
Abstract
In recent years, successful applications of singleton fuzzy inference systems have been made in a plethora of different kinds of problems, for example in the areas of control, digital image processing, time series prediction, fault detection and classification. However, there exists another relatively less explored approach, which is the use of non-singleton fuzzy inference systems. This approach offers an interesting way for handling uncertainty in complex problems by considering inputs with uncertainty, while the conventional Fuzzy Systems have their inputs with crisp values (singleton systems). Non-singleton systems have as inputs Type-1 membership functions, and this difference increases the complexity of the fuzzification, but provides the systems with additional non-linearities and robustness. The main limitations of using a non-singleton fuzzy inference system is that it requires an additional computational overhead and are usually more difficult to apply in some problems. Based on these limitations, we propose in this work an approach for efficiently processing non-singleton fuzzy systems. To verify the advantages of the proposed approach we consider the case of general type-2 fuzzy systems with non-singleton inputs and their application in the classification area. The main contribution of the paper is the implementation of non-singleton General Type-2 Fuzzy Inference Systems for the classification task, aiming at analyzing its potential advantage in classification problems. In the present paper we propose that the use of non-singleton inputs in Type-2 Fuzzy Classifiers can improve the classification rate and based on the realized experiments we can observe that General Type-2 Fuzzy Classifiers, but with non-singleton fuzzification, obtain better results in comparison with respect to their singleton counterparts.
Introduction
The use of fuzzy logic (type-1) for decision making in the solution of a wide range of classification problems, for example in medicine [1–5], engineering [6–11], urban applications [12, 13], fault detection [14–16], demonstrates the versatility of type-1 fuzzy systems in solving real world problems.
On the other hand, there exists different kinds of Fuzzy Logic models, and recently we have witnessed an increasing interest on the implementation of Type-2 Fuzzy Logic in real-world problems, for example in [17–21]. In addition, for achieving this goal many researchers have put forward alternatives for reducing the computational cost of these kinds of systems, for example reducing the computational cost of Type reduction [22–25] and approximation of General Type-2 Fuzzy Inference Systems [26–29].
Nevertheless, there exists another variation of Fuzzy Logic that is not so frequently used for real world problems because it also requires a high computational cost, specifically in the fuzzification, and this approach is the non-singleton Fuzzy Logic. In this approach, the inputs to the Fuzzy Inference Systems are non-crisp values, they are Type-1 Membership Functions, and where the fuzzification is not a simple evaluation of a crisp value. The fuzzification for non-singleton Fuzzy Inference Systems consists on obtaining the maximum value of the intersection of the input membership function and the membership function corresponding with the Fuzzy Inference System. Some examples of works focused on non-singleton Fuzzy Systems are the following: in [30] the authors focus on the implementation of Type-2 non-singleton inputs for fuzzy systems, in [31] the authors designed and compared singleton and non-singleton Type-1 and Type-2 Fuzzy Systems applied in time series focused on the uncertainty handling capabilities of non-singleton Type-2 Fuzzy Systems. Finally, in [32] the authors propose a genetic design of a non-singleton Fuzzy Classifier applied to the arrhythmia problem. However, even if the approach has successfully been applied in different problems with positive results, we cannot find many research articles about this topic. For example, if we search for “non-singleton” as a keyword in SCOPUS, we find that only 39 documents in the last 15 years (as can be observed in Fig. 1).
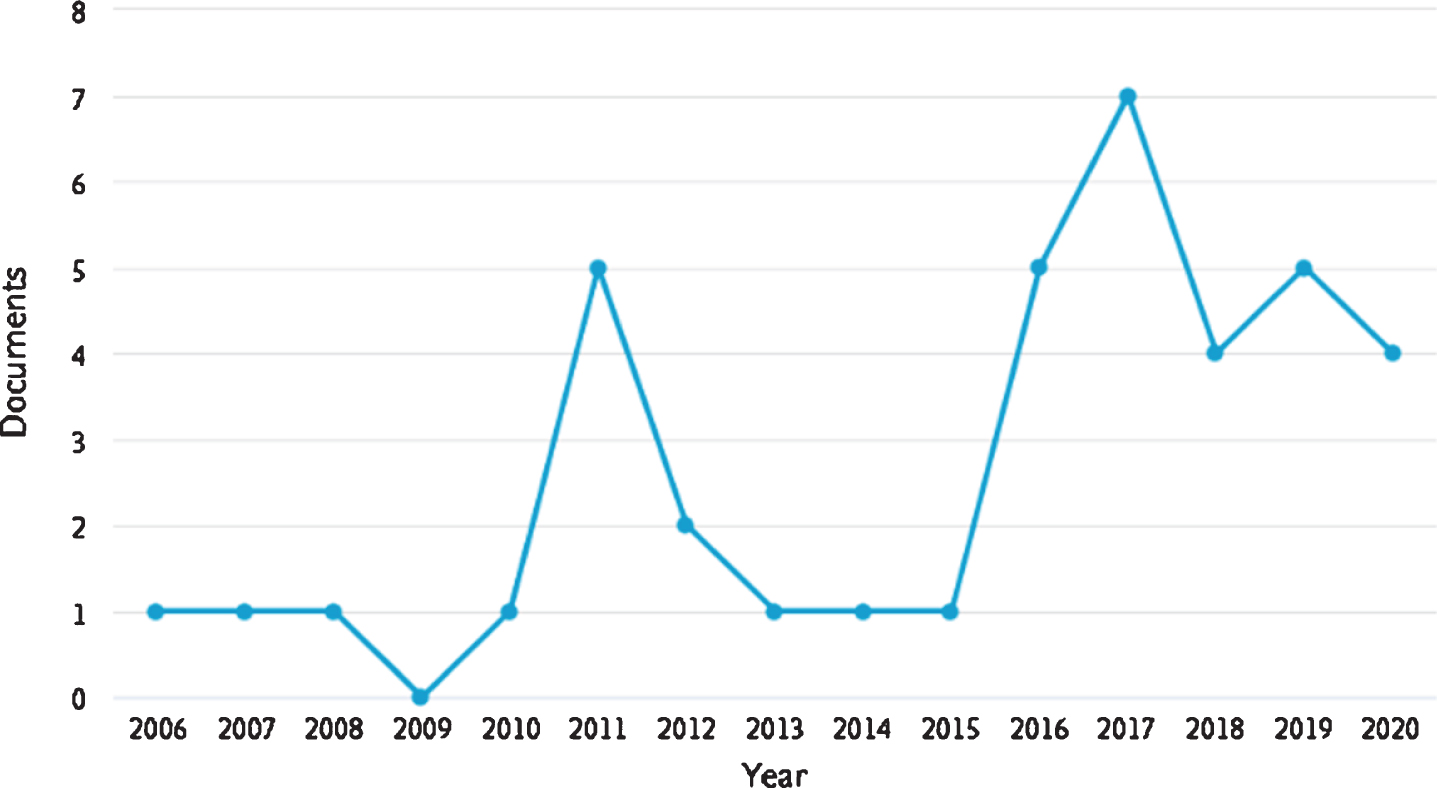
Non-singleton publications in the last 15 years.
In the same period time, we can find 4072 documents with the keywords “Type-2” and “Fuzzy” (as is illustrated in Fig. 2).
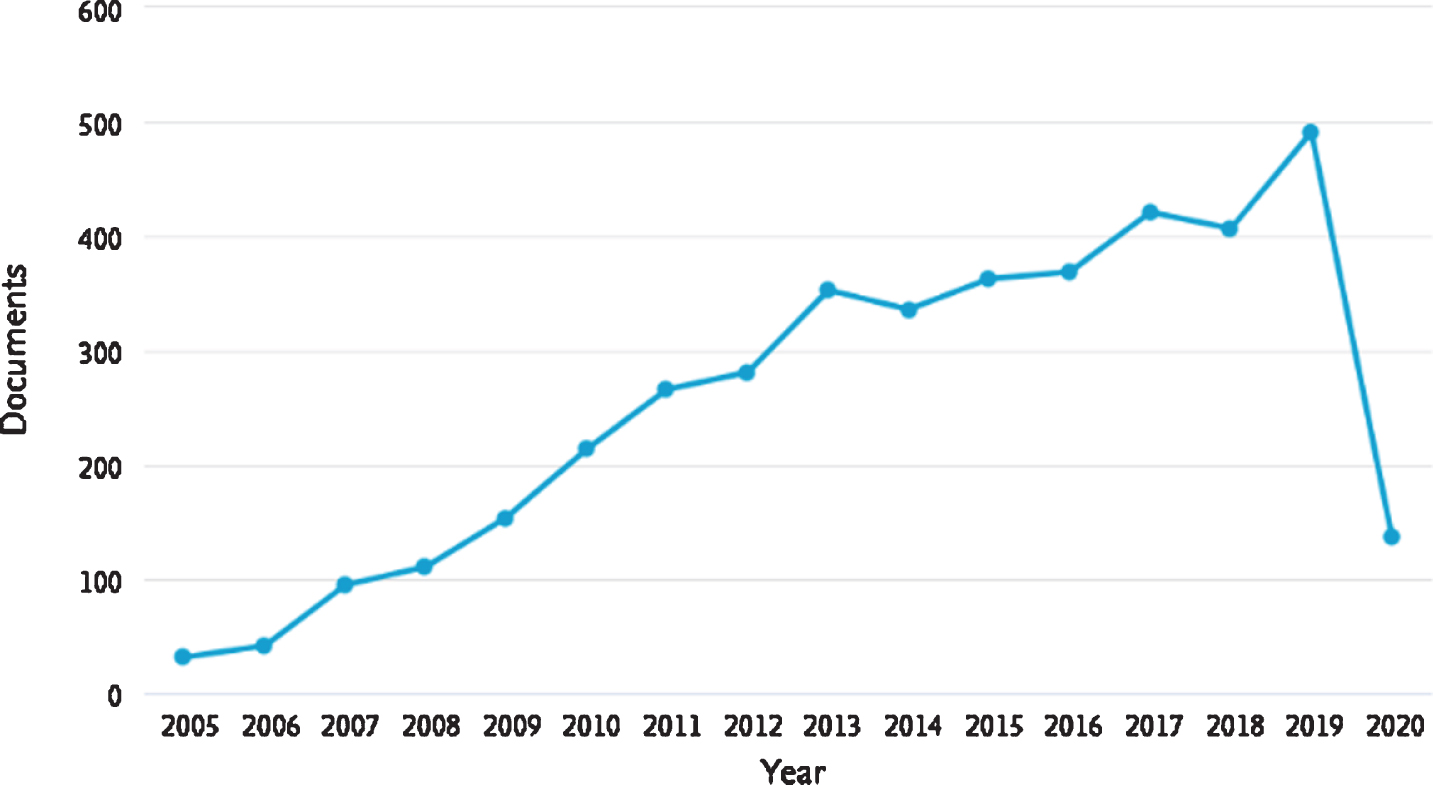
Non-singleton Fuzzy publications in the last 15 years.
The main contribution of the present paper is the design and evaluation of Non-singleton General Type-2 Fuzzy Classifiers, in order to compare the improvement with respect the conventional singleton approach, also it is proposed to implement a computational efficient approach based on recent advances in type reduction and α-plane aggregation. The main idea is evaluating how much the performance of a General Type-2 Fuzzy Classifier is improved with the inclusion of non-singleton inputs, and how is its performance in comparison with respect to other conventional approaches in the literature. This is relevant because is an opportunity to explore by how much the performance of a General Type-2 Fuzzy Classifier is improved if we consider non-singleton inputs.
The organization of the paper is as follows: Section 2 presents the basic concepts of Fuzzy Logic, Section 3 presents the proposed approach for non-singleton classifiers, Section 4 presents experimental results and analysis, and finally Section 5 contains the conclusions of the work.
In this section, a brief overview of Fuzzy Logic is presented. This is relevant because the design of the proposed approach is based on these concepts. Fuzzy Logic has been introduced by Lotfi Zadeh in 1965 [33], in order to model the vagueness and human knowledge for achieving intelligent computing, and these concepts have evolved and been applied successfully in many kind of applications and are called Type-1 Fuzzy Logic.
Type-2 fuzzy systems
On the other hand, the evolution of Type-1 Fuzzy Logic is Type-2 Fuzzy Logic [34–36], that allow us to model the uncertainty in addition to the vagueness in real world problems, which was not provided by the original Type-1 Fuzzy Logic.
There exist two variations of Type-2 Fuzzy Logic, the complete model called General Type-2 Fuzzy Logic, and a simplification called Interval Type-2 Fuzzy Logic, and both have been applied in solving real world problems as can be noted in the literature [37–39].
An Interval Type-2 Fuzzy Set is composed by two Type-1 Fuzzy Sets, called upper and lower, as can be observed in (1)
Another important concept is the Footprint of Uncertainty, which is the area inside the boundaries introduced in (1) [34, 40] and is related to the uncertainty of the fuzzy set, an example of this can be observed in Fig. 3.
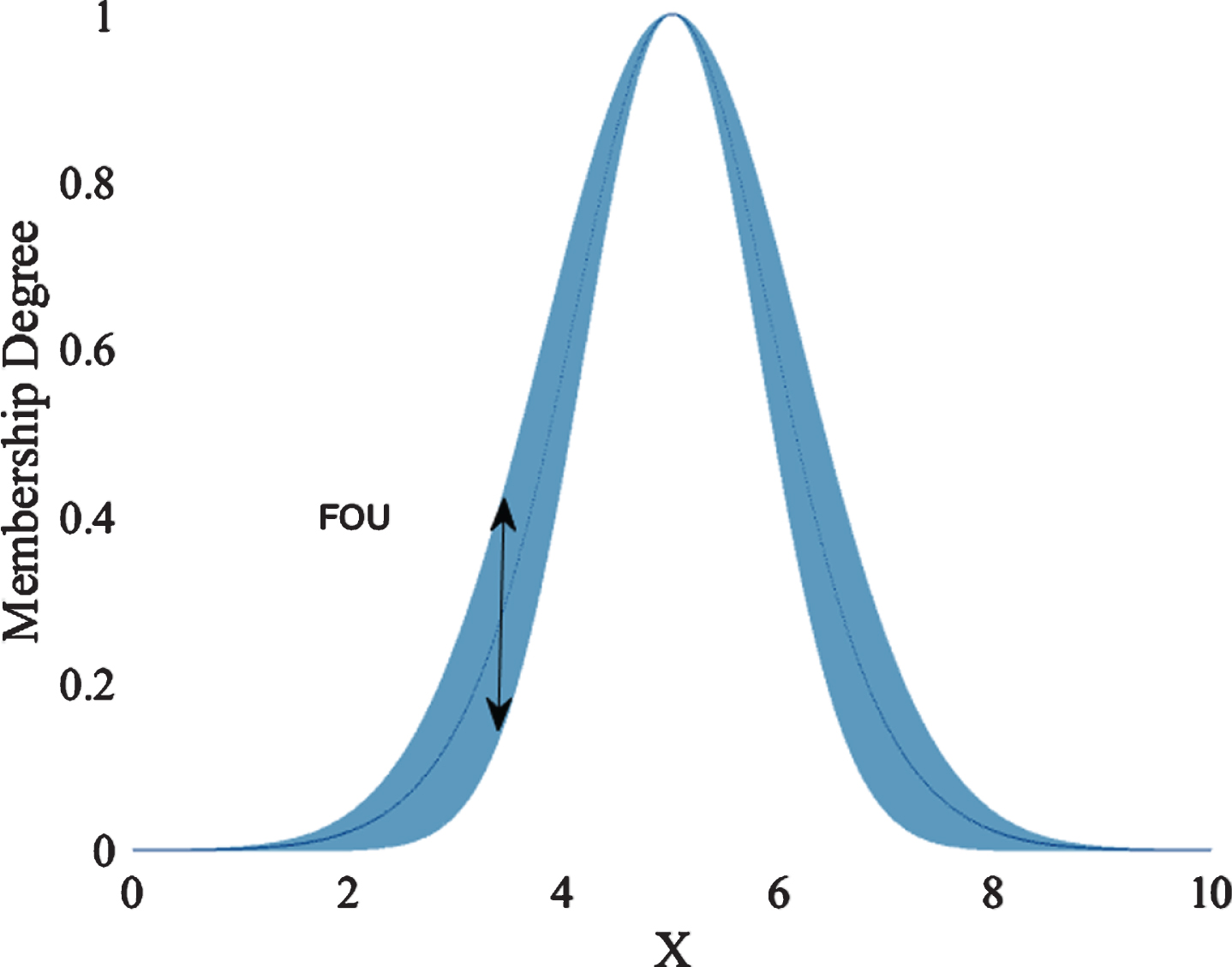
IT2 MF.
However, the complete model of Type-2 Fuzzy Logic is the called Generalized Type-2 Fuzzy Logic, where the boundaries of the FOU also exist, but they are not uniform, and the uncertainty is handled by an embedded secondary type-1 membership function for every point of the primary domain (2)
The problem with this kind of systems is because as we can observe, based on the theory, they have an infinite number of embedded secondary membership functions.
An example of this is illustrated in Fig. 4.
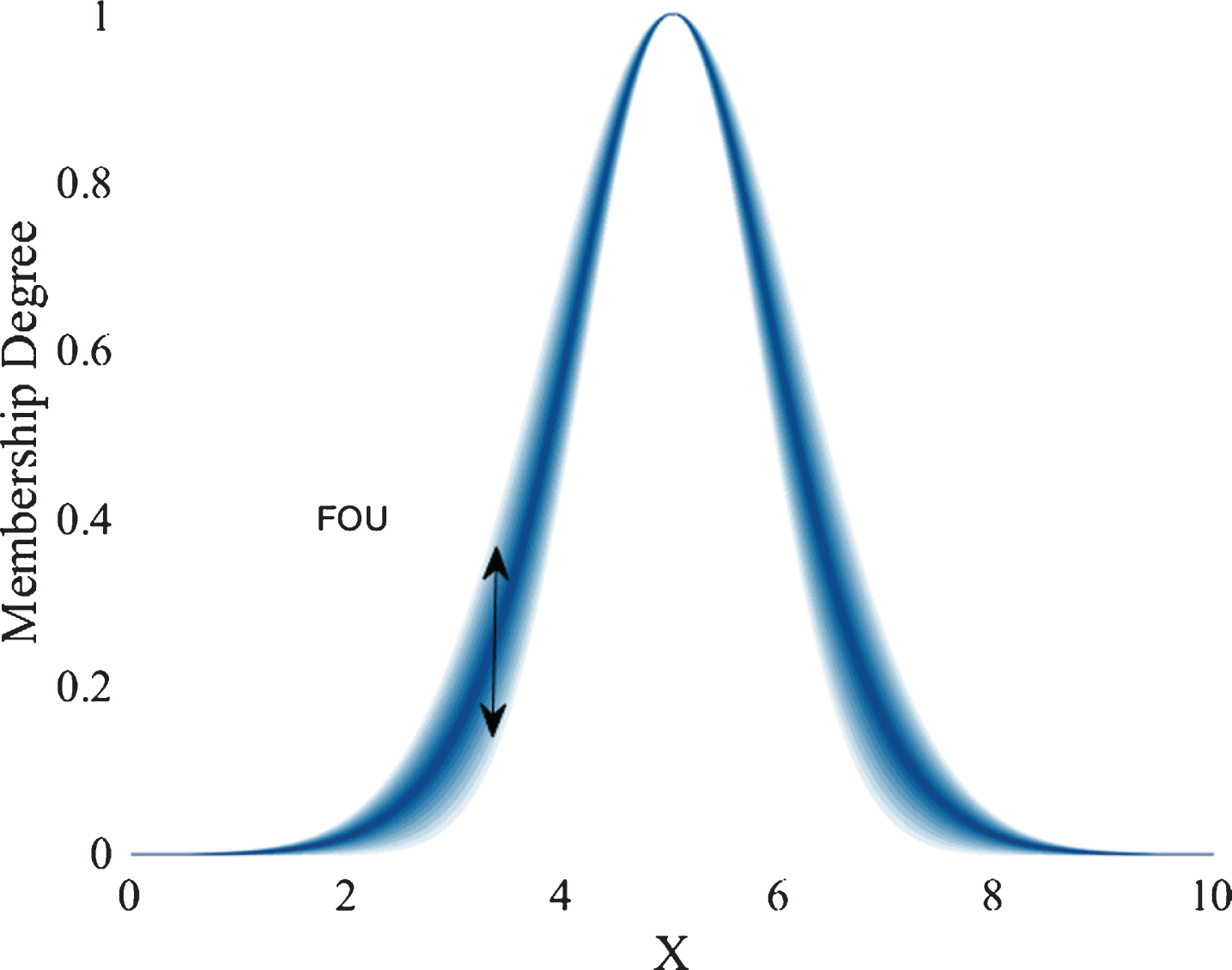
GT2 MF.
In addition, the computational effort of General Type-2 Fuzzy Systems is much higher than Interval Type-2 Fuzzy Systems and even more than Type-1 Fuzzy Systems.
However, in recent years several alternatives to approximate this kind of systems have emerged in this way reducing the computational cost, and some examples are, α-planes [27], zSlices [29] or Geometric approach [28]. Also exists alternatives focused on reducing the defuzzification time required for Type-2 Fuzzy Systems [25].
For this work, we decided to apply the approximation based on α-planes; this consists on the horizontal discretization of the tridimensional system in many dimensional systems that are equivalent to Interval Type-2 Fuzzy Systems and are called α-planes.
The mathematical expression of these α-planes can be found in (3)
The α-planes are solved individually and after aggregated based on numerical integration [26]. The conventional aggregation of the α-planes is expressed in (4).
The general idea of the α-planes approximation is illustrated in Fig. 5.
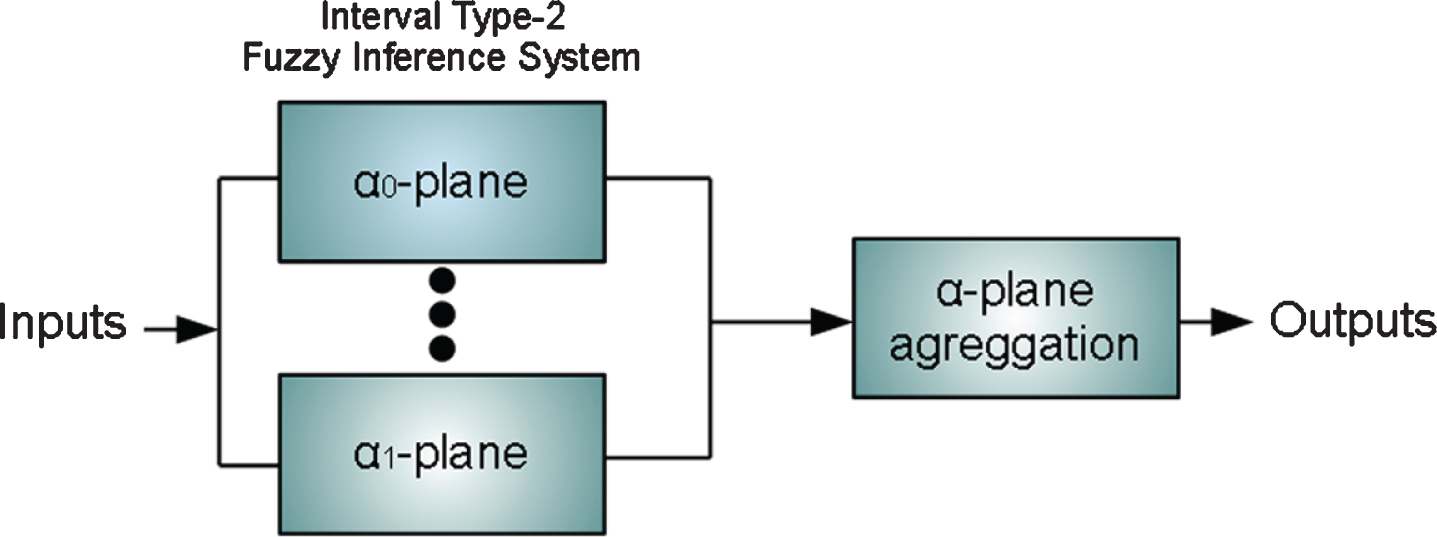
GT2 FIS based on α-planes.
This kind of Fuzzy Logic has not been used in many real-world applications because it demands an additional computational overhead in comparison with the conventional approach (Singleton Fuzzy Logic).
The difference between singleton Fuzzy Logic and non-singleton Fuzzy Logic is in the kind of input data and this affects the fuzzification process. While the conventional Fuzzy Systems have as inputs crisp values (singletons) that are evaluated in the membership functions, the non-singleton systems have as input Type-1 membership functions, and the fuzzification is more complex. However, the use of this kind of systems can provide the system with a kind of uncertainty handling which is comparable with the Interval Type-2 Fuzzy Logic as can be noticed in [31, 41].
The computation of the fuzzification of a singleton and non-singleton Fuzzy Inference Systems are expressed in (5) and (6) respectively
These kinds of fuzzification are illustrated in Fig. 6.
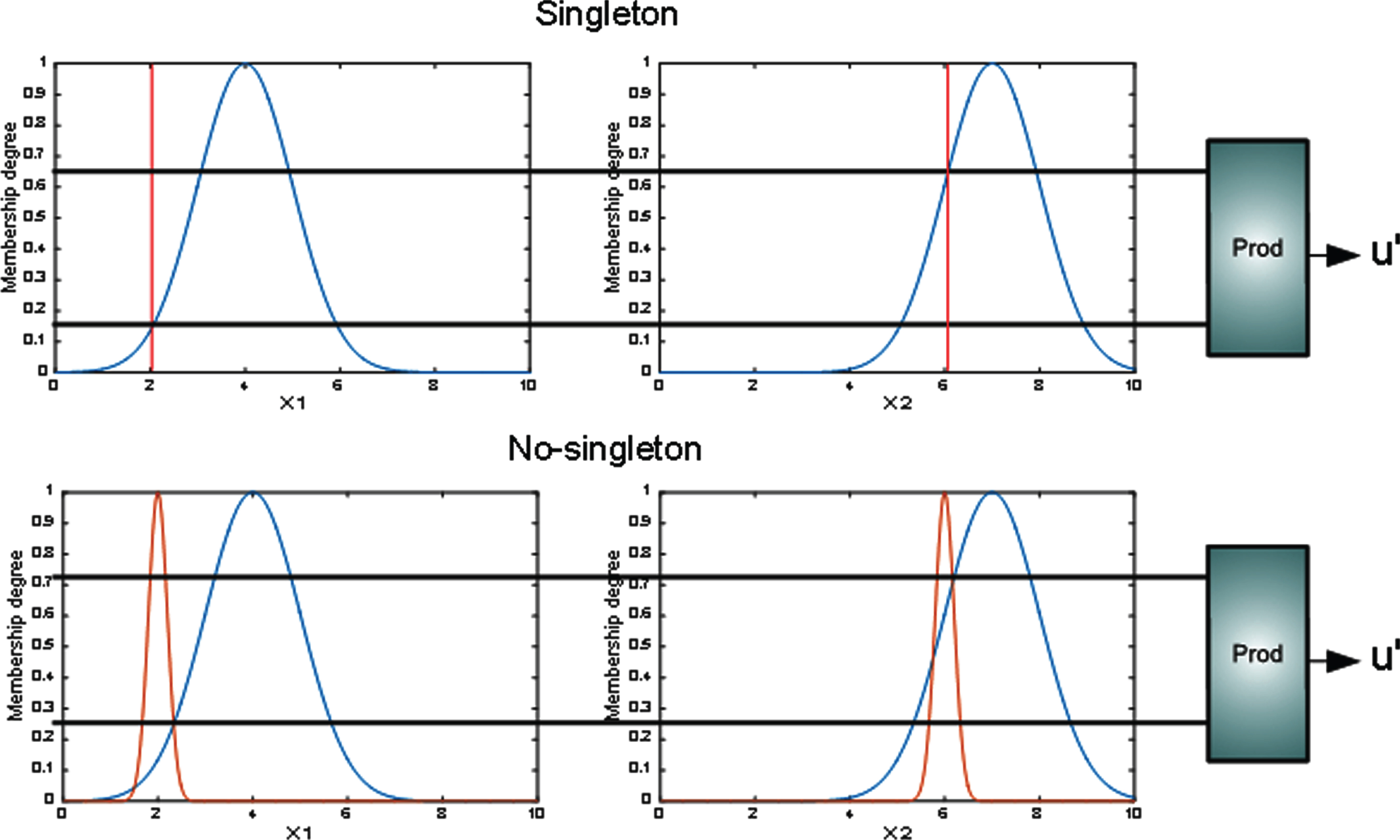
Type-1 singleton and non-singleton inference.
An example of this difference can be observed in Fig. 6. In Singleton inference, the fuzzification is a single evaluation of a mathematical function, however, in the Non-singleton the inference is the maximum point of the intersection of the membership function with the input (what also is a membership function).
As can be noted, the problem of using non-singleton inputs is in the fuzzification that demands a higher computational cost. However, non-singleton inputs add to the system additional information of the problem, and have the possibility of producing a better performance [42].
This problem is more complex in Type-2 Fuzzy Inference Systems, for example in Interval Type-2 Fuzzy Inference Systems.
In an IT2 Fuzzy Inference System, which is based on the concepts of meet and join, we know that the fuzzification is equivalent to two type-1 fuzzifications. Eqs (7) and (8) express how compute the fuzzification in IT2 Fuzzy Inference Systems for singleton and non-singleton respectively.
Both kinds of fuzzification are illustrated in Fig. 7.
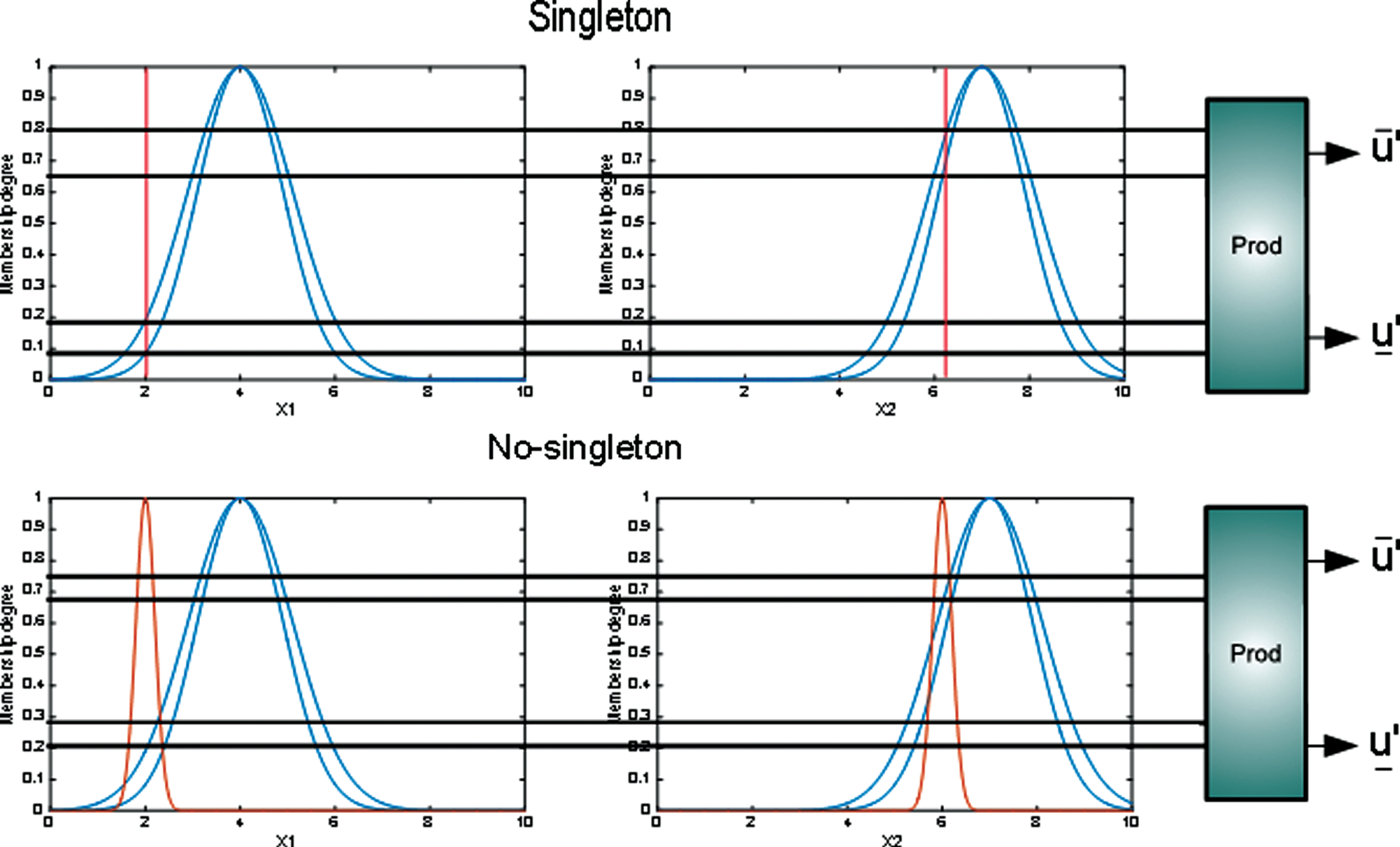
Interval Type-2 singleton and non-singleton inference.
In the case of the General Type-2 non-singleton fuzzification, in the present paper, this is realized by the α-planes approximation so, is not necessary to define it explicitly because each α-plane is solved as an Interval Type-2 Fuzzy Inference System.
In this section the proposed model for the GT2 Fuzzy Classifier is presented. The section starts with the specifications of the model and then a representative example is illustrated.
Non-singleton general Type-2 fuzzy classifier
Before the definition of the model, Table 1 summarizes the features of the proposed system.
Proposed approach
Proposed approach
The representation of the proposed system is illustrated in Fig. 8.
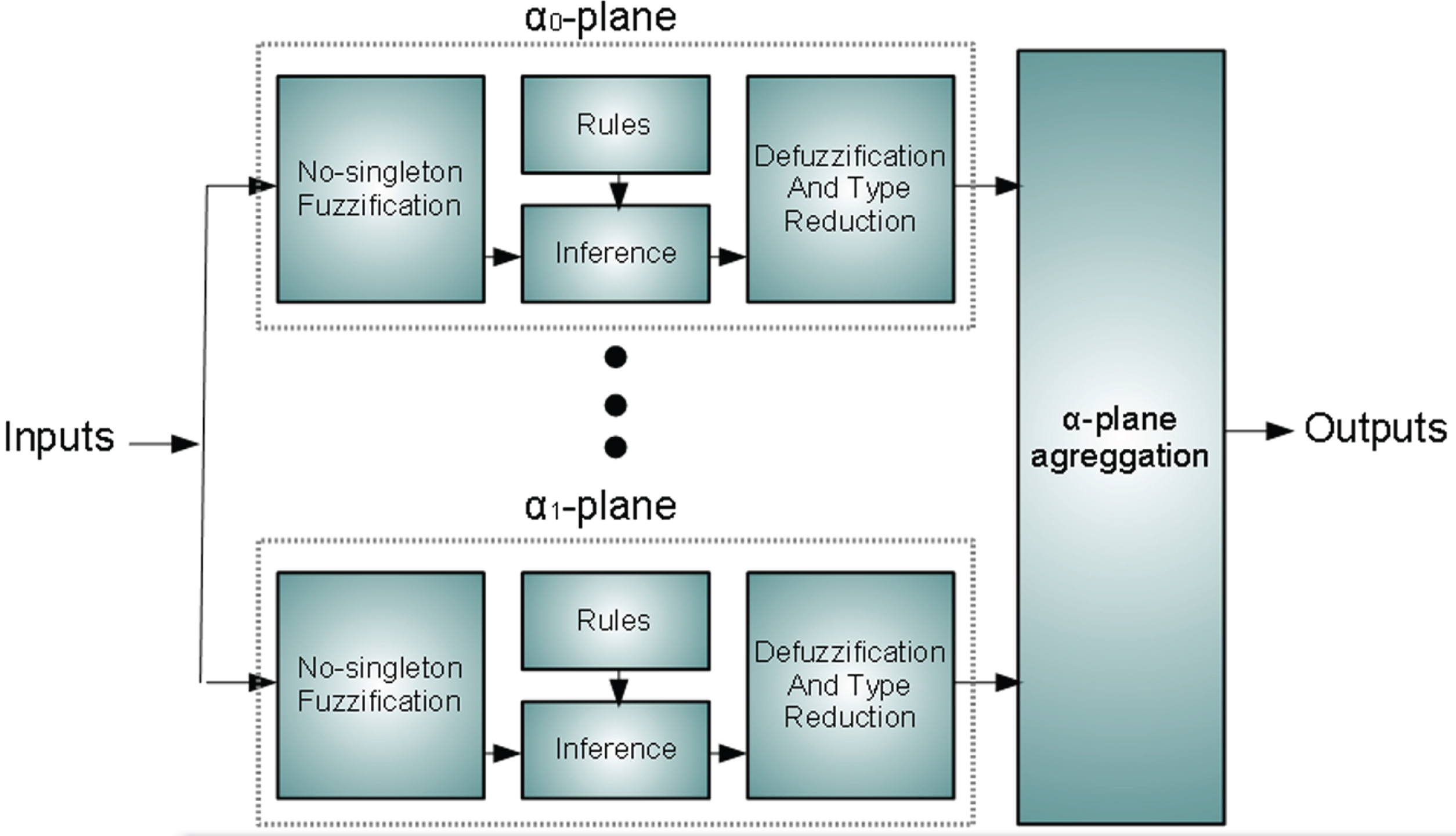
Proposed approach.
The steps for the automatic design are similar with the ones introduced in [43] but with the inclusion of the non-singleton conversion of the inputs as can be noticed in Fig. 9.

Non-singleton GT2 Classifier design flowchart.
The steps for the parameterization of the system (Parameters of the MFs and the output polynomials) are realized by the methodology proposed in [43, 44]. The example presented in this work is the Haberman’s survival dataset, using only two features, the years old and the number of axillary nodules, this dataset is to determine if a patient will survive 5 years or more.
The design of the classifier starts with the input data, as can be observed in Fig. 10.
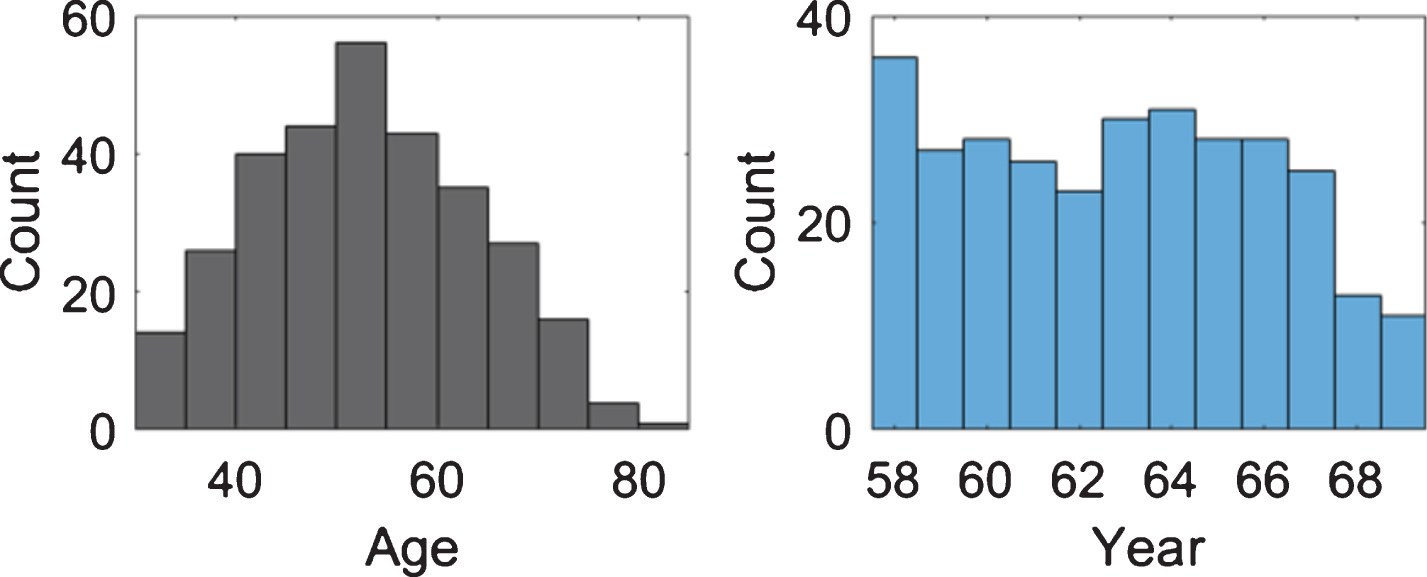
Attributes histogram.
Fig. 9 illustrates the attributes histogram only to observe the distribution of the data in a primary domain. The first step in obtaining the antecedent parameters is the generation of multiple sub data sets by using uniform random sampling with replacement. For every sub data set the FCM algorithm (Fuzzy C-Means) is applied for obtaining the center and membership degree of n clusters. Based on the data obtained for the FCM algorithm it is possible to generate a Type-1 Gaussian MF as is explained in [43]. Realizing these steps, we obtain a collection of many Type-1 Gaussian MFs and based on these Type-1 Gaussian MFs it is possible to define the parameters of the Generalized Type-2 antecedent MFs as can be observed in Fig. 11 and Fig. 12.
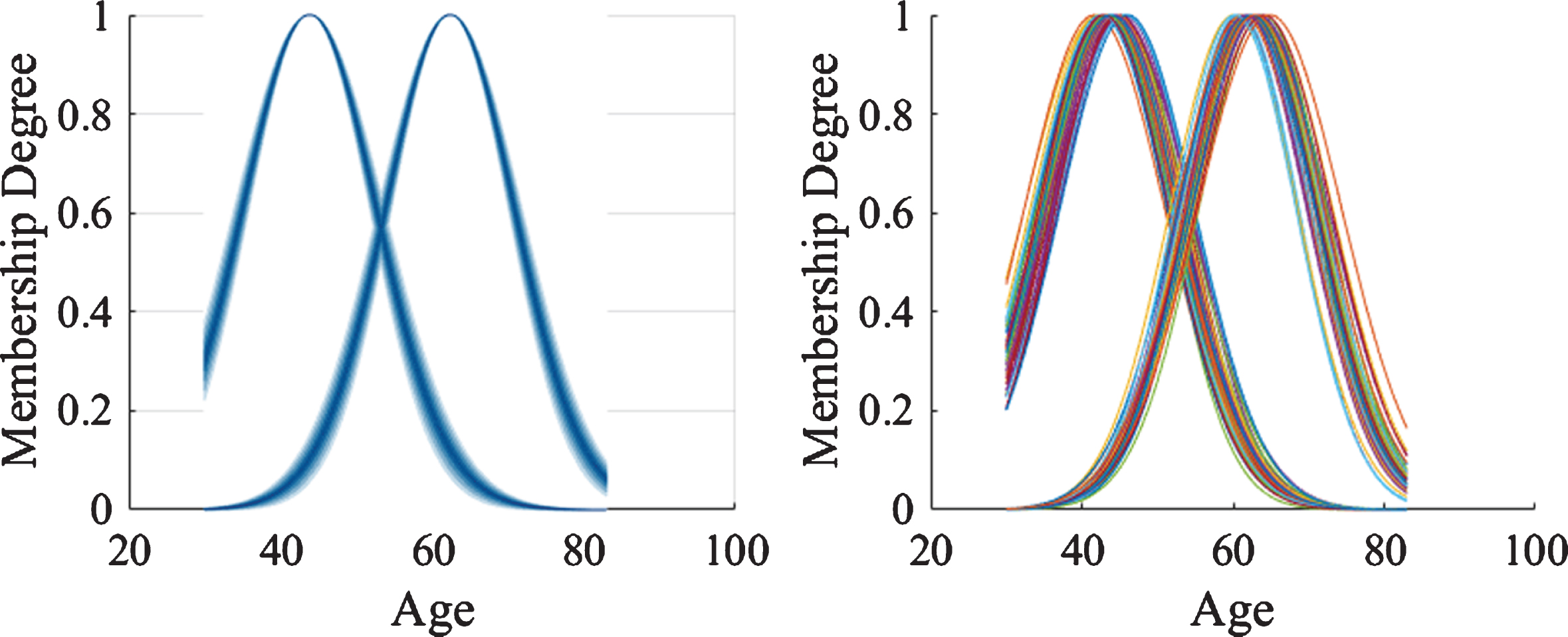
first attribute: a) GT2 b) Embedded Type-1.
Second attribute: a) GT2 b) Embedded Type-1.
The proposed architecture has predefined rules based on the original architecture of ANFIS. This set of predefined rules can be a disadvantage in some cases, but have an important advantage and is the scalability, because the number of rules depends on the number of clusters and not on the number of features or the number of possible rules, and this allows the implementation of this system in problems with many features or clusters.
On the other hand, the process of obtaining of the output polys is realized by the Least Square Error minimizing the error of the output, is relevant to see that in this case, the output that is minimized is the output of the α-plane with α= 1, which in this case can be considered as a Type-1 Fuzzy Inference System. The sum of the square errors is expressed in (9)
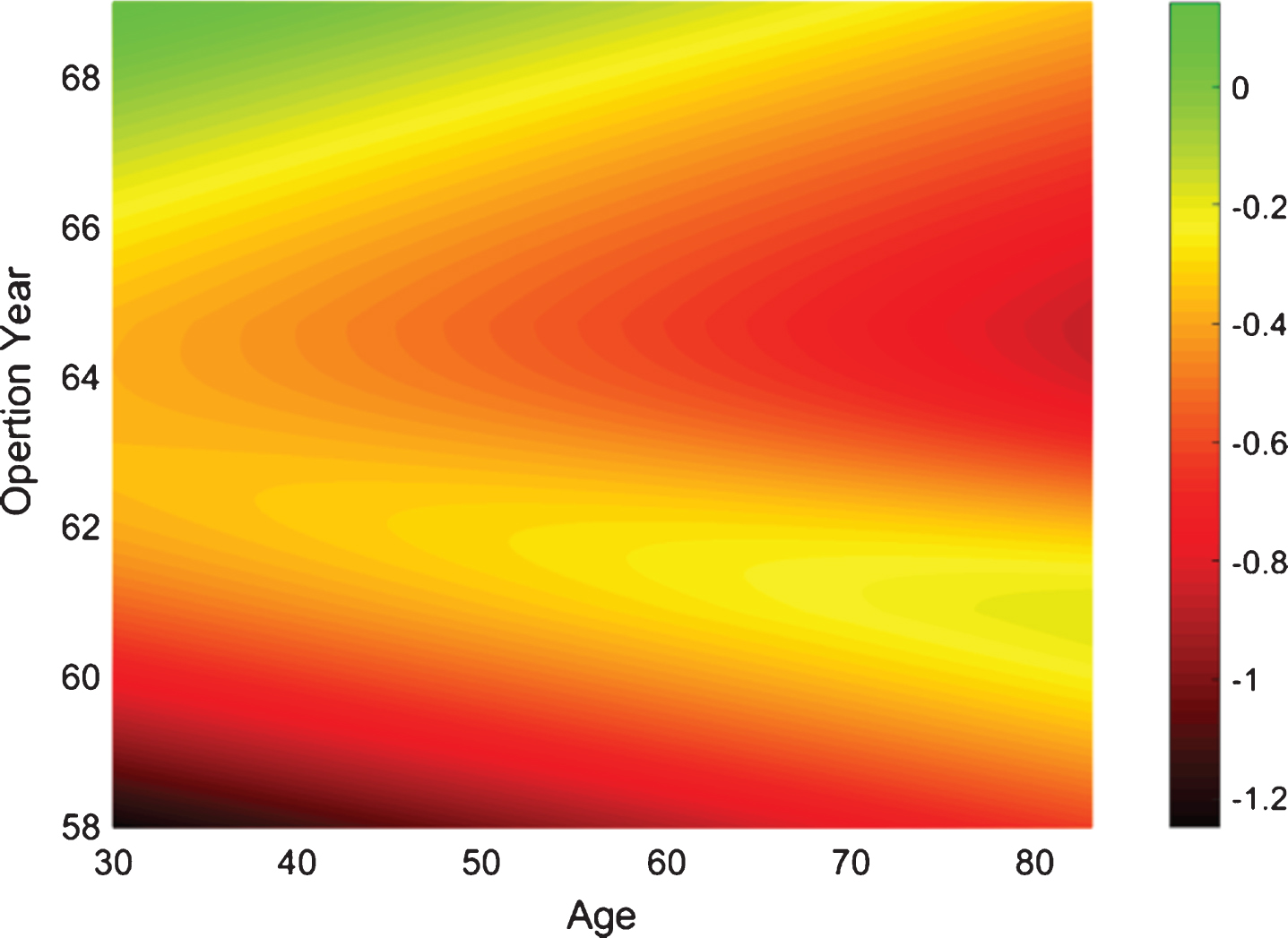
Based in these steps we can obtain a General Type-2 Fuzzy Classifier, and the behavior of this system can be observed in the classification map illustrated in Fig. 13 and the uncertainty map illustrated in Fig. 14, respectively.
Classification map.
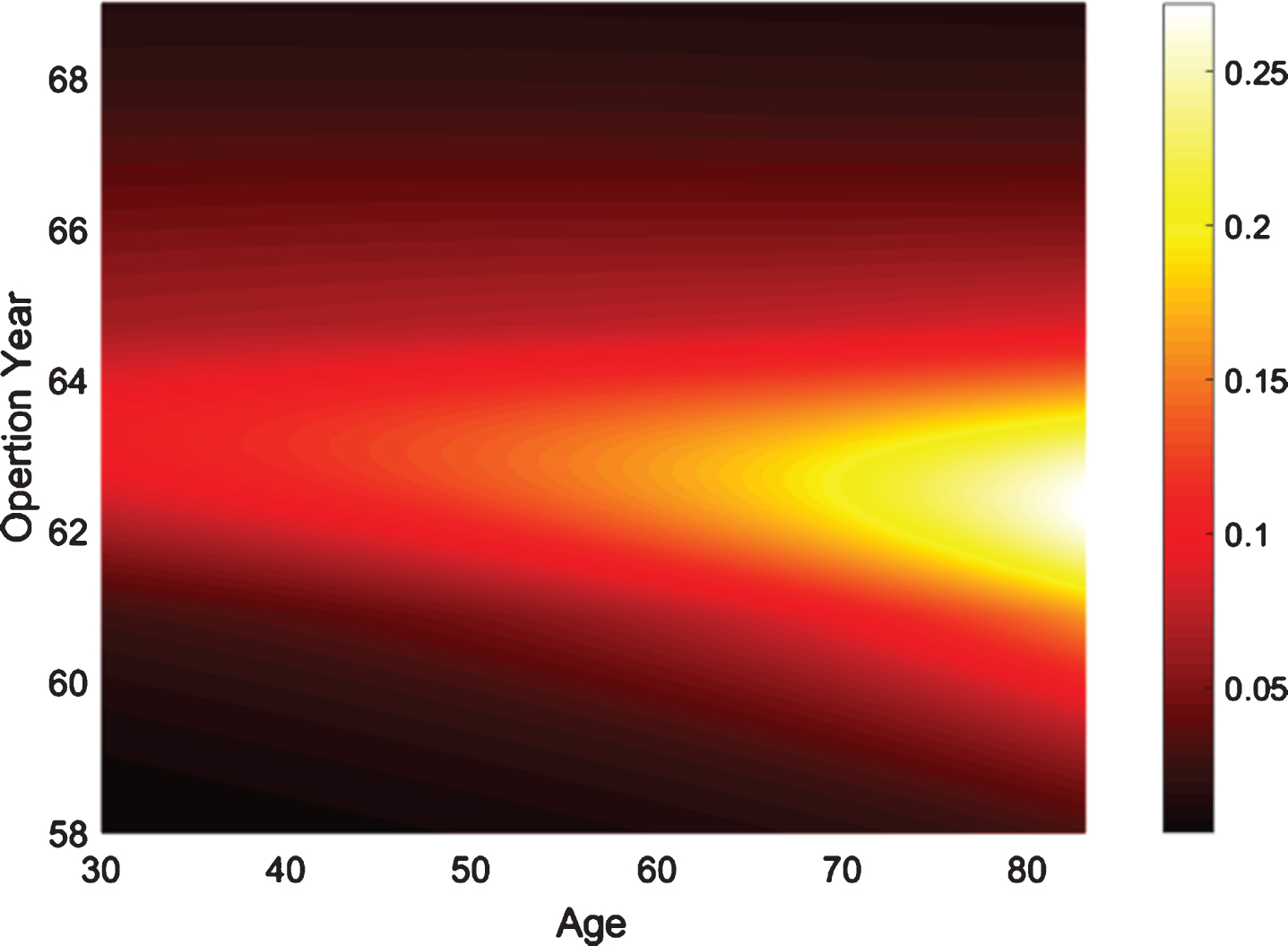
Uncertainty map.
In this classification map, the red area represents the patients that will not survive 5 years or more and the green area represents the patients that will survive 5 years or more.
The map is nonlinear, and interpretable, for example, of the map we can conclude that the young people have more chances of survival and that the medicine advances increase the survival chances in the observed ten years.
In addition, in the uncertainty map can be noted that the uncertainty is also non-linear and can be concluded that the classifier has more difficulty in classifying the oldest people between the years 62 and 64. On the other hand, in order to make this system a non-singleton system, the input data is converted to Type-1 Gaussian MFs by using the parameters expressed in (10)
In this way, every input data set is converted in a Type-1 Gaussian MF and the inference is computed as is explained in Section 2.1. Figs. 15 and 16 illustrate an example of the model inference for a non-singleton input and a singleton input, respectively.
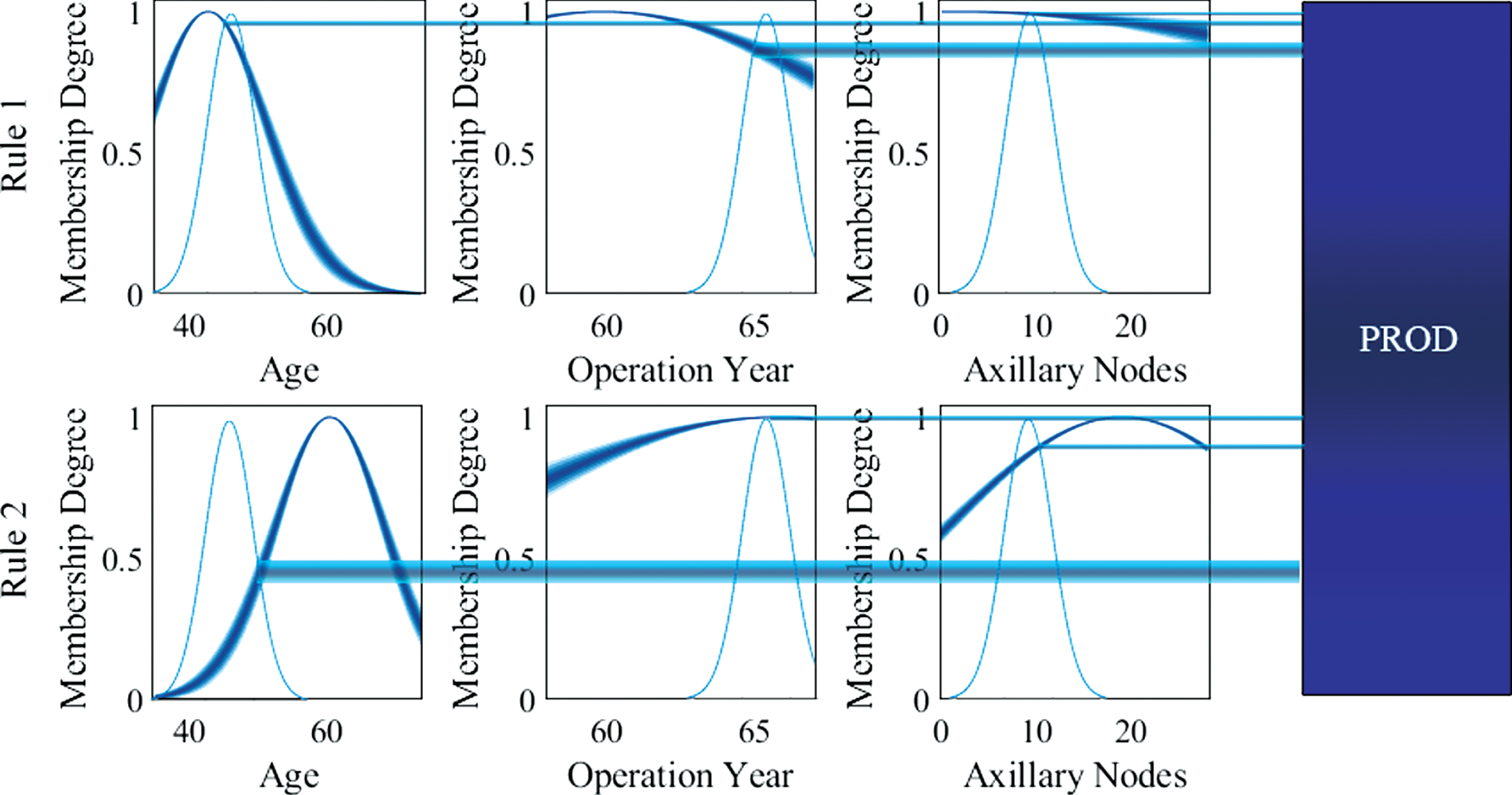
Non-singleton inference example.
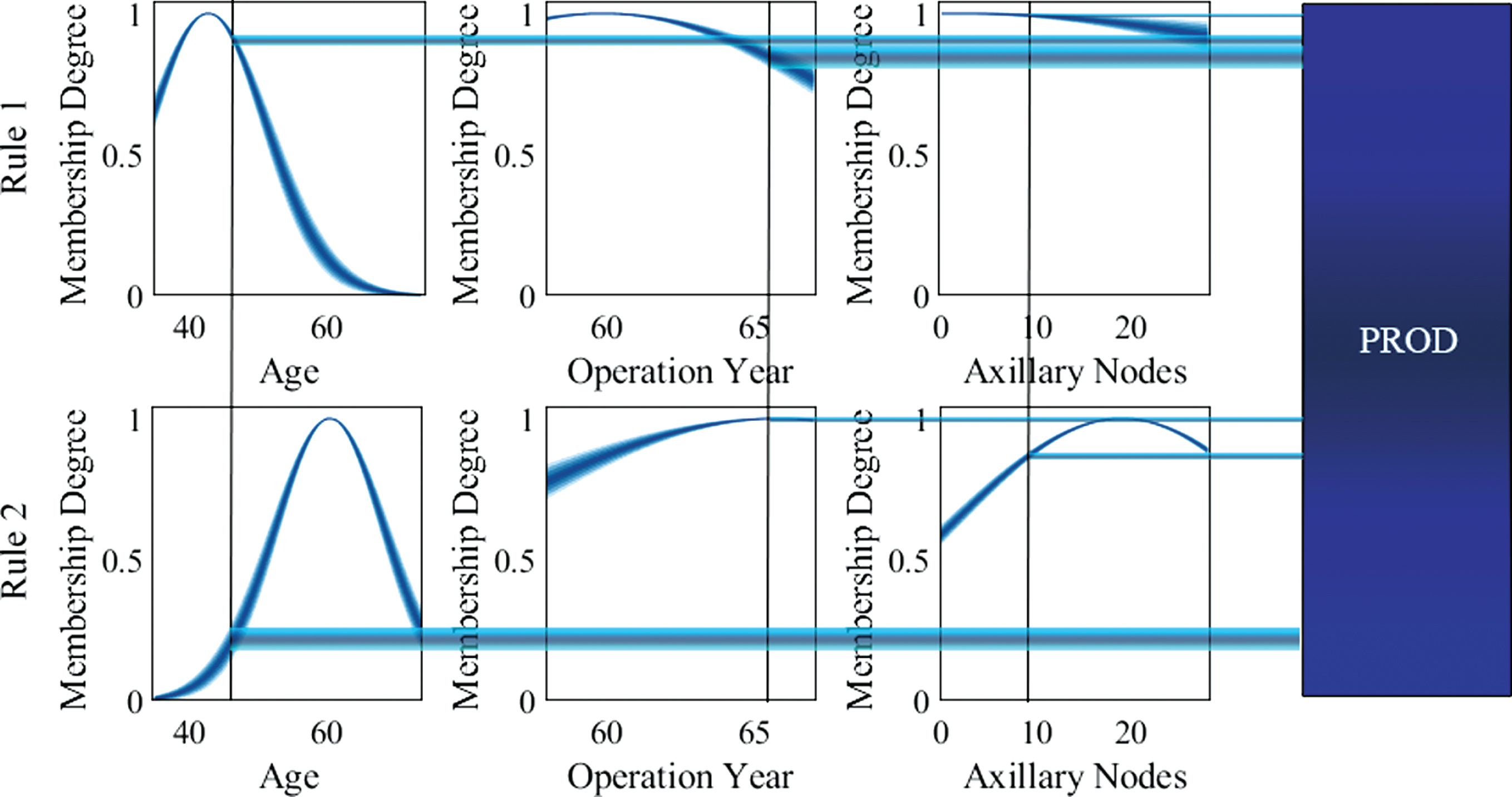
Singleton Inference example.
As can be observed, the system provides different outputs depending of the kind of input.
This section presents the experimental results realized in order to evaluate the performance of the proposed approach.
Benchmark problems
The datasets selected for experimentation have been widely used for evaluating the performance of different kinds of diagnosis systems or classifiers, and a brief description is provided below in Table 2.
Benchmark diagnosis datasets
Benchmark diagnosis datasets
This section contains the experimental results based on Cross Validation with different values of K, specifically for K = 3, K = 5 and K = 10. Here the average of 10 experiments are documented and compared with respect to the singleton approach based on General Type-2 Fuzzy Inference Systems [43]. Tables 3, 4 and 5 summarize the results obtained for K = 3, K = 5 and K = 10 respectively. Based on the results observed in Tables 3 5, a summary of the results can be found in Table 6. As can be observed, with the implementation of non-singleton GT2 Fuzzy Classifiers, the performance of the system is improved even in comparison with respect to equivalent Singleton GT2 Fuzzy Classifiers.
Summary of comparison of results based on Accuracy for K = 3
Summary of comparison of results based on Accuracy for K = 3
Summary of comparison of results based on Accuracy for K = 5
Summary of comparison of results based on Accuracy for K = 10
Proposed approach vs GT2 Approach in [43]
In order to put this in context, the performance obtained by the proposed approach, the results are compared with respect to other fuzzy classifiers of the literature. A summary of the results can be found in Tables 7 9.
Comparison based on 3-Folds CV
Comparison based on 3-Folds CV
Comparison based on 5-Folds CV
Comparison based on 10-Folds CV
This section presents a statistical comparison of the non-singleton approach with respect the conventional singleton approach in order to observe how much the kind of input affects the performance, and the experimental set up selected for this test is the use of 70% for training and 30% for testing.
The parameters of the Z-test selected for the statistical comparison are summarized in Table 10. On the other hand, Table 11 documents the result of the Z-test based on the mean and standard deviation of 30 experiments. We have to say that positive values of Z indicate that a significant advantage is obtained with the proposed approach. In addition, the higher the Z value, the larger is the statistical evidence in favor of our method.
Z-Test parameters
Z-Test parameters
Statistical comparison of Non-singleton and Singleton GT2 Fuzzy Classifiers
One of the objectives of the performed experiments was the comparison of the proposed approach with respect to an equivalent alternative with singleton inputs, and this is relevant because the core and innovation of the paper is the inclusion of the non-singleton inputs in a complicated environment such as in the classification area.
Based in the cross-validation analysis we can conclude that the inclusion of the non-singleton inputs has the potential to improve the performance of the classifiers. In particular, it can be observed that the maximum improvement is obtained for K = 3 and K = 5, and it is possible that the improvement requires a higher proportion of training data over than testing data.
On the other hand, the performance of the Z-test shows that the non-singleton approach is significantly better than the singleton approach. It is interesting that the input kind can affect the performance of the fuzzy system, in this way obtaining a better performance. In particular, based on Table 11 we can state that the proposed non-singleton method shows a significant improvement in 11 of the 13 datasets used in the statistical comparison.
Conclusions
As a conclusion, we can observe that the proposed classifiers, which combine the uncertainty handling of General Type-2 Fuzzy Logic and the robustness provided by non-singleton Fuzzy Logic, help in obtaining better performance with respect to a conventional General Type-2 Fuzzy Classifier with singleton inputs. The computational cost is the main issue for the proposed classifiers, and this is because the proposed approach is composed of probably the most computational expensive variants of Fuzzy Logic, Generalized Type-2 Fuzzy Logic and non-singleton Fuzzy Logic. However, with the use of high-order α-planes integration [26] the computational cost is significantly reduced by the use of only three α-planes in our approach.
On the other hand, in comparison with respect other approaches, the proposed approach demonstrates to be competitive and even better than the conventional approach. However, the proposed approach is only recommendable for critical problems, for example medical diagnosis, this is because the improvement is not enough to justify the computational cost for trivial problems. Of course, in medical diagnosis this extra computational cost is justified as the main goal is saving lives. Finally, the main features of the proposed approach are listed as follows. Higher robustness than the singleton approach. Higher computational cost, but computable. More non-linearity in the model that help perform a better classification.
The presented features motivate the implementation of conventional Type-2 Fuzzy Systems, but with non-singleton inputs for finding better performance in many application areas.