
Abstract
Feature pyramids are commonly applied to solve the scale variation problem for object detection. One of the most representative works of feature pyramid is Feature Pyramid Network (FPN), which is simple and efficient. However, the fully power of multi-scale features might not be completely exploited in FPN due to its design defects. In this paper, we first analyze the structure problems of FPN which prevent the multi-scale feature from being fully exploited, then propose a new feature pyramid structure named Mixed Group FPN
Introduction
One of the fundamental research of deep learning is object detection. With the fully development in deep convolutional networks, marvelous progress has been achieved in object detection.Existing object detectors can be briefly categorized into two branches:anchor-based detectors and anchor-free detectors. Anchor-based detectors can be roughly divided into one-stage methods including YOLOV3 [21], SSD [18], RetinaNet [17] which directly predict objects by anchors; and two-stage methods such as Faster R-CNN [22] and Mask R-CNN [8], which utilize candidate proposals for further refinement to infer the extracted region feature. Anchor-free detectors also make predictions in two different ways. One way is locating bounding boxes by predicting several pre-defined key points including CornerNet [15] and CenterNet [5]. Another way is to use the center point of bounding boxes and predict the four distances from center such as FCOS [28], YOLO [19].
However, the quick development of detectors and pattern of feature extracting still can not address the scale variation problem across object instances. The most intuitive solution of the problem is to exploit multi-scale image pyramid. But the huge cost of time and memory of this solution makes it impractical. Another solution is to utilize the feature pyramid to be a substitute for image pyramid at a lower computational cost. Among the methods of feature pyramid, FPN is the most representative one, which improves feature representation with combining the feature from shallow layers that is more detailed and features from high layers that is more semantic.
As is shown in Figure 1, the architecture design of FPN has the following intrinsic defects:

The design defects in feature pyramid network: 1) different dimension of feature maps reduces to the same low dimension, 2) semantic gap between feature maps with different receptive fields before feature summation.
In this paper, the FPN architecture has been rethinked and an alternative module is proposed to mitigate the problems mentioned above respectively. First, in the channel reduction stage of FPN, the module named
Without bells and whistles, Mixed Grouped FPN based FCOS outperforms the original FCOS by 1.0 Average Precision (AP) using ResNet50 as backbone. Also MGFPN can be easily extended to other anchor-based methods or anchor-free methods which have FPN module with little modifications. It proves the generality of MGFPN.
In summary, our main contributions are as follows: Revealing the problems of FPN architecture of channel reduction and semantic gap cause by summation, which prevent the multi-scale feature from being fully exploited. Proposing a MGFPN which inherits the merits of FPN and is able to alleviate the problems we mentioned above. Evaluating MGFPN equipped with various backbones and detectors on MS-COCO and its competitive results manifest the generality of MGFPN.
The remainder of this paper is organized as follows. Section 2 introduces related work of development of detectors, network architecture and attention mechanism. Section 3 presents the construction of our method, including MGConv and CA. In Section 4, experiments and analysis of our methods are represented. Finally, we conclude this research with future work in Section 5.
Deep object detectors
Object detectors conclude two methods: anchor-based detectors and anchor-free detectors. As for anchor-based detectors, the methods almost follow two paradigms, two-stage and one-stage. The advent of Faster R-CNN [22] establishes the dominant position of two-stage methods. Faster R-CNN improves from R-CNN and fuses a module named Region Proposal Network (RPN) [22] to detect objects. After that, a number of methods are proposed to improve the performance of Faster R-CNN, including architecture adjustment [25, 31], context and attention mechanism [11, 30], feature fusion and enhancement [27]. Contrary to two-stage methods, one-stage detectors have more advantages in computation yet less accurate. SSD [18] exploits multi-scale features to make dense predictions based on plenty of anchors. Although dense predictions improve recall of predictions of detectors, it makes detectors suffering from imbalance problem of easy and hard samples. Then RetinaNet [17] is proposed to introduce a novel focal loss to address the imbalance problem.
Anchor-free detectors also can be divided into two ways: one is keypoint-based methods which predict pre-defined key points and then generate bounding boxes. CornerNet [15] predicts a pair of Diagonal points to detect an object bounding box. CenterNet [5] predicts center point of bounding boxes based on CornerNet to improve its performance. Another is center-based method which predicts center points or center area of bounding boxes to differentiate positive and negative sampling, and then predicts the distances from positives to the four sides of bounding boxes. YOLO [19] divides the image into grids and the grid cell that contains the center of an object is defined positive to predict the object. FCOS defines positive points for the point which is inside a predefine bounding box and uses the point to predict four distances to perform detection.
Network architecture engineering
Network architecture engineering is one of the most prevailing domains in vision deep learning. The proposal of network design is achieving the balance of computation and performance and the optimal solution is obtained under the balance. An intuitive idea of network extension is to deepen the network VGG [24]. FracalNet [14] introduces a network of a binary path while Googlenet [25] introduces a multi-branch design where each branch has different receptive field and fuses features by concatenation. ResNet [9] proposes a short-cut mechanism to mitigate training unstable issues but fuses features by summation. ResNeXt [31] exploits the conception of cardinality which splits then merges features and leads to better classification accuracy. DenseNet [12] iteratively concatenates the input features with the output features, enabling features of all layers to have direct contact with the output layer.
Attention mechanism
A simple yet efficient function to enhance features is attention mechanism. SE-Net [11] propose a Squeeze-and-Excitation module to learn channel attention and achieves promising performance. Subsequently, SK-Net [16] uses multi-path and big kernels to refine the channel attention. CBAM[30] exploits both average and max pooling to aggregate features. GE [10] explores spatial attention by using a depth-wise convolution. The core idea of attention mechanism is to design a light weight but functional module which is good for feature aggregation.
Group convolution
Group convolution, which splits the feature maps by channel into groups and calculates with each groups respectively, is first used in AlexNet [13] to save the memory of GPUs. Interleaved Group Convolutions [33] is based on group convolution, which is a method of dividing the input channels into several partitions and performing a regular convolution over each partition separately. Depth-wise convolution is an extreme situation of groups convolution which divides all channels. The number of groups affects the performance of groups convolution and generally, the more groups come with the less representation of model. But the decomposition of reducing the redundancy of neural networks and parameter saving of group convolution shows that group convolution is worth involving with more research.
Proposed methods
The overall framework of MGFPN is shown in Figure 2. Following the setting of FCOS, features used to build the feature pyramid are denoted as C3, C4, C5. P3, P4, P5 are the features produced by feature pyramid. P6, P7 are the features extracted from P5, P6 respectively. The two components of MGFPN will be discussed in the following subsections.
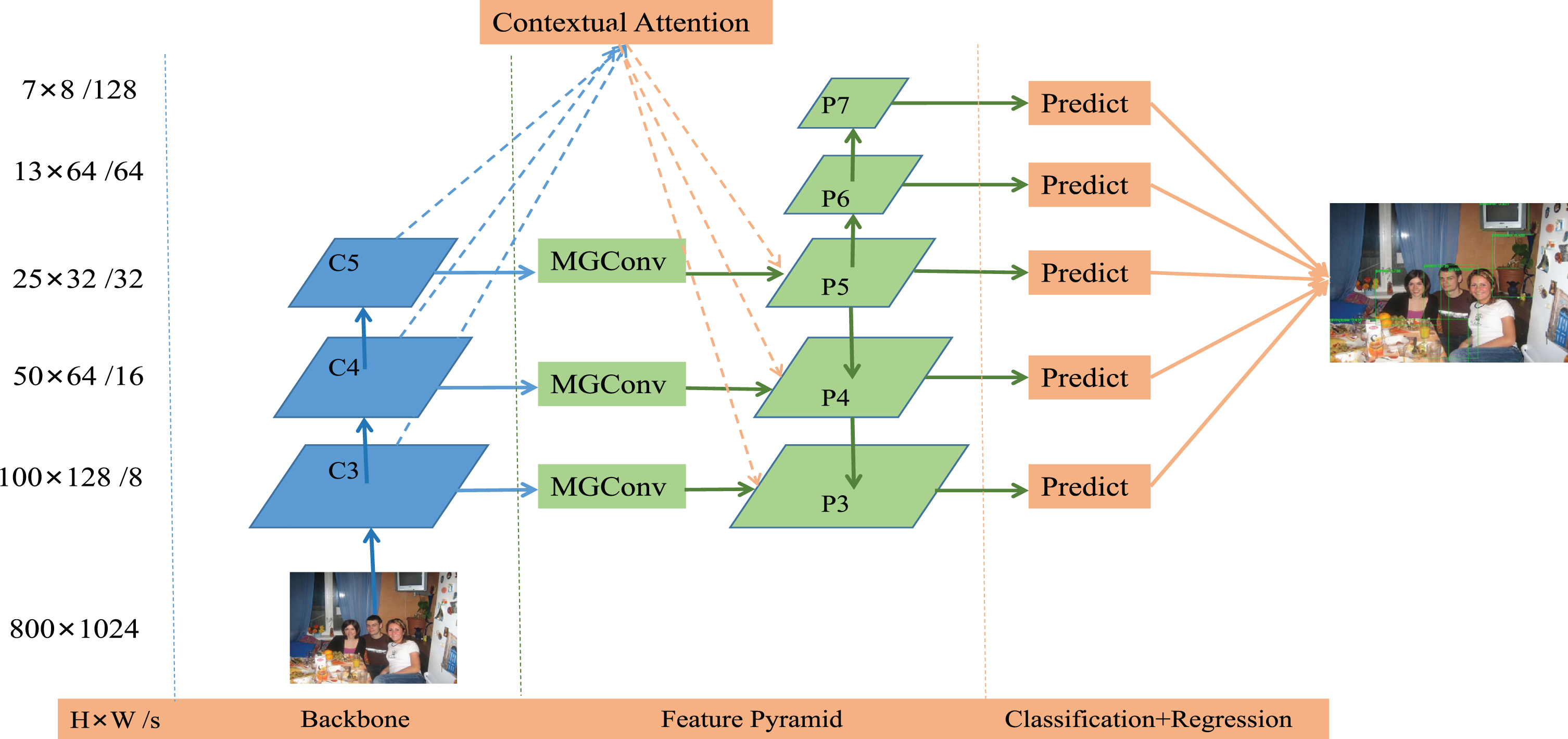
Here is the overall pipeline of MGFPN, where C3, C4 and C5 denote the features of backbone network and P3 to P7 are the feature levels used for the final prediction. H×W is the height and width of features. s (s = 8,16,...,128) is the down sampling ratio of the features at the level to input image.
The main idea of
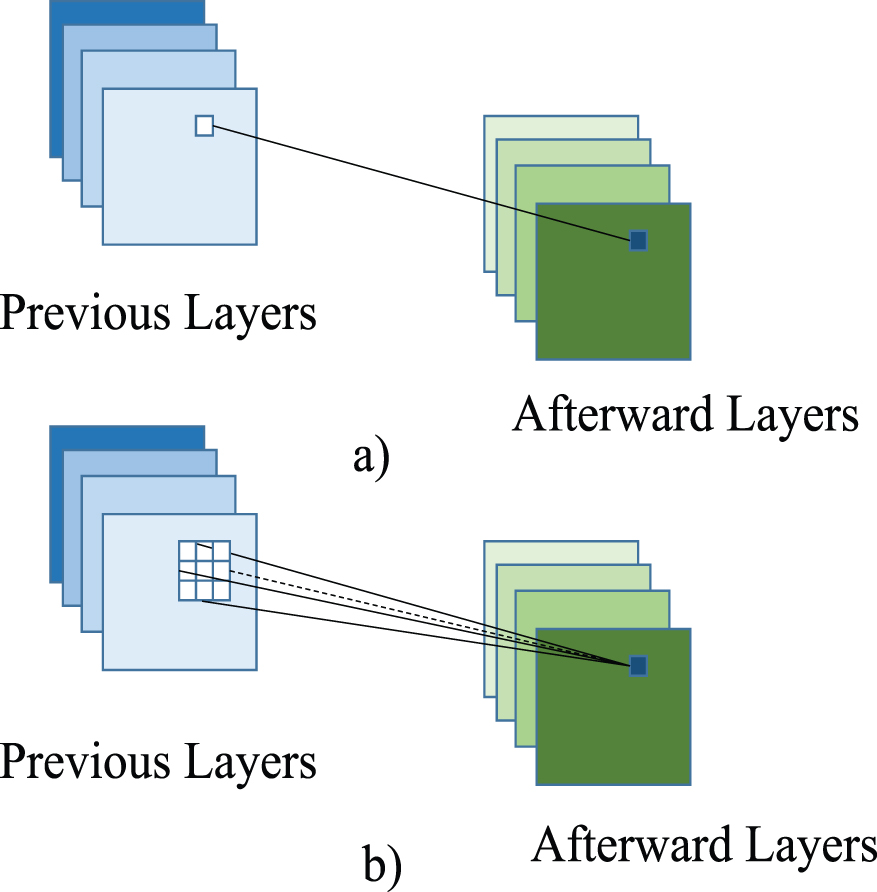
a) 1×1 Convolution. b) 3×3 Convolution. The figure shows that big kernel will introduce more spatial information from previous layers to afterward layers. Our module contains multiple big kernels to obtain more spatial information.
MGConv is a computational unit which can be built upon a transformation mapping and input
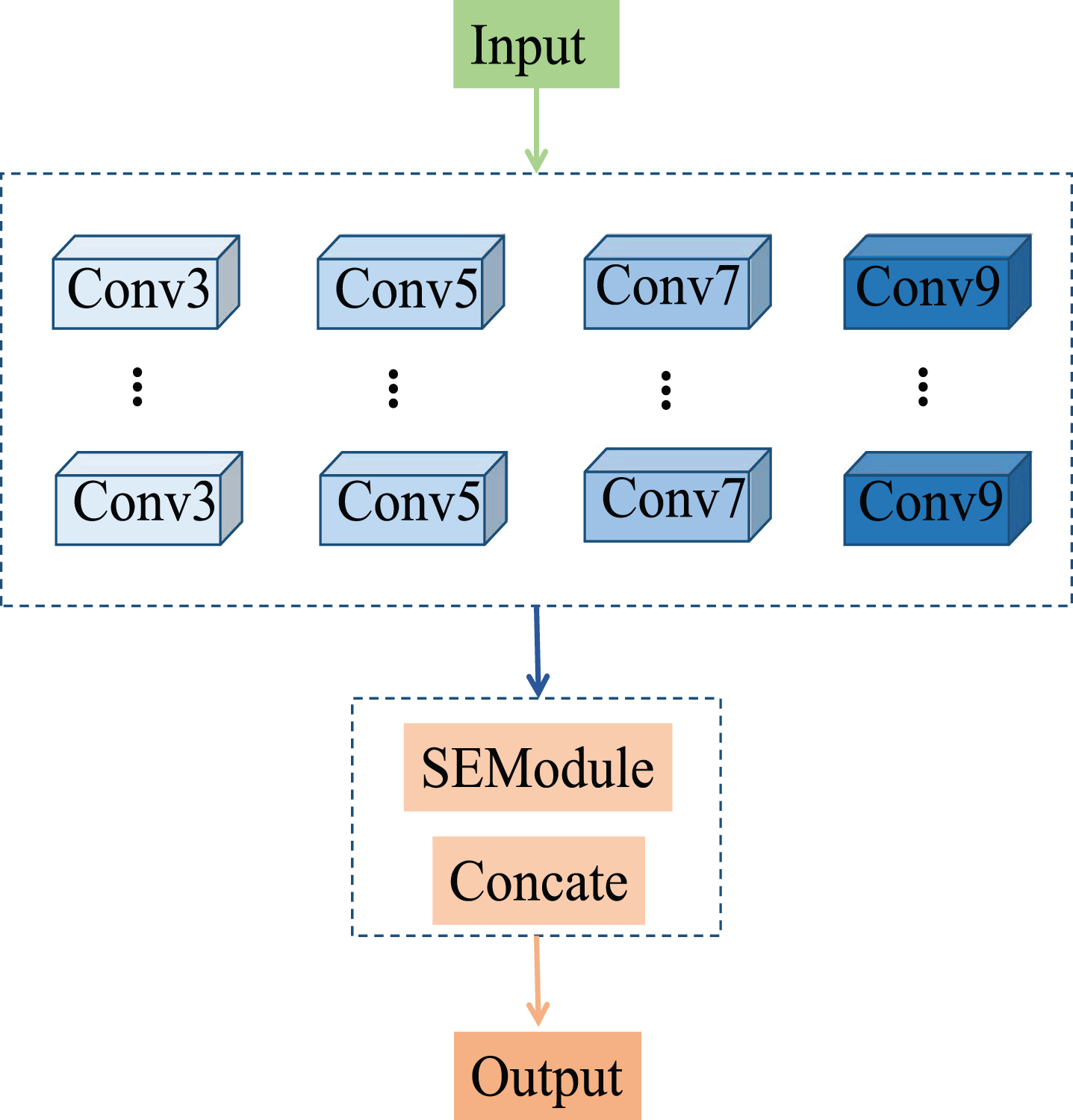
The module structure of MGConv. Ellipsis means the uncertain group numbers of group convolution of big kernels. MGFPN enhances the feature extraction using multiple spatial information.
1) The input and output data handled in these methods have the same dimension while our method aims to focus on the dimension reduction of data.To our best knowledge, there is seldom conducting multi-path in FPN.
2) These methods pay more attention to how to split features but our method concerns about fusing the split features.
CA is the complement of summation between shallow layer features and high layer features of MGFPN. CA is light-weight which simply composes by a group convolution and a 1×1 standard convolution (illustrated in Figure 5). Previous study [29] has shown that simple low-level feature sets can effectively encode context information for visual tasks and it may be an effective alternative to the iterative method based on high-level semantic features.
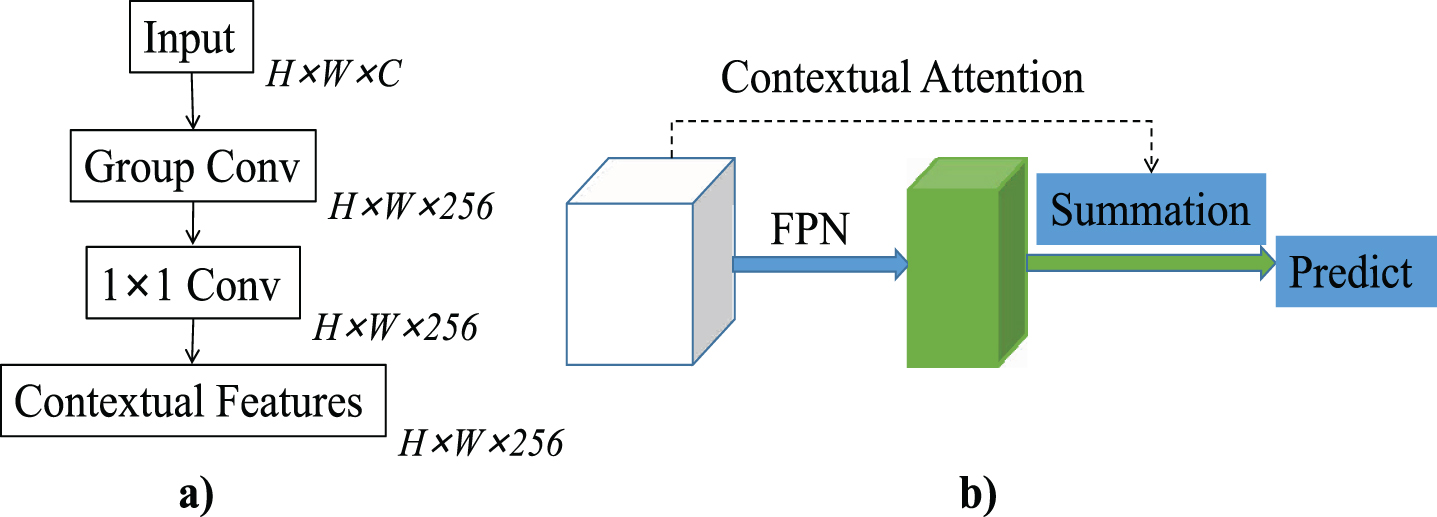
a) Module structure; b) Working flow of
By exploiting the group convolution, the context features are obtained in a low computation cost and a standard 1×1 convolution is beneficial for mitigating the sparse effect of group convolution. As shown in our ablation study in next section, the number of groups also affects the performance of CA.
The definition of loss function as follow:
Dataset and evaluation metrics
All experiments are performed on the MS COCO detection dataset with 80 categories. It contains 115k images for training, 5k images for validation and 20k images for testing. These models are trained on training sets and we report results of ablation study on minival sets which are identified with other baselines. The final results are also reported on minival sets. All reported results follow standard COCO-style Average Precision(AP) metrics.
Implementation details
As for ablation study, ResNet-50 based FCOS [28] is used as our backbone networks and the setting of hyper-parameters is same with FCOS. The other experiments which compared to other baselines follow all settings of these baselines. Specially, our network is trained with stochastic gradient descent(SGD) for 90K iterations with the initial learning rate being 0.01 and a mini-batch of 8 images. The learning rate is reduced by a factor of 10 at iteration 60K and 80K, respectively. Weight decay and momentum are set as 0.0001 and 0.9. The backbones of our model are initialized with the weights pre-trained on ImageNet [4]. And the newly added layers are initialized in [17]. The input images are resized to have their shorter side being 800 and their longer side less or equal to 1333. By default, these models are trained with 2 GPUs (4 images per GPU).
Main results
The evaluation of MGFPN on COCO minival set compared with other state-of-the-art one-stage and two-stage methods is conducted in this section. All results are shown in Table 1.
Comparasion with other baselines
Comparasion with other baselines
As for one-stage methods, the based model FCOS are set to use different backbones which provide the generalization of MGFPN on each backbone. By replacing FPN with MGFPN, backbones including ResNet-50, ResNet-101, MoblieNet-V2, ResNext-32x8d-101, ResNeXt-64x4d-101 of FCOS improve the performance by 1.0, 0.9, 0.7, 0.7 and 1.2 AP respectively. The heatmap comparison between FPN and MGFPN (the backbones of both models are ResNet-50) is shown in Figure 6.

Comparison of the responsive field of FPN and MGFPN. It is shown that MGFPN has more active fields than FPN on these illustrated images.
As for two-stage methods, the main idea of experiments is to validate the effectiveness of MGFPN on two different type of detectors. So experiments for two-stage methods are less than one-stage methods. As shown in Table 1, Mask R-CNN can be improved by 1.2 AP and 0.8 AP respectively when using ResNet-50 and ResNet-101 as backbone. These improvements show that MGFPN is a great alternative module for any other FPN based methods.
Finally, evaluation about some less computational but effective module are used in MGFPN-based FCOS to test whether MGFPN is conflicted with these implements. As can be seen in Table 1, FCOS is boosted to 1.2 AP and 1.4 AP when using GIOU and ATSS. Our experiments verify the robustness ability of MGFPN.
In this section, extensive ablation experiments are conducted to analyze the effects of individual components in our proposed method. All the ablation studies are conducted on ResNet-50 FCOS and other basic experiments settings are complied with the settings which are mentioned before.
As the formulation above illustrated, K h , K w , K c , K n means height, width, channel and number of kernels. Specially, K c is equal to the channel of input feature maps and K n is same with the channel of output channel feature maps.
As shown in Table 2, all the numbers of group of CA improve the baseline methods. This benefits from that CA narrow semantic gaps between the features after lateral connection and improves their semantic representation simultaneously. It is better to note that compared to the whole model, by choosing an optimal group number CA will introduce little extra parameters. Therefore it is worthy to add it to other FPN based detection models.
Ablation studies of CA on MS-COCO minival. “GN” is group number and “unfixed” means that the group number is the same as the dimension of input features
Performance comparison on COCO minival for different group numbers of each convolution kernels. The baseline is FCOS-ResNet50-MGFPN. "Time" is an approximate training time estimates and its measurement is hour
As we can see in Table 3, the performance of model is not closely relate to the computation cost. When the models consume more computing resources, the average precision may decrease. This is just like before ResNet [9] came into being, the more network layers, the larger the parameter quantity, which will damage the performance of the model. Therefore, the number of groups in group convolution needs more delicate design or a better design is needed to overcome its internal defects. It is worth noting that FLOPs of each model are close, the training time between them are roughly same.
As shown in Table 4, CA improves the baseline method by 0.7 AP. This benefits from that CA narrow semantic gaps between the features after lateral connection in pipeline of FPN. And MGConv improves the detection performance from 36.5 to 37.4 AP. It can be seen that after reduce the spatial information loss, the detector benefits objects in small scale.
Effect of each component. Results are reported on COCO minival.
Some qualitative results are shown in Fig. 7. In this paper, the inherent problems along with FPN is analyzed and the effect of multi-scale features is not fully exploited in FPN. A new alternative FPN structure named MGFPN is proposed to further exploit the potential of multi-scale features. With two simple yet effective modules named MGConv and CA, MGFPN can improve the baseline methods by a large margin on the challenging MS-COCO dataset. Based on our study, some research directions in future work with respect to MGFPN may focus on the following aspects: 1) Computation. The whole structure may introduce too much computation when utilizing small group numbers. 2) Speed. Group convolution needs to be optimized at Compute Unified Device Architecture, otherwise the computing speed will be very slow.

Here is part of detection results on COCO validation set. ResNet-50 is used as backbone of ours methods. As the figure illustrate, MGFPN perform well with a wide range of objects including crowded, occluded, highly overlapped, small and large objects.
Footnotes
Acknowledgments
This work is supported by the Natural Science Foundation of Guangdong Province No. 2018A030313318 and the Key-Area Research and Development Program of Guangdong Province No. 2019B111101001.