
Abstract
Feature selection is an essential part in the data preprocessing. In the text classification, most of the previous feature selection algorithms rarely consider the redundancy between features. This paper focuses on eliminating redundancy. After modifying the formula of feature correlation of original fast correlation-based filter (FCBF) and updating the algorithm strategy, we propose a new approach named improved feature size customized fast correlation-based filter (IFSC-FCBF). In addition, we combine IFSC-FCBF with Naive Bayes (NB) classifier for text classification, and test it in four typical text corpus data sets. The results demonstrate that with the same feature size, IFSC-FCBF method has the advantages of higher accuracy and shorter running time than other methods.
Introduction
With the development of the Internet, textual information and its diversity continue to increase. This makes the text classification more and more attention of the research community. Text classification is to assign a new document automatically to a predefined category [1]. A number of methods are now available to implement text classification, such as k-nearest neighbors (KNN) [2], decision tree [3], support vector machine [4], Naive Bayes [5], neural network [6]. Naive Bayes is the most popular among them due to its high computational efficiency and good performance of prediction [7].
Before text classification, the text needs to be vectorized. The text will be transformed into a vector or matrix that the computer can recognize. Text classification tasks commonly used text representation is vector space model (VSM) [8]. In this paper, we utilize this method to represent documents. The main idea is as follows: after word segmentation, the feature words in the training data are extracted to form a feature space (t1, t2 . . . t m ), where t k , k ∈ [1, m] are feature words, m is the dimension of the feature space. Then, the i th document will be expressed as D i = (w t 1 , w t 2 . . . w t k ), where w t k is the weight of feature t k in the document D i . If w t k = 0, it means t k is absent in document D i , otherwise w t k represents the frequency of t k appearing in the D i .
In the text classification, because of the large dimension of feature words, it takes a long time to train the classifier. What’s more, some features are useless and some redundant features may reduce the classification accuracy. Therefore, feature selection is especially important. There are two main methods of feature selection in machine learning [9]: filter and wrapper. The filtering method selects a feature subset as a preprocessing step, which works independently of the classification algorithm. While the wrapper method uses the accuracy of the classifiers as criteria to perform feature selection. Wrappers have a better performance because they select the feature subset based on predetermined algorithms [10]. However, the wrapper method is time-consuming and complicated, which is obviously not suitable for text classification [11]. Therefore, we pay more attention to filtering method.
Researchers have proposed many feature filter methods for text classification. Document frequency [12] and information gain (IG) [13] are the most popular ones among them. Although information gain is an effective method for feature selection, it has the drawback that information gain only gives each feature an IG value individually without considering redundancy between features [1].
In order to eliminate redundant features, Peng et al. proposed a typical method named MRMR [14], but the computational complexity is too high [1]. Lee et al. eliminated redundant information with the usage of divergence to improve information gain [15]. Uysal et al. proposed the distinguishing feature selector (DFS) based on feature probability [16]. However, although these methods can effectively remove redundant features, they are all of high complexity.
In order to perform feature selection faster, we focused on the fast correlation-based filter (FCBF) [12], which has been applied in various fields. Liu et al. used to diagnose diesel engines [13]. Chen et al. combined FCBF with RELIEF for gene selection [14]. Davood et al. integrated PCA with FCBF to select audio features and visual features for emotion recognition [15]. In the medical field, Sarojini et al. applied FCBF to select features for diabetes databases and achieved improvement in medical diagnosis [16], and Bahasen used it in the diagnosis of epilepsy [17]. At present, FCBF is often used in emotion recognition [31, 32]. Although Suchi Vora and others involved FCBF in the research of text classification feature extraction algorithm, the classification effect of FCBF is not ideal [30].
In this paper, we propose an improved feature size customized fast correlation-based filter (IFSC-FCBF). Based on the characteristics of text features, we improve the formula of feature correlation in original FCBF and upgrade the algorithm strategy. Therefore, we can customize the selected feature size, which makes the text feature selection more accurate.
In the experiments, we combine IFSC-FCBF with Naive Bayes classifier and test it in English and Chinese corpus data sets. The results show that compared with other feature selection algorithms, IFSC-FCBF can effectively eliminate redundant features in a shorter execution time and has higher accuracy.
The rest of the paper is organized as follows: The second part discusses the related research of the existing algorithms involved in this paper. The third part introduces the theoretical derivation of IFSC-FCBF in detail. The fourth part gives the simulation comparison results of this method and other feature selection methods. The fifth part is the conclusion and future research directions of this paper.
Related work
Naive Bayes text classification
The text classification problem belongs to discrete data classification. There are usually two kinds of Bayesian models [18]: one is the Bernoulli Naive Bayes (BNB) [19], which only considers whether the features appear in the documents; the other is the multinomial Naive Bayes (MNB) [20], which focuses on the frequency of features in the documents. The experiment shows that the classification effect of multinomial model is better than Bernoulli model [21]. In this paper, we choose the multinomial Naive Bayesian model [20]. The idea of the algorithm is as follows: first calculating the prior probability of each category; then using Bayes’ theorem to calculate the posterior probabilities of the feature belonging to the category; at last deciding how to categorize features based on the category selection with the maximum a posteriori (MAP).
Assume the document category collection C ={ C1, C2 . . . C
j
}, where j = 1, 2, 3 . . . V. D
i
is a training document which can be represented as D
i
={ tf (t1) , tf (t2) . . . . tf (t
m
) }. The category of the maximum probability is where the document D
i
belongs. It can be described as following:
where C map represents the final classification result.
According to Naive Bayes feature independence assumption, the equation (2) can be simplified as:
where m is the number of features, t k (k = 1, 2, 3.... m) is the kth feature word in the document D i .
Information gain (IG) is an evaluation method based on information entropy, which measures the impact of the presence of feature terms on text categories [33]. For a given random variable X ={ x1, x2, x3 … x
n
}, x
i
represent the probability that the ith random variable appears. The information entropy of X is defined as follows:
For a classification system, the information gain IG (t) of the feature term t is the difference between the information entropy of the classification system when t exists and does not exist in all texts. Obviously, the larger the information gain value of a feature item, the more valuable information it brings to the classification system. Calculated as follows:
where V is the number of classes, P (C
j
) is the probability of class C
j
, P (t
k
) is the probability of feature t
k
appearing and
DFS selects distinctive features while eliminating uninformative ones considering certain requirements on term characteristics [11]. According to the feature selection principle of DFS: If a feature often appears in one category and does not appear in other categories, it must score high. Conversely get low scores. Based on this principle, an initial scoring framework is constituted as
But according to another principle: if a feature appears in all categories, it is irrelevant and must be given a low score. the formulation is extended to
Where V is the number of classes, P (C
j
|t
k
) is the conditional probability of C
j
when t
k
appears,
FCBF utilizes symmetric uncertainty to measure the correlation between features. The idea is that a feature is good if it is highly correlated with the class but not highly correlated with any of the other features [12]. It is a typical heuristic sequence backward elimination method. The information entropy of the variable X is defined as:
where P (x
i
) represents the probability when the variable X equals x
i
, and the conditional information entropy of X given variable Y is defined as:
where P (y
j
) represents the probability when the variable Y equals y
i
, P (x
i
|y
i
) is the probability of variable X given variable Y. Information gain is the amount of additional information, which means the decreased entropy of X reflected by Y [22], given by
Therefore, symmetrical uncertainty can be calculated as following:
FCBF can be described as follows: if the symmetry uncertainty of a feature between categories is higher and relatively lower between other features, the feature is considered as the predominant feature. First, the symmetry uncertainty between each feature and category is SUf i ,c, and the feature corresponding to the maximum value of SU is selected as the predominant feature f q . The symmetry uncertainty of other features between predominant features is SUf q ,f p . If SUf q ,f p ≥ SUf p ,c, the feature f p will be removed. Then select the predominant features from the remaining features. Repeat the above steps until there are no feature remaining.
Although FCBF has made great achievements in many fields, the experiment in the next section shows that it is not ideal enough for text classification. On the one hand, the original FCBF algorithm does not consider the distribution of features in the text when computing information gain. On the other hand, when inputs are highly correlated, FCBF algorithm may eliminate too many features [22]. In order to improve this method, we use the characteristic distributions of features to improve corresponding information gain, and then calculate the correlation. Also, we add an additional parameter for customizing the feature size to balance feature selection.
Correlation between feature and category
Information entropy is a quantity that reflects the degree of uncertainty of a variable [23]. In information classification, it reflects the distribution of feature in the corpus. For categories and features, the information entropy is defined as:
where n is the number of training documents, V is the number of categories, C i is the class label of training document D i , P (t k ) is the probability of the feature word t k , tf (tk,i) is the frequency of the feature word t k appearing in the training document D i . L is a smoothing factor and we take L = 0.001. δ () is a binary which has mentioned before.
For feature t
k
, the conditional information entropy given the distribution of categories is:
where P (t k |C j ) is the conditional probability of feature word t k in class C j , tf (t k |C j ) is frequency of the feature word t k appearing in class C j , L is the smoothing factor and V is the number of categories.
The feature information gain is the variation of feature information entropy given distribution of category.
The formula is as following:
Therefore, the correlation between feature and category can be described as:
For feature tk1, the conditional information entropy given the distribution of feature tk2 is:
where P (tk1|tk2) is the conditional probability of feature tk1 given feature tk2, df (tk1, tk2|C j ) is the number of documents of tk1 and tk2 appearing concurrently in class C j , df (tk2|C j ) is the number of documents of tk2 appearing in class C j .
Therefore the information gain of feature tk1 given feature tk2 in class C
j
can be calculated as:
The correlation between tk1 and tk2 is as following:
In order to obtain the desirable feature size, we improve the procedure of FCBF. According to Yu [12], we find that the correlation between feature and category is predominant, which means that Corr (t k , C) is of more value. Therefore, if all the features are filtered, but the size of final output feature list is smaller than what we set before, we will choose the larger value of Corr (t k , C) to complement. So, we can get enough features directly from the final output. The algorithm only adds two judgement sentences based on the FCBF algorithm. Therefore, the complexity is the same as that of the FCBF algorithm, O (mn log n) [12].
Experimental data
In the experiment, we adopt four common data sets, which includes two English sets: 20 newsgroup [24, 25], Ruster21578 [24, 27], and two Chinese sets: Sogou Lab Corpus [28], Fudan University Chinese Corpus [27, 29]. The 20 newsgroups data set is a collection of approximately 20,000 newsgroup documents, partitioned evenly across 20 different newsgroups. Ruster21578 has 36 categories containing 10,835 documents. Sogou Lab Corpus is compiled from Sohu news, which includes 10 news categories. Each category contains 2000 documents. Fudan University Chinese Corpus is provided by Ronglu Li, which includes 10 categories containing 2,816 documents. In Ruster21578, the maximum class has 2875 documents and the minimum class has only 35 documents. We select 6 categories and 150 documents per class to do experiment. For other data sets we select 6 categories and 200 documents per class. The experiment was performed on an Ubuntu Intel (R) Xeon (R) CPU E5-2690 v4 @ 2.60 GHz, 125 G of RAM, and the experimental language was Python3.6. Use the document frequency as the criterion for selecting the feature words, and perform an average of 10-fold Cross Validation. The data distribution is shown in Table 2:
IFSC-FCBF Algorithm
IFSC-FCBF Algorithm
Data distribution
We preprocess the text through the PYTHON3.6 program. In English text preprocessing, we need to remove special symbols, Arabic numerals, stop words and stems. In Chinese text pre-processing, the Chinese word is first segmented using the JIEBA [29], and then special symbols, Arabic numerals, and stop words are removed. The text classification procedure is displayed as Fig. 1.
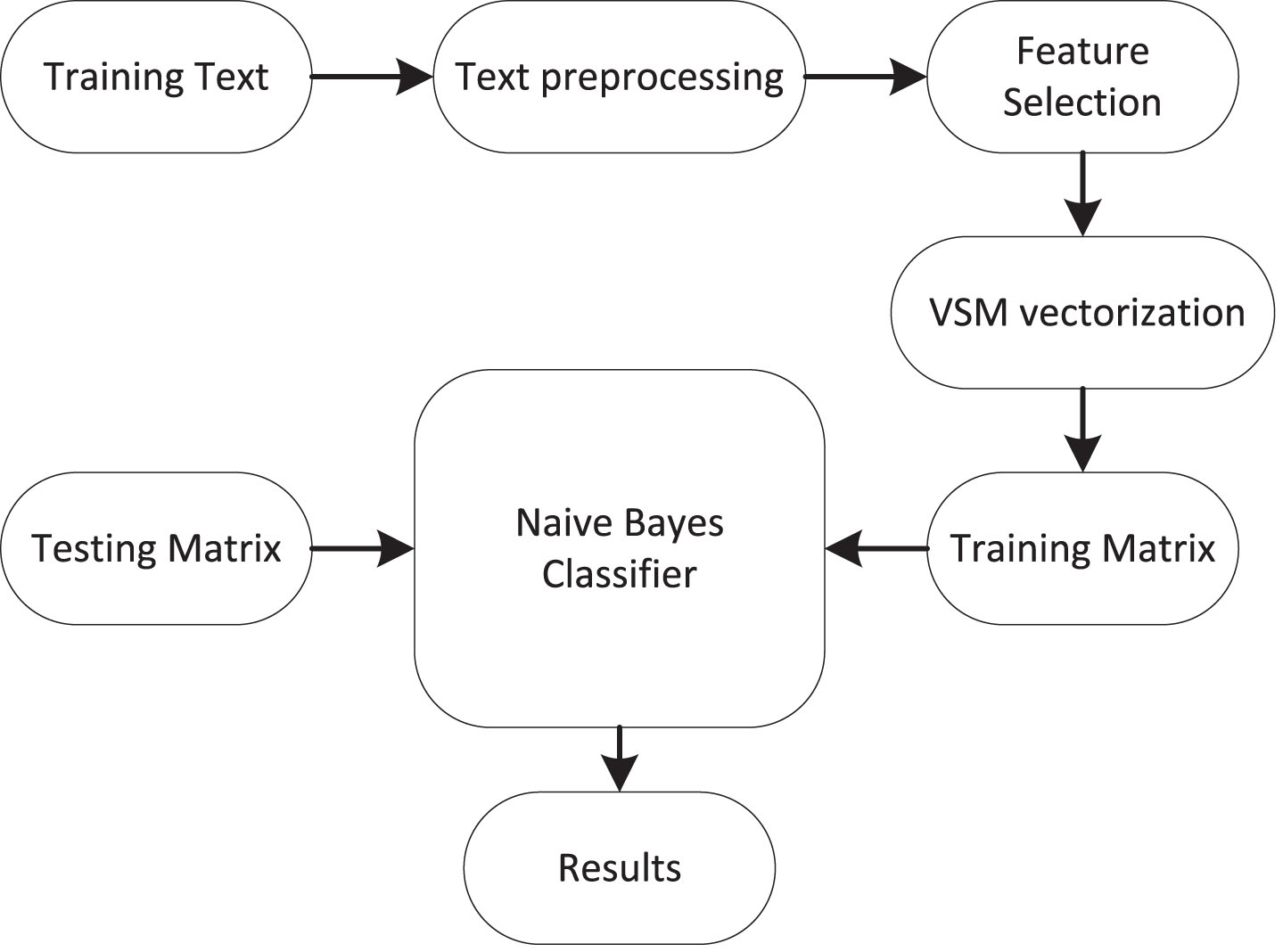
Text classification flowchart.
The experiment used precision (P), recall (R), F1 score, and Macro F1 score to evaluate the performance of classification algorithms. The formulas are as follows:
Parameters meaning
In this paper, we adopt four models for comparison,
FCBF, IG, DFS, SVM and IFSC-FCBF.
FCBF: Fast Correlation-Based Filter [12]
IG: Information gain feature selection approach [8].
DFS: Distinguishing feature selector [11]
SVM: Support vector machine [4]
IFSC-FCBF: Improved feature size customized fast correlation-based filter we propose.
We first perform experiments in English data sets. In order to observe the effect of the selected feature number on the Macro F1 score, we increase the number of features from 100 to 500 continuously, and compare the performance of the above five methods as shown in Figs. 2 and 3:
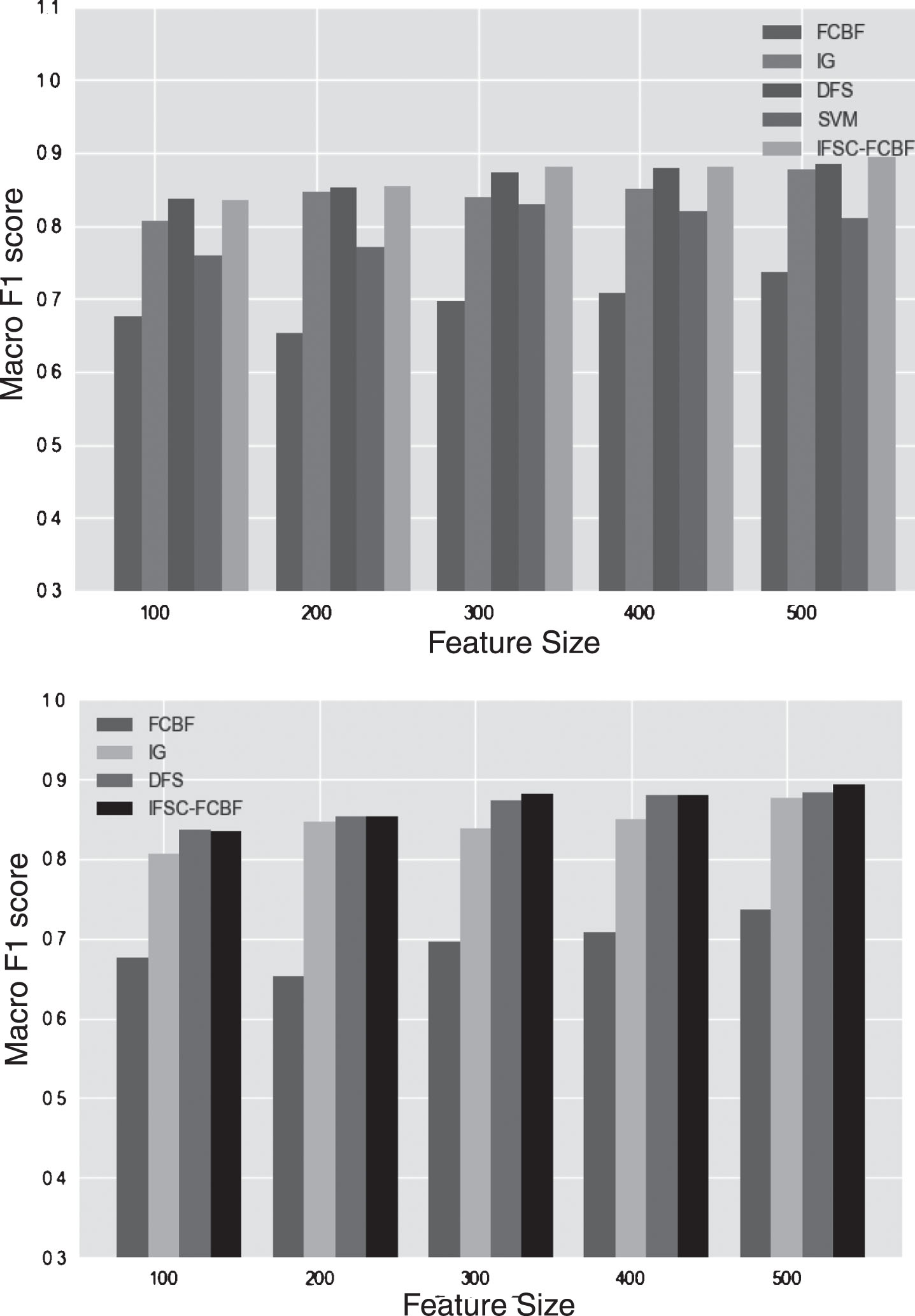
The Macro F1 score of algorithms on 20Newsgroup.
The Macro F1 score of algorithms on Ruster21578.
From Figs. 2 and 3, we notice a slight increase of Macro F1 score when the number of features increases in two English data sets. When the number of features reaches 300, the value of Macro F1 score gradually level off. What the two graphs have in common is that the IFSC-FCBF feature selection algorithm select features more efficiently and obtain the better Macro F1 score. For other four methods, the original FCBF algorithm eliminate too many features in the previous section, so it cannot get ideal results in text classification. SVM as a classic classification algorithm, the F1 value obtained is lower than other algorithms, except for FCBF. The DFS feature selection algorithm obtains higher F1 values than the IG algorithm, especially in the 20newsgroup data set. When the number of features reaches 300, the F1 value of DFS is about 3% higher than IG.
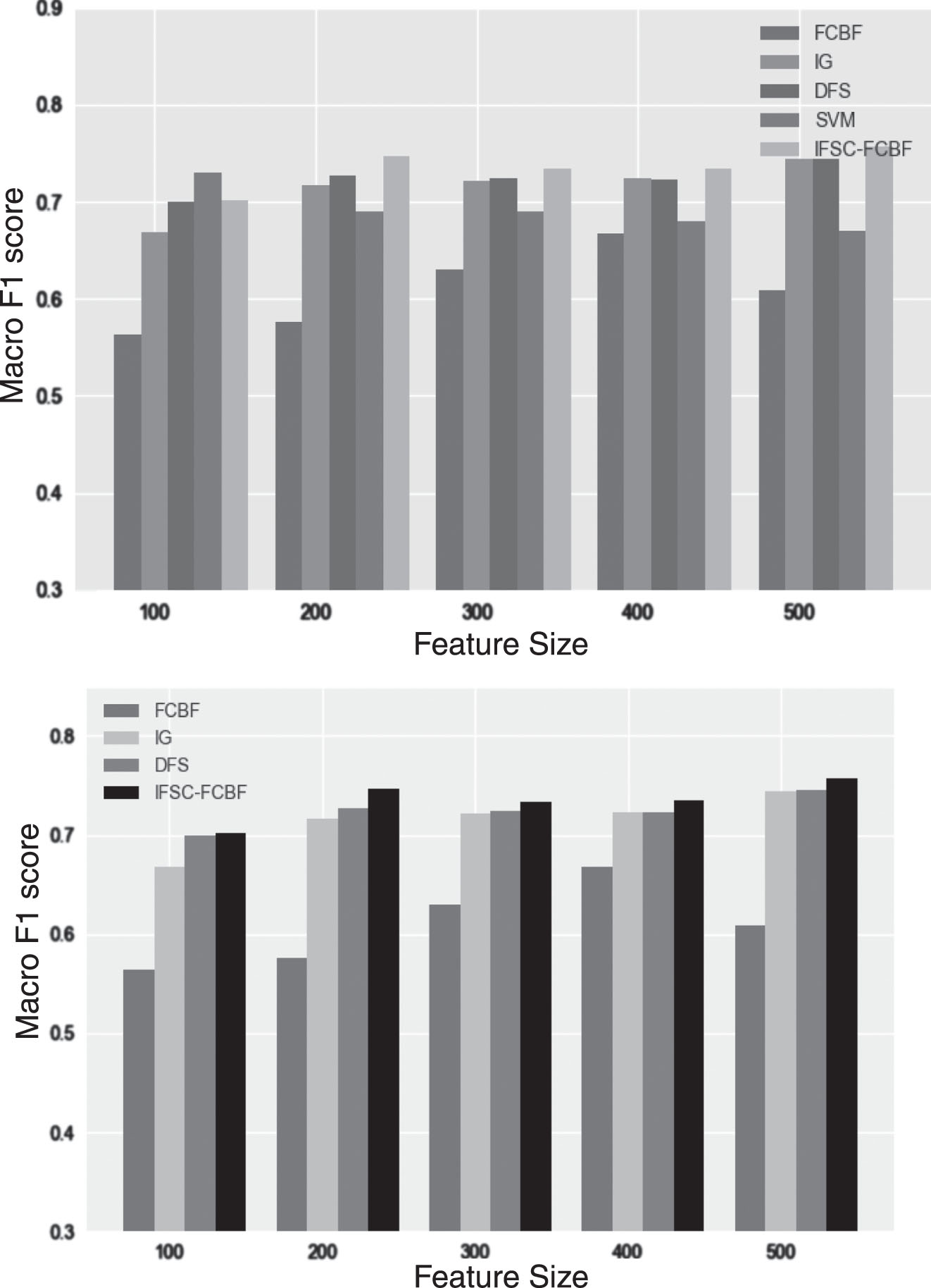
In the same way, the results we obtain in the Chinese data sets are shown as follows:
In Figs. 4 and 5, the change trend of the macro F1 score is similar to that of the English data set. This means that when the number of features reaches 300, the performance of the algorithm is no longer affected. The Macro F1 score of the DFS algorithm is higher than IG about 1.4% averagely in the Fudan corpus and higher than IG about 8% in the Sogou corpus. While the Macro F1 score of IFSC-FCBF algorithm is higher than DFS about 1.3% in the Fudan corpus and higher than DFS about 1.5% in Sogou corpus.
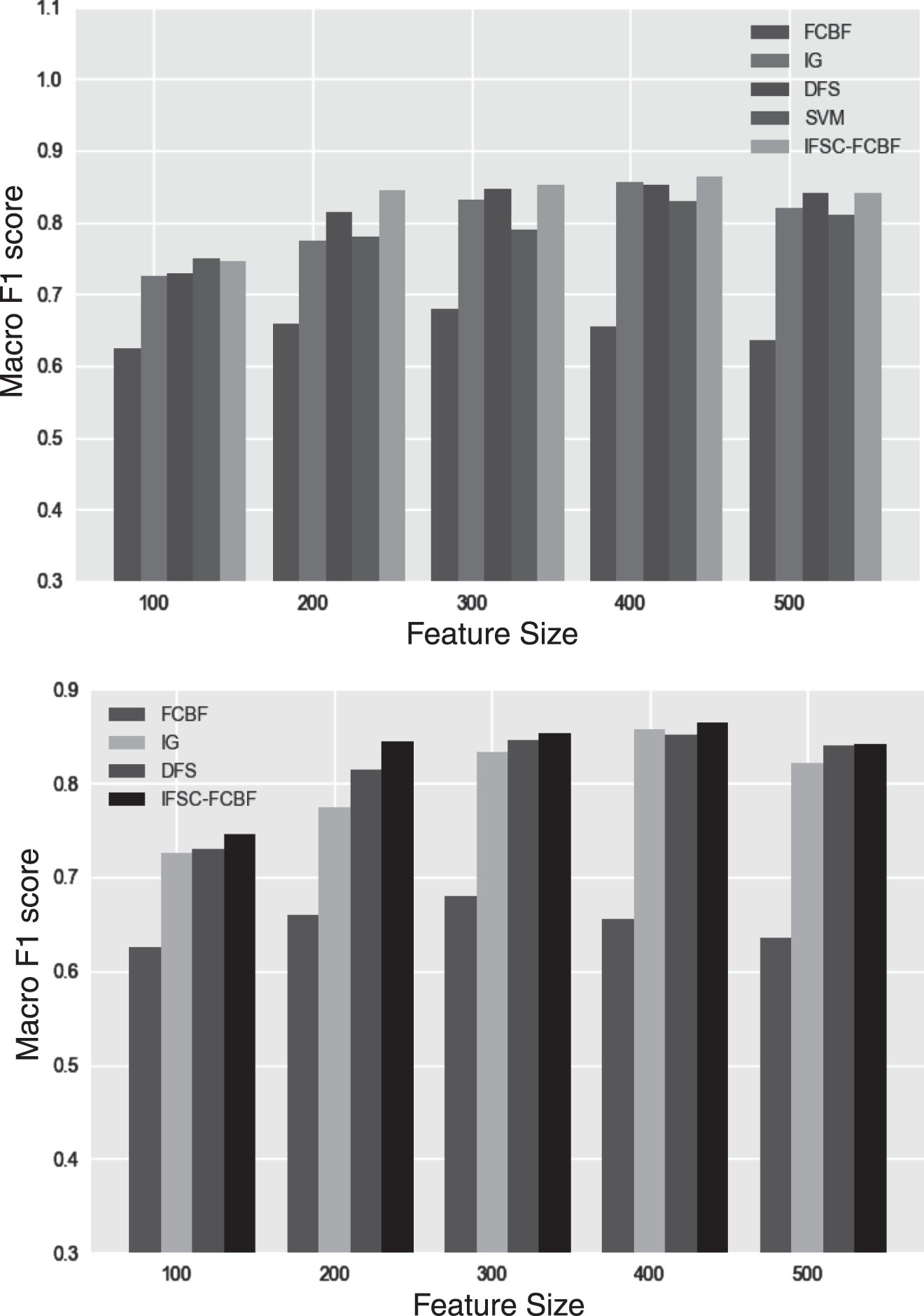
The Macro F1 score of algorithms on Fudan Corpus.
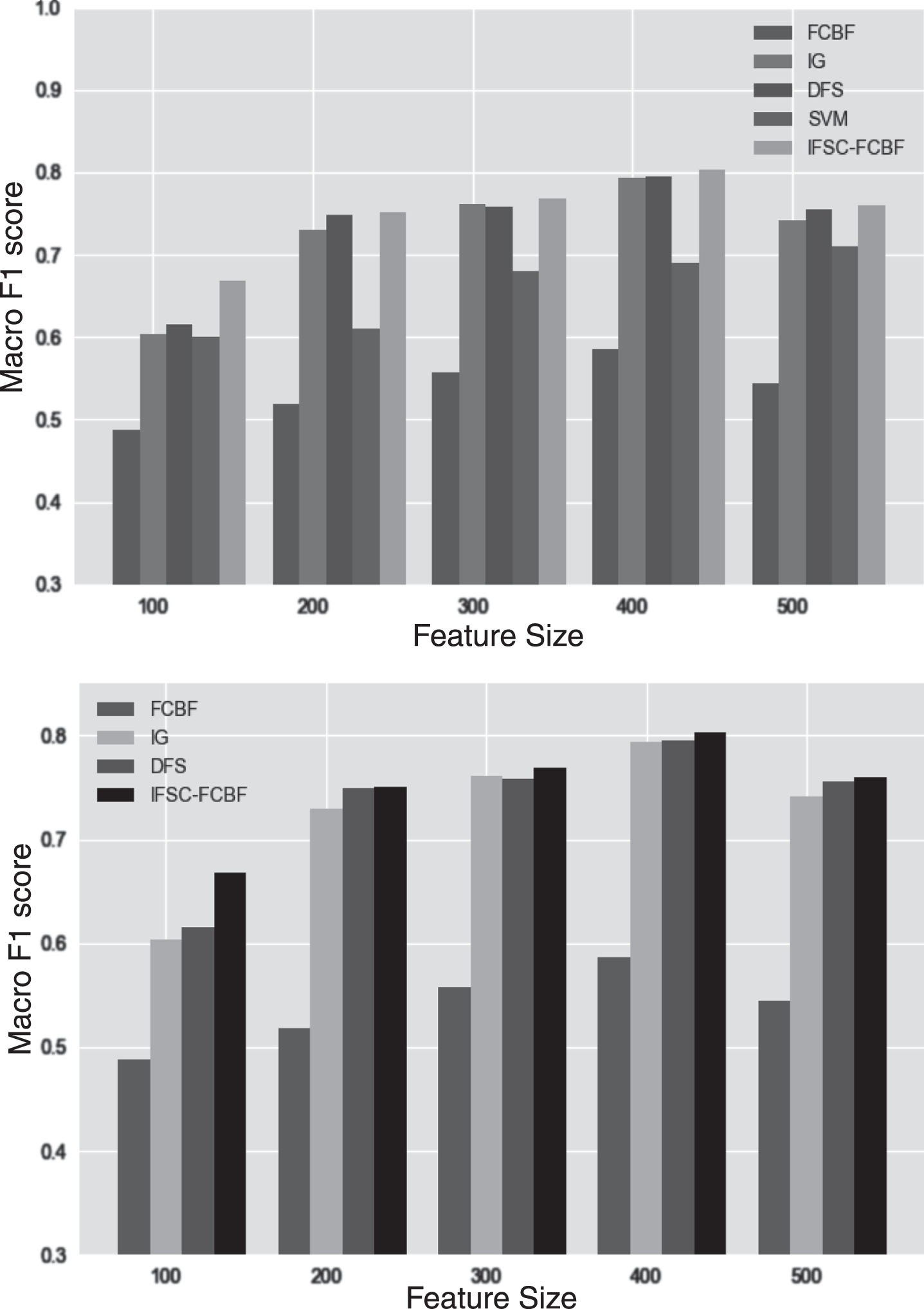
The Macro F1 score of algorithms on Sogou Corpus.
Then we set the feature size to 200. After comparing effects of feature selection algorithms in each category, the maximum value of F1 in each category is represented in bold. In addition, we calculate the average of each column and add it at the bottom of table.
The maximum average value of P, R and F1 is represented in bold. All above mentioned are shown in the following four tables.
From Tables 4 and 5, based on the comparison of four algorithms in the English data sets, we can find that most of maximum F1 values are obtained by IFSC-FCBF algorithm. However, because different feature selection algorithms focus on different features, which means that each algorithm has its own preferred features, the results will be beneficial to some specific categories. Therefore, we cannot guarantee that all the F1 values obtained by IFSC-FCBF are the best for all categories. We can only say that in these two English data sets, based on the comparison of precision, recall and F1 values, IFSC-FCBF algorithm has a better performance of feature selection.
Comparison of each category on 20Newsgroup
Comparison of each category on Ruster21578
By comparing the data in Tables 6 and 7, we find that in most categories, the IFSC-FCBF gets a higher F1 value than other algorithms. These categories are education, sports, and sports in the Fudan Corpus and health, education, and tourism in the Sogou Corpus. But the average value obtained by IFSC-FCBF algorithm are roughly the same as that of DFS algorithm. It is hard to say which one is better, especially the similar situation occurs before. In Fig. 2, the results of the IFSC-FCBF and DFS algorithms are very similar when comparing the performance of five algorithms in the 20 newsgroup data sets.
Comparison of each category on Fudan Corpus
Comparison of each category on Sogou Corpus
Therefore, for further comparison, we decide to analyze the algorithmic complexity as follows: first selecting 300 features randomly; then repeating experiments ten times and calculating the average running time. The approximate number of features in the data set is shown in Table 8 and the comparison of running timing is shown Fig. 6.
Approximate feature number in four data sets
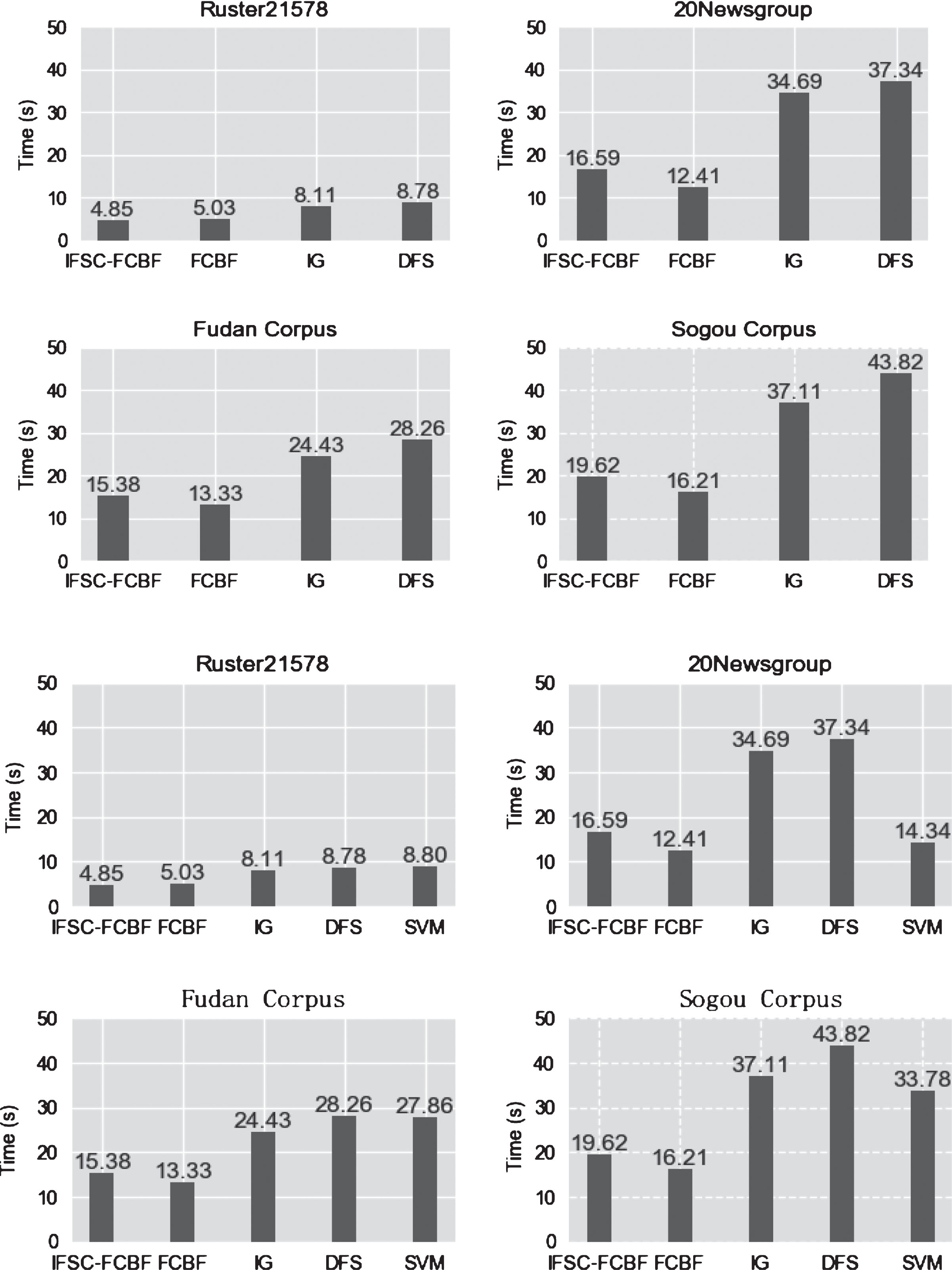
Timing analysis in four datasets.
From Table 8, it shows that different data sets contain different numbers of feature words. From Fig. 6, we can find that with the addition of features, the running time increases accordingly. For the algorithm FCBF, because it eliminates too many features, the running time of it is the shortest but the accuracy is unsatisfactory. The running time of algorithm IG, DFS and SVM are similar, while algorithm IFSC-FCBF only needs half of the time than them and has a higher degree of accuracy. Therefore, we believe that algorithm IFSC-FCBF has a better performance of text classification than others.
In this paper, as shown above, we propose a new approach of text classification named improved feature size customized fast correlation-based filter (IFSC-FCBF). It not only is a precedent of feature selection approach with consideration to eliminating redundancy, but also makes a trade-off between the accuracy and complexity. The result shows that the algorithm IFSC-FCBF can select more efficient features under the relatively shorter running time, which effectively improve the performance of text classification.
For further research, apart from the improvement of existing algorithm, we will extend the feature selection and use bigram model or N-gram model for validation. The effective approach proposed will be combined with the Naive Bayes weighting algorithm so that we could get a more effective method for text classification.
Footnotes
Acknowledgments
This research was supported by National Natural Science Foundation of China (No. 61302155, No. 61274080, No. 61871234); This work was also supported by National Natural Science Fund Incubation Project of China (NY214052).