
Abstract
It would be hard to deny the importance of fuzzy number ranking in fuzzy-based applications. The definition of fuzzy ranking, however, evades an easy description due to the overlapping of fuzzy sets. While many researchers have addressed this subject, close examination reveals that their results suffer from one or more shortcomings such as image-ranking problems or ranking two equally embedded fuzzy numbers with the same centroid and different spreads. This paper proposes a new fast and straightforward computational approach to ranking fuzzy numbers that aims to overcome such problems. The proposed approach considers several important factors such as spread, skewness and center, in addition to human intuition. Further, the proposed ranking approach involves a composition of these factors as demonstrated in the several examples provided and in comparison with other existing approaches.
Introduction
While researchers may find the ranking of fuzzy numbers a necessity in many real life applications, they have not yet accepted a universally agreed-upon definition. In other words, the most important question continually asked remains: can we in fact rank fuzzy numbers, and, if so, how? By ≤ or ≥, we can order real numbers, but those operators may not always trivially apply to fuzzy number ordering. In fact, fuzzy numbers, in most cases, overlap. This property of fuzzy numbers raises further questions: how would fuzzy numbers be ranked when they have the same centroid? How would they be ranked when one fuzzy number covers another? How would they be ranked when we talk about images of fuzzy numbers? 1 These and other questions surrounding the ranking of fuzzy numbers raise challenging issues, and only by answering such questions will we make progress towards an appropriate ranking methodology.
Since 1976, researchers have proposed more than thirty ranking approaches. The literature reports three classes of ranking approaches of fuzzy numbers based on defuzzification, reference sets, and fuzzy relation perspectives. Reviewing the literature chronically, first Jain [1] discussed ranking of fuzzy numbers. He maintained that to rank fuzzy numbers, one can use a ranking function F (R)to transform fuzzy numbers into real numbers and then rank them based on the resulting real numbers. In 1980, Yager [2] proposed a centroid index for ranking. Using the center of gravity for ranking was proposed in [3]. Probability concepts such as mean and standard deviation were used to rank fuzzy numbers in [4]. Artificial neural networks was also proposed for the automatic ranking of fuzzy numbers [5]. Area compensation is another way to rank fuzzy numbers that was conducted by Fortemps and Roubens [6]. Furthermore, Cheng [7] proposed a centroid index and computed the distance of fuzzy numbers’ centroid and original points. He also defined a coefficient variance index for ranking. Using the α-cut concept for ranking was introduced by Chen and Lu [8]. Chu and Tsao [9] proposed an approach by considering the area between the centroid and original points; however, their approach could lead to counter-intuitive results as reported by Wang and Lee [10]. A method based on α-cut sets and the signal/noise ratio that proposed in [11] took both qualities and quantities of fuzzy numbers into account.
In 2003, a method based on the center of gravity [12] and in 2005, a TOPSIS-based centroid index [13] were proposed to rank generalized trapezoidal fuzzy number. Considering belief features for ranking was discussed in [14]. Ranking based on screening lexicographic procedure was proposed by L. Wang et al. [15], but this approach could not differentiate between numbers with same centroids. Their approach’s drawback was later solved by Z. Wang et al. [16] using an index defined by deviation degree that revised in 2010 [17]. Employing the radius of gyration to rank fuzzy numbers was proposed in [18] that due to several non-intuitive results was later revised [19]. Defuzzification of distance minimization was also used for ranking in [20]. However, the approach gave equality for particular numbers that were intuitively different. This approach was later revised in [21] via an arbitrary epsilon-neighborhood technique. In addition, to solve the mentioned drawback, reference [22] proposed an approach based on a special magnitude of the trapezoidal fuzzy numbers; however, it leads to equality ranking of several different numbers. Ezzati et al. in [23] noticed the weakness of the approach in [22] and modified the magnitude definition.
Fuzzy numbers’ shapes and deviations was considered for ranking in [24]. An approach based on heights and spreads of fuzzy numbers was also addressed in [25]. Two indices in terms of a decision maker’s attitude towards risks as well as the left and the right areas between the idea points and fuzzy numbers were defined for ranking fuzzy numbers in [26]. In [27], an approach is suggested based on the convex hall of endpoints of the interval numbers. Authors in [28] considered the areas on the positive and negative sides as well as heights of the generalized fuzzy numbers to evaluate ranking scores; however, when the score is zero, the results appear to be unreasonable; therefore, the approach was later modified [29]. An approach that takes advantage of convex combination of upper and lower central gravity of α-level in calculating distance was addressed in [30]. In [31], a method was proposed based on the areas on the left and right sides of fuzzy numbers for ranking. Considering a trapezoidal fuzzy number as composed of two triangles and a rectangle, computing the centroid of their centroids is another approach. Along the same line, Rao and Shankar [32] used the Euclidean distance between the centroid point and the original point for ordering fuzzy numbers, while in [33], authors used the area between the centroid of centroids and the original point with considering mode and spreads factors. In [34], a modified weighted distance is presented for ranking fuzzy numbers. In [35], an approach is proposed based on the distance method. Thorani [36] proposed a ranking approach based on computing area, mode, spread, and weight for generalized trapezoidal fuzzy numbers. an approach based on α-cut was proposed to overcome the indiscriminative and counterintuitive shortcomings existing in fuzzy ranking approaches [37]. In [38], a method is proposed based on their in-center and in-radius. In addition, by means of numerical simulations, a comparative study about different fuzzy ranking approaches was provided in [39]. In 2013, authors in [40] attempted to overcome the shortcomings of deviation-degree-based approaches by considering the information of the left and the right areas between fuzzy numbers as well as their centroid points. They also considered decision maker’s attitude towards risks. The concept of ideal solutions and a distance-based similarity measure in [41] is used for comparing fuzzy numbers. In [42], the comparison result of fuzzy numbers is expressed as a fuzzy set to capture more uncertainty. In [43], an approach base on the Gergonne point of a triangle is proposed.
Since the reasoning behind above references is different, their apparently Conflicting points of view lead to different ordering results and sometimes fail to exhibit the consistency of human intuition. In fact, a full understanding of the circumstances faced by fuzzy number ranking may allow us to craft an approach to correct ranking.
This paper proposes an approach based on an intuitive interpretation of the ranking process. In particular, we suggest a measure for integrating various factors that can be derived axiomatically as well as perceptually. In the proposed approach, we consider spread, skewness, center, and human intuition. The composition of these factors is indicated as S - A index, and for handling three exceptions, is modified to S - A - e index. Dealing with closed-form, simple formulation is the most significant aspect, which separates our approach from many others. To this end, this paper is organized into five sections. Beginning with some preliminaries in Section 2, it continues with explaining the proposed approach in Section 3. It proceeds with several numerical examples in Section 4 to illustrate the approach. The final section provides the conclusion.
Preliminary
In the following paragraphs, we will review some basic definitions, which we need in the rest of the paper. Let X denote a universe set, A a fuzzy set, and A (x) a membership function.
A is continuous, A (x)is increasing on [a, b], decreasing on [c, d], one on [b, c] and zero outside [a, d], where a, b, c, d ∈ R and a ⩽ b ⩽ c ⩽ d.
We define the support set of A as S (A) = {x ∈ R|A (x) >0}.
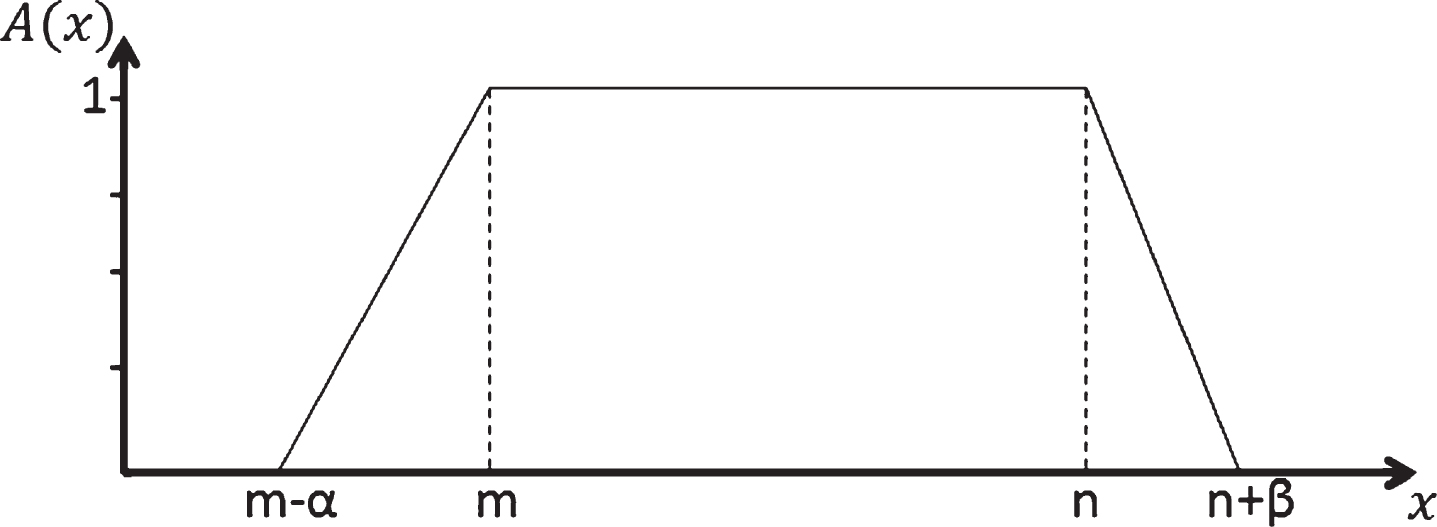
The four parameters (m, n, α, β) to define a trapezoidal fuzzy number.
As a particular case if m = n, the trapezoidal fuzzy number reduces to a triangular fuzzy number.
The multiplication ⊗ of A i and A i is A i ⊗ A j = (m i m j , n i n j , m i α j + m j α i - α i α j , β i β j + β i n j + β j n i ) LR .
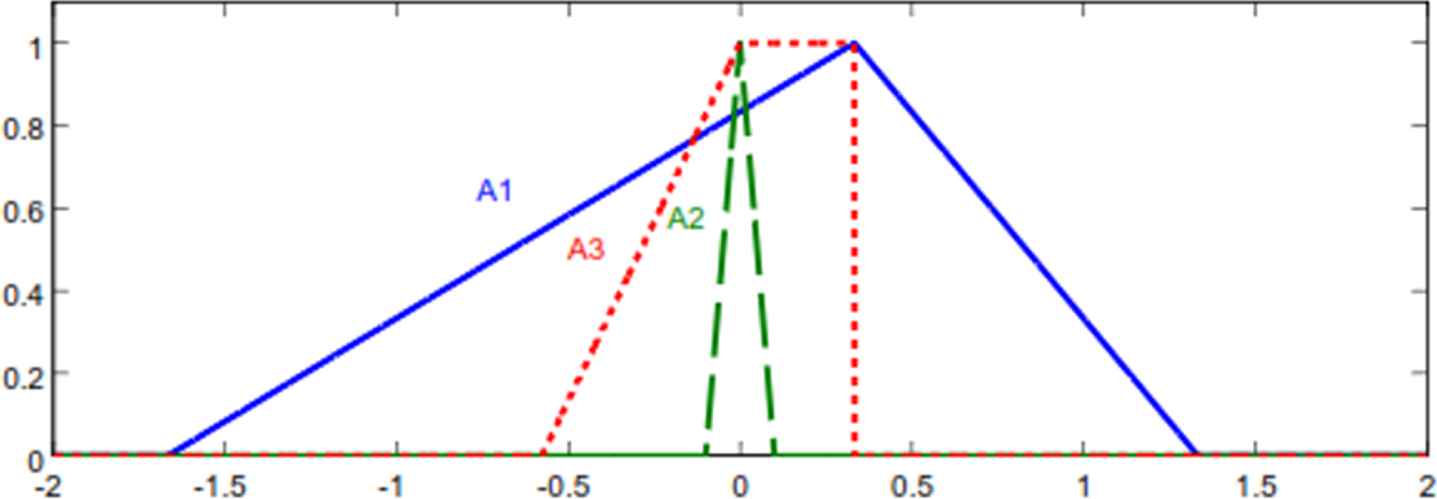
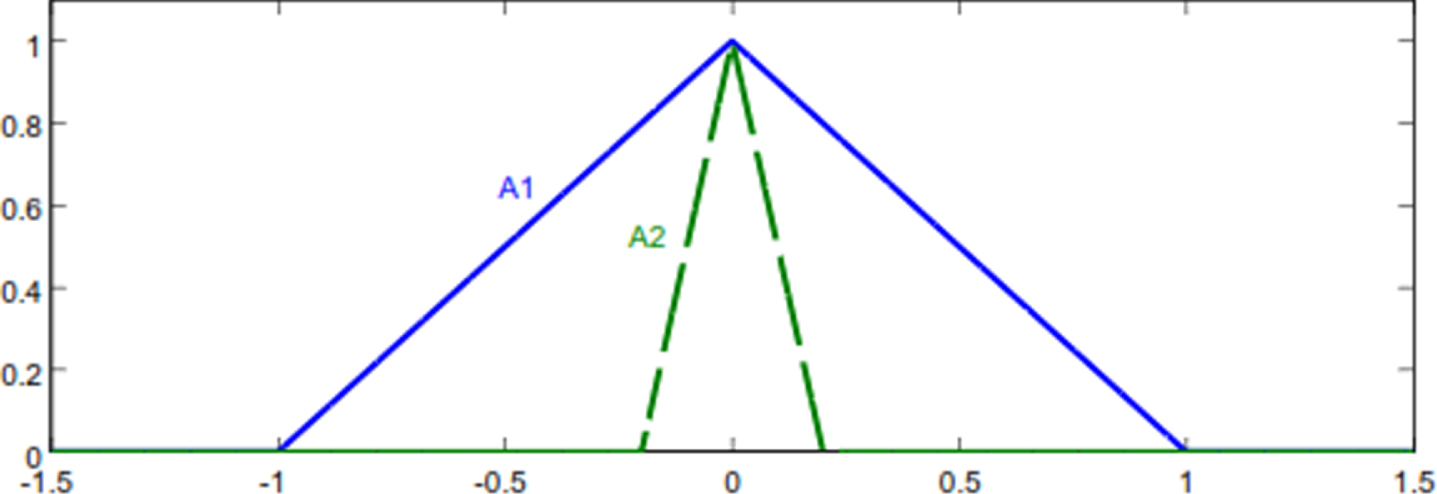
Two important notions characterize fuzzy numbers: dominance and the degree of indifference. Dominance refers to the absence of overlap between α-cut intervals of membership function [45], while we consider the degree of indifference between two numbers as the value of α-cut at which the overlap disappears. Dominance occurs in both overlap and non-overlap cases. Figure 2 illustrates the situations of dominance and indifference among three fuzzy numbers. In this figure, both fuzzy numbers A2 and A3 dominate A1, while numbers A2 and A3 face both dominance and indifference situations. In fact, the shaded area between A2 and A3 indicates their indifference.
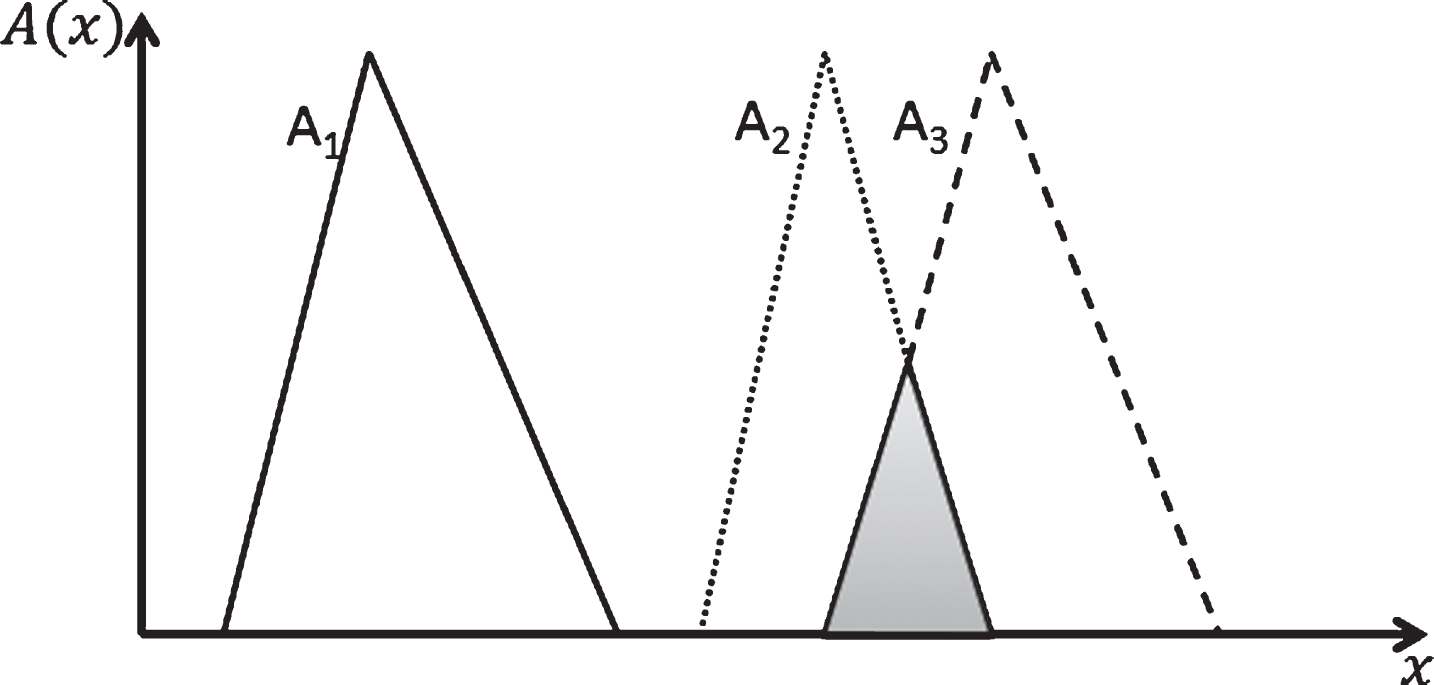
Dominance and indifference between three fuzzy numbers.
It should be noted that we use the following remarks as clues for evaluating ranking results.
In this section, we take a pragmatic and perception-inspired attitude that allows us to define a fuzzy number through different elements in a special structure. Every element may have a specific role in ranking. In other words, we consider that since fuzzy numbers differ from real numbers in quality of relevant features, it is essential to have a good understanding of the various aspects of fuzzy numbers and their interactions. Then, we discuss how we can integrate these different factors in a simple expression and move on to rank fuzzy numbers.
Structure of S - A index
The key elements of fuzzy numbers can be thought of as belonging to two classes. The first class is center, which is the principle part, and the other is a class of factors such as spread and skewness. The second class is, in fact, the driving force with which to search ways to rank numbers with the same centers. We also consider the effect of human intuition in formulating the index for ranking.
Conventional information about ranking typically relates to the center. When ranking numbers with different centers, the center can indeed be an intuitive way to increase confidence in ranking [48]. However, it is more difficult to determine ranking in cases of dominance and indifference situations while their centers are the same.
The measure of spread also remains important for correct ranking. In particular, when two fuzzy numbers have the same center, many ranking approaches will give a result of equality; but the inclusion of the spread factor in the calculation can help discriminate the numbers further. Consider a group of LR-fuzzy numbers A1, A2, . . . , A q that are described by A i (m i , n i , α i , β i ) LR , i = 1, . . . , q, where m i ⩽ n i and α i , β i ⩾ 0. The calculation of the proposed approach is adopted from this fact that measuring spread requires some knowledge of the fuzzy number boundaries and the length of support D (S (A i )). With the length of support, we mean the distance between m i - α i and n i + β i . Considering the total spread of a fuzzy number as α i + β i , we can conclude that it is less than or equal to the length of support.Therefore, using the length of support instead of spread, we can reduce computational load especially in trapezoidal type.
In certain cases, however, including spread is insufficient in ranking, and it may be necessary to integrate skewness using a special structure. To define that, let us denote the support center of A
i
(x) by G
i
and calculate it as G
i
= ((n
i
+ β
i
) + (m
i
- α
i
))/2. The center of support, G
i
, is a parameter of any interval number. Here, it is treated as the center of 0+ - cutsetof A
i
(x). We can, therefore, describe the self- skewness of any number in terms of the deviation from this center as,
Now, we integrate Equation 2 and the effect of center and spread to formulate S - Aindex for ranking fuzzy numbers as follows:
More specifically, let us suppose that D = {A1, . . . A n } denotes the set of fuzzy numbers to be ranked and AS-A be the highest rank chosen according to the S - A index. Then we can define minimizing set Amin and maximizing set Amax as follows [16]:
By this pattern, we rank fuzzy numbers using the following rules:
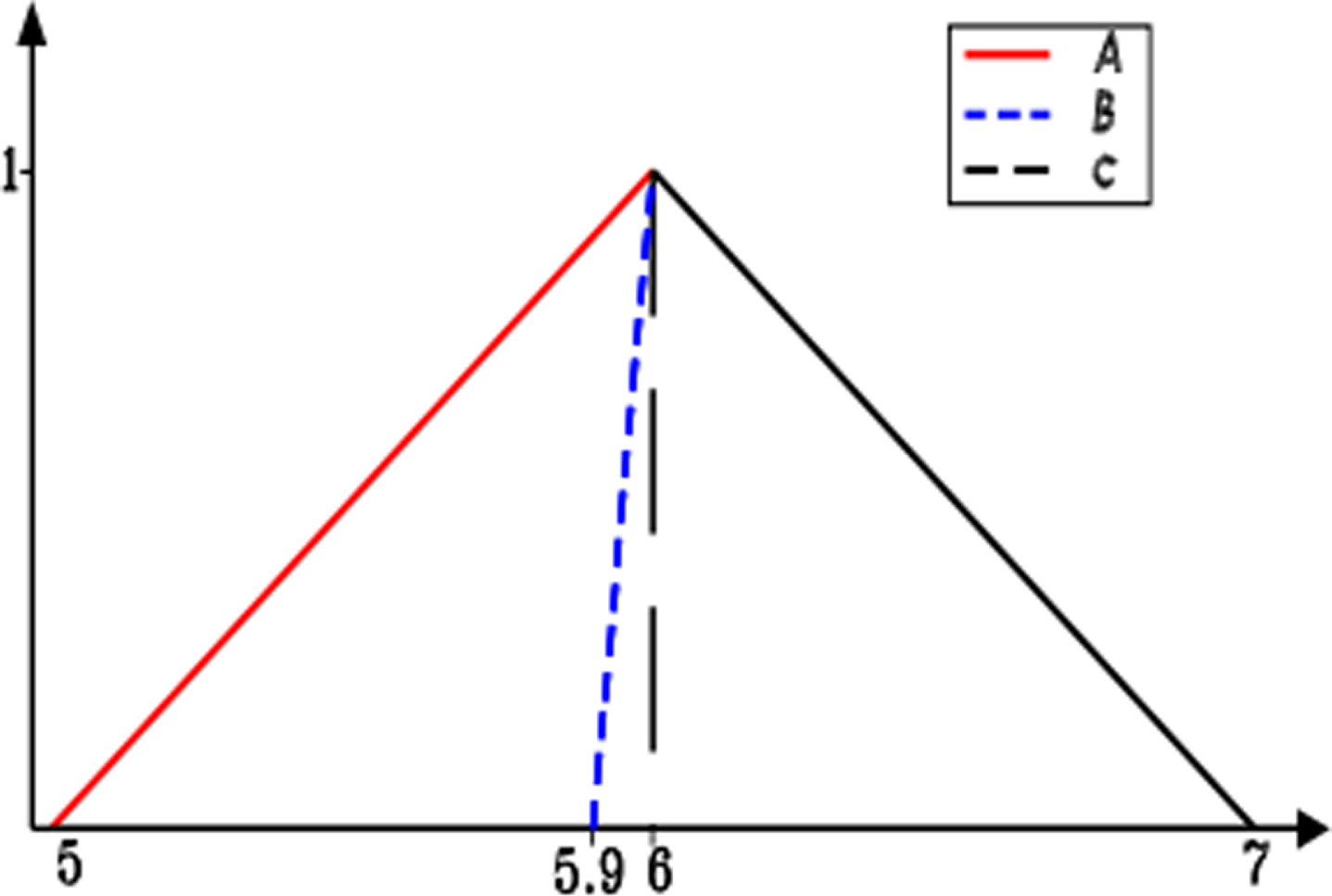
Comment 1: In S - Aindex, ɛ is used to handle situations of zero centered fuzzy numbers (Example 13). In computation, when it is not necessary, we can ignore ɛ.
S - A index shows a simple formula for ranking that characterizes most situations. However, there are three exceptions. First is when there is at least one C i that is zero and there is at least one center that is positive, second is when there is at least one D (S (A i )) that is zero, and third is when at least one G Rs i is zero, i = 1, . . . , q. Under these exceptions, S - A0 index is modified to:
In summary, the order is determined by the value returned from S - Aand S - A - eindices, where the rank of a fuzzy number A1 with respect to another number A2 is influenced by its relative spread, skewness, and center and the interaction of these factors using simple mathematical operations. It should be noted that the proposed approach can be easily generalized to Gaussian numbers using α - cut concept.
Now, consider the four fuzzy numbers A1, A2, A3, A4 and S - A,S - A - e ndices; the following properties from [50] hold.
Property P1:
Property P2: If
Property P3: If
Property P’4: If inf supp (A1) > sup supp (A2) then A1 ≻ A2.
Property P5: Suppose S and S′to be two arbitrary finite sets of fuzzy numbers and A1and A2 are in S ∩ S′; then A1 ≻ A2on S′ if and only if A1 ≻ A2 on S.
Property P6: If
Property P7: If
These properties provide the validation of the proposed ranking function, based on satisfying the reasonable properties of fuzzy quantities proposed in [50]. In addition, the indices satisfy two additional properties as follows:
Property P8: If
Property P9: If -A1 ∼ A1, -A2 ∼ A2 and
Note that since the approach belongs to the first class of categories proposed in [50], the order
The following theorem proves the aforementioned properties for the proposed indices.
Since the association is verified for real numbers, for example: (m1 + m2) + m3 = m1 + (m2 + m3), the remark is easily proved.
Numerical examples
In this section, we test the approach on several benchmark examples, taken from the literature, as well as those constructed by ourselves. We focus on different cases and on how the approach treats different situations. It should be noted that in all figures, vertical and horizontal axes represent the variable’s membership grade and universe, respectively. The value of parameter pis chosen two.
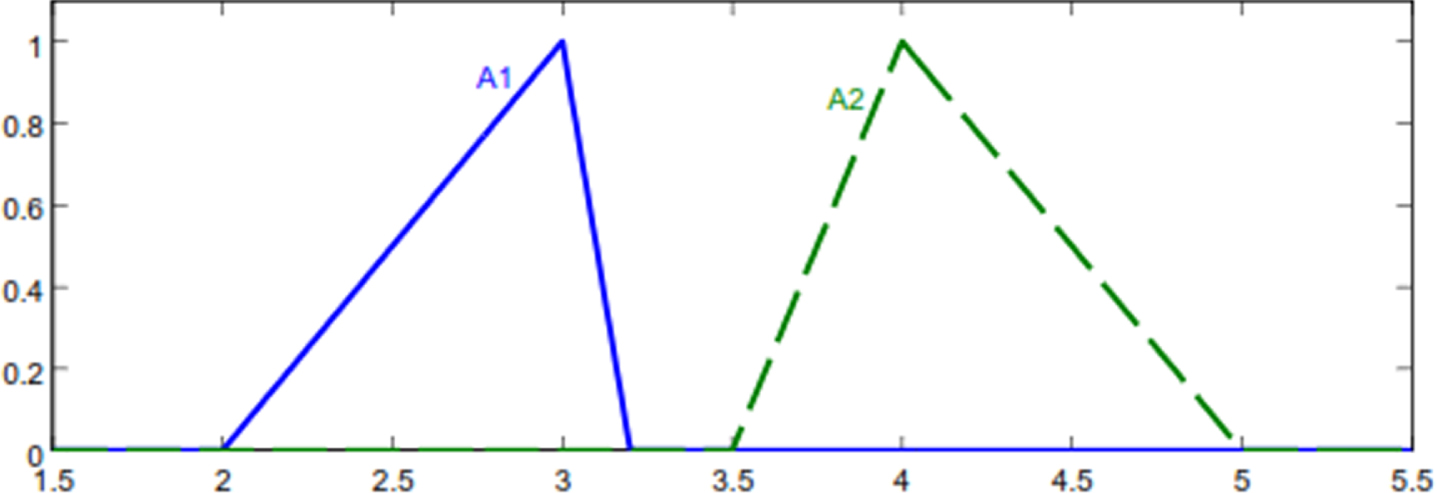
Fuzzy numbers of Example 1 for σ = 0.
By our approach, we have Γ (A1) =4.2959 and Γ (A2) =8.2293; therefore, A1 ≺ A2 that is consistent with human intuition. This example also shows that it is simple to handle ranking of two numbers where their differences are considerable and do not have overlap. In the following, we consider how the approach handles situations where differences between numbers are not as significant. For different σ values, results are specified in Fig. 4.
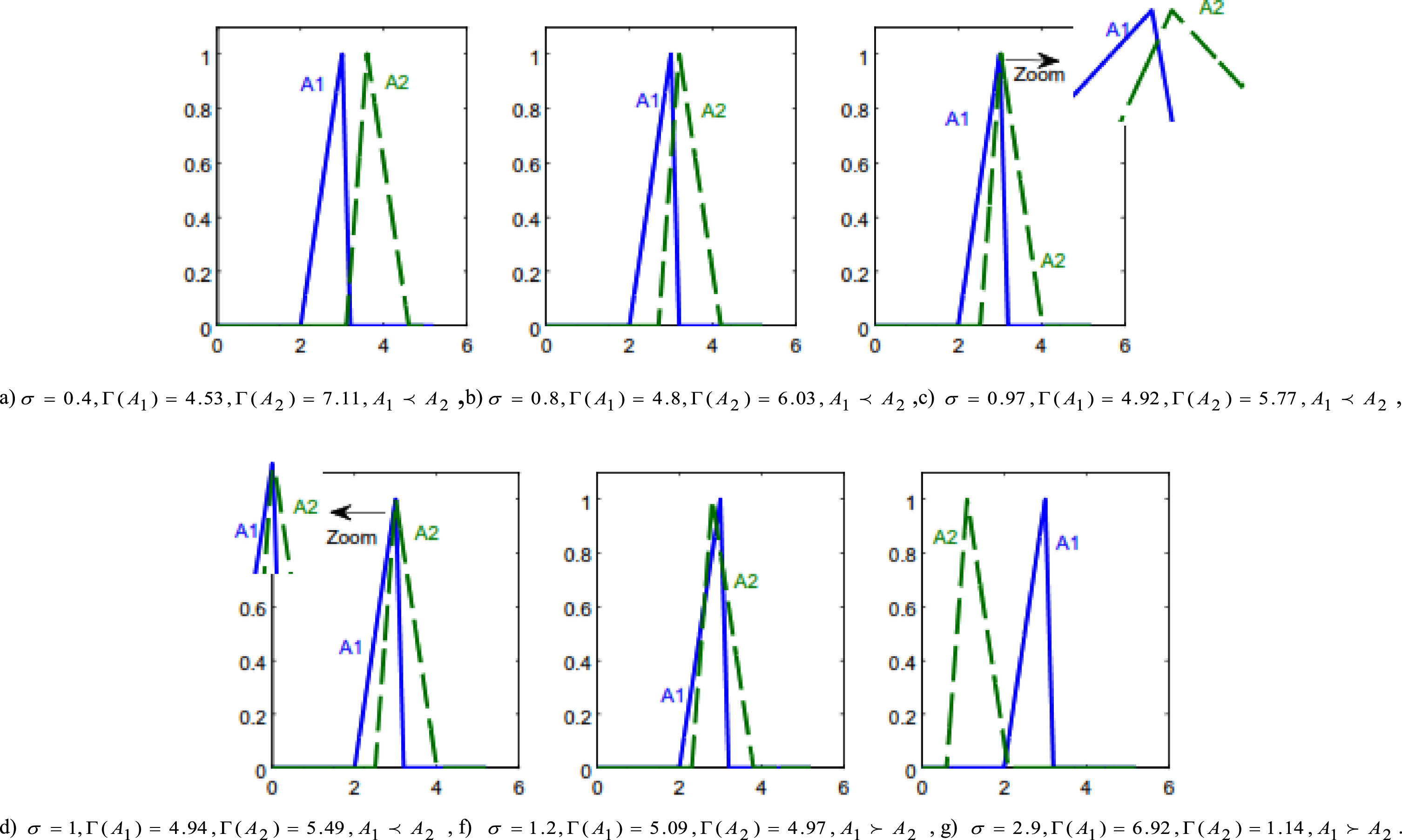
Fuzzy numbers of Example 1 for various σ values.
Without a loss of generality, we keep A1 the same and vary A2 in the below examples. For cases (a), (b) and (g), the two fuzzy numbers are distinctly different and they correspond to a high Γ difference as well. For other cases, the difference is not so clear, yet the Γ value continues to discriminate them successfully. For instance, in cases (c) and (d), the two fuzzy numbers A1and A2 are very close, and yet the Γ value shows the intuitively correct ranking. In the case of (f), where the result is no longer as clear, analysis shows A1 ≻ A2. Specifically, as the center of A1 moves beyond A1 with a smaller spread, A1 earns a higher chance to have a greater Γ.
This example clearly studies the different situations of dominance in both overlap and non-overlap cases. Figure 3 shows the non-overlap case where A2 strongly dominates A1. Figure 4 shows the overlap case. In (c) and (d) cases, A2 weakly dominates A1 and in (f) case, A1 weakly dominates A2, while in the case of (a), A2 strongly dominates A1 and in the case of (g), A1 strongly dominates A2. In fact, this example indicates the wide applicability of the proposed approach.
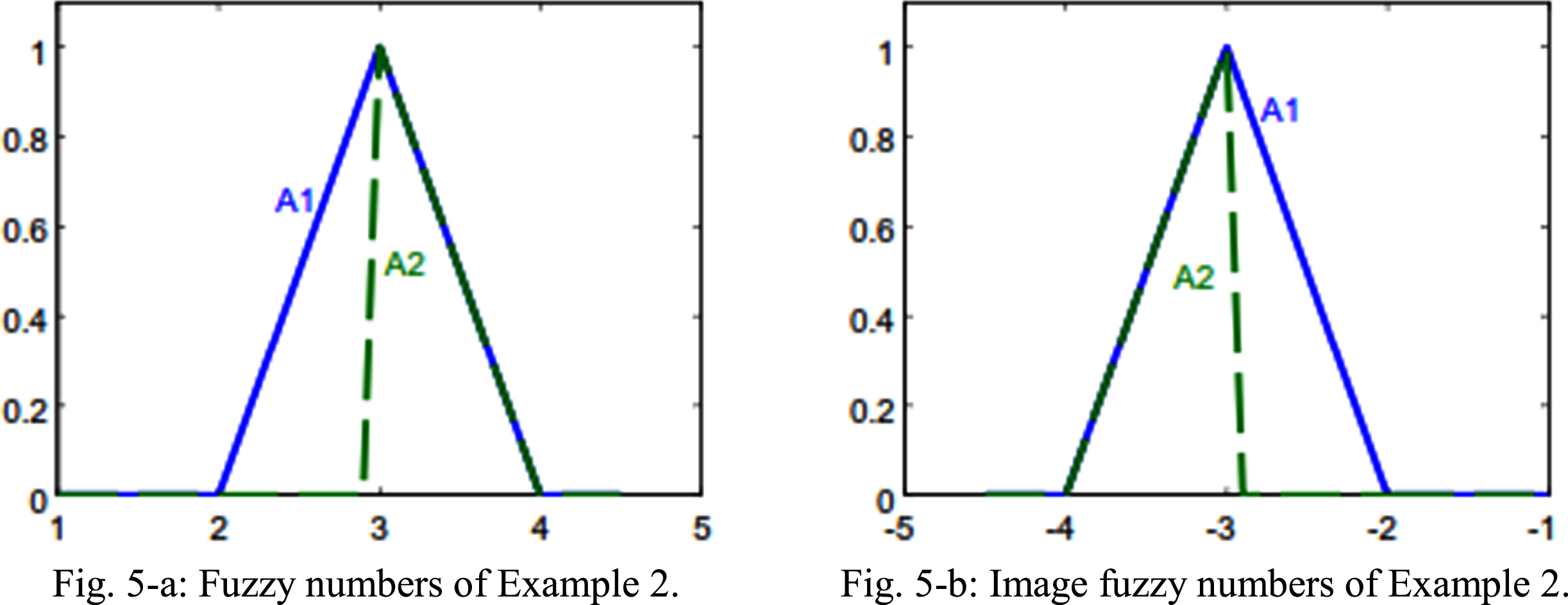
Fuzzy numbers of Example 2. 5-b Image fuzzy numbers of Example 2.
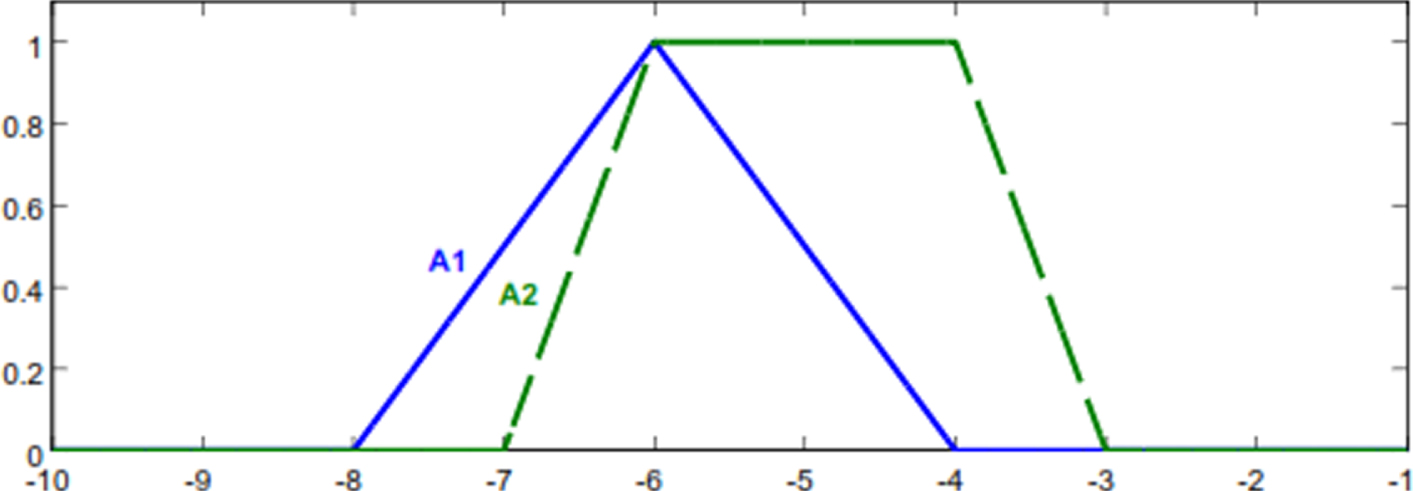
Fuzzy numbers of Example 3.
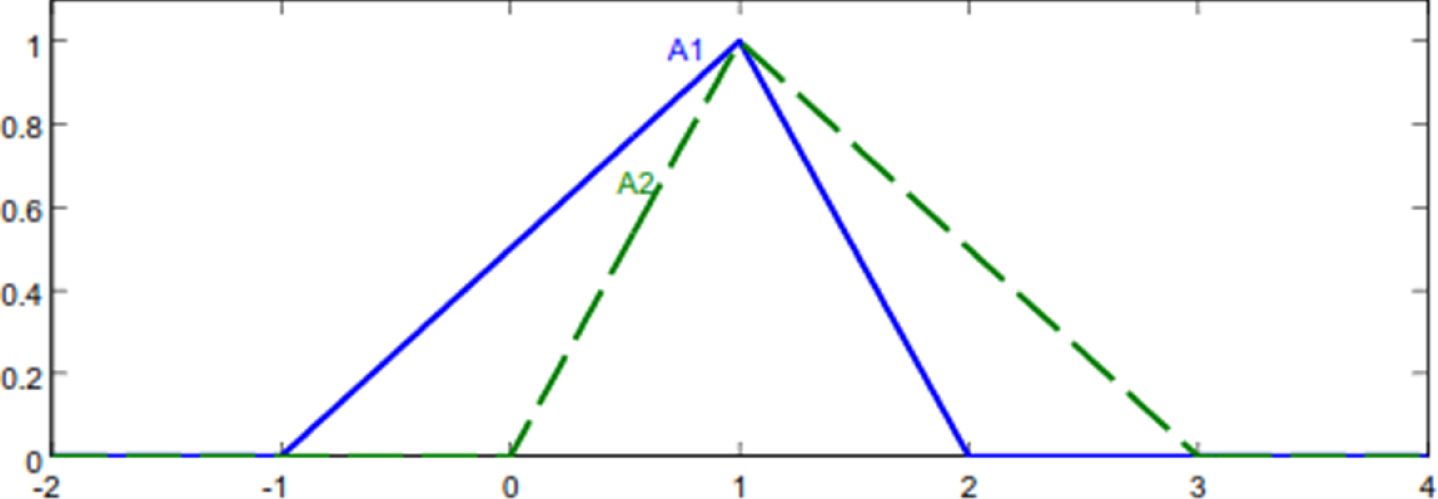
Fuzzy numbers of Example 4.
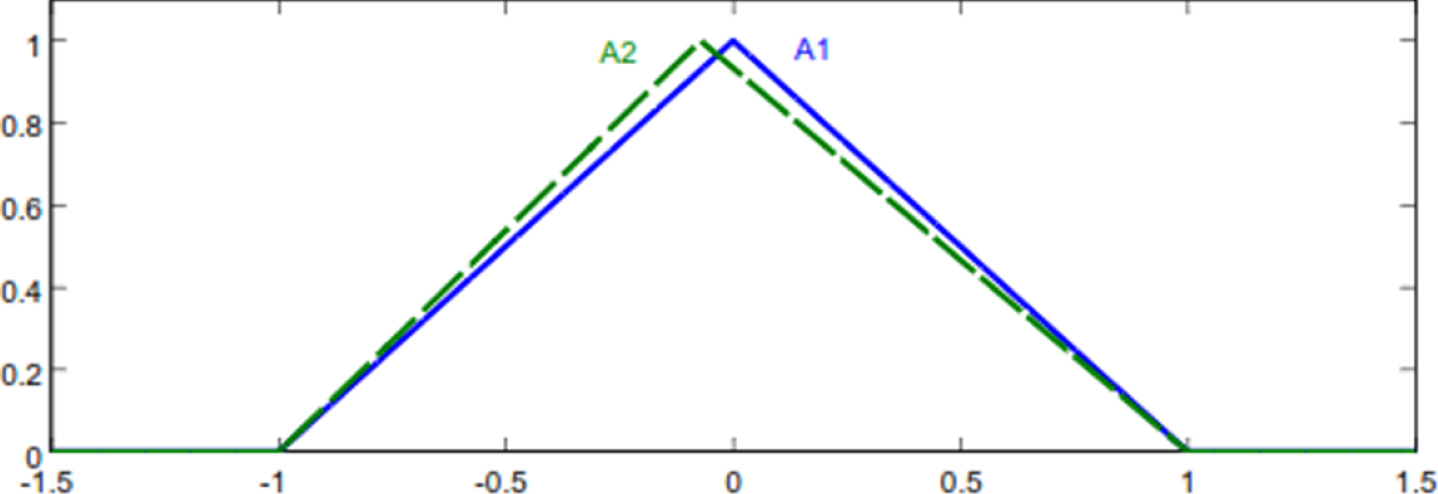
Fuzzy numbers of Example 5.
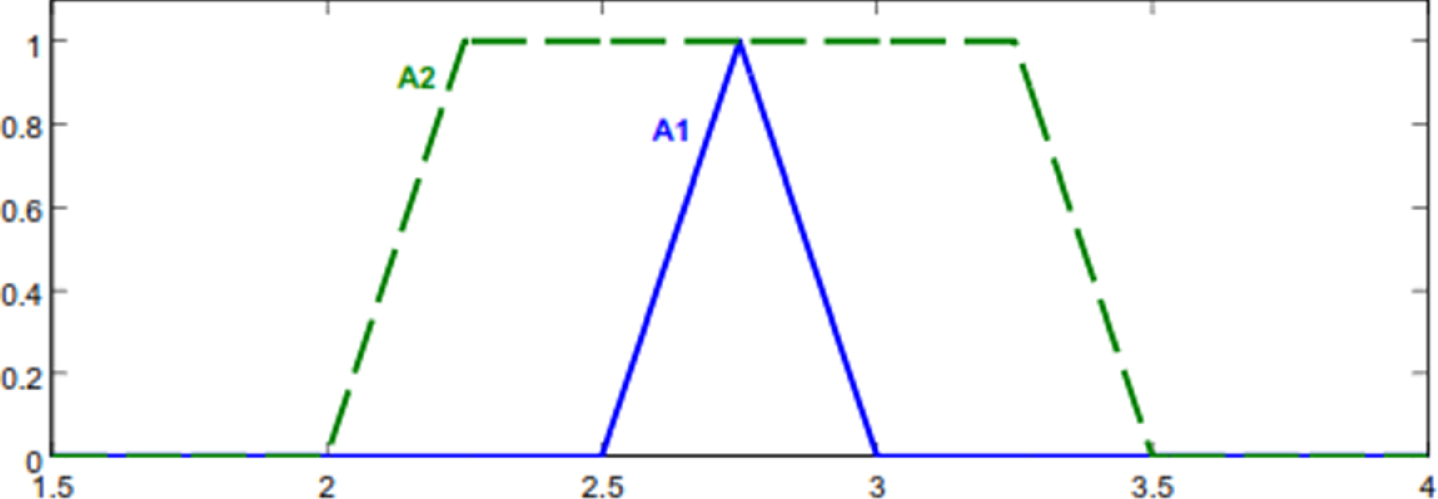
Fuzzy numbers of Example 6.
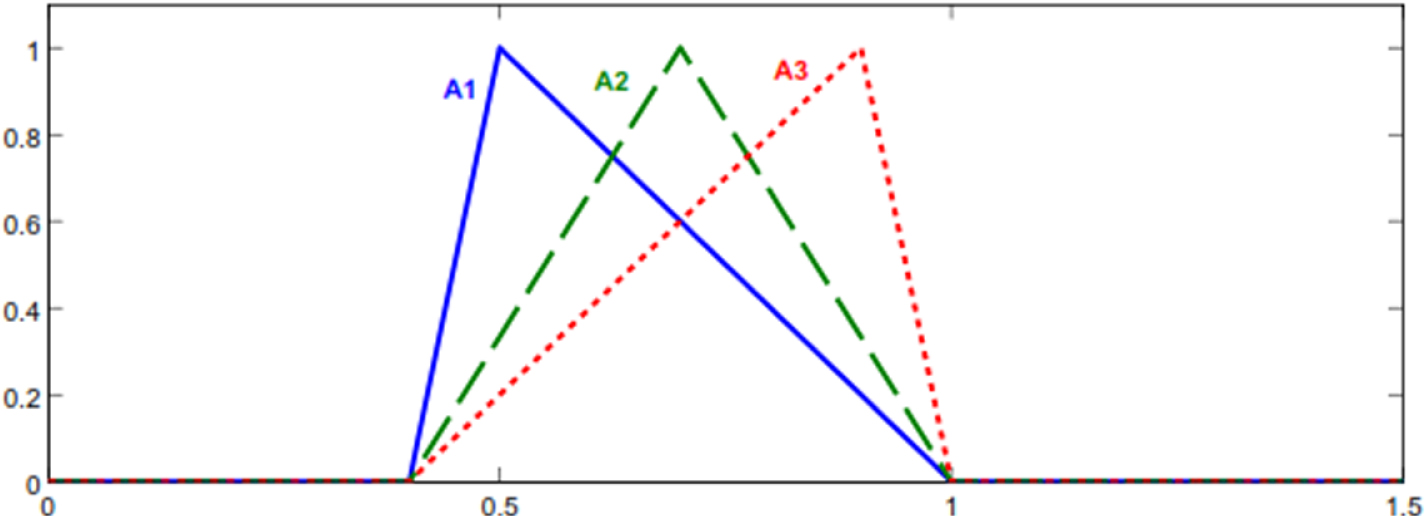
Fuzzy numbers of Example 7.
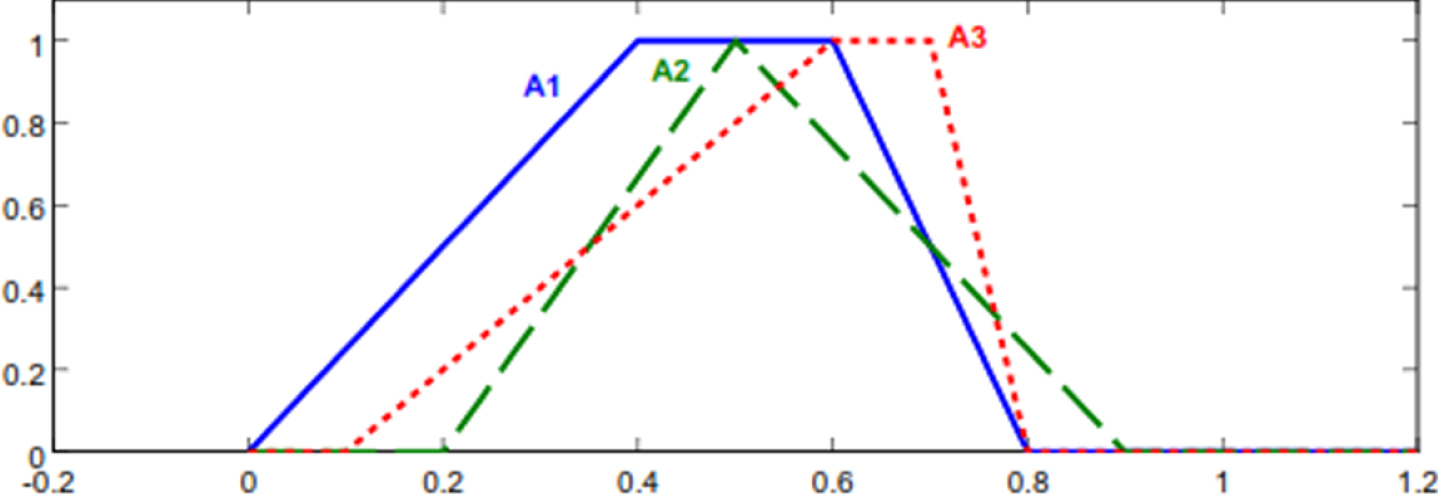
Fuzzy numbers of Example 8.
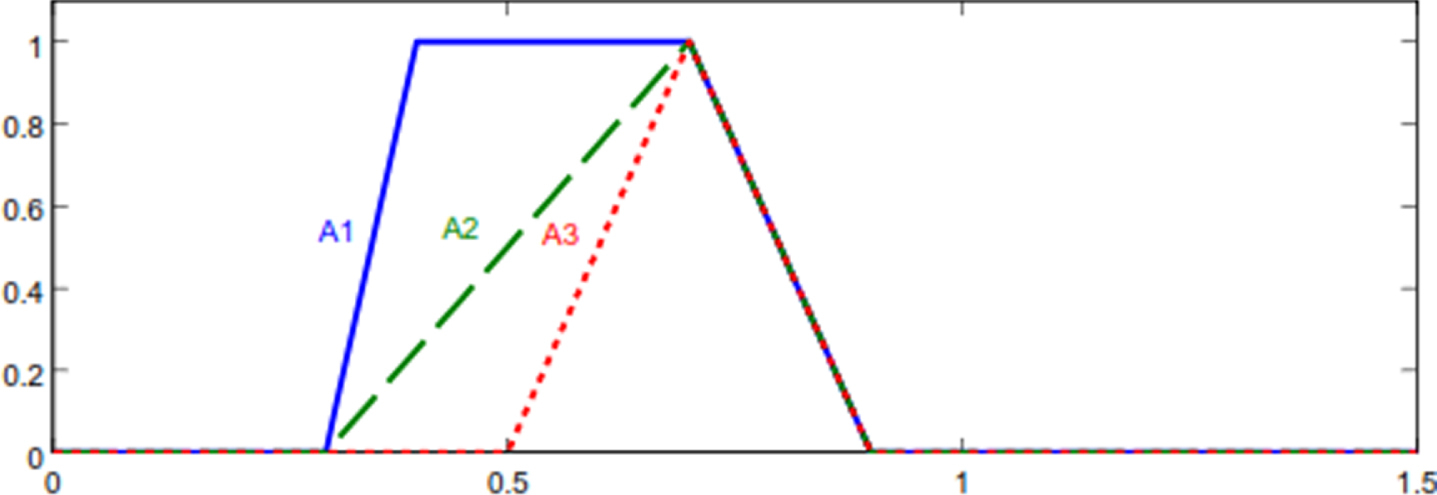
Fuzzy numbers of Example 9.
Thus far, we have been concerned with several ranking situations. As discussed in Section 3.2, it should be noted that, the equality of factors (same center, same spread, and same skewness) leads to indifference of fuzzy numbers. Moreover, for above examples, we observed that the S - Aindices of image numbers are image of the relevant numbers’ indices as well. Now in the following, we illustrate the above three exceptions in Section 3.
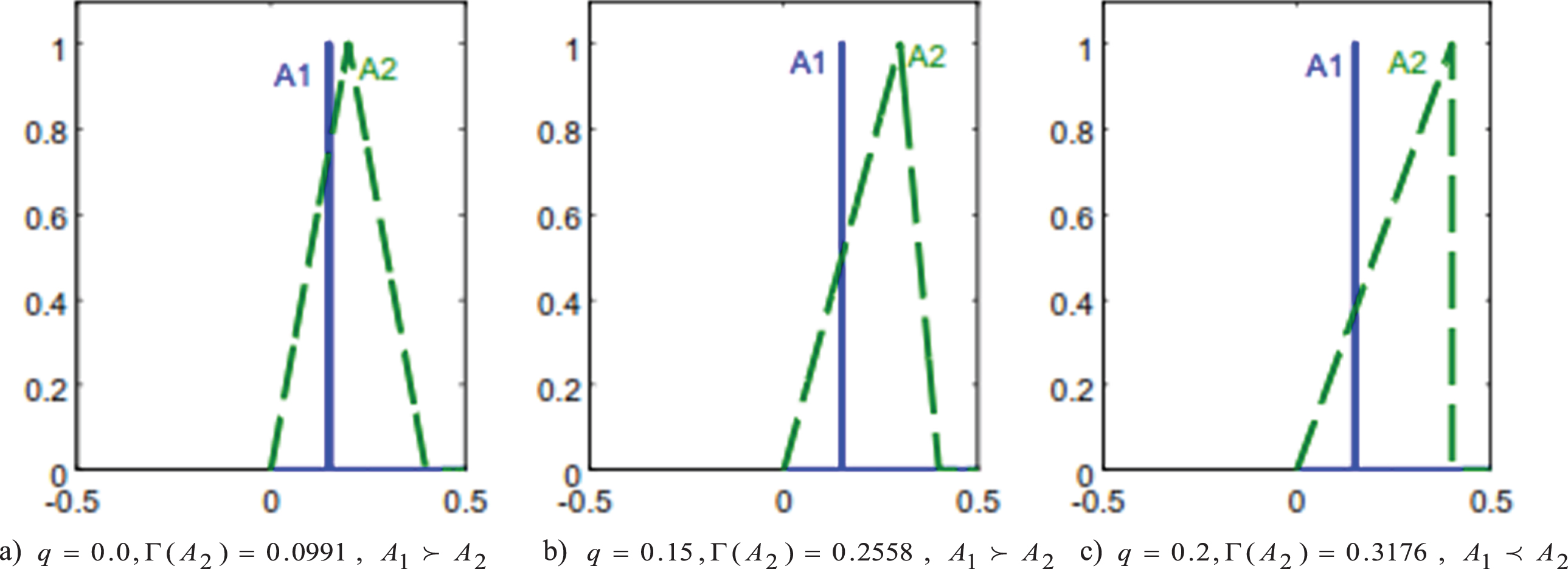
Fuzzy numbers of Example 10.
Fuzzy numbers of Example 11.
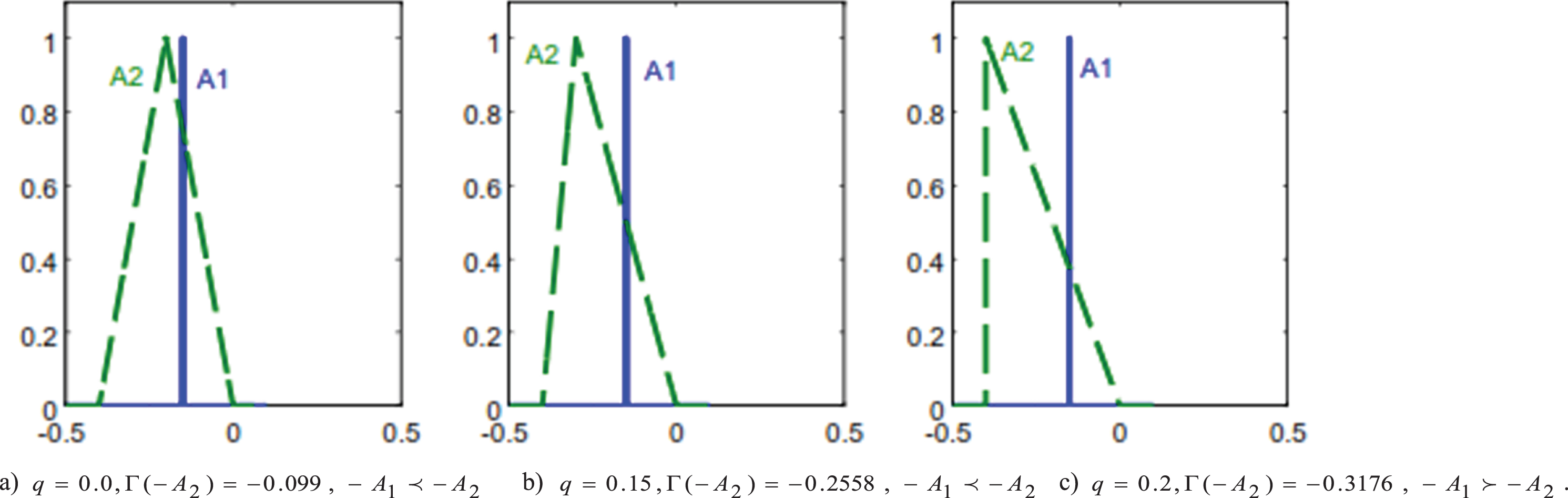
Image fuzzy numbers of Example 11.
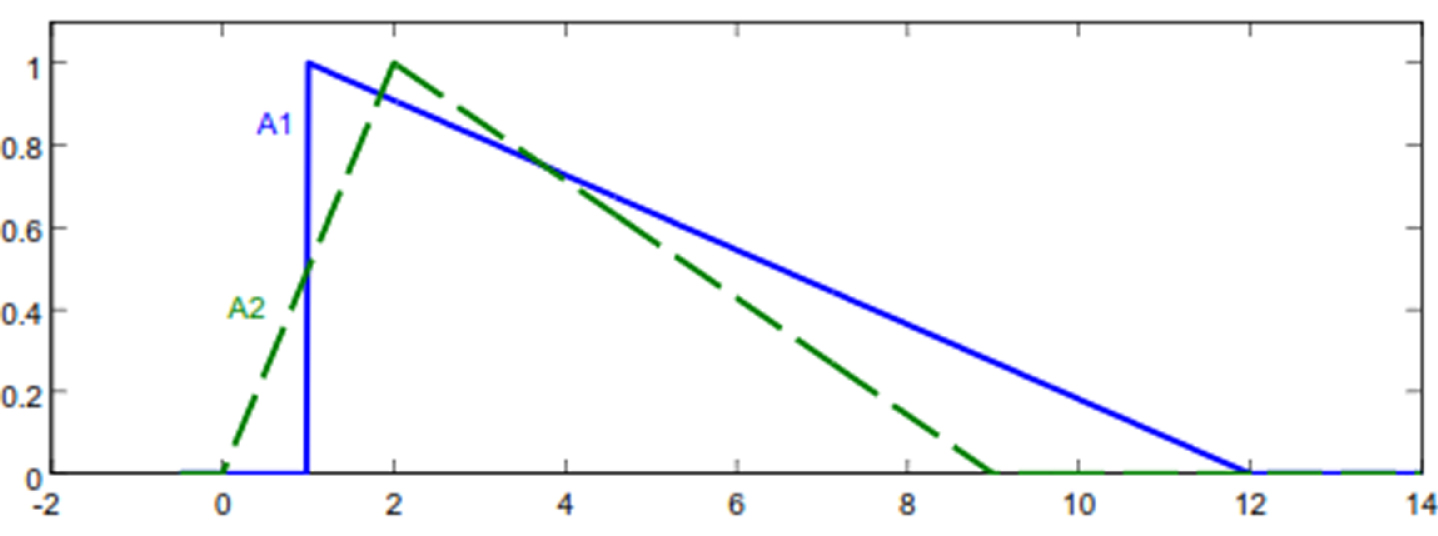
Fuzzy numbers of Example 12.
Fuzzy numbers of Example 13.
So far, we have been examining the approach by a variety of examples. As we have seen, the approach’s outlook is reasonable. Now, we provide a closer comparison of the approach against several known approaches by the following example.
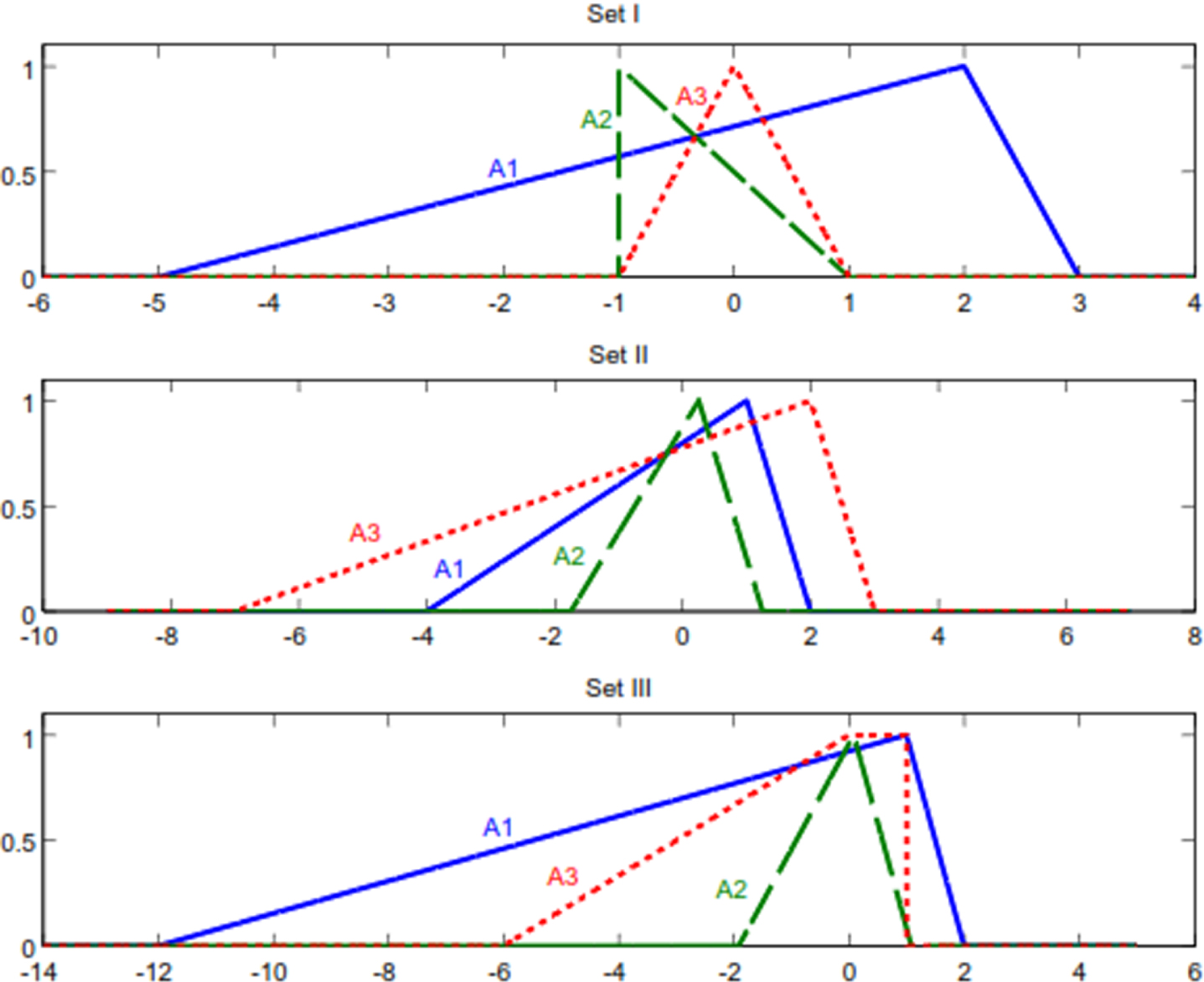
Fuzzy numbers of Example 14.
Set I: A1 (2, 2, 7, 1) LR , A2 (-1, - 1, 0, 2) LR , and A3 (0, 0, 1, 1) LR .
Set II: A1 (1, 1, 5, 1) LR , A2 (1/4, 1/4, 2, 1) LR , A3 (2, 2, 9, 1) LR .
Set III: A1 (1, 1, 13, 1) LR ,A2 (1/12, 1/12, 2, 1) LR , A3 (0, 1, 6, 0) LR .
The quantified comparisons of results for Example 14 are listed in Table 1, where the first column corresponds to a particular set. In each row, the values of ranking with respect to the corresponding references are reported.
Results for Example 14
As can be observed, different approaches yield to different orders, whereas some of those results may be unreasonable. Comparisons of results indicate that the level of recognizing ambiguity in fuzzy numbers plays a major role in distinguishing ranking results.
For Set I, our result is consistent with most of the other works, but our approach is simpler from the standpoint of computation. This set shows the importance of the center and skewness against the factor of spread. In Set II, interactions between the center and skewness are clear. In fact, these factors considerably reflect their influence on the results and show the center is not always a determining factor on evaluating ranking especially when differences among centers are not noticeable. Our result for Set II is A2 ≺ A3 ≺ A1. Regarding Fig. 17, it can be seen that the proposed approach yields to more convincing conclusions. The major point of departure between our result and others is provided by Set III, as most selected references generate the result A1 ≺ A3 ≺ A2.In contrast, the proposed approach produces A2 ≺ A1 ≺ A3. It is clear from Fig. 17 that this conclusion is more consistent with human sense once the confidence level interval [m - α, n + β]is considered. Reference [22] yields to A1 ∼ A2 ∼ A3, that seems to be an unreasonable conclusion.
Fuzzy numbers of Example 15 [35].
Fuzzy numbers of Example 16 [38].
Results for Example 16
As a number of examples in this paper clearly illustrate, ranking of fuzzy numbers is in general a kind of empiric process, one that does not always have a clearly right answer. Our basic hope here is to reach a ranking measure that is more intuitive while keeping computational efficiency. We view ranking of fuzzy numbers as a process of identifying and manipulating the richness of relations and conceptual interactions that exist among effective factors within the ranking framework. The resulting ranking approach, as proposed in this paper, yields to a unified, compact and intuitive formulation for ranking fuzzy numbers. Specifically, the proposed S - A index, and S - A - e index for exception handling, considers significant factors on ranking to be center, spread, skewness, as well as human intuition. When combined, these factors present a descriptive interpretation for ranking. The proposed approach first maps fuzzy numbers into R3 space by considering the three factors of mean, spread and skewness; subsequently maps into R space in the form of S - A or S - A - e indices by adding a factor of human intuition, and, finally compares indices for ranking. A number of numeric examples illustrates that such ranking approach is generally produces results either more consistent with a greater number of competing ranking approaches or results more intuitively acceptable, particularly under more challenging examples where these ranking approaches differ in their recommendations.
As for future work, we believe that a deeper insight to fuzzy numbers and considering other possible factors can lead to further improvements. For instance, the concept of indifference requires further study, which we hope to address in our future works.
Footnotes
Appendix
Proofs of the above properties trivially follow from rules 1-3 (Equation 7) due to Γmapping to real numbers; thus we just prove Properties for S - A; the proofs for S - A - e follow similarly. Suppose A1 (m1, n1, α1, β1) LR , A2 (m2, n2, α2, β2) LR , and A3 (m3, n3, α3, β3) LR are three fuzzy numbers.
Property P1: Since Γ (A1) is obtained as a real number and we have Γ (A1) ⩾ Γ (A1); we can realize,
Property P2: Since
Property P3: Since
Property P’4: Since inf supp (A1) > supsupp (A2), we conclude Γ (A1) > Γ (A2); therefore, A1 ≻ A2.
Property P5: Since A1 ≻ A2on S’, we have Γ (A1) > Γ (A2) and since A1 and A2 are in S ∩ S′; then Γ (A1) > Γ (A2) on S. Hence, A1 ≻ A2on S. Similarly, we can prove if A1 ≻ A2on S, then we have Γ (A1) > Γ (A2) and since A1and A2 are in S ∩ S′; then Γ (A1) > Γ (A2) on S’. then A1 ≻ A2on S’.
Property P6:. Since
and
In this case, since in the numerators and denominators of Γ (A1 + A3) and Γ (A2 + A3) comparing to Γ (A1) and Γ (A2), we have the same increased or decreased elements and know that Γ (A1) ⩾ Γ (A2); it follows that, Γ (A1 ⊕ A3) ⩾ Γ (A2 ⊕ A3), hence,
Property P7: Consider A1 ⊗ A3 = (m1 . m3, n1 . n3, m1 . α3 + m3 . α1 - α1 . α3, β1 . β3 + β1 . n3 + β3 . n1) LR and A2 ⊗ A3 = (m2 . m3, n2 . n3, m2 . α3 + m3 . α2 - α2 . α3, β2 . β3 + β2 . n3 + β3 . n2) LR , then we have
and
Note that in the case of
Property P8: Since
Property P9: Since -A1 ∼ A1, according to Rule 3, we have Γ (- A1) = Γ (A1). In addition, since -A2 ∼ A2, we have Γ (- A1) = Γ (A1). Also, according to Rule 2, since
The literature also refers to this as the opposite of fuzzy numbers.
This property is illustrated in Example 13.