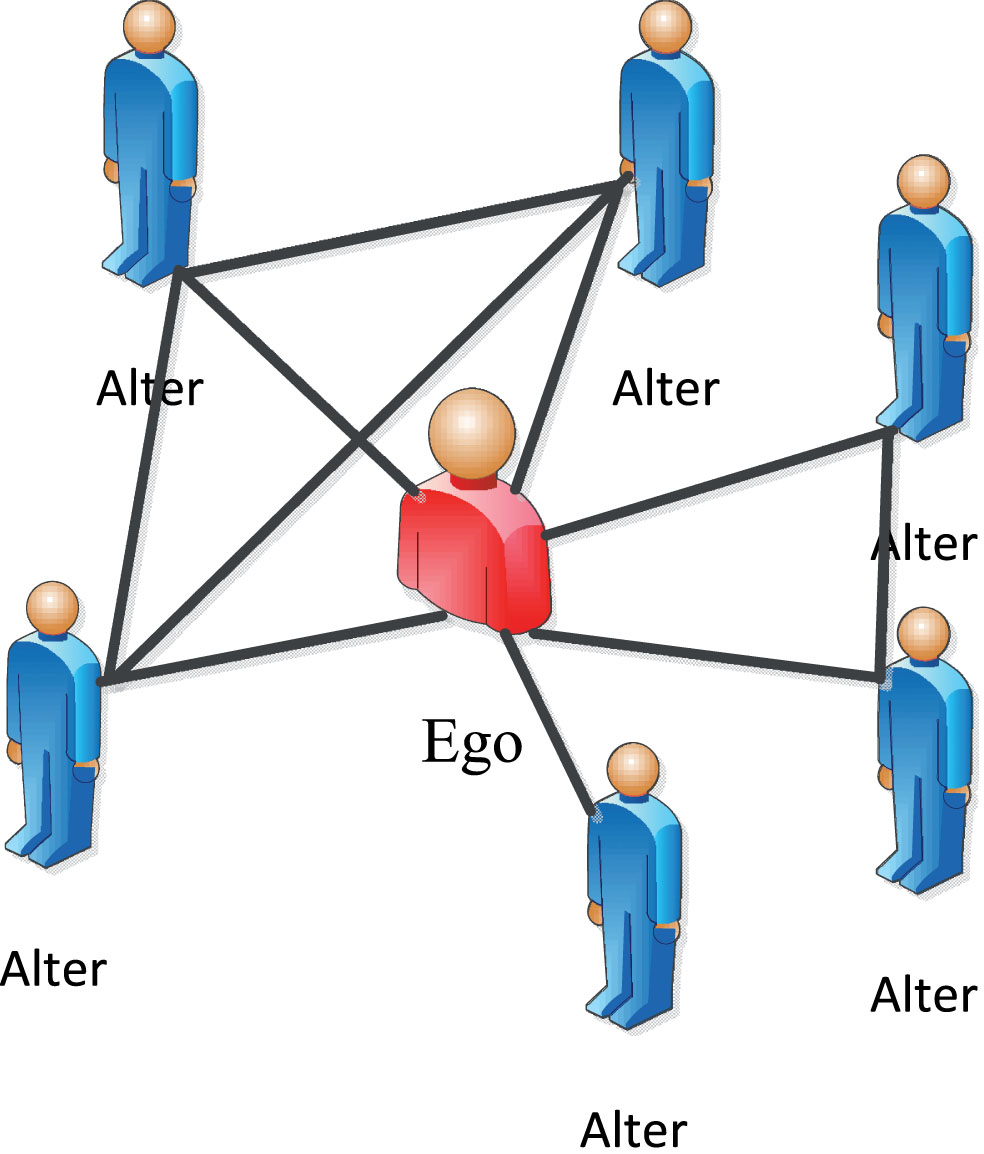
A sample EgoNet. The red person is called the Ego, and the blue persons are called Alters. the Ego, Alters, and relationships among these persons form an EgoNet.
In Section 2, we discuss various algorithms used for community detection in bipartite networks. In Section 3, we describe our proposed algorithm, OCDBEN, in detail. In Section 4. we introduce three evaluation methods: EQ b , bipartite partition density (Density), and normalized mutual information (NMI). In Section 5, we introduce two overlapping community detection methods: Cui’s method and Wang’s method. In Section 6, we present our experimental results and evaluation of the OCDBEN algorithm with several synthetic and real networks, and compare with the methods of Cui [41] and Wang [40]. Finally, we present our conclusions in Section 7.
As mentioned previously, community detection algorithms in bipartite networks fall into two categories: those that project bipartite networks into two one-mode networks and those that address bipartite networks directly.
Projecting a bipartite network into two one-mode networks using either weighted or unweighted projection is a widely used method. S.Dhillon [9] presented a new spectral co-clustering algorithm to solve a bipartite graph partitioning problem between documents and words. It used the second left and right singular vectors of an appropriate scaled word-document matrix to yield good bipartitions. Zhou et al. [36] were inspired by network-based resource-allocation dynamics and developed a weighted projection method for bipartite networks. A personal recommendation method was then proposed based on this method. Meghanathan et al. [29] proposed a community detection method based on spectral decomposition. This method projected nodes of different dimensions onto specific dimensions. It then used this projection to obtain the smallest eigenvalue and its corresponding eigenvector to detect communities in direct and indirect bipartite networks.
The second category addresses bipartite networks directly. Barber [25] proposed an algorithm called BRIM (bipartite, recursively induced modules). This technique extended the modularity measure proposed by Newman [23] to a bipartite modularity (Q b ). It then used Q b to identify some key properties of modularity matrix B and to detect community structures. Liu et al. [39] combined the LP (Label Propagation) and BRIM methods in a fast algorithm called LP&BRIM. This algorithm generated better community structures by recursively inducing division between the two types of nodes in bipartite networks. Larremore et al. [19] presented a bipartite stochastic block model (biSBM) to solve the community detection problem. This model explicitly included vertex type information was easily extended to k-partite networks. Others have proposed a number of algorithms designed to detect the overlapping community structure of bipartite networks. Classic methods such as that proposed by Cui et al. [41] introduced the key bi-community and free node concepts and proposed a novel algorithm for the detection of overlapping community structure in bipartite networks. Using this method, Wang et al. [40] defined the concept of intimate degree, and used it to obtain core communities with overlapping communities which were revealed via the merging rule. Li et al. [43] proposed a new quantitative function called bipartite partition density. Bipartite networks can be partitioned into reasonable overlapping communities by maximizing this quantitative function. Meanwhile, they also developed a heuristic adapted label propagation algorithm (BiLPA) in order to optimize the bipartite partition density in large-scale bipartite networks.
Table 1 shows the conceptual differences among these methods relative to our algorithm OCDBEN.
A comparison of bipartite community detection algorithm
A comparison of bipartite community detection algorithm
These methods described thus far all detect community structure from a macro perspective. Detecting community structure from the macro perspective, however, invariably misses local features between nodes of bipartite networks. To address this problem, we propose our new algorithm, OCDBEN, that detects community structure in bipartite networks from a micro perspective. OCDBEN extracts sub-bi-community structure from a micro perspective and merges sub-bi-communities from a macro perspective. This algorithm not only takes into consideration local features between network nodes and extracts sub-bi-communities using local features, but it also incorporates the advantages associated with a macro perspective.
We first consider a bipartite network BG(A, B, E) without self loops and multiple edges between any given pair of nodes. A and B represent two types of node sets, m is the number of A-type nodes, and n is the number of B-type nodes. we also define the set of edges E = {ea,b|a ∈ A, b ∈ B}.
Related definitions
Inspired by the definition of EgoNet, we refer to the Ego of our Bi-EgoNet as the bi-Ego. Each Alter of a Bi-EgoNet is referred to as a bi-Alter. We define a Bi-EgoNet as follows.
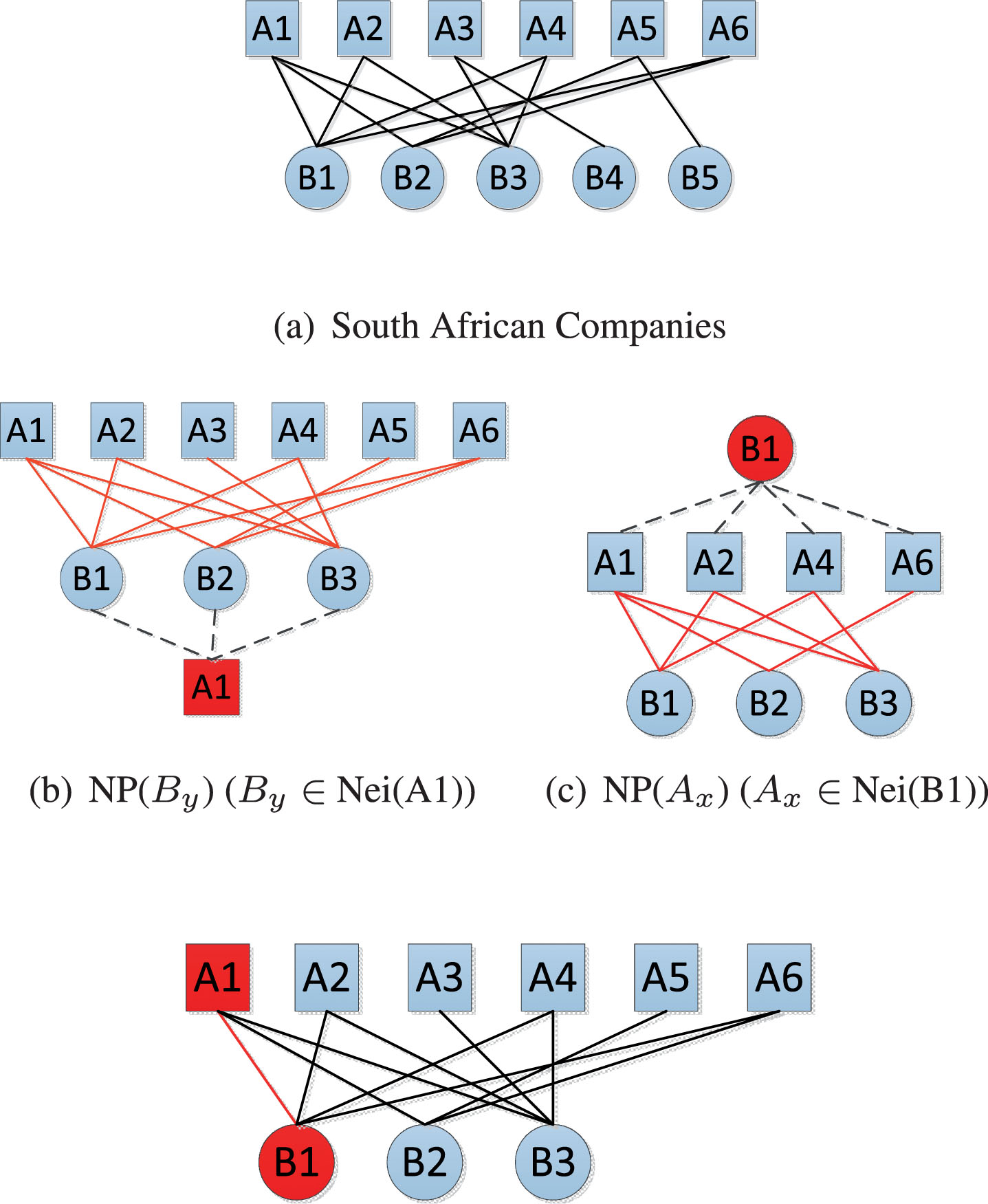
A sample Bi-EgoNet. (a) The bipartite network of South African Companies; (b) The neighboring node pair set of A1; (c) The neighboring node pair set of B1. (d) The Bi-EgoNet composed of (A1, B1), (a), and (b).
In this section, we describe in detail the two-stage execution process of our OCDBEN algorithm. The first stage is the extraction of sub-bi-communities set subBC (Definition 5), using the similarity of each Bi-EgoNet (Definition 4) of a bipartite network. The second stage is the merger of the subBCs using a double-merger strategy to GBC (Definition 6). The OCDBEN flowchart is shown in Fig. 4.
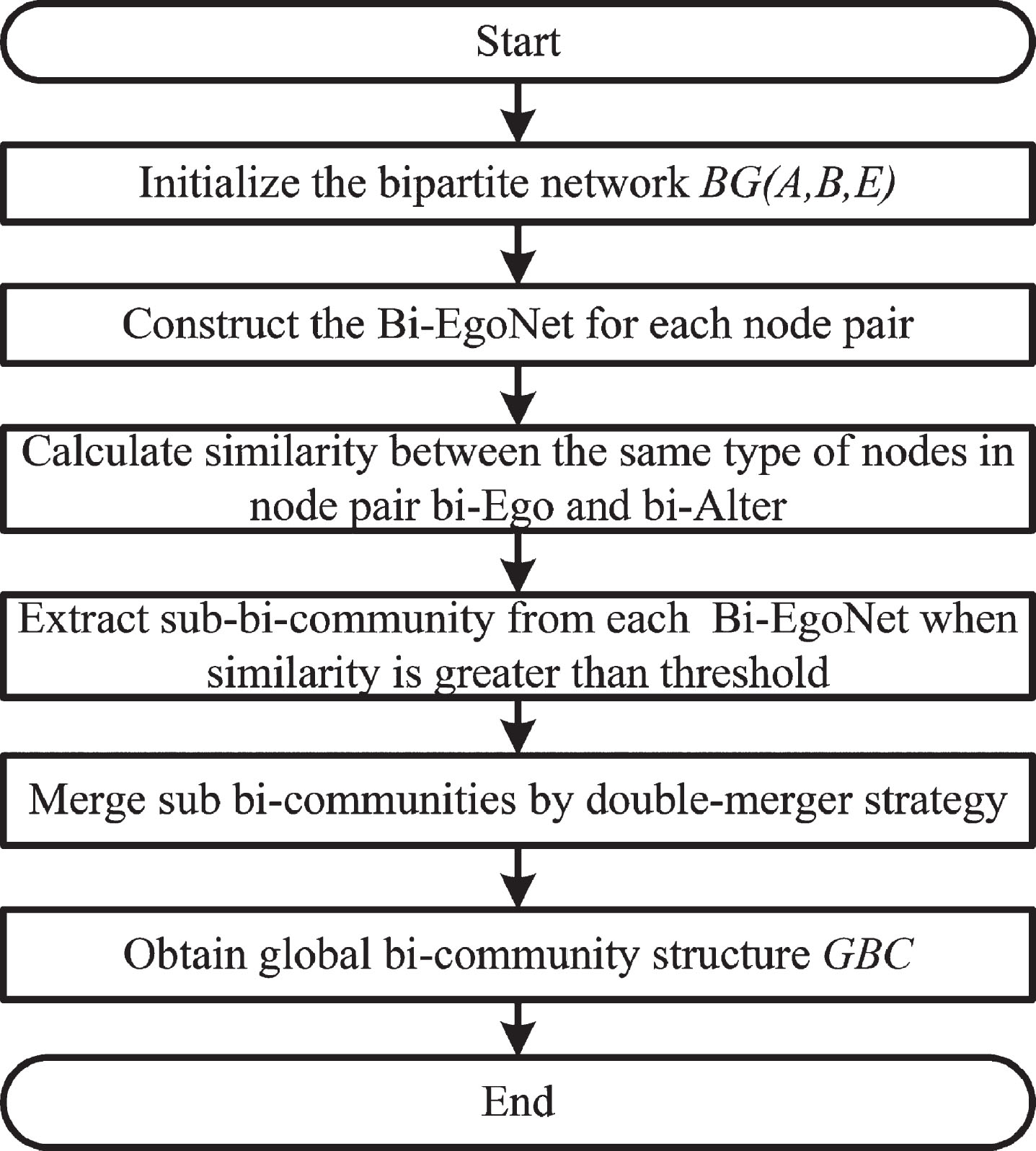
OCDBEN flowchart.
In this stage, the similarity calculations between a bi-Ego and each bi-Alter are a very important part of extracting sub-bi-community from Bi-EgoNet (Definition 5).
For a Bi-EgoNet bi-EN(a, b), similarity refers to the level of similarity for the same type of nodes between the bi-Ego and each bi-Alter. The definition of similarity is shown in formulas (6) and (7).
The pseudo-code of the stage is shown in Algorithm 1. And Fig. 5 shows the flow chart for the first stage.
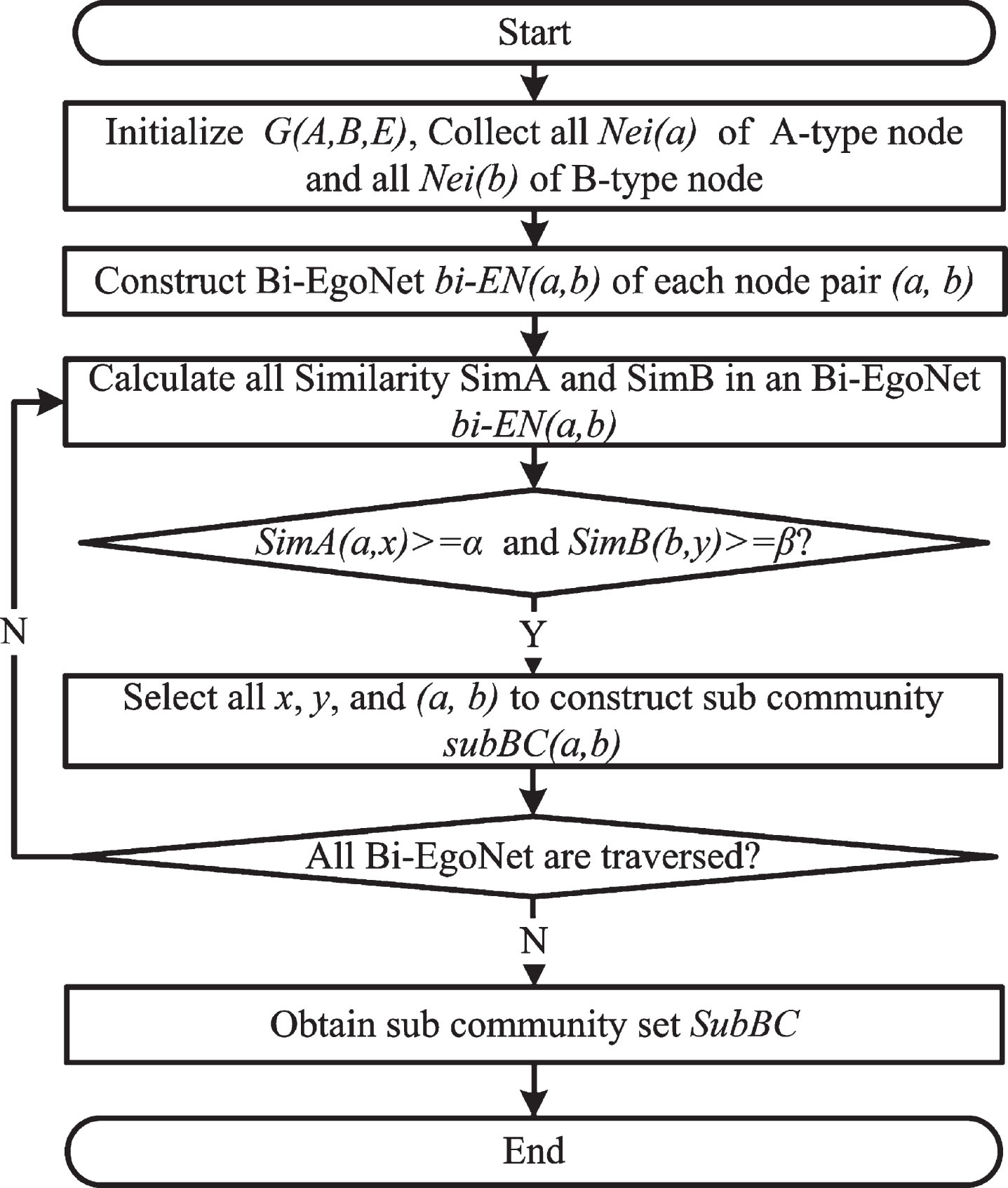
Flow chart of the first stage of OCDBEN.
In this stage, we apply a double-merger strategy to merge the sub-bi-communities. The double-merger strategy contains two different approaches for merging the sub-bi-communities. The first strategy is applied that only when both the similarity of the two same type nodes between the two sub-bi-communities are greater than a threshold. In this case, we consider the two sub-bi-communities to belonging to the same community and able to be merged. The second strategy is applied when there exists a large difference in the number between the two types of nodes, the nodes in the large group are highly similar, and the nodes in the smaller group are not very similar. In this case, when the similarity is greater than a threshold, we can merge the two sub-bi-communities.
Given two sub-bi-communities subBC1 and subBC2, (a, b) and (x, y) are bi-Egos of the two sub-bi-communities, respectively. The contact ratio CR represents their level of overlap between the two sub-bi-communities. The first measure of the contact ratio, called CR1, which includes CR1_A and CR1_B) is shown in Equations (8) and (9):
The other measurement of the contact ratio, called CR2, is given by:
Algorithm 2 presents the pseudo-code for the merging stage. Fig. 6 shows the flow chart for the second stage.
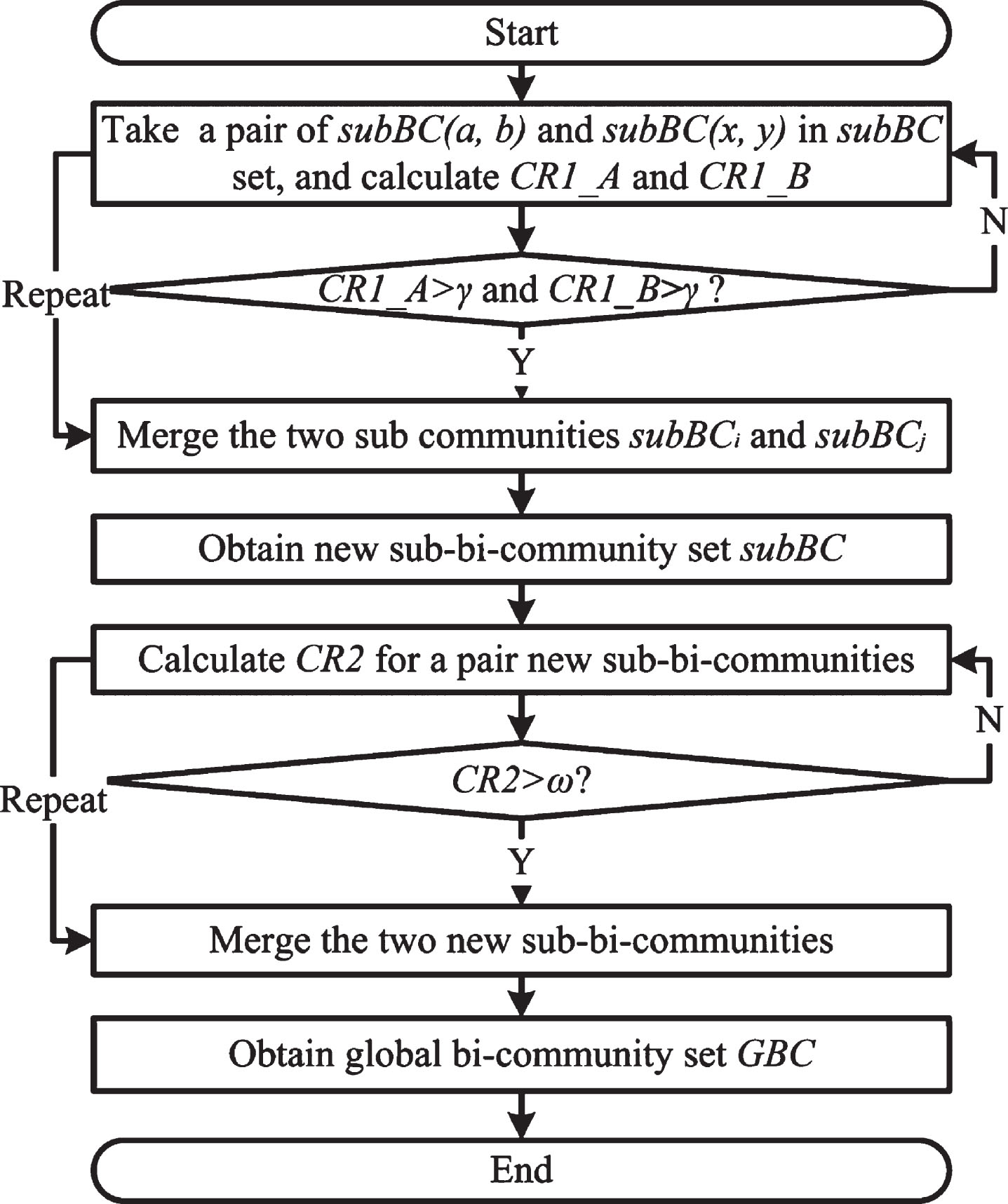
The second stage of OCDBEN flowchart.
The value of the parameter in OCDBEN was set as α = N (A)/N (E) ±0.1, β = N (B)/N (E) ±0.1, γ = 0.5 ± 0.1 and ω = 0.5 ± 0.1. To introduce the implementation of the OCDBEN algorithm, we use the South African companies network [35] (Fig. 1) as an example. Table 2 lists the detailed descriptions of 13 Bi-EgoNets in the South African companies network, including the Bi-EgoNet label, the bi-Ego, the set of bi-Alters, and the set subBC. In these 13 Bi-EgoNets, we set the similarity thresholds α and β to 0.5 and 0.4, respectively. We then extract the sub-bi-community sets subBC. Finally, we obtain three global bi-communities—{A1, A2, A4, A6, B1, B2, B3}, {A3, B3, B4}, {A5, B2, B5}—using double-merger strategy setting the thresholds of CR1 and CR2 as γ = 0.6 and ω = 0.6, respectively. And B2 and B3 are overlapping nodes. The community structure is shown in Fig. 7.
The Bi-EgoNet dataset of the South African Companies network
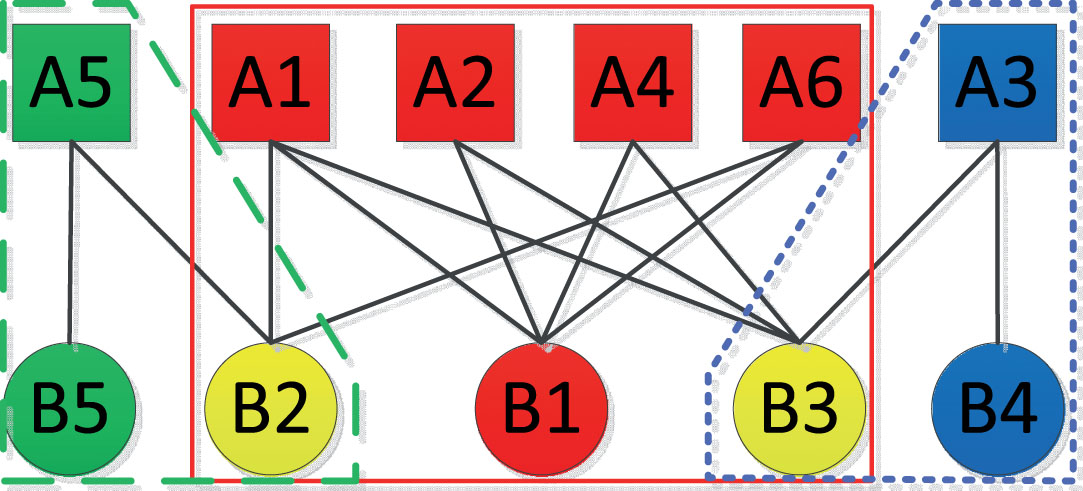
The community structure of the South African companies network. Red nodes, blue nodes, and green nodes represent three distinct communities. Yellow nodes (B2 and B3) are overlapping nodes.
OCDBEN consists of two main stages. We assume that there are m A-type and n B-type node in a bipartite network. In the sub-bi-communities extraction stage, the computational complexity of constructing the Bi-EgoNets for each pair of nodes in a bipartite network is O(m*n). The computational complexity of extracting the sub-communities from each Bi-EgoNet is O(m2*n2). In the merging stage, the maximum associated complexity is O(m2*n2). Thus, the worst-case time complexity of OCDBEN algorithm is O(m2*n2).
Evaluation criteria
In this section, we first extended Q b [25] to quantify the overlapping community structure of bipartite networks. We then introduce the bipartite partition density (Density) [43] and NMI measures.
Extended modularity of bipartite networks EQ b
Modularity measures the structural strength of a network community. Given an unweighted, undirected bipartite network BG(A, B, E), Barber [25] proposed the Q
b
measure and applied it to non-overlapping community structures. The formula for modularity Q
b
is
Since nodes in the real world may belong to more than one community, we extend the definition of δi,c to become a membership coefficient reflecting how much node i belongs to the community c. Shen et al. proposed the concept of the membership coefficient [34]. They point out that the membership coefficient should be normalized, such as 0 ≤ ψi,c ≤ 1, ∀i ∈ A, ∀c ∈ C and ∑c∈Cψ(i, c) =1. That means that if the node i belongs to k communities, the membership coefficient ψ(i, c) of node i in each community is
Li et al. [43] proposed a new quantitative function called bipartite partition density (Density) for community detection in bipartite networks and defined it as according to:
Mcdaid et al. [22] extended the traditional normalization of variation, enabling it to evaluate the overlap between community partition. The method compares the experimental result to the standard partition. The higher the value of NMI, the more similar the experimental result is to the standard partition. For a pair of communities X and Y expressed as matrices of cluster membership, their associated NMI is shown in Equation (14). The NMI always falls into the range 0-1.
As you known, OCDBEN is an algorithm which detects overlapping community structure using similarity from a micro view in bipartite networks. Both Cui’s method and Wang’s method can also detect overlapping community structure using different similarity (intimacy degree) from a macro view in bipartite networks. And these three methods have similarities and differences. Thus we compare OCDBEN with the two methods, the experimental results are very valuable and practicable. These two methods are described in detail below.
Cui’s method Cui et al. [41] defined two key concepts: key bi-communities and free node. In this algorithm, first, sorting nodes in order of increasing of node degree. Then constructing the basic key bi-community for each node, and merging these nodes using the intimacy degree between the basic key bi-communities of the each two nodes to form key bi-communities. Next, find out these nodes which do not belong to any key bi-communities, these nodes and their neighbors are free node. Finally, distribute these free nodes to key bi-communities.
Wang’s method Wang et al. [40] defined two parameters to show the intimacy relationships between the same type nodes and heterogeneous nodes, respectively. In Wang’s method, it first finds and expands core communities using intimacy relationships of the same type nodes. Then sub communities were obtained by merging the other type nodes to core communities using intimacy relationships between heterogeneous nodes. Lastly, final community structure is obtained by merging these sub communities.
Experimental design and results
In this section, we present the result of our evaluation of the accuracy and effectiveness of the OCDBEN algorithm on several synthetic and real-world networks. two studies ([40, 41]) have documented the strong effectiveness of the methods of Cui and Wang at detecting overlapping community structure in bipartite networks, we compared OCDBEN with these two methods.
Synthetic bipartite networks
We used synthetic networks to evaluate the accuracy of OCDBEN. Using the synthetic network generation model proposed by Larremore et al. [19], each synthetic network consisted of four communities with equal numbers of nodes. Each community was made up of A-type nodes and B-type nodes, and λ is called the mixing parameter, represents noise ratio. It ranged from 0 (all noise) to 1 (no noise).
In our experiments, we selected synthetic networks with 256 nodes. λ ranged from 0.1 to 1, and the average degree was 4. Each synthetic network contained 128 A-type nodes and 128 B-type nodes. We applied OCDBEN, Cui’s method, and Wang’s method to these synthetic networks. The NMI and EQ b results for the synthetic networks are shown in Fig. 8. In Fig. 8 (a) and (b), as λ declined, NMI values also gradually decreased. All of the algorithms accurately detected overlapping community structures in these synthetic networks when λ was 1. None of the methods detected community structures when λ was 0.1. When λ was between 0.1 and 1, the NMI and of the ODBCEN algorithm was greater than the NMI values of the other 2 methods for most synthetic networks. Thus, the community structures detected by our algorithm were closer to the actual community partition than the structure detected by the methods of Cui and Wang.
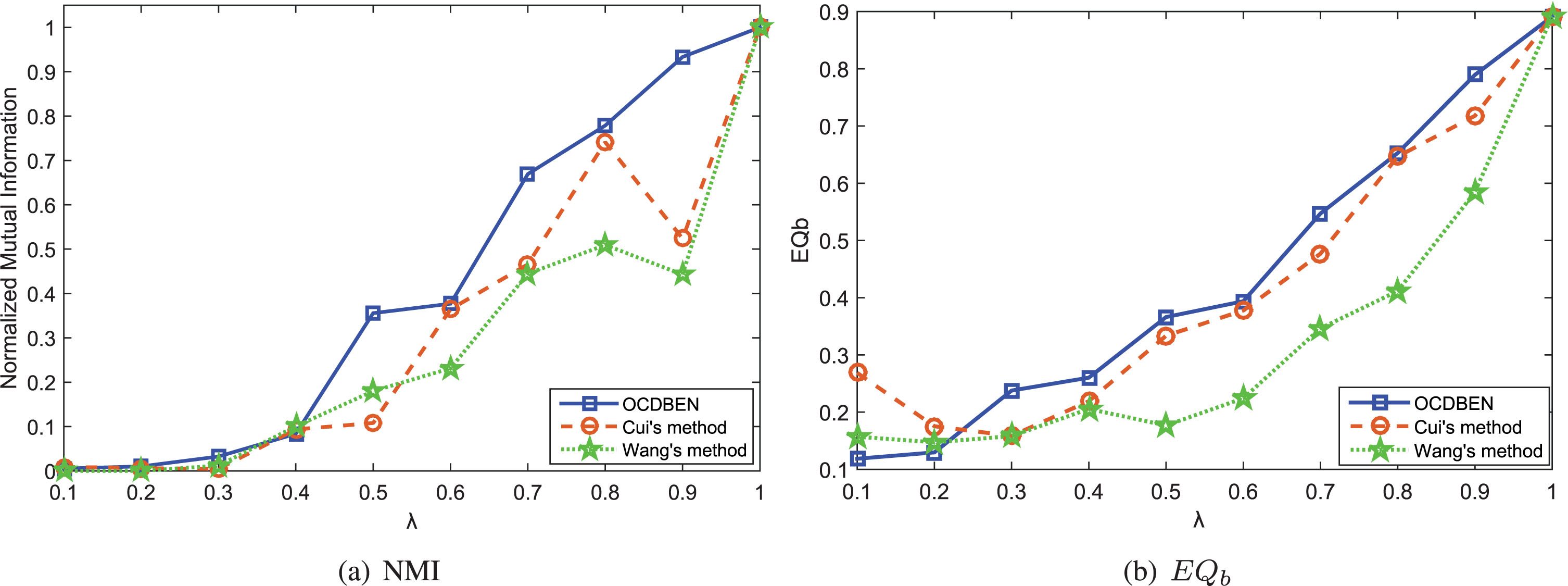
Comparison results in synthetic networks.
To further verify the OCDBEN algorithm, we tested OCDBEN with 14 real-world datasets and compared the results with those from the methods Cui and Wang. The detailed information of 14 real-world datasets is shown in Table 3. In Table 3, m and n represent the number of each node type. |E| is the number of edges. <k> is the average degree.
Details of the 14 datasets
Details of the 14 datasets
Table 4 shows experimental results with the number of communities C_num detected in each dataset. OCDBEN effectively detected overlapping community structures in all 14 bipartite networks from different domains. Both of Cui’s and Wang’s methods are failed in dataset SAC, the main reason is that the number of nodes in SAC is too small for the two methods to divide it into smaller communities. In datasets D-US and AR, Cui’s method are failed to detected overlapping community structures. Datasets D-US and AR share the most important feature that the number of nodes of one type is much smaller than the number of nodes of the other type, with communities formed from a single node of one type with multiple nodes of the other type. However, Cui’s method considered each single node and its neighbors to belong to a free node set. Thus, Cui’s method failed to detect the community structure in D-US and AR. Similarly, Wang’s method detected community structures effectively in most datasets, with the exception of dataset GP. Since the regulation of flexibility in Wang’s method is relatively weak (the value of parameter is 0.5), it was very difficult for this technique to detect community structures in the GP dataset. Finally, the numbers of nodes in M-UT and Col were both large, leading to the failure of Cui’s and Wang’s methods to complete in a reasonable amount of time (no exceed 5 hours).
Number of communities detected by the tested algorithms for different real-world datasets
We implemented the detection algorithms using the Java programming language on a personal computer with an Intel i5-3210M, 2.5 GHz processor, 4.0 GB of memory, and the Windows 10 operating system. Table 5 shows computation time required for each algorithm and dataset. As the network size grew, so did the computation time for all the three methods. However, OCDBEN’s time grew far more slowly than the methods Cui and wang.
Computation time (ms) Required by the three algorithms for the 13 real-world datasets
We also evaluated the overlapping community structures of OCDBEN by all three methods using, Density and EQ b in Figs. 9 (a) and (b). Fig. 9 (a) shows that the Density values from OCDBEN were all superior to those of Cui’s method. The Density values of OCDBEN with these datasets were also better than those of Wang’s method, with the exception of the D-US, AR and Malaria for which the Density values from OCDBEN were 0.02, 0.1625 and 0.1302 less, respectively, than those of Wang’s method. The average Density values of OCDBEN were 0.2776 and 0.1341 higher than those of Cui’s and Wang’s methods, respectively.
Similarity, Fig. 9(b) shows that the EQ b values from OCDBEN were better than those of Cui’s method, with the exception of SW, in which the EQ b of OCDBEN was 0.0447 less than that of Cui’s method. Likewise, the EQ b values from OCDBEN in these datasets were better than those of Wang’s method, with exception of AR and Crime datasets. The EQ b values of OCDBEN in the two datasets were 0.23 and 0.0583 less, respectively, than those of Wang’s method. The average EQ b values of OCDBEN were 0.1231 and 0.0937 which were greater than those of Cui’s and Wang’s methods, respectively.
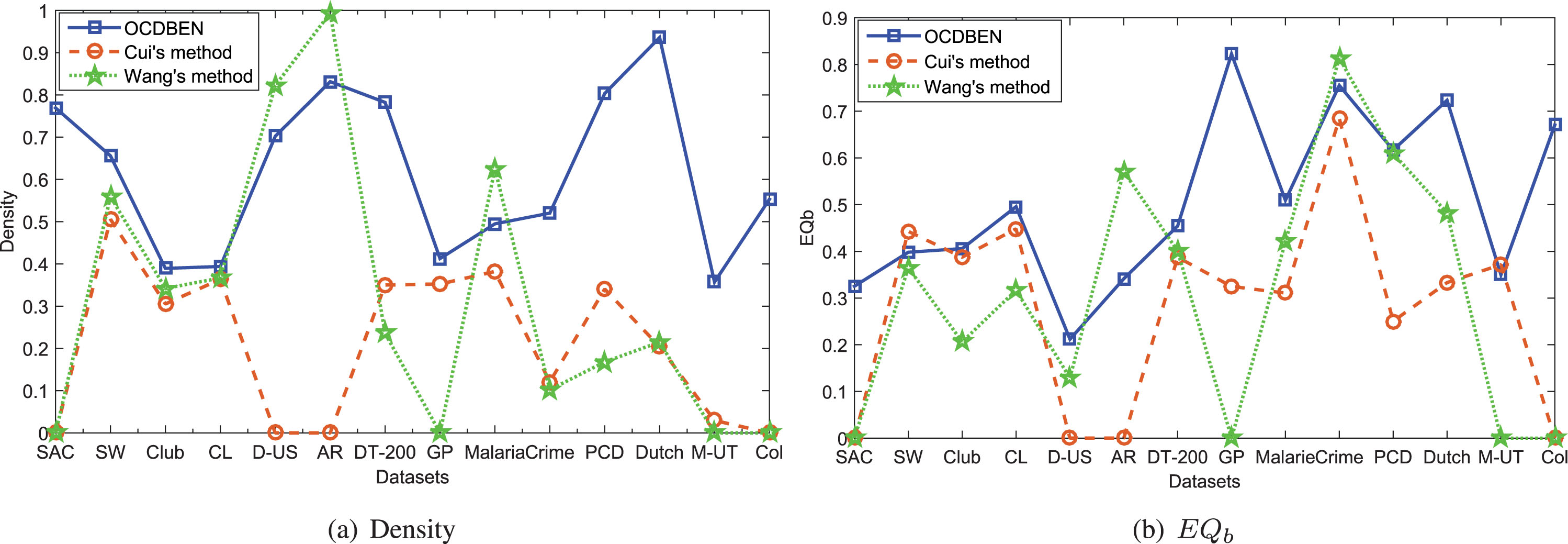
Comparison chart of evaluation results of different methods.
As is known to all, detecting community structure lays the foundation of personalized recommendation and other related applications in bipartite networks. In real life, most networks have overlapping community structure. If only considering the non-overlapping community structure of the network, the application scope of the algorithm will be greatly reduced. EgoNet is a micro one-mode network model, can be used to analyze and detect overlapping communities in one-mode networks from a micro view. In this paper, our contribution to this field of research is threefold. First, we have extended EgoNet, and proposed Bi-EgoNet for analyzing bipartite network structures from a micro perspective. Second, we have created the OCDBEN algorithm, which is based on Bi-EgoNet, to detect overlapping community structures. Third, we have introduced an evaluation method, EQ b , to determine the modularity of overlapping community structures in bipartite networks. We performed tests with synthetic and real-world networks to validate the new OCDBEN algorithm. Experimental results indicate that OCDBEN detected meaningful community structures in the original bipartite networks. The accuracy and effectiveness of OCDBEN were superior to those of other state-of-the-art algorithms. In the future, we will conduct further research in the following directions: to prove the characteristics of Bi-EgoNet using mathematical and statistical methods, to find a more efficient community detection method based on Bi-EgoNet for two-mode network, and to apply Bi-EgoNet to a recommendation model.