
Abstract
‘With the help of powerful image editing software, various image modifications are possible which are known as image forgeries. Copy-move is the easiest way of image manipulation, wherein an area of the image is copied and replicated in the same image. The major reason for performing this forgery is to conceal undesirable contents of the image. Thus, means are required to unveil the presence of duplicated areas in an image. In this article, an effective and efficient approach for copy-move forgery detection (CMFD) is proposed, which is based on stationary wavelet transform (SWT), speeded-up robust features (SURF), and a novel scaled density-based spatial clustering of applications with noise (sDBSCAN) clustering. The SWT allows the SURF descriptor to extract only energy-rich features from the input image. The SURF features can detect the tampered regions even under post-processing attacks like contrast adjustment, scaling, and affine transformation on the images. On the extracted features, a novel scaled density-based spatial clustering of applications with noise (sDBSCAN) clustering algorithm is applied to detect forged regions with high accuracy as it can easily identify the clusters of arbitrary shapes and sizes and can filter the outliers. For performance evaluation, three publicly available datasets namely MICC-F220, MICC-F2000, and image manipulation dataset (IMD) are employed. The qualitative and quantitative analysis demonstrates that the proposed approach outperforms state-of-the-art CMFD approaches in the presence of different post-processing attacks.
Introduction
In this digital era, people can capture their perfect moments using high resolution and low-cost smart devices like cameras, cell phones, tabs, etc. Similarly, several image editing tools like Adobe Photoshop are also available to change the look and feel of their images. Although the presence of such devices and image editing tools is delighting the people; however, at the same time, these are making the validity of digital images questionable. It is especially noticeable when these images can be used as proof in various criminal cases or presented for various insurance claims, news reporting, and other legal services.
A digital image can be tampered either by using image inpainting approach or copy-move forgery approach. Image inpainting is defined as the method of restoring or filling the missing or damaged components of the digital images. Image inpainting based approaches have achieved better accuracy for image restoration, object removal, occlusion, texture synthesis, etc., however, for video-based contents, its applicability is still a challenging task because of moving objects [1]. While the process of making the changes in the contents of digital images by using the data from the same image is called copy-move image forgery. The main similarity between the image inpainting and cope-move forgery is that the content from the same image is used in both types to perform image manipulations. However, the main difference among them is that copy-move forgery works by taking a continuous patch to manipulate the digital images, while in the case of image inpainting, the source of copied information could be non-continuous [2].
In the case of copy-move forgery, the approaches which are used for detecting the changes made in digital images are categorized into two main types, which are known as active and passive approaches [3]. For active approaches, such as digital signature and image watermarking, some additional information about the source image should be embedded during the capturing process of the image [4]. Therefore, these approaches are impractical in situations where such information is unavailable [5]. In the case of passive approaches, there is no such type of constraint [6]. The passive approaches are widely used, which are used to detect two kinds of digital image manipulations, which are splicing and copy-move. In splicing, the contents from more than two sources are merged to produce a manipulated image [7]. On the contrary, copy-move forgery (CMF) is a well-known form of digital image manipulation in which the content of the same image is used to manipulate it [8]. As the overall properties of original and copied parts of the image remain the same which makes it difficult to detect.
Figures 1 and 2 present an example of image splicing and CMF, respectively. In Fig. 1, a bird from a different image is cropped and made a part of another image which is called splicing. In Fig. 2, an elephant-shaped object is taken and linked with a statue in the same image which is the case of CMF. In literature, two main approaches are used for detecting the image forgeries: a) block-based manipulation detection approaches, b) keypoints-based forgery detection approaches [9]. Block-based CMFD approaches work by splitting a fake input image into overlapping blocks [10]. Several forgery detection approaches are used to perform different operations on the individual blocks, which are then compared by using metric or non-metric norms for detecting the changes made within them. This technique is robust to brightness changes, random additive noise, and JPEG lossy compression [5]. Whereas in the keypoints-based CMFD approaches, the keypoints are detected from the whole image on which feature matching process is applied and affine transformations are estimated. For these approaches, the region correlation map is used for identifying the tampered parts from the whole image. The keypoints-based approaches exhibit better detection performance, especially in the case of the highly textured forged images [11].

An example of image splicing [11].

An example of CMF [12].
The major challenges for block-based CMFD approaches are the higher computational cost and sensitivity against various affine transformations. On the other hand, keypoints-based approaches deal with these problems more efficiently. However, the keypoints-based approaches are suffering from the main challenges of enhancing their power while dealing with low contrast image features, their inability to detect the forged region from flat duplicated parts of the image, and reducing the time required for performing the clustering process. All of these issues are resolved in the proposed CMFD approach.
In this work, a novel approach is proposed to identify the single and multiple forged regions of digital images. Firstly, the SWT approach is employed to obtain the approximate image, on which the SURF descriptor is applied to obtain the optimal features. Then the sDBSCAN clustering approach is applied to the extracted features to group similar regions/clusters. After that, the Euclidian distance is employed to compute the matching among the extracted clusters due to its robustness and efficient performance as compared to other distance formulas [13]. Finally, the random sample consensus (RANSAC) algorithm is applied to remove the false matches from the detected forged regions of the images. The result of the proposed approach is tested over the five main digital image geometric transformations namely translation, scaling, rotation, blurring, and flipping, which are used to cause the forensic changes within the digital images. It can be seen from the experimental results that the proposed approach exhibits robust results as compared to the other latest CMFD approaches.
The following are the main contributions of this article: The sparsely encoded descriptor allows the proposed approach to detect manipulated parts in the given sample in more effective form even after post-processing attacks i.e. rotational and scale alterations, brightness change, and contrast change. The proposed approach utilizes the sDBSCAN clustering, which enables the faster detection of regular and irregular shaped tampered regions and mitigates the false detections in the forged image. The proposed approach can detect single and multiple copy-move forensic manipulations robustly even from small and extremely smooth regions of a forged image. The sparsely encoded descriptor, sDBSCAN clustering, and RANSAC not only just improve the detection accuracy of the proposed approach but they also improve the efficiency by faster detection of the optimal features and removal of false-matches from the forged image.
The remaining sections of this article are structured as follows: Section 2 presents the literature review of the CMFD approaches. In Section 3, the proposed approach is discussed in detail. While Section 4 presents the evaluation results and discussions, and the conclusion is discussed in Section 5.
In the last two decades, the researchers have proposed many approaches to identify the forgery in digital images. CMF is a well-known approach for forging digital images. In CMF, the contents from the same image are employed to hide some information. As in this approach, the copying source is the same, so it becomes difficult to identify the forensic changes made within image since the attributes like illumination, brightness, focus, and proportions remain the same.
Hashmi et al. [14] propose an approach to identify the image manipulations. Firstly, the dyadic wavelet transform (DyWT) is employed to obtain the image components. Then scale-invariant feature transform (SIFT) is utilized to the LL image-component to calculate the keypoints and compute its feature descriptor. This approach gives better matching accuracy and is efficient in different post-processing attacks but does not perform well under the presence of blurring and light variations within images. Chihaoui et al. [15] detected the forged regions of the image by applying SIFT descriptor, and feature matching are performed applying a singular value decomposition (SVD) algorithm. This technique performs better under various geometrical transformations; on the other hand, it is impractical for images with a huge number of features (more than 3000 features). Jaberi et al. [16] propose a novel approach to detect the image manipulations. The mirror invariant feature transform (MIFT) is employed to compute the image key-features. The RANSAC algorithm is utilized to detect the affine transformations among matching portions of the forged image. This approach exhibits better duplication detection performance. However, it does not perform well to detect the forensic changes from flat areas of images. Li et al. [17] introduce a novel solution for image alteration identification. Firstly, the input sample is categorized into overlapped circular blocks. Then the key-features from the image are selected by applying the polar harmonic transform (PHT) algorithm. Lexicographically sorting is applied to these extracted features. Finally, the Euclidean distance is applied for block feature matching. This approach improved the forgery detection efficiency, however, its performance lacks under blurring and noise attacks. Cozzolino et al. [18] presented a novel approach for CMFD called PatchMatch algorithm. The PatchMatch algorithm is used to compute the dense fields from the forged image and to detect the scale and rotation-invariant features. Then dense linear fitting is applied to reduce the overall complexity of the approach. This work is effective to resizing and other image geometric alterations. However, this approach is computationally complex for the images of high resolution.
Li et al. [6] introduce a technique by utilizing the concept of image segmentation for CMFD. The matching process consists of two stages; Firstly, suspicious parts are detected from the forged image, and then the expectation-maximization-based algorithm is used to confirm the presence of tampered parts in those detected regions. After detection of the tampered areas from the image, the iterative nearest neighbor algorithm is applied for improving the accuracy of tampered region detection. However, for images of high resolutions, the computational cost of this approach is high. Ardizzone et al. [19] propose an approach for CMFD by analyzing the structure of various objects present in a scene. The Harris detector, followed by SIFT and SURF descriptors, are employed to compute the image keypoints. The Delaunay triangulation is built on extracted points, and their color and angles perform triangle matching. The mean vertex descriptor is used to show forged areas. Finally, the RANSAC algorithm is applied to eliminate the outliers. This approach provides a robust solution to various geometric transformations. However, it showed the worst performance for complex scenes or when no interest points are found in flat areas. Al-Qershi et al. [20] introduce a technique for identifying the copied regions of an image. Image blocks are clustered using a k-means clustering approach. Then locality sensitive hashing (LSH) approach is utilized to identify the duplicate regions within clusters. This approach reduced the processing and detection time for CMFD; however, it gives low accuracy for some cases since the non-effective performance of the k-means algorithm when forged regions are found near the edges of the clusters. Zheng et al. [21] introduce an approach to improve the reliability of CMFD by performing the fusion of two approaches: the block-based and keypoint-based approaches. Initially, the input sample is categorized into non-overlapping regions. SIFT is employed to compute the keypoints of the input sample which are further classified into smooth and non-smooth regions. Finally, the Zernike moments and SIFT features are fused for robust forgery detection. This approach improves the detection reliability and efficiency however required a high computational cost.
Gong et al. [22] introduce a technique to tackle the challenges of keypoint based CMFD approaches of their inability to identify the forensic manipulations from the flat areas of image content. Initially, the input image is transformed into opponent color space [23] from RGB. SURF is employed to calculate the keypoints from the image. Then clustering is used to compute the underlying geometric transformations. This technique performs well with flat duplicated areas, however, it has a high computational rate. Uliyan et al. [24] propose an approach to show the region duplications in digital images. Firstly, the image is divided into many segments using statistical region merging (SRM) segmentation. Similar regions are clustered by employing the k-means approach. The angular radial partitioning (ARP) is applied to all regions to index them by their centroid coordinates in their respective clusters. Harris detector is applied to calculate the total Harris corners. The Hölder estimation regularity based (HGP-2) descriptor is applied to extract regularity-based features. The feature vector is calculated by computing the median absolute deviation (MAD). Finally, the Euclidean distance is used to identify the tampered regions. This approach is rotation-invariant, however, it exhibits poor performance under illumination and blurring variations. Zhu et al. [25] present an approach to improve the robustness and solve the false, matching problems of CMFD from digital images. Firstly, Gaussian scale space is created in which features from accelerated segment test (FAST), oriented FAST, and rotated BRIEF (ORB) features are extracted. Hamming distance is used to identify the matching features from both FAST and ORB features. Finally, false matches are removed by applying the RANSAC algorithm. This approach works effectively even under various geometric transformations like compression and noise attacks. However, for high-resolution images, this technique is computationally complex. Huang et al. [26] propose a robust approach for CMFD under the presence of various blurring, compression, and noise attacks. The fast Fourier transform (FFT), SVD, and principal component analysis (PCA) are used for extracting and matching the image features. Cascade filtering is used to identify the matching and duplicate blocks. This approach presents a threshold-free approach and shows a satisfactory performance under blurring, compression, and noise attacks. However, it is computationally complex.
Li et al. [27] introduce an approach to identify the manipulated portions from the image, especially for multiple copy-move forged images. Firstly, a maximally stable color region (MSCRs) detector is employed to collect image keypoints, and Zernike moment is used to represent these features. An improved matching strategy, referred to as g2NN, is used to detect the multiple copy-move forged areas within the image. Finally, the hierarchical cluster algorithm is employed to show the image forgery. This technique is computationally robust; however, the system is not effective in image post-processing attacks. Chen et al. [28] introduce a solution for CMF. Firstly, the input sample is converted into non-overlapping segments. Then block sampled matching with region growing (BSMRG) algorithm is applied to detect the matched blocks located in forged areas. Finally, the region growing approach is applied to show the forged section from these matched blocks. This approach exhibits good computational performance; however, it cannot specify the size of the segmented block automatically. Muzaffer et al. [29] introduce an approach to detect forged areas from digital images. SIFT algorithm is employed to compute the keypoints from the input sample. The altered regions from the image are identified through binarized descriptors. This approach decreases the computational time, however, it exhibits lower detection performance as compared to simple SIFT-based approaches. Alkawaz et al. [47] proposed a CMFD method that uses a Discrete Cosine Transform (DCT) to enable the method proposed to extract only the information-rich features. These features are matched using the Euclidean distance in a zig-zag pattern to ensure the fast and accurate feature matching. However, the block size has to be optimized to good results, wrongly sized blocks lead to lower accuracy. Another gradient-based CMFD method is proposed by Matern et al. [48] which uses an analytical method to examine the light direction on the objects by detecting the color and transformation in the shadow of the object in the tampered image. The proposed method in [48], also shows the better result if the tampered regions are compressed or resized. However, the proposed method failed to detect the multiple tampered regions in the input image. Chen et al. [49] presented a keypoint-based CMFD method that utilizes the SIFT descriptor to extract the feature set from the tampered image. The extracted features are grouped into clusters using the color and overlapped scaled, which ultimately reduces the computational cost of the proposed CMFD method in [49].
Methodology
This section present detail of a novel approach for CMFD, which is based on the SWT, SURF, sDBSCAN clustering, and RANSAC. After the pre-processing step, the image is transformed into the wavelet domain by employing SWT. The feature vectors are extracted by applying the SURF descriptor on the LL sub-band of the input image. As, shifting image through SWT results in multispectral parts, so image keypoints become more prominent, which results in robust feature representation [30]. After extracting the robust features, the clustering approach is applied to them based on the sDBSCAN clustering. After that, the similarity between clusters is measured to identify the forgeries in digital images. Finally, the RANSAC algorithm is applied to remove the false-matches. The image from the MICC-F220 dataset is selected to demonstrate the output result of the proposed approach as shown in Fig. 3. The complete methodology of the proposed approach is shown in Fig. 4. The detailed description of each module of the proposed approach is provided in the following subsequent sections:

Original image (left side), tampered image (center), ground-truth binary mask of the tampered image (right side) from the MICC-F220 dataset.
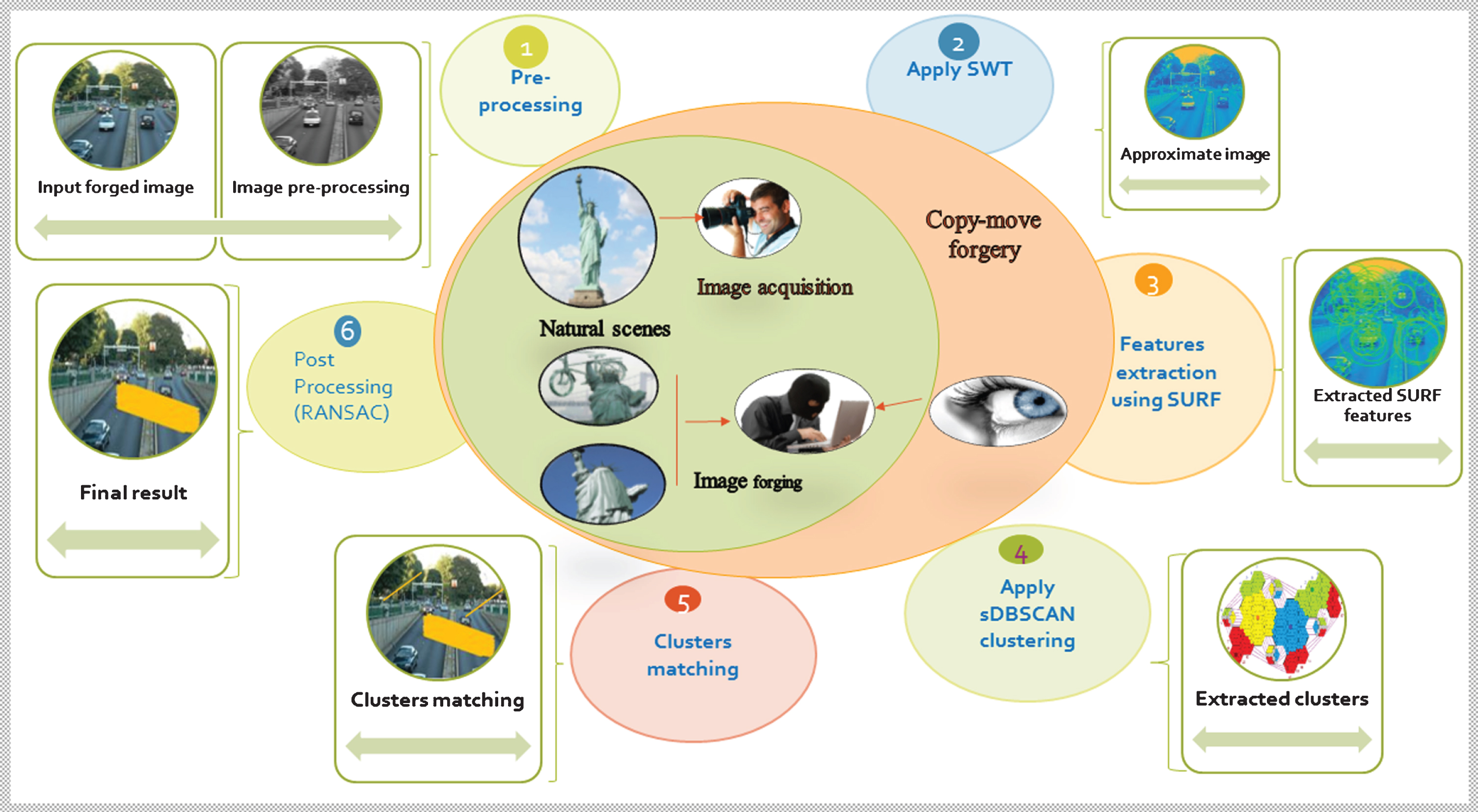
The framework of the proposed approach.
Initially, the forged input color image is transformed into grayscale using the following equation:
Where R, G, and B denote the red, green, and blue components of the color image. The I denotes the resultant grayscale image, which is used for the subsequent operations and it also reduces the computational complexity of the proposed approach.
To minimize the dimensions of the image, existing approaches [31–33] used the DWT technique, but it does not have the shift-invariance property. Moreover, DWT exhibits the pseudo-Gibbs phenomena around the singularities and generates uninspiring performance in texture examination, locating edges, and noise removal, etc. It has been found that with SWT, robust detection results can be obtained than the shift variant approach. Another main limitation of the DWT technique is that the small change in the image may produce different feature vector for the forged areas because it greatly affects the DWT coefficient at different scales. Therefore, to deal with the challenges of DWT, we utilized SWT that is more appropriate for forgery detection. After the pre-processing step, SWT is applied to a grayscale image to obtain a set of shift-invariance local features [34, 35].
For a given image I, the SWT is applied to it at its jth level, which is mathematically defined as follows:
The Eqs. (2–5) are used to obtain the LL, LH, HL, and HH sub-bands of the image. Where LL represents the approximation sub-band, while the HH, LH, and HL represent the diagonal, horizontal, and vertical sub-bands of the image, respectively. In SWT, the size of all obtained components is the same as that of the source image. The proposed approach works on LL sub-band for forgery detection because low-frequency component of the image provides more regional information than high-frequency components as shown in Fig. 5.

Result of the LL sub-band after applying SWT on the tampered image.
Bay et al. [36] proposed the SURF descriptor for extracting the features from images and videos for computer vision-based applications. The various existing works [15, 37] has been utilized the SIFT descriptor for extracting the features from an image, however, we have chosen SURF descriptor for the proposed approach for CMFD because of the following limitations of SIFT descriptor: a) It cannot work well when there are more blurring or changes in light intensity, b) It is computationally more complex than the SURF descriptor because of its lager feature vector length, c) It does not produce impressive results for large rotation or scale changes within image. The detail of the computation of the SURF feature vector is provided in the following subsequenct sections.
Computation of the integral image
Firstly, the integral image is computed by using an upright triangular area that improves both the performance and computational speed of the algorithm. For an image LL of the previous step and given point (a, b), it is calculated as follows:
Where I Σ represents the integral image that is computed by taking the summation of values between the given point (a, b) and the origin of the image.
SURF employs the Hessian matrix for keypoints computation. For a given image I and a point i = (x, y), the Hessian matrix is computed using the following equation:
Where L xx (x, σ) , L xy (x, σ), L xy (x, σ), and L yy (x, σ) represents the convolution of the Gaussian second-order derivative of an image I at position (x, y) and called Laplacian of Gaussian (LoG). Following equation is utilized to compute the determinant of the approximate Hessian matrix:
The SURF descriptor works by building a circular region around the selected set of features to allocate them distinct orientation. It is accomplished by using Haar wavelet filters and thus causing them invariant to image rotation and making this technique more robust with an overall low computational cost. Haar wavelets compute the gradients in both x and y directions. To make the proposed approach invariant to rotation of the image, selected features are mapped to a reproducible orientation. For this purpose, a circular patch having an angle of π/3 is rotated around the selected keypoints. Finally, the largest resulting magnitude is selected to define the orientation of the keypoint descriptor.
Generating keypoints descriptors
In this step, SURF builds a square area around the candidate keypoints, where the center is assigned to the point of interest. This area is then divided into further four regions and Haar wavelet responses are computed for each of them. Following equation is used to compute the responses:
Where d x represents the response captured in a horizontal direction, while dy represents the response in a vertical direction. The values computed from these small divided regions produce a feature vector of length of 64. The features extracted from the SURF descriptor are shown in Fig. 6.

Extracted features after applying the SURF descriptor to the LL sub-band of the image.
The DBSCAN clustering algorithm is proposed by Ester et al. [38]. It is the most widely used clustering algorithm applied in different computer vision-based applications for the clustering of the image features [39]. The main motivation of using the DBSCAN algorithm over the k-mean clustering algorithm is that it does not need to give the number of clusters in advance. Furthermore, the k-mean clustering algorithm can detect only the well-shaped clusters and is quite sensitive to outliers and noisy data, however, the DBSCAN clustering algorithm can identify the clusters of any arbitrary shapes and sizes and can filter the outliers from available information [40].
Let X = x
i
where i ∈ [0 - N] and X represents the set of extracted data points. This algorithm requires to define following two parameters in advance: the first parameter is ɛ, which represents the minimum distance required for a data point to declare it as a neighborhood of a given point and the second parameter is minPts, which presents the least quantity of data points needed to create a cluster. The methodology of the DBSCAN clustering algorithm is presented in the following steps: Start with a random datapoint x. Identify the neighborhoods of x by using ɛ distance. If extracted neighborhoods are equal or greater than minPts factor then cluster forming process is started and given x point is marked as visited datapoint, otherwise, it is marked as noise. If a point is the part of a cluster then all of its neighborhoods are also part of the cluster and again the above three steps are performed for each of them until each point is in its corresponding cluster. Then another unvisited datapoint is selected to discover the new clusters and noisy data as well. This process is continued until all data points are visited.
Matching of the clusters
In this step, the matching among formed clusters is computed by applying the Euclidian distance between the centroids of clusters, which is mathematically defined as follows:
Where d (a, b) represents the distance between two clusters, c a andc b shows the centroids of clusters a and b, and d t is the defined threshold value whose value is 0.6. Two clusters are said to be similar if the distance among their centroids is smaller than the given threshold value.
The effect of varying different values of threshold (T) on the performance of the proposed approach is presented in Table 1. After analyzing the experimental details presented in Table 1, it can be concluded that the smaller values of T (T < 0.6) produce high recall since a smaller number of features cause a smaller number of false matches using the proposed approach. However, if the value of T is higher then 0.6, then more features are matched that can cause a high number of false matches using the proposed approach. It can also be concluded that the value of T = 0.6 is the optimal value which produces the highest F1-score (accuracy) of the proposed approach as compared to the achieved performance on other reported values of T. All the results of T are reported by considering forged input image of Fig. 3(b).
Performance analysis of the proposed approach by varying different values of threshold T (bold value indicates the best performance)
In the proposed novel sDBSCAN clustering, the clusters from the DBSCAN clustering algorithm are scaled-up by the factor of 1.5 to extract more features from the clusters. The scaled-up clusters from sDBSCAN clustering tend to produce more SURF features, hence, increases the detection accuracy of the proposed approach as shown in Fig. 7.

Result of the clusters of a tampered image using the sDBSCAN clustering technique with false matches.
The output of the last step is the set of clusters, which may still contain false data points. To detect and correctly place the data points in their respective clusters, the RANSAC approach is employed [41]. The RANSAC approach works iteratively to compute the values of a model. A random set of matched data points from a cluster is chosen to estimate their transformation matrix H. The selected data points are transformed by using transformation matrix H. After this, the distance is measured between a data point (x i , y i ) and its matching pair. If it is less than the defined value of threshold γ then it is considered as inliers, otherwise, it is eliminated from the cluster. After this step, all the clusters having the members less than a defined threshold are discarded. Finally, in the last step, the results of the forgery detection are generated as shown in Fig. 8.

The final result after the RANSAC approach applied as the post-processing step.
This section presents the detail of the several experiments which are performed to check the evaluation power of the proposed approach against different post-processing operations such as rotational changes, scale variations, JPEG compression, additive noise, etc. The details about the datasets utilized for performance evaluation, parameter setting, and robustness testing against various post-processing attacks are discussed in the following sub-sequent sections.
Datasets
Several publicly datasets are available, which can be used for evaluating the results of forgery detection approaches. However, for the proposed approach, the experiments are performed using three benchmarks CMFD datasets namely MICC-F220 [42], MICC-F2000 [43, 44], and image manipulation dataset (IMD) [45]. The MICC-F220 dataset comprises of 220 JPG file format high-quality images, from which 110 are the real images, and the remaining 110 images are manipulated, which are created through the copy-move operation. The MICC-F2000 dataset is a more extensive set of forged images, which consists of a total of 2000 images. This dataset contains a total of 700 tampered images, while the remaining 1300 images are the real images. The average resolution of the images in this dataset is 2048×1536, while the forged area covers the 1.12% of the original image. The IMD dataset contains a total of 48 PNG file format high-resolution images. In this dataset, the manipulated images are also created by a copy-move operation, where the tampering is performed from smooth to highly textured image areas. Figure 9 is showing a sample of images from all of these three image datasets.

Image samples: (a–c) original images and (d–f) forged images of the MICC-F220, MICC-F2000, and IMD datasets.
The evaluation power of the proposed approach is analyzed using the following metrics: precision (p), recall (r), and F1-score, which are defined as under:
Where, T
p
represents the true positives: the tampered pixels in the image identified as tampered. F
p
represents the false positives: the original pixels in the image identified as tampered. F
n
represents the false negatives: the tampered pixels in the image identified as the original.
The F1-score is also calculated by employing the precision and recall rates; so, it can show the overall correctness of the proposed approach. It is defined as follows:
This section demonstrates the robustness testing of the proposed approach under simple CMF operation. To check the evaluation power of the proposed approach, various tests are conducted to identify the forgeries by a simple copy-move operation. In a simple CMF attack, the selected portion is selected and pasted onto another part in the same image. Figure 10 is presenting some of the visual results for simple copy-move operation, which shows that the proposed approach performed impressively.

Visual results: The first row is the original images, the second row is the forged images, and the third row is the detection results of the proposed approach.
Usually, an image manipulator may apply various post-procession operations to veil the visual trances of the forgeries. Consequently, the CMFD techniques should have proficiency against the post-processing operations. Therefore, the robustness of the proposed approach against post-processing attacks such as scaling, angle alterations, JPEG compression, and additive noise is performed as well.
The visual results of the experiments demonstrate that the proposed approach can identify the forensic manipulations accurately even if the post-processing operations have been performed over the altered images.
Analyzing performance on the scaling case
To check the robustness against scaling operation, the performance of the proposed approach is tested when the forged areas are scaled before pasting by various scaling parameters (S = 91 : 109, with step 2). Figure 11 is showing the visual output of the proposed approach for scaling attack, which shows that the proposed approach exhibited better performance when scaling operation is applied to the duplicated regions.

Visual results on sample images for scaling operation.
The efficacy of the proposed approach is also evaluated for the duplicated region that is rotated before pasting into the same image. To generate realistically but manipulated content, the rotation operation is often applied to image regions. Figure 12 is presenting the visual results of the proposed approach against the rotation operation. Figure 12 exhibit’s that the proposed approach can detect the forensic changes under rotation attack.

Visual results on sample images for rotation operation.
We also evaluated the effectiveness of the proposed approach under JPEG compression attacks. The sample visual results for JPEG compression (quality factor = 70, and 80) are presented in Fig. 13. The results indicate that the proposed approach can efficiently locate the image forgeries under the JPEG compression attack.

Visual results on sample images for the JPEG compression attack.
In this section, the effectiveness of the proposed approach is assessed under additive noise operation. The sample experimental results for the forged images contaminated with additive Gaussian noise with zero mean and standard deviations (δ=0.04, and 0.06) are presented in Fig. 14. The visual results are demonstrating that the proposed approach is robust against the additive noise attack as well.

Visual results on sample images for additive noise attack.
The accuracy of the presented approach is checked over the compelling case of CMF, in which an object is replicated multiple times in the given image to make the forensic changes. The obtained results are shown in Fig. 15. It can be visualized clearly through the obtained results that how accurately the proposed approach works under the presence of multi-forgery operations.

Visual results on sample images for multiple copy-move forgery attack.
The visual results of the experiments presented in Section 4 against various transformations demonstrate that the proposed approach is a useful approach for detecting CMF in digital images. Furthermore, this section compares the evaluation power of the proposed approach against other key-points based approaches presented in [46, 45], and [47]. Therefore, the overall performance of the proposed approach is checked on the altered images of MICC-F220, MICC-F2000, and IMD datasets. The average performance comparison of the proposed approach and other approaches against scaling, rotation, JPEG compression, and additive noise operations are reported in Figs. 16–19, respectively.
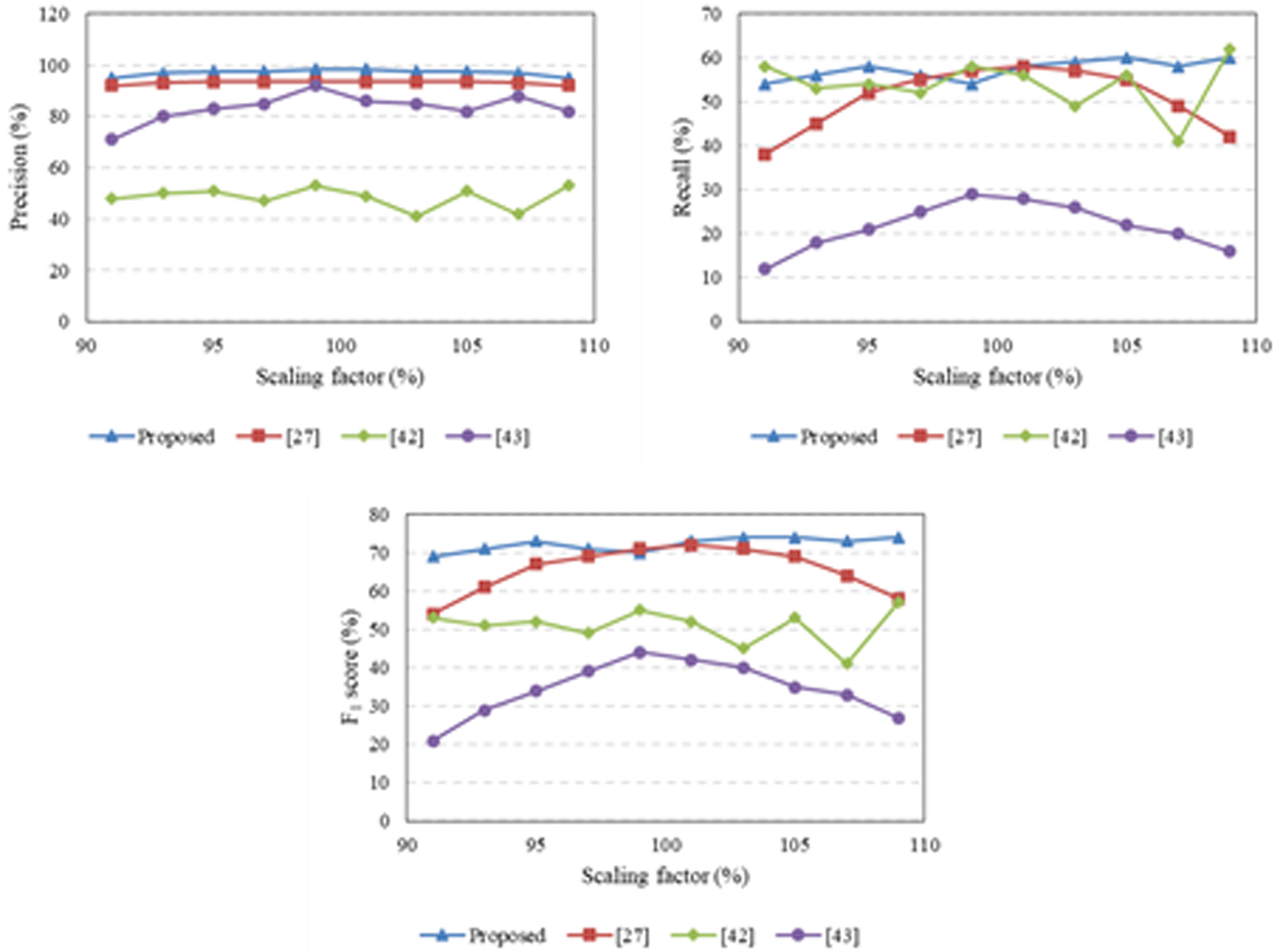
Results of precision, recall, and F1-score curves obtained against scaling operation.
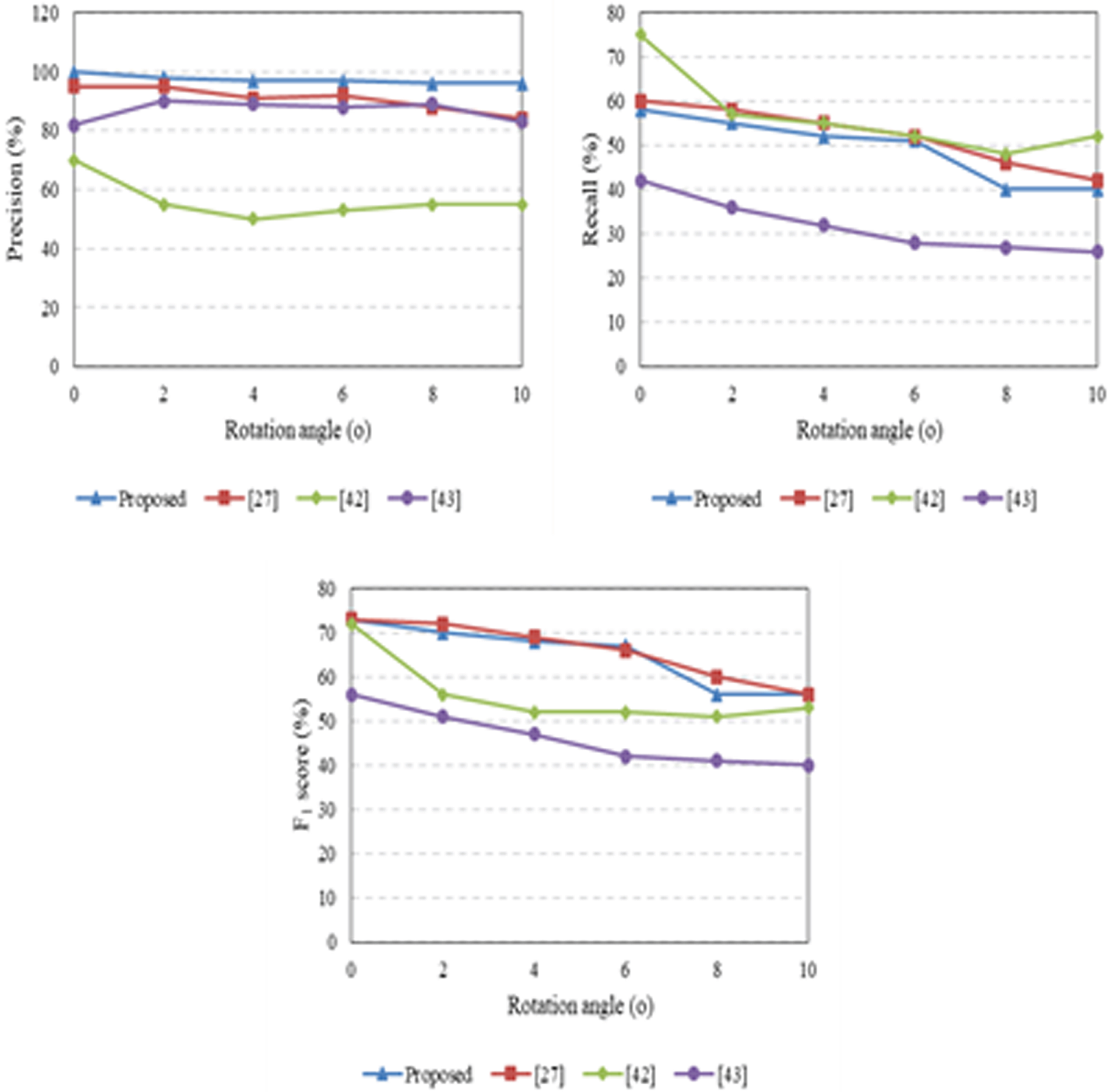
Results of precision, recall, and F1-score curves obtained against rotation operation.
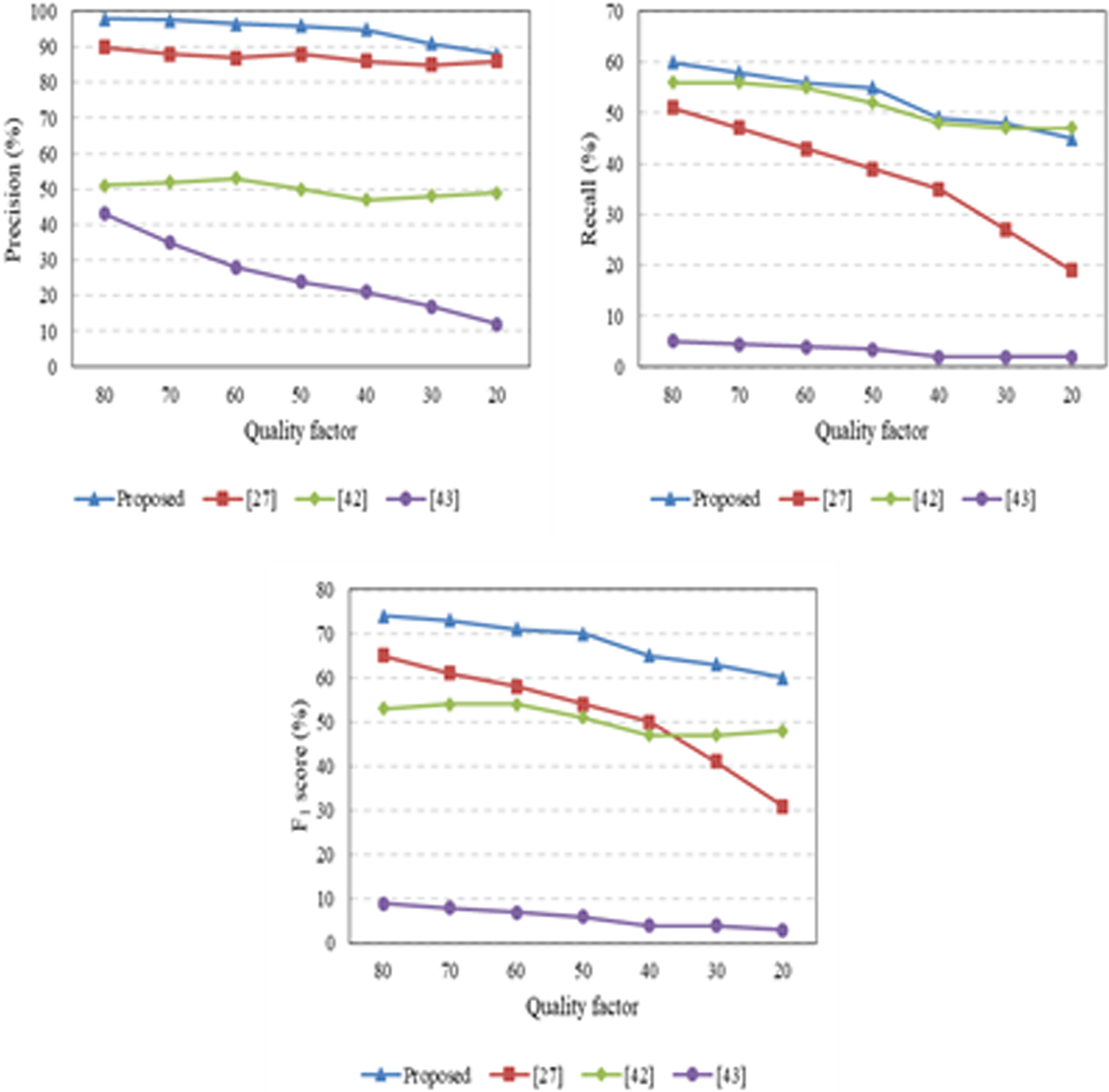
Results of precision, recall, and F1-score curves obtained against the JPEG compression attack.
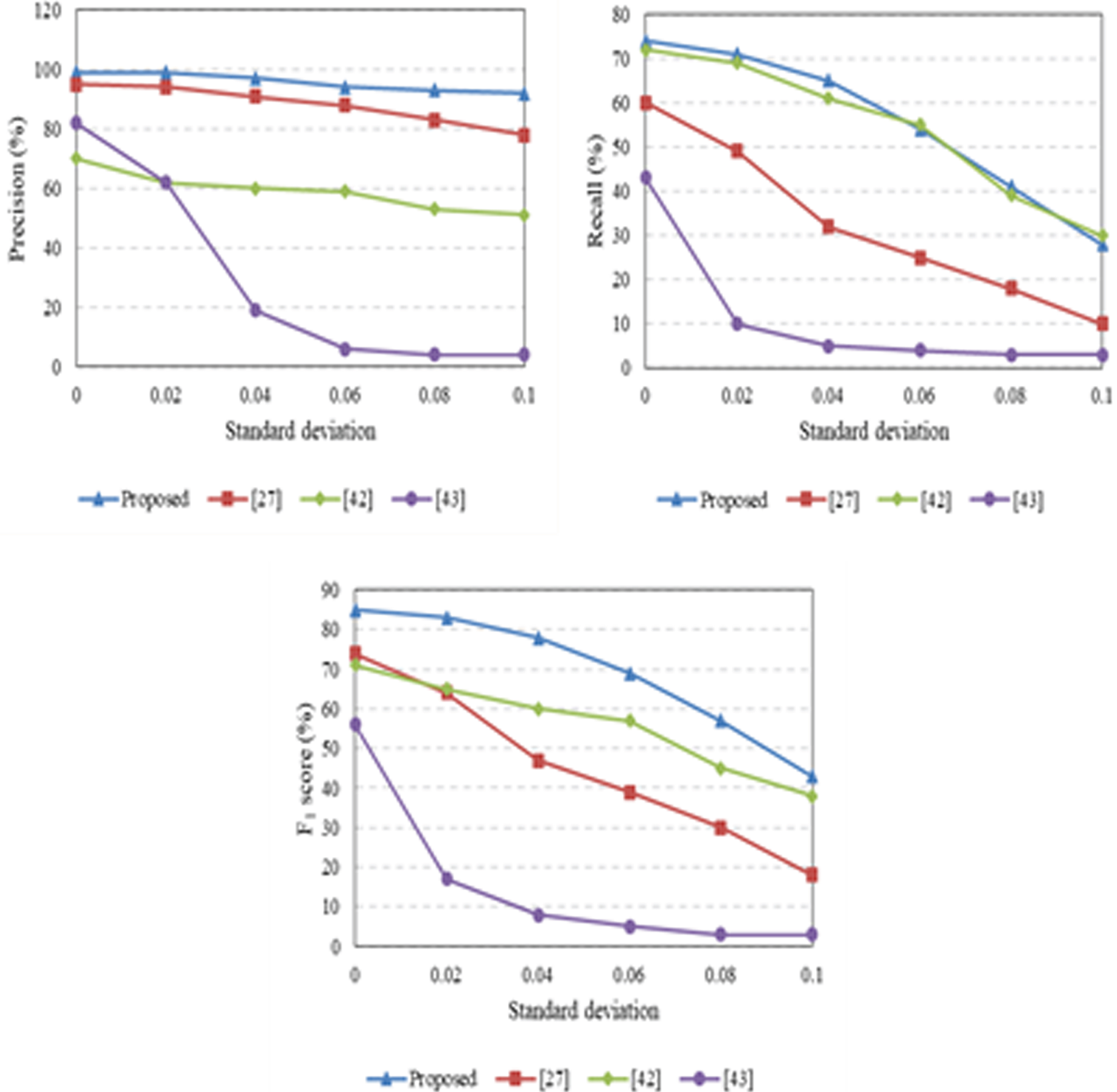
Average precision, recall, and F1-score curves obtained against additive noise.
To evaluate the performance against scaling operation, the forged areas are scaled down or up before generating the forged image by various scaling factors S. To check the evaluation power of the proposed approach against 10 different scaling factors (S = 91 : 109, with step 2). Figure 16 is indicting the average performance evaluation results of the proposed approach in the case of scaling. Figure 16 shows that the proposed approach is robust in detecting the forged areas as compared to other CMFD approaches.
We examined the proposed approach for duplicated regions that are rotated before pasting. The performance evaluation of the proposed approach is performed under different rotation angles (θ=0 : 10 with step 2). Figure 17 exhibits the experimental output for forged images where the rotation is performed at different angles, demonstrating the effectiveness of the proposed approach. It can be determined from Fig. 17 that the performance of the proposed approach is higher in terms of precision against rotation attack. However, the recall curve shows a weak performance due to the lower detection of key-points from the forged image.
The effectiveness of the proposed approach is also evaluated under different JPEG compression attack. The average evaluation results for JPEG compression of various quality factors are reported in Fig. 18. The results exhibit that the proposed approach produces a higher precision rate against a state-of-the-art, whereas the evaluation power of the proposed approach is reasonably good for recall, and the F1-score curve is high as well, which exhibits that the proposed approach performed impressively for JPEG compression attack.
The efficiency of the proposed approach is checked against the additive Gaussian noise operation. The intensities of the manipulated images were normalized between 0 and 1. The Gaussian noise with zero-mean with different standard deviations (δ=0 : 0.1 with step 0.02) are added to the manipulated images. Figure 19 is depicting the average experimental results against the additive noise operation. It can be noted from Fig. 19 that the proposed approach has a higher detection rate in the case of precision and comparable results in terms of recall. The performance comparison of the proposed approach against other latest CMFD approaches with the publicly available datasets is presented in Table 2.
Proposed approach performance comparison with state-of-the-art CMFD approaches on the MICC-F220 and MICC-F2000 datasets (best performances are marked in bold format)
The SURF descriptor empowers the proposed approach to identify manipulated areas fast and precisely even after post-processing attacks, furthermore the clustering approach reduces the search space to increase the efficiency and effectiveness of the proposed approach and allows it to detect single and multiple tampered regions accurately.
To evaluate the performance of the proposed approach for detecting the small and smooth copy-paste forged regions of the images, different images having small and smooth copy-paste forged regions are selected from the MICC-F220, MICC-F2000, and IMD datasets. The experimental results of the proposed approach on different sample images of these datasets are shown in Figs. 20–22. The performance analysis of the proposed approach in terms of precision, recall, and F1-score is presented in Table 3, which shows that the proposed approach produces robust accuracy even for the small and smooth copy-paste forged regions in the tampered images.

MICC-F220 dataset sample images: (a) Original images, (b) forged images, (c) results of the proposed approach, (d) ground-truth images.

MICC-F2000 dataset sample images: (a) Original images, (b) forged images, (c) results of the proposed approach, (d) ground-truth images.

IMD dataset sample images: (a) Original images, (b) forged images, (c) results of the proposed approach, (d) ground-truth images.
Performance evaluation of small and smooth copy-move forged regions using the proposed approach
Comparison of the computational cost of the proposed approach with state-of-the-art CMFD approaches (best performances are marked in bold format)
This section present detail of the performance comparison in terms of the computational complexity of the proposed approach with recent CMFD approaches. The experiments are performed using MATLAB 2015B (64-bit version) and Microsoft Windows 8.1 (64-bit version), which are installed on a PC having a specification of Core i7 processor with 8GB RAM and 250 GB hard drive. The computational cost of the proposed approach is presented in Table 3 in terms of false-positive-rate (FPR), true-positive-rate (TRP), and CPU time (in seconds) on the standard dataset of MICC-F220.
Conclusion
We have presented an efficient and effective approach for CMFD, which is based on the SWT, SURF, sDBSCAN clustering, and RANSAC. The SURF features are extracted from the approximation sub-band of shift-invariant SWT. The sDBSCAN clustering is applied over-extracted features to improve the accuracy of CMFD as the sDBSCAN clustering can easily identify the clusters of arbitrary shapes, sizes, and can filter the outliers from the forged image. The RANSAC is used to remove false-matches from the forged image. The experimental results of the proposed approach show substantial improvement against other CMFD approaches in the presence of various kinds of post-processing attacks such as rotation, JPEG compression, scaling, and additive noise. The extensive quantitative and qualitative analysis of the proposed approach shows that it outperforms the existing CMFD approaches in terms of evaluation metrics. As the proposed approach for CMFD can unveil the copy-move forgeries under various digital image post-processing operations, thus, it can play a significant role in the field of image forensics-based applications.
Compliance with ethical standards
a. Disclosure of potential conflicts of interest
All the authors declare no conflict of interest.
b. Research involving human participants and/or animals
This article does not contain any studies with human participants or animals performed by any of the authors.
c. Informed consent
Not applicable.
d. Funding
Not applicable.
e. Authors contributions
All the authors contributed equally.
f. Acknowledgments
Not applicable.