
Abstract
The feature selection of influencing factors of coal and gas outbursts is of great significance for presenting the most discriminative features and improving prediction performance of a classifier, the paper presents an effective hybrid feature selection and modified outbursts classifier framework which aims at solving exiting coal and gas outbursts prediction problems. First, a measurement standard based on maximum information coefficient(MIC) is employed to identify the wide correlations between two variables; Second, based on a ranking procedure using non-dominated sorting genetic algorithm(NSGAII), maximum relevance minimum redundancy(MRMR) algorithm is subsequently performed to find out candidate feature set highly related to the class label and uncorrelated with each other; Third, random forest(RF) is employed to search the optimal feature subset from the candidate feature set, then the optimal feature subset that influences the classification performance of coal and gas outbursts is obtained; Finally, an improved classifier model has been proposed that combines gradient boosting decision tree(GBDT) and k-nearest neighbor(KNN) for outbursts prediction. In the modified classifier model, the GBDT is utilized to assign different weights to features, then the weighted features are input into the KNN to verify the effectiveness of proposed method on coal and gas outbursts dataset. The experimental results conclude that our proposed scheme is effective in the number of feature and prediction accuracy when compared with other related state-of-the-art prediction models based on feature selection for coal and gas outbursts.
Keywords
Introduction
The disaster of gas and coal outbursts has become the major problem that the national economy, socially sustainable development, and mining development must solve [1]. However, the evolution characteristic of coal and gas outbursts has not been completely understood yet, and the outbursts disaster cannot be effectively prevented and controlled, which has bad impact on the safety production of coal mines in china [2]. It is necessary to predict accurately and quickly the coal and gas outbursts in order to make the relevant outbursts prevention measures. Because of the complicated mechanism of coal and gas outbursts, it is difficult to choose the sensitive indexes and critical value of outbursts prediction, which presents a low prediction accuracy. The process of coal and gas outbursts is a complex and multi-factors coupling nonlinear system, there exit the complicate relationships among the index features of coal and gas outbursts. At the same time there are redundancy and dependence between the influencing factors, and there also exit all kinds of relationships between the influencing factors and outbursts, the existence of redundant and irrelevant features will damage the performance of the classification algorithm, so the performance of exiting different classifiers on the coal and gas outbursts dataset is not ideal. Therefore, when performing the prediction of coal and gas outbursts, the feature selection is necessary, it can identify the effective features which are highly related to the outbursts, reduce the complexity of the prediction model, generate the understandable model, so improve the model prediction accuracy and reduce executing time. The relevant feature subset selected by feature selection is of great reference value for the study of significant factors affecting coal and gas outbursts. Finding out the most representative features and performing an effective classifier model, which are both vital for the prediction performance, are always interactional. Consequently, building them separately may lead to low accuracy. Hence, we intend to propose an excellent comprehensive model which not only can select the optimal features, but also can improve the performance of the classifier synchronously to achieve the highest recognition effect.
In the following section, we report different advanced works in the literatures which are related to the problem and the methodologies considered in this paper. The research results mainly focus on the two key links of feature selection of influencing factors and optimal design of outbursts classifier. Feature selection is an indispensable procedure for intelligent prediction model, the common feature selection methods for coal and gas outbursts are to select important features by setting weight subjectively or objectively considering the importance of each feature for the outbursts. The relevant methods are as follows: Network Analysis and Contact Entropy(NACE) [3], Rough Set(RS) [4], Entropy Weight(EW) [5], Fault Tree Analysis(FTA) [6], Genetic Projection Pursuit(GPP) [7], Analytic Hierarchy Process(AHP) [8], Fuzzy Comprehensive Evaluation(FCE) [8], Weighted Grey Relation Analysis(WGRA) [9]. These feature selection methods show excellence performance in improving the prediction and prevention ability of coal and gas outbursts. However, they generally suffer from many limitations: The weight of setting is subjective, the initial value is sensitive, the prediction indexes are assumed mutually independent, at the same time, there are complicated calculation, long learning time and large sample space, unreasonable index selection and low accurate classification. Existing feature selection methods evaluate the importance of features based on the contribution of a single feature to classification, then select the important feature and find out feature subset. The influence of correlation on outbursts classification is ignored, or the correlation between features is not considered enough, and the contribution of joint effect of features to classification is often ignored, so we need to propose advanced feature selection methods to solve above problems. It is of great significance to fully understand the main parameters of coal and gas outbursts. However, these parameters will also affect each other, which greatly increases the difficulty of evaluation. At present, considering the interaction between various factors, there is still great uncertainty about the influence of main parameters on coal and gas outbursts.
Feature selection uses a specific evaluation function to evaluate the effect of a feature or feature combination and studies how to identify the effective features for classification, so as to improve the classification efficiency and accuracy. Feature selection methods need to select suitable metrics to measure the correlation between features and class labels and the redundancy between features. According to the independence of feature selection, it can be divided into single variable methods and multi-variable methods. Single variable methods use specific evaluation criteria to evaluate each feature independently, multi-variable methods take into account the relationships between a feature and other feature when evaluating features. According to the different types of results, feature selection methods can also be divided into three types such as weighting method, ranking method and feature subset method. The weighting method refers to the feature selection that returns the weight value assigned to the feature, the ranking method that returns the ranking list of the feature, and the feature subset that returns the selected feature subset. Feature selection usually selects feature subsets with a strong correlation with the class label and a weak correlation between features. At present, the focus of feature selection is to employ suitable metrics to measure the correlation between features and class labels, and the redundancy between features, and select the corresponding searching strategies to find optimal features. The research focuses on the two aspects of feature ranking based on feature metric evaluation criteria and optimal features selection based on feature selection models.
For feature ranking approaches, the features are ranked according to some criteria, and the top n ranked features are selected. The feature importance ranking based on the evaluation criteria of feature metrics includes single variable metrics and multi-variable metrics, the single variable measurement improves feature selection performance by improving the measurement standard, including distance-based measurement standard, information theory-based measurement standard, dependency-based measurement standard and consistency based measurement standard, among which, Pearson Correlation Coefficient (PCC) and Information Gain(IG) are widely used to measure the linear between features. However, only linear relationship can be captured well using this metric when other kinds of relationships such as nonlinear, functional sin or cubic perform badly. In literature [10] the theory of Correlation Information Entropy is used to apply in feature selection and consider the combined effect of features, that is the multi-variable relationship between different features, but we will find it unreasonable that the dimension of the optimal feature subset is large or too small. However, it is difficult to describe a large number of non-linear relationships among features [11], Symmetric Uncertainty(SU) [12] can measure the non-linear relationship between features, but cannot determine the linear relationship. Mutual Information(MI) [13] can measure the linear and non-linear relationship between features, but it cannot effectively measure the non-functional dependency between features [14]. MIC is a new measure based on information theory, it can provide a wide information measurements such as the dependence, non-functional dependencies linear and nonlinear relations between two random variables, and it is also very effective for non-functional dependencies that cannot be represented by a single function, for example, the dependency relationship composed of multiple functions, the validity of the MIC has been verified in related references and it is introduced in the correlation metric of filter feature selection. For the single variable standard, only the correlation of a single feature is considered, and the joint contribution of multiple features to classification is not considered enough, the features with high identification degree for some categories cannot be selected, the redundancy between features cannot be considered in literature [15]. The traditional feature selection methods based on the traditional measurement standards is easy to ignore the intrinsic internal structure between features of coal mine outbursts process, and the feature combination with interdependence is particularly important for the construction of learning model. It does not fully consider the combination of multi variables to select feature subsets, there will be some differences between the prediction results and the actual situation. The goal of feature selection is to achieve the highest prediction accuracy and the smallest feature dimension, we can use multi-variable metrics to measure relationships between two variables, and it is a multi-objective optimization problem. At present, the algorithms such as non-dominated sorting genetic algorithm(NSGAII) [16] and the multi-objective particle swarm optimization algorithm (MOPSO) [17] have been widely used in different fields involving multi-objective optimization problems. In reference [18], combined with a multi-objective optimization algorithm, a feature selection framework FS-MOA based on the subset evaluation and multi-objective optimization is designed. They can get the corresponding Pareto optimal solution set by the weight vector multi-objective optimization based on the subset evaluation function, and then select the optimal weight vector corresponding to the knee point to determine the feature ranking. In reference [19] the NSGAII algorithm is used to select features and to determine the best feature ranking. Based on the feature selection, multi-objective optimization algorithm is carried out by constructing different feature subset evaluation functions, then obtain the optimal feature subset. The exiting learning algorithms based on the feature subset is easy to produce overfitting and reduce the learning performance, so we need advanced measurement method and multi-objective optimization algorithm to present highly ranked feature ranking.
In contrast to feature ranking, feature subset selection can select the most important or descriptive features, it can be divided into three models based on the evaluation criteria: Wrapper, Filter and Embedded method. The filter method is independent of a classifier, and the common filter methods include IG, CHI, RELIEF, FCBF and CFS. The related literatures also propose some novel methods such as MIFS-ND [19], FCBF-MIC [20], MIFS [21], NMIFS [22], MRMR [23], JMMC [24], JMI [25], CFMS [26], MRMCR [27]. The filter methods use evaluation functions to evaluate the importance and relevance of features, then order the feature according to the weights, so the features with the highest weights are selected as optimal feature subset. Therefore, this method has the advantages such as high computation efficiency; Therefore, the advantage of the filter method is that it consumes less computing resources, and its efficiency is low without considering the classification impact. However, due to its static greedy search mechanism, the selected features cannot be deleted in the future. The wrapper methods introduce learning algorithm to evaluate the performance of learning error or learning accuracy in the feature subset searching process, and take the feature subset with the best learning performance as the feature selection result. There are Sequential Forward Search(SFS), Sequential Backward Search(SBS) [28], Genetic Algorithm(GA) [29], Whale Optimization(WO) [30], Boruta [31], SVM-RFE [32], Random Forest(RF) [33], Evolutionary Computation (EC) [34–40] and other proposed optimization algorithms [41–46]. The wrapper methods select the best feature subset and achieves the highest performance through the evaluation of classification, however, these techniques have some defects such as high computational cost and low stability, which may require improvement, in addition, a search strategy is determined to search all possible combinations of features, evaluate the performance of the learning machine to guide or stop searching and choose the specific learning algorithm are the key problems of Wrapper method; The purpose of embedded technology is to evaluate the best feature subset of learning stage. The typical methods are as follows: LASSO and LARS. Embedded approaches are computationally less intensive than Wrapper methods. However, they still have high computational complexity and the selected feature subset is dependent on the learning algorithm, furtherly it is difficult for the method to construct a suitable function optimization model. Through the classifier evaluation, the Wrapper methods select the best feature subset that can get the highest performance, and can get the most effective and optimal method when the calculation is large. Although Wrappers and Embedded methods can obtain better performances, they are very time-consuming. As mentioned above, these feature selection have advantages and disadvantages, the hybrid feature selection model integrates the high efficiency of the filter and the high accuracy of the Wrapper or Embedded methods, and can present better performance. The filter method with high computational efficiency is used to remove redundant features, and the Wrapper or Embedded method is used to further search features highly related to learning targets in the remaining features, the related methods are as follows: MIFS-Boruta [47], MRMR-NSGAII [48], DFS-SVM [49], Relief-BPSO [50], FS-IG-SBS [51]. These methods use the evaluation function to evaluate the importance and correlation of features, then order the feature according to the feature weights, and select features with the highest weights as feature subset. Furthermore, these existing feature selection methods cannot judge the combined effect of the whole feature subset, divide and judge the feature relevance and redundancy, seldom consider the trade-off of relevance and redundancy between two variables, which result in the inexhaustible selection of indicators, so we need to propose a new hybrid feature selection method composed of filter and wrapper methods to solve the above problems.
In recent years, many researches about coal and gas outbursts prediction have been conducted, many classifiers such as BP Neural Network [52], Support Vector Machine(SVM) [53], Random Forestry(RF) [54], and other intelligent classifier technologies [55, 56] have been successfully applied and have greatly improved the reliability and accuracy of coal and gas outbursts prediction. Among them, the BP Neural Network has strong nonlinear mapping ability, but it needs many sample data to train and takes a long time to converge, so it is difficult to determine its network structure; SVM is highly dependent on the choice of the loss function, kernel function and related parameters, and there exits problem of inadequate interpretation, RF has some problems such as low prediction accuracy and low generalization ability. Among exiting classifiers, KNN [57] is a simple and effective classification algorithm based on distance measurement in pattern classification, which is not constrained by the statistical distribution of data samples and can deal with non-linear and multi-modal problems. However, it is necessary to find the nearest neighbor, measure the similarity between samples and calculation samples. In this distance, all features are given the same weight, regardless of the difference of features importance, the final classification effect is not stable, and the accuracy is not high. Considering the complex of influencing factors of coal and gas outbursts, different feature selection methods have been proposed. The influencing factors of coal and gas outbursts have different effects on outbursts, and feature weighting is used to measure the features importance for classification. The more important features for classification are given a higher weight, and the less important features for classification are given a lower weight. The importance of feature weight to datasets can change the distribution characteristics of samples, make the distribution between similar applications more compact, and the distribution between different applications looser, so the KNN is easier to partition the sample space. The commonly feature weighting methods are as follows: Entropy Weight(EW), Fault Tree Analysis(FTA), Decision Tree, Random Forest(RF) and Gradient Boosting Decision Tree (GBDT) etc. Therefore, considering the characteristics of coal and gas outbursts index features, the GBDT feature weighting method is used to assign different weights to each feature, the classifier effect of KNN is furtherly improved by weighting different features. However, the redundant initial input feature subset has great impact on the performance of GBDT, it could pose a significant challenge to the efficiency, the above hybrid feature selection is necessary for enhancing the performance of GBDT model.
There has still space to improve the performance of the existing outbursts prediction models in feature correlation measurement, feature subset selection and modification of classifier algorithm. In order to overcome the above limitations, we propose a comprehensive prediction model utilizing MIC-MRMR-ND + RF for feature selection and GBDT-KNN for synchronous feature weighting and optimization classifier algorithm. Firstly, a new simple and efficient measurement standard based on the MIC is proposed to measure the relationships between feature-feature and feature-class, the ranking idea of NSGAII is used to evaluate the feature importance according to trade-off of the redundancy and relevance, then we employ the modified MRMR algorithm to obtain the importance ranking of features. Secondly, RF is introduced to evaluate a feature subset within the possible subset space, remove the redundancy features and obtain the optimal feature subset that contributes to the effect classifier optimization. Finally, the GBDT is introduced to set the weight of different features in the optimal feature subset according to importance of different features that contribute to classification performance, different weights are set to strengthen the features with high relevance to the class label and weaken the features with low relevance to the class label, then the KNN classifiers are used to evaluate the robustness, efficiency and accuracy of the above feature selection methods. The results are verified by several statistical tests, and it is worth mentioning that the proposed GBDT-KNN classifier combing the above hybrid feature selection can obtain the higher accuracy than other classifiers combining with other exiting feature selection.
This paper is structured as follows: in the second part, we introduce the related algorithms briefly, and proposed the framework of hybrid feature selection and modified KNN classifier. The third section introduces the experimental environment and parameter setting, then introduces the experimental results and analysis. Finally, the fifth part summarizes the thesis and puts forward suggestions for future work.
Materials and methods
A flowchart of proposed feature selection scheme and outbursts classifier procedure is shown in Fig. 1. The proposed feature selection and outbursts classification method includes filter feature selection, wrapper feature reselection, feature weighting and outbursts classification as following description.
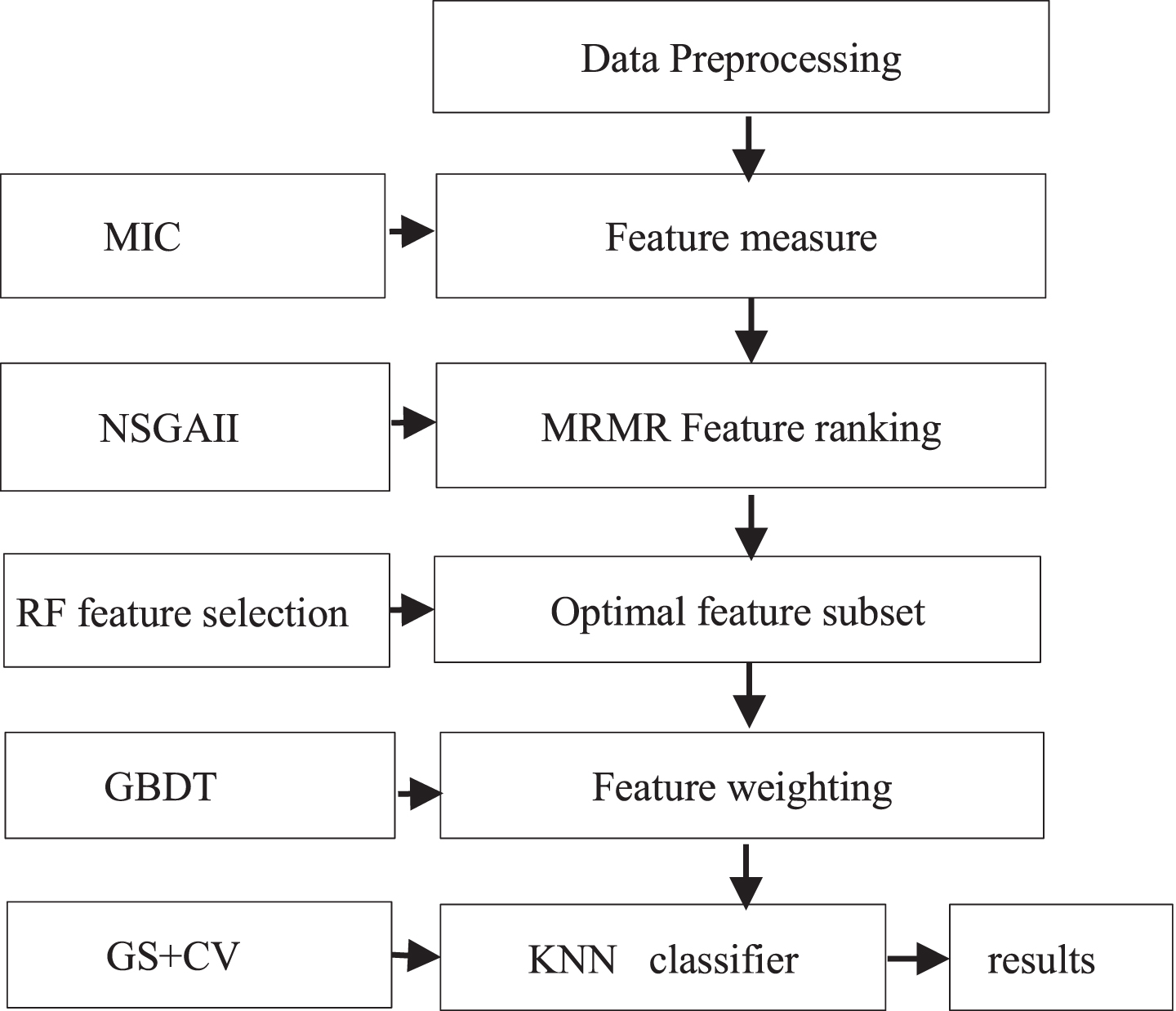
Flowchart of proposed feature selection and outbursts classifier model.
MIC
MIC [58] is the information standard that can effectively identity the widely correlations such as the linear, non-linear, dependence and non-functional dependence relationships between two variables, it possesses the two properties of generality and equitability, and has higher accuracy compared with MI. It mainly uses MI and grid division methods to calculate the values. Given variables X = {ai,i = 1,2 ... .n} and Y = {bi, i = 1,2..n}, n is the number of samples. The basic idea is as follows: For the relationship between two variables is discrete in two-dimensional space, and it can be represented by scatter diagram, the current two-dimensional space is divided into a certain number of intervals in the X and Y directions, and then check the current scatter in each grid, which is the calculation of joint probability, so as to solve the problem of joint probability in MI.
Among them, we suppose D = {(xi, yi), i = 1,2, ... ,n} is a finite set of ordered pairs, and define partition g to divide the value domain of variable X into x segments, and to divide the value domain of variable Y into y segments. G is the grid with a size of x*y, meanwhile, in each grid division, the MI(x, y) is calculated. There are many ways to divide the same x* y grid, the maximum value of MI(x, y) in different partition methods is regarded as the MI value of partition g, B(n) is the upper limit value of grid partition x*y, ω (1) ⩽ B (n) ⩽ o (n1 - ɛ), 0< ɛ<1. Generally, the B(n) value of related literature is n0.6, so this value is also used in the experiment. Given i and j, the scatter graph composed of x*y is gridded with i columns and j rows, and the MIC is calculated, then MIC under different scales is normalized and selected as MIC value.
The MIC is used to measure the relevance between feature-feature and feature-class. Relevance includes a strong relevant feature, weak relevant feature and irrelevant feature. For any feature, the greater the redundancy between Fi and Fj is, the stronger the redundancy is. If the value is 0, it means that Fi and Fj are independent. In this paper, the MIC is used to quantify the degree of redundancy between feature-feature and the relevance between feature-class.
There exit conflicts between the two objectives of maximum correlation and minimum redundancy. An optimal feature subset should have the least feature size and the highest classification accuracy. The improvement of the maximum relevance objective may cause the performance degradation of the minimum redundancy objective, while it is impossible to achieve the optimization of both objectives at the same time. Therefore, we can only achieve trade-off among the two objectives as optimal as possible. Pareto-optimal solution is composed of a multi-objective optimization algorithm, which can achieve coordinated optimization of conflicting objective functions. NSGAII is a multi-objective optimization algorithm based on genetic algorithm and Pareto-optimal solution, and it includes elite retention, congestion calculation and non-dominated sorting strategy based on NSGA. For further algorithm derivation, we can refer to reference [59]. The idea of NSGAII algorithm is as follows: Firstly, the initial population with n scale is randomly generated, and we can obtain the first generation of offspring population through three basic operations of the genetic algorithm: selection, crossover and mutation; Second, from the second generation, the parent population and the offspring population are combined for fast non-dominated sorting, and the crowding degree of each individual in each non-dominated layer is calculated according to the non-dominated level. The dominant relationship and crowding degree of individuals select the right individuals to form a new parent population; Finally, the basic operation of genetic algorithm is used to generate a new child population until the end of the program conditions is satisfied, in this paper, an optimal ranking procedure in NSGAII algorithm is applied in the following filter feature selection.
MIC-MRMR-ND
MRMR is a filter feature selection proposed by reference [23], it orders features considering MI between feature-feature and between feature-class. The feature subset is to make a trade-off that the MI between feature-feature is minimum and the MI between feature-class is maximum. The process of coal and gas outbursts is a complex multi-factor coupling nonlinear system, there exit complex interactions between feature-feature, between feature-class, and it is difficult to fully express the interaction between features by using the MI. The conventional MRMR uses the MI as the relevance and redundancy measurement. In this paper, based on reference [19], a modified version called MIC-MRMR-ND which employs MIC measurement and NSGAII ranking criteria, among which, MIC is used to measure the maximum relevance between feature-class, as well as the minimum redundancy between feature-feature in coal and gas outbursts, it selects a feature that has the highest feature–class MIC, but minimum feature–feature MIC using the optimal ranking procedure of NSGAII. The maximum relevance is as follows:
Among them, |S| represents the number of features in S, and the purpose of maximum relevance is to find the feature set MAX D(S, C) that maximizes the value. The feature set selected by maximum relevance is redundant, namely, the dependency between features is very large, and the expression of minimum redundancy is as follows:
The purpose of minimum redundancy is to find the feature set MIN(S) which minimizes the value of Equation (3). Combining the above two constraint indexes, according to the idea of maximum relevance and minimum redundancy, we can get the results, it is as follows:
Based on measurement of MIC and ranking of NSGAII, the MIC-MRMR-ND feature selection method is as follows: First, assume F is the original feature set, S is the selected feature set. We initiate S to be an empty subset. Second, calculate the relevance between feature-class, then is expressed as MIC(Xi, C). Third, find the feature with the biggest MIC(Xk, C).
Fourth, we have x ∈ Fm-1, x ∈ Sm-1 to find x ∈ k, according to the following criteria.
In this paper we calculate the MIC of feature-class, then put it into the selected feature subset, and delete the feature from the original feature subset. For the features that are not selected in the original features, we calculate the MIC between feature-class, and get the sum of the MIC between the features in the original features and other features, then obtain the average value of them. In this way, each feature to be selected in the original feature contains the value of the MIC between feature-class, and the average of the MIC between the feature-feature. The MIC of the feature-class represents the dominant quantity, and the MIC between the feature-feature represents the dominated quantity. According to these calculated eigenvalues, we use NSGAII method and compute the domination count and dominated count for every feature to select a strongly relevant but non-redundant feature, then we choose the maximum of the difference between the dominating and the dominated quantity as the selected features.
The feature selection we proposed uses the ranking mechanism provided by NSGAII, when selecting features, it is based on the principle of the MIC between feature-class, and the minimum of MIC between feature-feature, namely the principle of the MIC, which needs to be solved by optimization. The rationality of the method is that the selected features have strong relevance or weak redundancy, because strong relevance has high MIC between features and class label, weak redundancy has high MIC between features-class, and medium MIC between feature-feature. If the order of two features is the same, we select the MIC of feature-class according to the reference [19]. By calculating the difference ranking of feature relevance and redundancy of every feature, we can get ranked features that consider both strong relevance and non-redundancy. The algorithm1 is as follows:
In this way, n subsets of sequence features are candidates for the next feature reselection step,
RF
RF [54] is an integrated machine learning algorithm with randomness based on the decision trees. It adopts random resampling and node random splitting technology, trains multiple weak decision tree classifiers on multiple random sampling datasets, and determines the class label of the final feature according to the voting mechanism. The accuracy of the RF depends on the strength of single tree classifier and the measurement of their dependence. RF has many advantages such as high classification accuracy, fast operation speed, good robustness, and it is very suitable for processing small sample data of coal and gas outbursts. The steps of RF are presented in the following:
Feature selection with RF
RF [33] can calculate the importance of all features, and it is widely used to identify important features that contribute to high prediction and order the features according to their importance. When the features in each tree are randomly arranged, the importance of all features is calculated according to the classification accuracy. It is good at identifying effective features from original feature sets with small marginal effect and complex interaction, so it is very suitable for feature selection of coal and gas outbursts influencing factors. In particular, the RF calculates the variable importance score of each feature in original feature sets through the method of random disturbance samples, which helps to understand the impact of specific classification features on the target variables. Because the importance score of RF variables considers the influence of single feature on the target variable and the interaction of multiple features, it is very suitable to evaluate the correlation between two variables in the original feature dataset, and it can improve the quality of the feature subset and the performance of the classification model. The key element of feature subset is to measure the performance of feature subset through the evaluation index of feature importance. In order to investigate the importance of these features, this paper uses the importance generated by the RF construction process as the feature importance evaluation index to determine how much contribution each feature makes to each tree in the RF, then takes an average value, and finally compares the contribution of every features. The contribution can be calculated by out of bag data which are not involved in the original dataset is used as the testing set to evaluate the error rate of the decision tree. For the decision tree T in the RF, the number of out of bag data correctly classified is recorded as countt,ini, a new set of testing dataset of t are obtained by randomly arranging any characteristic v of the out of bag data, we use t to test this group of data. If the number of correctly classified data is recorded as countt,v, then the importance of feature v can be obtained through Equation (9).
Among them, N represents the number of decision trees in a random forest, and the importance of the feature objectively reflects the impact of the features on the classification results. The unique hierarchical topological structure of decision trees in a RF makes them have unique advantages in dealing with the problem of interaction between features. When the features in each tree are randomly arranged, the importance of all features is calculated according to the classification accuracy. Then, the features that do not contribute to better classification performance are removed, a new RF is built iteratively. Repeat this iteration process until there are no other features to remove, the best feature set can be determined from the forest with the lowest error rate, the feature selection process of RF is as follows.
Firstly, the top features with the largest variable importance score are selected iteratively as the prediction variables to train the RF classifier. Secondly, the optimal feature subsets are selected in multiple feature subsets according to the classification accuracy of RF. In order to ensure the stability and reliability of the models, and facilitate the performance comparison with other algorithms, the ten-fold cross-validation method is used in the process of calculating the importance score of RF variables to build the classification model. In each iteration, the dataset are divided into ten equal parts, and stratified sampling is used to ensure that the subset is the same as the class distribution of the original dataset. Nine of them are used as the training prediction model of the training set, and the remaining one is used as the testing set to verify the prediction performance of the model. The iteration with the highest classification accuracy of RF in the training dataset is selected to generate variable importance score. It is used as the standard to evaluate the importance of features. Finally, the feature subset with the highest average classification accuracy in ten times is regarded as the optimal feature subset.
MIC-MRMR-ND method can calculate the correlation between feature-class and the redundancy between feature-feature according to the MIC, and features with higher scores are selected according to the NSGAII ranking. This method focuses on the evaluation of a single feature attribute, although the efficiency is very high, the results are only ordered according to the importance of features, and the algorithm cannot give the optimal feature subset. RF aims at high classification accuracy, searching several feature combination schemes and evaluating the combination results, focusing on the evaluation of feature subsets, it can effectively deal with the independent and interdependent features. It is good at dealing with the data with the complex interaction between features based on the variable importance score, during the process of the training model, considering the influence of a single feature on the class label and the relationships between multiple features, a model with high classification accuracy and good comprehensibility is finally generated. According to the classification accuracy, the optimal feature subset is selected iteratively in multiple feature subsets, and the selected feature subset has a lower redundancy between features and a higher relevance with the class label.
Therefore, we use the RF and MIC-MRMR-ND method to produce hybrid feature selection to obtain a feature ranking and achieve the optimal feature subset. In the hybrid model, the MIC-MRMR-ND method can obtain more relationships between two random variables. According to the improved MRMR algorithm, it can quickly eliminate some irrelevant features, reduce the searching scope of the optimized feature subset, and output the most important features in the order of the feature importance. Although it cannot select a small-scale optimized feature subset, the RF can use the feature ranking results obtained by MIC-MRMR-ND method as the feature subset evaluation function to provide more flexible feature searching, quickly eliminate the irrelevant features and noise features between features when selecting the most important features, and find all features highly related to the class labels in the candidates, so as to find the optimal feature subset. In this way, the characteristics of the two methods are well complementary, which can be used to design an efficient feature selection to select a group of features with low redundancy and high relevance. The proposed feature selection can be concluded as heuristic feature subset searching based on the filter method to improve searching efficiency, and stop searching based on RF to improve classification effect. In the algorithm, the relevant variables are initialized, the importance of the output features of MIC-MRMR-ND is used to order the original features, and then the process of feature subset selection is performed by RF. The first top features are selected in turn to form the new feature subset through circulation, and the RF classifier is trained on the feature subset, and the classification accuracy of RF is used to evaluate the quality of the selected feature subset. To ensure the stability and reliability of the results, the average classification accuracy of the RF generated in ten iterations is used as the basis for evaluating the quality of the optimal feature subset. The feature subset with the highest accuracy on feature subsets, the classification model, and classification accuracy on the feature subset can be obtained, in the final step, the optimal feature subset, classification model and maximal classification accuracy are regarded as output. The flow chart of our proposed hybrid feature selection is shown in Fig. 2.
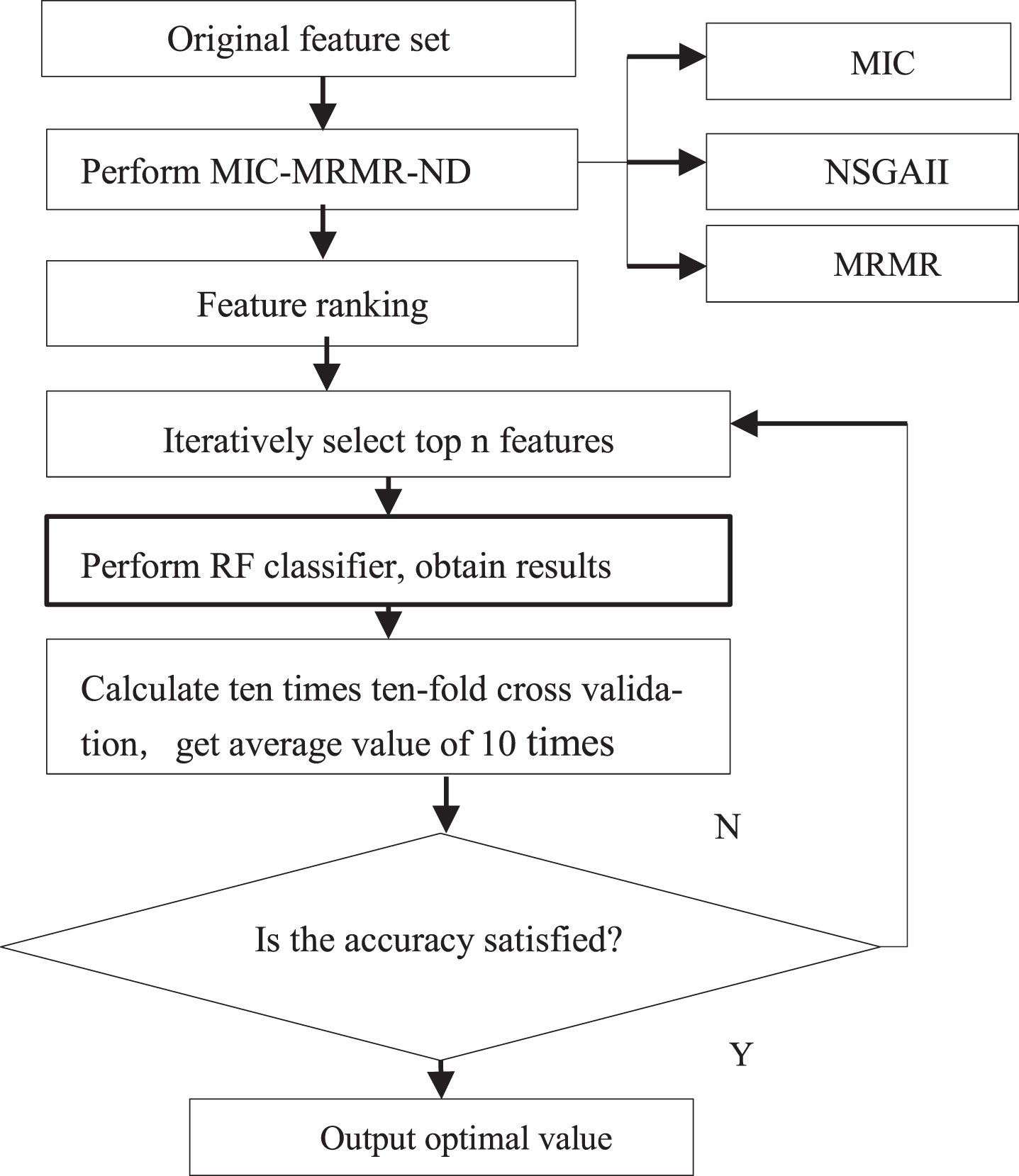
Flowchart of hybrid feature selection.
Feature weighting with GBDT
The basic idea of GBDT [60] is to combine a series of weak base classifiers into a strong classifier. Different from the traditional method of weighted positive and negative samples, it converges globally along the direction of a negative gradient. Given dataset The weak learner is initialized:
For each sample, the number of iterations M = 1: m (M is the number of iterations), the gradient direction of the residual is calculated:
The weak learner is used to fit the sample data and get the initial model. According to the least square method, the parameters of the model are obtained, a model h (x
i
; a) is fitted.
Loss function is minimized, according to Equation (12), a new step size of the model, namely the current model weight is calculated.
The following model is updated:
The features selected in this paper include the key factors affecting coal and gas outbursts. Every influencing factor has a different influencing on the occurrence of outburst events. Therefore, it is very important to choose appropriate methods to determine the influencing weight of each factor on coal and gas outbursts, and usually weight coefficient can reflect the difference of importance, so feature weighting can be used to measure the importance of features for classification. It gives a higher weight to the more important features and assigns a lower weight to the unimportant features. The importance of feature weight to sample dataset changes the distribution characteristics of samples, making that the distribution between similar applications is more compact, and the distribution between different applications is looser, the classifier can partition the sample space much easier.
The GBDT can be used for feature selection, through which the feature weighting can be obtained, which gives different features corresponding weights according to the relevance to the class label. Then, each class is given the corresponding weight coefficient according to the information gain between feature-class. The weight coefficient includes class information by setting different weights, the relevance information can strengthen the feature of high relevance to the class label and weaken the feature of low relevance to the class label. Therefore, this paper uses GBDT to weight different features according to the degree of the classification information contained in the features, different weights are assigned to different features, and the relevance between feature-class is integrated into the weight coefficient of the features. The global importance of feature J is measured by the average value of the importance of feature J in a single tree is as follows:
Where M is the number of trees, and the importance of characteristic J in a single tree is as follows:
Among them, L is the number of leaf nodes in the tree, L-1 is the number of non-leaf nodes in the tree, Vt is the feature associated with the node, and
KNN [61] has good generalization and easy implementation, it is widely applied in classification. However, it is very sensitive to input sample data and feature indexes. The prediction results of the samples to be tested are determined by their k-nearest training samples. Different features have different importance for the classification of the same class label, and the same feature has different importance for different class label. Some features are very important for one class label, but are not so important for the other class label, even are not relevant. Therefore, different features should be given corresponding weights according to their importance to the class label. However, when KNN calculates the distance between samples, all features are given the same importance, unimportant features are treated equally, which will interfere with the selection of the nearest neighbors and affect the classification effect. When KNN finds the nearest neighbor, measures the similarity between samples and calculates the distance between samples, all features are given the same weight, regardless of the difference of importance between features [62].
Our proposed feature selection can find the important features with a low correlation and reduces the initial input of GBDT. Therefore, this paper uses GBDT to weight different features to improve the classifier effect of KNN, according to the degree of the classification information contained in the features, different weights are assigned to different features. For each class particle, according to the size of the MI between feature-class, the corresponding weight coefficient is given to the feature. The weight coefficient contains the information of class correlation, and can find more appropriate nearest neighbor training samples for the samples to be tested. Finally, according to the class information of the nearest neighbor training samples, the class posterior probability value of the sample to be tested can be calculated, and the corresponding class of the sample to be tested can be predicted.
Experiment
Dataset description and performance evaluation
According to data provided in the reference [56] and actual outbursts datasets collected at the Pingdingshan coal mine located within the Henan Province, a total of coal and gas outbursts sample data are taken as the research object in this paper. The coal and gas outbursts is mainly affected by three factors: gas, ground stress and coal structure. Gas occurrence state variables of coal: gas pressure (1), the initial speed of gas output (2); Structural parameters of coal: the initial speed of gas emission (3), structural coal thickness (4); firmness coefficient (5); Stress state of coal: fault structure complexity (6), these six indexes are used as the influencing factors of coal and gas outbursts prediction, the influence of these evaluation indexes on coal and gas outbursts has been explained in reference [56], and the class labels (7) include outbursts and normal. These indexes are operability, extensive and applicable in engineering practice. Outbursts is a bipartition problem, namely 1 for the outbursts type and 0 for the non-outbursts type, as listed in column 7, and the part of data for model training is given in Table 1.
Raw data for coal and gas outbursts
Raw data for coal and gas outbursts
In order to evaluate the performance of feature selection and classification, the runtime, the number of selected features, accuracy, precision, sensitivity, specificity are introduced, moreover, in order to reduce the impact of the features with high value, datasets are implemented by normalizing into the range [0,1], the normalization can be used to perform a proper and honest comparison of the results.
To test the performance of the proposed architecture for outbursts prediction, all of the case studies are performed on the following platform: a 64-bit, Intel Core, i5 9300 CPU, 2.40 GHZ, 8GB of RAM, Python3.7 environment running on Windows10. The source code of all the different methods used in this paper is implemented in python with the help of some scikit-learning packages. Scikit-learn contains many top-level machine learning algorithms.
The parameter setting in the experiment is set by the combination of grid search and ten-fold cross-validation. Before training the model, we use grid search and 10-fold cross-validation to determine the corresponding parameters of SVM, RF and KNN according to the experimental settings. For SVM, the kernel function is Gaussian kernel function, and the penalty factor (C) and the adjustable parameter of Gaussian kernel function are determined using grid search optimization, the range of k value in KNN is [1,10, 1,10], and optimal value is obtained in the experiments, the parameters of RF employ default values, in order to eliminate the randomness factor, each experiment is repeated ten times with different random seeds for RF, the averaged performance of these ten repetitions is reported as the final result in this paper.
Results and discussion
This section presents extensive experimental results on validating the performance of the proposed comprehensive model. The investigations include the following: (1) Experimentally investigating the effective of different filter feature selection methods with different measurements in the first experiment. (2) Experimentally investigating the effective of RF feature selection combining with the above proposed filter feature selection in the second experiment. (3) The third experiment furtherly verify the importance of different features and combination features based on the proposed hybrid feature selection. (4) Experimentally investigating the effective and stability of different classifiers based on different sample numbers in the forth experiment. (5) Comparing the performance of feature weighting using different classifiers in the fifth experiment. (6) Comparing the performance of different coal and gas outbursts influencing factors feature selection algorithms in literatures in the last experiment, the next subsections provide the results of conducted experiments.
Comparison with different filter feature selection methods based on different metrics using different classifiers
KNN, NB, SVM and RF classifiers are used to verify the classification ability of selected feature subsets. These merits of classifiers are not only their popularity, but also are their unique learning mechanisms. First, we measure the correlation between coal and gas outbursts influencing factors, the correlation between influencing factors and class label using different measurements, and order them according to the importance of influence factors using an optimization criterion used in the NSGAII algorithm, in which, the combination of different features exhibit different results on common classifiers. Table 2–5 and Fig. 3 shows the feature ranking results, features combination, classification accuracy and execution time of different metrics on three different classifiers. From Tables we can see that MIC-MRMR-ND method has obvious advantages in performance. For example, the highest accuracy of MIC-MRMR-ND method on different classifiers such as SVM,KNN,NB and RF are 91.6%, 88%,83% and 80% respectively, which are significantly higher than other measurements using these different classifiers, the highest accuracy of PCC, NMI and MI using different classifiers such as SVM,KNN,NB and RF are 89%, 88%, 77% and 79.6% respectively. For PCC-MRMR-ND, MI-MRMR-ND and NMI-MRMR-ND, the feature sizes of MIC-MRMR-ND become much smaller than PCC, NMI and MI, but the classification accuracy increases. After feature selection based on different measurements, the performance of the prediction models are all improved. In terms of execution time, the PCC has the highest efficiency, which is 0.0013 second, while the MIC has the lowest efficiency, which is 0.0030 second. From two aspects of feature size and classification accuracy, MIC has higher comprehensive performance than other measurements.
Comparison of different metrics based on SVM
Comparison of different metrics based on SVM
Comparison of different metrics based on KNN
Comparison of different metrics based on NB
Comparison of different metrics based on RF
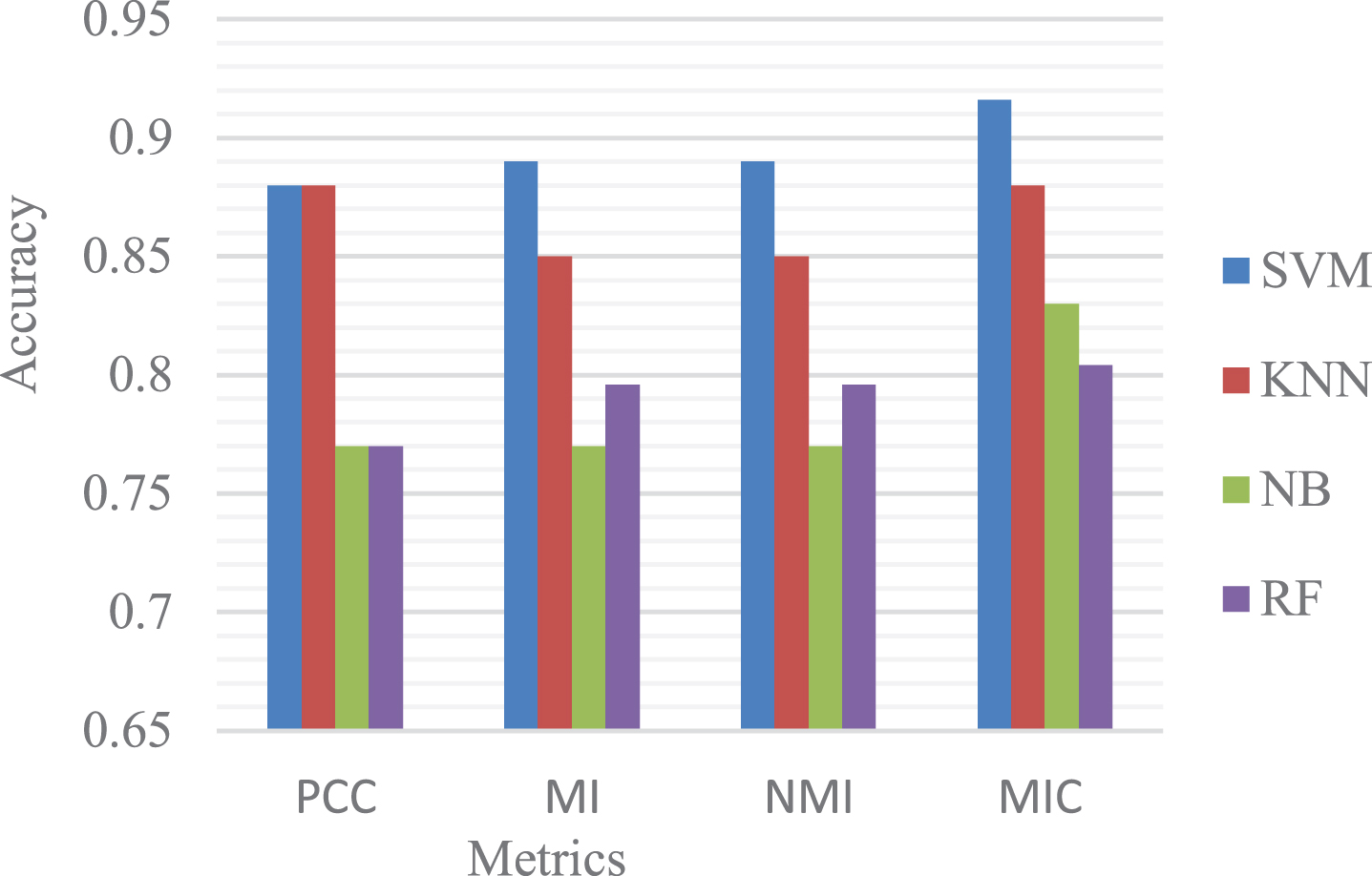
Different filter feature selection using different metrics.
There are various relationships between coal and gas outbursts influencing factors, and PCC, MI and NMI methods cannot measure complete relationships between coal and gas outbursts, and the information that they capture are not comprehensive, so the classification effect is not very good. However, MIC can measure the linear, non-linear and non-functional dependence relationships between two variables, so the classification accuracy is improved greatly, but the execution time is relatively long, while the execution time of the PCC, MI and NMI methods are much smaller. The PCC studies the variance according to the mean value of a pair of features in a certain type of sample, it only measures linear relationship between two variables, there are certain limitations. The MI and NMI can measure the linear, nonlinear and exponential relationships between two variables, and the measurement range of MI is larger than that of PCC, it is an uncertain algorithm, and the value range is relatively large, which is very easy to produce multi-value feature points problem, there are errors and redundancy, and both of them cannot measure non-functional dependence relationship between two variables, so the effect is not as good as that of the MIC. In summary, MIC is the best measurement for two variables, which can measure more relationships between two variables, and the MRMR-ND combining NSGAII algorithm can select a feature that has the highest feature-class MIC but minimum feature-feature MIC, which requires solving an optimization problem for the trade-off of relevance and redundancy, the comprehensive analyses demonstrate the MIC-MRMR-ND combining different classifiers can select high ranked optimal features and achieve highest accuracy with a low dimension.
To compare the efficacy of combination of MIC + MRMR-ND and RF, from Table 6–9, we can see the performance comparison on four different classifiers. Only the classification accuracy and feature size are compared here in the section, and other indicators are shown in the Table 6–9. The accuracy of MIC-MRMR-ND on different classifiers are 88%, 77%, 77% and 77% respectively, and the feature size is 6. After the combination of RF feature selection is performed, the accuracy on different classifiers are 91.6%, 83%, 88% and 80% respectively, which improve 3% on average. However, the feature size is 3, which is lower than the MIC-MRMR-ND method. The accuracy of the feature selection on SVM is the highest, the performance of NB, RF and NB classifier are similar in these experiments.
Results for different feature selection using SVM
Results for different feature selection using SVM
Results for different feature selection using NB
Results for different feature selection using KNN
Results for different feature selection using RF
Through the results, we can analyze that the feature selection method which only performs feature ranking is poor on three classifiers, the classification accuracy is low, and the feature number is also the high. This shows that there are redundant and uncorrelated features in the influencing factors of coal and gas outbursts, which increases the complexity of calculation and reduces the classification accuracy. Compared with the method of feature ranking only, wrapper feature selection based on the importance score of RF variables can effectively eliminate irrelevant features and redundant features while maintaining or improving the classification performance of the classifier. Therefore, before classification is performed, effective feature selection is necessary to improve the classification performance. MIC-MRMR-ND is a filter feature selection, and RF is a wrapper feature selection, they have their own advantages and disadvantages, only by combination they can produce better performance, also, it can offer a trade-off between filter and wrapper. This combination is very promising and we can obtain the highest 92% classification accuracy.
To further investigate the effect of the number of features on different classifiers, we formed six feature subsets by selecting the top ranked features obtained from filter feature selection method MIC-MRMR-ND, in the following experiments, we will choose different classifiers and different feature dimensions to discuss the prediction accuracy of proposed hybrid feature selection. Fig. 4 shows the classification accuracy with the increasement of feature dimension using different classifiers, we can see that if the local fluctuation is ignored, the overall accuracy will show a parabola shape with the increasement of feature dimension, and the accuracy gradually increases when the feature dimension is varied from 1 to 3, the accuracy reaches the peak when the number of features is 3, but more features are added, the accuracy begins to decline. The results show that it is not enough to have only a few key features in classification, only when the feature dimension reaches a certain number, the accuracy can reach the peak, of course, redundant features will lead to low accuracy. With different classifiers, when the feature dimension is less than 3, the classifier accuracy increases significantly. When the feature dimension is more than 3, the classifier accuracy does not change significantly, so the optimal feature dimension is 3, it can contain most of the classification information and has higher efficiency, achieving better classification effect. In summary, for classifiers, when the feature size changes from low to high, the recognition accuracy increases gradually, but the increasing extent cannot keep the same, the reason is that the additional features do not improve the classification performance of the evaluation model, and some of them have a negative impact on the classification, this result shows the necessity of feature selection in pattern recognition.
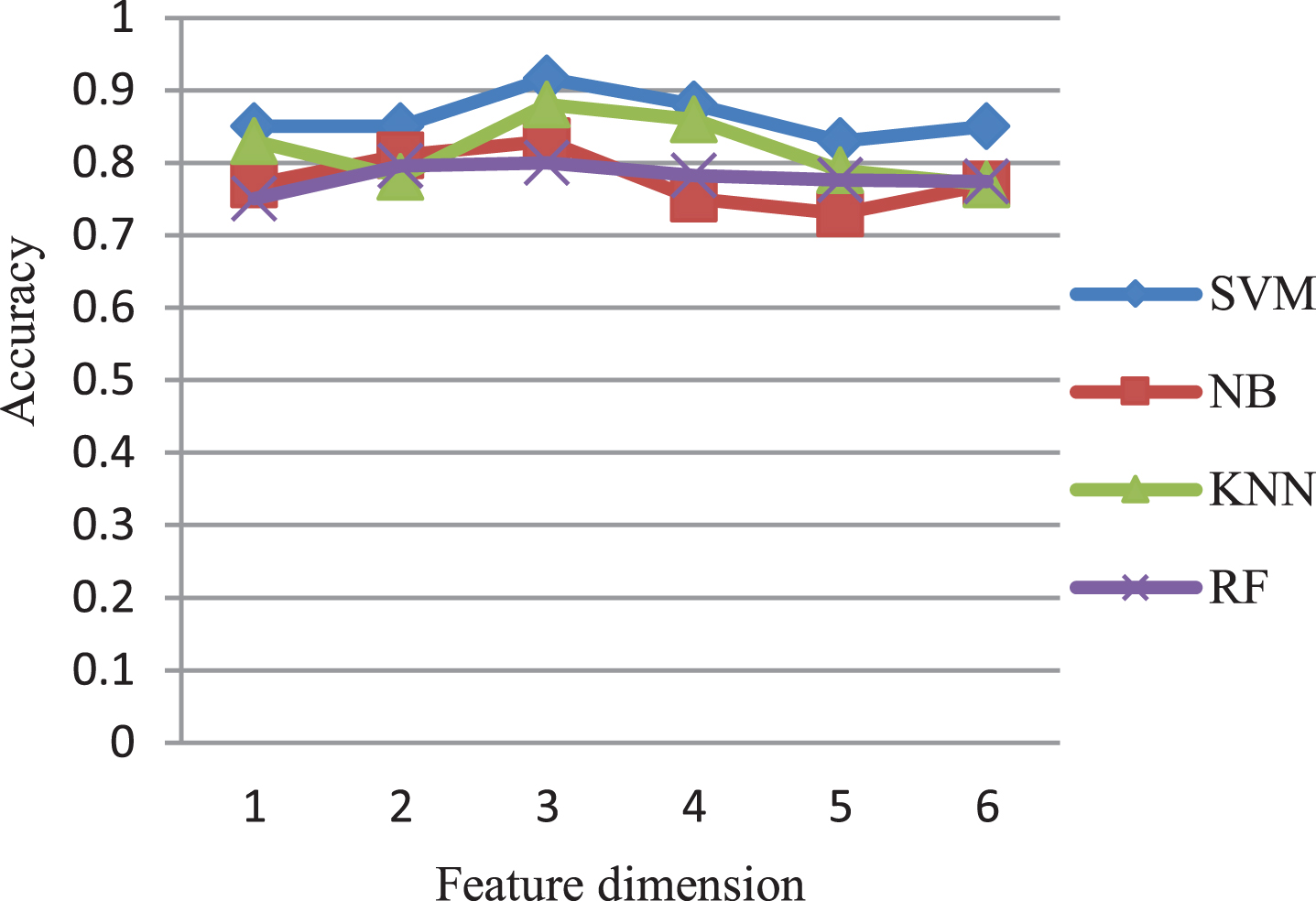
Comparison of feature dimension using different classifiers.
During the classification process of coal and gas outbursts, it is very important to select effective features. If some invalid features are selected, it is easy to reduce the performance of feature selection and classification algorithm. In this section, six features are selected for recognition, and will identity the importance of different features and feature combination which can affect the final recognition results, the relative importance of each of the independent features is also evaluated. It mainly includes two aspects: one is to use only one feature at a time, and then analyze its impact on the recognition results; the other is to remove a feature respectively, then analyze the final recognition results of feature combination.
As can be seen in Table 10 and Fig. 5, the accuracy obtained when using only a single feature is given, and the classifier used is a common classification algorithm. It can be seen that the accuracy of feature 6, 3 and 2 are relatively high, their accuracy are 85%, 83% and 76% of SVM, 83%, 74% and 65% of KNN, 77%, 73% and 65% of NB, respectively, which are higher than the accuracy of the other features on these different classifiers, especially for the feature 6, the accuracy on different classifiers such as SVM, KNN and NB is the highest, feature 3 and 2 follow it.
Accuracy for single feature using different classifiers
Accuracy for single feature using different classifiers
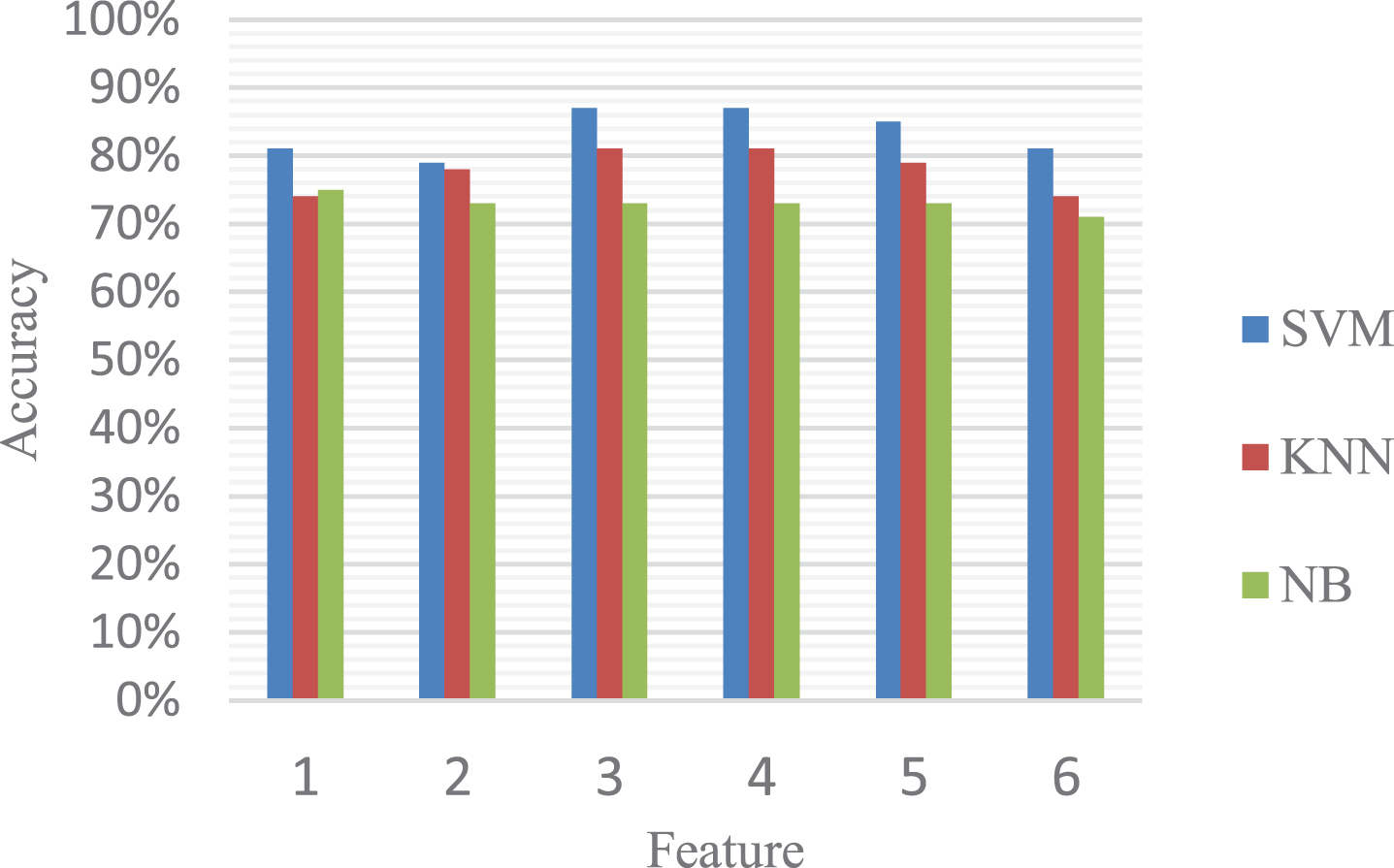
Accuracy for adding single feature using different classifiers.
As can also be seen in Table 11 and Fig. 6, the accuracy obtained when the signal feature on different classifiers are removed respectively is given. When the feature 6, 1 and 2 are removed respectively, the accuracy are 81%,81% and 79% of SVM, 74%,74% and 78% of KNN, 71%,75% and 73% of NB, which are lower than that of using the other features on these different classifiers. Especially when the feature 6 is removed, the accuracy on different classifiers are the lowest, reaching 81%, 74% and 71% respectively. it can conclude that the feature 6 is very important, it can have dependence with other features, the combination of them can achieve excellence performance, feature 2 and 1 follow it.
Accuracy for removing single feature using different classifiers
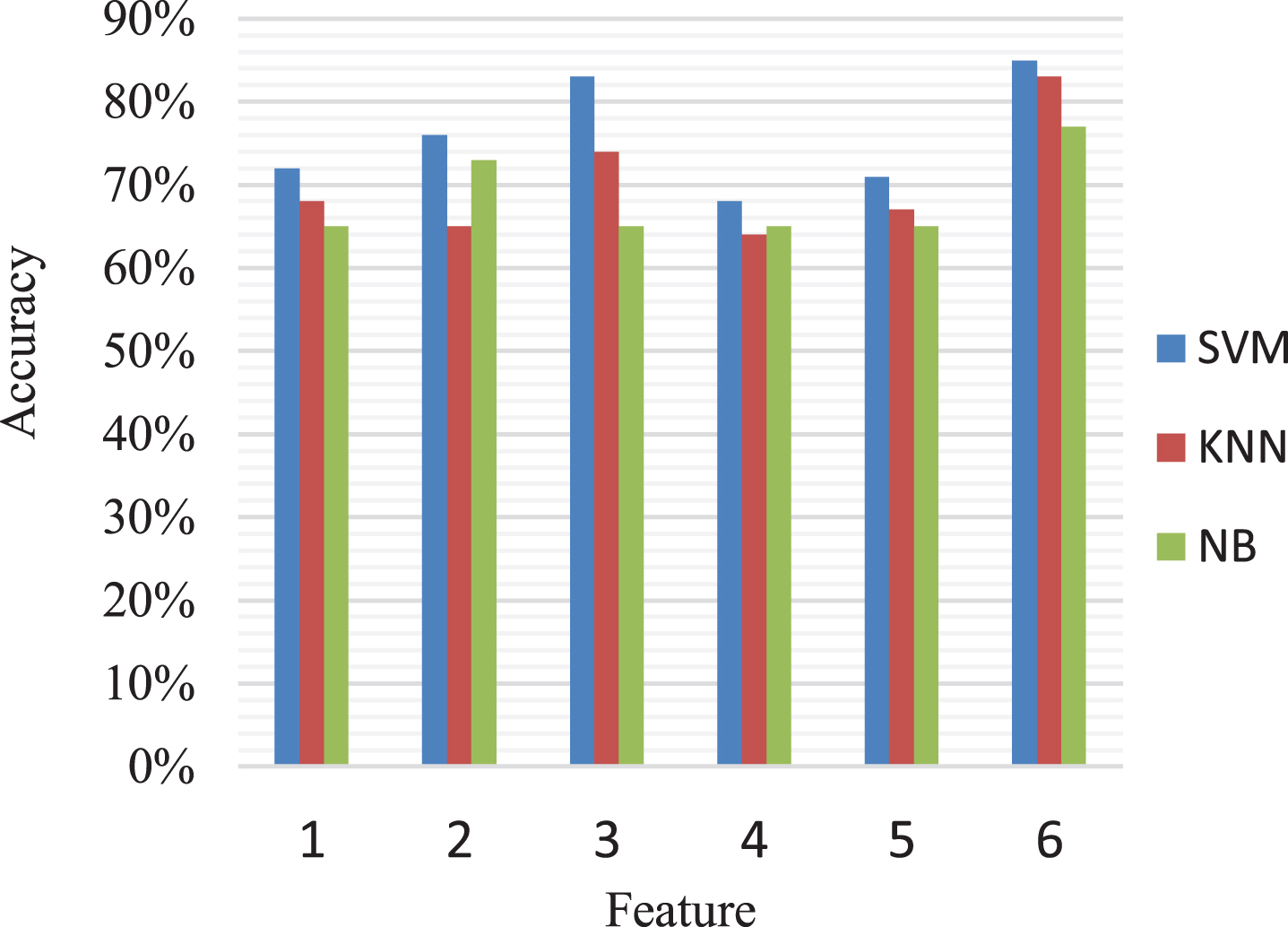
Accuracy for removing single feature using different classifiers.
In a word, we can see that the selected six features all play a similar role in the outbursts recognition, among which, feature 6, 3, 2 and 1 perform significantly and have much more impact on the outbursts than other features, especially the feature 6 is the most important variable in determining coal and gas outbursts, if the feature 6 is excluded from the model, it will have a more negative effect on the predictive accuracy of the models than the exclusion of other features, individually. The experimental result concludes that the three best features are 6,3 and 2 respectively, which denotes gas, coal and geological factors, and it is also further verify the validity of the proposed hybrid feature selection method.
The stability of the classifier refers to whether the classification algorithm can produce repeatable results on different training sets with the same distribution when sample in the dataset with a certain distribution changes slightly. In this experiment, 25%, 50%, 75% and 100% of dataset samples are cross-validated with 10 times on the data, and the classification accuracy of the four classifiers are compared and analyzed. A different number of samples are randomly selected from all sample sets, and the number of samples increases from 25% to 100%. Different number of samples are input into different classifiers such as SVM, KNN, GBDT-KNN, RF and NB for classification experiments, and the relationships between the number of samples and the accuracy are observed. Fig. 7 shows the statistical curves of the accuracy of four classification algorithms, although the accuracy of different classifiers are different, the overall trend is that the accuracy changes smoothly when the number of sample data is between 25% and 100%. Among them, KNN and GBDT-KNN tend to fluctuate little, the classification quality of them are less sensitive to the number of samples, the trend of SVM follows KNN and GBDT-KNN, RF and NB tend to fluctuate larger, while the classification quality of RF and NB are relatively affected by the number of samples, and are sensitive to the change of the number of data samples.
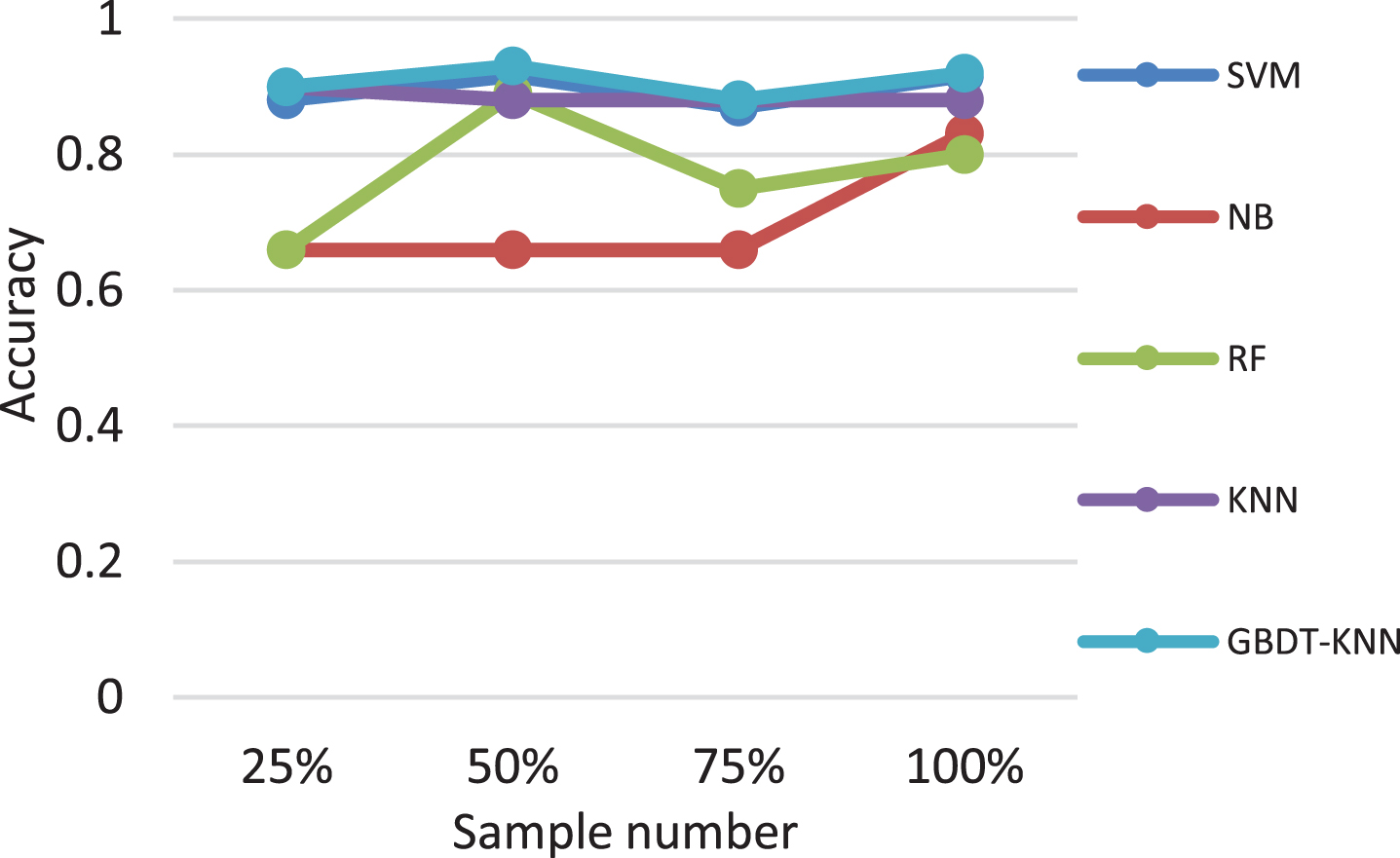
Comparison of different number using different classifiers.
The reason is that RF is a combination of forecasting methods, is also a non-linear, small sample forecasting method, but there are randomness and poor generalization ability with RF, resulting in the bad classification performance. NB needs to calculate density and probability, so the eigenvalue is positive, it cannot be implemented normally, and assumes that the conditions between features are independent, and the existence of redundancy between features reduces the prediction performance of the model. For the accuracy comparison of different classifiers in 3 features, KNN and SVM give a higher accuracy than that of NB and RF with three features. GBDT-KNN method is much suitable for solving the classification of these outbursts sample data, and it is relatively robust to variations in the number, so it can obtain a better prediction accuracy, which also shows that the classification accuracy is related to the classifier itself and distribution characteristics of data samples, at the same time we also see that the GBDT-KNN method has excellence classification ability according to the characteristic of the coal and gas outbursts, achieving the highest prediction accuracy with selected 3 features, and it can be used to evaluate the quality of the feature subset, furtherly its stable performance is better than that of NB, RF and KNN.
To compare the efficacy of our feature weighting in the proposed method over MIC-MRMR-ND + RF, from Table 12, we can see the performance comparison of feature selection methods such as MIC-MRMR-ND + RF and our proposed method on different classifiers. The accuracy of MIC-MRMR-ND + RF on different classifiers are 91.6%, 88%, 80% and 83% respectively, after feature weighting, the accuracy of KNN improves 4% on average, however, the accuracy of SVM, RF and NB keep the same. The reason is that feature weighting can enhance the influence of important features on recognition effect and reduce the interference of unimportant features on recognition effect. It makes the samples of the same type more compact and the samples of different types much looser. Based on the above principle, KNN perform the classification of the samples according to the distance between the same kind and different kinds, feature weighting can make it easier for the KNN classifier to divide the sample space. The feature weighting can improve the performance of the classifier is that the value range of the feature weight matrix is in the range of [0,1]. The original binary sample matrix has the function of mapping, which can map the original matrix to a smaller space, and the classifier is more easily to partition the sample space, thus improving the classifier performance; Therefore, the proposed feature selection method improves the accuracy significantly after feature weighting, the difference between MIC-MRMR-ND + RF and ours on KNN is that the former does not use feature weighting, so MIC-MRMR-ND + RF cannot get the similar level in classification, but the classification effects of feature weighting on SVM, RF and NB classifier cannot be improved, which also shows that the classification accuracy is related to the classifier itself and distribution characteristics of data samples.
Comparison results for feature weighting using different classifiers
Comparison results for feature weighting using different classifiers
In summary, for different classifiers, the effect on the same feature set may be different, and there is no optimal feature subset that is suitable for all classifiers. For KNN classifier, we find that its performance is limited, while the input features and sample data of KNN classifier are weighed by GDBT method, the accuracy obtains the absolutely superior results compared to KNN and other conventional classifiers. Results suggest that the proposed method GDBT-KNN can obtain higher classification performances than the other feature selection methods.
In order to verify the effectiveness of the proposed MIC-MRMR-ND + RF + GDBT-KNN model, we compare the traditional feature selection and the feature selection methods of coal and gas outbursts appearing in the literatures. In order to perform a proper and honest comparison of the results, these methods all use KNN as a classifier. In general classification, the accuracy is usually concerned as the standard of evaluation algorithm. Only the classification accuracy and the number of features are compared here, and other indicators are shown in Table 13.
Performance comparison with exiting feature selection using KNN
Performance comparison with exiting feature selection using KNN
From Table 13, we can see that the proposed feature selection method in this paper is superior to traditional feature selection methods, for example, filter methods such as Relief, CFS; wrapper methods such as GA, SBS and SFS; and the 92% accuracy of our proposed method in this paper is the highest, and other feature selection methods vary from 75% to 86%, which are much lower than our proposed method. The other indicators in Table 13 also find that our proposed method has significant advantages that can generally provide better performance in terms of feature subset size and classification accuracy, then we compare our best results with those obtained by other feature selection methods in the literatures. Table 13 are the comparative analysis of feature selection methods in this paper and literatures, including FCBF, MIFS, NMIFS, MRMR and MIFS-ND. The results show that the classification performance of proposed method in this paper are better than that in literatures. By verifying the results of feature selection with KNN classifiers, we find that the accuracy of these feature selection methods are between 79–88%, the highest is 88%. Compared with FCBF, MIFS, NMIFS, MRMR and MIFS-ND, the classification accuracy of ours is improved by 7–13% on average, and the feature size is less than most of these methods. The main reason is that Relief performs feature selection according to distance, only considering feature relevance but not dealing with feature redundancy, the interference of redundant features to classification results in performance degradation, completely ignoring the classification information provided by the interaction between features, and cannot effectively remove redundant features. While CFS is a supervised feature selection based on relevance, which cannot effectively perform the combination of multiply features, and cannot consider the redundancy between feature-feature. SBS and SFS are fast heuristic searching algorithm, which order features by certain criteria to achieve fast dimensionality reduction. By examining the contribution of each feature to the construction of hyperplane, the importance of features is measured, and the key features are selected based on the distinguishing ability of features. The disadvantage is that redundant features are not considered and cannot obtain optimal feature subset. GA is a random feature selection method, which segments the redundancy between feature-feature and the relevance between feature-class, resulting in a low accuracy. There are some defects in filter and wrapper feature selection methods, so the hybrid feature selection method combining filter and wrapper methods can make up for each other defects and improve the prediction accuracy. Therefore, the hybrid feature selection method proposed in this paper is suitable for the feature selection of coal and gas outburst influencing factors. The various indexes in Table 13 also find that the advantages of ours for FCBF, MIFS, NMIFS, MRMR, MIFS-ND are significant. This shows that the proposed feature selection in this paper can improve the prediction performance of a classifier. The main reason is that FCBF, MIFS, NMIFS, MRMR and MIFS-ND cannot consider fully the relevance between the feature-class, and the redundancy between the feature-feature, overestimate the important role of some features, ignore the joint role between the combined features, and the incomplete measurement of the correlation information between the features also leads to inaccurate classification results.
Table 13 is the comparative analysis of the feature selection methods in this paper and other documents. The feature selection methods appearing in the coal and gas outbursts prediction documents include GRA, EW and RS. We find that the accuracy of these feature selection methods are between 75–81%, the highest accuracy is 81%. Compared with GRA, EW and RS, the accuracy of the proposed approach can improve by 11–17% on average. Moreover, the feature size is much smaller than that of these methods. The various indicators in Table 13 also find that the advantages of ours are significant. The main reason is that GRA is complex in the calculation and artificial in the evaluation of the severity of highlighting, but it has the defect of weight setting subjectively. EW can assign the different weights to features objectively, but it is limited if the values difference are very small. The main advantage of RS is that the reasoning process is objective and can form explicit rules, but it may still bring over-fitting phenomenon. These methods segment the relevance between feature-feature, and redundancy between feature- outbursts, resulting in low accuracy and high runtime. When experts select features, only the prediction ability of each feature is considered, but the relevance between multiple features is not considered. However, the association of multiple features may make the combination of several weak features have strong discrimination ability. Therefore, the classification accuracy of these methods in this paper are poor, the results are very similar.
Feature selection and classifier optimization are interdependent in traditional outbursts prediction models in literatures, if we conduct them separately, it may not achieve high accuracy. Therefore, in this paper feature selection and optimization classifier are considered synchronously in outbursts prediction, in terms of classification accuracy and the number of features, our proposed method maintains the higher performance compared with the exiting state-of-art methods.
It is a challenging problem to find the optimal feature subset from the coal and gas outbursts influencing factors and improve the accuracy of exiting classifier for the coal and gas outbursts prediction, in this paper, a novel feature selection model combining modified KNN classifier which can conduct the feature selection and outbursts prediction was proposed for achieving the optimal performance, the related experiments verify the superiority of the proposed comprehensive model. The research can be concluded as follows:
In order to select high ranked features, the MRMR algorithm with MIC and an optimization ranking procedure using NSGAII was proposed, the comparison results prove that MIC can capture more information compared to other measurements, which contributes to the feature ranking.
In order to obtain subsets of highly relevant features, based on the high ranked feature ranking, we employ the feature selection ability of the RF, then the ranked feature subsets are evaluated to remove redundancy features based on the full consideration of the correlation between the single feature and multiple features, the results show that the optimal feature subset that RF obtained can achieve better classification results for coal and gas outbursts, furtherly the contribution of each independent feature on the dependent feature is measured through the evaluation of the change in the performance of the model when the feature is absent.
The related experiments have been conducted to prove the robustness of KNN classifier and importance of GBDT weighting in the optimal feature subset, the results indicate that our classifier method can maintain relatively stable results for increasing the numbers of sample, and achieve accurate results for coal and gas outbursts prediction.
The hybrid feature selection method and modified KNN classifier proposed in this paper are validated on the actual data set of coal and gas outbursts compared with other feature selection methods and traditional classifier algorithms, As the proposed feature selection and KNN optimization process are conducted at the same time, and the validation results show that it is effective to achieve the optimal prediction accuracy with the corresponding optimal feature subset. So, it is believable that proposed method is very suitable and efficient for feature selection and outbursts prediction.
However, the method has several deficiencies. Firstly, the hybrid feature selection consumes much time when calculating MIC, it needs improvement to improve efficiency. Secondly, the stability of RF is poor, which leads to uncertain results. Finally, the trade-off of the relevance between the feature-outbursts and redundancy between the feature-feature is difficulty to control and achieve the best optimal results, which is our next research objective.
Availability of data and material
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study. Some or all data, models, or code generated or used during the study are available from the corresponding author by request.
Declaration of competing interest
The authors declare no competing financial interest.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (U1704242). In addition, the authors also thank the editors and the anonymous reviewers for their valuable comments that greatly improved the quality of this paper.