
Abstract
The multi-granulation rough sets serve as important hierarchical models for intelligent systems. However, their mainstream optimistic and pessimistic models are respectively too loose and strict, and this defect becomes especially serious in hierarchical processing on an attribute-expansion sequence. Aiming at the attribute-addition chain, compromised multi-granulation rough set models are proposed to systematically complement and balance the optimistic and pessimistic models. According to the knowledge refinement and measure order induced by the attribute-enlargement sequence, the basic measurement positioning and corresponding pointer labeling based on equilibrium statistics are used, and thus we construct four types of compromised models at three levels of knowledge, approximation, and accuracy. At the knowledge level, the median positioning of ordered granulations derives Compromised-Model 1; at the approximation level, the average positioning of approximation cardinalities is performed, and thus the separation and integration of dual approximations respectively generate Compromised-Models 2 and 3; at the accuracy level, the average positioning of applied accuracies yields Compromised-Model 4. Compromised-Models 1–4 adopt distinctive cognitive levels and statistical perspectives to improve and perfect the multi-granulation rough sets, and their properties and effectiveness are finally verified by information systems and data experiments.
Keywords
Introduction
The rough set theory is an important theory for intelligent system processing [13], and its basis is the knowledge granulation induced by a specific equivalence relation. In granular computing, multiple equivalence relations and their systematic constructions are practically required, and thus multiple granulations emerge. In particular, multi-granulation rough sets were proposed by Qian et al. [15], and their basic models –the optimistic and pessimistic multi-granulation rough sets –adopt different logical fusions of multiple equivalence relations to establish dual approximations [16, 17]. Nowadays, the multi-granulation rough sets have been deeply studied and applied in the extended modeling [4, 28], uncertainty measurement [6, 27], three-way analysis [14, 32], attribute reduction [7, 23], decision making [20, 30], and classification learning [5, 19], etc, where multiple information factors (such as the fuzziness, neighborhood, and covering) were introduced as well. For example, Yao and She [28] offered four rough set models in multi-granulation spaces by using both the combination orders of relation and approximation and the set operations of intersection and union; Huang et al. [6] introduced the intuitionistic fuzzy measures to discuss multi-granulation intuitionistic fuzzy decision-theoretic rough sets; Sun et al. [22] proposed a neighborhood multi-granulation rough sets-based attribute reduction method by using Lebesgue and entropy measures in incomplete neighborhood decision systems; Senthil Kumar and Hannah Inbarani [19] explored the cardiac arrhythmia classification by applying the optimistic and pessimistic multi-granulation rough sets.
Regarding the multi-granulation rough sets, the classical optimistic and pessimistic models respectively use logical fusions of disjunction and conjunction to determine extreme values of dual approximations [15–17], so they have outstanding advantages of construction simpleness and attitude clearness. On the other side, the optimistic and pessimistic multi-granulation models cause some shortcomings including the attitude extreme, value broadness, and feature deviation; unfortunately, these drawbacks may be magnified especially when the multiple granulations prominently exhibit a strength deviation or a biased distribution. Thus, novel compromised multi-granulation models can characterize systematic equilibriums to provide the intermediate objectivity and attitude improvement, i.e., they can balance and improve the existing optimistic and pessimistic models, so they are worth deeply constructing to underlie wide applications of intelligent systems. However, there hardly have relevant studies, because how to reasonably make the compromised modeling in complex environments becomes a difficulty. This paper aims to make a preliminary attempt to construct compromised multi-granulation rough set models by adopting a neutral and objective attitude based on the statistics principle, and it mainly resorts to a specific but valuable scenario regarding an attribute-enlargement sequence; thus, we can provide more robust application models for intelligent and uncertainty processing.
A distinctive kind of multiple granulations is formed by an attribute-extension chain, and the relevant granulation monotonicity underlies optimization constructions [1, 24]. For example, Wang [24] studied monotonic uncertainty measures and their attribute reduction in probabilistic rough sets, and thus the attribute-extension chain essentially functions in both the measure construction and reduct search. In fact, the attribute-extension chain contains a refinement sequence of multiple granulations to transcend the simplicity of parallel or dispersive attributes, and it can deeply and effectively probe the knowledge hierarchy of the power set space with overall attributes and all attribute subsets; therefore, underlying total-order features are beneficial to granular computing of complex non-linear interactions, and the attribute-extension chain becomes a usual and important tool for the relevant granulation construction, hierarchy processing, and knowledge discovery, etc. In terms of the attribute-enlargement chain, the optimistic and pessimistic models respectively become too loose and strict, so compromised models are urgently required to objectively reflect the data draw and system characteristic. This paper mainly focuses on the attribute-addition chain to establish compromised multi-granulation rough sets. By statistical characteristics of equilibriums, the basic measurement positioning and matching pointer labeling are used to construct four types of compromised models at three levels of the knowledge, approximation, and accuracy; furthermore, the relevant modeling properties and improvement effectiveness are verified by information systems and data experiments. Regarding contributions, compromised multi-granulation rough sets are proposed to improve both the optimistic and pessimistic multi-granulation rough sets and thus they enrich multi-granulation rough sets, mainly by virtue of an attribute-enlargement sequence; hence, four types of compromised models emerge to offer more application spaces for granular computing and cognitive analysis.
The remainder of this paper is organized as follows. Section 2 reviews the multi-granulation rough sets, mainly the optimistic and pessimistic models. Section 3 constructs four types of compromised multi-granulation rough sets based on an attribute-addition chain, including three parts of the basic modeling, comprehensive summary, and example illustration. Section 4 implements the data experiment verification by using seven UCI datasets. Finally, Section 5 concludes this paper.
Multi-granulation rough sets
In this section, multi-granulation rough sets are reviewed by Refs. [15–17].
Let S = (U, AT, f) be a complete information system. Herein, U is a finite non-empty universe of objects, AT is a finite non-empty set of attributes, and f is an information function. Each attribute subset Q ⊆ AT determines a binary indiscernibility relation IND (Q) = {(x, y) ∈ U2 : ∀ a ∈ Q, f (x, a) = f (y, a)}. This equivalence relation induces the equivalence class [x] Q and equivalence partition U/IND (Q); the former means a granule containing sample x, while the latter implies a granulation called knowledge. Thus, the rough set modeling mainly resorts to the granular block and granulation structure to approximate a target concept X ⊆ U, and the approximation and accuracy serve as core notions. Let ||, ∼, ⌊⌋ denote the cardinality, complement, rounding functions, respectively.
Definition 1 and Proposition 1 reflect classical rough sets. By the knowledge granulation, the lower and upper approximations bidirectionally approach the basic set, thus determining the rough set modeling. The accuracy becomes the approximation cardinality ratio to represent a sort of knowledge-based completeness degrees for a concept, thus becoming an applied measure for the exactness and certainty characterizations.
The above traditional modeling concerns only a granulation induced by an attribute subset. In practice, multiple granulations induced by multiple attribute subsets are required. Accordingly, the multi-granulation rough sets are generated by aggregating an attribute subset sequence Q1, Q2, ⋯ , Q m ⊆ AT and its multiple granulations U/IND (Q1), U/IND (Q2), ⋯, U/IND (Q m ), and they utilize logical fusions of concept approximations to establish the mainstream optimistic and pessimistic models.
As a supplement, the strength relation of knowledge granulation is recalled [33]. In S = (U, AT, f), let R1, R2 ⊆ AT be two attribute subsets. Knowledge granulation U/R2 is finer than granulation U/R1 (noted as U/R1 ≽ U/R2), if ∀ [x] R 2 ∈ U/IND (R2), ∃ [x′] R 1 ∈ U/IND (R1), s.t., [x] R 2 ⊆ [x′] R 1 . The knowledge refinement U/R1 ≽ U/R2 can be naturally achieved by attribute enlargement R1 ⊆ R2, and it includes a strict case U/R1 ≻ U/R2 when U/IND (R1) ≠ U/IND (R2). The symmetrical knowledge coarsening is similarly and oppositely determined, and it uses symbols ⪯, ≺.
The multi-granulation rough sets have two main models. By Definition 2, the optimistic and pessimistic models respectively adopt logical disjunctions and conjunctions to determine dual approximations. This concise modeling adheres to extreme attitudes and maximum/minimum characteristics, so it has some limitations of broadness and bias. In-depth models are worth constructing to comprehensively characterize the multi-granulation system.
Aiming at the hierarchical application of an attribute-addition chain, we next propose compromised multi-granulation models to well balance the classical optimistic and pessimistic models. Concretely, statistical characteristics of equilibriums are utilized for the approximation positioning, and thus four types of compromised models are established at three levels to achieve their compromised properties and mutual relationships. In S = (U, AT, f), the attribute-enlargement sequence is supposed to be
Herein, the basic compromised modeling is implemented. For this purpose, basic properties of the attribute-addition chain are first provided to clarify the relevant reasonability and implementation.
IND (Q1) ⊇ IND (Q2) ⊇ ⋯ ⊇ IND (Q
m
), U/IND (Q1) ≽ ⋯ ≽ U/IND (Q
m
),
while the pessimistic model offers
By Lemma 1, the attribute-enlargement chain causes some total-order changes of feature strengths, such as the weakening of equivalence relations, refinement of knowledge granulations, expansion of lower approximations, contraction of upper approximations, and increase of accuracy measures. Thus by Lemma 2 and Corollary 1, the optimistic and pessimistic models naturally intercept the extreme values at two endpoints; that is, the optimistic/pessimistic model is completely embodied by the largest/least subset at the right/left endpoint. Regarding the two models, their strength characteristic of interactions still exists on the attribute-addition chain, but it becomes particularly extreme; thus, their maximum/minimum statistics with the great deviation cannot well evaluate the system characteristics.
To effectively characterize the integrality of the attribute-enlargement chain, we next make the compromised modeling by the equilibrium statistic and balance positioning, and we mainly resort to an explicit identification, i.e., a positioning pointer of natural number indexes (as well as its corresponding chain-element subset). Accordingly, suitable chain points (rather than endpoints) are optimally selected to determine compromised models and their connotations. Then, four compromised models are positioned by pointers
The attribute-expansion chain contains several total-order strengths (such as the knowledge refinement), and the optimistic and pessimistic models rely on the chain endpoints to embody the degeneration and extreme. In contrast, a simple compromised model is to locate the chain midpoint, and this median statistic can directly indicate some systematicness and representativeness. Accordingly, the first model is proposed as follows.
Compromised-Model 1 uses the chain median to directly establish the approximation and accuracy, so it acquires an intuitionistic equilibrium between the optimistic and pessimistic models. The modeling simply considers the ordinal ranking statistic of knowledge granulations to offer advantages of the direct mechanism and easy operation, but it never involves the concept description. Improved models need adding relevant concept information, and two-level compromised models are next constructed by introducing the approximation cardinalities and accuracy values.
Rough set models mainly embrace dual approximations. For the compromised modeling, the approximation level can be utilized, and its relevant cardinalities underlie statistical evaluations. By Lemmas 3.1 and 3.2, Corollary 3.1, the approximation cardinalities have total orders:
while the optimistic and pessimistic models are positioned at the extreme bounds. To acquire the balance and representativeness, two means of approximation cardinality sequences can provide two systematic locations for compromised lower and upper approximations. Next, two types of compromised models are constructed by two strategies, i.e., the respective and uniform positioning pointers for dual approximations.
of lower approximations is closely realized by s (s ∈ [1, m]) indexes:
thus, a locating tag is set up by the middle index, i.e.,
(1) The pointer pair
In Definition 4, the average statistics of dual approximation cardinalities are utilized to construct two compromised models, where pointers
Furthermore, the accuracy fuses dual approximation cardinalities to carry the basic certainty measurement and valuable application message, so it is worth introducing for the compromised modeling. By Lemmas 3.1 and 3.1, Corollary 3.1, the accuracy exhibits the monotonic increase on the attribute-addition chain, while the accuracies in optimistic and pessimistic models also reach the maximum and minimum with extreme statistics. Accordingly, the statistical average accuracy on the attribute chain can inspire a positioning pointer to implement the compromised modeling, and this process is similar to the above ones regarding Compromised-Models 2 and 3.
is closely realized by l (l ∈ [1, m]) indexes:
and a locating pointer is set up by the middle index:
Compromised-Model 4 considers the accuracy to well characterize the systematic completeness or the average certainty on the overall attribute-expansion chain, and thus it balances and improves the optimistic and pessimistic models. This new model has the fundamental significance for the systematic measurement and related application embracing concepts.
Thus far, four types of compromised multi-granulation rough set models have been established, mainly on an attribute-extension chain. Herein, they are summarized to offer their comparative analysis, integral property, and systematic algorithm.
At first, the compromised modeling mechanisms are clarified in Fig. 1. Based on multiple granulations from the attribute-increase line, the optimistic and pessimistic models involve only two chain endpoints, i.e., they are respectively realized by ordinal locations of (m, Q m ) and (1, Q1), and thus their relevant extreme and span go against the integral representation of the multi-granulation system. In contrast, our compromised models rationally pursue the multi-granulation systematicness and representativeness, and the relevant modeling mainly depends on the vivid moderation positioning. According to the total-order strength contained in the extension chain, several equilibrium statistics are reasonably used to construct four compromised models, and we refer to the tri-level analysis [29, 34].
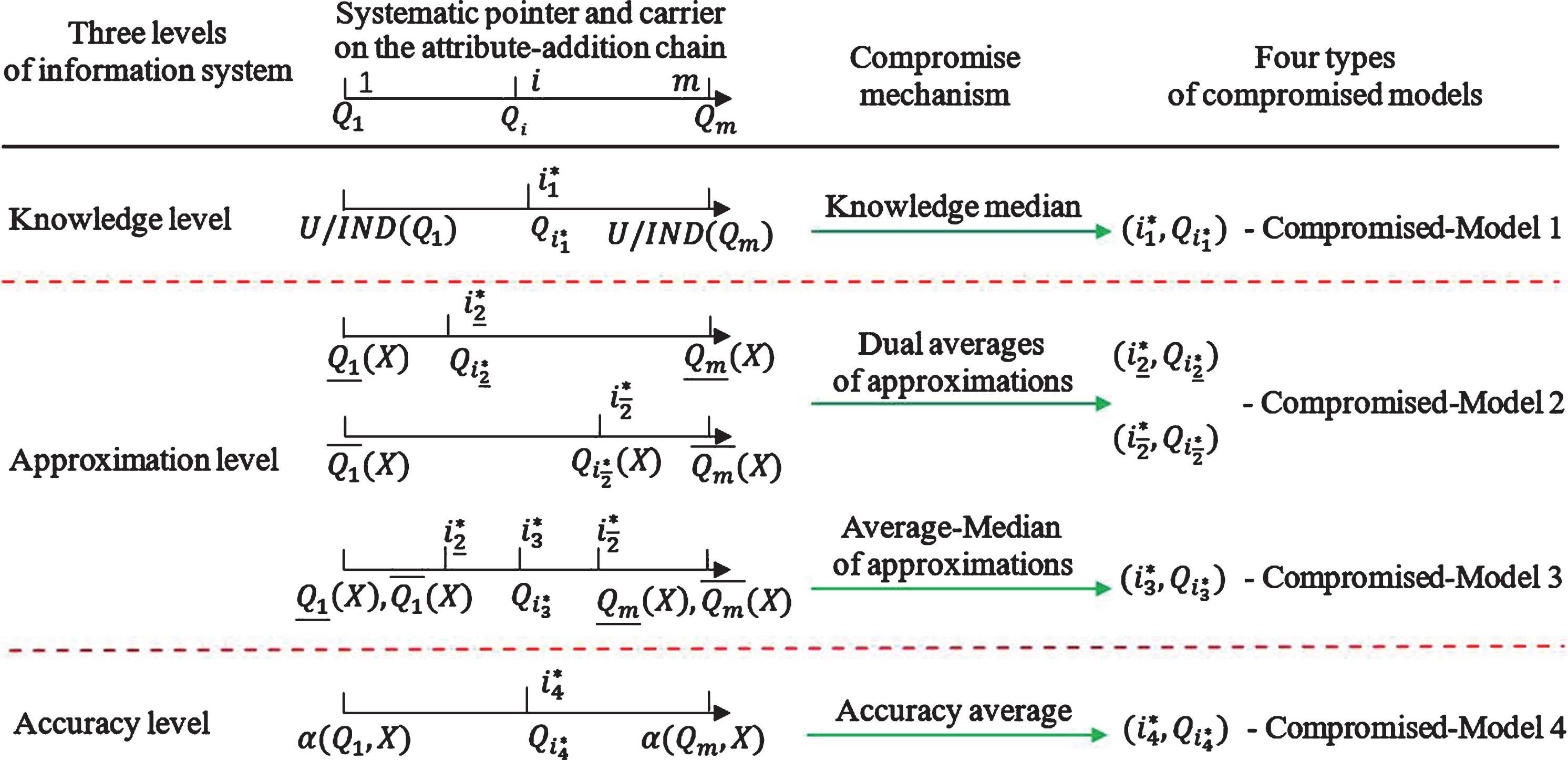
Four compromised multi-granulation models at three levels and their statistical positioning mechanisms.
(1) At the knowledge level, the granulation becomes finer on the attribute-increase chain. Thus, ordinal median
The four compromised models adopt different cognition levels and compromise viewpoints to provide multiple use choices. By comparisons, Compromised-Models 2 and 4 have more advantages. By adhering to the central approximation cardinalities, Compromised-Model 2 separately deals with dual approximations, and this independent compromise brings more balances. By integrating the dual approximation information, Compromised-Model 4 highlights the accuracy measurement, and its compromise pointer and subset are systematically extracted to efficiently underlie the metric processing and practical application.
By Proposition 3, our compromised models all satisfy the perfect equilibrium for the optimistic and pessimistic models, which are actually extreme. Therefore, Compromised-Models 1–4 are theoretically effective, and they practically have different comprise focuses and application emphases. In essence, they resort to the suitable knowledge positioning to pursue the systematic characterization, so they adhere to the balanced and representative single-granulation. Concretely, Compromised-Model k depends on only single granulation
(1)
(2)
(3)
(4)
when k = 1, we further have
(5)
(6)
(7)
In Proposition 4, relevant operation properties are revealed for the compromised models, where Compromised-Model 2 separately considers lower and upper approximations by double pointers
and this implies a sort of increase movability between two sequences of lower approximation cardinalities:
thus, pointer
Compromised-Models 1–4 are completely defined by their positioning pointers, so pointers’ size relationships determine model relationships. In terms of complete interactions, pointer
If If
The compromised models can be calculated by a comprehensive algorithm. Thus, Algorithm 1 follows relevant definitions and formulas, and the locating pointers act as basic tools to produce the compromised models (mainly the approximation and accuracy). Step 1 directly provides the first pointer
Herein, Compromised-Models 1–4 are illustrated by a table example. The complete information system S = (U, AT, f) is given in Table 1, and it is a decision table to have universe U = {x1, x2, ⋯ , x15} (i.e., U = {1, 2, ⋯ , 15}), condition attribute set C = {c1, c2, ⋯ , c9} ⊆ AT, and decision attribute set D = {d} ⊆ AT. (1) The special multiple granulations are formed by a natural attribute-addition chain:
X2 = {x2, x6, x9, x10, x11} = {2, 6, 9, 10, 11},
X3 = {x5, x12, x14, x15} = {5, 12, 14, 15}.
Regarding the attribute chain and decision class, the initial approximation sets are given in Table 2, the statistical cardinality and precision are shown in Table 3, while the final model results are presented in Table 4.
An information system of a decision table
Approximations of decision classes based on the attribute chain
Information statistics of approximation cardinalities and accuracy values on the attribute-addition chain
Four compromised models based on positioning pointers
Tables 2, 3, 4 can illustrate some details, and the Algorithm 1’s process and modeling pointers are focused on for analyses. (1) First consider the knowledge level. The index set {1, 2, ⋯ , 9} on the attribute chain exhibits median 5, and thus pointer
Finally regarding X3, its pointers also become
For the properties in Propositions 3–5, the compromise feature and interaction relationship are clear, while the operation rule needs further verifications.
In this section, Compromised-Models 1–4 are effectively verified by data experiments. Seven datasets are chosen from UCI Machine Learning Repository [http://archive.ics.uci.edu/ml], and their information is shown in Table 5. The relevant setting and processing are similar to those in the above example illustration, but the optimistic and pessimistic models are properly highlighted. We still adopt the natural attribute-addition chain in Equation (14) and all decision classes X j .
Basic information of seven UCI datasets
Basic information of seven UCI datasets
Regarding the attribute-addition chain, the approximation cardinalities and accuracy values, as well as their monotonicity changes, all become measurement bases for the compromised modeling, especially for main Compromised-Models 2–4 with the pointer positing. These basic measures have been thoroughly computed, and relevant results and further statistical information are given in Tables 6–12, where only eight samples on attribute c34 in (d) Dermatology exhibit missing values and thus are rationally filled. Herein, a decision class is chosen as an example for vivid demonstrations; in usual, the first class X1 is chosen, while only (f) SolarFlare uses X5 to pursue a better manifestation. (1) Three types of measure chains are depicted in Fig. 2, where La and Ua respectively denote lower and upper approximation cardinalities. (2) All chain-based three-dimensional points with form (La, Ua, Accuracy) constitute a line chart on surface function
Statistics of approximations and accuracies on (a) Glass
Statistics of approximations and accuracies on (b) Zoo
Statistics of approximations and accuracies on (c) Lymphography
Statistics of approximations and accuracies on (d) Dermatology
Statistics of approximations and accuracies on (e) Wdbc
Statistics of approximations and accuracies on (f) SolarFlare
Statistics of approximations and accuracies on (g) Cmc
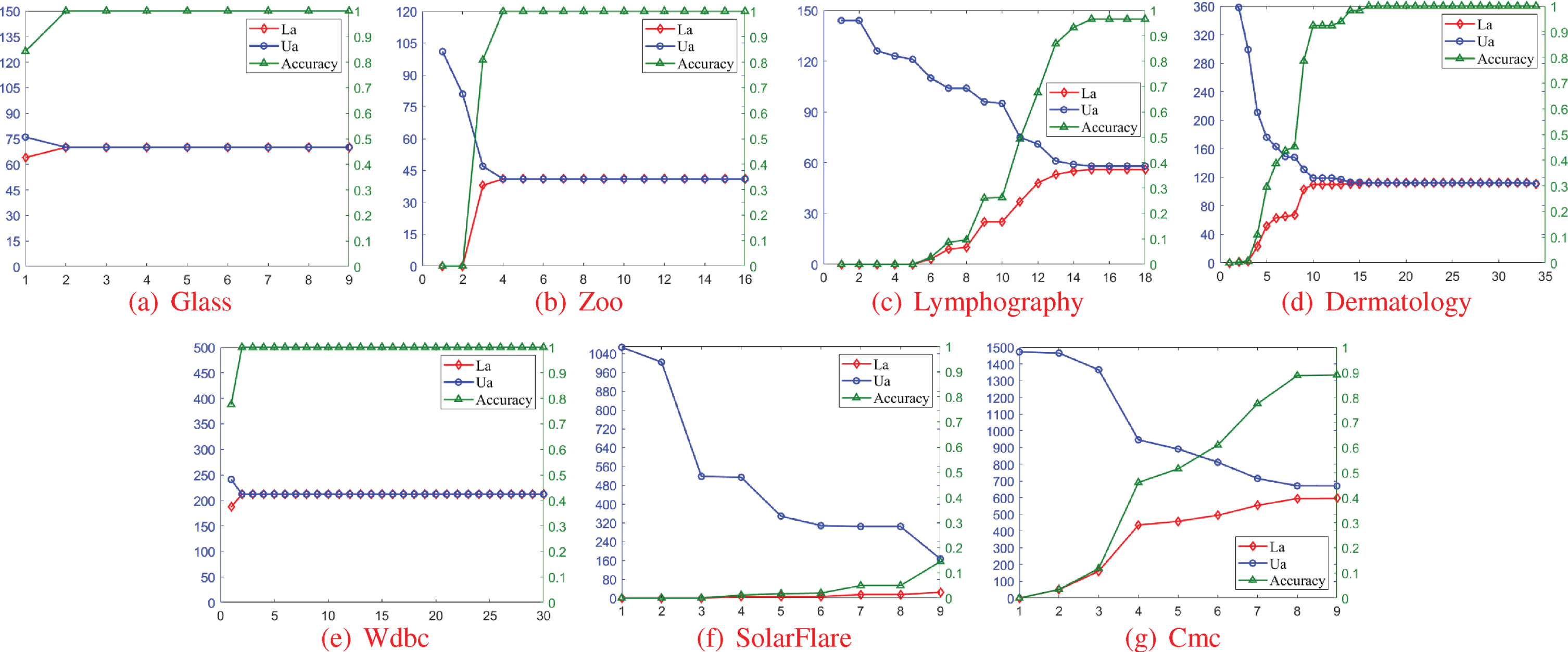
Approximation cardinalities and accuracy values based on the attribute-addition chain and decision class X1 or X5.
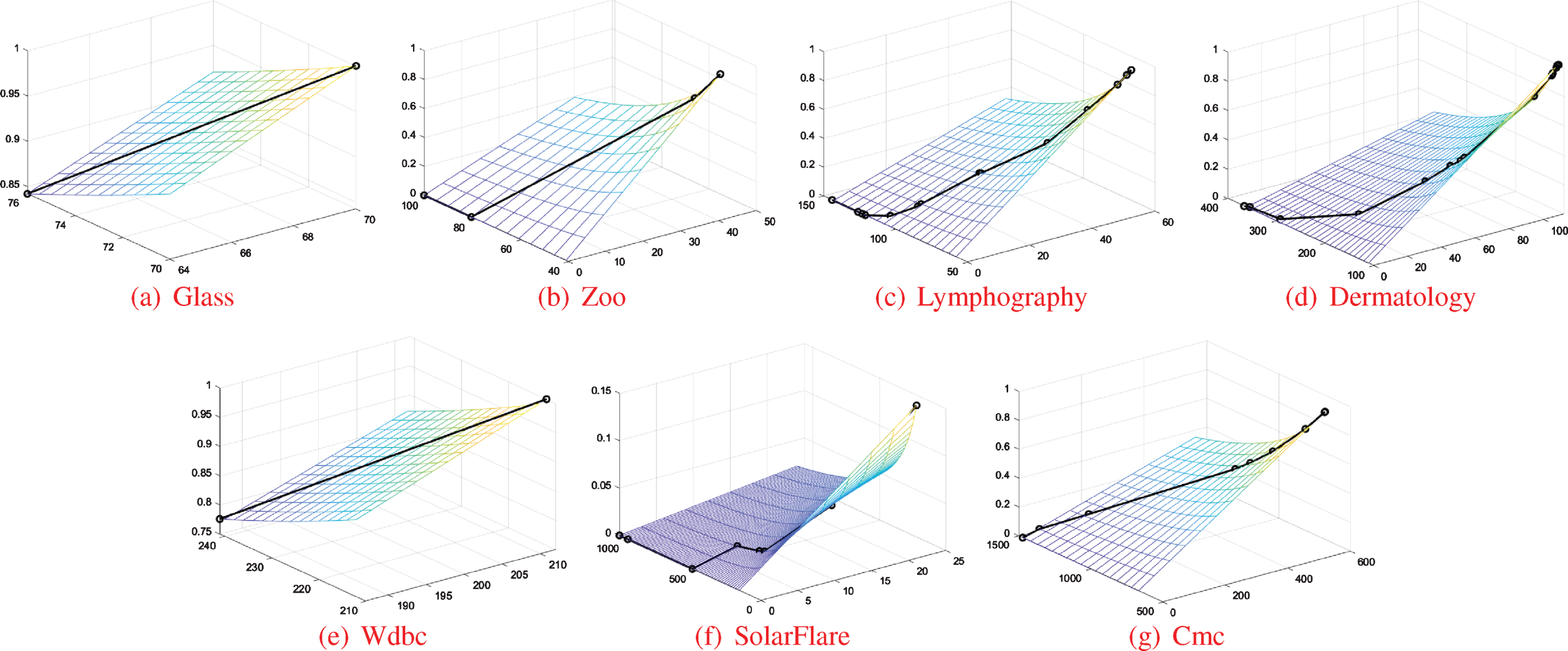
Three-dimensional surfaces of approximation cardinalities and accuracy values regarding decision class X1 or X5.
For each dataset, the locating pointers become key for the multiple multi-granulation models. At first, the optimistic and pessimistic models respectively adhere to pointers
Statistical results of six multi-granulation rough set models based on location pointers
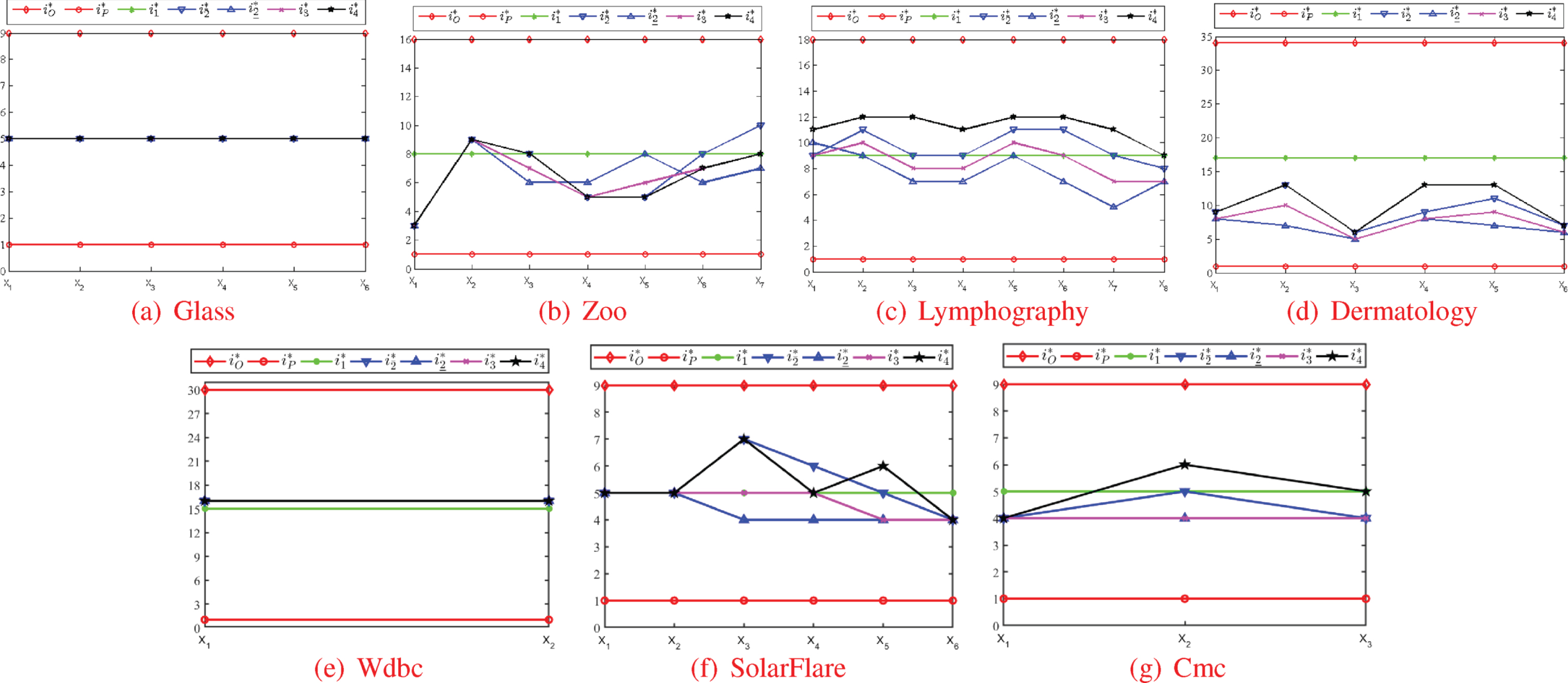
Pointer curves of six types of multi-granulation models regarding all decision classes.
According to the above pointer results, the approximation and accuracy of all the multi-granulation rough set models (including Compromised-Models 1–4 as well as the optimistic and pessimistic models) can be eventually achieved. The relevant statistical results of approximation cardinality and accuracy value are offered in Table 13, where Model-k (k = O, P, 1, 2, 3, 4) label related models. In fact, we have obtained all modeling results, including the approximation sets. As an example or supplement, we provide the case of (c) Lymphography regarding decision class X1. (1) For the optimistic model, the lower and upper approximations respectively contain 56 and 58 samples: {5, 7, 8, ⋯ , 145, 147}, {5, 7, 8, ⋯ , 145, 147}.
(2) The pessimistic lower and upper approximation respectively become ∅ and U. (3) For Compromised-Model 1, the lower and upper approximations respectively yield 25 and 96 elements: {13, 19, 24, ⋯ , 139, 141}, {4, 5, 6, ⋯ , 145, 147}.
(4) For Compromised-Model 2, the lower and upper approximations respectively have 25 and 95 elements: {13, 19, 24, ⋯ , 139, 141}, {4, 5, 6, ⋯ , 145, 147}.
(5) For Compromised-Model 3, the lower and upper approximations respectively carry 25 and 96 samples: {13, 19, 24, ⋯ , 139, 141}, {4, 5, 6, ⋯ , 145, 147}.
(6) For Compromised-Model 4, the lower and upper approximations respectively offer 37 and 75 ones: {13, 19, 20, ⋯ , 139, 141}, {5, 7, 8, ⋯ , 145, 147}.
Finally, the main characteristics of proposed methods are highlighted to offer some comparisons. The attribute-addition chain brings multiple total-orders while the optimistic and pessimistic models correspond to the extreme bounds, so the four types of compromised models adopt different order indexes and their own compromised location pointers to pursue the systematic balance. Concretely, Compromised-Models 1–4 respectively concern the ordinal numbers and their averages of knowledge, approximation, approximation fusion, and accuracy, and they can be completely determined and effectively exhibited by relevant label pointers. The relevant modeling mechanism, especially Algorithm 1, naturally induces the experiment results. According to the ultima Table 14 and Fig. 4, we can make the following comparative analyses to verify both the effectiveness and property of our compromised modeling. (1) First compare the compromised models with the optimistic and pessimistic models, and we achieve
In terms of the attribute-addition chain, four types of compromised multi-granulation rough sets have been established at three levels of knowledge, approximation, and accuracy by four kinds of statistical strategies. These new models characterize both the systematicness of knowledge bases and the generality of data laws, so they balance and improve the optimistic and pessimistic models, which are respectively too loose and strict. Regarding the proposed compromised methods, their total-order mechanism and pointer-orientation characteristic can be systematically clarified by Fig. 1 and Algorithm 1, and the relevant essence induces the main definitions, properties, examples, and experiments.
This study is worth future studying from five aspects. (1) Compromised-Models 1–4 adopt the three levels of knowledge, approximation, and accuracy, and thus their relevant tri-level analysis can be deeply implemented, especially by referring to relevant methods in [29, 34]. (2) For clear manifestations, the compromised modeling mainly embraces the average locating pointers and corresponding carrier subsets, and thus it can further consider the essential granular division and other statistical strategies. (3) The compromised modeling is closely related to the multi-granular modeling which offers some recent proposals [2, 12], so the former can further utilizes the latter to make more discussions and developments on granular computing. (4) Our preliminary works are restricted to a basic precondition of an attribute-extension sequence, and thus the general case without the hierarchical hypothesis is needed to be extensively explored. (5) The compromised models, in both the special and general cases, are worth promoting and utilizing to the dependency-based machine learning (such as the feature selection), and thus the approximation cardinality and accuracy at the concept/class level can be integrated into systematic measures at the classification level (such as the dependency degree and information entropy).
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Footnotes
Acknowledgments
The authors thank both the editors and reviewers for their valuable suggestions, which substantially improve this paper.
This work was supported by National Natural Science Foundation of China (61673285 and 11671284), Sichuan Science and Technology Program of China (20YFG0290 and 19YYJC2845), and a joint research project of Laurent Mathematics Center of Sichuan Normal University and National-Local Joint Engineering Laboratory of System Credibility Automatic Verification.