Abstract
In this paper, a speech-to-text translation model has been developed for Malaysian speakers based on 41 classes of Phonemes. A simple data acquisition algorithm has been used to develop a MATLAB graphical user interface (GUI) for recording the isolated word speech signals from 35 non-native Malaysian speakers. The collected database consists of 86 words with 41 classes of phoneme based on Affricatives, Diphthongs, Fricatives, Liquid, Nasals, Semivowels and Glides, Stop and Vowels. The speech samples are preprocessed to eliminate the undesirable artifacts and the fuzzy voice classifier has been employed to classify the samples into voiced sequence and unvoiced sequence. The voiced sequences are divided into frame segments and for each frame, the Linear Predictive co-efficients features are obtained from the voiced sequence. Then the feature sets are formed by deriving the LPC features from all the extracted voiced sequences, and used for classification. The isolated words chosen based on the phonemes are associated with the extracted features to establish classification system input-output mapping. The data are then normalized and randomized to rearrange the values into definite range. The Multilayer Neural Network (MLNN) model has been developed with four combinations of input and hidden activation functions. The neural network models are trained with 60%, 70% and 80% of the total data samples. The neural network architecture was aimed at creating a robust model with 60%, 70%, and 80% of the feature set with 25 trials. The trained network model is validated by simulating the network with the remaining 40%, 30%, and 20% of the set. The reliability of trained network models were compared by measuring true-positive, false-negative, and network classification accuracy. The LPC features show better discrimination and the MLNN neural network models trained using the LPC spectral band features gives better recognition.
Keywords
Introduction
This SPEECH is an idealized model of communication and efficient user interface for human. The English language used among Malaysians varies wildly from one ethnic community to another and varies emphatically [1]. The study of speech to text translation system is important as it can be used in many applications such as learning aid, keyboard less data entry and also automated speech therapy for hearing impaired person. The literary works and the research approach towards the speech to text translation system based on multilayer neural network models are explained in subsequent sections.
Malaysian English pronunciation
Malaysian English is generally non-rhotic and it is originally derived from the British English pronunciation as a result of British colonialism in the present day of Malaysia. English in Malaysia has been categorized into three levels as acrolect, mesolect and basilect [2]. The acrolect English speakers are the core and literates though they started speaking English from early schooling and only a small percentage of Malaysians are skilled in it. Malaysian English belongs to mesolect, and it mostly used by the academics, professionals and other English educated Malaysians. Malaysian English pronunciation uses the similar pronunciation system as British English. However, most Malaysians speak with a distinctive dialect as it is due to the influence of their mother tongue [3–5].
Voiced/unvoiced classification of speech signal
Speech signals are composed of phonemes which consist of both voiced/unvoiced portions. Automatic voiced / unvoiced separation of articulated signals provides highly adaptive speech processing models, which significantly reduces the information transfer rate in addition. To date scientists have utilized classic methods for the separations of speech signals, such as Zero Crossing Rate (ZCR) and energy [6]. Many research works have used statistical analyses of wavelet-based frequency distribution, average energy, zero crossing rates, and average energy of short-time segments of the speech signal. For various speakers and utterances, these approach has been evaluated with a wide speech database containing a broad range of speech records [7–9]. Generally, the speech signals can be categorized in two classes practically; buzz or hizz (periodic or aperiodic) sounds based on the frequency component of the speech spectrum [10]. It is also evident from previous studies that speech signals have high frequency components, but speech signals that incorporates aspirates and plosives often have low frequency components. In addition, there has been no research on the segmentation system (voiced / unvoiced speech signals) that differentiates the voiced and unvoiced portions of the various phonemes, and there is also no methodology that offers a generalized method for segmenting signals involving different phonemes. Therefore, a fuzzy-based methodology using energy and change in energy features is proposed in this research to identify voiced / unvoiced portions using recorded speech signals containing 41 classes of phonemes.
Phoneme based speech to text translation
Automatic Speech Recognition (ASR) focuses on the translation of an audible speech input into a text representation in recognition of a set of characters [7]. ASRs have been established to classify either isolated words or phonemes. An isolated word recognition system is used in applications where fixed vocabulary is required and convenient to execute using Hidden Markov Models (HMM), Artificial Neural Networks (ANN) and Support Vector Machines (SVM) [11–15].
Phonetic-based speech recognition is very useful because it is free of vocabulary. Further, the efficiency of the Large Vocabulary ASR (LVASR) device depends on the consistency of the phoneme recognition [16–18]. Phoneme-based speech recognition can be established using two proven methods. The first is focused primarily on manually segmenting speech signal into phonemes, and the second method is focused on segmenting speech signals into equal numbers of frames. [19] has presented a frame-wise classification system for phoneme recognition in which features such as the ZCR and the MSF are being proposed and classifier performance was compared with the use of the LPC features as well.
From the literature review, ASR limitations were found to be strongly correlated with increased rates of complexity and increased number of isolated words in the database, including lack of adaptation to other languages. In these contexts, Phoneme-based speech recognition systems are one of the alternatives to developing ASRs that overcomes several limitations. As we realize that the number of phonemes in every language ranges from 40 to 50 and certain phonemes are almost the same for all languages, ASRs based on phonemes can be configured for any speaker. In this analysis, the extracted voiced portions are analyzed using LPCC features. The extracted LPCC features are used to develop the MLNN models. The MLNN models are developed based on the eight classes of phoneme categories and simple fusion based MLNN architecture has been developed to classify the isolated words. The block diagram of the proposed speech to text translation system is shown in Fig. 1.
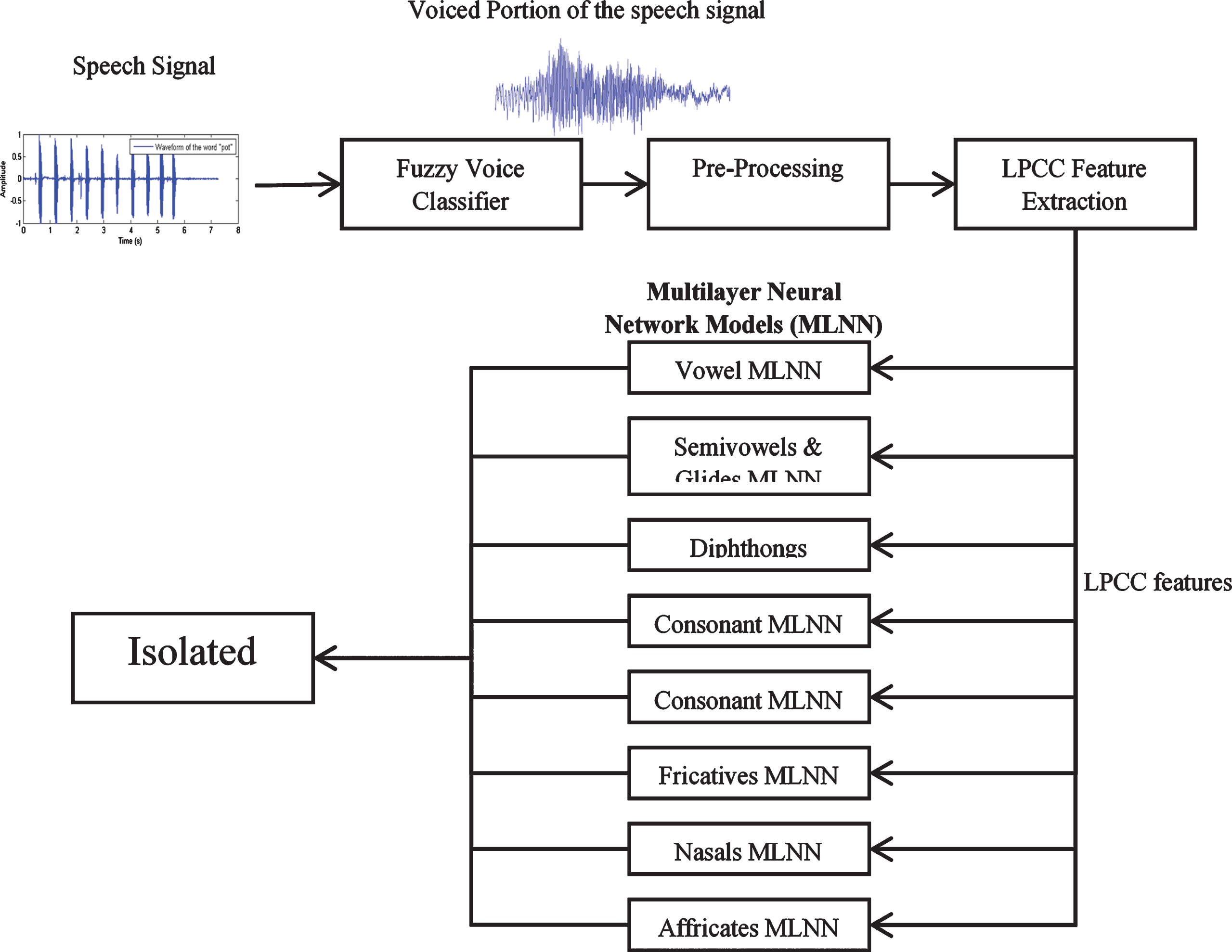
Block diagram of the speech to text translation system based on phoneme classes.
Phoneme is the smallest unit of sound in which the meaning of a word can be changed with different combination of phonemes. There are many languages exists in this world, when different languages are compared the phonemic discrimination can be observe and the total number of phonemes is finite. To build a speech to text translation system for the Malaysian English language, the isolated word database has been developed with 85 isolated with having 41 class of English phonemes (i.e. PCWD), which are used to train and develop the speech to text network model.
Selection of non-native Malaysian speakers
In the work with the dataset of phoneme based isolated word speech, different recording personnel are involved. Many number of research works has discussed the techniques for recording speech data from non native speakers in the context of a language tutoring system [20, 21]. An English language speech database built with both newspaper and conversational sentences and imitated speech (imitated the speech of native speakers) has been developed by [22].
The primary concern is also to establish methods and frameworks that are feasible to be used in Malaysia for the speech-to-text translation system. The ethnic heterogeneity of Malaysia is well known that there are three dominant ethnicities are there (Malays, Chinese and Indians). Therefore, the PCWD database was created with 35 ethnic heterogeneity Malaysians. The collected speaker’s population contains almost equal numbers of subjects of races from different parts of Malaysia. The 86 words with 41 phoneme classes and are represented in Appendix Table A.1. The selected 86 English words are very easy to pronounce by the native speakers. The subjects were asked to pronounce the selected words and corresponding speech signals were recorded.
Experimental setup
Sound can be described as a phenomenon which can often generally be sensed between 20 and 20,000 Hz thus in the listening mechanisms [22]. In the experimental setup, the speech signals were collected via the standard phone headset (> =85 dB level, sensitivity –58 dB±2 dB and Impedance level of 2.2 k) in a cabin room using a standard phone headset with fluorescent lamps and the air conditioner were switched off and the data was recorded during the day time.
In the data acquisition phase, 19 male and 16 female subjects were chosen from the student, staff and faculty community of Universiti Malaysia Perlis, Perlis and Politeknik Tuanku Syed Sirajuddin, Perlis.
The subjects were from the age group of 20–40 years. The data collection was done in a cabin room. The developed wordlist has 86 words and hence the recording was conducted in two different sessions in a day for one person.
Phoneme Class Word Database (PCWD)
Speech recognition and speech translation of non native Malaysian English speech is getting more and more important for speech to text translation system. Due to the essential characteristics of non native speech signal, speech recognition systems are still showing severe performance loss when faced with it [23, 24]. The Malaysian English speech database is an isolated word speech database of non-native pronunciations of English. Such a database is essential for the ongoing development of multilingual automatic speech to text translation systems. In this study, the wordlist is developed with 86 words with 41 classes of phoneme based on Affricatives, Diphthongs, Fricatives, Liquid, Nasals, Semivowels and Glides, Stop and Vowels. A typical phoneme based isolated word is shown in Fig. 2.
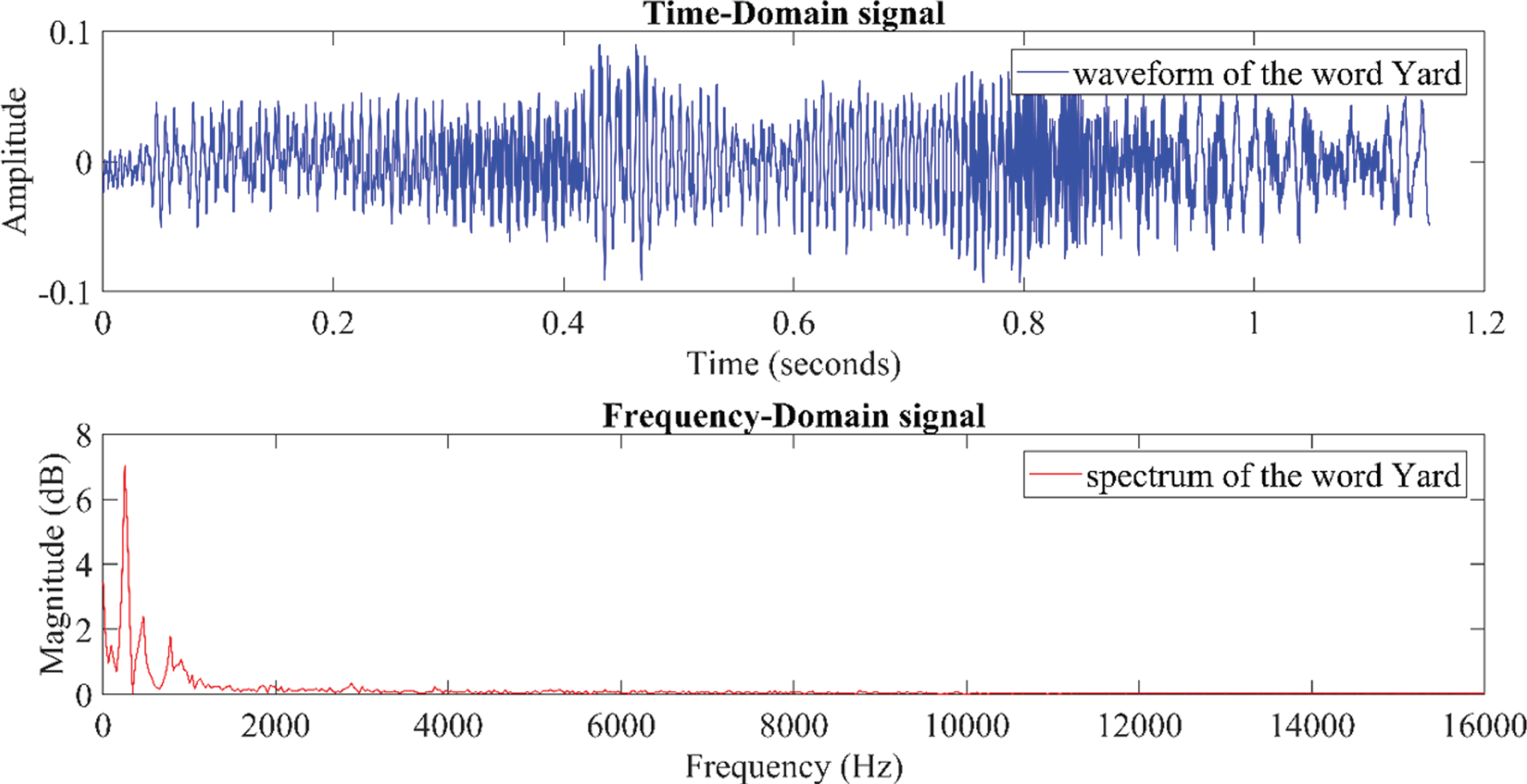
Typical Isolated word speech signal of the word ‘yard’.
The PCWD database comprised of 86 isolated words in which the subjects were asked to pronounce each word repeatedly for ten times. The PCWD database is built with 30,100 isolated words speech signals. The data collected is stored in the native ‘WAV’ for further processing through MATLAB.
Speech pre-processing is a standard method intended to improve the magnitude of higher frequencies of speech signals relative to their magnitude of lower frequencies. To increase the overall signal-to-noise level, the ambient sound noise should be minimized and recording devices saturated. Correspondingly, the simple pre-emphasis procedure incorporating a high-pass digital filter has been designed in this analysis, splitting the speech signal across 3 dB and extracting the frequencies in between 100 Hz and 1 kHz [25]. The noise in the speech signal is removed using a high pass filter as described in Equation (1).
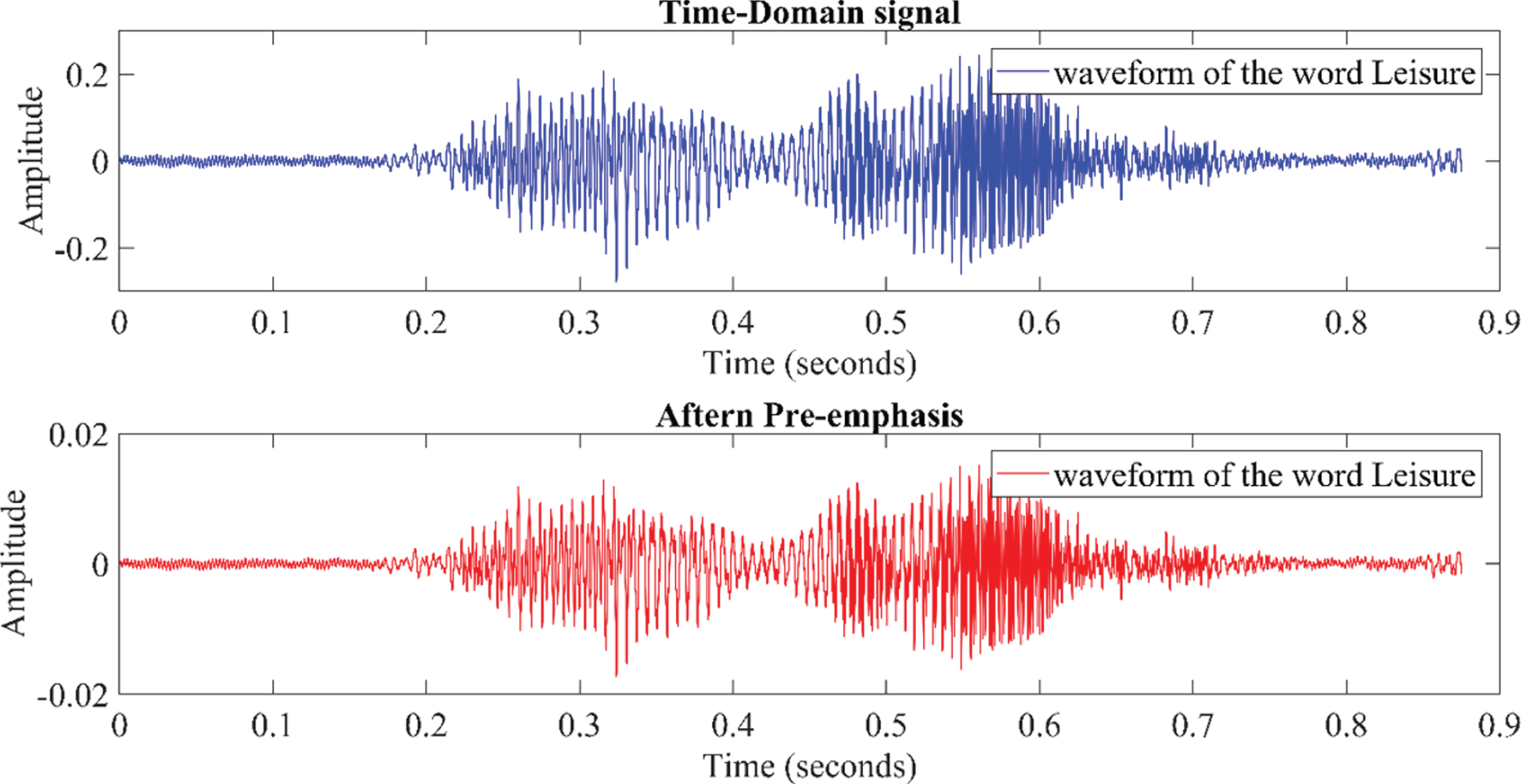
Typical normal isolated word speech signal and the corresponding pre-emphasized signal.
In the past three decades, researchers have worked extensively on voiced / unvoiced separation through statistical analysis and machine learning algorithms [27–29].
In most of the existing algorithms, the classifier needs intensive training data and threshold for classification [30]. The accuracy of the voiced/unvoiced classification method is limited. The proposed fuzzy voice classifier has been developed with the use of energy and change in energy as the feature set. Fuzzy logic systems are suitable for problems requiring approximate rather than exact solutions. The proposed fuzzy voice classifier consists of frame blocking of the speech signal, feature extraction algorithms and the fuzzy classifier developed for the purpose of voiced/unvoiced classification. Frame blocking
To split the isolated word speech signal as voiced/unvoiced and to study the features effectively, Pre-emphasized speech signals are subdivided into frames with a sample size of N –256 each, with an overlap of 50 percent, i.e. 128 samples (M) (M < N). The discrete time domain of the isolated speech signal is identified as (X) and can be seen in Equation (1). The first frame consists of the first N (256) samples, with the subsequent frame beginning at the first signal with an overlap of (N - M) 128 samples. The frame blocking of a speech signal is depicted in Fig. 4. This procedure is performed until all speech samples for the segmentation process are taken into consideration [31] and is represented in Equation (2).
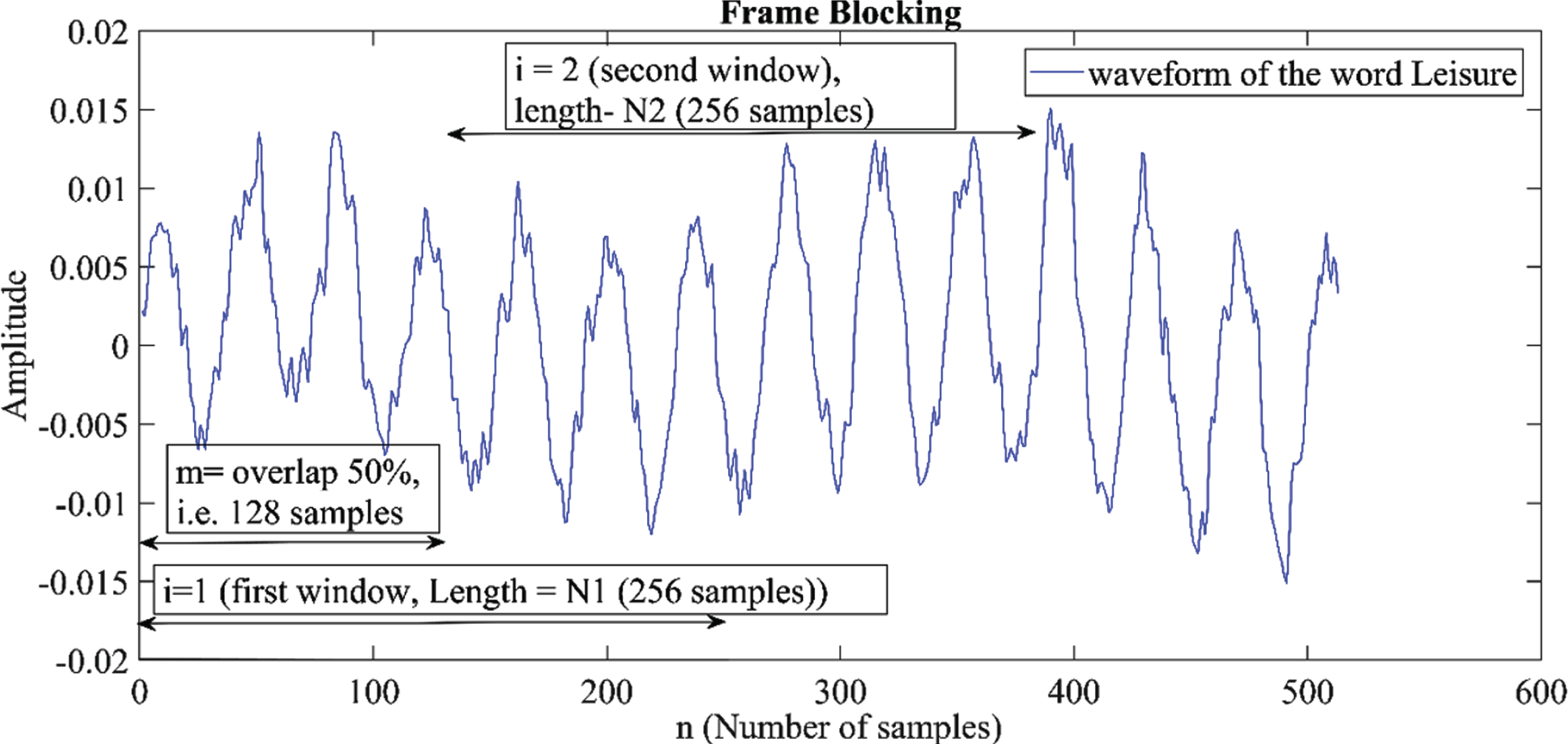
An isolated word speech signal blocked with frame size of 256 samples and an overlap of 50 percentage.
X
i
is the i
th
frame and it is represented as:
Thus, the segmented frames then used as an input for the proposed voiced / unvoiced classifier algorithm. This section now presents the feature extraction and voiced/unvoiced classification procedure.
Energy and ZCR methods are the most common end-point detection methods for a speech signal, but they are very prone to noise and get reasonable results when environmental noise is sensitively minimal. The energy per frame of the isolated word speech signal provides a preliminary significance for the classification of voiced/unvoiced parts. This indicates that, irrespective of their periodic nature, the voiced portion of the speech signal has high energy features, while the unvoiced segment has low energy features.
In our study on the energy components of all phonemes has shown that the increase in energy and the energy distribution across the speech signals is closely associated. Interstingly, it was observed that the speech signal is unvoiced if the change in energy (Δe
i
) is high and the energy component (e
i
) in the signal is low. though if the change in energy (Δe
i
) is low, energy (e
i
) and the next frame energy (ei+1) is very high, then the speech signal is voiced. The (e
i
) and (Δe
i
) of the frame segments are calculated using the Equations (3) to (5). The raw speech signal recorded at 16 kHz and the frame energy, change in energy distribution is shown in Fig. 5.
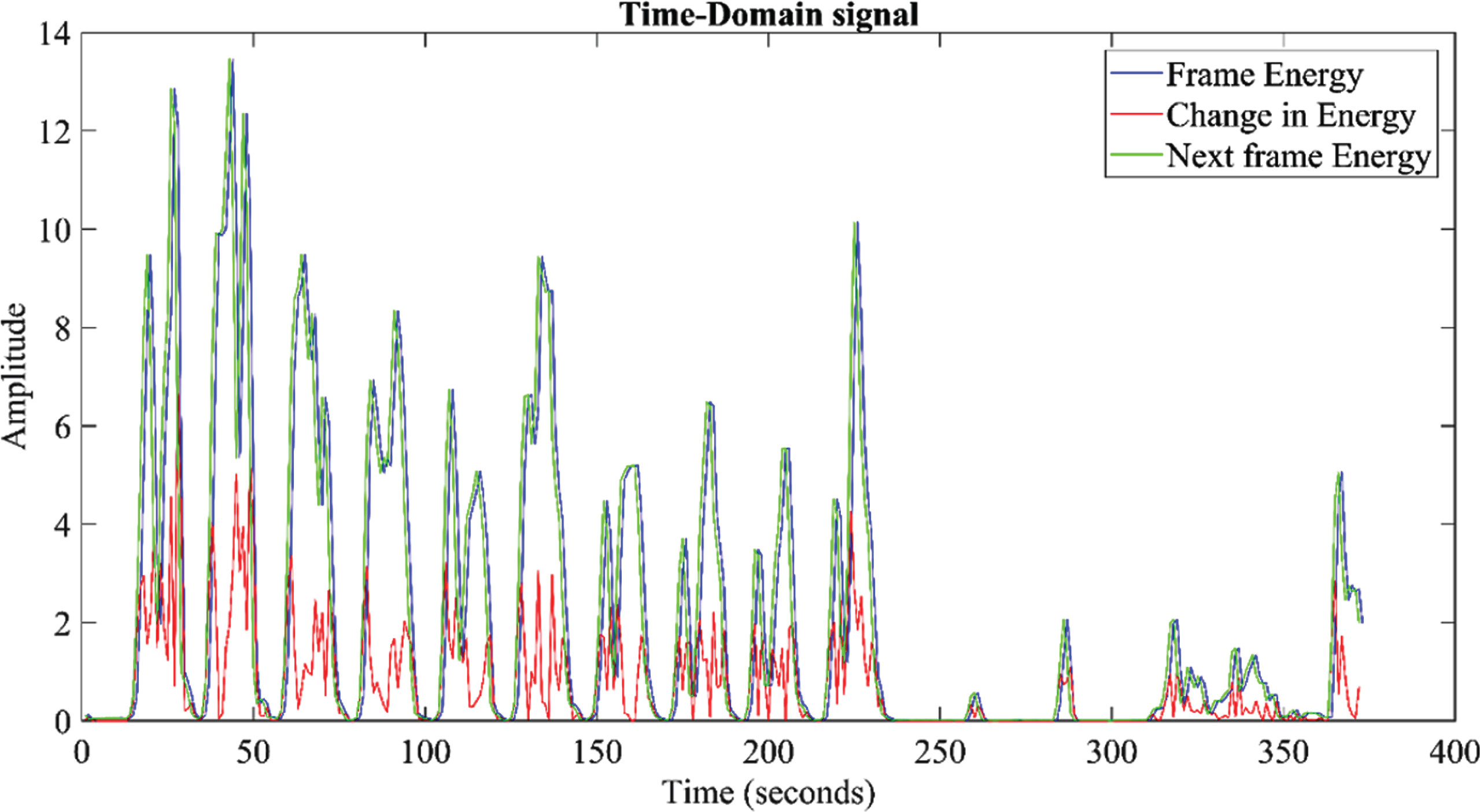
Frame energy, change in energy distribution of the recorded speech signal.
The change in energy c be described as the difference between the voiced signal’s two consecutive frame energy. The Fig. 6 clearly shows the energy mapping of the voiced component of the speech signal. The e i , Δe i and (ei+1) features are extracted and used to develop the fuzzy voice classifier to extract the voiced segments from the 10-second signal recorded with ten isolated words. The outputs of voiced segments from the fuzzy classifier has been programmed to create an isolated word using simple algorithms. In addition, all speech segments reflecting each word in the 10-second signal were extracted. similarly, Isolated words from all speech signals are then extracted and the database has been developed.
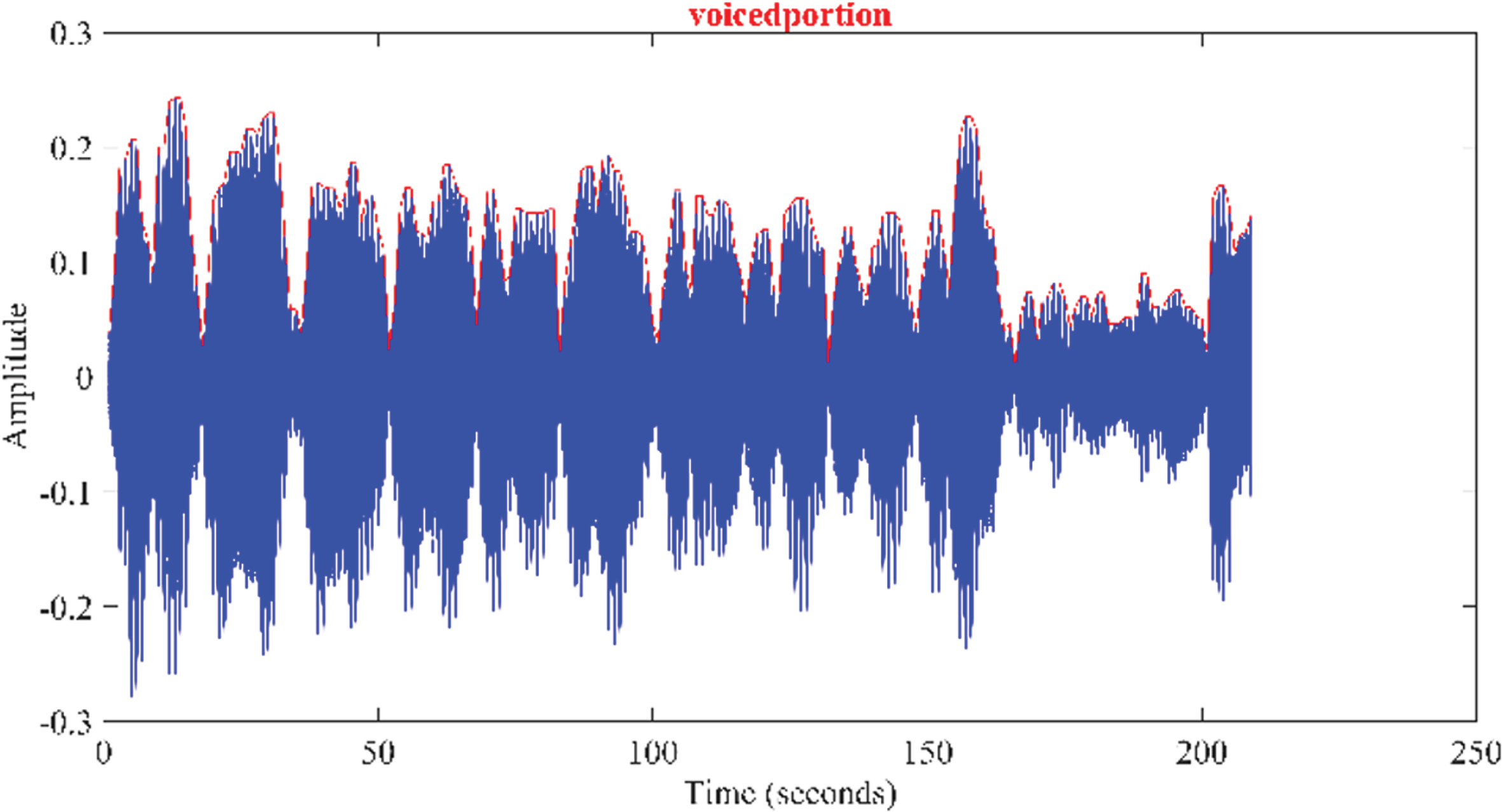
Frame energy mapping on the voiced portion of the recorded isolated word speech signal.
Fuzzy set theory includes the expert opinion on the classification patterns, decisions, features and objects with mathematical tools and processes. Fuzzy classification is a type of pattern recognition algorithm that uses fuzzy sets at all during processing. Fuzzy patter recognition is often associated with fuzzy clustering or if-then else systems used as classifiers [32, 33]. Fuzzy classifiers can also be “transparent” or “interpretive,” based on if-then rules, i.e. the end-user can verify the classification model [34]. Figure 7 shows the overall speech recognition architecture.
Block diagram of the proposed Fuzzy voice classifier.
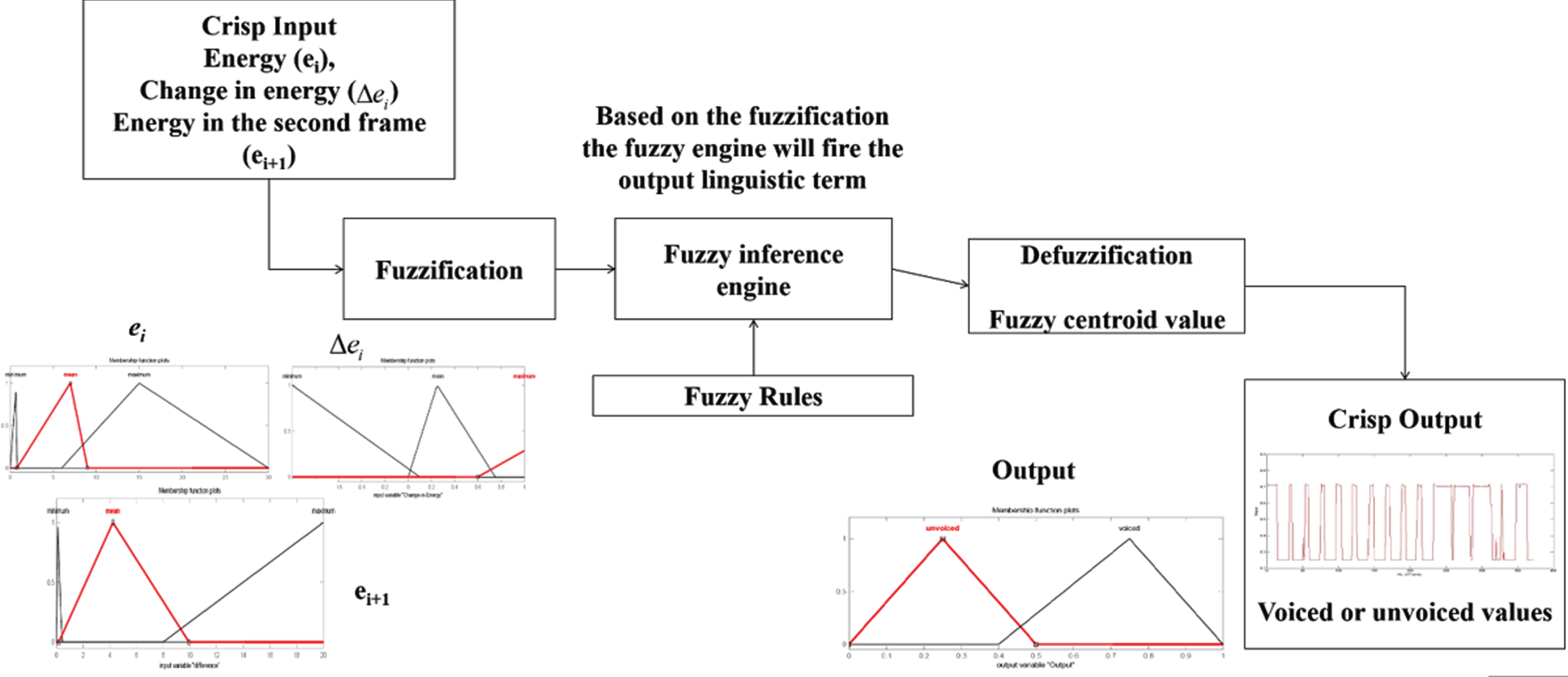
Fuzzy logic systems are high-level decision-makers and are a very effective method for achieving reliable findings even with relatively large noise concentrations. Fuzzy logic systems have been designed by means of fuzzy sets that are sets of multiple membership levels [35]. Fuzzy logic systems are usually developed using “if-then” rules and membership functions. Hence, in the proposed fuzzy voice classifier, the classifier consists of a fuzzification block, a fuzzy knowledge based- inference block, and a de-fuzzification block.
The fuzzy voice classifier and isolated word segmentation algorithms are designed using MATLAB GUI software platform. The fuzzy process transforms input variables (frame energy, change in energy and the next frame energy) into crisp input through the fuzzification process, using the set of fuzzy mapping rules to approximate the entire feature. Three Membership functions are used in the fuzzication process and two membership functions are used in the defuzzication process and thery are used to quantify the linguistic terms used in the processing.
During the initial development of the fuzzy voice classifier, standard triangular membership functions were used in both the fuzzy input (fuzzification process) and the fuzzy output sets (defuzzification process). The base values of each triangular membership function are chosen equally and are used to split the voiced portion of the speech signal. Later, the input membership functions are designed based on the observations made on the minimum and maximum values of the e i , Δe i and (ei+1) features, due to the exploitation of fuzzy rules are minimized and yields very less accuracy in the classification. The three linguistic terms used in the fuzzification process are low, medium and high. The designed input fuzzy sets are shown in Figs 8 10.
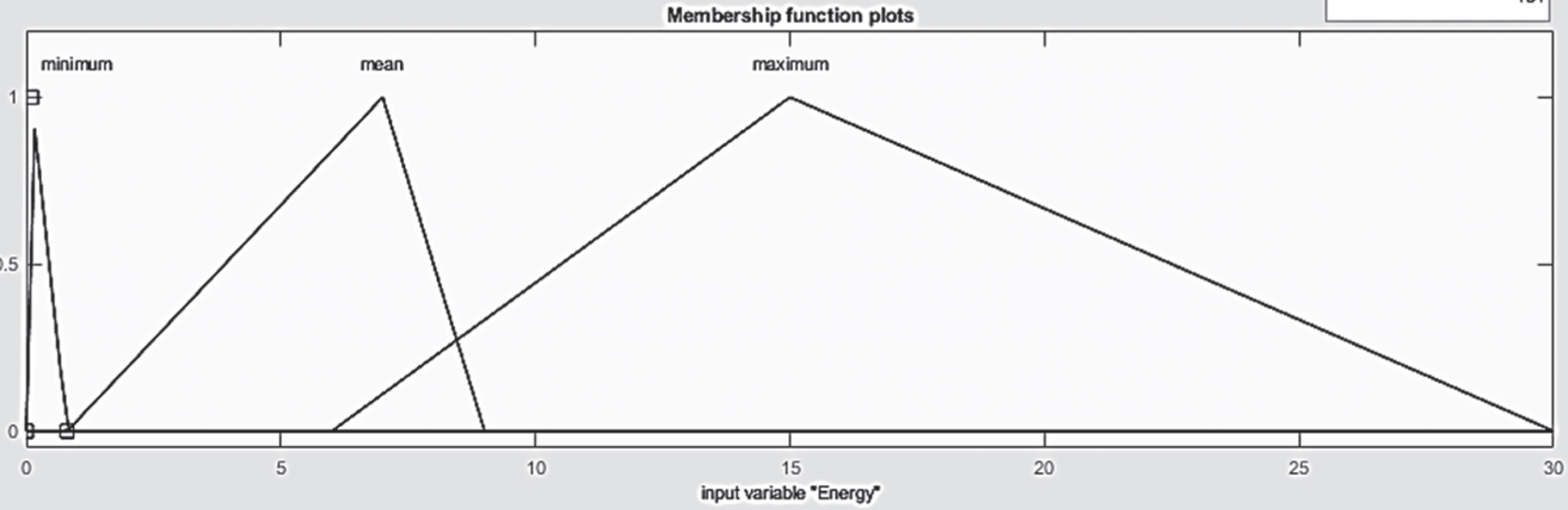
Membership function for e i .
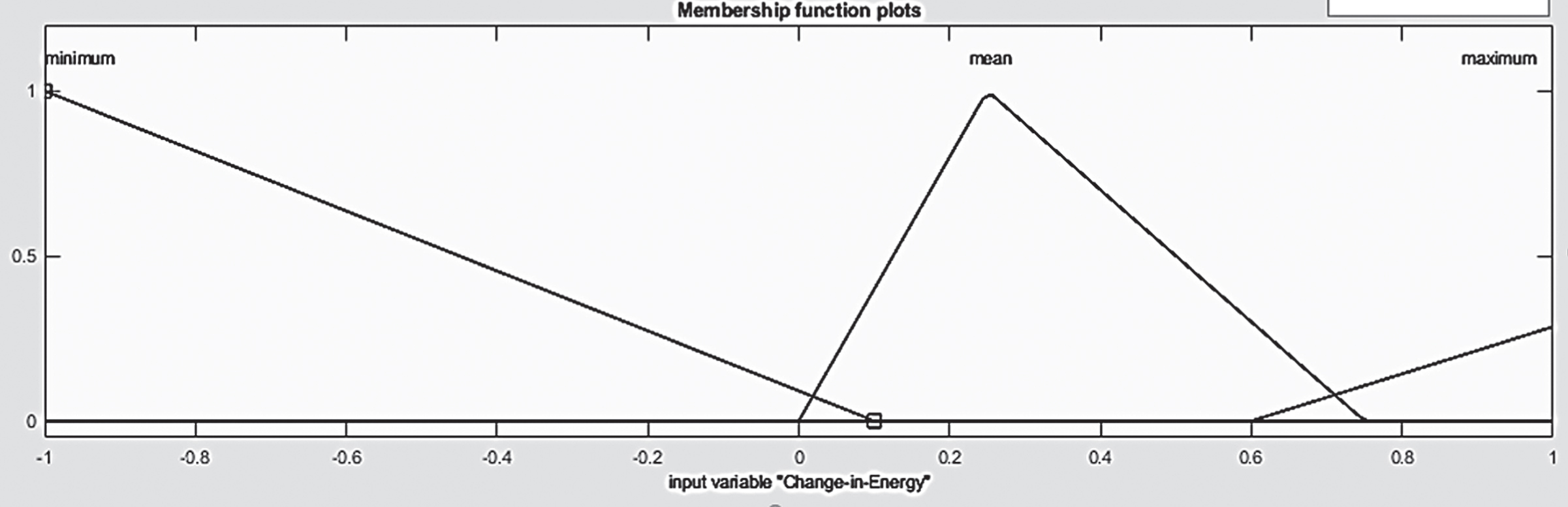
Membership function for Δe i .
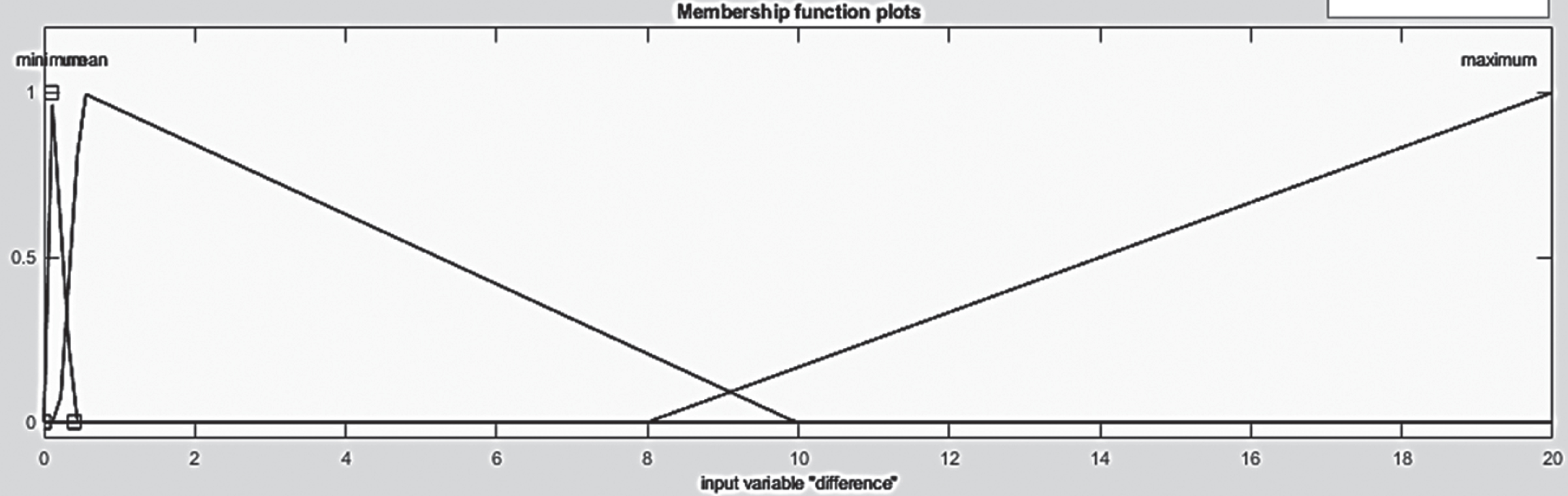
Membership function for energy in the (ei+1) frame.
The fuzzy inference engine then uses the knowledge base developed using if-then rules to generate output based on the fuzzy set of chrisp inputs. The Fuzzy Inference Rules of Mamdani type have been used in this research. The fuzzy linguistic terms were used to design 21 if–then–else rules for identifying the voiced and unvoiced segments [27]. The fuzzy rules chosen based on the observation are depicted in Table 1.
Rules formulated for the fuzzy voice classifier
The frame energy, change in energy and energy in the second frame levels are fuzzified and the weighted membership function enables the voiced/unvoiced output membership function. The designed output fuzzy sets are shown in Fig. 11. The linguistic terms used for the output fuzzy are ‘voiced’ and ‘unvoiced’ using standard triangular membership functions.
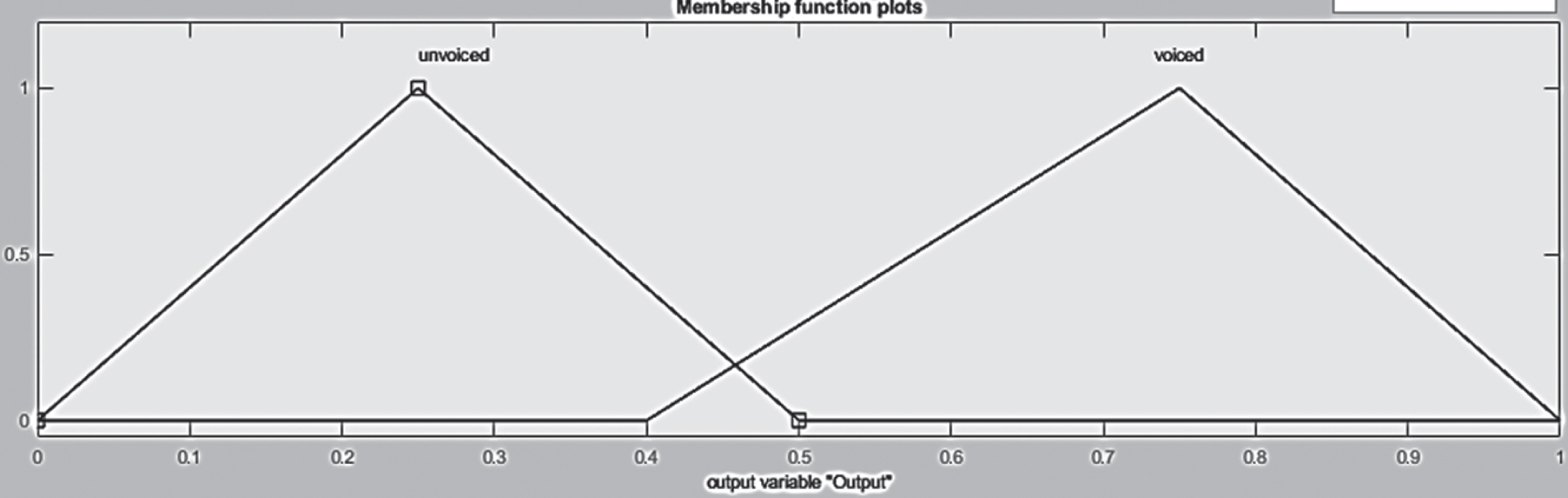
Membership function for fuzzy voiced/unvoiced output.
After the evaluation has been carried out in a fuzzy inference engine, the overall result is a cristp output. This result is defuzzified using centroid defuzzification method [35–37] to obtain the output. The output of the defuzzificiation is then used to extract the voiced portion from the speech signal using a simple algorithm. The extracted voice portion is shown in Fig. 12. The voiced portions are segmented and further used for isolated word recognition and speech to text translation system.
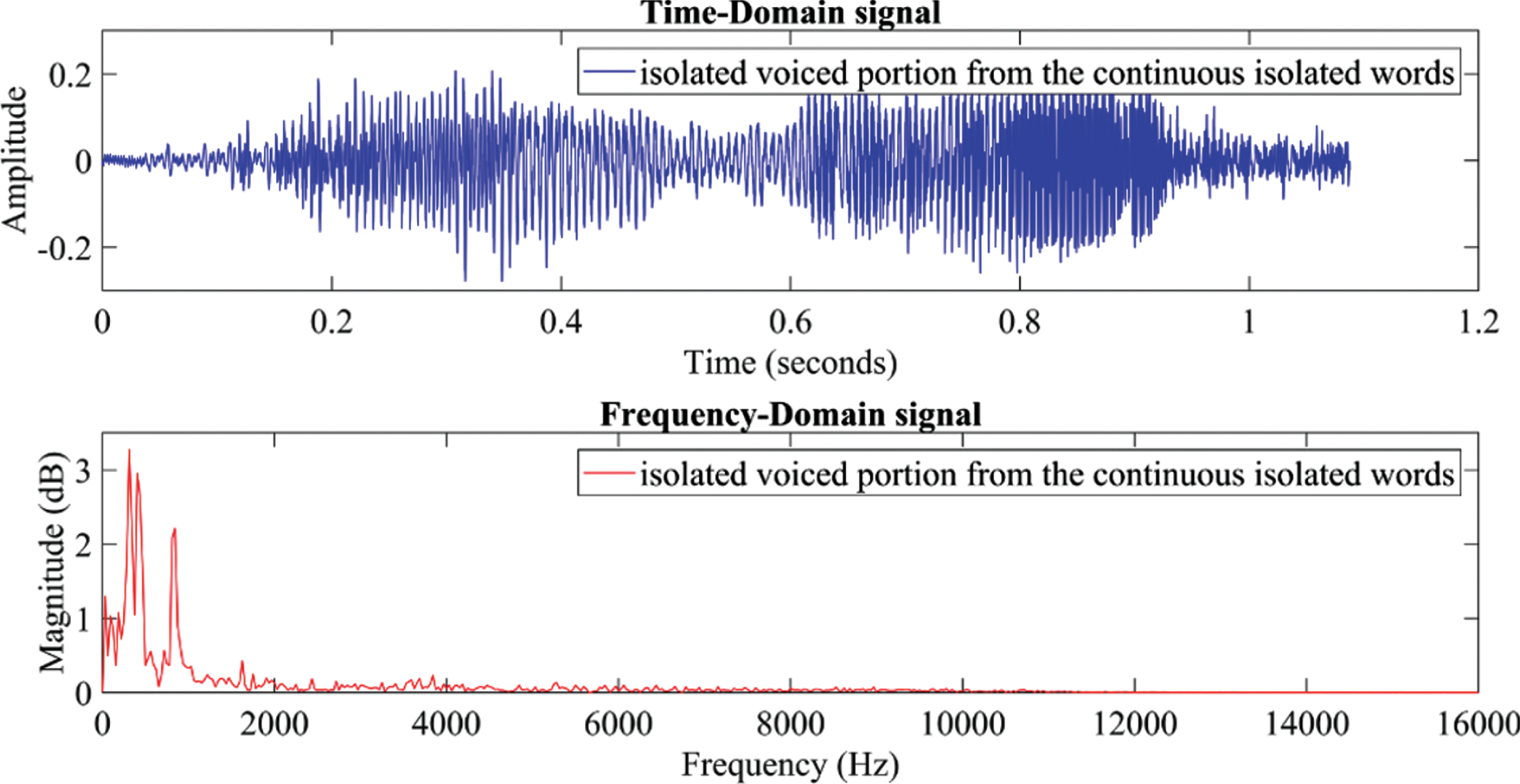
A typical extracted isolated voiced portion from the continuous isolated words.
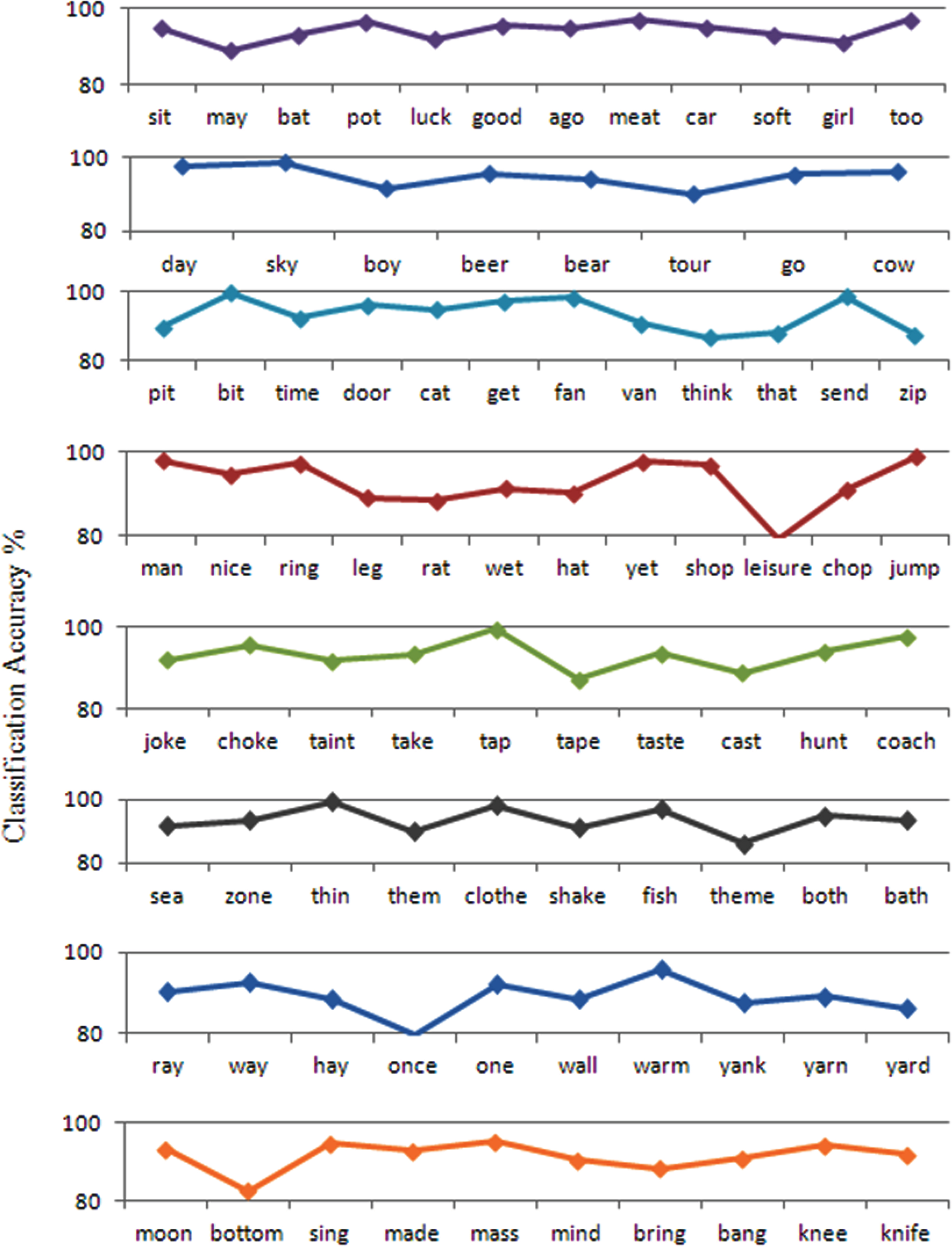
The fuzzy voice classifier for the classification of voiced and unvoiced portions are developed based on the features extracted from the speech signals and subsequently extracted the voiced portion using suitable algorithms. The FIS editor function available in MATLAB fuzzy toolbox is used to create the membership function, model and simulate the fuzzy voice classifier. The result of the fuzzy voice classifier such as recognition rate for each class of phonemes is represented in Appendix Fig. A.2.
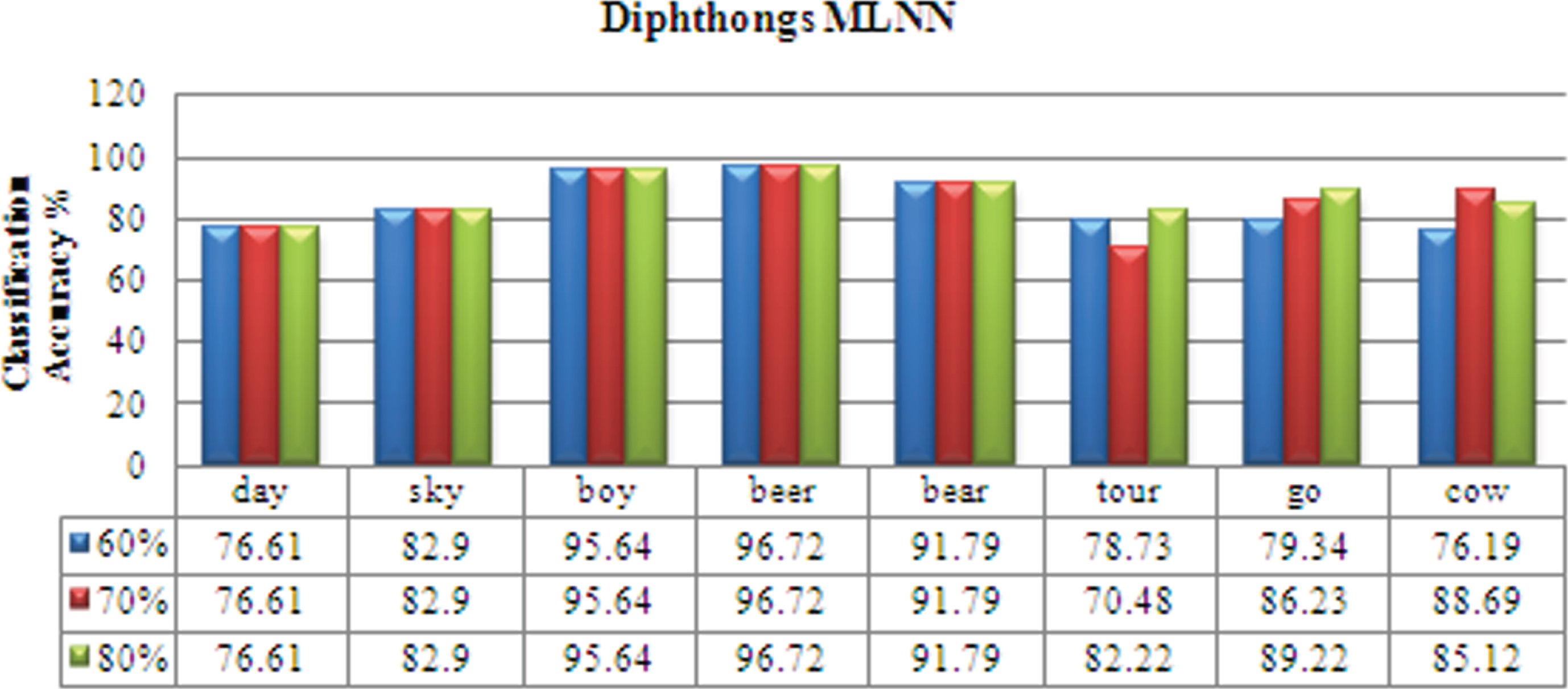
From Fig. A.2, it can be emphasized that the isolated word ‘may’ has the minimum recognition rate of 89.14 % and the isolated word ‘too’ has the highest recognition of 97.14 % using the vowels database. For the diphthongs database, the isolated word ‘tour’ has the minimum recognition of 90 % and the isolated word ‘sky’ has the highest recognition of 98.85 %. The overall mean recognition is 95 %.
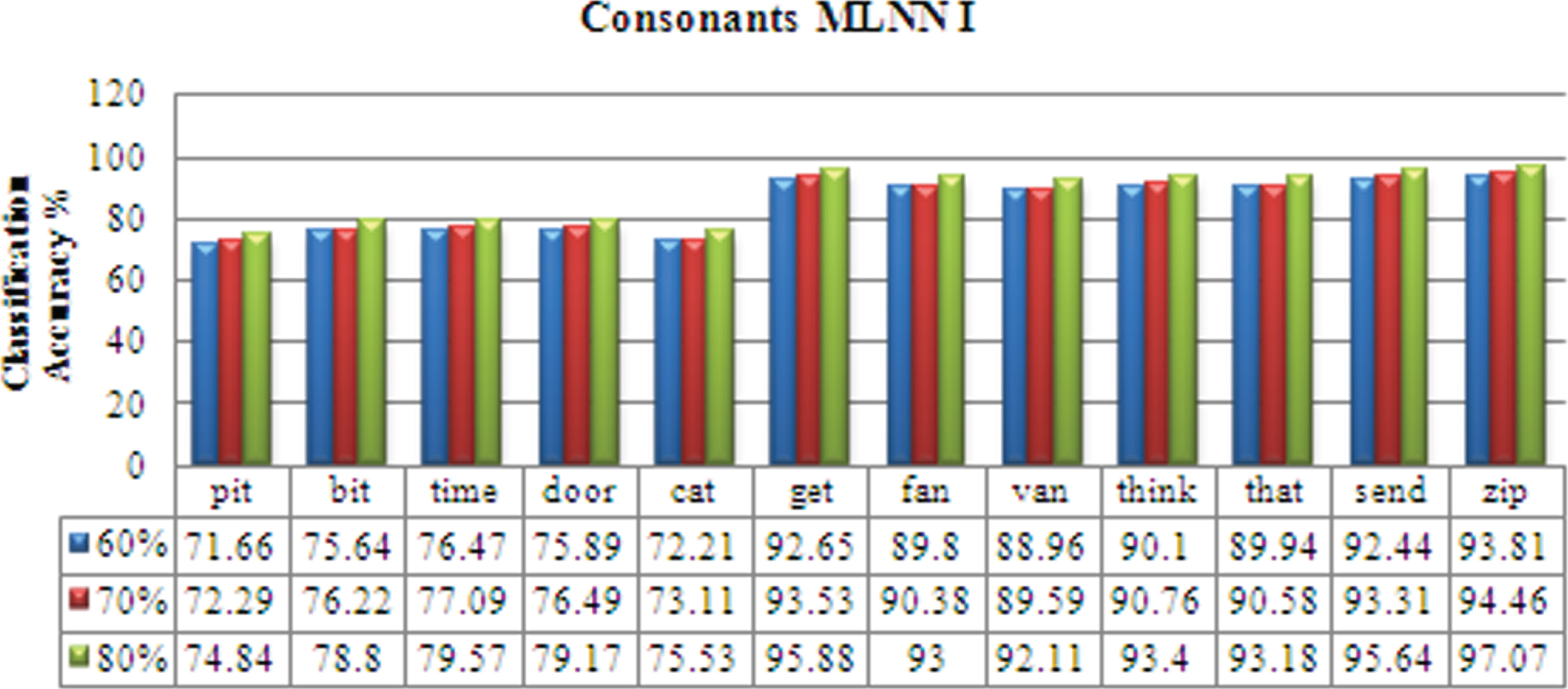
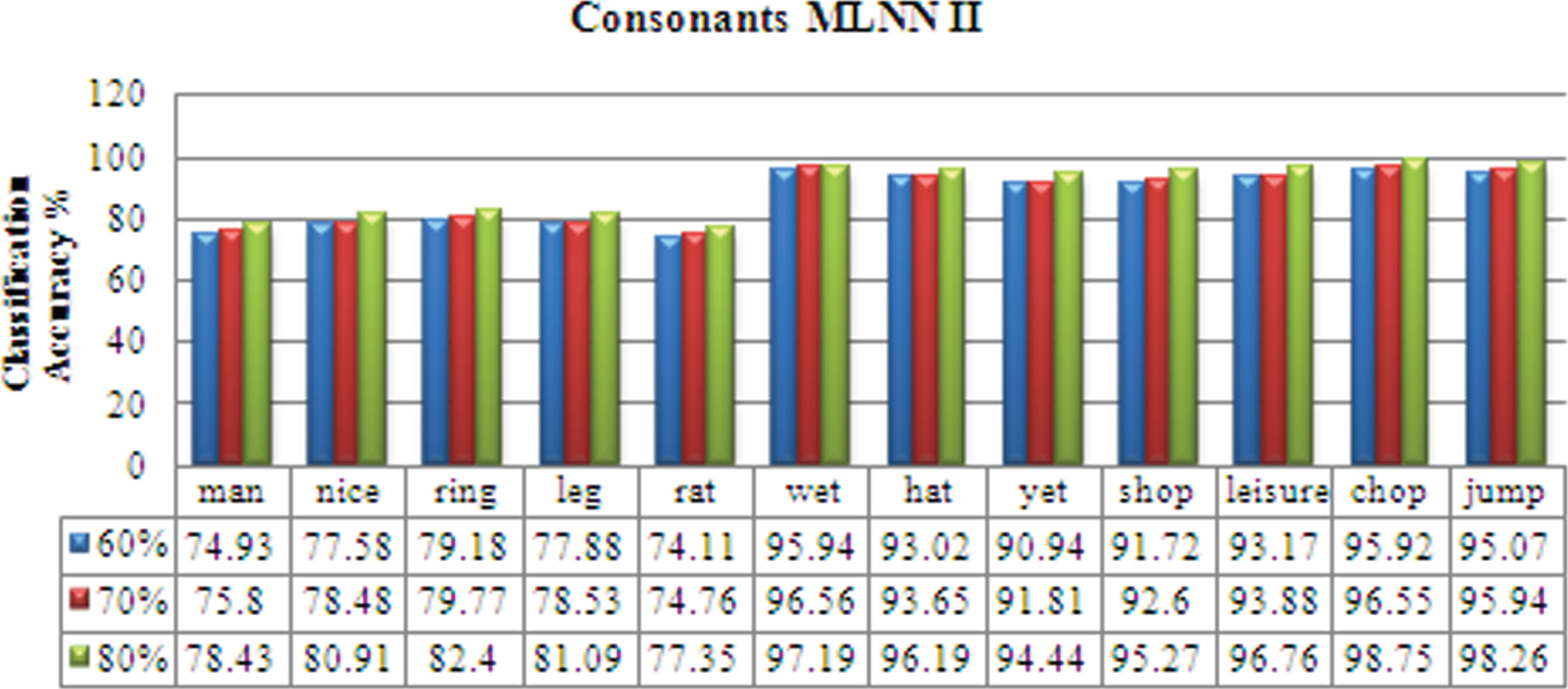
For the consonants I database, it can be emphasized that the isolated word ‘think’ has the minimum recognition of 86.85 % and the isolated word ‘pot’ & ‘bit’ has the highest recognition of 99.71 %. The overall mean recognition is 93.3 %. For the consonants II database, It can be inferred that the isolated word ‘leisure’ has the minimum recognition of 79.42% and the isolated word ‘jump’ has the highest recognition of 98.85 %. The overall mean recognition is 92.78 %.
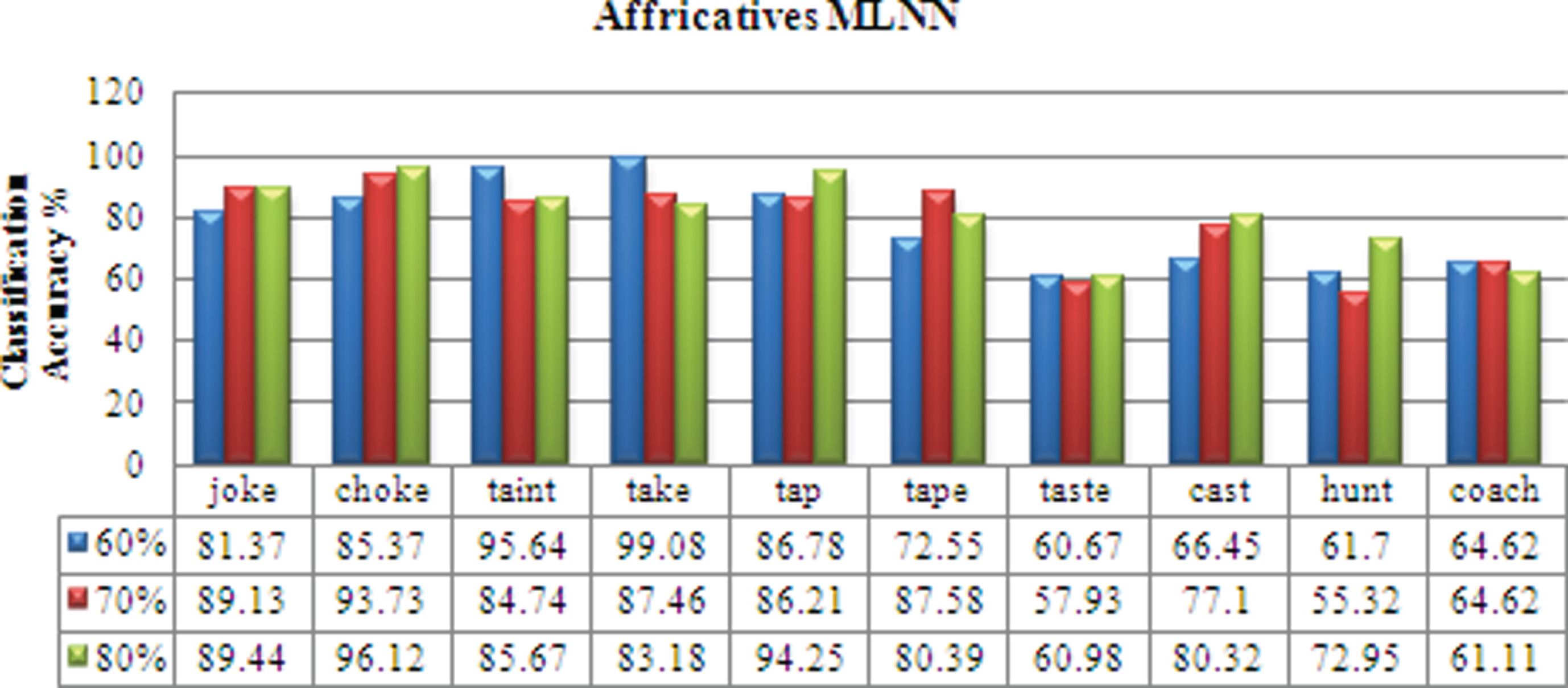
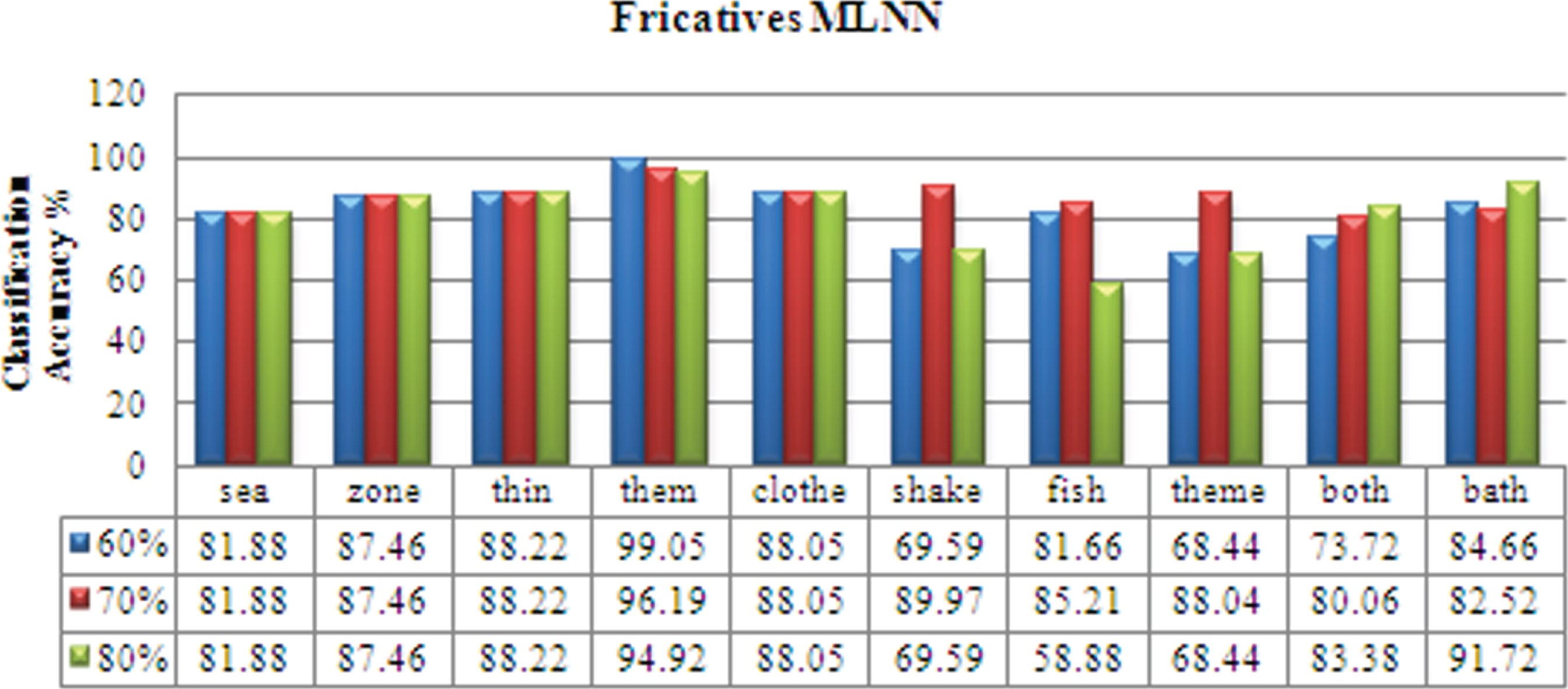
For the Affricatives database, It can be inferred that the isolated word ‘tape’ has the minimum recognition of 87.42 % and the isolated word ‘tap’ has the highest recognition of 99.42 %. The overall mean recognition is 93.42 %. For the Fricatives database, It can be inferred that the isolated word ‘theme’ has the minimum recognition of 86 % and the isolated word ‘thin’ has the highest recognition of 99.42 %. The overall mean recognition is 93.42 %.
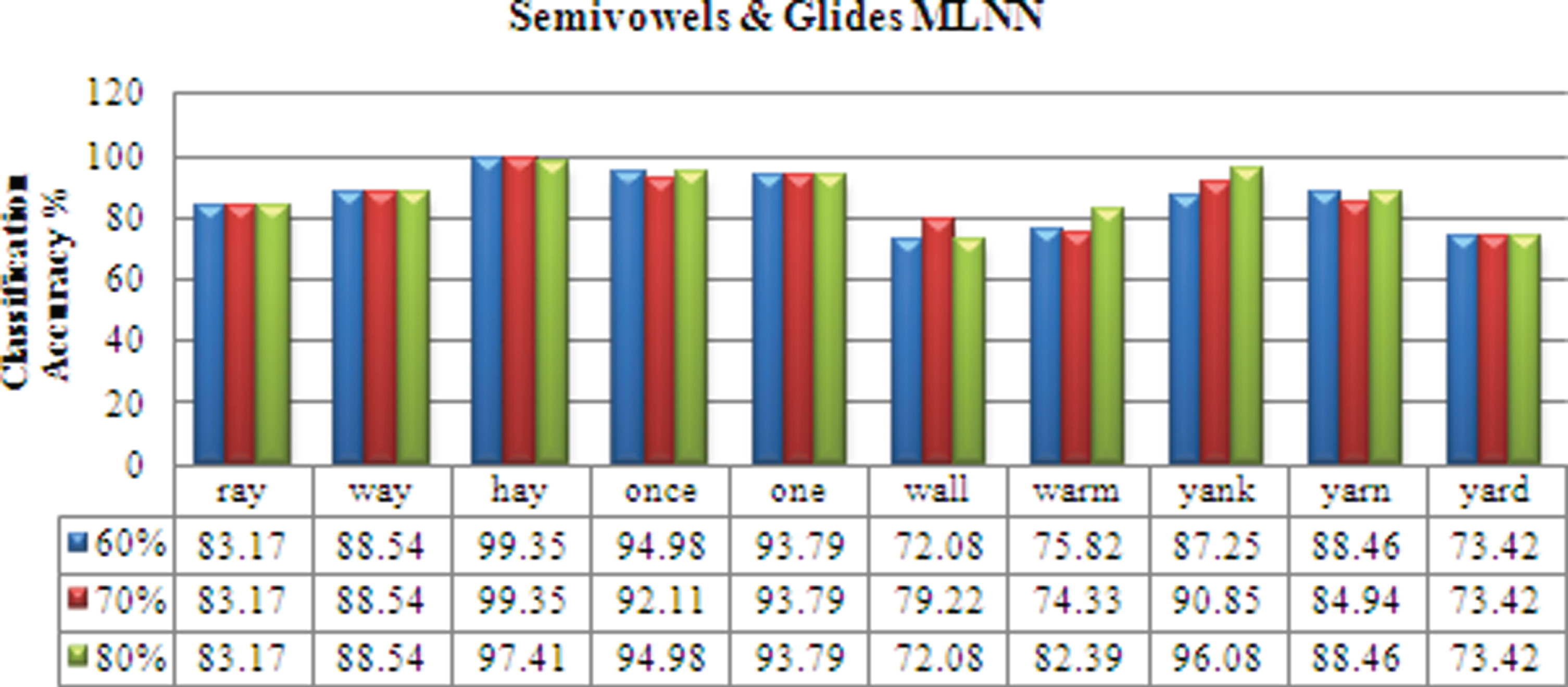
For the Semivowels & glides database, it can be inferred that the isolated word ‘once’ has the minimum recognition of 79.71 % and the isolated word ‘warm’ has the highest recognition of 95.71 %. The overall mean recognition is 89.02 %. For the Nasals database, It can be inferred that the isolated word ‘bottom’ has the minimum recognition of 82.57 % and the isolated word ‘mass’ has the highest recognition of 95.14 %. The overall mean recognition is 91.18 %.
Speech to text translation system
The speech to text translation system based on multilayer neural network models consists of pre-processing, feature extraction, development of network models and the classification of isolated words.
Feature extraction using Linear Predictive Co-efficient (LPCC)
Linear Predictive Coding (LPC) is the most effective technique used to describe the compressed form of the spectral envelope of the speech signal, and one of the most efficient methods of encoding low-bit speech with reliable consistency. This gives exceptionally precise estimates and is comparatively quick to measure speaker parameters [38].
The LPCC features are extracted from each frame of the speech signal using the built in function available in MATLAB signal processing toolbox. The first step is to perform the autocorrelation analysis of frame signal after multiplying it with a hamming window. After computing the autocorrelation sequence, the toeplitz auto correlation matrix of size p X p is generated as shown in the Equation (6). The LPC features are computed by direct matrix multiplication method as given in Equation (7).
The MLNN models [39] are developed based on the eight classes of phoneme. The architecture of the proposed multilayer feedforward neural network model fusion is shown in Fig. 13. Each MLNN network consists of an input layer, hidden layers and output laters. The input to the MLNN models are the features extracted using LPC feature extraction algorithm. The hidden layers and output layers are activated using the logistic sigmoidal activation function. The sigmoid activation function was chosen based on the results of the previous research using the speech database [40].
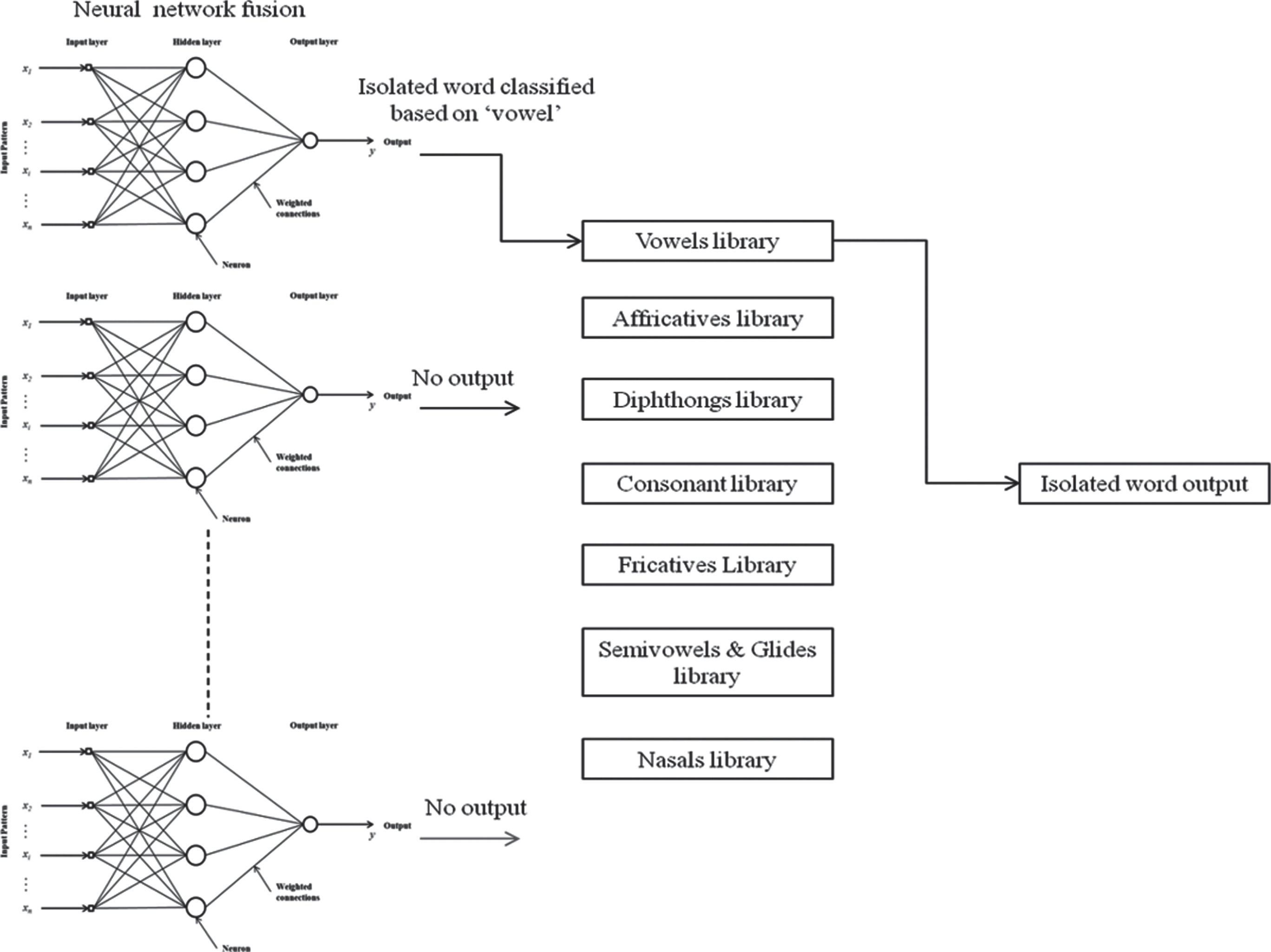
MLNN architecture for PCWD database (Isolated word Classification).
The logistic sigmoidal transfer function can be written in the form:
The predicted pattern is compared to the actual pattern and Mean Square error (MSE) were determined using Equation 8. If the MSE is greater than the tolerance level, the MLNN architecture weights are modified using the backpropagation algorithm. This procedure is repeated until the MSE is below the tolerance value.
sum squared error (MSE)
tpjand ypj are the target out put and the actual output respectively.
Similarly, the mean square error is observed in all the multilayer neural network models until it reaches less than The tolerance value. Outputs from all network models are collected and discriminated using the target output assigned in the data pre-processing stage. The estimated output is indexed in the phonemes database, identifying an isolated word. The discrete word is then sampled to be pronounced through the speaker and displayed in a GUI using a basic algorithm.
The Multilayer neural network models developed for the isolated word classifications are based on the features extracted from each speech signal of the segmented voiced portion. The extracted LPCC features consist of Vowel (3941 X 12), Diphthong (2660 X 12), Consonants (3922 X 12), Consonants (3202 X 12), Affricatives (3897 X 12), Fricatives (3269 X 12), Semi vowels and glides (3270 X 12), Nasals (3116 X 12). feature set. The extracted features are further processed to label and then associated with the eleven vowel classes. The feature set is normalized, randomized and split in to 60%, 70% and 80% and the testing sample has 100%. The processed features contain the input –output association. The network contains three layers namely input, hidden and output. The input layer is provided with the feature vectors which constitutes the input neurons to the network. The output layer is associated with the target vectors corresponding to the input vectors. The hidden neurons in the hidden layer are allocated experimentally. The hidden neurons contribute towards the weighted connections of the neural network. The network models are trained for 25 times per each trial. Five trials are performed per each neural network model.
The consolidated training parameters of the developed MLNN models for the classification of isolated words based on the LPCC features are tabulated in Table II. The consolidated mean recognition of the developed eight MLNN models for the classification of isolated words based on the phoneme classes are represented in Fig. 14. The corresponding confusion matrix for each network model is represented in Appendix Fig. A.3 to Fig. A.10.
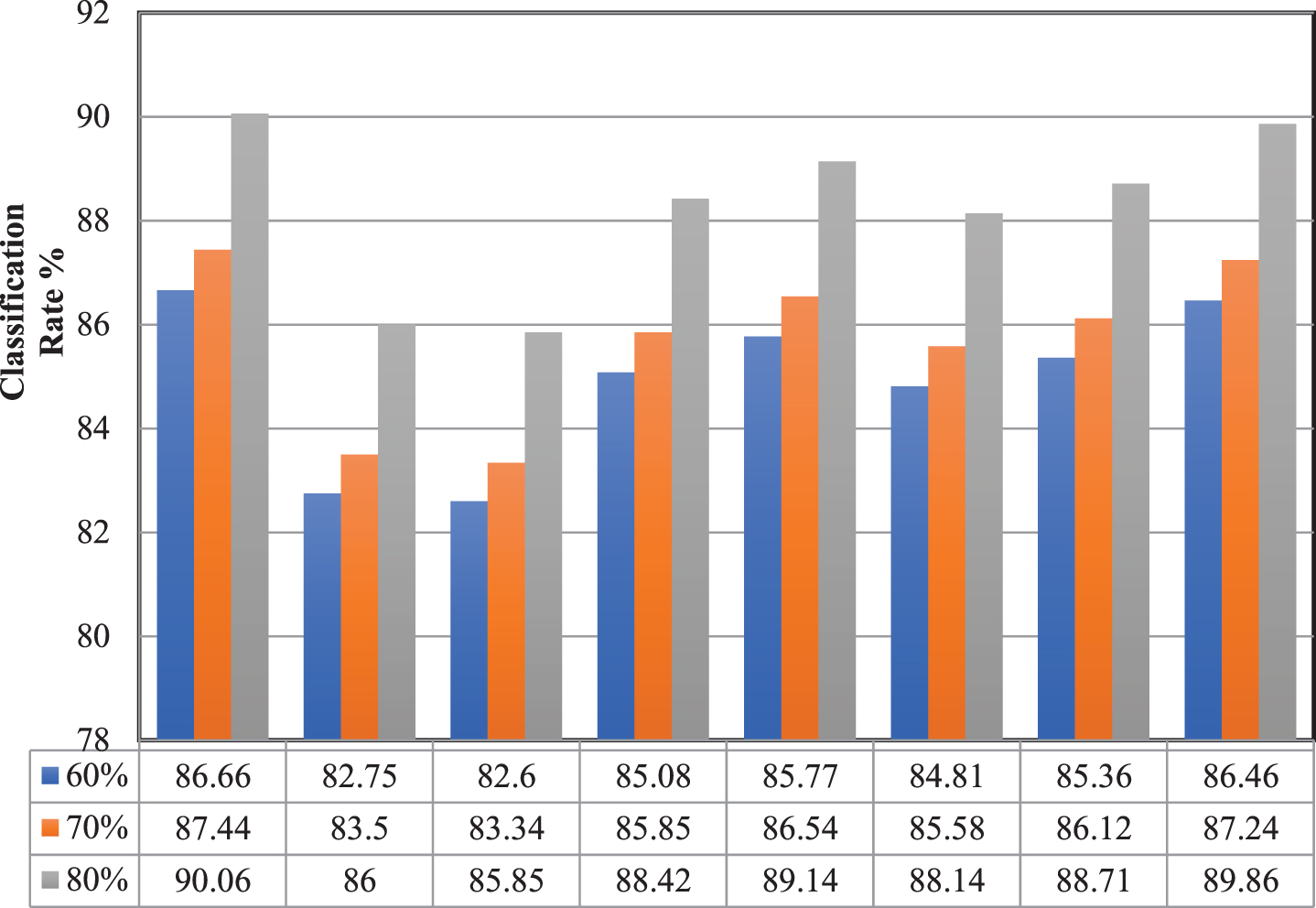
Mean recognition for the MLNN models.
From Table 2, It can be inferred that the neural network model trained using the diphthongs features set has the Average minimum training time of 342 seconds and the neural network model trained using the fricatives features set has the Average maximum training time of 564 seconds.
Network training parameters and Training time (LPCC features)
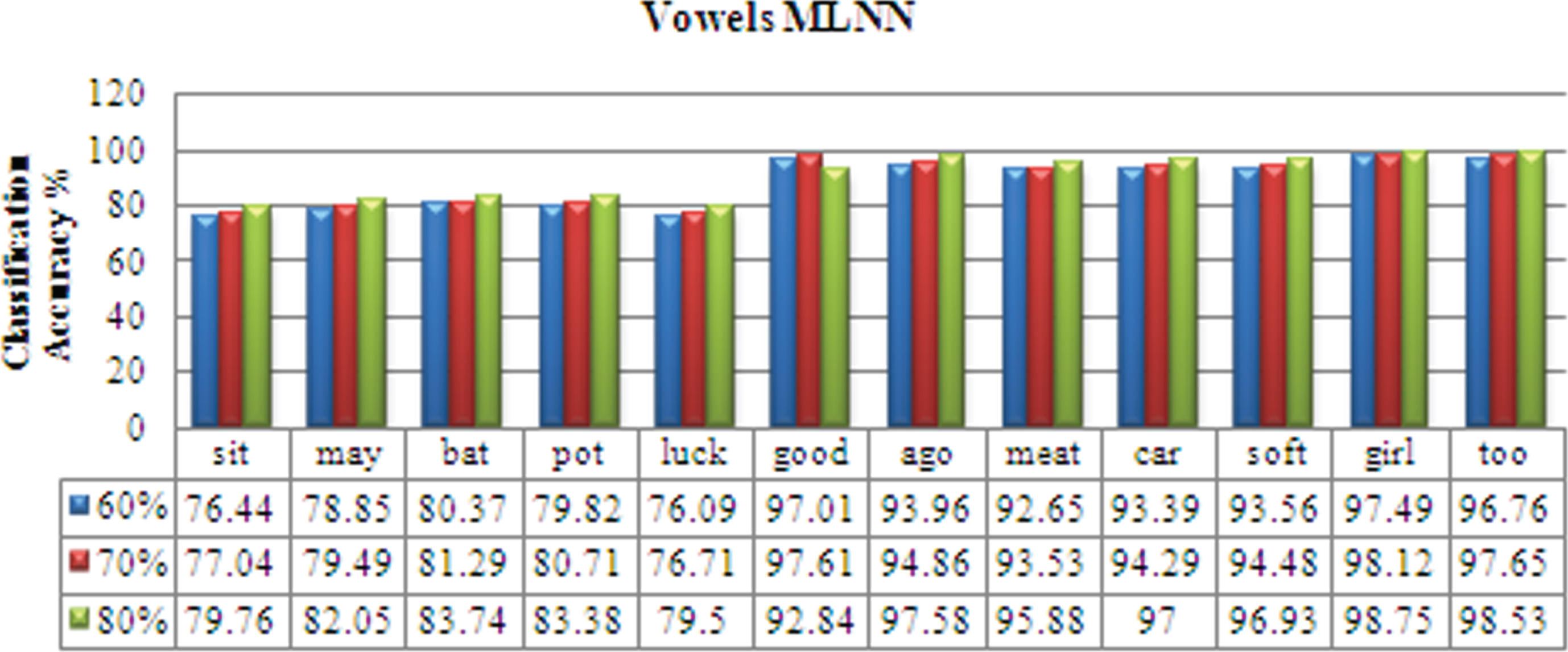
From Fig. 14, It can be inferred that the Consonant 1 MLNN model has the Average minimum recognition of 82.60 % and the Vowel MLNN model has the Average maximum recognition of 86.66 % using 60% of the data samples. The Consonant 1 MLNN model has the Average minimum recognition of 83.34 % and the Vowel MLNN model has the Average maximum recognition of 87.44 % using 70% of the data samples. The Consonant 1 MLNN model has the Average minimum recognition of 85.85 % and the Vowel MLNN model has the Average maximum recognition of 90.06 % using 80% of the data samples.
From Fig. 15, it is inferred that the Vowels network model has the Average minimum epoch of 822 and the Consonants 1 network model has the Average maximum epoch of 1621 using 60% of the data samples. The Vowels network model has the Average minimum epoch of 863 and the Consonants 1 network model has the Average maximum epoch of 1702 using 70% of the data samples. Further, the Vowels network model has the Average minimum epoch of 871 and the Consonants 1 network model has the Average maximum epoch of 1717 using 80% of the data samples.
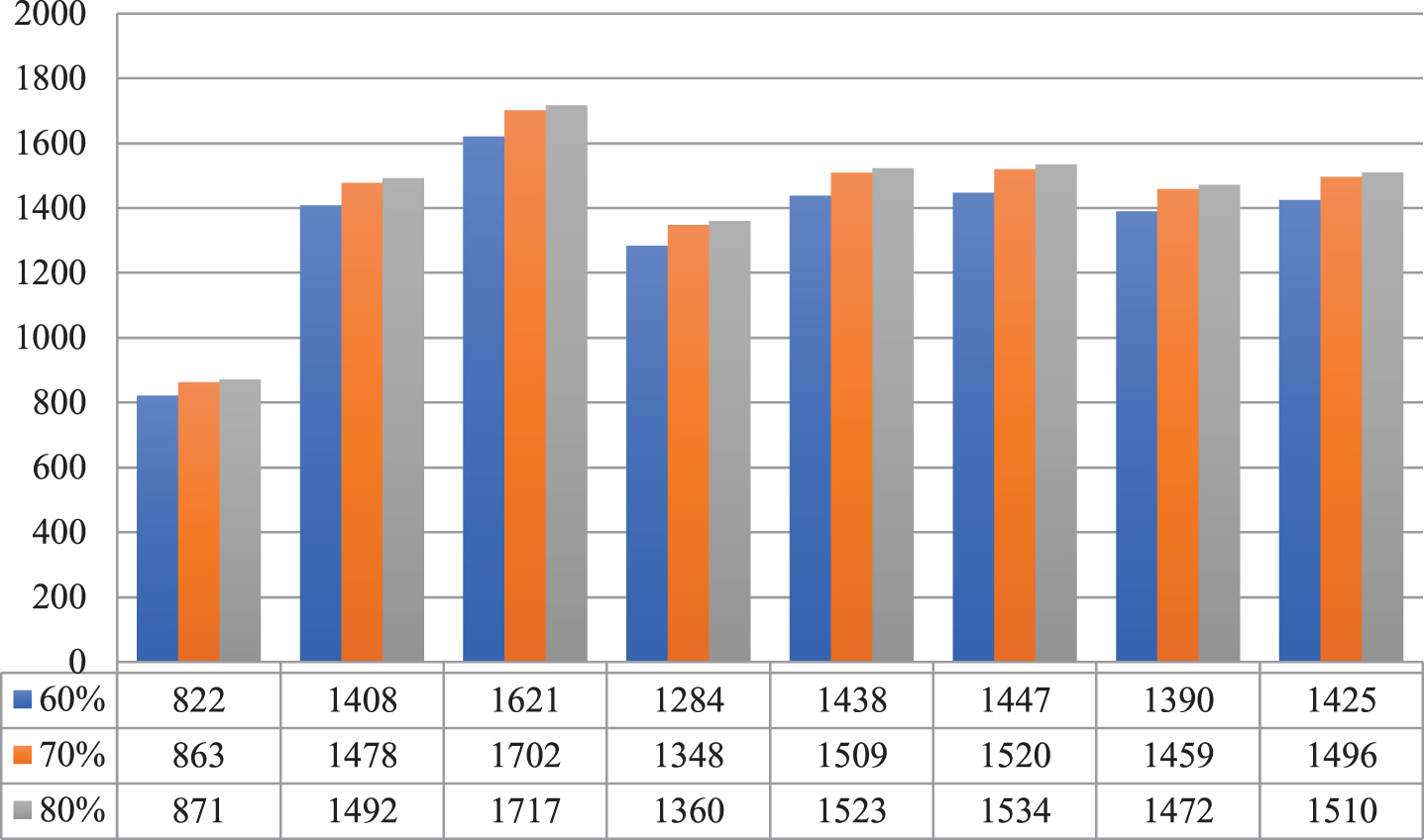
MLNN classification performance for LPCC features.
The regards to the objective of the research work, the recorded isolated word speech signals are split into voiced/unvoiced portion using the proposed fuzzy voice classifier. Feature extraction algorithms using LPCC is used to extract the features from the voiced portion of the speech signal. Methods for data processing were developed to formulate vectors for classifier models. Neural network algorithms were implemented to identify the isolated words and phonemes using the features derived from the isolated word speech.
For the PCWD database, the overall minimum and maximum mean recognition of the developed fuzzy voice classifier are 79.42 % (Isolated word ‘leisure’) and 99.71 % (Isolated words ‘pot’ & ‘bit’). The word /zip/ has the minimum average voice extraction time of 9.61 seconds and the word /fan/ and /may/ has the maximum average voice extraction time of 12.89 seconds. Further from the confusion matrices, the overall minimum and maximum recognition of the isolated word developed for the PCWD are 55.32 % (The isolated word ‘Hunt’) using the Affricatives network model and 99.35 % (the isolated word ‘Hay’) using the Semivowels and glides network model.
Following the current research, the following work may well be carried out to improve the speech-to –text translation system. An intelligent algorithm would be proposed in order to assemble the phonemes and compile the isolated word. Advanced experimental methods can be used for capturing speech signals from different ethnic groups of students from different regions. Since the proposed methodology (energy, change in energy for the fuzzy voice classification and LPCC features for the isolated word recognition) provides more than 90 % accuracy, different techniques for extracting features and optimizing features can be developed in order to improve device reliability and information transfer rate. Neuro-fuzzy classifiers can be developed to further study speech-to- text translation.
Footnotes
Appendix
Isolated wordlist based on phonemic variation Performance of the fuzzy voice classifier. Recognition of the vowels MLNN confusion matrix. Recognition of the diphthongs MLNN confusion matrix. Recognition of the consonants I MLNN confusion matrix. Recognition of the consonants II MLNN confusion matrix. Recognition of the affricatives MLNN confusion matrix. Recognition of the Fricatives MLNN confusion matrix. Recognition of the Semivowels and Glides MLNN confusion matrix.
Vowel phonemes
Diphthongs
Consonant phonemes
Affricates
Fricatives
Semivowels &Glides
Nasals
sit may bat pot luck good ago meat car soft girl too
day sky boy beer bear tour go cow
pit bit time door cat get fan van think that send zip
man nice ring leg rat wet hat yet shop leisure chop jump
joke choke taint take tap tape taste cast hunt coach
sea zone thin them clothe shake fish theme both bath
ray way hay once one wall warm yank yarn yard
moon bottom sing made mass mind bring bang knee knife